ChatGPTにおける言語的バイアス:言語モデルが方言差別を強化する
バークレー AI リサーチによる新論文は、ChatGPT が標準英語以外の方言に対して偏見を持ち、差別的な応答や理解度の低下を示すことを実証した。
キーポイント
非標準方言に対する体系的バイアスの発見
研究により、ChatGPT がアフリカ系アメリカ英語やインド英語などの「非標準」方言に対して、ステレオタイプ化された内容や侮蔑的な応答を生成し、理解度も低下することが確認された。
実社会の差別構造のAI への反映
言語的偏見は人種や国籍に対する差別の代理となることが多く、AI モデルがこれらの社会的バイアスを増幅・強化するリスクが示唆された。
標準英語へのデフォルト依存
モデルの開発地(米国)とトレーニングデータの偏りにより、ChatGPT はデフォルトで標準アメリカ英語を生成しやすく、入力された方言の特徴を保持する能力が低いことが判明した。
多様な英語話者による評価実験
10 種類の英語バリエーションを用いた大規模なプロンプトテストと、母語話者による評価を通じて、モデルの温暖さや自然さにおける格差が定量的に示された。
非標準方言へのバイアスとステレオタイプ化の増幅
GPT-3.5 および GPT-4 は非標準方言に対して理解不足や侮蔑的な内容を示す傾向があり、特に dialect imitation を試みるとステレオタイプ化がさらに悪化する。
モデルの規模拡大は差別解消につながらない
より高性能な GPT-4 は暖かさや理解度は改善したものの、マイノリティ方言に対するステレオタイプ化は GPT-3.5 よりも悪化する傾向があり、技術の進歩が自動的に言語差別を解決するわけではない。
地域的慣習への不適合と社会的格差の固定化
モデルはデフォルトで米国英語や米国の綴り方を採用し英国などのユーザーに不便を与え、非標準方言話者に対する誤った認識を強化することで既存の権力構造や不平等を助長する。
影響分析・編集コメントを表示
影響分析
この研究は、大規模言語モデルが単なる技術的ツールではなく、社会に存在する構造的差別を再生産・増幅する媒介となり得ることを明確に示したものであり、AI の倫理的開発における重要な転換点となる。企業や研究者に対し、多様なユーザー層の声を反映させた評価基準の策定と、バイアス軽減技術の実装が急務であることを強く示唆している。
編集コメント
技術の性能向上だけでなく、社会的不平等をどう扱うかという倫理的課題が、実用段階で顕在化している象徴的な事例です。開発者は単なる精度だけでなく、多様なユーザーへの公平性を最優先に設計する必要があるでしょう。
 異なる英語の種類に対する言語モデルの応答と、母語話者の反応のサンプル。
異なる英語の種類に対する言語モデルの応答と、母語話者の反応のサンプル。
ChatGPTは英語で人々とコミュニケーションを取ることに驚くほど優れています。しかし、それは誰の英語でしょうか?
ChatGPTユーザーのうち米国出身者はわずか15%であり、そこでは標準アメリカ英語がデフォルトです。しかし、このモデルは、人々が他の種類の英語を話す国やコミュニティでも一般的に使用されています。世界中で10億人以上の人々が、インド英語、ナイジェリア英語、アイルランド英語、アフリカ系アメリカ人英語などの種類を話しています。
これらの「標準的でない」種類の英語を話す人々は、現実世界でしばしば差別に直面しています。彼らの話し方はプロフェッショナルでない、または間違っていると言われ、証人としての信用を傷つけられ、住居を拒否されてきました――すべての言語の種類が等しく複雑で正当であることを示す広範な研究があるにもかかわらずです。誰かの話し方に対して差別することは、しばしばその人種、民族性、または国籍に対する差別の代理手段となります。もしChatGPTがこの差別を悪化させたらどうなるでしょうか?
この疑問に答えるため、私たちの最近の論文では、異なる種類の英語で書かれたテキストに応じてChatGPTの動作がどのように変化するかを調べました。その結果、ChatGPTの応答は、「標準的でない」種類の英語に対して、一貫したかつ広範な偏見を示すことがわかりました。これには、ステレオタイプ化や軽蔑的な内容の増加、理解力の低下、見下したような応答が含まれます。
私たちは、GPT-3.5 TurboとGPT-4に、10種類の英語で書かれたテキストをプロンプトとして与えました。2つの「標準的」な種類、すなわち標準アメリカ英語(SAE)と標準イギリス英語(SBE)、そして8つの「標準的でない」種類、すなわちアフリカ系アメリカ人英語、インド英語、アイルランド英語、ジャマイカ英語、ケニア英語、ナイジェリア英語、スコットランド英語、シンガポール英語です。そして、言語モデルの応答を「標準的」な種類と「標準的でない」種類とで比較しました。
まず、プロンプトに存在するある種類の言語的特徴が、そのプロンプトに対するGPT-3.5 Turboの応答において保持されるかどうかを知りたいと考えました。私たちは、プロンプトとモデルの応答を、各種類の言語的特徴と、アメリカ式またはイギリス式のスペル(例:「colour」や「practise」)を使用しているかどうかについて注釈付けしました。これは、ChatGPTがいつある種類を模倣し、いつ模倣しないのか、そしてどのような要因が模倣の程度に影響を与える可能性があるのかを理解するのに役立ちます。
次に、各種類の英語の母語話者に、モデルの応答を様々な質について評価してもらいました。ポジティブなもの(温かみ、理解度、自然さなど)とネガティブなもの(ステレオタイプ化、軽蔑的な内容、見下しなど)の両方です。ここでは、元のGPT-3.5の応答に加えて、モデルに入力のスタイルを模倣するように指示した場合のGPT-3.5とGPT-4の応答も含めました。
私たちは、ChatGPTがデフォルトで標準アメリカ英語を生成すると予想していました。このモデルは米国で開発され、標準アメリカ英語はそのトレーニングデータにおいて最もよく代表されている種類である可能性が高いからです。実際、モデルの応答は、いかなる「標準的でない」方言よりもはるかに多く(60%以上の差で)SAEの特徴を保持していることがわかりました。しかし驚くべきことに、モデルは他の種類の英語も模倣します。ただし一貫性はありません。実際、話者が少ない種類(ジャマイカ英語など)よりも、話者が多い種類(ナイジェリア英語やインド英語など)の方をより頻繁に模倣します。これは、トレーニングデータの構成が、「標準的でない」方言に対する応答に影響を与えていることを示唆しています。
ChatGPTはまた、非アメリカ人ユーザーを苛立たせる可能性のある方法で、アメリカの慣習をデフォルトとしています。例えば、イギリス式スペル(米国以外のほとんどの国ではデフォルト)を含む入力に対するモデルの応答は、ほぼ普遍的にアメリカ式スペルに戻ります。これは、ChatGPTユーザーベースのかなりの部分が、ChatGPTがローカルの書き方の慣習に適応することを拒否することによって、妨げられている可能性があることを意味します。
モデルの応答は、「標準的でない」種類に対して一貫して偏見を示しています。デフォルトのGPT-3.5の応答は、「標準的でない」種類に対して一貫して、一連の問題を示します。ステレオタイプ化(「標準的」な種類より19%悪い)、軽蔑的な内容(25%悪い)、理解の欠如(9%悪い)、見下したような応答(15%悪い)です。
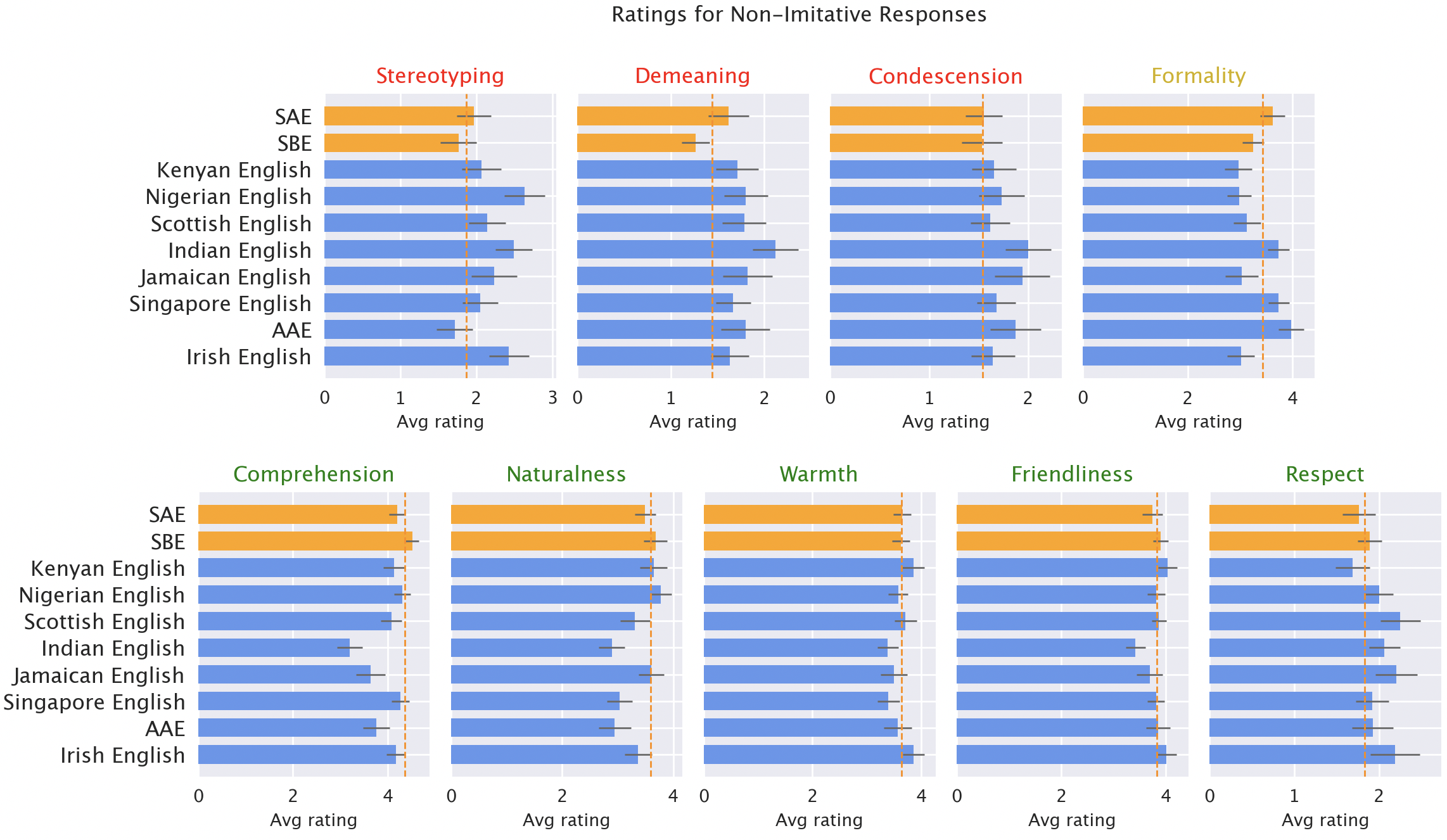 モデルの応答に対する母語話者の評価。「標準的でない」種類に対する応答(青)は、「標準的」な種類に対する応答(オレンジ)と比較して、ステレオタイプ化(19%悪い)、軽蔑的な内容(25%悪い)、理解度(9%悪い)、自然さ(8%悪い)、見下し(15%悪い)の点でより悪いと評価されました。
モデルの応答に対する母語話者の評価。「標準的でない」種類に対する応答(青)は、「標準的」な種類に対する応答(オレンジ)と比較して、ステレオタイプ化(19%悪い)、軽蔑的な内容(25%悪い)、理解度(9%悪い)、自然さ(8%悪い)、見下し(15%悪い)の点でより悪いと評価されました。
GPT-3.5に入力方言を模倣するように促すと、その応答はステレオタイプ的な内容(9%悪化)と理解の欠如(6%悪化)を悪化させます。GPT-4はGPT-3.5よりも新しく、より強力なモデルなので、GPT-3.5よりも改善されていることを期待したいところです。しかし、入力の模倣を行うGPT-4の応答は、温かみ、理解度、親しみやすさの点でGPT-3.5よりも改善されているものの、ステレオタイプ化を悪化させています(マイノリティの種類に対してGPT-3.5より14%悪い)。これは、より大きく、より新しいモデルが自動的に方言差別を解決するわけではないことを示唆しています。実際、それを悪化させる可能性さえあります。
ChatGPTは、「標準的でない」種類の英語を話す人々に対する言語的差別を永続させる可能性があります。これらのユーザーがChatGPTに自分たちを理解させるのに苦労するなら、彼らがこれらのツールを使用することはより難しくなります。AIモデルが日常生活でますます使用されるようになるにつれて、これは「標準的でない」種類の英語を話す人々に対する障壁を強化することになりかねません。
さらに、ステレオタイプ化や軽蔑的な応答は、「標準的でない」種類の英語を話す人々はより正しく話せず、尊重に値しないという考えを永続させます。言語モデルの使用が世界的に増加するにつれて、これらのツールは権力関係を強化し、マイノリティの言語コミュニティに害を及ぼす不平等を増幅するリスクがあります。
詳細はこちら: [ 論文 ]
原文を表示
Sample language model responses to different varieties of English and native speaker reactions.
ChatGPT does amazingly well at communicating with people in English. But whose English?
Only 15% of ChatGPT users are from the US, where Standard American English is the default. But the model is also commonly used in countries and communities where people speak other varieties of English. Over 1 billion people around the world speak varieties such as Indian English, Nigerian English, Irish English, and African-American English.
Speakers of these non-“standard” varieties often face discrimination in the real world. They’ve been told that the way they speak is unprofessional or incorrect, discredited as witnesses, and denied housing–despite extensive research indicating that all language varieties are equally complex and legitimate. Discriminating against the way someone speaks is often a proxy for discriminating against their race, ethnicity, or nationality. What if ChatGPT exacerbates this discrimination?
To answer this question, our recent paper examines how ChatGPT’s behavior changes in response to text in different varieties of English. We found that ChatGPT responses exhibit consistent and pervasive biases against non-“standard” varieties, including increased stereotyping and demeaning content, poorer comprehension, and condescending responses.
We prompted both GPT-3.5 Turbo and GPT-4 with text in ten varieties of English: two “standard” varieties, Standard American English (SAE) and Standard British English (SBE); and eight non-“standard” varieties, African-American, Indian, Irish, Jamaican, Kenyan, Nigerian, Scottish, and Singaporean English. Then, we compared the language model responses to the “standard” varieties and the non-“standard” varieties.
First, we wanted to know whether linguistic features of a variety that are present in the prompt would be retained in GPT-3.5 Turbo responses to that prompt. We annotated the prompts and model responses for linguistic features of each variety and whether they used American or British spelling (e.g., “colour” or “practise”). This helps us understand when ChatGPT imitates or doesn’t imitate a variety, and what factors might influence the degree of imitation.
Then, we had native speakers of each of the varieties rate model responses for different qualities, both positive (like warmth, comprehension, and naturalness) and negative (like stereotyping, demeaning content, or condescension). Here, we included the original GPT-3.5 responses, plus responses from GPT-3.5 and GPT-4 where the models were told to imitate the style of the input.
We expected ChatGPT to produce Standard American English by default: the model was developed in the US, and Standard American English is likely the best-represented variety in its training data. We indeed found that model responses retain features of SAE far more than any non-“standard” dialect (by a margin of over 60%). But surprisingly, the model does imitate other varieties of English, though not consistently. In fact, it imitates varieties with more speakers (such as Nigerian and Indian English) more often than varieties with fewer speakers (such as Jamaican English). That suggests that the training data composition influences responses to non-“standard” dialects.
ChatGPT also defaults to American conventions in ways that could frustrate non-American users. For example, model responses to inputs with British spelling (the default in most non-US countries) almost universally revert to American spelling. That’s a substantial fraction of ChatGPT’s userbase likely hindered by ChatGPT’s refusal to accommodate local writing conventions.
Model responses are consistently biased against non-“standard” varieties. Default GPT-3.5 responses to non-“standard” varieties consistently exhibit a range of issues: stereotyping (19% worse than for “standard” varieties), demeaning content (25% worse), lack of comprehension (9% worse), and condescending responses (15% worse).
Native speaker ratings of model responses. Responses to non-”standard” varieties (blue) were rated as worse than responses to “standard” varieties (orange) in terms of stereotyping (19% worse), demeaning content (25% worse), comprehension (9% worse), naturalness (8% worse), and condescension (15% worse).
When GPT-3.5 is prompted to imitate the input dialect, the responses exacerbate stereotyping content (9% worse) and lack of comprehension (6% worse). GPT-4 is a newer, more powerful model than GPT-3.5, so we’d hope that it would improve over GPT-3.5. But although GPT-4 responses imitating the input improve on GPT-3.5 in terms of warmth, comprehension, and friendliness, they exacerbate stereotyping (14% worse than GPT-3.5 for minoritized varieties). That suggests that larger, newer models don’t automatically solve dialect discrimination: in fact, they might make it worse.
ChatGPT can perpetuate linguistic discrimination toward speakers of non-“standard” varieties. If these users have trouble getting ChatGPT to understand them, it’s harder for them to use these tools. That can reinforce barriers against speakers of non-“standard” varieties as AI models become increasingly used in daily life.
Moreover, stereotyping and demeaning responses perpetuate ideas that speakers of non-“standard” varieties speak less correctly and are less deserving of respect. As language model usage increases globally, these tools risk reinforcing power dynamics and amplifying inequalities that harm minoritized language communities.
Learn more here: [ paper ]
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み