マルチ画像推論への準備はできているか?VHs:ビジュアル・ヘイスタック・ベンチマークの発表!
Berkeley AI Research は、単一画像処理に依存する従来の VQA の限界を克服し、大規模な画像集合からの視覚的情報検索と推論能力を評価するための「Visual Haystacks (VHs)」ベンチマークを発表した。
キーポイント
多画像推論(MIQA)の必要性
医療画像、衛星写真、監視映像など、数百から数千枚にわたる画像集合からのパターン認識やクロス画像分析は、従来の単一画像 VQA では不可能であり、新しい課題設定が必要である。
視覚中心型 NIAH ベンチマークの導入
既存のテキスト検索に依存する「Needle-In-A-Haystack」手法を拡張し、画像内の視覚的情報そのものを対象とした「Visual Haystacks (VHs)」ベンチマークを世界で初めて提案した。
大規模未関連画像セットでの評価
1 万枚に及ぶ無相関な画像集合の中から特定の視覚的情報を検索・推論する能力を、約 1,000 の二値 QA ペアを用いて厳密にテストする枠組みを提供する。
既存モデルの限界と課題
Google Gemini-v1.5 で導入された視覚 NIAH は OCR 能力に依存して高いスコアを出したが、純粋な視覚的推論を問う VHs では既存モデルの性能がどう振る舞うかが新たな検証対象となる。
視覚的ノイズへの対応困難
画像数が増加してもオラクル精度は高いにもかかわらず、モデルの性能が顕著に低下し、特に視覚的なノイズ(distractors)に対する検索能力に課題があることが示された。
コンテキストとペイロード制限
オープンソースモデルはコンテキスト長の制約により処理可能な画像数が限られる一方、プロプライエタリモデルも API 呼び出し時のペイロードサイズ制限のため、1000 枚を超える画像の処理で失敗する傾向がある。
推測による回避不可能な設計
画像を見ずに一般的な常識や推測だけで回答すると正解率が 50% に留まるよう設計されており、真に視覚的な検索と推論能力を評価できる。
影響分析・編集コメントを表示
影響分析
このベンチマークは、大規模多モーダルモデル(LMM)の真の「視覚的推論」能力を測るための重要な指標となり、単なる画像認識やテキスト検索を超えた高度な認知機能の評価基準を提供します。業界全体が、医療診断や衛星解析など実社会で求められる複雑な視覚タスクに対する AI の成熟度を客観的に比較・評価できるようになるでしょう。
編集コメント
単一画像の処理能力が向上した現在、次なるボトルネックである「大規模画像集合からの推論」を評価する指標として極めて重要です。OCR 依存から脱却し、純粋な視覚理解力を問うこのベンチマークは、LMM の真の実力測定の転換点となるでしょう。
【厳守ルール】
- 原文の段落構造(空行区切り)を完全に保持してください。原文がN段落なら、翻訳もN段落にしてください。
- 段落の結合・分割は禁止です。
- 各段落の間は空行1行(\n\n)で区切ってください。
- 自然で読みやすい日本語にしてください。要約ではなく全文翻訳です。
- 翻訳文のみを返してください(前置き・説明・記号は不要)。
人間は膨大な視覚情報の配列を処理することに長けており、このスキルは人工汎用知能(AGI)の実現において極めて重要です。過去数十年にわたり、AI研究者たちは単一画像内のシーンを解釈し関連する質問に答えるための視覚質問応答(VQA)システムを開発してきました。基盤モデルの最近の進歩により、人間と機械の視覚処理の間のギャップは大幅に縮まりましたが、従来のVQAは一度に単一画像のみについて推論することに制限されており、視覚データの集合全体を扱うことはできませんでした。
この制限は、より複雑なシナリオにおいて課題を生み出します。例えば、医療画像の集合からパターンを見分ける課題、衛星画像を通じた森林伐採の監視、自律走行データを用いた都市の変化のマッピング、大規模な美術コレクションにわたる主題要素の分析、小売監視映像からの消費者行動の理解などが挙げられます。これらのシナリオのそれぞれは、数百または数千枚の画像にわたる視覚処理だけでなく、これらの知見をまたいだ画像間処理も必要とします。このギャップに対処するため、本プロジェクトは従来のVQAシステムの範囲を超える「マルチ画像質問応答」(MIQA)タスクに焦点を当てています。
 Visual Haystacks: 大規模マルチモーダルモデル(LMM)の長文脈視覚情報処理能力を厳密に評価するために設計された、初の「視覚中心」の針-in-a-干し草(NIAH)ベンチマーク。
Visual Haystacks: 大規模マルチモーダルモデル(LMM)の長文脈視覚情報処理能力を厳密に評価するために設計された、初の「視覚中心」の針-in-a-干し草(NIAH)ベンチマーク。
MIQAにおいてVQAモデルをベンチマークするにはどうすればよいか?
「針-in-a-干し草」(NIAH)課題は最近、大規模な入力データ(長文書、動画、数百枚の画像など)を含む「長文脈」を処理するLLMの能力をベンチマークする最も一般的なパラダイムの一つとなりました。このタスクでは、特定の質問への答えを含む本質的な情報(「針」)が、大量のデータ(「干し草」)の中に埋め込まれています。システムは関連情報を検索し、質問に正しく答えなければなりません。
視覚推論のための最初のNIAHベンチマークは、GoogleによってGemini-v1.5技術報告書で紹介されました。この報告書では、モデルに対して長い動画の中の単一フレームに重ねられたテキストを検索するよう求めました。既存のモデルは、主に強力なOCR検索能力により、このタスクでかなり良好に機能することが判明しています。しかし、より視覚的な質問をしたらどうなるでしょうか?モデルは依然として同じように機能するのでしょうか?
Visual Haystacks (VHs) ベンチマークとは何か?
「視覚中心」の長文脈推論能力を評価することを目指し、我々は「Visual Haystacks (VHs)」ベンチマークを紹介します。この新しいベンチマークは、大規模な無相関画像セットにわたる視覚的検索と推論において大規模マルチモーダルモデル(LMM)を評価するために設計されています。VHsは約1Kの二択質問応答ペアを特徴とし、各セットには1枚から10K枚までの画像が含まれます。テキストの検索と推論に焦点を当てた以前のベンチマークとは異なり、VHsの質問は、COCOデータセットの画像とアノテーションを利用して、物体などの特定の視覚的コンテンツの存在を識別することに中心を置いています。
VHsベンチマークは、クエリに応答する前に関連画像を正確に特定し分析するモデルの能力をテストするために設計された、二つの主要な課題に分けられます。我々は、画像を見ずに推測したり常識的推論に頼ったりしても何の利点も得られない(つまり、二択QAタスクで50%の正答率になる)ように、データセットを注意深く設計しました。
シングルニードル課題: 画像の干し草山の中に単一の針画像のみが存在します。質問は、「アンカーオブジェクトを含む画像において、ターゲットオブジェクトは存在しますか?」という形で構成されます。
マルチニードル課題: 画像の干し草山の中に2枚から5枚の針画像が存在します。質問は、「アンカーオブジェクトを含む全ての画像において、それら全てがターゲットオブジェクトを含みますか?」または「アンカーオブジェクトを含む全ての画像において、それらのいずれかがターゲットオブジェクトを含みますか?」のいずれかの形で構成されます。
VHsから得られた三つの重要な知見
Visual Haystacks (VHs) ベンチマークは、現在の大規模マルチモーダルモデル(LMM)が広範な視覚入力を処理する際に直面する重大な課題を明らかにしています。我々のシングルおよびマルチニードルモードにわたる実験1において、LLaVA-v1.5、GPT-4o、Claude-3 Opus、Gemini-v1.5-proを含むいくつかのオープンソースおよびプロプライエタリ手法を評価しました。さらに、LLaVAを使用して最初に画像をキャプション化し、その後Llama3を使用してキャプションテキストの内容で質問に答えるという二段階アプローチを採用した「キャプショニング」ベースラインを含めました。以下に三つの重要な洞察を示します:
視覚的ディストラクタへの苦戦
シングルニードル設定では、以前のテキストベースのGeminiスタイルのベンチマークには見られなかった高いオラクル精度を維持しているにもかかわらず、画像数が増加するにつれて性能の顕著な低下が観察されました。これは、既存のモデルが主に視覚的検索、特に困難な視覚的ディストラクタが存在する状況に苦戦している可能性があることを示しています。さらに、2Kの文脈長制限により最大3枚の画像しか処理できないLLaVAのようなオープンソースLMMの制約を強調することが重要です。一方、Gemini-v1.5やGPT-4oのようなプロプライエタリモデルは、拡張された文脈能力を主張しているにもかかわらず、API呼び出し時のペイロードサイズ制限のため、画像数が1Kを超えるとリクエストを管理できないことがよくあります。
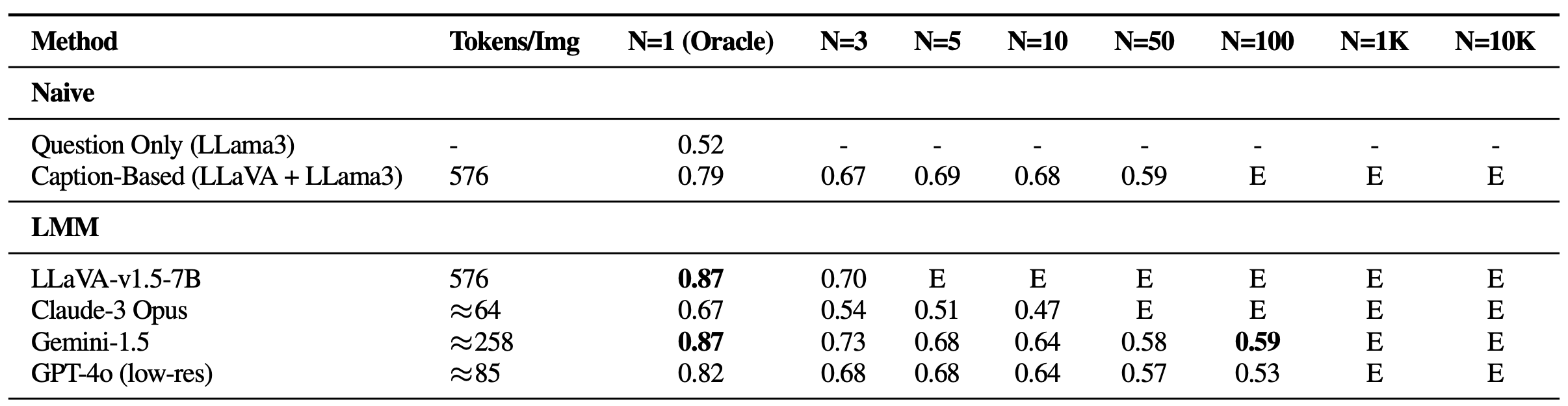 シングルニードル質問に対するVHsでの性能。干し草山(N)のサイズが増加するにつれて、全てのモデルが大幅な性能低下を経験しており、視覚的ディストラクタに対してどれも頑健ではないことを示唆している。E: 文脈長を超える。
シングルニードル質問に対するVHsでの性能。干し草山(N)のサイズが増加するにつれて、全てのモデルが大幅な性能低下を経験しており、視覚的ディストラクタに対してどれも頑健ではないことを示唆している。E: 文脈長を超える。
複数画像にわたる推論の困難さ
興味深いことに、全てのLMMベース手法は、キャプショニングモデル(LLaVA)とLLMアグリゲータ(Llama3)を連鎖させる基本的なアプローチと比較して、単一画像QAにおける5枚以上の画像および全てのマルチニードル設定において弱い性能を示しました。この不一致は、LLMが長文脈キャプションを効果的に統合できる一方で、既存のLMMベースのソリューションは複数画像にわたる情報の処理と統合には不十分であることを示唆しています。特に、マルチ画像シナリオでは性能が大きく悪化し、Claude-3 Opusはオラクル画像のみでも弱い結果を示し、Gemini-1.5/GPT-4oは50枚のより大きなセットでは50%の精度(ランダムな推測と同様)まで低下しました。
 マルチニードル質問に対するVHsでの結果。視覚を認識する全てのモデルは性能が低く、モデルが視覚情報を暗黙的に統合することに課題を感じていることを示している。
マルチニードル質問に対するVHsでの結果。視覚を認識する全てのモデルは性能が低く、モデルが視覚情報を暗黙的に統合することに課題を感じていることを示している。
視覚領域における現象
最後に、LMMの精度は入力シーケンス内での針画像の位置に大きく影響されることがわかりました。例えば、LLaVAは針画像が質問の直前に配置された場合に性能が向上し、そうでない場合最大26.5%の低下を示します。対照的に、プロプライエタリモデルは一般に画像が先頭に配置された場合に性能が良く、そうでない場合最大28.5%の低下を経験します。このパターンは、自然言語処理(NLP)分野で見られる「真ん中で失われる」現象を彷彿とさせます。そこでは、文脈の始めまたは終わりに配置された重要な情報がモデルの性能に影響を与えます。この問題は、テキストの検索と推論のみを必要とした以前のGeminiスタイルのNIAH評価では明らかではなかったため、我々のVHsベンチマークが提起する独自の課題を浮き彫りにしています。
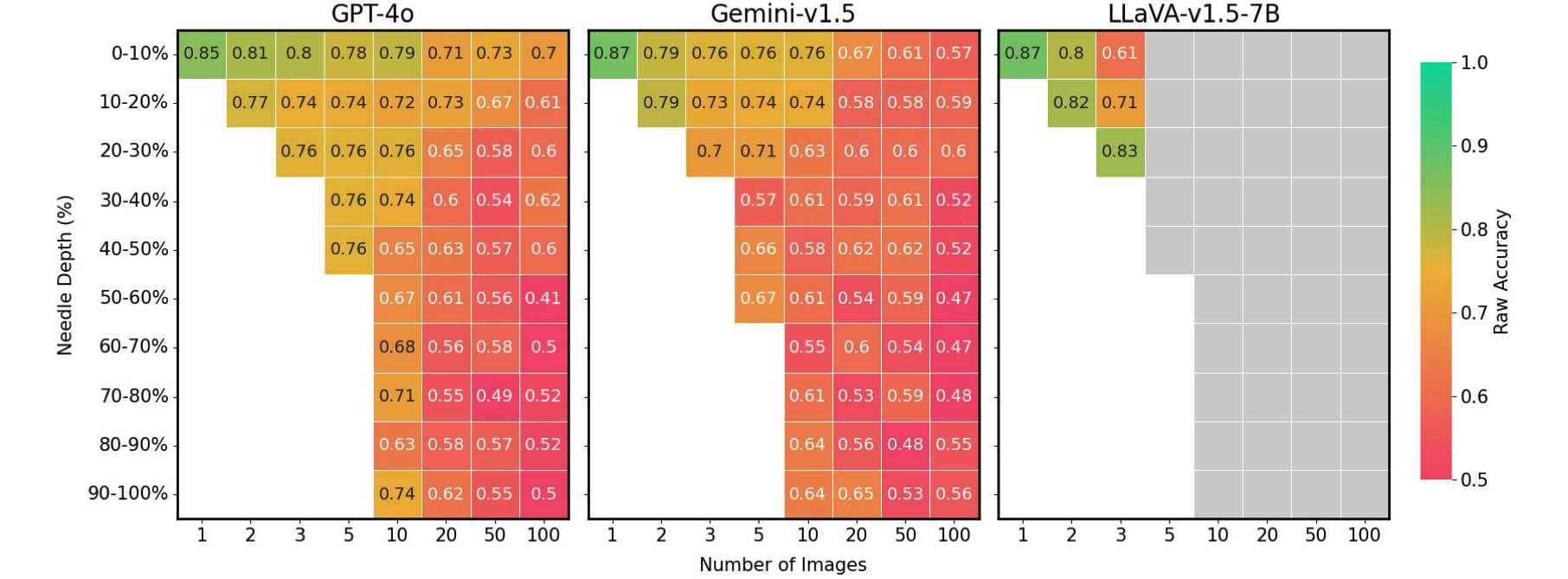 様々な画像設定におけるVHsでの針の位置と性能の関係。既存のLMMは、針が理想的に配置されていない場合、最大41%の性能低下を示す。灰色ボックス: 文脈長を超える。
様々な画像設定におけるVHsでの針の位置と性能の関係。既存のLMMは、針が理想的に配置されていない場合、最大41%の性能低下を示す。灰色ボックス: 文脈長を超える。
MIRAGE: VHs性能向上のためのRAGベースソリューション
上記の実験結果に基づくと、MIQAにおける既存ソリューションの核心的な課題は、ab
原文を表示
Humans excel at processing vast arrays of visual information, a skill that is crucial for achieving artificial general intelligence (AGI). Over the decades, AI researchers have developed Visual Question Answering (VQA) systems to interpret scenes within single images and answer related questions. While recent advancements in foundation models have significantly closed the gap between human and machine visual processing, conventional VQA has been restricted to reason about only single images at a time rather than whole collections of visual data.
This limitation poses challenges in more complex scenarios. Take, for example, the challenges of discerning patterns in collections of medical images, monitoring deforestation through satellite imagery, mapping urban changes using autonomous navigation data, analyzing thematic elements across large art collections, or understanding consumer behavior from retail surveillance footage. Each of these scenarios entails not only visual processing across hundreds or thousands of images but also necessitates cross-image processing of these findings. To address this gap, this project focuses on the “Multi-Image Question Answering” (MIQA) task, which exceeds the reach of traditional VQA systems.
Visual Haystacks: the first "visual-centric" Needle-In-A-Haystack (NIAH) benchmark designed to rigorously evaluate Large Multimodal Models (LMMs) in processing long-context visual information.
How to Benchmark VQA Models on MIQA?
The “Needle-In-A-Haystack” (NIAH) challenge has recently become one of the most popular paradigms for benchmarking LLM’s ability to process inputs containing “long contexts”, large sets of input data (such as long documents, videos, or hundreds of images). In this task, essential information (“the needle”), which contains the answer to a specific question, is embedded within a vast amount of data (“the haystack”). The system must then retrieve the relevant information and answer the question correctly.
The first NIAH benchmark for visual reasoning was introduced by Google in the Gemini-v1.5 technical report. In this report, they asked their models to retrieve text overlaid on a single frame in a large video. It turns out that existing models perform quite well on this task—primarily due to their strong OCR retrieval capabilities. But what if we ask more visual questions? Do models still perform as well?
What is the Visual Haystacks (VHs) Benchmark?
In pursuit of evaluating “visual-centric” long-context reasoning capabilities, we introduce the “Visual Haystacks (VHs)” benchmark. This new benchmark is designed to assess Large Multimodal Models (LMMs) in visual retrieval and reasoning across large uncorrelated image sets. VHs features approximately 1K binary question-answer pairs, with each set containing anywhere from 1 to 10K images. Unlike previous benchmarks that focused on textual retrieval and reasoning, VHs questions center on identifying the presence of specific visual content, such as objects, utilizing images and annotations from the COCO dataset.
The VHs benchmark is divided into two main challenges, each designed to test the model’s ability to accurately locate and analyze relevant images before responding to queries. We have carefully designed the dataset to ensure that guessing or relying on common sense reasoning without viewing the image won’t get any advantages (i.e., resulting in a 50% accuracy rate on a binary QA task).
Single-Needle Challenge: Only a single needle image exists in the haystack of images. The question is framed as, “For the image with the anchor object, is there a target object?”
Multi-Needle Challenge: Two to five needle images exist in the haystack of images. The question is framed as either, “For all images with the anchor object, do all of them contain the target object?” or “For all images with the anchor object, do any of them contain the target object?”
Three Important Findings from VHs
The Visual Haystacks (VHs) benchmark reveals significant challenges faced by current Large Multimodal Models (LMMs) when processing extensive visual inputs. In our experiments1 across both single and multi-needle modes, we evaluated several open-source and proprietary methods including LLaVA-v1.5, GPT-4o, Claude-3 Opus, and Gemini-v1.5-pro. Additionally, we include a “Captioning” baseline, employing a two-stage approach where images are initially captioned using LLaVA, followed by answering the question using the captions’ text content with Llama3. Below are three pivotal insights:
Struggles with Visual Distractors
In single-needle settings, a notable decline in performance was observed as the number of images increased, despite maintaining high oracle accuracy—a scenario absent in prior text-based Gemini-style benchmarks. This shows that existing models may mainly struggle with visual retrieval, especially in the presence of challenging visual distractors. Furthermore, it’s crucial to highlight the constraints on open-source LMMs like LLaVA, which can handle only up to three images due to a 2K context length limit. On the other hand, proprietary models such as Gemini-v1.5 and GPT-4o, despite their claims of extended context capabilities, often fail to manage requests when the image count exceeds 1K, due to payload size limits when using the API call.
Performance on VHs for single-needle questions. All models experience significant falloff as the size of the haystack (N) increases, suggesting none of them are robust against visual distractors. E: Exceeds context length.
Difficulty Reasoning Across Multiple Images
Interestingly, all LMM-based methods showed weak performance with 5+ images in single-image QA and all multi-needle settings compared to a basic approach chaining a captioning model (LLaVA) with an LLM aggregator (Llama3). This discrepancy suggests that while LLMs are capable of integrating long-context captions effectively, existing LMM-based solutions are inadequate for processing and integrating information across multiple images. Notably, the performance hugely deteriorates in multi-image scenarios, with Claude-3 Opus showing weak results with only oracle images, and Gemini-1.5/GPT-4o dropping to 50% accuracy (just like a random guess) with larger sets of 50 images.
Results on VHs for multi-needle questions. All visually-aware models perform poorly, indicating that models find it challenging to implicitly integrate visual information.
Phenomena in Visual Domain
Finally, we found that the accuracy of LMMs is hugely affected by the position of the needle image within the input sequence. For instance, LLaVA shows better performance when the needle image is placed immediately before the question, suffering up to a 26.5% drop otherwise. In contrast, proprietary models generally perform better when the image is positioned at the start, experiencing up to a 28.5% decrease when not. This pattern echoes the “lost-in-the-middle” phenomenon seen in the field of Natural Language Processing (NLP), where crucial information positioned at the beginning or end of the context influences model performance. This issue was not evident in previous Gemini-style NIAH evaluation, which only required text retrieval and reasoning, underscoring the unique challenges posed by our VHs benchmark.
Needle position vs. performance on VHs for various image settings. Existing LMMs show up to 41% performance drop when the needle is not ideally placed. Gray boxes: Exceeds context length.
MIRAGE: A RAG-based Solution for Improved VHs Performance
Based on the experimental results above, it is clear that the core challenges of existing solutions in MIQA lie in the ability to (1) accurately retrieve relevant images from a vast pool of potentially unrelated images without positional biases and (2) integrate relevant visual information from these images to correctly answer the question. To address these issues, we introduce an open-source and simple single-stage training paradigm, “MIRAGE” (Multi-Image Retrieval Augmented Generation), which extends the LLaVA model to handle MIQA tasks. The image below shows our model architecture.
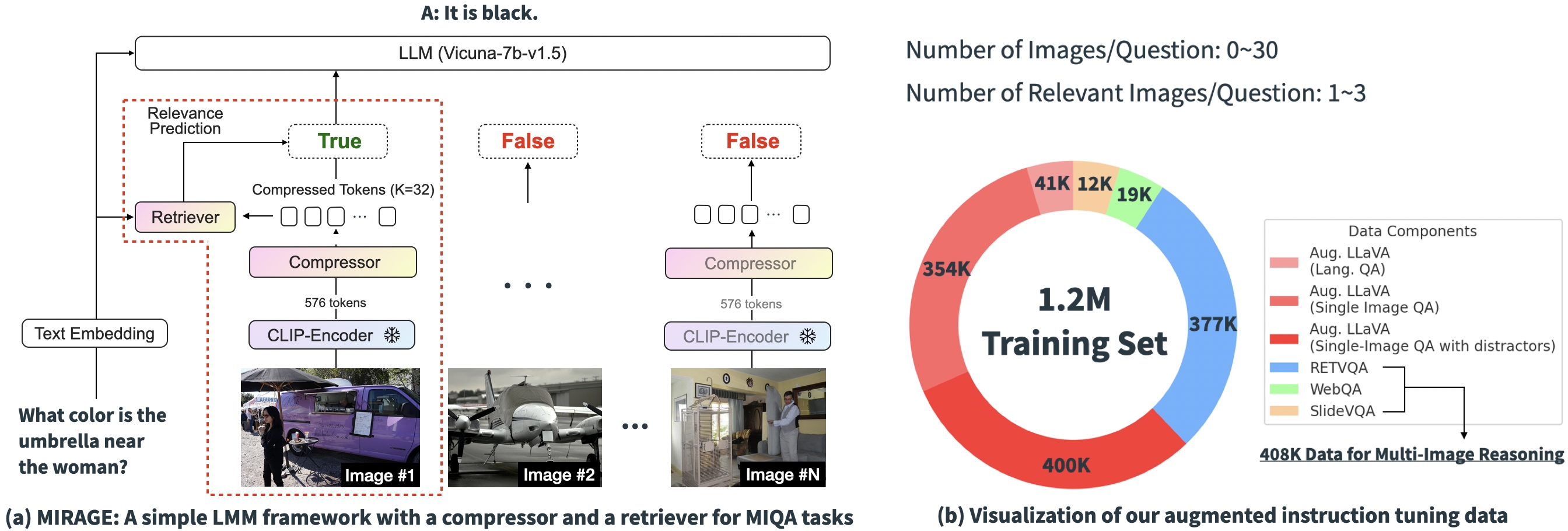
Our proposed paradigm consists of several components, each designed to alleviate key issues in the MIQA task:
Compress existing encodings: The MIRAGE paradigm leverages a query-aware compression model to reduce the visual encoder tokens to a smaller subset (10x smaller), allowing for more images in the same context length.
Employ retriever to filter out irrelevant message: MIRAGE uses a retriever trained in-line with the LLM fine-tuning, to predict if an image will be relevant, and dynamically drop irrelevant images.
Multi-Image Training Data: MIRAGE augments existing single-image instruction fine-tuning data with multi-image reasoning data, and synthetic multi-image reasoning data.
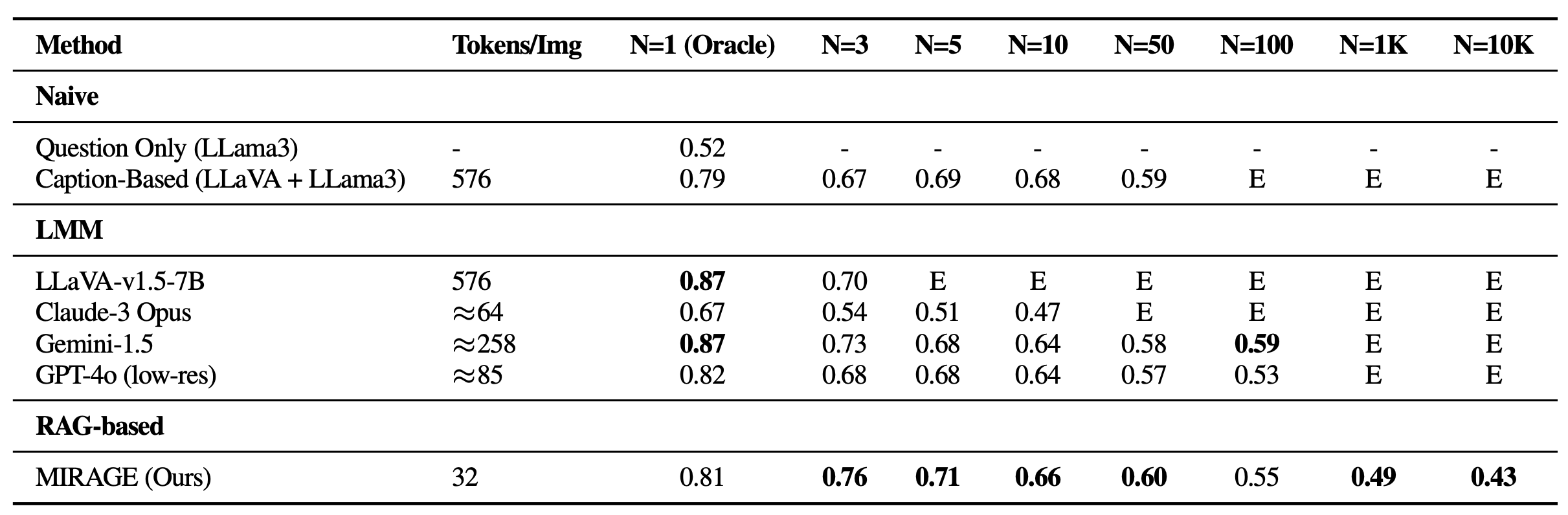
We revisit the VHs benchmark with MIRAGE. In addition to being capable of handling 1K or 10K images, MIRAGE achieves state-of-the-art performance on most single-needle tasks, despite having a weaker single-image QA backbone with only 32 tokens per image!
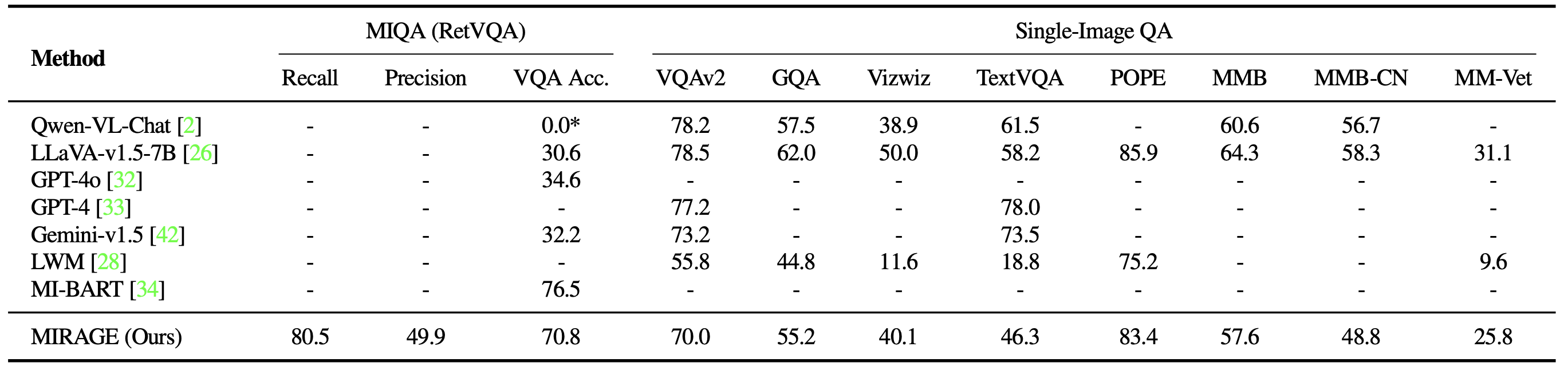
We also benchmark MIRAGE and other LMM-based models on a variety of VQA tasks. On multi-image tasks, MIRAGE demonstrates strong recall and precision capabilities, significantly outperforming strong competitors like GPT-4, Gemini-v1.5, and the Large World Model (LWM). Additionally, it shows competitive single-image QA performance.
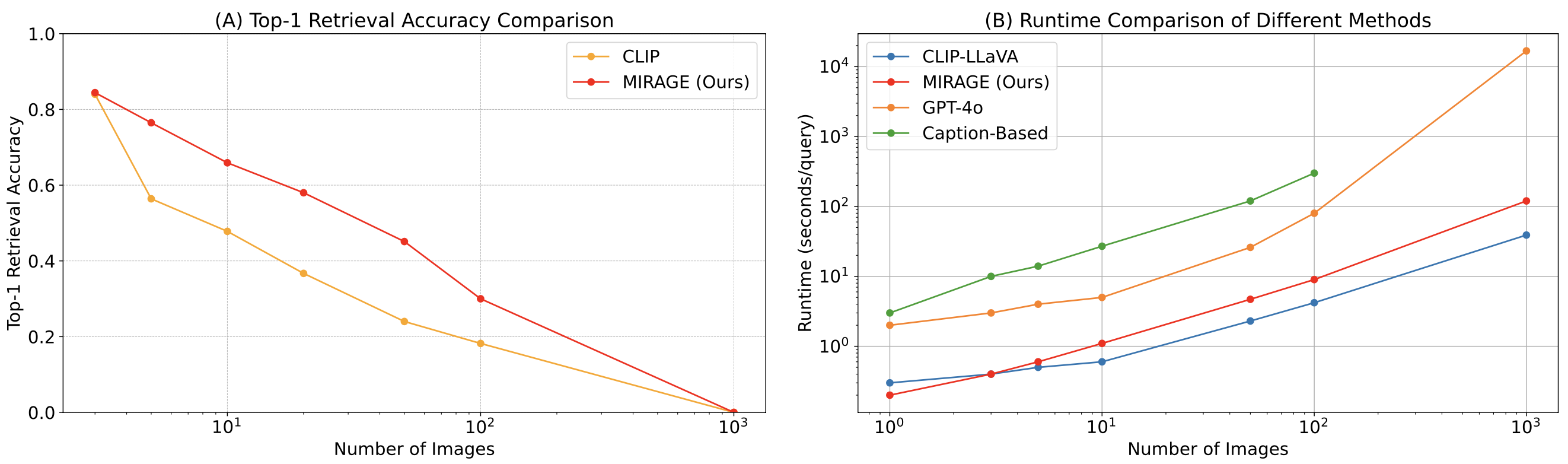
Finally, we compare MIRAGE’s co-trained retriever with CLIP. Our retriever performs significantly better than CLIP without losing efficiency. This shows that while CLIP models can be good retrievers for open-vocabulary image retrieval, they may not work well when dealing with question-like texts!
In this work, we develop the Visual Haystacks (VHs) benchmark and identified three prevalent deficiencies in existing Large Multimodal Models (LMMs):
Struggles with Visual Distractors: In single-needle tasks, LMMs exhibit a sharp performance decline as the number of images increases, indicating a significant challenge in filtering out irrelevant visual information.
Difficulty Reasoning Across Multiple Images: In multi-needle settings, simplistic approaches like captioning followed by language-based QA outperform all existing LMMs, highlighting LMMs’ inadequate ability to process information across multiple images.
Phenomena in Visual Domain: Both proprietary and open-source models display sensitivity to the position of the needle information within image sequences, exhibiting a “loss-in-the-middle” phenomenon in the visual domain.
In response, we propose MIRAGE, a pioneering visual Retriever-Augmented Generator (visual-RAG) framework. MIRAGE addresses these challenges with an innovative visual token compressor, a co-trained retriever, and augmented multi-image instruction tuning data.
After exploring this blog post, we encourage all future LMM projects to benchmark their models using the Visual Haystacks framework to identify and rectify potential deficiencies before deployment. We also urge the community to explore multi-image question answering as a means to advance the frontiers of true Artificial General Intelligence (AGI).
Last but not least, please check out our project page, and arxiv paper, and click the star button in our github repo!
@article{wu2024visual, titl
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み