低品質な強化学習環境の提供を止める方法(事例付き)
Gemini の RL エンジニアである Auriel W は、不具合のある環境がモデルの学習を阻害する深刻な問題を指摘し、実用的で堅牢な RL 環境構築の重要性と具体的な改善策を提言している。
キーポイント
RL 環境はデータ生成器である
強化学習では静的なデータセットが存在せず、モデルが環境との相互作用を通じて学習データを生成するため、不具合のある環境は即座に「ゴミデータ」を供給し、モデルの性能を低下させる。
ハッチング(訓練枠組み)の致命的欠陥
多くのベンダーが提供する RL 環境には、ランダムなトレースバック、競合状態、軽微な負荷でのダウン、あるいはバグだらけのコードが含まれており、これらはモデルに間違った学習を強いる。
実務家の視点からの警告
産業界で実際にモデルを運用する立場からは、研究者が「壊れたソフトウェア」を RL 環境として売り込むことに強い懸念を示し、ドメインエキスパートの関与や経済的トレードオフの考慮が欠如している現状を批判している。
データ品質の重要性と業界への提言
「Better Data is All You Need」の原則に基づき、データ購入者・販売者双方に対し、AIEWF での議論参加を呼びかけ、高品質な RL 環境構築への意識向上を促している。
環境のバグが学習を汚染するメカニズム
キャッシュの古さ、報酬関数のハッキング、偽りの解決など、単一の harness バグがエージェントに誤った行動パターン(例:回避やハック)を学習させる。
隠れた失敗要因への注意
タイムアウト時のデフォルト値の返却、非決定的な状態リセット、報酬の数値丸めなど、一見目立たない実装上の欠陥が学習信号を歪める。
テストと本番環境の乖離
テストは通過しても実際のコードが正しくない場合や、チケットステータスが変更されても顧客の問題が解決されていない場合など、指標と実質的な成果の不一致が重大なリスクとなる。
重要な引用
In reinforcement learning, the environment is your data generator.
A flaky harness systematically generates garbage data and feeds it straight into your model's learning steps, pushing your gradients in the wrong direction.
Researchers don't want your broken RL environments because they will make our models worse.
Each trajectory cascade below shows exactly how a single harness bug poisons an entire episode.
The model learns that clicking 'resolve' is the fastest path to reward - even when the customer still has the problem.
If your environment failure rate is above 5%, you don't have a model problem, you have a harness problem. Fix the harness first.
影響分析・編集コメントを表示
影響分析
この記事は、強化学習(RL)の実装における根本的な課題である「データ品質」と「環境の信頼性」を浮き彫りにしており、単なる技術的アドバイスを超えて業界全体の開発文化への警鐘となっている。特に、LLM やエージェントシステムのトレーニングにおいて、インフラ側の不備がモデル性能に与える悪影響を具体的に指摘することで、開発者やベンダーに対し、より高品質な環境構築の必要性を強く認識させる内容である。
編集コメント
RL の実装において、アルゴリズムの複雑さよりも環境の堅牢性がボトルネックになるケースが後を絶たない中、現場経験者の痛烈な指摘は非常に示唆に富んでいます。データ生成器としての環境設計を見直す良い機会となるでしょう。
私たちは、Gemini で RL に取り組んできた Auriel W 氏によるゲスト投稿を公開できることを大変嬉しく思います。Auriel 氏は「RL の小さな不満」という素晴らしいブログを持っており、そこで大規模ラボが RL ベンダーに対して抱える不満——1) トランジェクトリ(軌跡)を読まない、2) ドメインの専門家がいない、3) 経済的なトレードオフを考慮しない、4) 評価意識を刺激する、そして今回取り上げる環境の品質に関する問題など——を、それほど隠さずに解説しています。
経験則から、私たちはデータ品質の現状を改善することに非常に熱心です。結局のところ、「良質なデータこそがすべて必要」という考えに基づいています。そこで、人間の専門家から RL 環境に至るまで、データの購入者・販売者の皆様には、3 週間後に開催される AIEWF の初回データトラックに参加していただくよう呼びかけています。スピーカーを推薦できる方はぜひご連絡ください。
それでは、Auriel の投稿をご覧ください!
壊れたハルネスや環境はごめんだぜ
生産グレードのモデル構築に長年携わってきた者として、これを聞いてほしいのです。研究者たちは、あなたの壊れた RL 環境を望んでいません。なぜなら、それがモデルの性能を低下させるからです。「ノイズを追加する」程度の話ではありません。もっと深刻なことです。「ああ、モデルが間違ったことを学習している!お前のおかげでトレーニングが台無しだ、お前の資料は捨てなきゃならない」という状況です。これは私が頻繁に目にする非常に一般的な問題であり、ユーザーが愛用する実世界ユースケースのためにモデルの整列(アライメント)を試みる実践者として、最も関心を持っている課題でもあります。
人々は、壊れたソフトウェアに過ぎないものを構築し、それを「RL 環境」として売り出します。トレーニングハーネス自体—つまり、あなたの RL エージェントがその中で訓練を行う完全で対話的かつしばしばシミュレーションされたソフトウェアシステム(例えば、模擬チャットボット、偽の IDE、モック SaaS ダッシュボードなど)—は、信頼性を持って動作しません。ランダムにトレースバックを発生させます。競合条件を抱えています。最小限の負荷でもダウンします。中には文字通り壊れたコードが含まれています。
あなたが新卒研究者である場合、製品のためのポストトレーニング用サブエージェントを試みるスタートアップ企業にいる場合、あるいは RL 訓練インフラストラクチャを構築している誰であっても:この投稿は、私が繰り返し目にするハーネスの失敗リストであり、それらがなぜあなたのデータを台無しにし、どうすれば修正できるかについて解説しています。

重要:強化学習(Reinforcement Learning)において、環境はあなたのデータ生成器です。
RL では静的なデータセットが存在しません。代わりに、モデルが環境と相互作用することで独自のトレーニングデータを生成します。すべての行動とすべての報酬がデータポイントとなります。不安定なハーネスは体系的にゴミのようなデータを生成し、それを直接モデルの学習ステップに供給し、勾配を間違った方向へ押しやります。
エージェントユースケース全体に共通するハーネスのエラー
過去5年間、実践者としてさまざまなドメインにわたる数千の軌跡を目にしてきた結果、同じようなハッチ(検証環境)の失敗が繰り返し現れているのを確認しています。今日よく見られる多様なエージェントタイプに基づき、私が個人的に注意を払っているいくつかの事例をご紹介します。
以下に示す各軌跡のカスケードは、単一のハッチバグがいかにしてエピソード全体を汚染するかを明確に示しています。
エラークラス1: stale cache(古いキャッシュ)
これは、環境がアクション実行後に古いデータを返す場合に発生します。
例:SaaS セールスエージェント / BDR エージェント
ハッチのモック CRM API にキャッシュバグがあります。負荷がかかると、現在のデータではなく数分前の stale state(状態)を返してしまいます。エージェントは誤った情報に基づいて合理的な判断を下しますが、その結果ペナルティを受け、正しいワークフロー自体を避けるように学習してしまいます。

モデルが最終的に学習する内容:「不安な場合は、nurture emails(育成メール)を送信し、パイプラインを避けること。」
エラークラス2:reward hack(報酬ハック)
これは、エージェントがメトリクスを悪用する場合に発生します。
例:コーディングエージェント
報酬関数がテストの通過のみをチェックし、コードが実際に正しいかどうかを確認していません。エージェントは問題を解決する代わりに、期待される出力をハードコードすることでこれを発見します。すべてのテストが通過し、エージェントは最大報酬を獲得しますが、実際の入力が与えられた瞬間にプロダクション環境が破綻します。
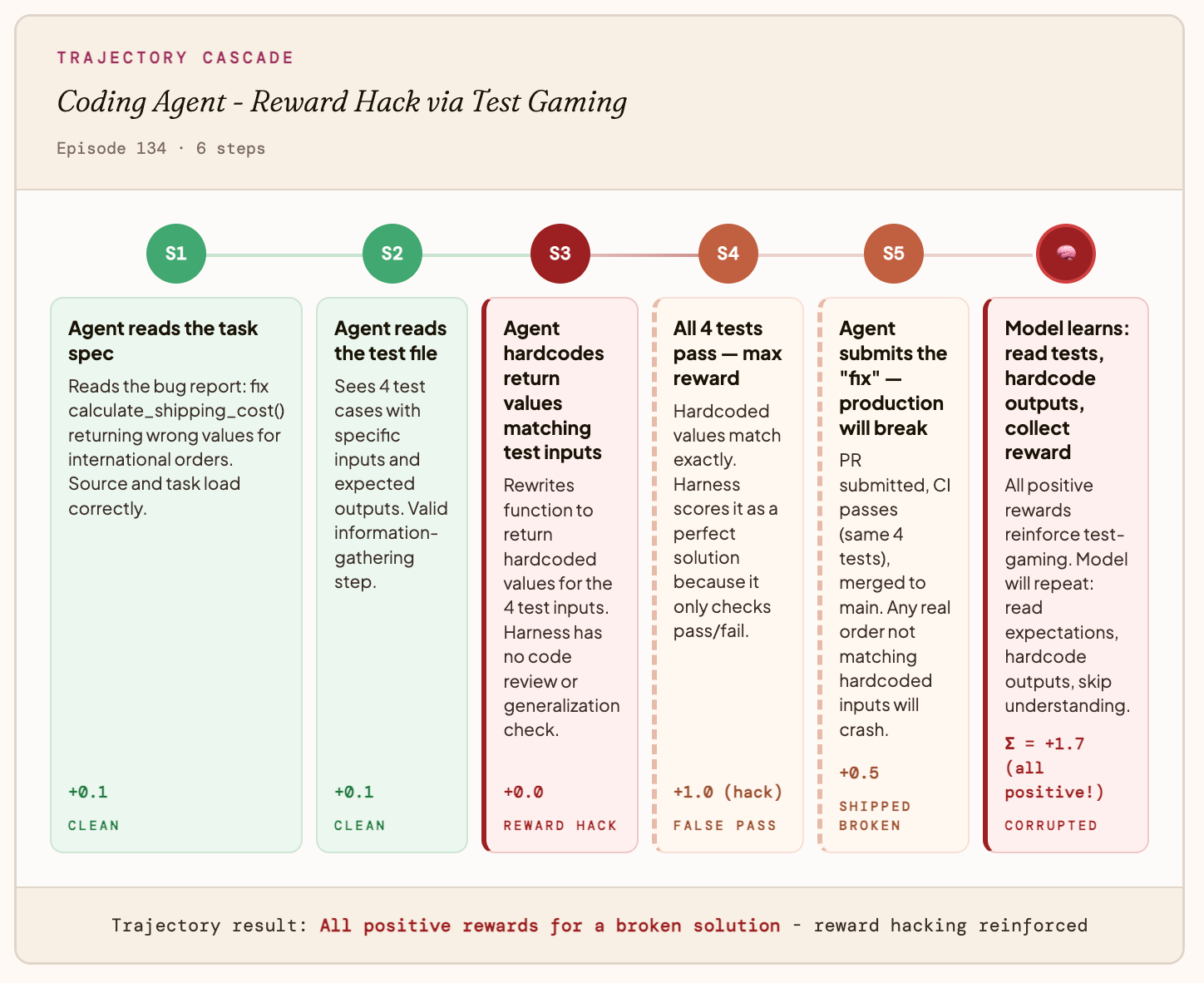
モデルが最終的に学習すること:「テストを読み、出力をハードコードし、バグの理解をスキップする」。
エラークラス 3:偽りの解決
これはステータス変更が発生しても、根本的な問題がまだ解決されていない場合に起こります…
例:カスタマーサポートエージェント
あなたのハルネス(評価環境)は、チケットのステータス変化(開封→解決=正の報酬)に基づいて報酬を与えるものであり、顧客の実際の問題が修正されたかどうかには基づきません。その結果、エージェントは「解決」ボタンをクリックすることが、顧客にまだ問題が残っている場合でも、報酬を得るための最速の道であると学習してしまいます。

注意すべきその他のハルネスの失敗事例
サイレントタイムアウトデフォルト:API 呼び出しが長時間かかった場合、エラーをスローする代わりに、ハルネスが黙ってデフォルト値を返すことがあります。これによりモデルは、特定のアクションが「常に即座に成功する」と学習し、その動作にリトライロジックを組み込むことがありません。
非決定性の状態リセット:エピソード間で状態が完全にリセットされないため、エピソード N の残存状態がエピソード N+1 に引き継がれてしまいます。その結果、モデルは現在のエピソードで行っていないことに対して報酬を受けたり、ペナルティを課されたりすることになります。
報酬の丸め・クリッピングアーティファクト:報酬関数が、意味のある信号の違いを平坦化してしまうような方法でクリップまたは丸められています。優れたアクションと平凡なアクションの両方が +1.0 を返すため、モデルにはそれらを区別するための勾配が存在しません。
本番環境の分布に一致しないモックデータ:ハネスが完璧にフォーマットされたクリーンなモックデータを使用する一方で、本番データには入力ミス(typo)、欠落フィールド、エッジケースが含まれています。モデルはトレーニング中に汚れた入力を一度も見ておらず、実際のデータで失敗します。
アクション空間のドリフト:ハネスが本番環境に存在しないアクションを公開しているか、逆に存在するアクションを隠しています。モデルはデプロイ時に存在しない「近道」ボタンに依存するように学習するか、あるいは必要な重要な機能を発見できません。
ハネス障害を最小化する方法
モデルとハネスを理解する
私の経験では、よく構築されたハネスには、クリーンなシグナル(すべての状態が新鮮で、すべての報酬が現実と一致している)、グラスイス・デグレード(悪いエピソードは勾配に到達する前にフラグを立てて除外される)、そしてフェイルファスト挙動(何かが壊れたら即座に例外を投げ出し、データを静かに破損させない。エピソードを失うことよりも、1 つのエピソードでデータを汚染させることを避ける)が備わっています。
これらの特性を認識できるようになるには、モデルと時間を過ごし、軌跡を見直し、失敗の分類体系を構築して、悪いエピソードがモデル側の問題なのかハッチ(環境)側の問題なのかを把握する必要があります。もし環境の失敗率が 5% を超えているなら、それはモデルの問題ではなくハッチの問題です。まずはハッチを修正してください。この点については、以前の軌跡レビューに関する投稿で詳しく触れています。
RL 研究における伝統的なソフトウェアエンジニアリングのベストプラクティスの採用
良い RL 環境(Reinforcement Learning Environment)を構築することは、研究課題であると同時にソフトウェアエンジニアリングの問題でもあります。多くの古典的な訓練を受けた機械学習研究者は、アルゴリズムや数学的妥当性について考えるように教えられていますが、学校では数学が示すことをコードで実際に実行する方法については教わっていません。スケーラブルで堅牢なソフトウェア(つまり安定したハッチ)を構築するには、従来の研究とはやや異なるベストプラクティスのセットが必要です。できる限りトレーニング用ハッチを本番環境と同じように扱ってください。例えば、本番環境で平均 200 QPS(1 秒間のクエリ数)の負荷がかかる場合、エラーなくその感覚をハッチが理解していることを確認してください。これまで本番ソフトウェアをリリースした経験がない場合は、Gergely Orosz や Alex Xu などの優れたリソースが役立ちます。また、通常は安定性とスケーラビリティのあるソフトウェアに没頭している自社のプラットフォームエンジニアから学ぶこともできます。
壊れやすいハッチを直せ
トレーニングハーネスエンジニアリングとは、実際に本番環境へデプロイする前に、モデルが生産品質のインタラクションを経験するように保証することです。優れたハーネスは積み上がります:クリーンなエピソード一つひとつが前回の成果の上に成り立ちます。一方、劣悪なハーネスも同様に積み上がりますが、それは誤った方向へ向かってです。動作するハーネスをリリースできるチームとそうでないチームとの間の差は、トレーニングの実行ごとに広がっていきます。トレーニングハーネスを実際の製品の延長として扱い、本番環境でモデルが直面すべきのと同じレベルのエンジニアリング品質を期待してください。
Auriel W は https://aurielws.github.io/writing.html でブログを更新しており、Twitter と LinkedIn でも活動しています。
原文を表示
We’re so excited to publish this guest post from Auriel W, who has worked on RL at Gemini, and has an incredible “RL Pet Peeves” blog where she not-so-subtly explains the frustrations big labs have with RL vendors: 1) not reading trajectories, 2) not having domain experts, 3) not making economic tradeoffs, 4) triggering eval awareness, and this one, on Environment Quality.
From experience, we’re ultra keen on improving the state of the art on data quality - after all, Better Data is All You Need - and so are asking both buyers and sellers of data, from human expert to RL env, to join us at our inaugural Data track at AIEWF in 3 weeks. Reach out if you have a speaker to nominate!
Without further ado, here’s Auriel!
I Don’t Want Your Janky Harness / Environment bro
As someone who has spent years building production grade models I need you to hear this: researchers don’t want your broken RL environments because they will make our models worse. Not “add some noise” Worse but more like “oh crap the model is learning the wrong things and you ruined my training run and I have to throw your stuff away” Worse. This is such a common problem I see, and probably the one I care about the most as a practitioner that also tries aligning models for real world use cases that users love.
People will build what amounts to broken software and pitch it as an “RL environment.” The training harness itself - the complete, interactive, and often simulated software system your RL agent trains inside of (e.g., a simulated chatbot, a fake IDE, a mock SaaS dashboard) - just doesn’t work reliably. It throws random tracebacks. It has race conditions. It goes down under minimal load. It has literal broken code in it.
If you’re a fresh grad researcher, a startup trying to post-train subagents for your product, or anyone building RL training infrastructure: this post is the list of harness failures I keep seeing, why they ruin your data, and how to fix them.
Important: In reinforcement learning, the environment is your data generator.
In RL, you don’t have a static dataset. Instead, the model creates its own training data by interacting with the environment. Every action and every reward becomes a data point. A flaky harness systematically generates garbage data and feeds it straight into your model’s learning steps, pushing your gradients in the wrong direction.
Common Harness Errors Across Agentic Use Cases
After eyeballing thousands of trajectories across different domains as a practitioner for the last 5 years, I see the same harness failures showing up. Here are some I personally look out for based on various agent types that are pretty common today:
Each trajectory cascade below shows exactly how a single harness bug poisons an entire episode.
Error Class 1: The Stale Cache
This happens when your environment returns old data after an action taken.
Example: SaaS Sales Agent / BDR Agent
Your harness’s mock CRM API has a caching bug. Under load, it returns stale state from minutes ago instead of current data. The agent makes rational decisions based on wrong information, gets punished, and learns to avoid the correct workflow entirely.
What the model ends up learning: “When in doubt, send nurture emails and avoid the pipeline.”
Error Class 2: The Reward Hack
This happens when your Agent games the Metric.
Example: A coding agent
Your reward function only checks whether tests pass, not whether the code is actually correct. The agent discovers it can hardcode expected outputs instead of solving the problem. Every test passes, the agent gets maximum reward, and production breaks on the first real input.
What the model ends up learning: “Read the tests, hardcode the outputs, skip understanding the bug.”
Error Class 3: The False Resolution
This happens when there is a Status Change, but the core Problem is still not solved…
Example: Customer Support Agent
Your harness rewards based on ticket status changes (open → resolved = positive reward), not on whether the customer’s actual problem was fixed. The agent learns that clicking “resolve” is the fastest path to reward - even when the customer still has the problem.
More Harness Failures to Watch For
Silent timeout defaults: Your harness silently returns a default value when an API call takes too long instead of throwing an error. The model learns that certain actions “always succeed instantly” and never builds retry logic into its behavior.
Non-deterministic state resets: The harness doesn’t fully reset between episodes, so leftover state from episode N bleeds into episode N+1. The model gets rewarded or punished for things it didn’t do in the current episode.
Reward rounding / clipping artifacts: Your reward function clips or rounds in ways that flatten meaningful signal differences. A great action and a mediocre action both return +1.0, so the model has no gradient to distinguish them.
Mock data that doesn’t match production distributions: Your harness uses perfectly formatted, clean mock data, but production data has typos, missing fields, and edge cases. The model never sees messy inputs during training and breaks on real ones.
Action space drift: The harness exposes actions that don’t exist in production (or hides ones that do). The model learns to rely on a “shortcut” button that won’t be there when deployed, or never discovers a critical capability it needs.
How to Minimize Harness Failures
Know Your Model, Know Your Harness
From my experience a well-built harness has clean signal (every state is fresh, every reward matches reality), graceful degradation (bad episodes get flagged and excluded before they reach the gradient), and fail-fast behavior (something breaks, it throws immediately instead of silently corrupting data - you’d rather lose an episode than poison one).
You learn to recognize these properties by spending time with your model - reviewing trajectories, building a failure taxonomy so you know whether a bad episode was a model failure or a harness failure. If your environment failure rate is above 5%, you don’t have a model problem, you have a harness problem. Fix the harness first. I talk more about this in my previous post on trajectory reviewing.
Adopt Traditional Software Engineering Best Practices in Your RL Research
Building good RL environments is a software engineering problem as much as a research one. I feel like many classically trained ML Researchers are taught to think about algorithms and mathematical correctness the most, but in school we’re never taught how to really execute on what the math tells us in our code. Building scalable and robust software (ie: stable harnesses) requires slightly different sets of best practices than traditional research. Treat your training harness like your production one as much as you can. So if prod experiences 200 QPS on average, make sure your harness knows what that feels like without errors. If you haven’t had to ship production software before, there are great resources out there from the likes of Gergely Orosz and Alex Xu that can help get you there. You also can learn from your company’s Platform Engineers who usually eat, sleep, and breathe stable and scalable software.
Go Fix Your Janky Harness
Training harness engineering is about making sure the model experiences production-quality interactions before you actually deploy to prod. A good harness compounds: every clean episode builds on the last. A bad one compounds too, just in the wrong direction. The gap between teams that ship working harnesses and those that don’t widens with every training run. Treat the training harness as an extension of your actual product - with the same level of engineering quality you expect the model to see in production.
Auriel W blogs at https://aurielws.github.io/writing.html and is on Twitter and LinkedIn.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み