自律的コンテキスト圧縮
LangChainはDeep Agents SDKとCLIに、エージェントが自らのコンテキストウィンドウを適切なタイミングで圧縮できるツールを追加し、固定閾値圧縮の限界を超える自律的コンテキスト管理を実現した。
キーポイント
自律的コンテキスト圧縮の実装
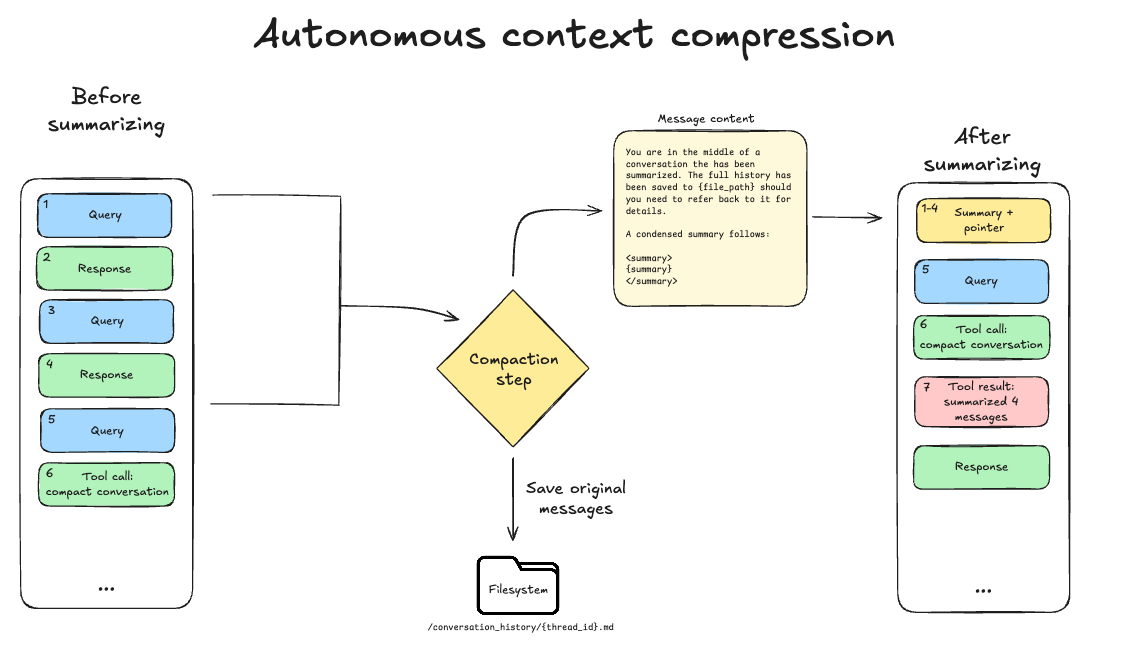
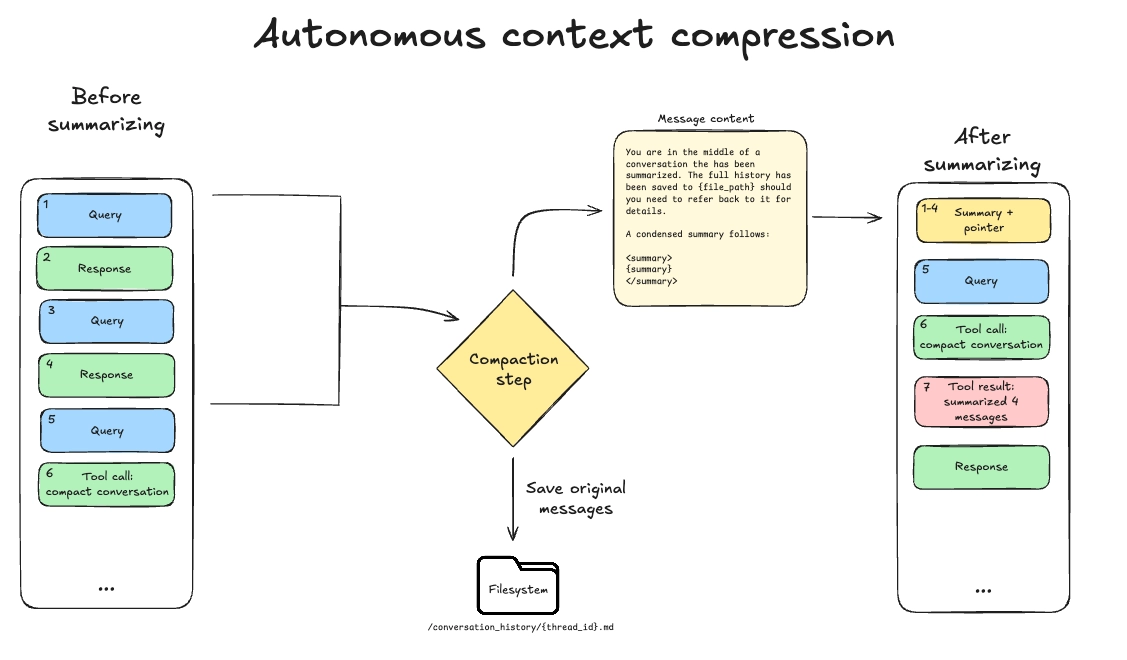
Deep Agents SDKとCLIに、エージェントが自発的にコンテキスト圧縮をトリガーできるツールを追加した。これにより、ユーザーが手動で圧縮コマンドを実行する必要がなくなり、より機会的な圧縮が可能になった。
固定閾値圧縮からの脱却
従来の85%閾値での自動圧縮は、複雑な作業中など不適切なタイミングで圧縮が発生する問題があった。新ツールはエージェント自身が適切なタイミングを判断し、コンテキストロットを防ぎつつ作業の連続性を保つ。
圧縮適切タイミングの具体例
新しいタスク開始時、大量コンテキストからの結果抽出後、長文生成前、複数ステッププロセス開始前、以前のコンテキストが無効化された時など、様々な状況で圧縮が有効であることを示した。
ハーネスの役割縮小とエージェント自律性向上
「ハーネスは可能な限り『邪魔をしない』ようにすべき」という哲学に基づき、基盤となる推論モデルの改善を活かす方向性を示した。これは「苦い教訓」の一例として、手動でのハーネス調整を避けるためのアプローチである。
影響分析・編集コメントを表示
影響分析
この機能は、有限コンテキストウィンドウというLLMの根本的制約に対して、より知的な管理手法を提供する。エージェント開発において、ハーネス設計の複雑さを軽減しつつ、エージェント自体の判断能力を高める方向性を示しており、実用的なエージェントシステムの進化に寄与する。
編集コメント
エージェントの自律性を高める実用的な機能追加で、特に長い対話セッションを必要とするコーディング支援ツールなどでの価値が大きい。技術的にはシンプルだが、エージェント設計の哲学的な方向性を示す点で注目に値する。
 imageTL;DR: Deep Agents SDK (Python) および CLI に、モデルが適切なタイミングで自身のコンテキストウィンドウを圧縮できるツールを追加しました。
imageTL;DR: Deep Agents SDK (Python) および CLI に、モデルが適切なタイミングで自身のコンテキストウィンドウを圧縮できるツールを追加しました。
動機
コンテキスト圧縮とは、エージェントの作業メモリ内の情報を削減するアクションです。古いメッセージは、タスクに関連する内容を保持した要約、あるいは凝縮された表現に置き換えられます。このアクションは、有限のコンテキストウィンドウに対応し、コンテキストの腐敗を軽減するためにしばしば必要となります。
エージェントハーネスは、多くの場合、固定のトークンしきい値で圧縮することでこれを制御します(deepagents はモデルプロファイルを使用し、任意のモデルのコンテキスト制限の85%に達した時点で圧縮します)。この設計は最適とは言えません。なぜなら、圧縮に適したタイミングと不適切なタイミングがあるからです。
- 複雑なリファクタリングの最中に圧縮するのは理想的ではありません。
- 新しいタスクを開始するとき、あるいは以前のコンテキストが関連性を失うと考えられるときに圧縮する方が良いでしょう。
多くのインタラクティブなコーディングツールには /compact コマンドや類似の機能があり、ユーザーが適切なタイミングで手動でコンテキスト圧縮をトリガーできます。私たちは deepagents の最新リリースでこれを一歩進め、エージェント自身がコンテキスト圧縮をトリガーできるツールを公開しました。これにより、アプリケーションのユーザーが有限のコンテキストウィンドウを意識したり、特定のコマンドを発行したりする必要なく、より機会的な圧縮が可能になります。
このツールは現在、Deep Agents CLI ではデフォルトで有効、deepagents SDK ではオプトイン(選択式)です。
私たちは一般的に、ハーネスは可能な限り「邪魔をしない」ようにし、基盤となる推論モデルの改善を活用すべきだという考えに賛同しています。これは「苦い教訓」の一例です。ハーネスを手動で調整することを避けるために、エージェントに自身のコンテキストに対するより多くの制御を与えることはできないでしょうか?
いつ圧縮すべきか?
コンテキスト圧縮が有効と考えられる状況は多岐にわたります。
- 明確なタスク境界で:
- ユーザーが、以前のコンテキストがおそらく無関係になる新しいタスクに移行することを示したとき
- エージェントが成果物を完了し、ユーザーがタスク完了を確認したとき
- 大量のコンテキストから結果を抽出した後:
- エージェントが、調査タスクのように大量のコンテキストを消費して事実、結論、要約、またはその他の結果を得たとき
- 大量の新しいコンテキストを消費する前:
- エージェントが長い草案を生成しようとしているとき
- エージェントが大量の新しいコンテキストを読もうとしているとき
- 複雑な多段階プロセスに入る前:
- エージェントが長いリファクタリング、移行、マルチファイル編集、またはインシデント対応を開始しようとしているとき
- エージェントが計画を作成し、ステップの実行を開始しようとしているとき
- 以前のコンテキストに優先する決定がなされたとき:
- 以前のコンテキストを無効にする新しい要件が明らかになったとき
- 多くの余談や行き止まりがあり、それらを要約に集約できるとき
すべての可能なシナリオを列挙することは現実的ではありません。しかし私たちの観察では、人間とLLMはこれらのシナリオを識別し、適切なタイミングで圧縮を行うことができ、結果としてコンテキストウィンドウが制限に近づいてから慌てて圧縮する必要性を減らせます。このツールに関してモデルに提供しているガイダンスは、システムプロンプトでご覧いただけます。
ツールが呼び出されると何が起こるか?
このツールは、既存の Deep Agents 要約ミドルウェアと同じパラメータで動作します。最近のメッセージ(利用可能なコンテキストの10%)を保持し、それ以前の内容を要約します。圧縮ツールの呼び出しとそれに対する応答を含む最近のメッセージは、保持されたままになります。
 imageトレース例を参照してください。
imageトレース例を参照してください。
使用方法
このツールは独立したミドルウェアとして実装されているため、create_deep_agent のミドルウェアリストに追加することで有効にできます。
from deepagents import create_deep_agent
from deepagents.backends import StateBackend
from deepagents.middleware.summarization import (
create_summarization_tool_middleware,
)
backend = StateBackend # デフォルトバックエンドを使用する場合
model = "openai:gpt-5.4"
agent = create_deep_agent(
model=model,
middleware=[
create_summarization_tool_middleware(model, backend),
],
)詳細は SDK ドキュメントを参照してください。
CLI では、コンテキストを整理したり新しいタスクに移行したりする準備ができたら、単に /compact を実行してください。
この機能に関する私たちの経験
私たちは、この機能が保守的になるように調整しました。Deep Agents はすべての会話履歴を仮想ファイルシステムに保持し、要約後のコンテキストの復元を可能にしています。しかし、誤ったコンテキスト圧縮は作業の流れを乱すためです。私たちは以下のテストを行いました。
- カスタム評価スイート: (自社の) LangSmith トレースを用い、圧縮が妥当なスレッドと不要なスレッドにフォローアッププロンプトを注入して評価。
- Terminal-bench-2: 自律的圧縮が行われるインスタンスは観察されませんでした。
- Deep Agents CLI での自社のコーディングタスク
実際には、エージェントは圧縮のトリガーに対して保守的ですが、トリガーする場合は、それが明らかにワークフローを改善する瞬間を選択する傾向があります。
自律的コンテキスト圧縮は小さな機能ですが、エージェント設計におけるより広範な方向性を示しています。それは、モデルに自身の作業メモリに対するより多くの制御を与え、ハーネス内の硬直的で手動調整されたルールを減らすという方向性です。長時間実行される、あるいはインタラクティブなエージェントを構築している場合は、Deep Agents SDK または CLI でお試しいただき、フィードバックや次に扱ってほしいパターンについてお聞かせください。
原文を表示
imageTL;DR: We've added a tool to the Deep Agents SDK (Python) and CLI that allows models to compress their own context windows at opportune times.
Motivation
Context compression is an action that reduces the information in an agent’s working memory. Older messages are replaced by a summary or condensed representation of an agent’s progress that preserves what’s relevant to a task. This action is often necessary to accommodate finite context windows and reduce context rot.
Agent harnesses often control this by compacting at a fixed token threshold (deepagents uses model profiles to compact at 85% of any given model’s context limit). This design is suboptimal because there are good times and bad times to compact:
It is not ideal to compact when you’re in the middle of a complex refactor;
It is better to compact when you are starting a new task or otherwise believe that prior context will lose relevance.
Many interactive coding tools feature a /compact command or similar, which allows users to manually trigger a context compression step at opportune times. We take this one step further in the latest release of deepagentsand expose a tool to the agent that lets it trigger context compression itself. This enables more opportunistic compaction without requiring your application’s users to be aware of finite context windows or issue specific commands.
This tool is currently enabled in Deep Agents CLI and opt-in in the deepagents SDK.
We are generally bullish on the idea that harnesses should, where possible, “get out of the way” and take advantage of improvements in the underlying reasoning models. This is an instance of the bitter lesson: can we give agents more control over their own context to avoid tuning their harness by hand?
When should we compact?
There is a variety of situations that could warrant a context compression action.
At clean task boundaries:
A user signals that they are moving on to a new task for which earlier context is likely irrelevant
The agent has finished a deliverable and the user acknowledges task completion
After extracting a result from a large amount of context:
The agent has obtained a fact, conclusion, summary, or other result by consuming a significant amount of context, as in a research task
Before consuming a large amount of new context:
The agent is about to generate a long draft
The agent is about to read a large amount of new context
Before entering a complex multi-step process:
The agent is about to start a lengthy refactor, migration, multi-file edit, or incident response
The agent has produced a plan and is about to begin executing the steps
A decision has been made that supersedes prior context:
New requirements have come to light that invalidate previous context
There are many tangents or dead-ends that can be reduced to a summary
Enumerating all possible scenarios is not practical, but our observation is that people and LLMs can identify these scenarios and compact at opportune times, saving the need for a compaction step later on when the context window is nearing its limit. You can read the guidance we provide the model around this tool in its system prompt.
What happens when the tool is called?
The tool is parametrized the same as the existing Deep Agents summarization middleware: we retain recent messages (10% of available context) and summarize what comes before. Recent messages, including the call to the compaction tool and associated response, are retained in the recent context.
imageSee example trace.
How to use
The tool is implemented as a separate middleware, so you can enable it by adding it to the middleware list in create_deep_agent:
from deepagents import create_deep_agent
from deepagents.backends import StateBackend
from deepagents.middleware.summarization import (
create_summarization_tool_middleware,
)
backend = StateBackend # if using default backend
model = "openai:gpt-5.4"
agent = create_deep_agent(
model=model,
middleware=[
create_summarization_tool_middleware(model, backend),
],
)
See the SDK docs for more details.
In the CLI, simply call /compact when you’re ready to trim context or move onto a new task.
Our experience with this feature
We tuned this feature to be conservative. Deep Agents preserves all conversation history in its virtual filesystem, allowing for recovery of context post-summarization, but an erroneous context compression step is disruptive. We tested:
A custom evaluation suite, in which we used (our own) LangSmith traces to inject follow-up prompts to threads that do and do not warrant compaction;
Terminal-bench-2, in which we did not observe any instances of autonomous compaction;
Our own coding tasks in Deep Agents CLI.
In practice agents are conservative about triggering compaction, but when they do they tend to choose moments where it clearly improves the workflow.
Autonomous context compression is a small feature, but it points at a broader direction for agent design: giving models more control over their own working memory and fewer rigid, hand-tuned rules in the harness. If you’re building long-running or interactive agents, try it out in the Deep Agents SDK or CLI and let us know your feedback and what patterns you’d like to see it handle next.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み