frontier AI 能力を測定するオープンワールド評価
AIモデルのベンチマーク飽和を背景に、実世界での複雑なタスク遂行能力を評価する「オープンワールド評価」の概念とベストプラクティスを提唱し、CRUXによる実証実験でAIエージェントのアプリ開発能力とスパムリスクを明らかにした。
キーポイント
ベンチマークの限界とオープンワールド評価の必要性
従来のベンチマークは最適化されやすく、実世界での汎用性を過大評価または過小評価する可能性があるため、長期的で messy な実世界タスクによる評価が必要とされている。
CRUXによる実証実験と成果
17人の研究者からなるCRUXが、Claudeエージェントを用いてiOSアプリをApp Storeに公開する実験を行い、2つのエラー(うち1つは手動介入必要)でほぼ完了したことを報告。
セキュリティリスクと早期警告
AIによるアプリ自動生成能力の向上は、App Storeスパムの増加という重大なリスクを示唆しており、この結果はAppleへ事前に開示された。
今後の研究ビジョン
科学実験の完遂や行政手続きの処理など、他の実世界ドメインでも同様の評価を実施し、AI能力の早期警告を発信する主要な実証プロジェクトとして展開する。
オープンワールド評価の定義と特徴
従来の自動化されたベンチマークとは異なり、小規模なサンプル数と人間の介入を必要とする、複雑で現実的な長期評価手法である。
オープンワールド評価の重要性
サンプルサイズや再現性の欠如という限界はあるものの、新たなAI能力の早期警告や既存ベンチマークの見落としを特定するために不可欠である。
CRUXプロジェクトの概要
政府、学界、非営利団体からなるチームが、AIの現在の能力に関する実証証拠を提供し、定期的なオープンワールド評価を実施する「CRUX」プロジェクトを立ち上げた。
重要な引用
We call these evals “open-world evaluations”.
an AI agent built and published an iOS app to the App Store, making just two errors
an early warning about the potential for AI-driven app store spam
「これらの評価は、AIの能力に関する証拠を集めるために重要であり、社会レジリエンスを高めるための emerging capabilities への早期警告を提供し、既存のベンチマークにおける盲点を特定する助けとなる。」
「CRUX(Collaborative Research for Updating AI eXpectations)は、政府、学界、非営利団体からの協力者で構成され、現在のコストがかかる評価であってもAIシステムの現在の能力に関する実証証拠を提供することを目指している。」
「AIシステムがより有能力になるにつれて、フロンティアの能力を引き出すための評価はより複雑にならなければならず、オープンワールド評価はそのような複雑さの増大における最新の段階である。」
影響分析・編集コメントを表示
影響分析
この記事は、AI評価のパラダイムシフトを示唆しており、単なるベンチマークスコア競争から「実世界での自律行動とリスク」への注目へ移行しつつあることを示しています。特に、AIが実際に製品をリリースできるレベルに達していることは、技術的な進歩だけでなく、プラットフォームセキュリティや規制対応において緊急の対策が必要な段階に入ったことを意味します。
編集コメント
ベンチマークの限界を指摘し、実世界での自律行動とリスクを評価する「オープンワールド評価」の重要性を明確に示した重要な提言です。AIエージェントが実際に製品を公開できるレベルにあることは、開発者だけでなくセキュリティ担当者にとっても無視できない事実です。
この投稿は8,000語に及び、新興タイプのAI評価に関する私たちの新しい共同論文です。この論文は、ここではPDF形式でも公開されています。
要約:AIモデルは主要なベンチマークのほとんどを飽和させ始めています。しかし、それは現実的な製品を開発・リリースできるか、科学実験をエンドツーエンドで実行できるか、あるいは政府の官僚機構をナビゲートできることを意味するのでしょうか?研究者たちは、このような現実的な環境でAIをテストし始めています。私たちはこれらの評価を「オープンワールド評価」と呼んでいます。このエッセイでは、オープンワールド評価の定義、これまでに得られた教訓の調査、およびそれらを実施するためのベストプラクティスの提示を行います。
また、学術界、政府、市民社会、業界から17人の研究者による協力団体「CRUX」を紹介しています。この団体は、オープンワールド評価を通じて最先端のAI能力を定期的に評価します。私たちの最初の試みでは、AIエージェントがiOSアプリを開発しApp Storeに公開しました。その際、2つのエラーが発生しましたが、そのうち1つは手動での介入を必要としました。これは有用な能力の潜在的な兆候を示す初期の指標であり、さらに重要なのは、AI駆動型App Storeスパムの可能性に関する早期警報でもあります(この結果は公開の1ヶ月前にAppleに開示しました)。
私たちは、他の現実的なドメイン全体にわたって早期警報を浮上させるために同様の実験を実施することを目指しています。これが、今後1年間の私たちの主要な実証プロジェクトの一つとなります。
著者は以下の通りです:Sayash Kapoor, Peter Kirgis, Andrew Schwartz, Stephan Rabanser, J.J. Allaire, Rishi Bommasani, Magda Dubois, Gillian Hadfield, Andy Hall, Sara Hooker, Seth Lazar, Steve Newman, Dimitris Papailiopoulos, Shoshannah Tekofsky, Helen Toner, Cozmin Ududec, Arvind Narayanan
AIの能力をどのように追跡し、予測すべきでしょうか?現在、AIコミュニティにおける支配的な回答はベンチマークです。例えば、METRのタイムホライズングラフは、政策アナリスト、業界リーダー、およびAIリスクを研究する組織によって、AIの能力が急速に増加していることを示す証拠として使用されてきました。
しかし、ベンチマークは進歩を過大評価することもあれば、過小評価することもあります。あるタスクをベンチマークにするためには、それが正確に指定され、自動的に検証可能である必要があります。ここで重要なのは、ベンチマークに十分な精度を持つものは、最適化の対象としても十分精度高く、AIエージェントがそのようなタスクで優れた成果を上げられる可能性があるという点です。逆説的に言えば、ベンチマークでの精度が低い場合でも、ウェブサイト上のCAPTCHA(ロボット判定テスト)に遭遇するなどといった偶発的な失敗によるものであり、エージェントが根本的なタスクを解決する能力を持っている可能性もあります。
これらの限界に対処するため、多くの研究者がベンチマークを超えた、長く不規則で現実的な評価である新しい種類の評価に注目しています。AnthropicのNicholas Carliniは、Claudeエージェントを使用してLinuxカーネルをコンパイルできるCコンパイラを構築しました。AnthropicとAndon Labsは、Claudeにオフィス内の小さな店舗の運営を任せる自由形式の実験を設計しました。ベンチマークは自動化された方法で評価される数十のタスクから成りますが、オープンワールド評価(open-world evaluations)は小規模なサンプルで構成され、多くの場合人間の介入を必要とし、エージェントのログ分析などによって開かれた方法で評価されます。
これらを非科学的として片付けるのは容易です。各評価はサンプルサイズが1であり、標準化や再現性が欠如しているからです。これらの限界にもかかわらず、私たちはAIの能力に関する証拠を収集する上でこのような評価が重要であると信じています。これらは、社会的レジリエンス(resilience)の構築に向けた取り組みに情報を提供するために、新たな能力の出現に関する早期警告を提供し、評価者が既存のベンチマークにおける盲点を特定するのを助け、また企業に対してAIシステムが間もなく実行しうるタスクのより明確な像を提供し、AIに関する戦略的意思決定に役立ちます。私たちはこれらをオープンワールド評価と呼びます。
本エッセイでは、オープンワールド評価の概念を整理し、それらの実施におけるベストプラクティスと落とし穴を特定するために過去の例を検証し、新しいオープンワールド評価を定期的に実施することを目的としたプロジェクトCRUXを紹介します。以下が私たちの主な洞察です。
オープンワールド評価は、AI評価の重要な新興カテゴリです。AIシステムが高度化するにつれて、最先端の能力を引き出すための評価も複雑さを増さなければなりません。オープンワールド評価は、増加する複雑さを持つ一連の評価における最新のものと言えます。私たちは過去1年間に実施された10件の主要なオープンワールド評価を調査し、ベストプラクティスと重要な教訓を特定しました。
CRUX(Collaborative Research for Updating AI eXpectations:AI期待の更新のための共同研究)は、オープンワールド評価を体系的に実施しようとする私たちの試みです。チームには政府、学界、非営利団体からの協力者が含まれており、その多くはオープンワールド評価を主導してきた経験を持ち、AIの未来に対して多様な見解を持っています。私たちは現在のコストがかかっても構わないため、AIシステムの現在の能力に関する実証証拠を提供し、まもなく普及する可能性のある能力に対する早期警告を発することを目指しています。私たちは定期的に新しいオープンワールド評価を公開する予定です。
最初のCRUX実験では、AIエージェントにiOSアプリを開発し、App Storeに公開するタスクを課しました。多くのベンチマークはエージェントのコード記述能力を試すものですが、iOSアプリの公開には署名やプライバシーポリシーをウェブページに掲載すること、Appleのフォームへの入力、そして審査プロセスを通すなど、他の多くのステップが含まれます。私たちはエージェントがコードを書く能力よりも、アプリを公開するという現実世界の要件を満たすことに成功したかどうかに関心があったため、シンプルなアプリの構築とiOS App Storeへの提出プロセスを完了させるタスクを与えました。
エージェントは2つのエラーを犯した後、成功しました。そのうち1つは手動での介入が必要でした(正しい認証情報の保存場所を忘れたこと、およびApp Storeの審査プロセスのために架空の電話番号を作成したことです)。このアプリの開発と公開には約1,000ドルのコストがかかりました。現在、このアプリはiOS App Storeで公開されています。私たちはコストをさらに大幅に削減できたと考えています:アプリの開発と提出にはわずか25ドルしかかかりませんでした。トークンの大部分はアプリのステータス監視に費やされました。私たちはこの論文の公開1ヶ月前にAppleに連絡し、実験の結果を開示しました。App Storeの運営者は、エージェントを使用して自律的に提出される数千件のアプリケーションが間もなく殺到する可能性があるため、スパム提出への備えと監視を準備する必要があります。
オープンワールド評価をどのように改善できるか?次なるステップは何か?オープンワールド評価の有用性を高めるために、評価者は人間の介入が許可される範囲と量を明確にし、エージェントがタスクを解決する際に収集したログを公開し、そのログを分析してエージェントがタスク解決の過程で何を行ったかを報告すべきである。今後の CRUXes では、AI 研究開発(R&D)の自動化、AI ガバナンス、およびその他の多くの領域を評価する予定である。
オープンワールド評価は、重要な新興の AI 評価カテゴリーである
このセクションでは、オープンワールド評価を定義し、そのような評価の新興する状況を検証して、その成功と限界に関する洞察を引き出す。ベンチマークのいくつかの盲点を克服できるオープンワールド評価の可能性のある領域について議論する。私たちの見解では、AI システムがより高度になるにつれて、最先端の能力を引き出すための評価はより複雑化する必要があり、オープンワールド評価は、複雑さが増す一連の評価における最新のものである。また、ベンチマークと比較したオープンワールド評価の限界についても議論する。
以下に、オープンワールド評価を定義する5つの緩やかな基準について議論します(「オープンワールド評価とは?」参照)。ただし、長期かつ複雑なベンチマークタスクとオープンワールド評価の境界は曖昧であることに留意する価値があります。実際、私たちが議論している多くの評価はサンドボックス化されています。それでも、これらをオープンワールド評価のリストに含めています。なぜなら、他の基準を満たしているからです(例:Carlini氏のCコンパイラはサンドボックス化されていますが、評価の一部として単一の長時間実行タスク、人間の介入、および定性的分析を伴います)。
ベンチマークは進歩を過大評価も過小評価もする
AIに関する見解が極端に異なる人々でも、現在のAIベンチマークはまもなく飽和状態に達する可能性があることに同意しています。多くの主要なベンチマークは過去2年間で飽和しており、評価者は「後継」ベンチマークの公開を競ってきました。これらの更新されたベンチマークの多くも、すでに飽和に近い状態にあります。
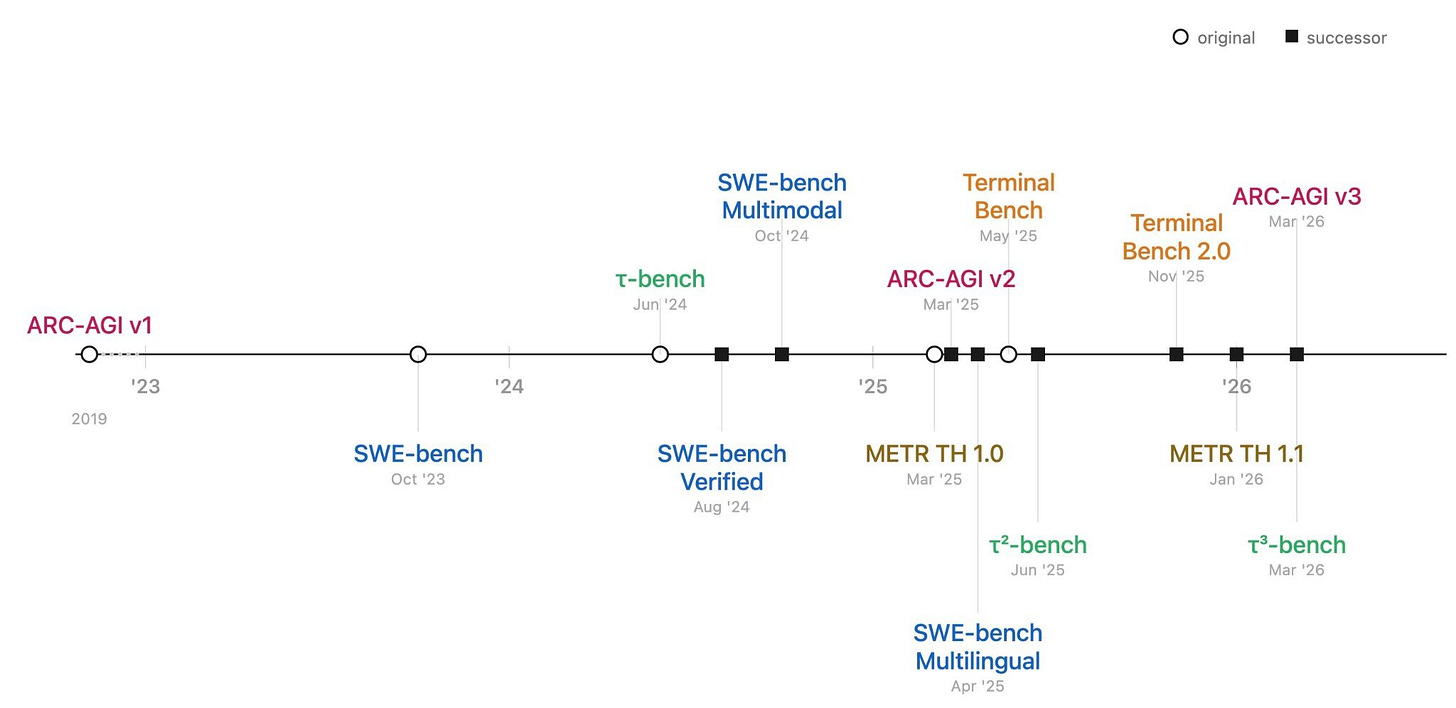
多くの人気のあるベンチマーク(SWE-Bench、ARC-AGI、τ-bench、Terminal Bench、METRのTime Horizonタスクスイートなど)では、過去2年間で後継ベンチマークが公開されています。
これは、AI システムがまもなくあらゆるタスクを解決できるようになることを意味するのでしょうか。必ずしもそうではありません。ベンチマークの改善は実際の能力向上を示す可能性がありますが、進歩を過大評価することもあります。例えば、ベンチマークには構成妥当性の限界があり、特定のタスクに対する正確さをテストしているだけで、一般的な能力を評価していない場合があるためです。また、エージェントが現実世界の環境の複雑さや不確実性をどの程度処理できるかをテストしていません。
その逆のケースとして、測定されている能力とは本質的に関連しない環境やインフラストラクチャ上の課題(例えば CAPTCHA の出現など)により、ベンチマークが進歩を過小評価することもあります。
より包括的な状況把握を得るための一つの方法は、正確性以外の指標を使用することです。例えば、最近共同で執筆したプレプリントにおいて、私たちはエージェントが能力指標(平均正確性など)の観点からは劇的に改善している一方で、信頼性を測定する指標における改善は著しく遅れていることを示しました。同様に、テストをパスしたために正解とみなされた SWE-bench 課題に対する多くのエージェントソリューションは、プロジェクトのメンテナーによって却下されることになります。
しかし、これでは依然として AI 能力の上限を測定することはできません。今日可能である能力(有利な条件下でのみであっても)は、まもなく広く普及する可能性があります。私たちはその普及に先立ってそれを見通す必要があります。このような早期警告を提供することで、企業には新しい機会を活用するための追加の時間を与え、機関にはレジリエンス(回復力)を構築する時間を提供し、政策立案者にはリスクに対処する猶予を与えることができます。
では、ベンチマークが能力を過大評価し、かつ過小評価する理由についてより詳しく議論しましょう。ベンチマークが能力を過大評価する理由は以下の通りです。
ベンチマークは、現代の強化学習(Reinforcement Learning: RL)技術に適したタスクに類似しています。あるタスクをベンチマークにするには、それを正確に指定し、自動的に検証可能にする必要があります。しかし、ベンチマークとして測定できるほど精密なものは、最適化の対象としても十分精密であり、現代の RL トレーニングの実行はベンチマーク自体の形状にますます似通ってきています。これにより、ベンチマークを用いて測定可能なあらゆるタスクを飽和させることが容易になります。
これは、RL トレーニングプラットフォームとしても機能する Harbor などの主要な評価プラットフォームにおいて、すでに事実となっています。その結果、AI モデルはこれらのプラットフォームに含まれる多くの著名なベンチマークのデータから直接学習することができます。ベンチマークにホールドアウト(held-out)テストセットが含まれていても、モデルはテストセットで遭遇する可能性が高いタスクと非常に似通ったトレーニングセットのタスクから学習することがあります。したがって、ベンチマークは、パフォーマンスが現実世界にどのように一般化するかを理解するのに役立ちません。
ベンチマークは、現実世界の複雑さを避けます。現実のタスクには、予期せぬ状況への対応や、オープンエンドな環境でのナビゲーションなど、完全にサンドボックス化できない未定義の相互作用が含まれます。ベンチマークは複雑な環境をシミュレートするいくつかのステップを取ることができますが、それらを完全に複製することはできません。
ベンチマークが能力を過小評価する理由は以下の通りです。
最先端の能力を引き出すには多額の費用がかかる。大規模で長時間にわたる実験の実行は高価であり、ベンチマークが依存するサンプルサイズを達成するのは現実的ではない。AnthropicのCコンパイラの開発コストは約2万ドル、以下で詳述するタスク(CRUX #1のためのiOSアプリの開発と公開)の実行コストは約1,000ドルであった。このような実験を数百回実行することはできないため、各ベンチマークタスクの予算と複雑さに制限が生じる。
平均的なパフォーマンスは、上限能力を引き出すこととは大きく異なる。ベンチマークスイートで数十(あるいは数百)のタスクを実行するのは、平均的なパフォーマンスを測定するために必要である。しかし、エージェントが何を行えるかの最前線を理解しようとする場合、目的はベストケースのパフォーマンス、すなわち偶発的な失敗を回避するために十分なリソースと支援が与えられた場合にエージェントが達成し得ること、を理解することにシフトする。これは、まもなく広く普及する可能性のある能力に対する早期警告を提供するために必要である。
人間の介入は、能力の上限を引き出すのに役立つ可能性がある。現実世界のタスクに取り組むエージェントは、ポリシー拒否に直面したり、CAPTCHAの解決を必要としたり、または他のインフラストラクチャの問題に遭遇して立ち往生することがある。これらはパフォーマンスに悪影響を及ぼす可能性がある。しかし、これらの失敗は測定されている能力にとって偶発的なものに過ぎない。人間のオペレーターがこれらを処理できれば、能力の上限を引き出すことができる。このような手動介入は、実行されるたびに数百のベンチマークタスクに対しては現実的ではない。
AIの能力が向上するにつれて、コーディング、深層調査、カスタマーサービスにおけるAIの能力をテストするサンドボックス評価は、エージェントに挑戦し、汚染や報酬ハッキングを避けるために、非常に緻密に設計された環境を必要としています。例えば、エージェントのウェブベンチマークでのパフォーマンスは、エージェントがCAPTCHAに遭遇する頻度によって影響を受けており、エージェントの真の基礎能力を引き出すものではありません。最近の研究では、AIエージェントがオンラインで回答を見つけたり、評価のバグを悪用したり、テストはパスするものの生産環境の基準を満たさないコードを生成したりすることが指摘されています。これは、平均的なベンチマークスコアの洪水の中で失われがちな失敗モードや問題解決戦略をよりよく理解するのに役立つ、AIエージェントのパフォーマンスに対するより深い定性的評価への移行の必要性を浮き彫りにしています。
しかし、これらの妥当性への脅威は簡単に解決できるものではありません。ベンチマークに対して定性的なログ分析を行うことで、これらの懸念の一部に対処できますが、ログ分析を用いてベンチマーク結果に妥当性の問題を見つけたとしても、更新されたベンチマークをリリースする以外にできることはほとんどなく、それには数ヶ月かかる可能性があります。オープンワールド評価(open-world evals)により、実際のテストランの前に問題を修正するためのドライランを実施し、評価中に発見された問題を手動で修正することができます。1
もちろん、これらの限界があるにもかかわらず、ベンチマークは有用です。2 また、オープンワールド評価にも独自の限界があり、これについては本論文の後ほど議論します。とはいえ、このリストがベンチマークにおける体系的な盲点を浮き彫りにしていることを願っています。AI エージェントの能力が向上するにつれて、従来のベンチマークと現実世界の能力の間に特定されたギャップは拡大し続けます。成功指標は、特定のタスクにおける多様な目的を捉えるために多面的である必要がありまます。ベンチマークは、主要なボトルネック(人間の支援)や雑多な環境(インターネットナビゲーション)を組み込む必要があり、それぞれが内部および外部の有効性に関する追加の問題をもたらします。オープンワールド評価は代替案を提供します。
オープンワールド評価とは何ですか?
評価方法が AI の能力と並行して成熟するにつれて、評価のグラデーション(段階的な連続体)が出現しました。一端には、初期段階の能力に対してよく機能するシンプルで自動化可能かつスケーラブルな方法があります。他端には、能力が向上し単純な指標が行き詰まるようになると必要になる、より豊かで労働集約的な方法があります。
ある分野での能力が向上するにつれて、単純な評価と補完的な洞察を得るために、グラデーションのより先にある評価が重要になります。これまでのところ、このグラデーションは概ね5つのレベルに分かれると考えており、それぞれに強みと限界があります:
Q&A ベンチマーク(例:MMLU、GPQA)は広範な知識の評価に有用ですが、最先端モデルにとっては飽和状態になりつつあります。採点の容易さから複数選択問題として構成されることが多いものの、ユーザーがモデルと対話する際に複数選択問題を問うことは稀であるため、構成妥当性(コンストラクトバリデティ)が低いという結果を招いています。
オープンエンドのチャットベンチマーク(例:WildBench、Arena-hard-auto)はより微妙なニュアンスを捉えますが、依然として単一ターンまたは短い対話に限定されています。
成果のみを評価するエージェントベンチマーク(例:SWE-Bench、WebArena)は、実際のタスクにおけるエージェントのパフォーマンスをテストしますが、タスクがどのように完了されたかではなく、完了したかどうかのみを測定します。その結果、これらのベンチマークには限界があります。例えば、SWE-Bench で合格した解決策のほとんどはリポジトリのメンテナーによって承認されません。
ログ分析を伴うエージェントベンチマーク(例:UK AISI 転記分析、METR Time Horizon)は、エージェントがどのように成功または失敗するかを調査し、エージェントのログを分析してエラーや報酬ハッキング(レワード・ハッキング)を発見することで、より深い洞察を提供します。しかし、これらは依然として定義済みのタスクを持つサンドボックス環境で動作しています。
オープンワールド評価:成功を明確に指定したり自動採点したりできない、現実世界の環境における長期タスクです。これにより、能力の上限を引き出すことができます。ただし、これは再現性と標準化の欠如(これらはベンチマークの利点です。制限事項のセクションを参照)という代償を伴います。
このスペクトルのカテゴリを曖昧にする評価も存在します。例えば、OpenAI の GDPVal は長期のエージェントベンチマークであり、専門家の品質評価に基づいて手動で採点されるように設計されています。この構造はオープンワールド評価と非常に似ていますが、主に出力に焦点を当て、ログの分析には重点を置いていません。同時に、GDPVal の結果は一般的に GDPval-AA を用いて報告されますが、これは自動化された LLM による採点を使用します。この評価設定は、成果のみを対象とするエージェントベンチマークに似ています。
オープンワールド評価とは、現実の環境において少数の長期タスクに対してエージェントを実行し、ログ分析ツールを用いてその結果を定性的に評価することを指します。これらの評価はベンチマークと補完関係にあり、その多くの限界に対処するのに役立ちます。また、現在の AI システムが到達できないタスクを発見し、将来のベンチマーク作業のための対象となる可能性も示唆します。
オープンワールド評価の境界を明確にするため、大まかな分類体系を提供します。単一の次元だけで実験が「オープンワールド」に該当するかどうかが決まるわけではありません。代わりに、以下のすべての次元全体のパターンに基づいて判断されます。
開放性。この評価はサンドボックス環境ではなく、実際のデプロイメント設定で行われるものか?
複雑さ/長さ。このタスクは、数分や数時間ではなく、人間が数日または数週間をかけて完了する必要があるものか?
タスク数。これは単独のタスク、あるいは少数のタスクセットか(大規模な評価スイートやベンチマークではないか)?
人間の介入。能力の上限を引き出すために、エージェントが壁にぶつかった際に(単に環境を設定したりセットアップの問題を解決するだけでなく)、人間が介入できるかどうかが問われます。
評価方法。この評価は、単一の平均的な指標によって導き出される結果ではなく、詳細なログの評価を主眼としているかどうかが問われます。
エージェントを用いて何らかの新しいことを成し遂げるのと、単なる「評価」と呼ぶべきものの境界はどこにあるのでしょうか?例えば、AnthropicはAIエージェントを用いて、Mozilla Firefoxのような主要なオープンソースソフトウェアのセキュリティ脆弱性を発見しました。これはオープンワールド評価の例と言えるでしょうか?エージェントが行った部分と人間专家が行った部分、そして最終的な結果を含む、エージェントの役割が体系的かつ公に文書化されている場合、私たちはこれらを依然としてオープンワールド評価と見なします。
複雑なベンチマークタスクとオープンワールド評価の境界もまた曖昧です。例えば、以下のオープンワールド評価リストに含まれるいくつかの評価はサンドボックス化されています(例:Claude Plays PokemonとAnthropicのCコンパイラはどちらもサンドボックス環境で実行されましたが、これらは単一の複雑で長時間にわたるタスクから成り、評価中に人間の介入があり、定性的に評価されるため、私たちはこれらをオープンワールド評価と見なしています)。
この2種類の評価は補完関係にあります。エージェントが解決できないタスクを把握するためにオープンワールド評価を用い、それが新たなベンチマーク構築への第一歩となることを想定できます。また、オープンワールド評価を
原文を表示
This post is 8,000 words long—it is our new collaborative paper on an emerging type of AI evaluation. The paper is also published in a PDF format here.
Summary: AI models have started to saturate most major benchmarks. But does that mean they can build and ship a real product, or conduct a scientific experiment end-to-end, or navigate a government bureaucracy? Researchers have started testing AI in such real-world settings. We call these evals “open-world evaluations”. This essay defines open-world evaluations, surveys the lessons learned so far, and lays out best practices for conducting them.
We also introduce CRUX, a collaboration of 17 researchers from academia, government, civil society, and industry that will regularly evaluate frontier AI capabilities through open-world evaluations. In our first experiment, an AI agent built and published an iOS app to the App Store, making just two errors, one of which required manual intervention. This gives us an early indication of potentially useful capabilities and, more importantly, an early warning about the potential for AI-driven app store spam (we disclosed this result to Apple a month before publication).
We hope to conduct similar experiments to surface early warnings across other real-world domains; this will be one of our main empirical projects over the coming year.
The authors are: Sayash Kapoor, Peter Kirgis, Andrew Schwartz, Stephan Rabanser, J.J. Allaire, Rishi Bommasani, Magda Dubois, Gillian Hadfield, Andy Hall, Sara Hooker, Seth Lazar, Steve Newman, Dimitris Papailiopoulos, Shoshannah Tekofsky, Helen Toner, Cozmin Ududec, Arvind Narayanan
How should we track and predict AI capabilities? The AI community’s dominant answer today is benchmarking. For example, METR’s time horizon graph has been used by policy analysts, industry leaders, and organizations researching AI risks to argue that AI capabilities are rapidly increasing.
But benchmarks can both overestimate and underestimate progress. To turn a task into a benchmark, it needs to be precisely specified and automatically verifiable. The catch is that whatever is precise enough to benchmark is also precise enough to optimize for, allowing AI agents to excel at such tasks. On the flip side, low accuracy on benchmarks might result from incidental failures such as encountering CAPTCHA on a website, even if agents are capable of solving the underlying task.
To address these limitations, many researchers are turning to a new kind of evaluation: long, messy, real-world evaluations that go beyond benchmarks. Nicholas Carlini at Anthropic used Claude agents to build a C compiler that could compile the Linux kernel. Anthropic and Andon Labs designed a free-form experiment where Claude was tasked with maintaining a small shop in their office. While benchmarks consist of dozens of tasks evaluated in an automated way, open-world evaluations consist of small samples, often require human intervention, and are evaluated in an open-ended way, such as by analyzing agent logs.
It is easy to dismiss these as unscientific: each such evaluation has a sample size of 1, and they lack standardization and reproducibility. Despite these limitations, we think such evaluations are important for collecting evidence about AI capabilities. They can provide early warnings about emerging capabilities to inform efforts at building societal resilience, help evaluators identify blind spots in existing benchmarks, and give companies a clearer picture of what tasks AI systems could soon carry out, informing strategic decisions about AI. We call them open-world evaluations.
In this essay, we conceptualize open-world evaluations, review past examples to identify best practices and pitfalls in conducting them, and introduce CRUX, a project aimed at regularly conducting new open-world evaluations. Here are our main insights:
Open-world evaluations are an important emerging class of AI evaluation. As AI systems become more capable, evaluations to elicit frontier capabilities must also increase in complexity. Open-world evaluations are the latest in a long line of evaluations of increasing complexity. We survey 10 prominent open-world evals conducted over the last year to identify best practices and key takeaways.
CRUX (Collaborative Research for Updating AI eXpectations) is our attempt at systematically conducting open-world evaluations. The team consists of collaborators from government, academia, and non-profits, many of whom have led open-world evaluations, and who have a range of expectations about the future of AI. We aim to provide empirical evidence about the present capabilities of AI systems, even if they are currently costly, and to provide early warnings for capabilities that might soon be widespread. We plan to release new open-world evaluations regularly.
In our first CRUX experiment, we tasked an AI agent with developing and publishing a simple iOS app to the App Store. Many benchmarks test agents’ ability to write code. But publishing an iOS app involves many other steps: signing the app, publishing a privacy policy on a webpage, filling out Apple’s forms, and taking the app through the review process. We were more interested in whether the agent succeeded at the real-world requirements of publishing the app rather than its ability to write code, so we tasked it with building a simple app and taking it through the iOS App Store submission process.
The agent was successful after making two errors, one of which required manual intervention (forgetting where the correct credentials were stored and fabricating a fictional phone number for the App Store review process). The process of developing and publishing the app cost about $1,000. The app is now live on the iOS App Store. We think the cost could have been far lower: the app development and submission only cost $25; the vast majority of tokens were spent monitoring the app’s status. We reached out to Apple a month before the publication of this essay to disclose the results of our experiment. App store operators should prepare for and police spam submissions, as they might soon see thousands of applications submitted autonomously using agents.
How can we improve open-world evaluations? What’s next? To increase the usefulness of open-world evaluations, evaluators should specify what and how much human intervention is allowed, release logs collected while the agent was solving the task, and analyze logs to report what an agent did in the course of solving the task. In future CRUXes, we will evaluate AI R&D automation, AI governance, and many other areas.
Open-world evaluations are an important emerging class of AI evaluation
In this section, we define open-world evaluations and survey the emerging landscape of such evaluations to extract insights about their success and limitations. We discuss areas where open-world evals can overcome some of the blind spots of benchmarks. In our view, as AI systems become more capable, evaluations to elicit frontier capabilities must become more complex; open-world evaluations are the latest in a series of evaluations of increasing complexity. We also discuss the limits of open-world evaluations compared to benchmarks.
We discuss five loose criteria that define open-world evaluations below (see “What are open-world evaluations?”). But it is worth noting that the line between long, complex benchmark tasks and open-world evaluations is blurry. Indeed, many of the evaluations we discuss are sandboxed. We still include them in our list of open-world evals, because they satisfy our other criteria (e.g., Carlini’s C compiler is sandboxed, but involves just one long-running task, human intervention, and qualitative analysis as part of the evaluation).
Benchmarks can both overestimate and underestimate progress
People with drastically different views on AI agree that current AI benchmarks might soon be saturated. Many prominent benchmarks have been saturated in the last two years, and evaluators have raced to release “successor” benchmarks. Many of these updated benchmarks are themselves near saturation.
Many popular benchmarks (such as SWE-Bench, ARC-AGI, τ-bench, Terminal Bench, and METR’s Time Horizon task suite) have seen successor benchmarks being released in the last two years.
Does this mean AI systems will soon be capable of solving any task? Not necessarily. Benchmark improvements could indicate real capability gains, but they can also overstate progress: for example, because benchmarks have limited construct validity—they may test accuracy on narrow tasks rather than general ability—and they don’t test how well agents handle the messiness of real-world environments.
On the flip side, benchmarks could also underestimate progress due to challenges in the environment or infrastructure that are only incidental to the capabilities being measured, such as encountering CAPTCHA.
One way to get a fuller picture is to use metrics other than accuracy. For example, in a recent preprint several of us coauthored, we showed that even though agents are improving drastically in terms of capability metrics (such as average accuracy), they have improved much more slowly on metrics that measure reliability. Similarly, many agent solutions to SWE-bench tasks that were judged correct because they pass tests, would nevertheless be rejected by project maintainers.
But this still doesn’t allow us to measure the upper bounds of AI capabilities. Capabilities that are possible today (even if only under favorable conditions) might soon be widespread, and we need to anticipate them before they are. Providing such early warnings gives businesses extra time to capitalize on new opportunities, institutions to build resilience, and policymakers to address risks.
Now let’s discuss in more detail why benchmarks can both overestimate and underestimate capabilities. They can overestimate capabilities because:
Benchmarks resemble tasks amenable to modern reinforcement learning (RL) techniques. To turn a task into a benchmark, it needs to be precisely specified and automatically verifiable. But whatever is precise enough to benchmark is also precise enough to optimize for, and modern RL training runs increasingly resemble the shape of the benchmarks themselves. This makes it easy to saturate any task that can be measured using benchmarks.
This is already the case for leading evaluation platforms like Harbor, which double as RL training platforms. As a result, AI models could be directly trained on data from many prominent benchmarks included on these platforms. Even if benchmarks include held-out test sets, models might be trained on tasks from the training set that look very similar to those they would encounter in the test set. So benchmarks don’t help us understand how well performance generalizes to the real-world.
Benchmarks avoid real-world messiness. Real-world tasks involve underspecified interactions that can’t be fully sandboxed, such as responding to unexpected situations or navigating environments that are open-ended. Benchmarks can take some steps to simulate messy environments, but they can’t fully replicate them.
Benchmarks can also underestimate capabilities, because:
Eliciting frontier capabilities is costly. Running large-scale, long-running experiments is expensive, making it impractical to achieve the sample sizes that benchmarks rely on. Anthropic’s C compiler cost ~$20k; the task we describe running below (developing and publishing an iOS app for CRUX #1) cost ~$1,000. We can’t run such experiments hundreds of times, limiting the budget and complexity for each benchmark task.
Average performance is very different from upper-bound capability elicitation. Trying to run dozens (or 100s) of tasks in a benchmark suite is only necessary to measure average performance. But when we are trying to understand the frontier of what agents can do, the goal shifts to understanding best-case performance: what can agents accomplish when given sufficient resources and support to work around incidental failures? This is necessary for providing early warnings for capabilities that might soon be widespread.
Human intervention can help elicit capability upper bounds. Agents working on real-world tasks could encounter policy refusals, require solving CAPTCHAs, or encounter other infrastructure issues where they get stuck. This could negatively affect their performance. But these failures are only incidental to the capability being measured. If human operators can handle these, it would allow us to elicit upper bounds of capability. Such manual intervention is impractical for 100s of benchmark tasks each time they are run.
As AI capabilities improve, sandboxed evaluations that test AI capabilities in coding, deep research, and customer service require intensely engineered environments to challenge agents and avoid contamination or reward hacking. For example, the performance of agents on web benchmarks has been affected by how often agents encounter CAPTCHA, rather than eliciting the true underlying capabilities of agents. Recent work has highlighted AI agents finding answers online, exploiting bugs in evaluations, and producing code that passes tests but fails to meet standards for production. This highlights the need for a shift towards deeper qualitative evaluations of AI agent performance that can help us better understand failure modes and problem-solving strategies that can be lost in the barrage of average benchmark scores.
But these threats to validity are not straightforward to address. We can conduct qualitative log analysis for benchmarks to address some of these concerns, but even when we find validity issues in benchmark results using log analysis, there’s little we can do about it except releasing an updated benchmark, which could take a few months. Open-world evals allow us to conduct dry runs to fix issues before the real test run, and manually intervene to fix issues found during the evaluation.1
Of course, benchmarks can be helpful despite these limitations.2 And open-world evaluations have their own limitations, which we discuss later in this paper. That said, we hope this list illustrates the systematic blind spots in benchmarking. As AI agents become more capable, the gaps we identify between traditional benchmarking and real-world capability will continue to grow. Success metrics will need to be multi-faceted to capture the diversity of objectives in a given task. Benchmarks will need to incorporate key bottlenecks (human assistance) and messy environments (internet navigation), each of which introduces additional issues of internal and external validity. Open-world evaluations offer an alternative.
What are open-world evaluations?
As evaluation methods have matured alongside AI capabilities, a gradient in evaluation has emerged. At one end are simple, automated, scalable methods that work well for early-stage capabilities. At the other end are richer, more labor-intensive methods that become necessary as capabilities improve and saturate simpler metrics.
As capabilities in a domain improve, evaluations further along the gradient become important to get insights that are complementary to simpler evaluations. We think of this gradient as having roughly five levels so far, each with their strengths and limitations:
Q&A benchmarks (e.g., MMLU, GPQA): useful for broad knowledge assessment, but increasingly saturated for frontier models. Often formatted as multiple-choice questions for ease of grading, but as a result have low construct validity, since users rarely interact with models by asking multiple-choice questions.
Open-ended chat benchmarks (e.g., WildBench, Arena-hard-auto): capture more nuance, but still limited to single-turn or short interactions.
Outcome-only agent benchmarks (e.g., SWE-Bench, WebArena): test agent performance on real tasks, but only measure whether the task was completed, not how. As a result, they have limitations. For example, most passing SWE-Bench solutions are not accepted by repository maintainers.
Agent benchmarks with log analysis (e.g., UK AISI transcript analysis, METR Time Horizon): go deeper by examining how agents succeed or fail and uncovering errors and reward hacking by analyzing agent logs. But they still operate in sandboxed environments with predefined tasks.
Open-world evaluations: long-horizon tasks in real-world environments, where success can’t be neatly specified or automatically graded. This allows eliciting upper bounds of capabilities. But this comes at the cost of lack of reproducibility and standardization (which are both benefits of benchmarking; see section on Limitations).
Some evaluations blur the categories of this spectrum. For example, OpenAI’s GDPVal, a long-horizon agent benchmark, is designed to be manually graded based on expert’s opinions on quality. This structure is very similar to an open-world evaluation, though they primarily focus on outputs but not on analyzing the logs. At the same time, results on GDPVal are commonly reported using GDPval-AA, which uses automated LLM grading; this evaluation setting resembles an outcome-only agent benchmark.
Open-world evaluations consist of running agents on a small number of long-horizon tasks in real-world settings, and qualitatively evaluating their results using tools for log analysis. These evaluations are complementary to benchmarking and help address many of their limitations. They can also uncover tasks that remain out of reach for current AI systems for future benchmarking efforts.
We provide a rough taxonomy to clarify the boundary of what constitutes open-world evaluations. No single dimension determines whether an experiment qualifies as “open-world”. Instead, it depends on the overall pattern across all of the dimensions below.
Openness. Is this evaluation in a real-world deployment setting (as opposed to a sandboxed environment)?
Complexity/length. Does the task require a human days or weeks at a time to complete (as opposed to a few minutes or hours)?
Number of tasks. Is this a stand-alone task or a small set of tasks (as opposed to a large evaluation suite or benchmark)?
Human intervention. To help elicit upper-bounds of capabilities, are humans able to intervene when agents hit a hurdle (as opposed to just setting up the environment or resolving setup issues)?
Method of evaluation. Does the evaluation primarily consist of in-depth log evaluation (as opposed to the result driven by a single average metric)?
When do we call something an evaluation as opposed to simply using agents to accomplish something novel? For example, Anthropic used AI agents to find security vulnerabilities in leading open-source software such as Mozilla Firefox—is this an example of an open-world evaluation? We still consider these open-world evals if the role of the agent is systematically and publicly documented (including the parts carried out by the agent carried and the human experts, and the end result).
The line between complex benchmark tasks and open-world evaluations is also blurry. For example, some evaluations in our list of open-world evals below are sandboxed (e.g., Claude Plays Pokemon and Anthropic’s C compiler were both run in sandboxed environments, but we still consider them open-world evaluations because they consist of a single, complex, long-running task, have human intervention during the evaluation, and are evaluated qualitatively).
The two types of evals are also complementary: we could imagine using open-world evaluations to understand what tasks remain unsolvable by agents as a first step towards building new benchmarks, and also use open-world evals to
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み