現在利用可能な Hugging Face 上の最良の無料画像生成ツール
本記事は、Hugging Face に存在する約9万個のテキスト画像生成モデルの中から、2026年時点で実用性と品質を兼ね備えた7つの無料モデルを厳選し、ブラウザ利用とローカル実行の両方の活用方法を詳述している。
キーポイント
Hugging Face の二重活用戦略
記事は、GPUやインストールが不要な「Spaces」での即座の試行と、ComfyUI や Diffusers を用いたローカル環境での高品質・非制限生成という、2 つの異なる利用形態を明確に区別して解説している。
厳選された 7 つのモデル紹介
90,000 以上の候補から、出力品質が有料ツールと競合し、ライセンスも明確でメンテナンスされている FLUX.1 Schnell など 7 つのモデルに絞り込み、それぞれの強みとトレードオフを提示している。
実装要件とアクセス方法の明示
各モデルについて、必要な VRAM や Python 環境といったローカル実行のハードルや、ブラウザベースでの利用可否を具体的に記載し、ユーザーのスキルレベルに合わせた選択を支援している。
Midjourney/DALL-E の代替としての価値
多くのユーザーが知らないうちにこれらのモデルのアーキテクチャや重みを利用している事実を指摘し、Hugging Face が無料かつオープンな代替手段として強力な役割を果たすことを強調している。
Apache 2.0 ライセンスによる商用利用の自由
このモデルは Apache 2.0 ライセンスの下でリリースされており、個人・学術用途だけでなく、製品化やパイプラインへの統合を含む商業利用もライセンス交渉なしに可能です。
高速推論と高い品質の両立
ガイダンス蒸留(guidance distillation)技術により従来の拡散モデルよりも少ない 1〜4 ステップで画像を生成でき、消費者向けハードウェアでも実用的な速度を実現しています。
用途に応じた使い分けの推奨
即座に商用アプリや製品を構築したい場合に最適ですが、絶対的なフォトリアリズムの詳細さが最優先される場合は、より高品質だがライセンス制限のある FLUX.1 Dev の利用が推奨されます。
重要な引用
"A quick search on Hugging Face returns over 90,000 text-to-image models alone."
"Most people who want a free AI image generator end up on Midjourney or DALL-E without realizing that Hugging Face hosts the actual models powering those tools."
"This article cuts through the 90,000 options to the seven models worth your time in 2026."
"Apache 2.0 is as permissive as open-source licensing gets — you can build a product, ship it commercially, integrate it into a pipeline, and do it all without licensing negotiations or usage fees."
"Schnell was trained using guidance distillation to generate in 1–4 inference steps rather than the 20–50 that traditional diffusion models require."
For non-commercial use, it is the highest-quality freely available model on the platform right now.
影響分析・編集コメントを表示
影響分析
本記事は、AI 画像生成の民主化を加速させる重要な指針となる。ユーザーに対し、高コストな有料ツールへの依存から脱却し、オープンソースモデルを活用する具体的なルート(ブラウザ利用とローカル環境)を提供することで、開発者やクリエイターの実践的な選択肢を広げる。特に、9 万を超えるモデルの中から信頼性の高いものをフィルタリングした情報は、学習コストを大幅に削減し、現場での導入スピードを向上させる。
編集コメント
膨大な数のモデルが存在する中で、実際に使えるものを特定し、利用方法まで具体的に示している点は非常に実用的です。有料ツールの代替として、あるいは学習の場として Hugging Face を活用したい層にとって必読の内容と言えます。
 image**
image**
# イントロダクション
Hugging Face で簡単な検索を行うと、テキストから画像を生成するモデルだけで 90,000 以上 がヒットします。この数字は参考情報であり、買い物リストではありません。無料で AI 画像生成ツールを探している人々は、気づかないうちに Midjourney や DALL-E にたどり着きますが、実はこれらのツールの背後にある実際のモデル(同じアーキテクチャ、場合によっては同じ重み)を Hugging Face がホストしており、ブラウザベースの Spaces デモを通じて無料で利用可能であったり、ダウンロードしてローカルで実行したりすることも可能です。
この記事では、90,000 以上の選択肢の中から、2026 年に時間を割く価値がある 7 つのモデルに焦点を当てます。選定基準は、有料ツールと競合する出力品質、ブラウザ利用またはダウンロードによる真に無料でのアクセス、活発なメンテナンス活動、そして異なるスキルレベルにおける実用性です。各モデルについて、Hugging Face のリンク、ライセンス内容とその実際の許可範囲、そのモデルが特に得意とする分野、そして正直なトレードオフ(利点と欠点)を解説します。
# Hugging Face を画像生成に活用する方法
Hugging Face に関するまず理解すべき点は、利用方法には明確に 2 つの異なる形態があり、それぞれが異なるユーザー層に適しているということです。
- Hugging Face Spaces は、ブラウザ上で動作する無料のデモです。Space の URL にアクセスしてプロンプトを入力するだけで画像が生成されます。GPU が必要なく、インストールも不要で、API キーやアカウント登録もほとんどの場合必要ありません。ピーク時には一部のモデルでキュー待ちが発生しますが、高性能な Spaces は専用ハードウェア上で動作し、迅速にレスポンスします。これは、より複雑な取り組みを行う前に、モデルの能力を探求したり、一度きりの生成を行ったり、テストしたりするための最適な入り口です。この記事で紹介されているすべてのモデルには、すぐに試せるリンク付きの Space が用意されています。
- モデルの重み(weights)をダウンロードし、diffusers Python ライブラリ、ComfyUI、または Forge を介してローカルで実行すれば、キュー待ちなしでの大量生成が可能になり、パラメータに対する完全な制御権とプライバシーが得られます。つまり、データは一切外部に送信されません。これには対応する GPU(VRAM 要件は後述の各項目ごとに記載)と Python 環境が必要です。
# 1. FLUX.1 Schnell
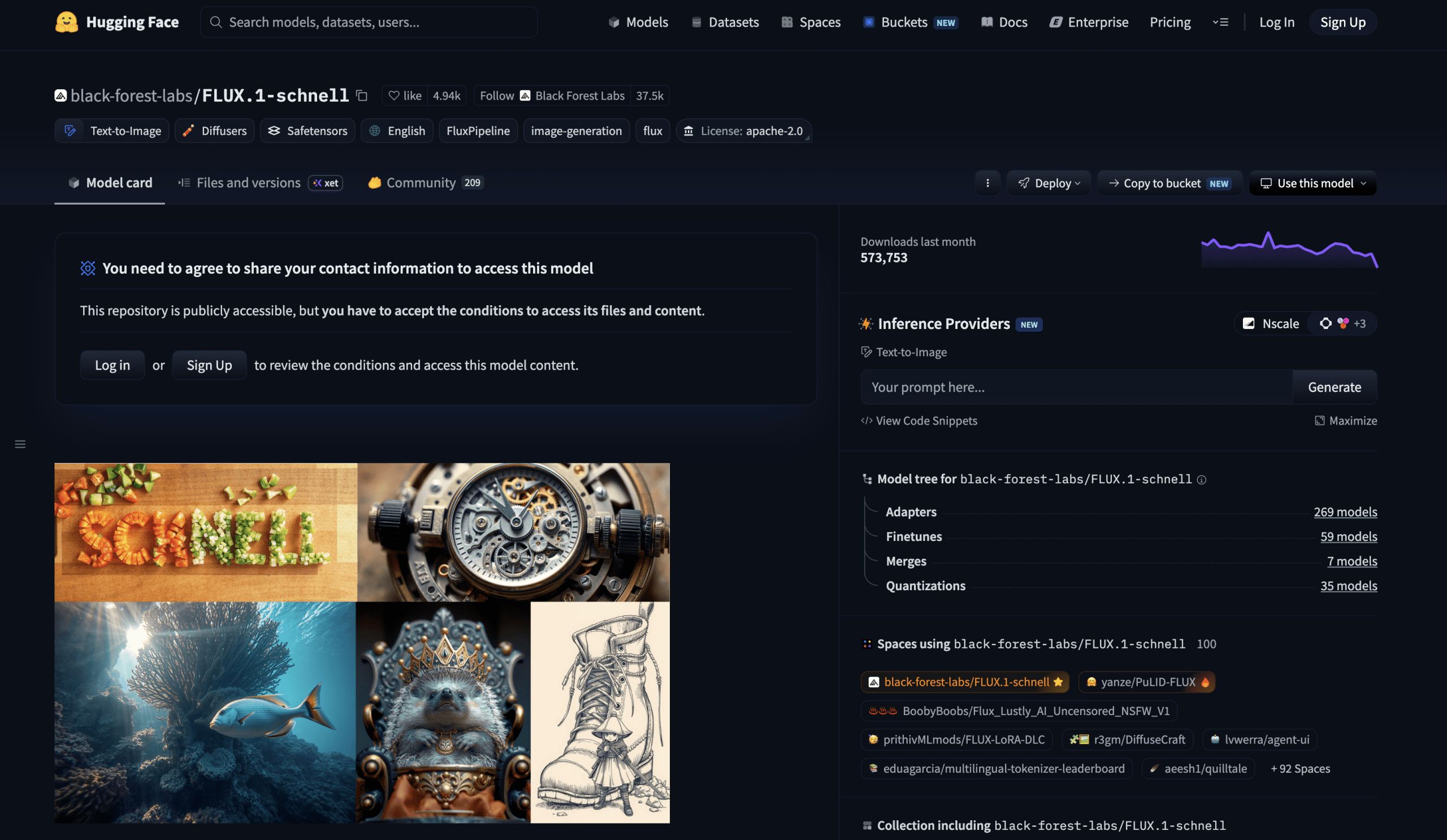
FLUX.1 Schnell ダッシュボード
フィールド**
詳細
開発元
ライセンス
Apache 2.0 — 個人利用、科学研究、商用利用可
パラメータ数
12B
アーキテクチャ
Rectified flow transformer(整流フロー・トランスフォーマー)
VRAM(ローカル実行時)
約 16 GB(CPU オフロードを有効化すれば約 10 GB でも動作可能)
最適な用途
高速生成、商用利用、アプリ構築
FLUX.1 Schnell は Apache 2.0 ライセンスの下でリリースされています。これは、個人利用、科学研究、商業利用のいずれにも使用可能であることを意味します。この単一の事実が、本リストにある他のフラッグシップ品質モデルすべてと FLUX.1 Schnell を区別しています。Apache 2.0 はオープンソースライセンスの中で最も寛容なものであり、製品を構築して商用リリースし、パイプラインに統合しても、ライセンス交渉や利用料の支払いなしでこれらすべてを行うことができます。
Schnell はガイダンス蒸留(guidance distillation)を用いてトレーニングされており、従来の拡散モデルが必要とする 20〜50 ステップではなく、推論ステップを 1〜4 に抑えて生成を行います。そのステップあたりの品質は極めて卓越しています。Black Forest Labs が製造するモデルの中で最高品質なのは FLUX.1 Dev または FLUX.2 ですが、Schnell は 1 年前のモデルの多くを凌駕する出力を生み出し、一般消費者向けのハードウェアでも本格的に高速な生成速度を実現します。
ただし、絶対的なフォトリアリスティックな詳細さが要求されるシーンには最適ではありません。そのような用途では、FLUX.1 Dev がより高い品質上限を提供しますが、Apache 2.0 に基づく商用の自由は提供されません。
# 2. FLUX.1 Dev
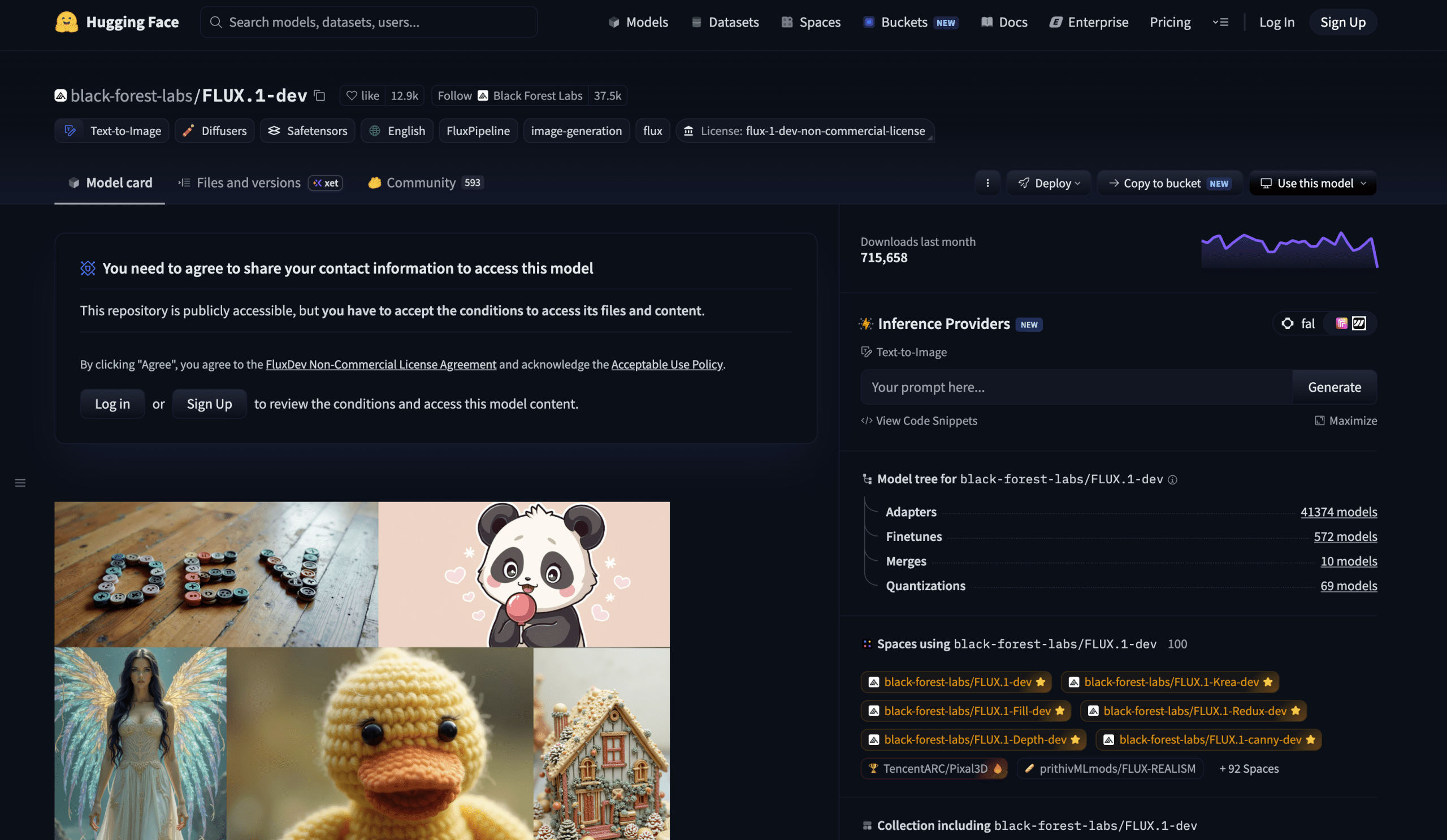 image**
image**
FLUX.1 Dev ダッシュボード | 画像作成:著者
フィールド**
詳細
開発者
ライセンス
FLUX.1 Dev 非商用ライセンス
パラメータ数
12B(120億)
アーキテクチャ
Rectified flow transformer(整流フロー・トランスフォーマー)
VRAM(ローカル環境)
推奨約 24 GB
最適な用途
研究、芸術プロジェクト、高品質な個人利用
FLUX.1 Dev は 120 億パラメータの整流フロー・トランスフォーマー です。これは FLUX.1 Pro から直接蒸留されたモデルであり、同じサイズの標準モデルよりも効率的でありながら、同様の品質とプロンプトへの忠実度を達成しています。非商用利用においては、現在このプラットフォーム上で入手可能な最も高品質な無料モデルです。
ポートレートや製品写真に関するプロンプトにおける写実性は、他の無料ツールが生成するものとは比較にならないほど 優れています。ポートレートの一貫性、繊細な生地の質感、建築の詳細、画像内テキストのレンダリングはすべて、コミュニティのベンチマークとして置き換えられた以前の世代モデルよりも明らかに向上しています。
ライセンスの明確さはここにおいて重要です。モデル重みそのものは非商用利用のみを目的としており、Black Forest Labs に連絡することなく、このモデルを用いて有料製品を構築することはできません。ただし、FLUX.1 Dev で生成された画像は、ライセンスで記述されている通り、個人的・科学的・商業的な目的で使用することが可能です。この区別は重要です:自身の商業的作業のために画像を生成する目的でモデルを使用することは、一般的に許可されています。一方、モデルそのものを商用製品や API のエンジンとして利用することは、Black Forest Labs と別途協議が必要な別の話題となります。
# 3. FLUX.1 Kontext Dev
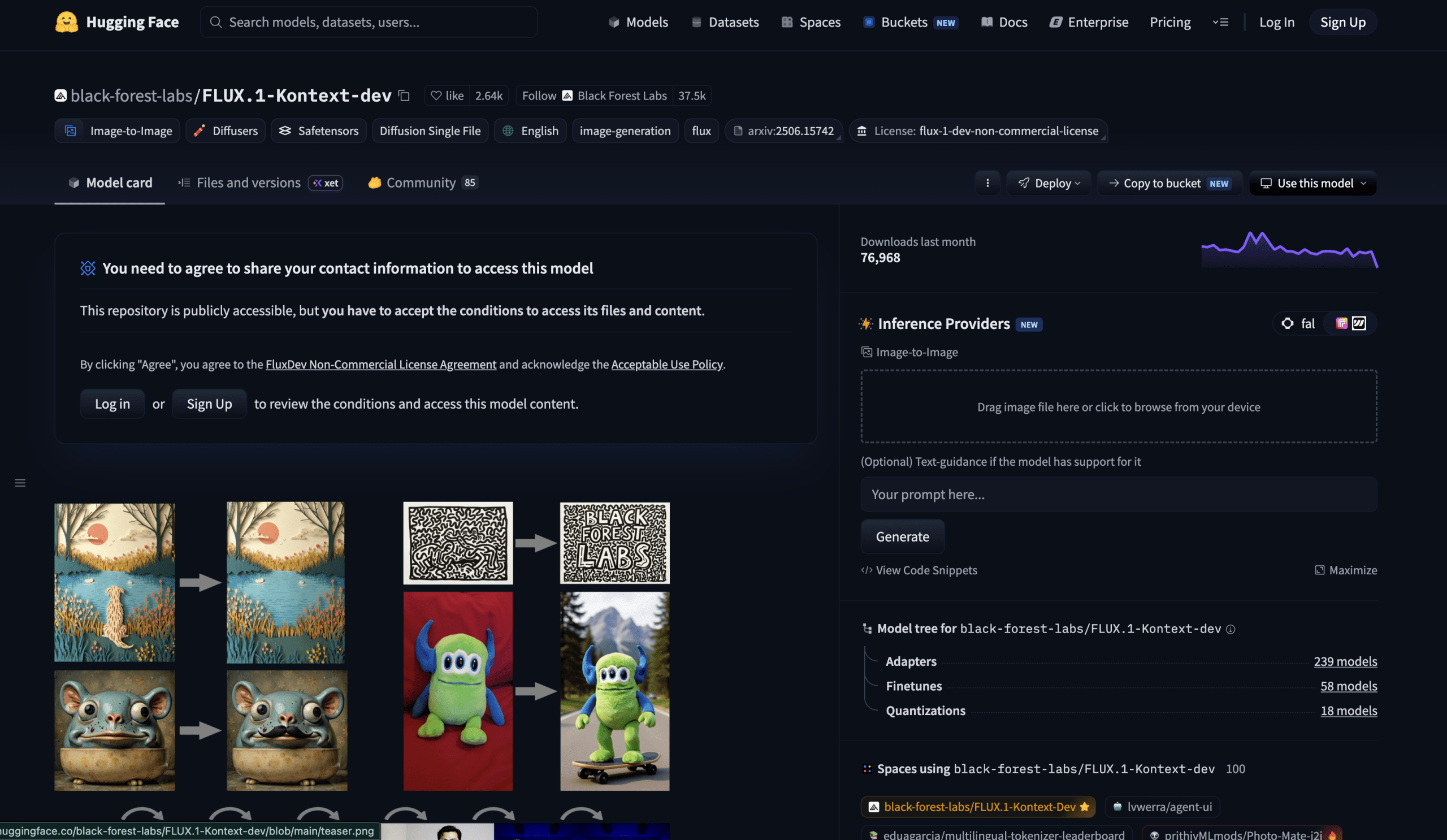 image**
image**
FLUX.1 Kontext Dev ダッシュボード | 画像提供:著者
フィールド**
詳細
開発元
ライセンス
FLUX.1 Dev 非商用ライセンス
パラメータ数
12B(120 億)
リリース日
2025 年 5 月
アーキテクチャ
コンテキスト条件付き整流フロー・トランスフォーマー (Rectified flow transformer with in-context conditioning)
主な用途
画像編集、キャラクターの一貫性維持、スタイル転送、反復的改良
このリストにある他のすべてのモデルはテキストプロンプトを受け取ってゼロから画像を生成しますが、FLUX.1 Kontext Dev は既存の画像を受け取り、テキスト指示に基づいてそれを変更します。
FLUX.1 Kontext Dev は、テキスト指示に基づいて画像を編集する能力を持ち、微調整なしでキャラクター、スタイル、オブジェクトの参照をサポートしています。堅牢な一貫性により、ユーザーは視覚的なズレを最小限に抑えながら、複数の連続した編集を通じて画像を洗練させることができます。最後の点は技術的に難しい部分です。ほとんどの画像編集モデルではドリフト(ズレ)が発生し、3 回の連続した編集を行うと、3 回目の反復時にはキャラクターが別人のように見えてしまいます。Kontext は、このアーキテクチャ以前にはオープンソースモデルで不可能だった安定性をもって、連続する編集を通じてアイデンティティを維持します。
これによって可能になる実用的なワークフローは、キャラクター、製品、またはシーンを一度生成した後、反復して「サングラスを追加」「背景を夕暮れの山に変更」「ジャケットを赤くする」「モーションブラーを追加」といった指示を出し、コアとなる視覚的アイデンティティが全体を通じて維持されるようにすることです。商品撮影やキャラクターデザイン、および反復処理を伴うあらゆるワークフローにおいて、これは無料のオープンソースツールができることの質的な転換点となります。
Space デモは非常にシンプルで、画像をアップロードし、指示を入力し、ガイダンス強度とシード値を調整するだけです。huggingface.co/spaces/black-forest-labs/FLUX.1-Kontext-Dev のインターフェースは、純粋なテキストから画像への生成(text-to-image)のために、ソース画像なしでの画像から画像への生成(image-to-image)もサポートしています。
# 4. Stable Diffusion 3.5 Large
Stable Diffusion 3.5 Large Dashboard | Image by Author
Field Detail**
Developer
License
Stability AI Community License (permissive for most uses)
Parameters
8B
Architecture
Multimodal diffusion transformer (MMDiT) [マルチモーダル拡散トランスフォーマー]
VRAM (local)
~10–16 GB
Best for
Community fine-tunes, ControlNets, broad customization
Stable Diffusion 3.5 is available under a permissive community license, is customizable, runs on consumer hardware, and comes with full inference code on GitHub。しかし、このリストに掲載されている主な理由はライセンスやダウンロード数ではありません。
SD 3.5 が重要視される理由は、その周辺に存在するエコシステムにあります。Hugging Face には数千ものファインチューン済みモデルがあり、特定のスタイルや被写体向けに訓練された数百の LoRA モデル、ガイド付き生成(カニエッジ、深度マップ、ポーズ制御など)用の ControlNet バリアント、そして長年にわたり構築・洗練されてきたツールリングエコシステム — AUTOMATIC1111、ComfyUI、Forge など — が存在します。他のモデルアーキテクチャには、まだこれほど深いコミュニティインフラストラクチャーは備わっていません。
SD 3.5 Medium も注目すべきモデルです:より小型のバリアントは、8〜10 GB の VRAM に比較的余裕を持って搭載でき、生成速度も速くなりますが、最高品質とのトレードオフとなります。どちらも無料です。独自のデータでモデルをファインチューニングしたり、カスタム ControlNet ワークフローを構築したり、コミュニティのアートスタイルの最も広範なライブラリにアクセスしたい方にとって、Stable Diffusion 3.5 が採用すべきアーキテクチャです。
# 5. FLUX.2 Dev
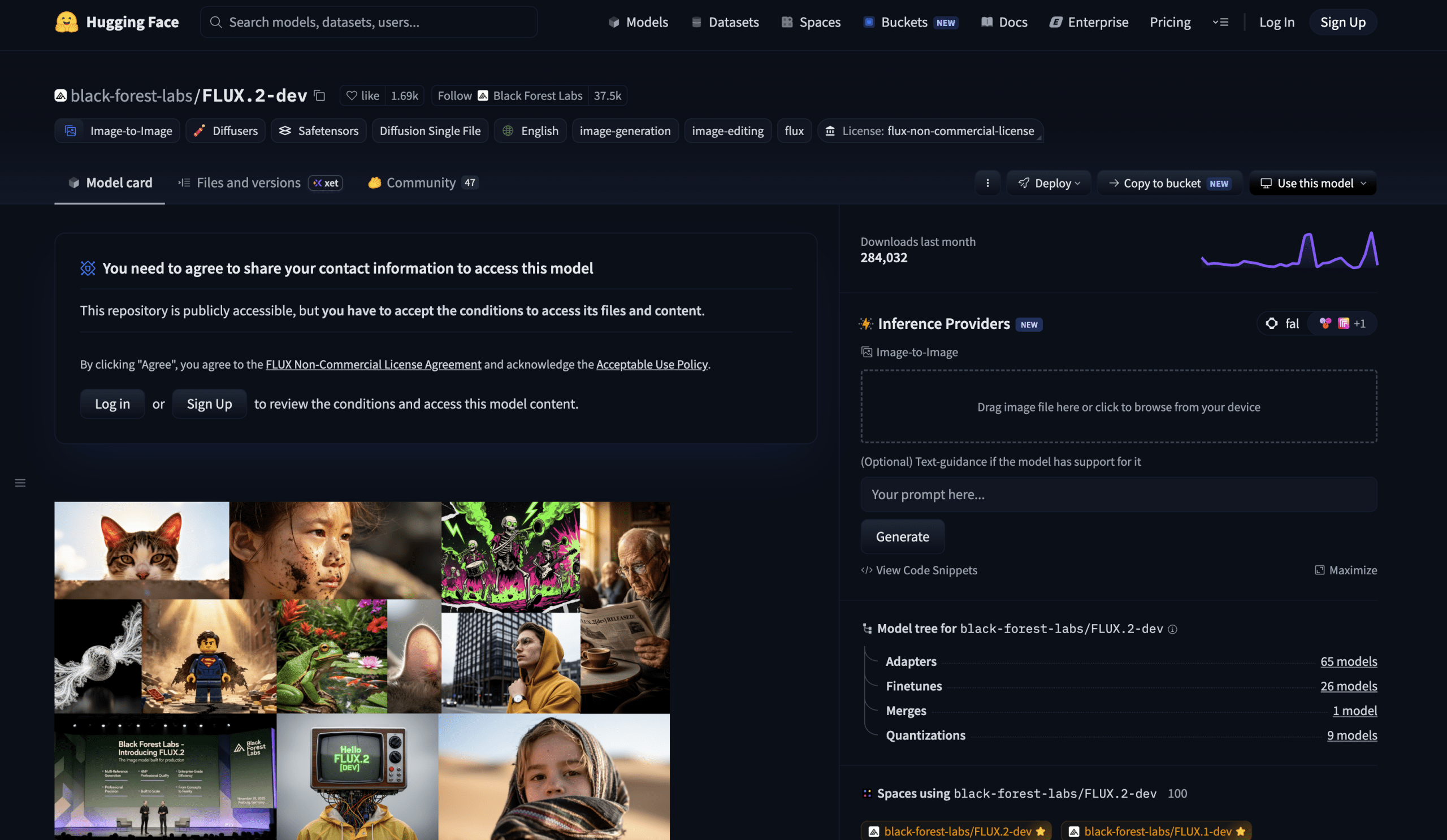 image**
image**
FLUX.2 Dev Dashboard | Image by Author
Field**
Detail
Developer
License
FLUX.2-dev Non-Commercial; 4B variants = Apache 2.0
Parameters
32B (full dev); 4B (smaller variants)
Architecture
Improved DiT (Diffusion Transformer) backbone
Released
November 2025
Best for
Production-grade photorealism, 4K resolution output, multi-reference generation
Black Forest Labs が 2025 年 11 月にリリースした FLUX.2 は、実験的な画像生成から真の生産レベルの視覚的創作へと大きな飛躍を遂げたモデルです。2026 年版ではネイティブ 4 メガピクセル解像度をサポートし、大幅に改善された拡散トランスフォーマー(DiT)バックボーンを導入しています。特筆すべき機能は、生成中に複数の入力画像を同時に参照できる機能を内蔵したマルチリファレンス対応です。
ここで注意すべき点はハードウェア要件です。フルサイズの FLUX.2 Dev モデルには相当な VRAM が必要で、32B バリアントでは H100 クラスの GPU が要求されます。Black Forest Labs は Hugging Face と提携し、RTX 4090 向けの構成(リモートテキストエンコーダー付き)など、コンシューマー向けハードウェアで動作する量子化バージョンを提供しています。Apache 2.0 ライセンスが付与された 4B バリアントは、データセンター環境を持たない多くの開発者にとって現実的な入門点となります。
# 6. Playground v2.5
 image**
image**
Playground v2.5 ダッシュボード | 画像提供:著者
フィールド**
詳細
開発元
ライセンス
Playground v2.5 コミュニティライセンス
解像度
ネイティブ 1024px
アーキテクチャ
CLIP-L および OpenCLIP-G テキストエンコーダーを備えた SDXL ベースのアーキテクチャ
最も適している用途
芸術的な構成、人間中心の画像、美意識を最優先した生成
FLUX モデルは写実性とプロンプトへの忠実さにおいて優れていますが、Playground v2.5 はそれとは異なる点で勝利しています。それは、技術的に生成されたものというよりは、意図的に芸術的であるように見える出力です。
これは美しさを追求するために特別にトレーニングされました。自然な比例を持つ人間像、視覚デザイン原則に従った構成、恣意的ではなく意図的な色調補正が特徴です。クリエイティブプロジェクトの参考画像、ムードボード、キャラクターアート、「美しく見えること」が主要な基準となるあらゆる用途でリファレンス画像を生成する場合、Playground v2.5 はプロンプトによる生成というよりは、意図的なデザインワークと見分けがつかない結果を一貫して生み出します。
コミュニティライセンスは特定の条件下での商用利用を許可しています。出荷する前に、モデルカード の完全なライセンスを確認してください。このモデルは SDXL インフラ上で動作するため、SDXL 用の広範なファインチューンやツールとの互換性があります。
# 7. Kolors
 image**
image**
Kolors | 画像作成:著者
分野**
詳細
開発者
ライセンス
Apache 2.0 — 商用利用も完全に無料
トレーニング
数十億のテキスト画像ペア
アーキテクチャ
GLM テキストエンコーダーを備えた潜在拡散モデル
最適な用途
中国語・英語バイリンガルコンテンツ、画像内の文字レンダリング、高い写実性
Kolors は、数十億のテキスト画像ペアでトレーニングされた大規模なテキストから画像への生成モデルです。中国語と英語の両方の文字において、視覚的品質、複雑な意味の正確性、そして文字レンダリング能力において顕著な利点を示します。これは、両言語の理解を強化する一般言語モデル(GLM)の上に構築されています。
この GLM のバックボーンこそが、他との決定的な違いです。多くの西洋由来のオープンソースモデルは、テキストエンコーダーとして T5 または CLIP を使用していますが、これらは深い中国語の理解を目的として設計されたアーキテクチャではありません。Kolors は、ネイティブの中国語・英語バイリンガル機能を最初から備えて構築されており、中国語でプロンプトを入力したり、中国語の文字や文化的文脈、あるいは混合言語のシーンを含むコンテンツを生成する際にも、意味的に優れた結果を生み出します。
文字レンダリング能力も特に優れています。画像内に可読なテキストを生成することは、拡散モデルにおける長年の弱点でした。Apache 2.0 ライセンスにより、商用利用には一切の制限がありません。あなたの製品やコンテンツが中国語・英語の両方の聴衆を対象とする場合、このモデルこそが実際のユースケースを適切に処理するものです。
# どのモデルを使うべきか?
**
「どのモデルが最も優れているか」ではなく、「あなたの特定の状況にどのモデルが適合するか」が問われています。
Apache 2.0 ライセンスによる商用利用の自由と高速な生成を必要とするなら、FLUX.1 Schnell が明白な答えです。これは、完全に制限のない商用権限を持つ唯一のフラッグシップ・モデルです。
品質の上限が唯一の変数であり、個人的または研究目的で利用する場合は、FLUX.1 Dev が非商用領域においてプロンプトあたりの最高出力を生み出します。そのスペースデモ(Space demo)を見れば、あなたのユースケースにとって非商用ライセンスの条件に見合う品質レベルかどうかを即座に判断できます。
既存画像の編集や反復的な改良がワークフローに含まれ、ゼロからの生成ではない場合は、FLUX.1 Kontext Dev が、ファインチューニング(fine-tuning)なしでそのワークフローを可能にするモデルです。
最も深いエコシステム——ファインチューン済みモデル、LoRA、ControlNet、互換性のあるツール類——を求めるなら、Stable Diffusion 3.5 が構築の基盤となります。最先端における生モデルの品質は既にそれを上回っていますが、コミュニティインフラストラクチャにおいてこれに匹敵するものは他にありません。
もしあなたのコンテンツが中国語と英語のバイリンガル対象者を含む場合、または生成された画像内で読みやすいテキストをレンダリングする必要がある場合は、Apache 2.0 ライセンスを持つ Kolors が、このトピックに関する多くの英語中心の記事が見過ごしている目的に特化した回答となります。
# 結論
Hugging Face は、本格的なオープンソース画像生成の事実上の拠点となりました。90,000 以上のモデル数は一見圧倒的に思えますが、2026 年において実際に重要なのは短くまとまったリストに含まれるモデルのみであり、それらはすべて無料です。Black Forest Labs の FLUX ファミリーは、完全商用利用可能な Apache 2.0 ライセンスの生成(Schnell)から非商用における品質の上限(Dev)、指示に基づく編集(Kontext)まで、あらゆるスペクトラムをカバーしています。Stable Diffusion 3.5 は、過去 3 年間構築されてきたコミュニティエコシステムを支える基盤となっています。Kolors は、西洋中心のモデルが放置した多言語対応のギャップを埋めます。
これら 7 つのモデルすべてに、ブラウザ上でセットアップ不要ですぐに使用できる Spaces が用意されています。ローカル環境へのセットアップを決定する前に、各モデルの Space URL を試してみてください。プロンプトを 5 回実行するだけで、そのモデルの出力スタイルがあなたが構築しようとしているものに合致するかどうかがわかります。
Shittu Olumide はソフトウェアエンジニアであり技術ライターで、最先端の技術を駆使して説得力のある物語を創り出すことに情熱を注いでいます。細部への鋭い眼と複雑な概念を簡素化する才能を持っています。また、Twitter でも Shittu を見つけることができます。
原文を表示
**
# Introduction
A quick search on Hugging Face returns over 90,000 text-to-image models alone. That number is useful context, not a shopping list. Most people who want a free AI image generator end up on Midjourney or DALL-E without realizing that Hugging Face hosts the actual models powering those tools — the same architectures, sometimes the same weights — available free through browser-based Spaces demos or available to download and run locally.
This article cuts through the 90,000 options to the seven models worth your time in 2026. The selection criteria: output quality that competes with paid tools, genuinely free access (browser or download), active maintenance, and real-world usefulness across different skill levels. For each model, you get the Hugging Face link, the license and what it actually permits, what the model is distinctly good at, and honest trade-offs.
# How to Use Hugging Face for Image Generation
The first thing to understand about Hugging Face is that there are two distinct ways to use it, and they suit different people.
- Hugging Face Spaces are free browser-based demos. You go to the Space URL, type a prompt, and get an image — no GPU, no installation, no API key, no account required for most of them. During peak hours, some models have queue waits, but the better Spaces run on dedicated hardware and respond quickly. This is the right entry point for exploration, one-off generation, and testing what a model can do before committing to anything more involved. Every model in this article has a linked Space where you can try it immediately.
- Downloading model weights and running locally via the diffusers Python library, ComfyUI, or Forge gives you volume generation with no queue, full control over parameters, and privacy — nothing leaves your machine. This requires a compatible GPU (VRAM requirements are listed per model in each entry below) and a Python environment.
# 1. FLUX.1 Schnell
FLUX.1 Schnell Dashboard
Field**
Detail
Developer
License
Apache 2.0 — personal, scientific, and commercial use
Parameters
12B
Architecture
Rectified flow transformer
VRAM (local)
~16 GB (or ~10 GB with CPU offload enabled)
Best for
Fast generation, commercial use, building apps
FLUX.1 Schnell is released under the Apache 2.0 license, which means it can be used for personal, scientific, and commercial purposes. That single fact separates it from every other flagship-quality model on this list. Apache 2.0 is as permissive as open-source licensing gets — you can build a product, ship it commercially, integrate it into a pipeline, and do it all without licensing negotiations or usage fees.
Schnell was trained using guidance distillation to generate in 1–4 inference steps rather than the 20–50 that traditional diffusion models require. The quality-per-step is exceptional. It is not the highest-quality model Black Forest Labs makes — that is FLUX.1 Dev or FLUX.2 — but it produces output that beats most models from a year ago, at a generation speed that is genuinely fast even on consumer hardware.
What it is not ideal for: scenes that require the absolute maximum photorealistic detail, where no other constraint matters. For those, FLUX.1 Dev delivers a higher ceiling but without the Apache 2.0 commercial freedom.
# 2. FLUX.1 Dev
**
FLUX.1 Dev Dashboard | Image by Author
Field**
Detail
Developer
License
FLUX.1 Dev Non-Commercial License
Parameters
12B
Architecture
Rectified flow transformer
VRAM (local)
~24 GB recommended
Best for
Research, artistic projects, high-quality personal use
FLUX.1 Dev is a 12 billion parameter rectified flow transformer. Distilled directly from FLUX.1 Pro, it achieves similar quality and prompt adherence while being more efficient than a standard model of the same size. For non-commercial use, it is the highest-quality freely available model on the platform right now.
The photorealism in portrait and product photography prompts is categorically superior to what other free tools produce. Portrait consistency, fine fabric texture, architectural detail, and text-in-image rendering are all noticeably better than the generation-earlier models it has replaced as the community benchmark.
License clarity is important here. The model weights themselves are for non-commercial use — you cannot take the model and build a paid product on top of it without contacting Black Forest Labs. But the images you generate with FLUX.1 Dev can be used for personal, scientific, and commercial purposes as described in the license. The distinction matters: using the model to generate images for your own commercial work is generally permitted. Using the model itself as the engine of a commercial product or API is a separate conversation with Black Forest Labs.
# 3. FLUX.1 Kontext Dev
**
FLUX.1 Kontext Dev Dashboard | Image by Author
Field**
Detail
Developer
License
FLUX.1 Dev Non-Commercial License
Parameters
12B
Released
May 2025
Architecture
Rectified flow transformer with in-context conditioning
Best for
Image editing, character consistency, style transfer, iterative refinement
Every other model on this list takes a text prompt and generates from scratch. FLUX.1 Kontext Dev takes an existing image and changes it based on a text instruction.
FLUX.1 Kontext Dev is capable of editing images based on text instructions, supporting character, style, and object reference without any fine-tuning. Robust consistency allows users to refine an image through multiple successive edits with minimal visual drift. That last point is the technically hard part. Most image editing models drift — make three consecutive edits, and the character looks like a different person by the third iteration. Kontext maintains identity across successive edits with a stability that was not possible in open-source models before this architecture.
The practical workflow this unlocks: generate a character, product, or scene once, then iterate — "add sunglasses," "change the background to a mountain at sunset," "make the jacket red," "add motion blur" — and the core visual identity stays intact throughout. For product photography, character design, and any workflow involving iteration, this is a qualitative shift in what free open-source tools can do.
The Space demo is straightforward: upload an image, type an instruction, adjust guidance strength and seed. The interface at huggingface.co/spaces/black-forest-labs/FLUX.1-Kontext-Dev also supports image-to-image generation without a source image for pure text-to-image use.
# 4. Stable Diffusion 3.5 Large

**
Stable Diffusion 3.5 Large Dashboard | Image by Author
Field**
Detail
Developer
License
Stability AI Community License (permissive for most uses)
Parameters
8B
Architecture
Multimodal diffusion transformer (MMDiT)
VRAM (local)
~10–16 GB
Best for
Community fine-tunes, ControlNets, broad customization
Stable Diffusion 3.5 is available under a permissive community license, is customizable, runs on consumer hardware, and comes with full inference code on GitHub. But the license and the download numbers are not the main reason it is on this list.
The reason SD 3.5 matters is what exists around it. Thousands of fine-tuned models on Hugging Face, hundreds of LoRAs trained on specific styles and subjects, ControlNet variants for guided generation (canny edges, depth maps, pose control), and a tooling ecosystem — AUTOMATIC1111, ComfyUI, and Forge — that has been built and refined over years. No other model architecture has that depth of community infrastructure yet.
SD 3.5 Medium is also worth noting: the smaller variant fits more comfortably on 8–10 GB VRAM and generates faster, trading peak quality for accessibility. Both are free. For anyone who wants to fine-tune a model on their own data, build custom ControlNet workflows, or access the widest library of community art styles, Stable Diffusion 3.5 is the architecture to use.
# 5. FLUX.2 Dev
**
FLUX.2 Dev Dashboard | Image by Author
Field**
Detail
Developer
License
FLUX.2-dev Non-Commercial; 4B variants = Apache 2.0
Parameters
32B (full dev); 4B (smaller variants)
Architecture
Improved DiT (Diffusion Transformer) backbone
Released
November 2025
Best for
Production-grade photorealism, 4K resolution output, multi-reference generation
Released in November 2025 by Black Forest Labs, FLUX.2 marks a major leap from experimental image generation toward true production-grade visual creation. The 2026 iteration supports native 4-megapixel resolution and introduces a significantly improved diffusion transformer (DiT) backbone. A standout feature is built-in multi-reference support — the ability to reference multiple input images simultaneously during generation.
The hardware requirement is the honest caveat here. The full FLUX.2 Dev model requires considerable VRAM — an H100-class GPU for the 32B variant. Black Forest Labs has partnered with Hugging Face to make quantized versions that run on consumer hardware, including configurations for an RTX 4090 with a remote text encoder. The 4B variants with Apache 2.0 licensing are the realistic entry point for most developers without datacenter hardware.
# 6. Playground v2.5
**
Playground v2.5 Dashboard | Image by Author
Field**
Detail
Developer
License
Playground v2.5 Community License
Resolution
1024px native
Architecture
SDXL-based with CLIP-L + OpenCLIP-G text encoders
Best for
Artistic compositions, human-centric imagery, aesthetic-first generation
FLUX models win on photorealism and prompt adherence. Playground v2.5 wins on something different — outputs that look artistically intentional rather than technically generated.
It was specifically trained for aesthetic quality: human figures rendered with natural proportions, compositions that follow visual design principles, and color grading that reads as deliberate rather than arbitrary. If you are generating reference images for creative projects, mood boards, character art, or anything where "looks beautiful" is the primary criterion, Playground v2.5 consistently produces results that are harder to distinguish from intentional design work than from a prompted generation.
The community license permits commercial use under specific terms — read the full license on the model card before shipping. The model runs on SDXL infrastructure, which means it is compatible with the broad ecosystem of SDXL fine-tunes and tools.
# 7. Kolors
**
Kolors | Image by Author
Model Card · Try Kolors Portrait Space
Field**
Detail
Developer
License
Apache 2.0 — fully free for commercial use
Training
Billions of text-image pairs
Architecture
Latent diffusion with GLM text encoder
Best for
Chinese-English bilingual content, text rendering in images, high photorealism
Kolors is a large-scale text-to-image generation model trained on billions of text-image pairs. It exhibits significant advantages in visual quality, complex semantic accuracy, and text rendering for both Chinese and English characters. It is built upon the General Language Model (GLM), which enhances comprehension of both languages.
The GLM backbone is what makes it different. Most Western open-source models use T5 or CLIP as their text encoder — architectures that were not designed with deep Chinese language understanding. Kolors was built with native Chinese-English bilingual capability from the ground up, which produces meaningfully better results when prompting in Chinese or generating content that involves Chinese text, cultural context, or mixed-language scenes.
The text-rendering capability is also notably strong. Generating readable text inside images is a longstanding weakness of diffusion models. The Apache 2.0 license means zero restrictions for commercial use. If your product or content involves Chinese-English audiences, this is the model that actually handles your use case well.
# Which Model Should You Use?
**
The choice is not about which model is "best" — it is about which one fits your specific situation.
If you need Apache 2.0 commercial freedom and fast generation, FLUX.1 Schnell is the obvious answer. It is the only flagship-tier model with fully unrestricted commercial rights.
If quality ceiling is the only variable and you are doing personal or research work, FLUX.1 Dev produces the best output per prompt in the non-commercial space. The Space demo will show you immediately whether its quality level is worth the non-commercial license terms for your use case.
If your workflow involves editing and iterating on existing images rather than generating from scratch, FLUX.1 Kontext Dev is the model that makes that workflow viable without fine-tuning.
If you want the deepest ecosystem — fine-tunes, LoRAs, ControlNets, compatible tooling — Stable Diffusion 3.5 is what you build on. Raw model quality has moved past it at the frontier, but nothing else has the community infrastructure it does.
If your content involves Chinese-English bilingual audiences or requires readable text rendered inside the generated image, Kolors — with its Apache 2.0 license — is the purpose-built answer that most English-centric articles on this topic simply miss.
# Conclusion
Hugging Face has become the de facto home for serious open-source image generation. The 90,000+ model count sounds overwhelming, but the models that actually matter in 2026 fit on a short list, and all of them are free. The FLUX family from Black Forest Labs now covers the full spectrum — from fully commercial Apache 2.0 generation (Schnell) to non-commercial quality ceiling (Dev) to instruction-based editing (Kontext). Stable Diffusion 3.5 anchors the community ecosystem that has been building for three years. Kolors fills the multilingual gap that Western-centric models leave open.
All seven models have Spaces you can use in a browser right now with no setup. Start with the Space URL for each model before committing to local setup. You will know within five prompts whether a model's output style fits what you are building.
Shittu Olumide** is a software engineer and technical writer passionate about leveraging cutting-edge technologies to craft compelling narratives, with a keen eye for detail and a knack for simplifying complex concepts. You can also find Shittu on Twitter.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み