AWS SMGS が Amazon Bedrock AgentCore を活用した AI 搭載型会話アシスタントで業務管理を革新する方法
AWS は Amazon Bedrock AgentCore を活用した対話型 AI エージェント「NarrateAI」を構築し、複雑なビジネスデータの断片化や準備時間の課題を解消して、経営層に即座かつ正確なインサイトを提供する仕組みを実現しました。
キーポイント
既存の BI 課題の克服
従来の静的ダッシュボードや手動レポートによるデータ断片化、準備時間の浪費、専門知識への依存という課題を明確に指摘し、対話型 AI による解決を提案しています。
二層アーキテクチャの採用
バッチ処理によるナラティブ生成と、リアルタイムインタラクションを分離したアーキテクチャを採用することで、スケーラビリティと即時性を両立しています。
Amazon Bedrock AgentCore の活用
データレイク上の情報を基盤とし、AgentCore を用いて高度なルーティングや検証を行う専門 AI エージェントを構築し、自然言語での質問に即座に回答する能力を実現しました。
実装パターンと展開
AWS SMGS 組織向けに本格的に導入された事例として、生産環境へのデプロイにおける重要なエンジニアリングパターンや構築手法を共有しています。
重要な引用
Traditional business intelligence relies on static dashboards and manual reports, which creates delays and limits organizational agility.
NarrateAI delivers on-demand, context-rich business intelligence to leaders across AWS, from the Chief Executive Officer (CEO) to the field.
The preparation process involved navigating multiple dashboards, reconciling data across disparate sources, and manually synthesizing insights.
影響分析・編集コメントを表示
影響分析
この記事は、大規模組織におけるビジネスインテリジェンスのあり方を「静的なレポート」から「動的な対話型エージェント」へと転換させる具体的な実装例を示しています。Amazon Bedrock AgentCore の活用により、データレイク上の複雑な情報を自然言語で即座に解釈・提供できる技術的実現性が証明され、企業内の意思決定プロセスの効率化と敏捷性向上への道筋を明確に示すものです。
編集コメント
AWS が自社の複雑なビジネス課題を解決するために、最新の AI エージェント技術を即座に実装・展開した事例は、他社における同様の導入に対する強力なロールモデルとなります。特に「AgentCore」を用いたアーキテクチャ設計は、信頼性とスケーラビリティを両立させるための重要な示唆を含んでいます。
AWS のリーダーたちは、複数の階層にわたる複雑なデータを管理しながら、グローバルな運用に影響を与える時間制約のある意思決定を行っています。従来のビジネスインテリジェンスは静的なダッシュボードと手動レポートに依存しており、これが遅延を生み、組織の俊敏性を制限しています。
NarrateAI は、私たちのデータレイクと Amazon Bedrock AgentCore に支えられた対話型エージェント AI によってこの課題に対処する、インテリジェントな対話型ソリューションです。Amazon Quick の対話型インターフェースを通じてアクセス可能で、NarrateAI は CEO から現場の担当者まで AWS 全体のリーダーに対し、オンデマンドかつ文脈に富んだビジネスインテリジェンスを提供します。ビジネスパフォーマンスに関する自然言語での質問に応えることで、NarrateAI は即座に正確で実行可能な洞察をもたらし、リーダーとデータとの間の障壁を取り除きます。
本稿では、AWS の SMGS(Sales, Marketing and Global Services)組織向けに大規模なビジネスインテリジェンスを提供するために、Amazon Bedrock AgentCore を活用して NarrateAI をどのように構築したかについて共有します。ここでは以下の点について学びます:
- バッチ処理とリアルタイムインタラクションを分離する 2 レイヤーアーキテクチャ。
- インテリジェントなルーティングと検証を担う専門的な AI エージェント。
- 本番環境でのデプロイに向けた主要なエンジニアリングパターン。
- AWS サービスを用いて同様のソリューションを構築する方法。
スケールしたビジネスインテリジェンス:主要な障壁
AWS は、従来のビジネスインテリジェンス手法の有効性を制限する課題に直面していました。
時間がかかる準備プロセス: AWS のリーダーたちは従来、ビジネスレビューの前にデータを人手で収集するために何時間も費やしていました。この準備プロセスには、複数のダッシュボードを移動し、異なるソース間のデータを照合し、手動で洞察を統合することが含まれており、戦略的な推論と意思決定に割く時間がほとんど残されていませんでした。
データの断片化: ビジネスの洞察は複数のシステムやダッシュボードに散在しており、リーダーたちは断片化したデータソースから一貫した物語を組み立てる必要がありました。この断片化により指標に矛盾が生じ、階層やデータセット全体にわたるビジネスパフォーマンスの一元的なビューを維持することが困難になりました。
限られたアクセシビリティ: 複雑なダッシュボードは効果的にナビゲートするために専門知識を必要とし、中間のレポートチームへの依存を生み出しました。リーダーたちはオンデマンドで洞察にアクセスできず、代わりにキュレーションされたレポートを待つ必要があり、これが重要なビジネス意思決定を遅らせ、組織のアジリティを制限していました。
ソリューション概要
NarrateAI は、バッチによるナラティブ生成とリアルタイム対話という 2 レイヤーのアーキテクチャを通じて、複雑なビジネスデータを会話形式で扱えるようにする課題に取り組んでいます。この分離により、事前の包括的なデータ処理を可能にしつつ、自然な対話を通じて即座に文脈に即した正確な回答を提供します。
Amazon Bedrock AgentCore は、カスタムオーケストレーションインフラストラクチャの構築を不要とし、サーバーレスアーキテクチャ、組み込み認証、メモリ管理、およびファウンデーションモデルとの統合を提供しました。これにより、ネイティブの Amazon CloudWatch 統合と自動セッション管理を通じて生産環境レベルの観測性とセキュリティを維持したまま、展開期間を数ヶ月から数週間に短縮できました。
自動化されたナラティブ生成レイヤー(バッチ処理)
NarrateAI は、3 つの段階パイプラインを通じて、各ユーザーに対してパーソナベースの包括的なナラティブをバッチ生成します:
- データ抽出 — 設定駆動型の構造化クエリ言語(SQL)テンプレート(各ユーザーの役割と権限に適応するパラメータ化されたクエリ)が、Amazon Redshift から構造化データを抽出します。これらのテンプレートは、多段階での内訳分析や時系列分析をサポートしつつ、ユーザー固有のアクセス制御を強制します。
- データ変換 — AWS Lambda は、セクションタイプロジック(オブジェクト、配列、内訳、コンテナ)とフィールドマッピング、階層構造を用いて、抽出されたデータを構造化された JavaScript Object Notation(JSON)に変換します。
- ナラティブレンダリング — Jinja テンプレート(広く使用されている Python テンプレートエンジン)が、構造化データから人間が読みやすいナラティブを生成します。階層的かつビジネスドメインを意識したチャンキング戦略により、大規模データセットも効率的に処理されます。システムは各ユーザーのナラティブをテキストファイルとして Amazon Simple Storage Service(Amazon S3)に保存し、完全なデータ分離を通じて行レベルセキュリティをサポートします。
コンバーサショナル AI インターフェース層(リアルタイム)
リーダーは、Amazon Bedrock AgentCore によって駆動される自然言語による対話を通じて、自らのナラティブと対話します。質問が到来すると、AgentCore は専門的な AI エージェントを調整し、Amazon S3 に保存された関連するペルソナベースのナラティブを検索して、それを知識源として活用します。エージェントはその内容を推論し、Anthropic の Claude Sonnet 4 を用いて文脈に根ざした回答を生成します。AgentCore のネイティブなマルチエージェント調整フレームワークにより、システムは単純なクエリを即座に処理できます。複雑な質問については、包括的な回答を得るために自動的に並列サブタスクに分割されます。
主要機能
このアーキテクチャ基盤は、リーダーがビジネスデータと対話する方法を変える3つの中核機能を支えています。
事前生成された知識を用いた自然言語によるビジネスクエリ
リーダーは平易な英語で複雑なビジネス質問を投げかけ、Amazon S3 に保存された構造化された知識から即座に回答を受け取ります。システムはビジネス用語を理解し、地域、製品、顧客セグメント、期間にわたる多次元分析を文脈理解に基づいてナビゲートします。
ユーザー固有のナラティブを通じた行レベルセキュリティ
NarrateAI は、ナラティブ生成時に行レベルセキュリティを適用し、各ユーザーの知識エンジンに許可されたデータのみが含まれるようにします。データ処理中にユーザー権限が適用され、Amazon S3 内の各ユーザーのナラティブファイルは完全に隔離されるため、組織全体でのユーザー間データ漏洩を防ぐのに役立ちます。
ペルソナベースのフィルタリングによる役割に特化した体験
NarrateAI は、ユーザーの役割や組織レベルに基づいて応答を適応させます。CEO には組織全体のハイレベルな戦略的洞察が提供され、地域マネージャーには特定の地域の詳細な運用指標が提供されます。
これらの機能は、専門的な AI エージェントと AWS サービスを組み合わせたモジュラーアーキテクチャによって支えられており、スケーラブルでインテリジェントなビジネスインテリジェンスの提供を実現しています。
アーキテクチャコンポーネント
当社のアーキテクチャは、複数の AWS サービスと専門的な AI エージェントを組み合わせ、モジュラーかつスケーラブルな設計を通じて、文脈を意識したインテリジェンなビジネス洞察を提供します。以下の図はエンドツーエンドのアーキテクチャを示しています。
ユーザーは、Amazon Quick(会話型インターフェース)と Web UI という 2 つのエントリーポイントを通じて NarrateAI と対話します。これらはどちらも、リクエスト処理のために Amazon Bedrock AgentCore Runtime に接続されています。このアーキテクチャには、主に 2 つのフローがあります:リアルタイムクエリパス(左側)とバッチデータ処理パス(右側)。
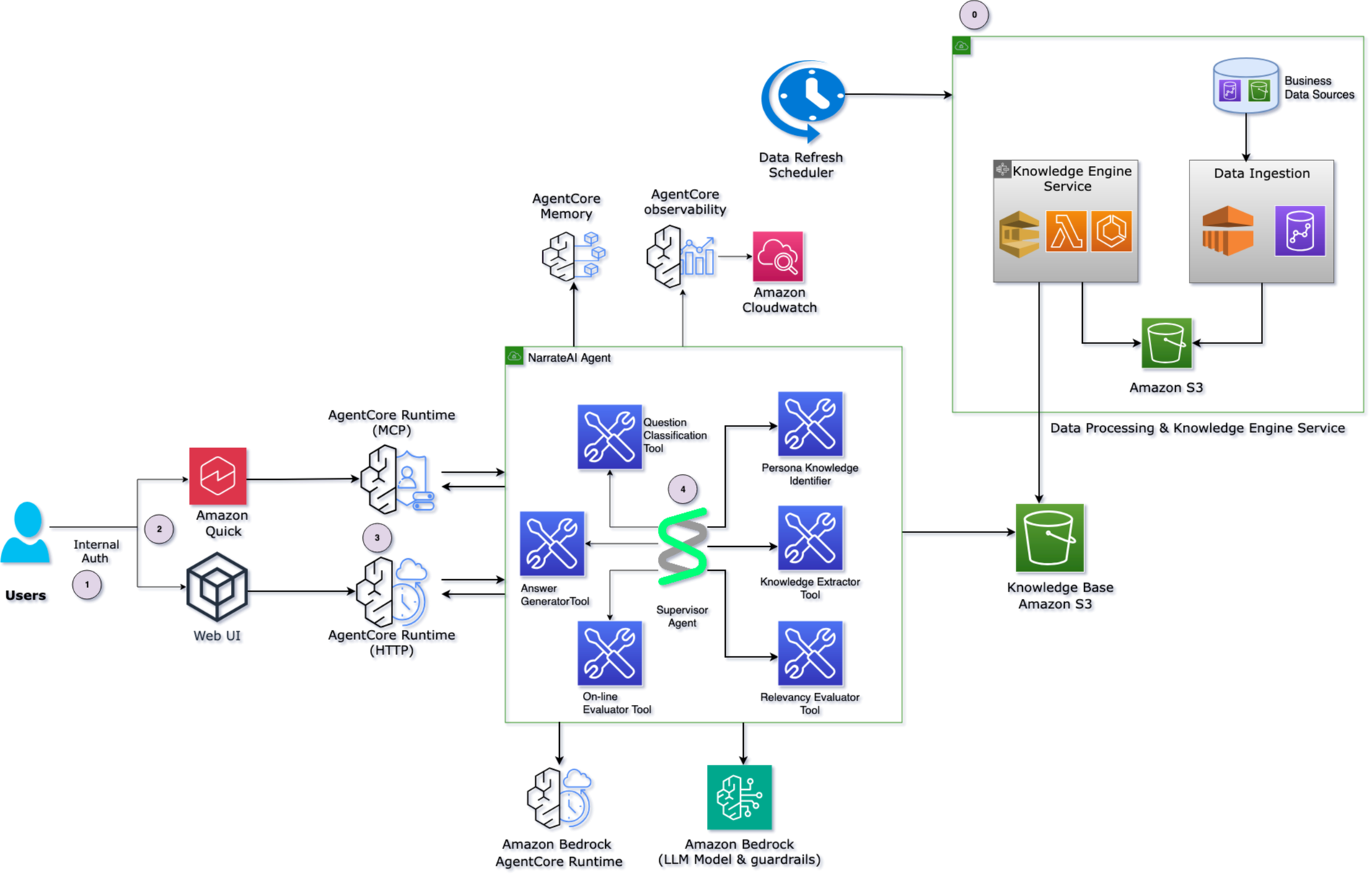
NarrateAI エージェント(Strands エージェント): クエリ処理フロー
アーキテクチャの中心には、マルチエージェントオーケストレーションのために Amazon Bedrock AgentCore で構築された NarrateAI エージェントが位置しています。Supervisor エージェントは、6 つの専門ツールを通じてエンドツーエンドのクエリワークフローを調整します。
- クエリ分類 — クエリが到着すると、このツールはユーザーの意図を分析し、クエリの複雑さを判定します。単純なクエリ(例:「今四半期のチームの収益はいくらですか?」)は即座に解決できるよう高速パスで処理されます。複雑な多段階の質問(例:「全製品ラインにわたる上位 5 つのアカウントの成長率を比較してください」)は、自動的に並列サブタスクに分割されます。
- ペルソナ知識識別子 — ユーザーの役割、組織レベル、データアクセス権限を特定し、Amazon S3 からどのナラティブファイル(文書)を取得するかを決定します。
- 知識抽出器 — 表形式目次(TOC: Table of Contents)に基づく検索アプローチを用いて、ユーザーのナラティブから関連するセクションのみを抽出し、ファイル全体をスキャンすることなく処理します。これにより、ナラティブが成長しても検索速度は維持されます。
- 関連性評価器 — 抽出されたコンテンツをユーザーの質問と比較し、どのセクションが最も関連性が高いかを判定して、本題から外れた情報をフィルタリングします。
- 回答生成器 — Anthropic の Claude Sonnet 4 を Amazon Bedrock(AWS が提供する AI モデル管理プラットフォーム)を通じて活用し、関連データから一貫性のある自然言語による応答を合成します。
- オンライン評価器 — 送信前にすべての応答を検証します。生成された数値をソースデータと照合し、論理的整合性を確認するとともに、主張がユーザーのナラティブに基づいていることを保証します。
応答時間は、クエリの複雑さと基盤となるデータソースによって異なります。
知識エンジン:データ処理フロー
アーキテクチャ図の右側では、会話層のためにビジネスデータがどのように準備されるかが示されています:
- データ取り込み — Amazon Redshift やその他のエンタープライズデータソースから生きたビジネスデータが、知識エンジンサービスへ流れ込みます。
- データ変換 — AWS Lambda 関数が構成駆動型のテンプレートを用いてデータを処理・変換し、ユーザー固有の権限や組織階層を適用します。
- 知識アーティファクト保存 — 処理されたデータは、Amazon S3 に構造化されたペルソナ固有のナラティブファイルとして保存され、行レベルセキュリティのためにユーザー間で完全なデータ分離が保たれます。
- データ更新 — データ更新スケジューラーが定期的な更新を自動化し、ナラティブが最新のビジネスデータを反映するようにします。
バッチデータ処理とリアルタイムクエリ処理のこの分離により、NarrateAI は基盤となるデータを最新かつ正確に保ちながら、即座に応答を提供できます。
インフラストラクチャと AI 基盤
NarrateAI は、信頼性、精度、およびスケーラビリティのために設計された、密接に統合された AWS サービスのセットの上に構築されています。
データストレージと処理 — システムは、ビジネスデータを構造化された知識アーティファクトとして Amazon S3 に保存・処理します。AWS Lambda がサーバーレスなデータ変換を担い、Amazon Redshift が基盤となるデータウェアハウスとして機能します。カスタム取得システムでは、目次(TOC)アプローチを採用することで、ファイル全体をスキャンすることなく関連するドキュメントセクションを迅速に特定できます。これにより、知識エンジンが成長しても応答速度は維持されます。
ファウンデーションモデル — Amazon Bedrock は、Anthropic の Claude Sonnet 4 を含む最先端のファウンデーションモデルへのアクセスを提供します。これは NarrateAI の自然言語理解、複雑なビジネス推論、および応答生成を駆動しています。このサービスのモデル柔軟性により、アーキテクチャを変更することなく新しいモデルバージョンへのテストやアップグレードが可能となり、より能力の高いモデルが登場するにつれてクエリ理解が向上し、応答時間が短縮されます。
安全性とガードレール — Amazon Bedrock Guardrails は、NarrateAI のユースケースに特化した 3 つのカスタム設定済みフィルタを通じて安全性を確保します:
- コンテンツフィルタリング — 不適切または有害な言語をブロックします。
- PII 赤化(PII redaction)— 機密性の高い個人識別情報(PII)の偶発的な露出を防ぐのに役立ちます。
- トーンガードレール — すべての応答が AWS のリーダーシップに適した専門的なトーンを維持するように保証します。
エージェント展開インフラストラクチャ — 基盤となるオーケストレーション層として Amazon Bedrock AgentCore を使用しています。AgentCore は、高度な観測機能、認証プロバイダーの統合、サーバーレスメモリ管理を含む包括的なエージェンシー機能を提供します。
観測性(Observability) — AgentCore Observability は、Amazon CloudWatch との統合による監視とアラートを通じて完全な運用可視性をサポートし、エンドツーエンドのエージェントセッション実行の詳細なインサイトを提供します。AgentCore に組み込まれた OpenTelemetry を通じたトレーサビリティ機能により、デバッグ効率が向上しました。トラブルシューティングにかかる時間は、数十分または数時間から単一桁の分に短縮されました。
メモリ管理 — 会話履歴(短期記憶)を、カスタム Amazon DynamoDB ベースのソリューションから AgentCore のネイティブメモリ機能へ移行しました。この移行により:
- カスタムのセッション管理コードを維持する必要がなくなりました。
- メモリ管理を AgentCore のサーバーレスインフラストラクチャ内に統合することで、アーキテクチャが簡素化されました。
- 組み込みのセッション処理機能により、機能開発が迅速化されました。
本番環境向けのエンジニアリング
基盤となるインフラストラクチャが整ったことで、NarrateAI を大規模に展開するには、すべての本番 AI システムが対処しなければならない4 つの重要なエンジニアリング課題を解決する必要がありました。
最初の課題は精度と信頼性です。AI モデルは正しく聞こえる回答を生成する一方で誤りを含むことがあり、これは意思決定を行うビジネスにとって深刻なリスクとなります。これに対処するため、すべての回答は配信前に検証され、数値が正確か、指標が一貫しているか、論理的に妥当であるかが確認されます。また、ハルシネーション(幻覚)のリスクを低減するために、大規模言語モデル (LLM) の関与を数値計算から制限し、回答がユーザーに届く前に不適切な言語を自動チェックで検出します。
2 つ目の課題は、組織階層全体における文脈認識です。異なるリーダーには異なるデータが表示される必要があります。地域マネージャーには自地域の数字のみを表示し、経営陣には会社全体のビューを提供する必要があります。システムは自動的に質問者が誰か、そして彼らがアクセス許可されているデータが何かを特定します。その後、手動でのフィルタリングを必要とせず、回答者の役割と報告構造に基づいてすべての回答の範囲を自動的に設定します。
スケーラビリティにおける応答遅延が第 3 の課題となりました。初期バージョンでは複雑な質問に対して著しい応答遅延が発生し、ユーザーのフラストレーションや採用率の低下を招きました。現在は、質問の複雑度に基づいてルーティングが行われています。単純な問い合わせは迅速に回答され、複雑な多段階の質問は並列処理によって処理されます。応答時間はユースケース、質問の性質、および基盤となるデータソースに応じて変動します。また、データ取り込み時に文書構造を事前に分析することで、1 件あたりの情報検索遅延がさらに削減されています。
最後に、スコープとトピックのカバレッジには細心の注意が必要でした。ビジネスインテリジェンスは複数のドメイン(営業、財務、マーケティングなど)にまたがり、それぞれ固有の用語やロジックを持っています。チームはドメイン専門家と協力し、標準化されたテンプレートアプローチを通じて組織の知見をエンコードすることで、かつて数ヶ月かかったカスタム開発を数週間で完了させることに成功しました。
この取り組みから得られた重要な教訓は、生産環境での準備には、AI の柔軟性とルールベースの精度のバランスを取り、データアクセスをソースレベルで強制し、最も一般的なユースケースに対して最適化しつつも、複雑なケースも確実に処理できることが必要であるということです。
結果と影響
導入以降、NarrateAI はビジネスインテリジェンスへのアクセシビリティと意思決定の速度において測定可能な改善をもたらしました:
- AWS の経営陣全体(CEO から地域マネージャーまで)に、4,000 人以上のアクティブユーザーが利用しています。
- ビジネスレビューの準備にかかる時間が数時間から数分に短縮されました。
- 決定論的な計算とオンライン評価ツールによるチェックを通じて、包括的なデータ精度検証が行われています。
経営陣は、データに基づく意思決定に対する自信を高め、ダッシュボードの操作ではなく自然な会話を通じてビジネスパフォーマンスを検証する能力が向上したと報告しています。Amazon Bedrock AgentCore を活用することで、当社のエンジニアリング運用は手動のビジネスインテリジェンスプロセスから、AI によるセルフサービスハブへと転換しました。このアプローチにより効率性が向上し、レビュー準備時間を数時間から数分に短縮するとともに、組み込まれたガードレールと行レベルでのアクセス強制機能を通じてセキュリティおよびコンプライアンス制御を強化しました。
Future vision: From reactive to proactive
NarrateAI は、単なる会話型アシスタントから進化し、リーダーが質問する前に洞察を積極的に提供し、異常を検出し、アクションを提案する自律型エージェントへと発展します。これはビジネスカレンダー、リアルタイムデータの変化、組織の文脈によってトリガーされます。強化された Amazon Bedrock AgentCore のオーケストレーション、イベント駆動アーキテクチャ、そして高度なマルチエージェントシステム(ナレッジエージェント、予測エージェント、ポリシーエージェント)によって支えられ、完全なポリシーと監査レイヤーによって管理される安全で説明可能な自律的アクションを伴う予測分析を提供します。この進化により、NarrateAI は組織全体でニーズを先取りし、積極的な意思決定を推進する知的ビジネスパートナーとしての地位を確立します。
Conclusion
本稿では、AWS SMGS において大規模な会話型ビジネスインテリジェンスを実現するために、Amazon Bedrock AgentCore を活用して NarrateAI を構築した方法について紹介しました。バッチによるナラティブ生成とリアルタイム対話を分離する二層アーキテクチャ、すべてのレスポンスをルーティングおよび検証する専門的なエージェント、そして本番環境での運用を可能にするエンジニアリングパターンについて解説しました。
同じ AWS サービスを使用して、独自の会話型ビジネスインテリジェンスソリューションを構築できます。Amazon Bedrock AgentCore は、大規模な AI エージェントの構築、デプロイ、運用のためのモジュール型サービスを提供し、マルチエージェントオーケストレーション、メモリ管理、観測機能に対するネイティブサポートを備えています。Amazon Redshift は、分析ワークロード向けの堅牢なデータウェアハウスとして機能します。
紹介したアーキテクチャパターンは業界を超えて適用可能です。これには、検索精度と生成の柔軟性を組み合わせたカスタマイズされた知識検索、複雑なナレッジベースのインテリジェントなナビゲーションをサポートする階層型ドキュメント処理、マルチテナント環境における安全なデータアクセスを実現するロールベースのアクセス制御、そして大規模でも応答性の高いパフォーマンスを提供する並列エージェント処理が含まれます。
業務の変革をお考えですか?まずは Amazon Bedrock AgentCore の詳細ページ をご覧いただき、AgentCore ドキュメント を確認し、
原文を表示
AWS leaders manage complex data across multiple hierarchies while making time-sensitive decisions that impact global operations. Traditional business intelligence relies on static dashboards and manual reports, which creates delays and limits organizational agility.
NarrateAI, our intelligent conversational solution, addresses this through conversational agentic AI powered by our data lake and Amazon Bedrock AgentCore. Accessible through the Amazon Quick conversational interface, NarrateAI delivers on-demand, context-rich business intelligence to leaders across AWS, from the Chief Executive Officer (CEO) to the field. By answering natural language questions about business performance, NarrateAI provides immediate, accurate, and actionable insights that remove barriers between leaders and their data.
In this post, we share how we built NarrateAI using Amazon Bedrock AgentCore to deliver business intelligence at scale for the AWS SMGS (Sales, Marketing and Global Services) organization. You will learn about:
- The two-layer architecture that separates batch processing from real-time interaction.
- The specialized AI agents that power intelligent routing and validation.
- Key engineering patterns for production deployment.
- How to build similar solutions with AWS services.
Business intelligence at scale: Key obstacles
AWS faced challenges that limited the effectiveness of traditional business intelligence approaches:
Time-intensive preparation: AWS leaders traditionally lost hours gathering data manually before business reviews. The preparation process involved navigating multiple dashboards, reconciling data across disparate sources, and manually synthesizing insights, leaving little time for strategic reasoning and decision-making.
Data fragmentation: Business insights were scattered across multiple systems and dashboards, requiring leaders to piece together a coherent narrative from fragmented data sources. This fragmentation created inconsistencies in metrics and made it difficult to maintain a unified view of business performance across hierarchies and datasets.
Limited accessibility: Complex dashboards required specialized knowledge to navigate effectively, creating dependencies on intermediary reporting teams. Leaders could not access insights on-demand and instead had to wait for curated reports, which delayed critical business decisions and limited organizational agility.
Solution overview
NarrateAI addresses the challenge of making complex business data conversational through a two-layer architecture: batch narrative generation and real-time interaction. This separation supports comprehensive data processing upfront while delivering instant, contextually accurate responses through natural conversation.
Amazon Bedrock AgentCore removed the need to build custom orchestration infrastructure, providing serverless architecture, built-in authentication, memory management, and integration with foundation models. This accelerated our deployment from months to weeks while maintaining production-quality observability and security through native Amazon CloudWatch integration and automated session management.
Automated narrative generation layer (batch processing)
NarrateAI batch-generates comprehensive persona-based narratives for each user through a three-stage pipeline:
- Data extraction — Configuration-driven Structured Query Language (SQL) templates (parameterized queries that adapt to each user’s role and permissions) extract structured data from Amazon Redshift. These templates support multi-level breakdowns and time series analysis while enforcing user-specific access controls.
- Data transformation — AWS Lambda transforms the extracted data into structured JavaScript Object Notation (JSON) using section-type logic (objects, arrays, breakdowns, and containers) with field mappings and hierarchical organization.
- Narrative rendering — Jinja templates (a widely used Python templating engine) render human-readable narratives from the structured data. A hierarchical, business domain-aware chunking strategy handles large datasets efficiently. The system stores each user’s narrative as a text file in Amazon Simple Storage Service (Amazon S3), supporting row-level security through full data isolation.
Conversational AI interface layer (real-time)
Leaders interact with their narratives through natural language conversation powered by Amazon Bedrock AgentCore. When a question arrives, AgentCore orchestrates specialized AI agents to retrieve the relevant persona-based narrative from Amazon S3 and use it as the knowledge source. The agents reason over its contents to generate contextually grounded responses with Anthropic’s Claude Sonnet 4. AgentCore’s native multi-agent coordination framework lets the system handle simple queries instantly. For complex questions, it automatically breaks them into parallel sub-tasks for comprehensive answers.
Key capabilities
This architectural foundation supports three core capabilities that change how leaders interact with business data.
Natural language business queries with pre-generated knowledge
Leaders ask complex business questions in plain English and receive immediate responses from structured knowledge stored in Amazon S3. The system understands business terminology and navigates multi-dimensional analysis across regions, products, customer segments, and time periods with contextual understanding.
Inherent row-level security through user-specific narratives
NarrateAI applies row-level security during narrative generation, making sure each user’s knowledge engine contains only authorized data. User permissions are applied during data processing, and each user’s narrative file in Amazon S3 is fully isolated, helping prevent cross-user data leakage across the organization.
Role-tailored experience through persona-based filtering
NarrateAI adapts responses based on user roles and organizational levels. A CEO receives high-level strategic insights across the organization, while a regional manager receives detailed operational metrics for their specific region.
These capabilities are supported by a modular architecture that combines specialized AI agents with AWS services for scalable, intelligent business intelligence delivery.
Architecture components
Our architecture combines multiple AWS services and specialized AI agents to deliver intelligent, context-aware business insights through a modular, scalable design. The following diagram illustrates the end-to-end architecture.
Users interact with NarrateAI through two entry points, Amazon Quick (a conversational interface) and a Web UI, both connecting to Amazon Bedrock AgentCore Runtime for request processing. The architecture has two main flows: a real-time query path (left side) and a batch data processing path (right side).
NarrateAI agent (Strands agent): Query processing flow
At the center of the architecture sits the NarrateAI Agent, built on Amazon Bedrock AgentCore for multi-agent orchestration. A Supervisor Agent coordinates the end-to-end query workflow through six specialized tools:
- Question classification — When a question arrives, this tool analyzes the user’s intent and determines query complexity. Simple queries (for example, “What is my team’s revenue this quarter?”) take a fast path for immediate resolution. Complex, multi-part questions (for example, “Compare my top 5 accounts’ growth rates across all product lines”) are automatically broken into parallel sub-tasks.
- Persona knowledge identifier — Identifies the user’s role, organizational level, and data permissions to determine which narrative file to retrieve from Amazon S3.
- Knowledge extractor — Uses a table-of-contents (TOC) based retrieval approach to pull only the relevant sections from the user’s narrative, rather than scanning the entire file. This keeps retrieval fast even as narratives grow.
- Relevancy evaluator — Assesses the extracted content against the user’s question to determine which sections are most pertinent, filtering out tangential information.
- Answer generator — Synthesizes a coherent, natural language response from the relevant data, powered by Anthropic’s Claude Sonnet 4 through Amazon Bedrock.
- Online evaluator — Validates every response before delivery by cross-referencing generated numbers against source data, checking logical coherence, and confirming that claims are grounded in the user’s narrative.
Response times vary based on query complexity and the underlying data sources.
Knowledge engine: Data processing flow
The right side of the architecture diagram shows how business data is prepared for the conversational layer:
- Data ingestion — Raw business data flows from Amazon Redshift and other enterprise data sources into the Knowledge Engine Service.
- Data transformation — AWS Lambda functions process and transform the data with configuration-driven templates, applying user-specific permissions and organizational hierarchies.
- Knowledge artifact storage — The processed data is stored as structured, persona-specific narrative files in Amazon S3, with full data isolation between users for row-level security.
- Data refresh — A Data Refresh Scheduler automates periodic updates, so narratives reflect the latest business data.
This separation between batch data processing and real-time query handling lets NarrateAI deliver instant responses while keeping the underlying data current and accurate.
Infrastructure and AI foundation
NarrateAI is built on a tightly integrated set of AWS services designed for reliability, accuracy, and scale.
Data storage and processing — The system processes and stores business data as structured knowledge artifacts in Amazon S3. AWS Lambda handles serverless data transformation, while Amazon Redshift serves as the underlying data warehouse. A custom retrieval system uses a table-of-contents (TOC) approach to locate relevant document sections quickly, without scanning entire files. This keeps responses fast even as the knowledge engine grows.
Foundation models — Amazon Bedrock provides access to leading foundation models, including Anthropic’s Claude Sonnet 4, which powers NarrateAI’s natural language understanding, complex business reasoning, and response generation. The service’s model flexibility lets us test and upgrade to newer model versions without architectural changes, improving query understanding and reducing response times as more capable models emerge.
Safety and guardrails — Amazon Bedrock Guardrails enforce safety through three custom-configured filters tailored to NarrateAI’s use case:
- Content filtering — Blocks inappropriate or harmful language.
- PII redaction — Helps prevent accidental exposure of sensitive personally identifiable information (PII).
- Tone guardrails — Makes sure every response maintains a professional voice appropriate for AWS leadership.
Agent deployment infrastructure — We use Amazon Bedrock AgentCore as our foundational orchestration layer. AgentCore provides comprehensive agentic capabilities, including advanced observability, authentication provider integration, and serverless memory management.
Observability — AgentCore Observability delivers detailed insights into end-to-end agent session execution, supporting full operational visibility through integration with Amazon CloudWatch for monitoring and alerting. The traceability capabilities through OpenTelemetry built into AgentCore have improved our debugging efficiency. Troubleshooting time dropped from tens of minutes or hours down to single-digit minutes.
Memory management — We migrated our conversation history (short-term memory) from a custom Amazon DynamoDB-based solution to AgentCore’s native memory capabilities. This migration:
- Removed the need to maintain custom session management code.
- Simplified our architecture by consolidating memory management within AgentCore’s serverless infrastructure.
- Enabled faster feature development with built-in session handling.
Engineering for production
With the foundational infrastructure in place, deploying NarrateAI at scale required solving four critical engineering challenges that every production AI system must address.
The first challenge was accuracy and trust. AI models can generate answers that sound correct but contain errors, which is a serious risk for business decision-making. To address this, every response is validated before delivery, checking that numbers are accurate, metrics are consistent, and the answer is logically sound. The architecture limits large language model (LLM) involvement in numeric calculations to reduce hallucination risk, and automated checks flag inappropriate language before responses reach users.
The second challenge was context awareness across organizational hierarchies. Different leaders need to see different data. A regional manager should see only their region’s numbers, while an executive needs a company-wide view. The system automatically identifies who is asking and what data they are permitted to see. It then scopes every response to their role and reporting structure without requiring manual filters.
Response latency at scale presented the third challenge. Early versions experienced significant response delays on complex questions, leading to user frustration and lower adoption. The system now routes questions based on complexity. Straightforward queries are answered quickly and complex multi-part questions are handled through parallel processing. Response times vary based on the use case, the nature of the query, and underlying data sources. Pre-analyzing document structure during data ingestion further reduces information retrieval latency per query.
Finally, scope and topic coverage required careful attention. Business intelligence spans multiple domains (sales, finance, marketing, and so on), each with its own terminology and logic. The team collaborated with domain experts to encode institutional knowledge through a standardized template approach, reducing what once took months of custom development to a matter of weeks.
The key lesson from this work is that production readiness requires balancing AI flexibility with rule-based accuracy, enforcing data access at the source, and optimizing for the most common use cases while reliably handling complex ones.
Results and impact
Since deployment, NarrateAI has delivered measurable improvements in business intelligence accessibility and decision-making speed:
- More than 4,000 active users across AWS leadership, from CEO to regional managers.
- Hours reduced to minutes in business review preparation time.
- Comprehensive data accuracy validation through deterministic calculations and Online Evaluator Tool checks.
Leaders report increased confidence in data-driven decisions and improved ability to explore business performance through natural conversation rather than dashboard navigation. With Amazon Bedrock AgentCore, we shifted our engineering operations from manual business intelligence processes to an AI-powered self-service hub. This approach improved efficiency, reduced review preparation time from hours to minutes, and strengthened security and compliance controls through built-in guardrails and row-level access enforcement.
Future vision: From reactive to proactive
NarrateAI will evolve from a conversational assistant into an autonomous agent that proactively delivers insights, surfaces anomalies, and suggests actions before leaders ask. It will be triggered by business calendars, real-time data changes, and organizational context. Powered by enhanced Amazon Bedrock AgentCore orchestration, event-driven architecture, and advanced multi-agent systems (Knowledge, Forecast, and Policy Agents), the system will deliver predictive analytics with safe, explainable autonomous actions governed by a full policy and audit layer. This evolution positions NarrateAI as an intelligent business partner that anticipates needs and drives proactive decision-making across the organization.
Conclusion
In this post, we showed how we built NarrateAI on Amazon Bedrock AgentCore to deliver conversational business intelligence at scale across AWS SMGS. We covered the two-layer architecture that separates batch narrative generation from real-time interaction, the specialized agents that route and validate every response, and the engineering patterns that make the solution production-ready.
You can use the same AWS services that power our solution to build your own conversational business intelligence solutions. Amazon Bedrock AgentCore offers modular services for building, deploying, and operating AI agents at scale, with native support for multi-agent orchestration, memory management, and observability. Amazon Redshift serves as a robust data warehouse for analytical workloads.
The architecture patterns demonstrated are applicable across industries. These include customized knowledge retrieval that combines retrieval accuracy with generative flexibility, hierarchical document processing that supports intelligent navigation of complex knowledge bases, role-based access control that supports secure data access in multi-tenant environments, and parallel agent processing that delivers responsive performance at scale.
Ready to transform your operations? To get started, explore the Amazon Bedrock AgentCore detail page, review the AgentCore documentation, and try the
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み