Together GPUクラスターの新機能:自動スケーリング、可観測性、自己修復
Together AIはGPUクラスターの運用効率を向上させるため、Kubernetesベースの自動スケーリング、RBAC、完全な観測性、自己修復機能を統合したエンタープライズ版「Together GPU Clusters」を発表した。
キーポイント
自動スケーリングの実装
Kubernetes Cluster Autoscalerを活用し、トレーニングや推論の需要に応じてノードを動的に増減させ、アイドルコストを抑えながらパフォーマンスを維持する。
運用管理の高度化
ロールベースのアクセス制御(RBAC)とフルスタックの観測性を導入し、大規模クラスターにおける権限管理とパフォーマンスボトルネックの可視化を可能にした。
自律的な障害回復
アクティブヘルスチェックとセルフサービスノード修復機能により、GPUハードウェア故障時のMTTR(平均復旧時間)を短縮し、トレーニングの中断リスクを低減する。
重要な引用
We are integrating autoscaling, Role-Based Access Control (RBAC), full-stack observability, self-serve node repair, and active health checks directly into the core cluster experience — giving teams the elasticity of a virtualized stack with the performance profile of bare metal.
Instead of statically allocating GPU capacity for peak load, you enable “auto-scaling” and allow the cluster to expand or contract based on real-time resource needs.
The outcome is straightforward: you maintain performance under load without paying for idle GPU Nodes.
影響分析・編集コメントを表示
影響分析
この発表は、AIインフラストラクチャが単なる実験環境から本番運用基盤へと移行する過程で、スケーラビリティと信頼性が最重要課題であることを示している。Together AIのような専用GPUホスティング事業者が、Kubernetesエコシステムとの統合を深めることで、大規模企業におけるAI開発のハードルはさらに下がる可能性がある。
編集コメント
GPUリソースの効率化は現在のAI業界共通の課題であり、Together AIが提供する「自動スケーリング」と「自己修復」は、大規模トレーニングを行うチームにとって実用的な価値が高い。ただし、これは既存のKubernetesエコシステムを応用したものであり、画期的な新技術というよりは運用基盤の成熟を示すものと言える。
AI インフラストラクチャは、静かにして生産環境のインフラへと進化しました。チームはもはや数台の GPU を使って実験している段階ではありません。単一ノードのプロトタイプが、数百ものアクセラレータにまたがる分散トレーニングワークロードへと急速に進化します。実際のユーザーにサービスを提供する推論システムでは、予測不能なトラフィックの急増が発生することもあります。そして、クラスターが共有環境となるにつれて、ML 研究者からエンタープライズプラットフォームエンジニアに至るまで、すべての人にとって運用上の基準が変わります。
しかし、このインフラがスケールするにつれ、手動管理は負債となります。静的なプロビジョニングは非効率的で高コストです。権限管理は脆くなります。観測性のギャップによりパフォーマンスのボトルネックが見えなくなり、GPU ハードウェアが故障した際(それは避けられないことですが)、不安定な単一ノードによって数時間にわたるトレーニング時間が無駄になる可能性があります。
本日、私たちはTogether GPU Clusters(旧 Instant Clusters)に対して、主要なエンタープライズ向け機能強化を発表します。自動スケーリング、ロールベースアクセス制御 (RBAC)、フルスタック観測性、セルフサービスノード修復、アクティブヘルスチェックを、コアとなるクラスター体験に直接統合しました。これにより、チームは仮想化されたスタックの弾力性と、ベアメタルの性能プロファイルを両立させることができます。
自動スケーリング:過剰なプロビジョニングなしで弾力的なキャパシティを実現
ピーク負荷に対して GPU キャパシティを静的に割り当てるのではなく、「自動スケーリング」を有効化し、クラスターがリアルタイムのリソース需要に基づいて拡張または縮小できるようにします。
Kubernetes Cluster Autoscaler(Kubernetes Cluster Autoscaler)によって駆動され、分散トレーニングやバースト性の高い推論トラフィックから GPU 制約のあるワークロード(保留中のポッド)を監視します。需要が急増すると追加のノードが自動的にオンラインになり、需要が落ち着くとキャパシティは縮小されます。
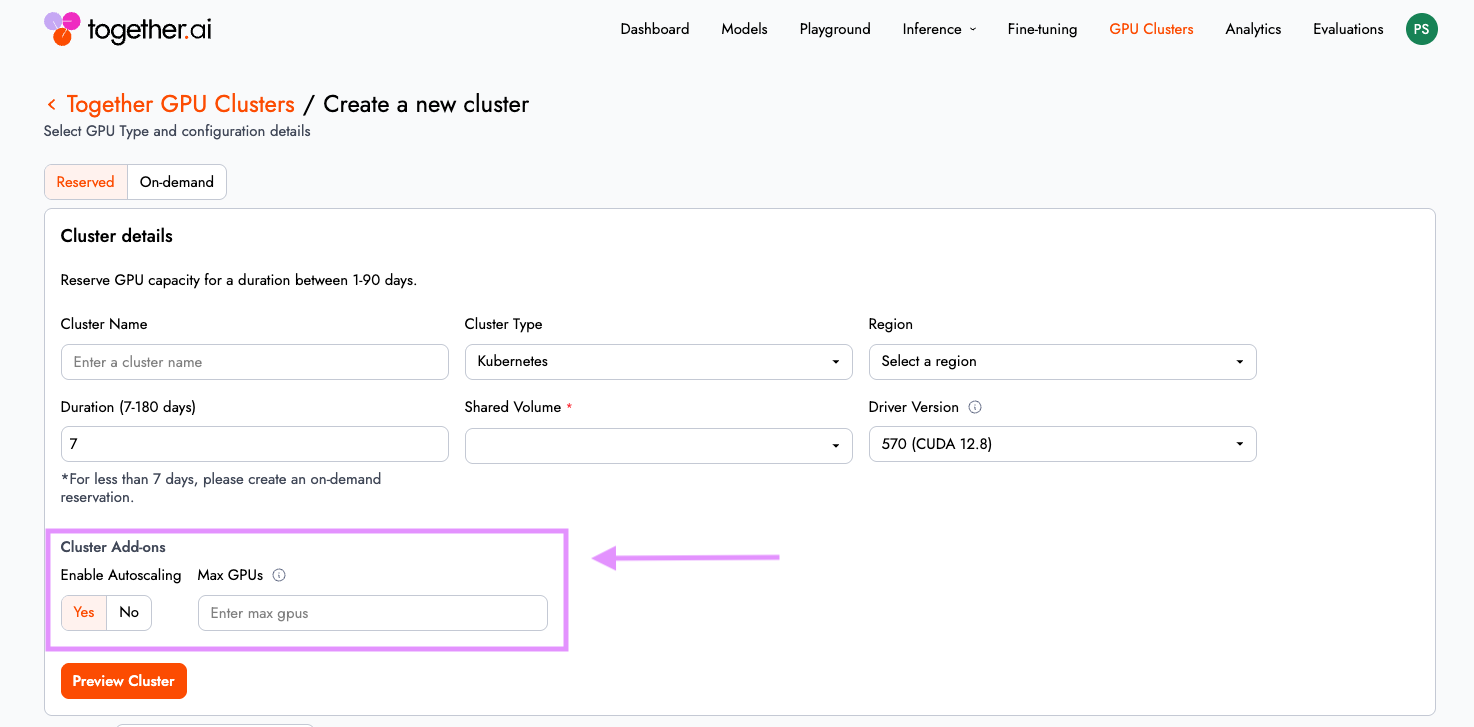
結果は明白です。アイドル状態の GPU ノードに対して支払いを行うことなく、負荷下でもパフォーマンスを維持できます。これにより、Together GPU Clusters は長時間実行されるトレーニングジョブと変動する推論ワークロードの両方に適しています。この機能の詳細については、ドキュメントをご覧ください。
アクティブなヘルスチェック、より深い受入テスト、セルフサービスによるノード修復:障害時の MTTR(平均復旧時間)を削減
大規模な GPU ファームにおけるハードウェアの不安定性は仮説上のリスクではなく、運用上の現実です。分散トレーニングワークロードにおいて、単一のノード障害がジョブ実行全体を無効化してしまう可能性があります。
Together GPU Clusters には、セルフサービス型のアクティブヘルスチェック機能が追加されました。大規模なトレーニングジョブを開始する前に、ユーザーは UI から基本的な DCGM Diag 3(DCGM Diag)からマルチノード NCCL や InfiniBand の書き込み帯域幅テストに至るまで多様なテストをトリガーでき、詳細な出力とともに合格/不合格の結果を受け取ることができます。

この機能は、単一ノードの障害がジョブ実行全体を無効化しうる分散型トレーニングワークロードにおいて特に重要です。ユーザーは、大規模なトレーニングジョブを開始する前にインフラに対して一連の詳細チェックを実行できるようになり、ワークロードの継続性を維持しつつ、計算サイクルの浪費を削減できます。
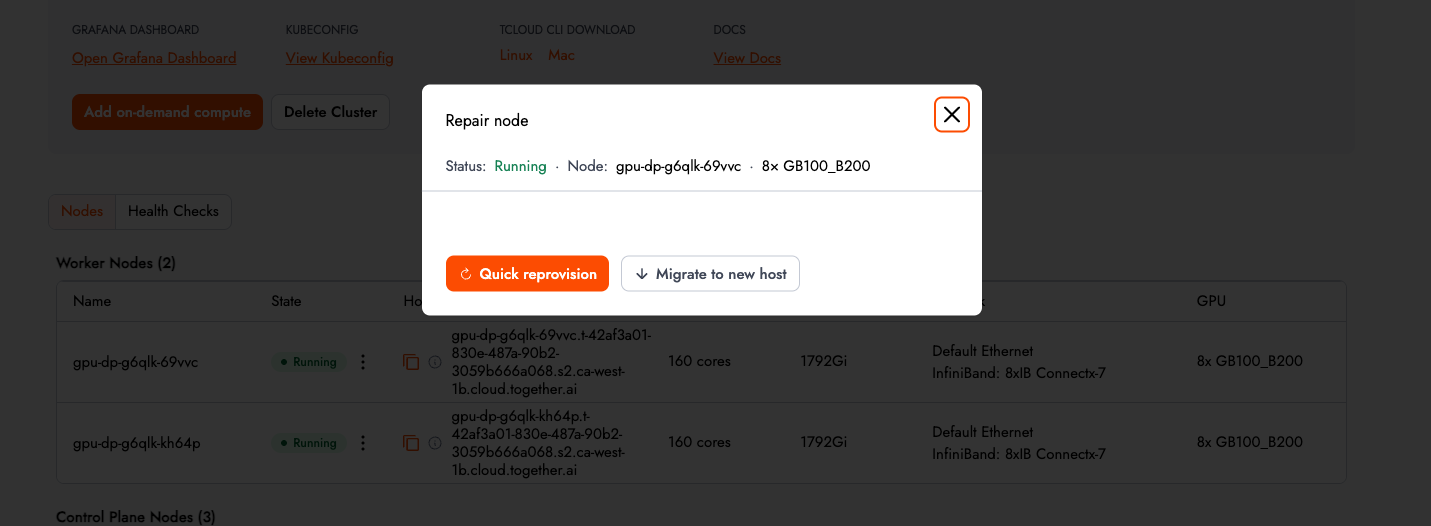
ノードに障害が発生した場合、ユーザーは 3 クリックで自己修復を実行できます。コントロールプレーンが自動的にノードをコルドン(隔離)し、ドレイン(データ転送完了待ち)して、新しいホストまたは既存のホスト上で再作成します。これにより、クラスターは数分以内に健全な状態に戻ります。プロビジョニング中にも自動で受入テストが実行され、合格するまでクラスターのステータスは「Ready」と表示されません。受入テストの完全リストはこちら ドキュメント をご覧ください。
ロールベースアクセス制御:構造化された多チームガバナンス
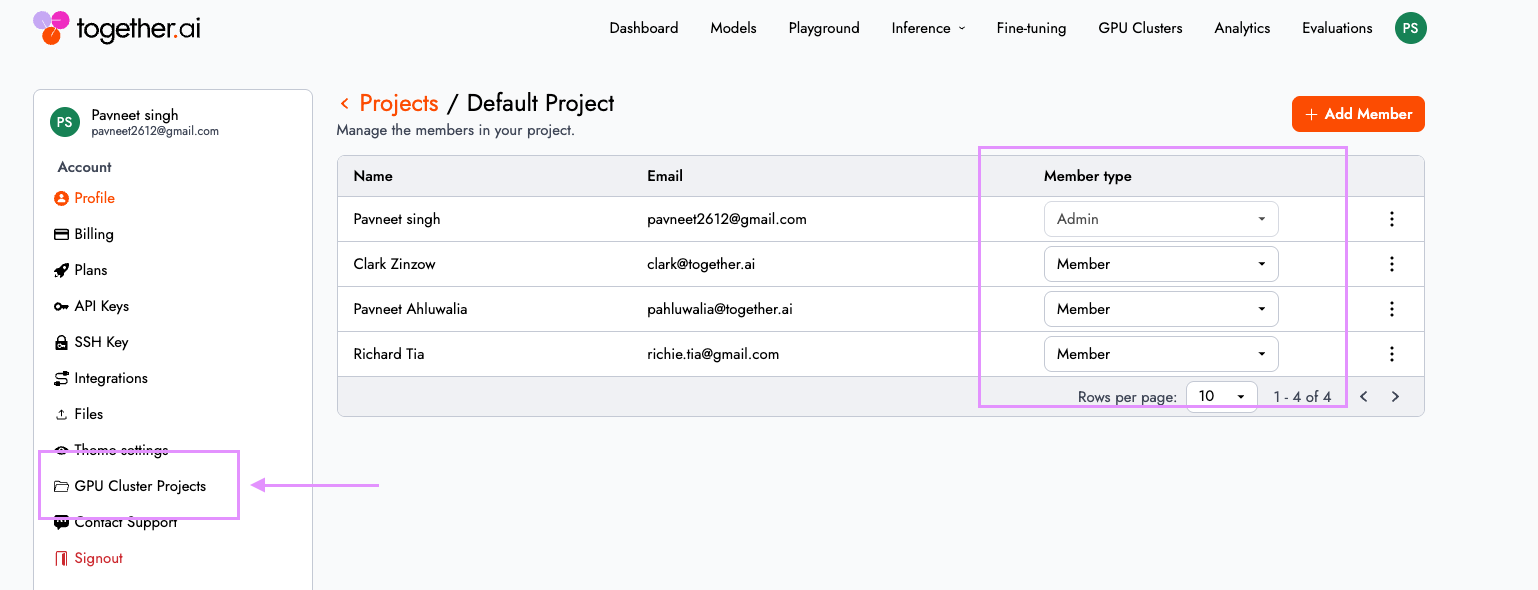
クラスターが実験段階から共有インフラへ移行するにつれ、アクセス制御は基盤となります。Together GPU Clusters では、「プロジェクト」がチーム間のコラボレーションと分離の境界を定義し、クラスターおよびストレージボリュームは各プロジェクトに厳密にスコープされます。
管理者は、エンタープライズガバナンスに整合した構造化されたアクセス制御を適用できます。デフォルトでは、プロジェクトには 2 つのロールが含まれています:
- 管理者:コントロールプレーン(クラスターの作成・削除)に対する完全な読み取り/書き込みアクセス権と、Slurm クラスターにおける sudo アクセス権を付与されます。
- メンバー:データプレーンへの書き込みアクセス権(GPU ワーカーノードおよび実行中のワークロードへのアクセス)が付与されます。
この明確な分離により、プラットフォームエンジニアはインフラストラクチャのプロビジョニングを厳格に管理しつつ、研究チームやアプリケーション開発チームには境界内での安全なワークロード実行の自由を提供できます。
プロジェクトメンバーシップとユーザーロールは、クラウドコンソール にて「設定」>「GPU クラスタープロジェクト」へ移動することで管理可能です。
この機能の詳細については、こちら のドキュメントをご覧ください。
フルスタック観測性(プライベートプレビュー)
すべての Together GPU クラスタープロジェクトに、クラスター詳細ページから直接アクセス可能な、事前構築済みダッシュボードを備えた専用 Grafana インスタンスが用意されました。
テレメトリはフルスタックにわたって収集されます:
- GPU 利用率:DCGM メトリクスは、アクセラレータの健全性とパフォーマンスに関する直接的な洞察を提供します。
- ネットワーク:InfiniBand および NIC レベルのテレメトリーは、スループットと帯域幅のパターンを明らかにします。
- ストレージ & オーケストレーション:I/O パフォーマンス指標は隠れたボトルネックを浮き彫りにし、Kubernetes テレメトリーはオーケストレーションの健全性とリソース割り当てに関する可視性を提供します。
テレメトリーは、クラスターがプロビジョニングされた直後に利用可能です。プラットフォームチームにとっては、デバッグとパフォーマンスチューニングが加速され、財務および運用チームにとっては、キャパシティプランニングとコスト効率性が向上します。
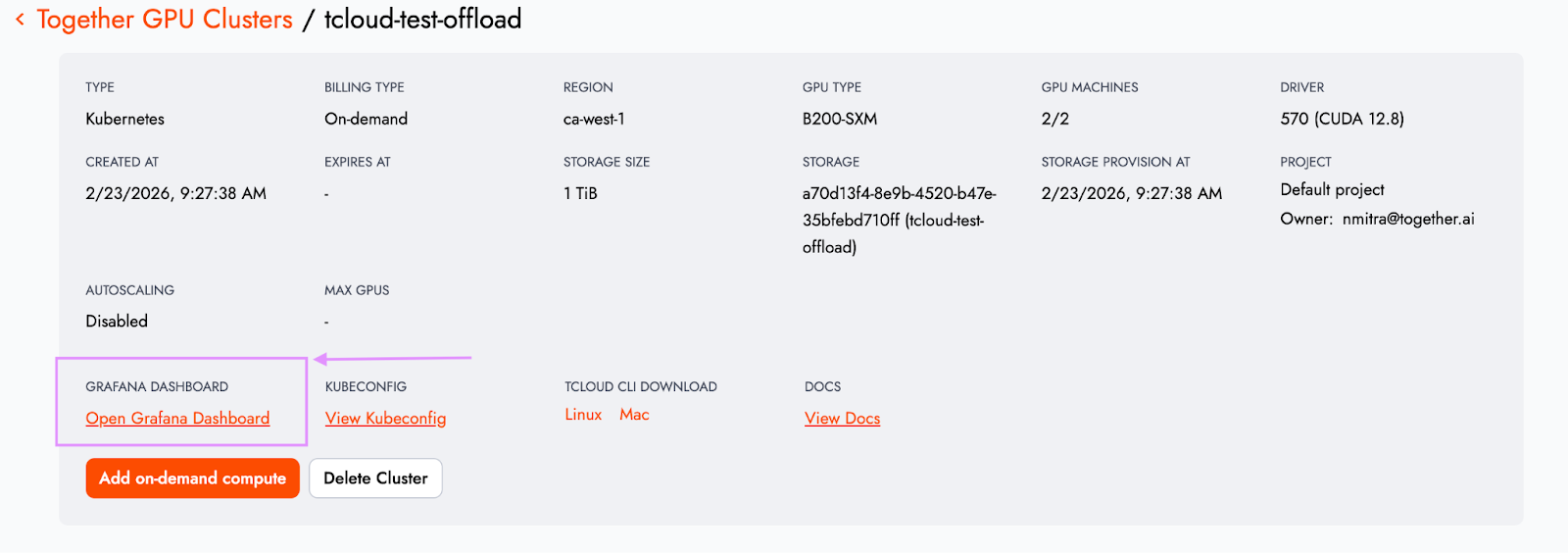
この機能は現在プライベートプレビュー中です。Grafana インスタンスへのアクセスを取得するには、サポートまたはアカウントチームまでお問い合わせください。
実験段階から運用段階へ
自動スケーリング、RBAC(ロールベースのアクセス制御)、観測可能性、ターンキーヘルスチェック、およびリメディエーションがプラットフォームに統合されたことで、Together GPU Clusters は単なる GPU のプロビジョニングを超え、本番環境対応の完全マネージドインフラへと進化しました。
これにより、チームはハードウェア障害が計算時間の損失に連鎖することを心配することなく、大規模な分散トレーニングジョブを実行する自信を得られます。また、組織全体に対して tailored な価値を提供します:
- プラットフォームエンジニアは、共有環境内で複数の内部関係者を安全にサポートできます。
- 運用担当者は、モデルパフォーマンスが低下する前にネットワークまたはストレージのボトルネックを特定できます。
- 財務チームは、GPU の支出を実際の利用率パターンにより密接に整合させることができます。
最も重要なのは、組織がサードパーティ製ツールをつなぎ合わせたり、内部制御プレーンをゼロから構築したりすることなく、実験的な AI システムから運用可能な AI プラットフォームへと移行できることです。
始め方
これらの機能は、現在 Together GPU Clusters で利用可能です。
始めるには、Together AI に サインアップ し、クラスターを起動 してください。

8S
DeepSeek R1

ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
パフォーマンスとスケーラビリティ
本文のここにロレム・イプサム・ドロール・シット・アメットが入ります。
- ここに箇条書きを、ロレム・イプサム
- ここに箇条書きを、ロレム・イプサム
- ここに箇条書きを、ロレム・イプサム
インフラストラクチャ
最適な用途
- より高速な処理速度(全体的なクエリレイテンシの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- 関数呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
ロレム・イプサム・ドロール・シット・アメット、コンセクテトゥール・アディピスキング・エリート、セド・ドゥイウスモル・テンポル・インシディディット・ウト・ラボレ・エト・ドローレ・マグナ・アリクァ。ウト・エニム・アド・ミニム・ヴェニアム、キス・ノストル・エクセルシタティオン・ウラムコ・ラボリス・ニシ・ウト・アリキップ・エク・エア・コモダ・コンセクワット。
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグ内に配置してください。推論は以下のルールに従って記述してください:推論を行う際はアラビア語でのみ回答し、他の言語は一切使用できません。
質問:
Natalia は 4 月に友人 48 人にクリップを販売し、5 月にはその半分の数を販売しました。Natalia は 4 月と 5 月の合計で何個のクリップを販売したでしょうか?
XX
タイトル
本文のここにロレム・イプサム・ドロール・シット・アメットが入ります
XX
タイトル
本文のここにロレム・イプサム・ドロール・シット・アメットが入ります
XX
タイトル
本文のここにロレム・イプサム・ドロール・シット・アメットが入ります
原文を表示
AI infrastructure has quietly become production infrastructure. Teams are no longer experimenting with a handful of GPUs. A single-node prototype can quickly evolve into a distributed training workload spanning hundreds of accelerators. Inference systems serving real users can experience unpredictable traffic spikes. And as clusters become shared environments, the operational bar changes for everyone — from ML researchers to enterprise platform engineers.
But as this infrastructure scales, manual management becomes a liability. Static provisioning is inefficient and expensive. Permission management turns brittle. Observability gaps obscure performance bottlenecks, and when GPU hardware fails — as it inevitably does — a single unstable node can derail hours of training time.
Today, we’re introducing major enterprise enhancements to Together GPU Clusters (formerly Instant Clusters). We are integrating autoscaling, Role-Based Access Control (RBAC), full-stack observability, self-serve node repair, and active health checks directly into the core cluster experience — giving teams the elasticity of a virtualized stack with the performance profile of bare metal.
Autoscaling: Elastic capacity without overprovisioning
Instead of statically allocating GPU capacity for peak load, you enable “auto-scaling” and allow the cluster to expand or contract based on real-time resource needs.
Powered by the Kubernetes Cluster Autoscaler which monitors for GPU-constrained workloads (pending pods) from distributed training or bursty inference traffic. When demand spikes, additional nodes are automatically brought online. When demand subsides, capacity scales down.
The outcome is straightforward: you maintain performance under load without paying for idle GPU Nodes. This makes Together GPU Clusters well suited for both long-running training jobs and variable inference workloads. To learn more about this feature, visit our documentation.
Active health checks, deeper acceptance testing and self-serve node repair: Reduce MTTR for failures
Hardware instability is not a hypothetical risk in large GPU fleets — it is an operational reality. For distributed training workloads, a single node failure can invalidate an entire job run.
Together GPU Clusters now includes self-serve active health checks. Before spinning up a massive training job, users can trigger tests ranging from basic DCGM Diag 3 to multi-node NCCL or InfiniBand write bandwidth tests directly from the UI, receiving pass/fail results with detailed outputs.
This capability is especially critical for distributed training workloads, where a single node failure can invalidate an entire job run. Users can now trigger a series of deep checks on the infra, before spinning up a big training job and preserve workload continuity and reduce wasted compute cycles.
If a node fails, users can execute a self-repair in three clicks. The control plane will automatically cordon, drain, and recreate the node on a new or existing host, bringing the cluster back to a healthy state within minutes. Acceptance tests now run automatically during provisioning, and clusters are not marked Ready until they pass. See the complete list of acceptance tests here documentation.
Role-Based Access Control: Structured multi-team governance
As clusters move from experimentation to shared infrastructure, access control becomes foundational. In Together GPU Clusters, "Projects" now define the collaboration and isolation boundaries for teams, with clusters and storage volumes strictly scoped to each project.
Administrators can enforce structured access controls aligned with enterprise governance. By default, projects include two roles:
- Admin: Full read/write access to the control plane (create/delete clusters) and sudo access for the Slurm cluster.
- Member: Write access to the data plane (access to GPU worker nodes and running workloads).
This clean split allows platform engineers to lock down infrastructure provisioning while giving research and application teams the freedom to run workloads safely within their boundaries.
You can manage your project membership and user roles from within the cloud console by navigating to Settings > GPU Cluster Projects
To learn more about this feature, visit our documentation here.
Full-stack observability (private preview)
Every Together GPU Cluster project now includes a dedicated Grafana instance with pre-built dashboards, accessible directly from the cluster details page.
Telemetry spans the full stack:
- GPU utilization: DCGM metrics provide direct insight into accelerator health and performance.
- Networking: InfiniBand and NIC-level telemetry expose throughput and bandwidth patterns.
- Storage & orchestration: I/O performance metrics surface hidden bottlenecks, while Kubernetes telemetry provides visibility into orchestration health and resource allocation.
Telemetry is available as soon as the cluster is provisioned. For platform teams, this accelerates debugging and performance tuning. For finance and operations teams, it improves capacity planning and cost efficiency.
Move from experimental to operational
With autoscaling, RBAC, observability, turn-key health checks, and remediations integrated into the platform, Together GPU Clusters move beyond raw GPU provisioning into production ready fully managed infrastructure.
This gives teams the confidence to run large-scale distributed training jobs without worrying that hardware failures will cascade into lost compute time. It also provides tailored value across the organization:
- Platform engineers can safely support multiple internal stakeholders within shared environments.
- Operators can pinpoint networking or storage bottlenecks before they degrade model performance.
- Finance teams can align GPU spend more closely with actual utilization patterns.
Most importantly, organizations can move from experimental AI systems to operational AI platforms — without stitching together third-party tools or building internal control planes from scratch.
Getting started
These capabilities are available today within Together GPU Clusters.
To get started, sign-up at Together AI and spin up your cluster.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み