[AINews] フィンチューニングの終焉
OpenAI のファインチューニング API 廃止を契機に、業界が「従来のファインチューニングから、オープンモデルの RLFT や超長文プロンプトへシフトする」パラダイム転換を示唆している。
キーポイント
OpenAI のファインチューニング API 廃止と業界の潮流変化
OpenAI がファインチューニング API を非推奨とし、過去に「o1 パフォーマンスを低価格で」と謳われていた手法が、2026 年の「Side Quest massacre」の一環として淘汰されつつある。
トップティア企業の戦略転換:RLFT とオープンモデルの台頭
Cursor や Cognition などの最先端企業はむしろオープンモデルの RLFT(Reinforcement Learning from Feedback)利用を増加させており、カスタム ASIC や超長文プロンプトへの依存が高まっている。
研究ベンチマークの高度化とアジェンシーシステムの進化
数学や医学分野で難易度の高い新ベンチマーク(Soohak, Medmarks)が導入され、Google DeepMind の AI Co-Mathematician などが科学・数学領域でのアジェンシー能力を劇的に向上させている。
Agentic Systems Break New Benchmarks
AI Co-Mathematician, physics-intern, and ProgramBench demonstrate significant performance jumps in science, math, and coding by utilizing asynchronous, stateful agent architectures.
Efficiency Gains via Specialized Retrieval
LightOn's Agent-ModernColBERT achieves near 10% improvement on BrowseComp-Plus with a tiny 149M parameter retriever, suggesting small models can outperform larger ones in agentic search loops.
Optimization and Formal Methods Integration
New optimizer variants like SOAP-Muon reduce training steps significantly, while Lean4-based superoptimizers are emerging to automatically discover high-performance kernels like FlashAttention2.
大規模 MoE の推論インフラと効率化
NVIDIA GB200 NVL72 が Hopper よりも大規模 MoE 推論において大幅なレイテンシ削減を実現し、Perplexity は Qwen3 235B のサービス基盤として採用。また、RoCEv2 を活用したクラスタリングにより GPU あたりのトークンスループットが最大 7 倍向上する可能性が示された。
影響分析・編集コメントを表示
影響分析
この記事は、AI エンジニアリングの標準的なワークフローが「ファインチューニング依存」から「RLFT やプロンプト設計中心」へと大きく舵を切る転換点であることを示しています。企業にとっては、既存のファインチューニング資産の見直しと、オープンソースモデルを活用した新しい学習手法や、複雑なアジェンシーシステムの構築への投資が急務となるでしょう。
編集コメント
「ファインチューニングの終焉」というセンセーショナルなタイトルだが、実際には手法の淘汰と、より高度で柔軟な RLFT やプロンプト設計への移行を意味しています。現場のエンジニアは、従来の「モデルを微調整する」発想から脱却し、オープンモデルの特性を活かした新しいアプローチを学ぶ必要があります。
本日のオピニオン記事の直接的な原因は、OpenAI がファインチューニング API の廃止を発表したことである。
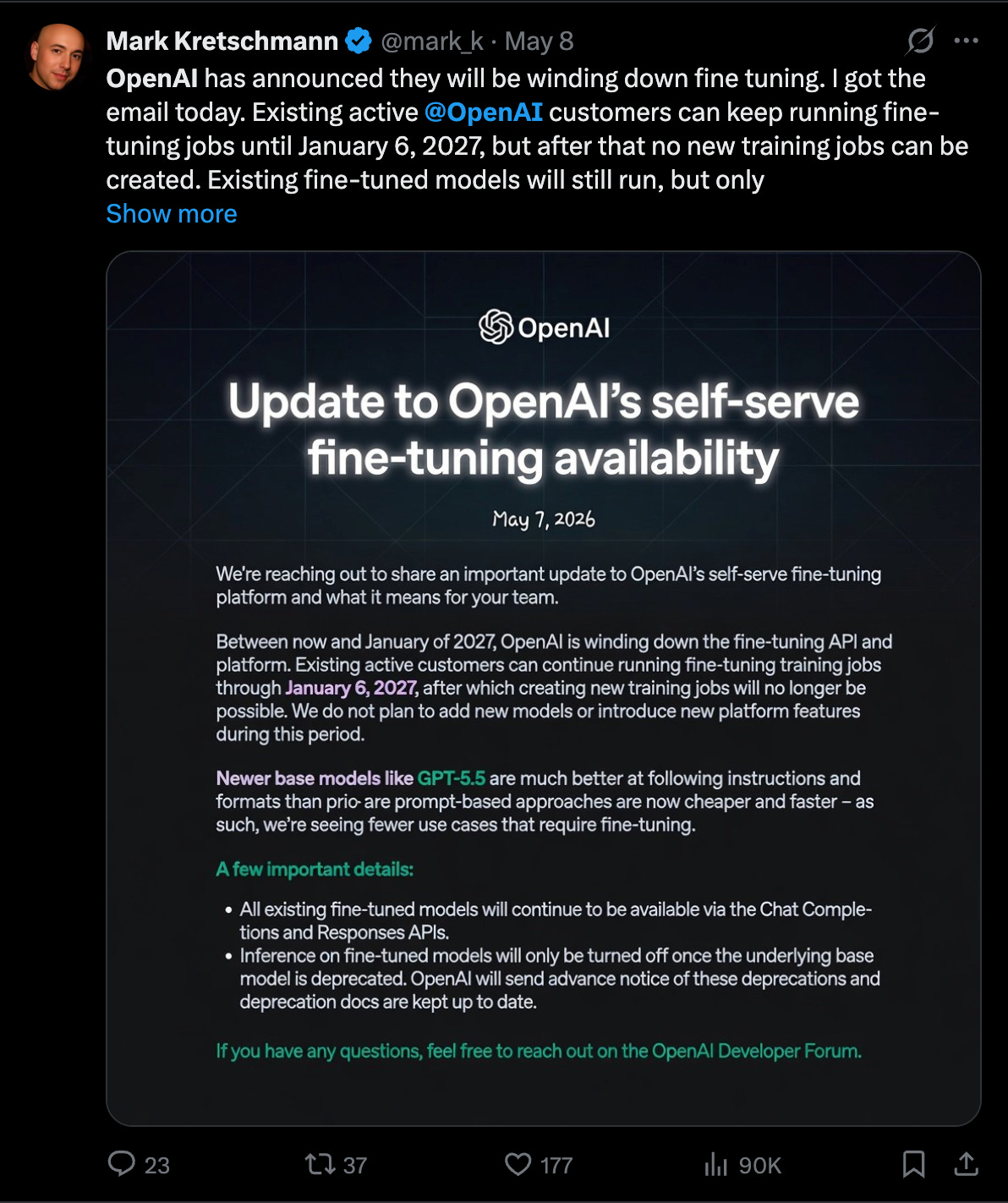
長年にわたり、OpenAI は大手研究機関の中でファインチューニングのサポートにおいて際立っており、多くの講演やコンテンツ、そして AI エンジニアが、「o1 のパフォーマンスを 4o の価格で実現できる」といった変種が可能だと説き、それがツールのキットにおける重要な一部であると主張し続けてきた。
しかし今、潮目は変わり、Anthropic は初めて OpenAI よりも高いバリュエーションで評価される可能性があり、ファインチューニングは「Sora」に続く 2026 年のサイドクエスト虐殺の次の犠牲者となるだろう。極端な GPU の不足を想定すればそれは理にかなっているが、劇的な計算リソースの制約がなくても、AI エンジニアリング業界の過半数(80%)はすでにその方向へ向かっていたはずであり、ジェレミー・ハワードは 2023 年にもすでにポッドキャストでそれを指摘していた。
「終焉」という言葉は、多くの人の場合、そのものの完全な終わりを意味するわけではありません。実際、トップティアの企業である Cursor や Cognition(同社の 250 億ドル規模のラウンドが現在公的な議論の対象となっています)は、オープンモデルの RLFT(Reinforcement Learning from Feedback/Feedback-based Fine-Tuning)およびその利用を減少させるどころか、むしろ増加させています。オープンモデルのファインチューニングは、カスタム ASIC の仮説においても中心的な役割を果たす可能性がありますが、Taalas のモデルや継続的な P/D 分離推論ソリューションが示唆するところによれば、おそらく「非常に長いプロンプト」(Claude の憲法のようなもの)だけで十分なのかもしれません…
2026 年 5 月 11 日〜5 月 12 日の AI ニュース。私たちは 12 のサブレッド、544 のツイートを確認し、Discord はさらに確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のためにお伝えしますが、AINews は現在 Latent Space の一部となっています。メールの頻度を選択的にオン/オフにすることができます!
AI Twitter リキャップ
研究ベンチマーク、ハードな評価、およびエージェント型科学システム
研究レベルの推論ベンチマークはますます困難になっています:Soohak が 64 人の数学者(そのうち 38 人が教員)によってゼロから作成した 439 の研究レベルの数学問題を導入しました。これは標準的なオリンピック形式の数学よりも上位の能力を明確に狙ったものです。医療評価においては、@SophontAI が Medmarks v1.0 をリリースし、オープンな医療ベンチマークスイートを 20 から 30 のベンチマークへ、46 から 61 のモデルへと拡大しました。また、古い評価指標が飽和しているという認識が高まっています:@polynoamial は、均一に高得点となるベンチマークは廃止し、低得点でフロンティアを挑戦するテストに置き換えるべきだと主張しています。
エージェント型システムは、科学および数学のベンチマークの最前線において動き始めています。Google DeepMind の AI Co-Mathematician は数学者向けの非同期かつ状態を保持する研究用ワークベンチとして記述されており、アイデア創出、文献発見、計算分析、定理検証、形式化された出力をサポートしつつ、FrontierMath Tier 4 で約 48% に達したと報じられています。理論物理学の分野では、physics-intern が Gemini 3.1 Pro の CritPt でのスコアを 17.7% から 31.4% に引き上げるために、専門化されたエージェントへの分解を行いました。コーディングやプログラム合成においては、ProgramBench の最初のタスクが GPT-5.5 high/xhigh によって解決されたと報じられており、xhigh は Opus 4.7 xhigh をあらゆる指標で上回っています。
検索および検索ベンチマークは、小型の専門化されたモデルに対して報酬を与えています。LightOn の Agent-ModernColBERT は、検索器を 1.49 億パラメータに保ちつつ、BrowseComp-Plus において Reason-ModernColBERT にさらに約 10% を上乗せし、生成器と組み合わせることではるかに大規模なモデルベースのシステムに匹敵あるいは凌駕するとの主張をしています。@xuzihuan4 による関連する議論では、エージェントが自身のクエリを反復的に精緻化できる場合、エージェント型検索ループにおいて語彙検索だけで十分ではないかという問いが投げかけられています。
トレーニング、最適化、およびスケーリング則の技術
オプティマイザの改良は、トレーニングコストの圧縮と小規模実験の改善を続けています:SOAP/Muon 型更新の高速バリアントに焦点を当てた複数のツイートがありました。@torchcompiled は、SOAP ベース更新に対して接線ステップと Stiefel 多様体への再射影(retraction)を適用し、安定性のためのドリフトチェックや QR 分解フォールバックに関するフォローアップ議論を行いました。Modded-NanoGPT コミュニティでは、SOAP-Muon が 3150 ステップ(従来比 -60)という新記録を樹立しました。また、NorMuonH に対する早期の MuLoCo 型外側 Nesterov SGD ラップも結果を改善し、両方とも p 値報告によって裏付けられています。
形式手法とスーパー最適化が、機械学習システムの研究と融合し始めています:@leloykun は、Lean4 から TileLang のテンソルプログラムへの変換を行うスーパーオプティマイザを紹介しました。これにより FlashAttention2、FlashNorm、split-k 行列乗算などのカーネルを自動的に発見でき、A100 上で幾何平均で約 1.8 倍の高速化を実現したと報告しています。同フレームワークは、カーネル、オプティマイザ、ハイパーパラメータ転移ルール、スケーリング則を同時に探索する基盤としても位置づけられています。
スケーリング則とトレーニング指標が再検討されています:@che_shr_cat は、古典的な「パラメータあたり 20 トークン」という枠組みはトークナイザーに依存しており、スケーリングはトークン数ではなくバイト数で測定すべきだと主張しています。一方、@JJitsev は、記述的なスケーリング則が予測のためだけでなく、異なるスケール間での学習手順を比較するための体系的な基盤としても価値があると強調しました。
トレーニング時のみの効率化トリックはより興味深いものになりつつあります:Nous の Lighthouse Attention は、バニラ・アテンションのサブ二次関数トレーニングラッパーとして注目されており、回復フェーズ後にトレーニング終了間際に削除可能で、標準的なデプロイ時推論を維持しつつ、長文コンテキスト事前学習のコストを削減します。同様の精神に基づき、Prime Intellect の Renderers は、RL トレーナーとエージェント環境間のトークン/メッセージのインピーダンスミスマッチに対処し、人気のあるオープンモデルでスループットが 3 倍以上になると主張しています。
推論システム、サービングスタック、およびランタイムインフラストラクチャ
Blackwell ラックは、大規模 MoE(Mixture of Experts)のサービングにおける参照プラットフォームとして台頭しています:Perplexity は NVIDIA GB200 NVL72 システム上でトレーニング済み Qwen3 235B のサービングに関する詳細を公開し、GB200 が Hopper に比べて大規模 MoE にとって主要な推論ステップアップであると主張しました。そのベンチマークでは、NVLs のオールリデュースレイテンシが H200 の 586.1µs から GB200 で 313.3µs に低下し、EP=4 の MoE プレフィルコンバインが 730.1µs から 438.5µs に低下し、高トークンレートでのデコードスループットも向上していると示されています。@AravSrinivas はこれを、大規模 MoE をサービングするためのプレフィル/デコードのディスアグリゲーションを本質的に変化させるものとして位置づけました。
推論オーケストレーションはますます専門化しており、「単なる Kubernetes」ではなくなっています。Modal は、推論には専用のスタックが必要だと主張し、計算管理、クラウドネイティブキャッシング、CRIU、GPU チェックポイントに関する研究を根拠に挙げています。このポジション付けは、Perceptron によって即座に実世界で支持されました。同社は、ネイティブ動画、構造化出力、ハイブリッド推論が特殊なコールドスタートとスケーリング要件を生み出すため、すべての Mk1 推論実行を Modal で実行していると述べています。
オープンソース(OSS)の推論経済性は急速に改善し続けています。SemiAnalysis の報告によると、RoCEv2 CX-7 を介して複数の B200 8-GPU マシンをクラスタリングし、PD 分離(PD disaggregation)を行うことで、1 GPU あたりのトークンスループットが最大 7 倍向上し、結果としてトークンあたりのコストも同程度に削減できると示唆されています。ベクトルデータベース側では、Qdrant 1.18 に TurboQuant が追加され、メモリ使用量を半分にしつつスカラー量子化に近い再現率を達成すると主張しています。これに加え、メモリの監視機能や名前付きベクトルのライフサイクル操作も提供されています。
エージェントランタイムは、バージョン管理システムのような基盤へと進化しています。注目すべきシステムアイデアの一つが、@ai_satoru_chan によって要約された Stanford の Shepherd です。これは、エージェントの実行を Git に例え、第一級タスク、効果、スコープ、トレース、完全な再生実行、ブランチ作成、ロールバック、そして Lean による形式的保証を提供するものです。報告されている結果には、CooperBench におけるライブ監視の向上(28.8% から 54.7%)、より高速な反事実的最適化、およびツリー RL の展開が含まれます。
製品とモデルのリリース:マルチモーダル、動画、検索、埋め込み
Perceptron Mk1 は、一連のモデルリリースの中で最も実質的な新登場でした:@perceptroninc が Perceptron Mk1 を、先端的な動画および具現化推論用のモデルとして発表しました。ネイティブの動画サポートは最大 2 FPS で、時間的グラウンディング(temporal grounding)、マルチモーダル・インコンテキスト学習、構造化された空間出力を備えています。OpenRouter の要約によると、32k のマルチモーダル・コンテキストと、ポイント、ボックス、ポリゴン、クリップといった一流の出力が特徴です。このリリースは汎用的な VLM(Vision-Language Model)というよりは、物理世界推論スタックとして位置づけられています。
Google と Meta はともに、単体のモデル仕様ではなく、マルチモーダル・インタラクション層を強化しました:Google DeepMind の AI 搭載マウスポインターデモでは、カーソルが Gemini に紐付いた文脈指向のポインティング・インターフェースとして再定義され、ユーザーは画面上のコンテンツを指差して簡略化された指示を発話できるようになります。並行して、Meta は Muse Spark を基盤とした Meta AI の音声会話機能を発表し、中断機能、言語切り替え、画像生成、ライブカメラグラウンディングによるインタラクションを追加しました。
埋め込みモデルおよび検索モデルの更新も注目されました:Jina はテキスト、画像、オーディオ、動画に対応する汎用埋め込みモデル「jina-embeddings-v5-omni」を、1.57B 版と 0.95B 版でリリースしました。両バージョンとも Matryoshka 切り捨て(Matryoshka truncation)をサポートし、既存の v5-text インデックスとの後方互換性を維持しています。また、Meta は静かに「Sapiens2」をリリースしました。これはヒューマンセントリックな高解像度 ViT(Vision Transformer)ファミリーで、0.1B から 5B パラメータまでをカバーし、ポーズ推定、セグメンテーション、法線ベクトル算出、ポイントマップ生成に対応しています。
拡散モデルと画像処理ツールは進化を続けています:Hugging Face の Diffusers 0.38.0 では、Ace-Step 1.5、LongCat-AudioDiT、Ernie-Image を含む新しいパイプラインが追加され、Flash Attention 4(フラッシュアテンション 4)、FlashPack ローディング、コンテキスト並列化のための Ring Anything へのサポートも実装されました。その他の研究リリースには、連続空間におけるテキスト拡散モデルである ELF: Embedded Language Flows(埋め込み言語フロー)や、ピクセル単位で 3D 生成を行う Tencent の Pixal3D が含まれています。
エージェント、ツール、開発者ワークフロー
エージェント製品はデモから運用プラットフォームへと移行しています:OpenAI は Symphony を発表し、これはすべてのオープンタスクに実行中の Codex エージェントが割り当てられるシステムであり、同時に Codex によるフル takeover(完全乗っ取り)を伴わずにアプリ間を横断して動作するコンピュータ操作機能も強調しました。LangChain は再オープンソース化した改修版 Chat LangChain アプリを発表し、これは週に約 2 トリオントークンを処理する生産環境向けの Q&A エージェントであると説明しています。
長期実行型エージェントの状態管理は、システム上の主要な課題となっています:LangGraph の新しい DeltaChannel スナップショットは、スケーラブルで永続的な実行のために完全状態のチェックポイント化を置き換えることを目指しており、LangChain は同様のメカニズムが deepagents v0.6 におけるメッセージ履歴やファイルストレージを支えていると述べています。このより広範なパターンは、Google の Gemini Interactions API ガイドにも見られ、暗号化された思考署名により、状態あり・状態なしの両モードでターン間の推論コンテキストが保持され、開発者が手動で署名注入を管理する必要がないようになっています。
合成データと RL(強化学習)環境の生成が実用化されつつあります:@Vtrivedy10 は、有用な実践者の視点として、モデル重みからの標的型合成データ抽出はスケーラブルに困難であり、特に長文シーケンスなどの未表現分布においてはなおさらであること、そして効果的なパイプラインにはプログラムによるテスト、検証器、判定者、およびアジェンティックな長期ホライズンの枠組みが必要であることを指摘しました。インフラストラクチャの側では、Tau2-Infinity は、DAG(有向非巡回グラフ)ウォークや失敗仮説からの世界生成を通じて、RL 後期トレーニング用のハードなツール使用タスクを自律的にマイニングすることを形式化しています。
エンゲージメントに基づく主要ツイート(技術的関連性でフィルタリング):
OS レベルの知能層としての Gemini:Google の Gemini Intelligence、Googlebook、および AI ポインタデモは、チャットウィンドウからオペレーティングシステムへと移行するアジェンティックな UX を示唆しています。
Isomorphic Labs の資金調達:@demishassabis は、AI 駆動型創薬のための新たな 21 億ドルの資金調達が発表されました。これは、適用 AI プラットフォームに直接結びついた本データセットにおける最大の資本コミットメントの一つです。
音声から音声へのベンチマーク:Artificial Analysis の τ-Voice ベンチマークでは、最良の S2S(Speech-to-Speech)モデルでさえ、現実的なカスタマーサービスシナリオの約半分しか解決できないことが判明しました。その中で、Grok Voice Think Fast 1.0 が 52.1% で首位に立っています。
Claude Opus 4.7 のファストモード:Anthropic のファストモードリリースは API および Claude Code に到達し、Cursor は 6 倍のコストで 2.5 倍の速度向上を報告しています。これはレイテンシと価格のフロンティアにおける具体的な新たな指標です。
セキュリティ、サプライチェーン、および安全なコーディング
最も緊急性の高い運用上の出来事は、Mini Shai-Hulud サプライチェーン攻撃でした。@IntCyberDigest は、このキャンペーンが TanStack だけでなく npm や PyPI にまたがり、OpenSearch、Mistral AI、Guardrails AI、UiPath などへ拡大し、特に AI 開発者向けツールを標的としていると報じました。注目に値する技術的な詳細は持続性です。同攻撃は Claude Code (.claude/settings.json) や VS Code (.vscode/tasks.json) にフックを仕掛け、パッケージの削除後であっても将来のツールイベントで侵害が再実行されるように仕組まれているとされています。Guardrails AI は後に、自社の 0.10.1 パッケージが侵害され、約 2 時間以内に隔離されたことを確認しました。
即座に実行可能な緩和策が提示されました。@ramimacisabird は、minimumReleaseAge の設定に加え、チームは blockExoticSubdeps を有効化して、リモート GitHub リファレンスが依存関係グラフに紛れ込むのを防ぐべきだと指摘しました。@elithrar は、GitHub の pull_request_target が、フォークベースの PR 自動化における最も危険な CI/CD の罠の一つであるとし、その注意を再確認させました。またワークステーションレベルでは、@andersonbcdefg が、機密情報を至る所に存在するローカルの .env ファイルから、適切なシークレットマネージャへ移動させることを推奨しました。
より安全なコード生成は独自の研究分野となりつつあります:スタンフォード大学と連携した SecureForge の取り組みは、プロンプト最適化を通じて LLM 生成コードの脆弱性発見・防止を目的としており、対応する論文リストではこれをコード生成とセキュリティ評価をつなぐ架け橋として位置付けています。より広い視点での要点は、コーディングエージェントがすでに十分に強力になったため、サプライチェーンの強化や安全な生成の評価は、脇道の問題ではなく中核的なインフラとして扱う必要があるという点です。
AI Reddit レビュー
/r/LocalLlama + /r/localLLM レビュー
- Qwen 3.6 MTP と長文コンテキストのローカル評価
Unsloth における MTP(アクティビティ数:727):画像は Hugging Face の活動スクリーンショットで、Unsloth AI が MTP を保持した GGUF ビルドを公開・更新している様子を示しています。具体的には unsloth/Qwen3.6-27B-GGUF-MTP および unsloth/Qwen3.6-35B-A3B-GGUF-MTP です。技術的な意義は、これらの GGUF が MTP(Multi-Token Prediction)/次トークン予測の補助層を保持している点ですが、ユーザー報告によると、デフォルトの llama.cpp のサポートに頼るのではなく、特定の llama.cpp MTP プルリクエストをチェックアウトしてビルドする必要があるとされています。あるコメントではランタイムまたはモデル読み込みのアサーションエラーが発生し、「GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0")」というメッセージが表示され、これらの MTP GGUF に対するツールやメタデータのサポートがまだ不安定であることを示唆しています。コメント投稿者の多くは、アップストリーム側の推論サポートを待っている状態であり、ある人は llama.cpp や vLLM の GitHub リポジトリを絶えずリフレッシュすることについて冗談めかして述べています。また、llama.cpp で MTP が「そのまま」サポートされているかどうかについても不透明さがあり、本投稿ではまだ対応していないと示唆されています。
新しい 27B GGUF モデルをコンパイル/実行しているユーザーから、qwen35_mtp.cpp でハードアサーションエラーが発生したとの報告がありました。具体的には「GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0") failed」というエラーです。これは、現在の実装において Qwen3.5 MTP の実行に必須である nextn_predict_layers が、読み込まれている GGUF モデルのメタデータに含まれていないか、あるいは公開されていないことを示唆しています。
いくつかのコメントでは、llama.cpp や vLLM においてネイティブな MTP(Multi-Token Prediction)[多トークン予測] サポートが実装されたかが追跡されており、あるユーザーは「llama.cpp は今や MTP をそのままサポートしているのか」と明確に質問しています。このスレッドからは、バックエンド間でのサポート状況はまだ流動的であり、GGUF 形式の MTP モデルとの互換性についてユーザーが上位リポジトリを注視していることが伺えます。
技術的な教訓として、ローカル推論における GGUF の MTP サポートは重要視されており、特に前述の 35B A3B モデルのような Qwen スタイルの変種においてその重要性が高まっています。あるコメントでは、期待されるコンテキスト長の向上という点から、35B A3B バリアントが特に関心を集めていると指摘されています。
Qwen 3.6 35B A3B の hype は本物です!!!(アクティビティ:713): あるユーザーが、ゲート付きデルタネットやハイブリッド Mamba2、スライディングウィンドウアテンションなどの長文脈メカニズムを通じて、学術論文とそれに付随する研究コードを各モデルに読み込ませるというニッチな「論文からコードへの理解」タスクにおいて、Qwen 3.6 35B A3B、Qwen 3.6 27B、Gemma 4 26B A4B、Nemotron 3 Nano をベンチマークしました。詳細な調査結果では、これら 4 つの小型/ローカル向けオープンウェイトモデルが、Devstral Small 2 などの以前の小型モデルベースラインを大幅に上回っており、Qwen 3.6 35B A3B が最も優れていると評価されました。一方、Devstral Small 2 は 32GB の VRAM/RAM では長文脈ワークロードに対応できませんでした。コメント欄では実用的なトレードオフが指摘されています:Qwen 35B は長文脈処理やリファクタリングに好まれますが、思考モードでは冗長になりやすく処理が遅い傾向があります。一方、Gemma 26B はコード修正やチャットにはより高速です。q4(4bit量子化)の場合、あるユーザーによると Qwen 35B は約 20GB、Gemma 26B は約 15GB のメモリを必要とし、両モデルを同時にロード可能であることが報告されています。また別のコメントでは、推論設定の文書化が不足しているため再現性が限られるとして、この評価手法への批判も寄せられています。
複数のユーザーが Gemma 26B と Qwen 35B を用いたローカルワークフローを比較し、両モデルとも q4 量子化であれば約 20GB の Qwen 35B と約 15GB の Gemma 26B として同時に常駐可能であると指摘しています。あるユーザーは、素早いコード修正やチャットには Gemma 26B の思考モードを、より長い文脈を要するリファクタリングには Qwen 35B の思考モードを使用していますが、Qwen 35B は最終出力に至るまでの推論の冗長性が高いためレイテンシが大きいと報告しています。
コーディングに特化したレポートでは、より強力なモデルやコーディングエージェントによって初期プロジェクト設定をブートストラップし、その後継続作業のために Qwen に切り替えることで、Qwen 27B が大規模プロジェクト(100k 行以上のコード)を効果的に処理できると主張されています。ユーザーは、自身のユースケースにおいては Qwen 27B と DeepSeek V4 の間に実用的な違いはほとんど見られなかったと報告していますが、Qwen は時折ループ状態に陥り、手動での中断や継続プロンプトが必要になることがありました。
あるコメントでは、Qwen 27B/35B のパフォーマンスが推論設定、特に温度(temperature)やサンプリングパラメータに敏感であり、モデル重みまたは KV キャッシュのいずれにおいても過度に積極的な量子化を避けるべきであると強調されました。また別のユーザーは、元の主張の詳細(量子化レベル、サンプリャ設定、コンテキスト長、バックエンド、ハードウェアなど)がなければ評価が困難であるため、欠落している実行設定を求めています。
- メモリ階層型および電力効率に優れたローカル推論
Intel Optane Persistent Memory を使用したコンピュータ構築 - 1 兆パラメータモデルを 4 トークン/秒以上で実行可能(アクティビティ:964): この画像は、Intel Optane DC Persistent Memory DIMM を採用した高メモリ構成の Xeon ワークステーション/サーバーの内部を示しており、llama.cpp のハイブリッド GPU/CPU 推論により、Kimi K2.5 という約 1T パラメータの MoE モデルをローカル環境で約 4 トークン/s で実行するという投稿の主張と一致しています。技術的な核心は、768GB の Optane PMem をメモリモードで使用している点です。このモードでは Optane がシステム RAM として認識され、192GB の DDR4 ECC DRAM がキャッシュとして機能します。これにより、モデルのスプースなエキスパート重みを PMem に配置しつつ、アテンション/密結合/共有エキスパート/ルーティングテンソルを RTX 3060 12GB(override-tensor または ngl auto/cmoe を使用)に収容することが可能になります。画像のコメント欄では、よりコア数の多い Cascade Lake Xeon(例:ES 8260/QQ89)を使用すればスループットが向上すると指摘され、Optane のストレージモードに mmap を併用した場合がメモリモードよりも優れているかどうかについて議論が行われました。また、他のコメントからはこの構築は印象的であるものの、対話型利用において 4 トークン/秒という速度が実用的に許容できるものか疑問視する声もありました。
詳細なハードウェアに関する注記では、性能向上にはよりコア数の多い Cascade Lake Xeon(例:QQ89 ES または Xeon Gold 8260 クラスの 24 コア)を使用することが現在の Xeon Gold 6246(12 コア)よりも有効であると示唆されています。また、コメント投稿者は Optane PMem のストレージモード+mmap とメモリモードをベンチマークするよう提案しており、メモリモードでは DRAM が透明なキャッシュとして機能し、CPU 実行前にページが DRAM にスワップバックされる必要があるため、通常の RAM レイテンシとは等価ではないと指摘しています。
あるコメント投稿者が、Optane PMem プラットフォームの互換性について簡潔な内訳を提供しています。LGA3647 Skylake/Cascade Lake では 1 世代目の Optane NMA が 2666 MT/s で動作し、一方 LGA4189 では 2 世代目の NMB を使用し、Cooper Lake では 2666、Ice Lake では 3200 で動作します。また、Cascade Lake において Optane と DRAM を混在させると、影響を受けるチャネルが 2666 にダウンクロックされる可能性があり、この時代の多くの Xeons は、高メモリ SKU または後続のプラットフォームを使用しない限り、DRAM と Optane の合計で 1 TB というメモリの上限がある点にも言及しています。
技術的な注意点が指摘されています。すなわち、トリリオンパラメータモデルでの生成速度が約 4 トークン/秒であれば一部の用途では許容可能であっても、この種のメモリ階層におけるプロンプト処理(prefill)の速度はさらに大幅に低下する可能性が高いというものです。別のコメントでは、中古市場で構築した場合の総コストを約 2060 ドル〜2500 ドルと見積もっており、これには Xeon Gold 6246、TYAN S5630GMRE-CGN、RTX 3060 12GB、192 GB DDR4 ECC RDIMM、および 768 GB Intel Optane DCPMM が含まれています。
電力の無駄遣いをやめよう(アクティビティ:905): あるユーザーが llam
原文を表示
The proximal cause of today’s op-ed is OpenAI’s deprecation of their finetuning APIs.
For years, OpenAI stood out among the big labs for their finetuning support, and many many many talks and content pieces and AI engineers promoted how you can get some variant of “get o1 performance at 4o prices” and insisting that it was an important part of the toolkit.
Now the tide is out, Anthropic will probably raise at a higher valuation than OpenAI for the first time ever, and Finetuning is the next casualty of the 2026 Side Quest massacre (after Sora). If you assume an extreme GPU crunch, that makes sense, but even without dramatic compute constraints, the modal 80% of the AI Engineering industry was probably trending there anyway, with Jeremy Howard calling it out on the pod as early as 2023.
The “End” of a thing for most people does NOT mean the “End” of a thing period - and in fact the top tier, like Cursor and Cognition (whose $25B round is now public discussion) have both INCREASED open model RLFT and usage, rather than decreased. Open Model finetunes may also be central to the Custom ASIC Thesis, but if Taalas’ model and continued P/D Disaggregation inference solutions are any indication, then maybe Just Very Long Prompts (like Claude’s Constitution) are all you need…
AI News for 5/11/2026-5/12/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Research Benchmarks, Hard Evals, and Agentic Science Systems
Research-level reasoning benchmarks keep getting harder: Soohak introduces 439 research-level math problems authored from scratch by 64 mathematicians (including 38 faculty), explicitly targeting capabilities above standard olympiad-style math. In medical evaluation, @SophontAI released Medmarks v1.0, expanding its open medical benchmark suite from 20→30 benchmarks and 46→61 models. There’s also growing sentiment that old evals are saturating: @polynoamial argues benchmarks with uniformly high scores should be retired in favor of lower-scoring, frontier-challenging tests.
Agentic systems are starting to move benchmark frontiers in science and math: Google DeepMind’s AI Co-Mathematician is described as an asynchronous, stateful research workbench for mathematicians, reportedly reaching 48% on FrontierMath Tier 4 while supporting ideation, literature discovery, computational analysis, theorem verification, and formal outputs. In theoretical physics, physics-intern boosts Gemini 3.1 Pro from 17.7% to 31.4% on CritPt via decomposition into specialized agents. On coding/program synthesis, ProgramBench’s first task was reportedly solved by GPT-5.5 high/xhigh, with xhigh outperforming Opus 4.7 xhigh across metrics.
Retrieval and search benchmarks are rewarding small, specialized models: LightOn’s Agent-ModernColBERT stacks another ~10% over Reason-ModernColBERT on BrowseComp-Plus while keeping the retriever at 149M parameters, with claims of matching or exceeding much larger model-based systems when paired with a generator. Related discussion from @xuzihuan4 asks whether lexical retrieval may suffice in agentic search loops when agents can iteratively refine their own queries.
Training, Optimization, and Scaling-Law Techniques
Optimizer work continues to compress training cost and improve small-scale experimentation: Several tweets centered on fast variants of SOAP/Muon-style updates. @torchcompiled applied tangent-step + Stiefel manifold retraction to SOAP basis updates, with follow-up discussion on drift checks and QR fallback for stability. In the Modded-NanoGPT community, SOAP-Muon set a new record at 3150 steps (-60), while an earlier MuLoCo-style outer Nesterov SGD wrap on NorMuonH also improved results, both backed by p-value reporting.
Formal methods and superoptimization are beginning to merge with ML systems work: @leloykun described a Lean4-to-TileLang tensor program superoptimizer that can automatically discover kernels such as FlashAttention2, FlashNorm, and split-k matmul, reporting roughly 1.8× geomean speedup on A100s. The same framework is positioned to jointly search over kernels, optimizers, hyperparameter transfer rules, and scaling laws.
Scaling laws and training metrics are being re-examined: @che_shr_cat argues the classic “20 tokens per parameter” framing is tokenizer-dependent and that scaling should be measured in bytes, not tokens. Separately, @JJitsev emphasized that prescriptive scaling laws are valuable not just for prediction, but as a systematic basis for comparing learning procedures across scales.
Training-time-only efficiency tricks are getting more interesting: Lighthouse Attention from Nous is highlighted as a subquadratic training wrapper around vanilla attention that can be removed near the end of training after a recovery phase, preserving standard deployment-time inference while reducing long-context pretraining cost. In a similar spirit, Renderers from Prime Intellect addresses the token/message impedance mismatch between RL trainers and agent environments, claiming >3× throughput on popular open models.
Inference Systems, Serving Stacks, and Runtime Infrastructure
Blackwell racks are emerging as the reference platform for large-MoE serving: Perplexity published details on serving post-trained Qwen3 235B on NVIDIA GB200 NVL72 systems, arguing GB200 is a major inference step up over Hopper for large MoEs. Their benchmarks cite NVLS all-reduce latency dropping from 586.1µs on H200 to 313.3µs on GB200, and MoE prefill combine at EP=4 dropping from 730.1µs to 438.5µs, with better decode throughput at high token rates. @AravSrinivas framed this as materially changing prefill/decode disaggregation for serving large MoEs.
Inference orchestration is increasingly specialized, not “just Kubernetes”: Modal argues inference needs a dedicated stack, citing work on compute management, cloud-native caching, CRIU, and GPU checkpointing. That positioning got an immediate real-world endorsement from Perceptron, which said all Mk1 inference runs on Modal because native video, structured outputs, and hybrid reasoning create unusual cold-start and scaling requirements.
OSS inference economics continue to improve fast: SemiAnalysis reported that clustering multiple B200 8-GPU machines over RoCEv2 CX-7 with PD disaggregation can lift per-GPU token throughput by up to 7×, implying comparable cost-per-token reductions. On the vector DB side, Qdrant 1.18 added TurboQuant, claiming recall near scalar quantization with 2× less memory, alongside memory monitoring and named-vector lifecycle operations.
Agent runtimes are becoming version-control-like substrates: A standout systems idea was Stanford’s Shepherd, summarized by @ai_satoru_chan, which treats agent execution more like Git: first-class tasks, effects, scopes, and traces; exact replay; branching; rollback; and formal guarantees in Lean. Claimed results include live-supervision gains on CooperBench from 28.8%→54.7%, plus faster counterfactual optimization and tree-RL rollouts.
Product and Model Releases: Multimodal, Video, Retrieval, and Embeddings
Perceptron Mk1 was the most substantive new model release in the set: @perceptroninc launched Perceptron Mk1 as a model for frontier video and embodied reasoning, with native video support at up to 2 FPS, temporal grounding, multimodal in-context learning, and structured spatial outputs. OpenRouter’s summary notes a 32k multimodal context and first-class outputs like points, boxes, polygons, and clips. The release is framed less as a generic VLM and more as a physical-world reasoning stack.
Google and Meta both pushed multimodal interaction layers rather than standalone model specs: Google DeepMind’s AI-enabled mouse pointer demos reimagine the cursor as a contextual pointing interface tied to Gemini, allowing users to point at on-screen content and speak shorthand instructions. In parallel, Meta announced Meta AI voice conversations powered by Muse Spark, adding interruption, language switching, image generation, and live camera-grounded interaction.
Embedding and retrieval model updates were notable: Jina released jina-embeddings-v5-omni, a universal embedding model for text, images, audio, and video, in 1.57B and 0.95B variants, both with Matryoshka truncation and backward compatibility with existing v5-text indexes. Meta quietly released Sapiens2, a family of human-centric high-resolution ViTs spanning 0.1B→5B params for pose estimation, segmentation, normals, and pointmaps.
Diffusion and image tooling kept moving: Hugging Face’s Diffusers 0.38.0 added new pipelines including Ace-Step 1.5, LongCat-AudioDiT, and Ernie-Image, plus support for Flash Attention 4, FlashPack loading, and Ring Anything for context parallelism. Other research releases included ELF: Embedded Language Flows, a continuous-space text diffusion model, and Tencent’s Pixal3D for pixel-aligned 3D generation.
Agents, Tooling, and Developer Workflow
Agent products are shifting from demos to operational platforms: OpenAI teased Symphony as a system where every open task gets a running Codex agent, and separately highlighted computer use for Codex to work across apps without full takeover. LangChain re-open-sourced its revamped Chat LangChain app, describing it as a production Q&A agent handling nearly 2T tokens/week.
Long-running-agent state management is becoming a first-class systems problem: LangGraph’s new DeltaChannel snapshots aim to replace full-state checkpointing for scalable durable execution; LangChain says the same mechanism now powers message histories and file storage in deepagents v0.6. The broader pattern also shows up in Google’s Gemini Interactions API guide, where encrypted thought signatures preserve reasoning context across turns in both stateful and stateless modes without forcing developers to manage signature injection manually.
Synthetic data and RL environment generation are being operationalized: @Vtrivedy10 offered a useful practitioner perspective: targeted synthetic data extraction from model weights is hard at scale, especially for underrepresented distributions like long sequences, and effective pipelines need programmatic tests, verifiers, judges, and agentic long-horizon framing. On the infrastructure side, Tau2-Infinity formalizes autonomous mining of hard tool-use tasks for RL post-training via DAG walks or world-generation from failure hypotheses.
Top tweets (by engagement, filtered for technical relevance):
Gemini as an OS-level intelligence layer: Google’s Gemini Intelligence, Googlebook, and AI pointer demos collectively point to agentic UX moving from chat windows into the operating system.
Isomorphic Labs funding: @demishassabis announced $2.1B in new funding for AI-driven drug discovery, one of the largest capital commitments in this dataset tied directly to an applied AI platform.
Speech-to-speech benchmarking: Artificial Analysis’ τ-Voice benchmark found even the best S2S models solve only about half of realistic customer service scenarios, with Grok Voice Think Fast 1.0 leading at 52.1%.
Claude Opus 4.7 fast mode: Anthropic’s fast mode release reached APIs and Claude Code, with Cursor noting 2.5× speed at 6× cost, a concrete new point on the latency/price frontier.
Security, Supply Chain, and Safer Coding
The most urgent operational story was the Mini Shai-Hulud supply-chain attack: @IntCyberDigest reported the campaign had expanded beyond TanStack to hit OpenSearch, Mistral AI, Guardrails AI, UiPath, and others across npm and PyPI, specifically targeting AI developer tooling. The noteworthy technical detail is persistence: it allegedly hooks into Claude Code (.claude/settings.json) and VS Code (.vscode/tasks.json) so the compromise can re-execute on future tool events even after package removal. Guardrails AI later confirmed its 0.10.1 package was compromised and quarantined within about 2 hours.
Actionable mitigations surfaced quickly: @ramimacisabird noted that beyond minimumReleaseAge, teams should enable blockExoticSubdeps to prevent remote GitHub references from slipping into dependency graphs. @elithrar reiterated that GitHub’s pull_request_target remains one of the sharpest CI/CD footguns for fork-based PR automation. And at the workstation level, @andersonbcdefg recommended moving secrets out of ubiquitous local .env files into a proper secrets manager.
Safer codegen is becoming its own research track: Stanford-aligned work on SecureForge targets vulnerability discovery/prevention in LLM-generated code via prompt optimization, while the corresponding paper listing frames it as a bridge between codegen and security evaluation. The broader point: coding agents are now strong enough that supply-chain hardening and secure-generation evaluation need to be treated as core infra, not side concerns.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
- Qwen 3.6 MTP and Long-Context Local Evals
MTP on Unsloth (Activity: 727): The image is a Hugging Face activity screenshot showing Unsloth AI publishing/updating MTP-preserved GGUF builds: unsloth/Qwen3.6-27B-GGUF-MTP and unsloth/Qwen3.6-35B-A3B-GGUF-MTP. The technical significance is that these GGUFs retain the MTP / next-token-prediction auxiliary layer, but users reportedly still need to checkout and build a specific llama.cpp MTP PR rather than relying on default llama.cpp support. One commenter hit a runtime/model-load assertion, GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0"), suggesting tooling or metadata support is still fragile for these MTP GGUFs. Commenters are mainly waiting on upstream inference support, with one joking about constantly refreshing llama.cpp and vLLM GitHub repos. There is also uncertainty over whether MTP is supported “out of the box” in llama.cpp; the post indicates it is not yet.
A user compiling/running the new 27B GGUF model reports a hard assertion failure in qwen35_mtp.cpp: GGML_ASSERT(hparams.nextn_predict_layers > 0 && "QWEN35_MTP requires nextn_predict_layers > 0") failed. This suggests the GGUF/model metadata being loaded is missing or not exposing nextn_predict_layers, which is required for Qwen3.5 MTP execution in the current implementation.
Several commenters are tracking whether llama.cpp and vLLM have landed native MTP support, with one explicitly asking whether llama.cpp now supports MTP “out of the box.” The thread implies support is still in flux across backends and that users are watching upstream repositories for compatibility with GGUF MTP models.
One technical takeaway is that MTP support in GGUF is viewed as important for local inference, especially for Qwen-style variants such as the mentioned 35B A3B model. A commenter highlights the 35B A3B variant as interesting specifically because of expected context-length improvements.
The Qwen 3.6 35B A3B hype is real!!! (Activity: 713): A user benchmarked Qwen 3.6 35B A3B, Qwen 3.6 27B, Gemma 4 26B A4B, and Nemotron 3 Nano on a niche paper-to-code comprehension task, feeding each model an academic paper plus accompanying research code via long-context mechanisms such as gated delta nets, hybrid Mamba2, and sliding-window attention. In their detailed findings, all four small/local open-weight models substantially outperformed prior small-model baselines such as Devstral Small 2, with Qwen 3.6 35B A3B judged strongest; Devstral Small 2 could not fit the long-context workload in 32GB VRAM/RAM. Commenters noted practical tradeoffs: Qwen 35B is preferred for long-context/refactoring but can be verbose/slow in thinking mode, while Gemma 26B is faster for code fixes/chats; at q4, one user reports ~20GB for Qwen 35B and ~15GB for Gemma 26B, allowing both to stay loaded. Another commenter criticized the evaluation for not documenting inference settings, which limits reproducibility.
Several users compared local workflows using Gemma 26B and Qwen 35B, noting that both can be kept resident simultaneously at q4 quantization because Qwen 35B is about 20 GB and Gemma 26B about 15 GB. One commenter uses Gemma 26B thinking mode for quick code fixes/chat and Qwen 35B thinking mode for longer-context refactoring, but reports Qwen 35B has high latency due to excessive reasoning verbosity before final output.
A coding-focused report claimed Qwen 27B can handle large projects (100k+ LOC) effectively when bootstrapped by a stronger model/coding agent for initial project setup, then switched to Qwen for continued work. The user found little practical difference between Qwen 27B and DeepSeek V4 for their use case, though Qwen occasionally entered loops requiring manual interruption and continuation prompting.
One commenter emphasized that Qwen 27B/35B performance is sensitive to inference configuration, specifically temperature/sampling parameters and avoiding overly aggressive quantization of either the model weights or KV cache. Another asked for the missing run settings, implying the original claims are hard to evaluate without details like quantization level, sampler settings, context length, backend, or hardware.
- Memory-Tiered and Power-Efficient Local Inference
Computer build using Intel Optane Persistent Memory - Can run 1 trillion parameter model at over 4 tokens/sec (Activity: 964): The image shows the internals of a high-memory Xeon workstation/server build using Intel Optane DC Persistent Memory DIMMs, matching the post’s claim of running Kimi K2.5, a ~1T parameter MoE model, locally at about 4 tokens/s via llama.cpp hybrid GPU/CPU inference. The key technical point is the use of 768GB Optane PMem in Memory Mode, where Optane appears as system RAM and 192GB DDR4 ECC DRAM acts as cache, allowing the model’s sparse expert weights to reside in PMem while attention/dense/shared expert/routing tensors fit on an RTX 3060 12GB using override-tensor or ngl auto/cmoe. Image Commenters noted that a higher-core-count Cascade Lake Xeon, such as an ES 8260/QQ89, could improve throughput, and debated whether Optane Storage Mode plus mmap might outperform Memory Mode. Others found the build impressive but questioned whether 4 tokens/s is practically tolerable for interactive use.
A detailed hardware note suggests performance may improve with a higher-core-count Cascade Lake Xeon, e.g. QQ89 ES / Xeon Gold 8260-class 24-core, versus the current Xeon Gold 6246 12-core. The commenter also proposes benchmarking Optane PMem in storage mode + mmap versus memory mode, noting that memory mode uses DRAM as a transparent cache and requires pages to be swapped back into DRAM before CPU execution, so it is not equivalent to normal RAM latency.
One commenter provides a concise Optane PMem platform compatibility breakdown: LGA3647 Skylake/Cascade Lake uses 1st-gen Optane NMA at 2666 MT/s, while LGA4189 uses 2nd-gen NMB, running at 2666 on Cooper Lake and 3200 on Ice Lake. They also note that mixing Optane with DRAM on Cascade Lake can downclock affected channels to 2666, and that many Xeons from this era have a 1 TB total memory limit across DRAM + Optane, unless using high-memory SKUs or later platforms.
A technical caveat is raised that while ~4 tokens/sec generation on a trillion-parameter model may be tolerable for some uses, prompt processing/prefill speed is likely to be much worse on this kind of memory hierarchy. Another comment estimates the full used-market build cost at roughly $2060–$2500, including a Xeon Gold 6246, TYAN S5630GMRE-CGN, RTX 3060 12GB, 192 GB DDR4 ECC RDIMM, and 768 GB Intel Optane DCPMM.
Stop wasting electricity (Activity: 905): A user benchmarked llam
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み