FlashAttention-4:非対称ハードウェア拡張のためのアルゴリズムとカーネルパイプラインの協調設計
Together AIは、Blackwell GPUなどの非対称なハードウェアスケーリングに対応するため、アルゴリズムとカーネルパイプラインを共同設計したFlashAttention-4を発表し、推論速度の大幅な向上を実現した。
キーポイント
非対称ハードウェアへの最適化
Blackwell GPUなど、計算能力とメモリ帯域幅のバランスが偏った次世代アクセラレータ向けに、FlashAttention-4はアルゴリズムとカーネルの実装を共同設計することで最適化されている。
アルゴリズムとカーネルの共同設計
従来の分離されたアプローチではなく、アルゴリズムの革新と低レベルなカーネルパイプラインの最適化を統合し、ハードウェア固有のボトルネックを解消している。
オープンソース実装の提供
論文(arXiv)とGitHub上の完全なコードが公開されており、開発者は最新のハードウェア環境でFlashAttentionの性能を直接検証・利用可能である。
影響分析・編集コメントを表示
影響分析
FlashAttention-4の登場は、ハードウェアベンダーが追求している「非対称なスケーリング」戦略に対して、ソフトウェア層でどのように追従し、性能を引き出すかという重要な指針を示している。特にBlackwell世代のような新アーキテクチャにおいて、推論速度のボトルネックを解消する実用的な解決策となるため、大規模言語モデル(LLM)の運用コスト削減と速度改善に直結する影響がある。
編集コメント
ハードウェアの進化がアルゴリズム設計に与える影響を明確に示した事例であり、次世代GPU導入時のソフトウェアスタック見直しにおいて重要な参考となる。

Presenting FlashAttention-4: [Paper] [Code]
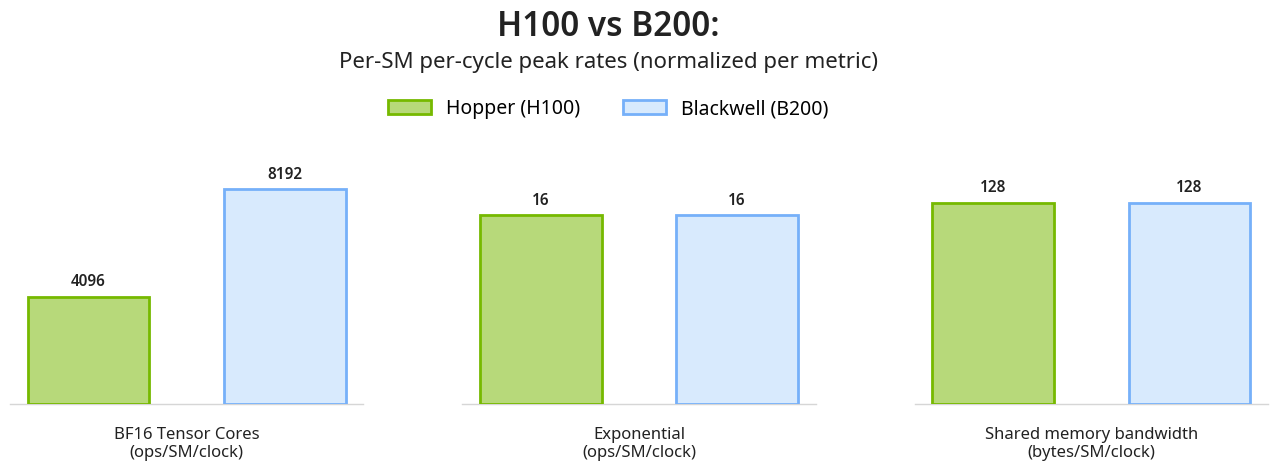
Modern accelerators like Blackwell GPUs continue the trend of asymmetric hardware scaling, where tensor core throughput grows far faster than other resources such as shared memory bandwidth, special function units (SFUs) for transcendental operations like exponential, and general-purpose integer and floating-point ALUs. From the Hopper H100 to the Blackwell B200, for instance, BF16 tensor core throughput increases from 1 to 2.25 PFLOPs, while both the SFU count and shared memory bandwidth remains unchanged.
This scaling asymmetry has profound implications for optimizing complex kernels like attention for the Blackwell architecture. At its core, attention comprises two GEMMs and with softmax in-between; in practice, it also involves substantial plumbing and bookkeeping: data movement, synchronization, layout transforms, element-wise ops, scheduling, masking, etc.
A naive viewpoint on attention might be that the speed of the GEMMs completely controls the kernel performance and one can effectively disregard these other attention components, at least to first order. However, doing a “feeds and speeds” analysis for B200 in fact shows the opposite: the main performance bottleneck lies not in how fast the tensor cores can do MMA, but rather (a) in the SFU units for softmax exponential during the FWD computation, and (b) in the shared-memory traffic during the BWD computation.
In this blog post, we present FlashAttention-4, an algorithm and kernel co-design that maximizes overlap between matmul and these other resource bottlenecks. On B200 with BF16, it reaches up to *1605 TFLOPs/s* (71% utilization), up to *1.3×* faster than cuDNN version *9.13* and *2.7×* faster than Triton.
Our main algorithmic and kernel co-design ideas are as follows:
- New pipelining for maximum overlap: New forward and backward software pipelines that exploit Blackwell fully asynchronous MMA and larger tile sizes, overlapping tensor cores, softmax exponential, and memory operations.
- Forward (FWD) pass: A software emulation of the exponential function implemented via polynomial approximation on FMA units to mitigate the exponential bottleneck, plus conditional online softmax rescaling.
- Backward (BWD) pass: Storing intermediate results in tensor memory to relieve shared-memory traffic, combined with Blackwell's new 2-CTA MMA mode to reduce shared memory traffic further and also cut atomic reduction in half, and additional support for deterministic execution mode for reproducible training.
- Scheduling: New tile scheduler to mitigate load imbalance from causal mask and variable sequence length.
New hardware features on Blackwell
- Tensor memory (TMEM): On B200, each of the 148 SMs has 256 KB of TMEM, an on chip scratchpad wired into the tensor cores for warp synchronous intermediate storage.
- Fully asynchronous 5th gen tensor cores: tcgen05.mma is asynchronous and accumulates in TMEM. For BF16 and FP16, the largest single CTA UMMA tile is 128×256×16, which is about 2× larger than the largest Hopper WGMMA atom. UMMA is launched by a single thread, easing register pressure and making larger tiles and deeper pipelines practical without the spilling pain points of Hopper warpgroup MMA. This also makes warp specialization more viable, with some warps moving tiles while others issue MMA to overlap matrix multiply accumulate with softmax and memory traffic. tcgen05.mma can also source operand A from TMEM.
- 2-CTA MMA.: Blackwell can execute one UMMA across a CTA pair in the same cluster, spanning the TMEM of both peer CTAs. One thread in the leader CTA launches the MMA, but both CTAs must stay active while it is in flight. This scales the MMA tile dimension up to 256×256×16 by splitting M and N across the pair, reducing redundant traffic and lowering per CTA footprint. The CTA group size, 1 or 2, must remain constant across TMEM and tensor core operations within a kernel.

Feeds and Speeds
For M=N=D=128
Feeds on B200 (per SM):
- Tensor Cores (BF16):
- Exponential unit:
- Shared Memory traffic:
Speeds (clock-cycles per tile):
- Forward (2 MMAs + MN exp)Tensor Cores:
- Exp:
- SMEM:
- Backward (5 MMAs + MN exp): 1-CTATensor Cores:
- Exp:
- SMEM:
Takeaway: Forward is bottlenecked by compute and exponential, backward is bottlenecked by shared memory bandwidth. So we overlap softmax with MMA in the forward pass and reduce shared memory traffic in the backward pass.
Forward pass: New softmax pipelining with conditional rescaling
The forward pass has two matmuls, QK^T and PV. On Blackwell, tensor cores got much faster, but the exponential unit (MUFU.EX2) did not. So softmax is no longer “just the thing between the two matmuls”, it is a bottleneck that must be carefully pipelined.
The FWD pass in short:
- Ping-pong schedule Q and O tiles per CTA: maximize overlap between MMA and Softmax
- 2x softmax warpgroups: per tile softmax with synchronization to not overlap when computing exponentialSoftware emulation of : distribute exp computation across hardware's MUFU and software emulated on FMA
- Store P in TMEM in stages: mitigate register pressure
- Correction warpgroup: designated "correction" warpgroup to perform rescaling to remove from critical pathOnline softmax (conditional) rescaling: Rescale less frequently to minimize non-matmul operations

Pipeline: Ping-pong Q tiles plus a dedicated correction stage
FlashAttention-4 computes two query tiles per CTA — and — each covering 128 query tokens, and alternates them in a ping-pong schedule.
Blackwell changes the softmax mapping. The accumulator tile for S = QK^T is 128×128 and lives in tensor memory; however, upon being read into registers, we have one thread per row for the partitioning of the tile as dictated by the hardware. We use two 128 thread warpgroups, one per Q tile, and each softmax warpgroup executes the following sequence of operations:
- Each thread loads one 128 element row of S from tensor memory into registers
- Reduce rowmax and rowsum
- Using a tunable parameter, decide which portion of the 128 elements uses hardware's MUFU vs. software-emulated
- Compute P = softmax(S) and convert to BF16 precision
- Store P back to tensor memory in stages to relieve register pressure (as opposed to holding 128 elements of S and 64 (BF16) elements of P simultaneously)
- Trigger the corresponding PV matmul as soon as a th chunk of P is stored
The critical detail is that exp is the bottlenecked section. We explicitly synchronize the two softmax warpgroups so they do not evaluate exp at the same time, thereby reducing MUFU contention.
To keep rescaling off the critical path, the kernel assigns it to a dedicated warpgroup. The correction warpgroup computes:
- Only rescale when the max jump is large:
-
- Apply the final normalization at the end of the iteration
- Optionally compute and store LSE
At the end we still normalize using the true final statistics, so skipping small rescale steps preserves the final output while deleting many vector computations from the critical path. We make the decision at warp granularity to avoid divergence.
Faster exponential: Distribute across MUFU.EX2 and FMA (software emulation)
Softmax requires many exponentials, and MUFU throughput is much lower than tensor core throughput. FlashAttention-4 increases effective exp throughput by running the software emulation of exp2 alongside the hardware MUFU.EX2 path, using FMA units that would otherwise be underutilized.
Range-reduction (Cody-Waite): We use the classical technique of Cody-Waite range reduction to decompose the exponential computation into the integer and the fractional part: . In IEEE 754 float32, scaling by is just an exponent update.
Polynomial approximation of (Horner’s Method): To ****approximate we rewrite in Horner's form for efficient evaluation.
The coefficients p0 = 1.0, p1 ≈ 0.6951, p2 ≈ 0.2276, p3 ≈ 0.0771 are chosen using the Sollya software package to minimize the relative approximation error over .
Exponent bits shift and add: The final step is to combine the integer part n and the fractional approximation 2^{f} to form 2^{x} \approx 2^{n}\cdot 2^{f} . Since 2^f \in[1,2) has float32 exponent 127, multiplying by 2^{n} is just shifting the integer n into the exponent field and then adding the mantissa bits of 2^{f}.
Scheduling
Causal masking and variable sequence length make attention load imbalanced because different worktiles have different mainloop lengths, so FA4 improves grid linearization and applies *longest-processing-time-first (LPT)* scheduling to reduce the tail. In fact, these ideas are non-specific to Blackwell or any particular GPU architecture, and we also use them in FA3.
For causal masking, the standard (mblocks, heads, batches) grid order suboptimally processes tiles from shortest to longest, so FA4 swizzles batch-heads into L2-sized sections and traverses the grid by batch-head section, iterating mblocks in reverse order and then the batch-heads within each section.
For variable sequence length, since different batches involve different amounts of work, the given batch-processing order is typically suboptimal from the point of view of the LPT scheduling heuristic. To rectify this, we can launch a preprocessing kernel that sorts batches by maximum per-worktile execution time and writes a virtual to actual batch index mapping that the attention kernel uses to traverse batches in sorted order; moreover, the metadata can be cached so that sorting adds no performance loss. At the time of this writing, we have validated this idea and implemented it for FA3, and we expect to incorporate sorting and other metadata preparation more generally into F4 in the near future.
Language and framework: CuTe-DSL
FA4 is implemented entirely in CuTe-DSL, CUTLASS’ Python kernel DSL. Kernels are written in Python; the DSL lowers to PTX, then the CUDA toolkit compiles to GPU machine code. The programming model mirrors CuTe/CUTLASS abstractions with a PTX escape hatch, while cutting compile times by ~20–30× vs C++ templates.
Attention Benchmarks
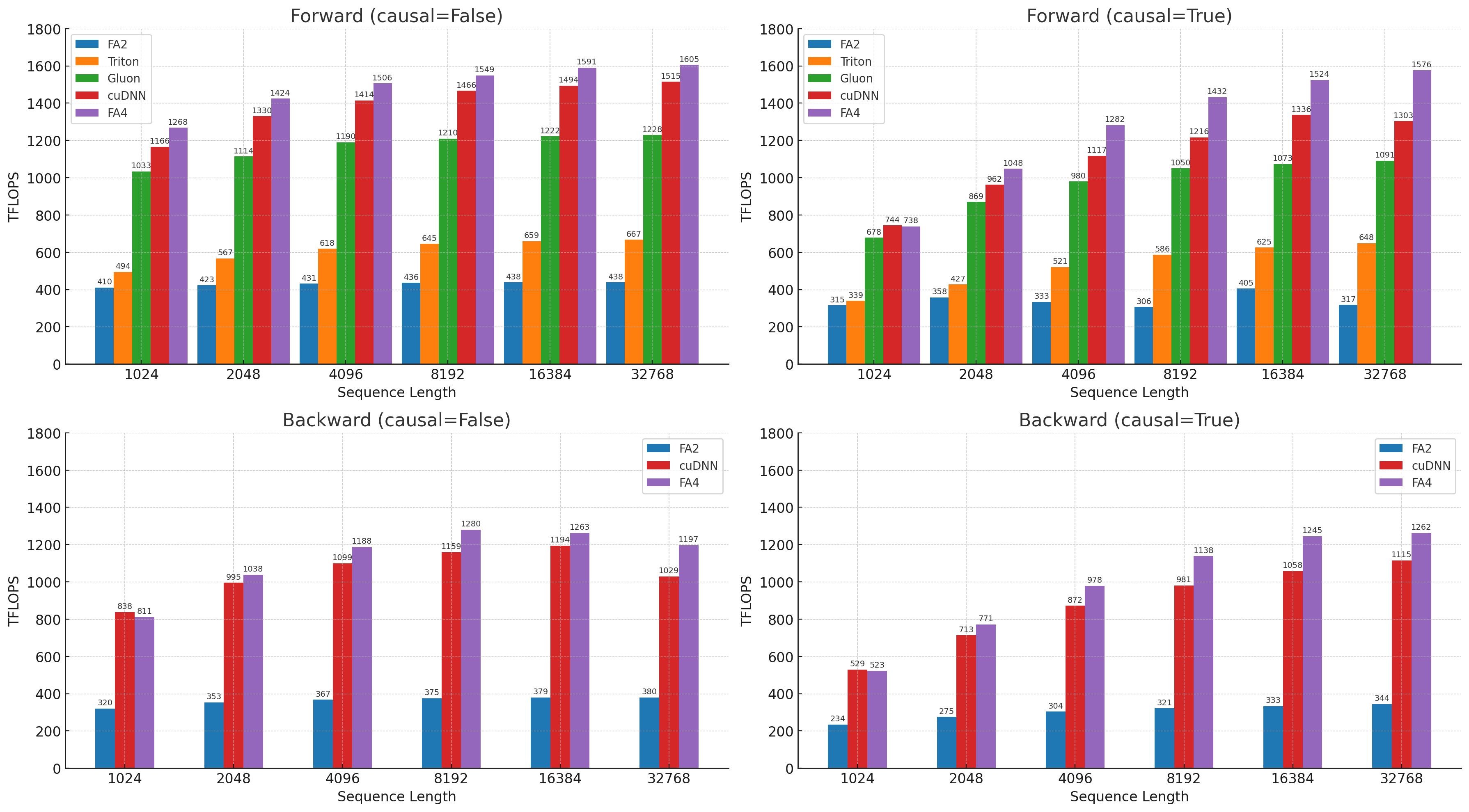
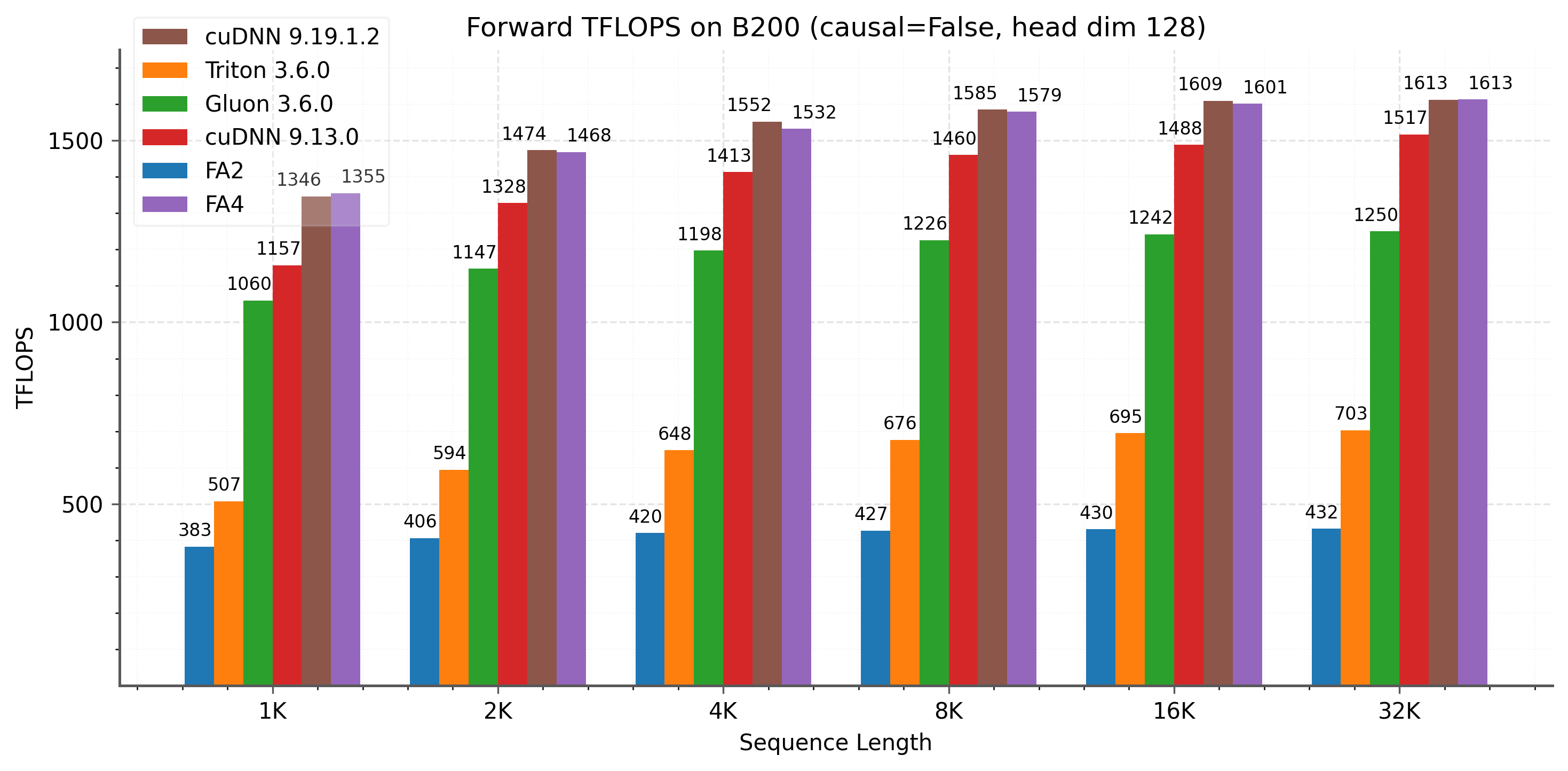
We show results for FlashAttention-4 on B200 (BF16) and compare it to FlashAttention-2, as well as to implementations in Triton, Gluon, and cuDNN. For cuDNN, we compare against cuDNN 9.13 and the latest version, 9.19.1.2. Starting with versions 9.13 and 9.14, we have worked with the cuDNN team to incorporate some techniques from FlashAttention-4 into cuDNN, so that our work can benefit as many practitioners as possible. For backward FlashAttention-4 consistently outperforms the other baselines for large sequence lengths. In the forward pass, FlashAttention-4 is 1.1-1.3x faster than cuDNN 9.13 and 2.1-2.7x faster than Triton.




Acknowledgements
We thank Together AI, Meta, xAI, and Princeton Language and Intelligence (PLI) for compute support. We want to further thank the following teams at Nvidia: CuDNN, TensorRT-LLM, and CUTLASS teams for constant discussions, ideas, and feedback.

8S
DeepSeek R1

Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
Aurora:推論効率を向上させるオープンソース強化学習フレームワーク
Auroraは、推論効率を1.25倍向上させるオープンソースの強化学習フレームワークです。これは、推論を単なるオフライン設定から、リクエストごとに自己改善するシステムへと変革します。
e スクーター創業者が宇宙データセンター構築に 500 万ドルを調達
e スクーターの創業者が、宇宙空間でのデータセンター建設プロジェクトのために 500 万ドルの資金調達を実現した。
NVIDIA Blackwell で NVFP4 を使用し、JAX と MaxText でモデルの学習を高速化
NVIDIA は、Blackwell アーキテクチャ上で NVFP4 技術を活用することで、JAX および MaxText を用いた大規模言語モデルの前学習処理におけるスループットが向上し、学習速度が大幅に改善されることを発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み