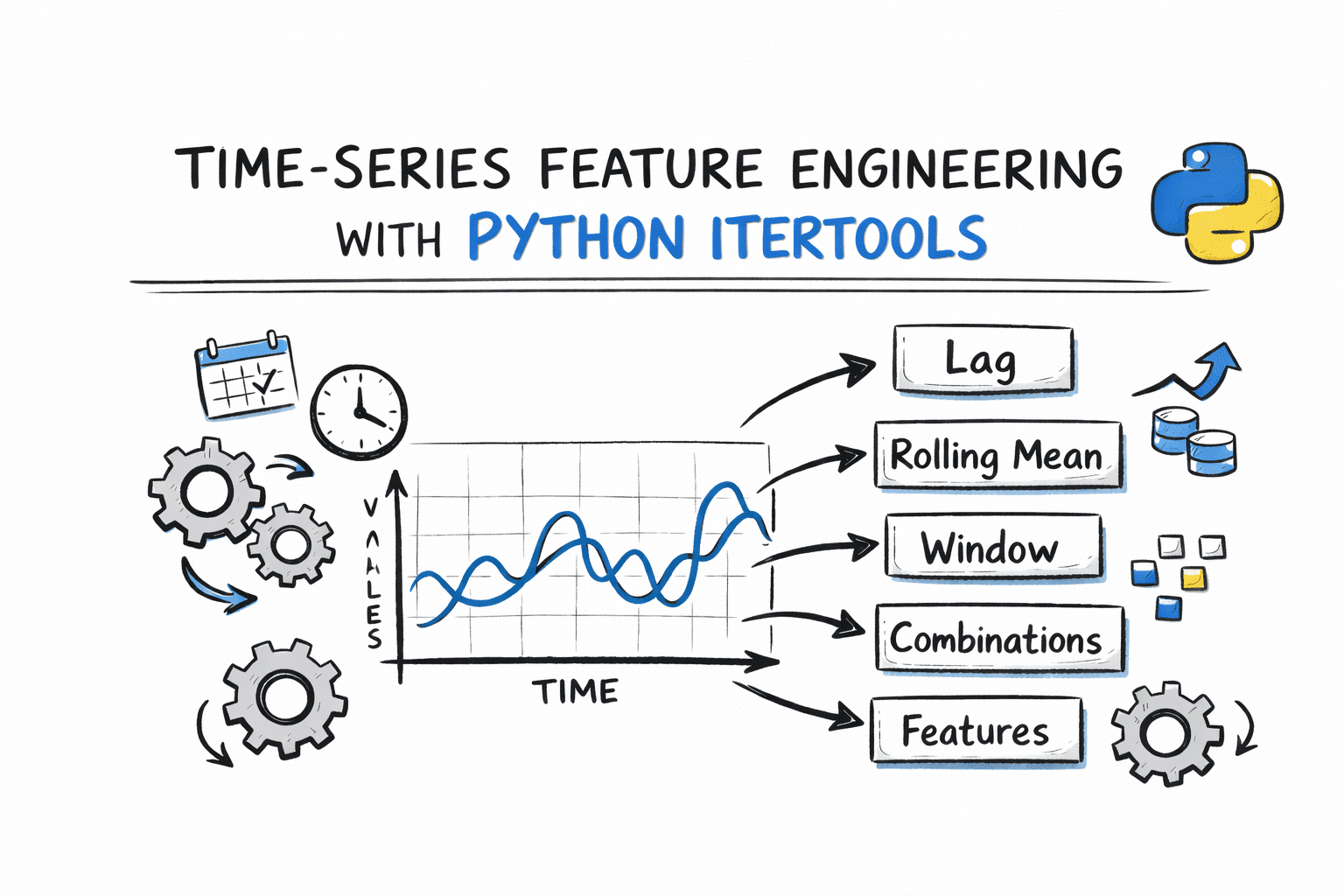
Python の itertools を用いた時系列特徴量エンジニアリング
この記事は、時系列データの特徴量エンジニアリングにおいて、高レベルなpandas関数に依存せずPythonのitertoolsモジュールを用いて低レベルで柔軟な特徴量を構築する手法と実装コードを解説している。
キーポイント
時系列データの特性と特徴量エンジニアリングの難しさ
時系列データは観測値が独立しておらず、順序が重要であるため、単なる数値ではなく変化率やラグ比較など時間軸に沿ったパターンを抽出する必要がある。
itertoolsモジュールの活用とpandasとの関係
itertoolsはpandasの.rolling()などの高機能関数を代替するものではなく、特定のロジックに合わせた低レベルなビルディングブロックとして機能し、完全な制御を可能にする。
サンプルデータセットの構築と特徴量の分類
気温、湿度、電力消費などを含む1週間分の時系列データを生成し、7 つのカテゴリに分けた特徴量エンジニアリングの実装例を示している。
ラグ特徴量の定義と目的
ラグ特徴量は過去の変数値(例:1時間前、24時間前)を用いて、短期的な変動や季節性などの異なるパターンを捉えるための時系列データの基本機能です。
islice を用いた効率的な生成とインデックス整合
itertools.islice を使用して過去データを抽出し、先頭に None をパディングすることで元のタイムスタンプインデックスとの整合性を保ちながら特徴量を作成します。
Rolling Window Feature Construction
利用して過去のデータポイントからウィンドウを抽出し、平均や標準偏差などの統計量を計算することで、時系列のトレンドや変動性を捉える特徴量を作成します。
Efficient Statistics with Accumulate
accumulate 関数を用いてウィンドウ内の累積和を一度に計算し、平均値を算出することで、データへの複数回のパスを避け、ストリーミング処理における効率性を高めています。
影響分析・編集コメントを表示
影響分析
この記事は、データサイエンティストが時系列分析において標準的なライブラリ関数に頼りすぎず、より細部まで制御可能な手法を習得する上で有用な実践的ガイドとなる。特に複雑なビジネスロジックや特殊な時系列パターンに対応する必要がある現場において、itertoolsを活用したカスタム実装の価値を再認識させる内容である。
編集コメント
時系列データ処理において、高レベルなライブラリだけでなく基礎的なイテレーションツールを駆使する視点を持つことは、複雑な課題解決力を高めるために重要です。
 image**
image**
# イントロダクション
時系列特徴量のエンジニアリングは、表形式データとは異なるルールに従います。観測値は独立しておらず、行の順序も偶然のものではなく、最も有用な特徴量は単一の読み取り値であることはめったにありません。変化率やラグ比較、ローリングベースラインからの逸脱など、時間全体にわたるパターンを特定する必要があります。
ラグの作成、スライディングウィンドウ、解像度ごとのグループ化は、すべて本質的には順序付けられたシーケンスに対する反復処理の問題です。Python の itertools モジュール は、このような作業に自然な適性を持っています。これは .rolling() などの高レベルの pandas 抽象化を置き換えるものではありませんが、必要な特徴量を正確に構築するための低レベルなビルディングブロックを提供し、ロジックに対する完全な制御権を与えてくれます。
この記事では、itertools を用いて時系列の特徴量の七つのカテゴリを作成します。また、それぞれを実際のサンプルデータセットに適用します。
# サンプルデータセットの作成
**
特徴量の構築を開始する前に、この記事全体で作業するためのサンプルセンサーデータセットを準備しましょう。
import numpy as np
import pandas as pd
import itertools
np.random.seed(42)
periods = 168 # 1 時間の読み取りを 1 週間分
index = pd.date_range(start="2024-03-01", periods=periods, freq="h")
hours = np.arange(periods)
温度 (°C): 日周期 + 緩やかなドリフト + ノイズ
temp_base = 3.5
temp_daily = 1.2 * np.sin(2 * np.pi * hours / 24)
temp_drift = 0.003 * hours
temp_noise = np.random.normal(0, 0.3, periods)
temperature = temp_base + temp_daily + temp_drift + temp_noise
湿度 (%): 温度との逆相関関係 + ノイズ
humidity = 78 - 2.1 * (temperature - temp_base) + np.random.normal(0, 1.2, periods)
電力消費量 (kW): ビジネス時間にピーク、平日の方が高い
day_of_week = index.dayofweek
business_hours = ((index.hour >= 8) & (index.hour <= 18)).astype(int)
weekend_factor = np.where(day_of_week >= 5, 0.6, 1.0)
power = (
42.0
+ 18.0 * business_hours * weekend_factor
+ np.random.normal(0, 2.1, periods)
)
df = pd.DataFrame({
"temperature_c": np.round(temperature, 3),
"humidity_pct": np.round(humidity, 2),
"power_kw": np.round(power, 2),
}, index=index)
df.index.name = "timestamp"
print(df.head(8))
print(f"\nShape: {df.shape}")
Output:
temperature_c humidity_pct power_kw
timestamp
2024-03-01 00:00:00 3.649 77.39 40.27
2024-03-01 01:00:00 3.772 76.52 41.33
2024-03-01 02:00:00 4.300 75.25 42.87
2024-03-01 03:00:00 4.814 74.26 40.82
2024-03-01 04:00:00 4.481 75.85 40.27
2024-03-01 05:00:00 4.604 76.09 42.51
2024-03-01 06:00:00 5.192 74.78 42.51
2024-03-01 07:00:00 4.910 76.03 40.94
Shape: (168, 3)
これで、3 つのセンサーチャンネルにわたる 168 件の時間ごとの読み取りデータが揃いました。では、次に特徴量(feature)を作成していきましょう。
# 1. islice を用いたラグ特徴量の生成
ラグ特徴量は、時系列分析における最も基本的な特徴量の一種です。過去に固定されたステップ数分遡った時点での変数の値を指します。例えば、1 ステップ前、6 ステップ前、24 ステップ前の値はそれぞれ、短期的な変動、周期内の反復的な振る舞い、より長期的な傾向や季節性といった、異なるパターンを捉えることができます。
では、islice を用いてサンプルデータセットに対してラグ特徴量を作成してみましょう:
sensor_readings = df["temperature_c"].tolist()
lag_offsets = [1, 6, 12, 24]
lag_features = {}
for lag in lag_offsets:
lagged = list(itertools.islice(sensor_readings, 0, len(sensor_readings) - lag))
# インデックスの整合性を保つために先頭に None でパディングする
lag_features[f"temp_lag_{lag}h"] = [None] * lag + lagged
lag_df = pd.DataFrame(lag_features, index=df.index)
lag_df["temperature_c"] = df["temperature_c"]
print(lag_df.iloc[24:30])
出力:
temp_lag_1h temp_lag_6h temp_lag_12h temp_lag_24h
timestamp
2024-03-02 00:00:00 2.831 2.082 3.609 3.649
2024-03-02 01:00:00 3.409 1.974 2.654 3.772
2024-03-02 02:00:00 3.919 2.960 2.425 4.300
2024-03-02 03:00:00 3.833 2.647 2.528 4.814
2024-03-02 04:00:00 4.542 2.986 2.205 4.481
2024-03-02 05:00:00 4.443 2.831 2.486 4.604
temperature_c
timestamp
2024-03-02 00:00:00 3.409
2024-03-02 01:00:00 3.919
2024-03-02 02:00:00 3.833
2024-03-02 03:00:00 4.542
2024-03-02 04:00:00 4.443
2024-03-02 05:00:00 4.659
islice(sensor_readings, 0, len - lag) は、完全なリストのコピーを作成することなく、lag ステップ分だけ後ろにずれたシーケンスを抽出します。先頭に追加される None パディングにより、すべてのラグ特徴量が元のインデックスと整列したまま保たれます。これは後でモデル学習のために NaN を削除する際に重要です。
# 2. islice と accumulate を用いたローリングウィンドウ特徴量の構築
**
単一のラグ値は、センサーが過去の特定の時点で何を検知していたかを示します。一方、ローリング統計量は、一定の時間窓にわたってセンサーがどのような挙動を示してきたかを表しており、これはしばしばはるかに有用です。
readings = df["temperature_c"].tolist()
window_size = 6 # 6 時間のローリングウィンドウ
rolling_features = []
for i in range(len(readings)):
if i < window_size:
rolling_features.append({
"rolling_mean_6h": None,
"rolling_std_6h": None,
"rolling_min_6h": None,
"rolling_max_6h": None,
})
continue
window = list(itertools.islice(readings, i - window_size, i))
# accumulate を使用して、平均値の計算に累積和を利用する
running_sum = list(itertools.accumulate(window))
window_mean = running_sum[-1] / window_size
window_mean_sq = sum(x**2 for x in window) / window_size
rolling_features.append({
"rolling_mean_6h": round(window_mean, 4),
"rolling_std_6h": round((window_mean_sq - window_mean2) 0.5, 4),
"rolling_min_6h": round(min(window), 4),
"rolling_max_6h": round(max(window), 4),
})
roll_df = pd.DataFrame(rolling_features, index=df.index)
roll_df["temperature_c"] = df["temperature_c"]
print(roll_df.iloc[6:12])
Output:
rolling_mean_6h rolling_std_6h rolling_min_6h
timestamp
2024-03-01 06:00:00 4.2700 0.4256 3.649
2024-03-01 07:00:00 4.5272 0.4386 3.772
2024-03-01 08:00:00 4.7168 0.2929 4.300
2024-03-01 09:00:00 4.7372 0.2662 4.422
2024-03-01 10:00:00 4.6912 0.2728 4.422
2024-03-01 11:00:00 4.6095 0.3769 3.991
rolling_max_6h temperature_c
timestamp
2024-03-01 06:00:00 4.814 5.192
2024-03-01 07:00:00 5.192 4.910
2024-03-01 08:00:00 5.192 4.422
2024-03-01 09:00:00 5.192 4.538
2024-03-01 10:00:00 5.192 3.991
2024-03-01 11:00:00 5.192 3.704
ここで accumulate を呼び出すことで、ウィンドウの累積和(running sum)を計算し、sum() を別途呼び出すことなく、一度のパスで合計値(running_sum[-1])を取得できます。ストリーミング処理で大量データを扱う場合、同じデータに対して冗長なパスを行わないことは効率的です。
# 3. product を用いた季節的相互作用特徴量の作成
多くの時系列データは層状の季節性(seasonality)を示し、複数の時間サイクルが相互に作用します。例えば、一日内の時刻、曜日、より広範な運用期間や循環周期などがそれです。これらの次元を組み合わせる相互作用特徴量(interaction features)は、個々の時間成分だけでは見逃してしまうパターンを捉えることができます。
では、製品との相互作用特徴量を構築しましょう:
hours_of_day = list(range(24))
day_types = ["weekday", "weekend"]
operational_shifts = ["off_peak", "on_peak"] # on_peak: 08:00–18:00
すべての組み合わせに対する完全なルックアップグリッドを構築する
season_grid = list(itertools.product(hours_of_day, day_types, operational_shifts))
season_df = pd.DataFrame(season_grid, columns=["hour", "day_type", "shift"])
各組み合わせごとの期待されるベースライン温度をシミュレートする
np.random.seed(14)
season_df["baseline_temp_c"] = np.round(
3.5
+ 0.8 * np.sin(2 * np.pi * season_df["hour"] / 24)
+ np.where(season_df["day_type"] == "weekend", 0.3, 0.0)
+ np.where(season_df["shift"] == "on_peak", 0.5, 0.0)
+ np.random.normal(0, 0.1, len(season_df)),
3
)
print(season_df[season_df["hour"].isin([0, 8, 14, 20])].head(16).to_string(index=False))
print(f"\nTotal grid combinations: {len(season_df)}")
出力:
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
時間・曜日種別 シフト ベースライン気温_c
0 平日 オフピーク 3.655
0 平日 オンピーク 4.008
0 週末 オフピーク 3.817
0 週末 オンピーク 4.293
8 平日 オフピーク 4.325
8 平日 オンピーク 4.601
8 週末 オフピーク 4.446
8 週末 オンピーク 4.978
14 平日 オフピーク 3.370
14 平日 オンピーク 3.628
14 週末 オフピーク 3.279
14 週末 オンピーク 3.959
20 平日 オフピーク 2.726
20 平日 オンピーク 3.256
20 週末 オフピーク 3.056
20 週末 オンピーク 3.530
グリッドの総組み合わせ数:96
このグリッドは、各行に対して baseline_temp_c という特徴量としてメインデータセットに結合され、各観測値に文脈に応じた期待値が与えられます。その後、そのベースラインからの偏差(temperature_c - baseline_temp_c)が有用な異常検出の特徴量となります。
# 4. tee を用いたスライディングウィンドウ統計量の抽出
時系列データを複数の統計的レンズ(平均値、分散、変化率など)で同時に処理する必要がある場合でも、それを複数回反復せずに済むようにしたいことがあります。itertools.tee は単一のソースから独立したイテレータを作成するもので、まさに必要な機能です。
def sliding_window_stats(series, window_size):
"""tee を用いてスライディングウィンドウ上で平均値、範囲、変化率を計算する。"""
results = []
it = iter(series)
window = list(itertools.islice(it, window_size))
if len(window) < window_size:
return results
results.append({
"window_mean": round(sum(window) / window_size, 4),
"window_range": round(max(window) - min(window), 4),
"rate_of_change": round(window[-1] - window[0], 4),
})
for next_val in it:
window = window[1:] + [next_val]
# tee creates two independent iterators over the same window
iter_a, iter_b = itertools.tee(iter(window))
values_a = list(iter_a)
values_b = list(iter_b)
mean_val = sum(values_a) / window_size
results.append({
"window_mean": round(mean_val, 4),
"window_range": round(max(values_b) - min(values_b), 4),
"rate_of_change": round(window[-1] - window[0], 4),
})
return results
power_readings = df["power_kw"].tolist()
stats = sliding_window_stats(power_readings, window_size=8)
stats_df = pd.DataFrame(stats, index=df.index[7:])
stats_df["power_kw"] = df["power_kw"].iloc[7:].values
print(stats_df.iloc[0:8])
window_mean window_range rate_of_change power_kw
timestamp
2024-03-01 07:00:00 41.4400 2.60 0.67 40.94
2024-03-01 08:00:00 43.7825 18.74 17.68 59.01
2024-03-01 09:00:00 46.1775 20.22 17.62 60.49
2024-03-01 10:00:00 47.9387 20.22 16.14 56.96
2024-03-01 11:00:00 49.9663 20.22 16.77 57.04
2024-03-01 12:00:00 52.2437 19.55 15.98 58.49
2024-03-01 13:00:00 54.3738 19.55 17.04 59.55
2024-03-01 14:00:00 56.6412 19.71 19.71 60.65
ご覧の通り、tee を使用すれば、リストを巻き戻したりコピーしたりすることなく、同じウィンドウイテレータ(iterator)を2つの独立した後段処理に渡すことができます。
# 5. chain を用いた多解像度時系列特徴量の結合
有用な時系列の特徴量は、しばしば複数の時間解像度を同時に組み合わせて得られます。具体的には、生データの時間ごとの読み取り値、6時間の移動平均、24時間の移動平均、そして「1日の時刻」のようなカレンダー機能です。これらは通常別々の配列に格納されており、それらを1つのクリーンな特徴量リストとして統合する必要があります。以下に、chain を用いてこれらの特徴量を結合する方法を示します:
humidity = df["humidity_pct"].tolist()
def rolling_means(series, window):
means = []
for i in range(len(series)):
if i < window:
means.append(None)
else:
w = list(itertools.islice(series, i - window, i))
means.append(round(sum(w) / window, 3))
return means
rolling_6h = rolling_means(humidity, 6)
rolling_24h = rolling_means(humidity, 24)
hour_of_day = df.index.hour.tolist()
is_business_hour = [1 if 8 <= h <= 18 else 0 for h in hour_of_day]
chain assembles feature name list from logically grouped sublists
feature_names = list(itertools.chain(
["humidity_raw"],
["humidity_roll_6h", "humidity_roll_24h"],
["hour_of_day", "is_business_hour"],
))
multi_res_df = pd.DataFrame({
name: vals for name, vals in zip(
feature_names,
[humidity, rolling_6h, rolling_24h, hour_of_day, is_business_hour]
)
}, index=df.index)
print(multi_res_df.iloc[24:30])
Output:
humidity_raw humidity_roll_6h humidity_roll_24h \
timestamp
2024-03-02 00:00:00 78.45 79.622 78.055
2024-03-02 01:00:00 75.63 79.105 78.100
2024-03-02 02:00:00 77.51 78.190 78.062
2024-03-02 03:00:00 76.27 78.088 78.157
2024-03-02 04:00:00 74.96 77.805 78.240
2024-03-02 05:00:00 75.75 77.208 78.203
hour_of_day is_business_hour
timestamp
2024-03-02 00:00:00 0 0
2024-03-02 01:00:00 1 0
2024-03-02 02:00:00 2 0
2024-03-02 03:00:00 3 0
2024-03-02 04:00:00 4 0
2024-03-02 05:00:00 5 0
chain は、論理的にグループ化されたサブリスト(生センサーデータ、ローリング集計値、カレンダー特徴量)から特徴名リストを組み立てます。センサーチャネルや解像度が増え、特徴セットが拡大しても、chain を用いることでその組み立てプロセスを可読性高く、拡張しやすい状態に保つことができます。
# 6. combinations を用いた時系列ペア相関の計算
マルチセンサー環境では、時間経過に伴う変数間の関係性に、個々の測定値だけでは捉えきれない貴重なシグナルが含まれていることがよくあります。例えば、2 つのセンサーで同時に増加が見られる場合、それぞれを単独で分析した場合には不明瞭な新たな状況や相互作用が浮かび上がることがあります。
これらの同時的なダイナミクスを反映する特徴量を取り入れることで、モデルが微妙なパターンや依存関係を検出する能力を向上させることができます。では、combinations を用いてペア相関を構築してみましょう:
sensor_cols = ["temperature_c", "humidity_pct", "power_kw"]
window_size = 12
pairwise_features = {}
for col_a, col_b in itertools.combinations(sensor_cols, 2):
feature_name = f"corr_{col_a[:4]}_{col_b[:4]}_12h"
correlations = []
series_a = df[col_a].tolist()
series_b = df[col_b].tolist()
for i in range(len(series_a)):
if i < window_size:
correlations.append(None)
continue
win_a = list(itertools.islice(series_a, i - window_size, i))
win_b = list(itertools.islice(series_b, i - window_size, i))
mean_a = sum(win_a) / window_size
mean_b = sum(win_b) / window_size
cov = sum((a - mean_a) * (b - mean_b) for a, b in zip(win_a, win_b)) / window_size
std_a = (sum((a - mean_a)2 for a in win_a) / window_size) 0.5
std_b = (sum((b - mean_b)2 for b in win_b) / window_size) 0.5
corr = round(cov / (std_a * std_b), 4) if std_a > 0 and std_b > 0 else None
correlations.append(corr)
pairwise_features[feature_name] = correlations
corr_df = pd.DataFrame(pairwise_features, index=df.index)
print(corr_df.iloc[12:18])
Output:
corr_temp_humi_12h corr_temp_powe_12h \
timestamp
2024-03-01 12:00:00 -0.6700 -0.2281
2024-03-01 13:00:00 -0.7208 -0.4960
2024-03-01 14:00:00 -0.7442 -0.6669
2024-03-01 15:00:00 -0.7678 -0.7076
2024-03-01 16:00:00 -0.8116 -0.7265
2024-03-01 17:00:00 -0.8368 -0.7482
corr_humi_powe_12h
timestamp
2024-03-01 12:00:00 0.5380
2024-03-01 13:00:00 0.6614
2024-03-01 14:00:00 0.7202
2024-03-01 15:00:00 0.7311
2024-03-01 16:00:00 0.7233
2024-03-01 17:00:00 0.7219
# 7. accumulate を用いた累積ベースラインの作成
ある値が持つ意味は、それがシーケンス内のいつ発生するかによって異なります。重要なのは、その時点までの経過する平均(running mean)である進化するベースラインからの乖離です。accumulate という逐次的アプローチを使用することで、履歴全体を保存することなく、この累積平均を効率的に計算できます。
readings = df["temperature_c"].tolist()
running_sums = list(itertools.accumulate(readings))
running_counts = list(itertools.accumulate([1] * len(readings)))
running_means = [
round(s / c, 4)
for s, c in zip(running_sums, running_counts)
]
Running max — 過去最高温度。逸脱追跡に有用
running_max = list(itertools.accumulate(readings, func=max))
deviation_from_baseline = [
round(r - m, 4)
for r, m in zip(readings, running_means)
]
baseline_df = pd.DataFrame({
"temperature_c": readings,
"running_mean": running_means,
"running_max": running_max,
"deviation_from_baseline": deviation_from_baseline,
}, index=df.index)
print(baseline_df.iloc[20:28])
Output:
temperature_c running_mean running_max \
timestamp
2024-03-01 20:00:00 2.960 3.5857 5.192
2024-03-01 21:00:00 2.647 3.5430 5.192
2024-03-01 22:00:00 2.986 3.5188 5.192
2024-03-01 23:00:00 2.831 3.4902 5.192
2024-03-02 00:00:00 3.409 3.4869 5.192
2024-03-02 01:00:00 3.919 3.5035 5.192
2024-03-02 02:00:00 3.833 3.5157 5.192
2024-03-02 03:00:00 4.542 3.5524 5.192
deviation_from_baseline
timestamp
2024-03-01 20:00:00 -0.6257
2024-03-01 21:00:00 -0.8960
2024-03-01 22:00:00 -0.5328
2024-03-01 23:00:00 -0.6592
2024-03-02 00:00:00 -0.0779
2024-03-02 01:00:00 0.4155
2024-03-02 02:00:00 0.3173
2024-03-02 03:00:00 0.9896
# Summary
Time series feature engineering is fundamentally about describing *context* — what has this signal been doing, relative to what we expect it to be doing? Every function covered here is a different way of formalizing that question into a number a model can learn from.
Here's a summary of the patterns we've covered in this article:
itertools Function
Time Series Feature
Example
islice
Lag features
Temperature 1h, 6h, 24h ago
islice + accumulate
ローリングウィンドウ統計量
6 時間の平均、標準偏差、最小値、最大値
product
季節的相互作用グリッド
時間 × 日種別 × シフトベースライン
tee
並列ウィンドウ統計量
平均値 + 範囲 + 変化率
chain
多解像度特徴の組み立て
生データ + ローリング + カレンダー特徴
combinations
ペアごとのクロスセンサー相関
温度–湿度、温度–電力のローリング相関
accumulate
ランニングベースラインと偏差
歴史的平均からのドリフト検出
そして itertools はイテレータレベルで動作するため、これらすべてのパターンはストリーミングパイプラインにもきれいに組み合わせることができます。楽しい特徴エンジニアリングを!
Bala Priya C はインド出身の開発者かつ技術ライターです。数学、プログラミング、データサイエンス、コンテンツ作成が交差する領域での作業を好んでいます。彼女の興味分野および専門知識には DevOps、データサイエンス、自然言語処理が含まれます。読書、執筆、コーディング、そしてコーヒーを楽しむのが好きです。現在、チュートリアル、ハウツーガイド、意見記事などを執筆することで開発者コミュニティに知識を共有し、学習に取り組んでいます。Bala はまた、魅力的なリソース概要やコーディングチュートリアルも作成しています。
原文を表示
**
# Introduction
Time series feature engineering doesn't follow the same rules as tabular data. Observations aren't independent, row order isn't incidental, and the most useful features are rarely individual readings. You'll have to identify patterns across time like rates of change, lag comparisons, deviations from a rolling baseline, and more.
Building lags, sliding windows, and grouping across resolutions are all, at their core, iteration problems over ordered sequences. Python's itertools module is a natural fit for this kind of work. It doesn't replace high-level pandas** abstractions like .rolling(), but it gives you lower-level building blocks to construct exactly the features you need, with full control over the logic.
In this article, you'll build seven categories of time series features using itertools. You'll also apply each to a sample dataset.
You can get the code on GitHub.
# Creating a Sample Dataset
**
Before we start building the features, let's spin up a sample sensor dataset to work with throughout the article.
import numpy as np
import pandas as pd
import itertools
np.random.seed(42)
periods = 168 # one week of hourly readings
index = pd.date_range(start="2024-03-01", periods=periods, freq="h")
hours = np.arange(periods)
# Temperature (°C): daily cycle + gradual drift + noise
temp_base = 3.5
temp_daily = 1.2 * np.sin(2 * np.pi * hours / 24)
temp_drift = 0.003 * hours
temp_noise = np.random.normal(0, 0.3, periods)
temperature = temp_base + temp_daily + temp_drift + temp_noise
# Humidity (%): inverse relationship with temperature + noise
humidity = 78 - 2.1 * (temperature - temp_base) + np.random.normal(0, 1.2, periods)
# Power draw (kW): peaks during business hours, higher on weekdays
day_of_week = index.dayofweek
business_hours = ((index.hour >= 8) & (index.hour <= 18)).astype(int)
weekend_factor = np.where(day_of_week >= 5, 0.6, 1.0)
power = (
42.0
+ 18.0 * business_hours * weekend_factor
+ np.random.normal(0, 2.1, periods)
)
df = pd.DataFrame({
"temperature_c": np.round(temperature, 3),
"humidity_pct": np.round(humidity, 2),
"power_kw": np.round(power, 2),
}, index=index)
df.index.name = "timestamp"
print(df.head(8))
print(f"\nShape: {df.shape}")Output:
temperature_c humidity_pct power_kw
timestamp
2024-03-01 00:00:00 3.649 77.39 40.27
2024-03-01 01:00:00 3.772 76.52 41.33
2024-03-01 02:00:00 4.300 75.25 42.87
2024-03-01 03:00:00 4.814 74.26 40.82
2024-03-01 04:00:00 4.481 75.85 40.27
2024-03-01 05:00:00 4.604 76.09 42.51
2024-03-01 06:00:00 5.192 74.78 42.51
2024-03-01 07:00:00 4.910 76.03 40.94
Shape: (168, 3)We now have 168 hourly readings across three sensor channels. Now let's build features.
# 1. Generating Lag Features with islice
Lag features are the most fundamental time series feature: the value of a variable at a fixed number of steps in the past**. For example, values from 1 step ago, 6 steps ago, or 24 steps ago can each capture distinct patterns such as short-term fluctuations, recurring intra-period behavior, and longer-term trends or seasonality.
Let's build lag features for our sample dataset using islice:
sensor_readings = df["temperature_c"].tolist()
lag_offsets = [1, 6, 12, 24]
lag_features = {}
for lag in lag_offsets:
lagged = list(itertools.islice(sensor_readings, 0, len(sensor_readings) - lag))
# Pad the beginning with None to preserve index alignment
lag_features[f"temp_lag_{lag}h"] = [None] * lag + lagged
lag_df = pd.DataFrame(lag_features, index=df.index)
lag_df["temperature_c"] = df["temperature_c"]
print(lag_df.iloc[24:30])Output:
temp_lag_1h temp_lag_6h temp_lag_12h temp_lag_24h \
timestamp
2024-03-02 00:00:00 2.831 2.082 3.609 3.649
2024-03-02 01:00:00 3.409 1.974 2.654 3.772
2024-03-02 02:00:00 3.919 2.960 2.425 4.300
2024-03-02 03:00:00 3.833 2.647 2.528 4.814
2024-03-02 04:00:00 4.542 2.986 2.205 4.481
2024-03-02 05:00:00 4.443 2.831 2.486 4.604
temperature_c
timestamp
2024-03-02 00:00:00 3.409
2024-03-02 01:00:00 3.919
2024-03-02 02:00:00 3.833
2024-03-02 03:00:00 4.542
2024-03-02 04:00:00 4.443
2024-03-02 05:00:00 4.659islice(sensor_readings, 0, len - lag) extracts the sequence shifted back by lag steps without creating a copy of the full list. The None padding at the front keeps every lag feature aligned with the original index. This matters when you later drop NaNs for model training.
# 2. Building Rolling Window Features with islice and accumulate
**
A single lag value tells you what the sensor read at a point in the past. A rolling statistic tells you what the sensor has been doing over a window of time, which is often far more useful.
readings = df["temperature_c"].tolist()
window_size = 6 # 6-hour rolling window
rolling_features = []
for i in range(len(readings)):
if i < window_size:
rolling_features.append({
"rolling_mean_6h": None,
"rolling_std_6h": None,
"rolling_min_6h": None,
"rolling_max_6h": None,
})
continue
window = list(itertools.islice(readings, i - window_size, i))
# Use accumulate to compute running sum for mean
running_sum = list(itertools.accumulate(window))
window_mean = running_sum[-1] / window_size
window_mean_sq = sum(x**2 for x in window) / window_size
rolling_features.append({
"rolling_mean_6h": round(window_mean, 4),
"rolling_std_6h": round((window_mean_sq - window_mean**2) ** 0.5, 4),
"rolling_min_6h": round(min(window), 4),
"rolling_max_6h": round(max(window), 4),
})
roll_df = pd.DataFrame(rolling_features, index=df.index)
roll_df["temperature_c"] = df["temperature_c"]
print(roll_df.iloc[6:12])Output:
rolling_mean_6h rolling_std_6h rolling_min_6h \
timestamp
2024-03-01 06:00:00 4.2700 0.4256 3.649
2024-03-01 07:00:00 4.5272 0.4386 3.772
2024-03-01 08:00:00 4.7168 0.2929 4.300
2024-03-01 09:00:00 4.7372 0.2662 4.422
2024-03-01 10:00:00 4.6912 0.2728 4.422
2024-03-01 11:00:00 4.6095 0.3769 3.991
rolling_max_6h temperature_c
timestamp
2024-03-01 06:00:00 4.814 5.192
2024-03-01 07:00:00 5.192 4.910
2024-03-01 08:00:00 5.192 4.422
2024-03-01 09:00:00 5.192 4.538
2024-03-01 10:00:00 5.192 3.991
2024-03-01 11:00:00 5.192 3.704The accumulate call here computes the running sum of the window so we get the total in one pass — running_sum[-1] — without calling sum() separately. For large datasets processed in a streaming fashion, avoiding redundant passes over the same data is efficient.
# 3. Creating Seasonal Interaction Features with product
Many time series exhibit layered seasonality, where multiple temporal cycles interact — such as time of day, day of week, and broader operational or cyclical periods. Interaction features that combine these dimensions can capture patterns that individual time components alone may overlook.
Now let's build interaction features with product:
hours_of_day = list(range(24))
day_types = ["weekday", "weekend"]
operational_shifts = ["off_peak", "on_peak"] # on_peak: 08:00–18:00
# Build a full lookup grid for all combinations
season_grid = list(itertools.product(hours_of_day, day_types, operational_shifts))
season_df = pd.DataFrame(season_grid, columns=["hour", "day_type", "shift"])
# Simulate expected baseline temperature per combination
np.random.seed(14)
season_df["baseline_temp_c"] = np.round(
3.5
+ 0.8 * np.sin(2 * np.pi * season_df["hour"] / 24)
+ np.where(season_df["day_type"] == "weekend", 0.3, 0.0)
+ np.where(season_df["shift"] == "on_peak", 0.5, 0.0)
+ np.random.normal(0, 0.1, len(season_df)),
3
)
print(season_df[season_df["hour"].isin([0, 8, 14, 20])].head(16).to_string(index=False))
print(f"\nTotal grid combinations: {len(season_df)}")Output:
hour day_type shift baseline_temp_c
0 weekday off_peak 3.655
0 weekday on_peak 4.008
0 weekend off_peak 3.817
0 weekend on_peak 4.293
8 weekday off_peak 4.325
8 weekday on_peak 4.601
8 weekend off_peak 4.446
8 weekend on_peak 4.978
14 weekday off_peak 3.370
14 weekday on_peak 3.628
14 weekend off_peak 3.279
14 weekend on_peak 3.959
20 weekday off_peak 2.726
20 weekday on_peak 3.256
20 weekend off_peak 3.056
20 weekend on_peak 3.530
Total grid combinations: 96This grid merges back onto your main dataset as a baseline_temp_c feature per row — giving every reading a context-aware expected value. The deviation from that baseline, temperature_c - baseline_temp_c, is then a useful anomaly detection feature.
# 4. Extracting Sliding Window Statistics with tee
Sometimes you need to process the same sequence through multiple statistical lenses simultaneously — mean, variance, rate of change — without iterating over it multiple times. itertools.tee creates independent iterators from a single source, which is exactly what you need.
def sliding_window_stats(series, window_size):
"""Compute mean, range and rate-of-change over sliding windows using tee."""
results = []
it = iter(series)
window = list(itertools.islice(it, window_size))
if len(window) < window_size:
return results
results.append({
"window_mean": round(sum(window) / window_size, 4),
"window_range": round(max(window) - min(window), 4),
"rate_of_change": round(window[-1] - window[0], 4),
})
for next_val in it:
window = window[1:] + [next_val]
# tee creates two independent iterators over the same window
iter_a, iter_b = itertools.tee(iter(window))
values_a = list(iter_a)
values_b = list(iter_b)
mean_val = sum(values_a) / window_size
results.append({
"window_mean": round(mean_val, 4),
"window_range": round(max(values_b) - min(values_b), 4),
"rate_of_change": round(window[-1] - window[0], 4),
})
return results
power_readings = df["power_kw"].tolist()
stats = sliding_window_stats(power_readings, window_size=8)
stats_df = pd.DataFrame(stats, index=df.index[7:])
stats_df["power_kw"] = df["power_kw"].iloc[7:].values
print(stats_df.iloc[0:8])Output:
window_mean window_range rate_of_change power_kw
timestamp
2024-03-01 07:00:00 41.4400 2.60 0.67 40.94
2024-03-01 08:00:00 43.7825 18.74 17.68 59.01
2024-03-01 09:00:00 46.1775 20.22 17.62 60.49
2024-03-01 10:00:00 47.9387 20.22 16.14 56.96
2024-03-01 11:00:00 49.9663 20.22 16.77 57.04
2024-03-01 12:00:00 52.2437 19.55 15.98 58.49
2024-03-01 13:00:00 54.3738 19.55 17.04 59.55
2024-03-01 14:00:00 56.6412 19.71 19.71 60.65As seen, tee lets you pass the same window iterator into two separate downstream computations without rewinding or copying the list yourself.
# 5. Combining Multi-Resolution Time Features with chain
Useful time series features often come from multiple temporal resolutions simultaneously: the raw hourly reading, a 6-hour rolling mean, a 24-hour rolling mean, and a calendar feature like hour-of-day. These are usually in separate arrays and need assembling into one clean feature list. Here's how you can use chain to combine such features:
humidity = df["humidity_pct"].tolist()
def rolling_means(series, window):
means = []
for i in range(len(series)):
if i < window:
means.append(None)
else:
w = list(itertools.islice(series, i - window, i))
means.append(round(sum(w) / window, 3))
return means
rolling_6h = rolling_means(humidity, 6)
rolling_24h = rolling_means(humidity, 24)
hour_of_day = df.index.hour.tolist()
is_business_hour = [1 if 8 <= h <= 18 else 0 for h in hour_of_day]
# chain assembles feature name list from logically grouped sublists
feature_names = list(itertools.chain(
["humidity_raw"],
["humidity_roll_6h", "humidity_roll_24h"],
["hour_of_day", "is_business_hour"],
))
multi_res_df = pd.DataFrame({
name: vals for name, vals in zip(
feature_names,
[humidity, rolling_6h, rolling_24h, hour_of_day, is_business_hour]
)
}, index=df.index)
print(multi_res_df.iloc[24:30])Output:
humidity_raw humidity_roll_6h humidity_roll_24h \
timestamp
2024-03-02 00:00:00 78.45 79.622 78.055
2024-03-02 01:00:00 75.63 79.105 78.100
2024-03-02 02:00:00 77.51 78.190 78.062
2024-03-02 03:00:00 76.27 78.088 78.157
2024-03-02 04:00:00 74.96 77.805 78.240
2024-03-02 05:00:00 75.75 77.208 78.203
hour_of_day is_business_hour
timestamp
2024-03-02 00:00:00 0 0
2024-03-02 01:00:00 1 0
2024-03-02 02:00:00 2 0
2024-03-02 03:00:00 3 0
2024-03-02 04:00:00 4 0
2024-03-02 05:00:00 5 0chain here assembles the feature name list from logically grouped sublists — raw sensor, rolling aggregates, calendar features. As your feature set grows across more sensor channels and more resolutions, chain keeps that assembly readable and easy to extend.
# 6. Computing Pairwise Temporal Correlations with combinations
In a multi-sensor setting, the relationships between variables over time often contain valuable signals that individual measurements alone cannot capture. For example, simultaneous increases across two sensors may reveal emerging conditions or interactions that would not be apparent when each series is analyzed in isolation.
Incorporating features that reflect these joint dynamics can improve a model's ability to detect subtle patterns and dependencies. Let's try building pairwise correlations using combinations:
sensor_cols = ["temperature_c", "humidity_pct", "power_kw"]
window_size = 12
pairwise_features = {}
for col_a, col_b in itertools.combinations(sensor_cols, 2):
feature_name = f"corr_{col_a[:4]}_{col_b[:4]}_12h"
correlations = []
series_a = df[col_a].tolist()
series_b = df[col_b].tolist()
for i in range(len(series_a)):
if i < window_size:
correlations.append(None)
continue
win_a = list(itertools.islice(series_a, i - window_size, i))
win_b = list(itertools.islice(series_b, i - window_size, i))
mean_a = sum(win_a) / window_size
mean_b = sum(win_b) / window_size
cov = sum((a - mean_a) * (b - mean_b) for a, b in zip(win_a, win_b)) / window_size
std_a = (sum((a - mean_a)**2 for a in win_a) / window_size) ** 0.5
std_b = (sum((b - mean_b)**2 for b in win_b) / window_size) ** 0.5
corr = round(cov / (std_a * std_b), 4) if std_a > 0 and std_b > 0 else None
correlations.append(corr)
pairwise_features[feature_name] = correlations
corr_df = pd.DataFrame(pairwise_features, index=df.index)
print(corr_df.iloc[12:18])Output:
corr_temp_humi_12h corr_temp_powe_12h \
timestamp
2024-03-01 12:00:00 -0.6700 -0.2281
2024-03-01 13:00:00 -0.7208 -0.4960
2024-03-01 14:00:00 -0.7442 -0.6669
2024-03-01 15:00:00 -0.7678 -0.7076
2024-03-01 16:00:00 -0.8116 -0.7265
2024-03-01 17:00:00 -0.8368 -0.7482
corr_humi_powe_12h
timestamp
2024-03-01 12:00:00 0.5380
2024-03-01 13:00:00 0.6614
2024-03-01 14:00:00 0.7202
2024-03-01 15:00:00 0.7311
2024-03-01 16:00:00 0.7233
2024-03-01 17:00:00 0.7219# 7. Accumulating Running Baselines with accumulate
A given value can carry different significance depending on when it occurs in a sequence. What matters is its deviation from the evolving baseline — the running mean up to that point in time. Using an incremental approach such as accumulate, you can compute this running mean efficiently without storing the entire history.
readings = df["temperature_c"].tolist()
running_sums = list(itertools.accumulate(readings))
running_counts = list(itertools.accumulate([1] * len(readings)))
running_means = [
round(s / c, 4)
for s, c in zip(running_sums, running_counts)
]
# Running max — highest temperature seen so far, useful for breach tracking
running_max = list(itertools.accumulate(readings, func=max))
deviation_from_baseline = [
round(r - m, 4)
for r, m in zip(readings, running_means)
]
baseline_df = pd.DataFrame({
"temperature_c": readings,
"running_mean": running_means,
"running_max": running_max,
"deviation_from_baseline": deviation_from_baseline,
}, index=df.index)
print(baseline_df.iloc[20:28])Output:
temperature_c running_mean running_max \
timestamp
2024-03-01 20:00:00 2.960 3.5857 5.192
2024-03-01 21:00:00 2.647 3.5430 5.192
2024-03-01 22:00:00 2.986 3.5188 5.192
2024-03-01 23:00:00 2.831 3.4902 5.192
2024-03-02 00:00:00 3.409 3.4869 5.192
2024-03-02 01:00:00 3.919 3.5035 5.192
2024-03-02 02:00:00 3.833 3.5157 5.192
2024-03-02 03:00:00 4.542 3.5524 5.192
deviation_from_baseline
timestamp
2024-03-01 20:00:00 -0.6257
2024-03-01 21:00:00 -0.8960
2024-03-01 22:00:00 -0.5328
2024-03-01 23:00:00 -0.6592
2024-03-02 00:00:00 -0.0779
2024-03-02 01:00:00 0.4155
2024-03-02 02:00:00 0.3173
2024-03-02 03:00:00 0.9896# Summary
Time series feature engineering is fundamentally about describing *context* — what has this signal been doing, relative to what we expect it to be doing? Every function covered here is a different way of formalizing that question into a number a model can learn from.
Here's a summary of the patterns we've covered in this article:
itertools Function
Time Series Feature
Example
islice
Lag features
Temperature 1h, 6h, 24h ago
islice + accumulate
Rolling window stats
6h mean, std, min, max
product
Seasonal interaction grid
Hour × day type × shift baseline
tee
Parallel window statistics
Mean + range + rate of change
chain
Multi-resolution feature assembly
Raw + rolling + calendar features
combinations
Pairwise cross-sensor correlations
Temp–humidity, temp–power rolling corr
accumulate
Running baseline + deviation
Drift detection from historical mean
And because itertools works at the iterator level, all of these patterns compose cleanly into streaming pipelines as well. Happy feature engineering!
Bala Priya C** is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み