再帰型言語モデルの強化:強化学習による効率的な実装
この記事は、リインフォースメントラーニングを用いて 4B パラメータのモデルを再帰型言語モデル(RLM)として微調整し、大規模モデルに匹敵する性能を維持しつつコストとサイズを大幅に削減する手法について詳述している。
キーポイント
共有ポリシーによる効率化
親 RLM と子 RLM の両方に共通のポリシーをトレーニングすることで、タスクごとの性能を維持しながら複数のモデルを必要としない構成を実現する。
大規模モデルとの性能比較
テスト結果において、この手法は Claude Sonnet 4.6 などのより大きなモデルと同等のタスクパフォーマンスを発揮することが確認された。
コストとリソースの削減
生産環境向けに設計されたこのアプローチにより、計算リソースと運用コストを大幅に削減しながら、効率的なタスク特化型動作が可能となる。
影響分析・編集コメントを表示
影響分析
このアプローチは、高コストな大規模言語モデルへの依存を減らし、特定のタスクに特化した軽量な AI システムの構築を現実的なものにする画期的な進展です。企業や開発者が、コスト効率とパフォーマンスのバランスを最適化しながら、より広範な生産環境での AI 導入を加速させる可能性を秘めています。
編集コメント
大規模モデルの性能を維持しつつ、コストとサイズを劇的に削減できる技術は、AI の民主化と実装コストの低下に大きく寄与する重要なブレークスルーです。
*私たちは、親および子 RLM(再帰型言語モデル)を単一の共有ポリシーの下で訓練することで、小規模(4B パラメータ)モデルをネイティブな再帰型言語モデルとして振る舞うように RL 微調整を行います。RL を用いることで、小規模モデルはプロンプトや SFT(教師あり微調整)では引き出せないタスク固有の RLM 行動を学習できます。このブログ記事では、RLM に関する基本的な知識があることを前提としています。RLM について学ぶための素晴らしいリソースとして、元の RLM ブログ投稿があります。*
目次
私たちは、本番環境で RLM として使用するために 4B モデルを RL 微調整する方法を探求します。RLM は強力な推論戦略ですが、予測不能なレイテンシを持つ可能性があり、一貫した行動を引き出すために広範なプロンプトチューニングが必要になる場合があります。RL 微調整により、低コストで展開可能な目的特化型の RLM を訓練することが可能になります。
親および子 RLM のための個別のポリシーモデルを訓練するのではなく、親分解者および子サブエージェントという両方の役割を果たす単一のモデルを訓練します。私たちは、子 RLM からのロールアウトがそれを生成した親 RLM のロールアウトの利点を継承するというシンプルな RL 訓練設定を使用しており、これにより単一のポリシーを訓練することが可能になります。これにより、個々の子 RLM 軌道に対する追加のリワード信号が必要なくなります。
複数の科学文書にわたる証拠選択タスクにおいて、RL 微調整された 4B モデルが、同じ RLM ハーネスおよび REPL(対話型実行環境)環境下で Claude Sonnet 4.6 と同等の性能を発揮することを示します。これは、モデルサイズとコストがその一部であるにもかかわらず達成される結果です。
Our code は、トレーニングスクリプト、当社の RLM スキャフォールドの実装、および証拠選択環境を含んでおり、SkyRL で利用可能です。
RLM(Recursive Language Model)は、長いユーザープロンプト(コンテキスト)を格納するプログラム環境内で言語モデル(LM: Language Model)を起動します。このコンテキストは、従来は LM のコンテキストウィンドウに直接読み込まれていました。この環境では、コンテキストは外部オブジェクトであり、LM はプログラム操作を通じてこれを検査し、最終的にユーザーのクエリに対する回答を得ることを目的として、自分自身を再帰的に呼び出すことで分解することができます。
元の RLM 論文と同様に、私たちは Python の Read-Eval-Print-Loop(REPL)を環境として使用します。コードの実行を単なるツールの一つとして扱うのではなく、REPL 内の RLM は、モデルがデータを検査・変換するための主要なインターフェースとしてコードを利用します。各ターンで、モデルは実行したいコードを書き、REPL がそのコードを実行し、RLM オーケストレーターが実行結果(主に print() 文)をユーザーメッセージとしてモデルに返し、次のターンへと進めます。
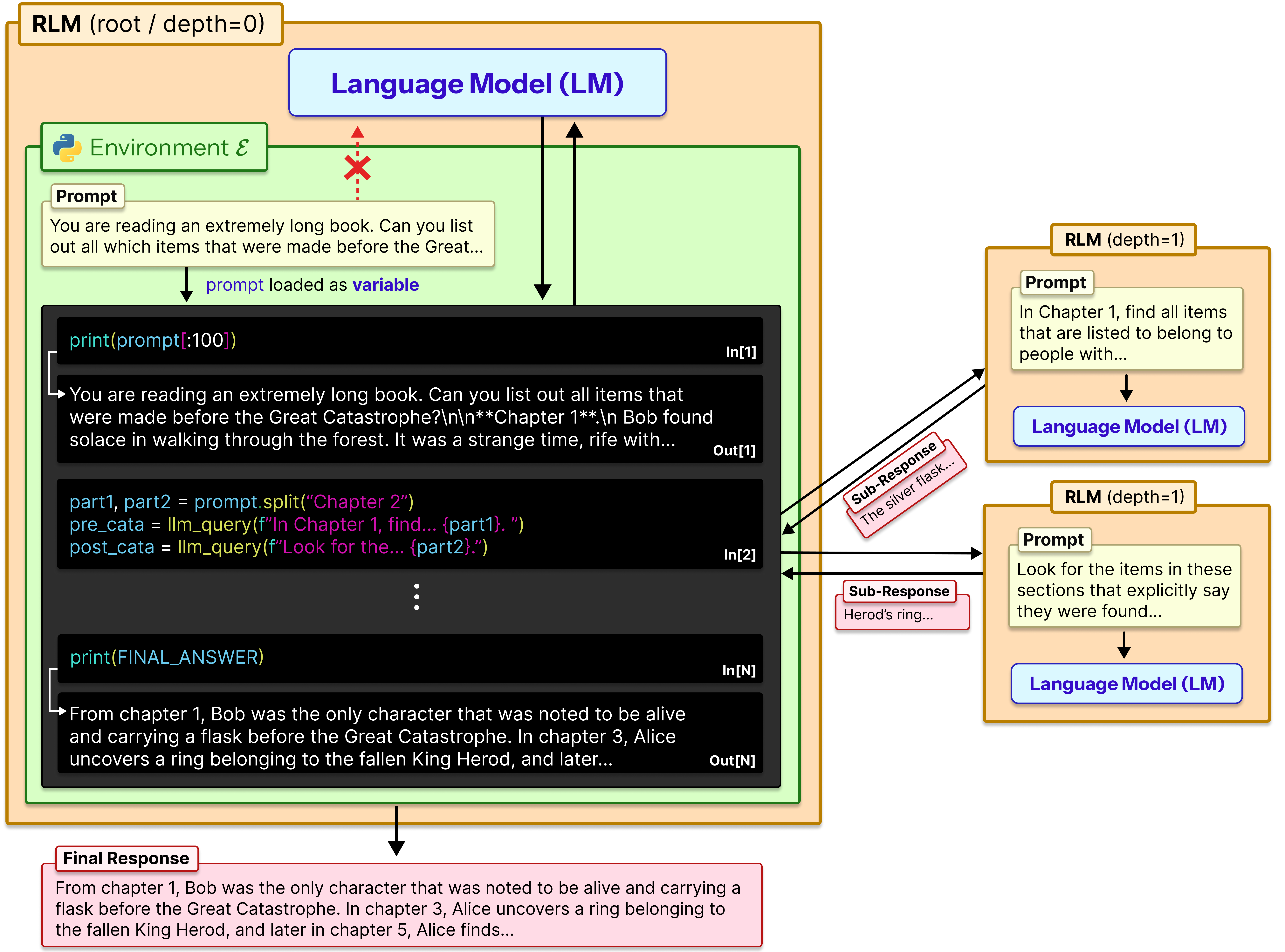 image RLM は Python REPL 環境内でコンテキストと対話します。大きなプロンプトを分解するために自分自身を再帰的に呼び出すことができます。図出典:[[1]](https://www.alphaxiv.org/abs/2512.24601)。
image RLM は Python REPL 環境内でコンテキストと対話します。大きなプロンプトを分解するために自分自身を再帰的に呼び出すことができます。図出典:[[1]](https://www.alphaxiv.org/abs/2512.24601)。
REPL はモデルに対して一連の組み込み関数を公開しています:
- FINAL(answer) / FINAL_VAR(variable_name) — ロールアウトの終了を示すマークです。FINAL(...) はリテラル文字列を最終回答として返し、FINAL_VAR(...) は指定された名前の既存の REPL 変数を参照してその値を返します。
- rlm_query(prompt, context=None) — 指定されたプロンプト(およびオプションのコンテキスト上書き)を用いて単一の子 RLM ロールアウトを開始し、同じポリシーの下で新しいエージェントループを実行し、子の最終回答文字列を親の REPL に返します。
- rlm_query_batched(prompts, context_list=None) — rlm_query と同様ですが、複数の子を並列に起動(プロンプトごとに 1 つずつ、対応するコンテキストとペアにして)し、それらの最終回答を順序どおりのリストとして返します。
文脈をプログラム的に操作したり、サブ RLM やサブ LM を起動できる能力により、RLM は長いコンテキストの問題に対処するための非常に強力な推論戦略となっています。
本ブログでは、科学文献からの証拠選択というタスクに焦点を当てます。質問と arXiv 論文のセットが与えられた場合、目的は質問に答えるための論文からのスニペットを返すことです。このタスクのために REPL に保存されるコンテキストは、特定の質問に対するセット内のすべての論文の全文です。
 imageRLM(再帰的言語モデル)に質問「この論文でどのようなベースラインが使用されていますか?」に対して返してほしい黄金の断片
imageRLM(再帰的言語モデル)に質問「この論文でどのようなベースラインが使用されていますか?」に対して返してほしい黄金の断片
step 1 · 論文を検索
hits = search("baseline")
step 2 · スライスを参照
hits[:3]
↳ [(p.4, "...CodeAct (+ BM25) ..."),
(p.6, "...この戦略を適用して..."),
(p.7, "...vs. ReAct ベースライン...")]
step 3 · スパンを保存
ev = []
ev.append(extract_section(hits[1]))
step 4 · 変数の妥当性を確認
len(ev), ev[0][:48]
↳ (1, "We compare CodeAct (+ BM25) against...")
step 5 · 回答をマーク
FINAL_VAR(ev)
各ターンで、モデルはコードの断片を生成します。REPL(実行環境)がそれを実行し、結果を表示します。プロンプトと中間状態(論文、ヒット結果、ev)は、モデルのコンテキストウィンドウ内ではなく、REPL 内に存在します。
単一の論文の場合、元の RLM 論文に関する以下の質問を想定してください:*この論文でどのようなベースラインが使用されていますか?* RLM が採用できる単純な戦略として、文脈に対してキーワード検索関数を呼び出し、用語 "baseline" で照合し、最も関連性の高い断片を返す方法があります。
これを複数の論文に拡張すると、タスクは分解可能であり、サブ RLM(再帰言語モデル)を用いて並列化できることが明確になります。明白なアプローチとして、ルート RLM がさらに探索する価値のある論文を特定し、個別の論文からスニペットを抽出するためにサブ RLM を起動させる方法があります。ここで強調すべき点は、RLM の利点が長いコンテキストタスクに限定されないことです。この特定のタスクは、そもそも非常に長いコンテキストを持つわけではありません(数百の論文を試すことは今後検討したいと考えていますが)、しかし極めて並列化可能です。タスクの並列化可能性を受け入れることは、単に実行時間を短縮するだけでなく、実際にはタスクのパフォーマンスも向上させます。いくつかの研究では、逐次的な推論は LLM(大規模言語モデル)を「プレフィックス」トラップに陥らせると示されています。これは、モデルが最初に探索した内容のみを追跡してしまう状態を指します。
parent · REPLdepth 0RLM
ctx: {paper_id → full_text}
ids = list(ctx.keys())
titles = [ctx[id].title for id in ids]
relevant = triage(titles, q) ↳ [0, 2, 5]
dispatch a child RLM per paper
evidence = [rlm(ctx[ids[i]], q) for i in relevant]
- paper+sub-questionchild rlm · paper [0]depth 1RLMq: "methods & baselines used?"own REPLev = []hits = search("baseline")ev.append(extract_section(hits[1]))ev.append(extract_section(hits[2]))FINAL_VAR(ev)returns 2 spans · 412 tok···child rlm · paper [5]depth 1RLMq: "methods & baselines used?"own REPLev = []hits = search("baseline")ev.append(extract_section(hits[0]))ev.append(extract_section(hits[3]))FINAL_VAR(ev)returns 2 spans · 503 tokverbatim spansparent · aggregatedepth 0RLMevidence = [[…2 spans…], […1 span…], […2 spans…]]
flattened_evidence = flatten(evidence)
FINAL_VAR(flattened_evidence) ↳ 5 spans · 1 113 tokdispatch (paper + question)return (verbatim spans)The parent RLM triages titles, then calls rlm(paper, q) on each promising paper. Each child is also an RLM: it gets its own REPL with the assigned paper as a variable, runs search / extract_section turns, and returns verbatim spans. The parent flattens the children's results. One policy plays both roles and child rollouts inherit the parent's advantage at training time.
An important distinction here from other tasks that RLMs have typically been evaluated on is that the root RLM spawns true sub-RLMs that have access to a REPL environment. For other datasets like OOLONG, RLMs have only been trained to make sub-LM calls to an external, frozen model.
To abstract away certain basic operations, we initialize REPL environments with four predefined functions:
list_papers(ctx) は、コンテキスト辞書内のすべての論文を反復処理し、各論文の ID、タイトル、要約を出力します。最終的にタイトルリストを返します。
- search(text, keyword, window=300, bidirectional=True): 大文字小文字を区別しないキーワード検索機能で、一致した箇所周辺の文単位にスニペットを返します。text が辞書型の場合、すべての論文を検索して結果を論文 ID でグループ化しますが、文字列型の場合は単一の文字列のみを検索します。
- extract_section(snippet, start_phrase, end_phrase): スニペット内において、start_phrase から始まる部分文字列を抽出し、end_phrase(両端とも含む)で終了させます。大文字小文字は区別しません。いずれのフレーズも見つからない場合は、スニペットの先頭から開始するか、末尾まで読み進めます。
- get_paper_abstract(ctx, paper_id): コンテキスト辞書内から指定された 1 つの論文を検索し、「Paper ID / Title / Abstract」形式の文字列を返します。これは子プロンプトにタグ付けするために使用され、ワーカーが現在処理中の論文を識別できるようにするためのものです。
これらの事前定義済み関数は、従来の多段階・ReAct エージェントループにおけるツール呼び出しと同等の役割を果たします。
私たちは科学的な問い合わせとそれを裏付ける証拠を合成データとして生成します。まず、alphaXiv からランダムに論文を 1 編選択し、そこから意味的に類似した論文を最大 9 編取得してグループ化します。この際、高評価の論文を優先します。その後、OCR モデルがグループ内の各論文を段落ごとに分割し、フロンティアモデル(最先端の言語モデル)がその質問に対して関連する段落をサブセットから選択しながら問い合わせを生成します。グループ内のすべての論文に、その質問に関連する段落があるわけではありません。OCR モデルは、クリーンな正解証拠(ground-truth evidence)を構築するためにのみ使用されます。テスト時には、モデルは PDF 解析ライブラリからのノイズの多いテキストを受け取り、これは新規ドキュメントに対して毎回 OCR を実行することが非効率で高コストとなる実運用環境を模倣したものです。全体として、最大 10 編の論文からなるグループを対象に、グループあたり最大 3 件の問い合わせを含む計 1000 件の問い合わせを合成データとして生成します。
sample row
input papers (7)
ResNet1512.03385VGG1409.1556DenseNet1608.06993SENet1707.02921PReLU-net1502.01852ViT-22B2511.14329Pre-act ResNet1603.05027
question
What are the reported ImageNet top-5 validation error rates for the ensemble models of VGG, the PReLU-enhanced Model C, and the original ResNet?
ground-truth evidence
1409.1556 · VGG**"VGG (7 nets) — 24.7 / 7.5 / 7.3; VGG (1 net) — 25.9 / 8.0 / –"
1512.03385 · ResNet
「私たちの 152 レイヤーの ResNet は、単一モデルによるトップ 5 検証誤差が 4.49% です。…異なる深さを持つ 6 つのモデルを組み合わせアンサンブルを構成しました。これにより、テストセットにおけるトップ 5 誤差は 3.57% となりました。このエントリーは ILSVRC 2015 で第 1 位を獲得しました。」
データセットからの単一行です。RLM(再帰的言語モデル)は 7 つの論文すべてをコンテキストとして受け取り、質問に対する証拠を含むものを特定する必要があります。各入力論文からの全文は PDF パーシングライブラリから生成され、ルート RLM へのコンテキストとして渡すためにデータセットに含まれています。ハイライトされた論文が、真値となる支持論文です。
もう一つ明確にしておくべき点は、RAG(Retrieval-Augmented Generation:検索強化型生成)はこのタスクには不向きだということです。モデルは、固定サイズのトップ k ではなく、長さや件数が異なる文字列の正確なスパンを動的に返す必要があります。ただし、RAG と RLM は排他的なものではありません。インデックス化されたチャンクは、検索やセクション抽出 alongside の REPL ツールとして追加で公開することも可能です。
元の RLM 論文では、Qwen3-Coder-480B-A35B-Instruct から得た RLM に似た推論軌道を用いて Qwen3-8B を SFT(Supervised Fine-Tuning:教師あり微調整)しています。SFT の目的は、モデルに REPL 環境の操作方法を教えることであり、これには回答を送信するための RLM 固有の構文や、サブ LM(言語モデル)への呼び出し方法も含まれます。ただし、特定のタスクやデータセット向けに RLM を訓練するために SFT が使用されたわけではありません。
推論モデルおよび従来のエージェント・ハーンスにおいて、強化学習(RL)は、純粋な SFT ベースのアプローチに伴う壊滅的な忘却を伴わずに、特定タスクに対するモデルの能力を向上させる堅牢な手段であることが証明されています。これを RLM へどのように拡張できるでしょうか?
RLM(サブコールなし)
RLM の再帰的要素を検討する前に、まず証拠選択タスクの単一論文バリアントにおいて Qwen3.5-4B を RL でファインチューニングできるかを確認したいと考えています。このタスクでは子 RLM を起動する必要はありません。これらの初期実行からは、共有する価値のあるいくつかのポイントが得られました。
タスク戦略。特定のタスク戦略はプロンプト内に明示する必要があります。これには、RLM を誘導しロールアウト生成を加速するための事前定義済み関数の説明が含まれます。単一論文タスクの場合の戦略は、検索機能を用いて複数のキーワード変種で論文を検索し、最も有望なスニペットを精緻化された検索呼び出しで拡張し、最終的に extract_section 関数を用いて回答を送信するというものです。これは全体で 5〜7 ターンにわたって行われます。明示的な戦略がない場合、Sonnet 4.6 のような最先端モデルでもロールアウト生成に 90 秒を要しますが、戦略を与えられた場合は 30 秒で完了します。
コールドスタート SFT。大規模モデルでは必ずしも必要ではないかもしれませんが、RLM ハーンスは十分に複雑であるため、優れたプロンプトと事前定義済みツールがあっても、Qwen3.5-4B の pass@16 スコアは 0 になります。RLM ベースのタスクは、ほとんどの小規模モデルにとって能力の限界を超えています。
SFT(教師あり微調整)フェーズなしでトレーニングを行った場合、元のRLM論文で観察されたのと同じ多くの失敗モードが確認されました。これには、最終回答を提出する際に誤った構文を使用したり、ターン全体にわたってモデルのコンテキストウィンドウを肥大化させる過度な推論やツール呼び出しが含まれます。
SFTフェーズ自体については、[参照文献] で使用されたのと同じ手法を採用しました。Qwen3.5-397B-A17Bを使用して、同じ証拠選択タスクで教師モデルであるRLMのロールアウトを生成し、REPLエラーを含むものや、取得した証拠スニペットとゴールド(正解)証拠スニペットとの文字範囲重なりにおけるF1スコアがゼロのものについては除外しました。私たちのSFTデータセットは、RLデータセットから少数数十例のサンプルを保持して抽出した小規模な部分でした。初期の実行では、RLトレーニングデータセット全体で生成されたトレースに対してSFTを行うと(データセット自体は大きくないにもかかわらず)、エントロピーの崩壊とその後の不安定性が生じることが分かりました。
SFT 全トレーニングセット、4 エポック
SFT 全トレーニングセット
SFT 小規模保持外しセット
ポリシー KL
平均生報酬(EMA)
ポリシー KL 発散(左)と平均生得報酬(右)は、マルチ論文証拠選択タスクでのトレーニング時に SFT コールドスタート変種全体にわたって示されています。フルトレーニングセット上での SFT は大きな KL のスパイクと報酬の崩壊を引き起こしますが、小さなホールドアウトサブセット上での SFT は安定しており効果的にトレーニングされます。
段階的トレーニング。 RLM スキャフォールドのもう一つの微妙な点は、連続するターンがプレフィックスを共有しないことです。ユーザープロンプトは永続的なチャット履歴の一部ではなく、各ターンの前に付加されます。これは、元のユーザークエリがモデルのコンテキストウィンドウの奥深くに埋もれてしまうのを防ぎ、RLM にそのタスクを思い出させるためのものです。
典型的なチャット RL
1 つの軌道につき 1 シーケンス
sys
user q
think
a₁
o₁
think
a₂
o₂
think
a₃
段階的・RLM
n 個の別々のシーケンス
1
sys
user q
think
a₁
2
sys
a₁
o₁
user q
think
a₂
3
sys
a₁
o₁
a₂
o₂
user q
think
a₃
各ターンは、システムメッセージと REPL の履歴、ユーザーの質問、そして新しいアクションを組み合わせて新たに構築されます。ユーザープロンプトは REPL 履歴の後に配置され(これは各ターンで再付加されるものであり、先頭に固定されるものではありません)、勾配に寄与するのは新しいアクションのみです。1 つの軌道からは n 個の短い対数尤度配列が得られ、これらはすべて最終的なアドバンテージ A を共有します。
各ターンのユーザープロンプトは蓄積されるのではなく書き換えられるため、ロールアウトを単一のトレーニング例として使用することはできません。各ターンは個別のトレーニングサンプルとなる必要があり、N ターン分のロールアウトは N 個のサンプルを生み出します。アドバンテージ計算においては、軌道の最終ステップに対応するロールアウトのみが GRPO グループに含まれ、そのアドバンテージは以前のターンのロールアウトに対してブロードキャストされます。ステップごとの RL 学習の詳細については こちら をご覧ください。
LLM ジャッジ。 私たちは報酬付与にルールベースの LLM ジャッジを使用しています。当初は、選択されたスニペットの F1 スコアのような検証可能な報酬を試みましたが、これは非常にノイズが多かったことが判明しました。「X ベースラインでどの手法が最高スコアを記録するか?」といった質問には複数のテキスト選択で回答可能であり、その中にはラベルに含まれていないものも含まれていました。私たちは 検索エージェントに関する以前の研究 でも同様の課題に直面しました。これを回避するため、元のクエリ、正解テキスト、予測テキストを提示されたルールベースの LLM ジャッジを採用しました。ルールベースのジャッジは、報酬ハッキングに対してより堅牢であることが示されています。ルールベース報酬に関する優れた概説は Cameron Wolfe 氏による こちら でご覧いただけます。
これらの考慮事項を踏まえると、RL(強化学習)ファインチューニングにより単一論文タスクで顕著な改善がもたらされ、Qwen3.5-4B における評価ジャッジスコアは約 0.6 から 0.8 に上昇しました。
raw reward
5-step moving avg
Claude Sonnet 4.6 (0.80)
単一論文証拠選択タスクにおける Qwen-3.5-4B エージェントの 95 訓練ステップにわたる評価報酬。モデルは約 0.46 から約 0.80 に上昇し、Claude Sonnet 4.6 ベースライン(破線)と一致します。
SFT モデルの上に RL を適用しているため、トレーニングは報酬 0.6 から開始され、ゼロからではない点に注意してください。これは、コールドスタート SFT フェーズの重要性を示しています。
RLM (サブコール付き)
それでは、真の RLM(再帰型言語モデル)を必要とする複数論文ケースについて考えてみましょう。ルートの RLM は、子 RLM を派遣する価値のある論文を特定し、子 RLM は割り当てられた論文から関連する記述部分を抽出する必要があります。
ルートと子の RLM に対して別々のポリシーを訓練したくなるかもしれません。しかし、これには 2 つのセットの報酬信号と、2 つのポリシーを訓練するための扱いにくいトレーニングパイプラインが必要です。あるいは、サブコールには凍結されたモデルを使用し、ルートの RLM のみに対するモデルを訓練するというアプローチもあります(これは元の RLM 論文で採用された方法です)。しかし、SFT(監督微調整)された 4B モデルでは子タスクを成功裏に実行できないため、何らかのオンポリシー学習が必要です。私たちは、異なる RLM タスク間で一般化可能であり、単一のポリシーがルートの RLM と子の RLM の両方の役割を効果的に学習できるようにするトレーニング目標と RL(強化学習)の訓練設定を考案しました。
簡単に言えば。 ルート RLM のロールアウトに対するアドバンテージは、標準的な GRPO を用いて計算されます。各子ロールアウトは親ルートからのアドバンテージを引き継ぎ、損失への子の寄与は平均化(そのロールアウトにおける子の数 kgk_g で除算)されるため、より多くのサブコールを生成したルートが過剰に重み付けられることはありません。
あるいは、より形式的には。 バッチ内の各クエリ x に対して、G 個のルートロールアウトのグループをサンプリングします:
{y_g}_{(g = 1)}^G ∼ π_{θ_old}(· | x)
各ルート RLM ロールアウト y_g は、その rlm_query または rlm_query_batched 呼び出しを通じて、子プロンプトの集合 ϕ(y_g)={x_{g,i}}_{i=1}^{k_g} を決定論的に誘発し、子供たちは同じポリシーからサンプリングされます:
y_{g,i} ∼ π_{θ_old}(⋅∣x_{g,i}), i = 1, …, k_g
アドバンテージ計算。検証可能な報酬 r_g = R(x, y_g) を受け取るのはルート RLM ロールアウトのみです。グループ相対的なアドバンテージは、G 個のルートロールアウト全体で計算されます:
A_g = (r_g - mean({r_{g'}}_{g'=1}^G)) / std({r_{g'}}_{g'=1}^G)
アドバンテージ継承。簡略化のため、y_g のすべての子供は y_g のアドバンテージを継承します。
A_{g,i} := A_g (すべての i = 1, …, k_g に対して)
GRPO オブジェクト関数。以下と定義します:
ρ_θ(y∣x) = π_θ(y∣x) / π_{θ_old}(y∣x)
これは、明瞭さのためにトークンインデックスを省略した、トークンごとの重要性比率 (importance ratio) を表します。
RLM ツリー全体に拡張された GRPO オブジェクト関数は以下の通りです:
J(θ)=Ex,{yg},{yg,i}[1G∑g=1G(Lgroot(θ)⏟root rollout+1kg∑i=1kgLg,ichild(θ)⏟child rollouts)]−β DKL[πθ∥πref]
where each per-rollout clipped surrogate is
Lgroot(θ)=1∣yg∣∑t=1∣yg∣min(ρθ(yg(t))Ag, clip(ρθ(yg(t)),1−ϵ,1+ϵ)Ag)
Lg,ichild(θ)=1∣yg,i∣∑t=1∣yg,i∣min(ρθ(yg,i(t))Ag,i, clip(ρθ(yg,i(t)),1−ϵ,1+ϵ)Ag,i)
Note that we add a normalization term 1kg when summing the loss contributions of the child RLM rollouts. This is to ensure that the contribution across all depths of the RLM is balanced. Without normalization, child rollouts dominate the gradient update when kg≫1.
上記のトレーニング目的は最大 RLM デプス(深さ)を 1 と仮定していますが、この目的関数は美しい再帰構造を用いて任意の RLM デプスに拡張可能です。ある RLM 軌道 y に対して、再帰的サブツリー損失は以下のようになります。
Lsubtree(y,A)=Lnode(y,A)+1ky∑i=1kyLsubtree(yi,A)
ここで、{xi}i=1ky は y が送信した子 RLM プロンプトの集合であり、A は y に割り当てられたアドバンテージ(利得)です。また、各子 RLM のロールアウトは yi∼πθold(⋅∣xi) によってサンプリングされます。
子が親の軌道の最終的なアドバンテージを継承する背後にある理由は、GRPO(Group Relative Policy Optimization)において異なるトークンがシーケンスレベルのアドバンテージに異なる寄与をしているにもかかわらず、すべてのトークンに同じシーケンスレベルのアドバンテージを割り当てる理由と同じです。これは真の勾配に対する不偏推定量であり、十分なトレーニングステップを経ることで安定した結果をもたらします。
あるいは、子 RLM のロールアウトが非常に反復的である場合、すべての kg に対して平均化するのではなく、ランダムに 1 つを選択して勾配計算に寄与させることもできます。このアプローチはトレーニングを高速化できる可能性がありますが、同時にノイズが大きくなるという欠点もあります。
j∼Uniform(1,…,kg)
J(θ)=Ex,{yg},{yg,i}[1G∑g=1G(Lgroot(θ)⏟root rollout+Lg,jchild(θ)⏟sampled child)]−β DKL[πθ∥πref]
最終的なマルチ論文 RLM(再帰言語モデル)のトレーニングでは、SFT(教師あり微調整)済み Qwen3.5-4B モデルを対象に学習を行います。トレーニングは 8xH200 の単一ノード上でバッチサイズ 16、プロンプトあたり 8 サンプルという設定で実施されます。親モデルあたり最大 4 つの子 RLM を持つ構成では、生成処理が最大 512 の並列ロールアウトに達し、当初は子 RLM における REPL(REPL: リモート実行環境)のタイムアウトに関連する競合状態が発生しました。これらの問題を修正した後、一貫性があり安定した報酬曲線を確認できました。
生データ報酬
5 ステップ移動平均
Claude Sonnet 4.6 (0.65)
マルチ論文再帰的証拠選択タスクにおける Qwen-3.5-4B エージェントのトレーニングステップごとの評価報酬。モデルは約 0.30 から約 0.60 に上昇し、Claude Sonnet 4.6 のベースライン(破線、0.65)に近づきます。
RL(強化学習)によるポストトレーニングを通じて、4B モデルの平均ルブリックスコアはトレーニングデータセット上で 0.3 から 0.6 に跳ね上がります。評価データセットにおいても、同じ RLM スキャフォールド(骨格構造)を用いた他の最先端モデルと比較して、微調整済み RLM は十分に競合できる性能を示します。
Claude Sonnet 4.6<text x="0" y="0" dy="12" text-anchor="middle" fill="#3a3e45" font-family="IBM
原文を表示
*We RL fine-tune small (4B) models to behave as native recursive language models (RLMs) by training parent and child RLMs under a single, shared policy. With RL, small models can learn task-specific, RLM behavior that cannot be elicited through prompting or even SFT. This blog assumes a basic level of familiarity with RLMs. A great resource for learning about them is the original RLM blog post.*
Contents
We investigate RL fine-tuning 4B models to be used as RLMs in production settings. While RLMs are a powerful inference strategy, they can have unpredictable latency and can require extensive prompt tuning to elicit consistent behavior. RL fine-tuning allows us to train purpose-built RLMs that are cheap to deploy.
Rather than training separate policy models for parent and child RLMs, we train one model to play both roles of a parent decomposer and child sub-agent. We use a simple RL training setup where rollouts from children RLMs inherit the advantages of rollouts of the parent RLMs that spawned them, which allows us to train a single policy. This eliminates the need for additional reward signals for individual child RLM trajectories.
On an evidence selection task over several scientific documents, we show that an RL fine-tuned 4B model performs just as well as Claude Sonnet 4.6 with an identical RLM harness and REPL environment, all while being a fraction of the size and cost.
Our code, which includes training scripts, our implementation of the RLM scaffold, and our evidence selection environment, is available on SkyRL.
RLMs spawn language models (LMs) inside a programmatic environment that stores long user prompts (context), which are traditionally fed directly into the context window of an LM. In this environment, the context is an external object that the LM can inspect through programmatic operations and decompose by recursively calling itself with the ultimate goal of answering some user query about the context.
Like the original RLM paper, we use a Python Read-Eval-Print-Loop (REPL) as our environment. Rather than treating code execution as just another tool, RLMs in a REPL make code the primary interface through which the model inspects and transforms data. Every turn, the model writes code it wants to execute, the REPL executes the code, and the RLM orchestrator returns the results of the executed code (primarily print() statements) as a user message back to the model for the next turn.
![RLMs interact with their context inside of a Python REPL environment. They can recursively call themselves to decompose large prompts. Figure from [[1]](https://www.alphaxiv.org/abs/2512.24601).](https://www.alphaxiv.org/assets/rlm-overview-Bir1v2Vm.png)
The REPL exposes a set of built-in functions to the model:
- FINAL(answer) / FINAL_VAR(variable_name) — Marks the end of the rollout: FINAL(...) returns the literal string as the final answer, while FINAL_VAR(...) looks up an existing REPL variable by name and returns its value.
- rlm_query(prompt, context=None) — Spawns a single child RLM rollout with the given prompt (and optional context override), running a fresh agent loop under the same policy, and returns the child's final answer string back into the parent's REPL.
- rlm_query_batched(prompts, context_list=None) — Same as rlm_query but dispatches multiple children in parallel (one per prompt, paired with the corresponding context) and returns a list of their final answers in order.
The ability to interact with context programmatically and spawn sub-RLMs or sub-LMs makes RLMs a very powerful inference strategy for tackling long context problems.
For this blog, we'll focus on the task of evidence selection from scientific documents. Given a question and a set of arXiv papers, the objective is to return snippets from the papers that answer the question. The context that is stored in the REPL for this task is the full text of all of the papers in the set for a given question.
In the single paper case, consider the following question about the original RLM paper: *What baselines are used for this paper?* A simple strategy that the RLM can use is to call a keyword search function with the term "baseline" over the context, analyze the matches, and return the most relevant snippets.
When extending this to multiple papers, it's clear the task can be decomposed and parallelized with sub-RLMs. An obvious approach is to have the root RLM identify which papers are worth further exploring and spawn sub-RLMs to extract snippets from individual papers. One point worth highlighting here is that the benefits of RLMs extend beyond just long-context tasks. This particular task doesn't have an incredibly long context to begin with (experimenting with several hundred papers is something we want to try), but it is highly parallelizable. Not only does embracing the parallelizable nature of the task improve wall-clock time, but it actually also improves task performance. Several works show that sequential reasoning throws LLMs into the "prefix" trap, which is where the model ends up exploring whatever it first explores.
Another point to make clear is that RAG is a poor fit for this task. The model needs to dynamically return verbatim spans of varying length and count, not a fixed-size top-k. RAG and RLMs aren't mutually exclusive though, indexed chunks could be exposed as just another REPL tool alongside search and extract_section.
The original RLM paper SFTs Qwen3-8B with RLM-like reasoning trajectories from Qwen3-Coder-480B-A35B-Instruct. The purpose of SFT is to teach the model how to navigate a REPL environment, including RLM-specific syntax for submitting an answer and making sub-LM calls. However, SFT was not used to train RLMs for a specific task or dataset.
For reasoning models and traditional agent harnesses, RL has proven to be a robust way to improve the capabilities of a model for a specific task without the catastrophic forgetting that accompanies pure SFT-based approaches. How can we extend this to RLMs?
RLM (no sub-calls)
Before considering the recursive element of RLMs, we want to first confirm we can RL fine-tune Qwen3.5-4B on the single-paper variant of our evidence selection task, which doesn't involve spawning child RLMs. There are a couple of takeaways from these initial runs that are worth sharing.
Task Strategy. The specific task strategy has to be in the prompt. This includes descriptions of predefined functions to guide the RLM and expedite rollout generation. For the single-paper task, the strategy is searching the paper with multiple keyword variants using search, expanding the most promising snippets with refined search calls, and then submitting final answers with extract_section, all across 5-7 turns. Without an explicit strategy, even a frontier model like Sonnet 4.6 will take 90 seconds to generate a rollout compared to 30 seconds when given a strategy.
Cold-start SFT. While this may not be needed with larger models, the RLM harness is tricky enough that even with a good prompt and predefined tools, Qwen3.5-4B will have 0 pass@16 scores. RLM-based tasks are outside the edge of competence for most small models.
When training without an SFT phase, we observed many of the same failure modes observed in the original RLM paper, which include using the wrong syntax to submit final answers and excessive reasoning and tool calls that would bloat the model's context window across turns.
For the SFT phase itself, we use the same methodology from . We generated teacher RLM rollouts with Qwen3.5-397B-A17B on the same evidence selection task and filtered out rollouts that either contained REPL errors or scored zero F1 on character-span overlap between retrieved evidence snippets and gold evidence snippets. Our SFT dataset was a small, held-out portion of the RL dataset of a few dozen examples. In initial runs, we found that doing SFT on traces produced over the entire RL training dataset (even though it isn't a large dataset) led to entropy collapse and subsequent instability .
Stepwise Training. Another nuance of the RLM scaffold is that successive turns do not share prefixes. The user prompt is not part of the persistent chat history and is instead appended before each turn. The point of this is to ensure the original user query is not buried deep into the context window of the model and that the RLM is reminded of its task.
Because the per-turn user prompt is rewritten rather than accumulated, you cannot use a rollout as a single training example. Each turn has to be a separate training sample, so a rollout of N turns produces N samples. For advantage calculation, only rollouts corresponding to the last step of trajectories are included in the GRPO group, and the advantage is broadcast to rollouts from previous turns. See more about step-wise RL training here.
LLM Judges. We use rubric-based LLM judges for reward assignment. We initially tried verifiable rewards like F1 of selected snippets, but this proved to be very noisy. Questions like "Which method scores the best on X baseline?" could be answered with several selections of text, some of which weren't included in our labels. We experienced a similar issue in our previous work on retrieval agents. To circumvent this, we used rubric-based LLM judges that were provided with the original query, the ground truth text, and the predicted text. Rubric-based judges have been shown to be more robust to reward hacking . A great overview of rubric-based rewards by Cameron Wolfe can be found here.
With these considerations, RL fine-tuning yields significant improvements on the single-paper task, with eval judge scores jumping from around 0.6 to 0.8 with Qwen3.5-4B.
Note that because we RL on top of an SFT model, training begins at 0.6 reward rather than zero, demonstrating the importance of a cold-start SFT phase.
RLM (with sub-calls)
Now let's consider the multi-paper case, which requires a true RLM with recursive sub-calls. We want the root RLM to identify which papers are worth dispatching child RLMs to, and child RLMs should extract the relevant passages from their assigned paper.
It might be tempting to train separate policies for root and children RLMs. However, this would require two sets of reward signals and an unwieldy training pipeline to train two policies. Alternatively, we can use a frozen model for sub-calls and only train a model for the root RLM, which is the approach taken by the original RLM paper. However, given that an SFT 4B model is unable to perform the child task successfully, some form of on-policy training is necessary. We devise a training objective and an RL training setup that can generalize across different RLM tasks and enables a single policy to effectively learn both root and child RLM roles.
Put simply. Advantages are computed for root RLM rollouts using standard GRPO.
Each child rollout inherits the advantage of its parent root, and child contributions to the loss
are averaged (divided by kgk_g, the number of children in that rollout) so no single root is
overweighted for spawning more sub-calls.
Or more formally. For each query xx in the batch, sample a group of GG root rollouts:
{yg}(g=1)G∼πθold(⋅∣x)\lbrace y_g \rbrace_{(g = 1)}^G \sim \pi_{\theta_{\text{old}}}(\cdot \mid x)
Each root RLM rollout ygy_g deterministically induces a set of child prompts ϕ(yg)={xg,i}i=1kg\phi(y_g) = \lbrace x_{g,i} \rbrace_{i=1}^{k_g} via its rlm_query or rlm_query_batched calls, and children are sampled from the same policy:
yg,i∼πθold(⋅∣xg,i),i=1,…,kgy_{g,i} \sim \pi_{\theta_{\text{old}}}(\cdot \mid x_{g,i}), \quad i = 1, \dots, k_g
Advantage Calculation. Only root RLM rollouts receive a verifiable reward rg=R(x,yg)r_g = R(x, y_g). Group-relative advantages are computed over the GG root rollouts:
Ag=rg−mean ({rg′}g′=1G)std ({rg′}g′=1G)A_g = \dfrac{r_g - \text{mean}\!\left(\lbrace r_{g'} \rbrace_{g'=1}^G\right)}{\text{std}\!\left(\lbrace r_{g'} \rbrace_{g'=1}^G\right)}
Advantage Inheritance. For simplicity, we have every child of ygy_g inherit ygy_g's advantage.
Ag,i:=Agfor all i=1,…,kgA_{g,i} := {A_g} \quad \text{for all } i = 1, \dots, k_g
GRPO Objective. Let
ρθ(y∣x)=πθ(y∣x)πθold(y∣x)\rho_\theta(y \mid x) = \dfrac{\pi_\theta(y \mid x)}{\pi_{\theta_{\text{old}}}(y \mid x)}
denote the per-token importance ratio (token index suppressed for clarity).
The GRPO objective extended over the RLM tree is:
J(θ)=Ex,{yg},{yg,i}[1G∑g=1G(Lgroot(θ)⏟root rollout+1kg∑i=1kgLg,ichild(θ)⏟child rollouts)]−β DKL[πθ∥πref]\mathcal{J}(\theta) = \mathbb{E}_{x, \lbrace y_g \rbrace, \lbrace y_{g,i} \rbrace} \Bigg[ \dfrac{1}{G} \sum\limits_{g=1}^{G} \Bigg( \underbrace{\mathcal{L}_g^{\text{root}}(\theta)}_{\text{root rollout}} + {\color{red}\dfrac{1}{k_g} \sum\limits_{i=1}^{k_g} \underbrace{\mathcal{L}_{g,i}^{\text{child}}(\theta)}_{\text{child rollouts}}} \Bigg) \Bigg] - \beta \, \mathbb{D}_{\text{KL}}[\pi_\theta \| \pi_{\text{ref}}]
where each per-rollout clipped surrogate is
Lgroot(θ)=1∣yg∣∑t=1∣yg∣min(ρθ(yg(t))Ag, clip(ρθ(yg(t)),1−ϵ,1+ϵ)Ag)\mathcal{L}_g^{\text{root}}(\theta) = \dfrac{1}{|y_g|} \sum\limits_{t=1}^{|y_g|} \min\Big( \rho_\theta(y_g^{(t)}) A_g, \; \text{clip}(\rho_\theta(y_g^{(t)}), 1-\epsilon, 1+\epsilon) A_g \Big)
Lg,ichild(θ)=1∣yg,i∣∑t=1∣yg,i∣min(ρθ(yg,i(t))Ag,i, clip(ρθ(yg,i(t)),1−ϵ,1+ϵ)Ag,i)\mathcal{L}_{g,i}^{\text{child}}(\theta) = \dfrac{1}{|y_{g,i}|} \sum\limits_{t=1}^{|y_{g,i}|} \min\Big( \rho_\theta(y_{g,i}^{(t)}) A_{g,i}, \; \text{clip}(\rho_\theta(y_{g,i}^{(t)}), 1-\epsilon, 1+\epsilon) A_{g,i} \Big)
Note that we add a normalization term 1kg\frac{1}{k_{g}} when summing the loss contributions of the child RLM rollouts. This is to ensure that the contribution across all depths of the RLM is balanced. Without normalization, child rollouts dominate the gradient update when kg≫1k_g \gg 1.
While the training objective above assumes a max RLM depth of 1, this objective can be expanded to any RLM depth with a nice recursive structure. For a given RLM trajectory yy, the recursive subtree loss is:
Lsubtree(y,A)=Lnode(y,A)+1ky∑i=1kyLsubtree(yi,A)\mathcal{L}_{\text{subtree}}(y, A) = \mathcal{L}_{\text{node}}(y, A) + \frac{1}{k_y} \sum_{i=1}^{k_y} \mathcal{L}_{\text{subtree}}(y_i, A)
where {xi}i=1ky\lbrace x_i \rbrace_{i=1}^{k_y} is the set of child RLM prompts dispatched by yy, AA is the advantage assigned to yy, and each child RLM rollout is sampled by yi∼πθold(⋅∣xi)y_i \sim \pi_{\theta_{\text{old}}}(\cdot \mid x_i).
The rationale behind having children inherit their parent trajectory's final advantage is the same rationale behind assigning every token the same sequence-level advantage in GRPO, even though different tokens make different contributions to the sequence-level advantage. This is an unbiased estimator of the true gradient that, with sufficient training steps, yields stable results.
Alternatively, if the child RLM rollouts are highly repetitive, you can randomly sample one to contribute to the gradient instead of averaging across all kgk_g. While this approach can speed up training, it can also be very noisy.
j∼Uniform(1,…,kg)j \sim \text{Uniform}(1, \dots, k_g)
J(θ)=Ex,{yg},{yg,i}[1G∑g=1G(Lgroot(θ)⏟root rollout+Lg,jchild(θ)⏟sampled child)]−β DKL[πθ∥πref]\mathcal{J}(\theta) = \mathbb{E}_{x, \lbrace y_g \rbrace, \lbrace y_{g,i} \rbrace} \Bigg[ \dfrac{1}{G} \sum\limits_{g=1}^{G} \Bigg( \underbrace{\mathcal{L}_g^{\text{root}}(\theta)}_{\text{root rollout}} + {\color{red}\underbrace{\mathcal{L}_{g,j}^{\text{child}}(\theta)}_{\text{sampled child}}} \Bigg) \Bigg] - \beta \, \mathbb{D}_{\text{KL}}[\pi_\theta \| \pi_{\text{ref}}]
For the final multi-paper RLM training runs, we train on an SFT Qwen3.5-4B model. Training is done on a single 8xH200 node with a batch size of 16 and 8 samples per prompt. With up to 4 child RLMs per parent, generation can hit 512 concurrent rollouts, which initially surfaced race conditions around REPL timeouts for child RLMs. After fixing these, we observe a consistent and stable reward curve.
Through RL post-training the 4B model, the average rubric score jumps from 0.3 to 0.6 on the training dataset. On the eval dataset, the fine-tuned RLM stacks up well against other frontier models using the same RLM scaffold.
Claude Sonnet 4.6<text x="0" y="0" dy="12" text-anchor="middle" fill="#3a3e45" font-family=""IBM
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み