Aurora:推論効率を向上させるオープンソース強化学習フレームワーク
Together AIは、推論トレースからリアルタイムで学習しドラフトモデルを継続的に更新するRLベースのオープンソースフレームワーク「Aurora」を公開し、静的な推論加速の限界を超える自律型最適化を実現した。
キーポイント
Auroraの核心機能
ライブな推論トレースから直接学習し、サービス中断なく非同期でspeculator(ドラフトモデル)を更新するRLベースのフレームワーク。
静的モデルの課題解決
従来のオフライン再トレーニングでは追いつけないトラフィックの分布ミスマッチやモデル陳腐化を、オンライン学習でリアルタイムに補正する。
実証された性能向上
Qwen3やLlama3などの主要モデルにおいて、十分に訓練された静的speculatorと比較して1.25倍の追加速度向上を実現した。
インフラコストの削減
大規模な活性化データ収集パイプラインを不要にし、アルゴリズムに依存しない設計により将来のspeculator設計とも互換性を持つ。
重要な引用
Speculative decoding goes stale in production — draft models can drift and offline retraining can't always keep pace with live traffic.
Aurora fixes this. It's an open-source, RL-based framework that learns directly from live inference traces and continuously updates the speculator without interrupting serving.
The headline finding: online training from scratch can outperform a carefully pretrained static baseline.
影響分析・編集コメントを表示
影響分析
Together AIのAuroraは、LLM推論における「コスト対パフォーマンス」のトレードオフを根本から見直す可能性を秘めている。特に、静的なドラフトモデルが抱える陳腐化問題に対処するリアルタイム適応能力は、大規模なLLMサービスを提供する企業にとってインフラコスト削減とレイテンシ改善の両立を実現する重要な技術革新となる。
編集コメント
推論速度の最適化において「静的な事前学習」から「動的なオンライン学習」へパラダイムがシフトしつつある。Auroraのような自律型適応システムは、変動するユーザートラフィックに対応する次世代LLMインフラの標準となり得る。
要約
プロダクション環境における推論用デコード(speculative decoding)は陳腐化しやすい。ドラフトモデルがドリフトし、オフラインでの再トレーニングでは生トラフィックのペースに追いつけないことがある。
Aurora はこれを解決する。これはライブな推論トレースから直接学習し、サービス提供を中断することなくスペキュレーター(speculator)を継続的に更新する、強化学習ベースのオープンソースフレームワークである。
主要な結果:
→ 変化するトラフィックドメイン全体でのリアルタイム適応
→ 十分にトレーニングされた静的なスペキュレーターと比較して追加で 1.25 倍の高速化
注目すべき発見:ゼロからオンラインで学習することは、注意深く事前トレーニングされた静的なベースラインを上回る可能性がある。
プロダクション環境で大規模言語モデル(LLM)を実行することは、パフォーマンスとコストの間での絶え間ないトレードオフを伴う。推論用デコードは標準的な手段である:原理的には推論を高速化するが、実際には期待通りの成果が出ないことが多い。ドラフトモデルが陳腐化し、受容率がドリフトし、生トラフィックのペースに追いつくためにオフラインで再トレーニングを行うのは遅すぎて高価すぎるからだ。もしシステムが、自身が処理しているリクエストそのものから継続的かつリアルタイムで学習できるならどうだろうか。
昨年は ATLAS を紹介した。これは適応型スペキュレーターへの我々の第一歩である。この研究は基盤を築いたが、目標はずっと以前から、サービス提供とトレーニングの間のループを閉じる完全自律型のシステムであった。
本日、Aurora をリリースします。これは、ライブ推論トレースから学習し、予測器を非同期で更新するオープンソースの強化学習(RL)ベースのフレームワークです。これにより、推測的デコーディングは静的な一度きりの設定から、動的で自己改善型のフライホイールへと進化します。この統合された設計により、標準的なパイプラインでは達成が難しい機能が可能になります。具体的には、(1) 分布ミスマッチの直接的な緩和(強力なオフラインベースラインに対して 1.25 倍の向上)、(2) 大規模な活性化収集パイプラインを不要にするためのインフラコスト削減、(3) 将来の予測器設計と互換性のあるアルゴリズム非依存フレームワーク、そして (4) 多様で不均一なユーザーニーズへの対応です。
実験結果では、Aurora は広く使用されているモデル(Qwen3 や Llama3 など)において、よく訓練されたが静的な予測器と比較して追加で 1.25 倍の高速化を達成しました。
論文の結果を再現するためのコードは オープンソース で公開されており、コミュニティからの貢献を歓迎します。
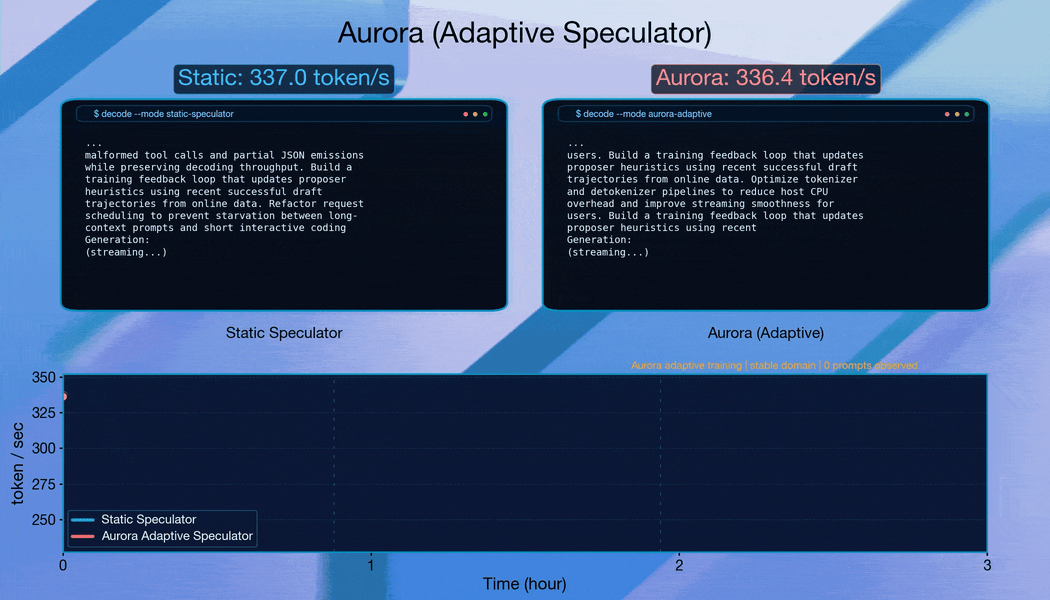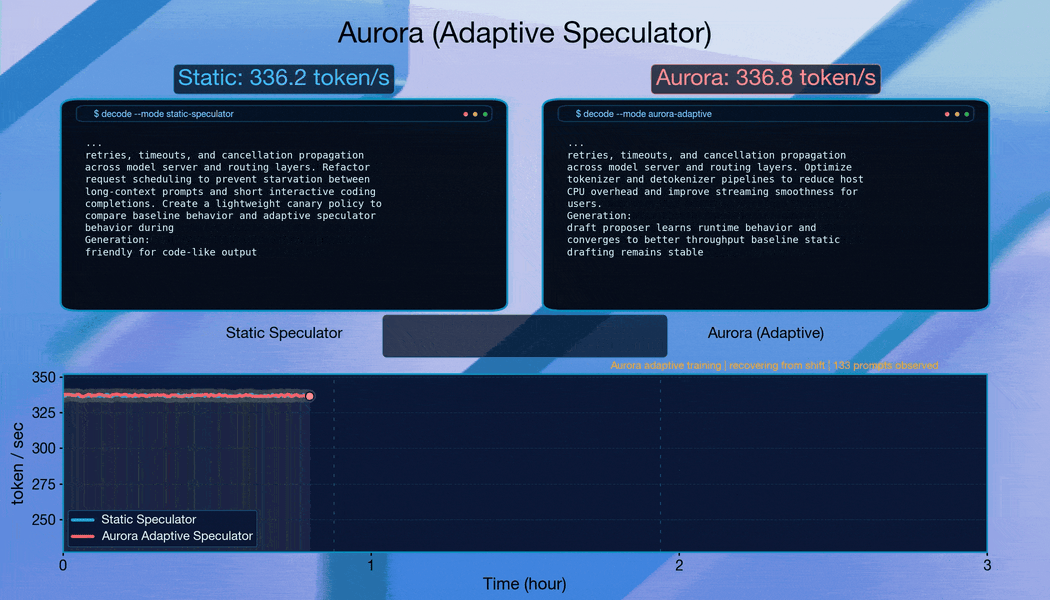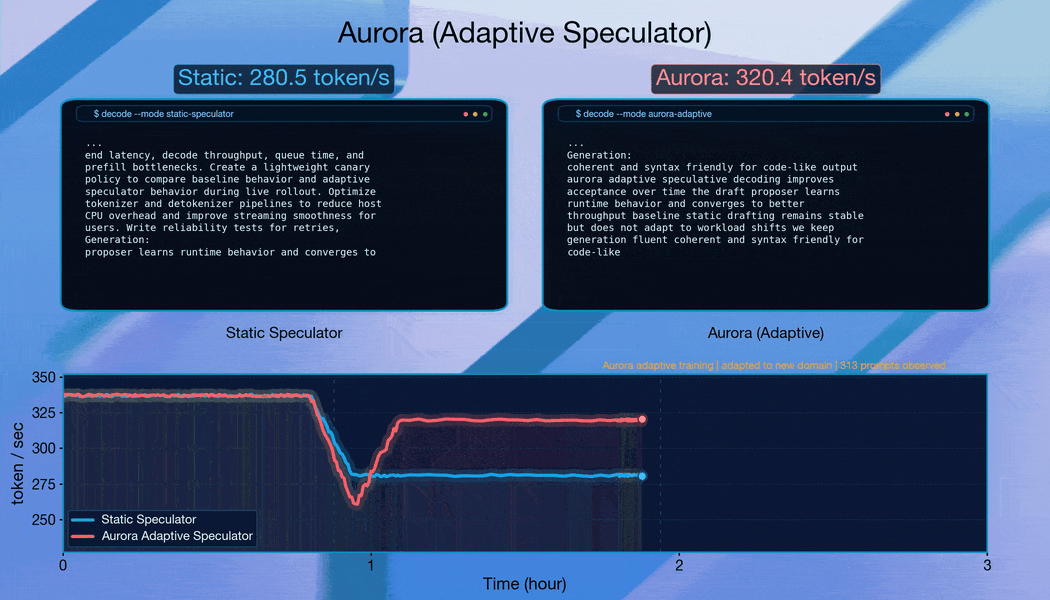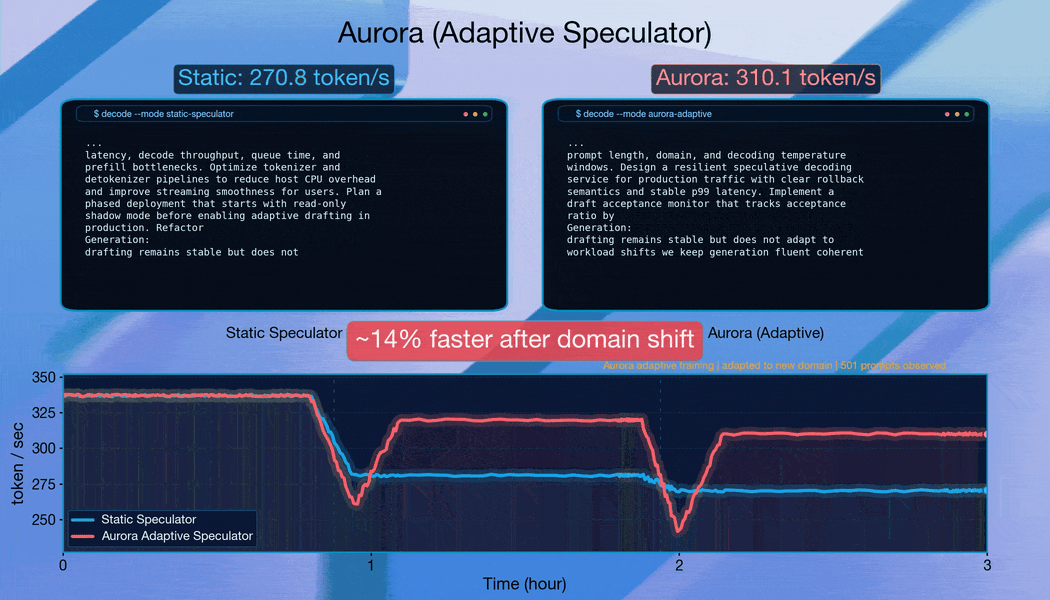
Aurora は変化するドメインにすばやく適応します。
バッチサイズが異なる場合のエンドツーエンドのスループット
MiniMax M2.5 (FP8, lookahead 5):
BS
Config
OTPS Mean
OTPS P50
OTPS P05
OTPS P95
Speedup
Acc Len
1
w/o spec
147.06
146.45
140.46
154.72
--
--
w/ spec
240.39
226.57
186.98
325.36
1.63×
2.41
8
w/o spec
109.41
106.49
99.56
126.57
--
--
w/ spec
160.95
157.42
123.72
207.04
1.47×
2.40
16
w/o spec
93.12
89.56
82.64
113.29
--
--
w/ spec
134.70
129.95
100.97
179.02
1.45×
2.40
32
w/o spec
80.44
77.57
71.77
96.84
--
--
w/ spec
120.67
115.04
92.49
162.77
1.50×
2.45
OTPS = 出力トークン数/秒 (output tokens-per-second)。テストデータセット(198 例)。
Qwen3-Coder-Next-FP8 (lookahead 5):
BS
Config
OTPS Mean
OTPS P50
OTPS P05
OTPS P95
Speedup
Acc Len
1
w/o spec
195.21
195.23
194.75
195.75
--
--
w/ spec
375.49
350.37
251.92
574.03
1.92×
3.05
8
w/o spec
160.08
157.69
155.81
175.40
--
--
w/ spec
279.09
250.65
188.27
414.05
1.74×
3.10
16
w/o spec
138.70
137.92
130.05
150.44
--
--
w/ spec
221.56
202.96
143.80
323.54
1.60×
2.96
32
w/o spec
117.50
114.36
108.95
130.10
--
--
w/ spec
184.23
166.56
124.03
278.96
1.57×
3.00
OTPS = output tokens-per-second(出力トークン数/秒)。テスト用データセット(198 例)。
1. なぜ標準的な「学習後、提供」パイプラインが機能しなくなるのか
オフラインでの推測的トレーニングは組織上は便利だが、実運用においてはいくつかの実践的な課題を導入し、その効果を制限する。従来のパイプラインは一方向の通り道であり、モデルが陳腐化し、現実世界のパフォーマンスとの乖離を生み出す。
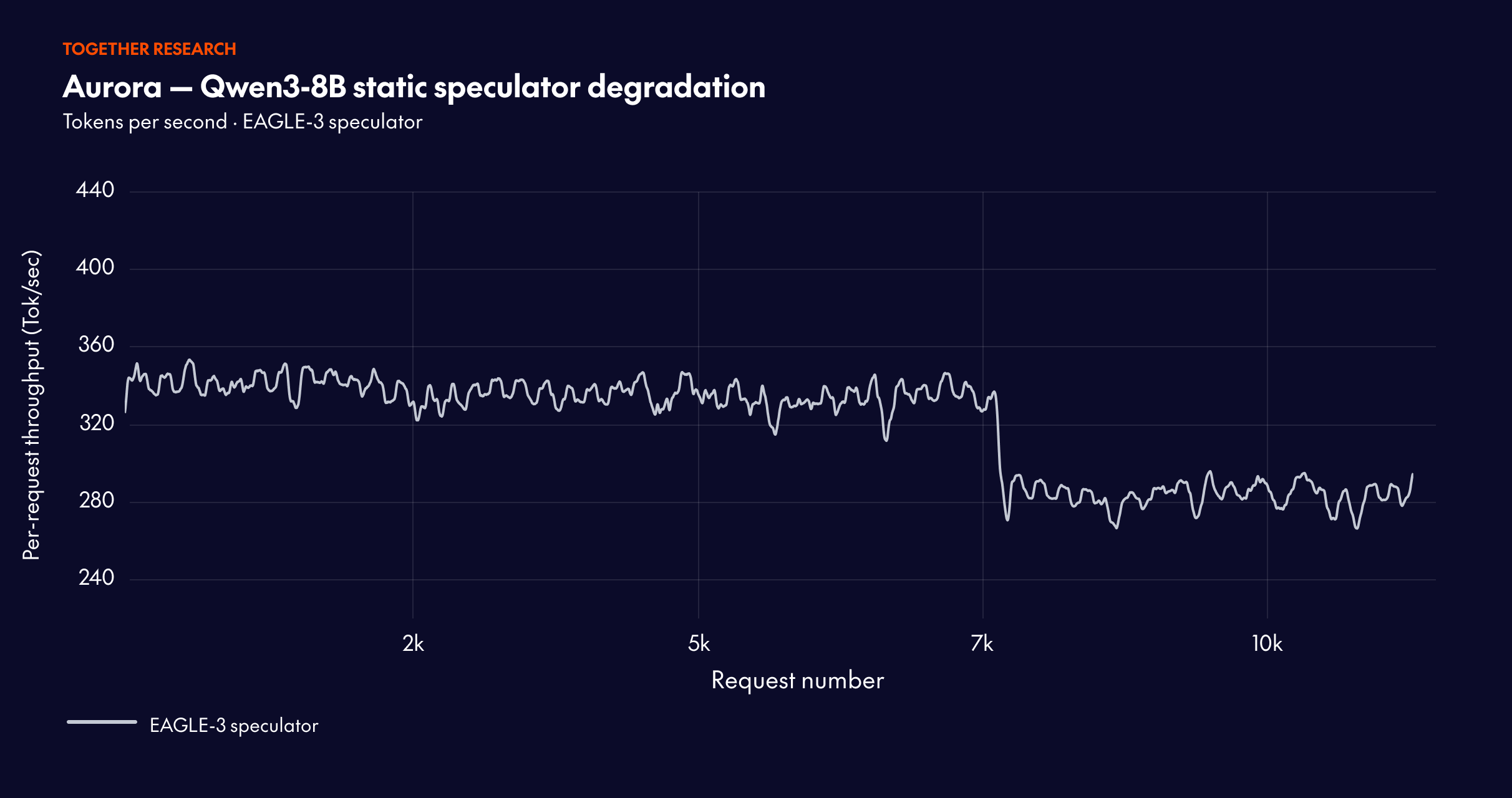
静的な推測者は、通常、トラフィックパターンが変化すると性能が低下します。従来の推論的デコーディングは時間とともに劣化する線形かつ静的なフローに従いますが、Aurora は円形的で継続的に適応するアプローチを導入しています。
検証器は移動しますが、ドラフターは遅れます。 品質、安全性、コスト、またはハードウェア移行のために、本番環境のターゲットモデルが変更されることがあります。推測者はしばしばよりゆっくりと更新されるため、陳腐化し、時間とともに推論性能が低下します。
オフライン蒸留パイプラインは高価です。 ドラフターのトレーニングのための活性化収集および再生パイプラインを大規模に保存・運用するには非常に高額になる可能性があります。本番環境のスケールでは、ストレージのフットプリントはペタバイトレベルに達し、メモリ、帯域幅、運用複雑性において高いコストがかかります。Aurora は、ライブサービングトレースから直接学習することでこの負担を軽減します。
受容率が実際の速度向上と同じではありません。 オフライントレーニングではラボ環境での受容率を最適化できますが、本番環境での速度向上は、カーネル、数値精度(FP8/FP4)、バッチ処理、スケジューリング、ハードウェアの動作など、実際のサービングスタックに依存します。オフラインで最良のドラフトモデルであっても、オンラインでは最良とは限りません。実際には、多くのチームが複数のドラフターをトレーニングしますが、最終的に1 つのみを選択します。Aurora はオンラインで動作するため、直接的な速度向上の比較を可能にします。
これらのギャップは、推論的デコーディングを単なるモデル化問題(「より良いドラフターを訓練する」)として扱うのではなく、学習とサービングの統合された問題として扱うべきであることを示唆しています。
2. コアとなるアイデア:強化学習(RL)によって駆動される、推論から学習へと繋がるフライホイール
Aurora は、予測デコーディングを推論から学習へと繋がるフライホイールに変換します。スペキュレーター(予測器)を静的な成果物として扱うのではなく、提供されたすべてのリクエストから継続的に学習する仕組みです。

Aurora は、強化学習(RL)によって駆動される推論から学習へと繋がるフライホイールを提供します。このシステムは、2 つの独立したコンポーネントを中心に構築されています。推論サーバーでは、ターゲットモデルとドラフトモデルを備えた予測デコーディングエンジン(SGLang または vLLM をベースに構築)が稼働しています。各リクエストに対して、ドラフトモデルが一連のトークンシーケンスを提案し、その後、ターゲットモデルによって並列検証が行われます。受け入れられたトークンと拒否されたトークンの結果、および EAGLE 型トレーニング用の隠れ状態(hidden states)は、分散データバッファへストリーミングされます。学習サーバーは非同期で動作し、バッファからトレーニングデータのバッチを取得してドラフトモデルのコピーに対して勾配更新を行い、定期的に改善された重みをサービス中断なしに推論サーバーへホットスワップします。
この設計は、2 つの生産上の現実を基盤としています。第一に、真の目的はサービス効率性であり、SLO 条件下でのレイテンシ、スループット、コスト/トークンです。第二に、同期は遅延実行かつ非破壊的である必要があります。頻繁な重みプッシュはキャッシュ無効化やレイテンシの揺らぎを引き起こす可能性があります。この設計を確実に機能させるために、オンライン推測トレーニングを非対称強化学習 (Reinforcement Learning: RL) 問題として再定式化します。
これは単なる理論上の利便性ではなく、オフラインでの模倣品質だけでなく、実際の展開における実用性と学習信号を直接整合させます。推測的デコーディングは自然に強化学習へとマッピングされます:
推測的デコーディング → RL マッピング
ドラフトモデル → ポリシー (π)
ターゲット検証器 → 環境
受け入れられたトークン → 正の報酬
拒否された提案 → 負の/反事実フィードバック
この枠組みにおいて、リターンを最大化することは、直接的に受容長を最大化することに等しく、それはデコード速度の向上に直結します。Aurora の微妙かつ強力な点の一つは、それが受容されたトークンからの学習だけでなく行うことです。受容損失(模倣)は、受容されたトークンに対する交差エントロピーを用いて、ドラフトが検証者によって承認された継続を再現することを促します。一方、拒否損失(破棄サンプリング)は、拒否された分岐を反事実的監督として用いることで、ドラフトに何を提案すべきでないかを教えます。
推測デコードの結果が生み出す複雑な分岐構造を効率的に処理するために、私たちは専用のツリーアテンション機構を採用しています。推測ツリーの因果構造を尊重するカスタムアテンションマスクを構築することで、すべての受容された分岐と拒否された分岐を、単一のバッチ化された順伝播および逆伝播パスで処理することが可能になります。
3. 分布シフトへの適応
Aurora の堅牢性をテストするため、数学的推論、テキストから SQL への変換、コード生成、金融、一般会話という 5 つのドメインにわたる 40,000 件のプロンプトストリームを用いて、ライブサービングトラフィックをシミュレーションしました。この構成は、サービングトラフィックが異質かつ変動するタスク分布を示す現実的な展開シナリオを反映しています。私たちは 2 つのトラフィックパターンを評価しました:(i) オーダー付きストリームでは、リクエストがドメインごとにグループ化されて急激な分布シフトを引き起こし、(ii) ミックスストリームでは、プロンプトがランダムにシャッフルされて定常的なトラフィックを近似します。
ドメインごとにリクエストをグループ化して急激な分布変化を引き起こす場合、Aurora は継続的に適応します。各シフト後、システムは約 10,000 リクエストのうちに受容長(acceptance length)を回復し、堅牢なオンライン適応能力を示しています。
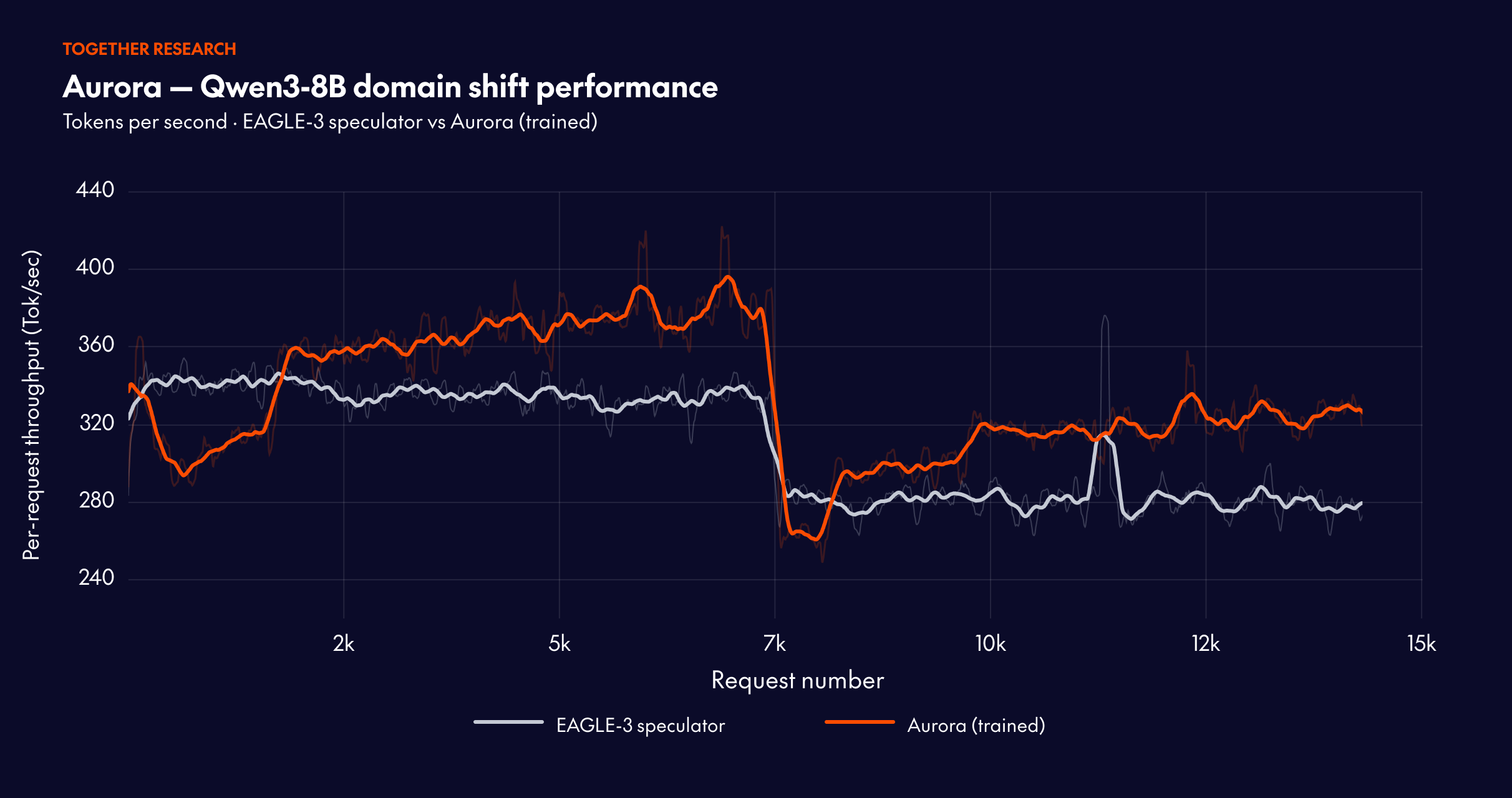
Aurora は、Qwen3-8B のトラフィックシフトに伴い、よく訓練された静的な予測器(static speculator)を上回ります。すでに訓練済みの予測器から出発し、Aurora は継続的な適応を通じて静的ベースラインに対して追加で 1.25 倍の高速化を達成します。これは、Aurora の利点が既存のオフライン学習投資の上に積み重なることを示しています。
混合トラフィックの結果は特に顕著です。ゼロからオンライン学習を行うことで、注意深く事前訓練された予測器のパフォーマンスを超えることが可能です。受容長は 3.08 に達し(静的ベースラインの 2.63 および事前訓練後に微調整を行ったベースラインの 2.99 を上回る)、スループットは 302.3 トークン/秒で安定します。これは、推測的デコーディング(speculative decoding)には広範なオフライン事前学習が必要であるという従来の常識に根本的な挑戦を投げかけるものです。
4. 結論
Aurora は単なる別の推測的デコーディングアルゴリズムではありません。それはシステム全体のパラダイムシフトです。Aurora は、推測的デコーディングを静的でオフラインのタスクから、動的でオンライン学習プロセスへと変革します。
このシフトにより、リアルタイムのユーティリティフィードバック、ドメインドリフト下での適応、大規模なオフライン蒸留パイプラインと比較したインフラコストの削減、そして将来の推測アルゴリズムと互換性のあるシステム層が実現されます。そのため、推測的デコーディングにおける適切な抽象化はもはや孤立したドラフトトレーニングの改善だけではありません——それは統合されたトレーニング・サービングループなのです。

8S
DeepSeek R1

ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
パフォーマンスとスケーラビリティ
本文コピーはここに lorem ipsum dolor sit amet
- 箇条書き項目はここに lorem ipsum
- 箇条書き項目はここに lorem ipsum
- 箇条書き項目はここに lorem ipsum
インフラストラクチャ
最適用途
- より高速な処理速度(全体的なクエリ遅延の低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- 関数呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
ローレム イプサム ドロール シット アメト,コンセクテタル アディピスシン エリット,セド ドイウスモル テンポル インシディドゥト ウト ラボレ エト ドロレ マグナアリクア。ウト エニム アド ミニム ヴェニアム,キス ノストル エクセルチタティオン ウルマコウ ラボリス ニシィ ウト アリキップ エク エア コモドゥオ コンセクアトゥ。
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグ内に配置してください。推論は以下のルールに従って記述してください:推論を行う際はアラビア語でのみ回答し、他の言語は一切使用できません。 ここに質問があります:
ナタリアは 4 月に友人 48 人にクリップを販売し、5 月にはその半分の数を販売しました。ナタリアが 4 月と 5 月に合計で販売したクリップの数は何ですか?
XX
タイトル
本文コピーはここにローレム イプサム ドロール シット アメト
XX
タイトル
本文コピーはここにローレム イプサム ドロール シット アメト
XX
タイトル
本文コピーはここにローレム イプサム ドロール シット アメト
原文を表示
Summary
Speculative decoding goes stale in production — draft models can drift and offline retraining can't always keep pace.
Aurora fixes this. It's an open-source, RL-based framework that learns directly from live inference traces and continuously updates the speculator without interrupting serving.
Key results:
→ Real-time adaptation across shifting traffic domains**→ 1.25x additional speedup over a well-trained static speculator
The headline finding: online training from scratch can outperform a carefully pretrained static baseline.
Running large language models in production is a constant tradeoff between performance and cost. Speculative decoding is the standard lever: in principle, it speeds up inference. In practice, it often under-delivers—draft models go stale, acceptance rates drift, and offline retraining is too slow and too expensive to keep pace with live traffic. What if your system could learn continuously, on the fly, from the very requests it's serving?
Last year, we introduced ATLAS — our first step toward an adaptive speculator. That work laid the foundation, but the goal was always a fully autonomous system that closes the loop between serving and training.
Today, we're releasing Aurora**, an open-source, RL-based framework that learns from live inference traces and updates the speculator asynchronously—turning speculative decoding from a static, one-time setup into a dynamic, self-improving flywheel. This unified design unlocks capabilities that are difficult to achieve in standard pipelines, including: (1) direct mitigation of distribution mismatch, achieving a 1.25x improvement over a strong offline baseline; (2) reduced infrastructure cost by eliminating large-scale activation-collection pipelines; (3) an algorithm-agnostic framework compatible with future speculator designs; and (4) support for diverse, heterogeneous user demands.
Across experiments, Aurora achieves an additional 1.25x speedup over a well-trained but static speculator on widely used models (e.g., Qwen3 and Llama3).
The code to reproduce the paper’s results is open-sourced, and we welcome contributions from the community.
End-to-end throughput under varying batch sizes
MiniMax M2.5 (FP8, lookahead 5):
BS
Config
OTPS Mean
OTPS P50
OTPS P05
OTPS P95
Speedup
Acc Len
1
w/o spec
147.06
146.45
140.46
154.72
--
--
w/ spec
240.39
226.57
186.98
325.36
1.63×
2.41
8
w/o spec
109.41
106.49
99.56
126.57
--
--
w/ spec
160.95
157.42
123.72
207.04
1.47×
2.40
16
w/o spec
93.12
89.56
82.64
113.29
--
--
w/ spec
134.70
129.95
100.97
179.02
1.45×
2.40
32
w/o spec
80.44
77.57
71.77
96.84
--
--
w/ spec
120.67
115.04
92.49
162.77
1.50×
2.45
OTPS = output tokens-per-second. Testing dataset (198 examples).
Qwen3-Coder-Next-FP8 (lookahead 5):
BS
Config
OTPS Mean
OTPS P50
OTPS P05
OTPS P95
Speedup
Acc Len
1
w/o spec
195.21
195.23
194.75
195.75
--
--
w/ spec
375.49
350.37
251.92
574.03
1.92×
3.05
8
w/o spec
160.08
157.69
155.81
175.40
--
--
w/ spec
279.09
250.65
188.27
414.05
1.74×
3.10
16
w/o spec
138.70
137.92
130.05
150.44
--
--
w/ spec
221.56
202.96
143.80
323.54
1.60×
2.96
32
w/o spec
117.50
114.36
108.95
130.10
--
--
w/ spec
184.23
166.56
124.03
278.96
1.57×
3.00
OTPS = output tokens-per-second. Testing dataset (198 examples).
1. Why the standard train-then-serve pipeline breaks down
Offline speculative training is convenient organizationally, but it introduces several practical issues in production that limit its effectiveness. The traditional pipeline is a one-way street — leading to stale models and a disconnect from real-world performance.
Traditional speculative decoding follows a linear, static flow that degrades over time. Aurora introduces a circular, continuously adaptive approach.
The verifier moves, but the drafter lags. Production target models change — for quality, safety, cost, or hardware migration. The speculator often updates much more slowly, so it becomes stale and speculative performance degrades over time.
Offline distillation pipelines are expensive. Activation collection and replay pipelines for drafter training can be extremely costly to store and operate at scale. At production scale, the storage footprint can reach petabyte-level magnitude, with high cost in memory, bandwidth, and operational complexity. Aurora reduces this burden by learning directly from live serving traces.
Acceptance rate is not the same as real speedup. Offline training can optimize acceptance in a lab setting, but production speedup depends on the actual serving stack: kernels, numeric precision (FP8/FP4), batching, scheduling, and hardware behavior. The best draft model offline may not be the best model online. In practice, most teams train multiple drafters but end up selecting only one — Aurora enables a direct speedup comparison because it operates online.
These gaps suggest that speculative decoding should not be treated merely as a modeling problem ("train a better drafter"), but as a joint learning-and-serving problem.
2. The core idea: A serve-to-train flywheel powered by RL
Aurora turns speculative decoding into a serve-to-train flywheel. Rather than treating the speculator as a static artifact, it learns continuously from every request it serves.
The system is built around two decoupled components. The Inference Server runs a speculative decoding engine (based on SGLang or vLLM) with a target model and a draft model. For each request, the draft model proposes a sequence of tokens, which are then verified in parallel by the target model. The results of both accepted and rejected tokens — along with hidden states for EAGLE-style training — are streamed to a distributed data buffer. The Training Server runs asynchronously: it fetches batches of training data from the buffer, performs gradient updates on a copy of the draft model, and periodically hot-swaps improved weights back to the inference server without service interruption.
This design is built around two production realities. First, serving efficiency is the real objective — latency, throughput, and cost/token under SLOs. Second, synchronization must be lazy and non-disruptive — frequent weight pushes can cause cache invalidation and latency jitter. To make this design work reliably, we re-formulate the online speculative training as an asynchronous Reinforcement Learning (RL) problem.
This is not just a theoretical convenience — it directly aligns the training signal with real deployment utility, not just offline imitation quality. Speculative decoding maps naturally to reinforcement learning:
Speculative Decoding
RL Mapping
Draft Model
→
Policy (π)
Target Verifier
→
Environment
Accepted Tokens
→
Positive Reward
Rejected Proposals
→
Negative / Counterfactual Feedback
In this framing, maximizing the return maps directly to maximizing acceptance length — which maps directly to decoding speedup. A subtle but powerful part of Aurora is that it does not only learn from accepted tokens. Acceptance loss (imitation) uses cross-entropy on accepted tokens, encouraging the draft to reproduce verifier-approved continuations. Rejection loss (Discard Sampling) teaches the draft what not to propose, using rejected branches as counterfactual supervision.
To efficiently process the complex branching structure of speculative decoding results, we employ a specialized Tree Attention mechanism. By constructing a custom attention mask that respects the causal structure of the speculative tree, we can process all accepted and rejected branches in a single batched forward and backward pass.
3. Adaptation to distribution shift
To test Aurora's robustness, we simulated live serving traffic using a stream of 40,000 prompts spanning five domains: mathematical reasoning, text-to-SQL, code generation, finance, and general conversation. This composition reflects realistic deployment scenarios where serving traffic exhibits heterogeneous and shifting task distributions. We evaluated two traffic patterns: (i) ordered streams, where requests are grouped by domain to induce abrupt distribution shift, and (ii) mixed streams, where prompts are randomly shuffled to approximate stationary traffic.
When requests are grouped by domain to induce abrupt distribution changes, Aurora adapts continuously. The system recovers acceptance length within approximately 10,000 requests after each shift, demonstrating robust online adaptation.
Starting from a well-trained speculator, Aurora achieves an additional 1.25x speedup over the static baseline through continuous adaptation. This demonstrates that Aurora’s benefits compound on top of existing offline training investments.
The mixed traffic results are particularly striking: online training from scratch can exceed the performance of a carefully pretrained speculator. The acceptance length reaches 3.08 (surpassing both the static baseline at 2.63 and the pretrained-then-finetuned baseline at 2.99), with throughput stabilizing at 302.3 tokens/s. This fundamentally challenges the conventional wisdom that speculative decoding requires extensive offline pretraining.
4. Conclusion
Aurora is not just another speculative decoding algorithm. It is a systems shift. It changes speculative decoding from a static, offline task to a dynamic, online learning process.
This shift unlocks real-time utility feedback, adaptation under domain drift, lower infrastructure cost compared to large offline distillation pipelines, and a system layer that is compatible with future speculator algorithms. That’s why the right abstraction for speculative decoding is no longer just better draft training in isolation — it’s a unified training-serving loop.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み