自己修復型エージェントループの構築(読了時間:39 分)
OpenAI は、エージェントが出力を検証しフィードバックに基づいて自己修復を行う「クローズドループ」ワークフローの実装パターンと、Codex CLI を用いた具体的な技術ドキュメント修復の例を公開した。
キーポイント
自己修復型エージェントループの定義
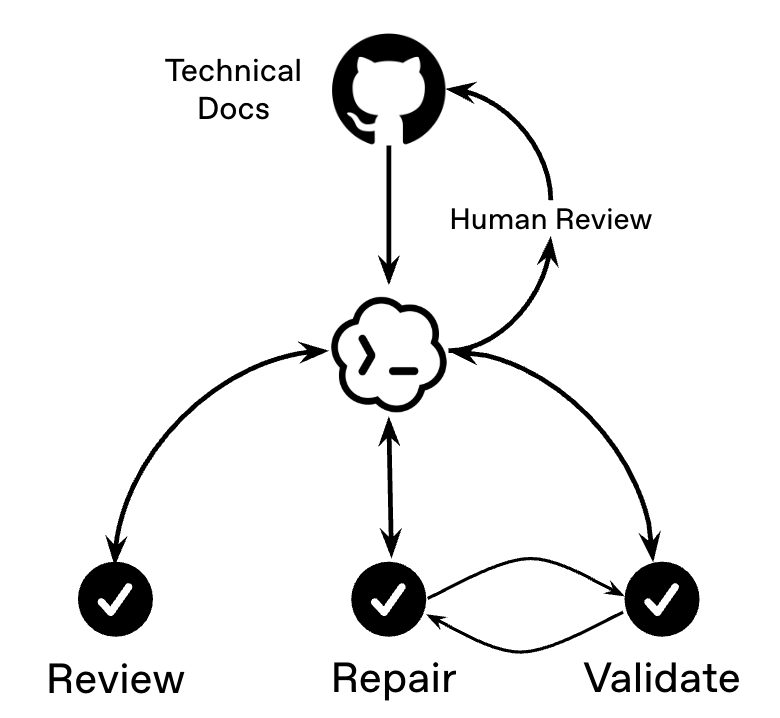
エージェントが出力を作成し、検証を行い、フィードバックを用いて次の試行を改善するクローズドループワークフローのパターンを示している。
3 つのフェーズによる実装構成
Review(現状分析と構造化された発見)、Repair(修正適用)、Validate(チェック実行と残課題報告)という 3 フェーズでループを構築する。
Codex CLI を活用した自動化修復
チャット UI に依存せず、Python コードからヘッドレスモードの Codex CLI を呼び出して、意図的に古くなったノートブックの自動修復を実行する方法を解説している。
汎用パターンとしての応用可能性
このノートブック例は単なる事例であり、信頼できるフィードバックでエージェントの出力を測定可能なあらゆる場面で適用可能な一般化されたパターンである。
ヘッドレスモードでの実行環境構築
チャットUIではなくPythonセルから直接修復ステップを実行できるよう、Codex CLIをヘッドレスモードで使用し、特定のバージョン(0.130.0)で固定して再現性を確保しています。
環境変数によるモデルとパスの制御
REPAIR_MODELやOPENAI_API_KEYなどの環境変数を設定することで、使用するLLMモデルを切り替えたり、実行ディレクトリを指定したりして柔軟に実験可能です。
サンプルデータと依存関係の検証
ノートブックを実行する前に、必要なサンプルデータ(data/docs)が存在するかチェックし、存在しない場合は明確なエラーメッセージを表示して実行を停止します。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェントが単発的なタスク実行から、自律的に品質を維持・改善する「自己修復型」システムへ進化するための具体的な実装指針を提供しています。開発者が信頼性の高い自動化ワークフローを構築する際の標準パターンとして定着し、ドキュメント管理やコードレビューなどの現場課題解決に即座に活用できる実用性が高いです。
編集コメント
「生成」から「検証・修復」へと視座を移した、実務レベルの信頼性向上アプローチとして非常に価値が高い記事です。
このクックブックは、出力を生成し、それを検証し、フィードバックを用いて次の処理を改善するエージェントによるクローズドループワークフローについて解説しています。
ここでは、古くなったり壊れたりした API や SDK のサンプルを検出し、修復し、検証するドキュメント信頼性ワークフローを探ります。この実演例では、このクックブックリポジトリから意図的に古くされたノートブックを流用しています。
このエージェントループは Codex を用いて構築します。Codex は現在の状態を検証し、焦点を絞った変更を加え、検証を実行し、フィードバックに未解決の問題が残っている場合は繰り返します。
このノートのタスクは単なる例示です。このパターンは、エージェントの出力が信頼できるフィードバックで測定可能なあらゆる場面で適用可能です。
ワークフローには 3 つのフェーズがあります:
- 検証: 現在のアーティファクトを検査し、ファイルを編集せずに構造化された所見を返します。
- 修復: 所見と最新の検証フィードバックを用いて、コピーしたアーティファクトに対して焦点を絞った編集を適用します。
- 検証: 関連するチェックを実行し、まだ作業が必要な箇所を報告します。
検証がループを閉じます。修復されたノートブックは、重要なチェックを満たさなければならず、残っている問題は次の修復入力となります。
このノートブックはヘッドレスモードで Codex CLI を使用するため、修復ステップはチャット UI ではなく Python セルから実行できます。最初のコードセルでは CLI のインストールが行われます。すでに入手済みの場合は、そのセルをスキップしてください。
ライブ修復ループを実行する前に、環境変数に OPENAI_API_KEY を設定してください。
このノートブックはデフォルトで高速な修復モデルを使用するため、完全な例を合理的な時間で完了できます。異なるモデルで実験したい場合は、開始前に REPAIR_MODEL を設定してください。インストールセルでは再現性のために既知の Codex CLI バージョンを固定しています;新しい CLI の動作が必要な場合は、意図的にそのバージョンを更新してください。
!npm install -g @openai/codex@0.130.0
import concurrent.futures
import json
import os
import shlex
import shutil
import subprocess
import tempfile
from pathlib import Path
from typing import Any
CANDIDATE_EXAMPLE_DIRS = [Path("."), Path("examples/codex")]
EXAMPLE_DIR = next((base for base in CANDIDATE_EXAMPLE_DIRS if (base / "data" / "docs").exists()), None)
if EXAMPLE_DIR is None:
raise RuntimeError(
"This notebook needs its companion sample notebooks. "
"Download the data folder that ships with this example and place it next to "
"this notebook as ./data/docs, or run from a checkout where examples/codex/data/docs exists."
)
DATA_DIR = EXAMPLE_DIR / "data" / "docs"
DEFAULT_RUNS_DIR = Path(tempfile.gettempdir()) / "codex_iterative_repair_loop_outputs"
RUNS_DIR = Path(os.getenv("CODEX_REPAIR_RUNS_DIR", str(DEFAULT_RUNS_DIR))).expanduser()
RUNS_DIR.mkdir(parents=True, exist_ok=True)
MODEL = os.getenv("REPAIR_MODEL", "gpt-5.4-mini")
COOKBOOK_CHAT_MODEL = os.getenv("COOKBOOK_CHAT_MODEL", "gpt-5.5")
REPAIR_REASONING_EFFORT = os.getenv("REPAIR_REASONING_EFFORT", "low")
if not os.environ.get("OPENAI_API_KEY"):
raise ValueError("Set the OPENAI_API_KEY environment variable before running the live Codex repair loop.")
CODEX_CLI = shutil.which("codex")
if CODEX_CLI is None:
raise RuntimeError("Run the install cell before continuing; Codex CLI is not on PATH.")
以下のセルは、修復ループを駆動する 3 つのコンパニオンノートブックを読み込み、そのメタデータを要約します。
サンプルは意図的に小さく設定されています。実行が速い一方で、アーキテクチャを実際に検証しています:レビューで実質的な問題を見つけ、修復で焦点を絞った編集を行い、検証で次のパスのためのフィードバックを生成します。
このノートブック単体でダウンロードする場合は、コンパニオンの data/docs/ フォルダも一緒にダウンロードし、以下のセルを実行する前にノートブックの隣に配置してください。コードは、これらのサンプルノートブックがローカルに存在することを前提としています。
この例では、検証は修復されたノートブックをエンドツーエンドで実行します。別のドメインでは、検証はユニットテスト、ポリシーチェック、スキーマバリデーター、シミュレーション、または人間の承認ステップになる可能性があります。重要な点は、失敗が行き止まりではなく構造化されたフィードバックになることです。
NOTEBOOKS = [
DATA_DIR / "qdrant_embeddings_search_pre_repair.ipynb",
DATA_DIR / "getting_started_evals_pre_repair.ipynb",
DATA_DIR / "knowledge_retrieval_pre_repair.ipynb",
]
def read_notebook(path: Path) -> dict[str, Any]:
return json.loads(path.read_text(encoding="utf-8"))
def case_metadata(path: Path) -> dict[str, Any]:
return read_notebook(path).get("metadata", {}).get("codex_case_study", {})
cases = []
for notebook_path in NOTEBOOKS:
notebook = read_notebook(notebook_path)
metadata = notebook.get("metadata", {}).get("codex_case_study", {})
repair_story = metadata.get("repair_story", {})
cases.append(
{
"notebook": notebook_path.name,
"cells": len(notebook["cells"]),
"code_cells": sum(cell["cell_type"] == "code" for cell in notebook["cells"]),
"source": metadata.get("source_path"),
"target_iteration": repair_story.get("target_iteration"),
"repair_depth": repair_story.get("repair_depth", ""),
}
)
cases
[{'notebook': 'qdrant_embeddings_search_pre_repair.ipynb',
'cells': 5,
'code_cells': 4,
'source': 'examples/vector_databases/qdrant/Using_Qdrant_for_embeddings_search.ipynb',
'target_iteration': 1,
'repair_depth': 'One-pass cleanup: modernize the local Qdrant query path and clarify the sampled fixture framing.'},
{'notebook': 'getting_started_evals_pre_repair.ipynb',
'cells': 5,
'code_cells': 4,
'source': 'examples/evaluation/Getting_Started_with_OpenAI_Evals.ipynb',
'target_iteration': 2,
'repair_depth': 'Two-pass cleanup: first modernize the obvious stale Evals flow, then use validation feedback to remove result-log brittleness.'},
{'notebook': 'knowledge_retrieval_pre_repair.ipynb',
'cells': 5,
'code_cells': 4,
'source': 'examples/How_to_call_functions_for_knowledge_retrieval.ipynb',
'target_iteration': 3,
'repair_depth': 'Three-pass cleanup: modernize model/API shape, then tighten runnable local setup, then restore the full retrieval teaching flow.'}]
Codex にアーティファクトのレビューや修復を依頼する前に、小さな共通契約(共有規約)を与えてください。これにより、ループが重要な課題に集中し、モデルが最初からすべての製品ルールやスタイル規則を推測する必要がなくなります。
以下のルールは、これらの例用ノートブックにおける「良い」状態の定義です:現在の API パターン、明確なセットアップ、実行可能なローカルサンプル、そして元の教育目標の維持です。別のワークフローでは、この契約はそのドメインにおける真実の源泉(ソース・オブ・トゥルース)を記述することになります。
business_rules = {
"preferred_chat_model": COOKBOOK_CHAT_MODEL,
"preferred_embedding_model": "text-embedding-3-large",
"modernize": [
"client.chat.completions.create -> client.responses.create",
"legacy function-calling schemas -> current tools schema",
"qdrant.search -> qdrant.query_points",
"oaieval CLI examples -> current Evals API workflow",
],
"reader_experience": [
"Make fresh-environment setup explicit.",
"Keep the included examples runnable with local data and the standard library.",
"Keep sample repairs self-contained unless the notebook explicitly teaches external setup.",
"Remove manual result-file placeholders.",
"State runtime prerequisites and side effects before readers run cells.",
"Preserve the original teaching goal while modernizing the implementation.",
],
}
business_rules
各フェーズは構造化データを返すため、次のフェーズで具体的なデータを利用できます。
レビューでは発見事項を返し、修復では変更サマリーと更新されたアーティファクトへのパスを返し、検証では次のパスに残る差分を返します。構造化された引き継ぎにより、ループのデバッグ、再実行、および他のアーティファクトタイプへの適応が容易になります。
def object_schema(properties: dict[str, Any], required: list[str] | None = None) -> dict[str, Any]:
return {
"type": "object",
"properties": properties,
"required": required or list(properties),
"additionalProperties": False,
}
def string_array() -> dict[str, Any]:
return {"type": "array", "items": {"type": "string"}}
finding_schema = object_schema(
{
"artifact": {"type": "string"},
"issue_type": {"type": "string"},
"severity": {"type": "string"},
"description": {"type": "string"},
"suggested_fix_direction": {"type": "string"},
}
)
review_schema = object_schema(
{"findings": {"type": "array", "items": finding_schema}}
)
fix_schema = object_schema(
{
"artifact": {"type": "string"},
"iteration": {"type": "integer"},
"changes_made": string_array(),
"unresolved_items": string_array(),
"updated_artifact_path": {"type": "string"},
}
)
validation_case_schema = object_schema(
{
"name": {"type": "string"},
"passed": {"type": "boolean"},
"severity": {"type": "string"},
"evidence": {"type": "string"},
"feedback": {"type": "string"},
}
)
validation_schema = object_schema(
{
"overall_passed": {"type": "boolean"},
"cases": {"type": "array", "items": validation_case_schema},
"remaining_delta": string_array(),
}
)
レビューフェーズはアーティファクトを読み込み、構造化された所見を返します。検証を実行するわけでもなく、ファイルを編集するわけでもありません。この分離により、最初のステップが明確に保たれます:何らかの変更を加える前に、潜在的な問題を特定することです。
レビュープロンプトを codex exec に JSON スキーマと共に送信します。このスキーマによって結果が機械可読形式となり、後のセルで前回の回答から文章をスクレイピングするのではなく、所見を直接修復用プロンプトに渡すことができます。
def notebook_text(path: Path, max_chars: int = 7000) -> str:
chunks = []
for index, cell in enumerate(read_notebook(path)["cells"]):
source = "".join(cell.get("source", []))
chunks.append(f"cell {index} ({cell['cell_type']})\n{source}")
text = "\n\n".join(chunks)
if len(text) <= max_chars:
return text
return text[:max_chars] + "\n\n[truncated for prompt size]"
def run_command(command: str, *, stdin: str | None = None, cwd: Path | None = None, timeout: int | None = None):
cwd = Path.cwd() if cwd is None else cwd
return subprocess.run(
shlex.split(command),
input=stdin,
cwd=cwd,
capture_output=True,
text=True,
timeout=timeout,
check=False,
)
def run_codex_json(prompt: str, schema: dict[str, Any], run_dir: Path) -> dict[str, Any]:
run_dir.mkdir(parents=True, exist_ok=True)
prompt_file = run_dir / "prompt.txt"
schema_file = run_dir / "schema.json"
answer_file = run_dir / "answer.json"
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "レビューフェーズはアーティファクトを読み込み、構造化された所見を返します。検証を実行するわけでもなく、ファイルを編集するわけでもありません。この分離により、最初のステップが明確に保たれます:何らかの変更を加える前に、潜在的な問題を特定することです。\n\nレビュープロンプトを codex exec に JSON スキーマと共に送信します。このスキーマによって結果が機械可読形式となり、後のセルで前回の回答から文章をスクレイピングするのではなく、所見を直接修復用プロンプトに渡すことができます。\n\ndef notebook_text(path: Path, max_chars: int = 7000) -> str:\n chunks = []\n for index, cell in enumerate(read_notebook(path)["cells"]):\n source = "".join(cell.get("source", []))\n chunks.append(f"cell {index} ({cell['cell_type']})\\n{source}")\n text = "\\n\\n".join(chunks)\n if len(text) <= max_chars:\n return text\n return text[:max_chars] + "\\n\\n[truncated for prompt size]"\n\ndef run_command(command: str, *, stdin: str | None = None, cwd: Path | None = None, timeout: int | None = None):\n cwd = Path.cwd() if cwd is None else cwd\n return subprocess.run(\n shlex.split(command),\n input=stdin,\n cwd=cwd,\n capture_output=True,\n text=True,\n timeout=timeout,\n check=False,\n )\n\ndef run_codex_json(prompt: str, schema: dict[str, Any], run_dir: Path) -> dict[str, Any]:\n run_dir.mkdir(parents=True, exist_ok=True)\n prompt_file = run_dir / "prompt.txt"\n schema_file = run_dir / "schema.json"\n answer_file = run_dir / "answer.json"\n\n必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:\n{\"translation\": \"レビューフェーズはアーティファクトを読み込み、構造化された所見を返します。検証を実行するわけでもなく、ファイルを編集するわけでもありません。この分離により、最初のステップが明確に保たれます:何らかの変更を加える前に、潜在的な問題を特定することです。\\n\\nレビュープロンプトを codex exec に JSON スキーマと共に送信します。このスキーマによって結果が機械可読形式となり、後のセルで前回の回答から文章をスクレイピングするのではなく、所見を直接修復用プロンプトに渡すことができます。\\n\\ndef notebook_text(path: Path, max_chars: int = 7000) -> str:\\n chunks = []\\n for index, cell in enumerate(read_notebook(path)[\\"cells\"])::\\n source = \"\".join(cell.get(\\"source\\", []))\\n chunks.append(f\\"cell {index} ({cell['cell_type']})\\\\n{source}")\\n text = \\\"\\\\n\\\\n\".join(chunks)\\n if len(text) <= max_chars:\\n return text\\n return text[:max_chars] + \\\"\\\\n\\\\n[truncated for prompt size]\"\\n\\ndef run_command(command: str, *, stdin: str | None = None, cwd: Path | None = None, timeout: int | None = None):\\n cwd = Path.cwd() if cwd is None else cwd\\n return subprocess.run(\\n shlex.split(command),\\n input=stdin,\\n cwd=cwd,\\n capture_output=True,\\n text=True,\\n timeout=timeout,\\n check=False,\\n )\\n\\ndef run_codex_json(prompt: str, schema: dict[str, Any], run_dir: Path) -> dict[str, Any]:\\n run_dir.mkdir(parents=True, exist_ok=True)\\n prompt_file = run_dir / \\\"prompt.txt\\"\\n schema_file = run_dir / \\\"schema.json\\"\\n answer_file = run_dir / \\\"answer.json\\"\n}
prompt_file.write_text(prompt, encoding="utf-8")
schema_file.write_text(json.dumps(schema, indent=2), encoding="utf-8")
command = f"""
{CODEX_CLI} exec
--model {MODEL}
--sandbox workspace-write
--ask-for-approval never
--config model_reasoning_effort={REPAIR_REASONING_EFFORT}
--output-schema {schema_file}
--output-last-message {answer_file}
-
"""
result = run_command(command, stdin=prompt)
(run_dir / "stdout.txt").write_text(result.stdout, encoding="utf-8")
(run_dir / "stderr.txt").write_text(result.stderr, encoding="utf-8")
if result.returncode != 0:
raise RuntimeError(f"Codex exited with {result.returncode}. See {run_dir / 'stderr.txt'}.")
return json.loads(answer_file.read_text(encoding="utf-8"))
def review_notebook(path: Path, run_dir: Path) -> list[dict[str, Any]]:
prompt = "\n".join(
[
"You are reviewing a public OpenAI Cookbook notebook before publication.",
f"Artifact: {path.name}",
"Find issues that would make the notebook stale, hard to run, or confusing for a developer reader.",
"Do not execute the notebook or edit files.",
"Use concise issue_type labels such as stale_model, deprecated_api, setup_gap, runtime_risk, or clarity_issue.",
f"Business rules: {json.dumps(business_rules)}",
"Base findings only on the notebook content below.",
"Keep the findings focused; three strong findings are better than a long list.",
"",
notebook_text(path),
]
)
return run_codex_json(prompt, review_schema, run_dir)["findings"]
def run_initial_review(path: Path) -> tuple[str, list[dict[str, Any]]]:
return path.name, review_notebook(path, RUNS_DIR / "initial_review" / path.stem)
with concurrent.futures.ThreadPoolExecutor(max_workers=min(3, len(NOTEBOOKS))) as executor:
initial_reviews = dict(executor.map(run_initial_review, NOTEBOOKS))
initial_reviews
The repair phase gets the current artifact, review findings, business rules, and any validation feedback from the previous pass. The prompt gets more specific as the loop learns.
Codex は反復ディレクトリ内のコピーを編集し、変更箇所の短い要約を返します。このループは編集が成功したと仮定せず、次ステップで検証によって判断されます。
def repair_prompt(path: Path, updated_path: Path, findings: list[dict[str, Any]], remaining_delta: list[str], iteration: int) -> str:
repair_story = case_metadata(path).get("repair_story", {})
return "\n".join(
[
"あなたは、公開されている OpenAI Cookbook のノートブックのコピーを修復しています。",
f"ソースノートブック:{path}",
f"編集可能なコピー:{updated_path}",
f"反復回数:{iteration}",
"レビューの指摘と検証の差分に対応する、最小限で有用な修正を行ってください。",
"ノートブックの教育的流れと本来の目的を維持してください。",
"サンプル修復は、ノートブックが明示的に外部セットアップを教えない限り、完結したものに保ちます。",
"段階的な例については、一度にすべて書き直すのではなく、今回のパスで最も重要な残存課題に焦点を当ててください。",
"編集可能なコピーのみを編集してください。ノートブックが検証に合格したと主張しないでください。",
f"修復の深さ:{json.dumps(repair_story, indent=2)}",
f"ビジネスルール:{json.dumps(business_rules, indent=2)}",
f"レビューの指摘:{json.dumps(findings, indent=2)}",
f"残存する検証差分:{json.dumps(remaining_delta, indent=2)}",
]
)
def repair_notebook(path: Path, iteration: int, findings: list[dict[str, Any]], remaining_delta: list[str], case_dir: Path) -> dict[str, Any]:
updated_path = case_dir / "updated.ipynb"
updated_path.parent.mkdir(parents=True, exist_ok=True)
shutil.copy2(path, updated_path)
prompt = repair_prompt(path, updated_path, findings, remaining_delta, iteration)
return run_codex_json(prompt, fix_schema, case_dir / "repair")
検証は小規模な評価(eval)のように機能します。私たちは望ましい動作を定義し、関連するチェックを実行し、その基準に対して結果を採点するよう判事(judge)に依頼します。
ドキュメントの例では、実行が先に行われます。多くのノートブックの問題はランタイム時になって初めて現れます:インポートの欠落、古いファイルパス、古い API 応答に依存するセル、あるいは著者には明確だったものの新規読者には不明瞭なセットアップガイダンスなどです。
検証に失敗した場合、その失敗は次の修復パスにおける証拠となります。これにより、次の修復が単なる差分(diff)で正しそうに見えるものではなく、観測された動作に基づいて行われるようになります。
VALIDATION_CASES = [
{
"name": "api_modernization",
"question": "このノートブックは、古くなった OpenAI API のパターンや、レガシーな関数呼び出し構文、および時代遅れのモデル名を避けていますか?",
},
{
"name": "setup_reproducibility",
"question": "読者は、隠れた手動手順なしに新鮮な環境からこのノートブックを実行できますか?",
},
{
"name": "artifact_integrity",
"question": "更新により、ノートブックの教育的フローが維持され、実質的なセルが削除されていないことは確認できましたか?",
},
]
def short_output(value: Any, limit: int = 1200) -> str:
if value is None:
return ""
if isinstance(value, bytes):
value = value.decode("utf-8", errors="replace")
return str(value)[-limit:]
def execute_notebook(path: Path) -> dict[str, Any]:
code_cells = sum(cell["cell_type"] == "code" for cell in read_notebook(path)["cells"])
command = f"jupyter nbconvert --to notebook --execute --inplace {path.name}"
try:
result = run_command(
command,
cwd=path.parent,
timeout=int(os.getenv("SAMPLE_NOTEBOOK_TIMEOUT_SECONDS", "300")),
)
except FileNotFoundError:
return {
"status": "failed",
"executed_code_cells": 0,
"error": "Jupyter or nbconvert is not installed or is not available on PATH.",
"summary": "Install Jupyter with nbconvert before running the validation loop.",
}
except subprocess.TimeoutExpired as exc:
return {
"status": "failed",
"executed_code_cells": 0,
"error": f"Notebook execution timed out after {exc.timeout} seconds.",
"summary": short_output(exc.stderr or exc.stdout),
}
output = result.stderr or result.stdout
return {
"status": "passed" if result.returncode == 0 else "failed",
"executed_code_cells": code_cells if result.returncode == 0 else 0,
"error": "" if result.returncode == 0 else f"Notebook execution exited with code {result.returncode}.",
"summary": short_output(output),
}
def validation_prompt(updated_path: Path, before_path: Path, execution: dict[str, Any], iteration: int) -> str:
repair_story = case_metadata(before_path).get("repair_story", {})
return "\n".join(
[
"あなたは修復された OpenAI Cookbook のノートブックを審査する役割です。",
f"イテレーション:{iteration}",
"各検証ケースを独立して採点し、次の修復パスのための簡潔なフィードバックを提供してください。",
"実行が失敗した場合や、いずれかのケースに重大な問題がある場合は、overall_passed を false に設定してください。",
"実行が失敗した場合は、その失敗を remaining_delta に含め、次の修復パスで対応できるようにしてください。",
"現在のモデル名と API ターゲットについては、ビジネスルールを真実の源として使用してください。",
"優先される埋め込みモデルやチャットモデルを古くさいものとしてマークしないでください。",
"ローカル例については、ノートブックが意図的に自己完結型であると明記されている場合、追加のサービスやパッケージインストールは不要とみなしてください。",
f"修復の深さ:{json.dumps(repair_story, indent=2)}",
f"ビジネスルール:{json.dumps(business_rules, indent=2)}",
f"検証ケース:{json.dumps(VALIDATION_CASES, indent=2)}",
f"実行証拠:{json.dumps(execution, indent=2)}",
f"元のセル数:{len(read_notebook(before_path)['cells'])}",
f"更新後のセル数:{len(read_notebook(updated_path)['cells'])}",
"",
notebook_text(updated_path),
]
)
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
def staged_delta(before_path: Path, iteration: int) -> list[str]:
repair_story = case_metadata(before_path).get("repair_story", {})
target = int(repair_story.get("target_iteration") or 1)
if iteration >= target:
return []
depth = repair_story.get("repair_depth", "This case is intentionally staged across multiple repair passes.")
return [f"Continue to iteration {iteration + 1}: {depth}"]
def evaluate_notebook(updated_path: Path, before_path: Path, run_dir: Path, iteration: int) -> dict[str, Any]:
execution = execute_notebook(updated_path)
judged = run_codex_json(validation_prompt(updated_path, before_path, execution, iteration), validation_schema, run_dir)
failed_cases = [case for case in judged["cases"] if not case["passed"]]
execution_delta = []
if execution["status"] != "passed":
execution_delta.append(f"Execution failed: {execution.get('error') or execution.get('summary')}")
stage_delta = staged_delta(before_path, iteration)
return {
"passed": judged["overall_passed"] and execution["status"] == "passed" and not stage_delta,
"execution_status": execution["status"],
"executed_code_cells": execution["executed_code_cells"],
"execution_summary": execution["summary"],
"findings": failed_cases,
"remaining_delta": execution_delta + stage_delta + judged["remaining_delta"],
}
各反復処理は record.json ファイルを出力し、この例では CODEX_REPAIR_RUNS_DIR/iteration_N/<sample_name>/ 配下に修復されたノートブックが作成されます。CODEX_REPAIR_RUNS_DIR を設定しない場合、ノートブックはシステムの一時ディレクトリに書き込まれるため、通常のリポジトリチェックアウト状態をクリーンに保つことができます。
これらのファイルは監査証跡(audit trail)です。レビューで何が見つかり、Codex が何を修正し、実行が成功したか、そして次の反復処理へ引き継がれたフィードバックが何かを確認できます。
record.json ファイルは、1 回のループ試行に対する領収書のようなものです。各フェーズ間の受け渡し情報を一箇所に集約します:
{
"review": [{"issue_type": "deprecated_api", "severity": "high"}],
"repair": {
"changes_made": ["Updated the notebook to use the current API pattern."],
"updated_artifact_path": "/tmp/codex_iterative_repair_loop_outputs/iteration_1/sample/updated.ipynb"
},
"validation": {
"passed": false,
"remaining_delta": ["One setup instruction is still unclear."]
}
}
このコンパクトな記録により、メンテナーはノートブックの差分やターミナルログから実行全体を再構築することなく、ループの内容を検査できます。
def save_json(payload: Any, path: Path) -> None:
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(json.dumps(payload, indent=2) + "\n", encoding="utf-8")
def iteration_dir(number: int) -> Path:
path = RUNS_DIR / f"iteration_{number}"
path.mkdir(parents=True, exist_ok=True)
return path
各ノートブックケースは独立しているため、ケースを並列処理します。これによりデモの速度を維持しつつ、すべてのサンプルに対して同じレビュー・修復・検証フローが保証されます。
1 回目の反復では、以前のレビューセルからの初期レビュー結果を再利用します。このパスの後、返されたブール値を検査してください:合格したケースはそこで停止し、不合格だったケースは検証フィードバックを次のパスに引き継ぎます。
current_notebooks = {path.name: path for path in NOTEBOOKS}
history: dict[int, dict[str, Any]] = {}
def review_findings_for(original: Path, current_path: Path, case_dir: Path, previous_results: dict[str, Any] | None) -> list[dict[str, Any]]:
if previous_results is None:
return initial_reviews[original.name]
return review_notebook(current_path, case_dir / "review")
def run_case(number: int, original: Path, run_dir: Path, previous_results: dict[str, Any] | None) -> tuple[str, dict[str, Any], Path]:
name = original.name
case_dir = run_dir / original.stem
current_path = current_notebooks[name]
findings = review_findings_for(original, current_path, case_dir, previous_results)
delta = [] if previous_resu
原文を表示
This cookbook is about closed-loop agent workflows: agents that produce an output, validate it, and use the feedback to improve the next pass.
We’ll explore a documentation reliability workflow that detects, repairs, and validates stale or broken API and SDK examples. The worked example uses intentionally stale notebooks adapted from this Cookbook repository.
We’ll build this agent loop with Codex. Codex reviews the current state, applies focused changes, runs validation, and repeats when the feedback shows remaining issues.
The notebook task is only the example. The pattern applies wherever agent output can be measured with trustworthy feedback.
The workflow has three phases:
- Review: inspect the current artifact and return structured findings without editing files.
- Repair: apply focused edits to a copied artifact using the findings and the latest validation feedback.
- Validate: run the relevant checks and report what still needs work.
Validation closes the loop. The repaired notebook has to satisfy the checks that matter, and any remaining issues become the next repair input.
This notebook uses Codex CLI in headless mode, so the repair steps can run from Python cells instead of a chat UI. The first code cell installs the CLI; if you already have it, you can skip that cell.
Before you run the live repair loop, set OPENAI_API_KEY in your environment.
The notebook defaults to a fast repair model so the full example can finish in a reasonable amount of time. To experiment with a different model, set REPAIR_MODEL before you start. The install cell pins a known Codex CLI version for reproducibility; update that version intentionally when you want newer CLI behavior.
!npm install -g @openai/codex@0.130.0import concurrent.futures
import json
import os
import shlex
import shutil
import subprocess
import tempfile
from pathlib import Path
from typing import Any
CANDIDATE_EXAMPLE_DIRS = [Path("."), Path("examples/codex")]
EXAMPLE_DIR = next((base for base in CANDIDATE_EXAMPLE_DIRS if (base / "data" / "docs").exists()), None)
if EXAMPLE_DIR is None:
raise RuntimeError(
"This notebook needs its companion sample notebooks. "
"Download the data folder that ships with this example and place it next to "
"this notebook as ./data/docs, or run from a checkout where examples/codex/data/docs exists."
)
DATA_DIR = EXAMPLE_DIR / "data" / "docs"
DEFAULT_RUNS_DIR = Path(tempfile.gettempdir()) / "codex_iterative_repair_loop_outputs"
RUNS_DIR = Path(os.getenv("CODEX_REPAIR_RUNS_DIR", str(DEFAULT_RUNS_DIR))).expanduser()
RUNS_DIR.mkdir(parents=True, exist_ok=True)MODEL = os.getenv("REPAIR_MODEL", "gpt-5.4-mini")
COOKBOOK_CHAT_MODEL = os.getenv("COOKBOOK_CHAT_MODEL", "gpt-5.5")
REPAIR_REASONING_EFFORT = os.getenv("REPAIR_REASONING_EFFORT", "low")
if not os.environ.get("OPENAI_API_KEY"):
raise ValueError("Set the OPENAI_API_KEY environment variable before running the live Codex repair loop.")
CODEX_CLI = shutil.which("codex")
if CODEX_CLI is None:
raise RuntimeError("Run the install cell before continuing; Codex CLI is not on PATH.")The cells below load the three companion notebooks and summarize the metadata that drives the repair loop.
The samples are small on purpose. They run quickly, but they still exercise the architecture: review finds substantive issues, repair makes focused edits, and validation produces feedback for the next pass.
If you download this notebook by itself, also download the companion data/docs/ folder and place it next to the notebook before running the cells below. The code expects those sample notebooks to be available locally.
In this example, validation executes each repaired notebook end to end. In another domain, validation might be a unit test, policy check, schema validator, simulation, or human approval step. The important part is that failures become structured feedback instead of a dead end.
NOTEBOOKS = [
DATA_DIR / "qdrant_embeddings_search_pre_repair.ipynb",
DATA_DIR / "getting_started_evals_pre_repair.ipynb",
DATA_DIR / "knowledge_retrieval_pre_repair.ipynb",
]
def read_notebook(path: Path) -> dict[str, Any]:
return json.loads(path.read_text(encoding="utf-8"))
def case_metadata(path: Path) -> dict[str, Any]:
return read_notebook(path).get("metadata", {}).get("codex_case_study", {})
cases = []
for notebook_path in NOTEBOOKS:
notebook = read_notebook(notebook_path)
metadata = notebook.get("metadata", {}).get("codex_case_study", {})
repair_story = metadata.get("repair_story", {})
cases.append(
{
"notebook": notebook_path.name,
"cells": len(notebook["cells"]),
"code_cells": sum(cell["cell_type"] == "code" for cell in notebook["cells"]),
"source": metadata.get("source_path"),
"target_iteration": repair_story.get("target_iteration"),
"repair_depth": repair_story.get("repair_depth", ""),
}
)
cases[{'notebook': 'qdrant_embeddings_search_pre_repair.ipynb',
'cells': 5,
'code_cells': 4,
'source': 'examples/vector_databases/qdrant/Using_Qdrant_for_embeddings_search.ipynb',
'target_iteration': 1,
'repair_depth': 'One-pass cleanup: modernize the local Qdrant query path and clarify the sampled fixture framing.'},
{'notebook': 'getting_started_evals_pre_repair.ipynb',
'cells': 5,
'code_cells': 4,
'source': 'examples/evaluation/Getting_Started_with_OpenAI_Evals.ipynb',
'target_iteration': 2,
'repair_depth': 'Two-pass cleanup: first modernize the obvious stale Evals flow, then use validation feedback to remove result-log brittleness.'},
{'notebook': 'knowledge_retrieval_pre_repair.ipynb',
'cells': 5,
'code_cells': 4,
'source': 'examples/How_to_call_functions_for_knowledge_retrieval.ipynb',
'target_iteration': 3,
'repair_depth': 'Three-pass cleanup: modernize model/API shape, then tighten runnable local setup, then restore the full retrieval teaching flow.'}]Before asking Codex to review or repair an artifact, give it a small shared contract. That keeps the loop focused on the issues that matter, instead of asking the model to infer every product and style rule from scratch.
The rules below define what “good” means for these example notebooks: current API patterns, clear setup, runnable local samples, and preservation of the original teaching goal. In another workflow, this contract would describe that domain’s source of truth.
business_rules = {
"preferred_chat_model": COOKBOOK_CHAT_MODEL,
"preferred_embedding_model": "text-embedding-3-large",
"modernize": [
"client.chat.completions.create -> client.responses.create",
"legacy function-calling schemas -> current tools schema",
"qdrant.search -> qdrant.query_points",
"oaieval CLI examples -> current Evals API workflow",
],
"reader_experience": [
"Make fresh-environment setup explicit.",
"Keep the included examples runnable with local data and the standard library.",
"Keep sample repairs self-contained unless the notebook explicitly teaches external setup.",
"Remove manual result-file placeholders.",
"State runtime prerequisites and side effects before readers run cells.",
"Preserve the original teaching goal while modernizing the implementation.",
],
}
business_rulesEach phase returns structured data so the next phase has something concrete to use.
Review returns findings. Repair returns a change summary and the path to the updated artifact. Validation returns the remaining delta for the next pass. With structured handoffs, the loop is easier to debug, rerun, and adapt to other artifact types.
def object_schema(properties: dict[str, Any], required: list[str] | None = None) -> dict[str, Any]:
return {
"type": "object",
"properties": properties,
"required": required or list(properties),
"additionalProperties": False,
}
def string_array() -> dict[str, Any]:
return {"type": "array", "items": {"type": "string"}}
finding_schema = object_schema(
{
"artifact": {"type": "string"},
"issue_type": {"type": "string"},
"severity": {"type": "string"},
"description": {"type": "string"},
"suggested_fix_direction": {"type": "string"},
}
)
review_schema = object_schema(
{"findings": {"type": "array", "items": finding_schema}}
)
fix_schema = object_schema(
{
"artifact": {"type": "string"},
"iteration": {"type": "integer"},
"changes_made": string_array(),
"unresolved_items": string_array(),
"updated_artifact_path": {"type": "string"},
}
)
validation_case_schema = object_schema(
{
"name": {"type": "string"},
"passed": {"type": "boolean"},
"severity": {"type": "string"},
"evidence": {"type": "string"},
"feedback": {"type": "string"},
}
)
validation_schema = object_schema(
{
"overall_passed": {"type": "boolean"},
"cases": {"type": "array", "items": validation_case_schema},
"remaining_delta": string_array(),
}
)The review phase reads the artifact and returns structured findings. It does not run validation and it does not edit files. That separation keeps the first step focused: identify likely problems before changing anything.
We send the review prompt to codex exec with a JSON schema. The schema keeps the result machine-readable, so later cells can pass findings directly into the repair prompt instead of scraping prose from a previous answer.
def notebook_text(path: Path, max_chars: int = 7000) -> str:
chunks = []
for index, cell in enumerate(read_notebook(path)["cells"]):
source = "".join(cell.get("source", []))
chunks.append(f"cell {index} ({cell['cell_type']})\n{source}")
text = "\n\n".join(chunks)
if len(text) <= max_chars:
return text
return text[:max_chars] + "\n\n[truncated for prompt size]"
def run_command(command: str, *, stdin: str | None = None, cwd: Path | None = None, timeout: int | None = None):
cwd = Path.cwd() if cwd is None else cwd
return subprocess.run(
shlex.split(command),
input=stdin,
cwd=cwd,
capture_output=True,
text=True,
timeout=timeout,
check=False,
)
def run_codex_json(prompt: str, schema: dict[str, Any], run_dir: Path) -> dict[str, Any]:
run_dir.mkdir(parents=True, exist_ok=True)
prompt_file = run_dir / "prompt.txt"
schema_file = run_dir / "schema.json"
answer_file = run_dir / "answer.json"
prompt_file.write_text(prompt, encoding="utf-8")
schema_file.write_text(json.dumps(schema, indent=2), encoding="utf-8")
command = f"""
{CODEX_CLI} exec
--model {MODEL}
--sandbox workspace-write
--ask-for-approval never
--config model_reasoning_effort={REPAIR_REASONING_EFFORT}
--output-schema {schema_file}
--output-last-message {answer_file}
-
"""
result = run_command(command, stdin=prompt)
(run_dir / "stdout.txt").write_text(result.stdout, encoding="utf-8")
(run_dir / "stderr.txt").write_text(result.stderr, encoding="utf-8")
if result.returncode != 0:
raise RuntimeError(f"Codex exited with {result.returncode}. See {run_dir / 'stderr.txt'}.")
return json.loads(answer_file.read_text(encoding="utf-8"))
def review_notebook(path: Path, run_dir: Path) -> list[dict[str, Any]]:
prompt = "\n".join(
[
"You are reviewing a public OpenAI Cookbook notebook before publication.",
f"Artifact: {path.name}",
"Find issues that would make the notebook stale, hard to run, or confusing for a developer reader.",
"Do not execute the notebook or edit files.",
"Use concise issue_type labels such as stale_model, deprecated_api, setup_gap, runtime_risk, or clarity_issue.",
f"Business rules: {json.dumps(business_rules)}",
"Base findings only on the notebook content below.",
"Keep the findings focused; three strong findings are better than a long list.",
"",
notebook_text(path),
]
)
return run_codex_json(prompt, review_schema, run_dir)["findings"]def run_initial_review(path: Path) -> tuple[str, list[dict[str, Any]]]:
return path.name, review_notebook(path, RUNS_DIR / "initial_review" / path.stem)
with concurrent.futures.ThreadPoolExecutor(max_workers=min(3, len(NOTEBOOKS))) as executor:
initial_reviews = dict(executor.map(run_initial_review, NOTEBOOKS))
initial_reviewsThe repair phase gets the current artifact, review findings, business rules, and any validation feedback from the previous pass. The prompt gets more specific as the loop learns.
Codex edits a copy inside the iteration directory and returns a short summary of what changed. The loop does not assume the edit worked; validation decides that in the next step.
def repair_prompt(path: Path, updated_path: Path, findings: list[dict[str, Any]], remaining_delta: list[str], iteration: int) -> str:
repair_story = case_metadata(path).get("repair_story", {})
return "\n".join(
[
"You are repairing a copy of a public OpenAI Cookbook notebook.",
f"Source notebook: {path}",
f"Editable copy: {updated_path}",
f"Iteration: {iteration}",
"Make the smallest useful edits that address the review findings and validation delta.",
"Preserve the notebook's teaching flow and original purpose.",
"Keep sample repairs self-contained unless the notebook explicitly teaches external setup.",
"For staged examples, focus on the most important remaining issue for this pass instead of rewriting everything at once.",
"Edit only the editable copy. Do not claim the notebook passes validation.",
f"Repair depth: {json.dumps(repair_story, indent=2)}",
f"Business rules: {json.dumps(business_rules, indent=2)}",
f"Review findings: {json.dumps(findings, indent=2)}",
f"Remaining validation delta: {json.dumps(remaining_delta, indent=2)}",
]
)
def repair_notebook(path: Path, iteration: int, findings: list[dict[str, Any]], remaining_delta: list[str], case_dir: Path) -> dict[str, Any]:
updated_path = case_dir / "updated.ipynb"
updated_path.parent.mkdir(parents=True, exist_ok=True)
shutil.copy2(path, updated_path)
prompt = repair_prompt(path, updated_path, findings, remaining_delta, iteration)
return run_codex_json(prompt, fix_schema, case_dir / "repair")Validation works like a small eval. We define the behavior we want, run the relevant check, and ask a judge to score the result against that rubric.
For the documentation example, execution comes first. Many notebook problems only appear at runtime: a missing import, a stale file path, a cell that depends on an old API response, or setup guidance that was clear to the author but not to a fresh reader.
If validation fails, the failure becomes evidence for the next repair pass. This keeps the next repair grounded in observed behavior, not just what looked right in the diff.
VALIDATION_CASES = [
{
"name": "api_modernization",
"question": "Does the notebook avoid stale OpenAI API patterns, legacy function-calling syntax, and outdated model names?",
},
{
"name": "setup_reproducibility",
"question": "Could a reader run the notebook from a fresh environment without hidden manual steps?",
},
{
"name": "artifact_integrity",
"question": "Did the update preserve the notebook's teaching flow and avoid deleting substantive cells?",
},
]
def short_output(value: Any, limit: int = 1200) -> str:
if value is None:
return ""
if isinstance(value, bytes):
value = value.decode("utf-8", errors="replace")
return str(value)[-limit:]
def execute_notebook(path: Path) -> dict[str, Any]:
code_cells = sum(cell["cell_type"] == "code" for cell in read_notebook(path)["cells"])
command = f"jupyter nbconvert --to notebook --execute --inplace {path.name}"
try:
result = run_command(
command,
cwd=path.parent,
timeout=int(os.getenv("SAMPLE_NOTEBOOK_TIMEOUT_SECONDS", "300")),
)
except FileNotFoundError:
return {
"status": "failed",
"executed_code_cells": 0,
"error": "Jupyter or nbconvert is not installed or is not available on PATH.",
"summary": "Install Jupyter with nbconvert before running the validation loop.",
}
except subprocess.TimeoutExpired as exc:
return {
"status": "failed",
"executed_code_cells": 0,
"error": f"Notebook execution timed out after {exc.timeout} seconds.",
"summary": short_output(exc.stderr or exc.stdout),
}
output = result.stderr or result.stdout
return {
"status": "passed" if result.returncode == 0 else "failed",
"executed_code_cells": code_cells if result.returncode == 0 else 0,
"error": "" if result.returncode == 0 else f"Notebook execution exited with code {result.returncode}.",
"summary": short_output(output),
}
def validation_prompt(updated_path: Path, before_path: Path, execution: dict[str, Any], iteration: int) -> str:
repair_story = case_metadata(before_path).get("repair_story", {})
return "\n".join(
[
"You are judging a repaired OpenAI Cookbook notebook.",
f"Iteration: {iteration}",
"Score each validation case independently and give concise feedback for the next repair pass.",
"Set overall_passed to false when execution failed or any case has a material issue.",
"When execution failed, include the failure in remaining_delta so the next repair pass can address it.",
"Use the business rules as the source of truth for current model names and API targets.",
"Do not mark the preferred embedding model or preferred chat model as stale.",
"For local examples, do not require extra services or package installs when the notebook says it is intentionally self-contained.",
f"Repair depth: {json.dumps(repair_story, indent=2)}",
f"Business rules: {json.dumps(business_rules, indent=2)}",
f"Validation cases: {json.dumps(VALIDATION_CASES, indent=2)}",
f"Execution evidence: {json.dumps(execution, indent=2)}",
f"Original cell count: {len(read_notebook(before_path)['cells'])}",
f"Updated cell count: {len(read_notebook(updated_path)['cells'])}",
"",
notebook_text(updated_path),
]
)
def staged_delta(before_path: Path, iteration: int) -> list[str]:
repair_story = case_metadata(before_path).get("repair_story", {})
target = int(repair_story.get("target_iteration") or 1)
if iteration >= target:
return []
depth = repair_story.get("repair_depth", "This case is intentionally staged across multiple repair passes.")
return [f"Continue to iteration {iteration + 1}: {depth}"]
def evaluate_notebook(updated_path: Path, before_path: Path, run_dir: Path, iteration: int) -> dict[str, Any]:
execution = execute_notebook(updated_path)
judged = run_codex_json(validation_prompt(updated_path, before_path, execution, iteration), validation_schema, run_dir)
failed_cases = [case for case in judged["cases"] if not case["passed"]]
execution_delta = []
if execution["status"] != "passed":
execution_delta.append(f"Execution failed: {execution.get('error') or execution.get('summary')}")
stage_delta = staged_delta(before_path, iteration)
return {
"passed": judged["overall_passed"] and execution["status"] == "passed" and not stage_delta,
"execution_status": execution["status"],
"executed_code_cells": execution["executed_code_cells"],
"execution_summary": execution["summary"],
"findings": failed_cases,
"remaining_delta": execution_delta + stage_delta + judged["remaining_delta"],
}Each iteration writes a record.json file and, for this example, a repaired notebook under CODEX_REPAIR_RUNS_DIR/iteration_N/<sample_name>/. If you do not set CODEX_REPAIR_RUNS_DIR, the notebook writes to your system temp directory so a normal repo checkout stays clean.
Those files are the audit trail. You can see what the review found, what Codex changed, whether execution passed, and what feedback carried into the next iteration.
A record.json file is the receipt for one loop attempt. It keeps the handoff between phases in one place:
{
"review": [{"issue_type": "deprecated_api", "severity": "high"}],
"repair": {
"changes_made": ["Updated the notebook to use the current API pattern."],
"updated_artifact_path": "/tmp/codex_iterative_repair_loop_outputs/iteration_1/sample/updated.ipynb"
},
"validation": {
"passed": false,
"remaining_delta": ["One setup instruction is still unclear."]
}
}That compact record is what lets a maintainer review the loop without reconstructing the whole run from notebook diffs and terminal logs.
def save_json(payload: Any, path: Path) -> None:
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(json.dumps(payload, indent=2) + "\n", encoding="utf-8")
def iteration_dir(number: int) -> Path:
path = RUNS_DIR / f"iteration_{number}"
path.mkdir(parents=True, exist_ok=True)
return pathEach notebook case is independent, so we process the cases concurrently. This keeps the demo fast while preserving the same review, repair, and validation flow for every sample.
Iteration 1 reuses the initial review findings from the earlier review cell. After this pass, inspect the returned booleans: passing cases can stop, and failing cases carry their validation feedback into the next pass.
current_notebooks = {path.name: path for path in NOTEBOOKS}
history: dict[int, dict[str, Any]] = {}
def review_findings_for(original: Path, current_path: Path, case_dir: Path, previous_results: dict[str, Any] | None) -> list[dict[str, Any]]:
if previous_results is None:
return initial_reviews[original.name]
return review_notebook(current_path, case_dir / "review")
def run_case(number: int, original: Path, run_dir: Path, previous_results: dict[str, Any] | None) -> tuple[str, dict[str, Any], Path]:
name = original.name
case_dir = run_dir / original.stem
current_path = current_notebooks[name]
findings = review_findings_for(original, current_path, case_dir, previous_results)
delta = [] if previous_resu
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み