Together AI が世界最速の音声テキスト変換スタックを構築した方法
Together AI は、TensorRT の最適化や CPU プリプロセスの改善など、システム全体のボトルネックを解消することで、世界最速の音声認識スタックを実現した。
キーポイント
ASR のシステム全体最適化アプローチ
LLM と異なりパラメータ数が少ない ASR モデルでは、GPU 実行だけでなく CPU プリプロセスやメモリ移動などデータパス全体の最適化が重要であるとし、全工程を統合的に改善した。
TensorRT と CUDA グラフの活用
可変長の音声入力に対応するため、TensorRT のマルチプロファイルエンジンと条件付き CUDA グラフを採用し、エンコーダーのコンパイルを最適化して遅延を大幅に削減した。
CPU 側の処理効率向上
音声デコード、リサンプリング、ノイズフィルタリングなどの前処理を低コピーパスとし、イベント駆動型のストリーミング I/O を導入することで、転送遅延を最小化した。
Python GC とランタイム制御
Python のガベージコレクションによるジッターを回避するための対策を実装し、オフラインとストリーミングの両モードにおいて安定した低遅延性能を達成した。
重要な引用
ASR serving a full-path systems problem spanning GPU execution, CPU preprocessing, memory movement, transport, connection scheduling, and runtime behavior.
The same Harry Potter corpus as audiobooks is 5 to 10 GB, roughly three orders of magnitude larger than the text.
NVIDIA Parakeet-TDT 0.6B v3 can transcribe roughly 20 hours of speech... in under 10 seconds.
影響分析・編集コメントを表示
影響分析
この記事は、大規模言語モデル(LLM)への注目が集まる中で、音声認識のような軽量モデルにおけるシステムエンジニアリングの重要性を浮き彫りにしています。特に、ハードウェアのポテンシャルを引き出すための詳細な最適化手法(TensorRT プロファイル、GC 制御など)が公開されることで、実運用環境での低遅延 ASR サービス構築に対する技術的ベンチマークを示すものとなっています。
編集コメント
LLM の推論速度が注目されがちですが、この記事は音声認識のような軽量モデルにおいても、システム全体のボトルネック解消が性能を左右する重要な事例を示しています。実運用での低遅延化に向けた具体的な技術スタックの公開は、エンジニアにとって非常に参考になる内容です。
NVIDIA TensorRT のマルチプロファイルエンジン、条件付き NVIDIA CUDA グラフ、イベント駆動型 I/O、共有メモリ、そして Together 社の ASR レイテンシ結果を支える Python GC(ガベージコレクション)の修正について。
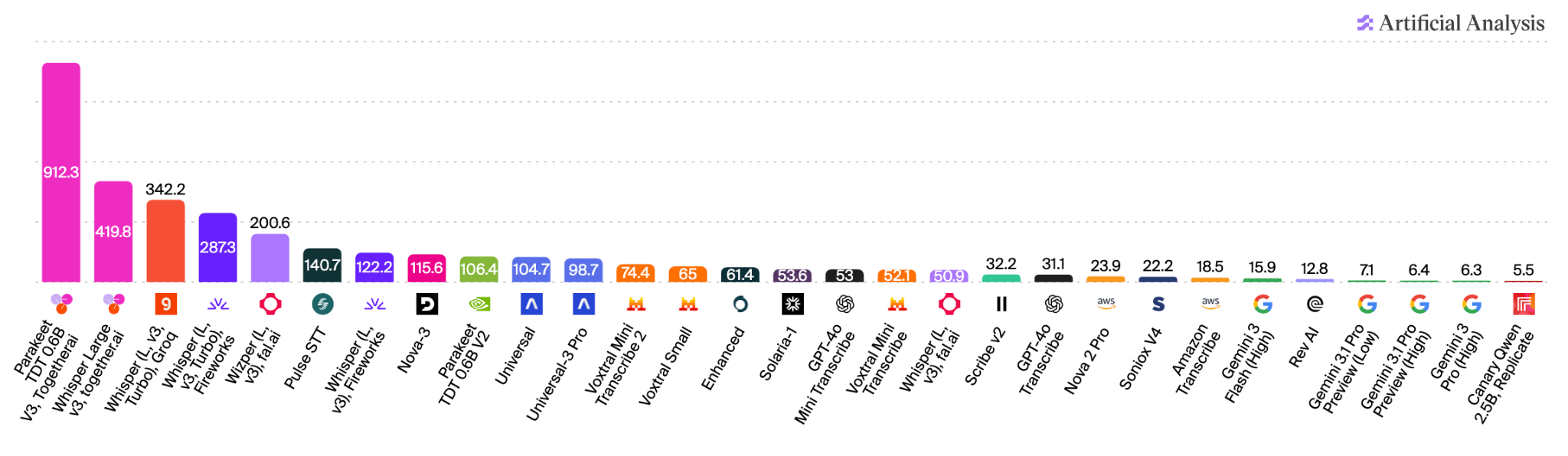
Artificial Analysis が報告した速度係数(入力音声の 1 秒あたりにトランスクリプト化される秒数)—— 高いほど優れています。
モダリティが重要である
1M トークンのテキストプロンプトであれば、ハリー・ポッターシリーズ全体を収容しても重さは約 5 MB に過ぎません。この規模は巨大に聞こえますが、入力自体はコンパクトです。テキストも推論の直前までほぼ準備できており、トークン化し、バッチ処理し、モデル内を通過させるだけです。
オーディオは問題の形状を変えます。同じハリー・ポッターのコーパスをオーディオブックとして扱う場合、サイズは 5〜10 GB に達し、テキストと比較して約 3 オーダー(1000 倍)も大きくなります。GPU に到達する前に、サーバー側でコンテナのデコード、リサンプリング、ノイズフィルタリング、VAD(音声活動検出)、音声セグメンテーション、そしてオーディオ特徴量の計算を行う必要があります。
モデル側の構造も逆転します。現在の LLM(大規模言語モデル)は数百億から数兆ものパラメータを有するため、推論サービスは自然と GPU 内部に集中します:量子化、KV キャッシュ、アテンションカーネル、バッチ処理、並列化などです。一方、音声認識モデルははるかに小さく、パラメータ数は通常数億から数十億程度であるため、周辺データパスの重要性がより高まります。
これにより、ASR サービングは、GPU 実行、CPU プリプロセッシング、メモリアクセス、転送、接続スケジューリング、ランタイム動作にわたるフルパスのシステム問題となります。同じスタックは、スループットが最も重要となるオフライン文字起こしと、レイテンシとジッターが支配的となるストリーミング文字起こしの、2 つの異なるレジームも同時に処理する必要があります。
Together の ASR スタックは、Artificial Analysis によってランク付けされた、世界で最も低遅延な 2 つの音声からテキストへの変換モデル、すなわち NVIDIA の Parakeet-TDT 0.6B v3 と OpenAI の Whisper Large v3 をサポートしています。この 2 つのうちより高速な NVIDIA Parakeet-TDT 0.6B v3 は、ハリー・ポッター映画シリーズの上映時間である約 20 時間の音声を、10 秒未満で文字起こしすることができます。
本稿の後半では、この結果を実現したプロダクション環境における変更点について解説します。これには、実際の音声形状に合わせた TensorRT プロファイル(TensorRT profiles)、GPU 側でのデコーダー制御フロー、コピー数を削減した CPU パス、イベント駆動型のストリーミング I/O、そしてランタイム GC(Garbage Collection)制御が含まれます。
実際の音声形状向けにエンコーダをコンパイルする
Parakeet はエンコーダー・デコーダーアーキテクチャを採用しており、その重みの約 95% がエンコーダーに存在します。エンコーダーは可変長の音声セグメントを受け取り、デコーダー用の音響フレームを生成するため、最適化の最初の対象となりました。
音声入力は、200 ミリ秒のストリーミングパケットから 30 秒間の連続した音声まで、非常に幅広い長さの範囲にわたります。ある入力形状向けに調整されたカーネルプランは、別の形状では大幅に低速になる可能性があるため、エンジン側でコンパイル時に遭遇する形状の分布を把握しておく必要があります。
TensorRT を導入する前、私たちは torch.compile と CUDA グラフを活用した最適化された PyTorch パスを使用しており、同じ形状プロファイルに対してチューニングを施していました。これにより、PyTook チェーンから離れることなく、形状認識型の実行を実現し、強力なベースラインを確立しました。
TensorRT は、本番環境向けのより高速なエンコーダパスを提供します。これは事前に関数を実行計画として構築し、可能な限りカーネルを融合させ、メモリレイアウトを最適化し、提供が予想される形状範囲に対してカーネルのバリエーションをベンチマークします。
重要な詳細はプロファイルチューニングにあります。最大の入力形状のみでチューニングされた単一のエンジンを使用すると、短いオーディオセグメントはパディングされたパスに強制され、ストリーミングチャンクや短い発話において特にコスト高となります。一方、マルチプロファイルの TensorRT エンジンを使用すれば、メモリ上にエンコーダ重みのコピーを 1 つだけ保持しつつ、リクエストごとに最適な最適化プロファイルを選択できます。
メモリ削減効果は限定的で、約 6GB から 5GB の減少でした。より大きな成果は、不適切な形状マッチの回避と、チューニングされたプロファイルに対して最適化された PyTorch から TensorRT へ移行した点にあります。小入力領域では、形状認識型の TensorRT は、これらのリクエストを大きなパディング済みプロファイル経由で送信する場合に比べて数倍高速になる可能性があります。
エンコーダの最適化が完了した後、デコーダーループが次のボトルネックとなりました。
デコーダーループから CPU を排除する
Parakeet のデコーダーは、エンコーダの音響フレームを反復処理し、転写文を進めないフレームに対してトークンまたは BLANK を出力します。コードは本質的に以下のようになります:
state = init()
for frame in encoder_output:
token = predict(frame, state)
if token != BLANK:
emit(token)
state = update(state, token)
プロファイリングを行ったところ、predict と update の両方が高速であることが分かりました。1 回ごとの GPU での処理時間はマイクロ秒単位で測定されました。
コストのかかる行はブランチ部分でした:
if token != BLANK:
このブランチでは、CPU がどのパスを取るかを決定するために、GPU メモリからトークンを再度読み取る必要があります。このホスト同期により、デコードループが単一の CUDA グラフとしてキャプチャできず、毎回の反復で Python を経由して往復する必要があります。GPU は数マイクロ秒の処理を行い、CPU の応答を待ち、次のカーネルを開始し、そのパターンをリクエストあたり数千回繰り返します。
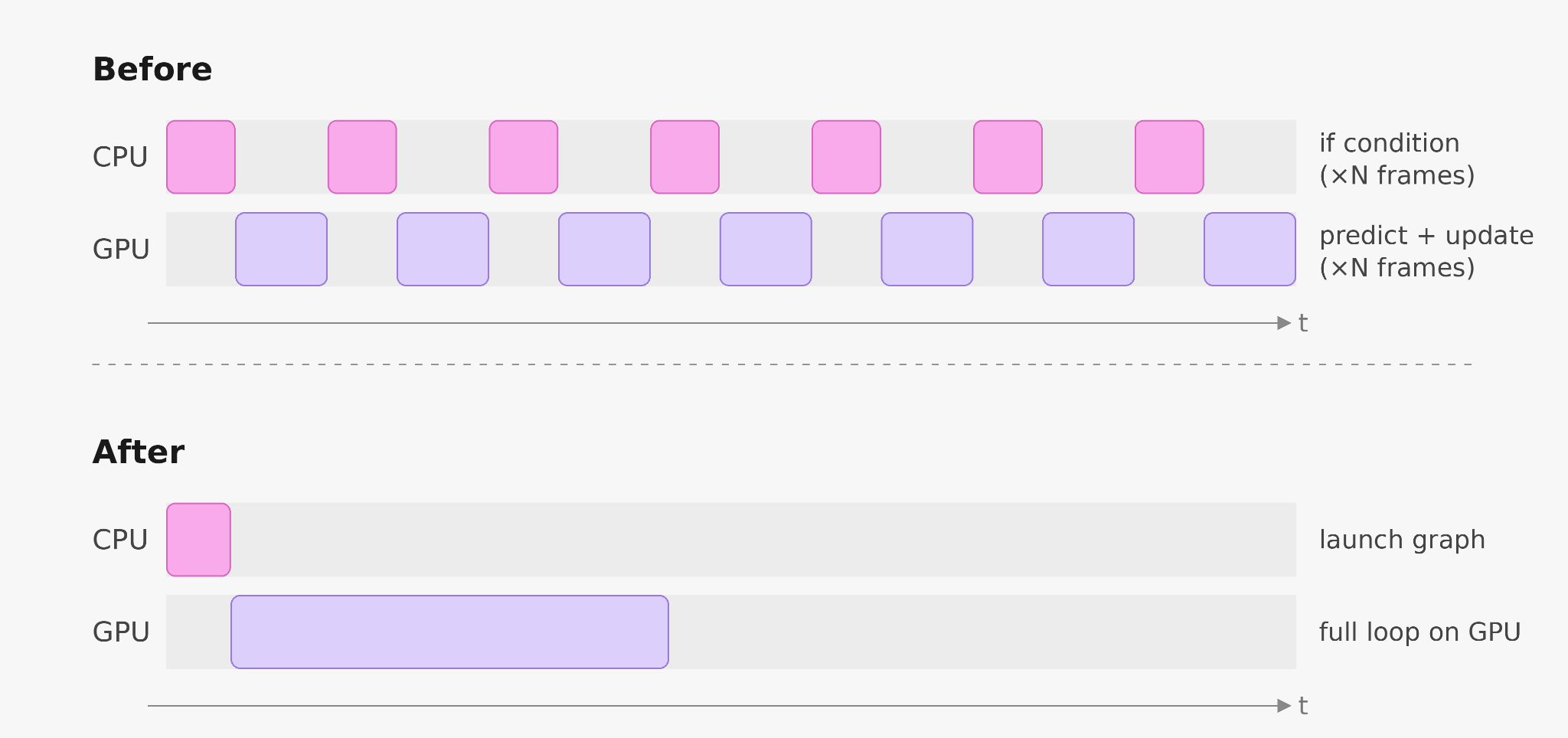
条件付き CUDA グラフノードにより、このブランチが GPU 上に移動しました。小さなデバイス側カーネルが条件を評価し、トークン発行と状態更新のサブグラフに入るかどうかを CUDA ランタイムに伝えます。ブランチは GPU を離れることなく解決されるため、デコーダーループ全体、カウンター、条件、emit、および状態更新を単一の CUDA グラフとしてキャプチャして起動することが可能になります。
CPU はデコーダーの内部ループから外れ、その結果、デコーダーが 2 倍から 3 倍高速化されました。
オーディオバイトのコピーを止めよう
エンコーダーとデコーダーが正常に動作するようになった後、残りのレイテンシはモデル周辺の CPU パスから発生していました。これが、私たちが監査した ASR(Automatic Speech Recognition:自動音声認識)コードのほとんどでレイテンシ予算の大部分を占めている箇所です。ここでは冗長なコピー、ホットパス上の不要なプロセスホップ、そして並列性を高めることで改善が見込めるシングルスレッド関数が問題となっています。
最初の対策は、不必要なプロセス境界を統合することでした。
オーディオ前処理(ファイルデコード、リサンプリング、音声活動検出 (VAD)、特徴量抽出、チャンク処理など)の多くは I/O またはネイティブ C/C++ の作業であり、Python のグローバルインタープリターロック (GIL) を解放します。典型的なマイクロサービスアーキテクチャでは、前処理を 3 つまたは 4 つの別々のプロセスに分割しており、ワークロードが不要とする隔離のためにコストを支払っています。この作業の大部分を少数のプロセスに統合することで、カーネルコピーやシリアライズ/デシリアライズのパスを削減でき、大規模ファイルでは数百ミリ秒もの遅延を防ぐことができます。
プロセス間通信が本当に必要な場合でも、ZeroMQ などの一般的なオプションには意味のあるオーバーヘッドが存在します。私たちのワークロードでは、永続的な Unix ドメインソケット上で生オーディオバイトを転送するシンプルな独自プロトコルが、高並行下で最も優れたパフォーマンスを発揮しました。これはフレーム構成を最小限に抑え、繰り返し接続設定を行う必要がないためです。
大規模ファイルの場合、ソケットは依然として2回のコピーを課します:送信側のユーザー空間からカーネルバッファへ、そしてカーネルバッファから受信側のユーザー空間へ。この経路を回避するために、私たちは共有メモリを使用しています。共有メモリでは、両方のプロセスが同じ物理領域をマッピングするため、プロデューサーによって書き込まれたデータは、カーネルとの往復通信なしにコンシューマーにも即座に可視化されます。これにより、ゼロコピーのデータパスを実現しています。
複雑性のコストは現実的なものなので、共有メモリを使用するのはデータ量がそれを正当化する場合に限るべきです。
ストリーミングにはイベント駆動I/Oを使用する
ストリーミングASR(自動音声認識)は、接続ライフサイクルという別の問題も追加します。
私たちの最初のストリーミング実装では、1接続あたり1スレッドを使用していました。数百のストリームが同時にチャンクを送信すると、数百のスレッドが一斉に起動し、GIL(グローバルインタプリタロック)の競合が爆発的に増大し、尾部レイテンシが急上昇しました。
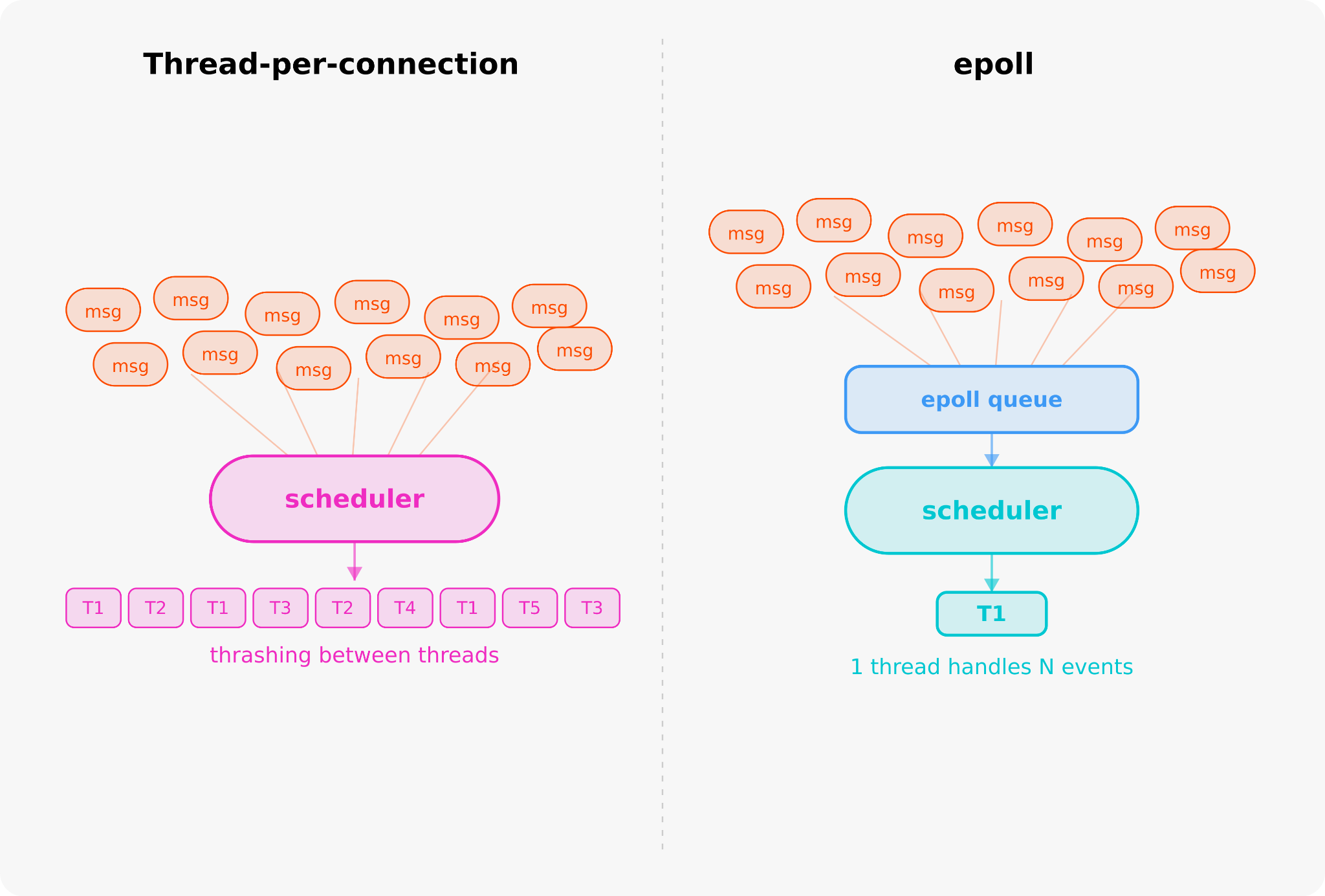
私たちは、epollでブロックされる1スレッド方式へ移行しました。
epollを使用すれば、1つのスレッドで数千の接続を登録でき、カーネルに対して単一のシステムコールで「これらのいずれかにデータがあれば目覚めさせてください」と指示できます。メッセージが到着すると、カーネルは準備完了したセット全体を返します。そのスレッドは、再びスリープする前にアクティブなソケットを処理します。
同じ負荷でも、スケジューラの圧力は大幅に軽減されます。ストリーミングASRにおいては、この予測可能性が重要です。なぜなら、遅延した部分トランスクリプトがあると、平均レイテンシが良好に見えていても、音声システムが遅く感じられてしまうからです。
起動状態を凍結してGCの尾部レイテンシを排除する
私たちはこれをほぼ見逃していました。
ストリーミングワークロードの負荷下では、p50 および p90 のレイテンシは健全に見えたものの、p95 は定期的に約 200 ミリ秒スパイクしました。ログを確認するとキュー深度は小さく GPU 処理時間も正常でしたが、通常は 5 ミリ秒未満で完了する CPU 関数が突然 100 ミリ秒以上を要するようになりました。
何かがバックグラウンドでリクエストループの時間を奪っていました。
プロファイリングの結果、Python のガベージコレクタ (GC) が疑われました。Python はメモリ管理の大部分に参照カウントを使用し、参照サイクルを検出するためのサイクル検出型コレクタを備えています。このコレクタは世代別で動作します。最も古い世代には長寿命オブジェクトが含まれており、フルコレクションでは大規模なオブジェクトグラフ全体を走査することになります。
私たちはスタートアップ時に、定常状態での割り当て遅延を回避するために、バッファ、モデル状態、ルックアップテーブルの大規模プールを事前に割り当てていました。これらの長寿命オブジェクトは最も古い世代に配置されたため、フル GC パスでは数十万の参照が走査されました。これが 200 ミリ秒のストップの原因でした。
解決策は、スタートアップ後の事前割り当ての直後に 1 行追加するだけでした:
gc.freeze()
gc.freeze() は、Python に事前割り当てされた状態を今後の GC スキャンから除外するように指示します。これにより、通常のリクエストスコープ内のオブジェクトは依然として収集されますが、巨大な初期状態はそのまま維持されます。
p95 のスパイクは消え去り、p50 も改善しました。これはシステムがより滑らかなトラフィックパターンを維持できるようになったためです。
教訓は、モデルを超えてプロファイリングを継続することでした。GPU 処理時間、キュー深度、モデル実行時間はすべて正常に見えたものの、レイテンシスパイクの真の原因は Python ランタイム内にありました。
Voice latency is an end-to-end systems problem
Voice agents usually run as a cascade: ASR produces a transcript, an LLM generates the response, and TTS produces audio. ASR is the first stage in that path, so its latency and jitter set the earliest bound on user-visible response time.
The optimizations above target different parts of that path. TensorRT multi-profile engines tune encoder execution for real audio shapes. Conditional CUDA graphs remove CPU round trips from the decoder loop. Persistent Unix domain sockets, shared memory, and epoll reduce CPU-path overhead. gc.freeze() removes a runtime-level p95 failure mode.
The same constraint applies to the rest of the stack: every stage has to control both median latency and tail latency across model execution, preprocessing, transport, scheduling, and runtime behavior.
NVIDIA Parakeet-TDT 0.6B v3 and OpenAI Whisper Large v3 are available on Together. Reach out if you're scaling voice AI in production.
*Parakeet v3 は、Hugging Face Open ASR リーダーボードにおいて単一言語のスループットでペースを決定した英語専用モデルである v2 の後継です。v3 はその基盤を大幅に拡張し、言語サポートを英語から 25 ヶ国の欧州言語へ拡大し、言語プロンプトを必要としない自動言語検出機能を追加しました。また、NVIDIA の Granary 多言語コーパスを含む 170 万時間の音声データでトレーニングされています。
原文を表示
NVIDIA TensorRT multi-profile engines, conditional NVIDIA CUDA graphs, evented I/O, shared memory, and the Python GC fix behind Together’s ASR latency results.
Modality matters
A 1M-token text prompt can fit the entire Harry Potter series and still only weigh around 5 MB. That scale sounds enormous, but the input itself is compact. Text also arrives almost ready for inference: tokenize it, batch it, and move it through the model.
Audio changes the shape of the problem. The same Harry Potter corpus as audiobooks is 5 to 10 GB, roughly three orders of magnitude larger than the text. Before any of it reaches the GPU, the server has to decode the container, resample, filter noise, run VAD, segment speech, and compute audio features.
The model side flips too. LLMs these days have hundreds of billions or trillions of parameters, so serving work naturally concentrates inside the GPU: quantization, KV cache, attention kernels, batching, and parallelism. Speech-to-text models are much smaller, often in the hundreds of millions to low billions of parameters, so the surrounding data path matters much more.
That makes ASR serving a full-path systems problem spanning GPU execution, CPU preprocessing, memory movement, transport, connection scheduling, and runtime behavior. The same stack also has to serve two different regimes: offline transcription, where throughput matters most, and streaming transcription, where latency and jitter dominate.
Together’s ASR stack serves the two lowest-latency speech-to-text models ranked by Artificial Analysis: NVIDIA’s Parakeet-TDT 0.6B v3 and OpenAI’s Whisper Large v3. The faster of the two, NVIDIA Parakeet-TDT 0.6B v3, can transcribe roughly 20 hours of speech, about the runtime of the Harry Potter film franchise, in under 10 seconds.
The rest of this post breaks down the production changes behind that result: TensorRT profiles for real audio shapes, GPU-side decoder control flow, lower-copy CPU paths, evented streaming I/O, and runtime GC control.
Compile the encoder for real audio shapes
Parakeet uses an encoder-decoder architecture, and roughly 95% of its weights sit in the encoder. The encoder takes a variable-length speech segment and produces acoustic frames for the decoder, which made it the first place to optimize.
Audio inputs span a wide range of lengths, from a 200 ms streaming packet to 30 seconds of uninterrupted speech. A kernel plan tuned for one input shape can be substantially slower at another, so the engine needs to know the shape distribution it will see at compile time.
Before TensorRT, we were already using an optimized PyTorch path with torch.compile and CUDA graphs, tuned across the same shape profiles. That gave us a strong baseline: profile-aware execution without leaving the PyTorch stack.
TensorRT gave us a faster encoder path for production. It builds an optimized execution plan ahead of time, fusing kernels where possible, tuning memory layouts, and benchmarking kernel variants for the shape ranges we expect to serve.
The important detail is profile tuning. A single engine tuned only for the largest input shape forces shorter audio segments into a padded path, which is especially costly for streaming chunks and short utterances. A multi-profile TensorRT engine lets us keep one copy of the encoder weights in memory while selecting the right optimization profile per request.
The memory savings were modest, roughly 6 GB to 5 GB. The larger win was avoiding bad shape matches and moving from optimized PyTorch to TensorRT for tuned profiles. In the small-input regime, profile-aware TensorRT can be several times faster than sending those requests through a large padded profile.
With the encoder optimized, the decoder loop became the next bottleneck.
Remove the CPU from the decoder loop
Parakeet’s decoder iterates over the encoder’s acoustic frames and emits either a token or a BLANK for frames that do not advance the transcript. The code is essentially:
state = init()
for frame in encoder_output:
token = predict(frame, state)
if token != BLANK:
emit(token)
state = update(state, token)
When profiling, we found that predict and update were both fast. The per-iteration GPU work was measured in microseconds.
The expensive line was the branch:
if token != BLANK:
That branch requires the CPU to read the token back from GPU memory to decide which path to take. This host sync prevents the decode loop from being captured as a single CUDA graph and forces every iteration to round-trip through Python. The GPU does a few microseconds of work, waits for the CPU, launches the next kernel, and repeats that pattern thousands of times per request.
Conditional CUDA graph nodes moved that branch onto the GPU. A small device-side kernel evaluates the condition and tells the CUDA runtime whether to enter the token-emission and state-update subgraph. The branch resolves without leaving the GPU, so the entire decoder loop, counter, condition, emit, and state update, can be captured and launched as one CUDA graph.
The CPU leaves the decoder’s inner loop, and the result is a 2 to 3x faster decoder.
Stop copying audio bytes
Once the encoder and decoder were running well, the remaining latency came from the CPU path around the model. That is where most ASR code we’ve audited spends its latency budget: redundant copies, unnecessary process hops on the hot path, and single-threaded functions that would benefit from higher parallelism.
The first lever was collapsing unnecessary process boundaries.
Audio preprocessing, whether file decoding, resampling, voice activity detection (VAD), feature extraction, or chunk handling, is mostly I/O or native C/C++ work that releases the Python Global Interpreter Lock (GIL). A typical microservice architecture splits preprocessing across three or four separate processes, paying for isolation the workload does not need. Collapsing most of that work into fewer processes removes kernel copies and serialization/deserialization passes that can cost hundreds of milliseconds on large files.
When inter-process communication is genuinely needed, common options like ZeroMQ also carry meaningful overhead. In our workload, a simple custom protocol over persistent Unix domain sockets carrying raw audio bytes performs best under high concurrency because it keeps framing minimal and avoids repeated connection setup.
For large files, sockets still impose two copies: sender userspace to kernel buffer, then kernel buffer to receiver userspace. To avoid that path, we use shared memory. With shared memory, both processes map the same physical region, so data written by the producer is visible to the consumer without a kernel round trip. That gives us a zero-copy data path.
The complexity cost is real, so shared memory is worth reaching for only when the data volume justifies it.
Use evented I/O for streaming
Streaming ASR adds another problem: connection lifecycle.
Our first streaming implementation used one thread per connection. When hundreds of streams sent chunks at once, hundreds of threads woke up together, GIL contention exploded, and tail latency spiked.
We moved to one thread blocked on epoll.
epoll lets one thread register thousands of connections and ask the kernel in a single syscall: “wake me up when any of these has data.” When messages arrive, the kernel returns the full ready set, and that thread processes the active sockets before going back to sleep.
Same workload, far less scheduler pressure. For streaming ASR, that predictability matters because delayed partial transcripts can make a voice system feel slow even when average latency looks fine.
Freeze startup state to remove GC tail latency
We almost missed this one.
Under load for streaming workflows, p50 and p90 latency looked healthy, but p95 would periodically spike by about 200 ms. The logs showed small queue depth and normal GPU times, but CPU functions that normally ran in under 5 ms suddenly took over 100 ms.
Something in the background was stealing time from the request loop.
Profiling pointed at Python’s garbage collector (GC). Python uses reference counting for most memory management, with a cycle-detecting collector to catch reference cycles. That collector runs in generations. The oldest generation contains long-lived objects, and full collections can walk a large object graph.
We had preallocated a large pool of buffers, model state, and lookup tables at startup specifically to avoid allocation latency at steady state. Those long-lived objects landed in the oldest generation, so full GC passes walked hundreds of thousands of references. That was the 200 ms stall.
The fix was one line after startup preallocation:
gc.freeze()
gc.freeze() tells Python to exclude the preallocated state from future GC scans, so normal request-scoped objects still get collected while the giant initial state is left alone.
The p95 spikes disappeared, and p50 improved because the system could sustain smoother traffic patterns.
The lesson was to keep profiling beyond the model. GPU time, queue depth, and model execution all looked normal; the latency spike lived in the Python runtime.
Voice latency is an end-to-end systems problem
Voice agents usually run as a cascade: ASR produces a transcript, an LLM generates the response, and TTS produces audio. ASR is the first stage in that path, so its latency and jitter set the earliest bound on user-visible response time.
The optimizations above target different parts of that path. TensorRT multi-profile engines tune encoder execution for real audio shapes. Conditional CUDA graphs remove CPU round trips from the decoder loop. Persistent Unix domain sockets, shared memory, and epoll reduce CPU-path overhead. gc.freeze() removes a runtime-level p95 failure mode.
The same constraint applies to the rest of the stack: every stage has to control both median latency and tail latency across model execution, preprocessing, transport, scheduling, and runtime behavior.
NVIDIA Parakeet-TDT 0.6B v3 and OpenAI Whisper Large v3 are available on Together. Reach out if you’re scaling voice AI in production.
*Parakeet v3 is the successor to v2, which was an English-only model that set the pace on the Hugging Face Open ASR Leaderboard for single-language throughput. v3 extends that foundation significantly, expanding language support from English to 25 European languages, adding automatic language detection without requiring a language prompt, and was trained on 1.7 million hours of audio data — including NVIDIA's Granary multilingual corpus.*
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み