DeepSeek の 10 兆ドル戦略に関する宝玉氏の解説
記事は、DeepSeek が単なるモデル開発企業ではなく、独自の技術革新を通じて中国の AI ハードウェア生態系を牽引し、10 兆ドル規模の産業と 1 兆ドルの自社時価総額を目指す「英雄の旅」を描く戦略的ビジョンを分析している。
キーポイント
逆走する技術戦略と独自アルゴリズム
DeepSeek は競合が稠密モデルや多機能に注力する中、MoE(混合专家模型)、GRPO 強化学習、RLVR、MTP などの独自技術を駆使し、コスト効率と推論性能の極限を追求している。
ハードウェアリソースの最適化技術
ゼロバブル並列処理や KV キャッシュ削減技術(MLA/DSA 等)、メモリ換算力機能(Engram)などにより、限られた GPU リソースを最大限に活用するインフラ戦略を展開している。
10 兆ドル産業と 1 兆ドル時価総額のビジョン
DeepSeek の真の目的はプログラミングサブスクリプションの販売ではなく、中国全体の AI ハードウェアエコシステムを活性化させ、巨大な産業規模を創出することにある。
オープンソースによる生態系拡大
競合他社が閉鎖的になる中、DeepSeek はロードバランサーや並列処理戦略などを積極的に开源し、業界全体の標準化とコスト低下を促すことで自社の地位を確立しようとしている。
影響分析・編集コメントを表示
影響分析
この分析は、DeepSeek の技術的進歩を単なる性能向上ではなく、中国 AI ハードウェア産業全体の再構築に向けた戦略的動きとして捉え直す視点を提供します。同社のオープンソース戦略と独自アルゴリズムが業界の標準となり、結果的にハードウェア需要やコスト構造に劇的な変化をもたらす可能性を示唆しています。
編集コメント
本記事は、DeepSeek の技術的詳細を列挙するだけでなく、その背後にある「産業生態系全体を支配する」という壮大な戦略意図を浮き彫りにしており、業界の動向を捉える上で非常に示唆に富んでいます。
DeepSeek の 10 兆ドルの壮大なる戦略
著者:GDP (@bookwormengr)**
あなたは考えたことがありますか、DeepSeek は一体どのようにして、そしてどうやって巨額の利益を得るつもりなのでしょうか?
彼らは智譜(GLM)、月之暗面(MoonShot)、MiniMax のように競争力のあるプログラミングサブスクリプションプランを推出していません。また、マルチモーダルや音声、ビデオモデルも持っていません。今日に至るまで、彼らにはまだ評価フレームワーク(Harness、モデルの性能をテスト・評価するためのベンチマークツール**)さえ存在しません(ただし最近、そのための採用活動を開始したという噂はあります)。さらに、DeepSeek は長年にわたりオープンソースに尽力し、自らの「秘伝のレシピ」を惜しみなく共有しています。これは狂気の沙汰なのでしょうか?それとも単なる資金の浪費なのでしょうか?彼らに 100 億ドルの投資を検討している投資家たちは、いったい何をしようとしているのでしょうか?
いいえ、私の見解では、その逆です!!!
ここでは、私がこれまで彼らの行動について観察してきたことと、彼らが実践しているように見える戦略についてお話ししたいと思います。DeepSeek の創業者である梁文鋒の目は明らかに、はるかに大きな最終的な賞杯を捉えています——彼ら自身も 1 兆ドルの時価総額に到達できるだけでなく、中国に 10 兆ドル規模の産業巨人を生み出す手助けさえも行うのです!

DeepSeek の「英雄の旅」を再考する
DeepSeek はいつも風上を向いて進みます。彼らは他社よりわずかに優れるような微調整モデルに執着せず、また現在のアプリケーション(各種プログラミングプランなど)を急いで販売することもありません。私は 2025 年 1 月 27 日、私が目撃した光景について語ったバイラルな投稿を行いましたが、現在のストーリーはますます精彩を帯びています。
- 皆が密結合モデル(Dense Models、すべてのパラメータが計算に参加する従来の大規模言語モデルの構造)に執着している間、DeepSeek はあえて困難に立ち向かい、訓練が極めて難しい混合専門家モデル(MoE, Mixture of Experts)を選択しました。
- 彼らは「第一原理」(First Principles)から出発し、強化学習(RL, Reinforcement Learning)において支配的な地位を占めつつも実装コストが極めて高い PPO アルゴリズムに代わる、全く新しい GRPO アルゴリズムを発明しました。
- 検証報酬に基づく強化学習(RLVR, Reinforcement Learning from Verified Rewards)を開発し、これをモデルの推論能力を向上させる決定的な武器として位置づけました。
- 「マルチトークン予測」(MTP, Multi-Token Prediction)を通じて、優れた投機的デコーディング(Speculative Decoding、大規模モデルの生成速度を加速するために後続単語を予測する技術)戦略を提案し、同時に訓練信号をより密集させました。
- 彼らは完璧な「ゼロバブル」(Zero-Bubble)パイプライン並列化技術を構築し、限られた GPU リソースを限界まで絞り出しました。
- 彼らは専門家負荷分散器(Expert Load Balancer)をオープンソース化し、誰もが容易に混合専門家モデルを展開できるようにしました。特に「ワイド専門家並列」(Wide Expert Parallel)戦略を通じて、モデルは大量バッチで実行可能となり、サービスコストが大幅に削減されました。
- 彼らは MLA、DSA、CSA、HCA など一連の魔改造されたアテンション・メカニズム技術を発明し、KV キャッシュ(大規模モデル推論時に過去の対話記憶を保存するためのビデオメモリ領域)の需要を劇的に削減しました。これにより、文脈が無限に延長される状況でも計算需要はほぼ一定に保たれるようになりました。
- 彼らは Engram(エングラム:印迹モジュール)を発明し、メモリを計算力に変換するという驚くべき操作を実現しました。
- 彼らは mHC(修正超接続)を発明し、モデルの規模が急激に増大する際のトレーニングの安定性という難題を解決しました。この革新のリストはさらに長く続けることができます……
英雄の旅という最も古典的な物語構造において、主人公は当初、自身の究極の使命が何であるかを知りません。彼は道中で苦闘し、徐々に偉大な天命に気づき、あらゆる困難を排除してそれを達成しようとします。その過程で、彼は無数の冷ややかな嘲笑に直面しますが、それらを無視して進みます;彼は意図的に敵対する相手にも遭遇します;彼自身にも致命的な弱点や短所があります——しかし最終的には自己を超え、使命を達成します。彼は乗り越えられないように見える難関に正面から向き合いながら、常に巧妙に同盟を結び、貴重な資源を賢く統合します。これが観客が知らず知らずのうちに主人公のために声援を送る理由です。また、これが DeepSeek が世界中で無数の熱狂的なファンを獲得し尊敬を集める一方で、多くの議論も招いた理由でもあります。
次に、DeepSeek がこの道においてすでに十分に遠くまで到達しており、彼らの究極の宿命を垣間見ていることを詳しく解説します。彼らの視野は単なるプログラミングサブスクリプションの販売などというレベルではなく、10 兆ドル規模の中国 AI ハードウェア・エコシステムを揺さぶり、それによって自社の時価総額を自然と 1 兆ドルに引き上げることにあります。その過程で、彼らは西洋のハードウェア・エコシステムにおける新たなプレイヤーたちにもついでに手を貸すことになるでしょう。
ご意見やご指摘を歓迎します。

まず、面白い KV キャッシュの計算をしてみましょう:
著名な半導体分析機関 @SemiAnalysis_ が発表したこの非常にタイムリーなツイートを振り返ってみましょう。

まずは少し面白い KV キャッシュの数学問題を解いてみましょう。もしあなたが数学が苦手でもご安心ください。私たちは最近公開された KV キャッシュ計算機を使い、DeepSeek V4 Pro が具体的にどれだけの KV キャッシュを節約できるかを確認し、最新の智譜 GLM やアリババ通義千問(Qwen)モデルと比較します。
私は文脈長 100 万(1M)を例に計算を行います。KV の精度は 8 ビット(8-bit)、インデクサーの精度は 16 ビット(16-bit)と仮定してください。ご自身もこちらのサイトで遊んでみてください:
https://kvcache.ai/tools/kv-cache-calculator/
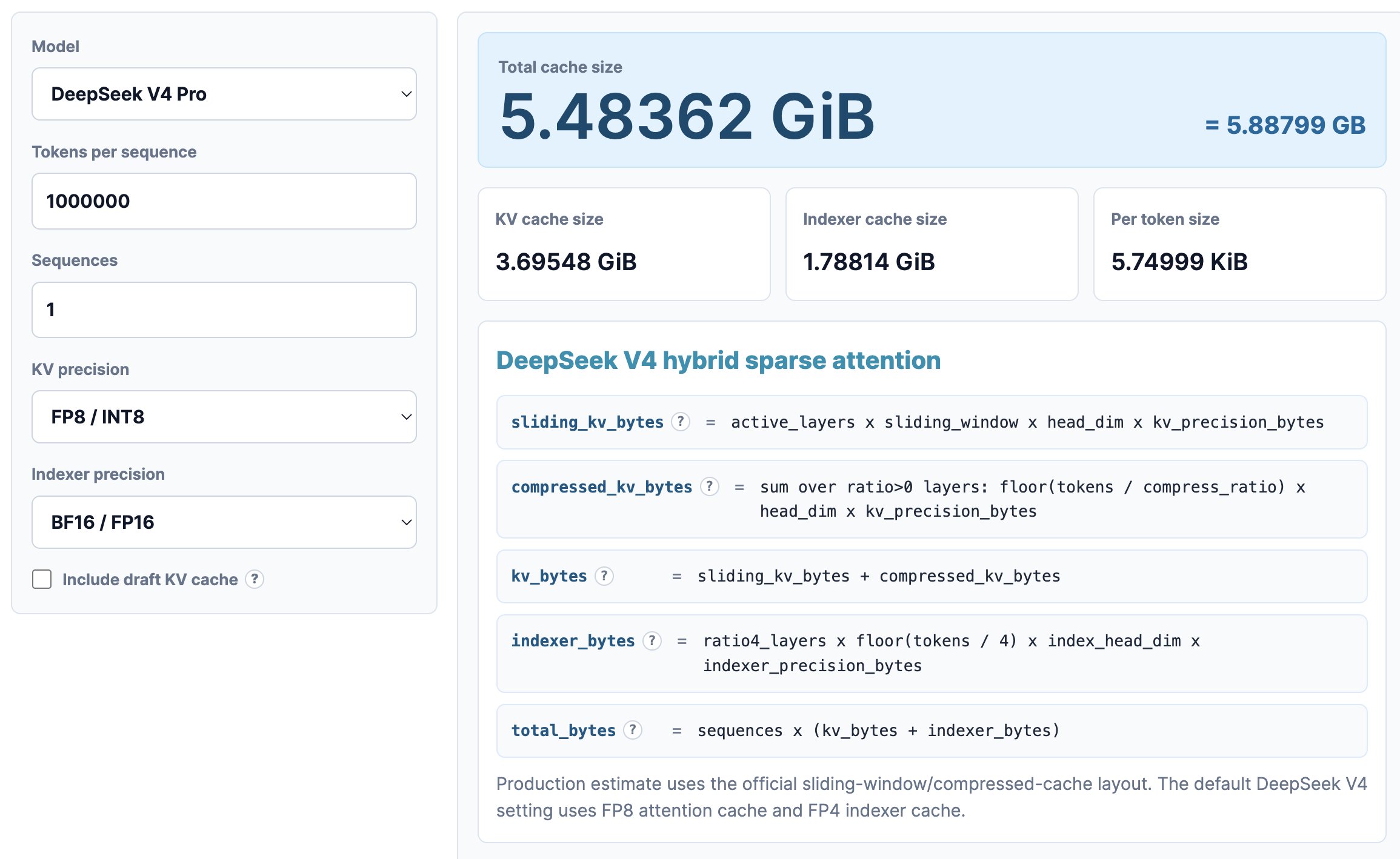
文脈深度 100 万の場合:
- DeepSeek V4 はなんと高帯域幅メモリ(HBM, High Bandwidth Memory:トップクラスの AI グラフィックボードに広く使用される高速ビデオメモリ)をわずか 5.48 GB で済ませます。
- GLM5 では 60 GB の HBM が必要です。
- Qwen3-235B-A22B ではなんと 89 GB のビデオメモリが必要になります!
ただし、これは以下の前提条件のもとでの話です:
- DeepSeek は、1.6 兆(1.6T)パラメータを有する巨大モデルです。
- GLM5 は約 7000 億(700B)パラメータであり、DeepSeek の MLA や DSA 技術をすでに採用していますが、最新の圧縮アテンション機構はまだ使用されていません。
- Qwen3-235B-A22B は 2350 億パラメータのみで、比較的伝統的な GQA(グループクエリアテンション)を採用しています。
DeepSeek は VRAM の負荷軽減において画期的な貢献を果たしました。この革新が業界全体に広く採用されれば、超長文タスクを処理するロングホライズンエージェント(Long-horizon Agents)のコストは信じられないほど低廉となり、次世代の新たなアプリケーションシーンが完全に解放されるでしょう。
狂気の背後にある精密な戦略:
モデルの品質を一切犠牲にすることなく、KV キャッシュ(Key-Value Cache)をこれほどまでに圧縮できることが、彼らがロングヘルドキャッシュ(Long-held Cache)の価格を白菜並みにまで押し下げられる自信の源泉です。その価格は Anthropic 傘下の Claude Sonnet 4.6 のキャッシュヒット価格の 3% に満たず、しかも数時間分の保存を無料で提供してくれます。
長期的なタスクにおいては、キャッシュ量が極めて小さいため、それを SSD(ソリッドステートドライブ)にオフロードし、必要に応じて再読み込みすることが非常に経済的になります。これにより、HBM(ハイバンド幅メモリ)への依存が劇的に低下します。ご承知の通り、現在の HBM は世界的に深刻な供給不足に陥っており、中国の AI ハードウェア産業の観点から見れば、これは製造難度が極めて高い核心的な痛点でもあります。さらに驚くべきことに、DeepSeek は SSD から KV キャッシュを極めて高速で再読み込みする技術も開発しており、その詳細は彼らの論文に記載されています:https://arxiv.org/pdf/2602.21548
この「KV キャッシュ圧縮戦争」の直接的な受益者は誰か?
SSD を大量に供給しているのは誰でしょうか。長江存储(YMTC)が世界の 3D NAND フラッシュメモリ大手として台頭していることを忘れてはいけません。フラッシュ技術(NAND)により、DeepSeek はキャッシュを直接読み込むことが可能になり、毎回 KV の再計算という莫大な計算リソースの浪費を防いでいます。逆に DeepSeek は、NAND フラッシュと SSD 向けに極めて巨大な新市場を創出しており、これは長江存储だけでなく、サプライチェーン全体のすべてのプレイヤーが巨額の利益を得ることを意味します。

しかし、その構図は NAND や SSD に限定されるものではありません:
低功耗内存(LPDDR)同样蕴藏着巨大的潜力,可以用作存放模型权重(Weights)的“大后方”,并在需要时源源不断地“流式传输”到 HBM 中,从而进一步减轻 HBM 的容量压力。你可以参考这篇博客:https://www.lmsys.org/blog/2025-09-25-gb200-part-2/ 。下面我用一张图来解释这套方案是如何运作的:
虽然 DeepSeek 并没有专门针对这一方案做特殊开发,但他们那拥有庞大专家数量、并且支持 4 位(4-bit)权重的混合专家模型架构,完美契合了这套方案,使得其实施起来易如反掌。
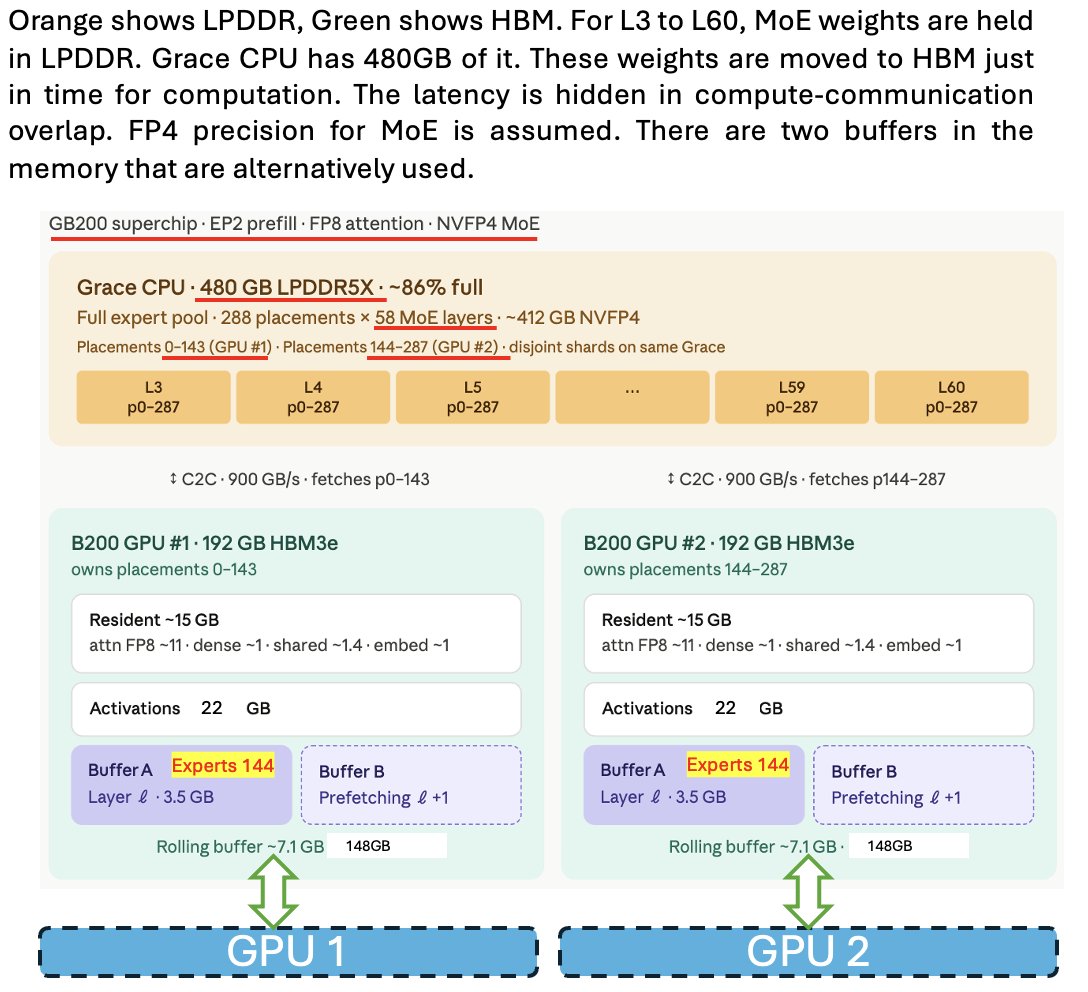
这种创新配合上他们那堪称逆天的无损超紧凑 KV 缓存技术,让系统对 HBM 的吞吐和容量需求出现了断崖式下跌。
中国谁在做 LPDDR?长鑫存储(CXMT)。目前他们在 LPDDR 的速度上仅落后国际顶尖水平半代,在容量密度上仅落后一代。差距非常小!这意味着在不久的将来,除了管够的 NAND 闪存,中国本土生态还将迎来铺天盖地的 LPDDR 内存。那这能缓解算力芯片的压力吗?答案是:绝对能。请接着往下看……

聪明地玩转存储,还能顺手给 GPU 和 ASIC 减负
道理很容易理解:用 NAND 闪存来存放 KV 缓存,不仅能延长缓存的保存时间、减轻 HBM 的压力,还能免去重复计算的烦恼,这等于变相给 GPU 和 ASIC(专用集成电路,即各类定制化 AI 算力芯片)的计算单元松了绑。那么,除了作为模型权重的“即时流式传送带”之外,LPDDR 还能以其他方式帮上忙吗?答案同样是:可以。
LPDDR を用いて、膨大な量の「エングラム(印迹模块)」を保存することが可能です。DeepSeek は彼らの論文(https://arxiv.org/pdf/2601.07372)において、混合専門家モデルアーキテクチャが条件計算(Conditional Computation)によってモデルの容量を拡張できる一方で、従来の Transformer アーキテクチャには本来的な知識検索メカニズムが存在せず、高価な「計算」を通じて無理やり「検索」を模倣するしかない点を指摘しています。そこで彼らはエングラムモジュールを導入し、古典的な N-gram 埋め込み技術を、ハッシュベースで時間計算量が $O(1)$ の瞬間検索へと進化させ、「条件メモリ(Conditional Memory)」と呼ばれる新たな疎次元を創出しました。これにより計算量は劇的に削減されましたが、その代償としてこの膨大な埋め込みテーブルを格納するための巨大なメモリ空間が必要となります。これは典型的な「空間(ストレージ)で時間を(計算)買う」戦略であり、その巧妙さは、「ストレージ」からの読み出しコストが計算を行うコストよりもはるかに安い点にあります(LPDDR 内で検索する方が、大規模モデルを前向き伝播させる一巡を実行するよりも遥かに安上がりです)。大規模展開においては、これは非常に割に合う取引です。これが彼らがメモリへの巨額投資によって計算リソースを節約する秘密です!!!
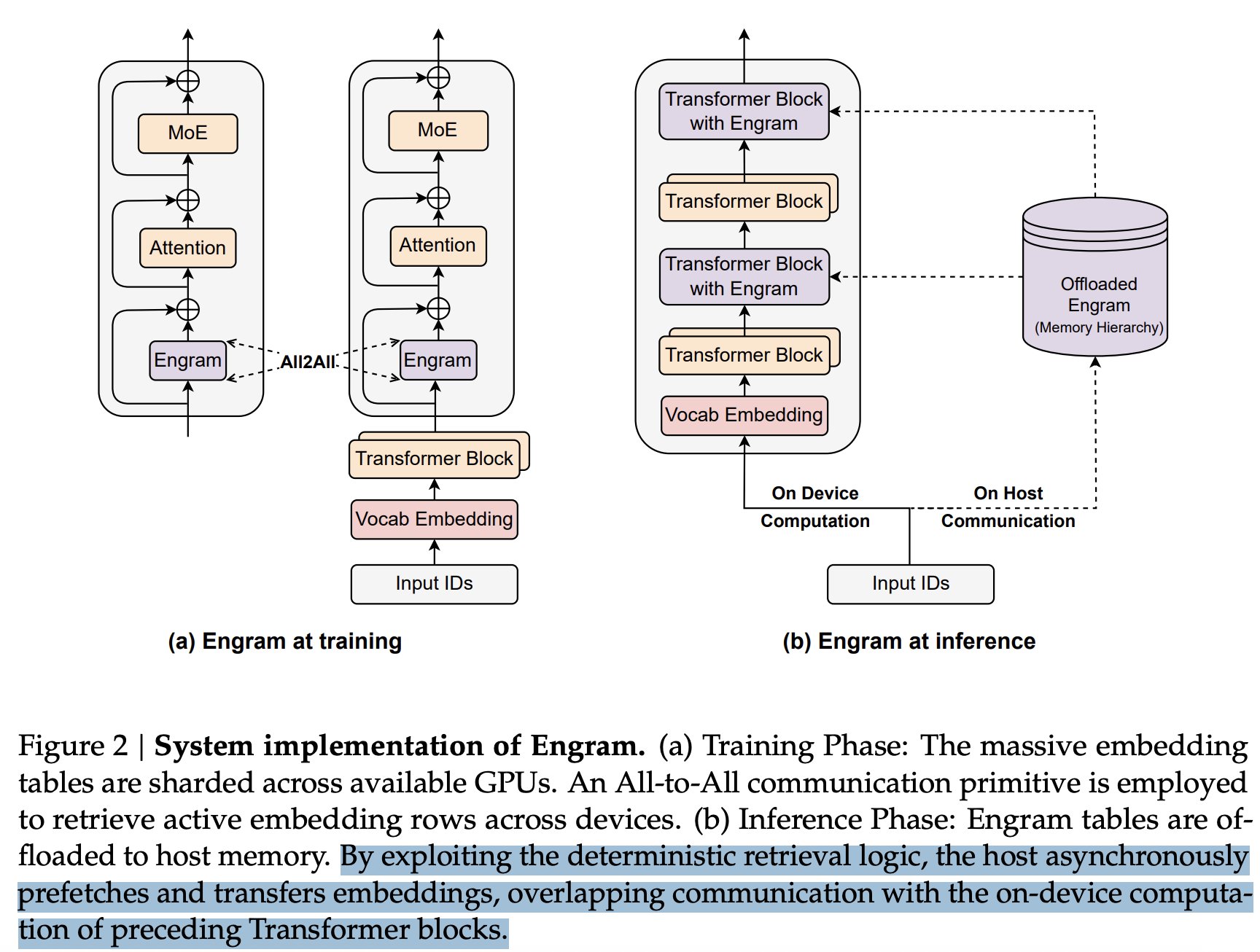
このトレードオフはまさに価値があります:極紫外線リソグラフィ装置(EUV)が不足しているため、単一のチップレット上で同等のトランジスタ密度を実現できず、中国の GPU および ASIC は純粋な原始浮動小数点演算能力(FLOPs)において、長期間にわたり西側の最高峰グラフィックスカードに遅れをとる運命にあります。同時に、国内における先進パッケージング技術も追走段階です。したがって、国内で生産余力が豊富かつ低コストな NAND および LPDDR メモリを活用して計算能力の劣位を補うという、「長所を活かし短所を避ける」戦略はまさに完璧な組み合わせです。
DeepSeek の大いなる棋譜を振り返る:
これらの目を見張るような革新と、彼らが下してきた数々の決断(現時点ではマルチモーダル化も音声モデルの構築も行わず、動画生成に至っては「それは何だ?」という状態)を総覧すれば、DeepSeek の野心が眼前の僅かな数億ドルの利益に留まるものではないことは明らかです。彼らは極めて忍耐強く、西側とは独立した「代替ハードウェアエコシステム」を手取り早く確立することを目的とした、10 兆ドル規模の大棋譜を指し進めています。
これは中国のストレージ半導体メーカーが世界の AI ハードウェア舞台において主力軍へと躍り出ることを可能にするだけでなく、大規模モデルのトレーニングおよび推論におけるリソースのハードルを根本から引き下げます。AI モデルの実行コストが低下すれば、従来は性能がやや劣る国产 GPU/ASIC チップやネットワークスイッチングチップもすべて、「十分で使いやすい」確実な選択肢へと生まれ変わります。さらに、これらのオープンソースによる革新は西側のオープンソースコミュニティにも還元され、英伟达(NVIDIA)への挑戦を試みる西側の半導体スタートアップ企業に新たな光明をもたらすでしょう。
すべての手がかりが一致しています。彼らが業界を震撼させた数々の革新を一つずつ紐解いてみましょう:
- DeepSeek V2 では、混合専門家モデル(MoE)と MLA(Multi-head Latent Attention:多头潜在注意力机制)が導入されました。MoE により、極めて賢いモデルの訓練に必要な計算リソースを 40% から 50% 削減することが可能になりました。また、MLA は KV キャッシュを直接 90% も削減し、キャッシュを SSD に転送する処理を極めて効率的にしました。これらの理念は、彼らが 2024 年 5 月に発表した論文(https://arxiv.org/pdf/2405.04434)で初めて提案されたものです。まさにこれらの技術的強みのおかげで、後に彼らは、トップクラスのクローズドソースモデルに匹敵する DeepSeek V3 を、わずか 2048 枚の性能を制限された H800 GPU だけで訓練することに成功しました。
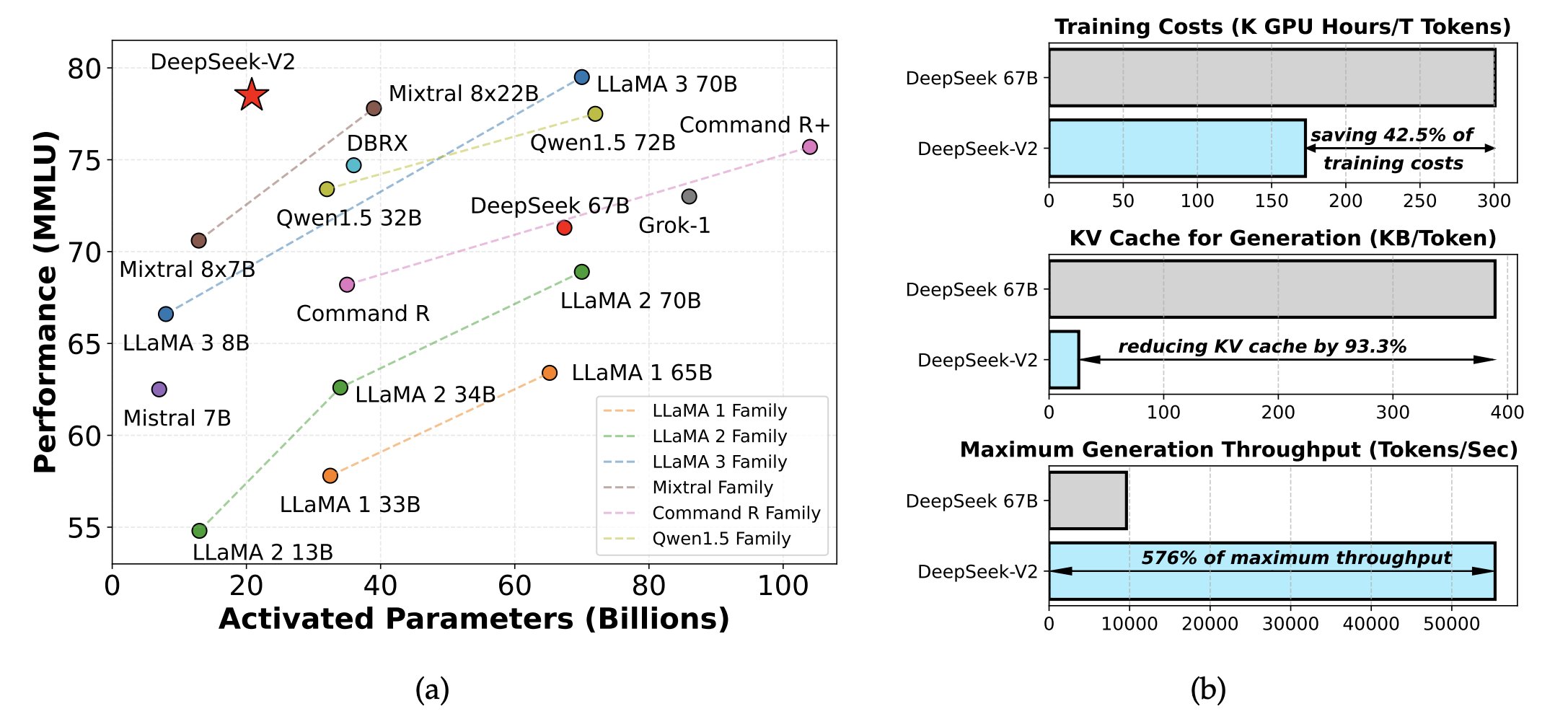
- DSA(密集跳跃注意力机制:Dense Skip Attention)は、論文(https://arxiv.org/pdf/2512.02556)で発表され、長いコンテキスト(文脈)を扱う際の計算量を削減し、同時に HBM の帯域幅への負荷を軽減することを目的としています。これにより、コンテキストが長くなるにつれて計算量が爆発的に増加するのを防ぎます。以下のグラフをご覧ください——DeepSeek-v3.2 は、コンテキストが長くなっても処理時間が依然として安定しています。
- mHC(修正超连接:Modified Hyper-Connections)は、2025 年 12 月の論文(https://arxiv.org/pdf/2512.24880)で初めて登場しました。mHC は DeepSeek におけるマクロアーキテクチャ上の一大革新であり、大規模モデルの各層間の従来の信号伝達方式を根本から覆すものです。従来は ResNet の時代から受け継がれた標準的な残差接続($x + F(x)$)が使われていましたが、mHC はこの残差フローを複数の並列な「情報ハイウェイ」に拡張し、モデル自身がどのように混合するかを学習できるようにしました。最も重要なのは、数学的な手段(混合行列を Sinkhorn-Knopp 射影によって Birkhoff 多胞体上に制約する)を用いて、これらの混合行列が双随机性(doubly stochasticity)を満たすことを強制することで、数学的に完璧に保証している点です。これにより、信号が任意の深さのネットワーク層を通過しても強度が減衰しないことが保証されます。
- これは、以前から無制約超接続(Hyper-Connections:ハイパーコネクション、元々は字节跳动(ByteDance)が発明)に悩まされていた壊滅的な不安定性の問題を完全に解決しました。従来、270 億(27B)パラメータ規模では信号増幅係数が暴走して 3000 倍にも達し、訓練全体が崩壊する事態が発生していました。
- その計算コストは極めて微小です。mHC は注意力層や前馈网络(FFN, Feed-Forward Network:フィードフォワードネットワーク)層の元の浮動小数点演算量には一切変更を加えず、単に出力が各層間をルーティングされる方式を変えただけであるため、実際の訓練時間へのオーバーヘッドはわずか 6.7% のみです。
- しかし、もたらされる性能向上は極めて劇的です。同等のモデルサイズとほぼ同じ計算リソース予算の下で、mHC を採用した 27B パラメータ規模のモデルは、複雑な BIG-Bench Hard 推論テストで 7.2 ポイント急上昇し、DROP 評価では 3.2 ポイント向上、GSM8K 数学テストでは 2.8 ポイント向上、MMLU 総合学問知識では 1.4 ポイント向上しました。
要するに、mHC はネットワークにより豊かで表現力豊かな層間情報ルーティングトポロジーを与えることで、ほとんど追加の計算リソースを費やすことなく、単位パラメータあたりの「知能」を著しく高めることに成功しています。
- CSA と HSA:これらは 2026 年 4 月に発表された DeepSeek V4 Pro の技術ドキュメント(https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf)で登場しました。KV Token を深く圧縮することで、もともと非常に小さい KV キャッシュの需要をさらに 90% も削減!同時に必要な浮動小数点演算量を大幅に減らし、HBM(High Bandwidth Memory:高帯域幅メモリ)や GPU/ASIC を完全に解放する成果を挙げました。
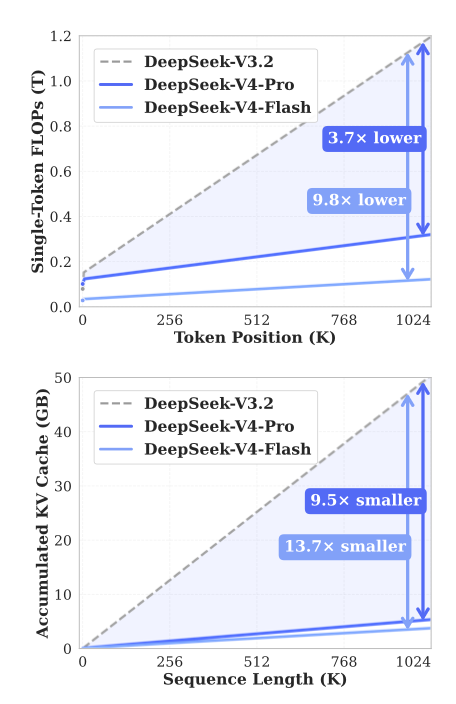
- 論文(https://arxiv.org/pdf/2601.07372)は 2026 年第 1 四半期に発表されました。前述の通り、これはある意味で「メモリ(LPDDR:Low Power Double Data Rate SDRAM)を計算能力と交換する」アプローチを実現したものです。下の詳細なグラフは、全体のパラメータ予算が完全に同一である条件下で、Engram がもたらす劇的な性能向上を示しています。

- 計算と通信の重なりを極限まで引き出す:「デュアルパス(Dual Path)」のような基盤レベルの大幅な改修は、表面上はハードウェア資源の封鎖を回避するためのやむを得ない動きに見えます。しかし DeepSeek はさらに一歩進み、チップハードウェアメーカーの ASIC アーキテクチャ設計に対してさえ指針を示し、いかにして貴重なシリコン資源を一丝たりとも無駄にしないかという設計方法を伝えています。以下のスクリーンショットはまさに DeepSeek V4 Pro の公式ドキュメントからのものです:

- TileLang への集中的な投資:これは明確に、彼らの視点が自社の計算資源不足の課題を超え、中国全体のハードウェアエコシステムが西洋と互角に渡り合える競争力を備えることに注力していることを示しています。高性能計算カーネルを記述するためのオープンソースプログラミング言語である TileLang を用いれば、エンジニアは計算カーネルコードを一度記述するだけで、TileLang バックエンドに対応したあらゆる異なるハードウェアプラットフォーム上でシームレスに実行できます。私は国内の他の AI ラボもまもなくこの陣営に加わるだろうと予測しています——これが中国のハードウェアメーカーを側面から支援し、英伟达(NVIDIA)が数十年かけて築き上げた壊れない「CUDA の壁」(CUDA Moat:NVIDIA が長年苦心して構築した専用並列計算アーキテクチャエコシステムであり、その最も広い城郭である)を迂回する手助けとなるでしょう。同時に、AMD などの西洋の他のハードウェアメーカーも解放されることになります。
注:国内の多くの AI ハードウェアプラットフォーム自体が CUDA 互換性や CUDA コンパイル変換層を提供しています。その中で、モアースレッド(Moore Threads)、沐曦(MetaX)、壁仞(Biren)、天数智芯(Iluvatar CoreX)は、変換層を通じて CUDA との互換性が最も高い中国のチップ企業であり、理論上これらは TileLang の支援を必要としません。

大規模強化学習と自動化科学的研究:
計算ニーズが劇的に低下し、利用可能な国内ハードウェアも多様化する中、DeepSeek はついに、これまで畏怖の念を抱かせていた壮大な訓練計画、特に強化学習段階におけるポストトレーニング(Post-training)に挑戦する余地を得ました。強化学習では膨大な数の思考軌道(Trajectories)を生成する必要があり、その数は数兆トークンに達することさえあります。これは過去において、資金消費のスピードが極めて恐ろしいものでした。さらに、100 万程度のコンテキストをサポートするモデルを訓練するためには、同様の長さの思考軌道を生成しなければなりません。この超長軌道の中でモデルを鍛え上げることで初めて、複雑な長期タスクを解決する能力を真に解放できるのです。
それだけでなく、ハードウェア選択の多様化により、DeepSeek は「自動化人工知能研究」(RSI, Research on Silicon Intelligence、すなわち AI が科学者として振る舞い、自らアルゴリズム実験を設計・実行する自律進化技術)への挑戦に余剰な計算リソースを投入できるようになります。AI 同士が互いに競い合い、自律的に進化するこの模式には多大な試行錯誤が伴い、費用は極めて高額になります。しかし、アルゴリズム設計の未知領域を徹底的に探求するためには、RSI は避けて通れない道です。汎用人工知能(AGI)さらには超人工知能(ASI)への道において、DeepSeek はまずこの RSI という技術ツリーを点灯させなければなりません。
DeepSeek 今日の実証の場、業界明日の教科書:
現在、DeepSeek が混合専門家モデル(MoE)、MLA、DSA に関して行った一連の驚異的な革新は、すでに中国および世界の主要な AI ラボラトリーズによって規範として崇められ、模倣が競われています。
例えば、GLM シリーズモデルを開発した智譜 AI は既に MLA と DSA を採用しています。また、月之暗面(Kimi)も自社の最新アーキテクチャが DeepSeek の進化に基づいていることを率直に認めています。礼尚往来として、DeepSeek も大規模訓練において Muon 最適化器を採用しており、この最適化器の超大规模訓練における威力は、Kimi チームによって最初に発見され証明されたものです。
(*注:*
- 混合専門家モデル(MoE)アーキテクチャは、最先端の学者らにより 2017 年の古典的論文(https://arxiv.org/pdf/1701.06538)で最初に提案されましたが、DeepSeek の功績はそれを前例のない規模へと押し上げ、多数の独自技術を融合させた点にあります。
- Muon(ニュートン・シュルツ動量直交化に基づく)最適化器は、機械学習研究者である Keller Jordan によって 2024 年末に発明されましたが、Kimi チームがこれを超大规模モデル訓練に適用した世界初の事例となりました。)*
ここまでお話ししましたが、結局どうやって大儲けするのでしょうか?
OpenAI の非常に興味深い古典的な事例を見てみましょう。OpenAI は AMD および Cerebras(NVIDIA に挑戦するウェハレベル超大規模チップの新興企業)と協定を結びました。これは、OpenAI がこれらの企業のチップを購入・消費し、特定のマイルストーンに達した時点で、OpenAI がこれらの企業の株式ワラント(Warrants)またはオプションを極めて低い価格で取得できるという内容です。AMD と Cerebras にとって、これは OpenAI という計算資源を貪欲に消費する巨大な存在と深く結びつくことで、長期的な競争において勝つ確率が大幅に高まる、双方に利益のある絶妙取引でした。
AMD の公式プレスリリース(https://www.amd.com/en/newsroom/press-releases/2025-10-6-amd-and-openai-announce-strategic-partnership-to-d.html)によると、「本契約の一環として、両社の戦略的利害を深く結びつけるため、AMD は OpenAI に対し最大で 1 億 6,000 万株の AMD 普通株式に対する行使権(ワラント)を付与しました。これらの株式は、特定のマイルストーン達成に応じて段階的に解放されます。第一段階では、初期導入が 1 ギガワット(GW)の計算能力センターに達した時点で解放され、その後の割合は調達規模が 6 ギガワットまで拡大するにつれて順次解放されていきます……」

私は大胆にも予測しますが、DeepSeek は現在、国内の記憶装置メーカー、ASIC 計算チップメーカー、CPU メーカー、およびネットワークプロトコルスタック(ネットワークプロトコルスタック)関連企業と、同様の賭け契約や利害結合契約を締結している最中です。深い共同最適化を通じて、DeepSeek はこれらの国産ハードウェアが世界最高峰の AI コアワークロードを実行する際にも、真に西洋製ハードウェアの代替となり得るだけでなく、それを凌駕することさえ可能にするでしょう。
現在、西方諸国(その東アジアの同盟国を含む)におけるすべての AI 関連株式の時価総額はすでに 10 兆ドルを超えています。この「技術で株式を交換し、エコシステム支援で利益配分を行う」という巧妙なビジネスモデルを通じて、DeepSeek は中国にも同規模の驚異的なスーパーハードウェア産業を再現するだけでなく、その中で最も肥えた部分を切り取り、自らを 1 兆ドル時価総額のスーパークラブへと導くことになります。
これにより、彼らは単なるサブスクリプションソフトウェアの販売よりもはるかに多くの実利を得られるだけでなく、同時に彼らが口にする「汎用人工知能をすべての人に届ける」という壮大なビジョンも実現することになります。伝説的なクオンツ(定量的分析)の巨匠であるジェームズ・シモンズ(Jim Simons)の熱烈なファンである梁文鋒は、間違いなくトップクラスの賢明な資本家であり、この大盤を逃すはずがありません!
あなたが振り返って DeepSeek 至今までのすべての異様な動きを結びつけて見れば、これがすべてを完璧に説明する唯一の根本的な論理……
これらの根本的な技術革新の詳細な解説記事は、今週末に公開予定です。興味のある方は私の Substack 专栏(サブスタックコラム)をご購読ください:https://polymath707.substack.com/ ...
原文を表示
DeepSeek 的 10 万亿美元宏伟战略
作者:GDP (@bookwormengr)**
标题:DeepSeek's 10 trillion USD grand strategy
你有没有想过,DeepSeek 到底打算怎么赚钱,而且是赚大钱?
他们没有像智谱(GLM)、月之暗面(MoonShot)和 MiniMax 那样推出有竞争力的编程订阅计划。他们没有多模态、语音或视频模型。时至今日,他们甚至连一个评测框架(Harness,用于测试和评估模型性能的基准测试工具**)都没有(虽然最近听说他们开始招人做了)。而且,DeepSeek 还长期致力于开源,乐此不疲地分享自己的“独家秘方”。这难道是疯了吗?还是纯粹在烧钱?那些正准备给他们投资 100 亿美元的投资人们,难道是在把钱往水里扔吗?
不,在我看来,恰恰相反!!!
在这里,我想聊聊我对他们至今所作所为的观察,以及他们似乎正在践行的战略。DeepSeek 创始人梁文锋的眼光显然盯着一个大得多的终极奖杯——他们不仅自己能冲击 1 万亿美元的市值,还能顺便帮中国催生出一个高达 10 万亿美元的产业巨兽!
重新审视 DeepSeek 的“英雄之旅”
DeepSeek 总是逆风而行,他们不屑于去卷那种“比别人好一点点”的微调模型,也不急着去卖当下的应用(比如各种编程套餐)。我在 2025 年 1 月 27 日发过一条疯传的推文,谈到了我所看到的景象,而现在的剧情正变得越来越精彩。
- 当大家都在死磕稠密模型(Dense Models,所有参数都参与计算的传统大模型结构)时,DeepSeek 却迎难而上,选择了极难训练的混合专家模型(MoE, Mixture of Experts)。
- 他们从“第一性原理”(First Principles)出发,发明了全新的 GRPO 算法,取代了在强化学习(RL, Reinforcement Learning)中虽然占据统治地位、但实现成本极高的 PPO 算法。
- 他们摸索出了基于验证奖励的强化学习(RLVR, Reinforcement Learning from Verified Rewards),并将其作为提升模型推理能力的杀手锏。
- 他们通过“多 Token 预测”(MTP, Multi-Token Prediction)提出了一种绝妙的投机解码(Speculative Decoding,一种通过预判后续单词来加速大模型生成速度的技术)策略,同时还让训练信号变得更加密集。
- 他们完美打造了“零气泡”(Zero-Bubble)流水线并行技术,把有限的 GPU 资源压榨到了极致。
- 他们开源了专家负载均衡器(Expert Load Balancer),让所有人都能轻松部署混合专家模型。特别是通过“宽专家并行”(Wide Expert Parallel)策略,模型可以在大批次下运行,使得服务成本大幅降低。
- 他们发明了 MLA、DSA、CSA 和 HCA 等一系列魔改注意力机制的技术,极大地缩减了 KV 缓存(KV Cache,大模型推理时用于存储历史对话记忆的显存空间)的需求,让计算需求在面对无限拉长的上下文时几乎保持恒定。
- 他们发明了 Engram(印迹模块),实现了用内存换算力的神奇操作。
- 他们发明了 mHC(修正超连接),解决了模型体量暴增时的训练稳定性难题。这个创新清单还能一直列下去……
在英雄之旅这个最经典的叙事结构里,主角一开始并不知道自己的终极使命是什么。他是在一路上摸爬滚打,逐渐领悟了伟大的天命,然后排除万难去完成它。在这个过程中,他会遇到无数的冷嘲热讽,但他选择无视;他会遇到不怀好意的对手;他本身也有致命的弱点或短板——但他最终战胜了自我,达成了使命。他直面那些看似无法逾越的难关,却总能巧妙地结盟、精明地整合宝贵的资源。这就是为什么观众会不自觉地为英雄摇旗呐喊。这也是为什么 DeepSeek 在赢得全球无数粉丝狂热追捧和尊敬的同时,也招来了不少争议。
接下来我将为你详细拆解,DeepSeek 在这条路上已经走得足够远,并且已经窥见了他们的终极宿命:他们的格局根本不是卖什么编程订阅,而是去撬动一个价值 10 万亿美元的中国 AI 硬件生态圈,并以此顺理成章地让自己斩获 1 万亿美元的市值。在这个过程中,他们甚至还会顺手帮一把西方硬件生态中的一众新玩家。
欢迎大家探讨与指正。
先来算一笔好玩的 KV 缓存账:
来看看知名半导体分析机构 @SemiAnalysis_ 发布的这条非常及时的推文:
我们先来做点有趣的 KV 缓存数学题。别担心,如果你讨厌数学,我们也只是用最近发布的 KV 缓存计算器,来看看 DeepSeek V4 Pro 到底能省下多少 KV 缓存,并把它跟最新的智谱 GLM 和阿里通义千问(Qwen)模型做个对比。
我以 100 万(1M)上下文长度为例进行计算,假设 KV 精度为 8 位(8-bit),索引器精度为 16 位(16-bit)。你自己也可以去这个网站上玩玩:
https://kvcache.ai/tools/kv-cache-calculator/
在 100 万上下文深度下:
- DeepSeek V4 居然只需要 5.48 GB 的高带宽内存(HBM, High Bandwidth Memory,一种常用于顶尖 AI 显卡的高速显存)。
- GLM5 需要 60 GB 的 HBM。
- Qwen3-235B-A22B 则需要高达 89 GB 的显存!
请注意,这还是在以下前提下:
- DeepSeek 是一个拥有 1.6 万亿(1.6T)参数的巨无霸模型。
- GLM5 大约是 7000 亿(700B)参数,而且它已经借鉴了 DeepSeek 的 MLA 和 DSA 技术,只是还没用上最新的压缩注意力机制。
- Qwen3-235B-A22B 只有 2350 亿参数,使用的是相对传统的 GQA(分组查询注意力机制)。
DeepSeek 在缓解显存压力方面做出了奠基性的贡献。如果这项创新被行业广泛采纳,将让那些需要处理超长任务的长程 AI 智能体(Long-horizon Agents)成本低到难以置信,从而彻底解锁下一代崭新的应用场景。
疯狂背后的精密章法:
能够在完全不牺牲模型质量的前提下,把 KV 缓存压缩得如此之小,正是他们敢把长时缓存(Long-held Cache)价格压到白菜价的底气所在——其价格甚至不到 Anthropic 旗下 Claude Sonnet 4.6 缓存命中价格的 3%,而且他们还能帮你免费保留好几个小时!
对于长程任务来说,由于缓存体量极小,将其“转存”(Offloading)到固态硬盘(SSD)并在需要时重新加载,就变得极为划算。这就大大降低了对 HBM 的依赖。要知道,HBM 目前全球严重短缺,而且从中国 AI 硬件产业的角度来看,这也是制造难度极高的核心痛点。更绝的是,DeepSeek 还开发了一套能从 SSD 中以极高速度重新加载 KV 缓存的技术,具体细节都在他们的论文里:https://arxiv.org/pdf/2602.21548
谁是这场“KV 缓存压缩战”的直接受益者?
谁在大量供应 SSD?别忘了长江存储(YMTC)正在崛起为全球 3D NAND 闪存巨头。闪存技术(NAND)让 DeepSeek 能够直接读取缓存,从而避免了每次都重新计算 KV 的巨大算力浪费。反过来,DeepSeek 正在为 NAND 闪存和固态硬盘创造一个无比庞大的新市场——这不仅让长江存储受益,也让整个产业链所有玩家跟着大赚。
然而,格局绝不仅仅局限于 NAND 和 SSD:
低功耗内存(LPDDR)同样蕴藏着巨大的潜力,可以用作存放模型权重(Weights)的“大后方”,并在需要时源源不断地“流式传输”到 HBM 中,从而进一步减轻 HBM 的容量压力。你可以参考这篇博客:https://www.lmsys.org/blog/2025-09-25-gb200-part-2/ 。下面我用一张图来解释这套方案是如何运作的:
虽然 DeepSeek 并没有专门针对这一方案做特殊开发,但他们那拥有庞大专家数量、并且支持 4 位(4-bit)权重的混合专家模型架构,完美契合了这套方案,使得其实施起来易如反掌。
这种创新配合上他们那堪称逆天的无损超紧凑 KV 缓存技术,让系统对 HBM 的吞吐和容量需求出现了断崖式下跌。
中国谁在做 LPDDR?长鑫存储(CXMT)。目前他们在 LPDDR 的速度上仅落后国际顶尖水平半代,在容量密度上仅落后一代。差距非常小!这意味着在不久的将来,除了管够的 NAND 闪存,中国本土生态还将迎来铺天盖地的 LPDDR 内存。那这能缓解算力芯片的压力吗?答案是:绝对能。请接着往下看……
聪明地玩转存储,还能顺手给 GPU 和 ASIC 减负
道理很容易理解:用 NAND 闪存来存放 KV 缓存,不仅能延长缓存的保存时间、减轻 HBM 的压力,还能免去重复计算的烦恼,这等于变相给 GPU 和 ASIC(专用集成电路,即各类定制化 AI 算力芯片)的计算单元松了绑。那么,除了作为模型权重的“即时流式传送带”之外,LPDDR 还能以其他方式帮上忙吗?答案同样是:可以。
LPDDR 可以用来存储海量的“Engram”(印迹模块)。DeepSeek 在他们的论文(https://arxiv.org/pdf/2601.07372)中指出,虽然混合专家模型架构可以通过条件计算(Conditional Computation)来扩充模型的容量,但传统的 Transformer 架构缺乏一种天然的知识检索机制,只能笨拙地通过高昂的“计算”去模拟“检索”。为此,他们引入了 Engram 模块,将经典的 N-gram 嵌入技术升级为基于哈希、时间复杂度为 $O(1)$ 的瞬间查找,创造了一个他们称之为“条件内存”(Conditional Memory)的全新稀疏维度。这极大地省下了计算量,但代价是需要巨大的内存空间来存放这个庞大的嵌入表。这是一次经典的“用空间(存储)换时间(计算)”,其高明之处在于,读取“存储”的成本远比进行计算要便宜得多(在 LPDDR 里查一下,可比让大模型整整跑一轮前向传播省钱太多了)。在大规模部署时,这是一笔划算到家了的买卖。这就是他们如何通过狂砸内存来省下算力的秘密!!!
这种取舍简直太值了:由于缺乏极紫外光刻机(EUV),无法在单个芯粒(Chiplet)上做到同等的晶体管密度,中国的 GPU 和 ASIC 在纯粹的原始浮点运算能力(FLOPs)上,注定会长期落后于西方顶尖显卡。同时,国内在先进封装技术上也处于追赶状态。因此,如果能利用国内产能充足、成本低廉的 NAND 和 LPDDR 内存来弥补算力的劣势,这种“扬长避短”的打法简直是绝配。
盘点 DeepSeek 的一盘大棋:
纵观这些令人眼花缭乱的创新和他们做出的种种抉择(至今不做多模态、不做语音模型,至于视频生成?那是什么东西?),DeepSeek 的野心显然不是眼前那区区几亿美元的蝇头小利。他们正在极有耐心地下一盘 10 万亿美元的大棋,目的是亲手扶持起一套独立于西方之外的“备选硬件生态”。
这不仅让中国的存储芯片厂商在全球 AI 硬件舞台上跃升为主力军,更从根本上降低了大模型训练和推理的资源门槛。当运行 AI 模型的成本降下来后,原本性能稍逊的国产 GPU/ASIC 芯片以及网络交换芯片也将全部变成“够用、好用”的切实选项。而且,这些开源创新也将反哺西方的开源社区,并给西方那些试图挑战英伟达的芯片初创企业带来一线生机。
所有的蛛丝马迹都对上了。让我们来逐一细数他们抛出的那些震撼行业的创新:
- 在 DeepSeek V2 中引入混合专家模型(MoE)和 MLA:MoE 让训练一个极度聪明的模型减少了 40% 到 50% 的算力消耗;而多头潜在注意力机制(MLA, Multi-head Latent Attention)更是把 KV 缓存直接砍掉了 90%,使得将缓存转存到 SSD 变得极为高效。这些理念最早在他们 2024 年 5 月的论文(https://arxiv.org/pdf/2405.04434)中提出。正是凭借这些绝活,他们后来才能仅仅用 2048 张被阉割过的 H800 GPU,就硬生生训练出了媲美顶级闭源模型的 DeepSeek V3。
- DSA(密集跳跃注意力机制):在论文(https://arxiv.org/pdf/2512.02556)中推出,旨在削减长上下文场景下的计算量,同时缓解 HBM 的带宽压力。它确保了计算量不会随着上下文的拉长而发生爆炸式增长。看看下面的图表——DeepSeek-v3.2 的处理时间在上下文拉长时依然稳如泰山。
- mHC(修正超连接):在 2025 年 12 月的论文(https://arxiv.org/pdf/2512.24880)中首次亮相。mHC 是 DeepSeek 在宏观架构上的一大创新,它彻底颠覆了大模型各层之间传统的信号传输方式。过去大家都在用自 ResNet 时代流传下来的标准残差连接($x + F(x)$),而 mHC 则把这条残差流扩展成了多条并行的“信息高速公路”,并允许模型自主学习如何进行混合。最为关键的是,它通过数学手段(将混合矩阵通过 Sinkhorn-Knopp 投影约束在 Birkhoff 多胞形上)强制让这些混合矩阵满足双随机性,从而在数学上完美确保了信号强度在穿过任意深度的网络层时都不会衰减。
- 这彻底解决了此前困扰无约束超连接(Hyper-Connections,最早由字节跳动发明)的灾难性不稳定难题——此前在 270 亿(27B)参数规模下,信号放大系数会疯狂飙升到 3000 倍,导致整个训练彻底崩盘。
- 而它的计算成本却微乎其微:由于它完全没有改变注意力层或前馈网络(FFN, Feed-Forward Network)层的原始浮点运算量,仅仅改变了输出在各层之间的路由方式,因此它只增加了区区 6.7% 的实际训练时间开销。
- 然而它带来的性能提升却极为震撼:在同等模型大小和几乎完全相同的算力预算下,27B 规模的模型在 mHC 的加持下,在复杂的 BIG-Bench Hard 推理测试中暴涨了 7.2 分,DROP 评测提升 3.2 分,GSM8K 数学测试提升 2.8 分,MMLU 综合学科知识提升 1.4 分。
简而言之,mHC 通过给网络赋予一套更丰富、更有表现力的跨层信息路由拓扑结构,在几乎不需要额外多花一丁点算力的情况下,让单位参数发挥出了显著更高的“智商”。
- CSA 与 HSA:在 2026 年 4 月发布的 DeepSeek V4 Pro 技术文档(https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf)中亮相。它们通过对 KV Token 进行深度压缩,把本来就已经很小的 KV 缓存需求又砍掉了 90%!同时大幅降低了所需的浮点运算量,一举帮 HBM 和 GPU/ASIC 彻底解套。
- 论文(https://arxiv.org/pdf/2601.07372)于 2026 年第一季度推出,正如前面所说,它在某种意义上实现了“用内存(LPDDR)换算力”。下面的详细图表展示了在总体参数预算完全一致的情况下,Engram 带来的巨大性能跃升。
- 将计算与通信的重叠压榨到极致:诸如“双路径”(Dual Path)这样的底层魔改,表面上看是为了绕过硬件资源的封锁而被迫进行的闪转腾挪。但 DeepSeek 更进一步,甚至开始反过来对芯片硬件厂商的 ASIC 架构设计指点迷津,告诉他们如何设计芯片才能避免浪费哪怕一丝一毫宝贵的硅片资源。以下截图正是出自 DeepSeek V4 Pro 的官方文档:
- 对 TileLang 的重度投入:这明确无误地表明,他们的目光早已超越了自家算力紧缺的困境,而是致力于让整个中国硬件生态具备与西方掰手腕的竞争力。有了 TileLang(一种用于编写高性能算力内核的开源编程语言),工程师只需要编写一次算力内核代码,就能在任何适配了 TileLang 后端的不同硬件平台上无缝跑起来。我预计国内其他 AI 实验室很快也会纷纷加入这个阵营——这将合力帮助中国硬件厂商从侧面解围,绕开英伟达坚不可摧的“CUDA 壁垒”(CUDA Moat,英伟达苦心经营数十年的专用并行计算架构生态,是其最宽的护城河)。同时,这也能顺便解放 AMD 等西方的其他硬件厂商。
注:国内许多 AI 硬件平台本身也提供 CUDA 兼容性或 CUDA 编译转换层。其中,摩尔线程、沐曦、壁仞和天数智芯是通过转换层实现与 CUDA 兼容度最高的几家中国芯片公司,理论上它们不需要 TileLang 的协助。
大规模强化学习与自动化科学研究:
随着计算需求的断崖式下降,以及可供选择的本土硬件变得越来越多,DeepSeek 终于能够放开手脚,去挑战那些此前让人望而却步的宏大训练计划——尤其是强化学习阶段的后训练(Post-training)。强化学习需要生成海量的思考轨迹(Trajectories),动辄就会产生数万亿的 Token,这在过去烧钱速度极其恐怖。此外,要训练出支持 100 万上下文的模型,你就必须生成同样长度的思考轨迹。只有让模型在这种超长轨迹中经受锤炼,才能真正解锁解决复杂长程任务的能力。
不仅如此,硬件选择的多元化将让 DeepSeek 拥有富余的算力去冲击“自动化人工智能研究”(RSI, Research on Silicon Intelligence,即让 AI 充当科学家,自己设计并执行算法实验的自主进化技术)。这种让 AI 左右互搏、自主进化的模式伴随着大量的试错,耗资极度高昂。但如果想要彻底探寻整个算法设计的未知空间,RSI 是必经之路。在通往通用人工智能(AGI)乃至超级人工智能(ASI)的道路上,DeepSeek 必须先点亮 RSI 这颗科技树。
DeepSeek 今日的试金石,行业明天的教科书:
如今,DeepSeek 围绕混合专家模型、MLA、DSA 的一连串疯狂创新,早已被中国乃至全球的各大 AI 实验室奉为圭臬并争相抄作业。
比如,打造了 GLM 系列模型的智谱 AI 已经用上了 MLA 和 DSA;月之暗面(Kimi)也大方承认自家的最新架构正是基于 DeepSeek 的演进。作为礼尚往来,DeepSeek 在大规模训练中也采用了 Muon 优化器,而该优化器在超大规模训练中的威力,正是被 Kimi 团队首先发掘并证明的。
(*注:*
- 混合专家模型(MoE)架构最早由顶尖学者在 2017 年的经典论文(https://arxiv.org/pdf/1701.06538)中提出,而 DeepSeek 的功劳在于成功将其推向了前所未有的庞大规模,并融入了大量自研的独门绝技。*
- Muon(基于牛顿 - 舒尔茨动量正交化)优化器由机器学习研究员 Keller Jordan 于 2024 年底发明,而 Kimi 团队则是全球第一个将其应用到超大规模模型训练中的吃螃蟹者。)*
说了这么多,那到底怎么赚大钱呢?
我们可以看看 OpenAI 一个非常有趣的经典案例。OpenAI 曾与 AMD 以及 Cerebras(一家挑战英伟达的晶圆级超大芯片初创公司)达成协议:随着 OpenAI 采购并消耗这两家公司的芯片达到特定里程碑,OpenAI 就能以极低的价格获得这两家公司的股票认股权证(Warrants)或期权。这对于 AMD 和 Cerebras 来说是一笔双赢的绝妙交易——有了 OpenAI 这头吞噬算力的巨兽深度绑定,它们在长跑中胜出的概率大增。
根据 AMD 官方发布的新闻稿(https://www.amd.com/en/newsroom/press-releases/2025-10-6-amd-and-openai-announce-strategic-partnership-to-d.html):“作为协议的一部分,为了深度绑定双方的战略利益,AMD 已向 OpenAI 授予了高达 1.6 亿股 AMD 普通股的认股权证。这些股权将随着特定里程碑的达成而逐步解锁。第一阶段将在初始部署达到 1 吉瓦(GW)算力中心时解锁,随后的份额将随着采购规模扩大至 6 吉瓦而陆续解锁……”
我大胆预测,DeepSeek 目前正在与国内一众存储、ASIC 算力芯片、CPU 以及网络协议栈厂商签署类似的对赌与利益绑定协议。通过深度联合调优,DeepSeek 将帮助这些本土硬件在运行全球最顶尖的 AI 核心工作负载时,真正做到平替、甚至超越西方硬件。
眼下,西方(包括其东亚盟友)所有 AI 概念股的总市值早已突破了 10 万亿美元。通过这种“用技术换股权、用生态扶持分蛋糕”的精妙商业模式,DeepSeek 不仅能在中国复制出一个同样体量惊人的超级硬件产业,还能在其中切下最肥美的一块蛋糕,进而将自己送入 1 万亿美元市值的超级俱乐部。
这不仅能让他们赚到比卖什么订阅软件多得多的真金白银,还能顺便实现他们口中“让通用人工智能惠及每一个人”的宏伟愿景。梁文锋作为传奇量化大师詹姆斯·西蒙斯(Jim Simons)的铁杆粉丝,绝对是一位顶级聪明的资本家,他绝不可能漏掉这盘大棋!
只要你回过头把 DeepSeek 至今为止所有的反常举动串联起来,这就是唯一能完美解释一切的底层逻辑……
关于这些底层技术创新的详细拆解长文将在本周末发布,感兴趣的朋友欢迎关注我的 Substack 专栏:https://polymath707.substack.com/ ...
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み