Anthropic:Claude を複数製品にまたがって安全に管理する方法
Anthropic は、自律型エージェントの導入リスクを管理するため、人間の監視によるアプローチと環境制御によるアプローチの二つの戦略を提示し、後者の重要性を強調している。
キーポイント
リスク評価パラダイムの転換
モデル能力が向上するにつれて「不採用のコスト」が増大しており、安全性を担保しつつも爆発半径(blast radius)を制限することが開発の焦点となっている。
人間による監視の限界と疲労
各アクションごとに許可を求める従来の手法は、ユーザーが 93% を承認する傾向にあることから「承認疲れ」を生み、監視の質を低下させる脆弱性がある。
環境制御による爆発半径の制限
自律エージェントの行動範囲や影響度を物理的・論理的に制限することで、高い能力を持ちつつも安全に実装可能にするアプローチが有効である。
重要な引用
The risk of these deployments has two components: how likely a failure is, and how much damage one could do.
Our telemetry showed users approved roughly 93% of permission prompts. The more approvals a user sees, the less attention they pay to each...
When bounds can be placed on the relative damage of an autonomous agent —such as through control over its environment—high-utility capabilities can motivate deployment.
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェントが単なるチャットボットから自律的な業務遂行ツールへと進化していく過程における、最も重要なセキュリティ課題の一つ——「制御と信頼のバランス」——に焦点を当てています。企業や開発者が高度な AI を実社会に導入する際、従来の「人間による監視」モデルが限界を迎えていることを示唆しており、今後は環境隔離やサンドボックス化といった技術的アプローチが標準的なセキュリティ基準となる可能性が高いです。
編集コメント
AI エージェントの普及において、技術的な能力向上以上に「いかに被害を限定するか」という設計思想が成否を分ける重要な転換点です。
12 ヶ月前であれば、Claude に内部の Anthropic サービスを停止させるのに十分なアクセス権限を与えるというアイデアは、即座に却下されたでしょう。今日ではそのレベルのアクセス権が日常化しており、Anthropic の開発者はそれによってより生産性が高まっています。これらの展開におけるリスクには 2 つの要素があります:失敗する可能性と、一人が引き起こしうる被害の規模です。セーフガード(安全装置)やモデルトレーニングの進展により、前者は着実に低下しています;後者、つまり理論上の爆発半径は、機能とアクセス権が拡大するにつれて大きくなります。しかし、エージェントがかつて人間やチームにしかできなかった作業を遂行できるようになるにつれ、展開しないことのコストは十分に大きくなり、製品を安全にできる限り、リスク対リワードの計算は採用へと大きく傾きます。エンジニアリング上の問いは、爆発半径をどのように制限するかとなります。
自律型エージェントの相対的な被害に制限を設けることができる場合(例えば、その環境に対する制御を通じて)、高い有用性を備えた機能は導入を促す要因となります。Claude Mythos Preview は、2026 年 4 月の出荷には爆発半径が過度に大きいと判断されたモデルの一例です。しかし、防御側が重要システムを強化し、安全対策が成熟するにつれて、同程度の能力を持つモデルのより広範なリリースが適切になると予想しています。ただし、リスクは常に一部残存します。モデルの能力は、エージェント導入に伴う総リスクにおける重要な要素です。
これを行う方法は大きく分けて 2 つあります。
第一の手法は、人間をループに組み込んだ形でエージェントの行動を監視することです。Claude Code は以前、各ステップでユーザーに許可を求めることで、意図しないアクションを実行するエージェントから保護していました。理論的にはこのアプローチは機能しますが、実際には欠陥があることが判明しました。テレメトリデータによると、ユーザーは約 93% の承認プロンプトを承認しています。ユーザーが承認の要求を目にする回数が増えるほど、各要求に対する注意は薄れ、時間とともに監視の徹底度が低下します。私たちは最近、この承認疲れを軽減するために、Claude Code の自動モードを実装しました。これにより より安全な承認の自動化 が可能になりました。それでも脆弱性は残っており、確率的な防御手段にはゼロではない見落とし率があります。
爆発半径を制限する第二の手法、そして本稿の焦点となっているのは「封じ込め」です。エージェントが何を行うかを監視するのではなく、サンドボックス(隔離環境)、仮想マシン、出口制御などを介してアクセス境界を強制することで、エージェントが*できること*を監視します。ここが Anthropic のエンジニアリングチームが最も多くの労力を注いでいる領域であり、同時に最も驚くべきセキュリティ障害が発生した場所でもあります。
過去2年間で、私たちは3つの主要なエージェント製品をリリースしました:claude.ai、Claude Code、そして Claude Cowork です。それぞれが異なる対象者向けに設計されており、それぞれに適したコンテインメント(隔離)アーキテクチャが必要です。この記事では、何が機能し、何が失敗し、エージェントセキュリティについて何を学んできたかについて共有します。
3 つのリスクタイプと防御の3 つの構成要素
エージェントに対するセキュリティリスクは、以下の3つのカテゴリのいずれかに分類されます:
ユーザーによる誤用: ユーザーが悪意を持って、あるいは不注意によって、エージェントに有害な行動を指示することです。これには、自分が面倒だと感じるチェックを回避するようエージェントに求めること、理解していない破壊的なコマンドを実行させること、意図的な危害を指定することが含まれます。
モデルの振る舞いの誤り: エージェントが誰も求めなかった有害な行動をとることです。私たちのモデルは改善され、ほとんどの行動評価においてより整合性を持つようになりましたが、それが必ずしもリスクが縮小することを意味するわけではありません。能力の低いモデルほど状況を誤解し、明らかなエラーを犯す可能性が高いです。一方、能力の高いモデルはミスを減らしますが、同時に誰も書き留めていない制限を迂回することで、目的への予期せぬ経路を見つけるのが得意になります。
Anthropic では、Claude モデルがタスクを完了するために 「親切に」サンドボックスから脱出 したり、git の履歴を検索して コーディングテストの答えを見つけようとする 事例や、実行中のベンチマークを自発的に特定して その解答キーを解読しようとする 事例などを目にしてきました。各モデルは、予期せぬ形で活用されることもある新たな機能セットをもたらします。
外部攻撃者: エージェントは、ツール、ファイル、ネットワークアクセスなどの外部ベクトルを通じて攻撃を受けます。このカテゴリには、プロンプトインジェクションと、エージェントのランタイム、オーケストレーション層、またはプロキシに対する従来の攻撃の両方が含まれます。
コンテナ化および防御システムを構築する際、私たちは 3 つの主要なコンポーネントに対して防御策を適用します:
エージェントが実行される環境。 プロセスサンドボックス、仮想マシン (VM)、ファイルシステムの境界、および出口制御を用いて、エージェントがどこでどのように行動できるかを制限します。目標は、エージェントが到達可能な範囲に明確な境界線を引くことです。例えば、認証情報が一度もサンドボックス内に入らない場合、その原因がユーザーか、モデルによる「創造的な」経路の発見か、攻撃者によるものかにかかわらず、情報を外部へ持ち出されることはありません。
厳格な周辺領域の設定は、監視を緩和できることを意味します。Claude Code の 参照用 devcontainer は、まさにエージェントが個別のアクション承認なしで無人で実行できるようにするために存在しています。
エージェントが参照するモデル。 ここでのメカニズムには、システムプロンプト、分類器、プローブ、およびトレーニングの修正が含まれます。モデルは確率的であるため、これらはエージェントが理論的に実行可能なことではなく、*傾向として*行う行動のみを形作ります。
これらの防御策は強力です。プロンプトインジェクションへの耐性をテストする Gray Swan の Agent Red Teaming ベンチマークでは、Claude Opus 4.7 は単一の試行において攻撃の成功率を約 0.1% に抑え、100 回の適応的試行後でも 5〜6% に留まります。Claude Code の自動モードは、過剰な行動を実行する前に約 83% を検出します 実行前。しかし、最上位クラスの防御策を講じていても、モデル層における保護が 100% 有効になることは決してなく、そのため単独で機能することはできません。
エージェントがアクセス可能な外部コンテンツ。 MCP サーバー、サードパーティ製プラグイン、および Web 検索ツールは、すべてあなたが制御できないソースからエージェントのコンテキストにコンテンツを供給します。監査済みのコネクタと、監査済みのデータは同一ではありません。例えば、GitHub コネクタはマルウェアチェックに合格していても、汚染された README ファイルを直接モデルのコンテキストに読み込む可能性があります。ツールの権限を細かく制限することで、被害範囲(ブラスト半径)を限定できます。例えば、データベースへの読み取り専用アクセスを持つエージェントは、プロダクション環境へ書き込みを行うエージェントよりもはるかに広く展開することが可能です。
防御策は互いに重複し、補完し合うべきです。環境層の防御が利用できない場合、モデル層がその役割を担わなければなりません(これは Claude Code の 自動モード が設計されたまさにその目的です)。ローカル環境では、環境とモデルの防御が悪意あるツール出力から守りますが、ツールの機能やアクセス権限を制限することで、より上位のチェーン層にも防御を追加できます。
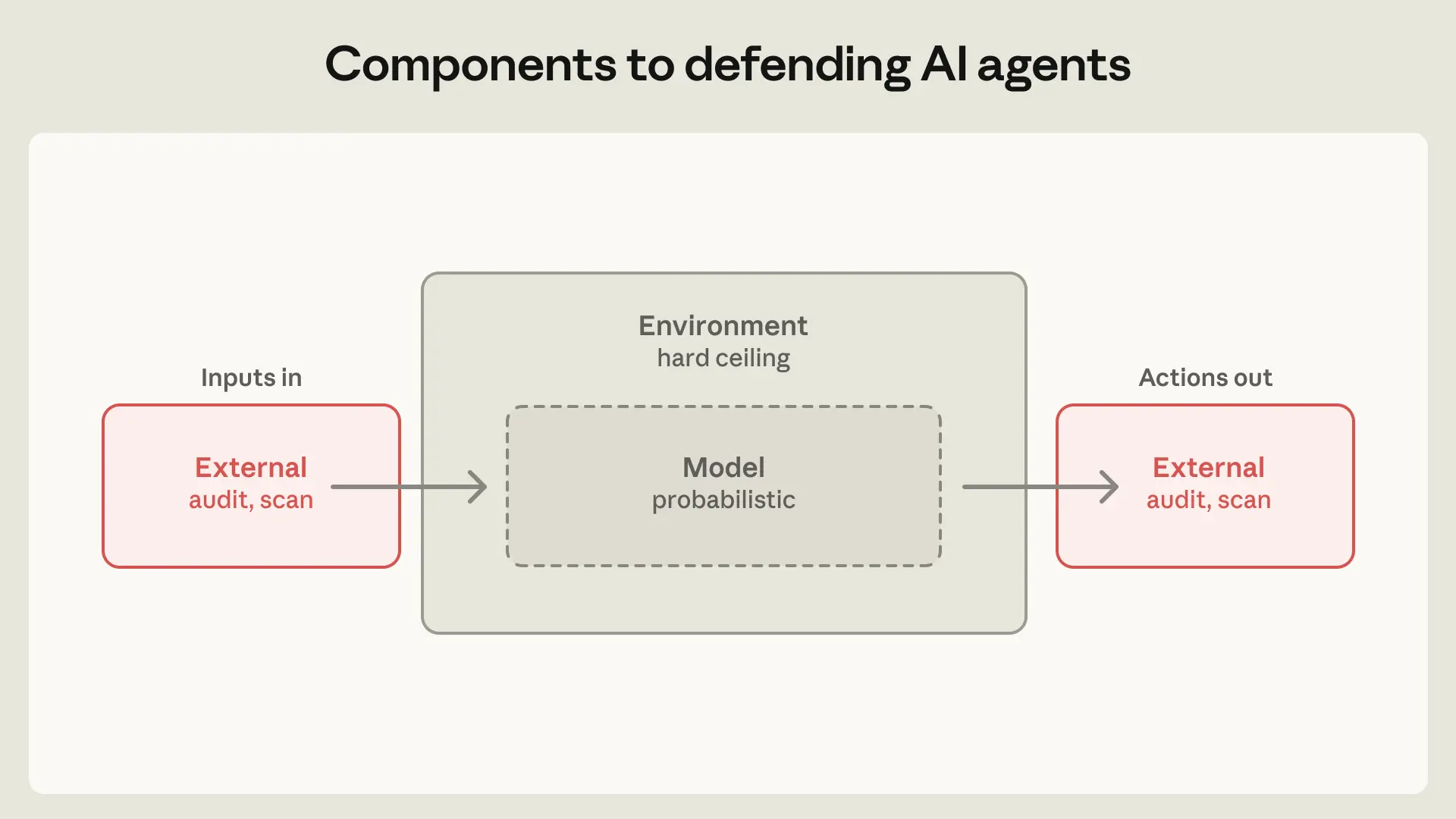 image*防御の三要素:モデル、その実行環境、およびエージェントが到達可能な外部コンテンツ*。
image*防御の三要素:モデル、その実行環境、およびエージェントが到達可能な外部コンテンツ*。
エージェントを封じ込めるためのパターン
環境層に焦点を当て、Claude プラットフォームそれぞれ(claude.ai、Claude Code、Cowork)にどのように適応させたかについて、三つの隔離パターンとその詳細を説明します。各設計は、エージェントに必要な機能とユーザーによる介入の程度とのバランスを見出す過程で、段階的に到達したものです。
パターン 1:一時的コンテナ(claude.ai のコード実行)
チャットインターフェースとして最もよく知られていますが、claude.ai はコードの作成と実行、ファイルの生成、コネクタの呼び出しも行います。Claude が claude.ai 内でコードを実行する際、それは隔離されたインフラストラクチャ上の gVisor コンテナ内で行われます。エージェントは完全にサーバーサイドにあり、ローカルマシンでコードが実行されることはなく、ファイルシステムは一時的(セッションごと)です。爆発半径は最小限ですが、Claude が行えることの上限も同様に低く、永続的なワークスペースはなく、ユーザーのファイルシステムへのアクセスもできません。
これにより、claude.ai はより伝統的な脅威モデルの対象ともなります。私たちはユーザーマシンをエージェントから守っているのではなく、自社のインフラストラクチャと各テナント同士を互いから守っています。claude.ai 向けの事前準備では、ネットワーク設定、内部サービス認証、オーケストレーションといった伝統的なセキュリティ作業が中心となりました。
この取り組みは、セキュリティにおける最も古い教訓を再確認させるものでした。つまり、最も脆弱な層とは自分たちで作ったものなのです。gVisor や seccomp は、リソースに余裕のある敵対者に対して、エージェント型 AI が存在するよりもはるかに長い間強化されてきたため、レビューの重点はそれらを取り巻いて新たに構築した部分に向けられました。これは後ほど改めて触れますが、私たちのカスタムプロキシこそが、最も重大なインシデントで破綻した箇所だからです。
パターン 2: ヒューマン・イン・ザ・ループ型サンドボックス(Claude Code)
Claude Code はユーザーのマシン上で動作し、ファイルシステム、シェル、ネットワークへのアクセス権限を持ちます。これがなければコーディングエージェントは有用性が限定されてしまうため、そのアクセスを安全に付与する方法を見つけることが不可欠です。
一つの手法として、ヒューマン・イン・ザ・ループ(人間が関与するプロセス)に依存するというものがあります。これは、平均的なユーザーがコーディング環境に精通した開発者であるという点においてのみ、Claude Code にとって実現可能な解決策となります。彼らは bash コードを読み解くことができ、rm -rf が何をするのかを理解しており、信頼できないソースからの npm install を週に数回実行する習慣さえあります。つまり、「これを許可しますか」というダイアログが表示された際、エージェントが何を試みているのか、そしてどのようなリスクを伴うのかを正確に評価するための専門知識を持っている可能性が極めて高いのです。こうした背景から、Claude Code は最もシンプルな防御策をもってローンチされました:読み取りは許可し、書き込み、bash 実行、ネットワークアクセスについては承認を必須とするのです。
しかし、前述した通り、承認疲れは数週間で現れました。皮肉にも、これは本来監視を提供するために設計された機能が、逆効果をもたらす可能性があることを意味します—一部のユーザーは単に関心を払わなくなるかもしれません。不用意な承認を緩和するための第一歩として、OSレベルのサンドボックス(macOS では Seatbelt、Linux では bubblewrap)を実装し、境界を強化しました:読み取りは許可され、ワークスペース内での書き込みも許可されますが、ネットワーク接続はデフォルトで拒否されます。サンドボックス内では、エージェントはほぼ中断なく実行されます。その結果、権限プロンプトが 84% 減少し、私たちは ランタイムをオープンソース化 しました。これにより、境界の監査が可能になっています。
私たちの匿名化された利用データによると、経験豊富なユーザーは新規ユーザーの約 2 倍の頻度で自動承認を行っていますが、同時に実行中にエージェントを中断する頻度も高いことが示されました。個々のステップにゲート(制限)を設けるのではなく、経験豊富なユーザーは、エージェントが軌道から外れた場合にのみ監督を行う傾向があります。これは人々がエージェントとどのように連携したいかという自然な進化かもしれませんが、この方法にも欠陥があり、まず第一にドリフト(逸脱)に気づくためにユーザー自身が技術的知識を持ち、注意深くいる必要があります。モデルの能力が向上し、エージェントがより野心的な bash スクリプトを記述するようになると、そのような逸脱を見つけることはますます困難になります。また、ユーザーが多エージェントシステムに移行すると、このアプローチは効果的な監視戦略である可能性もさらに低くなります。
私たちが見落としたリスク:信頼ダイアログ以前のすべて
2025 年中盤から 2026 年 1 月にかけて、責任ある開示プログラムを通じて、Claude Code における脆弱性の報告を受けました。これら 3 つの事例は、ユーザーが何らかの同意を行う前に実行されるコードを悪用したものです。これがどのように可能なのかを理解するために、最も直接的なケースを考えてみましょう。開発者がプルリクエストを確認するためにリポジトリをクローンし、そのリポジトリに .claude/settings.json ファイルが含まれており、そこでフック(hook)が定義されている場合です。Claude Code は起動時にプロジェクト設定を読み込みますが、これは標準的な「このフォルダを信頼しますか?」というプロンプトを表示する前に行われます。そのため、攻撃者が作成してコミットしたフックは自動的に実行されてしまいます。残りのケースも構造的には同様で、信頼の境界線が確立される前に、まだ信頼されていないディレクトリからの入力が解析されていました。
各ケースにおける修正内容は同じ形状をしていました:プロジェクトローカルの設定の解析と実行を、ユーザーが信頼プロンプトに同意するまで延期することです。同様のものを構築している場合は、プロジェクトのオープン、設定の読み込み、localhost リスナー(localhost listener)を、インターネットからのあらゆるインバウンドリクエストと同様に扱うべきです。それらがローカルに感じられ、かつユーザーの同意が得られる前に到着したからといって、暗黙的に信頼してはいけません。
私たちが見落としたリスク:ユーザーを介したインジェクションベクトル
2026 年 2 月、管理された内部レッドチーム演習において、ある研究者が従業員を騙し、Claude Code を悪意のあるプロンプトで起動させることに成功しました。そのフィッシングメールは通常の協力のようであり、「これを私に実行してもらえますか?」という内容のメールに、そのまま貼り付け可能なプロンプトが付属していました。そして、そのプロンプト自体も、日常的なタスク指示のように見えました。しかし、セットアップ手順のどこかに、Claude に ~/.aws/credentials ファイルを読み込み、その内容をエンコードして外部エンドポイントへ POST するよう穏やかに要求する記述が含まれていました。このプロンプトを 25 回試行した結果、Claude は 24 回のケースでデータ漏洩(exfiltration)を完了させました。
これは*直接的な*プロンプトインジェクションです。攻撃者の指示は、ツール出力や取得されたコンテンツを通じてではなく、ユーザーを介して届きました。私たちのモデル層の防御策はユーザーの意図に依存しています。つまり、指示を入力しているのがユーザー自身である場合、分類器が検出できる異常な点は存在しません。同じスクリプトを手渡した人間契約者も、同様の行動をとったでしょう。
この状況で機能する唯一の防御策は環境側のものであり、具体的には意図に関係なく POST 通信をブロックする出口制御(egress controls)と、最初から ~/.aws ディレクトリへのアクセスを制限するファイルシステム境界です。
(内部の Slack で作業用プロンプトを共有して議論した際、一部の内部エージェントが Slack を「読む」ことを指摘する人がいました。その結果、ペイロードは環境に埋め込まれてしまいました。何か拾い上げられた場合に気づけるよう、スレッドにカナリ文字列を追加しました。エージェントが何でも読み取る世界では、調査ツール自体も攻撃対象領域となり得ます。)
パターン 3:ローカル VM(Claude Cowork)
Claude Cowork は、ユーザーのデスクトップ上で動作し、ユーザーが選択したワークスペースフォルダにアクセスします。このプラットフォームはソフトウェアエンジニアリングではなく一般的な知識作業向けに構築されているため、平均的なユーザーは bash に精通している可能性は低くなります。
その結果、「人間をループに組み込む」サンドボックス戦略がそのまま転用できるとは限りません。技術的な知識を持たない知識労働者に対して、find . -name "*.tmp" -exec rm {} \; といった bash の呪文(コマンド)を判断させることを期待すべきではありません。例外の承認に専門知識が必要で、一般的なユーザーがそれを有していない場合、管理者は絶対的で常時有効な境界線を設定する必要があります。
これを実現するために、Claude Cowork の最初のバージョンは、プラットフォームベンダーのハイパーバイザー(macOS では Apple の Virtualization framework、Windows では HCS)を使用した完全な仮想マシン内で実行されました。この VM には独自の Linux カーネル、独自のファイルシステム、独自のプロセステーブルがあります。ユーザーが選択したワークスペースと .claude フォルダがマウントされ、ホスト上の他のものは一切表示されません。認証情報はホストのキーチェーン内に留まり、ゲストマシンに入ることはありません。この設計は、Claude が将来的に整合性の取れない行動をとる可能性から守るためのものです。侵害された Claude であってもワークスペースフォルダ内のものを損なうことは可能ですが、アーキテクチャはそれが *唯一* アクセス可能な対象となるように(ユーザーがコネクタを追加するまで)、かつそこにマウントされる内容をユーザーが制御できるように設計されています。
元のアーキテクチャ—私たちがフル VM モードと呼ぶもの—では、エージェントループ自体がゲスト内で実行されており、Claude はサンドボックス化されていることを意識しない通常の Linux ユーザーとして動作していました。これに対し、Claude Code では特権プロセスがサンドボックスの外側に位置し、コマンドごとにその適用を決定します。説得力のある注入プロンプトや疲労した承認クリックによって、このプロセスが非サンドボックス環境で何かを実行させることが可能です。ここでは、脱出ハッチの鍵を持つ外部プロセスが存在せず、例外を付与する権限を持つコンポーネントも存在しませんでした。
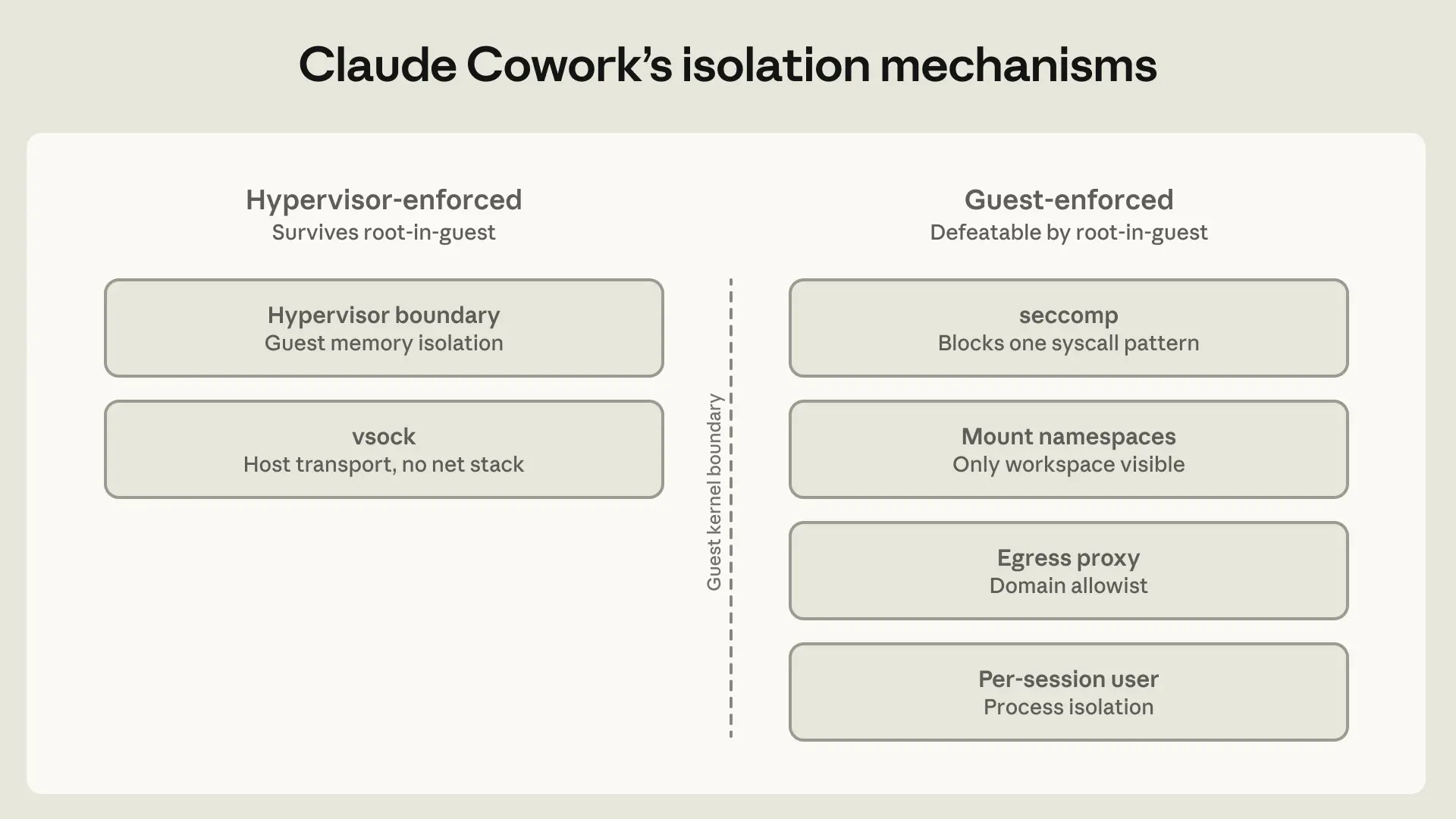 image*Claude Cowork の VM における主要な 6 つの分離メカニズム。そのうち 2 つはゲストカーネルの外側で強制されるため、エージェントが VM 内でルートレベルへのアクセスを達成しても存続します。残りの 4 つはゲスト側で強制され、外側のレイヤーが残りを担うため、あえて最小限に保たれています。
image*Claude Cowork の VM における主要な 6 つの分離メカニズム。そのうち 2 つはゲストカーネルの外側で強制されるため、エージェントが VM 内でルートレベルへのアクセスを達成しても存続します。残りの 4 つはゲスト側で強制され、外側のレイヤーが残りを担うため、あえて最小限に保たれています。
しかし、すぐに私たちはエージェント全体をフル VM モードで実行することが実用的な問題を引き起こすことに気づきました:VM の起動中のいかなる失敗も、Cowork を使用不能にしてしまいます。エージェントループを VM の外側に移動させつつ、コードの実行は VM 内に保つことで、Claude は依然としてユーザーに応答し、エラーでフリーズするのではなく問題をデバッグして支援できるようになりました。この変更によるセキュリティへの影響は最小限でした。なぜなら、VM がエージェントによって実行されるコードに対してファイルシステムおよびネットワーク制御を依然として強制しているためです。
別途、ローカル MCP サーバーを VM の外へ移設しました。VM 内で実行すると監査が困難になり、VM の更新時に依存関係の脆弱な問題が発生し、データベースなどのローカルプロセスとの対話を必要とする MCP をサポートできませんでした—そのようなサーバーは無論ホスト上で実行する必要がありました。この変更により、Claude Cowork は Claude Desktop で既に採用されているローカル MCP サーバーの動作方式に整合するようになり、ユーザーがインストールを選択する一般的なソフトウェアとして扱い、どのローカル MCP を有効にするか(もしあれば)を管理者に委ねる形となりました。リモート MCP サーバーはユーザーのマシン上で実行されないため影響を受けません。
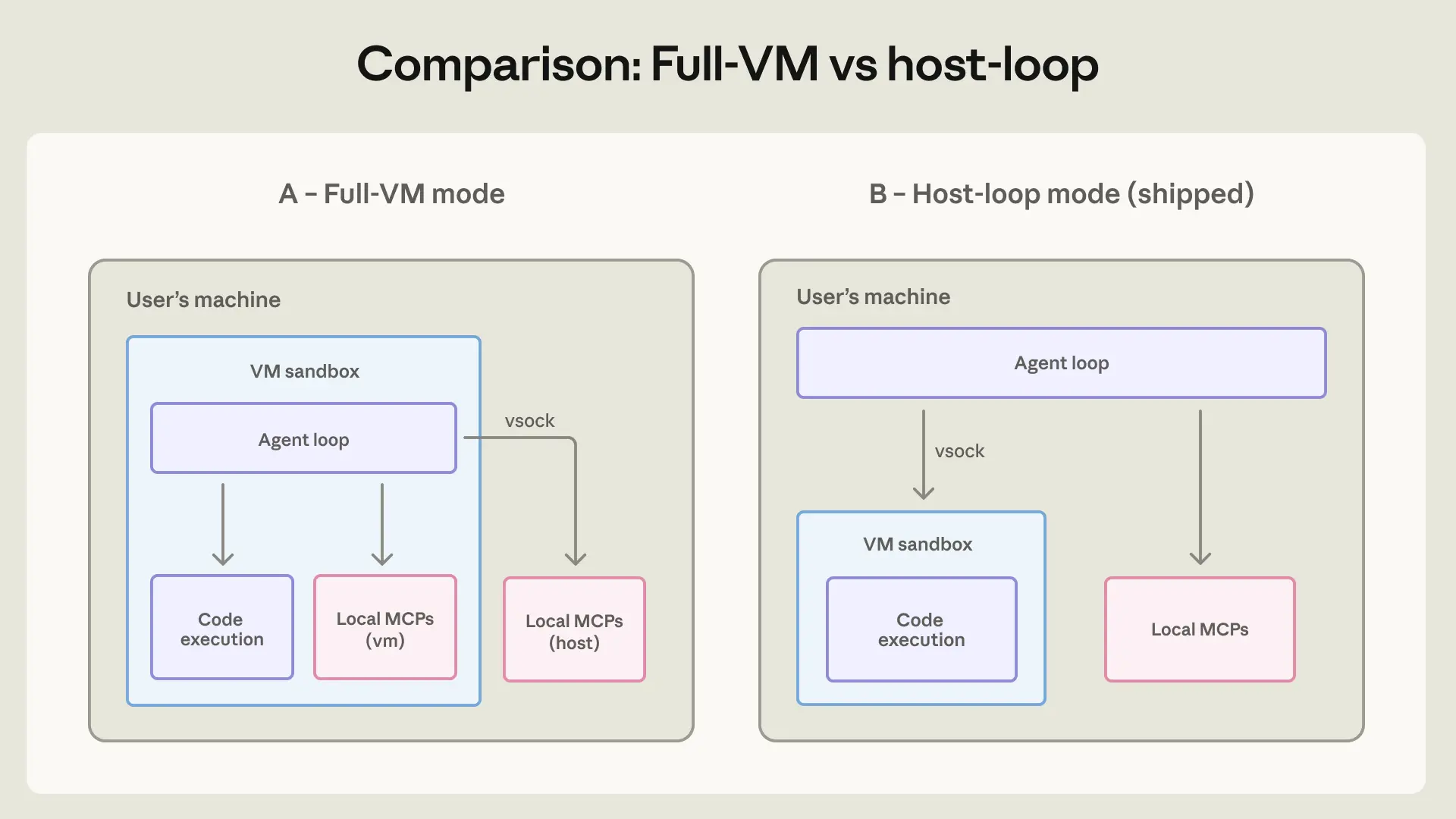 image*エージェントループを VM 内に配置していたため、VM 内のいかなる障害も Cowork を使用不能にしました。ホストモードはより信頼性が高く、VM がクラッシュしてもエージェントが応答し続けることができ、コード実行の分離により重要なセキュリティ保証を提供します。*
image*エージェントループを VM 内に配置していたため、VM 内のいかなる障害も Cowork を使用不能にしました。ホストモードはより信頼性が高く、VM がクラッシュしてもエージェントが応答し続けることができ、コード実行の分離により重要なセキュリティ保証を提供します。*
ファイルシステム制御は、もう一つの重要なアーキテクチャ上の選択でした。Claude が有用であるためにはホスト上の*ある程度の*ファイルにアクセスできる必要がありますが、私たちは爆発半径を最小化し、ユーザーに対してローカルファイルへのアクセスについて透明性を提供したかったのです。異なるファイルマウントモードを提供することでリスクを細かく制御できることが分かりました。Claude Cowork では、読み取り専用、読み書き可能、および読み書き可能だが削除不可の 3 つのモードが用意されています。ここで注意すべき点の一つは、シンボリックリンクの解決はパス検証*後*ではなく*前*に行われる必要があるということです。そうでないと、許可されたフォルダ内のシンボリックリンクが外部を指してエスケープしてしまう可能性があります。エンタープライズ顧客向けには、MDM 設定のマウントパスのホワイトリストを通じて管理者がこの制御を行えるようにしています。
見落としたリスク:承認されたドメインを通じたデータ漏洩
承認されたドメインを通じたデータ漏洩の明確な例が、第三者からの開示から得られました。Claude Cowork の出口(egress)ホワイトリストは、api.anthropic.com へのトラフィックを正しく通過させました。これは、製品が当社の API を呼び出さなければ機能しないためです。このケースでは、ユーザーのマウントされたワークスペースに配置された悪意のあるファイルに、攻撃者が制御する API キーと共に隠された指示が含まれていました。Claude はその指示に従ってワークスペース内の他のファイルを読み取り、攻撃者のキーを使用して Anthropic の Files API を呼び出しました。出口プロキシは宛先を確認し、api.anthropic.com であると判別して通過させました。ファイルは攻撃者の Anthropic アカウントにアップロードされました。サンドボックスは完璧に機能しましたが、それでもデータは漏洩していました。
以前、私たちはホワイトリストを「ドメインフィルタ」として概念化していました。つまり、「これらのドメインとは会話してもよい」と指示する仕組みです。しかし、これはむしろ「機能付与」として捉える方が適切かもしれません。ホワイトリスト上のどのドメインを通じてでも到達可能なすべての機能が、新たな攻撃対象領域(アタックサーフェス)となります。api.anthropic.com を許可することは、任意の Anthropic アカウントへのファイルアップロードを許可することと同義でした。
この問題は、VM 内部に配置された防御的な中間者プロキシ(ミドルマン・プロキシ)によって修正されました。このプロキシは API への通信を傍受し、VM 固有のプロビジョニングセッショントークンを付与したリクエストのみを通過させます。攻撃者が埋め込んだキーはプロキシによって拒否されます。また、サーバーサイドフェッチ(server-side fetch)を可能にするヘッダーもブロックします。このプロキシがサーバーではなく VM 内部に配置されているのは、真正性(プロベナンス)の情報を確認できるのが VM だけだからです。サーバー側から見れば、Cowork リクエストは他のどの API クライアントとも見分けがつきません。
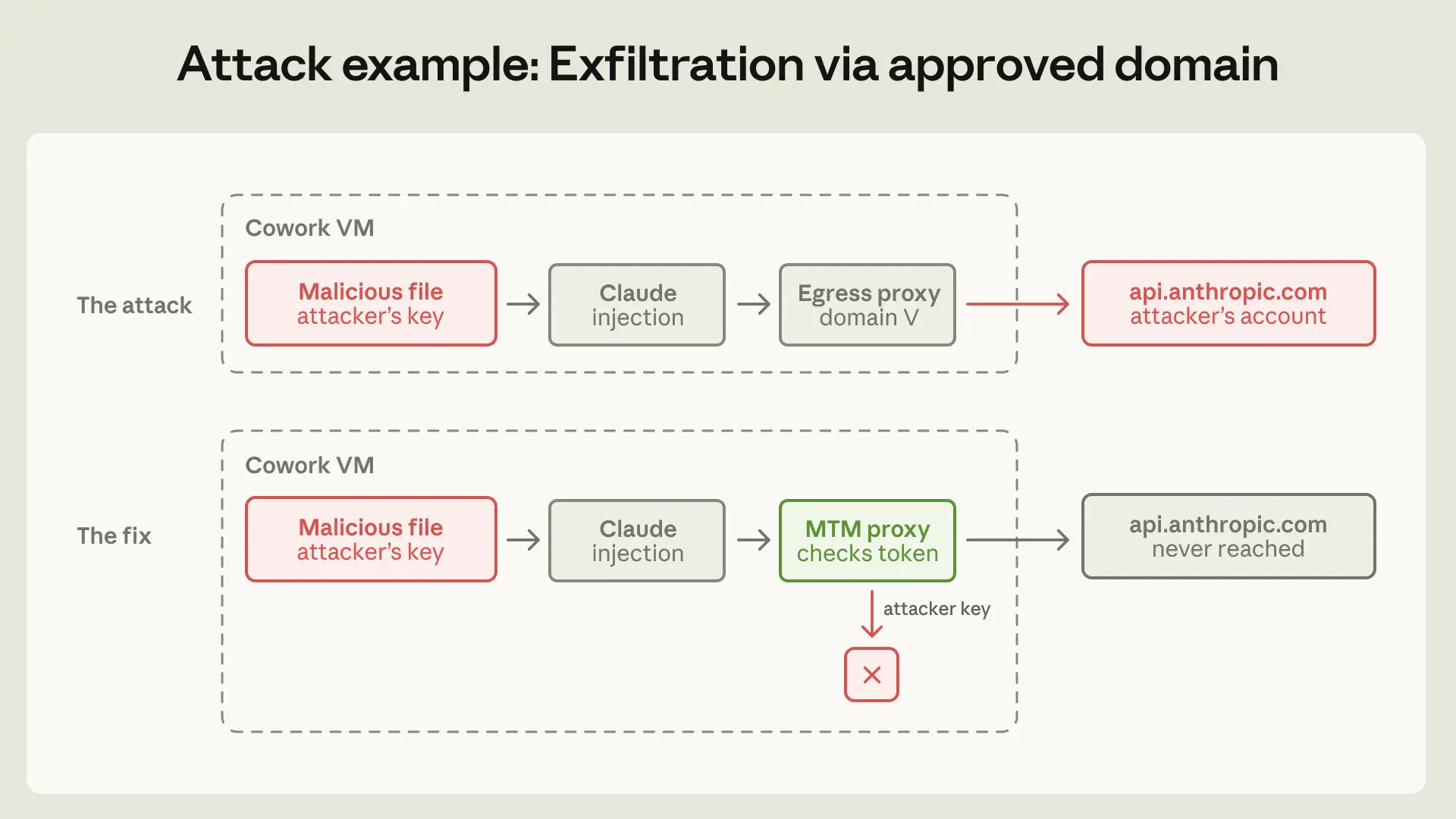 image*上段:api.anthropic.com への通信が許可され、外部送信(egress)が発生する様子。下段:API への通信を傍受する中間者プロキシによる修正後の様子。
image*上段:api.anthropic.com への通信が許可され、外部送信(egress)が発生する様子。下段:API への通信を傍受する中間者プロキシによる修正後の様子。
これはまた、「自社で構築したソフトウェアこそが最も脆弱である」という原則の二つ目の事例でもあります。当社の製品に採用されているハイパーバイザー、seccomp、gVisor は信頼性が高いものでしたが、失敗したのはカスタムホワイトリストプロキシという部分でした。
私たちが見落としたリスク:VM 隔離によりエンドポイント検出ソフトウェアも排除されていた
Claude Cowork を評価する際、エンタープライズセキュリティチームから「なぜ EDR が内部を監視できないのか」という質問が寄せられました。その答えは、Claude を封じ込めているのと同じ隔離機構が、ホストベースのエンドポイント検出およびレスポンス(EDR: Endpoint Detection and Response)も排除していたという点にあります。EDR の視点から見れば、Claude Cowork は不透明なハイパーバイザープロセスに過ぎません。ゲスト内部を検査することはできません。
隔離は可視性を低下させます。エンドポイントの可視性に依存するコンプライアンス体制を持つチームにとって、この不透明性は問題となります。現在の対策としては、後からイベントログを取得できるプルベースの OTLP エクスポートを利用していますが、これはリアルタイム監視とは異なります。同様の仕組みを構築する場合は、この課題について早期に議論するための予算を確保してください。
環境エフェメラルコンテナ(claude.ai)HITL サンドボックス(Claude Code)シールされた VM(Claude Cowork)
コスト:隔離オーバーヘッド**コンテナ起動低遅延ネイティブサンドボックスフル VM 起動
コスト:ユーザー依存度N/Abash の解釈が必要N/A
リスク:爆発半径サーバーサイドコンテナ(gVisor とホストインフラ境界により保護)ローカルワークスペースマウントされたワークスペース(vsock とハイパーバイザー境界により保護)
エージェントが読み込むものを信頼すること
企業からは、MCP 接続をどのようにセキュリティ確保するかという質問をよく受けます。これは良い質問ですが、より本質的な問いは MCP に限定されないものです。エージェントに提供されるあらゆる外部リソースは、同時に二つのリスクをもたらします。一つは従来のサプライチェーンの文脈におけるコード実行リスク、もう一つはプロンプトインジェクションのベクトルです。従来の依存関係監査(バージョンの固定、署名の確認、ソースレビュー)は前者には対応しますが、後者を見逃してしまいます。
「リモートかローカルか」の違いは、一見すると重要に見えないほどに重大です。 ローカルにインストールされたツールは監査可能です。コードを読み、バージョンを固定し、使用中に変更されないことを確認できます。一方、リモートのツール(ホストされた MCP サーバーやクラウドコネクタなど)は、承認した時点以降もいつでも挙動を変更する可能性があります。インストール時の信頼判断がもはや適用できなくなるのです。当社の コネクターディレクトリ は継続的なレビューを通じてこの課題に対処していますが、それ以外のものは信頼できないものとして扱うべきです。悪意のあるツールの影響範囲(ブラスト半径)を制限できる環境で、まず偽のデータに対して実行してください。
技術用語訳注:
- MCP: Model Context Protocol (モデル・コンテキスト・プロトコル)
- 依存関係監査: Dependency auditing
- プロンプトインジェクション: Prompt injection
- ブラスト半径: Blast radius
ツールの出力は、そのツールが信頼できる場合でも攻撃対象領域となります。 前述の GitHub README の例がまさにこれに該当します。Web ページに対して適用される入力スキャンは、ネットワーク接続可能なツールの結果に対しても同じ厳格さで適用されなければなりません。これはレイテンシを追加し、完璧な防御策ではないものの、私たちは生きた検査を優先する方針です。一度汚染されたツールの応答がエージェントを誘導してデータ漏洩を引き起こした場合、ログには単に成功した正規の API 呼び出しが表示されるだけであり、事後に検出できるシグナルは存在しません。
Claude Code および Claude Cowork では、ツール呼び出しはネットワークおよびファイルポリシーを強制し、モデルのコンテキストに入る前に戻り値を検査するプロキシを経由します。この検査を行う分類器は、小さく高速なモデルで構いません。推論を行っているものと同じである必要はありません。
今後の展望
モデルと製品は急速に進化しています。その進展に伴いリスクも変化・進化するため、それに対処するための緩和策も常に歩み寄る必要があります。
永続的なメモリ汚染。 セッションを跨いで保持されるエージェントのコンテキストの割合は増え続けています—これにはプロダクトメモリー、CLAUDE.md ファイル、マウントされたワークスペース、およびスケジュール実行・長時間稼働するエージェントの状態ディレクトリが含まれます。これらのいずれかにインジェクションが成功すると、エージェントが起動するたびに再読み込みされます。セッションを跨いで保持されるエージェント状態が増えるにつれ、古典的な事後利用の観点から新たな永続化メカニズムによる脅威に直面します。セッション起動時の良好な分類器は、より一般的になる必要があります。
マルチエージェントの信頼昇格。 一方、サブエージェントは信頼できないコンテンツを隔離し、生テキストではなく構造化された事実をメインエージェントに返すことができます。他方、これは悪用される可能性があります:サブエージェントからの出力が「私たち」から来たものであるため、生のツール結果よりも高い信頼性を持つと見なされると、プロンプトインジェクションの新たなベクトルが生じます。マルチエージェントシステムでは、異なる信頼レベルを割り当てることと、信頼昇格に脆弱になることの間にトレードオフが存在します。
エージェントのアイデンティティ。 Claude Cowork におけるエージェントのアイデンティティへの回答は具体的です:認証情報はホストキーチェーン内に保持され、VM にはセッションごとのスコープ限定トークンが付与され、そのトークンはユーザーとは独立して取り消すことができます。しかし、私たちは今や、クロスプラットフォームにわたるエージェントのアイデンティティというより広範な問いに取り組み始めています。エージェントは独自のプリンシパルアイデンティティを保有すべきか、それともユーザーの拡張として振る舞い、ユーザーの権限を引き継ぐべきでしょうか。最終的には、その答えは両者の組み合わせになる可能性があります。
エージェントの能力が高まるにつれて、攻撃対象領域は絶えず変化しています。私たちがこれまで見てきたような失敗の種類は、業界や研究所全体で繰り返される可能性があります。共有ベンチマークや開示規範から、共通のアイデンティティ標準やベンダー間でのレッドチーム演習に至るまで、エージェント固有のセキュリティ体制に対する集合的な投資が必要です。本稿ではコンテインメント(封じ込め)に焦点を当てていますが、これはエージェントのセキュリティにおける一部に過ぎません。ガバナンス、観測性、およびその他のスタックについては、NIST の AI エージェントアイデンティティと認可に関するプロジェクト、オーストラリアの ACSC が CISA と英国の NCSC を率いて策定した エージェント型 AI の採用に関する 6 機関ガイドライン、および AI 管理標準である ISO/IEC 42001 を参照してください。Glasswing イニシアチブは一つの貢献に過ぎませんが、この重要な課題についてはパートナー企業や競合他社とも連携して取り組んでいくことを楽しみにしています。
まとめ
要するに、私たちは繰り返し戻ってくるいくつかの原則があります:
環境層での封じ込めをまず設計し、モデル層で行動を誘導する。 私たちが最も教訓を得た 2 つのインシデント——従業員に対するフィッシング攻撃と第三者による許可リストの漏洩——はどちらも、データが許可された経路を通じて外部へ流出した「エグレス」の事例でした。それぞれのケースにおいて、モデル層では対応できず、検出すべき異常も存在しませんでした。確率的な対策がすべて失敗した際に機能するのが、決定論的な境界線です。
ユーザーの監視能力に合わせた隔離強度を適用する。 Bash を読みこなせる開発者と、できない知識労働者では、直面する脅威モデルは異なります。エージェントが行おうとしていることをユーザーが評価できるかどうかという問いは、封じ込め戦略を決定する手がかりとなるべきです。そして、その答えをどちらの方向に誤ることも——専門家には過度な摩擦を生み、非専門家には過剰な信頼を与えること——それ自体が失敗となります。
カスタムコンポーネントには警戒せよ。 実戦で検証されたハイパーバイザー、システムコールフィルタ、コンテナランタイムは、あなたが構築するいかなるものよりも多くの敵対的な攻撃に耐えてきた実績があります。ここで説明したすべてのデプロイメントにおいて、標準的なプリミティブ(基本構成要素)は機能し続けましたが、それらを取り巻く私たちの独自の実装が欠陥を露呈させました。
最終的に、エージェントはソフトウェアの新しいカテゴリである可能性がありますが、そのシステムレベルでの相互作用は新しいものではありません。依然としてファイルを読み込み、ソケットを開き、プロセスを起動します。このため、成熟したツールによるコンテナ化が極めて有効な防御手段となります。AI の発展に伴い、展開におけるリスクとリターンのバランスは常に変化し続けますが、爆発半径に厳格な制限を設けることで、そのバランスを適切な方向へ導くことができます。
謝辞
Max McGuinness, Mikaela Grace, Jiri De Jonghe, Jake Eaton, Abel Ribbink によって執筆されました。
また、Hanah Ho, Hasnain Lakhani, Pedram Navid, Molly Villagra, Maya Nielan, Akila Srinivasan, Sam Attard, Alfred Xing, Mohamad El Hajj, Gabby Curtis, David Dworken, Adam Jones, Amie Rotherham, Christian Ryan, Lucas Smedley, Brett Andrews、およびその他の貢献者の方々にも感謝いたします。
セキュリティチームとプロダクトエンジニアリングチーム、ならびに Claude プロダクトにおける脆弱性を報告してくださった個人や組織の皆様に特に感謝申し上げます。
脚注
- Claude Code の自動モードでは、コマンド承認の委任がモデルベースの分類器に委ねられます。これは、 benign なコマンドの約 0.4% がブロックされるという摩擦の最小化を実現しますが、その代償として危険なアクションの一部を見逃す(過剰な行動の約 17% が通過する)ことになります。したがって、これはサンドボックス内の防御の多層構造における一つの層であり、それを代替するものではありません。
原文を表示
Twelve months ago, we'd have rejected out of hand the idea of granting Claude access sufficient to take down an internal Anthropic service. Today that level of access is routine, and Anthropic developers are more productive for it. The risk of these deployments has two components: how likely a failure is, and how much damage one could do. Progress on safeguards and model training has steadily driven down the first; the second—the theoretical blast radius—only grows as capabilities and access expand. Yet as agents become capable of doing work that once required a person or even a team, the cost of *not* deploying grows large enough that the risk-reward calculation tips heavily toward adoption, as long as products can be made safe. The engineering question becomes how to cap the blast radius.
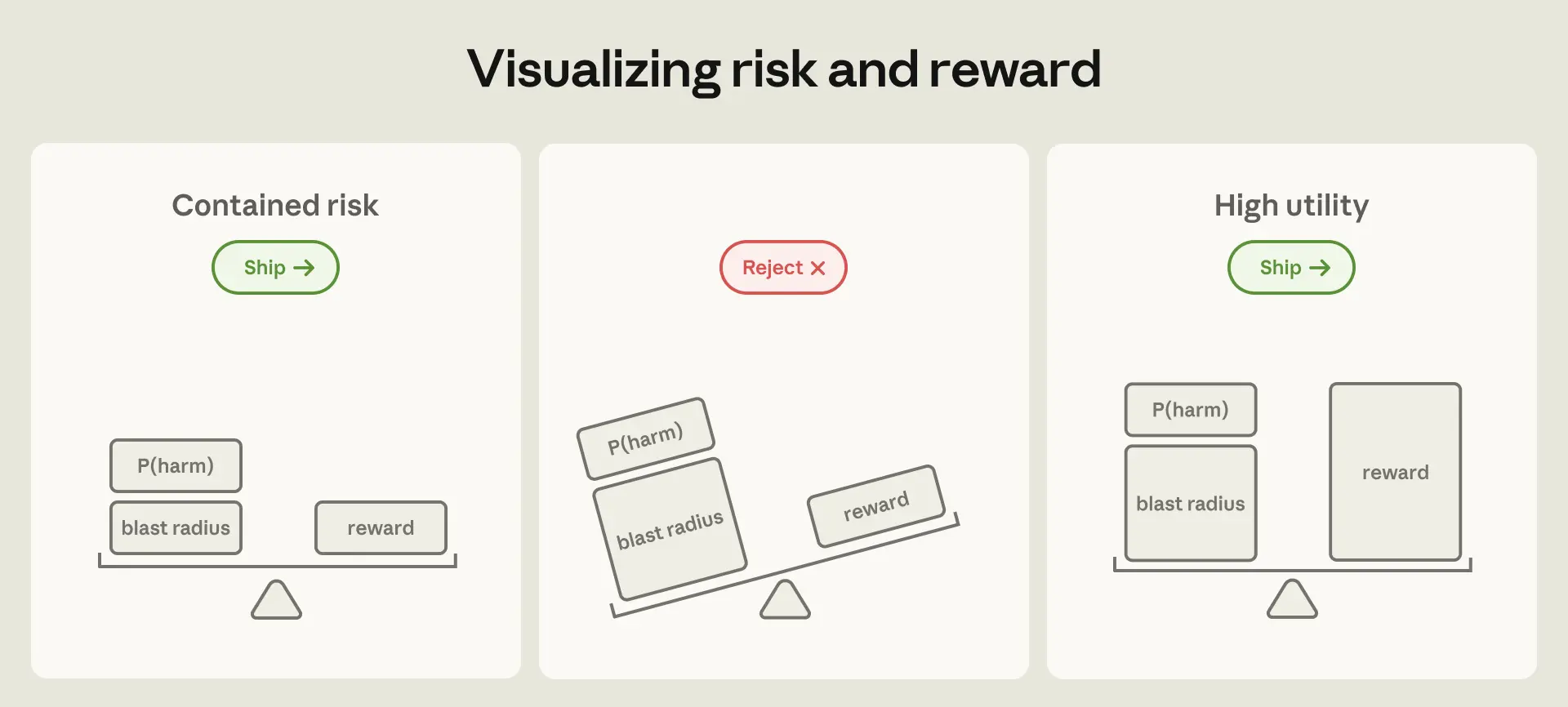
There are broadly two ways to do this.
The first is to supervise the agent’s behavior via a human-in-the-loop. Claude Code previously protected against agents taking unintended actions by asking users for permission at each turn. Theoretically that works, but we’ve found the approach to be fallible. Our telemetry showed users approved roughly 93% of permission prompts. The more approvals a user sees, the less attention they pay to each, becoming over time much less diligent in their supervision. We recently built Claude Code auto mode, which automates safer approvals in order to reduce this approval fatigue. Still, vulnerabilities remain—any probabilistic defense has a non-zero miss rate.1
The second approach to capping the blast radius—and the focus of much of this post—is containment. Rather than supervising what the agent does, we supervise what it’s *able* to do by enforcing access boundaries through, for example, sandboxes, virtual machines, and egress controls. This is where Anthropic engineering has devoted the most effort, and also where many of the most surprising security failures have occurred.
Over the past two years, we’ve shipped three primary agentic products: claude.ai, Claude Code, and Claude Cowork. Each serves a different audience, requiring a different containment architecture. This article shares what’s held up, what’s broken, and what we’ve learned about agent security along the way.
Three types of risk, three components of defense
Security risks to agents fall into one of three categories:
User misuse: A user—either maliciously or through carelessness—directs the agent to do something harmful. This includes everything from asking the agent to bypass a check they find annoying, to running a destructive command they don’t understand, to specifying intentional harm.
Model misbehavior: The agent takes a harmful action no one asked for. As our models have improved, they have become more aligned on most behavior evaluations, but this doesn’t mean risk necessarily shrinks. Less capable models are more likely to misread a situation and make obvious errors. More capable models make fewer mistakes, but they’re also better at finding unexpected paths to a goal, often by routing around restrictions nobody thought to write down.
At Anthropic, we’ve seen Claude models “helpfully” escape a sandbox in order to complete a task, examine git history to find answers to a coding test, and spontaneously identify the benchmark it was being run on in order to decrypt its answer key. Each model brings a new set of capabilities that are sometimes put to work in unexpected ways.
External attackers: The agent is attacked through external vectors such as tools, files, or network access. This category includes both prompt injection and conventional attacks on the agent's runtime, orchestration layer, or proxy.
When building containment and defense systems, we apply defenses to three main components:
The environment in which the agent runs. We constrain where and how an agent can act with process sandboxes, VMs, filesystem boundaries, and egress controls. The goal is to set a hard boundary on what an agent can reach. For example, if credentials never enter the sandbox, they can't be exfiltrated, regardless of whether the cause is a user, a model finding a “creative” path, or an attacker.
A tight perimeter also means you can relax oversight. Claude Code’s reference devcontainer exists precisely so that the agent can run unattended, without per-action approvals.
The model the agent consults. The mechanisms here include system prompts, classifiers, probes, and training modifications. Because models are probabilistic, these shape only what the agent *tends *to do, not what it is theoretically capable of doing.
These defenses are strong. On Gray Swan's Agent Red Teaming benchmark, which tests susceptibility to prompt injection, Claude Opus 4.7 holds attack success to roughly 0.1% on single attempts, and around 5–6% after 100 adaptive attempts. Claude Code auto mode catches roughly 83% of overeager behaviors before they execute. Yet even with best-in-class defenses, protection in the model layer will never be 100% effective, which is why it can't stand alone.
The external content the agent can reach. MCP servers, third-party plugins, and web search tools all feed content into the agent’s context from sources you don’t control. An audited connector isn’t the same as audited data—a GitHub connector, for instance, can load a poisoned README straight into the model’s context despite passing malware checks. Granularly limiting tool permissions can help limit the blast radius. An agent with read-only DB access, for instance, can be deployed far more broadly than one that writes to prod.
Defenses should overlap and complement each other. When environmental defenses aren’t available, the model layer has to pick up the slack (this is precisely what Claude Code’s auto mode is designed for). Locally, the environment and model defenses can guard against malicious tool outputs, but defenses can be added higher up the chain by limiting the tool’s capabilities and access.
Patterns for containing agents
Focusing on the environment layer, we describe three isolation patterns and how they’re tailored for each Claude platform—claude.ai, Claude Code, and Cowork. We arrived at each design gradually, after finding the balance between the capabilities we need from the agent and the degree of intervention required from the user.
Pattern 1: The ephemeral container (claude.ai code execution)
Though best known as a chat interface, claude.ai also writes and runs code, generates files, and calls connectors. When Claude runs code inside claude.ai, it does so in a gVisor container on isolated infrastructure. The agent is entirely server-side; no code runs on the local machine, and the filesystem is ephemeral (per-session). The blast radius is minimal, but so is the ceiling on what Claude can do—there's no persistent workspace and no access to the user's filesystem.
This also makes claude.ai subject to a more traditional threat model. We're not protecting user machines from agents; we're protecting our own infrastructure and each tenant from one another. Our pre-launch work for claude.ai was dominated by traditional security work like network configuration, internal service auth, and orchestration.
That work reinforced the oldest lesson in security: the weakest layer is the one you built yourself. gVisor and seccomp have been hardened against well-resourced adversaries for far longer than agentic AI has existed, so the review effort went into the newer pieces we'd built around them. We’ll come back to this later, since our custom proxy is also the piece that broke in our most consequential incident.
Pattern 2: The human-in-the-loop sandbox (Claude Code)
Claude Code runs on a user's machine and has access to their filesystem, shell, and network. Without this, coding agents have limited usefulness, so it’s imperative to find a way to grant that access safely.
One approach is to rely on a human-in-the-loop. This is only a tractable solution for Claude Code because the average user is a developer who’s familiar with coding environments: they can read bash, they understand what rm -rf does, and they already run npm install from untrusted sources several times a week. All that means that when an “allow this” dialog pops up, they are highly likely to have the expertise to accurately evaluate what the agent is attempting to do and the risk involved. Given this, Claude Code launched with the simplest possible defense: allow reads, require approval for write, bash, and network access.
However, as mentioned, approval fatigue showed up within weeks. Ironically, this meant that a feature originally designed to provide oversight could arguably have the opposite effect—some users might simply stop paying attention. As a first step to mitigate incautious approvals, we shipped an OS-level sandbox (Seatbelt on macOS, bubblewrap on Linux) that hardens the boundary: reads are allowed, writes are allowed inside the workspace, but network is denied by default. Within the sandbox, the agent runs largely without interruption. The result was an 84% reduction in permission prompts, and we open-sourced the runtime, so the boundary is auditable.
Our anonymized usage data also showed that experienced users auto-approve roughly twice as often as new users, but they also interrupt the agent mid-execution more frequently. Instead of gating individual steps, experienced users are more likely to supervise the agent only when it goes off track. While this may be a natural evolution in how people prefer to work with agents, this too is fallible, requiring users to be technical and attentive enough to notice drift in the first place. As model capabilities improve and agents begin writing increasingly ambitious bash, it becomes harder to notice any such drift. And as users move to multi-agent systems, this approach is also much less likely to be an effective oversight strategy.
Risk we missed: everything before the trust dialog
Between mid-2025 and January 2026, we received reports of vulnerabilities in Claude Code through our responsible disclosure program. Three exploited code that executes *before* the user has consented to anything. To understand how this is possible, consider the most direct case: a developer clones a repository to review a pull request, and that repository contains a .claude/settings.json which defines a hook. Because Claude Code reads project settings during startup—before presenting the standard "Do you trust this folder?" prompt—the hook the attacker had authored and committed would execute automatically. The remaining cases looked structurally similar, in which input from the not-yet-trusted directory was parsed before the trust boundary had been established.
The fix in each case had the same shape: defer parsing and execution of project-local configuration until after the user accepts the trust prompt. If you're building something similar, treat project-open, config-load, and localhost listeners the way you'd treat any inbound request from the internet. They shouldn’t be implicitly trusted just because they feel local and arrive before the user has consented.
Risk we missed: the user as an injection vector
In February 2026, during a controlled internal red-team exercise, a researcher successfully phished an employee into launching Claude Code with a malicious prompt. The phish looked like ordinary collaboration—a "can you run this for me?" email with a ready-to-paste prompt attached—and the prompt itself read like routine task instructions. But somewhere among the setup steps, it gently asked Claude to read ~/.aws/credentials, encode the contents, and POST them to an external endpoint. Across 25 retries of that prompt, Claude completed the exfiltration 24 times.
This is a *direct* prompt injection—the attacker's instructions arrived through the user, not through tool output or fetched content. Our model-layer defenses anchor on user intent—when the user is the one typing the instruction, there's nothing anomalous for a classifier to catch. A human contractor handed the same script would have done the same thing.
The only defense that holds in this situation is the environment, specifically egress controls that block the POST regardless of intent and filesystem boundaries that keep ~/.aws out of reach in the first place.
(When we shared the working prompt in internal Slack for discussion, someone pointed out that some internal agents *read* Slack. The payload was now ambient. We added a canary string to the thread so we'd notice if anything picked it up. In a world where agents read everything, the investigation tooling is also an attack surface.)
Pattern 3: The local VM (Claude Cowork)
Claude Cowork runs on a user's desktop with access to a workspace folder selected by the user. Because the platform is built for general knowledge work, not software engineering, the average user is much less likely to be fluent in bash.
As a result, the human-in-the-loop sandbox strategy may not transfer; a non-technical knowledge worker shouldn’t be expected to judge bash incantations such as find . -name "*.tmp" -exec rm {} \;. When approving an exception requires expertise the typical user doesn’t have, admins should set a boundary that is absolute and always-on.
To enable this, our first version of Claude Cowork ran inside a full virtual machine using the platform's vendor hypervisor (Apple's Virtualization framework on macOS, HCS on Windows). The VM has its own Linux kernel, its own filesystem, and its own process table. The user's selected workspace and .claude folder are mounted; nothing else on the host is visible. Credentials stay in the host's keychain and never enter the guest machine. This design protects against the possibility that Claude will, at some point, behave in a misaligned manner. A compromised Claude could still damage what's inside the workspace folder, so the architecture is designed to make sure that's the *only* thing it can reach (until the user adds connectors), and that the user controls what's mounted there.
In the original architecture—what we call full-VM mode—the agent loop itself ran inside the guest, so Claude executed as an ordinary Linux user with no awareness it was sandboxed. Compare this to Claude Code, where a privileged process sits outside the sandbox deciding per-command whether to enforce it; a persuasive injected prompt or a fatigued approval click can get that process to run something un-sandboxed. Here, there was no outer process holding an escape-hatch key, and so no component with the authority to grant an exception.
However, we soon realized that running the whole agent in full-VM mode caused practical problems: any failure during VM startup made Cowork unusable. Moving the agent loop *outside* of the VM, while keeping code execution inside of it, allowed Claude to still respond to the user and help debug issues rather than freeze on an error. This change caused minimal security impact because the VM still enforces filesystem and network controls over code executed by the agent.
Separately, we also moved local MCP servers outside the VM. Running them inside the VM made them harder to audit, created brittle dependency issues when the VM updated, and didn’t support MCPs that required interaction with local processes such as databases—such servers had to run on the host regardless. The change brings Claude Cowork in line with how local MCP servers already work in Claude Desktop: treating them like any software a user might choose to install and entrusting admins to decide which local MCPs to enable (if any). Remote MCP servers are unaffected since they do not run on the user's machine.
Filesystem controls were another important architectural choice. Claude needs to be able to access *some* files on the host in order to be useful, but we wanted to minimize the blast radius and provide transparency to the user about local file access. We found that offering different file-mount modes helps to granularly control risk; Claude Cowork offers read-only, read-write, and read-write-no-delete. One potential gotcha here is that symlink resolution has to happen *before* path validation, not after, or a symlink inside an authorized folder can point outside and escape. For enterprise customers, we allow admins to control this via mount-path allowlists in MDM settings.
Risk we missed: exfiltration through an approved domain
A clear example of exfiltration through an approved domain came from a third-party disclosure. Claude Cowork's egress allowlist correctly passed traffic to api.anthropic.com—the product can't function without calling our own API. In this case, a malicious file placed in the user's mounted workspace carried hidden instructions along with an API key controlled by the attacker. Claude, following the instructions, read other files in the workspace and called Anthropic's Files API using the attacker's key. The egress proxy checked the destination, saw api.anthropic.com, and let it through. The files were uploaded to the attacker's Anthropic account. The sandbox worked perfectly, and yet the data was exfiltrated.
Previously, we’d conceptualized the allowlist as a destination filter, something that told Claude *these domains are okay to talk to.* But it may be better conceptualized as a capability grant. Every function reachable through any domain on an allowlist is now an attack surface. Allowing api.anthropic.com meant allowing file uploads to arbitrary Anthropic accounts.
We fixed it using a defensive man-in-the-middle proxy inside the VM that intercepts traffic to our API. It only passes requests carrying the VM's own provisioned session token; an attacker-embedded key is rejected by the proxy. It also blocks headers that would enable server-side fetch. The proxy sits inside the VM rather than on our servers because only the VM knows provenance—from the server's perspective, a Cowork request is indistinguishable from any other API client.**
This is also a second instance of the principle that the software you build yourself is often the weakest. The hypervisor, seccomp, and gVisor across our products have been dependable. Our custom allowlist proxy was the piece that failed.
Risk we missed: VM isolation kept the endpoint detection software out too
When evaluating Claude Cowork, enterprise security teams asked, "Why can't our EDR see inside?" The answer was that the same isolation keeping Claude contained also kept host-based endpoint detection and response out. From the EDR's perspective, Claude Cowork is an opaque hypervisor process. It can't inspect the guest.
Isolation reduces visibility, and opacity is problematic for teams whose compliance posture depends on endpoint visibility. Our current mitigation is to use pull-based OTLP exports that let administrators retrieve event logs after the fact, but this is not the same as live monitoring. If you're building something similar, budget for this conversation early.
EnvironmentEphemeral container (claude.ai)HITL sandbox (Claude Code)Sealed VM (Claude Cowork)
Cost: Isolation Overhead**Container spin-upLow-latency native sandboxFull VM boot
Cost: User RelianceN/AMust interpret bashN/A
Risk: Blast RadiusServer-side container (guarded by gVisor + host infra boundary)Local workspaceMounted workspace (guarded by vsock + hypervisor boundary)
Trusting what the agent reads
Enterprises often ask us how to secure MCP connections. It's a good question, but the right one is broader than MCP specifically. Any external resource provided to an agent represents two risks at once: a code execution risk, in the traditional supply-chain sense, and a prompt injection vector. Traditional dependency auditing (pinning versions, verifying signatures, reviewing source) addresses the first, but misses the second.
Remote versus local is more important than it seems. A locally installed tool is auditable. You can read the code, pin the version, and know it won't change under you. A remote tool—a hosted MCP server, a cloud connector—can change behavior at any point after you’ve approved it; your install-time trust decision may no longer apply. Our connector directory addresses this through ongoing review, but anything outside it should be treated as untrusted. Run it against fake data first, in an environment where the blast radius of a malicious tool is contained.
Tool output is an attack surface even when the tool is trusted. The GitHub README example mentioned earlier is exactly this case; any input scanning applied to web pages needs to be applied to network-enabled tool results with the same rigor. Even though this adds latency and isn't a perfect defense, we err toward live inspection: once a poisoned tool return has steered the agent into exfiltrating data, the log just shows a successful, authorized API call. There's no after-the-fact signal to find.
In Claude Code and Claude Cowork, tool calls route through proxies that enforce network and file policy and can inspect return values before they enter the model's context. The classifier that does the inspection can be a small, fast model; it doesn't need to be the one doing the reasoning.
Looking ahead
Models and products are advancing fast. As they do, risks morph and evolve, and our mitigations must keep pace to meet them.
Persistent memory poisoning. The share of agent context that persists across sessions keeps growing—this includes product memory, CLAUDE.md files, mounted workspaces, and the state directories of scheduled and long-running agents. An injection that lands in any of these is reloaded each time the agent starts. As more agent state survives the session, we are threatened by new persistence mechanisms in the classic post-exploitation sense. Good classifiers on session startup will need to become more commonplace.
Multi-agent trust escalation. On the one hand, sub-agents can isolate untrusted content, returning structured facts rather than raw text up to the main agent. On the other hand, this can be abused: if a sub-agent's output is treated as higher-trust than raw tool results, because such output came from "us,” a new vector for prompt injection is introduced. In multi-agent systems, there is a tradeoff between allocating differing trust levels and becoming liable to trust escalation.
Agent identity. Claude Cowork's answer to agent identity is concrete: credentials stay in the host keychain, the VM gets a per-session scoped-down token, and that token can be revoked independently of the user's. However, we are starting to grapple with the broader question of cross-platform agent identity. Should an agent possess its own principal identity, or should it act as an extension of the user and inherit the user’s permissions? Ultimately, the answer may be a blend of the two.
As agents grow more capable, attack surfaces are constantly shifting. The types of failures we’ve seen are likely to be repeated across industries and labs. We need collective investment in agent-specific security posture, from shared benchmarks and disclosure norms to common identity standards and cross-vendor red-teaming. We focus on containment in this piece, but that's only one part of the security picture for agents. For governance, observability, and the rest of the stack, see NIST's project on AI agent identity and authorization, the six-agency guidance on adopting agentic AI led by Australia's ACSC with CISA and the UK's NCSC, and ISO/IEC 42001, the AI management standard.Our Glasswing initiative is one contribution, but we look forward to working with both partners and competitors on this critical issue.
Summary
In short, there are a few principles we keep returning to:
Design for containment at the environment layer first, then steer behavior at the model layer. Two of the incidents that taught us the most—the employee phish and the third-party allowlist disclosure—were both cases of egress, in which data left through a permitted path. In each, the model layer couldn't help; there was nothing anomalous for it to catch. The deterministic boundary is what gets hit when everything probabilistic misses.
Match isolation strength to the user's capacity for oversight. A developer who can read bash and a knowledge worker who can't are not running the same threat model. The question of whether a user can evaluate what an agent is about to do should help determine the containment strategy, and answering it wrong in either direction—too much friction for experts, too much trust for non-experts—is its own failure.
Be wary of custom components. Battle-tested hypervisors, syscall filters, and container runtimes have survived more adversarial attention than anything you'll build. Across every deployment described here, the standard primitives held while our own work around them exposed flaws.
Ultimately, while agents may be a new category of software, their system-level interactions are not. They still read files, open sockets, and spawn processes; this makes containment with mature tooling a crucially viable defense. The risk-reward balance of deployments will keep shifting as AI develops, but placing a hard limit on blast radius often forces that balance into the right direction.
Acknowledgements
Written by Max McGuinness, Mikaela Grace, Jiri De Jonghe, Jake Eaton, and Abel Ribbink.
We're also grateful to Hanah Ho, Hasnain Lakhani, Pedram Navid, Molly Villagra, Maya Nielan, Akila Srinivasan, Sam Attard, Alfred Xing, Mohamad El Hajj, Gabby Curtis, David Dworken, Adam Jones, Amie Rotherham, Christian Ryan, Lucas Smedley, Brett Andrews, and others for their contributions.
Special thanks to our security and product engineering teams, and to the individuals and organizations that have reported vulnerabilities in Claude products.
Footnotes
- Claude Code auto mode delegates command approvals to a model-based classifier; it minimizes friction (roughly 0.4% of benign commands blocked) at the cost of missing a fraction of risky ones (~17% of overeager actions get through), so it's one layer of defense-in-depth inside a sandbox, not a substitute for one.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み