より優れたモデルがエージェントを救うわけではない
Pinecone は、AI エージェントのボトルネックがモデル自体ではなく前段のデータ処理にあると指摘し、大規模な組織でスケーラブルな「コンテキストエンジニアリング」基盤の必要性を説いている。
キーポイント
エージェントの真のボトルネックは推論前段階にある
最先端モデルの推論能力自体が不足しているのではなく、タスク実行前の情報検索・評価・統合プロセスでトークンとレイテンシの大半を消費してしまっている。
コンテキストエンジニアリングの重要性
生データからモデルが利用可能な知識へ整形する「コンテキストエンジニアリング」が、エージェントインフラの核心となる分野として確立されつつある。
ドメイン固有の複雑性とスケーラビリティの課題
営業、法務、財務など各ドメインでコンテキストの形状が異なるため、手作業での構築は数社規模を超えて拡張不可能であり、自動化基盤が必要。
生産環境要件の4大基準
市場知能エージェントなどの実装には、再現性のある精度、秒単位のレイテンシ、コストバウンディング、およびガバナンス(権限・出典追跡)の同時満たしが必要。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェント開発の焦点が「より良いモデル」から「より賢いデータ処理基盤」へとシフトしていることを示唆しており、業界全体が RAG やコンテキスト管理の最適化にリソースを集中させるべきという方向性を打ち出しています。Pinecone 自身が提供するソリューションへの言及が含まれていますが、その背景にある技術的課題(スケーラビリティとガバナンス)は、多くの企業が直面する共通の壁であり、今後のエージェント開発の標準的なアプローチに影響を与える重要な洞察です。
編集コメント
モデルの性能向上ばかりに注目されがちですが、実運用におけるボトルネックはデータの前処理と管理にあるという本質的な指摘です。特に大規模組織でのスケーラビリティ課題を解決する「コンテキストエンジニアリング」への注目は、開発者が次に投資すべき領域を示唆しています。
今日、本番環境でエージェントを構築している誰もが同じ壁にぶつかったことがあるでしょう。モデル自体が制限要因となることは稀です。最先端のモデルは、必要な業務のほとんどに対応できる推論能力を持っています。問題が生じるのは、推論ステップに至るまでのプロセス全体です。エージェントはタスクを受け取り、情報が必要だと判断し、検索し、結果を取得・評価します。さらに情報が必要だと判断して再度検索し、読み込み、断片的な情報を組み合わせて部分的な像を構築し、ループします。モデルが回答を生成できる状態になる頃には、トークン数とレイテンシの予算のほとんどはすでに消費されてしまっています。
これが現在、エージェントインフラを定義するギャップです。この問題を中心に形成された分野が「コンテキストエンジニアリング」です。これは、クエリ実行時に生データから再構築させるのではなく、モデルが利用可能な知識としてデータを整形するアプローチです。
これらのコンテキストパイプラインを実装する際にチームがつまずくことが多く、特に実在する企業では、営業、法務、財務、サポート、研究開発、運用など、各ドメインに必要なコンテキストの形状が異なるため困難を極めます。ドメインごとに手作業で1 つずつコンテキスト層を構築する方法は、最初の 1〜2 つを超えてスケーリングできません。
私たちは過去 1 年間、この課題に取り組んできました。本稿の後半では、なぜこれが難しいのか、私たちが何を開発したか、そして次に何が来るべきだと考えているかを解説します。
具体的な例:市場インテリジェンスエージェント
投資会社における S&P 500 の 10-K 提出書類を分析する市場インテリジェンスエージェントを考えてみましょう。この質問は、エージェントが回答する必要のある数十の質問の一例です。
「NVIDIA、Microsoft、Walmart の各社について、それぞれの 10-K に開示された財政年度 2022 の自社株買い活動を比較してください。各企業について、(a) その財政年度における自社株買いのドル額と買戻し株式数、(b) 開示されている場合の当初プログラム承認規模および承認日、(c) 同社の財政年度末時点での残存承認枠を明記してください。」
このエージェントを実環境に導入するためには、コンテキスト層が以下の 4 つの要件を満たす必要があります:
- 精度: 正解であり、実行ごとに再現可能であること。70% の確率で正しいだけのカスレる(不安定な)エージェントは、実務上は機能しません。
- タスクレイテンシ: クエリは秒単位で完了し、数十秒や分単位ではなりません。
- トークンコスト: 1 回あたりのコストに上限があり、ワークフロー全体でエージェントの請求額が複利計算されることはありません。
- ガバナンス: フィールドレベルでの権限強制と、回答の出所を遡れる根拠ある出典情報の保証。
しかし、これら 4 つを同時に満たすことは、聞こえほど簡単ではありません。このようなエージェントワークロード向けのコンテキスト層を構築する際、チームは通常、1 つのチームを専任させ、数ヶ月にわたる反復作業を通じて、以下の 2 つのパターンのいずれかに注力します:
- Agentic RAG:10-K コーパスをチャンク化し、埋め込みを行い、ハイブリッド検索を利用する。エージェントにループ処理を行わせ、クエリを実行し、再ランク付けを行い、上位のチャンクを読み込み、回答に満足するまでループさせる。
- サンドボックス内のコーディングエージェント:ファイル一覧表示、ページ読み取り、grep 検索、全文書読込などのツールへのアクセスをエージェントに与え、ループ処理を行わせる。各 10-K ファイルを開き、資本収益セクションへ移動し、表を解析して回答を抽出する。
両方のアプローチは最終的に正しい答えに到達する可能性はあるが、実装するには通常、あまりにも遅く高価である。どちらも同じ根本的な課題を抱えている:各タスクに対してクエリ実行時に知識を組み立てさせようとしている点だ。Agentic RAG はエージェントにチャンクを渡し、回答をつなぎ合わせるよう求める。Agentic Sandbox はファイルを与え、検索、grep、解析を通じて回答へナビゲートするよう求める。これらのアプローチでは、作業の大部分が生データの取得と適切な文脈の構築に費やされ、推論にはほとんど使われない。
手動設計されたコンテキストからコンパイル済み知識へ
このような問題に対する解決策はよく知られている:消費者がクエリごとに構造を導出させないことだ。データに対して、消費者が関心を持つ構造をすでにエンコードした*アーティファクト*として事前に整形し、それらを提供することである。
これは新しい話ではありません。知識グラフ、エンティティカタログ、セマンティックレイヤーは数十年も前から存在しています。データインフラの各世代は、常に同じ直感に基づいたある種のバージョンを提供してきました:方向付け作業を一度行い、その結果を保存し、下流の消費者が直接それを読み取れるようにするのです。コンテキストエンジニアリングは、この直感の最新バージョンであり、現在はダッシュボードではなくエージェントに適用されています。
破綻する場所:ドメインごとの運用化
難しいのは概念そのものではありません。それを運用化することです。
*一つの*ドメインのために優れたアーティファクトレイヤーを構築するには、洗練されたチームと数ヶ月にわたる反復が必要であり、どの特定のキュレーション戦略、検索設計、評価ハネス、ガバナンスフックを使用するかを決定する必要があります。複雑な点は、実際の企業には一つのドメインしかないわけではないということです。数十ものドメイン(例えば営業、カスタマーサポート、法務、財務、研究開発など)があり、それぞれが独自のデータ形状、スキーマ、方言、アクセスパターンを持っています。
数ヶ月にわたる反復を、エージェントを必要とするすべてのドメインで掛け合わせると、これらのパイプラインを構築するリソースはすぐに枯渇してしまいます。実際には、最も価値の高い一、二つのドメインのためにのみレイヤーが構築されるか、あるいは全く構築されないという結果になります。
これがアジェンシー(エージェント)時代の課題です。企業のすべてのドメインでエージェントが稼働し、すべてのエージェントに shipped するためのコンテキストエンジニアリングが必要となるのです。
新しい知識インフラストラクチャのカテゴリー
この問題は、コンテキスト層がドメインごとに手動調整・構築されるのではなく、ドメイン横断的に自動で動作する「インフラストラクチャとして機能する」新しいカテゴリーの知識インフラストラクチャを必要としていることを示しています。この層は既に存在しており、あなたはそれに対してプロビジョニングを行うものであり、新たなユースケースが発生するたびにゼロから再構築する必要はありません。
私たちは過去 1 年間、これを開発してきました。その名はPinecone Nexus。エージェント専用の知識エンジン(Knowledge Engine)です。
知識エンジンの内部構造
知識エンジンは、以下の 4 つのプリミティブ(基本要素)から構築されています。各要素は、下の要素を構成するものとの組み合わせによって成り立っています:
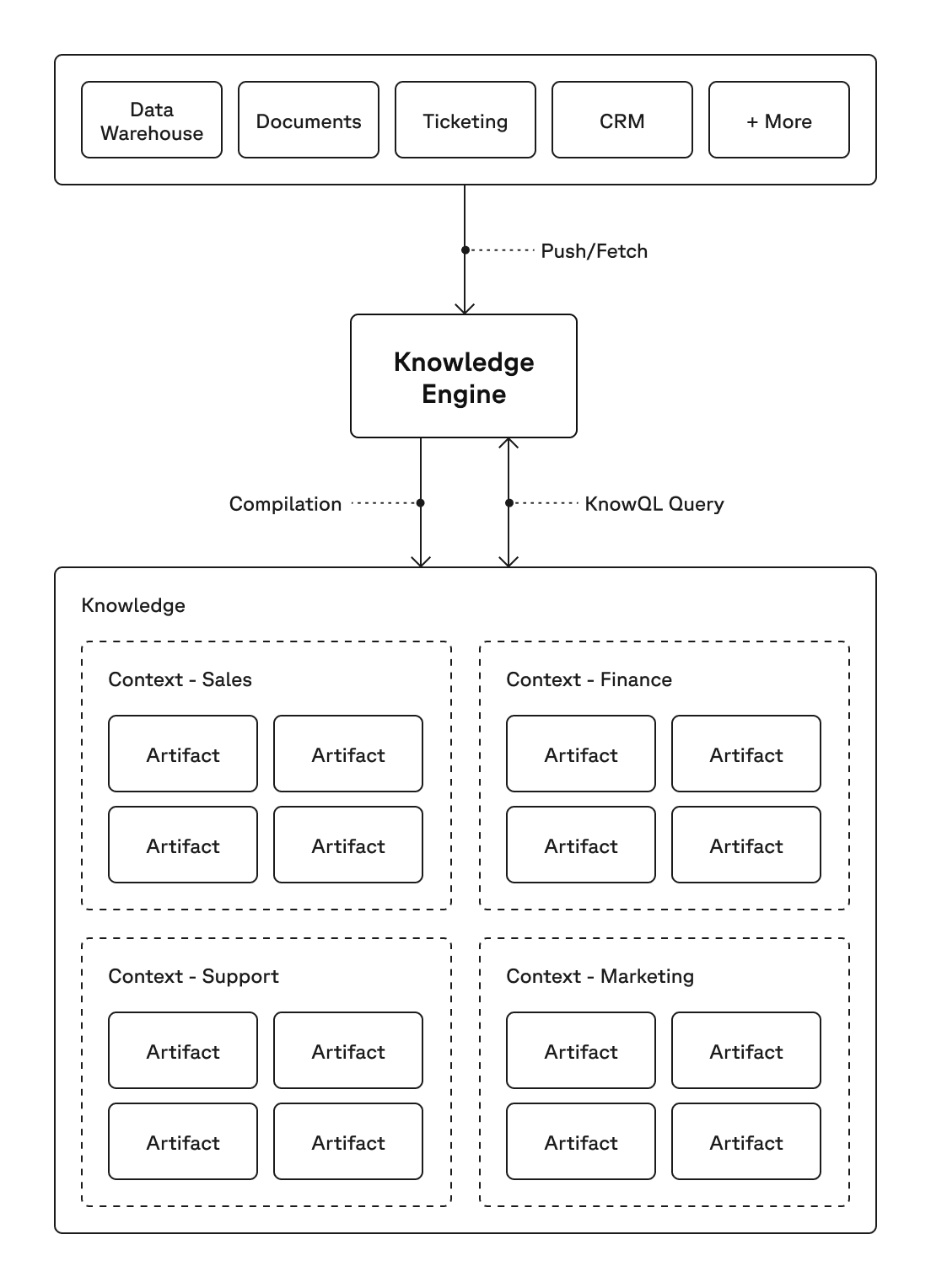
アーティファクト(Artifact): 特定のタスクや成果のために構築された、型付けされ管理された情報の断片です。同じ 10-K データからでも、財務指標(収益、資本利得など)を必要とする市場インテリジェンスエージェントが取得するアーティファクトは、リスク要因の開示を必要とするコンプライアンスエージェントが取得するものとは異なります。それぞれの形状こそが、基盤となる表現を各エージェントの業務に最適化し効率的にする要素です。
コンテキスト(Context): 特定の役割、チーム、またはワークフローのために設計された、アーティファクトの厳選されたセットです。アナリストの財務指標アーティファクトを、そのエージェントが必要とするナラティブセクション(MD&A、セグメント報告など)とバンドルしたものが、アナリストのコンテキストとなります。同様に、コンプライアンスチームにも独自のコンテキストが存在します。
知識。 企業内のすべてのコンテキストの集合体であり、アナリスト業務、コンプライアンス、M&A、ポートフォリオ監視などにおいてビジネスがどのように運営されているかを表します。知識に対するクエリは必要なだけ多くのコンテキストにまたがることができますが、ルーターはエンジン側で処理されます。
知識エンジン。 上記すべてを構築し提供するシステムです。その中核となるのは「Context Compiler(文脈コンパイラ)」であり、これは自律型コーディングエージェントとして、各ドメイン向けのキュレーションおよびクエリコードの記述と調整を行います。ビルドループが完了すると、生データからアーティファクトを構築し、それらをコンテキストに構成して、各エージェントの KnowQL クエリを提供します。
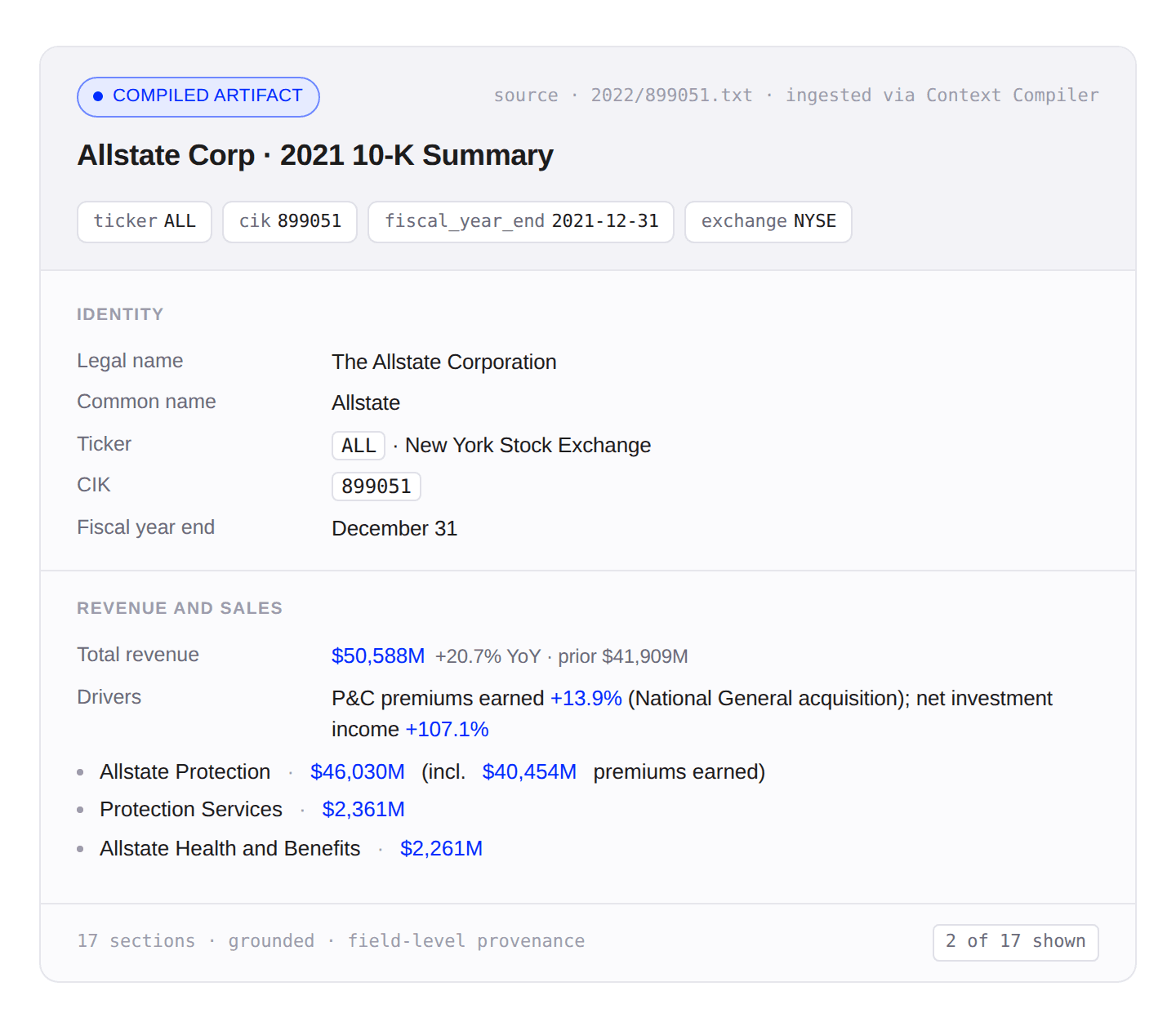
これは、市場インテリジェンスエージェント向けに 10k-SEC 提出書類を使用してコンパイルされた、企業レベルのアーティファクトの例です。
文脈コンパイラ
文脈コンパイラは、知識エンジンの中核をなす自律型コーディングエージェントです。タスク最適化された「Context(文脈)」を構築するために、コーディングエージェントと以下の 3 つの要素を組み合わせた「アジェンシー・ハーネスパターン」を採用しています:
- ドメインごとに定義する評価セット(既知の正解を持つ代表的なタスク)と、それに対応するデータソース
- 文書処理、エンティティ抽出、チャンク化などの事前検証済みスキルからなるライブラリ。エージェントはこれらのスキルを組み合わせてソリューションを構築します。
- 各イテレーションの評価信号に対してスコアリングを行うフィードバックループ。
このプロセスでは、コーディングエージェントが artifact construction(アーティファクト構築)用の curate() 関数と knowledge retrieval(知識検索)用の query() 関数の 2 つを修正し、評価セットを実行します。その後、失敗信号を用いてコードを改良し、評価に合格するまでこれを繰り返します。最終的な出力は、そのドメイン向けに動作し調整された Context です。
このアプローチにより、検索の専門知識がなくても、あらゆるドメインの専門家(リトリバル背景を持たない方でも)がエージェント最適化された Context を作成できます。なぜなら、スキーマや検索ロジック、アーティファクトの形状を事前に指定する必要がないからです。Context Compiler は評価結果に基づいて、適切なアーティファクト構造、粒度、および構築戦略を自動的に発見します。新しいドメインの多くは、既存のスキルを新たな方法で組み合わせることで対応可能です。もし何かが明らかに適合しない場合は、ライブラリに新しいスキルを追加します。
初期設計パートナーとの共同作業において、この Compiler は数ヶ月ではなく数日で新しいドメイン向けの Context を提供しました。まだ複数のドメインやエッジケースでの測定は継続中ですが、初期の信号は有望であり、私たちはこのハルネスベースのアジェンティックアプローチが知識インフラストラクチャの未来の基盤になると信じています。
KnowQL
コンテキストが作成された後、次のステップはエージェントがそれを効果的に活用できることを保証することです。もしエージェントが段落レベルの自然言語クエリを発行し、戻ってきたテキストの塊を解析しなければならない場合、各呼び出しで時間とトークンを消費して再方向付けを行うことで、以前の失敗がそのまま再発します。私たちは、エージェントが必要なものを「宣言」し、正確で型付き、引用付きの応答を受け取るようなインターフェースを望んでいました。それが KnowQL(Knowledge Query Language)です。
「宣言的」という部分が中核的な設計原則です。SQL では、必要なもの(例:結合、フィルタ、投影)を記述し、エンジンが実行計画を選択します。KnowQL も同じ考え方をエージェントによる知識検索に適用したものです。エージェントは、必要な答えをどのような形状で、どのような制約条件下で求めるかを指定します。Knowledge Engine がどのコンテキストを検索し、どのアーティファクトを読み取り、それらをどのように構成するかを決定します。
KnowQL クエリは、エージェントの生産要件を満たすために 4 つのカテゴリを組み合わせて構成されます:
- インテント:質問、レスポンスの形状、および対象となるコンテキスト。これは複数のコンテキストにまたがって構成される場合があります。
- フィルター:表面で強制される決定論的述語とアクセス制御ポリシー。エージェントが見られるのは、その呼び出し元が許可されている範囲のみです。
- 出所:構築時にフィールドレベルの引用として返され、後から再構築されるものではありません。すべての値にはそのソースが含まれます。
- コントロール:バジェットエンベロープ(深さとレイテンシ目標)。コストはトークン数ではなく結果に明記されます。
前述の S&P 10-K に関する質問に対する KnowQL クエリでは、エージェントが発行するクエリは以下のようになります:
{
"ask": "NVIDIA、Microsoft、Walmart のうち、2022 会計年度の自社株買いを比較してください:買戻し額、元のプログラム規模、および残りの承認額。",
"ground": true,
"shape": {
"type": "object",
"properties": {
"companies": {
"type": "array",
"items": {
"type": "object",
"properties": {
"company_name": { "type": "string" },
"repurchased_usd_millions": { "type": "number" },
"program_size_usd_millions": { "type": "number" },
"remaining_usd_millions": { "type": "number" }
}
}
}
}
}
}
エンジンが 1 つの型付きレスポンスを返し、エージェントの唯一の推論ステップは、すべての方向付け作業がビルド時に完了しているため、その型付きレスポンスオブジェクトを比較することだけです。
知識検索の影響を測定する
Nexus の価値を実証するためには、エージェントのパフォーマンスに対する知識検索の影響を定量化する必要がありました。既存のほとんどの検索ベンチマークは、単にリコール(再現率)のみを孤立して測定しており、異なる検索戦略がエンドツーエンドの多段階エージェントループに対して与える影響を比較していません。
このギャップを埋めるために、KRAFTBench (Knowledge Retrieval Assessment Framework for Text) を作成しました。このハーンチス(評価枠組み)は、一貫したコンポーザーモデル(claude-sonnet-4-6)から生成された応答の精度、レイテンシ、トークンコストを、異なる検索メカニズム間で測定します。これにより、エージェントタスクにおける品質、レイテンシ、またはトークンコストの違いは、すべて検索に起因するものとして特定できます。テストされた3 つの検索メカニズムは以下の通りです:
- コーディングエージェント:Claude-sonnet-4-6 に、読み取り専用のファイルシステムツールキット(list_files, read_file, find_filecontent, find_filename)を少量提供します。インデックスは用意しません。
- エージェント型 RAG:ファイルをチャンク化して Pinecone ベクトルインデックスに埋め込みます。クエリ拡張、RRF 融合、top-k 検索を利用し、完了と判断するまでループ処理を行います。
- Pinecone Nexus:Context Compiler を用いて生成されたアーティファクトです。各質問ごとの形状は Claude によって導出され、KnowQL クエリとしてフォーマットされ、必要に応じて多段階質問に対するフォローアップ要求も含まれます。
これらのエージェントは、S&P 500 企業の 2022 年 SEC 提出書類から抽出された 493 の自由記述形式の 10-K ファイル(各ファイル約 500KB、合計約 245MB)に対してテストされました。各エージェントには、9 つのセクターと 10 の財務トピック(従業員数、収益、資本支出、資本還元、研究開発、買収、セグメント内訳など)にまたがる 150 の難問への回答が課されました。これらの質問は、3 つの難易度形状でタグ付けされています:マルチファクト(同一エンティティに関する 2 つ以上の事実を組み合わせる)、マルチカンパニー(2 つ以上のエンティティ間で比較する)、マルチステップ(事実 A を取得し、それに基づいて事実 B を導出する)。
各質問には 120 秒の時間制限と 1M トークンのトークン制限が課され、各エージェントは確定的な回答ができるか制限を超すまで反復処理を行います。最終的な回答は、評価セットの正解出力に対して LLM ジャッジ(Claude-sonnet-4-6)によって精度が評価されます。
私たちの発見
3 つのアプローチを比較するために、各エージェントの平均レイテンシ(x 軸)と平均精度(y 軸)をプロットし、バブルサイズで完了率を表しました。目指すべきは左上の領域です。すなわち、高速かつ高精度であることです。Nexus は、最も低いレイテンシで、最も高い精度と完了率を実現しました。また、トークンコストも大幅に低く抑えられており(RAG と比較して約 7 倍、コーディングエージェントと比較して約 80 倍)です。Agentic RAG はほぼすべての質問を完了しますが、精度は低く、レイテンシは約 1.7 倍になります。一方、コーディングエージェントは最も遅く、信頼性が最も低いものでした。精度は中程度ですが、レイテンシは約 4 倍で、トークン予算または制限時間(wall-clock cap)に達する前に完了できたのは質問の 63% だけでした。
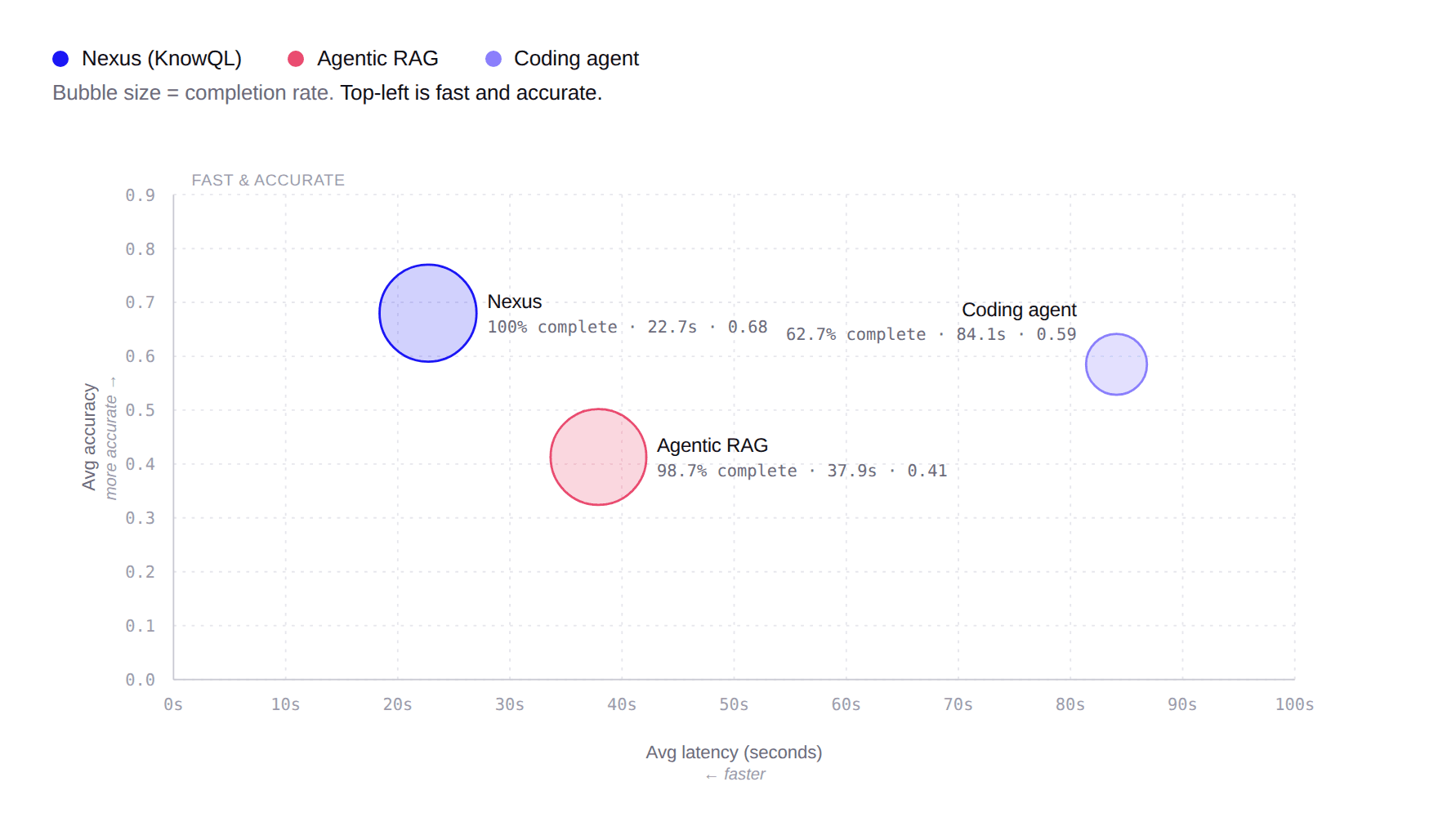
完了率 | 平均レイテンシ | 平均精度 | 平均トークン数 | 平均ステップ数
---|---|---|---|---
Pinecone Nexus | 100% (150/150) | 22.7 秒 | 0.68 | 6,733 | 1.69
Agentic RAG | 98.7% (148/150) | 37.9 秒 | 0.41 | 349,103 | 7.77
コーディングエージェント | 62.7% (94/150) | 84.1 秒 | 0.58 | 528,301 | 14.77
最も困難な質問には、複数企業の比較や多段階の推論チェーンが必要とされるものが含まれており、各エージェントの失敗モードはトレース(traces)において明確に現れています。
- Pinecone Nexus は、複数エンティティの比較や多段推論を容易にするために、企業レベルの「ファクトシート」アーティファクトをコンパイルします。関連するアーティファクトのセットを見つけ、1 回のパスで回答を組み立てます。
- エージェント型 RAG(Retrieval-Augmented Generation)は各質問を複数のリクエストに分解しますが、意味的類似性のみで検索する場合、各リクエストは情報の欠落または部分的な返答しか行いません。
- コーディングエージェントは grep を使用してテキスト内のキーワードを特定しますが、フレーズは各ドキュメント内で複数回出現する可能性があり、どの言及が正しいかを判断する方法がありません。その結果、予算または時間が尽きるまで曖昧さを解消しようとしてトークンの大部分を費やしてしまいます。
これをより具体的に示すために、財務エージェントに投げかけた元の質問の経路を追ってみましょう:
「NVIDIA、Microsoft、Walmart のうち、各社の 10-K に開示された財政年度 2022 年の自社株買い活動を比較してください。各社について、(a) 財政年度中の自社株買いのドル額と買戻し株式数、(b) 開示されている場合の当初プログラム承認規模と承認日、(c) 同社の財政年度末時点での残存承認額を明記してください。」
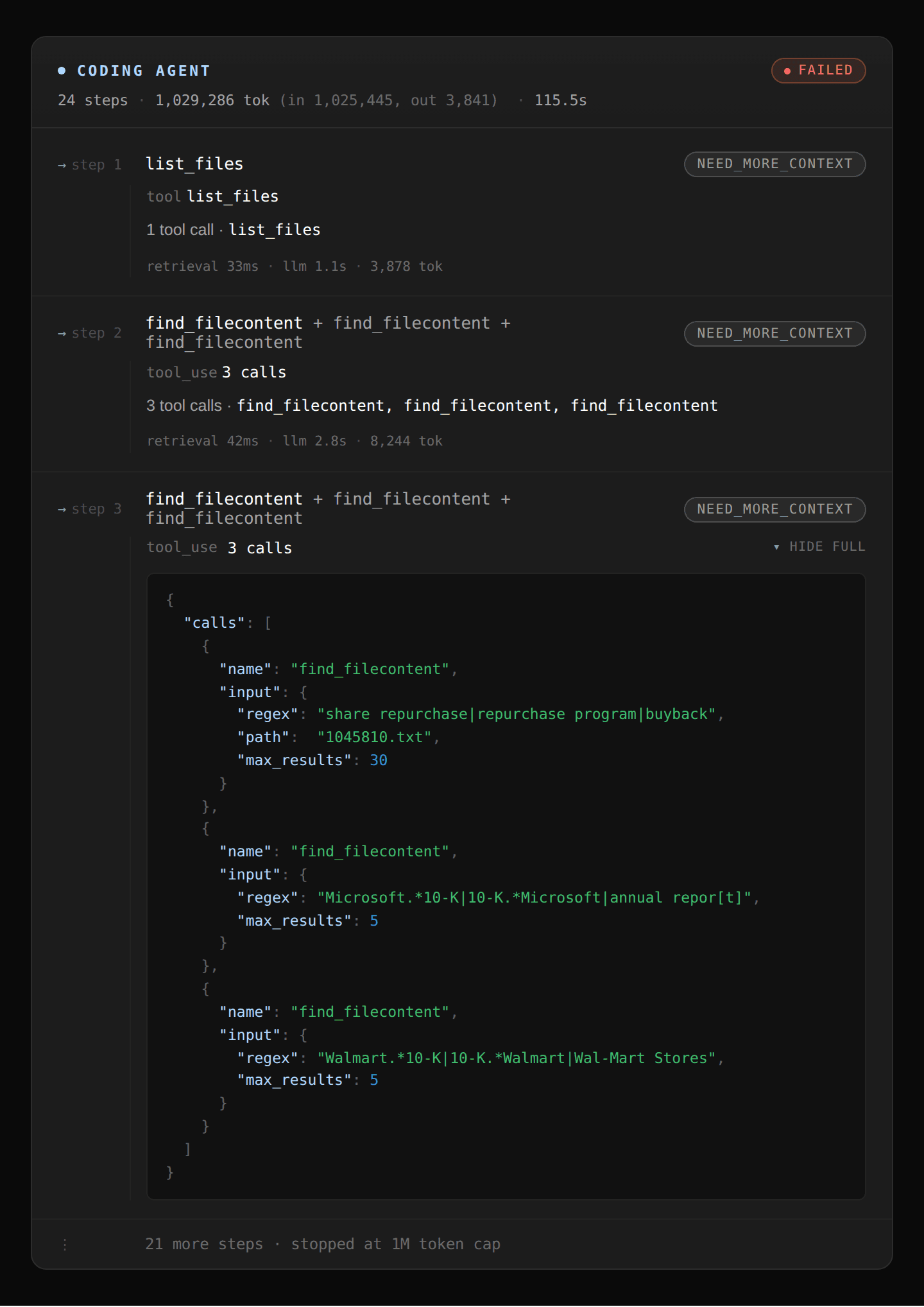
コーディングエージェント: コーディングエージェントは、「share repurchase」または「Microsoft」または「Walmart」という広範な正規表現スキャンから始め、コーパス内のすべての 10-K で数百件の一致を検出します。エンティティ名でさらに絞り込むと一致件数が増え、すぐにコンテキストウィンドウを埋め尽くし、最終的に 1M トークンの制限に達します。
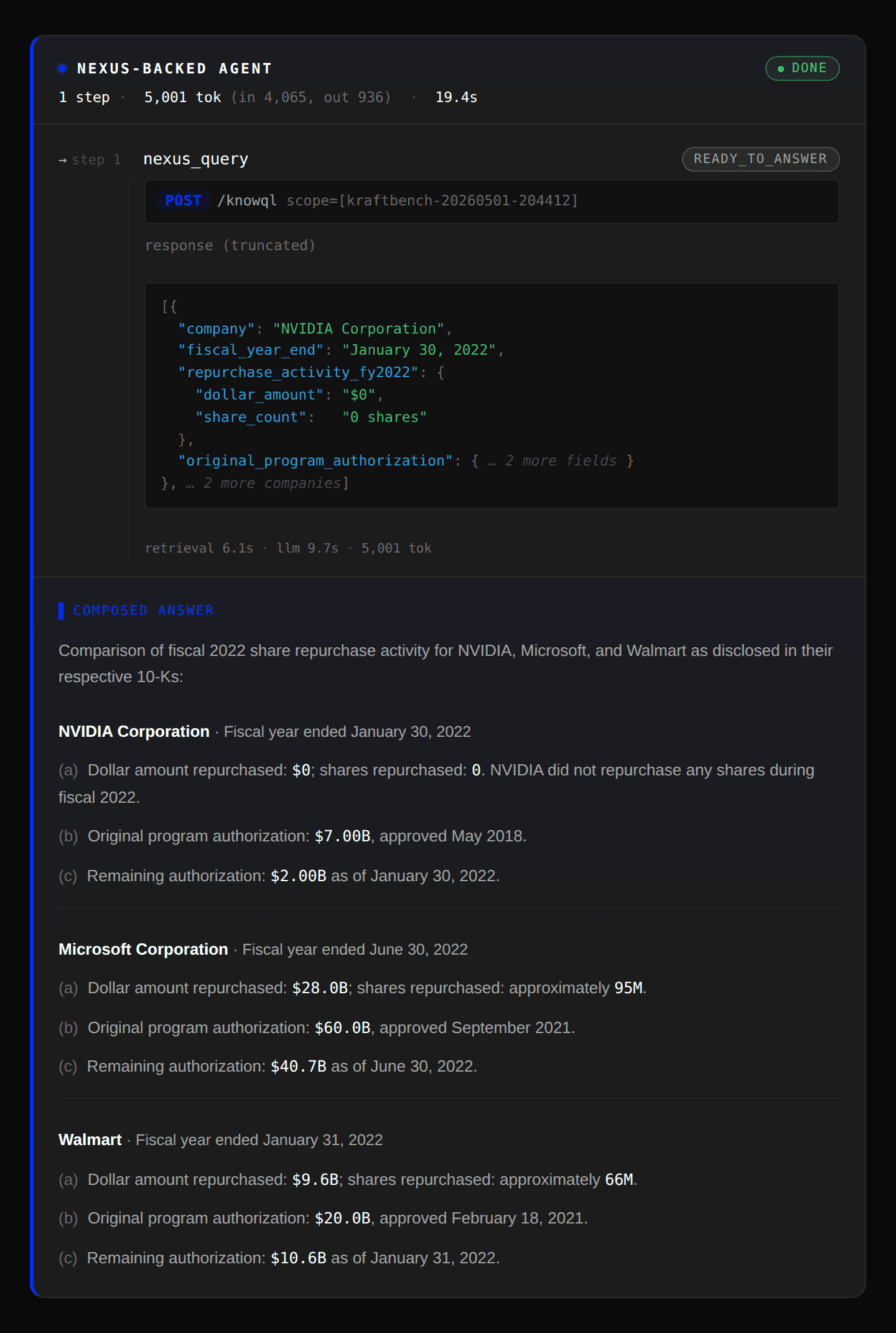
Agentic RAG: エージェントはまずクエリを 18 の事実へと分解し、各事実に対して返された上位 k 個のチャンクを検索・評価します。しかし、ドキュメント内で金額数値とチャンクが同一場所に配置されていなかったため、マイクロソフトとウォルマートの金額を見つけることができませんでした。その結果、データが存在するにもかかわらず、それらの数値を欠落していると誤ってマークしてしまいました。
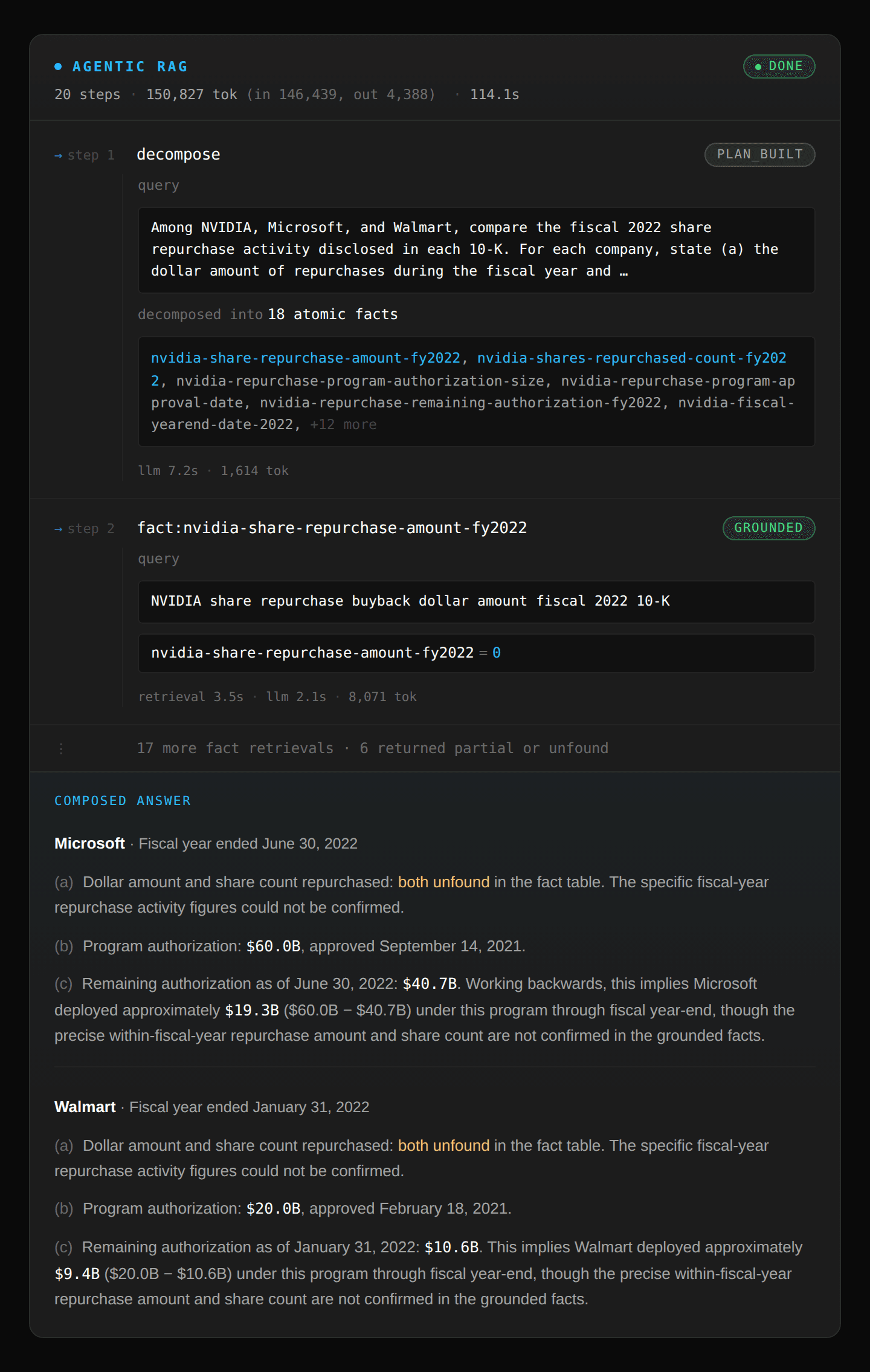
Pinecone Nexus: 完全な質問と所望の構造化出力形式を受け取り、一発で完了させます。これは、Nexus が各企業の主要統計を要約したアーティファクト(成果物)を生成するためです。また、トークン使用量を最小限に抑えるため、構造化された応答結果を JSON オブジェクトとして提供しました。
今後数週間で、KRAFTBench に関する詳細な解説記事を公開し、この手法と結果をより詳しくご紹介します。このベンチマークへの共同参加に関心がある場合は、こちらからお問い合わせください。
ソースから知識へ:Box → Unstructured → Pinecone のネクサス
Nexus を実際のエンタープライズデータで使用するために、重要なスタックの一部を所有する 2 つのエコシステムパートナーと統合しました。1 つはBoxで、ソースドキュメントとその権限が保管される場所です。もう 1 つはUnstructuredで、生のフォーマット(PDF や Word ドキュメント)を Nexus が直接消費できる構造化フォーマットに正規化する役割を果たします。
例として、Box に保存された CUAD データセット の契約書群を検証する法的レビューエージェントが、以下の質問をしたいとしましょう:
「固定の初期期間はあるが自動更新メカニズムがなく、延長には当事者が積極的に交渉する必要がある契約はどれか?」
Box(ソース): 契約書は、非競争条項、商業契約、承認書など、指定された Box フォルダに保存されます。アクセス制御リストを含むファイルメタデータにより、権限が尊重されるように保証されています。契約書の維持と更新は法務チームの責任です。
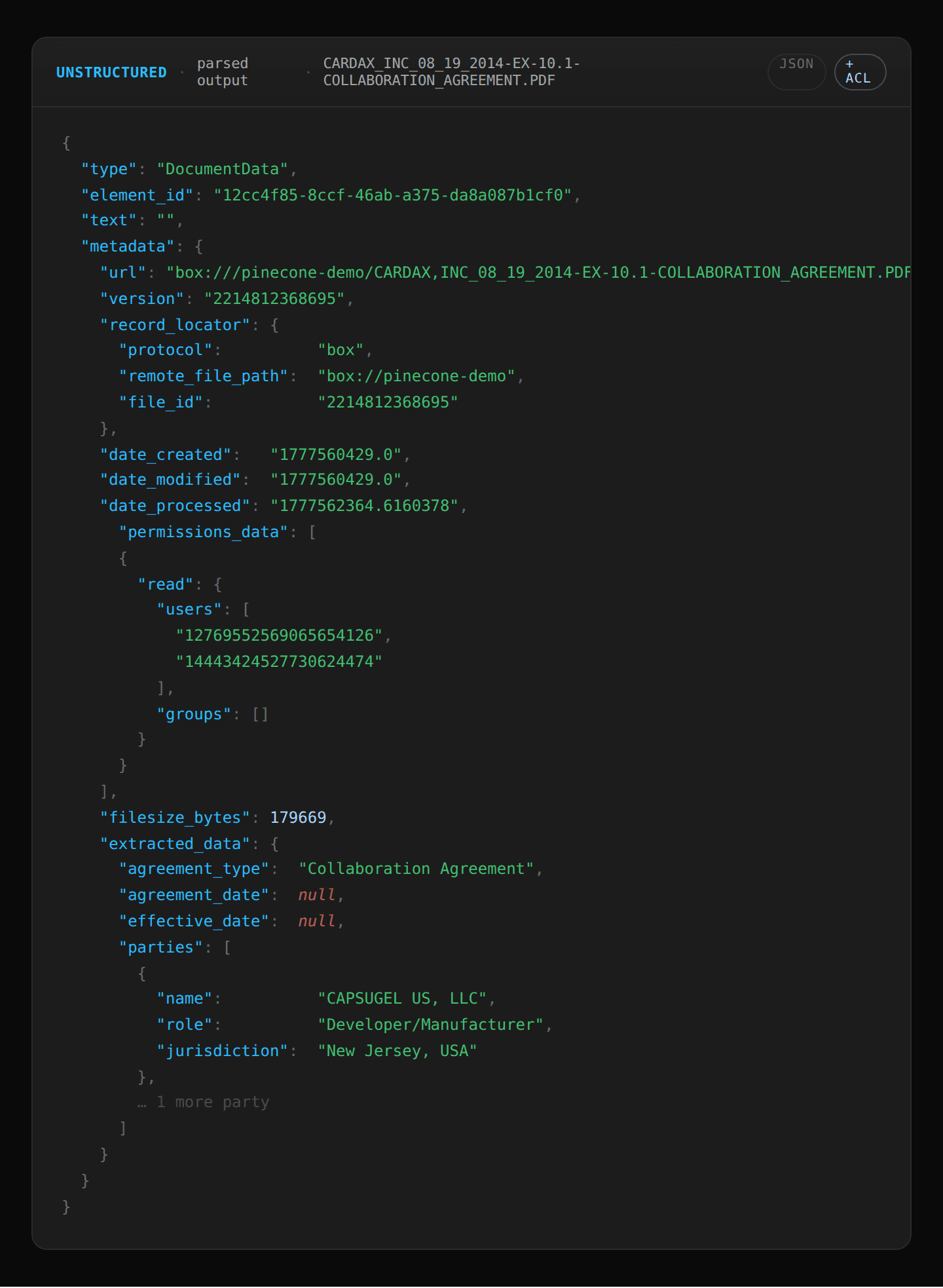
構造化されていないデータ(パース): Unstructured は Box の API を通じて接続し、各ファイルの内容とファイルメタデータ(ACLs を含む)をキャプチャします。法的契約書から主要なドキュメント要素、テーブル、エンティティ(parties\verb|parties|, agreement_date\verb|agreement_date|)を抽出し、ユーザーがアクセス権限を持つ契約書のみを表示できるようにするために、ファイル許可メタデータ(permission_data\verb|permission_data|)を渡します。
Pinecone Nexus(ナレッジエンジン): Unstructured によるパース結果がソースとして取り込まれ、抽出されたデータに対して Context Compiler が実行されます。その生成物の一つは、異なる契約書にわたる契約更新条項を集約したテーブルであり、これにより Nexus は複数のエンティティを検索するのではなく、単一のアーティファクトを取得することで質問に応答できます。クエリを構成する際、ユーザーがアクセス権限を持つ契約書のみに応答するようにするために、ファイル許可メタデータをフィルターとして渡します。
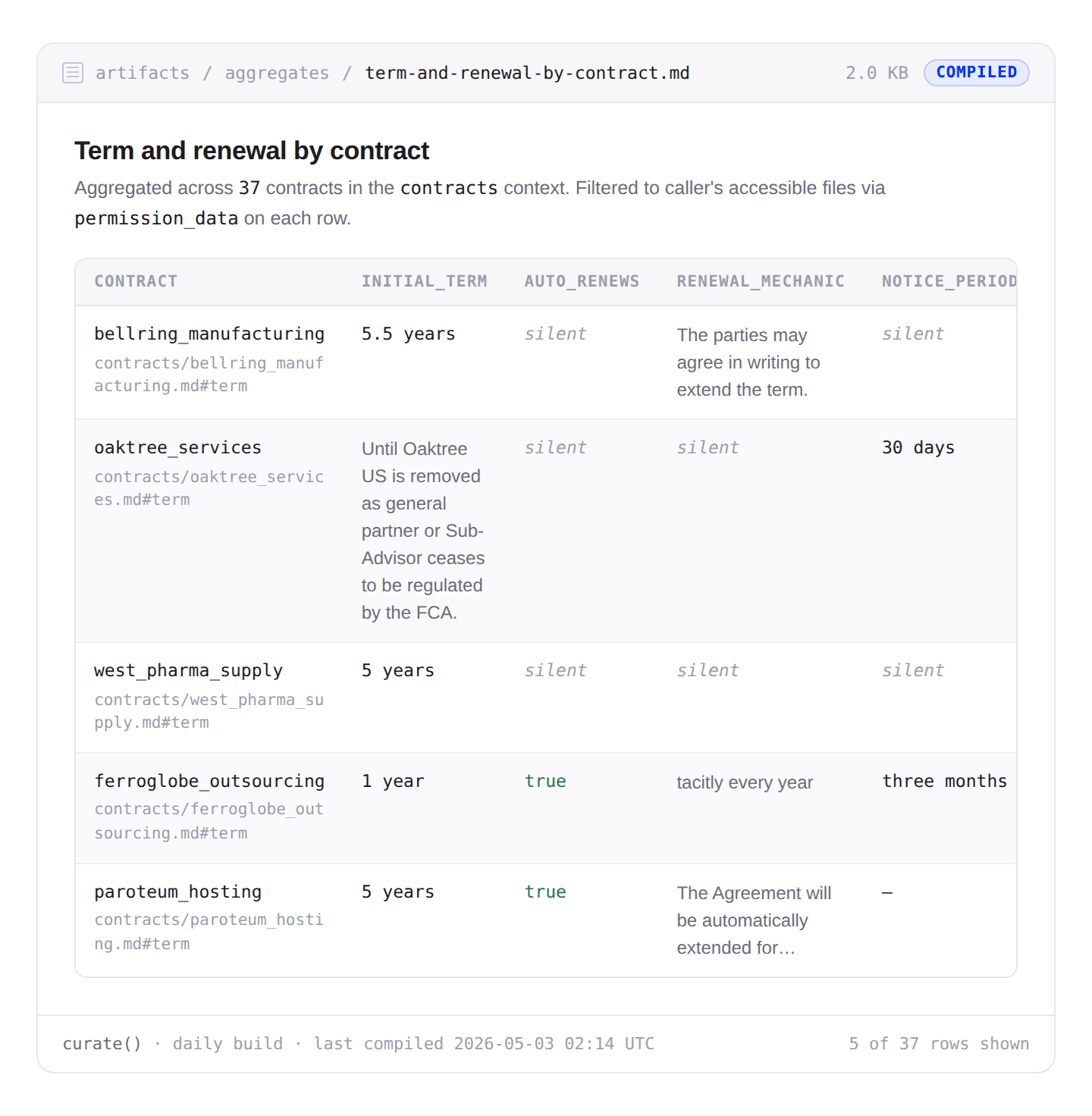
このシンプルな例は、Nexus が既存のデータパイプラインとどのように連携するかを示しています:Box が真偽情報のソースおよびファイル権限を管理し、Unstructured が解析と抽出を担当し、Nexus がアーティファクト層とクエリ表面を担います。同じ契約である Context は、法務部門向けの契約レビューエージェント、営業部門向けの更新リスクエージェント、GC 事務所のコンプライアンスエージェントなど、Box にある同一のソースコンテンツから構築された多様なエージェントに対してサービスを提供できます。
新しいカテゴリであり、より優れたパイプラインではない
本記事では、能力のあるモデルとそれらを支えるインフラストラクチャとの間のギャップについて言及しました:エージェントの努力の大部分は推論ではなく、状況把握(orientation)に費やされています。このギャップが、エージェントを大規模に導入できるかどうかを決定し、これを埋めるには新しいカテゴリのインフラストラクチャが必要です。
そのカテゴリとは知識エンジンです。私たちは、企業のあらゆるドメインがエージェントによって稼働し、各エージェントが自身のために設計されたコンテキストを必要とする未来へと進んでいます。ドメインごとに手作業で 1 つずつコンテキスト層を構築することはスケーラブルではなく、この需要に対応する唯一の方法は、インフラストラクチャ自体が自律的(agentic)であることです。Nexus はそのビジョンの具現化であり、Pinecone が長年構築してきた検索基盤上で動作する自律的な「コンテキストコンパイラ」です。エージェントが必要とする精度、レイテンシ、コストのために共同設計されています。
私たちは Pinecone を立ち上げる際、単一のミッションを掲げました:*AI に知識を持たせること*です。Nexus によって、そのミッションは具体化されます:あなたの企業のあらゆるチームに所属するすべてのエージェントが、自身のためにコンパイルされた知識(Knowledge)に基づいて動作します。
Pinecone Nexus Early Access
Nexus は本日、限られた数のデザインパートナー向けに早期アクセス版として利用可能です。次世代のエージェントを支える知識エンジンとの共同設計に関心がある方は、Nexus 早期アクセス に応募してください。
原文を表示
Anyone building agents in production today has run into the same wall. The model itself is rarely the limiting factor as frontier models are capable of the reasoning most jobs require. What breaks is everything before the reasoning step. The agent gets a task, decides it needs information, searches, retrieves, evaluates results, decides it needs more, searches again, reads, fragments together a partial picture, and loops. By the time the model is in a position to produce an answer, most of the token and latency budget is already gone.
This is the gap that defines agent infrastructure right now. The discipline that's emerged around this problem is context engineering: shaping data into knowledge the model can use, instead of asking the agent to reassemble it from raw data at query time.
Operationalizing these context pipelines is where teams get stuck, especially across a real company where the context needed for every domain (sales, legal, finance, support, R&D, ops) is shaped differently. Hand-building one context layer per domain doesn't scale past the first one or two.
We spent the last year working on this. The rest of this post is about why it's hard, what we built, and what we think comes next.
A concrete example: the market-intelligence agent
Let’s consider a market-intelligence agent at an investment firm looking over S&P 500 10-K filings. This question is an example of dozens the agent needs to answer:
“Among NVIDIA, Microsoft, and Walmart, compare the fiscal 2022 share repurchase activity disclosed in each 10-K. For each company, state (a) the dollar amount of repurchases during the fiscal year and the share count repurchased, (b) the original program authorization size and approval date if disclosed, and (c) the remaining authorization as of the company's fiscal year-end.”
For this agent to ship to production, the context layer needs to clear four requirements:
- Accuracy: Right answers, repeatable across runs. A flaky agent that's correct 70% of the time is non-functional in practice.
- Task latency: Query budgets in seconds, not tens of seconds or minutes.
- Token cost: Per-call cost is bounded; agent bills don't compound across the workflow.
- Governance: Field-level permission enforcement and grounded provenance so that answers can be traced back to their source.
However, satisfying all four simultaneously is harder than it sounds. When a team sets out to build a context layer for an agent workload like this, they typically dedicate a team and months of iteration to one of two patterns:
- Agentic RAG: Chunk the 10-K corpus, embed the chunks, and use hybrid retrieval. Let the agent loop: run the query, rerank, read the top chunks, and loop until it’s satisfied with the answer.
- Coding Agent in a sandbox: Give the agent access to file-list, page-read, grep, and full-doc-read tools and let it loop. It opens each 10-K, navigates to the capital returns section, parses the table and extracts the answer.
While both approaches may eventually get the right answer, it’s often far too slow and expensive to put into production. Both suffer from the same underlying challenge: they make the agent assemble knowledge for each task at query time. Agentic RAG hands the agent chunks and asks it to stitch the answer together. Agentic Sandbox hands the agent files and asks it to navigate to the answer through search, grep, and parsing. In these approaches, the vast majority of the work is spent retrieving raw data and assembling the right context instead of reasoning.
From Hand-Engineered Context to Compiled Knowledge
The solution for problems like this is well-known: don't make the consumer derive structure per query. Pre-shape the data into *artifacts* that already encode the structure consumers care about, and serve those.
This isn't new. Knowledge graphs, entity catalogs, and semantic layers have existed for decades. Every generation of data infrastructure has shipped some version of the same instinct: do the orientation work once, store the result, let downstream consumers read it directly. Context engineering is the latest version of that instinct, now applied to agents instead of dashboards.
Where it breaks: operationalizing per domain
What's hard though isn't the concept. It's operationalizing it.
Building a good artifact layer for *one* domain takes a sophisticated team and months of iteration, deciding which specific curation strategy, retrieval design, evaluation harness, and governance hooks to use. The complication is that a real company doesn't have one domain. It has dozens (e.g. sales, customer support, legal, finance, R&D) each with its own data shapes, schemas, dialects, and access patterns.
Multiply months-of-iteration by every domain that wants an agent and you’ll quickly run out of resources building these pipelines. In practice, what ends up happening is that the layer gets built for the one or two highest-value domains at most, or it doesn't get built at all.
This is the problem in the agentic era where every domain in a company will run agents and every agent needs context engineered to ship.
A new category of knowledge infrastructure
This problem points to the need for a new category of knowledge infrastructure: one where the context layer operates *as infrastructure*, automatic across domains, rather than hand-tuned and constructed per domain. The layer exists, you provision against it, you don't rebuild it from scratch every time you have a new use case.
We've spent the last year building one. It’s called Pinecone Nexus, a purpose-built Knowledge Engine for agents.
Inside a Knowledge Engine
A Knowledge Engine is built from four primitives, each a composition of the one below:
Artifact: A typed, governed piece of information constructed for a specific task or outcome. From the same 10-K data, a market-intelligence agent that wants financial metrics (e.g. revenue, capital gains) will get a different artifact than a compliance agent that wants risk-factor disclosures. Each shape is what makes the underlying representation efficient and tuned for each agent's job.
Context: A curated set of artifacts designed for a specific role, team, or workflow. We bundle the analyst's financial-metric artifacts together with the narrative sections their agent needs (MD&A, segment reporting), and that bundle is the analyst's context. The compliance team has its own.
Knowledge. The collective body of every context across the company, representing how the business is run across analyst, compliance, M&A, portfolio monitoring, and so on. A query against Knowledge can span as many contexts as it needs; the engine handles the routing.
Knowledge Engine. The system that builds and serves all of the above. The core of this is the Context Compiler, an autonomous coding agent that writes and tunes the curation and query code for each domain. Once the build loop completes, it constructs artifacts from raw data, composes them into contexts, and serves each agent's KnowQL query.
This is an example company-level artifact compiled using the 10k-SEC filings for the market-intelligence agent.
The Context Compiler
The Context Compiler is the autonomous coding agent at the core of the Knowledge Engine. It uses an agentic harness pattern to construct task-optimized Contexts by pairing a coding agent with three things:
- An eval set you define per domain (representative tasks with known right answers) with corresponding data sources
- A library of pre-vetted skills (e.g. document processing, entity extraction, chunking) the agent can compose into solutions.
- A feedback loop that scores each iteration against the eval signal.
With every iteration, the coding agent modifies two functions, curate() for artifact construction and query() for knowledge retrieval, runs the eval set, uses the failure signal to refine the code, and repeats until the evals pass. The output is a working, tuned Context for that domain.
With this approach, any domain expert (even without a retrieval background) can produce an agent-optimized Context since they don’t need to specify schemas, retrieval logic, or artifact shapes upfront. The Context Compiler automatically discovers the right artifact structure, granularity, and construction strategy based on the evals. Most new domains are served by recombining existing skills in new ways; when something genuinely doesn't fit, we add a new skill to the library.
In our work with early design partners, the compiler delivered Contexts for new domains in days rather than months. While we're still measuring across more domains and edge cases, the early signal has been promising and we believe this harness-based agentic approach is the foundation for the future of knowledge infrastructure.
KnowQL
Once the Context is created, the next step is ensuring the agent can use it effectively. If the agent has to issue a paragraph-level natural-language query and parse a blob of text back, the earlier failures come right back as the agent burns time and tokens re-orienting on every call. We wanted an interface where the agent *declares* what it needs and gets a precise, typed, cited response back. That's KnowQL (Knowledge Query Language).
The "declarative" part is the core design principle. In SQL, you describe what you want (ex. joins, filters, projections) and the engine picks the execution plan. KnowQL is the same idea applied to agentic knowledge retrieval: the agent specifies what answer it needs, in what shape, with what constraints. The Knowledge Engine decides which Contexts to search, which artifacts to read, and how to compose them.
A KnowQL query is a composition of four categories to ensure it meets the production requirements for agents:
- Intent: The question, the response shape, and the Contexts in scope. Note that this can be composed across multiple Contexts.
- Filter: Deterministic predicates and access-control policies enforced at the surface. The agent only sees what its caller is permitted to see.
- Provenance: Field-level citations returned by construction, not reconstructed after. Every value carries its source.
- Control: A budget envelope (depth and latency target). Cost declared in outcomes, not tokens.
For the earlier S&P 10-K question, the KnowQL query the agent issues looks like this:
{
"ask": "Among NVIDIA, Microsoft, and Walmart, compare fiscal 2022 share repurchases: amount repurchased, original program size, and remaining authorization.",
"ground": true,
"shape": {
"type": "object",
"properties": {
"companies": {
"type": "array",
"items": {
"type": "object",
"properties": {
"company_name": { "type": "string" },
"repurchased_usd_millions": { "type": "number" },
"program_size_usd_millions": { "type": "number" },
"remaining_usd_millions": { "type": "number" }
}
}
}
}
}
The Engine returns one typed response, and the agent's only reasoning step is comparing the typed response object as all the orientation work was done at build time.
Measuring the Impact of Knowledge Retrieval
To prove the value of Nexus, we needed to quantify the impact knowledge retrieval has on agent performance. Most existing retrieval benchmarks only measure recall in isolation and don't compare the impact of different retrieval strategies against the end-to-end multi-step agent loop.
We created KRAFTBench (Knowledge Retrieval Assessment Framework for Text) to address this gap. This harness measures the accuracy, latency, and token cost of responses generated from a consistent composer model (claude-sonnet-4-6\text{claude-sonnet-4-6}) across different retrieval mechanisms. This way any difference in quality, latency, or token cost of the agent task is attributable to retrieval. The three retrieval mechanisms tested were:
- Coding agent: Provide claude-sonnet-4-6\text{claude-sonnet-4-6} with a small read-only file system toolkit (list_files\verb|list_files|
, read_file\verb|read_file|
, find_filecontent\verb|find_filecontent|
, find_filename\verb|find_filename|
). No index provided.
- Agentic RAG: Chunk and embed files into a Pinecone vector index. Uses query expansion, RRF fusion, top-k retrieval, and loops until it determines completion.
- Pinecone Nexus: Artifacts generated using Context Compiler. Per-question shape derived by Claude, formatted as a KnowQL query and requests, optional follow-ups for multi-step questions.
The agents were tested against 493 free-form text 10-K filings (~500KB each, ~245MB total) from S&P 500 companies' 2022 SEC filings. Each agent was tasked to answer 150 hard questions spanning 9 sectors and 10 financial topics (headcount, revenue, capex, capital returns, R&D, acquisitions, segment breakdowns, etc.), tagged across three difficulty shapes: multi-fact (combine ≥2 facts about one entity), multi-company (compare across ≥2 entities), multi-step (retrieve fact A, then derive fact B from it).
Each question is given a constraint of 120 seconds and 1M tokens and each agent iterates until it can answer conclusively or exceeds the constraint. The final answer is then graded for accuracy by an LLM judge (claude-sonnet-4-6\text{claude-sonnet-4-6}) against the eval-set's ground truth output.
Our Findings
To compare the three approaches, we plotted each agent's average latency (x-axis) against average accuracy (y-axis), with bubble size encoding completion rate. The goal is the top-left: fast and accurate. Nexus delivered the highest accuracy, completion rate, at the lowest latency and at a significantly lower token cost (~7x vs. RAG, ~80x vs. Coding Agent). Agentic RAG completes nearly every question but at lower accuracy and ~1.7× the latency. The Coding agent is the slowest and least reliable: moderate accuracy, ~4× the latency, and only 63% of questions completed before hitting a token-budget or wall-clock cap.
CompletionLatency (avg)Accuracy (avg)Tokens (avg)Steps (avg)
Pinecone Nexus100% (150/150)22.7s0.6806,7331.69
Agentic RAG98.7% (148/150)37.9s0.41349,1037.77
Coding agent62.7% (94/15)84.1s0.585528,30114.77
The most challenging questions required multi-company comparisons or multi-step reasoning chains, and the failure mode for each agent shows up clearly in the traces:
- Pinecone Nexus compiled company-level “fact sheet” artifacts making multi-entity comparisons and multi-hop reasoning easier. It finds the relevant set of artifacts and composes the answer in one pass.
- Agentic RAG decomposes each question into multiple requests but each request either misses or returns partial information when only searching by semantic similarity.
- Coding Agent uses grep to identify the keywords in the text but phrases can appear multiple times in each document and there’s no way to determine which mention is the right one. It ends up spending most of its tokens trying to disambiguate until it runs out of budget or time.
To demonstrate this more concretely, let’s trace the path of the original question we asked the finance agent:
“Among NVIDIA, Microsoft, and Walmart, compare the fiscal 2022 share repurchase activity disclosed in each 10-K. For each company, state (a) the dollar amount of repurchases during the fiscal year and the share count repurchased, (b) the original program authorization size and approval date if disclosed, and (c) the remaining authorization as of the company's fiscal year-end.”
Coding agent: The coding agent starts with a broad regex sweep looking at “share repurchase” or “Microsoft” or “Walmart” that returns hundreds of matches across all 10-Ks in the corpus. Refining that further by entity name returns more matches and quickly fills up the context window and ultimately hits the 1M token limit.
Agentic RAG: The agent first decomposes the query into 18 facts to find and evaluates the top k chunks returned for each fact. However, it failed to find the dollar amounts for Microsoft and Walmart since the dollar figure and chunks were not colocated in the document and incorrectly marked those figures as missing even though the data does exist.
Pinecone Nexus: Takes the full question and a desired structured output shape and completes it in one shot because Nexus generated artifacts summarizing key statistics for each company. It also provided the structured output response as a JSON object to minimize token usage.
In the coming weeks, we’ll publish a deep dive on KRAFTBench to provide a closer look at this methodology and results. If you’re interested in collaborating on this benchmark, please reach out to us.
From Source to Knowledge: Box → Unstructured → Pinecone Nexus
To use Nexus with real enterprise data, we've integrated with two ecosystem partners that own important parts of that stack: Box, where the source documents and their permissions are kept; and Unstructured, which normalizes the raw formats (PDFs, Word docs) into structured formats Nexus can consume directly.
Let’s take the example of a legal review agent looking over a set of CUAD dataset contracts stored in Box that wants to ask the following question:
“Which contracts have a fixed initial term but no auto-renewal mechanism meaning the parties must affirmatively negotiate any extension?”
Box (source): Contracts live in a designated Box folder (e.g. non-competes, commercial contracts, endorsements) with file metadata including access control lists to ensure permissions are respected. The legal team is responsible for maintaining and updating the contract files as needed.
Unstructured (parsing): Unstructured connects through Box's APIs and captures each file’s content and file metadata (including ACLs). It extracts key document elements, tables, and entities from the legal contracts (parties\verb|parties|, agreement_date\verb|agreement_date|) and passes file permission metadata (permission_data\verb|permission_data|) to ensure users can only see the contracts they have access to.
Pinecone Nexus (Knowledge Engine): The Unstructured parsed output is ingested as a source and the Context Compiler runs against the extracted data. One of the artifacts it produces is a table aggregating contract renewal terms across different contracts which allows Nexus to answer the question by fetching a single artifact rather than searching across multiple entities. When composing the query, it passes the file permission metadata as a filter to ensure that it only responds with contracts users have access to.
This simple example demonstrates how Nexus composes with existing data pipelines: Box owns the source-of-truth and the file permissions; Unstructured owns the parsing and extraction; Nexus owns the artifact layer and the query surface. The same contract Context can serve a contract-review agent for legal-ops, a renewal-risk agent for sales, and a compliance agent for the GC's office, all built from the same source content in Box.
A New Category, Not a Better Pipeline
We opened this post with the gap between capable models and the infrastructure supporting them: most of an agent's effort goes into orientation, not reasoning. That gap is what determines whether agents ship at scale, and it requires a new category of infrastructure to close.
That category is the Knowledge Engine. We're heading into a future where every domain in a company runs on agents and every one of those agents needs context engineered for it. Hand-building one context layer per domain doesn't scale and the only way to keep pace with that demand is for the infrastructure itself to be agentic. Nexus is our expression of that vision: an autonomous Context Compiler running on the retrieval substrate Pinecone has spent years building, co-designed for the accuracy, latency, and cost agents require.
We launched Pinecone with a singular mission: *make AI knowledgeable*. With Nexus, that mission gets concrete: every agent in your company, on every team, working from Knowledge compiled for it.
Pinecone Nexus Early Access
Nexus is available in early access today for a limited number of design partners. If you're interested in working with us to co-design the knowledge engine powering the next wave of agents, come apply for the Nexus Early Access.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み