分布認識型推論特定デコーディングでRLロールアウトを最大50%高速化
Together AIは、強化学習(RL)後の学習におけるロールアウト処理のボトルネックを解消する「分布認識型推論/speculative decoding」技術を開発し、最大50%の高速化を実現した。
キーポイント
RLロールアウトのボトルネック解消
強化学習後のトレーニングプロセスにおいて、生成された出力(ロールアウト)の処理が計算リソースの主要な遅延要因となっていた問題を特定し、解決策を提示している。
分布認識型推論(DAS)の導入
適応的なspeculative decoding手法である「Distribution-Aware Speculative Decoding (DAS)」を採用し、推論速度を最大50%向上させることに成功した。
報酬品質の維持
処理速度の大幅な向上を実現しながらも、モデルが得る報酬(reward quality)の品質低下をゼロに保ち、学習精度への悪影響を防いでいる。
重要な引用
Rollout is the silent bottleneck in RL post-training.
DAS fixes it with adaptive speculative decoding — up to 50% faster, zero degradation in reward quality.
影響分析・編集コメントを表示
影響分析
この技術は、LLMの強化学習(特にRLHFやDPOなど)にかかる時間とコストを大幅に削減する可能性を秘めており、大規模言語モデルの開発サイクルの加速に寄与します。また、推論速度と学習品質の両立という課題に対し、具体的なアルゴリズム的解決策を示した点で業界標準となる可能性があります。
編集コメント
LLM開発において「学習」よりも「推論」の高速化が注目されがちだが、RLトレーニングにおけるロールアウト処理の効率化は、開発コスト削減において同等かそれ以上の重要性を持つ。Together AIはこのインフラ層での競争力を示唆している。
 imageimage要約
imageimage要約
Distribution-aware speculative decoding (DAS、分布認識型推測デコーディング) は、RL(強化学習)のポストトレーニングにおけるロールアウトのボトルネックを大幅に緩和する革新的なフレームワークであり、モデルの出力を変更することなく、最大50%の高速化を実現します。
ロールアウトのボトルネック
強化学習は、現代の大規模言語モデル(LLM)のポストトレーニングにおける中核をなす技術となっています。DeepSeek-R1 などのモデルは、その推論能力を RL(強化学習)のファインチューニングに負っています。しかし、モデルが大きくなるにつれて、重要なボトルネックが浮上してきました:それはロールアウトフェーズです。
RL トレーニングでは、次のトレーニングステップを開始する前に、モデルはバッチ内のすべてのプロンプトに対して完全な応答を生成する必要があります。*最も遅い*生成が全体のステップ時間を決定します——これは典型的なロングテール問題です。
総トレーニング時間の70%がロールアウトフェーズに消費されており、これはバックプロパゲーションとパラメータ更新のコストを合わせたものを超えています。
- 同期バリア:すべてのロールアウトが完了するまで、トレーニングは進行できません。1つの生成が遅延すると、バッチ全体がブロックされます。
- 伸長する長さ:現代の推論モデルは、ますます長い思考の連鎖を生成するため、ロングテール効果が顕著になります。
- GPUのアイドル時間:遅延発生ノード(ストラグラー)が処理を続けている間、他のGPUはアイドル状態となり、トレーニング実行ごとに数千ドル分の計算リソースが無駄になります。
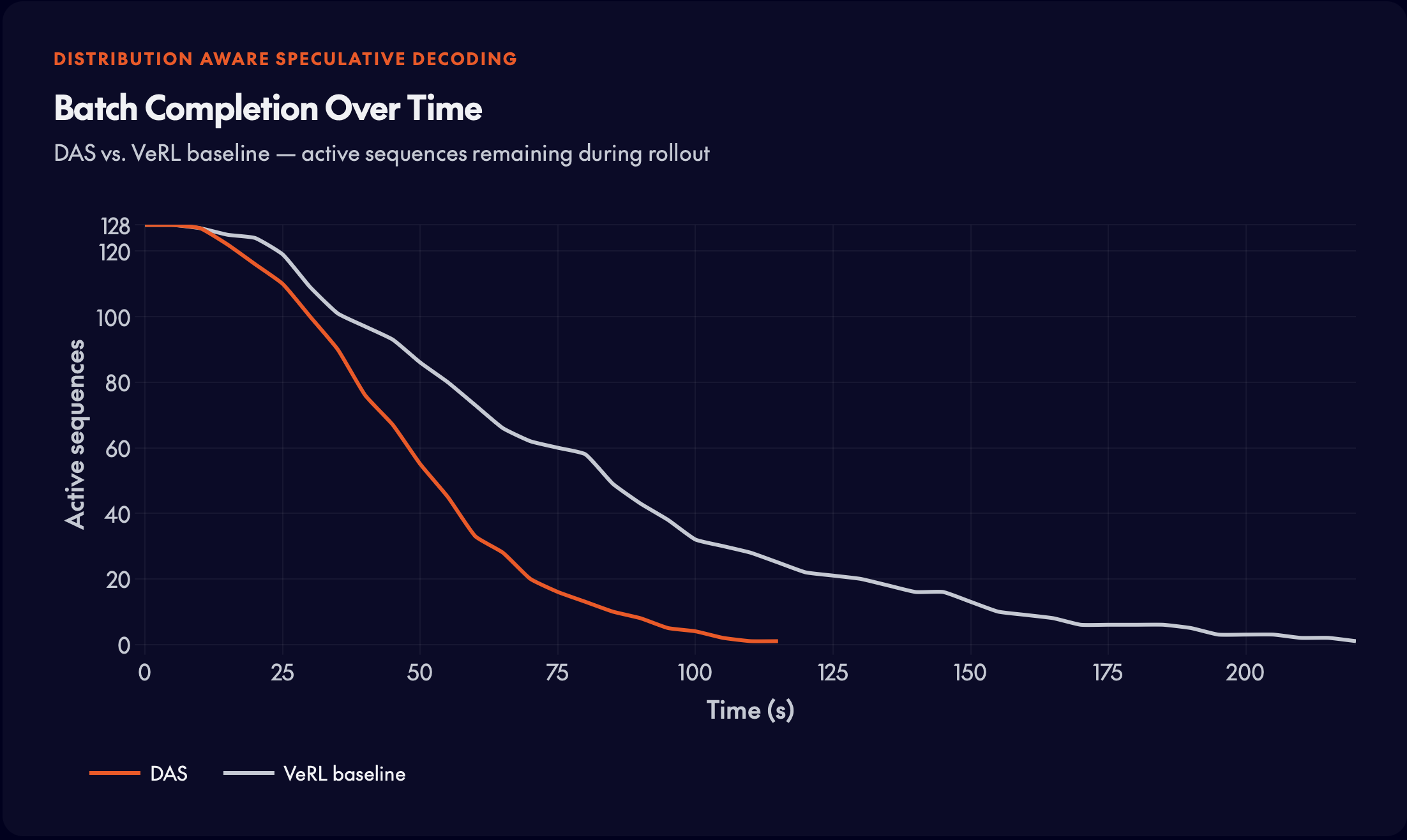
ロングテール問題の実際の例:ほとんどのシーケンスは早期に終了しますが、数少ない遅延発生ノードによってバッチ全体が待たされ、最も遅い生成が完了するまでGPUはアイドル状態になります。
主要な洞察
RL(強化学習)のポストトレーニングにおけるロールアウトフェーズには、標準的なLLM(大規模言語モデル)サービングのワークロードとは異なる3つの構造的性質があります。これらの性質が、DAS(Distribution-Aware Speculative decoding)のコアな設計思想を裏付けています。
- 長期にわたるロールアウトによるGPUの非効率化:強化学習(RL)のロールアウトは長期分布に従います。ほとんどの生成は短時間で完了しますが、一部は極めて長い軌道(トランジェクトリ)を生成します。トレーニングステップはすべてのロールアウトが完了するまで待機しなければならないため、これらの長いシーケンスが遅延要因となり、ステップのレイテンシを決定します。短いリクエストが早期に完了すると、GPUはアイドル状態になり、ハードウェアの利用率が著しく低下します。
- 過去の軌道からのシグナル:(一意のリクエストを処理する)サービングとは異なり、RLトレーニングではエポックを超えて同じプロンプトを再訪するため、活用可能な過去の生成履歴が豊富に存在します。
- 変化するモデルの重み:モデルはオプティマイザのステップごとに更新されます。以前のチェックポイントで訓練された静的なドラフターは、現在のポリシーとすぐに乖離してしまいます。
DASフレームワーク
これらの特性のそれぞれが、以下の設計要件を示しています:
- 再学習なしで最新の状態を維持するドラフター
- 遅延要因を無効化するスケジューラ、および
- RL固有のプロンプト再利用を活用するシステム。
DASは、これら3つすべてを、密に統合された2つのコンポーネントを通じて解決します。1つ目は、生成を加速し、長期のトレーニング期間にわたって滑らかにスケーリングする適応接尾辞木(suffix tree)ドラフターです。2つ目は、GPU間の負荷分散とGPU内の推論予算(speculation budget)の割り当てを通じてロールアウトの遅延要因を削減する、長さ aware なスケジリング戦略です。
適応接尾辞木ドラフター
なぜ接尾辞木(suffix trees)なのか?
強化学習(RL)のトレーニングを通じてポリシーが変化するにつれて、静的なドラフターはすぐに陳腐化してしまいます。そのためDASは、勾配更新を行わずにポリシーの変化に継続的に適応できるよう、直近のロールアウトから構築されたトレーニング不要のドラフターを使用します。
動作原理
DASは、直近のトラジェクトリのスライディングウィンドウから接尾辞木(suffix tree)を構築します。デコーディング中、現在のコンテキストとインデックスされた履歴の間でプレフィックスマッチを検索します。次に、候補となる次のトークンは、一致した部分木内での出現頻度によってスコアリングされ、最高スコアのトークンがスペキュラティブドラフトとして選択されます。
RLロールアウトとの適合性
ドラフトされたシーケンスはターゲットモデルによって並列で検証され、新たに検証されたトークンは即座に木に戻り、ドラフターが常に最新のポリシーと同期された状態を維持します。RLロールアウトではしばしば強力なトラジェクトリの再利用が行われるため、この非パラメトリックな設計は、別のニューラルドラフターを必要とせずに、繰り返されるプレフィックスを効果的に活用できます。
スケーラビリティ
接尾辞木はロールアウト前に構築され、各トレーニングステップ後に解放されるため、長期のトレーニング期間を通じてメモリが蓄積することはありません。木の構築とクリーンアップは問題ごとに並列化され、アクター更新とオーバーラップされるため、アクター更新レイテンシの変動は5%未満に抑えられ、オーバーヘッドがクリティカルパスから除外されます。
長さawareなスケジューリング
GPU間バランス調整
DASは、リクエストをラanks(計算ノード)間でインターリーブします。これにより、長時間の生成が特定のワーカーに集中するのを防ぎ、ロールアウトにおける遅延発生(ストラグラー)を軽減します。
長時間リクエストに対する早期の推論
DASは、ロールアウト開始時より、長時間のリクエストに対してスペキュレイティブ・ディコーディングを適用します。ロールアウトのレイテンシは、後期ステージまで残る少数の長時間ストラグラーによって支配されており、この段階ではバッチサイズが小さくなり、メモリ帯域幅がボトルネックとなります。これらのリクエストに対して早期に追加の計算コストを投じる価値があります。なぜなら、これは高価な後期ステージでのモデル順伝播を回避し、ロールアウトの尾部(完了までの時間)を短縮するからです。
GPU内での予算配分
各GPU内では、リクエストは過去のロールアウト統計に基づき、「Long(長時間)」「Medium(中程度)」「Short(短時間)」の3つのカテゴリに動的に分割されます。長時間リクエストには積極的なスペキュレイティブ・ディコーディングの予算が割り当てられ、中程度リクエストには適度な予算が使用され、短時間リクエストは推論を完全にスキップします。これにより、モデルの順伝播回数を削減できないようなケースでの計算資源の無駄を防ぎます。この分類ポリシーは、ランタイム時に動的に更新されます。
この設計は数段落で説明できるほどシンプルです。その正当性を裏付けるのは結果です。
実験結果
DASは、数学推論とコード生成という2つのRL(強化学習)ポストトレーニングタスクで評価されました。どちらのケースでも、重要なのは報酬品質の低下なしにロールアウト時間を削減できるかどうかです。
Math RL — DeepSeek-R1-Distill-Qwen-7B
DSR-subデータセット(1,209例)。DASは、ベースラインの報酬曲線と完全に一致させながら、ロールアウト時間を50%以上削減します。
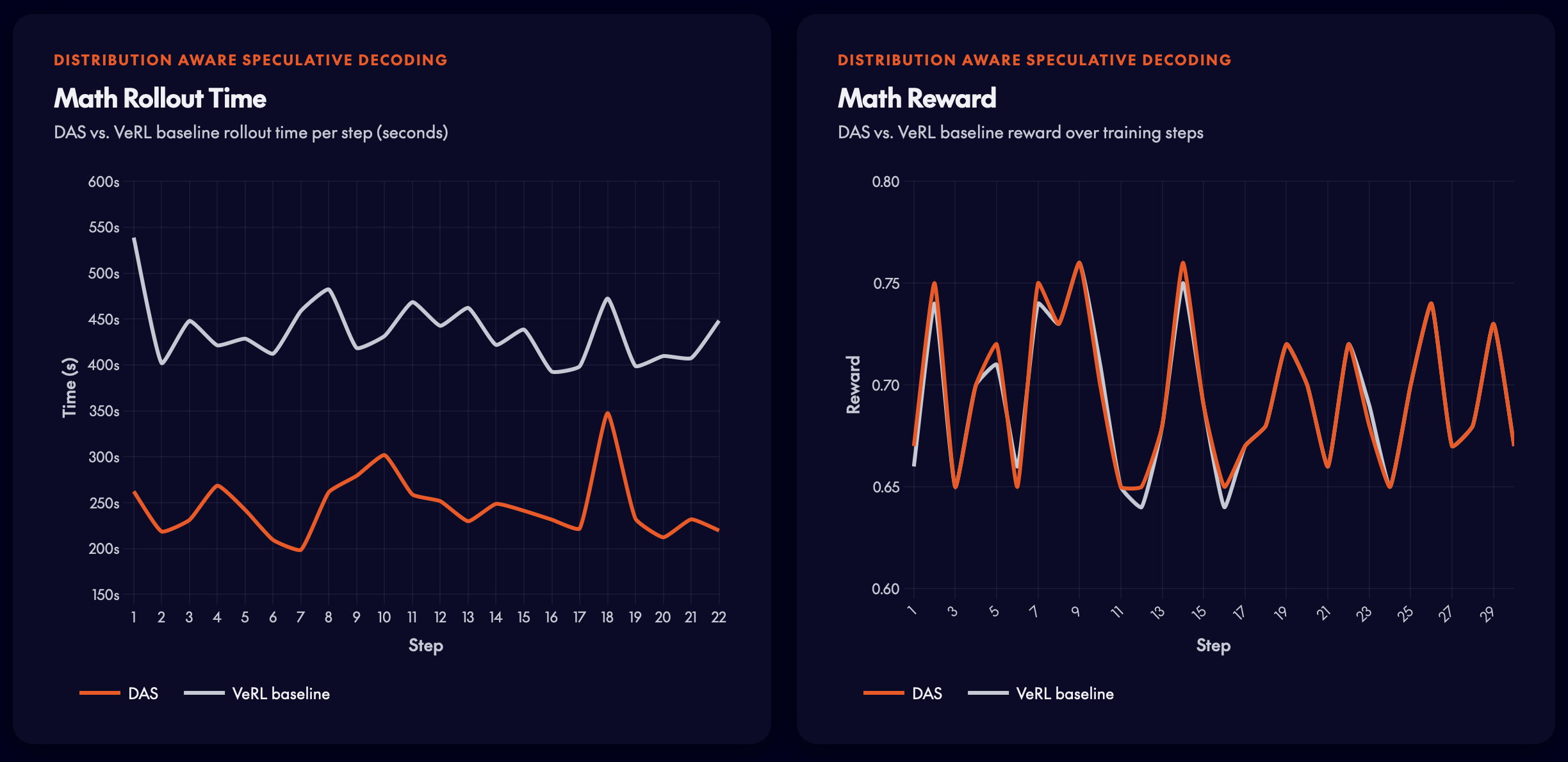
DSR-sub(1,209例)において、ベースラインの報酬曲線からの逸脱なくロールアウト時間を50%以上削減。これにより、学習信号が完全に保持されます。
Code RL — Qwen3-8B
ユニットテストによる報酬信号。DASは、報酬品質を維持しつつロールアウト時間を約25%削減します。
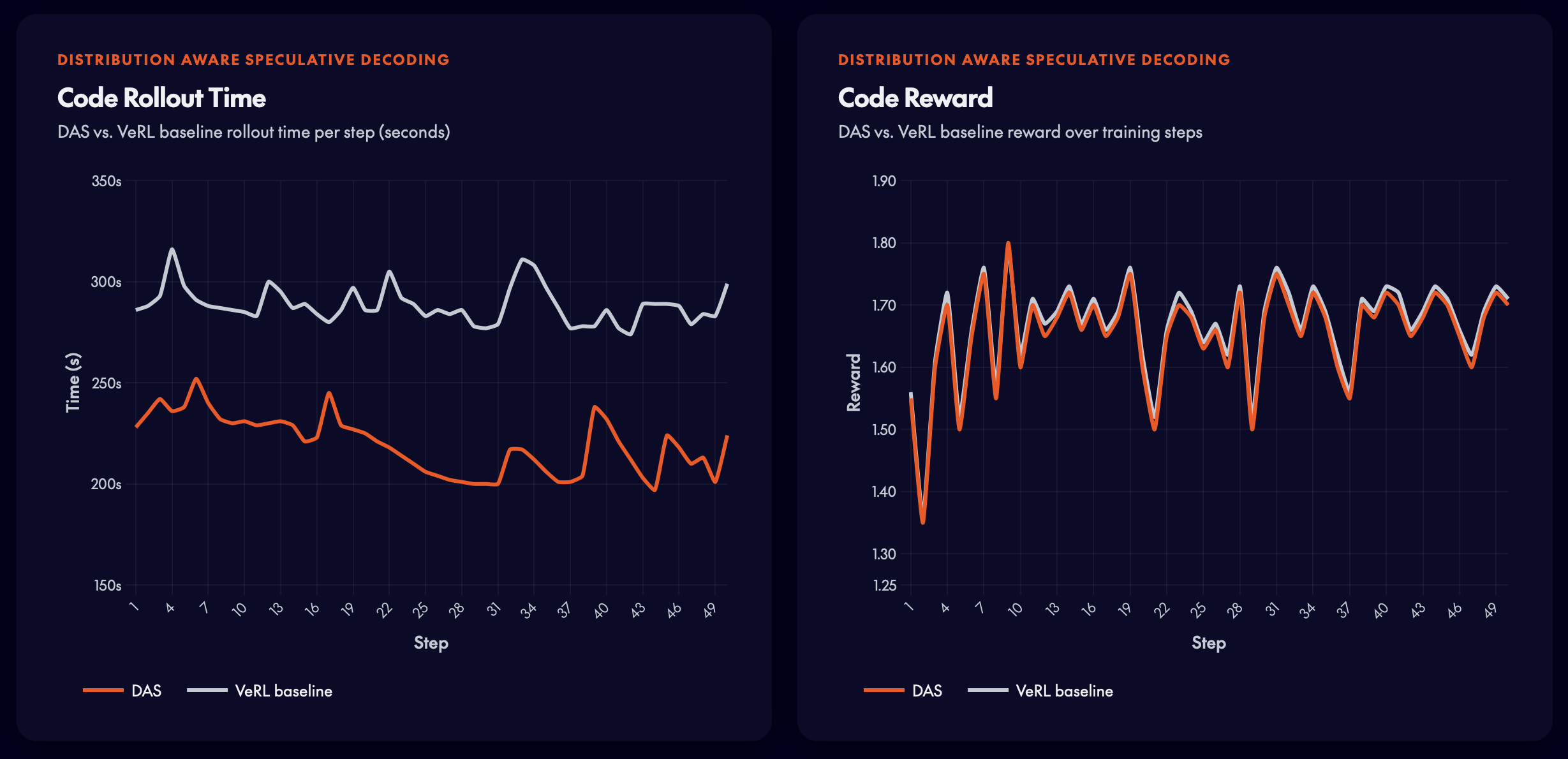
ユニットテストの報酬信号においてロールアウト時間を約25%削減。報酬品質は全体を通してベースラインを追跡しており、DASがポリシー学習(policy learning)に干渉しないことが確認されました。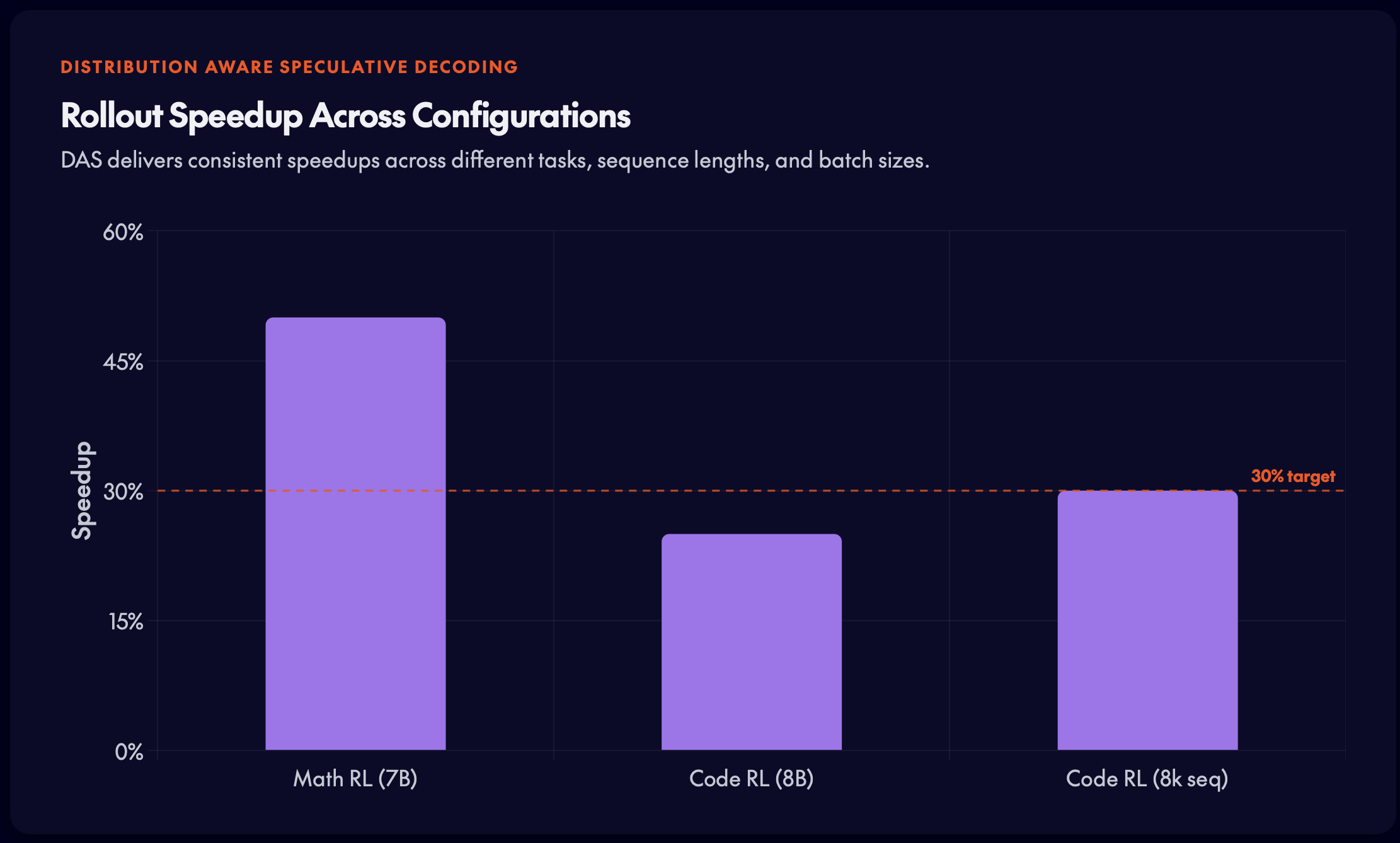 image
image
DASは、シーケンス長(8k〜16k)やバッチサイズ(16〜32) across 速度向上の優位性を維持しており、この利得が単一の動作点に限定されたものではないことが示されています。
Why this matters
DASは、これらが組み合わさって見つかることが稀な3つの特性を提供します。
- 損失のない高速化:DASは分布を保持するため、標準的なデコーディングと同じ出力となり、学習曲線も同一です。
- 多様な設定で堅牢:シーケンス長(8k〜16k)やバッチサイズ(16〜32)を超えて、速度向上が維持されます。
- コストゼロの適応:サフィックスツリー・ドラフターはロールアウト履歴から自己進化します。勾配更新もメンテナンスも不要です。
RLを用いてますます複雑なタスクに対して訓練される巨大モデルへの移行が進むにつれて、ロールアウトのボトルネックはさらに深刻化します。大規模なAI訓練というリソース制約の世界において、DASはモデル品質の低下なしに計算コストを最大50%削減できる魅力的な道筋を提供します——これは稀なウィンウィンの成果です。
論文を読んで詳細をご覧ください。

8S
DeepSeek R1

ネイティブオーディオとリアルな物理演算を備えた、プレミアムなシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオとリアルな物理演算を備えた、プレミアムなシネマティックビデオ生成。
8S
DeepSeek R1
ネイティブオーディオとリアルな物理演算を備えた、プレミアムなシネマティックビデオ生成。
パフォーマンスとスケール
本文ここにLorem ipsum dolor sit amet
- 箇条書き項目ここにLorem ipsum
- 箇条書き項目ここにLorem ipsum
- 箇条書き項目ここにLorem ipsum
インフラストラクチャ
最適な用途
- より高速な処理速度(全体のクエリレイテンシの低減)と運用コストの削減
- 明確に定義された、単純なタスクの実行
- ファンクションコール、JSONモード、または他の構造化された明確なタスク
リスト項目 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
ビルド
含まれる特典:
- ✔ プラットフォームクレジット最大$15K無料*
- ✔ フォワードデプロイされたエンジニアリング時間3時間無料。
資金調達:$5M未満
ビルド
含まれる特典:
- ✔ プラットフォームクレジット最大$15K無料*
- ✔ フォワードデプロイされたエンジニアリング時間3時間無料。
資金調達:$5M未満
ビルド
含まれる特典:
- ✔ プラットフォームクレジット最大$15,000無料*
- ✔ フォワードデプロイされたエンジニアリング時間3時間無料。
資金調達額:$5M未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグ内に記述してください。推論は以下のルールに従ってフォーマットしてください:推論する際は、アラビア語のみで応答し、他の言語は許可されない。 以下が質問です:
4月にNataliaは友人48人にクリップを売り、5月にはその半数のクリップを売りました。Nataliaは4月と5月に合計で何枚のクリップを売ったでしょうか?
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet と続きます
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet と続きます
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet と続きます
8S
DeepSeek R1
ネイティブオーディオとリアルな物理演算を備えたプレミアムシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオとリアルな物理演算を備えたプレミアムシネマティックビデオ生成。
8S
DeepSeek R1
ネイティブオーディオとリアルな物理演算を備えたプレミアムシネマティックビデオ生成。
パフォーマンスとスケール
本文のコピーはここにあり、Lorem ipsum dolor sit amet
- 箇条書きの項目はここにあり、Lorem ipsum
- 箇条書きの項目はここにあり、Lorem ipsum
- 箇条書きの項目はここにあり、Lorem ipsum
インフラストラクチャ
最適な用途
- より高速な処理速度(全体的なクエリレイテンシーの低減)と運用コストの削減
- 明確に定義された、単純なタスクの実行
- 関数呼び出し、JSON モード、またはその他の構造化されたタスク
リスト項目 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
ビルド
含まれる特典:
- ✔ プラットフォームクレジット最大 $15K 無料*
- ✔ フォワードデプロイされたエンジニアリング時間3時間無料。
資金調達:500万ドル未満
ビルド
含まれる特典:
- ✔ プラットフォームクレジット最大 $15K 無料*
- ✔ フォワードデプロイされたエンジニアリング時間3時間無料。
資金調達:500万ドル未満
ビルド
含まれる特典:
- ✔ プラットフォームクレジット最大 $15K 無料*
- ✔ フォワードデプロイされたエンジニアリング時間3時間無料。
資金調達:500万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグ内に記述してください。推論は以下のルールに従って行ってください:推論する際はアラビア語のみで応答し、他の言語は許可されません。
以下が質問です:
ナタリアは4月に友人48人にクリップを売り、5月にはその半分の数のクリップを売りました。ナタリアは4月と5月に合計で何個のクリップを売ったでしょうか?
XX
タイトル
本文はここに入ります。ローレム・イプサム・ドOLOR SIT AMET
XX
タイトル
本文はここに入ります。ローレム・イプサム・ドOLOR SIT AMET
XX
タイトル
本文はここに入ります。ローレム・イプサム・ドOLOR SIT AMET
原文を表示
Summary
Distribution-aware speculative decoding (DAS) is a novel framework that significantly alleviates the rollout bottleneck in RL post-training — delivering up to 50% speedup without touching model outputs.
The rollout bottleneck
Reinforcement learning has become the cornerstone of modern LLM post-training. Models like DeepSeek-R1 owe their reasoning capabilities to RL fine-tuning. But as models grow larger, a critical bottleneck has emerged: the rollout phase.
In RL training, the model must generate complete responses to every prompt in a batch before the next training step can begin. The *slowest* generation determines total step time — a textbook long-tail problem.
70% of total training time is consumed by the rollout phase — exceeding the cost of backpropagation and parameter updates combined.
- Synchronous barrier: All rollouts must complete before training proceeds. One slow generation blocks the entire batch.
- Growing lengths: Modern reasoning models generate increasingly long chains of thought, amplifying the long-tail effect.
- GPU idle time: As stragglers run, other GPUs sit idle — wasting thousands of dollars of compute per training run.
Key insights
The rollout phase in RL post-training has three structural properties that set it apart from standard LLM serving workloads. These properties motivate the core design choices in DAS.
- Long-tail rollouts cause GPU underutilization: RL rollouts follow a long-tail distribution: most generations finish quickly, while a few produce extremely long trajectories. Since training steps must wait for all rollouts to complete, these long sequences become stragglers that determine step latency. As shorter requests finish early, GPUs become idle, causing severe hardware underutilization.
- Historical trajectory signal: Unlike serving (unique requests), RL training revisits the same prompts across epochs — creating a rich history of prior generations to exploit.
- Evolving model weights: The model changes after every optimizer step. A static drafter trained on an earlier checkpoint quickly becomes misaligned with the current policy.
The DAS framework
Each of those properties points to a design requirement:
- A drafter that stays current without retraining
- A scheduler that neutralizes stragglers, and
- A system that exploits the prompt reuse unique to RL.
DAS addresses all three through two tightly integrated components. The first is an adaptive suffix tree drafter that accelerates generation and scales gracefully over long training horizons. The second is a length-aware scheduling strategy that reduces rollout stragglers through inter-GPU load balancing and intra-GPU speculation budget allocation.
Adaptive suffix tree drafter
Why suffix trees?
As the policy evolves throughout RL training, a static drafter quickly becomes stale. DAS therefore uses a training-free drafter built from recent rollouts, so it can continuously adapt to the changing policy without any gradient updates.
How it works
DAS constructs a suffix tree from a sliding window of recent trajectories. During decoding, it finds the prefix match between the current context and the indexed history. Candidate next tokens are then scored by their frequency in the matched subtree, and the highest-scoring token is selected as the speculative draft.
WHy it fits RL rollouts
The drafted sequence is verified in parallel by the target model, and newly verified tokens are immediately inserted back into the tree, keeping the drafter synchronized with the latest policy at all times. Since RL rollouts often contain strong trajectory reuse, this nonparametric design can effectively exploit repeated prefixes without requiring a separate neural drafter.
Scalability
Suffix trees are constructed before rollout and released after each training step, so memory does not accumulate over long training horizons. Tree construction and cleanup are parallelized per problem and overlapped with actor updates, leading to less than 5% fluctuation in actor update latency and keeping the overhead off the critical path.
Length-aware scheduling
Inter-GPU balancing
DAS interleaves long requests across ranks. This prevents long generations from concentrating on one worker and reduces rollout stragglers.
Early speculation for long requests
DAS applies speculative decoding to long requests from the start of rollout. Rollout latency is dominated by a few long stragglers that survive into the late stage, where decoding becomes small-batch and strongly memory-bound. Spending extra compute on these requests early is worthwhile — it avoids expensive late-stage model forwards and shortens the rollout tail.
Intra-GPU budget allocation
Within each GPU, requests are dynamically partitioned into Long, Medium, and Shortcategories based on historical rollout statistics. Long requests receive an aggressive speculative decoding budget, medium requests use a moderate budget, and short requests skip speculation entirely — avoiding wasted compute where speculation cannot reduce model forward passes. This classification policy updates dynamically at runtime.
The design is simple enough to describe in a few paragraphs. The results are what validate it.
Experimental results
DAS was evaluated on two RL post-training tasks — math reasoning and code generation. In both cases, the metric that matters is rollout time reduction without any degradation in reward quality.
Math RL — DeepSeek-R1-Distill-Qwen-7B
DSR-sub dataset (1,209 examples). DAS achieves over 50% rollout time reduction while matching the baseline reward curve exactly.
Code RL — Qwen3-8B
Unit-test reward signals. DAS achieves ~25% rollout time reduction while preserving reward quality.
Why this matters
DAS delivers three properties that are rare to find together:
- Lossless acceleration: DAS is distribution-preserving — identical outputs to standard decoding, identical training curves.
- Robust across configurations: Speedup holds across sequence lengths (8k–16k) and batch sizes (16–32).
- Zero-cost adaptation: The suffix tree drafter self-evolves from rollout history. No gradient updates, no maintenance.
As the AI community pushes toward ever-larger models trained with RL on increasingly complex tasks, the rollout bottleneck will only grow more severe. For practitioners running RL post-training at scale, DAS offers a compelling path to cutting compute costs by up to 50% with no degradation in model quality — a rare win-win in the resource-constrained world of large-scale AI training.
Read the paper to learn more.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み