Together AI、ツール呼び出し・推論・ビジョン対応のファインチューニングサービスを拡大
Together AIは、ツール呼び出し、推論、ビジョン言語モデルのファインチューニングに対応し、100B超パラメータ大規模モデルの高速学習とコスト見積もり機能を追加した「Together Fine-Tuning」サービスを拡大した。
キーポイント
3つの主要機能の追加
ツール呼び出し(Tool Call)の構造化アクション実行、推論トークンを用いた複雑なロジック学習、ドメイン固有の視覚データに特化したビジョン言語モデル(VLM)のファインチューニングをネイティブサポート。
大規模モデルと高速処理の実現
1兆(1T)パラメータまでの最新モデルの学習に対応し、トレーニングスタックをアップグレードすることで100B超パラメータモデルの処理スループットを最大6倍向上させた。
運用効率化とコスト透明性の向上
最大100GBのデータセットに対応し、学習前のコスト見積もりと学習中の所要時間(ETA)提供により、チームの実験計画とリソース管理を支援する機能を提供。
重要な引用
"Together AI does for fine-tuning and inference what Vercel does for LLM-based apps — it removes the infrastructure layer so we can focus on our product."
"That lets our existing team move from weekly to daily iteration, cut costs by 2–3×, and improve accuracy from 77% to 87%."
"Our fine-tuning service now delivers an end-to-end solution for re..."
影響分析・編集コメントを表示
影響分析
この発表は、大規模言語モデル(LLM)の適用範囲を単なるテキスト生成から、構造化されたアクション実行や高度な視覚理解、複雑な論理推論へと拡張する重要な一歩を示している。特に1Tパラメータ規模のモデルを効率的にファインチューニングできる環境は、企業固有のデータで高度なカスタマイズを行う際のハードルを大きく下げ、AI開発の民主化と実用化を加速させる可能性を秘めている。
編集コメント
1Tパラメータ規模のモデルを効率的にファインチューニングできる点は、大規模モデルの実装コスト削減において極めて重要な進展である。特にツール呼び出しと推論能力の強化は、実務レベルのエージェント開発において必須となる機能であり、競合他社との差別化要因として強く働く。
新機能
- ツール呼び出しファインチューニング:OpenAI 互換スキーマにおけるエンドツーエンドのファインチューニングと推論により、エージェントが構造化されたアクションを確実に実行できるようにします。
- 推論ファインチューニング:推論トレース内の「思考」トークンに対するモデル訓練のための専門的なサポートを提供し、複雑なロジックを学習可能にします。
- ビジョン言語モデルのファインチューニング:ビジョン言語モデルを複雑でドメイン固有の視覚データに整合させるためのネイティブなビジョン訓練サポート。
大規模モデル対応:高度に最適化され使いやすい当社のサービス上で、最大 1T パラメータを持つ最新モデルを訓練できます。
AI チームが単一ターンプロンプティングから高度なマルチターンワークフローへ移行するにつれ、信頼性の欠陥は予測可能な箇所で発生します。具体的には、スキーマに一致しないツール呼び出し、長期間の相互作用で劣化する推論、ドメイン固有の視覚信号を見逃すモデルです。これらの問題を解決するには通常、トレーニング後の調整が必要ですが、そのワークフローは断片的であり、反復が遅く、計画が困難であることが多々あります。
本日、AI ネイティブクラウドである Together AI は、ツール呼び出し、推論、およびビジョン言語モデル(VLM)のファインチューニングに対するネイティブサポートを備えた「Together Fine-Tuning」を拡張しました。フロンティア規模のポストトレーニングをサポートするため、トレーニングスタックもアップグレードされ、100B パラメータ以上のモデルをより効率的に処理できるようになり、スループットは最大 6 倍向上しました。さらに、サイズが最大 100GB のデータセットでのファインチューニングにも対応しています。最後に、トレーニング前にジョブコストの見積もりと、トレーニング中の推定所要時間(ETA)を提供することで、チームが実験をより効果的に計画できるようになりました。
*「Together AI は、LLM ベースのアプリケーション向けに Vercel が行うことと同様に、ファインチューニングと推論においてインフラストラクチャ層を排除し、私たちが製品開発に集中できるようにしています。私たちはシンプルな API 呼び出しを通じて顧客固有のモデルをファインチューニングしてデプロイします。これにより、既存のチームは週次から日次の反復開発へ移行でき、コストを 2〜3 倍削減し、精度を 77% から 87% に向上させることができました。」— ***Lamara De Brouwer, Co-Founder & CTO, XY.AI Labs
ツール呼び出しファインチューニング
ツール呼び出しは、多くの現代的なエージェントユースケースにおいて不可欠です。しかし、標準搭載のモデルではツール呼び出しに苦戦することが多く、パラメータの幻覚(ハルシネーション)や誤った関数の選択、あるいは多段階シーケンスの遵守失敗などが発生します。ツール呼び出しワークフローにおいては、わずかな不整合でも連鎖的に下流の障害へと発展する可能性があります。
当社のファインチューニングサービスは、信頼性の高い本番環境対応のツール呼び出し機能に対して、ファインチューニングから推論に至るまでのエンドツーエンドソリューションを提供するようになりました。ツール呼び出しは、OpenAI 互換スキーマを使用してトレーニングデータに含めることができます。関数はトップレベルの tools 配列内で定義され、当社のサービスがトレーニング開始前にすべての tool_calls エントリが宣言されたツールと一致していることを検証し、構造的に正しいデータを保証します。
推論時には、ツール呼び出しファインチューニングのメリットが生産環境のパフォーマンスとして反映されるよう、ツール呼び出しの信頼性を大幅に向上させました。コミュニティからの貢献と内部研究からキュレーションされた推論用ツール呼び出しデータセットによって支えられ、拡張された構文解析と検証機能により、幅広い実世界のユースケースにおける正確性が改善されています。
Qwen、Moonshot AI、Z.AI 製のモデルに対して、ツール呼び出しファインチューニングが利用可能です。始め方は ツール呼び出しドキュメント をご覧ください。コードでのツール呼び出し機能の例については、当社の クックブック をご参照ください。
Reasoning Fine-tuning
推論モデルは最終回答を生成する前に中間的な思考トレースを生成し、段階的な推論を可能にします。しかし、推論フォーマットはモデル間で標準化されておらず、推論ファインチューニングのプロセスに複雑さを導入しています。
Together Fine-tuning では、アシスタントメッセージ内の reasoning または reasoning_content フィールドを使用して、思考トレースに対して直接ファインチューニングを行うことが可能になりました。これにより、ドメイン固有の推論パターンをモデルに学習させつつ、トレースを構造化して再現性を確保できます。ツール呼び出しと同様に、推論推論も改善され、ファインチューニングされた機能が信頼性の高い下流パフォーマンスとして反映されることを保証しています。
推論ファインチューニングは、Qwen および Z.AI 製のモデルで利用可能です。対応するモデルと詳細については、ドキュメントページをご覧ください。推論ファインチューニングの完全なコードデモについては、クックブック をご参照ください。
ビジョン・ランゲージモデルのファインチューニング
多くの AI ワークフローでは、画像入力を解釈できるモデルが必要です。医療画像解析や e コマースといったドメイン固有のタスクにおいては、ビジョン・ランゲージモデル(VLMs)が効果的に機能するために新たな視覚パターンを学習する必要がある場合があります。
Together Fine-tuning サービスは now、ビジョン・ランゲージモデルのファインチューニングをサポートしています。ビジョントレーニングデータは、base64 符号化された画像を含むメッセージコンテンツ配列を使用してインラインで提供されます。ファインチューニングジョブではハイブリッドデータセットに対応しており、同じ実行内で画像とテキストの例およびテキストのみの例を両方含めることが可能です。
デフォルトでは、ビジョンエンコーダーを凍結し、言語層のみを更新します。train_vision=true を設定すると共同トレーニングが有効になり、ビジョンエンコーダーと言語層の両方に対する更新が可能になります。
VLM(Vision-Language Model)のファインチューニングは、Qwen、Google、Meta からのモデルで利用可能です。サポート対象リストと使用の詳細については、vision-language ドキュメントをご覧ください。また、ビジョン言語ファインチューニングのためのクックブックもご参照ください。
大規模モデルのファインチューニング
オープンソースモデルのサイズが大きくなり、コンテキストウィンドウが拡大するにつれ、基盤となるトレーニングインフラストラクチャもそれに追いつく必要があります。トリリオンパラメータモデルは単一のノードに収まらないため、複数のマシンにわたる慎重な通信とメモリ管理が必要です。また、数時間に及ぶトレーニング実行中にハードウェア障害が 1 つ発生しただけで進捗が失われる可能性があり、すべての最適化とフォールトトレランスの safeguards を実装するには多大な投資が必要になることもあります。
Together Fine-Tuning は、最新のオープンウェイトモデルに対するファインチューニングをサポートしています。トレーニングジョブを提出するだけで、必要な最適化はすべてバックグラウンドで処理されます。ファインチューニング可能な新モデルには以下が含まれます:
- Qwen 3.5-397B-A17B
- Qwen 3.5-122B-A10B
- Qwen 3.5-35B-A3B
- Qwen 3.5-35B-A3B-Base
- Kimi K2.5
- Kimi K2 (Instruct, Thinking)
- GLM-4.7
- GLM-4.6
サポートされているモデルの完全リストとコンテキスト長については、当社のドキュメントをご覧ください。
トレーニングの加速化
今回のアップデートでは、トレーニングスタックにおける最もインパクトの大きい最適化機会に引き続き注力しました。具体的には、過去 1 年間で発表された最強モデルの大半を占める「Mixture-of-Experts (MoE: 専門家の混合) アーキテクチャ」を対象としました。そのトレーニングを加速させるため、SonicMoE の変種である、メモリアクセスと計算処理を重畳させる入出力・タイル認識型最適化カーネル(I/O- and tile-aware optimized kernels)を統合しました。これらのカーネルをトレーニングワークロードに採用することで、トレーニング中の活性化メモリ使用量(activation memory footprint)が大幅に削減され、計算リソースの無駄も最小限に抑えられました。
また、損失計算用のカスタム CUDA カーネルを導入し、トレーニングループ内で不要なストールを引き起こしていた GPU と CPU の同期ポイントを複数削除しました。これにより、全体のパイプライン効率が劇的に向上しました。
その結果、すべてのモデルでスループットが少なくとも 2 倍に増加し、Kimi-K2 などの大規模モデルでは 6 倍以上の改善が見られました。トレーニング速度の向上は、1 日あたりの実験回数の増加と、本番環境への展開までの期間短縮を意味します。
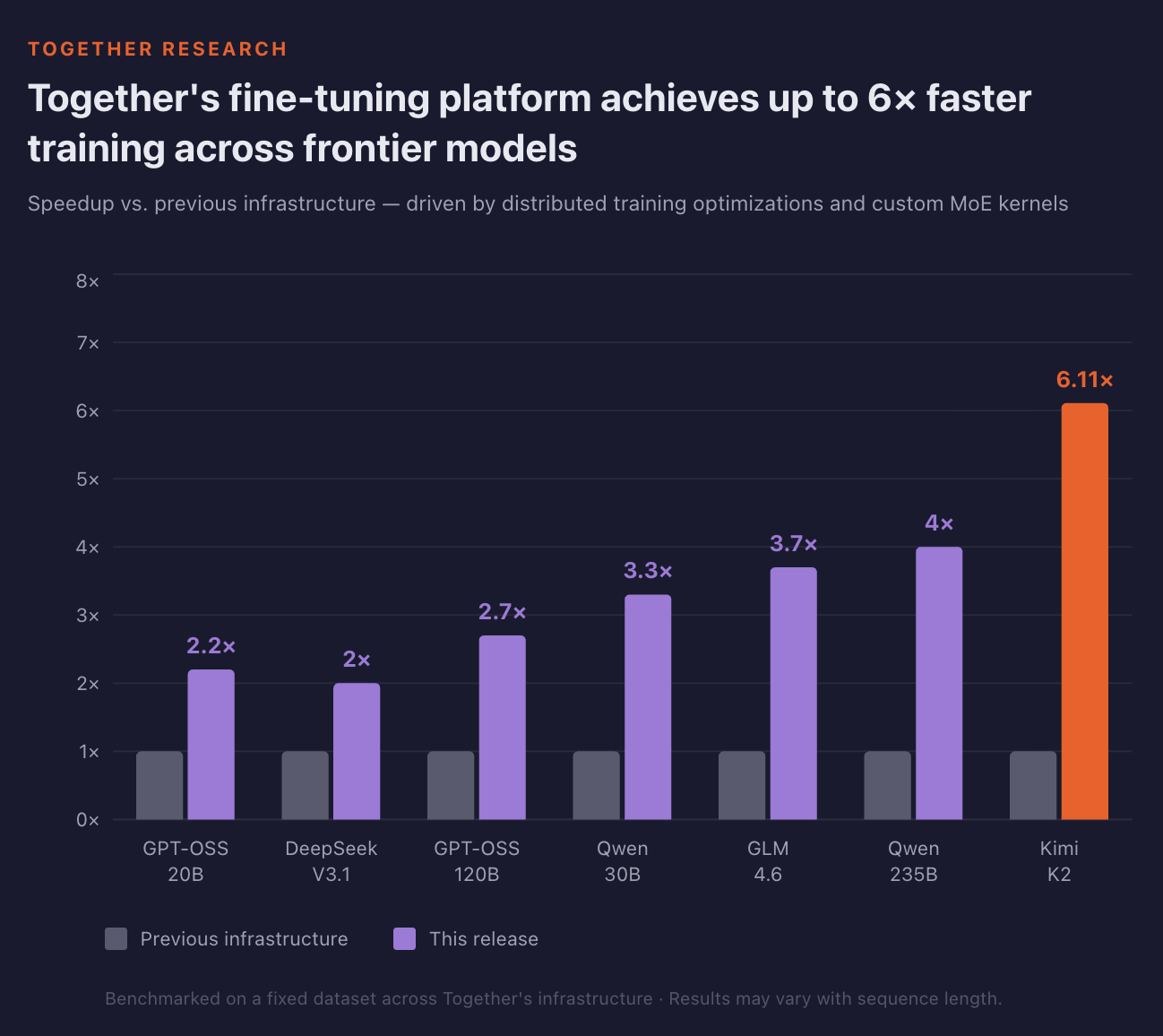
価格と所要時間の見積もり
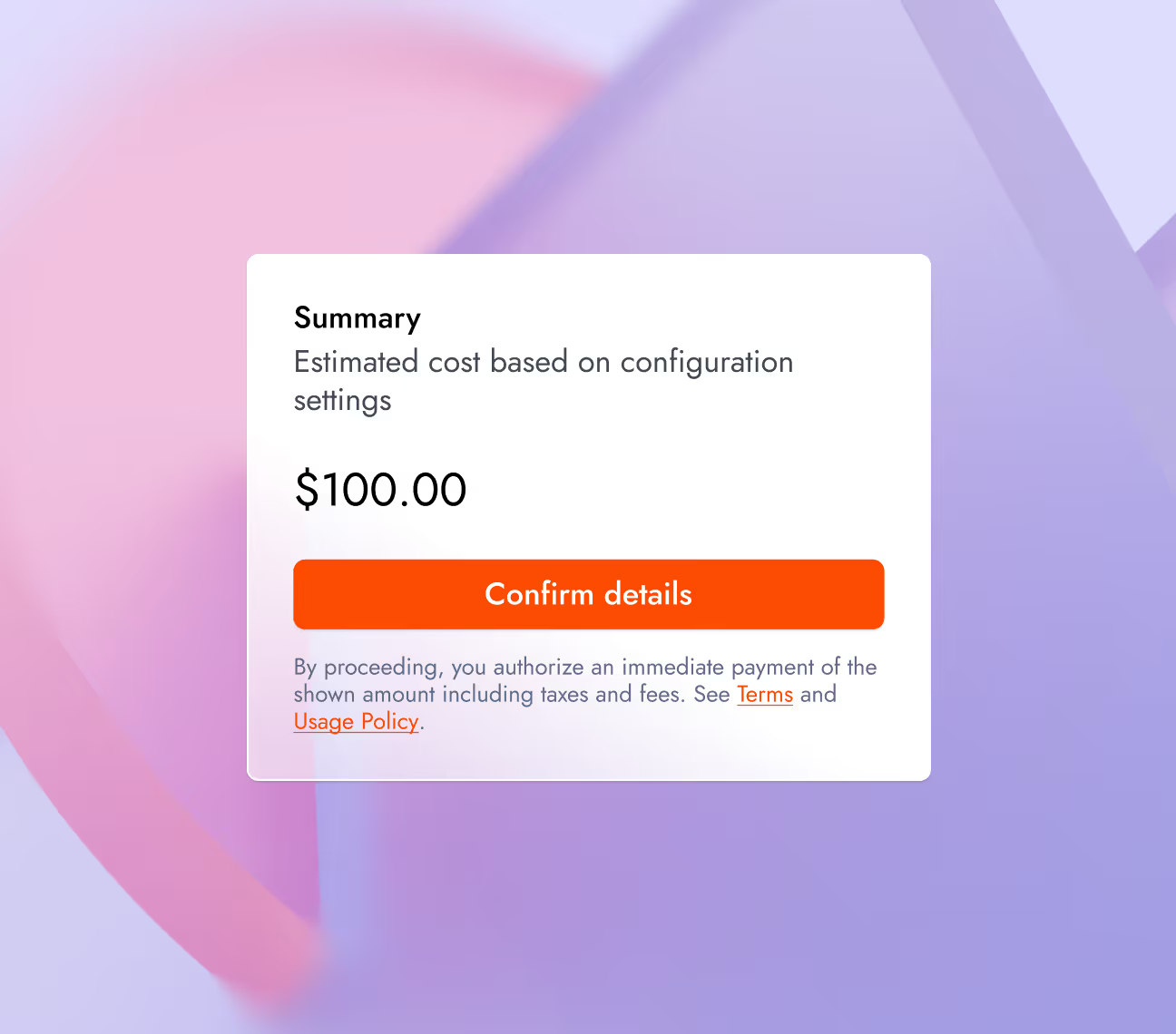
Together Fine-tuning では、ジョブ実行前に UI または CLI からトレーニングコストを見積もることが可能になりました。この価格の透明性により、予算に関する予期せぬ事態を防ぎます。
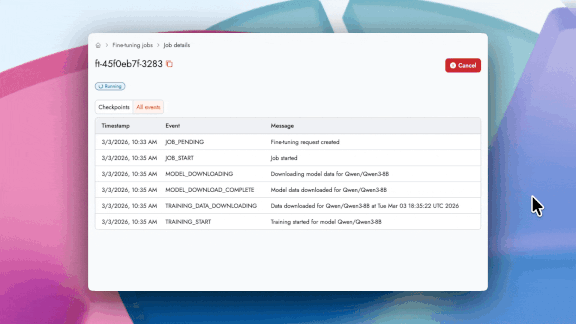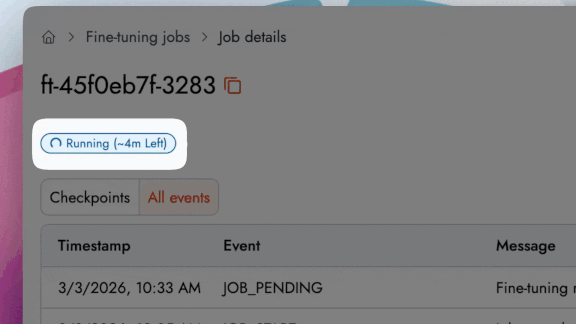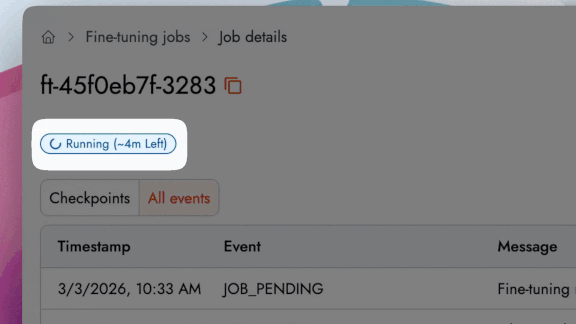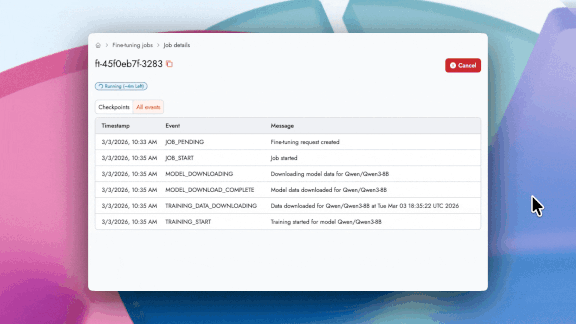
コスト見積もり: コストが発生する前にジョブの実行を開始する前に推定価格を確認し、トレーニングコストを把握できます。
所要時間見積もり: ジョブ実行中に動的に更新される推定完了時刻付きのライブ進行バーで進捗を追跡できます。

8S
DeepSeek R1

ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
パフォーマンスとスケーラビリティ
本文ここに lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
インフラストラクチャ
最適用途
- 処理速度の向上(全体的なクエリレイテンシの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- 関数呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
構築(Build)
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達:500 万ドル未満
構築(Build)
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達:500 万ドル未満
構築(Build)
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達:500 万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグの中に記述してください。推論は以下のルールに従って行ってください:推論を行う際はアラビア語でのみ回答し、他の言語は一切使用しないでください。
ここに質問があります:
ナタリアさんは 4 月に友人 48 人にクリップを販売し、5 月にはその半分の数のクリップを販売しました。ナタリアさんが 4 月と 5 月に合わせて販売したクリップの総数は何個ですか?
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
パフォーマンス & スケーラビリティ
本文コピーはここに lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
インフラストラクチャ
最適な用途
- より高速な処理速度(全体的なクエリレイテンシの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- 関数呼び出し、JSON モード、またはその他の構造化されたタスク
リスト項目 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
構築(Build)
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間の無償利用 3 時間。
資金調達:500 万ドル未満
構築(Build)
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間の無償利用 3 時間。
資金調達:500 万ドル未満
構築(Build)
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間の無償利用 3 時間。
資金調達:500 万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグの中に記述してください。推論は以下のルールに従って行ってください:推論を行う際はアラビア語でのみ回答し、他の言語は一切使用できません。
ここに質問があります:
ナタリアさんは 4 月に友人 48 人にクリップを販売し、5 月にはその半分の数のクリップを販売しました。ナタリアさんは 4 月と 5 月の合計で何個のクリップを販売したのでしょうか?
XX
タイトル
本文はここに lorem ipsum dolor sit amet と続きます
XX
タイトル
本文はここに lorem ipsum dolor sit amet と続きます
XX
タイトル
本文はここに lorem ipsum dolor sit amet と続きます
原文を表示
What’s New
- Tool call fine-tuning: Ensure agents execute structured actions reliably with end-to-end fine-tuning and inference on OpenAI-compatible schema.
- Reasoning fine-tuning: Specialized support for training models on “thinking” tokens in reasoning traces, allowing models to learn complex logic.
- Vision-language model fine-tuning: Native support for vision training to align vision-language models with complex, domain-specific visual data.
- Large model support: train the latest models with up to 1T parameters on our highly optimized and easy-to-use service.
As AI teams move from single-turn prompting to advanced multi-turn workflows, reliability breaks in predictable places: tool calls that don’t match schemas, reasoning that degrades over long interactions, and models that miss domain-specific visual signals. Fixing those issues usually requires post-training, but the workflow is often fragmented, slow to iterate, and hard to plan.
Today, Together AI, the AI Native Cloud, is expanding Together Fine-Tuning with native support for tool call, reasoning, and vision-language model (VLM) fine-tuning. To support frontier-scale post-training, we have also upgraded the training stack to handle 100B+ parameter models more efficiently, delivering up to 6× higher throughput. In addition, we now support fine-tuning on datasets of up to 100GB in size. Finally, we now provide job cost estimations before training and ETA during training, so teams can better plan their experiments.
"Together AI does for fine-tuning and inference what Vercel does for LLM-based apps — it removes the infrastructure layer so we can focus on our product. We fine‑tune and deploy customer‑specific models through simple API calls. That lets our existing team move from weekly to daily iteration, cut costs by 2–3×, and improve accuracy from 77% to 87%." — Lamara De Brouwer, Co-Founder & CTO, XY.AI Labs
Tool Call Fine-tuning
Tool calling is essential to many modern agentic use cases. Yet, out-of-the-box models often struggle with tool calling: hallucinating parameters, selecting incorrect functions, or failing to follow multi-step sequences. In tool calling workflows, even small inconsistencies can cascade into downstream failures.
Our fine-tuning service now delivers an end-to-end solution for reliable, production-grade tool calling, spanning fine-tuning through inference. Tool calls can be included in training data using the OpenAI-compatible schema. Functions are defined in a top-level tools array, and our service validates that every tool_calls entry matches a declared tool, ensuring structurally correct data before training begins.
At inference time, we’ve significantly improved tool call reliability to ensure the benefits of tool call fine-tuning translate into production performance. Enhanced parsing and validation improve correctness across a wide range of real-world use cases, supported by inference tool calling datasets curated from both community contributions and internal research.
Tool-call fine-tuning is available for models from Qwen, Moonshot AI, and Z.AI. See the tool calling documentation to get started. To see an example of tool call functionality in code, take a look at our cookbook.
Reasoning Fine-tuning
Reasoning models generate intermediate thinking traces before producing a final answer, enabling step-by-step reasoning. However, reasoning formats are not standardized across models, introducing complexity into the reasoning fine-tuning process.
Together Fine-tuning now supports fine-tuning directly on thinking traces using a reasoning or reasoning_content field in assistant messages. This lets you train models on domain-specific reasoning patterns while keeping traces structured and reproducible. As with tool calling, we have improved reasoning inference to ensure that fine-tuned capabilities translate into reliable downstream performance.
Reasoning fine-tuning is available for models from Qwen and Z.AI. See our documentation page for supported models and details. For an end-to-end code demo of reasoning fine-tuning, check out our cookbook
Vision-Language Model Fine-tuning
Many AI workflows require models that can interpret image inputs. For domain-specific tasks like medical imaging and eCommerce, vision-language models (VLMs) may need to learn new visual patterns to be effective.
Together Fine-tuning service now supports fine-tuning of vision-language models. Vision training data is provided inline using message content arrays with base64 encoded images. Fine-tuning jobs support hybrid datasets, allowing both image-text examples and text-only examples within the same run.
By default, we freeze the vision encoder and update only the language layers. Setting train_vision=true enables joint training, allowing updates to both the vision encoder and language layers.
VLM fine-tuning is available for models from Qwen, Google, and Meta. See the vision-language documentation for the supported list and usage details. You can also check out our cookbook for vision language fine-tuning here.
Large Model Fine-tuning
As the sizes of open models grow and context windows expand, the underlying training infrastructure has to keep pace. Trillion-parameter models cannot fit on a single node, thus needing careful communication and memory management across multiple machines. Even a single hardware fault during a multi-hour training run can lead to lost progress, and implementing all optimizations and fault tolerance safeguards can be a major investment.
Together Fine-Tuning now supports fine-tuning for the latest open-weights models. Submit a training job, and we handle all necessary optimizations under the hood. New models available for fine-tuning include:
- Qwen 3.5-397B-A17B
- Qwen 3.5-122B-A10B
- Qwen 3.5-35B-A3B
- Qwen 3.5-35B-A3B-Base
- Kimi K2.5
- Kimi K2 (Instruct, Thinking)
- GLM-4.7
- GLM-4.6
View the full list of supported models along with their context lengths in our documentation.
Training Acceleration
In this update, we continued to focus on the highest-impact optimization opportunities in the training stack. Specifically, we targeted mixture-of-experts architectures, as they represent the vast majority of strongest model releases over the past year. To accelerate their training, we integrated a variant of SonicMoE — I/O- and tile-aware optimized kernels that overlap memory operations with computation. Using these kernels in our training workloads significantly reduced the activation memory footprint during training and minimized wasted compute.
We also introduced custom CUDA kernels for loss computation and eliminated several GPU-to-CPU synchronization points in the training loop that were causing unnecessary stalls, significantly improving the overall pipeline efficiency.
As a result, every model saw at least a 2× increase in throughput, with larger models like Kimi-K2 improving by over 6×. Faster training means more experiments per day and a shorter time to production.
Price and Time Estimation
Together Fine-tuning now estimates training costs before a job is executed from the UI or CLI. This price transparency prevents budget surprises.
Cost Estimation: View estimated job price before launching to understand training costs before the cost is incurred.
Time Estimation: Track a live progress bar with an estimated completion time that dynamically updates as the job runs.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み