AIを通常の技術として捉える
ナイト第一修正権研究所が発表した論文は、AI を「超知能」や「別種族」と見なす極端な予測を否定し、電力やインターネットと同様に社会に徐々に浸透する「通常の技術」として捉えるべきだと主張している。
キーポイント
AI は「通常の技術」であるという枠組みの提示
AI を人間のような知能を持つ別個の存在として扱うのではなく、電力やインターネットと同様に社会に徐々に統合される「通常の技術」として定義し直す。
変革的インパクトは数十年スケールで遅延する
AI の手法(methods)、応用(applications)、そして普及(adoption)は異なるタイムスケールで起こるため、経済や社会への劇的な変化は即座ではなく数十年かけて進むと予測する。
人間と AI の役割分担と制御権の維持
「スーパーインテリジェンス」を非現実的な概念としつつ、高度な AI 環境下でも制御権は主に人間や組織が握り、業務における AI の管理比率が高まると考える。
リスク評価と緩和策の再定義
AI を「人間型」と見なす従来の視点とは異なり、事故、軍拡競争、悪用、アライメント問題に対するリスク評価と対策を根本的に再考する必要があると論じる。
政策目標とリスク管理
不確実性の低減を最優先の政策目標とし、壊滅的リスクにはレジリエンス(回復力)アプローチを採用すべきである。
過剰な介入の危険性
AI が制御不能な超知能であると仮定した極端な対策は、実際には AI が通常の技術であった場合に不平等などの既存の弊害を悪化させる恐れがある。
予測の限界と範囲
「急速なテイクオフ」シナリオを否定しているため、記述されたシナリオが実現した後の未来(電気やコンピュータのような新技術)を予測することは無意味であるとされている。
重要な引用
To view AI as normal is not to understate its impact—even transformative, general-purpose technologies such as electricity and the internet are 'normal' in our conception.
The statement 'AI is normal technology' is three things: a description of current AI, a prediction about the foreseeable future of AI, and a prescription about how we should treat it.
It rejects technological determinism, especially the notion of AI itself as an agent in determining its future.
We advocate for reducing uncertainty as a first-rate policy goal and resilience as the overarching approach to catastrophic risks.
Drastic interventions premised on the difficulty of controlling superintelligent AI will, in fact, make things much worse if AI turns out to be normal technology.
In other words, in this broad set of domains, AI diffusion lags decades behind innovation.
影響分析・編集コメントを表示
影響分析
この論文は、現在の AI バブル的な議論やパニックを冷静に抑制する重要な役割を果たし、政策立案者や技術者が AI の未来を現実的な時間軸で捉え直すよう促します。特に「技術的決定論」への批判と、過去の技術革命からの教訓の適用は、過度な期待や恐怖に基づく誤った規制や投資判断を防ぐための指針となります。
編集コメント
「AI は魔法ではない」という常識的な視点ですが、現在の過熱した議論において極めて重要なバランス感覚を提供する論文です。
本稿は15,000語を超えており、AIの未来に対する私たちのビジョンに関する新しい論文です。これらのアイデアを拡張した版が、私たちが共同で執筆する次なる書籍となることを発表できることを嬉しく思います。
この論文はまた、ナイト第一修正研究所(Knight First Amendment Institute)のウェブサイト上でHTML形式およびPDF形式でも公開されています。論文の草案に対して寄せられた広範なフィードバックに対し、深く感謝申し上げます。
更新(2025年9月):本エッセイに付随するガイド『AIを通常の技術として理解するためのガイド』を刊行しました。
私たちは、人工知能(AI: Artificial Intelligence)を通常の技術として捉えるビジョンを提示します。AIを「通常の」ものとして見なすことは、その影響を過小評価することを意味しません。電気やインターネットのような変革的で汎用性の高い技術でさえも、私たちの概念においては「通常の」ものです。しかしそれは、AIの未来に関するユートピア的およびディストピア的なビジョンとは対照的です。これらのビジョンには共通する傾向があり、AIを別種の生物、あるいは高度に自律し、潜在的に超知能を持つ実体と同様に扱う点にあります。
「AI は通常の技術である」という主張は、3 つの側面を持っています。現在の AI に関する記述、予測可能な未来の AI に関する予測、そして AI をどのように扱うべきかという処方箋です。私たちは AI を、私たちが制御可能であり、かつ制御すべきツールとして捉えています。また、この目標を達成するために劇的な政策介入や技術的ブレークスルーが必要であるとは主張しません。現在、AI を人間のような知性として見なすことは、その社会的影響を理解する上で正確でも有用でもないと考えており、私たちの未来像においてもそうなる可能性は低いと考えます。
通常の技術という枠組みは、技術と社会の関係性に関するものです。これは技術決定論、特に AI 自体がその未来を決定する主体であるという考え方を拒絶します。過去の技術革命からの教訓、すなわち技術の採用と普及が緩やかで不確実な性質を持つことに基づいて導かれています。また、社会的影響やこの軌道形成における制度の役割という点において、過去と AI の未来の軌道の間に連続性があることを強調します。
第 I 部では、なぜ変革的な経済的・社会的影響が数十年という時間スケールで緩やかに生じると考えるのかを説明し、AI の手法、AI の応用、そして AI の採用という3 つの概念を明確に区別して論じます。これらは異なる時間スケールで起こるものであると主張します。
第 II 部では、高度な AI(ただし「スーパーインテリジェント」AI は通常概念化されるように不整合であると私たちが考えるもの)が存在する世界における、人間と AI の間の潜在的な役割分担について議論します。この世界では、制御は主に人々や組織の手にあり、実際には、人々が職場で行うことのより大きな割合が AI による制御となっています。
第 III 部では、AI を通常の技術として捉えることが AI リスクにどのような含意を持つかを検討します。私たちは事故、軍拡競争、悪用、そしてアライメントのズレを分析し、AI を人間のようなものとして見るのと比較して、AI を通常の技術として見ることが緩和策に関する根本的に異なる結論をもたらすことを論じます。
もちろん、私たちの予測が確実であるとは言い切れませんが、私たちが中位の結果と考えるものを記述することを目的としています。確率を定量化しようとしたわけではありませんが、AI が通常の技術のように振る舞っているかどうかを判断できるような予測を試みました。
第 IV 部では、AI 政策への含意について議論します。私たちは不確実性の低減を最優先の政策目標とし、壊滅的なリスクに対する包括的なアプローチとしてレジリエンス(回復力)を提唱します。スーパーインテリジェント AI の制御が困難であるという前提に基づく過激な介入は、実際には AI が通常の技術であった場合、状況を大幅に悪化させることになるでしょう—そのデメリットは、資本主義社会で展開された過去の技術のそれら、例えば不平等などと同様のものになる可能性が高いです。
私たちが第 II 部で描く世界は、現在の AI よりもはるかに進化した世界です。私たちは、AI の進展—あるいは人間の進展—がその時点で止まると主張しているわけではありません。その後には何があるのでしょうか?私たちは知りません。この比喩を考えてみてください:第一次産業革命の黎明期において、工業化された世界がどのようなものか、そしてそれに向けてどのように準備すべきかを考えようとするのは有用だったでしょうが、電気やコンピュータを予測しようとするのは徒労に終わっていたはずです。ここで私たちが行っている試みもこれと似ています。「急速な取込み」シナリオを否定する以上、私たちが試みた範囲を超えたさらに先の世界を構想することは必要でも有益でもないと考えています。もし第 II 部で記述したシナリオが現実のものとなったならば、その後に何が来るのかについて、よりよく予測し準備することが可能になるでしょう。
読者への注釈。この論文には、主張を擁護するのではなく、世界観を提示するという珍しい目的があります。AI の超知能に関する文献は膨大です。我々は、潜在的な反論に対して一つひとつ応答を試みることはしていません。そうすれば論文が数倍の長さになってしまうからです。本稿は単に私たちの見解を最初に表明したものに過ぎず、様々な続編でこれらを詳しく展開する予定です。
続編を受け取るには購読してください。
第 I 部:進展の速度
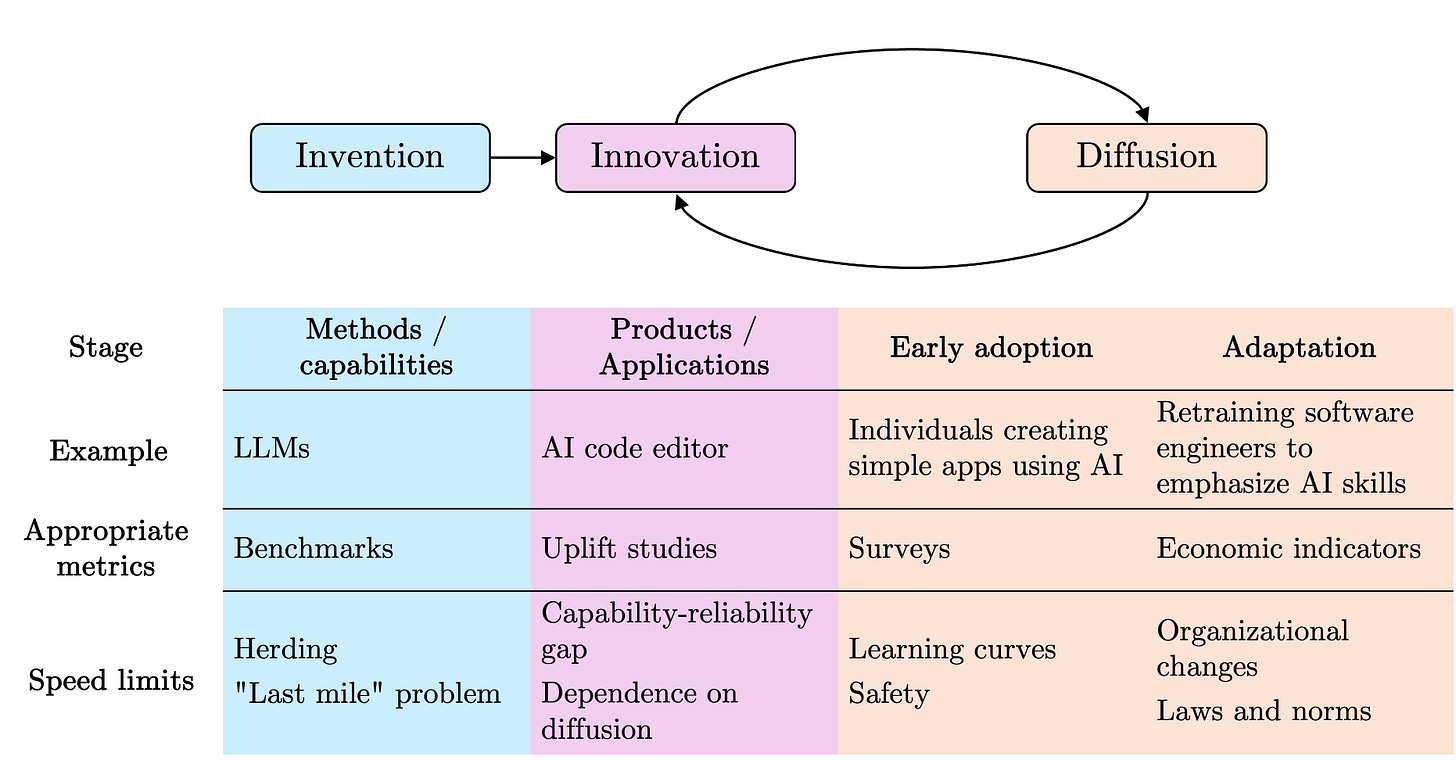
図 1。他の汎用技術と同様に、AI の影響は手法や能力が向上した時点ではなく、その改善が生産部門を通じてアプリケーションに転換され、拡散された際に現れます。4 各段階には速度制限が存在します。
AI の進展は漸進的なものとなり、AI の能力と採用が増加するにつれて人々や機関が適応できるものでしょうか、それとも大規模な混乱や技術的特異点さえも引き起こす飛躍的なものとなるでしょうか。この問いに対する私たちのアプローチは、重大度の高いタスクと低いタスクを別々に分析し、まず AI の採用と拡散の速度を分析した上で、イノベーションと発明の速度について再考することです。
私たちが「発明」と呼ぶのは、AI がさまざまなタスクを実行する能力を向上させる新しい AI 手法(大規模言語モデルなど)の開発のことです。「イノベーション」は、消費者や企業が利用可能な AI を用いた製品やアプリケーションの開発を指します。「採用」とは、個人(またはチームや企業)が技術を利用することを決定する行為であり、「拡散」とは、その採用レベルが高まる広範な社会的プロセスを指します。十分に破壊的な技術の場合、拡散には企業の構造や組織の構造の変更、ならびに社会規範や法律の変更が必要となる可能性があります。
安全上重要な分野における AI の拡散は緩やかです
『予測最適化への反対』という論文では、機械学習(ML)を用いて個人の将来の行動や結果を予測し、個人に関する意思決定を行う予測最適化の約 50 の応用例を包括的にリストアップしました。5 これらの応用例の多くは、犯罪リスク予測、保険リスク予測、あるいは児童虐待予測などであり、人々にとって重要な帰結を持つ意思決定を下すために用いられています。
これらの応用例が急増する一方で、決定的なニュアンスが存在します:ほとんどの場合、数十年も前の統計的手法が使用されており、これは単純で解釈可能なモデル(主に回帰分析)と、比較的小規模な手作業で作成された特徴量セットです。ランダムフォレストのようなより複雑な機械学習手法はほとんど使われておらず、トランスフォーマーのような現代的な手法はどこにも見当たりません。
つまり、この広範なドメインの集合において、AI の普及はイノベーションに数十年遅れています。その主な理由は安全性にあります:モデルがより複雑で理解しにくくなると、テストおよび検証プロセスにおいてすべての可能な展開条件を予測することが困難になります。良い例として、Epic の敗血症予測ツールがあります。これは内部検証では一見高い精度を示していましたが、病院での運用でははるかに悪く、敗血症症例の 3 分の 2 を見逃し、医師たちを誤ったアラートで圧倒しました。6
Epic の敗血症予測ツールは、複雑なモデルと制約のない特徴セットを扱う際に検出が困難なエラーのために失敗しました。7 特に、モデルの訓練に使用された特徴の一つには、「医師がすでに敗血症治療のために抗生物質を処方したか」という項目が含まれていました。つまり、テストおよび検証の間、モデルは未来から来た特徴を使用しており、結果に因果関係で依存する変数に頼っていたのです。もちろん、この特徴は実際の運用時には利用できません。解釈可能性や監査手法は間違いなく向上し、こうした問題を検出する能力が大幅に高まるでしょうが、まだその段階には至っていません。
生成 AI の場合、後から見れば極めて明白な失敗でさえも、テスト中に検出されませんでした。一例として、初期の Bing チャットボット「Sydney」は、長時間の会話中に制御不能な状態になりました。開発者は明らかに、会話が数回以上のターンに及ぶことを想定していなかったのです。8 同様に、Gemini の画像生成器は歴史上の人物に対してテストされた形跡がありませんでした。9 幸いにも、これらは重大な影響を及ぼすようなアプリケーションではありませんでした。
さまざまな応用分野におけるイノベーションと普及の遅れ、およびその理由を理解するためには、さらなる実証的な研究が有益である。しかし現時点では、私たちが先行研究で分析した証拠は、極めて重大な影響を及ぼすタスクにおいてすでに非常に強力な安全性関連の速度制限が存在するという見解と整合している。これらの制限は、医療機器に対する FDA の監督のような規制や、高リスク AI に対して厳格な要件を課す EU AI 法(EU Artificial Intelligence Act)といった新たな立法を通じてしばしば執行されている。10 実際、既存の高リスク AI 規制があまりにも過重であり、「官僚主義の暴走」を引き起こす可能性があるという(信頼性の高い)懸念が存在する。11 したがって、私たちは、極めて重大な影響を及ぼすタスクにおいては、普及の遅れが引き続き標準となるだろうと予測している。
いずれにせよ、AI が極めて重大な影響を及ぼす方法で使用できる新たな分野が生じた際、あるいはその時期には、それらを規制することは可能であり、また必須である。2010 年のフラッシュ・クラッシュ(Flash Crash)は良い例であり、ここでは自動高頻度取引が関与したと考えられている。これにより、サーキットブレーカー(circuit breakers)のような新たな取引制限が生じた。12
普及は、人間の速度、組織の変化の速度、そして制度的変化の速度によって制限される
安全性が重要な分野以外でも、AI の導入は一般的な報道が示唆するほど速くはありません。例えば、2024 年 8 月に米国の成人の 40% が生成 AI を使用しているという発見により、ある研究が注目を集めました。13 しかし、ほとんどの人が頻繁に使用しなかったため、これは労働時間の 0.5%〜3.5% に相当するのみであり(労働生産性への寄与は 0.125〜0.875 ポイントの増加に留まりました)。
現在の普及速度が過去よりも速いかどうかも明確ではありません。前述の研究では、米国の生成 AI の導入がパーソナルコンピュータ(PC)の導入よりも速かったと報告されています。具体的には、大衆向け製品の発売から 2 年以内に米国の成人の 40% が生成 AI を導入したのに対し、PC では 3 年以内に 20% でした。しかし、この比較は導入の強度(使用時間数)の違いや、PC の購入コストが生成 AI にアクセスするコストよりも高いという点を考慮していません。14 どのように導入を測定するかによって、生成 AI の導入速度が PC の導入速度よりもずっと遅かった可能性も十分にあります。
デジタル技術が一度に数十億台のデバイスに到達できるという事実を踏まえると、技術導入の速度が必ずしも増加しているわけではないという主張は驚くべき(あるいは明らかに誤っている)ように思えるかもしれません。しかし、導入とは利用可能性ではなくソフトウェアの使用に関するものであることを忘れないでください。新しい AI ベースのプロダクトが誰でも無料ですぐにオンライン上でリリースされたとしても、人々がその新製品のメリットを活用するためにワークフローや習慣を変え、リスクを避ける方法を学ぶまでには時間がかかります。
したがって、拡散の速度は、個人だけでなく組織や機関も技術に適応できる速度によって本質的に制限されます。これは過去の汎用技術でも見られた傾向であり、拡散は数年ではなく数十年をかけて起こります。
例として、ポール・A・デイヴィッドによる電化の分析では、生産性のメリットが完全に実現されるまでに数十年を要したことが示されています。エジソンの最初の中央発電所から約 40 年間、電気ダイナモは「至る所に存在したが、生産性統計には現れませんでした」。これは単なる技術的慣性ではなく、工場主たちは電化が実質的な効率向上をもたらさないことに気づいたのです。
最終的に利益を実現可能にしたのは、生産ラインの論理を中心に工場のレイアウト全体を再設計したことである。工場建築の変更に加え、普及には職場組織とプロセス制御の変更も必要であり、これらは業界横断的な実験を通じてのみ開発することができた。これらの変化により、労働者にはより多くの自律性と柔軟性が与えられ、同時に異なる採用および訓練慣行が必要となった。
外部世界が AI 革新に速度制限を課す
AI の技術的進歩が急速であったことは事実だが、AI の手法と応用を区別して見ると、状況ははるかに明確ではない。
我々は AI 手法の進展を、一般性の梯子として概念化する。18 この梯子の各段は、その下の段に支えられており、より一般的な計算能力への移行を反映している。つまり、コンピュータが新しいタスクを実行するために必要なプログラマーの努力を減らし、与えられたプログラマー(またはユーザー)の労力で実行可能なタスクのセットを増やすものである;図 2 を参照。例えば、機械学習は、各新しいタスクを解決するためのロジックをプログラマーが考案する必要をなくすことで一般性を高め、代わりにトレーニング例の収集のみを必要とする。
特定のアプリケーションを開発するために必要な努力は、私たちがより多くの階段を築き、人工一般知能(AGI)に到達するまで減少し続けるという結論を引き出すのは誘惑的です。人工一般知能とは、箱から出してすぐに何でもできる AI システムとして概念化されることが多く、それによってアプリケーションを開発する必要自体が不要になると考えられています。
いくつかの分野では、確かにこのようにアプリケーション開発に必要な努力が減少する傾向が見られます。自然言語処理においては、大規模言語モデルにより、言語翻訳アプリケーションを開発することが比較的容易になりました。あるいはゲームを考えてみましょう。AlphaZero は、ゲームの説明と十分な計算資源さえ与えられれば、自己対戦を通じてチェスなどのゲームを人間よりも上手にプレイすることを学習できます。これはかつてのゲーム用プログラムが開発されていた方法とは全く異なるものです。

図 2: コンピューティングにおける一般性の階段。一部のタスクにおいては、より高い階段の段に上がるほど、コンピュータに新しいタスクを実行させるために必要なプログラマーの努力は少なくて済み、与えられたプログラマー(またはユーザー)の努力で実行できるタスクの数も増えます。19
しかし、これは容易にシミュレーションできず、エラーのコストが高いような重大な実世界アプリケーションにおいては、この傾向にはなっていません。自動運転車を例にとりましょう:多くの点で、その開発の軌道は AlphaZero の自己対戦と似ています。技術の向上がより現実的な条件下での走行を可能にし、それによってより良質かつ/またはより現実的なデータの収集が可能となり、それがさらに技術の改善につながり、フィードバックループが完成します。しかし、このプロセスには AlphaZero の場合の数時間ではなく、20 年以上がかかりました。これは、安全性の考慮事項により、このループの各反復を前回の反復と比較してどの程度拡大できるかに制限が課されたためです。
この「能力と信頼性のギャップ」は繰り返し現れます。実世界のタスクを自動化できる有用な AI エージェント(agents)を構築する上で、これは主要な障壁となってきました。明確に述べておくと、エージェントの使用が想定されている多くのタスク、例えば旅行の予約やカスタマーサービスの提供などは、運転ほど重大ではありませんが、それでもコストが高く、エージェントが実世界の経験から学習することは容易ではないのです。
安全性に直接関与しないアプリケーションにおいても障壁は存在します。一般的に、組織内の多くの知識は暗黙知であり、文書化されておらず、ましてや受動的に学習可能な形式で記述されているわけではありません。これは、これらの開発フィードバックループが各セクター内で発生しなければならないことを意味し、より複雑なタスクにおいては、異なる組織間で別々に発生する必要さえ生じ、急速かつ並列的な学習の機会を制限することになります。並列学習が制限される他の理由としては、プライバシーへの懸念があります。組織や個人は、機密データを AI 企業と共有することに抵抗を示す可能性があり、医療などの文脈では規制により第三者と共有できるデータの種別が制限される場合があります。
AI における「苦い教訓」とは、計算能力の増大を活用する一般的な手法が、最終的に人間のドメイン知識を利用する手法を大幅に上回るという事実です。これは手法に関する貴重な洞察ですが、応用開発にも適用されると誤解されることがよくあります。AI ベースのプロダクト開発の文脈においては、「苦い教訓」は決して真実に近いものではありません。ソーシャルメディア上のレコメンデーションシステムを考えてみてください。これらは(次第に汎用的になる)機械学習モデルによって駆動されていますが、それでもなお、ビジネスロジック、フロントエンド、および他のコンポーネントの手動コーディングの必要性を不要にするものではなく、これらを合わせると約 100 万行規模のコードとなることもあります。
さらに、既存の人間の知識からの AI 学習を超えていく必要がある場合、新たな限界が生じます。24 私たちの最も貴重な種類の知識には、科学および社会科学が含まれており、これらは技術や大規模な社会組織(例えば政府)を通じて文明の進歩を可能にしてきました。AI がこのような知識の境界を押し広げるためには何が必要でしょうか?おそらく、薬物試験から経済政策に至るまで、人々や組織との相互作用、あるいはそれらに対する実験が必要となるでしょう。ここで、実験に伴う社会的コストのために、知識獲得の速度には厳しい限界が存在します。社会は、AI 開発のための実験の急速な拡大を(そしてすべきではないが)許容しない可能性が高いです。
ベンチマークは現実世界の有用性を測定していない
手法と応用の区別は、AI の進歩をどのように測定し予測するかという点において重要な示唆を持っています。AI ベンチマークは手法における進歩を測定するには有用ですが、残念ながら、これらは応用における進歩を測定するものとして誤解されることが多く、この混乱が、差し迫った経済変革に関する多くの過剰な期待(ハイプ)の原動力となってきました。
例えば、GPT-4 がバー試験受験者の上位 10% に相当するスコアを達成したと報じられていますが、これは AI の法律実務能力について驚くほど少ないことを示唆しています。25 バー試験は専門分野の知識を過剰に重視し、標準化されたコンピュータによる実施形式では測定がはるかに困難な現実世界のスキルを軽視しています。つまり、言語モデルが得意とする「記憶した情報の検索と適用」こそが、まさに強調されている点なのです。
より広く言えば、法律業界に最も大きな変化をもたらす可能性のあるタスクほど、評価が難しいものです。法的リクエストを法分野ごとに分類するタスクなどでは明確な正解があるため、評価は容易です。しかし、法的書類の作成のように創造性や判断力を要するタスクには単一の正解はなく、戦略については合理的な人々でも意見が分かれることがあります。後者のようなタスクこそ、もし自動化されれば業界に最も深い影響を与えるものなのです。26
この観察は法律に限ったことではありません。別の例として、AI が明らかに優れている自己完結型のコーディング問題と、その影響を測定するのが困難でむしろ限定的であるように見える現実世界のソフトウェアエンジニアリングとの間のギャップが挙げられます。27 トイ問題を越える高度な評価基準であっても、必然的に無視せざるを得ない点があります
原文を表示
This post is over 15,000 words long—it is a new paper on our vision for the future of AI. We are pleased to announce that an expanded version of these ideas will become our next book together.
The paper is also published in HTML and PDF formats on the Knight First Amendment Institute’s website. We are grateful for the extensive feedback we’ve received on drafts of the paper.
Update (September 2025): We have published a companion to this essay titled A guide to understanding AI as normal technology.
We articulate a vision of artificial intelligence (AI) as normal technology. To view AI as normal is not to understate its impact—even transformative, general-purpose technologies such as electricity and the internet are “normal” in our conception. But it is in contrast to both utopian and dystopian visions of the future of AI which have a common tendency to treat it akin to a separate species, a highly autonomous, potentially superintelligent entity.1
The statement “AI is normal technology” is three things: a description of current AI, a prediction about the foreseeable future of AI, and a prescription about how we should treat it. We view AI as a tool that we can and should remain in control of, and we argue that this goal does not require drastic policy interventions or technical breakthroughs. We do not think that viewing AI as a humanlike intelligence is currently accurate or useful for understanding its societal impacts, nor is it likely to be in our vision of the future.2
The normal technology frame is about the relationship between technology and society. It rejects technological determinism, especially the notion of AI itself as an agent in determining its future. It is guided by lessons from past technological revolutions, such as the slow and uncertain nature of technology adoption and diffusion. It also emphasizes continuity between the past and the future trajectory of AI in terms of societal impact and the role of institutions in shaping this trajectory.
In Part I, we explain why we think that transformative economic and societal impacts will be slow (on the timescale of decades), making a critical distinction between AI methods, AI applications, and AI adoption, arguing that the three happen at different timescales.
In Part II, we discuss a potential division of labor between humans and AI in a world with advanced AI (but not “superintelligent” AI, which we view as incoherent as usually conceptualized). In this world, control is primarily in the hands of people and organizations; indeed, a greater and greater proportion of what people do in their jobs is AI control.
In Part III, we examine the implications of AI as normal technology for AI risks. We analyze accidents, arms races, misuse, and misalignment, and argue that viewing AI as normal technology leads to fundamentally different conclusions about mitigations compared to viewing AI as being humanlike.
Of course, we cannot be certain of our predictions, but we aim to describe what we view as the median outcome. We have not tried to quantify probabilities, but we have tried to make predictions that can tell us whether or not AI is behaving like normal technology.
In Part IV, we discuss the implications for AI policy. We advocate for reducing uncertainty as a first-rate policy goal and resilience as the overarching approach to catastrophic risks. We argue that drastic interventions premised on the difficulty of controlling superintelligent AI will, in fact, make things much worse if AI turns out to be normal technology— the downsides of which will be likely to mirror those of previous technologies that are deployed in capitalistic societies, such as inequality.3
The world we describe in Part II is one in which AI is far more advanced than it is today. We are not claiming that AI progress—or human progress—will stop at that point. What comes after it? We do not know. Consider this analogy: At the dawn of the first Industrial Revolution, it would have been useful to try to think about what an industrial world would look like and how to prepare for it, but it would have been futile to try to predict electricity or computers. Our exercise here is similar. Since we reject “fast takeoff” scenarios, we do not see it as necessary or useful to envision a world further ahead than we have attempted to. If and when the scenario we describe in Part II materializes, we will be able to better anticipate and prepare for whatever comes next.
A note to readers. This essay has the unusual goal of stating a worldview rather than defending a proposition. The literature on AI superintelligence is copious. We have not tried to give a point-by-point response to potential counter arguments, as that would make the paper several times longer. This paper is merely the initial articulation of our views; we plan to elaborate on them in various follow ups.
Subscribe to receive follow-up essays.
Part I: The Speed of Progress
Figure 1. Like other general-purpose technologies, the impact of AI is materialized not when methods and capabilities improve, but when those improvements are translated into applications and are diffused through productive sectors of the economy.4 There are speed limits at each stage.
Will the progress of AI be gradual, allowing people and institutions to adapt as AI capabilities and adoption increase, or will there be jumps leading to massive disruption, or even a technological singularity? Our approach to this question is to analyze highly consequential tasks separately from less consequential tasks and to begin by analyzing the speed of adoption and diffusion of AI before returning to the speed of innovation and invention.
We use invention to refer to the development of new AI methods—such as large language models—that improve AI’s capabilities to carry out various tasks. Innovation refers to the development of products and applications using AI that consumers and businesses can use. Adoption refers to the decision by an individual (or team or firm) to use a technology, whereas diffusion refers to the broader social process through which the level of adoption increases. For sufficiently disruptive technologies, diffusion might require changes to the structure of firms and organizations, as well as to social norms and laws.
AI Diffusion in Safety-critical Areas Is Slow
In the paper Against Predictive Optimization, we compiled a comprehensive list of about 50 applications of predictive optimization, namely the use of machine learning (ML) to make decisions about individuals by predicting their future behavior or outcomes.5 Most of these applications, such as criminal risk prediction, insurance risk prediction, or child maltreatment prediction, are used to make decisions that have important consequences for people.
While these applications have proliferated, there is a crucial nuance: In most cases, decades-old statistical techniques are used—simple, interpretable models (mostly regression) and relatively small sets of handcrafted features. More complex machine learning methods, such as random forests, are rarely used, and modern methods, such as transformers, are nowhere to be found.
In other words, in this broad set of domains, AI diffusion lags decades behind innovation. A major reason is safety—when models are more complex and less intelligible, it is hard to anticipate all possible deployment conditions in the testing and validation process. A good example is Epic’s sepsis prediction tool which, despite having seemingly high accuracy when internally validated, performed far worse in hospitals, missing two thirds of sepsis cases and overwhelming physicians with false alerts.6
Epic’s sepsis prediction tool failed because of errors that are hard to catch when you have complex models with unconstrained feature sets.7 In particular, one of the features used to train the model was whether a physician had already prescribed antibiotics —to treat sepsis. In other words, during testing and validation, the model was using a feature from the future, relying on a variable that was causally dependent on the outcome. Of course, this feature would not be available during deployment. Interpretability and auditing methods will no doubt improve so that we will get much better at catching these issues, but we are not there yet.
In the case of generative AI, even failures that seem extremely obvious in hindsight were not caught during testing. One example is the early Bing chatbot “Sydney” that went off the rails during extended conversations; the developers evidently did not anticipate that conversations could last for more than a handful of turns.8 Similarly, the Gemini image generator was seemingly never tested on historical figures.9 Fortunately, these were not highly consequential applications.
More empirical work would be helpful for understanding the innovation-diffusion lag in various applications and the reasons for this lag. But, for now, the evidence that we have analyzed in our previous work is consistent with the view that there are already extremely strong safety-related speed limits in highly consequential tasks. These limits are often enforced through regulation, such as the FDA’s supervision of medical devices, as well as newer legislation such as the EU AI Act, which puts strict requirements on high-risk AI.10 In fact, there are (credible) concerns that existing regulation of high-risk AI is so onerous that it may lead to “runaway bureaucracy”.11 Thus, we predict that slow diffusion will continue to be the norm in high-consequence tasks.
At any rate, as and when new areas arise in which AI can be used in highly consequential ways, we can and must regulate them. A good example is the Flash Crash of 2010, in which automated high-frequency trading is thought to have played a part. This led to new curbs on trading, such as circuit breakers.12
Diffusion is Limited by the Speed of Human, Organizational, and Institutional Change
Even outside of safety-critical areas, AI adoption is slower than popular accounts would suggest. For example, a study made headlines due to the finding that, in August 2024, 40% of U.S. adults used generative AI.13 But, because most people used it infrequently, this only translated to 0.5%-3.5% of work hours (and a 0.125-0.875 percentage point increase in labor productivity).
It is not even clear if the speed of diffusion is greater today compared to the past. The aforementioned study reported that generative AI adoption in the U.S. has been faster than personal computer (PC) adoption, with 40% of U.S. adults adopting generative AI within two years of the first mass-market product release compared to 20 % within three years for PCs. But this comparison does not account for differences in the intensity of adoption (the number of hours of use) or the high cost of buying a PC compared to accessing generative AI.14 Depending on how we measure adoption, it is quite possible that the adoption of generative AI has been much slower than PC adoption.
The claim that the speed of technology adoption is not necessarily increasing may seem surprising (or even obviously wrong) given that digital technology can reach billions of devices at once. But it is important to remember that adoption is about software use, not availability. Even if a new AI-based product is instantly released online for anyone to use for free, it takes time to for people to change their workflows and habits to take advantage of the benefits of the new product and to learn to avoid the risks.
Thus, the speed of diffusion is inherently limited by the speed at which not only individuals, but also organizations and institutions, can adapt to technology. This is a trend that we have also seen for past general-purpose technologies: Diffusion occurs over decades, not years.15
As an example, Paul A. David’s analysis of electrification shows that the productivity benefits took decades to fully materialize.16 Electric dynamos were “everywhere but in the productivity statistics” for nearly 40 years after Edison’s first central generating station. 17 This was not just technological inertia; factory owners found that electrification did not bring substantial efficiency gains.
What eventually allowed gains to be realized was redesigning the entire layout of factories around the logic of production lines. In addition to changes to factory architecture, diffusion also required changes to workplace organization and process control, which could only be developed through experimentation across industries. Workers had more autonomy and flexibility as a result of the changes, which also necessitated different hiring and training practices.
The External World Puts a Speed Limit on AI Innovation
It is true that technical advances in AI have been rapid, but the picture is much less clear when we differentiate AI methods from applications.
We conceptualize progress in AI methods as a ladder of generality.18 Each step on this ladder rests on the ones below it and reflects a move toward more general computing capabilities. That is, it reduces the programmer effort needed to get the computer to perform a new task and increases the set of tasks that can be performed with a given amount of programmer (or user) effort; see Figure 2. For example, machine learning increases generality by obviating the need for the programmer to devise logic to solve each new task, only requiring the collection of training examples instead.
It is tempting to conclude that the effort required to develop specific applications will keep decreasing as we build more rungs of the ladder until we reach artificial general intelligence, often conceptualized as an AI system that can do everything out of the box, obviating the need to develop applications altogether.
In some domains, we are indeed seeing this trend of decreasing application development effort. In natural language processing, large language models have made it relatively trivial to develop a language translation application. Or consider games: AlphaZero can learn to play games such as chess better than any human through self-play given little more than a description of the game and enough computing power—a far cry from how game-playing programs used to be developed.
Figure 2: The Ladder of Generality in Computing. For some tasks, higher ladder rungs require less programmer effort to get a computer to perform a new task, and more tasks can be performed with a given amount of programmer (or user) effort.19
However, this has not been the trend in highly consequential, real-world applications that cannot easily be simulated and in which errors are costly. Consider self-driving cars: In many ways, the trajectory of their development is similar to AlphaZero’s self-play—improving the tech allowed them to drive in more realistic conditions, which enabled the collection of better and/or more realistic data, which in turn led to improvements in the tech, completing the feedback loop. But this process took over two decades instead of a few hours in the case of AlphaZero because safety considerations put a limit on the extent to which each iteration of this loop could be scaled up compared to the previous one.20
This “capability-reliability gap” shows up over and over. It has been a major barrier to building useful AI “agents” that can automate real-world tasks.21 To be clear, many tasks for which the use of agents is envisioned, such as booking travel or providing customer service, are far less consequential than driving, but still costly enough that having agents learn from real-world experiences is not straightforward.
Barriers also exist in non-safety-critical applications. In general, much knowledge is tacit in organizations and is not written down, much less in a form that can be learned passively. This means that these developmental feedback loops will have to happen in each sector and, for more complex tasks, may even need to occur separately in different organizations, limiting opportunities for rapid, parallel learning. Other reasons why parallel learning might be limited are privacy concerns: Organizations and individuals might be averse to sharing sensitive data with AI companies, and regulations might limit what kinds of data can be shared with third parties in contexts such as healthcare.
The “bitter lesson” in AI is that general methods that leverage increases in computational power eventually surpass methods that utilize human domain knowledge by a large margin.22 This is a valuable observation about methods, but it is often misinterpreted to encompass application development. In the context of AI-based product development, the bitter lesson has never been even close to true.23 Consider recommender systems on social media: They are powered by (increasingly general) machine learning models, but this has not obviated the need for manual coding of the business logic, the frontend, and other components which, together, can comprise on the order of a million lines of code.
Further limits arise when we need to go beyond AI learning from existing human knowledge.24 Some of our most valuable types of knowledge are scientific and social-scientific, and have allowed the progress of civilization through technology and large-scale social organizations (e.g., governments). What will it take for AI to push the boundaries of such knowledge? It will likely require interactions with, or even experiments on, people or organizations, ranging from drug testing to economic policy. Here, there are hard limits to the speed of knowledge acquisition because of the social costs of experimentation. Societies probably will not (and should not) allow the rapid scaling of experiments for AI development.
Benchmarks Do not Measure Real-World Utility
The methods-application distinction has important implications for how we measure and forecast AI progress. AI benchmarks are useful for measuring progress in methods; unfortunately, they have often been misunderstood as measuring progress in applications, and this confusion has been a driver of much hype about imminent economic transformation.
For example, while GPT-4 reportedly achieved scores in the top 10% of bar exam test takers, this tells us remarkably little about AI’s ability to practice law.25 The bar exam overemphasizes subject-matter knowledge and under-emphasizes real-world skills that are far harder to measure in a standardized, computer-administered format. In other words, it emphasizes precisely what language models are good at—retrieving and applying memorized information.
More broadly, tasks that would lead to the most significant changes to the legal profession are also the hardest ones to evaluate. Evaluation is straightforward for tasks like categorizing legal requests by area of law because there are clear correct answers. But for tasks that involve creativity and judgment, like preparing legal filings, there is no single correct answer, and reasonable people can disagree about strategy. These latter tasks are precisely the ones that, if automated, would have the most profound impact on the profession.26
This observation is in no way limited to law. Another example is the gap between self-contained coding problems at which AI demonstrably excels, and real-world software engineering in which its impact is hard to measure but appears to be modest.27 Even highly regarded coding benchmarks that go beyond toy problems must necessarily igno
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み