Mamba-3:推論専用SSMの登場
Together AIと学術機関の共同研究により、推論効率を最優先設計とした新しい状態空間モデル「Mamba-3」が公開され、1.5BスケールでTransformerであるLlama-3.2-1Bを上回る速度を実現した。
キーポイント
推論効率至上の設計思想
Mamba-2が学習速度を最適化していたのに対し、Mamba-3は推論時の効率性を主目的として設計されており、より表現力豊かな再帰式と複素数値状態追跡を採用している。
MIMOバリアントによる精度向上
マルチ入力・マルチ出力(MIMO)バリアントを導入することで、デコード速度を低下させることなく精度を向上させ、すべてのシーケンス長においてLlama-3.2-1Bを上回るプリフィル+デコードレイテンシを実現した。
高性能カーネルのオープンソース化
Triton、TileLang、CuTe DSLを組み合わせて構築されたハードウェア性能最大化のためのカーネルコードがオープンソースとして公開され、実装の透明性と再現性が確保された。
重要な引用
Mamba-3 is a new state space model (SSM) designed with inference efficiency as the primary goal — a departure from Mamba-2, which optimized for training speed.
The result: Mamba-3 SISO beats Mamba-2, Gated DeltaNet, and even Llama-3.2-1B (Transformer) on prefill+decode latency across all sequence lengths at the 1.5B scale.
影響分析・編集コメントを表示
影響分析
この発表は、Transformerアーキテクチャに対する強力な代替案としての状態空間モデル(SSM)の実用性を再確認させるものであり、特に推論コストと速度が課題となるエッジデバイスやリアルタイムアプリケーションへの適用可能性を高める。Together AIによるカーネル公開は、実装のハードルを下げる一方、業界標準の再定義を促す可能性がある。
編集コメント
推論効率を最優先としたMamba-3の登場は、Transformer一強状態への対抗軸として注目に値する。特に1.5B規模でLlamaを上回る速度を出した点は、コスト敏感な実装において大きな意味を持つ。
 imageimage要約
imageimage要約
Mamba-3 は、推論効率を主目的として設計された新しい状態空間モデル(State Space Model: SSM)です。これは、トレーニング速度の最適化に注力した Mamba-2 とは方向性が異なります。主なアップグレードとしては、より表現力の高い再帰式、複素数値による状態追跡、そしてデコーディング速度を落とすことなく精度を向上させる MIMO(Multi-Input, Multi-Output)バリアントが含まれます。
その結果、1.5B スケールにおいて、Mamba-3 の SISO 版は、すべてのシーケンス長にわたってプリフィルとデコードのレイテンシで、Mamba-2、Gated DeltaNet、さらには Llama-3.2-1B(Transformer)を上回りました。
チームはまた、最大限のハードウェアパフォーマンスを実現するために Triton、TileLang、CuTe DSL を組み合わせて構築したカーネルをオープンソース化しました。
このブログ記事は Goomba Lab のブログにもクロスポストされており、カーネギーメロン大学、プリンストン大学、Cartesia AI、Together AI の研究者間の共同研究による成果について取り上げています。
2024 年半ばに Mamba-2 がリリースされて以来、ほとんどのアーキテクチャが Mamba-1 から移行しました。その理由は何か?Mamba-2 は、状態空間モデル(SSM)における最大のボトルネックがトレーニング効率であると判断し、その基盤となる SSM メカニズムを簡素化することで、先行モデルと比較して 2〜8 倍の高速なトレーニングを実現し、より広範な採用につながりました。
それ以来、LLM の状況は変化し始めています。事前学習はまだ非常に重要ですが、より多くの注目がポストトレーニングとデプロイに向けられており、これらはいずれも推論に極めて依存しています。コードや数学における検証可能な報酬を用いた強化学習(RLVR)などを含むポストトレーニング手法のスケーリングには、膨大な量の生成ロールアウトが必要であり、最近では Codex、Claude Code、さらには OpenClaw といったエージェントワークフローが推論需要を空前の高みに押し上げました。
推論の明確かつ増大する重要性にもかかわらず、多くの線形アーキテクチャ(Mamba-2 を含む)は事前学習優先の視点から開発されました。事前学習を加速させるために、基盤となる SSM は*段階的に簡素化*されました(例えば、対角遷移がスカラー×単位行列に縮小された)。これによりトレーニング速度は向上しましたが、推論ステップは「単純すぎる」状態となり、明確にメモリーバウンドとなりました。GPU が「ブッ」と音を立てているのではなく、実際には大部分の時間をメモリ転送に費やしているのです。
この推論の新時代において、私たちは品質と効率性のフロンティアの限界を押し広げることに非常に注力しています:*より優れた*モデルが*より速く*動作することを望んでいます。
自然な疑問が生じます:
推論を意識して設計された SSM はどのようなものになるのでしょうか?
Mamba-3 モデル
何が欠けているのか? リニアモデルの主な魅力はその名前にあります:固定サイズの状態を持つため、計算量はシーケンス長に対して線形にスケールします。残念ながら、*無料の昼食はありません*。効率的な計算を可能にするこの固定された状態サイズは、モデルが過去のすべての情報を一つの表現に圧縮することを強要します。これは、KV キャッシュと呼ばれる継続的に成長する状態を通じて過去のすべての情報を保存するトランスフォーマーのExactly反対です。これは*根本的*な違いです。では、状態を成長させられない場合、どのようにしてこの固定された状態でより多くの作業を行わせるのでしょうか?
私たちは、以前の設計がトレーニングを高速化するために再帰と遷移行列を単純化したことを知っています。しかし、その変更はダイナミクスの*豊かさを低下*させ、デコーディングをメモリーバウンドの状態にしました:各トークンの更新では、メモリの移動に対して非常に少ない計算しか行われません。これにより、私たちが操作できる3 つのレバーが得られます:(1)再帰自体をより表現力豊かなものにする、(2)より豊かである遷移行列を使用する、そして(3)各更新内にさらに多くの並列処理(ほぼ無料の作業)を追加する。
これらの洞察に基づき、Mamba-2 を以下の 3 つのコアな方法で改善します:
- 指数台形離散化スキームから導出されたより一般的な再帰を通じて、SSM メカニズムの表現力を高め、
- 複素数値 SSM システムをモデル化することで状態追跡能力を拡張し、
- 現在の単一入力・単一出力 (SISO) SSM の代わりに、複数の SSM を並列にモデル化するマルチ入力・マルチ出力 (MIMO) SSM を使用して、デコードレイテンシへの影響を抑えつつモデルの全般的な性能を向上させる。
これらの 3 つの変更により、Mamba-3 は推論レイテンシを同程度に維持しつつ、性能の限界を押し広げます。
特筆すべきは、これら 3 つの変更すべてが、「古典的」な制御理論および状態空間モデル (state space model) の文献から着想を得ている点です。
私たちの研究は、再帰に対する代替解釈(線形アテンションやテスト時トレーニングなど)を採用し、これらの概念を容易に捉えることができない多くの現代的な線形アーキテクチャの流れに逆らうものです。
アーキテクチャ
Mamba-2 レイヤーでは何が変更されたのでしょうか?上記の核心となる SSM に対する 3 つの方法論的アップグレードに加え、従来の現代言語モデルとより整合性を持たせるためにアーキテクチャも一部見直しました。
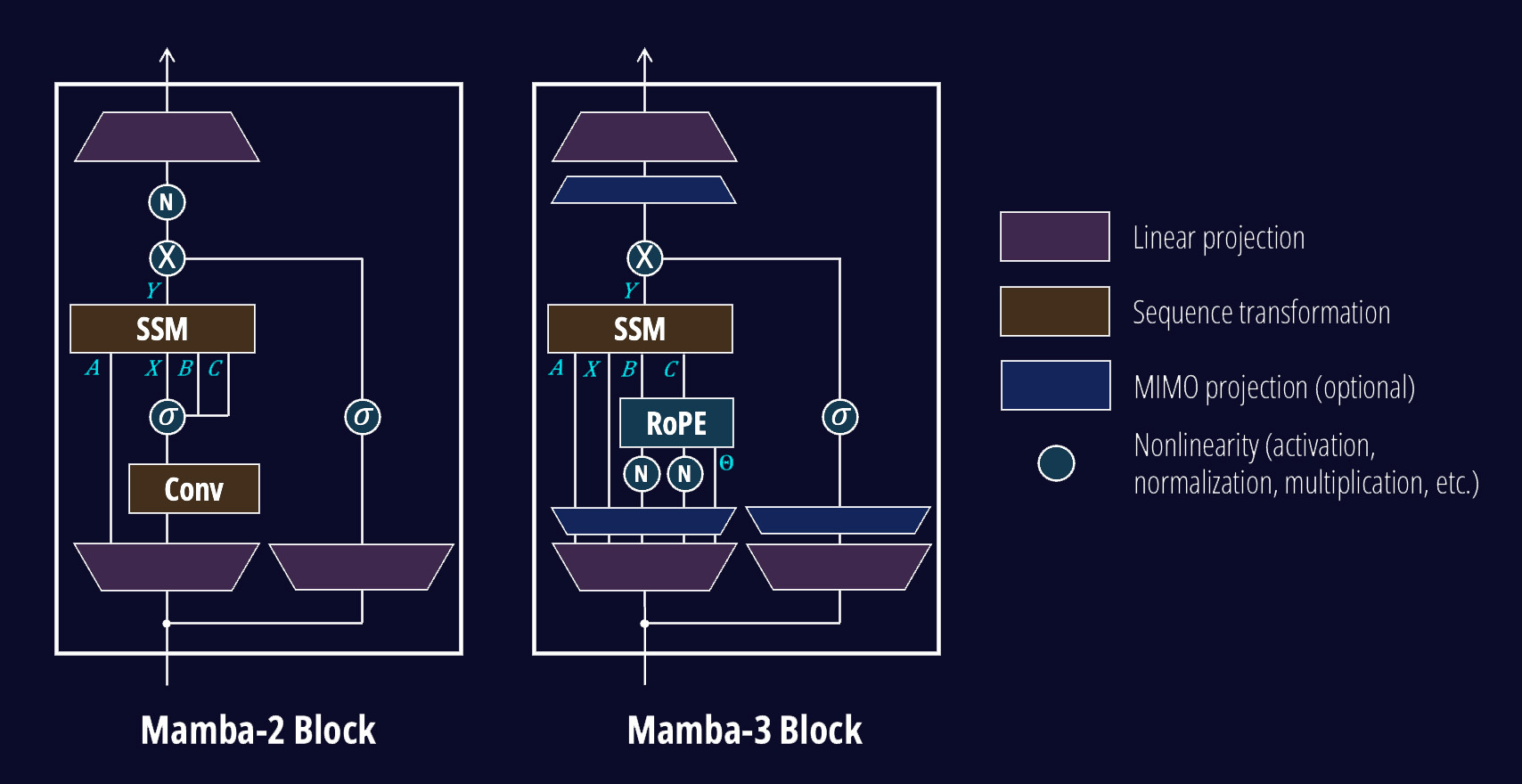
Mamba-3 アーキテクチャ図より、いくつかの変更点にお気づきいただけるでしょう。高レベルでは、
Norms. 私たちは、SSM の用語法における「BCNorm」として QKNorm を追加しました。これは Mamba-3 モデルのトレーニングを経験的に安定化させるものです。この正規化の追加により、Mamba-3 は現代の Transformer および Gated DeltaNet (GDN) モデルと整合性が取れるようになりました。QKNorm によって、Mamba-2 から継承された RMSNorm はオプションとなりました。しかし、長さ外挿能力を支援する可能性があるため、ハイブリッドモデルでは引き続き維持する価値があることを経験的に発見しました。これについては後ほど詳しく述べます。
Goodbye Short Conv. 私たちは、(1) BCNorm 後の B と C に対する単純なバイアスと (2) 新しい離散化に基づく再帰の組み合わせにより、Mamba-1/2 の厄介な短い因果畳み込みを排除することに成功しました。新しい再帰は、隠れ状態への入力に対して暗黙的に畳み込みを適用しますが、これがどのように行われるかは、当ブログのパート 2 で示します。
Can the short conv really be removed?
Mamba-3 の変更点は、SSM 再帰の内部に畳み込みのようなコンポーネントを追加するものですが、これは SSM 再帰の外部に配置される標準的な短い畳み込みとは完全に互換性があるわけではありません。
後者は Mamba-3 と併用することも可能ですが、採用しなかったという決定は経験的に下されたものです。私たちは、標準的な短い畳み込みを再度追加した場合について以下のように発見しました:
- パフォーマンスを向上させるものではなく、むしろわずかに悪化させます。また、より現実的なタスク(例:NIAH)における検索能力も低下させません。ただし、短い畳み込み層がないと、MQAR のような小規模な合成タスクでのトレーニングがやや困難になります。しかし、現実世界の検索挙動は影響を受けないため、これは主要な制限とはみなしていません。
なぜそうなるのか?理論的なメカニズムについては本研究では調査していませんが、論文内では、BC バイアスと指数台形再帰の両方が、外部の短い畳み込み層と同じ機能をempirically(経験的に)果たす畳み込みのようなメカニズムを同様に実行すると仮説を立てています。
短い畳み込みに関する簡潔な歴史解説
現在の最も高性能な線形モデルにおいて、短い畳み込みは中核コンポーネントとなっています。この短い畳み込みのバージョンは、まず H3(Anthropic の「smear」された誘導ヘッド研究に触発された「シフト SSM」という形式で)や RWKV-4(その「トークンシフト」メカニズムを通じて)の再帰的アーキテクチャで使用され、その後 Mamba-1 によって現在の形として普及しました。
これがこれほど一般的になった理由は、過去の研究が繰り返し、短い畳み込みが経験的なパフォーマンスを向上させるだけでなく、理論的にも誘導スタイルの検索能力をサポートすることを示しているからです。
最後に、いくつかの新しいコンポーネントに気づくでしょう。具体的には RoPE と MIMO 射影(MIMO projections) です。RoPE モジュールは、複素数の遷移を回転として解釈することで、複素数値 SSM(状態空間モデル)を表現し、高コストなカーネルの再実装を回避します。一方、MIMO 射影は、B および C 行列を MIMO SSM に必要な適切な表現に拡張します。
これらの 2 つに対する動機と正確な実装については、ブログの第 2 部でより詳細に掘り下げます(そこには多くの有益な情報があります 🎁)。現時点では、これらをモデルのパフォーマンスや/または能力を向上させるために個別に貢献する独立した根本的な改善として捉えておいてください。
最後に、全体のアーキテクチャは、Transformer や他の線形モデルの標準的な慣習に従い、インターリーブされた MLP レイヤーを採用しています。
実証結果
最終的な Mamba-3 モデルを、他の人気のある線形代替手法および Transformer ベースラインと比較して評価します。
言語モデリング
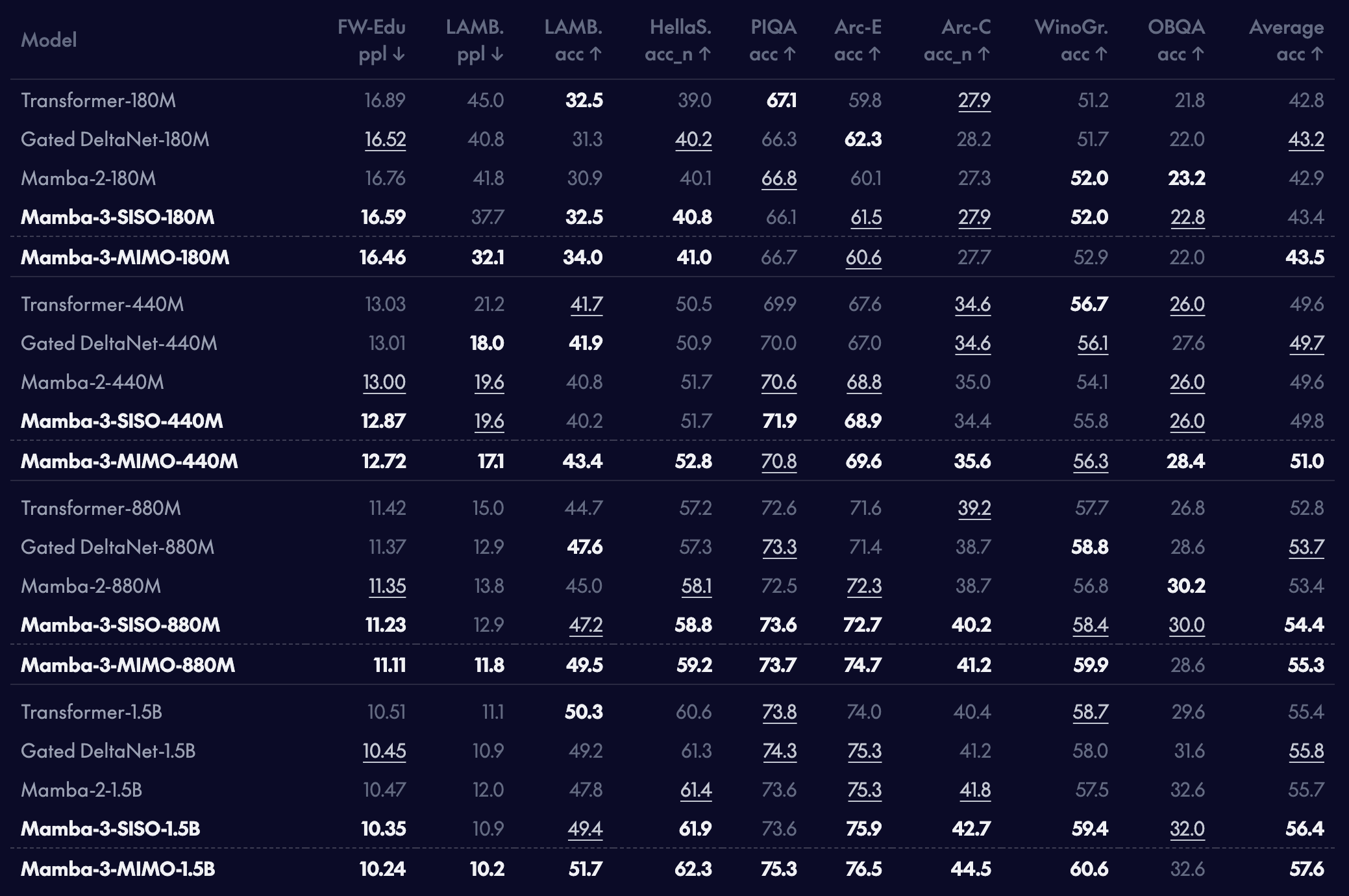
事前学習済みモデルのダウンストリーム言語モデリング評価
我々の新しい Mamba-3 モデルは、様々な事前学習済みモデルのスケーラにおいて、言語モデリングタスクにおいて既存の Mamba-2 モデルや GDN などの強力な線形アテンション代替案を上回る性能を示すことが分かりました。Mamba-3-SISO は従来の線形モデルと直接比較可能であり、例えばアーキテクチャ形状(モデル次元数、状態サイズなど)において Mamba-2 と完全に一致し、トレーニング時間も同等です。我々の MIMO 変種である Mamba-3 は、1B スケールにおいて通常の Mamba-3 よりもダウンストリームタスクの精度を 1 パーセントポイント以上向上させますが、その代償として MIMO はより長いトレーニング時間を要するものの、デコーディング時の遅延は増加しません!
トレーニングコストが増加してもなぜ推論速度は変わらないのか?
この点についてはブログの後半で詳しく解説しますが、ここでは読者の方々に少しだけ先取りしてお伝えします。
この二面性は、トレーニングと推論それぞれの計算量依存型とメモリ依存型の性質に起因するものです。現在の線形モデルは高速なトレーニングのために大量のGPU テンサーコア(Mamba-2 の主な貢献の一つ)を利用するように設計されていますが、デコーディング中では各タイムステップで必要な計算量が極めて少ないため、ハードウェアは大部分の時間をアイドル状態(コールド状態)のままになります。
したがって、もし各タイムステップに必要な FLOPs 量を増やすことだけを目的にアーキテクチャを設計すれば、推論遅延はおおむね一定に保たれます。なぜなら、アイドル中のコアの一部を利用できるからです --- しかしトレーニングにおいてはそうはいきません!
検索タスク
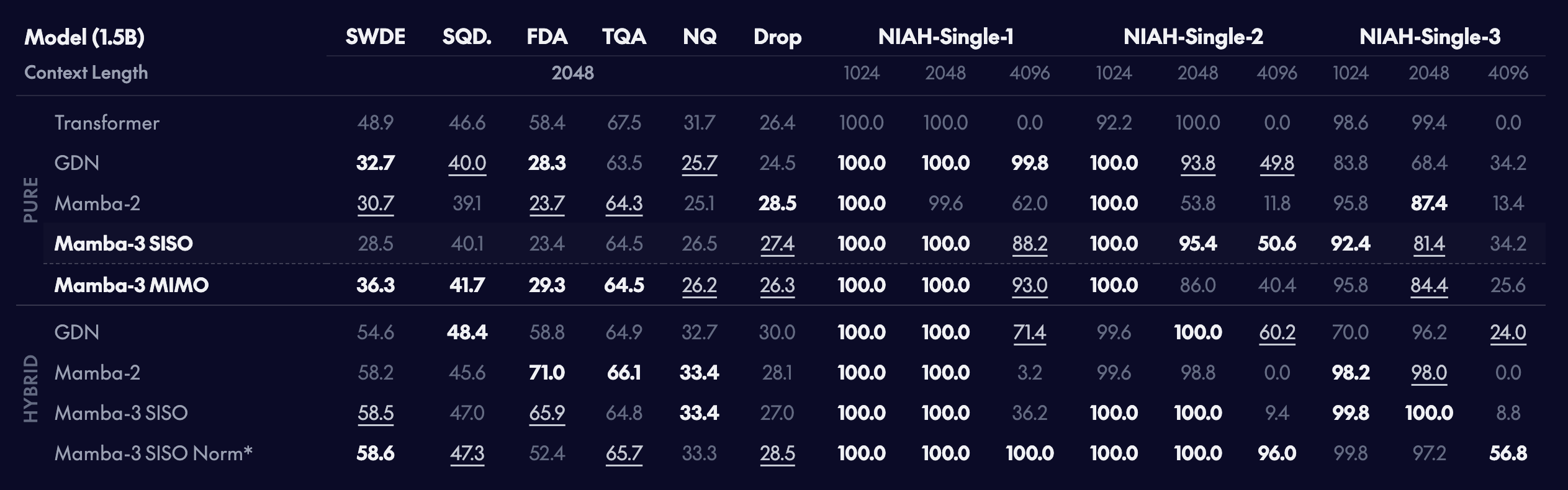
現実世界および合成された検索タスク
固定サイズの状態を持つ線形モデルは、本質的に 検索ベースのタスクにおいてそのトランスフォーマー(Transformer) counterpart に対して性能が劣ることが示されています。予想通り、純粋なモデル内では、トランスフォーマーは検索タスクにおいて優位ですが、Mamba-3 は二次未満(sub-quadratic)の代替手法のカテゴリー内では良好に機能します。興味深いことに、MIMO(Multiple Input Multiple Output)を追加することで、状態サイズを増やすことなく検索性能がさらに向上することが示されています。
この本質的な欠陥があるにもかかわらず、全体的なモデル化性能は強力であるため、
将来は線形層がグローバル自己注意層と組み合わせて主に使用されると予測します。*少なくとも言語モデリングにおいては*
線形層の一般的な「メモリのような」性質と、自己注意の KV キャッシュ(Key-Value Cache)の正確な「データベースのような」保存機能を組み合わせるハイブリッドモデルは、経験則として純粋なモデルよりも優れた性能を発揮し、大幅なメモリおよび計算リソースの節約を可能にすることが示されています。また、ここでは線形層と自己注意を組み合わせた方が、バニラ(vanilla)トランスフォーマーと比較してより良好な検索が可能であることも確認できました。
ただし、これらの線形モデルが自己注意機構とどのように相互作用するかという正確な仕組みは、まだ完全に解明されているわけではありません。例えば、Mamba-3 におけるオプションの出力前投影(pre-output projection)の使用は、合成された NIAH タスクにおける長さ一般化性能を向上させる一方で、コンテキスト内での実世界の検索タスクにはわずかなコストがかかることがわかりました。さらに、返されるノルムの詳細、例えば配置(ゲート前の pre-gate かゲート後の post-gate か)や種類(グループ化された grouped か通常の regular か)といった要素も、FDA や SWDE などの半構造化データおよび非構造化データで構成されたタスクにおける精度に無視できない影響を及ぼすことが示されています。
Kernels here, there, and everywhere
Mamba-3 を用いて人々がどのような成果を生み出すかを楽しみにしています。これを促進するため、私たちはカーネル(kernels)をオープンソース化しました。これらは速度の面で、オリジナルの Mamba-2 の Triton カーネルと同等です。
Benchmarking latencies
Prefill latency
Model
n=512
1024
2048
4096
16384
vLLM (Llama-3.2-1B)
0.26
0.52
1.08
2.08
12.17
Gated DeltaNet
0.51
1.01
2.01
4.00
16.21
Mamba-2
0.51
1.02
2.02
4.02
16.22
Mamba-3 (SISO)
0.51
1.01
2.02
4.01
16.22
Mamba-3 (MIMO r=4)
0.60
1.21
2.42
4.76
19.44
Prefill+decode latency
Model
n=512
1024
2048
4096
16384
vLLM (Llama-3.2-1B)
4.45
9.60
20.37
58.64
976.50
Gated DeltaNet
4.56
9.11
18.22
36.41
145.87
Mamba-2
4.66
9.32
18.62
37.22
149.02
Mamba-3 (SISO)
4.39
8.78
17.57
35.11
140.61
Mamba-3 (MIMO r=4)
4.74
9.48
18.96
37.85
151.81
Prefill と prefill+decode(両方の処理でトークン数は同一)のレイテンシを、単一の H100-SXM 80GB GPU 上で 1.5B モデルに対してシーケンス長ごとに測定した結果。すべてのシーケンス長においてバッチサイズは 128 とし、壁時計時間(秒単位)は 3 回の反復実験の結果を報告している。1.5B スケールでのモデル比較において、Mamba-3(SISO バリアント)はすべてのシーケンス長で最速の prefill + decode レイテンシを達成し、Mamba-2 や Gated DeltaNet、さらに高度に最適化された vLLM エコシステムを持つ Transformer をも上回っている。さらに、Mamba-3 MIMO は速度面では Mamba-2 と同等であるが、性能ははるかに優れている。
Mamba-3 SISO の Triton ベースの prefill は Mamba-2 とほぼ同等のパフォーマンスを維持しており、新しい離散化手法やデータ依存型 RoPE 埋め込みが追加オーバーヘッドをもたらさないことを示している。一方、Mamba-3 MIMO は効率的な TileLang 実装により prefill でわずかな速度低下が生じるのみである。両方の Mamba-3 バリアントにおける優れた decode パフォーマンスは、CuTe DSL 実装による部分が大きく、これは Mamba-3 コンポーネントのシンプルさによって大幅に容易になったものである。
デザイン上の選択
私たちは、使いやすさを損なうことなくカーネルを可能な限り高速化する方法について多くの時間を費やしました。その結果、以下のスタックを採用することにしました:Triton、TileLang、そしてCuTe DSLです。
Tritonの採用は非常に簡単な選択でした。これはアーキテクチャ開発において標準的な選択肢であり(優れた flash linear attention リポジトリも PyTorch と Triton のみで構築されています)、その理由として、制御されたタイリングとカーネル融合を可能にすることで標準的な PyTorch よりも優れたパフォーマンスを実現しつつ、プラットフォーム非依存の言語である点が挙げられます。また、Triton には PTX(GPU 指向のアセンブリ言語)の注入機能や、Hopper GPU における Tensor Memory Accelerator のサポートといった非常に便利な機能も備わっており、これらはグローバルメモリから共有メモリへの大量かつ非同期転送を可能にします。
一方、私たちの MIMO prefill カーネルはTileLangを用いて開発されました。バリアントに対応する追加の射影(プロジェクション)には、GPU のメモリアーキテクチャ全体にわたる戦略的な操作を通じてメモリ I/O を削減できる機会が存在します。残念ながら、Triton では私たちが望むような細粒度のメモリ制御を提供してくれなかったため、TileLang を採用しました。これにより、共有メモリのタイリングを明示的に宣言・制御し、レジスタフラグメントを作成することが可能となり、より効率的にメモリを再利用しながらも、カーネル開発を迅速に行える十分なレベルの高さを持っています。
推論とデコードの重要性を強調し続けてきたため、デコードカーネルにはCuTe DSLを採用しました。Python インターフェースを通じて、CUTLASS の高レベル抽象化を用いて低レベルカーネルを生成することが可能です。ここでは CUDA レベルの制御が可能となり、ハードウェア(今回は Hopper GPU)の仕様に合わせた高性能なカーネルを開発できます。テンソルレイアウトやワープ特化に対する微細な制御により、GPU に備わるあらゆる機能を活用したカーネルを構築しました。
重要なのは、これらの実装が、Mamba-3 のシンプルで軽量な追加機能とその巧妙なインスタンス化という基盤となるアルゴリズム設計によって、異なるレベルの GPU 抽象化にわたって可能になっている点です。融合構造の詳細やカーネル DSL については、完全版リリースにてより深く解説しています。
次のステップ
パート1の最後までお読みいただきありがとうございます!本記事では、カーネルや実験結果、アブレーション研究に関する多くの詳細を扱う時間がありませんでしたが、ご安心ください。これらすべては私たちの論文に記載されており、カーネルはmamba-ssmでオープンソース化されています。
次回は、シリーズの第 2 部(最終回)です。ここでは Mamba-3 の 3 つの中核的な改善点とそれらの SSM(状態空間モデル)の基礎について掘り下げ、特に興味を持っている方向性についても言及します。
参考文献
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces [PDF] Gu, A. and Dao, T., 2024.
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality [PDF] Dao, T. and Gu, A., 2024.
- Gated Delta Networks: Improving Mamba2 with Delta Rule [PDF] Yang, S., Kautz, J. and Hatamizadeh, A., 2025.
- Learning to (Learn at Test Time): RNNs with Expressive Hidden States [PDF] Sun, Y., Li, X., Dalal, K., Xu, J., Vikram, A., Zhang, G., Dubois, Y., Chen, X., Wang, X., Koyejo, S., Hashimoto, T. and Guestrin, C., 2025.
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models [PDF] Fu, D.Y., Dao, T., Saab, K.K., Thomas, A.W., Rudra, A. and Ré, C., 2023.
- In-context Learning and Induction Heads Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Johnston, S., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish, S. and Olah, C., 2022. Transformer Circuits Thread.
- RWKV: Reinventing RNNs for the Transformer Era [PDF] Peng, B., Alcaide, E., Anthony, Q., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M., Grella, M., GV, K.K., He, X., Hou, H., Lin, J., Kazienko, P., Kocon, J., Kong, J., Koptyra, B., Lau, H., Mantri, K.S.I., Mom, F., Saito, A., Song, G., Tang, X., Wang, B., Wind, J.S., Wozniak, S., Zhang, R., Zhang, Z., Zhao, Q., Zhou, P., Zhou, Q., Zhu, J. and Zhu, R., 2023.
- Test-time regression: a unifying framework for designing sequence models with associative memory [PDF] Wang, K.A., Shi, J. and Fox, E.B., 2025.
- An Empirical Study of Mamba-based Language Models [PDF] Waleffe, R., Byeon, W., Riach, D., Norick, B., Korthikanti, V., Dao, T., Gu, A., Hatamizadeh, A., Singh, S., Narayanan, D., Kulshreshtha, G., Singh, V., Casper, J., Kautz, J., Shoeybi, M. and Catanzaro, B., 2024.

8 秒
DeepSeek R1

ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティック動画生成。
DeepSeek R1
8 秒
オーディオ名
オーディオの説明
0:00
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティック動画生成。
8 秒
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティック動画生成。
パフォーマンスとスケーラビリティ
本文はここに lorem ipsum dolor sit amet
- 箇条書き項目はここに lorem ipsum
- 箇条書き項目はここに lorem ipsum
- 箇条書き項目はここに lorem ipsum
インフラストラクチャ
最適な用途
- より高速な処理速度(全体的なクエリレイテンシの低減)と低い運用コスト
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
DeepSeek R1
8 秒
オーディオ名
オーディオ説明
0:00
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
8 秒
DeepSeek R1
ネイティブオーディオと生々しい物理挙動を備えた、プレミアムなシネマティックビデオ生成。
パフォーマンスとスケーラビリティ
本文ここに挿入:ローラム イプサム ドロール シット アメット
- 箇条書きここに挿入:ローラム イプサム
- 箇条書きここに挿入:ローラム イプサム
- 箇条書きここに挿入:ローラム イプサム
インフラストラクチャ
最適用途
- より高速な処理速度(全体的なクエリレイテンシの低減)と低い運用コスト
- 明確に定義された単純なタスクの実行
- ファンクション呼び出し、JSON モード、または他の構造化されたタスク
リスト項目 #1
- ローラム イプサム ドロール シット アメット、コンセクテタル アディピシング エリート、セド ドゥイウスモム テンポル インキジデント。
- ローラム イプサム ドロール シット アメット、コンセクテタル アディピシング エリート、セド ドゥイウスモム テンポル インキジデント。
- ローラム イプサム ドロール シット アメット、コンセクテタル アディピシング エリート、セド ドゥイウスモム テンポル インキジデント。
リスト項目 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
原文を表示
tl;dr
Mamba-3 is a new state space model (SSM) designed with inference efficiency as the primary goal — a departure from Mamba-2, which optimized for training speed. The key upgrades are a more expressive recurrence formula, complex-valued state tracking, and a MIMO (multi-input, multi-output) variant that boosts accuracy without slowing down decoding.
The result: Mamba-3 SISO beats Mamba-2, Gated DeltaNet, and even Llama-3.2-1B (Transformer) on prefill+decode latency across all sequence lengths at the 1.5B scale.
The team also open-sourced the kernels, built using a mix of Triton, TileLang, and CuTe DSL for maximum hardware performance.
This blog is cross-posted on the Goomba Lab blog and covers work done in collaboration between researchers at Carnegie Mellon University, Princeton University, Cartesia AI, and Together AI.
Since the release of Mamba-2 in mid-2024, most architectures have switched from Mamba-1. Why? Mamba-2 made the bet that training efficiency was the largest bottleneck for state space models (SSMs), and thus simplified the underlying SSM mechanism to deliver 2−8× faster training compared to its predecessor, leading to wider adoption.
Since then, the LLM landscape has started to shift. While pretraining is still super important, more attention has been focused on post-training and deployment, both of which are *extremely inference-heavy*. The scaling of post-training methods, especially with reinforcement learning with verifiable rewards (RLVR) for coding or math, requires huge amounts of generated rollouts, and most recently, agentic workflows, such as Codex, Claude Code, or even OpenClaw, have pushed inference demand through the roof.
Despite the clear, growing importance of inference, many linear architectures (including Mamba-2) were developed from a training-first perspective. To accelerate pretraining, the underlying SSM was *progressively simplified* (e.g., the diagonal transition was reduced to a scalar times identity). While this brought training speed, it left the inference step "too simple" and squarely memory-bound --- the GPUs aren't brr-ing but moving memory most of the time.
In this new age of inference, we care a lot about pushing the boundaries of the quality-efficiency frontier: we want the *better* models to run *faster*.
A natural question arises:
What would an SSM designed with inference in mind look like?
The Mamba-3 model
What's missing? The main appeal of linear models is in their name: compute scales linearly with sequence length because of a fixed-size state. Unfortunately, there is *no free lunch*. The same fixed state size that enables efficient computation forces the model to compress all past information into one representation, the exact opposite of a Transformer, which stores all past information through a continuously growing state (the KV cache) --- a *fundamental* difference. So, if we can't grow the state, how do we make that fixed state do more work?
We see that earlier designs simplified the recurrence and the transition matrix to make training fast. However, the change also *reduced the richness* of the dynamics and left decoding memory-bound: each token update performs very little computation relative to memory movement. This provides us with three levers we can pull: (1) make the recurrence itself more expressive, (2) use a richer transition matrix, and (3) add more parallel (and almost free) work inside each update.
From these insights, we improve upon Mamba-2 in three core ways that:
- increase the expressivity of the SSM mechanism through a more general recurrence derived from our exponential-trapezoidal discretization scheme,
- expand the state-tracking capabilities by modeling a complex-valued SSM system, and
- improve the model's general performance with little impact on decode latency by using multi-input, multi-output (MIMO) SSMs, which model multiple SSMs in parallel, instead of the current single-input, single-output (SISO) SSMs.
Through these three changes, Mamba-3 pushes the frontier of performance while maintaining similar inference latency.
Notably, all three of these changes are inspired by the more "classical" control theory and state space model literature.
Our work goes against the grain of many modern linear architectures, which use alternative interpretations of recurrence (such as linear attention or test-time training) that *don't easily capture these concepts*.
Architecture
What has changed in the Mamba-2 layer? Beyond the three methodological upgrades to the core SSM discussed above, we've revamped the architecture a bit to make it more in line with conventional modern language models.
Based on the diagram, you'll notice we've changed a couple of things. On a high level,
Norms. We added in QKNormor "BCNorm" in SSM terminology, which empirically stabilizes the training of Mamba-3 models. The addition of this norm brings Mamba-3 in line with contemporary Transformer and Gated DeltaNet (GDN) models. With QKNorm, the RMSNorm from Mamba-2 becomes optional. However, we empirically find that it may still be worth keeping in hybrid models due to helping length extrapolation capabilities. More on this later.
Goodbye Short Conv. We've been able to get rid of the pesky short causal convolution of Mamba-1/2 by combining (1) simple biases on B and C after BCNorm with (2) our new discretization-based recurrence. The new recurrence implicitly applies a convolution on the input to the hidden state, and we show how this is the case in Part 2 of our blog.
Can the short conv really be removed?
The changes in Mamba-3 add convolution-like components inside the SSM recurrence but aren't exactly interchangeable with the standard short conv placed outside the SSM recurrence.
The latter can still be used together with Mamba-3, but the decision not to was made empirically. We find adding the standard short conv back:
- does not improve performance; in fact, it slightly worsens it, and
- does not degrade retrieval capabilities on more real-world tasks (e.g., NIAH). That said, without a short convolution, training on small-scale synthetic tasks like MQAR becomes somewhat harder. Since real-world retrieval behavior remains unaffected, though, we don't consider this a major limitation.
As for why? We didn't study the theoretical mechanisms, but in the paper, we hypothesize about how both the BC bias and the exponential-trapezoidal recurrence perform similar convolution-like mechanisms which empirically serve the same function as the external short conv.
Quick history lesson on the short conv.
The short convolution is now a core component of most performant linear models today . Versions of the short conv were first used in recurrent architectures by H3 (in the form of a “shift SSM” which was inspired by the "smeared" induction heads work by Anthropic ) and RWKV-4 (through its “token shift” mechanism), before being popularized in its current form by Mamba-1.
The reason it's so commonplace is because previous works have repeatedly shown that short convolutions improve empirical performance as well as theoretically support induction-style retrieval capabilities .
Finally, you'll notice a couple of new components, namely RoPE and MIMO projections. The RoPE module expresses complex-valued SSMs via the interpretation of complex transitions as rotations, forgoing the costly reimplementation of kernels. The MIMO projections expand the B and C matrices to the appropriate representation needed for MIMO SSMs.
We dig into the motivation and exact implementation of these two in greater detail in the second part of our blog (lots of goodies there 🎁), so for now, just think of them as standalone, fundamental improvements that individually contribute to improving the model's performance and/or capabilities.
Finally, our overall architecture now adopts interleaved MLP layers following the standard convention of Transformers and other linear models.
Empirical results
We evaluate our final Mamba-3 model against other popular linear alternatives and the Transformer baseline.
Language modeling
We find that our new Mamba-3 model *outperforms* the prior Mamba-2 model and strong linear attention alternatives, such as GDN, on language modeling across various pretrained model scales. Mamba-3-SISO is directly comparable to prior linear models; for example, it matches Mamba-2 exactly in architecture shapes (model dimensions, state size, etc.) and has comparable training time. Our MIMO variant of Mamba-3 further boosts accuracy on our downstream tasks by more than 1 percentage point over the regular Mamba-3 at the 1B scale, with the caveat that MIMO requires longer training times but not longer decoding latencies!
How can training costs go up but not inference?
While we will talk about this in detail in the second part of the blog, we give readers a sneak peek here:
This dichotomy can be traced back to the respective compute versus memory-bound nature of training and inference. Current linear models have been designed to use lots of GPU tensor cores (one of the main contributions of Mamba-2) for fast training, but during decoding, each timestep requires so little compute that the hardware remains cold most of the time.
Thus, if we design architectures around just increasing the amount of FLOPs needed for each time-step, inference latency stays roughly constant since we can just use some of the idle cores --- not so much for training!
Retrieval tasks
Linear models, with their fixed-size state, naturally underperform their Transformer counterparts on retrieval-based tasks. As expected, within pure models, the Transformer is superior on retrieval tasks, but Mamba-3 performs well within the class of sub-quadratic alternatives. Interestingly, the addition of MIMO further improves retrieval performance *without increasing the state size*.
Given this innate deficit but overall strong modeling performance,
we predict that linear layers will be predominantly used in conjunction with global self-attention layers in the future.*
at least for language modeling
Hybrid models that combine the general *memory-like* nature of linear layers with the exact *database-like* storage of self-attention's KV cache have been shown empirically to outperform pure models while enabling significant memory and compute savings , and we do find here that the combination of linear layers with self-attention enables better retrieval compared to a vanilla Transformer.
However, we highlight that the exact way that these linear models interact with self-attention is *not fully understood*. For instance, we find that the use of the optional pre-output projection for Mamba-3 improves the length generalization performance on the synthetic NIAH tasks at the slight cost of in-context real-world retrieval tasks. Furthermore, even the details of the returned norm such as placement, e.g., pre-gate vs post-gate, and type, grouped vs regular, have non-negligible effects on accuracy on tasks composed of semi-structured and unstructured data, such as FDA and SWDE.
Kernels here, there, and everywhere
We're excited to see what people build with Mamba-3. To help facilitate this, we are open-sourcing our kernels, which are on par in terms of speed with the original Mamba-2 Triton kernels.
Benchmarking latencies
Prefill latency
Model
n=512
1024
2048
4096
16384
vLLM (Llama-3.2-1B)
0.26
0.52
1.08
2.08
12.17
Gated DeltaNet
0.51
1.01
2.01
4.00
16.21
Mamba-2
0.51
1.02
2.02
4.02
16.22
Mamba-3 (SISO)
0.51
1.01
2.02
4.01
16.22
Mamba-3 (MIMO r=4)
0.60
1.21
2.42
4.76
19.44
Prefill+decode latency
Model
n=512
1024
2048
4096
16384
vLLM (Llama-3.2-1B)
4.45
9.60
20.37
58.64
976.50
Gated DeltaNet
4.56
9.11
18.22
36.41
145.87
Mamba-2
4.66
9.32
18.62
37.22
149.02
Mamba-3 (SISO)
4.39
8.78
17.57
35.11
140.61
Mamba-3 (MIMO r=4)
4.74
9.48
18.96
37.85
151.81
Prefill and prefill+decode (same token count for both prefill and decode) latencies across sequence lengths for a 1.5B model on a single H100-SXM 80GB GPU. A batch size of 128 was used for all sequence lengths, wall-clock times (in seconds) are reported over three repetitions.When comparing models at the 1.5B scale, Mamba-3 (SISO variant) *achieves the fastest prefill + decode latency* across all sequence lengths, outperforming Mamba-2, Gated DeltaNet, and even the Transformer with its highly optimized vLLM ecosystem. Furthermore, Mamba-3 MIMO is comparable to Mamba-2 in terms of speed but has much stronger performance.
Mamba-3 SISO's Triton-based prefill maintains nearly identical performance to Mamba-2, demonstrating that the new discretization and data-dependent RoPE embeddings do not introduce additional overhead, while Mamba-3 MIMO only incurs a moderate slowdown for prefill due to its efficient TileLang implementation. The strong decode performance for both Mamba-3 variants can be partially attributed to the CuTe DSL implementation, which was made significantly easier by the simplicity of Mamba-3 components.
Design choices
We spent a lot of time thinking about how to make the kernels as fast as possible without compromising on ease-of-use. We ended up using the following stack: Triton, TileLang, and CuTe DSL.
The use of Triton was quite an easy choice. It's pretty much standard for architecture development (the great flash linear attention repo is purely in PyTorch and Triton) for good reason, as it enables better performance than standard PyTorch by enabling controlled tiling and kernel fusion while being a platform-agnostic language. Triton also has some pretty nifty features, like PTX (a GPU-oriented assembly language) injection and its Tensor Memory Accelerator support (on Hopper GPUs) for bulk, asynchronous transfers from global to shared memory.
Our MIMO prefill kernels were developed with TileLang instead. The additional projections corresponding with the variant present an opportunity where we can reduce memory IO via strategic manipulation across a GPU's memory hierarchy. Unfortunately, Triton didn't provide the granularity of memory control we desired, so we opted for TileLang, which allows us to explicitly declare and control shared-memory tiles and create register fragments, reusing memory more efficiently while still being high-level enough for us to develop the kernels quickly.
Since we've been hammering the importance of inference and decode, we decided to use CuTe DSL for our decode kernels. Through its Python interface, we're able to generate low-level kernels using high-level abstractions from CUTLASS. Here, we practically have CUDA-level control, enabling us to develop highly-performant kernels tailored to the specifications of our hardware (Hopper GPUs, in this case). With fine-grained control over tensor layouts and warp specialization, we built a kernel that takes advantage of all the bells and whistles in the GPU.
Importantly, these implementations across varying levels of GPU abstraction are made possible by the underlying algorithmic design of Mamba-3's simple, lightweight additions and their clever instantiations. We discuss details such as the exact fusion structure and kernel DSL in more depth in our full release.
Next up
Glad you made it to the end of Part 1! There were a lot of details regarding our kernels and experimental results and ablations we didn't have time to cover in this post, but don't fret! Everything can be found in our paper, and the kernels have been open-sourced at mamba-ssm!
Up next, the second (and final) part of the series delves into the three core improvements to Mamba-3 and their SSM foundations, and gives some directions we're especially interested in.
References
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces [PDF]Gu, A. and Dao, T., 2024.
- Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality [PDF]Dao, T. and Gu, A., 2024.
- Gated Delta Networks: Improving Mamba2 with Delta Rule [PDF]Yang, S., Kautz, J. and Hatamizadeh, A., 2025.
- Learning to (Learn at Test Time): RNNs with Expressive Hidden States [PDF]Sun, Y., Li, X., Dalal, K., Xu, J., Vikram, A., Zhang, G., Dubois, Y., Chen, X., Wang, X., Koyejo, S., Hashimoto, T. and Guestrin, C., 2025.
- Hungry Hungry Hippos: Towards Language Modeling with State Space Models [PDF]Fu, D.Y., Dao, T., Saab, K.K., Thomas, A.W., Rudra, A. and Ré, C., 2023.
- In-context Learning and Induction HeadsOlsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Johnston, S., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish, S. and Olah, C., 2022. Transformer Circuits Thread.
- RWKV: Reinventing RNNs for the Transformer Era [PDF]Peng, B., Alcaide, E., Anthony, Q., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M., Grella, M., GV, K.K., He, X., Hou, H., Lin, J., Kazienko, P., Kocon, J., Kong, J., Koptyra, B., Lau, H., Mantri, K.S.I., Mom, F., Saito, A., Song, G., Tang, X., Wang, B., Wind, J.S., Wozniak, S., Zhang, R., Zhang, Z., Zhao, Q., Zhou, P., Zhou, Q., Zhu, J. and Zhu, R., 2023.
- Test-time regression: a unifying framework for designing sequence models with associative memory [PDF]Wang, K.A., Shi, J. and Fox, E.B., 2025.
- An Empirical Study of Mamba-based Language Models [PDF]Waleffe, R., Byeon, W., Riach, D., Norick, B., Korthikanti, V., Dao, T., Gu, A., Hatamizadeh, A., Singh, S., Narayanan, D., Kulshreshtha, G., Singh, V., Casper, J., Kautz, J., Shoeybi, M. and Catanzaro, B., 2024.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
- Faster processing speed (lower overall query latency) and lower operational costs
- Execution of clearly defined, straightforward tasks
- Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
- ✔ Up to $15K in free platform credits*
- ✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags *<answer>* and *</answer>*. Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み