Together AIのカーネルチーム内覧
Together AIのkernelチームが、Transformerアーキテクチャの最適化に関する常識を覆すFlashAttentionを開発し、GPUメモリ階層とデータ局所性の理解に基づき2〜3倍の高速化を実現した背景と、その技術的意義について解説している。
キーポイント
FlashAttentionの革新的成果
Memorial Day 2022に公開されたFlashAttentionは、従来のスパースや低ランク手法では10%程度だった実性能向上を、GPUのメモリ移動と計算パターンに焦点を当てることで2〜3倍の高速化へと引き上げた。
ボトルネックの再定義
最高のモデルとハードウェアだけでは不十分であり、数学的抽象化とシリコン命令を翻訳する「カーネル」というソフトウェア層の最適化が、現代AIにおける真のボトルネックであることを示した。
データベース原理のAIへの応用
目立たないが重要なデータ局所性やメモリ階層といった古典的なデータベースシステムの原則をアテンション機構に応用したことが、GPU最適化における巨大な潜在力の鍵となった。
AI Native Cloudの基盤
この研究は単なるパフォーマンス向上にとどまらず、現在最も影響力のあるkernel研究チームの基盤となり、AI Native Cloudにおける重要な構成要素へと発展した。
重要な引用
"The conventional wisdom was settled: transformer attention was already optimized. GPU experts had squeezed every drop of performance from the hardware. There wasn't much left to gain."
"The bottleneck is the gap between them: the software layer that translates mathematical operations into silicon instructions. That's where kernels come in."
"By applying classic database systems principles (unglamorous stuff about data locality and memory hierarchies) to attention, they achieved 2–3x speedups."
影響分析・編集コメントを表示
影響分析
この記事は、AIハードウェア最適化の歴史的文脈においてFlashAttentionが果たした革命的な役割を明確に位置づけています。単なるアルゴリズムの改良ではなく、GPUアーキテクチャの根本的な理解に基づいたアプローチが、業界全体の最適化基準を塗り替えたことを示唆しており、今後のAIインフラ開発においてソフトウェア層の最適化が最重要課題の一つであることを浮き彫りにしています。
編集コメント
FlashAttentionの成功は、AIハードウェア最適化において「メモリ階層の理解」が計算量よりも重要であることを示す歴史的転換点であり、インフラベンダー間の競争においてソフトウェアスタックの深さが差別化要因となることを示唆しています。
画期的な進展は、祝日の週末に訪れました。2022 年のメモリアルデーです。シリコンバレーの多くの人々がバーベキューを楽しんでいた中、ダン・フー、トリ・ダオ、そして彼らの同僚たちは、AI の権威ある人々の考えが間違っていることを証明しようとしていました。
当時の常識は確立されていました:トランスフォーマーのアテンション(注記:Transformer Attention)はすでに最適化されており、GPU 専門家がハードウェアから性能を最大限に引き出していたのです。これ以上得られる余地はほとんどないと考えられていました。
しかしその後、ダン、トリ、そして彼らの同僚たちは FlashAttention を発表しました。
当時テスラで AI 担当シニアディレクターだったアンドレイ・カルパティは、その日の午後これをツイートしました。数時間後には AI 研究のコミュニティ内で瞬く間に広まりました。「正直に言って、リリースした当時は誰も注目するとは思っていませんでした」とダンは振り返ります。「火曜日の朝にブログ記事やコード公開の準備をしていたのですが、月曜日の午後 7 時にカルパティがツイートしてくれたので、これで人々が注目していることがわかったのです。」

スパース性や低ランク手法に関する先行研究では理論的な高速化が示されていましたが、実際の性能向上はわずか 10% 程度でした。FlashAttention チームは異なるアプローチを採用しました:GPU のメモリ転送と計算パターンを深く理解することです。彼らは、古典的なデータベースシステムの原則(データ局所性やメモリアーキテクチャに関する地味な内容)をアテンションに応用することで、2〜3 倍の高速化を実現しました。
背後にいる研究者たちにとって、その示唆は明確でした。GPU の最適化にはまだ膨大な未開拓のポテンシャルが残っていました。あの単一の論文が、現在では AI において最も影響力のあるカーネル研究チームの一つとなり、AI ネイティブクラウドの重要な構成要素となる基盤となりました。
誰も話題にしなかった問題
AI について多くの人々が理解していないのは、最高のモデルと最高のハードウェアを備えていればそれで十分ではないという点です。ボトルネックは両者の間のギャップ、つまり数学的演算をシリコン指令に変換するソフトウェア層にあります。そこがカーネルの領域です。
研究者たちが設計したものと、実際にハードウェア上で高速に動作するものの間には広大な隔たりがあります。多くの基礎的なアーキテクチャ(ResNets, LSTMs, RNNs)は、スケーリングのパラダイムが確立される前に設計されました。研究者たちがモデルを数百億パラメータ規模へとスケールさせ始めたとき、ハードウェアもそれとともに進化しました。GPU は現代の AI を支配する Transformer アーキテクチャに最適化された、ますます専門化された行列演算マシンへと変貌を遂げました。
カーネルは数学的抽象とシリコンという現実の間の翻訳層です:GPU がデータをどのように移動し、計算を効率的に行うかを具体的に指示するソフトウェアです。これを正しく実装すればハードウェアの全パワーを引き出せますが、間違えればそのハードウェアはアイドル状態のまま放置されてしまいます。
AI ネイティブアプリケーション(コアに AI を組み込んで構築された製品)にとって、このギャップは存亡に関わる問題です。最適化されていない容量で動作するインフラストラクチャ上では、レスポンシブな AI ネイティブアプリを構築することはできません。推論コストが本来あるべき価格の 2 倍になる場合、AI ネイティブビジネスをスケールさせることは不可能です。AI ネイティブクラウドには、シリコンレベルから最適化された AI ネイティブインフラストラクチャが必要です。
1 週間で 1 年分の仕事を達成する
2025 年 3 月、当社のカーネルチームは約 15 名に成長していました。システム上の課題を追求する機械学習(ML: Machine Learning)研究者と、AI 分野へ移行した GPU ベテランの混合構成です。私たちは直近で、NVIDIA の最新世代ハードウェアである Blackwell GPU にアクセスできるようになりました。これは前世代とは根本的に異なる能力を持つ最新のハードウェアです。
課題は具体的でした。NVIDIA のチームは、Blackwell 向けの最適化されたカーネルを開発するために 1 年間を費やし、数十名のエンジニアが携わり、ハードウェアへの深い知識を持っていました。私たちに与えられたのはわずか 1 週間でした。
私たちは迅速に動き回るための手段が必要でした。その答えとなったのが ThunderKittens です。これはスタンフォード大学の研究者と共同で開発を進めてきたライブラリです。
「私たちは、カーネルを新しいハードウェアに適応させる経験があり、時間がかかることも知っていました」と Dan は語ります。「例えば、FlashAttention-3 は一般利用可能な Hopper アーキテクチャが登場してから 1 年後に発表されました。私たちは、新しいハードウェア世代向けに素早くカーネルを構築しやすくするためのツールを構築したかったのです。そして ThunderKittens がその答えでした。」
ThunderKittens は、GPU 上の行列乗算に特化したハードウェアユニットである NVIDIA のテンソルコア(tensor cores)を中心に構築されています。テンソルコアの周りに抽象化層を設けることで、かつては 1,000 行以上あった CUDA コードを 100〜200 行にまで削減しました。
チームは昼夜を問わず働き、Blackwell の新機能に対応する ThunderKittens の適応を進めました。具体的には、前世代より 2〜2.5 倍高速で動作する第 5 世代テンソルコア、さらに 256KB の超高速オンチップストレージを追加する新しい層のテンソルメモリ、そしてスレッドブロックがより深く協調可能にする CTA ペア(CTA pairs)です。
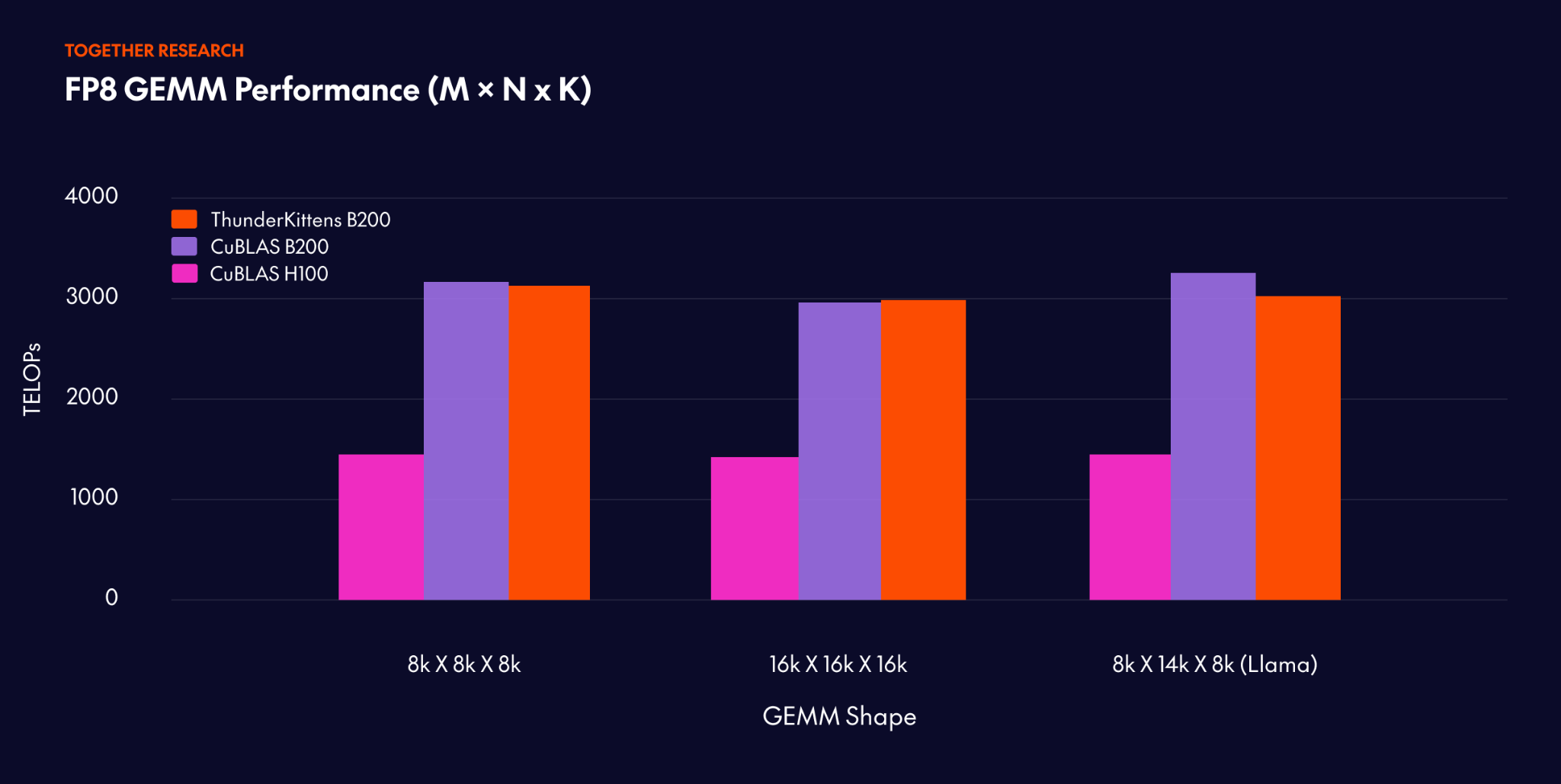
ハードウェアへのアクセスを開始してからわずか 1 週間で、Blackwell 向けに利用可能な 最速の FP4 および FP8 GEMM カーネル の一部を完成させました。H100 上での cuBLAS と比較して最大 2 倍の高速化を実現しています。
学術的エンジン
ThunderKittens は突然現れたものではありません。これは、このチームがどのように構築されているかというより広範なパターンの一部です。
Dan Fu は UCSD で研究室を運営しており、高リスクな基礎研究に焦点を当てています。その中には彼自身の情熱プロジェクトである FFT アルゴリズム(FFT: Fast Fourier Transform)の研究も含まれており、これは業界の研究者がほとんど手をつけないニッチな分野です。Together AI の共同創設者であり首席科学者の Tri Dao はプリンストン大学にいます。Simran Arora はカリフォルニア工科大学(Caltech)に所属しています。
このモデルは相生的です:学術界ではアイデアのリスクを軽減し、Together AI で実用化します。博士課程の学生が会社に参加し、Together AI のインターンは学術研究室でより長期的な研究に取り組みます。アイデアは双方向に流れます。
この哲学が採用方針を形作っています。私たちは単にコードをリリースしたいだけの人や、引用数を積み上げたい人を求めているわけではありません。メモリアクセスパターンについて夜も眠れなくなる人、データフロー図に美を見出す人、最先端の研究を実環境へ導入することに心から興奮する人を求めています。研究には本質的に繰り返しの失敗が伴います。何よりも純粋な関心によって駆動されることが必要です。FFT のように一時的に流行っていない分野でも、本当に興味深いものであれば追求する価値があります。
このチームは、理論と実装の間のギャップを埋めることができる次世代のシステム研究者たちのための跳躍台となっています。私たちは「卒業生」として、現在は上海NYUで准教授を務め、HeavyBall Research グループのリーダーであるYucheng 教授を送り出しました。
Together Megakernel:281ms から77ms へ
この学術エンジンを生産環境のユースケースに応用した一例として、主要なリアルタイム音声エージェント企業のひとつが挙げられます。彼らはTogether にて、64トークン目までの生成時間が約100ms を超えると会話体験が損なわれるという厳しい制約を提示しました。彼らの以前のセットアップではNVIDIA B200 GPU で展開されていましたが、281ms という結果に達していました。多くのワークロードにとっては高速ですが、彼らにとっては十分ではありません。
Together のカーネルチームは、彼らと協力してモデルアーキテクチャを選択し、NVIDIA H100 の HBM バンド幅の上限をターゲットとした、モデル全体を単一のカーネルで実行する Megakernel 実装を手動最適化しました。
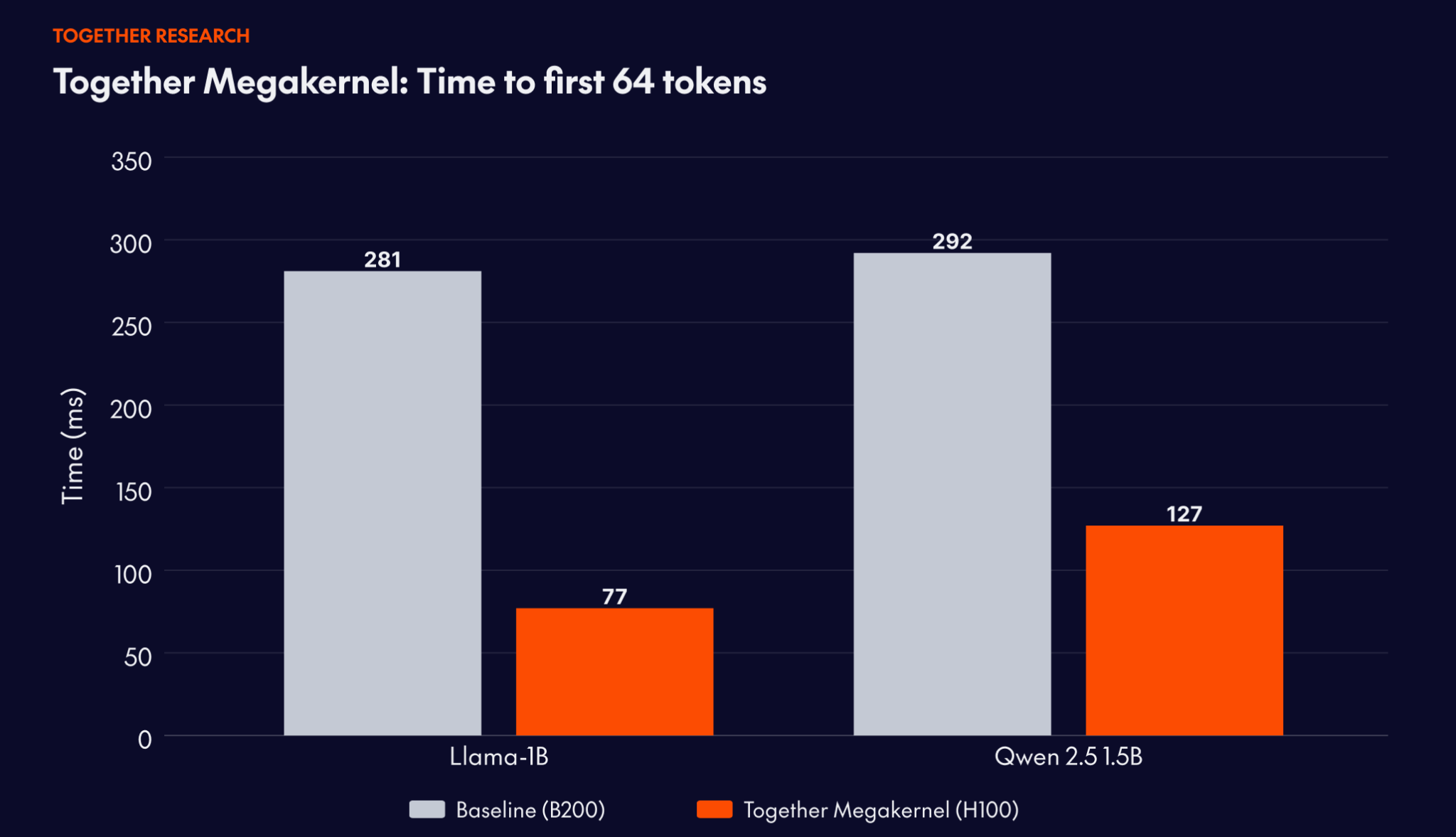
その結果、Llama-3.2-1B では 77ms を達成し、パフォーマンスは 3.6 倍向上し、単位あたりの経済性は従前のデプロイメントと比較して 7.2 倍改善されました。Qwen 2.5 1.5B では 127ms となり、B200 ベースラインの 292ms から大幅に短縮されています。
Together Megakernel は、スタンフォード大学の共同研究者らと共に開発されたオープンソース研究の実装版です。FlashAttention と同じ研究系譜に基づき、理論的に可能なことと実際にデプロイされたシステムが提供するものの間のギャップを埋めるためのハードウェア・ソフトウェアの協調設計となっています。
世界クラスの研究成果が生産現場で実証される
Together AI が他社と異なる点はここにあります。当社のカーネルチームは単に論文を発表する研究機関ではなく、顧客に直接対応し、戦略的パートナーと共に彼らのデプロイメントを改善するために活動しています。
Cursor の事例をご覧ください。遅延がミリ秒単位で重要であり、開発者がリアルタイムでコード補完を待っているような AI ネイティブな製品を構築する場合、汎用的なインフラでは不十分です。特定のワークロード、特定のモデル、特定の SLA(サービスレベルアグリーメント)要件に合わせたカスタム最適化が必要となります。
これが Together AI と提携した結果です:一流のカーネル研究チームへの直接アクセス。お客様のワークロードをプロファイリングし、ボトルネックを特定します。そしてそれらを解消するためのカスタムカーネルを作成します。私たちは大規模クラウド事業者ではなく、そこで小さな存在としてサポートチケットを提出し、誰かが最終的に問題を見てくれることを祈るような場所ではありません。
最も厳しい SLA(リアルタイム応答が必要な方々や、効率化のわずかな改善が数百万ドルのコスト削減につながる大規模運用を行う方々)を持つお客様向けに、カスタムソリューションを構築します。システムボトルネック用のカスタムカーネル。特定のモデルアーキテクチャ向けの最適化。お客様のデプロイメントを物理的に可能な限り高速にするために、研究チームの全リソースを注ぎ込みます。
これが実践における AI ネイティブクラウドの姿です:世界クラスの研究チームが AI ネイティブなビルダーと手を取り合い、理論上可能であることと実際に本番環境で稼働していることの間のギャップを埋めています。
協力的で好奇心旺盛かつ執念深い
私たちのチーム文化は、競争ではなく知的探求心と協力を基盤としています。ダン・フーが「やる気満々(gung ho)」と呼ぶマインドセットを持つ約15人のメンバーで構成されています。
「私たちは良い人たちです」とダンは言います。「ロックスターのようなエゴはありません。この時代をワクワクしながら過ごし、難しい問題を一緒に解決することを愛する人々だけです。」

チームには主に二つのタイプがあります。システム上の課題を求めている機械学習の専門家と、機械学習の分野へ移行する GPU/グラフィックスの専門家です。両者とも相手の分野を学ぶ必要があります。「すべての部品を理解することで、それらがどのように連携して動作するかを知ることができます」とダンは説明します。
私たちは、技術的な詳細に深く入り込み、あらゆる可能性を探求したい人々を求めています。単に「どうすれば動くか」ではなく、「なぜ動くのか」「どのようにより良くできるのか」、そしてその挙動を支配する根本的な原則は何なのかを理解できる人材です。
この仕事は必ずしも華やかではありません。カーネル最適化が実装されたことを発表することはありません。ただ、トレーニング時間の短縮、コストの削減、スループットの向上という結果があるだけです。これらは、プロダクションシステムが稼働するかどうかを決定する指標です。
しかし、これらのマージンはほぼ他のすべての要素よりも重要です。
これは、モデルのトレーニングに 3 週間かかるか 3 か月かかるかの違いであり、API の応答時間が 100 ミリ秒か 1 秒かの違いであり、同じ結果を得るために計算資源に 1,000 万ドルを費やすか 500 万ドルで済むかの違いです。次世代の AI ネイティブなアプリケーションや企業にとって、これらのマージンは、製品が瞬時に感じられるものになるのか、それとも遅延を感じるものになるのかを決定します。また、ユニットエコノミクスが成立するかどうか、あるいは数百万人のユーザーにスケールできるか、数千人で頭打ちになるかもこれによって決まります。
データの質は重要です。モデルのアーキテクチャも重要です。トレーニング手法も重要です。しかし、ハードウェアを効率的に動作させることができない場合、それらの他の要素はすべてスケーリングしません。
ある種のエンジニア、つまりメモリアクセスパターンや計算効率に美を見出し、他のすべてのことを可能にする見えない足場に取り組むことを望む人々にとって、これは最もエキサイティングな場所です。
私たちと一緒に参加してください
私たちはカーネル研究チームの採用を行っています。パフォーマンス最適化への情熱と、ハードウェアと AI の交差点で働く意欲をお持ちの方は、今日応募してください。
原文を表示
The breakthrough came on a holiday weekend. Memorial Day 2022. While most of Silicon Valley was at barbecues, Dan Fu, Tri Dao, and their colleagues were about to prove the AI establishment wrong.
The conventional wisdom was settled: transformer attention was already optimized. GPU experts had squeezed every drop of performance from the hardware. There wasn't much left to gain.
Then Dan, Tri, and their colleagues published FlashAttention.
Andrej Karpathy, then Senior Director of AI at Tesla, tweeted about it that afternoon. Within hours it was ricocheting through AI research channels. "Honestly, we weren't expecting anybody to see it when we released it," Dan recalls. "We were prepping some blogs and code release for Tuesday morning. But then we saw Karpathy tweet about it Monday at 7 p.m. — so then we knew it was something people were paying attention to."
Previous work on sparsity and low-rank methods showed theoretical speedup but only 10% real performance gains. The FlashAttention team took a different approach: understanding actual GPU memory movement and compute patterns. By applying classic database systems principles (unglamorous stuff about data locality and memory hierarchies) to attention, they achieved 2–3x speedups.
For the researchers behind it, the implications were clear. Enormous untapped potential remained in GPU optimization. That single paper became the foundation for what's now one of the most impactful kernel research teams in AI, and a critical building block of the AI Native Cloud.
The problem no one was talking about
Here's what most people don't understand about AI: having the best models and the best hardware isn't enough. The bottleneck is the gap between them: the software layer that translates mathematical operations into silicon instructions. That's where kernels come in.
The gap between what researchers design and what actually runs fast on hardware is vast. Many foundational architectures (ResNets, LSTMs, RNNs) were designed before the scaling paradigm took hold. As researchers began scaling models to hundreds of billions of parameters, hardware evolved with them. GPUs became increasingly specialized matrix multiplication machines, tuned for the Transformer architectures dominating modern AI.
Kernels are the translation layer between mathematical abstraction and silicon reality: the software that tells GPUs exactly how to move data and perform computations efficiently. Get them right, and you unlock the full power of the hardware. Get them wrong, and that hardware sits idle.
For AI-native applications (products built with AI at their core), this gap is existential. You can't build a responsive AI-native app on infrastructure running below optimal capacity. You can't scale an AI-native business when inference costs are 2x higher than they should be. The AI Native Cloud requires AI-native infrastructure, optimized from the silicon up.
One week to match a year's work
In March 2025, our kernels team had grown to about 15 people: a mix of ML researchers seeking systems challenges and GPU veterans moving into AI. We'd just gotten access to NVIDIA's new Blackwell GPUs, the latest generation of hardware with fundamentally different capabilities from their predecessors.
The challenge was specific: NVIDIA's teams had spent a year developing optimized kernels for Blackwell, with dozens of engineers and intimate knowledge of the hardware. We had a week.
We needed something that would let us move fast. That something was ThunderKittens, a library we'd been developing in collaboration with researchers at Stanford.
"We had experience adapting kernels to new hardware, and we knew it would take time," Dan says. "For example, FlashAttention-3 came out a year after general Hopper availability. We wanted to build tools to make it easier to quickly build kernels for the new hardware generation, and ThunderKittens was the answer."
ThunderKittens is built around NVIDIA's tensor cores, the hardware units on the GPU specialized for matrix multiplication. By building abstractions around tensor cores, ThunderKittens reduces what was once 1,000+ lines of CUDA code to 100–200 lines.
The team worked around the clock, adapting ThunderKittens to Blackwell's new features: Fifth-generation tensor cores that run 2–2.5x faster than the previous generation, a new layer of tensor memory providing an extra 256KB of ultra-fast on-chip storage, and CTA pairs that allow thread blocks to coordinate more deeply.
Within one week of hardware access, we had some of the fastest FP4 and FP8 GEMM kernels available for Blackwell, with up to 2x speedups over cuBLAS on H100s.
The academic engine
ThunderKittens didn't come from nowhere. It's part of a broader pattern in how this team is built.
Dan Fu runs a lab at UCSD focused on higher-risk fundamental research, including his personal passion project on FFT algorithms (a niche area most industry researchers would never touch). Together AI co-founder and Chief Scientist Tri Dao is at Princeton. Simran Arora is at Caltech.
The model is symbiotic: de-risk ideas in academia, productionize them at Together AI. PhD students join the company. Together AI interns work on longer-term research in academic labs. Ideas flow both ways.
This philosophy shapes hiring. We're not looking for people who just want to ship code or rack up citations. We want people who lose sleep over memory access patterns. Who find beauty in data flow diagrams. Who get genuinely excited about taking cutting-edge research into production. Research inherently involves repeated failure. You have to be driven by genuine interest above all else. Even non-trendy areas like FFT are worth pursuing if they're genuinely interesting.
The team has become a springboard for the next generation of systems researchers, people who can bridge the gap between theory and production. We've "graduated" Professor Yucheng Lu, now an assistant professor and leader of the HeavyBall Research group at NYU Shanghai.
Together Megakernel: From 281ms to 77ms
One example of applying this academic engine to production use cases involved one of the leading real-time voice agent companies. They came to Together with a hard constraint: time-to-first-64-tokens above roughly 100ms breaks the conversational experience. On their previous setup, deployed on NVIDIA B200 GPUs, they were hitting 281ms. Fast for most workloads. Not fast enough for theirs.
Together's kernels team worked with them to select a model architecture, then hand-optimized a Megakernel implementation that runs an entire model in a single kernel, targeting the HBM bandwidth ceiling of the NVIDIA H100.
The result: 77ms on Llama-3.2-1B, a 3.6x performance improvement and 7.2x better unit economics compared to their prior deployment. On Qwen 2.5 1.5B: 127ms, down from 292ms on the B200 baseline.
Together Megakernel is the production implementation of open-source research initially developed with collaborators at Stanford. Backed by the same research lineage as FlashAttention, it's hardware-software co-design that closes the gap between what's theoretically possible and what deployed systems actually deliver.
World-class research meets production reality
Here's what makes Together AI different: our kernels team isn't just a research organization publishing papers. We're customer-facing, working directly with strategic partners to improve their deployments.
Take Cursor. When you're building an AI-native product where every millisecond of latency matters, where developers are waiting for code completions in real-time, generic infrastructure doesn't cut it. You need custom optimization for your specific workload, your specific models, your specific SLA requirements.
That's what you get when you partner with Together AI: direct access to a top-tier kernel research team. We profile your workload. We identify bottlenecks. We write custom kernels to eliminate them. We're not a hyperscaler where you're a small fish in a big pond, filing support tickets and hoping someone eventually looks at your issue.
For customers with the tightest SLAs (the ones who need real-time responses, the ones running at massive scale where every percentage point of efficiency translates to millions in cost savings) we build custom solutions. Custom kernels for system bottlenecks. Custom optimizations for specific model architectures. The full weight of our research team focused on making your deployment as fast as physically possible.
This is what the AI Native Cloud looks like in practice: world-class research teams working hand-in-hand with AI-native builders, closing the gap between what's theoretically possible and what's actually running in production.
Collaborative, curious, relentless
Our team culture is built around intellectual curiosity and collaboration, not competition — about 15 people with what Dan Fu calls a "gung ho" mentality.
"We're nice people," Dan says. "No rockstar egos. Just people who are excited about this time and who love solving hard problems together."
The team has two main archetypes: ML people wanting systems challenges, and GPU/graphics people moving into ML. Both need to learn the other half. "You're understanding all the pieces so you know how they work together," Dan explains.
We're looking for people who want to get deep into technical details, to leave no stone unturned — not just how to make something work, but why it works, how it could work better, what fundamental principles govern its behavior.
The work is sometimes unglamorous. There's no announcement when a kernel optimization lands. Just faster training times, lower costs, higher throughput: The metrics that determine whether production systems run or don't.
But these margins matter more than almost anything else.
It’s the difference between a model that trains in three weeks versus three months; between an API that responds in 100 milliseconds versus 1 second; between spending $10 million on compute versus $5 million for the same results. For the next generation of AI-native applications and companies, these margins determine whether your product feels instant or sluggish. Whether your unit economics work or don't. Whether you can scale to millions of users or plateau at thousands.
Data quality matters. Model architecture matters. Training techniques matter. But if you can't make the hardware work efficiently, none of that other stuff scales.
And for a certain type of engineer, the kind who finds beauty in memory access patterns and computational efficiency, who wants to work on the invisible scaffolding that makes everything else possible, this is the most exciting place to be.
Join us
We're hiring for our kernel research team. If you're passionate about performance optimization and eager to work at the intersection of hardware and AI, apply today.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み