GroundedPlanBench: ロボット操作のための空間的に接地された長期タスク計画
Microsoft Researchは、ビジョン言語モデルの長期タスク計画における空間的曖昧性を解決するため、動作と場所を同時に学習する「GroundedPlanBench」と動画から訓練データを生成する「V2GP」枠組みを発表した。
キーポイント
分離型計画手法の限界
自然言語計画は行動と場所の指定で曖昧になりやすく、計画と実行を分離する従来のアプローチではエラーが蓄積・幻覚化する。
GroundedPlanBenchベンチマークの構築
DROIDデータセットの308シーンを用い、明示的・暗黙的指示のもとロボットの行動計画と空間的位置決定能力を測定する評価基準を提供。
V2GPフレームワークによる学習手法
ロボットのデモ動画を空間的にグラウンディングされた訓練データに変換し、計画とグラウンディングを同時に学習するパイプラインを実現。
ベンチマークと実機評価での優位性
分離型アプローチを凌駕し、タスク成功率と行動精度の両面で向上を確認。実ロボットを用いた検証でも有効性が裏付けられた。
ベンチマーク構築とタスク設計
DROIDデータセットの308シーンから1,009件のタスクを作成し、明示的指示と暗黙的指示の両方を定義。各タスクは4つの基本動作に分割され、画像内のバウンディングボックスと空間的に紐付けられている。
V2GPフレームワークによる自動計画生成
ロボットの手首信号、マルチモーダルLLM、SAM3セグメンテーションモデルを連携させ、1〜26アクションの4万3千件の空間 grounding 計画を自動生成している。
統合型計画と分離型の比較評価
Qwen3-VLモデルを用い、ゼロショットとファインチューニングの条件で評価。空間的に grounding された計画手法と、計画生成と位置特定を分離する従来アプローチの性能を比較している。
影響分析・編集コメントを表示
影響分析
本研究成果は、ビジョン言語モデルをロボティクスに応用する際のボトルネックである「行動と空間的位置の分離」を解消し、長期複雑タスクの実装可能性を大幅に高める。V2GPによる動画から訓練データへの変換手法は、ラベル付けコストを削減しつつモデルの汎化能力を向上させるため、産業用・家庭用ロボットの自律化推進に寄与する。
編集コメント
研究機関のブログ記事ながら、実機検証まで踏み込んだベンチマークと学習フレームワークの公開は業界標準確立に寄与する。実用化には計算コストとシミュレーションから現実への転移課題が残るが、自律ロボットの知能向上における重要なマイルストーンとなる。

一言で言うと
自然言語に基づくプランは、特に動作と場所の両方を指定する際に曖昧になりがちであるため、VLM(Vision-Language Model:視覚・言語モデル)ベースのロボットプランナーは、長期かつ複雑なタスクにおいて困難に直面します。
GroundedPlanBench は、多様な実世界のロボットシナリオにおいて、モデルが動作を計画し、その動作が行われる場所を特定できるかを評価するベンチマークです。
Video-to-Spatially Grounded Planning (V2GP)(動画から空間的に grounded なプランニングへの転換)は、ロボットのデモンストレーション動画を空間的に grounded なトレーニングデータに変換するフレームワークであり、これによりモデルがプランニングと grounding を同時に学習できるようになります。
Grounded planning(空間的に grounded なプランニング)は、タスクの成功確率と動作の精度の両方を向上させ、ベンチマークおよび実世界評価において、分離されたアプローチを上回る性能を発揮します。
ビジョン言語モデル(VLM)は画像とテキストを用いてロボットの行動を計画しますが、まだ「どの行動を取るべきか」「どこで行うべきか」を決定することに苦慮しています。ほとんどのシステムでは、これらの意思決定を2段階に分けています:まず VLM が自然言語で計画を生成し、別のモデルがそれを実行可能な行動に変換します。このアプローチは、長くて複雑なタスクにおいてはしばしば機能しません。なぜなら、行動や場所を指定する際に、自然言語の計画には曖昧さがあったり、場合によっては幻覚(ハルシネーション)が生じたりするためです(図 1)。計画と空間推論が別々に処理されるため、ある段階でのエラーが次の段階に伝播してしまう可能性があります。ここで重要な問いが生じます:VLM は「何をすべきか」と「どこで行うべきか」を同時に決定できるのでしょうか?
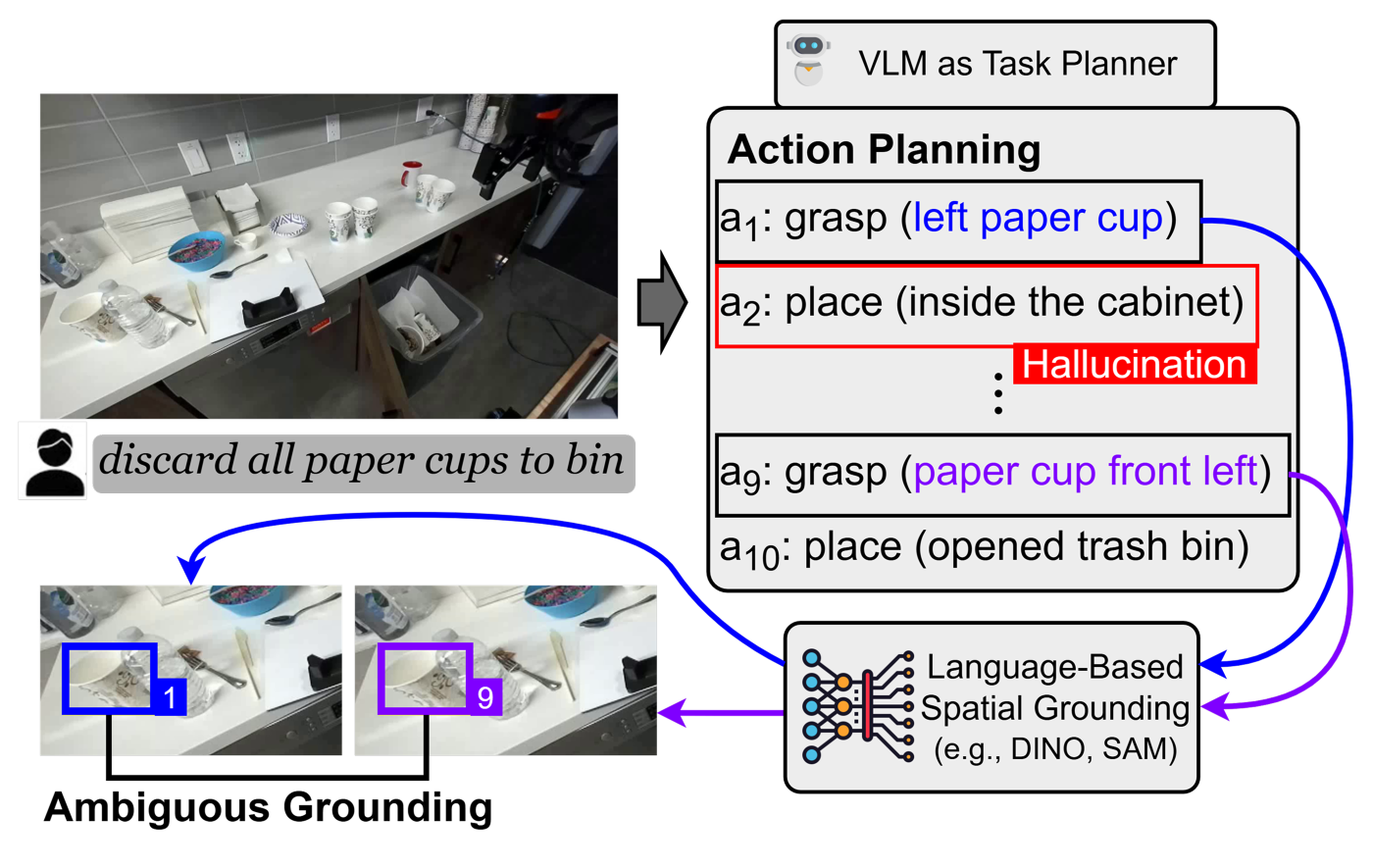 image図 1. VLM ベースのタスクプランナーにおける失敗事例。曖昧な言語表現が実行不可能な行動につながる例。
image図 1. VLM ベースのタスクプランナーにおける失敗事例。曖昧な言語表現が実行不可能な行動につながる例。
空間的根拠に基づく計画
この問題に対処するため、私たちは GroundedPlanBench(新しいタブで開く)を開発しました。論文「Spatially Grounded Long-Horizon Task Planning in the Wild」において、この新たなベンチマークが、VLM が多様な実世界環境において行動を計画し、その行動がどこで行われるべきかを決定できるかを評価する方法について詳述しています。また、VLM がこの能力を習得するのを支援するため、ロボットの実演動画をトレーニングデータに変換するフレームワーク「Video-to-Spatially Grounded Planning (V2GP)」も構築しました。
オープンソースおよびクローズドソースの両方の VLM を用いて評価を行った結果、長期かつ複雑なタスクに対する空間的根拠に基づく計画は困難であることが判明しました。一方で、V2GP は計画能力と空間的根拠の両方を向上させ、その効果は当ベンチマークおよびロボットを用いた実世界実験において検証されました。
GroundedPlanBench の仕組み
現実的なロボットシナリオを作成するために、私たちは DROID(Distributed Robot Interaction Dataset)に含まれる 308 のロボット操作シーンからベンチマークを構築しました。これは、タスクを実行するロボットの録画映像を多数収録した大規模コレクションです。各シーンを専門家とレビューし、ロボットが実行可能なタスクを定義しました。各タスクは 2 つのスタイルで記述されました:行動を明確に説明する明示的な指示(例:「白いお皿にスプーンを置く」)と、目標をより一般的に記述する暗黙的な指示(例:「テーブルを片付ける」)です。
各タスクについては、計画が 4 つの基本的なアクション——把持(grasp)、配置(place)、開閉(open)、閉鎖(close)——に分解されました。これらはそれぞれ画像内の特定の場所に関連付けられています。把持、開き、閉じのアクションは対象物体を囲むボックスに紐づけられ、配置アクションは物体を置くべき場所を示すボックスに紐づけられました。
図 2 は、中・長時間のタスクと、それに対応する明示的・暗黙的な指示を示しています。全体として、GroundedPlanBench には 1,009 のタスクが含まれており、アクション数が 1~4(345 タスク)、5~8(381 タスク)、9~26(283 タスク)の範囲にわたります。
 image図 2. GroundedPlanBench のタスク例。
image図 2. GroundedPlanBench のタスク例。
V2GP の動作原理
V2GP フレームワークは、まず記録されたグリッパー信号を用いてロボットがオブジェクトと相互作用する瞬間を検出します。その後、マルチモーダル言語モデルによって操作対象のオブジェクトに関するテキスト記述を生成します。この記述に基づき、システムは Meta の高度なオープンボキャブラリ画像・ビデオセグメンテーションモデルである SAM3 を用いて、動画全体を通じてそのオブジェクトを追跡します。続いて、追跡結果から空間的に grounded な計画(grounded plans)を構築し、オブジェクトが把持された瞬間の位置と、配置された場所を特定します。
このプロセスは図 3 に示されています。その結果、長さの異なる 43,000 件の grounded プランが生成されました:1~4 つのアクションを含むプランが 34,646 件、5~8 つのアクションを含むプランが 4,368 件、9~26 のアクションを含むプランが 4,448 件です。
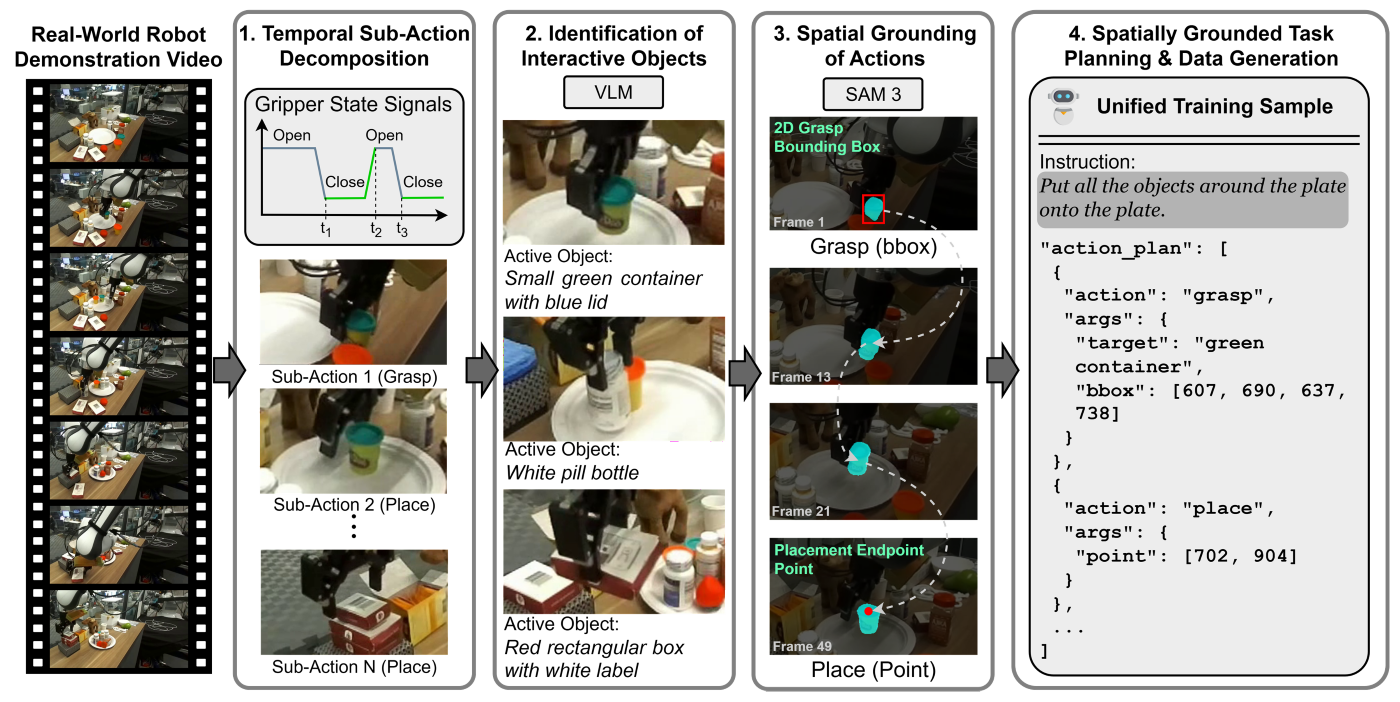 image図 3. V2GP フレームワークは、ロボットの動画を空間的に grounded なプランに変換します。
image図 3. V2GP フレームワークは、ロボットの動画を空間的に grounded なプランに変換します。
分離型計画と grounded 計画の評価
GroundedPlanBench を実世界のロボット環境で評価するために、ベースモデルとして Qwen3-VL (新しいタブで開く) を使用しました。Qwen3-VL はテキスト、画像、動画を処理して多モーダル推論をサポートするビジョン・ランゲージモデルです。追加のトレーニングなしに標準的な多モーダル推論ベンチマークにおいて良好なパフォーマンスを発揮します。まず、他の専用モデルとともに、特定のタスク向けのトレーニングを行わずに GroundedPlanBench で評価を行いました(表 1)。その後、V2GP のトレーニングデータでファインチューニングを行い、計画とグラウンディングを別々に処理するデカップルド・アプローチと比較しました。
この設定では、まず VLM がロボットが何を行うべきかを示す計画を生成します。このステップには GPT-5.2 または Qwen3-VL-4B を使用しました。その後、その計画は空間グラウンディングモデルである Embodied-R1 (新しいタブで開く) に渡され、実行可能な信号に変換されます。Embodied-R1 は、エンボディード推論とポインティングのためにトレーニングされた大規模ビジョン・ランゲージモデルであり、画像内の特定の場所を特定してロボットの行動を誘導するものです。空間グラウンディングにこれを選択したのは、その学習目標がエンボディードな空間推論とポイントベースの位置特定にあるためで、モデル出力を画像内の特定の場所に適切にグラウンディングするのに適しているからです。
図4は、このアプローチの重要な限界である自然言語における曖昧さを浮き彫りにしています。例えば、Qwen3-VL-4B はシーン内のすべてのナプキンに対して「テーブル上のナプキン」という表現を参照して把持動作を生成しましたが、その結果、Embodied-R1 は各動作を同じナプキンに grounding(位置付け)してしまいました。GPT-5.2 はより記述的なフレーズ、「左上のナプキン」や「上部中央のナプキン」などを生成しましたが、それでもモデルがそれらを確実に区別するには不十分であり、再び同じオブジェクトに grounding されてしまいました。
 image図4. デカップルド(分離)型とグラウンデッド(位置付け)型のプランニングの比較。曖昧な言語がどのようにして動作を誤ったオブジェクトに grounding させてしまうかを示しています。
image図4. デカップルド(分離)型とグラウンデッド(位置付け)型のプランニングの比較。曖昧な言語がどのようにして動作を誤ったオブジェクトに grounding させてしまうかを示しています。
この限界は、環境がしばしば散乱しており複雑である実世界のロボット操作においてより顕著になります。その結果、デカップルド型のアプローチは信頼性を持って機能することが困難となります。一方、我々のアプローチであるグラウンデッドプランニングでは、プランニングと grounding を単一のモデル内で統合的に実行することで、両方の性能を向上させています。
表1は、GroundedPlanBench におけるオープンソースおよびクローズドソースの VLM(Vision-Language Model:視覚言語モデル)の評価結果を示しています。すべてのモデルにおいて、多段階プランニングと暗黙的な指示への対応が課題となりましたが、Qwen3-VL-4B および Qwen3-VL-32B を V2GP でトレーニングしたことで、グラウンデッドプランニングの性能に顕著な改善が見られました。
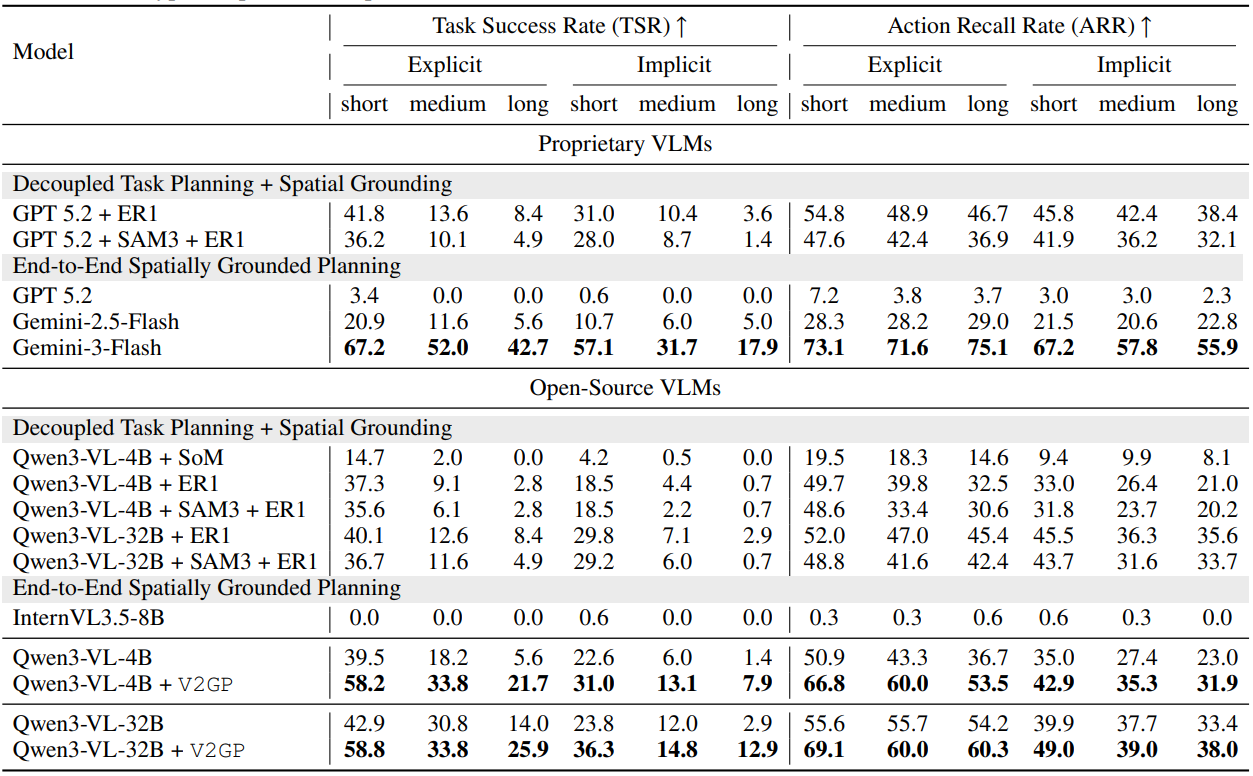 image 表 1. GroundedPlanBench における評価結果。タスク成功率(TSR)は、すべての行動が正しく計画されかつ空間的に grounded(位置付けられている)ことを要件として、正しく完了したタスクの割合を測定するものです。アクションリコール率(ARR)は、順序に関係なく、生成された行動のうちデータセットで定義されたサブアクションと一致するものの割合を測定します。V2GP アプローチは両方の指標において性能を向上させ、最良の結果(太字で表示)を達成しています。
image 表 1. GroundedPlanBench における評価結果。タスク成功率(TSR)は、すべての行動が正しく計画されかつ空間的に grounded(位置付けられている)ことを要件として、正しく完了したタスクの割合を測定するものです。アクションリコール率(ARR)は、順序に関係なく、生成された行動のうちデータセットで定義されたサブアクションと一致するものの割合を測定します。V2GP アプローチは両方の指標において性能を向上させ、最良の結果(太字で表示)を達成しています。
video series

On Second Thought
AI について誰もが抱いている疑問を中心に構成された、Sinead Bovell との動画シリーズです。Microsoft 全体から集まった専門家の声を通じて、この急速に変化する技術がもたらす緊張感と可能性を解きほぐし、何が進化しており、何が実現可能なのかを探求します。
Explore the series
新しいタブで開きます
Implications and looking forward
単一のモデル内で計画とグラウンディングを統合することは、実世界におけるより信頼性の高いロボット操作への道筋を提供します。別々の段階に依存するのではなく、このアプローチは「何をすべきか」と「どこで行動すべきか」に関する決定を密接に結合しますが、それでもモデルは長く多段階のタスクや暗黙的な指示に対して依然として苦戦しています。モデルは、より長いアクションシーケンスについて推論し、日常言語のように間接的に記述された多くのステップと目標全体で一貫性を維持する必要があります。
将来を見据えると、有望な方向性はグラウンディングされた計画をワールドモデルと組み合わせることであり、これによりロボットは実行前に行動の結果を予測できるようになります。これらの能力を組み合わせることで、ロボットが何をすべきか、どこで行動すべきか、そして次に何が起こるかを決断でき、実世界で信頼性を持って計画し行動できるシステムに近づきます。
謝辞
本研究は、韓国大学校、Microsoft Research、ウィスコンシン大学マディソン校との共同研究により実施され、韓国政府(MSIT)が資金を提供する情報通信技術計画評価研究所(IITP)の助成金(番号 RS-2025-25439490)によって支援されました。
新しいタブで開きます。この記事「GroundedPlanBench: Spatially grounded long-horizon task planning for robot manipulation」は、Microsoft Research の投稿として最初に掲載されました。
原文を表示
At a glance
VLM-based robot planners struggle with long, complex tasks because natural-language plans can be ambiguous, especially when specifying both actions and locations.
GroundedPlanBench evaluates whether models can plan actions and determine where they should occur across diverse, real-world robot scenarios.
Video-to-Spatially Grounded Planning (V2GP) is a framework that converts robot demonstration videos into spatially grounded training data, enabling models to learn planning and grounding jointly.
Grounded planning improves both task success and action accuracy, outperforming decoupled approaches in benchmark and real-world evaluations.
Vision-language models (VLMs) use images and text to plan robot actions, but they still struggle to decide what actions to take and where to take them. Most systems split these decisions into two steps: a VLM generates a plan in natural language, and a separate model translates it into executable actions. This approach often breaks down for long, complex tasks because natural-language plans can be ambiguous or even hallucinated when specifying actions and locations (Figure 1). Because planning and spatial reasoning are handled separately, errors in one stage can propagate to the next. This raises a key question: can a VLM determine both what to do and where to do it simultaneously?
imageFigure 1. Failures in VLM-based task planners, where ambiguous language leads to non-executable actions.
Planning with spatial grounding
To address this problem, we developed GroundedPlanBench (opens in new tab). In our paper, “Spatially Grounded Long-Horizon Task Planning in the Wild,” we describe how this new benchmark evaluates whether VLMs can plan actions and determine where those actions should occur across diverse real-world environments. We also built Video-to-Spatially Grounded Planning (V2GP), a framework that converts robot demonstration videos into training data to help VLMs learn this capability.
Evaluating these with both open- and closed-source VLMs, we found that grounded planning for long, complex tasks is challenging. At the same time, V2GP improves both planning and grounding, with gains validated on our benchmark and in real-world experiments using robots.
How GroundedPlanBench works
To create realistic robot scenarios, we built our benchmark from 308 robot manipulation scenes in the Distributed Robot Interaction Dataset (DROID) (opens in new tab), a large collection of recordings of robots performing tasks. We worked with experts to review each scene and define tasks that a robot could perform. Each task was written in two styles: explicit instructions that clearly describe the actions (e.g., “put a spoon on the white plate”) and implicit instructions that describe the goal more generally (e.g., “tidy up the table”).
For each task, the plan was broken down into four basic actions—grasp, place, open, and close—each tied to a specific location in the image. Grasp, open, and close actions were linked to a box drawn around the target object, while place actions were linked to a box showing where the object should be placed.
Figure 2 illustrates medium- and long-duration tasks, along with their explicit and implicit instructions. In total, GroundedPlanBench contains 1,009 tasks, ranging from 1–4 actions (345 tasks) to 5–8 (381) and 9–26 (283).
imageFigure 2. Examples of tasks in GroundedPlanBench.
How V2GP works
The V2GP framework first detects moments when the robot interacts with objects using the recorded gripper signals. It then generates a text description of the manipulated object with a multimodal language model. Guided by this description, the system tracks the object across the video using Meta’s advanced open-vocabulary image and video segmentation model, SAM3. The system then constructs grounded plans from the tracking results, identifying the object’s location at the moment it is grasped and where it is placed.
This process is illustrated in Figure 3. It yielded 43K grounded plans with varying lengths: 34,646 plans with 1–4 actions, 4,368 with 5–8 actions, and 4,448 with 9–26 actions.
imageFigure 3. The V2GP framework converts robot videos into spatially grounded plans.
Evaluating decoupled versus grounded planning
To evaluate GroundedPlanBench in real-world robotic settings, we used Qwen3-VL (opens in new tab) as our base model. Qwen3-VL is a vision-language model that processes text, images, and video to support multimodal reasoning. It performs well on standard multimodal reasoning benchmarks without additional training. We first evaluated it, along with other proprietary models, on GroundedPlanBench without any task-specific training (Table 1). We then fine-tuned it on V2GP training data and compared it with a decoupled approach, in which planning and grounding are handled separately.
In this setup, a VLM first generated a plan describing what the robot should do. We used GPT-5.2 or Qwen3-VL-4B for this step. The plan was then passed to a spatial grounding model, Embodied-R1 (opens in new tab), which converted the plans into executable signals. Embodied-R1 is a large vision-language model trained for embodied reasoning and pointing, where the model identifies specific locations in the image to guide the robot’s actions. We selected it for spatial grounding because its training targets embodied spatial reasoning and point-based localization, making it well suited for grounding model outputs to specific locations in an image.
Figure 4 highlights a key limitation of this approach: ambiguity in natural language. For example, Qwen3-VL-4B generated grasp actions by referring to “napkin on the table” for all four napkins in the scene, leading Embodied-R1 to ground each action the same napkin. GPT-5.2 produced more descriptive phrases, such as “top-left napkin” or “upper-center napkin,” but these were still too imprecise for the model to reliably distinguish between them and were again grounded to the same object.
imageFigure 4. Decoupled vs. grounded planning, illustrating how ambiguous language causes actions to be grounded to the wrong objects.
This limitation becomes more pronounced in real-world robot manipulation, where environments are often cluttered and complex. As a result, decoupled approaches struggle to work reliably. In contrast, our approach, grounded planning, performs planning and grounding jointly within a single model and improves both planning and grounding performance.
Table 1 presents evaluation results for open- and closed-source VLMs on GroundedPlanBench. Multi-step planning and handling of implicit instructions were challenging for all models, while training Qwen3-VL-4B and Qwen3-VL-32B with V2GP led to significant improvements in grounded planning.
imageTable 1. Evaluation results on GroundedPlanBench. Task Success Rate (TSR) measures the percentage of tasks completed correctly, requiring all actions to be both correctly planned and spatially grounded. Action Recall Rate (ARR) measures the proportion of generated actions that match the sub-actions defined in the dataset, regardless of order. The V2GP approach improves performance on both metrics and achieves the best results (shown in bold).
video series
image
On Second Thought
A video series with Sinead Bovell built around the questions everyone’s asking about AI. With expert voices from across Microsoft, we break down the tension and promise of this rapidly changing technology, exploring what’s evolving and what’s possible.
Explore the series
Opens in a new tab
Implications and looking forward
Integrating planning and grounding within a single model offers a path to more reliable robot manipulation in real-world settings. Rather than relying on separate stages, this approach keeps decisions about what to do and where to act tightly coupled, but models still struggle with longer, multi-step tasks and implicit instructions. Models must reason over longer sequences of actions and maintain consistency across many steps and goals described indirectly, as in everyday language.
Looking ahead, a promising direction combines grounded planning with world models, which enable robots to predict the outcomes of actions before executing them. Together, these capabilities could allow robots to decide what to do, where to act, and what will happen next, bringing us closer to systems that can plan and act reliably in the real world.
Acknowledgements
This research was conducted in collaboration with Korea University, Microsoft Research, University of Wisconsin-Madison, and supported by the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant (No. RS-2025-25439490) funded by the Korea government (MSIT).
Opens in a new tabThe post GroundedPlanBench: Spatially grounded long-horizon task planning for robot manipulation appeared first on Microsoft Research.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み