AIネイティブチームのためのマルチテナントGPUクラスター設計ガイド:競合のない容量確保
Together AIは、AIネイティブ企業向けにGPUリソースの共有とチームごとの隔離を両立するマルチテナントGPUクラスターの設計原則、失敗事例、および実践的な実装ガイドを公開した。
キーポイント
マルチテナントGPUクラスターの必要性
AI企業はインフラ戦略よりスケーリングが速く、チームごとの専用クラスターは非効率だが、完全共有は管理上の混乱を招くため、両者のバランスが求められる。
マルチテナントの定義と要件
単一ハードウェア上で複数のチームが動作し、データアクセス、資格情報、ストレージ、課金Visibilityにおいて厳格な隔離と保証が提供される環境を指す。
3つの必須要件
運用には「プーリングされた容量」によるアイドル時間の削減、「ハードクォータと予約」によるリソースの公平な配分、そして「自己管理型スケジューリング」によるチームの自律性が同時に満たされる必要がある。
重要な引用
The better architecture is shared, but shared in a way that teams experience as if clusters are their own. That’s the core design challenge of multi-tenancy at AI-native scale: pooled economics, without pooled chaos.
Unlike a traditional shared cluster, multi-tenant clusters have a guarantee of isolation. In a well-designed multi-tenant cluster, one team’s training job can’t impact another’s.
影響分析・編集コメントを表示
影響分析
この記事は、大規模なAI開発現場におけるリソース管理の現実的な課題と解決策を提示しており、インフラエンジニアリングやプラットフォーム設計に関わる技術者にとって実用的な指針となる。Together AIの自社サービス紹介という側面はあるものの、マルチテナンシーにおける「隔離」と「共有」のバランスを取るための具体的な設計原則は業界標準の構築に寄与する可能性がある。
編集コメント
自社プラットフォームのベストプラクティスを解説する記事ですが、GPUリソースの高コスト化が進む中、チーム間のリソース争奪戦を緩和する「隔離された共有」の概念は多くのAI企業にとって重要な検討事項です。
要約
マルチテナントGPUクラスターにより、AIネイティブ企業はチーム間で計算リソースを共有しつつ、分離性や制御性を損なうことなく運用できます。適切なアーキテクチャは、インフラストラクチャ層でGPUをプールすると同時に、各チームに専用ノード、ストレージ、セルフサービススケジューリングを提供します。これにより、真に共有されたインフラストラクチャに伴う政治的な摩擦を生じさせることなく、アイドル状態のリソースの無駄を排除します。このガイドでは、主要な設計原則、一般的な失敗パターン、Together AIのようなプラットフォームが実践でマルチテナンシーをどのように実装しているかについて解説します。
AIネイティブ企業にとってマルチテナントGPUクラスター設計が中核的なインフラストラクチャ問題である理由
AIネイティブ企業は、そのインフラストラクチャ戦略が追いつく速度よりも急速にスケールします。新しいチームが立ち上がるたびに、新たなモデル実験やトレーニング実行が行われ、共有計算リソースへの需要が生じます。その結果、AIプラットフォームエンジニアにとっておなじみの状況が発生します。組織的なGPUへの需要は複合的に増加しますが、リソースは依然として希少で高価なままです。
よくある対応策は、各チームに独自のクラスターとリソースを割り当てることで分離を図ることです。しかし、このアプローチは経済的にスケーラブルではありません。専用クラスターは夜間や週末、あるいはトレーニング実行が予定より早く終了した際にアイドル状態になります。誰も使用していない容量に対して支払いを行う一方で、他のチームはアクセスできないリソースを待ち行列で待機することになります。
より優れたアーキテクチャは共有型ですが、チームがクラスターを自分たちのものだと実感できる方法で共有されます。これがAIネイティブ規模におけるマルチテナンシーの中核的な設計課題です:共有された経済性を実現しつつ、共有に伴う混沌を避けることです。
マルチテナントGPUクラスターとは?
マルチテナントGPUクラスターは、複数のチームが同じ基盤ハードウェア上で稼働しながら、データアクセスの境界、認証情報(credentials)、ストレージボリューム、請求情報の可視性など、意味のある分離を維持する共有コンピューティング環境です。
従来の共有クラスターとは異なり、マルチテナントクラスターには分離の保証があります。適切に設計されたマルチテナントクラスターでは、あるチームのトレーニングジョブが他のチームに影響を与えることはありません。ハードクォータ(hard quotas)、予約ウィンドウ、スケジューリングのガードレールにより、リソースの過剰使用がチーム間の問題になるのを防ぎます。これは、モデル開発、推論(inference)、研究を担当する複数のチームが同じGPUを競合している場合、特に重要です。
マルチテナンシーの核心要件とは?
マルチテナンシーを機能させるためには、チームが同時に満たすべき3つの要件があります:
- プール型容量:チーム間で共有される単一の契約済みGPUプールは、アイドル状態の容量による無駄を排除します。ユニットエコノミクスが成立するのは、トレーニング実行、ファインチューニングジョブ、推論といったワークロード全体でGPU利用率を集約した場合であり、チームごとに孤立させて運用する場合ではありません。
- テナント分離:各チームには、専用ノード、ストレージ、個別の認証情報、そしてテナントごとの課金可視性が求められます。共有インフラストラクチャは、各テナントが境界を明確に保ち、隣接するワークロードがその範囲を超えないことを確認できる状態で、あたかも独自のクラスターを運用しているかのように感じられる場合に最も効果的に機能します。
- セルフサービスアクセス:チームは、容量を直接予約し、リアルタイムの可用性を確認し、数日ではなく数分で環境を起動できる必要があります。
インフラストラクチャのレイヤーはどのように構築すべきか?
AIネイティブなインフラストラクチャにとって最もクリーンなパターンは、基盤となる共有インフラストラクチャと、その上位にあるテナントごとのインフラストラクチャという2層構造です。
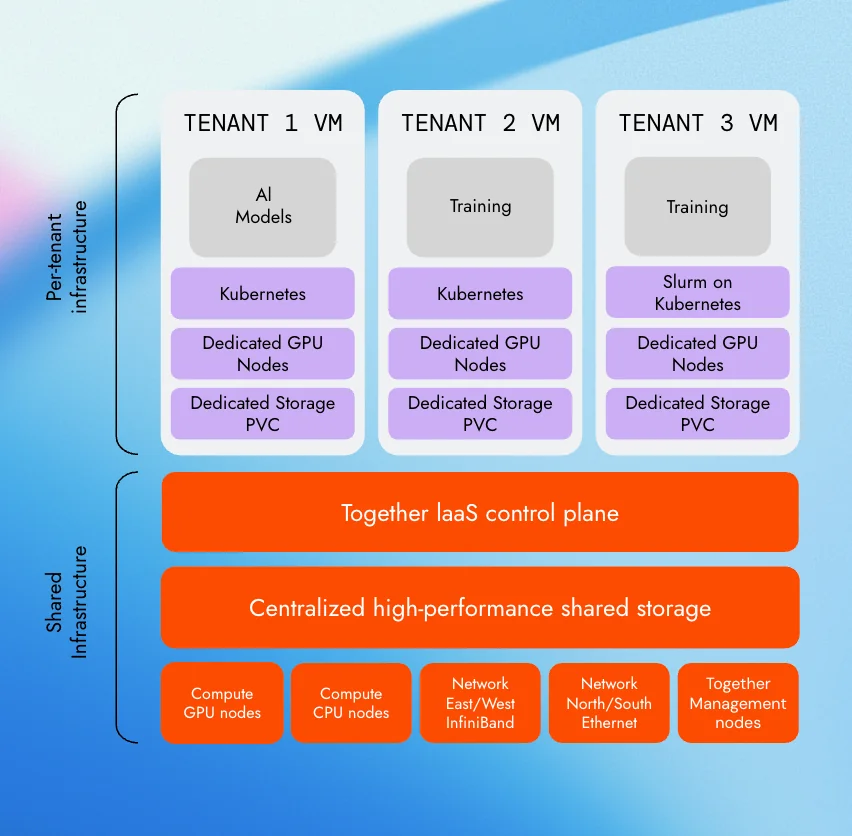
共有レイヤーでは、高性能な共有ストレージと共通のネットワークファブリックの上に中央管理制御プレーンが配置されます。クラスター内の東西南北(east/west)トラフィックには通常InfiniBandが使用され、これは大規模な分散トレーニングに不可欠です。南北(north/south)トラフィックにはEthernetが使用されます。GPUおよびCPUのコンピューティングノードは中央で管理され、Together AIのIaaS制御プレーンはこのパターンの強力な実装例として参照できます。
この共有基盤の上に、各チームには完全に分離された仮想環境が提供されます。これには専用GPUノード、専用ストレージPVC(Persistent Volume Claim)、そしてワークロードの種類に応じてKubernetes、Slurm、またはその他の構成から選べるオーケストレーション層が含まれます。基盤モデルのトレーニング、ファインチューニング、または推論ワークロードを実行する各チームは、それぞれ独自のクラスタで稼働し、隣接するテナントへの可視性はゼロです。
Together AIのマルチテナンティッククラスタは、このパターンの具体的な実装であり、AIネイティブなチームにとってクラウドのような柔軟性を備えたベアメタルパフォーマンスが実際にどのようなものかを示しています。これは、実際の使用量に基づいてテナントごとに直接請求される方式です。
1つのチームがすべてのGPU容量を消費しないようにするにはどうすればよいですか?
ここでのマルチテナンティック環境において、クォータベースの割り当てが不可欠となります。管理者は各チームごとにガードレールを設定し、GPU数、総支出額、または予約ウィンドウの長さで上限を設けます。これはソフトなポリシーではなく、スケジューラレベルで強制されます。
また、スケジューラは事前予約を処理し、その中に競合防止機能が組み込まれているべきです。チームは特定のウィンドウ(例えば、1か月の事前トレーニング実行や2週間のファインチューニングスプリングなど)に対してクラスタを予約し、システムは二重予約を防ぎます。UIにはライブの容量利用可能性が表示され、チームはコミットする前に正確に何が残っているかを確認できます。容量を認識したスケジューリングにより、予測可能な計画が可能になります。実行中の予期せぬ出来事やチーム間の干渉はありません。
クォータを超えてバーストが必要なチームにとって、適切な設計はオンデマンドの公開価格への自動的なオーバフローをサポートします。Together AI は管理者の承認を必要とせずにこれを処理するため、インフラストラクチャの官僚主義によってプロダクションの速度が制限されることはありません。
マルチテナントプラットフォームは AI チームにどのような設定の柔軟性を提供すべきか?
共有インフラストラクチャにおける一般的な失敗モードは、強制的なデフォルト値です。特定のオーケストレーションレイヤー、ドライバーバージョン、またはストレージ構成を強制するプラットフォームは、目に見えないトレードオフを生み出します。AI ネイティブチームは、プラットフォームに合わせてワークフローを適応させる結果になりがちですが、これは本来あるべき姿とは逆です。
正しいパターンは、予約時にア・ラ・カルト(個別選択)の設定です。オーケストレーションレイヤー、CUDA ドライバーバージョン、共有メモリサイズ、ストレージボリュームを、ワークロードの要件に基づいてチームが指定します。デフォルト値や強制的なトレードオフはありません。Slurm 上で Llama のファインチューニングを実行するチームが、Kubernetes 上で推論エンドポイントを提供するチームと同じ構成に強制されるべきではありません。
プロビジョニング後、クラスターには自動的な作成と削除、Grafana によるオウトオブザボックスの観測可能性(Observability)、そして即時の SSH アクセスが含まれているべきです。
マルチテナント環境において GPU の健全性とノード修復はどのように機能すべきか?
共有クラスターにおけるハードウェア障害は、波紋効果をもたらす可能性があります。それは単一のトレーニングジョブに影響を与えるだけでなく、同じ物理レイヤーを共有するチーム全体にカスケード(連鎖)する可能性があります。堅牢なヘルスチェックと修復のライフサイクルは必須です。
ベストプラクティスとして、テナントのクラスターに引き渡す前に各ノードで自動受入テストを実行します。テストには、DCGM(Data Center GPU Manager)診断、GPUバーンインテスト、シングルノードおよびマルチノードのNCCL(NVIDIA Collective Communications Library)テスト、CPU-GPU間のレイテンシと帯域幅の次元におけるNVBandwidth測定が含まれるべきです。
チームは、クラスターのプロビジョニング時だけでなく、ライフサイクルの任意の時点でUIからオンデマンドのヘルスチェックをトリガーできる必要があります。問題が検出された場合、対応は段階的に行うべきです:ソフトウェアの問題は迅速な再プロビジョニングをトリガーし、ハードウェアの障害はクラスターのマイグレーションを引き起こします。修復ライフサイクル全体を通じて、テナントは完全な可視性を確保できるべきです——遅いトレーニング実行がモデルの問題なのかノードの問題なのか、推測する必要はありません。
マルチテナントGPUインフラはあなたのチームに適しているか?
マルチテナントクラスターは、基盤モデルのトレーニング、ファインチューニング、推論、研究など、多様なワークロードを持つ複数のAIチームが同時に稼働している場合に、最大の価値を提供します。AIネイティブな組織にとって、リソースをプールすることの数学的利点は極めて大きいです。
重要な質問はインフラを共有するかどうかではなく、AIプラットフォームが分離(アイソレーション)をいかに厳密に適用するかです。そして、プロセスがシームレスに機能する場合、パブリッククラウドのパフォーマンス妥協なしでデータセンターの単位経済性(ユニットエコノミクス)を実現でき、AIネイティブなチームが期待するセルフサービス速度も得られます。
今すぐマルチテナントGPUインフラストラクチャでの構築を開始しよう
Togetherのマルチテナントクラスターは、共有されるGPUインフラストラクチャに伴う頭痛の種を共有したくないAIネイティブな組織のために特別に設計されています。キャパシティをプールし、チームを分離し、モデルが要求する速度で移動してください。
よくある質問
マルチテナントクラスター内のチームは、お互いのモデル、データ、トレーニング実行を確認できますか?
いいえ、正しく設計された環境ではできません。各テナントは、専用GPUノード、専用ストレージボリューム、および個別の認証情報で動作します。
チームが割り当てクォータを超えるキャパシティを必要とした場合、どうなりますか?
適切に設計されたプラットフォームは、チームがプール割り当てを超えた場合、オンデマンドレートへの自動バーストをサポートします。手動の管理者承認は不要です。計画されたキャパシティの端において、インフラストラクチャの官僚主義によってAIネイティブな速度が制限されてはいけません。
マルチテナントプラットフォームは、AIワークロードに対してどのオーケストレーションフレームワークをサポートすべきですか?
最低限、推論とサービングにはKubernetesを、分散トレーニングにはKubernetes上のSlurmをサポートする必要があります。AIネイティブなチームは両方を同時に実行する必要があることが多いため、プラットフォームは混合構成をサポートする必要があります。

8S
DeepSeek R1

ネイティブオーディオとリアルな物理演算を備えたプレミアムなシネマティックビデオ生成。
DeepSeek R1
8秒
オーディオ 名前
オーディオ説明
0:00
ネイティブオーディオとリアルな物理演算を備えたプレミアムなシネマティックビデオ生成。
8秒
DeepSeek R1
ネイティブオーディオとリアルな物理演算を備えたプレミアムなシネマティックビデオ生成。
パフォーマンスとスケーラビリティ
本文ここにLorem ipsum dolor sit amet
- 箇条書き項目ここにLorem ipsum
- 箇条書き項目ここにLorem ipsum
- 箇条書き項目ここにLorem ipsum
インフラストラクチャ
最適な用途
- より高速な処理速度(全体のクエリレイテンシの低減)と低い運用コスト
- 明確に定義された単純なタスクの実行
- ファンクションコール、JSONモード、または他の構造化された明確なタスク
リスト項目 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
ビルド
含まれる特典:
- ✔ プラットフォームクレジット最大15,000ドル分無料*
- ✔ フォワードデプロイされたエンジニアリング時間3時間無料。
資金調達:500万ドル未満
Build
含まれる特典:
- ✔ プラットフォームクレジット最大15,000ドル分無料*
- ✔ フォワードデプロイされたエンジニアリング時間3時間無料。
資金調達:500万ドル未満
Build
含まれる特典:
- ✔ プラットフォームクレジット最大15,000ドル分無料*
- ✔ フォワードデプロイされたエンジニアリング時間3時間無料。
資金調達:500万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグ内に記述してください。以下のルールに従って推論をフォーマットしてください:推論を行う際は、アラビア語のみで回答し、他の言語は許可されません。
質問:
4月にナタリアは友人48人にクリップを売り、5月にはその半数のクリップを売りました。ナタリアは4月と5月に合計で何枚のクリップを売ったでしょうか?
XX
タイトル
本文ここにロレム・イプサム・ドOLOR SIT AMETと入ります
XX
タイトル
本文ここにロレム・イプサム・ドOLOR SIT AMETと入ります
XX
タイトル
本文ここにロレム・イプサム・ドOLOR SIT AMETと入ります
8S
DeepSeek R1
ネイティブオーディオとリアルな物理演算を備えたプレミアムシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオとリアルな物理演算を備えたプレミアムシネマティックビデオ生成。

8S
DeepSeek R1

ネイティブオーディオとリアルな物理演算を備えた、プレミアム級のシネマティックビデオ生成。
パフォーマンスとスケーラビリティ
本文ここにLorem ipsum dolor sit amet
- 箇条書き項目ここにLorem ipsum
- 箇条書き項目ここにLorem ipsum
- 箇条書き項目ここにLorem ipsum
インフラストラクチャ(Infrastructure)
最適な用途
- より高速な処理速度(全体のクエリレイテンシーの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSONモード、または他の構造化された明確なタスク
リスト項目 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
ビルド(Build)
含まれる特典:
- ✔ 無料プラットフォームクレジット最大$15K*
- ✔ 無償のフォワードデプロイされたエンジニアリング時間3時間。
資金調達:$5M未満
ビルド(Build)
含まれる特典:
- ✔ プラットフォームクレジット最大15,000ドルの無料提供*
- ✔ フォワードデプロイされたエンジニアリング時間3時間の無償提供。
資金調達額:500万ドル未満
構築
含まれる特典:
- ✔ プラットフォームクレジット最大15,000ドルの無料提供*
- ✔ フォワードデプロイされたエンジニアリング時間3時間の無償提供。
資金調達額:500万ドル未満
段階的に思考し、最終的な答えのみを *<answer>* と *</answer> のタグ内に記述してください。推論は以下のルールに従って行ってください:推論を行う場合、アラビア語のみで回答し、他の言語は許可されません。
以下が質問です:
4月にナタリアは友人48人にクリップを売り、5月にはその半数のクリップを売りました。ナタリアは4月と5月に合計で何枚のクリップを売ったでしょうか?
XX
タイトル
本文はここに入ります。ローレム・イプサム・ドOLOR SIT AMET
XX
タイトル
本文はここに入ります。ローレム・イプサム・ドOLOR SIT AMET
XX
タイトル
本文はここに入ります。ローレム・イプサム・ドOLOR SIT AMET
原文を表示
Summary
Multi-tenant GPU clusters let AI-native companies share compute capacity across teams without sacrificing isolation or control. The right architecture pools GPUs at the infrastructure layer while giving each team dedicated nodes, storage, and self-serve scheduling, eliminating idle capacity waste without the politics of truly shared infrastructure. This guide covers the core design principles, common failure modes, and how platforms like Together AI implement multi-tenancy in practice.
Why multi-tenant GPU cluster design is a core infrastructure problem for AI-native companies
AI-native companies scale faster than their infrastructure strategies can keep up with. Every new team spins up new model experiments, training runs, and demands on shared compute. The result is a familiar situation for AI platform engineers: organizational demand for GPUs compounds, but they remain scarce and expensive.
The instinct is often to isolate, giving each team their own clusters and resources. But this approach doesn’t scale economically. Dedicated clusters sit idle overnight, on weekends, and when training runs finish ahead of schedule. You end up paying for capacity no one is using, while other teams queue for resources they can’t access.
The better architecture is shared, but shared in a way that teams experience as if clusters are their own. That’s the core design challenge of multi-tenancy at AI-native scale: pooled economics, without pooled chaos.
What is a multi-tenant GPU cluster?
A multi-tenant GPU cluster is a shared compute environment where multiple teams operate on the same underlying hardware while maintaining isolation that makes sense, including data access boundaries, credentials, storage volumes, and billing visibility.
Unlike a traditional shared cluster, multi-tenant clusters have a guarantee of isolation. In a well-designed multi-tenant cluster, one team’s training job can’t impact another’s. Hard quotas, reservation windows, and scheduling guardrails prevent overusing resources from becoming a cross-team problem — critical when you have teams across models, inference, and research all competing for the same GPUs.
What are the core requirements for multi-tenancy?
For multi-tenancy to work, there are three requirements teams should be meet simultaneously:
- Pooled capacity: A single negotiated GPU pool shared across teams eliminates idle-capacity waste. The unit economics only work when GPU utilization is aggregated across workloads — training runs, fine-tuning jobs, and inference — rather than isolated per team.
- Tenant isolation: Each team needs dedicated nodes, storage, separate credentials, and direct-to-tenant billing visibility. Shared infrastructure works best when every tenant feels like they’re operating their own cluster, with clear boundaries that no neighboring workload can cross.
- Self-serve access: Teams need to book capacity directly, see live availability, and spin up environments in minutes, not days.
How should you build your infra layers?
The cleanest pattern for AI-native infrastructure is two layers: shared infrastructure at the foundation, per-tenant infrastructure at the top.
At the shared layer, a centralized control plane sits above high-performance shared storage and a common network fabric, typically InfiniBand for east/west intra-cluster traffic (essential for distributed training at scale., and Ethernet for north/south. GPU and CPU compute nodes are managed centrally, with Together AI’s IaaS control plane being a strong reference implementation of this pattern.
On top of this shared foundation, each team gets a fully isolated virtual environment: dedicated GPU nodes, dedicated storage PVCs, and their choice of orchestration layer — Kubernetes, Slurm, or other configurations depending on workload type. Teams running foundation model training, fine-tuning, or inference workloads each operate in their own clusters, with zero visibility into adjacent tenants.
Together AI’s multi-tenant clusters are a concrete implementation of this pattern, demonstrating what bare-metal performance with cloud-like flexibility looks like for AI-native teams in practices, billed directly per tenant based on actual usage.
How do you prevent one team from consuming all GPU capacity?
This is where quota-based allocation becomes essential in any AI-native environment. Administrators set guardrails per team, capping by GPU count, total spend, or reservation window length — enforced at the scheduler level, not just as a soft policy.
The scheduler should also handle advance booking with conflict prevention built in. Teams reserve clusters for a specific window (say, a month-long pre-training run or two-week fine-tuning spring), and the system prevents double booking. Live capacity availability surfaces in the UI so teams can see exactly what’s available before committing. Capacity-aware scheduling means predictable planning: no surprises or cross-team interference mid-run.
For teams that need burst beyond their quota, the right design supports overflow to on-demand public rates automatically. Together AI handles this without requiring admin approval, so production velocity isn’t throttled by infrastructure bureaucracy.
What configuration flexibility should a multi-tenant platform provide AI teams?
A common failure mode in shared infrastructure is opinionated defaults. Platforms that force a specific orchestration layer, driver version, or storage configuration create hidden tradeoffs — AI-native teams end up adapting their workflows to the platform rather than the other way around, which is exactly backwards.
The right pattern is an á la carte configuration at booking time: orchestration layer, CUDA driver version, shared memory size, and storage volume, all specified by the team based on their workloads requirements. No defaults or forced tradeoffs. A team running Llama fine-tuning on Slurm shouldn’t be forced into the same configuration as a team serving inference endpoints on Kubernetes.
Once provisioned, clusters should come with automated creation and tear-down, out-of-the-box observability via Grafana, and immediate SSH access.
How should GPU health and node repair work in multi-tenant environments?
Hardware failures in a shared cluster can have a ripple effect. They don’t just impact one training job, but can cascade across teams sharing the same physical layer. A robust health check and repair lifecycle is a must.
Best practice is automatic acceptance testing on every node before it’s handed off to a tenant’s cluster. Tests should include DCGM diagnostics, GPU burn tests, single- and multi-node NCCL tests, and NVBandwidth measurements across CPU-GPU latency and bandwidth dimensions.
Teams should also be able to trigger on-demand health checks directly from the UI at any point during a cluster’s lifecycle, not just at provisioning time. When issues are detected, the response should be tiered: software problems trigger a quick reprovision, hardware failures result in cluster migration. Throughout the repair lifecycle, tenants should have full visibility — no guessing whether a slow training run is a model issue or node issue.
Is multi-tenant GPU infrastructure right for your team?
Multi-tenant clusters deliver the most value when you have multiple AI teams with heterogeneous workloads — foundation model training, fine-tuning, inference, and research — all running concurrently. For AI-native organizations, the math strongly favors pooling.
The critical question isn’t whether to share infrastructure, but instead how well your AI platform enforces isolation. And when the process works seamlessly, you get data center unit economics without the performance compromises of public cloud, and the self-service velocity AI-native teams expect.
Start building on multi-tenant GPU infrastructure today
Together’s multi-tenant clusters are purpose-built for AI-native organizations that need shared GPU infrastructure without shared headaches. Pool your capacity, isolate your teams, and move at the speed your models demand.
Get started with Together AI →
FAQs
Can teams in a multi-tenant cluster see each other’s models, data, or training runs?
No, not in a correctly architected environment. Each tenant operates with dedicated GPU nodes, dedicated storage volumes, and separate credentials.
What happens when a team needs more capacity than their quota allows?
Well-designed platforms support automatic bursting to on-demand rates when teams exceed their pool allocation, no manual admin approval required. AI-native velocity shouldn’t be throttled by infrastructure bureaucracy at the edges of planned capacity.
What orchestration frameworks should a multi-tenant platform support for AI workloads?
At minimum: Kubernetes for inference and serving, and Slurm on Kubernetes for distributed training. AI-native teams often need both running simultaneously, so the platform needs to support mixed configurations
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み