オープンモデルはどれほど遅れているのか?(17 分読了)
TLDR AI の分析により、オープンソースモデルとクローズドモデルの性能差が拡大しており、非公開ベンチマークでは約 8-10 ヶ月、公開ベンチマークでも 4-6 ヶ月の遅れが生じていることが示された。
キーポイント
オープンとクローズドのギャップ拡大
2025 年 1 月(DeepSeek R1 発表時)に最小だった性能差がその後拡大しており、非公開ベンチマークではオープンモデルがクローズドモデルより約 8-10 ヶ月遅れ、公開ベンチマークでも 4-6 ヶ月遅れている。
データ分析の信頼性
17 のベンチマーク(非公開 8、公開 9)から約 110 データポイントを用いた分析で、両者の傾向が一致していることから結果の信憑性は高いとされるが、一部データは自己申告や完全な非公開ではないという限界がある。
過去のトレンドとの対比
2023-2024 年のデータと比較し、オープンモデルの進化速度がクローズドモデル(API 提供型)に追いつくペースが低下している傾向が明確になった。
重要な引用
open models are roughly 8-10 months behind the closed frontier, while for public benchmarks the gap is roughly 4-6 months
the gap was smallest around the time of DeepSeek R1, in Jan 2025, and since then the gap has been growing
影響分析・編集コメントを表示
影響分析
この分析は、開発者がオープンソースモデルを本番環境で採用する際のリスク評価や、クローズドモデルへの依存度に関する意思決定に重要な示唆を与える。特に、オープンソースコミュニティがクローズドの最先端技術に追いつくペースが遅まっている現状は、AI エコシステムにおける競争構造の変化を示しており、企業戦略や研究リソースの配分見直しを促す可能性がある。
編集コメント
オープンソースとクローズドの性能差が逆転するどころか拡大しているという事実は、業界関係者にとって重要な警鐘です。特に非公開ベンチマークでの遅れは、実運用における期待値管理を再考させる内容となっています。
14
2026 年 5 月 28 日
14
オープンモデル、つまりオンラインで重み(weights)をダウンロードできる AI モデルは、通常、クローズドモデル(API を通じてのみ利用可能なモデル)の最前線と比較して能力が劣ります。では、その差はいくらくらいあり、時間とともにどのように変化しているのでしょうか? 我々は、様々な能力を測定する 17 のベンチマーク(8 つの非公開、9 つの公開、約 110 データポイント)からのデータを用いてこの問いに答えようとしています。本分析を再現するために必要なすべてのデータとコードは github で確認できます。
結果
我々の調査によると、本日現在、非公開ベンチマーク(データが一般にアクセスできない環境)では、オープンモデルはクローズドの最前線よりも約 8〜10 ヶ月遅れています。一方、公開ベンチマークにおける差は約 4〜6 ヶ月です。また、2025 年 1 月の DeepSeek R1 の発表時期にこの差が最も小さかったこと、そしてそれ以降、差は拡大していることも発見しました。
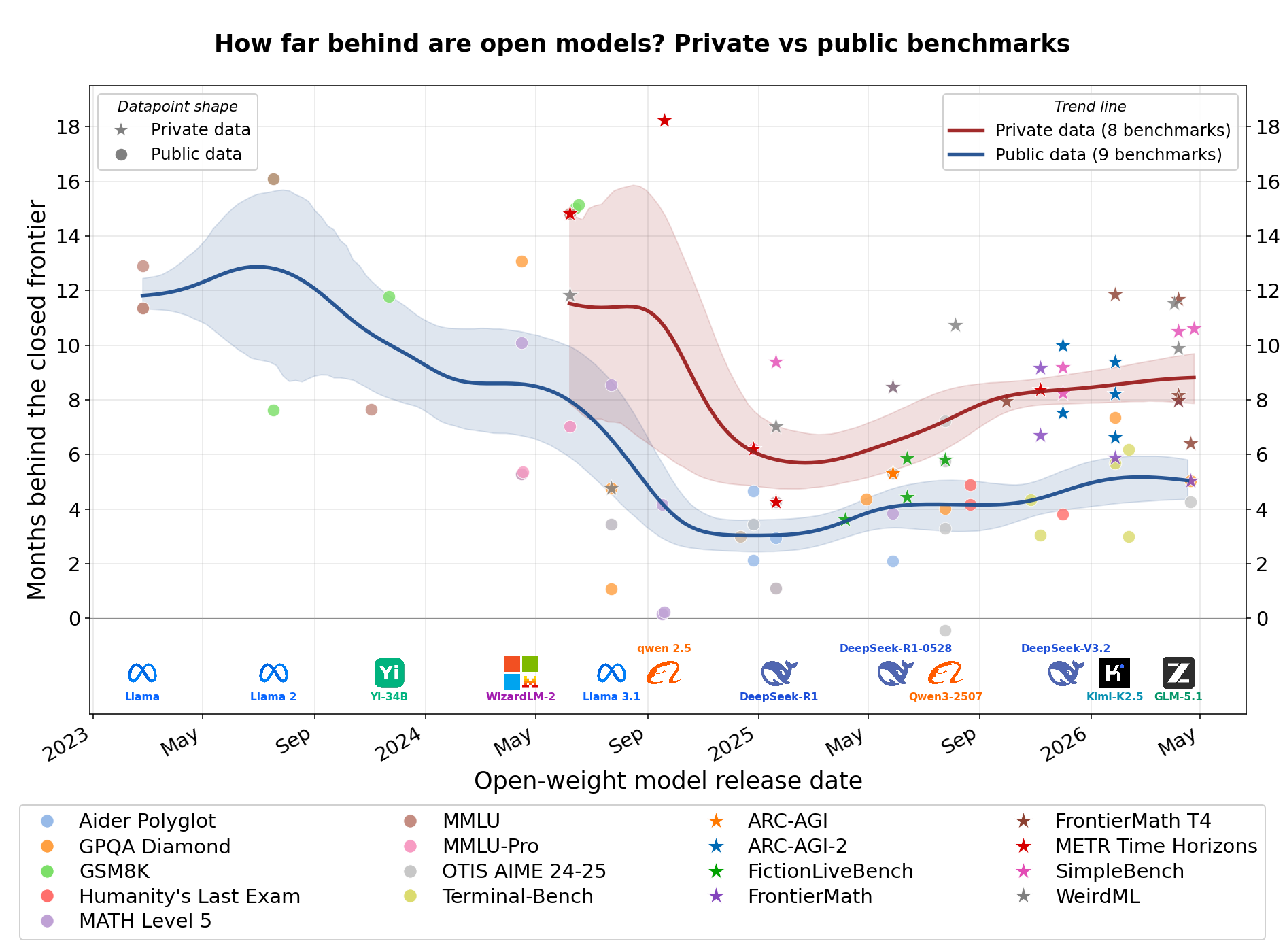 image時系列におけるオープンモデルとクローズドモデルの差。各点は、(ベンチマーク,スコア閾値) の組み合わせとして受け入れられた 1 データポイントを示し、オープンモデルが初めてその閾値を突破した日付に配置されます。縦軸の高さは、クローズドの最前線が初めてその閾値を突破したのが、オープンモデルより何ヶ月前であったかを示します。円は公開ベンチマーク、星印は非公開ベンチマークを表します(色 = ベンチマーク、凡例は後述)。2 つの曲線はガウス平滑化されたトレンドであり、90% のブートストラップ信頼区間を伴います。企業ロゴは注目すべきオープンモデルのリリースを示しています。
image時系列におけるオープンモデルとクローズドモデルの差。各点は、(ベンチマーク,スコア閾値) の組み合わせとして受け入れられた 1 データポイントを示し、オープンモデルが初めてその閾値を突破した日付に配置されます。縦軸の高さは、クローズドの最前線が初めてその閾値を突破したのが、オープンモデルより何ヶ月前であったかを示します。円は公開ベンチマーク、星印は非公開ベンチマークを表します(色 = ベンチマーク、凡例は後述)。2 つの曲線はガウス平滑化されたトレンドであり、90% のブートストラップ信頼区間を伴います。企業ロゴは注目すべきオープンモデルのリリースを示しています。
これらの数値は過去を振り返るものであり、プライベートベンチマークにおいて、現在最も優れたオープンモデルの性能は、8〜10か月前に存在した最も優れたクローズドモデルのレベルとほぼ同等であることを意味しています。
2023年および2024年の古いデータには一部自己申告スコアが含まれていますが、新しいデータは全体的により信頼性が高いものの、依然として重大な注意点があります(付録で議論されています)。その中には、「プライベート」ベンチマークのいくつかが完全に非公開ではないという問題も含まれています。これらのデータは完璧ではありませんが、中程度の労力で入手できた中で最良のデータです。
私的データと公的データの両方で本質的に同じ傾向が見られることは、これらが完全に独立したベンチマークセットであるにもかかわらず(実証するものではありませんが)、両方の傾向が現実のものであることを示唆しています。また、公的ベンチマークはオープンモデルとクローズドモデルの間のギャップを約2倍も過小評価しているものの、依然としてモデルの能力に関する有用な情報を提供していることも示唆されています。
プロバイダーの性能低下がギャップを過大評価する可能性がある
オープンな中国製モデルに対してプライベートベンチマークを実施する際、プライバシーデータを保護するために第三者プロバイダー(データ保持ゼロ)を利用することがあります。私たちが運営する WeirdML、METR(時間軸)、そして Epoch AI(Frontiermath)は、この理由から第三者プロバイダーの利用に細心の注意を払っていることを知っています。他の団体についても同様かどうかは確信が持てませんが、バグや実装上の問題により、オープンモデルを提供する際に第三者プロバイダーの性能が微妙に低下することがあります。これは通常、異なるプロバイダーをテストして比較することで対処可能ですが、微妙な性能低下を検出するのは難しく、完全に否定することも困難です。もしこのような性能低下が存在する場合、特にプライベートベンチマークにおいて、ギャップが実際よりも大きく見積もられるというバイアスが生じます。
実世界でのタスク
これは、このデータに基づいているというよりは、重要な考慮事項であるためここに追加した推測です。プライベートベンチマークとパブリックベンチマークの結果の差は、オープンモデルの開発者が、ベンチマークデータの完全なフィルタリングを行っていないか、テストへの過学習(あるいはテストに対するヒルクライミング)を行っていることを示唆しています。
そのようなことは、おそらくプライベートベンチマークにおいても同様に、より限定的ではあるが真実である。モデル開発者は、検証可能なタスクの学習を通じて無意識のうちにそうなる場合であっても、ベンチマークで遭遇する可能性の高い種類のタスクに対してトレーニングを行う。大規模でリソースに余裕のあるクローズドなラボは、多様なデータや企業顧客(および実際の使用からのフィードバック)へのアクセスがより多くあり、ベンチマークスコアに対する相対的な焦点は比較的少ない。これは、現実世界のタスクにおけるギャップが、プライベートベンチメントによって測定されたものよりもさらに大きい可能性を示唆している。
Methodology
各ベンチマークに対して一連の閾値スコアを定義し、ほとんどのベンチマークでは 0.05 から始まり 5% 間隔で上昇する閾値を設定する。その後、オープンモデルがこれらの各閾値に初めて到達した時点で、クローズドモデルがその閾値に最初に到達したのは何ヶ月前であったかを調査し、それをギャップの推定値として使用する。
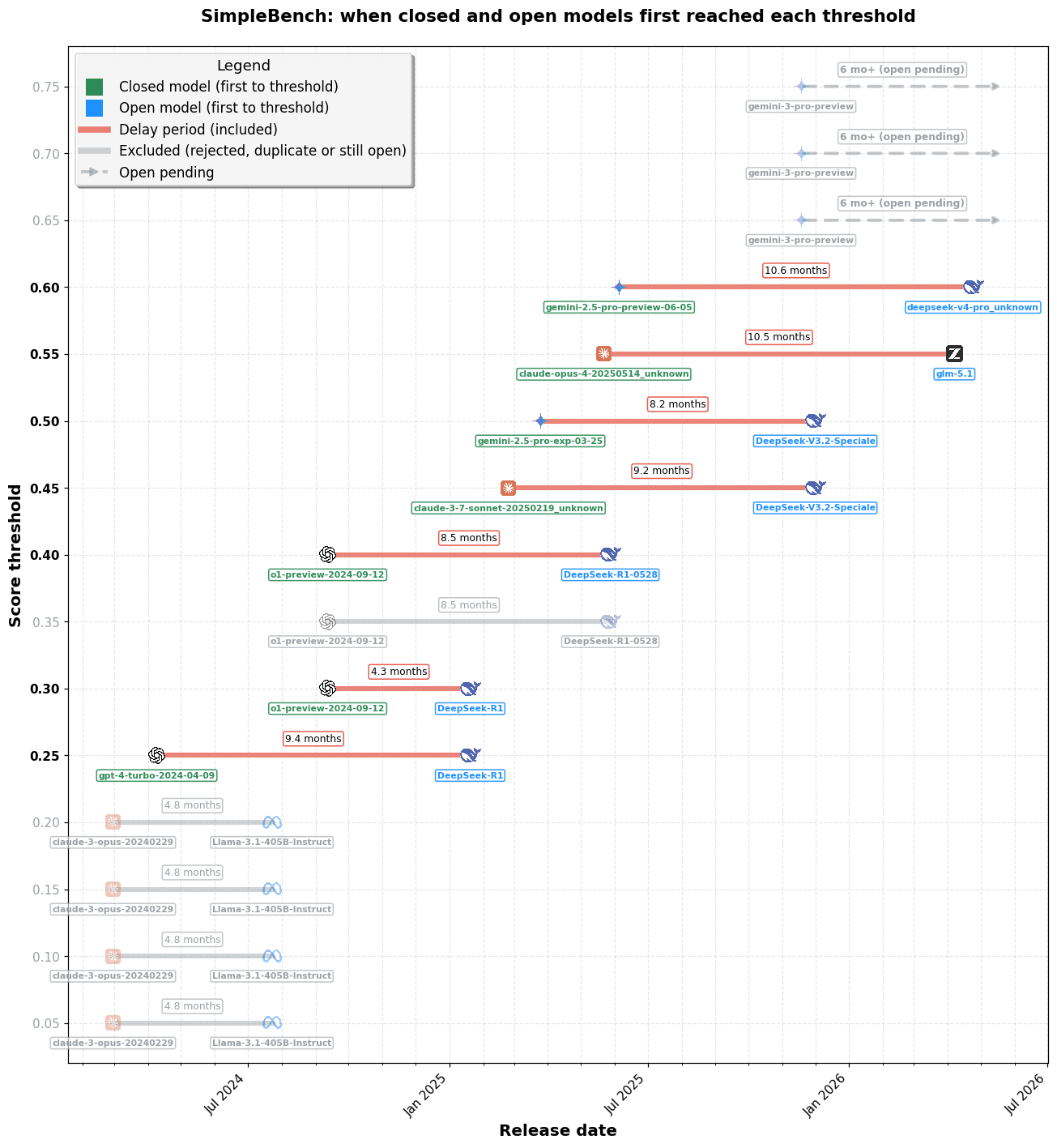 image各ベンチマークごとの「遅延タイムライン」(SimpleBench)は、本分析の構成要素です。各行はスコア閾値を示しており、緑色のマーカーはその閾値に到達した最初のクローズドモデル、青色のマーカーは最初のオープンモデル、赤いバーは両者のギャップ(月単位でラベル付け)を表します。太字の行は採用されたデータポイント、灰色の行は除外されました(真の初到達者ではない、重複している、あるいはまだオープン状態であるため)。破線の「オープン待機中」矢印は、クローズドフロンティアが到達したものの、まだどのオープンモデルも到達していない閾値を示しています。
image各ベンチマークごとの「遅延タイムライン」(SimpleBench)は、本分析の構成要素です。各行はスコア閾値を示しており、緑色のマーカーはその閾値に到達した最初のクローズドモデル、青色のマーカーは最初のオープンモデル、赤いバーは両者のギャップ(月単位でラベル付け)を表します。太字の行は採用されたデータポイント、灰色の行は除外されました(真の初到達者ではない、重複している、あるいはまだオープン状態であるため)。破線の「オープン待機中」矢印は、クローズドフロンティアが到達したものの、まだどのオープンモデルも到達していない閾値を示しています。
例えば、o1-preview は 2024 年 9 月 12 日にリリースされ、さまざまなベンチマークで複数の閾値を突破しました。DeepSeek R1 が 2025 年 1 月 20 日に同じ閾値のいくつかを突破した際、各突破をデータポイントとしてカウントし、2025 年 1 月 20 日時点でのギャップが約 4.3 ヶ月であると測定しました。
この手法は比較的シンプルで明確に定義されていますが、すべてのベンチマークが主要なオープンモデルとクローズドモデルの両方をテストしたという前提を置いており、実際には通常そのようにはなりません。実際の運用では、一定期間においてオープンモデルとクローズドモデルの双方に対して高品質な結果セットを持つベンチマークを見つけます。その後、各ベンチマークに入り、異なる閾値と、最初にその閾値を超えたオープンモデルおよびクローズドモデルを確認し、もし関連するすべてのモデルがテストされていれば、それぞれが実際に最初に閾値を超えたと考えられるかどうかを検討します。もし存在していればギャップを大幅に変える可能性のある主要なモデルがデータに含まれていない場合、その特定の閾値に関するデータポイントは除外されます。これらの判断は Claude Opus 4.7 によって行われ、その根拠は git リポジトリに提供されています。私たちは別途手動で確認を行い、Opus がやや保守的すぎると考えた一部の判断を覆し、特に高品質なデータポイントについては採用する方向で修正を行いました。
一般的に、ベンチマークの選定においては比較的慎重でありながら、選択されたベンチマークからの境界的なデータポイント、とりわけ高品質なものについては比較的自由に含める方針でした。
この手法には勝者の呪いバイアスがあり、特定の閾値を最初に突破するモデルは正の揺らぎを示す傾向があります。ベンチマークがクローズドモデルをより多く実行する場合(通常その通りです)、これはクローズドモデルに有利に働く可能性があります。より慎重な分析では、例えば ECI フレームワークに基づいてこの効果を推定しようと試みるべきでしょう。
後向きと前向きのギャップ
特定の閾値について、あるクローズドモデルが最初に突破し、その後オープンモデルが突破するという結果(上記の例では o1-preview と DeepSeek R1)を考慮すると、ギャップ(4.3 ヶ月)は明確に測定できます。しかし、このギャップをどの時点に関連付けるべきでしょうか?これは 2024 年 9 月の o1-preview のリリース時のギャップなのか、それとも 2025 年 1 月の R1 リリース時のギャップなのでしょうか?これらはそれぞれ前向きな視点と後向きな視点であり、やや異なる二つの問いに答えるものです。
将来志向の問いは、現在利用可能な最も優れたクローズドモデルを基準に、「オープンモデルがいつ同じレベルに達するか」を問うものです。一方、過去志向の視点では、「現在の最良のオープンモデルと同じレベルになるには、最良のクローズドモデルをどの程度過去の時点まで遡ればよいか」と問います。私たちは往々にして将来志向の問いにより関心を持ちますが、今日実際に回答できるのは(今日のトップクラスのオープンモデルについて言えば)過去志向の問いであり、本分析ではその視点を採用しています。具体的には、当手法が答える質問は「トップクラスのオープンモデルがリリースされた際に埋めるギャップは、どれほど長期間持続するのか?」です。そして、これらのギャップの長さ(月単位)をオープンモデルのリリース日と関連付けます。このようにギャップを定義することで、現在進行中のギャップ(クローズドモデルが突破した閾値だが、まだオープンモデルが到達していないもの)を除外することによるバイアスが現在のギャップ推定に含まれないことを保証し、現在のギャップを過去のギャップと比較可能にします。
追加分析
カテゴリ別におけるオープンとクローズドのギャップ
上記の主要図から、プライベートモデルとパブリックモデルの違いは、オープンモデルとクローズドモデルの間のギャップを理解する上で非常に重要な変数であることが明確です。しかし、ベンチマークのカテゴリもまた重要な変数であるかどうかを確認したいため、ベンチマークを4つのカテゴリに分類し、対応する傾向曲線を示しました。「推論」カテゴリは明らかに他のカテゴリよりも大きなギャップを持っていますが、このカテゴリを構成する3つのベンチマークはいずれもプライベートモデルであるため、おそらくそちらの方がより重要な要因です。カテゴリについて意味のあることを言うには、データが十分ではないと考えています。
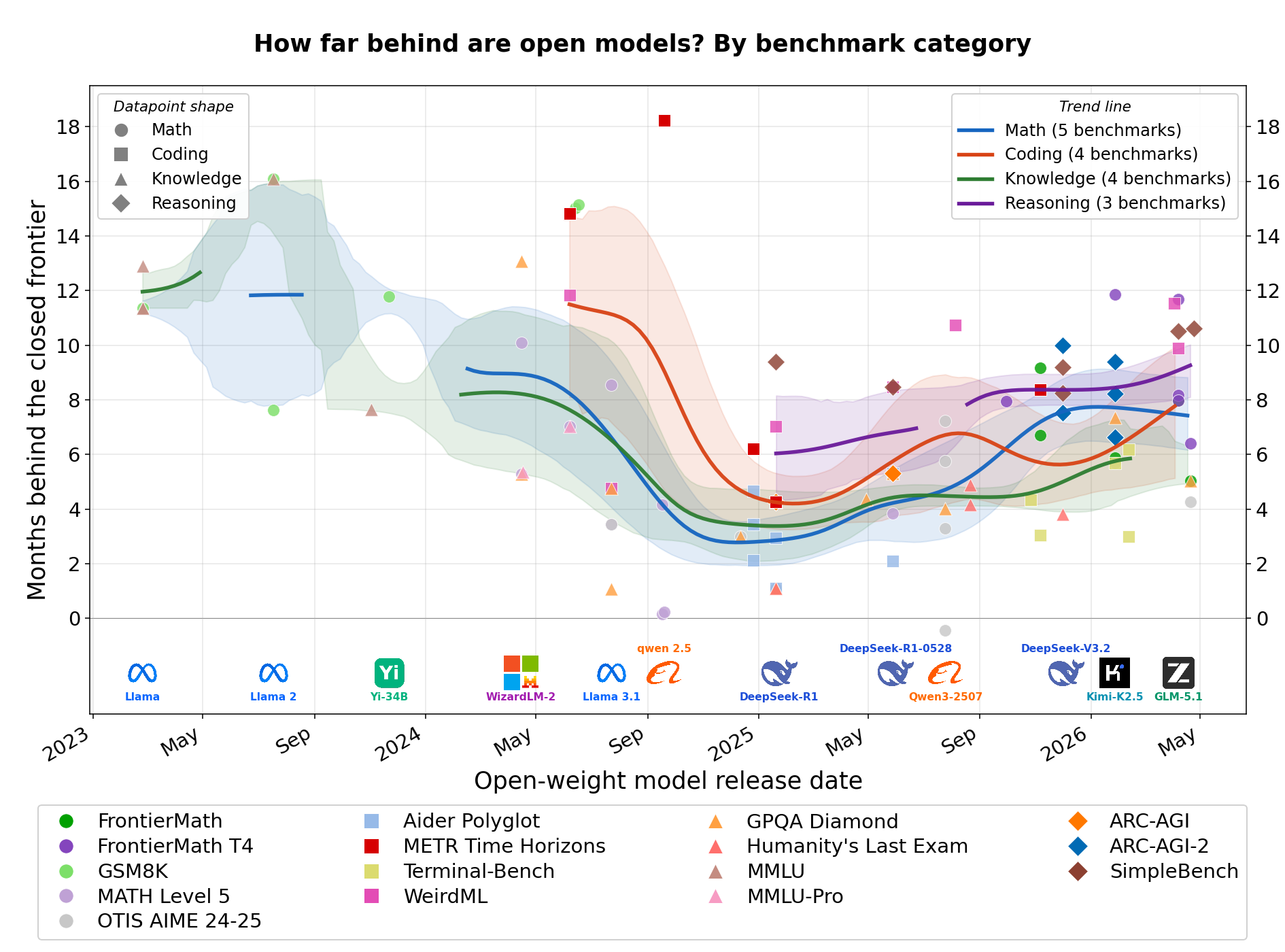 image主要図と同じ受け入れ済みデータポイントですが、傾向曲線はパブリック/プライベート別ではなく、能力カテゴリ別に分割されています(マーカーの形状でカテゴリをエンコード)。FictionLiveBench(長文コンテキスト対応)はいかなるカテゴリにも該当しないため、ここでは除外しています。
image主要図と同じ受け入れ済みデータポイントですが、傾向曲線はパブリック/プライベート別ではなく、能力カテゴリ別に分割されています(マーカーの形状でカテゴリをエンコード)。FictionLiveBench(長文コンテキスト対応)はいかなるカテゴリにも該当しないため、ここでは除外しています。
(オープン)中国製モデルとクローズドモデルの比較
主要結果と同様の分析を、中国製のオープンモデルに限定して行いました。結果は基本的に同様で、2024年7月のLlama 3.1(注:原文のまま保持)まで遡る場合を除き、それ以前においては中国製モデルのみを対象とした分析ではギャップが顕著に大きくなっています。
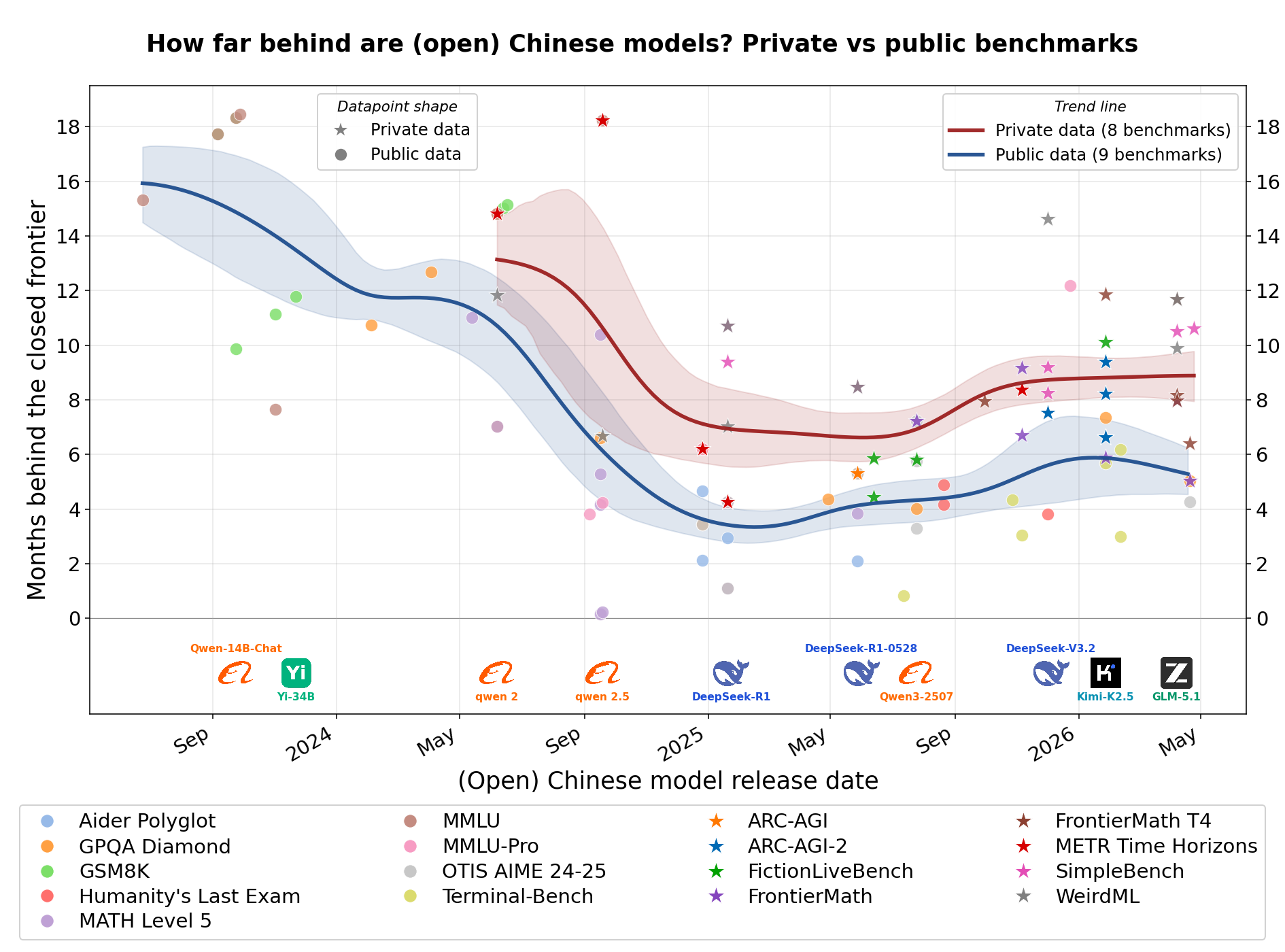 image中国製のオープンウェイトモデル(注:原文のまま保持)に限定した主要分析。
image中国製のオープンウェイトモデル(注:原文のまま保持)に限定した主要分析。
謝辞
ここで使用されたデータのほとんどは、Epoch AI Benchmarking Hub から提供されています。同チームがデータを収集・統合した取り組みにより、これらの分析が格段に容易になりました。
Claude Opus 4.7 は、コードのほぼすべてを記述し、異なるベンチマークやデータに関する調査を行いました。これは私たちが指示を出したものです。Opus はデータの採用・除外に関する提案と初期の根拠を示しましたが、最終的な判断は私たちが行い、いくつかの場合には Opus の意見を覆しました。また、最終的なデータが生データと一致しているかを確認するため、いくつかのスポットチェックも実施しました。
このブログ記事は、Appendix B を除いて私が執筆しました。Appendix B は完全に Opus によって書かれ、私たちが軽く編集したものです。
付録 A: 追加の図表
ここでは、いくつかのベンチマークにおける採用および拒否の閾値を示す追加の図表を掲載します。すべてのベンチマークに関する同様の図表と、選択の根拠については github にあります。
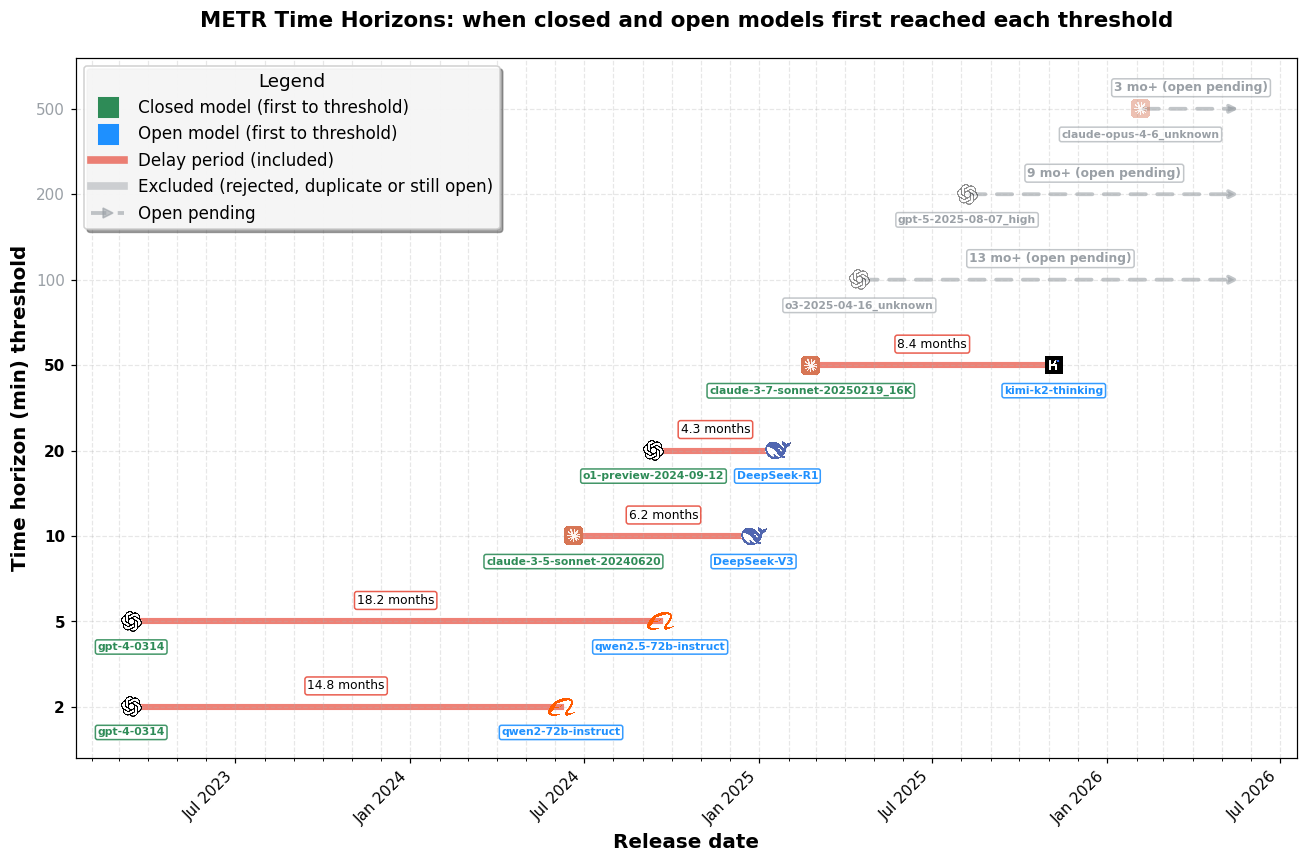 imageMETR の時間軸。SimpleBench の図表と同じ遅延タイムライン形式です。ここで示される閾値は精度ではなく、タスク完了までの時間軸(分単位)です(モデルが約 50% の確率で完了するタスクの長さ)。数値が高いほど優れています。
imageMETR の時間軸。SimpleBench の図表と同じ遅延タイムライン形式です。ここで示される閾値は精度ではなく、タスク完了までの時間軸(分単位)です(モデルが約 50% の確率で完了するタスクの長さ)。数値が高いほど優れています。
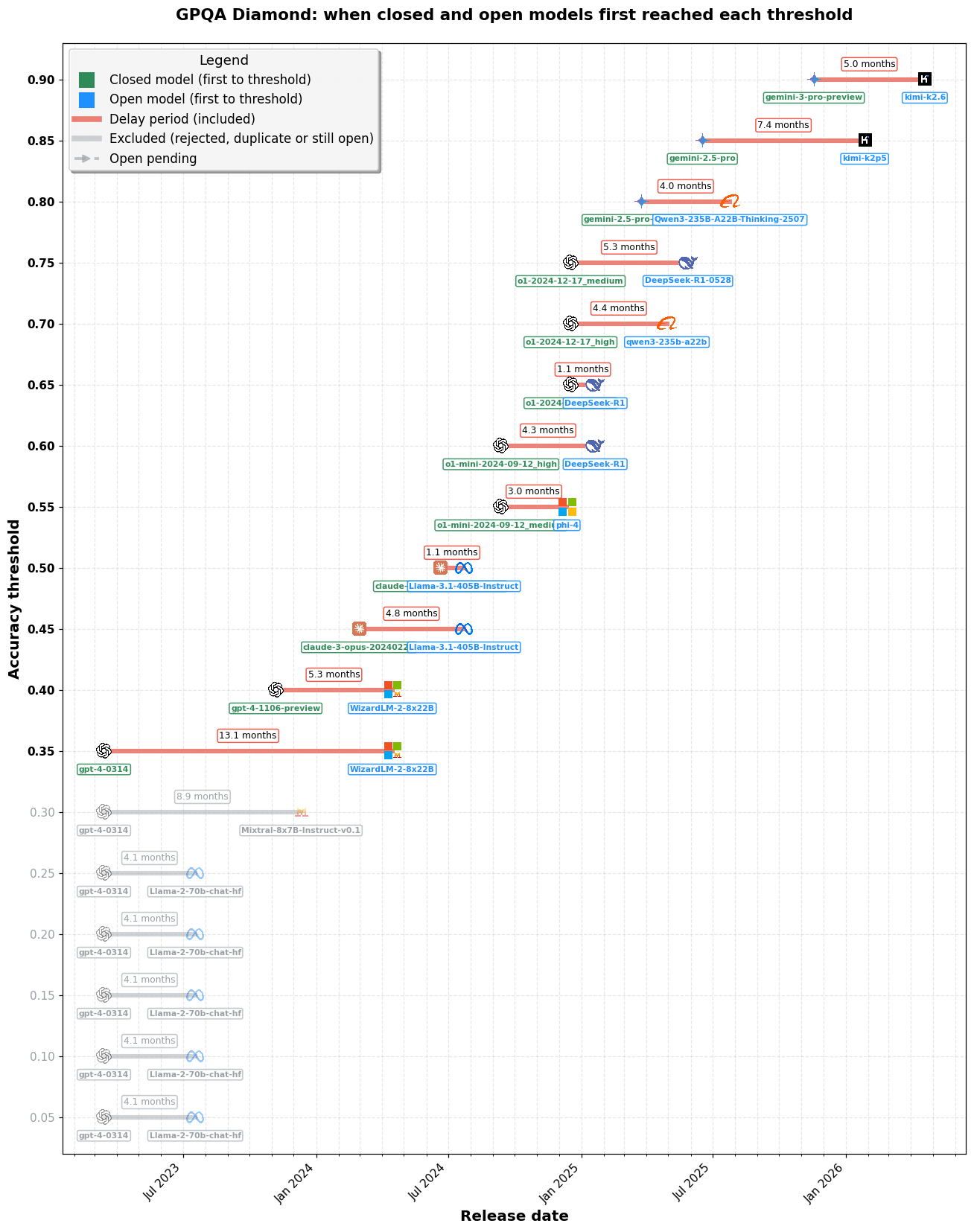 imageGPQA Diamond(大学院レベルの科学多肢選択問題)。SimpleBench 図と同じ遅延タイムライン形式。Epoch が実行した、明確に比較可能なベンチマーク。
imageGPQA Diamond(大学院レベルの科学多肢選択問題)。SimpleBench 図と同じ遅延タイムライン形式。Epoch が実行した、明確に比較可能なベンチマーク。
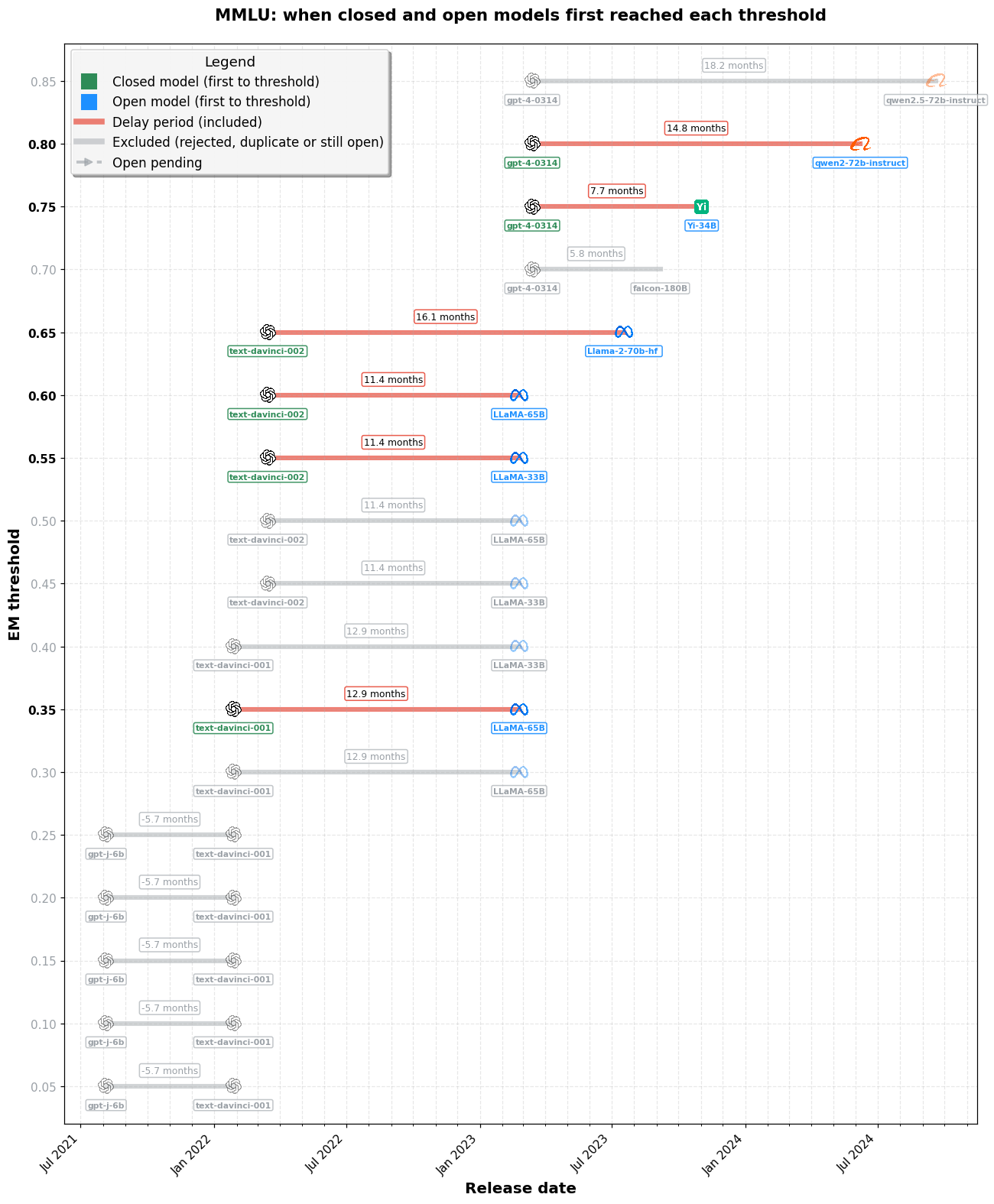 imageMMLU(4 択多肢選択、約 25% の確率)。SimpleBench 図と同じ遅延タイムライン形式。古く、ほぼ飽和状態にあるベンチマークで、スコアは主に自己申告式です(付録 B を参照)。初期段階のカバレッジを主目的として含めています。
imageMMLU(4 択多肢選択、約 25% の確率)。SimpleBench 図と同じ遅延タイムライン形式。古く、ほぼ飽和状態にあるベンチマークで、スコアは主に自己申告式です(付録 B を参照)。初期段階のカバレッジを主目的として含めています。
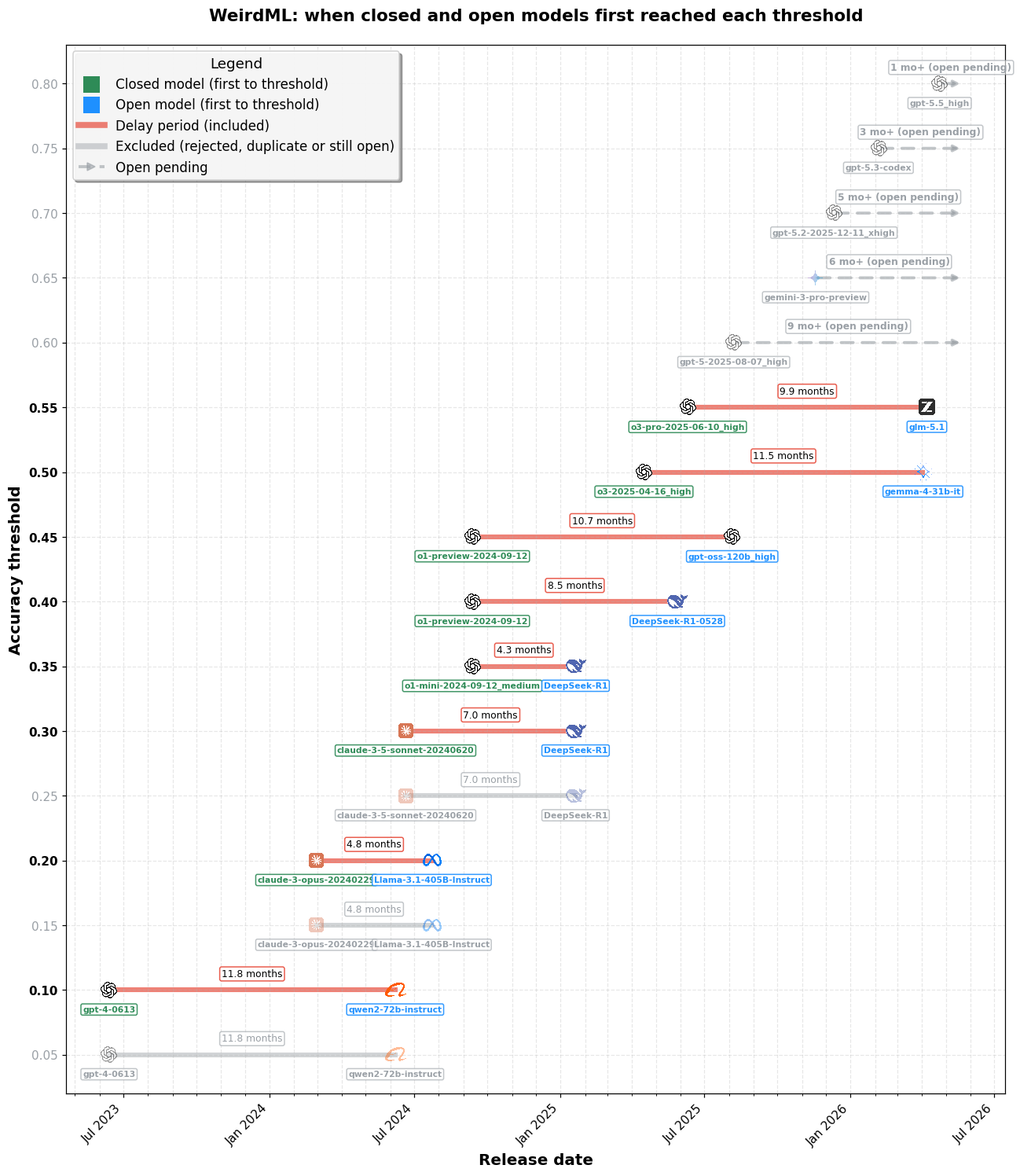 imageWeirdML(新規 ML コーディングタスクにおける精度;非公開、当社がエンドツーエンドで実行)。SimpleBench 図と同じ遅延タイムライン形式。
imageWeirdML(新規 ML コーディングタスクにおける精度;非公開、当社がエンドツーエンドで実行)。SimpleBench 図と同じ遅延タイムライン形式。
付録 B: ベンチマークスコアの由来
各ベンチマークにおいてオープンウェイトモデルが初めてクローズドな最前線に追いついた時期を測定するには、比較対象となるスコアが「信頼性があり、相互比較可能」である必要があります。理想的には、単一の独立した組織が一貫してすべてのモデルを同一の評価ハッチ(評価枠組み)で実行した結果であるべきです。各ラボが自らの都合の良い設定下で独自に報告するバラエティ豊かな数値の寄せ集めであってはなりません。私たちはこの点について、承認された 17 のベンチマークすべてを検証しました(ベンチマークごとに独立した Web 調査を 1 回実施)。結果は大きく異なり、その点を率直に述べる価値があると考えます。
以下の表は、各ベンチマークについて、実際に評価を実施した主体、Epoch AI の Benchmarking Hub(主要なデータソース)が評価自体を*実行*しているのか、それとも外部リーダーボードを単に*ミラーリング*しているだけなのか、そしてスコアが自己報告数値を含まず比較可能な設定を持つ独立した単一の評価者によるものかどうかという我々の判断を記録しています。
凡例: ✅ 独立した評価者が固定された環境で全モデルを実行 · ⚠️ 概ね該当するが、重要な留保事項あり · ❌ スコアは主に自己報告/提出されたもの、または比較可能な形で実行されていないもの。
ベンチマーク | 使用されたアクセス権限 | 評価実施者 | Epoch Hub | 独立・非自己報告・比較可能か? | ソース
GPQA Diamond | 公開 | Epoch AI (Inspect, モデルあたり16回実行) | 実行 | ✅ | リンク
MATH Level 5 | 公開 | Epoch AI (Inspect, モデルあたり8回実行) | 実行 | ✅ | リンク
OTIS Mock AIME 2024-25 | 公開 | Epoch AI (Inspect, モデルあたり16回実行) | 実行 | ✅ | リンク
GSM8K | 公開 | 単一の評価者なし — ベンダー技術報告の数値が約70%、ショット数混在 | ミラーリング | ❌ | リンク
MMLU | 公開 | 単一の評価者なし — 主に開発者による自己報告、n-shot の変動あり | ミラーリング | ❌ | リンク
MMLU-Pro | 公開 | TIGER-Lab ハーネス + コミュニティ提出 (Epoch は Artificial Analysis と併用) | ミラーリング¹ | ❌ | リンク
Aider Polyglot | 公開
Aider (P. Gauthier) + PR で提出された結果; モデルごとの設定は異なる
ミラーサイト
⚠️
Terminal-Bench
公開
harbor-framework (スタンフォード大学/Laude); PR で提出、スケフォールドは異なる
ミラーサイト
❌
Humanity's Last Exam
公開
CAIS と Scale が公式ボードを運営 (1 つのハネス)…
ミラーサイト
⚠️²
FrontierMath
非公開
Epoch AI
実行中
⚠️³
FrontierMath Tier 4
非公開
Epoch AI
実行中
⚠️³
WeirdML
非公開
Håvard Tveit Ihle (1 つのハネス、全モデル対象)
ミラーサイト
✅
SimpleBench
非公開
AI Explained チーム (非公開セット、AVG@5)
ミラーサイト
✅
METR Time Horizons
非公開
METR (独自のタスクスイートとスケフォールド)
ミラーサイト
✅
FictionLiveBench (120k)
非公開
fiction.live (単一プラットフォーム)
ミラーサイト
⚠️⁴
ARC-AGI
非公開
ARC Prize Foundation (半公開セット; デフォルトでは検証されていない)
ミラーサイト
⚠️⁵
ARC-AGI-2
非公開
ARC Prize Foundation (半公開セット; デフォルトでは検証されていない)
ミラーサイト
⚠️⁵
注釈:
- 私たちの MMLU-Pro CSV は、Epoch のデータダンプではなく、TIGER-Lab リーダーボードから直接構築されました。
- HLE(Human-Level Evaluation)の公式ボードではすべてのモデルを同一のハーンネスで実行しますが、Epoch のデータにはオープンソース中国語モデルがほとんど含まれていなかったため、私たちは公開または自己報告されたソースから 5 つを手動で追加しました。したがって、私たちの分析における HLE のオープン側での最初の閾値突破はすべて、これらの自己報告行に基づいています。
- FrontierMath は Epoch が運営し内部比較が可能ですが、OpenAI が資金を提供しており、ほとんどの問題にアクセスでき、独自の o3/o3-mini 数値を別途実行しています。この情報へのアクセスは閉鎖系(OpenAI)側のスコアのみを膨らませる可能性があります。閉鎖系のスコアが水増しされると、閉鎖系フロンティアが閾値をより早く突破することになり、測定されたギャップが上方にバイアスされます。つまり、ギャップが過大評価されることになります(これは私たちの結論と矛盾しますが、保守的な推定ではありません)。
- 単一ソースであり自己報告ではありませんが、採点方法は文書化されていません。
- スコアは ARC の「準非公開」セットに基づいています:公的にダウンロード可能ではありませんが、評価中に商用 API に送信されます(ARC Prize: 「商用 API に晒されており、漏洩のリスクを伴う」)。この曝露には非対称性があります。閉鎖系モデルは独自のファーストパーティ API を経由して入力を受け取り、オープン系モデルはサードパーティホストを経由します。したがって、いかなる汚染も閉鎖系側のスコアを膨らませることになり → 閉鎖系が閾値をより早く突破することになり → ギャップが過大評価されます。私たちは ARC を「非公開」として扱いますが、測定されたギャップが水増しされている可能性があり(準非公開/部分的に曝露済み)とフラグを立てています。
Takeaway
ベンチマークは明確なコアと、やや緩やかな周辺部に分かれています。独立して比較可能な形で実行されたもの: GPQA Diamond, MATH Level 5, OTIS Mock AIME(すべて Epoch 社が実施)、および WeirdML, SimpleBench, METR(それぞれ単一の組織によってエンドツーエンドで実行)。自己報告または提出ベースの集計データ: GSM8K, MMLU, MMLU-Pro, Aider Polyglot, Terminal-Bench、そして HLE のオープン版。私たちが最も依存している「非公開かつ汚染耐性のあるセット」自体は混合されていますが、FrontierMath, WeirdML, SimpleBench, METR はクリーンに実行されており、ARC-AGI/-2 は半非公開で部分的に API 経由でアクセス可能です。各ベンチマークの出自を個別に確認し、「安心できる一つの物語」として鵜呑みにしないでください。最も明確な汚染バイアス(FrontierMath の OpenAI アクセス権と ARC の API 暴露)はどちらもクローズド側に作用しており、クローズド側のスコアを水増しすることは、クローズド側のフロンティアが閾値に早期に到達する要因となります。したがって、これらのベンチマークにおいては、むしろギャップを実際よりも大きく見せる方向に働く可能性があります(FrontierMath や ARC の非公開側の数値は過大評価されている恐れがあります)。これらはオープンモデルを人為的に良く見せるものではなく、リスクとなるのはギャップの過小評価ではなく、過大評価です。
原文を表示
14
28th May 2026
14
Open models, AI models where you can download the weights online, are generally not as capable as the best closed models (models only available through an API), but how large is the gap, and how does it change over time? We try to answer this question by using data from 17 selected benchmarks (8 private, 9 public, ~110 datapoints) measuring various capabilities. All the data and code needed to reproduce this can be found on github.
Results
We find that, as of today, on private benchmarks, where the data is not publicly accessible, open models are roughly 8-10 months behind the closed frontier, while for public benchmarks the gap is roughly 4-6 months. We also find that the gap was smallest around the time of DeepSeek R1, in Jan 2025, and since then the gap has been growing.
These numbers are backward-looking, meaning that, on private benchmarks, the best open models now perform roughly at the level of the best closed models from 8-10 months ago.
The old data from 2023 and 2024 is partially self reported scores. Newer data is mostly better, but there are still major caveats (discussed in an appendix) including several of the "private" benchmarks not being fully private. These data are not perfect, but it's the best data that we were able to find with medium effort.
The fact that we see essentially the same trend in both the private and public data, completely disjoint sets of benchmarks, suggests (but does not demonstrate) that the trend in both is real. It also suggests that, while public benchmarks significantly underestimate the gap between open and closed models, almost by a factor of two, public benchmarks still provide useful information about model capabilities.
Provider degradation may inflate the gap
People running a private benchmark on open Chinese models might use third-party providers, with zero-data-retention, to protect their private data. We know that both we (who run WeirdML), METR (time-horizons) and Epoch AI (Frontiermath) are careful to use third-party providers for this reason, not sure about the others. Sometimes, due to bugs or implementation issues, third-party providers can have subtly degraded performance when serving open models. This can often be adressed by testing and comparing different providers, but it can be hard to detect subtle degradation, and it's also hard to rule it out completely. If present, such degradation would bias the gap to be larger, especially for the private benchmarks.
Real-world tasks
This is a speculation we're adding here because it's an important consideration, not because it's based much on these data. The difference in results on the private vs public benchmarks suggests that open model developers are doing some combination of not fully filtering out benchmark data and training to the test (or hillclimbing on the test).
Something like that is probably true, only to a lesser extent, for the private benchmarks as well. Model developers train on the kind of tasks they are likely to meet in benchmarks, even if only inadvertently by training on verifiable tasks, which are more easy to make benchmarks for. Big well-resourced closed labs probably have more access to varied data, more enterprise customers (and feedback from real use) and are relatively less focused on benchmark scores. This suggests that the gap on real-world tasks is probably even larger than that measured by private benchmarks.
Methodology
We define a set of threshold scores for each benchmark, for most benchmarks we define those at 5% intervals from 0.05 and upwards. Then, the first time an open model crosses each of these thresholds we find out how many months earlier a closed model first crossed the threshold, and use that as an estimate of the gap.
For example, o1-preview was released 12. September 2024, and crossed several thresholds in various benchmarks. When DeepSeek R1 crossed several of the same thresholds in 20. Jan 2025, we count each crossing as a datapoint measuring the gap at 20. Jan 2025 to be about 4.3 months.
This methodology is fairly simple and well-defined, but it assumes that all the benchmarks have tested all the major both open and closed models, which is not typically the case. In practice what we do is to find benchmarks that are high quality and have a good set of results for both open and closed models for some period of time. We then go into each benchmark and look at the different thresholds and the open and closed models that crossed the threshold first and ask if it's plausible that each of those would have been the first to cross the threshold if the benchmark had tested all the relevant models. If a major model that probably would have changed the gap significantly if it was there is not included in the data, then we reject the datapoint from this specific threshold. These judgements were made by Claude Opus 4.7, and the justifications are provided in the git repo. We separately went through manually and overruled some of the judgements, in all cases to accept some datapoints where we thought Opus was a bit too conservative.
In general we were fairly conservative in selecting benchmarks and relatively more liberal in including marginal datapoints from the selected benchmarks, especially high quality ones.
This methodology does have a winner's-curse bias, in that the first models to cross a certain threshold will tend to be a positive fluctuation. This could favor closed models if the benchmarks run more of them (which is typically the case). A more careful analysis could try to estimate this effect based, for example, on the ECI framework.
Backward-looking vs forward-looking gap
If we take the results from a single threshold that's first crossed by a certain closed model and then later crossed by an open model, say in the example above with o1-preview and DeepSeek R1, we have a clean measurement of the gap (4.3 months), but what time should we associate this gap with? Is this the gap in Sept 2024, when o1-preview was released, or is it the gap in Jan 2025, when R1 was released? These are the forward looking and backward looking perspectives, respectively, and they answer two somewhat different questions.
The forward looking question takes the best closed models now, and asks when open models will be at the same level. The backward looking perspective asks how long do I have to go back in time for the best closed models to be at the same level as the best open models today. While we often are more interested in the forward-looking question, what we can actually answer today (for todays top open models) is the backward looking question, and that is the perspective we are using in this analysis. Specifically the question our method answers are "How long-lived are the gaps that a top open model closes when it's released?". We then associate the length of these gaps (in months) with the release date of the open model. By defining the gap in this way we ensure that our estimate of the current gap is not biased by the exclusion of currently-open gaps (thresholds that closed models have crossed, but open models have not yet), and the current gap can be fairly compared to the gaps back in time.
Additional analyses
Open vs closed gap by category
It is clear from our main figure above that private vs public is a very important variable for understanding the gap between open and closed models. However we wanted to see if benchmark category was an important variable as well, so we grouped the benchmarks into four categories and here we show the corresponding trend curves. The "reasoning" category clearly has a larger gap than the others, but all the three benchmarks that make up this category are private, so that's probably the more important factor. I don't think we have enough data to say much meaningful about the categories.
(Open) Chinese models vs closed models
We did the same analysis as the main results only restricting ourselves to Chinese open models. The results are basically the same, with only a few exceptions, back to Llama 3.1 (in July 2024), but before this the gap is notably larger in the Chinese-only analysis.
Acknowledgements
Almost all the data used here are from the Epoch AI Benchmarking Hub, their work in curating and connecting all the data make these analyses much easier.
Claude Opus 4.7 wrote essentially all the code, and did the research into the different benchmarks and data, directed by us. Opus made suggestions and initial justifications for inclusion/exclusion of data, while we had the final say/judgement and overruled Opus in several cases. We also did several spot checks to see if the final data matched the raw data.
We wrote this blog post, with the exception of Appendix B, which is written entirely by Opus and lightly edited by us.
Appendix A: Additional figures
Here are some additional figures showing accepted and rejected thresholds for some of the benchmarks. Similar figures for all the benchmarks and reasoning behind the choices are on github.
Appendix B: Benchmark score provenance
To measure when open-weight models first matched the closed frontier on each benchmark, we need the scores being compared to be *trustworthy and comparable* — ideally produced by a single independent party running every model through one evaluation harness, rather than a grab-bag of numbers each lab reports for itself under its own favourable settings. We audited all 17 accepted benchmarks on this point (one independent web-research pass per benchmark). The results vary a lot, and we think it's worth being upfront about it.
The table below records, for each benchmark: who actually ran the evaluations, whether Epoch AI's Benchmarking Hub (our main data source) *runs* the eval itself or merely *mirrors* an external leaderboard, and our verdict on whether the scores come from a single independent evaluator with no self-reported numbers and comparable settings.
Legend: ✅ one independent evaluator ran every model in a fixed harness · ⚠️ mostly, but with a real caveat · ❌ scores are largely self-reported / submitted, or not run comparably.
Benchmark
Access used
Who ran the evaluations
Epoch Hub
Independent, no self-report, comparable?
Source
GPQA Diamond
public
Epoch AI (Inspect, 16 runs/model)
runs
✅
MATH Level 5
public
Epoch AI (Inspect, 8 runs/model)
runs
✅
OTIS Mock AIME 2024-25
public
Epoch AI (Inspect, 16 runs/model)
runs
✅
GSM8K
public
No single evaluator — ~70% vendor tech-report numbers, mixed shot counts
mirrors
❌
MMLU
public
No single evaluator — mostly developer self-reported, varying n-shot
mirrors
❌
MMLU-Pro
public
TIGER-Lab harness + community submissions (Epoch blends w/ Artificial Analysis)
mirrors¹
❌
Aider Polyglot
public
Aider (P. Gauthier) + PR-submitted results; per-model configs vary
mirrors
⚠️
Terminal-Bench
public
harbor-framework (Stanford/Laude); PR-submitted, scaffolds vary
mirrors
❌
Humanity's Last Exam
public
CAIS + Scale run the official board (one harness)…
mirrors
⚠️²
FrontierMath
private
Epoch AI
runs
⚠️³
FrontierMath Tier 4
private
Epoch AI
runs
⚠️³
WeirdML
private
Håvard Tveit Ihle (one harness, all models)
mirrors
✅
SimpleBench
private
AI Explained team (private set, AVG@5)
mirrors
✅
METR Time Horizons
private
METR (own task suite + scaffold)
mirrors
✅
FictionLiveBench (120k)
private
fiction.live (single platform)
mirrors
⚠️⁴
ARC-AGI
private
ARC Prize Foundation (semi-private set; not verified by default)
mirrors
⚠️⁵
ARC-AGI-2
private
ARC Prize Foundation (semi-private set; not verified by default)
mirrors
⚠️⁵
Notes:
- Our MMLU-Pro CSV was built directly from the TIGER-Lab leaderboard, not Epoch's data dump.
- HLE's official board runs all models in one harness, but Epoch's data had almost no open-Chinese models, so we hand-appended 5 from public/self-reported sources — and all of HLE's open-side first-crossings in our analysis are those self-reported rows.
- FrontierMath is Epoch-run and internally comparable, but OpenAI funded it and has access to most problems, and ran its own o3/o3-mini numbers separately. This exposure can only inflate the closed (OpenAI) side; an inflated closed score makes the closed frontier cross thresholds earlier, biasing the measured gap upward — i.e. it can overstate the gap (this cuts against our conclusion; it is not conservative).
- Single-source and not self-reported, but the grading method is undocumented.
- Scores are on the ARC "semi-private" set: not publicly downloadable, but transmitted to commercial APIs during evaluation (ARC Prize: "exposed to commercial APIs and thus carry some risk of leakage"). The exposure is asymmetric — closed models receive the inputs via their own first-party APIs, open models via third-party hosts — so any contamination inflates the closed side → closed crosses thresholds earlier → overstates the gap. We keep ARC as "private" but flag that its measured gap may be inflated (semi-private / partially exposed).
Takeaway
The benchmarks split into a clean core and a softer periphery. Independently and comparably run: GPQA Diamond, MATH Level 5, OTIS Mock AIME (all Epoch-run), plus WeirdML, SimpleBench and METR (each run end-to-end by a single party). Self-reported or submission-based aggregations: GSM8K, MMLU, MMLU-Pro, Aider Polyglot, Terminal-Bench, and HLE's open side. The private/contamination-resistant set we lean on most is itself mixed — FrontierMath, WeirdML, SimpleBench and METR are cleanly run, while ARC-AGI/-2 are semi-private and partially API-exposed. Read the provenance benchmark-by-benchmark rather than as one reassuring story: the two clearest contamination biases (FrontierMath's OpenAI access, ARC's API exposure) both act on the closed side, and inflating closed scores makes the closed frontier cross thresholds earlier — so on those benchmarks they would, if anything, make the gap look larger than it is (the private-side numbers from FrontierMath/ARC may be overstated). They do not make *open* look artificially good; the risk is over- not under-statement of the gap.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み