Together AIでリアルタイム音声エージェントを構築
Together AIは、STT、LLM、TTSを同一クラウド上に共置することで500ms未満の超低遅延を実現するリアルタイム音声エージェント構築ソリューションを発表した。
キーポイント
共置アーキテクチャによる超低遅延
STT、LLM、TTSを同一クラウドクラスター内に配置し、ベンダー間のネットワークホップを排除することで、ユーザー発話終了から音声出力開始までのエンドツーエンド遅延を500ms未満に達成した。
主要モデルのネイティブ統合
音声合成(TTS)にはCartesia Sonic-3、音声認識(STT)にはDeepgramのモデルをTogether AIインフラ上でネイティブにホストし、ビルダーへの選択肢を広げた。
エンタープライズ対応のセキュリティと簡素化
API、課金、デプロイメントを一元化し、ゼロデータ保持、SOC 2 Type II、HIPAA準拠、および専用データレジデンシーを提供することで、企業向けの安全な運用環境を整備した。
重要な引用
Together AI, the AI Native Cloud, announced a full suite of capabilities for building real-time voice agents — co-located STT, LLM, and TTS on one cloud, eliminating inter-vendor network hops for end-to-end pipeline latency under 500ms
Cartesia Sonic-3 (TTS) and Deepgram (STT) are now natively hosted on Together infrastructure, expanding model choice on the co-located stack
One API, one billing surface, one deployment surface — with zero data retention, SOC 2 Type II, HIPAA, and dedicated data residency for enterprise deployments
影響分析・編集コメントを表示
影響分析
この発表は、リアルタイム音声AIの実装における「遅延」と「セキュリティ」のトレードオフを解消する重要な進展である。特に、STT-LLM-TTSのパイプライン全体を単一クラウド内に閉じるアーキテクチャは、分散システム固有のネットワーク遅延を排除し、対話型AIの実用性を大幅に高める。これは、VoIPやカスタマーサポートなどの低遅延が必須な分野におけるインフラ標準の再定義につながりうる。
編集コメント
Together AIは、分散型スタックの課題を「共置」というインフラ最適化で解決するアプローチを示した。500msという数値は対話体験の質を左右する閾値であり、セキュリティ要件を満たしながらこれを達成した点は実装側にとって大きな価値を持つ。
概要
- AI ネイティブクラウドである Together AI は、リアルタイム音声エージェントの構築に向けた完全な機能スイートを発表しました。これは、STT(音声認識)、LLM(大規模言語モデル)、TTS(テキスト読み上げ)を同一クラウド上に配置し、エンドツーエンドのパイプライン遅延を 500 ミリ秒未満に抑えるために、ベンダー間のネットワークホップを排除するものです。
- Cartesia Sonic-3(TTS)および Deepgram(STT)が Together のインフラ上でネイティブにホストされるようになり、共配置スタックにおけるモデルの選択肢が拡大しました。
- 1 つの API、1 つの課金画面、1 つのデプロイ画面を提供。データ保持はゼロであり、SOC 2 Type II、HIPAA に準拠し、エンタープライズ向けデプロイには専用データレジデンシーも利用可能です。
このブログを読む代わりにアシスタントと話したい場合は、(847) 851-4323 へお電話ください。モデルや価格設定、音声エージェントのデプロイ方法についてアシスタントにお尋ねください。その後、話している最中に割り込んでみてください。このデモはリアルタイムのターンテイク(やり取り)を想定しており、応答が会話のように感じるほど高速です。このような体験を提供することは、断片化された音声スタックでは困難ですが、Together AI はまさにそのために生産規模で構築されています。
本日、AI ネイティブクラウドである Together AI は、共配置された STT(音声認識)、LLM(大規模言語モデル)、TTS(テキスト読み上げ)インフラ上でリアルタイム音声エージェントを構築するための業界初の統合ソリューションを提供する完全な機能スイートを発表しました。Together は、音声スタック全体を 1 つのクラウド上に維持することで、遅延を削減し、デプロイを簡素化し、信頼性を向上させます。また、Cartesia(TTS)および Deepgram(STT)からの業界をリードする音声モデルとのネイティブ統合を通じて、ビルダー向けの選択肢もさらに増やしました。
生産環境の音声システムでは、通常、チームは速度、モデル選択、運用安定性の間でトレードオフを迫られます。Together の統一型ソリューションはこのトレードオフを排除するために構築されています:ライブ通話のための低遅延インフラ、音声スタック全体にわたる柔軟なモデルサポート、そしてプロバイダー間での再構築なしに評価からデプロイまでチームをサポートする安全で本番環境対応のプラットフォームです。
アーキテクチャ:統一型モジュール型 vs 複数プロバイダースタック
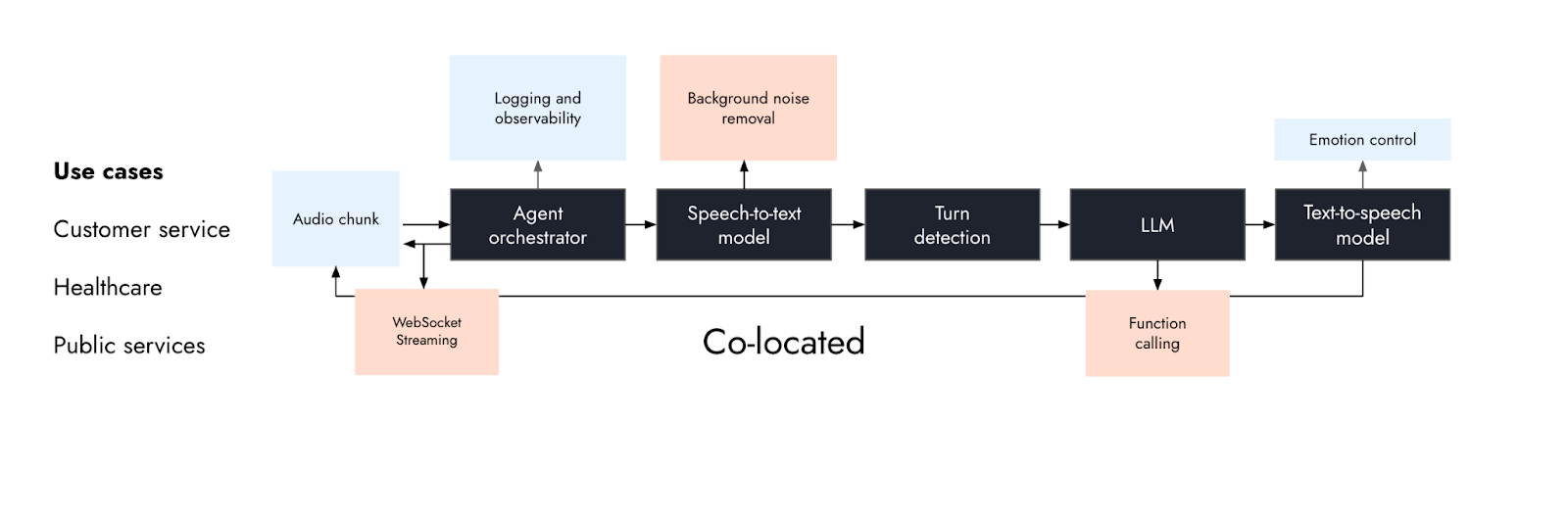
先ほどお呼びいただいたデモがリアルタイムであるのは、そのハンドオフを一つの Together AI クラスター内に維持し、通話者への往復遅延を低く保つリージョンから提供されているからです。すべてのコンポーネント(STT、LLM、TTS)は、専用エンドポイントで予備温められたキャパシティ上で動作しており、ユーザーの発話終了から最初の音声トークンまでのエンドツーエンド遅延は 500 ミリ秒未満です。
複数のベンダーにまたがる音声パイプラインを構築する場合、通常はオーディオとテキストを公開インターネット経由で個別の STT、LLM、TTS システム間でルーティングする必要があります。各ハンドオフは遅延を追加し、運用複雑性を高め、本番環境でのスタック管理を困難にします。Together AI の統一型モジュール型アーキテクチャは、STT、LLM、TTS を同じクラスター内に共置し、エンドユーザーに近いリージョンから提供することで、このオーバーヘッドを排除するように設計されています。
このアーキテクチャが重要である理由は三つあります:
- Speed: Voice agents は通常、STT(音声認識)、LLM(大規模言語モデル)、TTS(音声合成)が複数のクラウドプロバイダ間でオーディオとテキストをハンドオフする際に速度が低下します。ベンダー間のネットワークホップがパイプラインの各段階で遅延を追加し、リアルタイム会話の維持を困難にします。Together はこれらのハンドオフをパブリックインターネットではなくローカルデータセンター内のネットワーク上で実行することで、エンドツーエンドの遅延を 500 ミリ秒未満に抑え、自然なターンテイクに必要な応答性を可能にしています。
- Flexibility: モデルの柔軟性には選択肢が必要です。Together は、文字起こし、推論、合成のための主要な音声モデルを単一の場所でホストしており、チームが各ユースケースに必要なスタックを構成するための速度と制御権を提供します。また、不透明な音声対音声システムとは異なり、Together のモジュラー設計により、中間のトランスクリプトや応答テキストへのアクセスが維持されるため、チームは独自アプリケーションロジックの一部としてストリーミング中にデータを検査・修正・ルーティングできます。
- Reliability: 本番環境では信頼性が求められます。Together のゼロトラストアーキテクチャは機密性の高い音声データ向けに設計されており、その簡素化されたエンドツーエンドの管理体験により、複数のベンダーから異なるソリューションを接続する複雑さが排除されます。フルパイプラインを単一プラットフォーム上で実行することで、チームは 1 つの API、1 つの認証レイヤー、1 つの課金サーフェス、そして統合されたメトリクスを得られ、運用オーバーヘッドが削減され、遅延が低減し、本番環境でのコスト予測性が向上します。
エンタープライズ向けデプロイメントでは、データ保持ゼロ、SOC 2 Type II、HIPAA、および専用データレジデンシオプションを含む厳格な要件をサポートするようにプラットフォームは構築されています。
単一プラットフォームにおけるモデルの選択
チームは、スピードや表現豊かな音声合成、あるいはボイスクローニングのために、異なるプロバイダを無理やり組み合わせることで対応することが多く、その結果、インフラが脆弱なマルチベンダーのパッチワーク化してしまいます。Together AI はこれに代わり、単一のモデル非依存プラットフォームを提供します。開発者は必要な STT(音声認識)、LLM(大規模言語モデル)、TTS(テキスト読み上げ)のスタックを正確に構成でき、統合を再構築することなくモデルを切り替えることが可能です。
一つのプラットフォームを通じて、チームは Whisper Large v3、Minimax Speech 2.6 Turbo、Rime Arcana、Kokoro、そして Together の LLM カタログ全体を介して音声やテキストをルーティングできます。サポートされているモデルの完全なカタログは、当社の STT および TTS のドキュメントでご覧ください。
モデルライブラリの拡大のため、私たちは Deepgram(STT)および Cartesia (TTS) 向けのネイティブ統合をリリースします。これらのモデルを Together AI 上で直接ホストすることで、チームは業界最高水準の文字起こしと音声合成を利用できながら、すべてのハンドオフをコロケーションされたスタック内で安全に維持することが可能になります。
Cartesia は、Sonic-3 と Sonic-2 をプラットフォームに導入し、音声エージェントおよび本番環境での展開用に特別に設計された、表現力豊かで超低遅延のテキスト読み上げ(TTS)を提供します。
「Cartesia では、リアルタイムで表現豊かな音声 AI の限界を押し広げることに情熱を注いでいます。Together AI と連携することで、次世代の音声アプリケーションを開発するより多くの開発者にこの技術をもたらせることを嬉しく思います。」— Arjun Desai、Cartesia 共同創設者
Deepgram は、Nova-3、Nova-3 Multilingual(音声認識:STT)、Flux(会話型 STT)、そして Aura-2(テキスト読み上げ:TTS)をプラットフォームに導入し、リアルタイムの文字起こしからエンタープライズグレードの音声合成に至るまで、あらゆるニーズをカバーします。
「音声エージェントは遅延によって成り立つか破綻するかです。プロバイダー間のネットワークホップ一つひとつが、体験が崩壊する場所となり得ます。Deepgram の STT を Together AI のインフラ上でネイティブにホストすることで、開発者には妥協のない本番環境向けの文字起こしを提供しています。高速で正確であり、パイプラインの他の要素と同じ場所に配置されています。」— Abe Pursell、Deepgram 提携担当バイスプレジデント
Voice agent in production: Decagon
Decagon は、このスタック上で コンシェルジュ音声エージェント を本番環境で稼働させています。同社のエージェントは、請求に関する問い合わせの解決やアカウント情報の更新管理、技術的なトラブルシューティングの実行など、複雑なエンタープライズ顧客サポートワークフローを大規模に処理します。これらの環境では、自然な顧客体験を維持するために、文字起こしの精度、低遅延、およびインフラの稼働率が極めて重要です。Together AI 上でパイプラインを実行することで、流れるような会話に必要な厳格な遅延バウンドを提供しつつ、中間の文字起こしテキストと応答テキストに対する Decagon の制御権を維持することができます。

8S
DeepSeek R1

ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
DeepSeek R1
8S
Audio Name
Audio Description
0:00
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
インフラストラクチャ
最適な用途
- より高速な処理速度(全体的なクエリレイテンシの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
構築
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達: 500 万ドル未満
構築
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達: 500 万ドル未満
構築
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間無償 3 時間。
資金調達: 500 万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグの中に配置してください。推論は以下のルールに従って記述してください:推論を行う際はアラビア語でのみ回答し、他の言語は一切使用できません。以下が質問です:
Natalia は 4 月に友人 48 人にクリップを販売し、その後 5 月にはその半分の数のクリップを販売しました。Natalia は 4 月と 5 月の合計で何個のクリップを販売したでしょうか?
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet
XX
タイトル
本文コピーはここに lorem ipsum dolor sit amet
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
DeepSeek R1
8S
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えたプレミアムなシネマティックビデオ生成。
パフォーマンス & スケーラビリティ
本文コピーはここに lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
インフラストラクチャ
最適な用途
- より高速な処理速度(全体的なクエリレイテンシの低減)と運用コストの削減
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
構築
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間の無償利用 3 時間。
資金調達: 500 万ドル未満
構築
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間の無償利用 3 時間。
資金調達: 500 万ドル未満
構築
含まれる特典:
- ✔ プラットフォーム無料クレジット最大 15,000 ドル*
- ✔ フォワードデプロイされたエンジニアリング時間の無償利用 3 時間。
資金調達: 500 万ドル未満
ステップバイステップで考え、最終的な答えのみを *<answer>* と *</answer> のタグの中に配置してください。推論は以下のルールに従って記述してください:推論を行う際はアラビア語でのみ回答し、他の言語は一切使用できません。
ここに質問があります:
ナタリアは 4 月に友人 48 人にクリップを販売し、その後 5 月にはその半分の数のクリップを販売しました。ナタリアが 4 月と 5 月の合計で販売したクリップの数は何ですか?
XX
タイトル
本文コピーはここにロレム・イプサム・ドロール・シット・アメト
XX
タイトル
本文コピーはここにロレム・イプサム・ドロール・シット・アメト
XX
タイトル
本文コピーはここにロレム・イプサム・ドロール・シット・アメト
原文を表示
Summary
- Together AI, the AI Native Cloud, announced a full suite of capabilities for building real-time voice agents — co-located STT, LLM, and TTS on one cloud, eliminating inter-vendor network hops for end-to-end pipeline latency under 500ms
- Cartesia Sonic-3 (TTS) and Deepgram (STT) are now natively hosted on Together infrastructure, expanding model choice on the co-located stack
- One API, one billing surface, one deployment surface — with zero data retention, SOC 2 Type II, HIPAA, and dedicated data residency for enterprise deployments
Want to talk to an assistant instead of reading this blog? Call (847) 851-4323 and ask our assistant about models, pricing, or how to deploy a voice agent. Then interrupt it mid-sentence. The demo is designed for real-time turn-taking, with responses fast enough to feel conversational. That kind of experience is hard to deliver across fragmented voice stacks, and is exactly what Together AI is built to deliver at production scale.
Today, Together AI, the AI Native Cloud, launched a full suite of capabilities to deliver the industry’s first unified solution for building real-time voice agents on co-located STT, LLM, and TTS infrastructure. Together keeps the entire voice stack on one cloud, reducing latency, simplifying deployment, and improving reliability. We also added more choices for builders through native integrations with industry leading voice models from Cartesia (TTS) and Deepgram (STT).
Production voice systems usually force teams to trade off between speed, model choice, and operational stability. Together’s unified solution is built to remove that tradeoff: low-latency infrastructure for live conversation, flexible model support across the voice stack, and a secure, production-ready platform that takes teams from evaluation to deployment without rebuilding across providers.
The architecture: Unified modular vs. multi-provider stacks
The demo you just called stays real time because it keeps those handoffs inside one Together AI cluster, served from regions that keep round-trip latency to the caller low. Every component — STT, LLM, and TTS — runs on dedicated endpoints with pre-warmed capacity, with end-to-end latency under 500ms measured from the end of user speech to first audio token.
Building a voice pipeline across multiple vendors usually means routing audio and text between separate STT, LLM, and TTS systems over the public internet. Each handoff adds latency, increases operational complexity, and makes the stack harder to manage in production. Together AI’s unified modular architecture is built to remove that overhead by co-locating STT, the LLM, and TTS within the same cluster and serving them from regions close to the end user.
That architecture matters for three reasons:
- Speed: Voice agents usually slow down when STT, the LLM, and TTS hand off audio and text across multiple cloud providers. Those inter-vendor network hops add latency at every stage of the pipeline and make real-time conversation harder to maintain. Together keeps those handoffs on local datacenter networking instead of the public internet, enabling end-to-end latency below 500 milliseconds and the responsiveness required for natural turn-taking.
- Flexibility: Model flexibility demands choice. Together hosts leading voice models for transcription, reasoning, and synthesis in a single place, giving teams the speed and control to configure the stack they need for each use case. And unlike opaque speech-to-speech systems, Together’s modular design preserves access to the intermediate transcript and response text, so teams can inspect, modify, and route data mid-stream as part of their own application logic.
- Reliability: Production demands reliability. Together’s zero-trust architecture is designed for sensitive voice data, while its streamlined end-to-end management experience removes the complexity of stitching together disparate solutions from multiple vendors. Running the full pipeline on one platform gives teams one API, one authentication layer, one billing surface, and unified metrics — reducing operational overhead, lowering latency, and making costs more predictable in production.
For enterprise deployments, the platform is built to support strict requirements, including zero data retention, SOC 2 Type II, HIPAA, and dedicated data residency options.
Model choice on one platform
Teams often patch together different providers for speed, expressive synthesis, or voice cloning, turning their infrastructure into a fragile multi-vendor patchwork. Together AI replaces this with a single, model-agnostic platform. Developers can configure the exact STT, LLM, and TTS stack they need, and swap models without rebuilding integrations.
Through one platform, teams can route audio and text through models like Whisper Large v3, Minimax Speech 2.6 Turbo, Rime Arcana, Kokoro, and the full Together LLM catalog. View our complete catalog of supported models in our STT and TTS docs.
To expand our model library, we are launching native integrations for Deepgram (STT) and Cartesia (TTS). Hosting these models directly on Together AI means teams get industry-leading transcription and synthesis while keeping every handoff securely inside the co-located stack.
Cartesia brings Sonic-3 and Sonic-2 to the platform, delivering expressive, ultra-low-latency TTS purpose-built for voice agents and production deployments.
“At Cartesia, we’re driven to push the limits of real-time, expressive voice AI. By working with Together AI, we’re excited to bring this technology to more developers building the next generation of voice applications. - Arjun Desai, Co-Founder, Cartesia
Deepgram bringsNova-3,Nova-3 Multilingual (STT),Flux (conversational STT), andAura-2 (TTS) to the platform, covering everything from real-time transcription to enterprise-grade voice synthesis.
"Voice agents live or die by latency, and every network hop between providers is a place where the experience breaks down. By hosting Deepgram's STT natively on Together AI's infrastructure, we're giving developers production-grade transcription without the tradeoff. Fast, accurate, and co-located with the rest of the pipeline." - Abe Pursell, VP of Partnerships, Deepgram
Voice agent in production: Decagon
Decagon runs concierge voice agents in production on this stack. Their agents handle complex enterprise customer support workflows — like resolving billing inquiries, managing account updates, and executing technical troubleshooting — at scale. In these environments, transcription accuracy, low latency, and infrastructure uptime are critical to maintaining a natural customer experience. Running the pipeline on Together AI provides the strict latency bounds required for fluid conversation, all while preserving Decagon's control over the intermediate transcript and response text.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み