社内データ分析エージェントの構築方法について
GitHub は社内データ分析の課題解決のため、Copilot を活用した自律型エージェント「Qubot」を構築し、自然言語でのデータ問い合わせと即座の回答を可能にする実装事例を発表しました。
キーポイント
Qubot の概要と目的
GitHub 社内の「Qubot」という AI エージェントは、Copilot を基盤とし、専門知識がなくても自然言語でデータウェアハウス上の質問を行い、数秒以内に回答を得られるように設計されています。
アーキテクチャと多様なインターフェース
ユーザーインターフェースは Slack、VS Code、Copilot CLI に対応しており、Slack ではスレッドでの対話や PR へのレポート出力が可能で、開発フローにシームレスに統合されています。
階層的な文脈層(Context Layer)の構築
データウェアハウスの「Bronze(生データ)」、「Silver(加工済み)」、「Gold(ビジネス特化)」という異なる段階に応じ、各データタイプに最適化された知識を統合した連合型の文脈層が実装されています。
自己完結型分析の実現とコスト削減
このシステムは既存のダッシュボードやレポートツールの代替ではなく、探索的な分析を支援するものであり、メンテナンスコストゼロでチームが未知のデータセットに迅速に適応することを可能にします。
コンテキスト層の自動管理と評価フレームワーク
チームは標準化されたテンプレートを通じてコンテキストを提供し、エージェントがこれを構造化して保存します。すべての変更はプルリクエスト経由で提出され、回答の精度やレイテンシを測定するオフライン評価フレームワークを経てから本番環境に展開されます。
Kusto と Trino の自動切り替え機能
Qubot は Kusto をデフォルトとして使用し、質問の性質に応じて自動的に Trino に切り替えることで、ユーザーはどちらのエンジンを使用すべきかを意識する必要がありません。
構造化テストケースによる定量的評価
正解が既知のプロンプトと SQL を含むテストケースセットを用いて、自動スクリプトで並列実行を行い、完了率や精度、所要時間などの統計を算出することで構成変更の影響を比較します。
影響分析・編集コメントを表示
影響分析
この事例は、大規模組織におけるデータ分析の民主化と自己完結型の実現において、LLM を活用したエージェントアーキテクチャが実用的な解決策となり得ることを示す重要な証拠です。特に、既存の開発ワークフロー(Slack, VS Code)に AI エージェントを埋め込むことで、専門家のボトルネックを解消し、組織全体のデータリテラシーと意思決定速度を向上させる具体的なロードマップを提供しています。
編集コメント
大規模組織が直面する「データ民主化」の課題に対し、既存の AI ツール(Copilot)を応用した実証済みのアーキテクチャを示しており、他社への展開可能性も高い事例です。
大規模なデータおよび分析組織では、データやインサイトへのアクセスを真にセルフサービス化することによく苦労します。業界はこの問題の解決を試みて数十年間取り組んできましたが、その成果はあまり芳しくありませんでした。しかし現在、AI がそれを可能にする信頼性の高い手段を提供しています。
GitHub のスケールにおいて、数十もの製品チームに対して専用の分析サポートを提供することは困難であり、そのため多くのチームは自らの力でこの問題に取り組まざるを得ません。製品やエンジニアリングチームが意思決定に活用できる貴重な製品テレメトリデータは多く存在しますが、どのデータモデルを使用し、どの粒度で、どのようなフィルターを適用するかを見極め、クエリを作成して結果を検証することは、データアナリストのサポートなしには常に困難でした。
そこで登場したのが Qubot です。これは GitHub Copilot を活用した当社の内部分析エージェントです。Qubot により、Hubber(GitHub の従業員をこう呼んでいます)は、GitHub データウェアハウス内の任意のデータモデルについて自然言語で質問し、数秒以内に回答を得ることができます。
Qubot はレポート作成ツールやダッシュボードの代替品ではありません。むしろ、「この機能において最も高いリテンション率を示すユーザーコホートはどれか?」や「先週この指標を最も大きく改善した製品は何ですか?」といった探索的な質問に答えるために設計されています。Qubot の維持コストはゼロであり、 unfamiliar なデータセットについてもチームが迅速に適応できるよう支援します。
本ブログ記事では、Qubot をどのように構築したか、その変遷、そして私たちが得た教訓について解説します。
Qubot の仕組み
アーキテクチャには3つの主要コンポーネントがあります:ユーザーインターフェース、コンテキストレイヤー、クエリエンジンです。
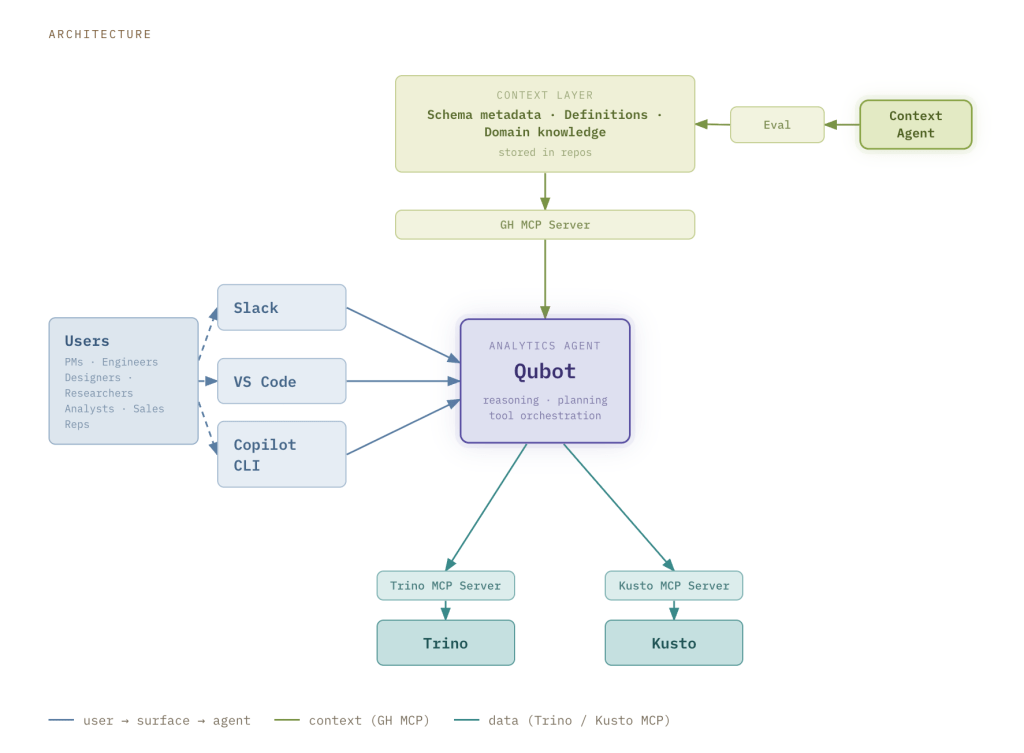
ユーザーインターフェース
Qubot は Slack、VS Code、Copilot CLI を通じてアクセス可能です。Slack でのインターフェースには設定が不要であり、Hubbers の間で最も好まれるコラボレーションツールとなっています。誰かが Qubot の Slack チャンネルに質問を投稿すると、github.com で実行される Copilot Cloud Agent として Qubot インスタンスが起動します。回答は直接 Slack に提供され、ユーザーは結果を他の人と共有できるほか、スレッド内で反復して質問を発展させたり洗練したりすることもできます。すべての結果は、プルリクエスト内のマークダウン形式のレポートとして保存され、ユーザーはこれを参照してクエリの微調整を行ったり、ダッシュボードで使用したりすることができます。
Qubot はまた、ワークフローにより密接に統合された体験を望むユーザー向けに VS Code と Copilot CLI でも利用可能です。Qubot は単一のコマンドでプラグインとしてインストールでき、ユーザーが設定した他のカスタムエージェント、スキル、ツールと同様に、VS Code や Copilot CLI のあらゆるエージェントセッションで使用可能になります。
コンテキストレイヤー
当社のデータウェアハウスには、キュレーションの異なる段階にあるデータが含まれています:生イベント(ブロンズ)、適合済み事実と次元(シルバー)、特定のビジネスユースケースのために設計されたキュレーション済みのデータセット(ゴールド)です。コンテキストレイヤーは連合型で構築されており、データのタイプに合わせた知識が提供されます。
ブロンズデータについては、製品チームから提供されたテレメトリコンテキストがあり、スキーマ情報やメタデータが含まれています。
シルバーデータについては、データおよび分析チームが維持するクエリの例、利用ガイダンス、必須フィルターなどが用意されています。
ゴールドデータについては、各データセットを所有するチームから提供されるビジネスルールや指標定義があります。
また、ETLパイプラインを活用して、追加のシグナルと派生メタデータを体系的にコンテキスト層に付加しています。このコンテキストは、GitHub MCP Server を介してランタイム時に読み込まれ、コンテキスト層から取得されます。
コンテキストエージェント
コンテキスト層には、複数のリポジトリにわたって永続化された新しい知識が絶えず追加されています。GitHub ではドキュメントに主に Markdown を使用しているため、複数の異なるツールとのインターフェースは不要です。
私たちは、コンテキストエージェントを通じて連合型のコンテキスト貢献を簡素化しました。チームは標準化されたテンプレートを利用するか、関連するコンテキストを含むリポジトリを参照することで貢献できます。その後、エージェントはこの情報を取り込み、整理し、Qubot における評価に基づき効果的であることが証明されている構造化形式に変換します。
評価フレームワーク
コンテキスト層またはエージェント構成に対するすべての変更は、リリース前に評価されます。新しい知識でコンテキスト層を拡張したい場合は、プルリクエストを開くことができます。新しいコンテキストは、オフライン評価フレームワークを通じて処理され、回答の精度、適切な回答を見つけるまでのレイテンシ(応答遅延)が測定され、ユーザーに到達する前の回帰(性能低下)が検出されます。
構造化されたテストケース全体で Qubot を評価するためのベンチマークフレームワークには、3 つのコンポーネントがあります:
テストケース:正解、真値 SQL、メタデータ(ドメイン、難易度)が既知のプロンプトから構成される厳選されたデータセット。
自動実行オーケストレーション:GitHub CLI の gh agent-task create コマンドを使用して各テストケースをエージェントタスクとして起動し、複数の並列試行を実行し、完了をポーリングして詳細な JSON 結果を保存するスクリプト。
統計集約:保存された結果を読み取り、各テストケースごとのメトリクス(完了率、精度、期間の平均/最小/最大)を計算するレポート作成スクリプト。
エンドツーエンドの流れは以下の通りです:テストケースの定義 → 各ケースで Qubot を N 回実行 → 結果の収集 → 統計の集約 → 構成の比較。
クエリエンジン
Qubot は、GitHub の分析ワークロードの大部分を支える 2 つのクエリエンジンである Kusto と Trino に、MCP サーバーを介して接続します。Trino の MCP サーバーについては独自の実装を開発しましたが、Kusto に対しては Fabric RTI MCP Server のローカル版を展開しました。Kusto は高速であり、直近のイベントデータに関する探索的な質問に最適です。一方、Trino は複雑な結合処理やより深い歴史的解析を扱います。
ユーザーがどちらを使用すべきかを知ることを強制するのではなく、Qubot はデフォルトで Kusto を使用し、質問の内容が必要とする場合に自動的に Trino に切り替えます。
何が変わり、何を学んだか
Qubot は GitHub で広く採用され、数百人の熱心なユーザーが数千回のクエリを実行しています。データおよび分析に関する Slack チャンネルで Hubbers が質問する数は劇的に減少しました。これは、彼らがより自律的にデータを探索できるようになり、複雑な質問の場合のみ支援を求めるようになったためです。また、これまでデータウェアハウスに手を伸ばすことを躊躇していた Hubbers もも、意思決定に必要なデータにアクセスできるようになりました。Slack、Copilot CLI、VS Code といった複数のインターフェースを提供している理由の一つは、Hubbers が非常に技術的である一方で、参入障壁がなく設定不要なオプションも提供したかったからです。
私たちはすぐに、コンテキスト層が Copilot の推論能力を強化し、専門的な分析エージェントを作成する上で鍵となることを発見しました。実験の結果、構造化され適切にキュレーションされたコンテキストは、Qubot をより正確にするだけでなく、正しい回答を返す速度を 3 倍に高めることがわかりました。これはデータモデリングの手法において、この種のアーティファクトが後回しではなく第一級市民として扱われるべきであることを意味するため、分析エンジニアリング分野に深い影響を与えます。
Qubot は、ハブ・アンド・スポーク型の実行における稀な成功例です。データおよび分析チームからの負担を軽減し、プロダクトチームは自らのサーフェスのテレメトリを所有し、ビジネスチームは自社のゴールドデータの定義を所有するという体制を実現しました。Qubot は、GitHub 全体で活用できる単一のツールに分散した知識を集約する重力のような役割を果たし、各ドメインに限定された複数のツールを作成するのではなく、パートナーチームが Qubot に貢献するためのインセンティブを提供しました。
謝辞
Qubot エンジニアリングチーム:Weijie Tan, Tobias Tschuemperlin, Vamsi Anamaneni
特別感謝:Yaswanth Anantharaju
「内部データ分析エージェントの構築方法」という記事は、The GitHub Blog で最初に公開されました。
原文を表示
Large data and analytics organizations often struggle to make access to data and insights truly self-serve. The industry tried to solve this problem, quite unsuccessfully, for decades, but now AI is giving us a credible way to do just that.
At GitHub scale, providing dedicated analytics support to dozens of product teams is challenging, and therefore many teams are left to solve this problem on their own. Though there is a lot of valuable product telemetry that product and engineering teams can use to make decisions, figuring out which data model, which grain, which filter, and then write the query and validate the result has always been difficult without the support of a data analyst.
Enter Qubot, our internal GitHub Copilot-powered analytics agent. Qubot allows any Hubber (that’s what we call GitHub employees) to ask questions about any data model in GitHub’s data warehouse in plain language and get an answer within seconds.
Qubot is not a reporting tool or a dashboard replacement. Instead, it’s intended for exploratory questions like “Which cohort of users has the highest retention on this feature?” or “What product contributed to move this metric the most last week?” Qubot has zero cost maintenance and helps teams ramp up quickly on datasets they may be unfamiliar with.
In this blog post, we’ll go over how we built Qubot, how it’s changed, and what we learned.
How Qubot works
The architecture has three main components: user interface, context layer, and query engine.
User interface
Qubot is accessible through Slack, VS Code, and the Copilot CLI. The Slack interface doesn’t require any configuration, and it is the preferred collaboration tool of Hubbers. When someone posts a question in the Qubot Slack channel, a Qubot instance is spawned as a Copilot Cloud Agent running on github.com. The answer is provided directly in Slack, allowing the user to share the result with others, but also iterate in the thread to evolve or refine the question. All the results are also stored as a markdown report in a pull request that the user can reference to fine tune the query or use it in a dashboard.
Qubot is also available in VS Code and the Copilot CLI, for users that want an experience more integrated with their workflows. Qubot can be installed with one command as a plugin, and it becomes available in any agent session in VS Code or Copilot CLI alongside any other custom agents, skills, and tools configured by the user.
Context layer
Our data warehouse contains data at different stages of curation: raw events (bronze), conformed facts and dimensions (silver), and curated datasets designed for specific business use cases (gold). The context layer is built in a federated way, with knowledge that is tailored to the type of data.
For bronze data, we have telemetry context contributed by product teams, with schema information and metadata.
For silver data, we have examples of queries, usage guidance, mandatory filters etc, maintained by the data and analytics team.
For gold data, we have business rules and metric definitions, contributed by teams owning those datasets.
We also leverage our ETL pipelines to systematically enrich the context layer with additional signals and derived metadata. The context is loaded at runtime via the GitHub MCP Server, fetching it from the context layer.
Context agent
The context layer is constantly enriched with new knowledge persisted across multiple repositories. At GitHub, we primarily use markdown for documentation, so we don’t need to interface with multiple different tools.
We’ve streamlined federated context contribution through a context agent. Teams can contribute via a standardized template or by referencing a repository containing relevant context. The agent then ingests, organizes, and normalizes this information into a structured format that has proven effective for Qubot based on our evaluations.
Evaluation framework
Every change to the context layer or agent configuration gets evaluated before it ships. When someone wants to enrich the context layer with new knowledge, they can open a pull request. The new context goes through an offline eval framework that measures accuracy of the response, latency in finding the right answer, and catches regressions before they reach users.
The benchmarking framework for evaluating Qubot across structured test cases has three components:
Test cases: A curated dataset of prompts with known correct answers, ground-truth SQL, and metadata (domain, difficulty).
Automated run orchestration: A script that automates launching each test case as an agent task with the GitHub CLI gh agent-task create, runs multiple parallel trials, polls for completion, and saves detailed JSON results.
Stats aggregation: A reporting script that reads the saved results and computes per-test-case metrics: completion rate, accuracy, and duration (avg/min/max).
The end-to-end flow is: define test cases → run Qubot N times per case → collect results → aggregate stats → compare configurations.
Query engine
Qubot connects to both Kusto and Trino, the two query engines that power most of GitHub’s analytics workloads, via a MCP server. We developed a custom implementation of the Trino MCP server, while for Kusto we deployed a local version of the Fabric RTI MCP Server. Kusto is fast and well-suited to exploratory questions over recent event data. Trino handles complex joins and deeper historical analysis.
Rather than forcing users to know which to use, Qubot defaults to Kusto and switches to Trino automatically when the question requires it.
What changed, and what we learned
Qubot has been widely adopted at GitHub, with hundreds of enthusiastic users running thousands of queries. The number of questions that Hubbers ask in the data and analytics Slack channels has reduced dramatically, because now they can explore the data with greater autonomy and reach out only for complicated questions. It also allows Hubbers that never dared to dip into the data warehouse to access the data they need to drive their decision making. That is one of the reasons for offering multiple interfaces like Slack, Copilot CLI, and VS Code; Hubbers are very technical, but we wanted to offer an option with no barrier to entry and zero configuration.
We quickly discovered that the context layer is key to enriching the reasoning capabilities of Copilot and to create an expert analytics agent. In our experiments we found that structured and well curated context not only makes Qubot more accurate, but also three times faster at returning the right answer. This has profound implications on the analytics engineering discipline, because it makes this type of artifact a first class citizen in how data is modeled, rather than an afterthought.
Qubot has been a rare example of successful hub-and-spoke execution. It removes strain from the data and analytics team, as product teams own the telemetry for their surfaces and business teams own the definition of their gold data. Qubot acted as a gravitational force to centralize all this distributed knowledge into a single tool that can benefit all GitHub, providing incentives to partner teams to contribute to Qubot, instead of creating multiple tools limited to their own domains.
Acknowledgements
Qubot engineering team: Weijie Tan, Tobias Tschuemperlin, Vamsi Anamaneni
Special thanks: Yaswanth Anantharaju
The post How we built an internal data analytics agent appeared first on The GitHub Blog.
関連記事
Photoshop と Premiere に AI アシスタントが搭載
Adobe が Creative Cloud の主要アプリに個別の AI アシスタントを公開ベータとして導入し、編集・デザイン業務を支援する機能を展開した。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
Claude Fable 5 と Mythos 5 の能力に関する記事
Anthropic は、Claude Fable 5 が米政府から不正アクセス(ジャイルブレイク)の懸念によりリリース後わずか3日で利用停止を命じられたと報じています。この措置により、多くのユーザーが失った機能への愛着を表明しています。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み