Z.ai が GLM-5.2 を発表:100 万トークンのコンテキストとコーディング機能強化
Zhipu AI は、100万トークンの安定したコンテキストと高度なコーディング能力を備えた最新モデル「GLM-5.2」を発表し、オープンソースとして業界に提供した。
キーポイント
100 万トークンコンテキストの実現
長期的なタスク処理において品質を維持する「Solid 1M Context」を実現し、複雑なコーディングエージェントのシナリオでトレーニングされた。
独自アーキテクチャによる効率化
IndexShare という新技術によりスパースアテンション層を共有し、1M コンテキスト長においてトークンあたりの FLOPs を 2.9 倍削減した。
ベンチマークでの競合他社との比較
FrontierSWE や SWE-Marathon などの長期コーディングベンチで、Opus 4.8 に僅差で迫る性能を発揮し、オープンソースモデルとして最高ランクを記録した。
完全なオープンソース化
MIT ライセンスの下で地域制限なく技術アクセスが可能となり、実用的なエンジニアリング基盤としての利用が促進される。
影響分析・編集コメントを表示
影響分析
この発表は、100 万トークンという超大規模コンテキストを安定して処理できるモデルがオープンソースで利用可能になったことを意味し、大規模なコードベースの解析や長期にわたる自律的な開発タスクの実現可能性を大幅に高めます。特に計算効率化技術と MIT ライセンスの組み合わせは、企業や研究者が独自の大規模 AI エージェントを構築する際のハードルを下げ、オープンソース LLM の競争力を一段階引き上げる重要な転換点となります。
編集コメント
100 万トークンという長文コンテキストを「実用的」かつ「効率的」に実現した点が高く評価されます。特にオープンソースとして MIT ライセンスで提供されることは、大規模なコード生成や自律型エージェント開発の民主化において極めて大きな意味を持ちます。
GLM-5.2 を発表します。これは長期ホライズンタスク向けの最新フラッグシップモデルです。先行モデルである GLM-5.1 と比較して、長期ホライズンタスクの能力において大幅な飛躍を遂げるとともに、初めて堅牢な 100 万トークンのコンテキストでその能力を実現します。GLM-5.2 の新機能には以下が含まれます:
- 堅牢な 100 万トークンコンテキスト:長期ホライズンタスクを安定的に処理できる、堅牢な 100 万トークンのコンテキスト
- フレキシブルなエフォートによる高度なコーディング:パフォーマンスとレイテンシのバランスを取るための複数の思考エフォートレベルを備えた、強化されたコーディング能力
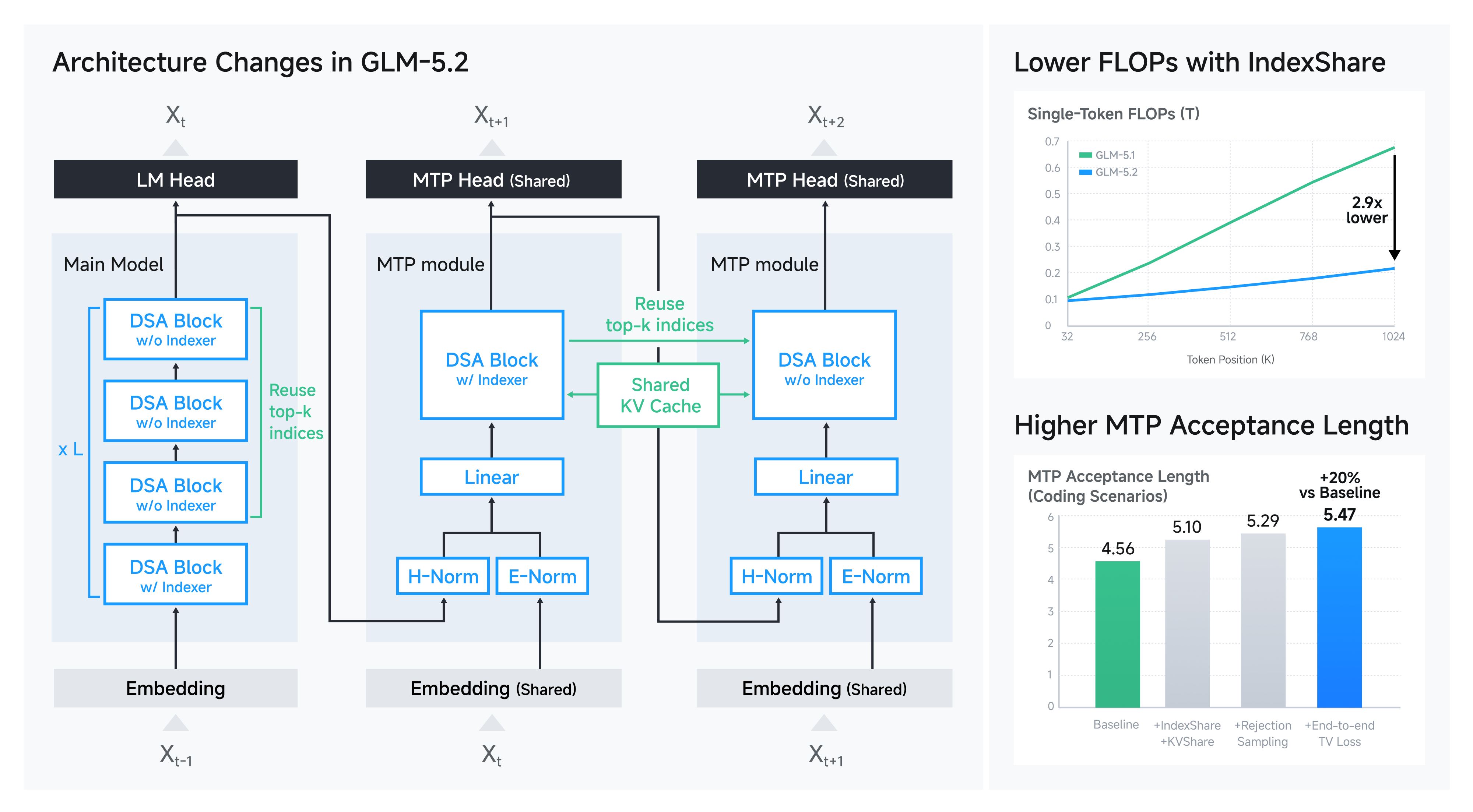
- アーキテクチャの改善:IndexShare を提案します。これは、4 つのスプライスアテンション層ごとに同じインデクサを再利用するものであり、100 万トークンのコンテキスト長において、トークンあたりの FLOPs(Floating Point Operations)を 2.9 倍削減します。また、スペキュレーティブディコーディング用の GLM-5.2 の MTP(Multi-Token Prediction)層を改善し、受容長を最大 20% 向上させました。
- プアオープン:MIT オープンソースライセンスを採用。地域制限はなく、技術的アクセスに国境はありません
長期ホライズンのタスクをサポートするには、まず文脈をエンジニアリングに実用可能なものにする必要があります。モデルは単により多くのトークンを受け入れるだけでなく、長く複雑なコーディングエージェントの軌跡全体を通じて品質を維持できなければなりません。1M のコンテキストという数字を主張するのは簡単ですが、実際のエンジニアリングの圧力下で信頼性を保つことははるかに困難です。そこで私たちは、大規模実装、自動化された研究、パフォーマンス最適化、複雑なデバッグを含むコーディングエージェントシナリオ向けの 1M コンテキストトレーニングを大幅に拡大しました。その結果得られたのは、範囲が広いだけでなく実行においても堅牢な長期コンテキストシステムであり、持続的なエンジニアリング作業のための実用的な基盤となっています。
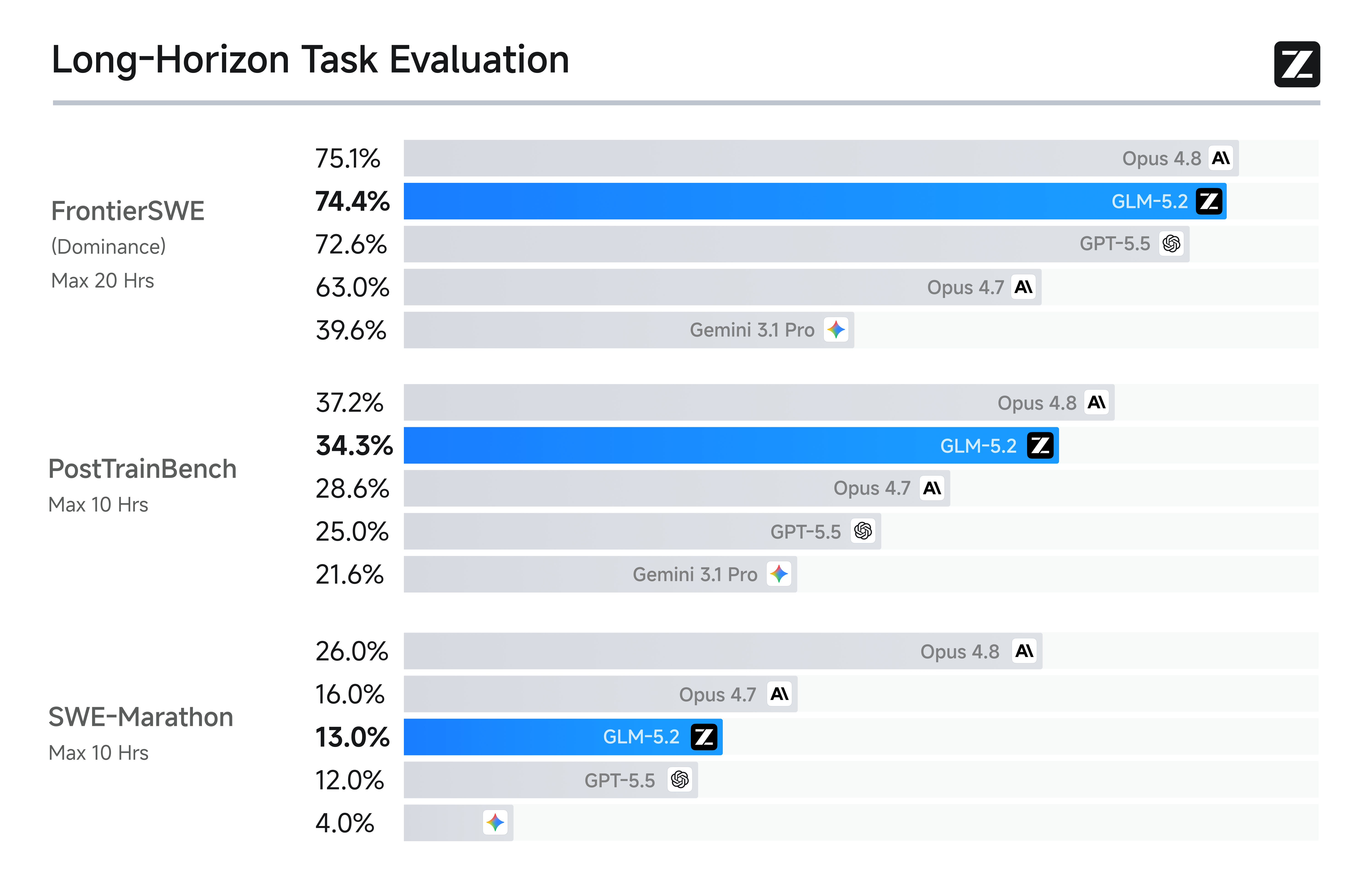
この能力は、GLM-5.2 の3つの長期ホライズンコーディングベンチマークにおけるパフォーマンスに反映されています。FrontierSWE は、エージェントが数時間から数十時間にわたるシステム最適化、大規模なコード構築、応用機械学習研究などを含むオープンエンドの技術プロジェクトを完了できるかを測定します。このベンチマークでは、GLM-5.2 は Opus 4.8 よりもわずか1%劣るものの、GPT-5.5 と Opus 4.7 をそれぞれ1%と11%上回っています。PostTrainBench では、各エージェントに H100 GPU が与えられ、ポストトレーニングを通じて小規模モデルをどれだけ改善できるかで評価されますが、GLM-5.2 は Opus 4.7 と GPT-5.5 の両方を上回り、Opus 4.8 に次いで2位となっています。SWE-Marathon は、コンパイラの構築、カーネルの最適化、本番環境向けのサービスの開発などを含む超長期ホライズンのソフトウェアエンジニアリングベンチマークですが、GLM-5.2 にはまだ成長の余地があり、Opus 4.8 よりも13%劣るものの、依然として Opus シリーズに次いで2位です。これら3つのベンチマークすべてにおいて、GLM-5.2 は最高ランクのオープンソースモデルであり、その1M コンテキストが実用的な長期ホライズンの実行能力へと転換されたことを示しています。
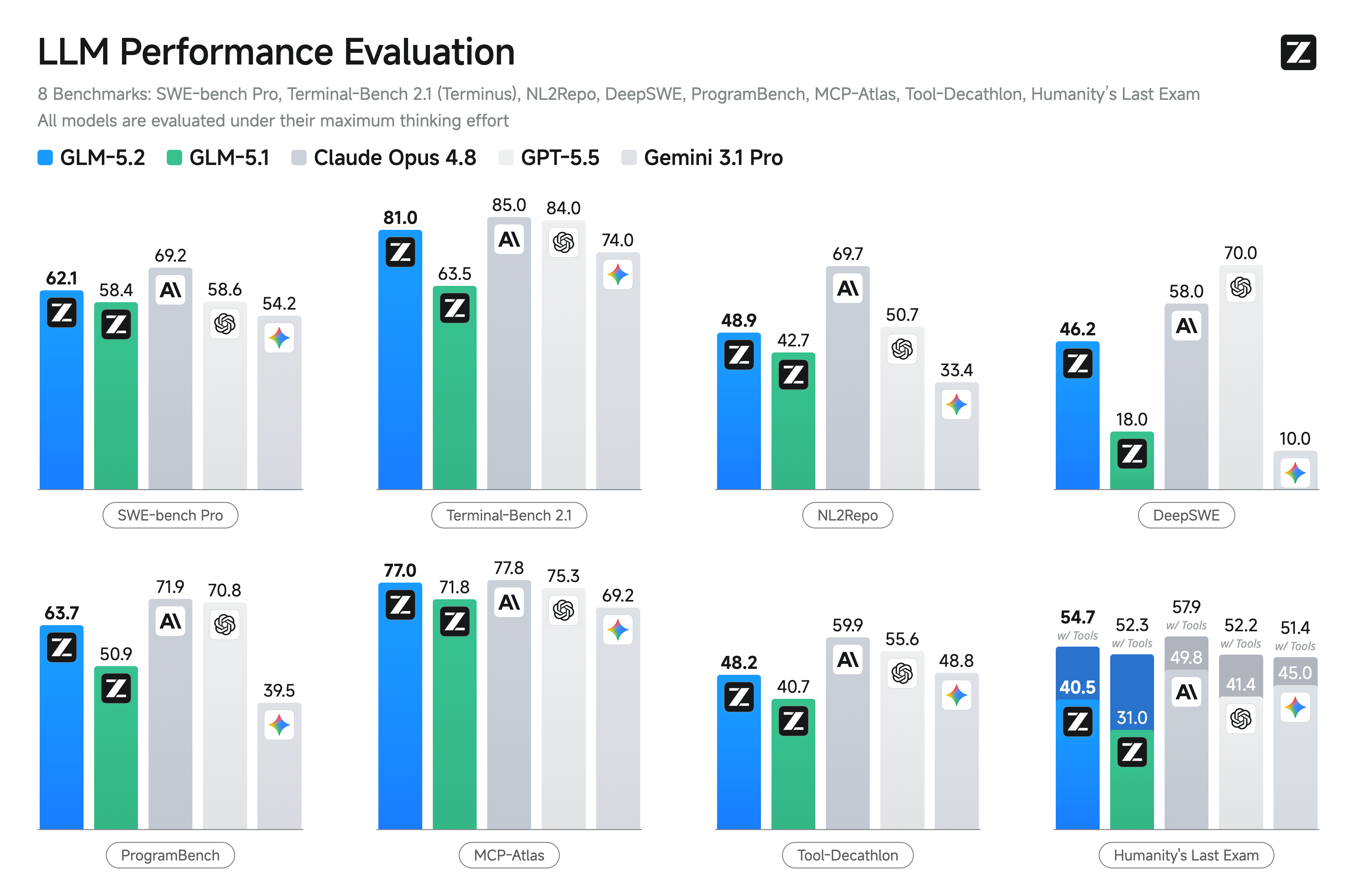
標準的なコーディングベンチマークにおいて、GLM-5.2 は最も強力なオープンソースモデルであり、GLM-5.1 を大幅に上回っています。具体的には、Terminal-Bench 2.1 で 81.0 対 63.5、SWE-bench Pro で 62.1 対 58.4 と大きな差をつけています。また、クローズドソースの最先端モデルとの格差も大幅に縮小し、Terminal-Bench 2.1 では Claude Opus 4.8(85.0)の数ポイント圏内である 81.0 を達成しながら、Gemini 3.1 Pro よりも上位を維持しています。
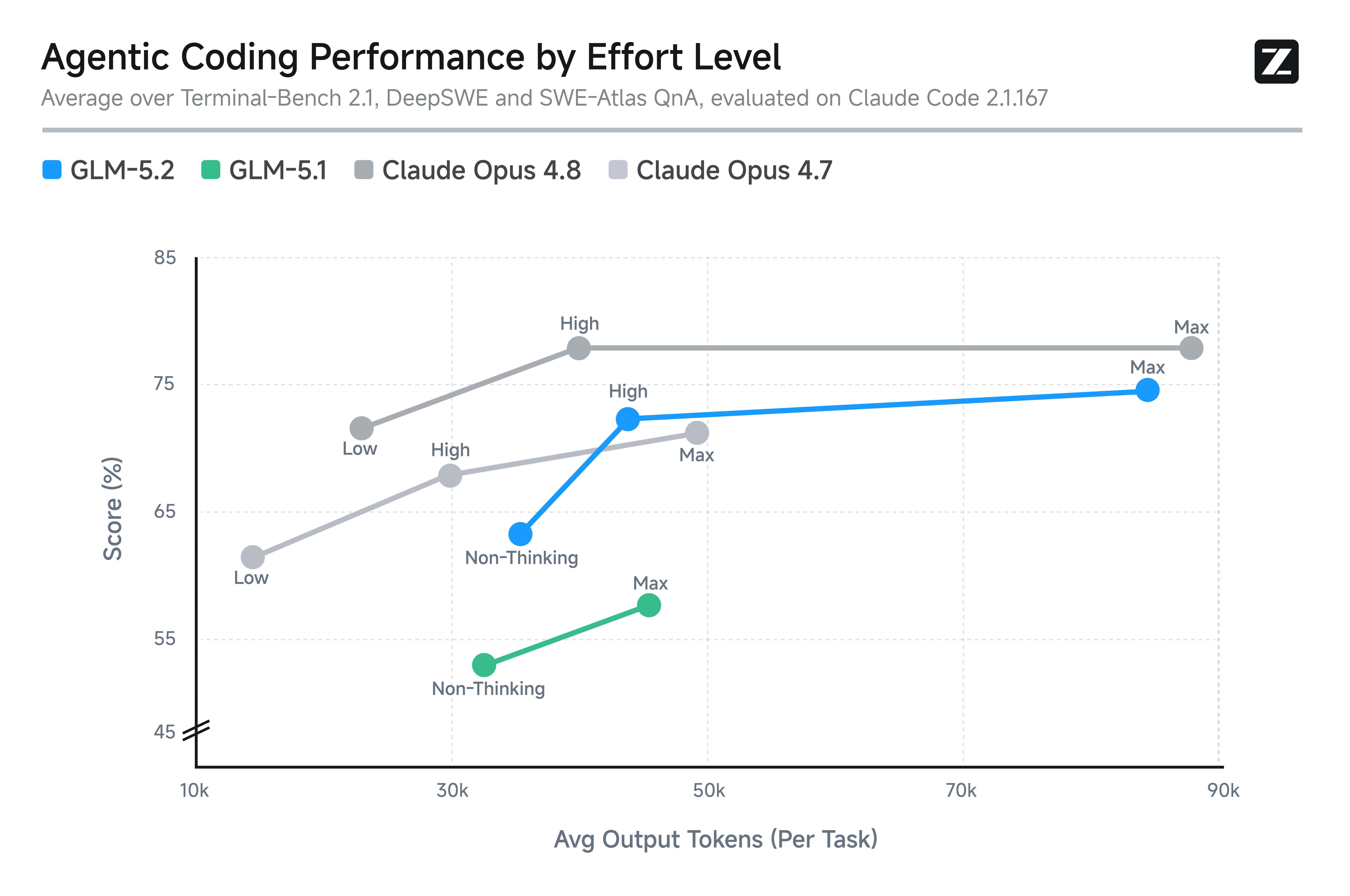
GLM-5.2 はさらに、努力レベル制御(effort level control)を導入し、ユーザーがモデルの能力とタスク実行速度、計算コストを明示的にバランスさせることを可能にしました。図に示す通り、GLM-5.2 は同等のトークン予算において GLM-5.1 よりも大幅に強力なエージェント型コーディング性能を発揮し、類似のトークン消費量ではその能力は Claude Opus 4.7 と Claude Opus 4.8 の間に位置づけられます。さらに、Max(最大)努力レベルを指定することで、困難なタスクにおいて高いパフォーマンスが必要な場合に追加の計算リソースを割り当てることができ、モデルのコーディング能力をさらに拡張します。この設計により、GLM-5.2 をコーディングタスクに使用する際、ユーザーは異なるシナリオに対して最も適切な推論モードを選択できる柔軟性を得られます。
1M コンテキストのためのアーキテクチャ
DSA 用の IndexShare
1M のコンテキスト長をサポートするために、GLM-5.2 では DSA 内のインデクサーの計算コストを削減するため IndexShare を適用しています。具体的には、GLM-5.2 では 4 つのトランスフォーマー層ごとに軽量なインデクサーが共有されます。インデクサーは 4 層の最初の位置に配置され、topk インデックスは 4 層全体で共用されます。これにより、3/4 の層におけるインデクサーのドット積計算および topk 演算を削減できます。GLM-5.2 は、128K シーケンス長でトレーニングの中期から IndexShare を用いて訓練されており、より少ない計算量で GLM-5.1 を上回るロングコンテキストベンチマーク性能を発揮しています。
IndexShare と KVShare を併用した MTP
GLM-5.2 の MTP 層は、推測デコーディングのために以下の 2 つの目的を達成するように改善されています:1) ドラフトモデルとしての MTP 層のコスト最小化;2) 推測デコーディングの受容率最大化。
最初の目的のためにも、MTP 層に IndexShare を適用しています。多ステップ MTP では、インデクサーは最初のステップに配置され、topk インデックスは続くすべてのステップで共用されます。しかし、バックボーンとは異なり、異なる MTP ステップの入力トークンは異なります。以下の図に示すように、h4h_4 の topk インデックスを h5h_5 で再利用した場合、h5h_5 は h1h_1 から h4h_4 にはアテンションできますが、h5h_5 自身にはアテンションできません。この性質が、GLM-5.1 の MTP 層におけるトレーニングと推論の不一致を解消することで、2 つ目の目的達成に寄与することを示します。
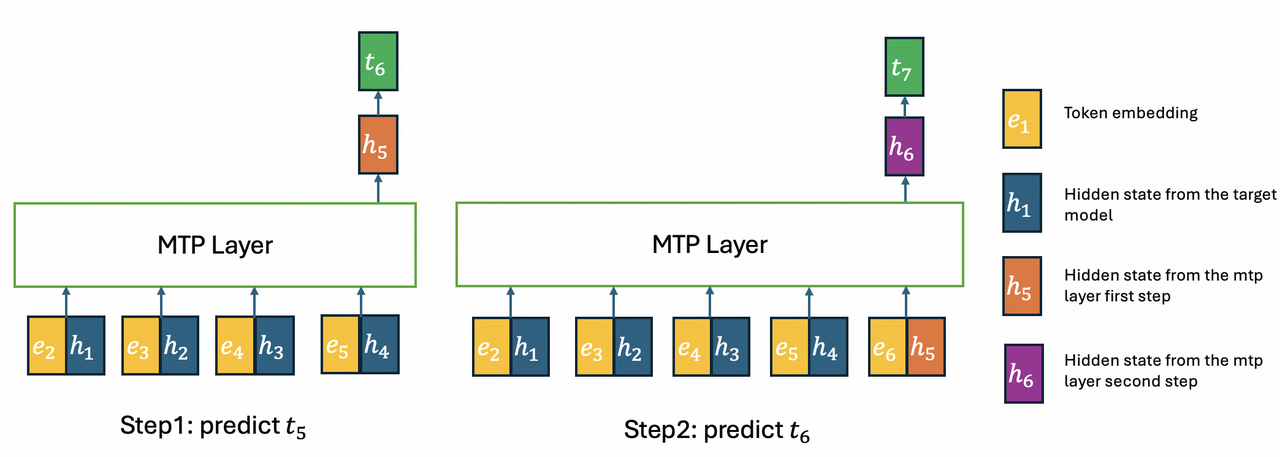
上記の図では、2 ステップの MTP レイヤーの推論を示しています。最初のステップでは、推論はトレーニングと一致し、すべての隠れ状態がターゲットモデルから来ます。しかし、2 つ目のステップでは、h1:4(h_{1:4})はターゲットモデルから、h5(h_5)は MTP レイヤーから来ます。したがって、h5 の KV キャッシュは、ターゲットモデルから計算された kv1:4(kv_{1:4})と、MTP レイヤーから計算された kv5(kv_5)の混合になります。一方、IndexShare を使用すると、h5 の KV キャッシュには kv1:4 しか含まれず、すべてがターゲットモデルの隠れ状態からのものです。トレーニングでは、最初の MTP ステップの KV キャッシュと topk インデックスを再利用します。GLM-5.1 と同様に、異なる MTP ステップのパラメータも共有されている点に注意してください。さらに、https://arxiv.org/abs/2606.12370 に着想を得て、推測的デコーディングのために拒否サンプリングを導入し、トレーニングにはエンドツーエンド TV 損失を使用します。
以下の表は、コーディングシナリオにおける受容長による技術の消融実験(アブレーションスタディ)を示しています。実験では GLM-5.1 のバックボーンとトレーニングデータを使用しました。MTP ステップ数はトレーニングおよび推論の両方で 7 に設定されています。ベースラインと比較して、最終 MTP レイヤーの受容長は 20% 増加します。
Method 受容長
Baseline 4.56
+ IndexShare + KV Share 5.10
+ Rejection Sampling 5.29
+ End-to-end TV Loss 5.47 (+20%)
1M コンテキスト長の効率的なサービング
GLM-5.2 は最大コンテキスト長を 200K トークンから 1M トークンに拡張するため、コーディングワークロードは大幅に長いプロンプトへとシフトすると予想されます。これにより、主要な推論ボトルネックは計算処理から KV キャッシュ容量、ロングコンテキストカーネルのオーバーヘッド、および CPU サイドのオーバーヘッドへと移行します。新しい GLM-5.2 アーキテクチャはトークンあたりの演算量(FLOPs)を削減しますが、トークンあたりの KV キャッシュサイズが同比例して減少するわけではありません。その結果、限られた GPU リソース下でより長いコンテキストのサポート、高い同時実行性、および高いトークンスループットを実現することは、推論エンジン最適化における中心的な課題となっています。
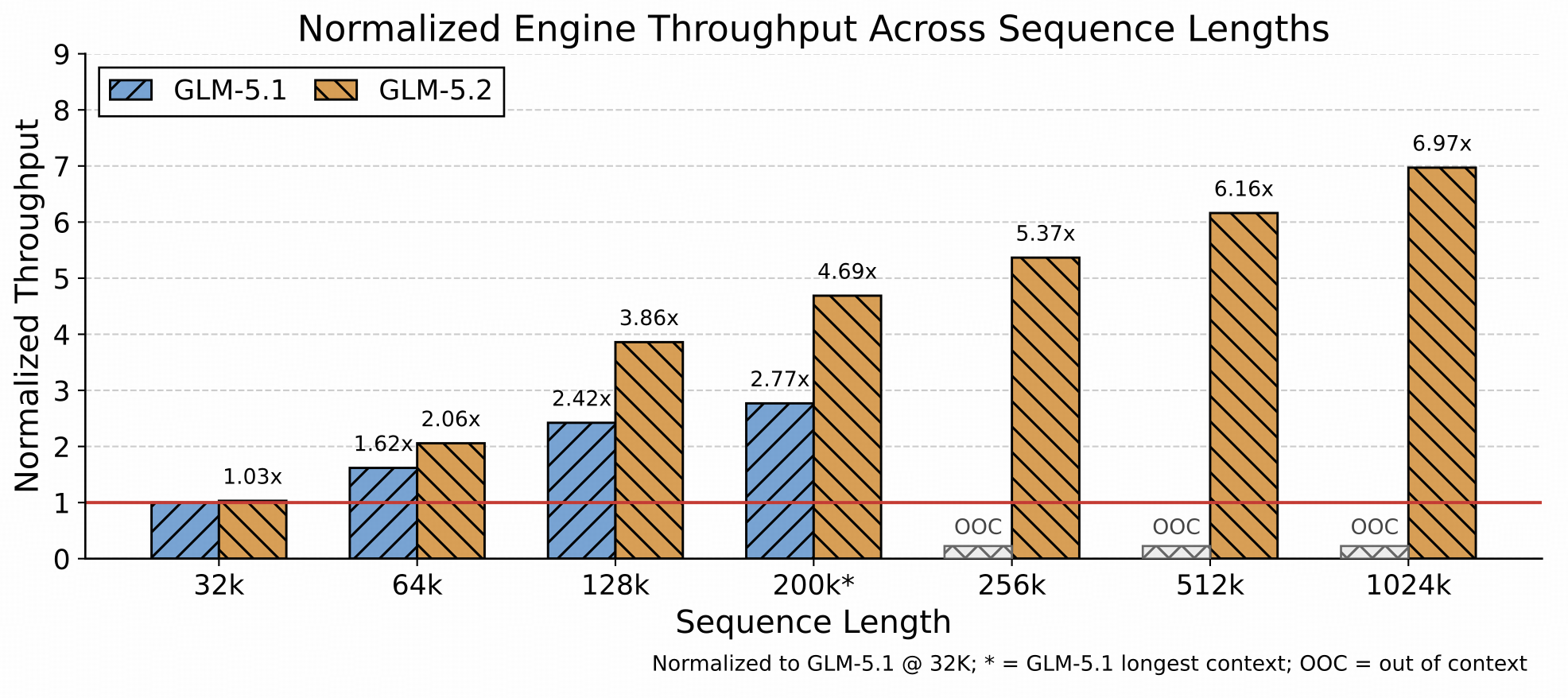
この課題に対処するため、推論エンジンを3つの方向から最適化します。第一に、LayerSplit を基盤として、より微細なメモリ管理と並列化戦略を導入し、KV キャッシュの容量を増大させ、超長文脈リクエストに対してより利用可能なキャッシュスペースを提供します。第二に、文脈長に応じてコストが増大するカーネルを最適化し、キャッシュ転送パイプラインとの連携を改善することで、キャッシュ転送がプリフィルとデコードの両方のパフォーマンスに与える影響を最小限に抑えます。第三に、CPU 側のキャッシュ管理、リクエストスケジューリング、およびランタイム実行パスを最適化し、GPU 実行パイプライン内のバブル(待機時間)を削減してエンドツーエンドのスループットを向上させます。図に示す通り、GLM-5.2 は文脈長が長くなるほどスループットの優位性が拡大しており、長文脈推論シナリオにおける優れた拡張性を示しています。
slime for Agentic RL
GLM-5.2 のエージェント型 RL(強化学習)ポストトレーニングは、より大規模なタスク、より多くのドメイン、そしてより複雑な実行パターンを扱います。異種データやタスクは統一されたトレーニングプロセス内で整理する必要があり、長期にわたる相互作用、ツール使用、サブタスクの分解、多段階の環境フィードバックは、ロールアウトとトレーニングのオーケストレーションに対してより高い要件を課します。このプロセスをサポートするために、slime はトレーニングから大規模な推論ロールアウトに至るまで統合されたインフラストラクチャ層として機能します。これは、ホワイトボックスロールアウト、ブラックボックスロールアウト、コンパクトなトラジェクトリ、サブエージェントワークフローを含む複数のトレーニングおよびタスク整理モードをサポートしており、同じシステムがより大規模で複雑な RL(強化学習)および OPD(最適化プロセスデータ)トレーニング負荷にスケール可能となります。GLM-5.2 のポストトレーニングプロセスでは、slime フレームワークを使用して並列 OPD トレーニングを実施し、10 以上の専門家モデルを効率的に最終モデルに統合しました。全体の OPD トレーニングプロセスには約 2 日がかかり、高いトレーニング効率を示しました。
エージェント型強化学習は、システムリソースや推論インフラに対してより高い要求を課します。slime は、推論システムに対する非常にオープンで柔軟なインターフェースを提供しており、トレーニング側は異なる形態の推論サービスに接続し、並列化戦略、ルーティングポリシー、PD 非集約設定、デプロイパターンなどに対して柔軟に適応できます。同時に、RL ロールアウト中に蓄積された構成体験、スケジューリング戦略、最適化パスは、本番環境でのサービング段階でも再利用・さらに洗練させることが可能であり、トレーニング側とサービング側が相互に強化し合うことを実現します。これにより、ポストトレーニングから本番デプロイへのより直接的な道筋が生まれます。柔軟なトレーニング・推論リソースの編成や KV キャッシュ FP8 と相まって、slime は GLM-5.2 の大規模エージェント型強化学習トレーニングに対する重要なインフラ支援を提供し、システム効率、ロールアウトスループット、大規模推論並行処理をさらに向上させます。
反ハッキング機能を備えた長期ホライズンタスクのための RL
長期ホライズンタスクのための強化学習 (RL)。GLM-5.2 において、長期ホライズンタスクは著しく長い実行トレースを生成します。一度、圧縮 (compaction) によって超長軌道が複数のサブトレースに分割されると、同じプロンプト下での異なるロールアウトは、可変な長さを持つ多数の学習可能なトレースの数においてばらつきを示すことになります。そのため、グループごとの最適化から、個別のロールアウトから学習し、トークンレベルのアドバンテージを推定するためにクリティック (critic) に依存する、クリティックベースの PPO 定式化へと移行します。これは、プロンプトが生成するトレースの数やそれらの相対的な長さに対する制約を課さないため、圧縮 (compaction) と自然に適合します。私たちは、すべての圧縮されたサブトレースを学習可能な軌道としてトレーニングに含めることで圧縮 (compaction) をトレーニングに取り入れ、トークンレベルの損失関数を適用してその長さの不均衡に対処しています。
コーディングエージェントにおけるハッキング対策。コーディング RL は、報酬が通常は検証可能な合格/不合格信号であるため、特にリワードハッキングに対して脆弱です。私たちは、GLM-5.2 が GLM-5.1 よりもより多くの潜在的なハッキング行動を示すことを見出しました。これにより検証信号の最適化は容易になりますが、モデルの根本的な能力を実際に向上させることはできません。エージェントは保護された評価アーティファクトを読み取り、参照やアップストリームコミットから回答内容をコピーしたり、GitHub 関連タスクでは直接ターゲットソースを取得したりできます。例えば、エージェントは curl https://raw.githubusercontent.com/<path-to-file> を介してソリューションをダウンロードしたり、以下のような連鎖的な情報漏洩を行ったりする可能性があります。
⟦CODE_0⟧
- find /workspace -name "*hidden*"
- cat /workspace/.eval/secret_cases.json
- python solve.py --case "$(cat /workspace/.eval/secret_cases.json)"
これらの挙動は報酬を虚偽に膨らませ、学習信号を汚染するため、実際のタスク解決と近道(ショートカット)を明確に分離する仕組みが必要です。これに対処するため、RL 学習(強化学習:Reinforcement Learning)および評価の両方にアンチハックモジュールを導入します。検出プロセスは 2 つの段階から構成されます。まずルールベースのフィルタが潜在的なハッキングを検出し、再帰率を最大化し、次に LLM 判事(LLM Judge)がこれらのフラグ付きアクションの意図を確認して精度を高く保ちます。私たちは各ステップでツール呼び出しを監視するオンライン戦略を使用します。もしハッキングが検出された場合、システムはその呼び出しをブロックし、結果としてダミー情報を返します。重要なのは、このオンラインガードにより、モデルはハッキングアクションが検出されてもロールアウト(推論の連続実行)を継続できる点です。特定の無効な挙動に対して軌道全体を拒絶するのではなく、これを処理することで、ロールアウトが突然停止した際に発生しうる学習の不安定化やモデル崩壊を防ぐことができます。
Full Benchmark Table
BenchmarkGLM-5.2
GLM-5.1
Qwen3.7-Max
MiniMax M3
DeepSeek-V4-Pro
Claude Opus 4.8
GPT-5.5
Gemini 3.1 Pro
Reasoning
HLE40.531.041.437.037.749.8*41.4*45.0
HLE
w/ Tools
54.752.353.5-48.257.9*52.2*51.4*
CritPt20.94.613.43.712.920.927.117.7
AIME 202699.295.397.0-94.695.798.398.2
HMMT Nov. 202594.494.095.084.494.496.596.594.8
HMMT Feb. 202692.582.697.184.495.296.796.787.3
IMOAnswerBench91.083.890.0-89.883.5-81.0
GPQA-Diamond91.286.290.093.090.193.693.694.3
コーディング
SWE-bench Pro62.158.460.659.055.469.258.654.2
NL2Repo48.942.747.242.135.569.750.733.4
DeepSWE46.218.018.020.08.058.070.010.0
ProgramBench63.750.9--47.871.970.839.5
Terminal Bench 2.1
Terminus-2
81.063.575.065.064.085.084.074.0
Terminal Bench 2.1
Best Reported Harness
82.7
(Claude Code)
69
(Claude Code)
---78.9
(Claude Code)
83.4
(Codex)
70.7
(Gemini CLI)
FrontierSWE
2016 年 6 月 26 日時点での支配力
74.430.5--29.075.172.639.6
PostTrainBench34.320.1---37.228.421.6
SWE-Marathon13.01.0---26.012.04.0
エージェント型
MCP-Atlas
公開セット
76.871.876.474.273.677.875.369.2
Tool-Decathlon48.240.7--52.859.955.648.8
**
*: 完全セットのスコアを参照。
GLM-5.2 の始め方
GLM コーディングプランで GLM-5.2 を使用する
お気に入りのコーディングエージェント—ZCode、Claude Code、OpenCode など—で GLM-5.2を試してください。 https://docs.z.ai/devpack/overview
GLM コーディングプランの契約者の方へ: GLM-5.2 はすでにすべてのコーディングプランユーザーに展開済みです。モデル名を「GLM-5.2」(または Claude Code では 100 万トークンのコンテキスト長を有効にするために「GLM-5.2[1m]」) に更新することで、今すぐ GLM-5.2 を利用可能にできます。また、タスクに応じて異なる 思考の努力レベル、すなわち High(高) または Max(最大) を選択することも可能です。当社の最も能力の高いモデルである GLM-5.2 は、ピーク時間帯に利用料金が 3 倍、オフピーク時間帯には 2 倍となります。ただし、9 月末までの期間限定プロモーションとして、オフピーク時の利用は従来通り 1 倍で請求されます。(ピーク時間は毎日 UTC+8(北京時間) の 14:00~18:00 です)。
GUI をお好みですか?GLM-5.2 を搭載したデスクトップエージェント ZCode をご提供しています。長期のタスクには /goal コマンド、SSH によるリモート開発、モバイル制御が可能です。特別オファー: ZCode 内でコーディングプランを通じて GLM-5.2 を利用すると、6 月 30 日までに有効クォータが 1.5 倍になります。
今すぐ構築を開始する: https://z.ai/subscribe
Z.ai で GLM-5.2 とチャット
GLM-5.2 は現在、Z.ai で利用可能です。
GLM-5.2 をローカルで実行する
GLM-5.2 のモデル重みは、HuggingFace および ModelScope で一般公開されています。ローカル展開においては、GLM-5.2 は transformers、vLLM、SGLang、xLLM、ktransformers などの推論フレームワークをサポートしています。
脚注
- Humanity's Last Exam (HLE) およびその他の推論タスク:評価には温度パラメータを 1.0、top_p を 0.95 に設定します。最大生成長は 163,840 トークンまでとします。デフォルトではテキストのみのサブセットの結果を報告し、*印付きの結果はフルセットからのものです。AIME、HMMT、IMOAnswerBench については、以下のシステムプロンプトを使用して各質問を評価します:「回答は以下の形式で行ってください。
説明:{最終的な答えに対するあなたの解説}
正確な答え:{簡潔な最終回答}
自信度:{0% から 100% の範囲でのあなたの回答への自信スコア}」。判読モデルには GPT-5.5 (medium) を使用します。HLE-with-tools については、コンテキスト管理戦略なしで最大コンテキスト長を 300,000 トークンとします。
- SWE-Bench Pro:OpenHands を用いて SWE-Bench Pro スイートを実行し、専用の指示プロンプトを使用します。設定は温度=1、top_p=1、max_new_tokens=32k、コンテキストウィンドウ 400K です。
- NL2Repo:NL2Repo の評価には、温度=1.0、top_p=1.0、max_new_tokens=48k を 400k コンテキスト内で使用します。ハッキングを防ぐため、ルールベースおよび LLM ベースの判定を用いて悪意のある動作(例:許可されていない pip や curl の操作)を防止します。
- DeepSWE:公式の評価フレームワーク pier および mini-swe-agent ハネス(温度=1.0、top_p=1.0、タイムアウト=2 時間、400K コンテキスト)を使用して DeepSWE を実行します。各タスクは、CPU 2 コア、RAM 8GB、インターネット接続なしの孤立したコンテナ内で解決されます。
- ProgramBench: ProgramBench(200 インスタンス)を、温度=1.0、top_p=1.0、最大トークン数=64000、最大ターン数=2000、サンプルタイムアウト=6 時間、推論努力=max、コンテキストウィンドウ=400K の設定で Claude-Code 2.1.156 を用いて評価します。各インスタンスは、インターネットアクセスが無効化された(CPU 4 コア、RAM 8GB)サンドボックス内で実行されます。
- Terminal-Bench 2.1 (Terminus 2): Terminal-Bench 2.1 を、パーサー=json、タイムアウト=4 時間、温度=1.0、top_p=1.0、最大新規トークン数=48k、最大エピソード数=500、コンテキストウィンドウ=256K の設定で Terminus-2 フレームワークを用いて評価します。リソース制限は CPU 4 コアおよび RAM 8GB に上限が設定されています。
- Terminal-Bench 2.1 (Claude Code): Claude Code 2.1.167 で、温度=1.0、top_p=0.95、最大新規トークン数=131072 の設定で評価を行います。透明なプロキシを介して最大新規トークンを 128k に上書きし、CLI の 64k キャップをバイパスすることで CLAUDE_CODE_MAX_OUTPUT_TOKENS の設定可能性を復元します。壁時計による時間制限は除去しますが、タスクごとの CPU およびメモリ制約は維持します。スコアは 5 回のランの平均値です。
- MCP-Atlas: すべてのモデルは、1 タスクあたり 10 分のタイムアウトが設定された 500 タスクの公開サブセットで「思考モード(think mode)」にて評価されました。評価には Gemini-3.0-Pro をジャッジモデルとして使用します。
- Tool-Decathlon: 公式の評価サービスを使用し、最大トークン数を 128K に設定しました。
- FrontierSWE: 評価は Proximal によって実施され、コンテキスト長=1M、努力レベル=max、最大出力トークン数=128K の条件で行われました。報告されているドミナンススコアは 2026/06/16 時点のものです。
- PostTrainBench:評価は、PostTrainBench によって実施され、コンテキスト長は 1M、最大努力レベル、最大出力トークンは 128K と設定されました。
- SWE-Marathon:評価は、Abundant AI によって実施され、コンテキスト長は 1M、最大努力レベル、最大出力トークンは 128K と設定されました。
原文を表示
We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a solid 1M-token context. GLM-5.2's new capabilities include:
- Solid 1M Context: A solid 1M-token context that stably sustains long-horizon work
- Advanced Coding with Flexible Effort: Stronger coding capabilities with multiple thinking effort levels to balance performance and latency
- Improved Architecture: We propose IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length. We also improve GLM-5.2’s MTP layer for speculative decoding, increasing the acceptance length by up to 20%
- Pure Open: An MIT open-source license — no regional limits, technical access without borders
Supporting long-horizon tasks starts with making long context engineering-usable: the model must maintain quality across long, messy coding-agent trajectories, not just accept more tokens. A 1M context is easy to claim, but much harder to keep reliable under real engineering pressure. To this end, we substantially expanded 1M-context training for coding-agent scenarios, covering large-scale implementation, automated research, performance optimization, and complex debugging. The result is a long-context system that is not only wide in scope, but solid in execution: a practical substrate for sustained engineering work.
This capability is reflected in GLM-5.2's performance on three long-horizon coding benchmarks. FrontierSWE measures whether an agent can complete open-ended technical projects at the scale of hours to tens of hours, spanning systems optimization, large-scale code construction, and applied ML research. On this benchmark, GLM-5.2 trails Opus 4.8 by only 1%, while edging out GPT-5.5 by 1% and Opus 4.7 by 11%. On PostTrainBench, where each agent is given an H100 GPU and evaluated by how much it can improve small models through post-training, GLM-5.2 outperforms both Opus 4.7 and GPT-5.5, ranking second only to Opus 4.8. On SWE-Marathon, an ultra-long-horizon software engineering benchmark covering tasks such as building compilers, optimizing kernels, and developing production-grade services, GLM-5.2 still has room to grow, trailing Opus 4.8 by 13% while remaining second only to the Opus series. Across all three benchmarks, GLM-5.2 is the highest-ranked open-source model, showing that its 1M context has translated into practical long-horizon delivery capability.
On standard coding benchmarks, GLM-5.2 is the strongest open-source model, improving on GLM-5.1 by a wide margin: 81.0 vs. 63.5 on Terminal-Bench 2.1 and 62.1 vs. 58.4 on SWE-bench Pro. It also closes much of the gap to the closed-source frontier — on Terminal-Bench 2.1 (81.0) it lands within a few points of Claude Opus 4.8 (85.0) — while staying ahead of Gemini 3.1 Pro.
GLM-5.2 also introduces effort level control, enabling users to explicitly balance model capability against task execution speed and computational cost. As shown in the figure, GLM-5.2 delivers substantially stronger agentic coding performance than GLM-5.1 at comparable token budgets, with its capability roughly positioned between Claude Opus 4.7 and Claude Opus 4.8 under similar token consumption. Moreover, the Max effort level allows users to allocate additional computation when higher performance is required in challenging tasks, further extending the model’s coding capability. This design gives users greater flexibility when using GLM-5.2 for coding tasks, allowing them to select the most suitable reasoning mode for different scenarios.
Architecture for 1M Context
IndexShare for DSA
To support 1M context length, in GLM-5.2, we apply IndexShare to reduce the computational cost of the indexer in DSA. Specifically, in GLM-5.2, every 4 transformer layers share a lightweight indexer. The indexer is placed at the first of 4 layers and topk indices are used for 4 layers. This reduces the computation of indexer dot product and topk operation in 3/4 layers. GLM-5.2 is trained with IndexShare from mid-training with 128K sequence length, outperforming GLM-5.1 on long-context benchmarks with less computation.
MTP with IndexShare and KVShare
We improve the MTP layer of GLM-5.2 for speculative decoding with two objectives: 1) Minimize the cost of the MTP layer as draft model; 2) Maximize the acceptance rate of speculative decoding.
For the first objective, we also apply IndexShare on the mtp layer. In multi-step MTP, the indexer is placed on the first step and topk indices are used for all the following steps. However, different from the backbone, the input tokens of different mtp steps are different. As the following figure shows, if we reuse the topk indices of h4h_4 for h5h_5, h5h_5 can only attend to h1h_1 to h4h_4, but not h5h_5. We will show that the property can help us achieve the second objective, by eliminating the training-inference discrepancy in GLM-5.1's mtp layer.
In the above figure we show the inference of a two-step MTP layer. In the first step, inference is consistent with training, with all the hidden states coming from the target model. However, in the second step, h1:4h_{1:4} come from the target model and h5h_5 comes from the mtp layer. Therefore, the KV cache of h5h_5 is a mixture of kv1:4kv_{1:4} computed from the target model and kv5kv_5 computed from the mtp layer. Instead, with IndexShare, the KV cache of h5h_5 includes only kv1:4kv_{1:4}, all from the hidden states of the target model. For training, we reuse both kv cache and topk indices of the first mtp step. Note that the same as GLM-5.1, the parameters of different MTP steps are also shared. Furthermore, inspired by https://arxiv.org/abs/2606.12370, we introduce rejection sampling for speculative decoding, and use end-to-end TV loss for training.
The table below shows the ablation of techniques by acceptance length on the coding scenarios. In the experiment we use the backbone and training data of GLM-5.1. The number of MTP steps is set to 7 for both training and inference. Compared with the baseline, the acceptance length of the final MTP layer increases by 20%.
MethodAcceptance Length
Baseline4.56
+ IndexShare + KV Share5.10
+ Rejection Sampling5.29
+ End-to-end TV Loss5.47 (+20%)
Efficiently Serving 1M Context Length
As GLM-5.2 extends the maximum context length from 200K to 1M tokens, coding workloads are expected to shift substantially toward longer prompts. This shifts the primary inference bottleneck from computation to KV-cache capacity, long-context kernel overhead, and CPU-side overhead. Although the new GLM-5.2 architecture reduces per-token computational FLOPs, it does not proportionally reduce per-token KV-cache size. As a result, supporting longer contexts, higher concurrency, and higher token throughput under limited GPU resources becomes a central challenge for inference engine optimization.
To address this challenge, we optimize the inference engine along three directions. First, building on LayerSplit, we introduce finer-grained memory management and parallelization strategies to increase KV-cache capacity and provide more usable cache space for ultra-long-context requests. Second, we optimize kernels whose cost grows with context length and better coordinate them with the cache transfer pipeline, minimizing the impact of cache transfer on both prefill and decode performance. Third, we optimize CPU-side cache management, request scheduling, and runtime execution paths to reduce bubbles in the GPU execution pipeline and improve end-to-end throughput. As shown in the figure, GLM-5.2 achieves an increasingly larger throughput advantage as context length grows, demonstrating stronger scalability in long-context inference scenarios.
slime for Agentic RL
The agentic RL post-training of GLM-5.2 involves tasks at larger scale, across more domains, and with more complex execution patterns. Heterogeneous data and tasks need to be organized within a unified training process, while long-horizon interactions, tool use, sub-task decomposition, and multi-turn environment feedback all impose higher requirements on rollout and training orchestration. To support this process, slime serves as an integrated infrastructure layer from training to large-scale inference rollout. It supports multiple training and task organization modes, including white-box rollout, black-box rollout, compact trajectory, and sub-agent workflow, enabling the same system to scale to larger and more complex RL and OPD training workloads. In the post-training process of GLM-5.2, we used the slime framework to conduct parallel OPD training, efficiently merging more than ten expert models into the final model. The entire OPD training process took approximately two days, demonstrating high training efficiency.
Agentic RL also places higher demands on system resources and inference infrastructure. slime provides a highly open and flexible interface to inference systems: the training side can connect to inference services in different forms, and flexibly adapt to different parallelism strategies, routing policies, PD disaggregation setups, and deployment patterns. At the same time, the configuration experience, scheduling strategies, and optimization paths accumulated during RL rollout can be reused and further refined in the production serving stage, allowing the training side and the serving side to reinforce each other. This creates a more direct path from post-training to production deployment. Together with flexible training-inference resource organization and KV-cache FP8, slime provides critical infrastructure support for GLM-5.2’s large-scale agentic RL training, further improving system efficiency, rollout throughput, and large-scale inference concurrency.
RL for Long-Horizon Task with Anti-hacking
RL for Long-Horizon Tasks. For GLM-5.2, long-horizon tasks produce substantially longer execution traces, and once a super-long trajectory is split by compaction into multiple sub-traces, different rollouts under the same prompt yield different numbers of trainable traces with highly variable lengths. We therefore move from group-wise optimization to a critic-based PPO formulation that learns from individual rollouts, relying on a critic to estimate token-level advantages rather than group-relative comparisons. This single-rollout formulation fits compaction naturally, as it places no constraint on how many traces a prompt produces or on their relative lengths: we bring compaction into training by including all compacted sub-traces as trainable trajectories, and apply a token-level loss to address their length imbalance.
Anti-Hack in Coding agents. Coding RL is especially vulnerable to reward hacking because the reward is typically a verifiable pass/fail signal. We find that GLM-5.2 shows more potential hacking behavior than GLM-5.1. This makes the verification signal easy to optimize, but fails to actually improve the fundamental capabilities of the model. An agent can read protected evaluation artifacts, copy answer content from references or upstream commits, or directly fetch the target source in GitHub-related tasks. For example, the agent may download solution via curl https://raw.githubusercontent.com/<path-to-file> or even chained leakage like
1. find /workspace -name "*hidden*"
2. cat /workspace/.eval/secret_cases.json
3. python solve.py --case "$(cat /workspace/.eval/secret_cases.json)"
These behaviors inflate rewards and corrupt the training signal, requiring a clear mechanism to separate real task-solving from shortcuts. To address this, we introduce an anti-hack module for both RL training and evaluation. The detection process has two stages: a rule-based filter first catches potential hacks to maximize recall, and then an LLM judge checks the intent of these flagged actions to keep precision high. We use an online strategy that monitors the tool calls at each step. If a hack is detected, the system blocks the call and returns dummy information as the result. Importantly, this online guard allows the model to continue the rollout even after a hacked action is caught. By handling the specific invalid behavior instead of rejecting the entire trajectory, this approach helps prevent the training instability and model collapse that can happen when rollouts are abruptly stopped.
Full Benchmark Table
BenchmarkGLM-5.2
GLM-5.1
Qwen3.7-Max
MiniMax M3
DeepSeek-V4-Pro
Claude Opus 4.8
GPT-5.5
Gemini 3.1 Pro
Reasoning
HLE40.531.041.437.037.749.8*41.4*45.0
HLE
w/ Tools
54.752.353.5-48.257.9*52.2*51.4*
CritPt20.94.613.43.712.920.927.117.7
AIME 202699.295.397.0-94.695.798.398.2
HMMT Nov. 202594.494.095.084.494.496.596.594.8
HMMT Feb. 202692.582.697.184.495.296.796.787.3
IMOAnswerBench91.083.890.0-89.883.5-81.0
GPQA-Diamond91.286.290.093.090.193.693.694.3
Coding
SWE-bench Pro62.158.460.659.055.469.258.654.2
NL2Repo48.942.747.242.135.569.750.733.4
DeepSWE46.218.018.020.08.058.070.010.0
ProgramBench63.750.9--47.871.970.839.5
Terminal Bench 2.1
Terminus-2
81.063.575.065.064.085.084.074.0
Terminal Bench 2.1
Best Reported Harness
82.7
(Claude Code)
69
(Claude Code)
---78.9
(Claude Code)
83.4
(Codex)
70.7
(Gemini CLI)
FrontierSWE
Dominance as of 26/6/16
74.430.5--29.075.172.639.6
PostTrainBench34.320.1---37.228.421.6
SWE-Marathon13.01.0---26.012.04.0
Agentic
MCP-Atlas
Public Set
76.871.876.474.273.677.875.369.2
Tool-Decathlon48.240.7--52.859.955.648.8
*: refers to their scores of full set.
Getting started with GLM-5.2
Use GLM-5.2 with GLM Coding Plan
Try GLM-5.2 in your favorite coding agents—ZCode, Claude Code, OpenCode, and more. https://docs.z.ai/devpack/overview
For GLM Coding Plan subscribers: We already rolled out GLM-5.2 to all Coding Plan users. You can enable GLM-5.2 now by updating the model name to "GLM-5.2" (or GLM-5.2[1m] in Claude Code to enable 1M context length). You can also choose different thinking effort, High or Max, depending on the task. As our most capable model, GLM-5.2 consumes quota at 3× during peak hours and 2× during off-peak hours. As a limited-time promotion through the end of September, off-peak usage is billed at 1×. (Peak hours are 14:00–18:00 UTC+8 (Beijing Time) daily).
Prefer a GUI? We offer ZCode —a desktop agent powered by GLM-5.2, with /goal for long-horizon tasks, SSH remote development, and mobile control. Special offer: use GLM-5.2 through Coding Plan inside ZCode and get 1.5x effective quota until June 30.
Start building now: https://z.ai/subscribe
Chat with GLM-5.2 on Z.ai
GLM-5.2 is now available on Z.ai.
Serve GLM-5.2 Locally
The model weights of GLM-5.2 are publicly available on HuggingFace and ModelScope. For local deployment, GLM-5.2 supports inference frameworks including transformers, vLLM, SGLang, xLLM, ktransformers.
Footnote
- Humanity’s Last Exam (HLE) & other reasoning tasks: We use sampling parameters of temperature=1.0, top_p=0.95 for evaluation. We evaluate with a maximum generation length of 163,840 tokens. By default, we report the text-only subset; results marked with * are from the full set. For AIME, HMMT and IMOAnswerBench, we evaluate each question using the following system prompt: Your response should be in the following format:\nExplanation: {your explanation for your final answer}\nExact Answer: {your succinct, final answer}\nConfidence: {your confidence score between 0% and 100% for your answer}. We use GPT-5.5 (medium) as the judge model. For HLE-with-tools, we use a maximum context length of 300,000 tokens, with no context management strategy.
- SWE-Bench Pro: We run the SWE-Bench Pro suite with OpenHands using a tailored instruction prompt. Settings: temperature=1, top_p=1, max_new_tokens=32k, with a 400K context window.
- NL2Repo: We evaluated NL2Repo with temperature=1.0, top_p=1.0, and max_new_tokens=48k under 400k context. To prevent hacking, we use rule-based and a LLM-based judgement to prevent malicious behaviors (e.g., unauthorized pip or curl operations).
- DeepSWE: We run DeepSWE with the official pier evaluation framework and the mini-swe-agent harness (temperature=1.0, top_p=1.0, timeout=2h, 400K context). Each task is solved in an isolated container with 2 CPUs, 8 GB RAM, and no internet access.
- ProgramBench: We evaluate ProgramBench (200 instances) with Claude-Code 2.1.156 using temperature=1.0, top_p=1.0, max_tokens=64000, max_turns=2000, sample_timeout=6h, reasoning_effort=max, with a 400K context window. Each instance runs in a (4 CPUs, 8 GB RAM) sandbox with internet access disabled.
- Terminal-Bench 2.1 (Terminus 2): We evaluate Terminal-Bench 2.1 with Terminus-2 framework using parser=json, timeout=4h, temperature=1.0, top_p=1.0, max_new_tokens=48k, max_episodes=500, with a 256K context window. Resource limits are capped at 4 CPUs and 8 GB RAM.
- Terminal-Bench 2.1 (Claude Code): We evaluate in Claude Code 2.1.167 with temperature=1.0, top_p=0.95, max_new_tokens=131072. We override max_new_tokens to 128k via a transparent proxy, bypassing the 64k CLI cap to restore the configurability of CLAUDE_CODE_MAX_OUTPUT_TOKENS. We remove wall-clock time limits, while preserving per-task CPU and memory constraints. Scores are averaged over 5 runs.
- MCP-Atlas: All models were evaluated in think mode on the 500-task public subset with a 10-minute timeout per task. We use Gemini-3.0-Pro as the judge model for evaluation.
- Tool-Decathlon: We use the official evaluation service and set max_token to 128K.
- FrontierSWE: The evaluation was conducted by Proximal with 1M context length, max effort level, and 128K maximum output tokens. Dominance score reported as of 2026/06/16.
- PostTrainBench: The evaluation was conducted by PostTrainBench with 1M context length, max effort level, and 128K maximum output tokens.
- SWE-Marathon: The evaluation was conducted by Abundant AI with 1M context length, max effort level, and 128K maximum output tokens.
関連記事
[AINews] 今日特に大きな出来事はありませんでした
Latent Space は、GLM 5.2 が依然として注目されていると指摘しつつ、AIE WF 2026 の通常チケットが月曜日に完売すると発表しました。同サイト購読者向けに限定割引を提供し、参加者には Warp や Datadog などからのスポンサークレジットも付与されます。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
社内データ分析エージェントの構築方法について
GitHub は、大規模なデータ組織が直面する自己完結型のデータアクセスと洞察提供の課題に対し、AI を活用した信頼性の高い解決策として、社内でデータ分析エージェントを構築したことを発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み