Claude Code の構築から学んだこと:プロンプトキャッシングが全てである
Anthropic の Claude Code チームが、大規模なエージェントシステムにおけるプロンプトキャッシングの最適化戦略と、コスト・レイテンシ削減のための具体的な実装パターンを公開した。
キーポイント
キャッシュ効率を最大化するプロンプト構成
API のプレフィックスマッチング特性を活かし、静的なシステムプロンプトやツール定義を先頭に配置し、動的な会話履歴を末尾に配置することで、セッション間のキャッシュヒット率を最大化する。
動的更新時のキャッシュ維持戦略
タイムスタンプやファイル変更などの動的情報をプロンプト自体に含めず、メッセージタグ(例:<system-reminder>)として次のターンで渡すことで、キャッシュミスを回避しコストを抑える。
セッション中のモデル変更の禁止
プロンプトキャッシュはモデル固有であるため、セッション途中でモデルを変更するとキャッシュが破棄され、計算リソースとコストが浪費されるため避ける必要がある。
影響分析・編集コメントを表示
影響分析
この記事は、LLM エージェントが実用レベルで展開される際に直面する「高レイテンシ」と「高額な推論コスト」の問題に対する、具体的なアーキテクチャ設計指針を提供しています。特に、プロンプトエンジニアリングの観点からキャッシュ戦略を最適化することで、スケーラブルな製品を実現できるという知見は、開発者にとって即座に適用可能な重要なベストプラクティスです。
編集コメント
エージェント開発において、単なるプロンプトの記述だけでなく、キャッシュというインフラ層を考慮した設計が不可欠であることを示す優れた事例です。実務レベルでのコスト管理に直結する知見として注目すべき記事です。
エンジニアリングの世界ではよく「キャッシュこそがすべてを支配する」と言われますが、エージェントにおいても同じ法則が成り立ちます。
Claude Code のような長時間稼働するエージェント製品は、プロンプトキャッシングによって実現可能になっています。これにより、過去のラウンドトリップからの計算結果を再利用でき、レイテンシとコストを大幅に削減できます。
Claude Code では、プロンプトキャッシングを中心に全体のハネス(枠組み)を構築しています。高いプロンプトキャッシュヒット率はコスト削減につながり、サブスクリプションプランに対してより寛容なレート制限を設定できるため、プロンプトキャッシュヒット率のアラートを常時監視し、値が低すぎる場合は SEV(重大インシデント)として宣言します。
これらは、大規模なプロンプトキャッシングの最適化を通じて得た(しばしば直感に反する)教訓です。
キャッシュを考慮したプロンプトの構成

Claude Code のシステムプロンプトは、安定した部分がキャッシュされ、会話自体がターンごとにのみ成長するように構成されています。プロンプトキャッシングはプレフィックスマッチングによって機能します。つまり、API はリクエストの先頭から各 cache_control ブレイクポイントまでのすべての内容をキャッシュします。これは、項目を配置する順序が極めて重要であることを意味しており、可能な限り多くのリクエストで共通のプレフィックスを持たせるようにする必要があります。
これを実現するための最良の方法は、「静的なコンテンツを先に、動的なコンテンツを後に」配置することです。Claude Code では以下のような構成になります:
- システムプロンプトとツール(グローバルキャッシュ)
- CLAUDE.md(プロジェクト内キャッシュ)
- セッションコンテキスト(セッション内キャッシュ)
- 会話メッセージ
このようにすることで、キャッシュヒットを共有するセッション数を最大化できます。
しかし、このアプローチは驚くほど脆いものです。以前、以下のような理由でこの順序を破ったことがあります:システムプロンプトに詳細なタイムスタンプを含める、ツールの定義順序を非決定論的にシャッフルする、ツールのパラメータを更新する(例:Agent ツールが呼び出せるエージェントの変更など)。
更新にはメッセージを使用する
プロンプト内の情報が古くなることがあります。例えば、時刻が経過した場合や、ユーザーがファイルを変更した場合などが該当します。プロンプトを更新したくなるかもしれませんが、それではキャッシュミスが発生し、結果としてユーザーにとって非常に高額なコストになる可能性があります。
代わりに、この情報をエージェントの次のターンでメッセージとして渡すことはできないか検討してください。Claude Code では、モデルに更新された情報を提供するために、次のユーザーメッセージまたはツール結果に <system-reminder> タグを追加しています。これによりキャッシュを維持できます。
セッション途中でモデルを変更しない
プロンプトキャッシュはモデルごとに固有のものであり、これがプロンプトキャッシングの計算を非常に直感的でないものにします。
例えば、Opus との会話で 10 万トークン進んだ段階で、比較的簡単な質問をしたい場合でも、Haiku に切り替える方が Opus で回答させるよりも実際には高額になります。なぜなら、Haiku 用のプロンプトキャッシュを再構築する必要があるからです。
モデルを切り替える必要がある場合は、サブエージェントを使用するのが最善の方法です。上記の例を拡張すると、タスク完了のために他のモデルに「引き継ぎ」メッセージを用意するよう Opus に指示するサブエージェントを展開できます。私たちは Claude Code の Explore エージェントでこれを頻繁に行っており、これらは Haiku を使用しています。
セッション中にツールを追加または削除しないこと
会話の途中でツールセットを変更することは、プロンプトキャッシュを破綻させる最も一般的な方法の一つです。直感的には「今モデルが必要とするツールだけを提供すべき」と思われるかもしれませんが、ツールはキャッシュされるプレフィックスの一部であるため、ツールの追加や削除を行うと、会話全体のキャッシュが無効化されてしまいます。
キャッシュ制約を考慮した Plan Mode の設計
Plan Mode は、キャッシュの制約を考慮して機能を設計する優れた例です。直感的なアプローチとしては、「ユーザーが Plan Mode に切り替えた際に、読み取り専用ツールのみを含むようにツールセットを差し替える」というものがありますが、これではキャッシュが破綻してしまいます。
代わりに、私たちは常にリクエストに*すべての*ツールを含め続け、EnterPlanMode と ExitPlanMode をそれ自体として機能するツールとして使用します。ユーザーが Plan Mode をオンに切り替えると、エージェントにはシステムメッセージが表示され、それが Plan Mode であることを説明し、指示内容(コードベースの探索、ファイル編集の禁止、計画完了時に ExitPlanMode の呼び出し)を伝えます。ツールの定義自体は変更されません。
これには追加のメリットがあります。EnterPlanMode はモデル自身が呼び出せるツールであるため、困難な問題を検出した際に、キャッシュを破断することなく自律的にプランモードに入ることができます。
削除ではなく遅延のためにツール検索を使用する
同じ原則が、ツール検索ツール にも適用されます。Claude Code では数十の MCP ツールを読み込める場合がありますが、すべてのツールを各リクエストに含めるとコストが高くなります。一方で、会話中にそれらを削除するとキャッシュが破断してしまいます。
私たちの解決策は defer_loading(遅延読み込み)です。ツールを削除するのではなく、必要な時にモデルが「発見」できるように、軽量なスタブ(ツール名のみで、defer_loading: true を付与したもの)を送信します。実際のツールスキーマは、モデルがそれらを選択した際にのみ読み込まれます。これにより、同じスタブが常に同じ順序で存在するため、キャッシュされるプレフィックスを安定させることができます。
この処理を簡素化するために、ツール検索ツール を API 経由で使用することもできます。
キャッシュを破断せずに圧縮する
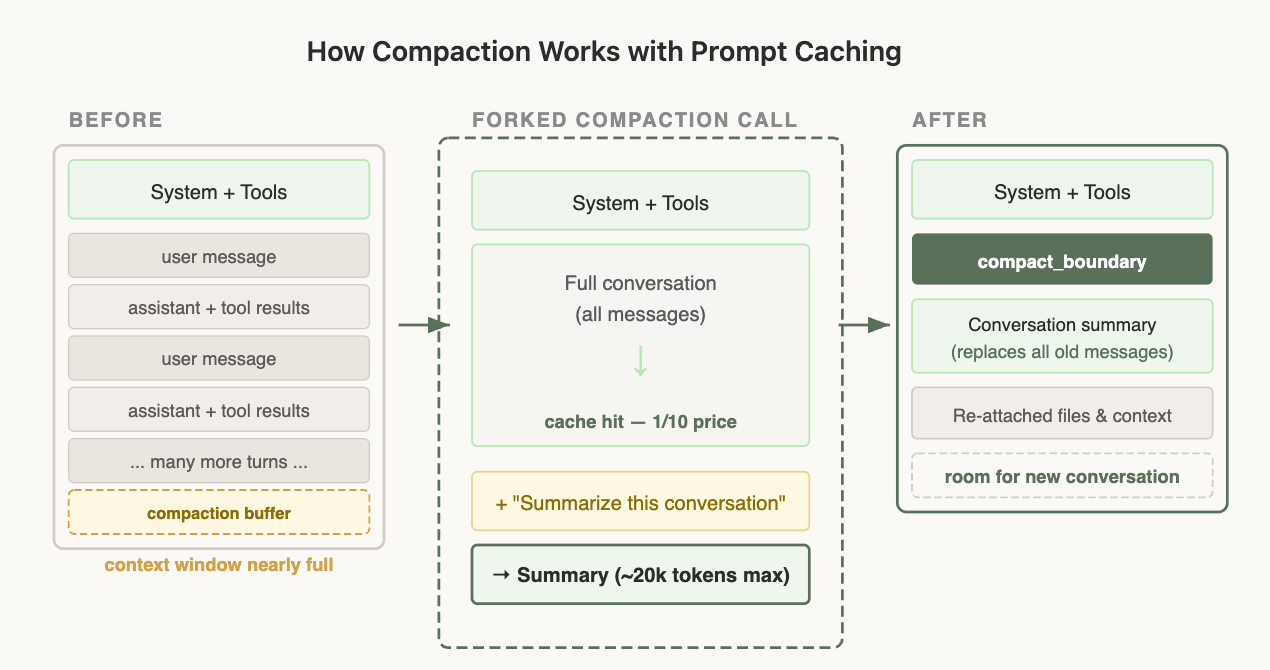
コンテキストウィンドウがいっぱいになると、Claude Code はキャッシュされた呼び出しをフォークして会話を要約し、その要約を元のメッセージの代わりに置いて処理を再開します。Compaction とは、コンテキストウィンドウを使い果たした際に発生するプロセスです。これまでの会話を要約し、その要約を用いて新しいセッションを継続します。
Compaction はプロンプトキャッシュと相互作用しますが、この関係性を誤解しやすい点があります。会話の要約を行うには、モデルが要約文を作成できるように、完全な会話内容をモデルに送信する必要があります。最も単純な方法は、独自のシステムプロンプト(「これを要約してください」のような内容)を持ち、ツールを一切付随させない別個の API 呼び出しを実行することですが、まさにここにコストの罠が存在します。プロンプトキャッシュが適用されるのは、リクエストのプレフィックスが既にキャッシュされているものと先頭からバイト単位で完全に一致する場合に限られます。メインの会話は特定のシステムプロンプトとツールセットの下でキャッシュされていますが、要約用の呼び出しでは異なるシステムプロンプトを使用し、かつツールを付随させないため、最初のトークン時点でプレフィックスが分岐してしまい、キャッシュの一切が適用されません。その結果、送信する会話全体に対して、キャッシュされていない入力レートでの完全な料金を支払うことになります。そして、会話が長ければ長いほど(つまり、そもそも compaction が必要となるケースほど)、この一度の呼び出しのコストは高騰します。
解決策:キャッシュ対応型のフォーク処理
コンパクションを実行する際、親会話と同じシステムプロンプト、ユーザーコンテキスト、システムコンテキスト、およびツール定義を*正確にそのまま*使用します。親の会話メッセージを先頭に追加し、その後ろにコンパクション用プロンプトを新しいユーザーメッセージとして末尾に付加します。
API の観点から見ると、このリクエストは親の最後のリクエストとほぼ同一に見えます——同じプレフィックス、同じツール、同じ履歴があるため、キャッシュされたプレフィックスが再利用されます。新たに生成されるトークンはコンパクション用プロンプトそのものだけです。
ただし、これには文脈ウィンドウ内にコンパクト化されたメッセージと要約出力トークンを収める十分な余地を確保するために、「コンパクションバッファ」を保存しておく必要があるという意味も含まれます。
コンパクションは難しいですが、幸運なことに、これらの教訓を自ら学ぶ必要はありません。Claude Code での経験に基づき、compaction を API に直接組み込んだため、ご自身のアプリケーションでもこれらのパターンを適用できます。
学んだ教訓
エージェント構築においてプロンプトキャッシングを最適化するために有用だと見なしたいくつかのパターンをご紹介します:
- プロンプトキャッシングはプレフィックス一致に基づきます。プレフィックス内のどこか一箇所でも変更があれば、その後のすべての内容が無効化されます。この制約を前提にシステム全体を設計してください。順序付けを正しく行えば、キャッシングの大半が自動的に機能します。
- システムプロンプトの変更ではなくメッセージを使用してください。プランモードへの移行や日付の変更などを行うためにシステムプロンプトを編集したくなるかもしれませんが、実際には会話中にこれらの情報をメッセージとして挿入する方がはるかに効果的です。
- 会話中にツールやモデルを変更しないでください。ツールセットそのものを変更するのではなく、ツールを使って状態遷移(プランモードなど)を表現してください。ツールの削除ではなく、ロードの遅延実行を検討してください。
- キャッシュヒット率を稼働率と同様に監視してください。キャッシュの切断が発生した場合はアラートを発令し、インシデントとして扱います。キャッシュミス率が数パーセント変化するだけで、コストやレイテンシーに劇的な影響を与えます。
- フォーク操作では親プロセスのプレフィックスを共有する必要があります。サイド計算(圧縮、要約、スキル実行など)を実行する必要がある場合は、親のプレフィックスでキャッシュヒットを得られるよう、同一のキャッシュ安全パラメータを使用してください。
Claude Code は初日からプロンプトキャッシングを中心に構築されています。エージェントを構築する際にも、同様にアプローチすることをお勧めします。
Claude Code で今日から始めましょう。
*この記事は、Claude Code チームの技術スタッフである Thariq Shihipar によって執筆されました。*
原文を表示
It is often said in engineering that "cache rules everything around me", and the same rule holds for agents.
Long running agentic products like Claude Code are made feasible by prompt cachingwhich allows us to reuse computation from previous roundtrips and significantly decrease latency and cost.
At Claude Code, we build our entire harness around prompt caching. A high prompt cache hit rate decreases costs and helps us create more generous rate limits for our subscription plans, so we run alerts on our prompt cache hit rate and declare SEVs if they're too low.
These are the (often unintuitive) lessons we've learned from optimizing prompt caching at scale.
Lay out your prompt for caching
Prompt caching works by prefix matching—the API caches everything from the start of the request up to each cache_control breakpoint. This means the order you put things in matters enormously, you want as many of your requests to share a prefix as possible.
The best way to do this is static content first, dynamic content last. For Claude Code this looks like:
- Static system prompt & Tools (globally cached)
- CLAUDE.md (cached within a project)
- Session context (cached within a session)
- Conversation messages
This way we maximize how many sessions share cache hits.
But this approach can be surprisingly fragile. We’ve broken this ordering before for a variety of reasons, including: putting an in-depth timestamp in the static system prompt, shuffling tool order definitions non-deterministically, and updating parameters of tools (e.g., what agents the Agent tool can call).
Use messages for updates
There may be times when the information you put in your prompt becomes out of date, for example if you have the time or if the user changes a file. It may be tempting to update the prompt, but that would result in a cache miss and could end up being quite expensive for the user.
Consider if you can pass in this information via messages in the agent’s next turn instead. In Claude Code, we add a <system-reminder> tag in the next user message or tool result with the updated information for the model, which helps preserve the cache.
Don't change models mid-session
Prompt caches are unique to models and this can make the math of prompt caching quite unintuitive.
For example, if you're 100k tokens into a conversation with Opus and want to ask a question that is fairly easy to answer, it would actually be more expensive to switch to Haiku than to have Opus answer, because we would need to rebuild the prompt cache for Haiku.
If you need to switch models, the best way to do it is with subagents; extending the above example, you could deploy a subagent that prompts Opus to prepare a "hand-off" message to another model on the task that it needs to get done. We do this often with the Claude Code’s Explore agents, which use Haiku.
Never add or remove tools mid-session
Changing the tool set in the middle of a conversation is one of the most common ways people break prompt caching. It seems intuitive—you should only give the model tools you think it needs right now. But because tools are part of the cached prefix, adding or removing a tool invalidates the cache for the entire conversation.
Using Plan Mode to design around the cache
Plan Mode is a great example of designing features around caching constraints. The intuitive approach would be: when the user enters plan mode, swap out the tool set to only include read-only tools, but that would break the cache.
Instead, we keep *all* tools in the request at all times and use EnterPlanMode and ExitPlanMode as tools themselves. When the user toggles Plan Mode on, the agent gets a system message explaining that it's in Plan Mode and what the instructions are: explore the codebase, don't edit files, and call ExitPlanMode when the plan is complete. The tool definitions never change.
This has a bonus benefit: because EnterPlanMode is a tool the model can call itself, it can autonomously enter plan mode when it detects a hard problem, without any cache break.
Use tool search to defer instead of remove
The same principle applies to our tool search tool. Claude Code can have dozens of MCP tools loaded, and including all of them in every request would be expensive, but removing them mid-conversation would break the cache.
Our solution: defer_loading. Instead of removing tools, we send lightweight stubs ( just the tool name, with defer_loading: true) that the model can "discover" via tool search when needed. The full tool schemas are only loaded when the model selects them. This keeps the cached prefix stable because the same stubs are always present in the same order.
You can also use the tool search tool through our API to simplify this.
Compacting without breaking the cache
Compaction is what happens when you run out of the context window. We summarize the conversation so far and continue a new session with that summary.
Compaction interacts with prompt caching in ways that are easy to get wrong. To compact a conversation, you have to send the full conversation to the model so it can write a summary. The simplest way to do that is a separate API call with its own system prompt (something like "summarize this") and no tools attached, but that's exactly where the cost trap is. Prompt caching only applies when a request's prefix matches what's already cached, byte for byte, from the start. Your main conversation is cached under one system prompt and tool set; the summarization call uses a different system prompt and no tools, so the prefixes diverge at the very first token and none of the cache applies. You end up paying the full, uncached input rate for the entire conversation you're sending in — and the longer the conversation (i.e., the more you need compaction in the first place), the more expensive that one call becomes.
The solution: cache-safe forking
When we run compaction, we use the *exact same* system prompt, user context, system context, and tool definitions as the parent conversation. We prepend the parent's conversation messages, then append the compaction prompt as a new user message at the end.
From the API's perspective, this request looks nearly identical to the parent's last request — same prefix, same tools, same history — so the cached prefix is reused. The only new tokens are the compaction prompt itself.
This does mean however that we need to save a "compaction buffer" so that we have enough room in the context window to include the compact message and the summary output tokens.
Compaction is tricky but luckily, you don't need to learn these lessons yourself—based on our learnings from Claude Code we builtcompaction directly into the API, so you can apply these patterns in your own applications.
Lessons learned
Here are a few patterns we’ve found useful for optimizing prompt caching when building an agent:
- Prompt caching is a prefix match. Any change anywhere in the prefix invalidates everything after it. Design your entire system around this constraint. Get the ordering right and most of the caching works for free.
- Use messages instead of system prompt changes. You may be tempted to edit the system prompt to do things like entering plan mode, changing the date, etc. but it would actually be better to insert these into messages during the conversation.
- Don't change tools or models mid-conversation. Use tools to model state transitions (like plan mode) rather than changing the tool set. Defer tool loading instead of removing tools.
- Monitor your cache hit rate like you monitor uptime. We alert on cache breaks and treat them as incidents. A few percentage points of cache miss rate can dramatically affect cost and latency.
- Fork operations need to share the parent's prefix. If you need to run a side computation (compaction, summarization, skill execution), use identical cache-safe parameters so you get cache hits on the parent's prefix.
Claude Code is built around prompt caching from day one; for the best results when building an agent, we suggest you do, too.
Get started* with Claude Code today. *
*This article was written by Thariq Shihipar, a member of technical staff on the Claude Code team. *
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み