Violin:言語の壁を破るオープンソース動画翻訳スキル
Together AI は、音声認識、LLM、音声合成を統合した完全オープンソースの動画翻訳ツール「Violin」を発表し、言語バリアを打破する新たなソリューションを提供しました。
キーポイント
Violin ツールの公開と機能
Together API を基盤とした完全オープンソースの動画翻訳パイプラインであり、高精度な音声認識、LLM による翻訳、音声合成を統合しています。
対話型・パーソナライズ機能
標準的な翻訳に加え、動画内容に依存したチャットアシスタントや、自然言語で声質を選択できる「Natural Language Voice Picker」などの独自機能を搭載しています。
グローバルな情報アクセスの拡大
英語中心の現状(トップ 250 チャンネルの 66%)に対し、多言語化を促進することで、世界中の視聴者が高品質な動画コンテンツにアクセス可能になることを目指しています。
実証事例の提示
Together AI の技術トーク(Percy Liang 氏)を中国語に翻訳したデモ映像を公開し、翻訳の質と多言語対応能力を実証しました。
3段階の処理プロセスと技術スタック
ASR(Whisper V3)、LLM翻訳(Deepseek V4 Pro)、TTS合成(Cartesia Sonic 3)の3段階で構成され、多言語対応かつ自然な音声を実現します。
マルチモーダル動画チャット機能
Qwen3.5-397B-A17Bなどのビジョンランゲージモデルを活用し、動画の音声と映像の両方を理解して質問に答えるチャットアシスタントを搭載しています。
多様な利用シーンとオープンソース化
Webアプリ、CLIツール、エージェントスキルに対応しており、MITライセンスでコードが公開され、コミュニティによる拡張を促しています。
影響分析・編集コメントを表示
影響分析
この発表は、動画翻訳分野におけるオープンソースコミュニティと大規模モデルの実用性を結びつける重要な一歩です。特に、LLM を活用した対話機能やカスタマイズ可能な音声合成を標準搭載することで、従来の静的な字幕翻訳とは異なる、双方向で没入感のある多言語体験を提供する可能性を示しています。
編集コメント
動画コンテンツのグローバル展開において、言語バリアを解消するオープンソースツールの登場は、開発者コミュニティにとって大きな追い風となるでしょう。特に LLM を活用した対話機能の追加は、受動的な視聴から能動的な情報探索への転換を促す画期的な要素です。
動画は情報共有のための最も人気のある媒体の一つとなっています。しかし、インターネット上の人気動画コンテンツの言語分布は、必ずしも世界の視聴者の多様性を反映しているわけではありません。例えば、ある先行研究では、トップ 250 の YouTube チャンネルからの動画の 66% が英語である一方、2 番目に一般的な言語であるスペイン語はわずか 15% を占めていることが示されており [1,2]、世界中の視聴者にとってこのコンテンツの多くがアクセスできない状態となっています。この格差は、スケーラブルな動画翻訳ソリューションの必要性を浮き彫りにしています。
最先端の AI が言語の壁を打破し、動画コンテンツを世界の視聴者により身近なものにできるでしょうか?
本日、私たちは Together API によって支えられた完全オープンソースの動画翻訳ツール「Violin」をご紹介できることを嬉しく思います。Violin のパイプラインは、最先端の音声認識技術、大規模言語モデル(LLM)、および音声合成を活用して、高品質な動画翻訳を実現します。
標準的な翻訳機能に加え、動画コンテンツを認識するチャットアシスタントや自然言語による音声ピッカーなど、対話的でパーソナライズされた機能も開発しています。Violin が多言語のユーザーが情報をより容易にアクセスできるよう支援し、高品質な動画コンテンツがウェブ上でさらに広く広がっていく手助けとなることを願っています。
Violin: 動画共有における言語の壁を打破する
Violin の能力を示すために、Together AI からの 最近の技術トーク を取り上げ、別の言語に翻訳しました。
Before translation
After translation in Chinese
Dr. Percy Liang の Together Talks シリーズの紹介を、翻訳前(左)と中国語への翻訳後(右)で視聴してください。
動画とチャットする。 Violin には、動画の内容に基づいて質問に答えるビルトインのマルチモーダル チャット アシスタントも含まれています。ユーザーは、動画内の詳細を照会したり、要約を求めたり、特定のトピックについてさらに深く掘り下げたりすることができます — これらすべてが同じインターフェース内で行えます。
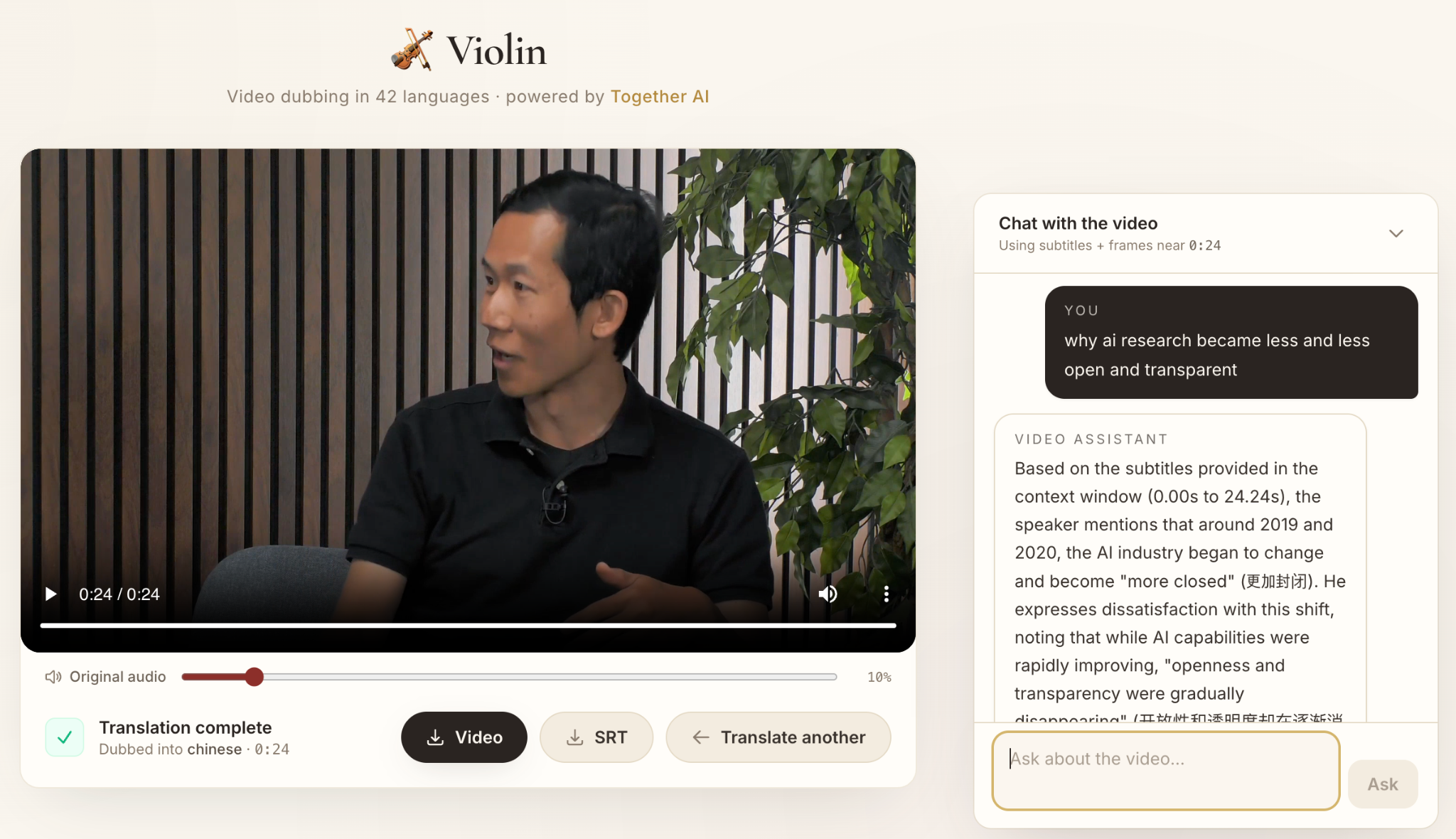
*Violin Video Assistant: 動画に関するあらゆる質問を行い、音声および視覚コンテンツに基づいた回答を受け取ります。*
Violin の仕組み
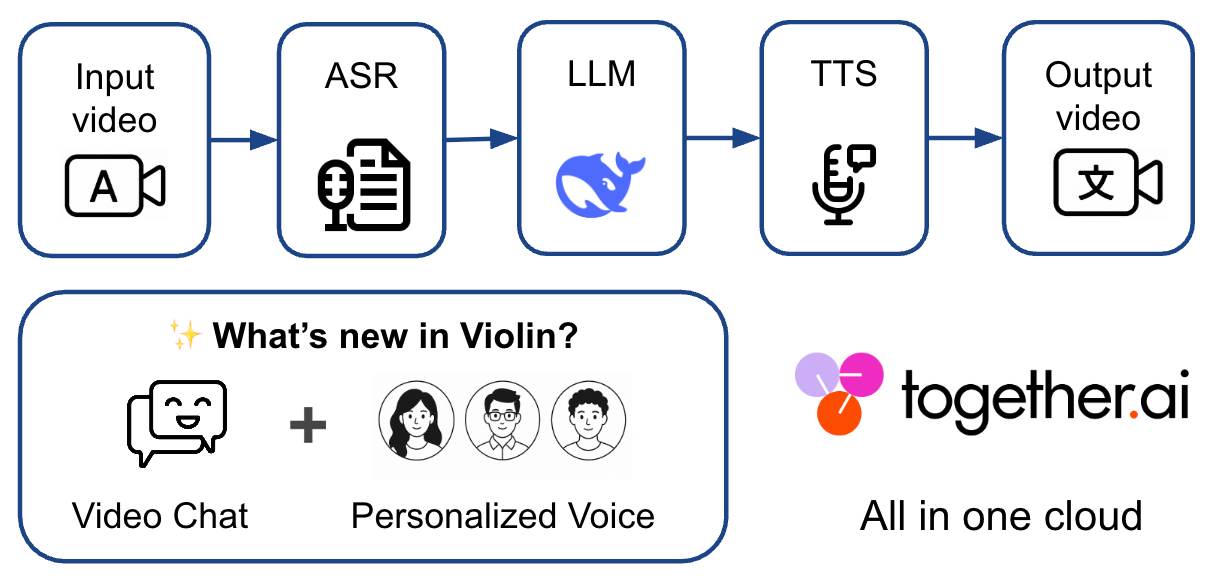
*Violin の仕組み: 入力動画から完全に翻訳された出力まで、Violin は ASR(自動音声認識)、LLM による翻訳、TTS(テキスト読み上げ)音声合成という 3 つのコア段階をオーケストレーションし、ビデオ チャット アシスタントと音声スタイルのパーソナライズもサポートします。すべて Together AI クラウド上で完結します。
Violin は 3 つの単純な段階で動作します。
まず、動画の音声を抽出してタイムスタンプ付きテキストに変換します。Together の Whisper V3 large エンドポイントを使用しており、最適化された速度で高品質な多言語トランスクリプションを提供します。
次に、大規模言語モデルがこのトランスクリプトを翻訳します。ここではデフォルトの翻訳エンジンとして、最新の Deepseek V4 Pro の進歩を活用しています。また、忠実性と正確性を維持するために、ユーザーが事前に定義された翻訳ルールのリストを入力できる機能も有効化しています。
最後に、TTS(Text-to-Speech)モデルが翻訳された音声データを生成し、ユーザーはプレーンテキストで希望する音声の特徴を指定できます。共同ホストされている Cartesia の Sonic 3 は、韓国語、オランダ語、イタリア語、中国語など、多様なネイティブスピーカーの声をサポートしており、翻訳された動画に自然な響きを与えます。なお、当ツールではボイスクローニングは許可されておらず、元の話者とは異なる独自の音声を使用し、デフォルトではその新しい音声を元の音声の上に低音量で重ね合わせる方式を採用しています。
さらに、ビデオチャットモジュールにより、動画に関する質問を行うことが可能です。これは、オーディオの内容と画面に表示されている内容を両方理解するビジョン・ランゲージモデルによって実現されています。具体的には、直近のビデオフレームと字幕コンテキストをサンプリングし、Qwen3.5-397B-A17B などのビジョン・ランゲージモデルに送信して自由形式の質問応答を行います。これにより、モデルはこれらの文脈に基づいて適切な回答を返すことができます。
誰でも使える設計:Web アプリ、CLI、エージェントスキル
Violin は使いやすさを中核として構築されました。シンプルな Web インターフェースを好むコンテンツクリエイター、コマンドラインで作業する開発者、あるいは自律型エージェントにツールを組み込む AI プラクティショナーなど、あらゆるユーザーに対応しています。
- Web アプリ – ビデオのアップロード、翻訳オプションの選択、結果のプレビュー、ビデオアシスタントとの対話を可能にする、クリーンでミニマルなフロントエンド。コード不要。
- CLI ツール – スクリプト作成、バッチ処理、既存のパイプラインへの統合のためのシンプルなコマンドラインインターフェース。
- エージェントスキル – Violin の機能を、一般的なエージェントフレームワークにそのまま組み込める「スキル」としてパッケージ化しました。
GUI からバックエンドモデル、そしてエージェントスキルに至るまで、すべてが完全にオープンソースです。私たちはコードベースを寛容な MIT ライセンスの下で公開し、コミュニティによる適応、拡張、改善を呼びかけています。オープンな協働こそが、ビデオコンテンツを真に言語非依存のものにするための最速の道であると信じています。
参加しよう
私たちはまだ始まったばかりです。あなたの助けが必要です。Violin が役に立つと感じたり、より良くするためのアイデアをお持ちの場合は:
- GitHub リポジトリをご覧ください:github.com/shang-zhu/violin
- メールでお問い合わせください:heyviolinai@gmail.com
- GitHub のイシューを開くか議論を開始してください – 皆様のフィードバックを大切にしています。
- デモアプリを試してみてください:https://violin-ai.com/(リリース後、短期間ホストされます)
謝辞
Martijn Bartelds, Yongchan Kwon, Federico Bianchi, Kaitlyn Zhouの皆さんに、貴重なフィードバックをいただき感謝いたします。Violin の基盤となっている Whisper、DeepSeek、Qwen、Cartesia のオープンソースモデル構築者の方々にも厚く御礼申し上げます。開発中に動画やフィードバックを提供いただいた Hassan El Mghari 氏と Percy Liang 氏にも特別に感謝します。
原文を表示
Video has become one of the most popular mediums for information sharing. Yet, the language distribution of popular video contents on the internet does not necessarily reflect the diversity of global audiences. For example, a prior study found that 66% of videos from the top 250 YouTube channels are in English, while Spanish, the second most common language, accounts for only 15% [1,2], leaving much of this content inaccessible to viewers around the world. This gap highlights the need for scalable video translation solutions.
Can cutting-edge AI help break down language barriers, making video content more accessible to global audiences?
Today, we are excited to introduce Violin — a fully open-source video translation tool, powered by Together API. The violin pipeline uses state-of-the-art speech recognition, large language models, and speech synthesis to achieve high-quality video translation.
Beyond standard translation, we develop interactive and personalized features, such as a video-content–aware chat assistant and natural language voice picker. We hope Violin can empower users across languages to access information more easily and can help high-quality video content travel further across the web.
Violin: Breaking the language barriers of video sharing
To illustrate Violin’s capabilities, we took a recent technical talk from Together AI and translated it into a different language.
Watch the introduction of Dr. Percy Liang’s Together Talks series before translation (Left), and after translation in Chinese (Right).
Chat with the video. Violin also includes a built-in multimodal chat assistant that can answer questions based on the video’s content. Users can query details from the video, ask for summaries, or dive deeper into specific topics — all within the same interface.
*The Violin Video Assistant: Ask any question about the video, and get answers grounded in the audio and visual contents.*
How Violin works
*How Violin Works:** From input video to fully translated output, Violin orchestrates three core stages: ASR (Automatic Speech Recognition), LLM translation, and TTS (Text-to-Speech) voice synthesis, while supporting Video chat assistant, and voice style personalization. All in Together AI cloud.*
Violin works in three straightforward stages:
First, it extracts and transcribes the video's audio into timestamped text. We use Together’s Whisper V3 large endpoint that provides high quality multi-lingual transcription at an optimized speed.
Then a large language model translates that transcript. Here we leverage the latest advances of Deepseek V4 Pro as default translator. We also enable the user's input of a predefined list of translation rules to maintain the faithfulness and accuracy.
Finally, the TTS model generates translated speech, allowing users to specify their desired voice characteristics in plain text. Together-hosted Cartesia’s Sonic 3 supports a wide range of native speaker’s voices such as Korean, Dutch, Italian, and Chinese, making the translated video sound natural. Note that we do not allow voice cloning in our tool, but rather using a distinct voice than the original speaker and by default overlaying the new voice on top of the original voice at a low volume.
Besides, the video chat module lets you ask questions about the video, powered by a vision-language model that understands both what was said in audio and shown on screen. This is implemented by sampling the recent video frame as well as the subtitle context and sent to a vision-language model like Qwen3.5-397B-A17B for free-form question-answering. In this way, the model can return the proper response based on these contexts.
Designed for everyone: Web app, CLI, and agent skills
We built Violin with usability at its core. Whether you’re a content creator who prefers a simple web interface, a developer who lives in the command line, or an AI practitioner integrating tools into autonomous agents, Violin has you covered:
- Web App – A clean, minimal frontend for uploading videos, selecting translation options, previewing results, and interacting with the video assistant. No code required.
- CLI Tool – A straightforward command-line interface for scripting, batch processing, and integration into existing pipelines.
- Agent Skills – We packaged Violin’s capabilities as a skill that can be dropped into common agent frameworks.
Everything — from the GUI to the backend models to the agent skills — is fully open source. We’re releasing the codebase under a permissive MIT license, inviting the community to adapt, extend, and improve. We believe open collaboration is the fastest path toward making video content truly language-agnostic.
Get involved
We’re just getting started, and we’d love your help. If you find Violin useful, or if you have ideas for how it could be better:
- Visit our GitHub repository: github.com/shang-zhu/violin
- Drop us a line at: heyviolinai@gmail.com
- Open a GitHub issue or start a discussion — we value every piece of feedback.
- Try our demo app at: https://violin-ai.com/ (this will be hosted for a short period of time after the release)
Acknowledgments
We are grateful to Martijn Bartelds, Yongchan Kwon, Federico Bianchi, and Kaitlyn Zhou for their thoughtful feedback. We thank the open-source model builders behind Whisper, DeepSeek, Qwen, and Cartesia, whose work forms the foundation of Violin. Special thanks to Hassan El Mghari and Percy Liang for providing videos and feedback during the development.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み