効率的な推論のための MiniMax-M3 の提供:後悔のない 100 万トークンコンテキストとマルチモーダル性の解放
Together AI は、MiniMax の最新モデル M3 を 100 万トークンのコンテキストとネイティブなマルチモーダル機能を備えた状態で効率的に推論できるよう、独自のカーネル最適化技術を用いて実装し、業界標準のインフラ基盤としての地位を確立した。
キーポイント
Together AI の公式パートナーシップとホスティング
Together AI が MiniMax M3 の優先クラウドパートナーに選定され、公開リリース後に開発者向けエンドポイントとしてモデルをホストする。
推論性能の劇的な向上を実現する技術的突破
KV-Block-Major 型スパースアテンションカーネルや Rust ベースのマルチモーダル前処理ゲートウェイなどの最適化により、並列度に応じてスループットが最大 125% 向上した。
MiniMax M3 の革新的なアーキテクチャ特性
MSA(MiniMax Sparse Attention)を採用し、クエリあたりのアテンショントークン数を制限することで、100 万トークンのコンテキストウィンドウを効率的に処理可能にした。
実世界での大規模運用への適応性
コード生成、エージェントワークフロー、長文書処理、画像理解などを統合したオールインワンモデルとして、複雑な実務タスクに対応する生産環境での検証が完了している。
重要な引用
Together AI is the preferred cloud partner for MiniMax M3.
significant engineering breakthroughs to serve M3 efficiently
81–125% throughput improvements across different concurrency levels
MiniMax Sparse Attention (MSA), which is designed to address the attention-computation bottleneck
影響分析・編集コメントを表示
影響分析
このニュースは、100 万トークンという超長文コンテキストとマルチモーダル機能を同時に扱うモデルの商業的・技術的実現可能性を裏付ける重要なマイルストーンです。Together AI の高度なカーネル最適化技術が、こうした大規模モデルの実用化におけるボトルネック(計算コストとメモリ管理)を克服したことを示しており、業界全体で長文処理や複雑な推論タスクへの投資加速に寄与するでしょう。
編集コメント
100 万トークンという驚異的なコンテキスト長を、実用的なスループットで提供できるインフラ基盤が整いつつあることは、RAG や大規模コード解析などの応用分野において大きな追い風となるでしょう。特に、独自開発のスパースアテンション技術によるパフォーマンス向上は、次世代モデルの実装における重要な指針を示しています。
- Together AI は MiniMax M3 の優先的なクラウドパートナーです。Together AI は、公開リリース時にオープンウェイトモデルを開発者向けエンドポイントとしてホストします。
- 当社の推論およびカーネルチームは、M3 を効率的に提供するために重要なエンジニアリングのブレークスルーを達成しました。これには、KV-Block-Major スパースアテンションカーネル、MSA 向けの革新的なページドアテンション統合、高度に最適化されたインデックススコアリングカーネル、そして Rust ベースのマルチモーダル前処理ゲートウェイといった主要な最適化が含まれており、異なる並行度レベル全体でスループットが 81–125% 向上しました。
- 本番環境で大規模に MiniMax M3 を提供することは、現実世界のデプロイを可能にする困難なシステム問題においてフロンティアを押し広げるモデルにとって、Together AI が推論プラットフォームとしての最適解であることを実証するものです。
MiniMax は最新かつ最先端のモデル M3 を発表し、Together AI がその主要なクラウドパートナーとして選定され、大規模な本番環境で MiniMax が M3 を効率的に提供できるよう支援しています。今後数日以内に MiniMax M3 がオープンウェイトモデルとしてリリースされると、Together AI は開発者向けのエンドポイントとしてもこのモデルをホストします。このスケールを支えているのは、推論チームとカーネルチームの卓越した取り組みです。彼らは深いパフォーマンス最適化を推進し、1M トークンのコンテキストウィンドウ、ネイティブなマルチモーダル性、そして効率的に提供するために高度なエンジニアリングを要するアーキテクチャを持つ、フロンティアを押し広げるモデルに対して本番グレードの信頼性を確保しました。この記事では、その実現に至ったプロセスを追って解説します。MiniMax チームによる画期的なモデル発表と継続的なイノベーションに対し、おめでとうございます。
MiniMax M3 は、最先端のコーディング性能、エージェントワークフローのサポート、そしてネイティブなマルチモーダル推論を統合したオールインワンのモデルです。これらの機能に加え、1M コンテキストをサポートしながらも、提供コストが極めて経済的になるよう設計されています。これにより、長いドキュメント、コードベース、ツール利用、画像、反復的な推論などが頻繁に複合的に現れる実世界のタスクに対して、非常に適したモデルとなっています。前世代と比較すると、M3 の提供はより多くの課題を伴います。新しい機能には、スパースアテンション計算、大規模な KV キャッシュ管理、マルチモーダル処理など、複数の次元における最適化が必要となるためです。
アーキテクチャ / 特徴
M3 における最も革新的なアーキテクチャの変更点は、MiniMax Sparse Attention (MSA) です。これは MiniMax M2.7 で見られたアテンション計算のボトルネックに対処するために設計されたものです。そのブロックスパースアテンション機構は、各クエリが参照できるトークンの最大数を制限することで、長文コンテキスト処理のコストを削減し、より長いコンテキストウィンドウを実用的なものにします。これにより、プリフィリング段階で 9 倍以上、デコーディング段階で 15 倍以上の速度向上をもたらします。
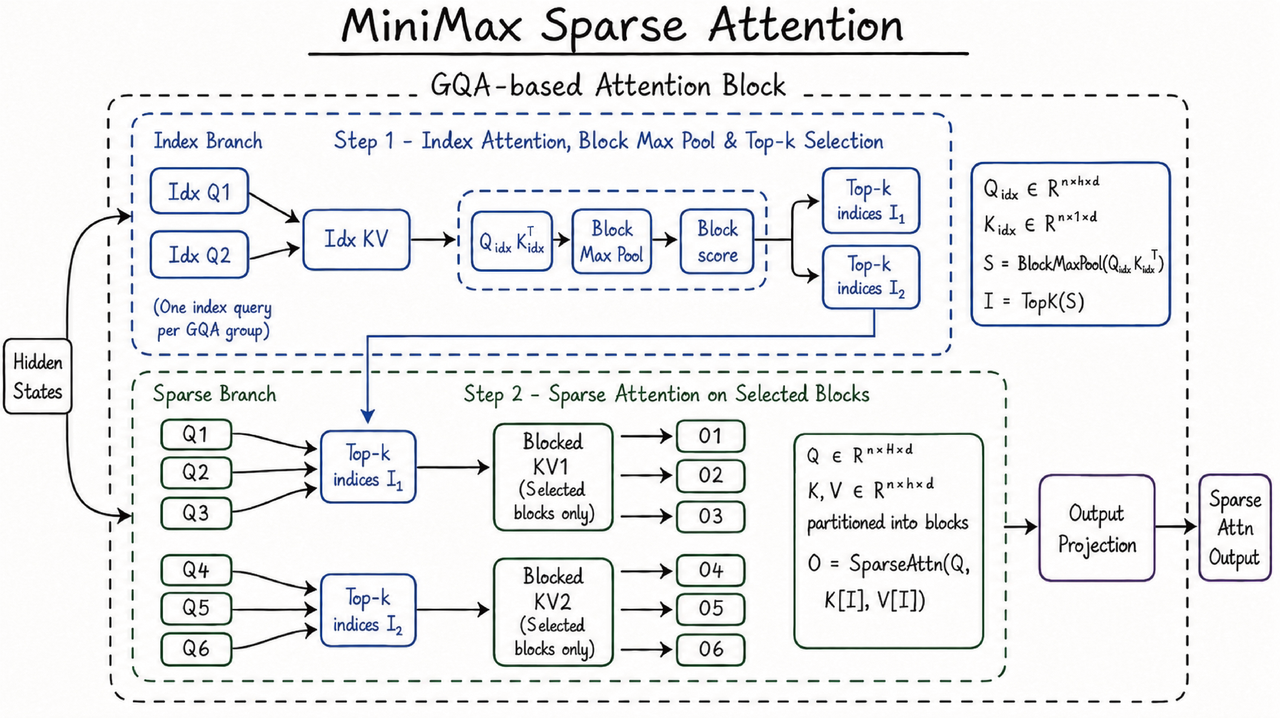
本質的に、MSA の計算は 2 つの部分で構成されています。まず、各 KV グループに対して参照すべき最も関連性の高い K ブロックを決定するためのスコア計算を行い、次にクエリトークンとそれらのブロックの間で密なアテンション(dense attention)を実行します。この設計により、KV グループ次元における表現力は維持されつつも、クエリトークンが参照する KV トークンの最大数には制限が設けられます。アテンション計算自体はコンテキスト長に対して N^2 でスケーリングしなくなるため、長文コンテキストワークロードに非常に適しています。
B200 上で、並行度 8 の条件下でエージェント型トラフィック形状(60k プレフィックスキャッシュ)におけるカーネル実行時間の内訳を測定しました。MSA は、各イテレーションあたりの実際のアテンション計算にかかる壁面時間(wall time)の割合を大幅に低下させます。
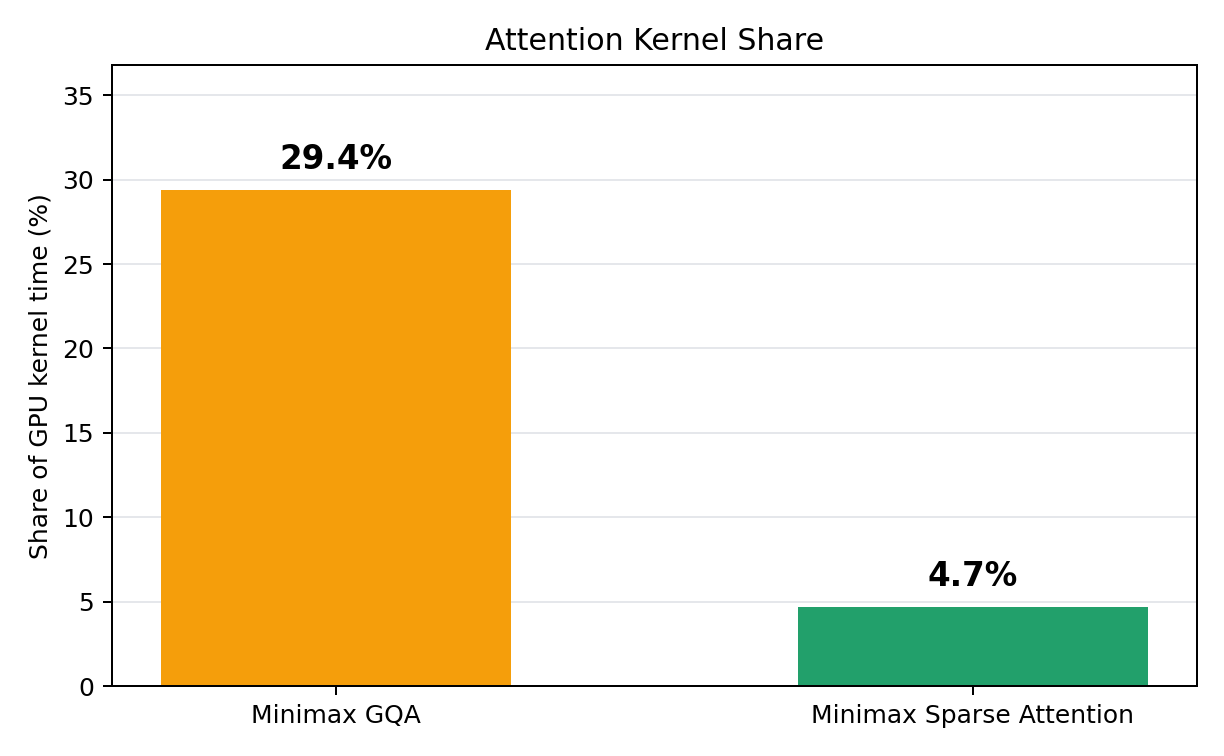
*アジェンシー型トラフィック下、60K のプレフィックスキャッシュ、並行度 8、NVIDIA B200 を用いた別カーネル実行の分析では、MSA(Multi-Head Sparse Attention)が各イテレーションにおける注意計算に費やされる壁面時間の割合を大幅に削減することが示されました。*
アテンションアーキテクチャの変更に加え、M3 はビジョンコンポーネントと新しい画像・ビデオ前処理機能を備えたマルチモーダルサポートも搭載されています。
これらの根本的な変更により、Together AI は MiniMax のエンジニアリングチームと緊密に協力し、新たに浮上した課題に取り組んできました。主な課題には以下が含まれます:
- MiniMax のスパースアテンション計算自体は非常に効率的ですが、1M トークンのコンテキスト長をサポートすることは、エンジニアリングの観点からは依然として困難です。
- ビデオおよび画像処理は、テキストトークン化よりも本質的に複雑です。
最適化
KV ブロック主軸スパースアテンション
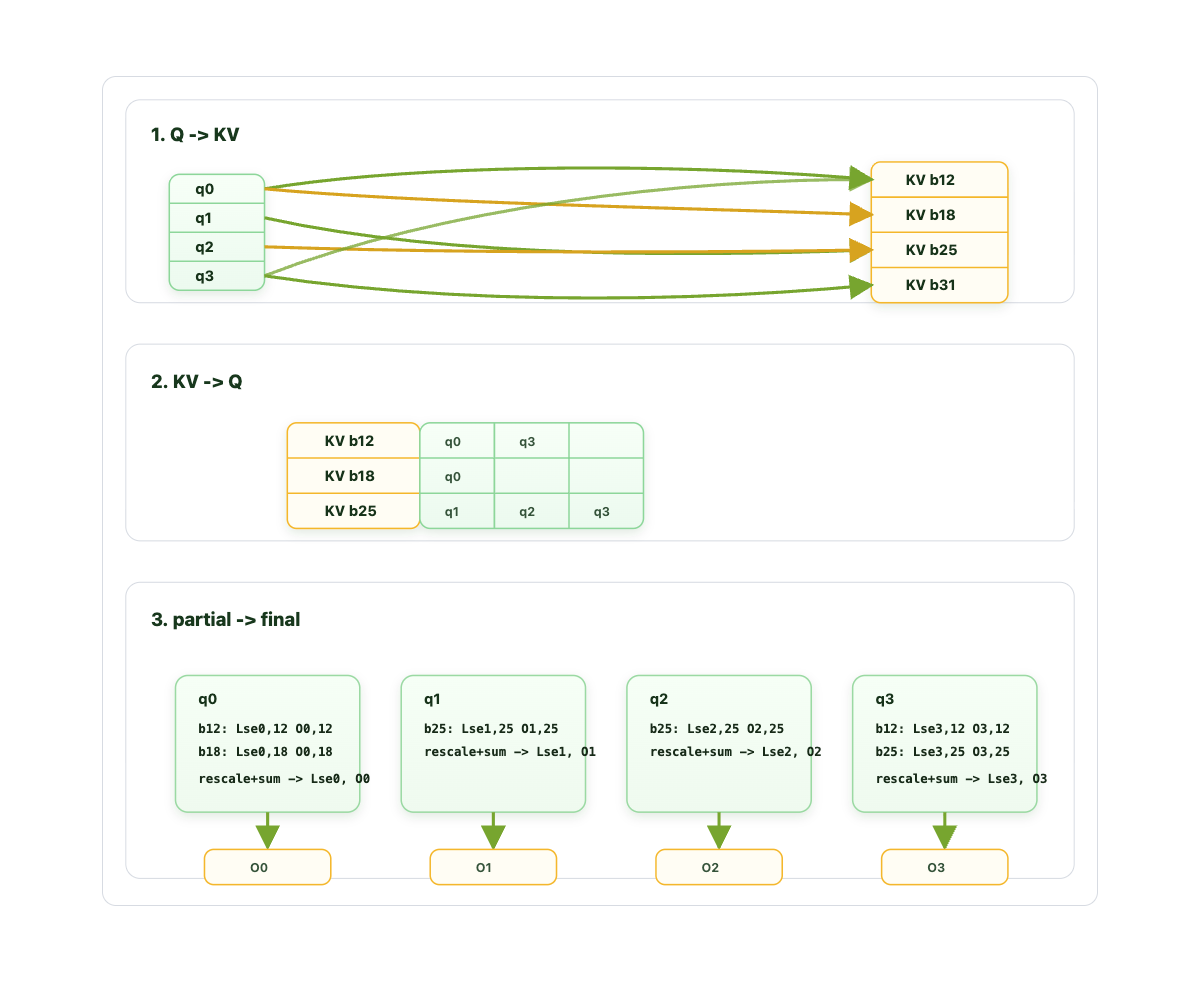
プリフェッチ(prefill)段階においても、長文コンテキスト入力に対して注意計算が大きな要因となり得ます。各トークンについて Selected *Block* * *KV Head Group* * *Tokens を計算する必要があるためです。ブロックスパースアテンションの性質上、複数のクエリが同じキー・バリュー(KV)ブロックにアテンションを向けることができます。したがって、各クエリを反復して KV ブロックとのアテンションを計算すると、GPU 上の HBM から SRAM への KV の移動が重複して行われることになります。一方、外側ループでキー・バリューグループを反復し、内側ループでクエリトークン間のアテンションを計算することで、KV キャッシュは一度だけ移動されるため、演算強度(arithmetic intensity)の向上が可能になります。
これを実現するには、{q, kv block} から {kv block, q} へのマッピングを再構成し、アテンションカーネルを再実装する必要があります。KV ブロックに対して部分的な O 出力のみを計算しているため、最終的に Log-Sum-Exp(対数和指数)に基づく「リダクション」を実行して、出力 O を再スケーリングし合計する必要があります。その手順は以下の通りです。
MSA を Paged Attention と統合する
現代の推論エンジンでは、リクエストごとの KV キャッシュ(Key-Value Cache)コンテキストを管理するために、ページ化アテンション(Paged Attention)が頻繁に使用されています。高度に最適化されたアテンションカーネルの多くは、固定サイズのページセットをサポートするように記述されています。これらのカーネルを使用できない要因は、KV グループ間で選択されるブロックが異なる点にあります。
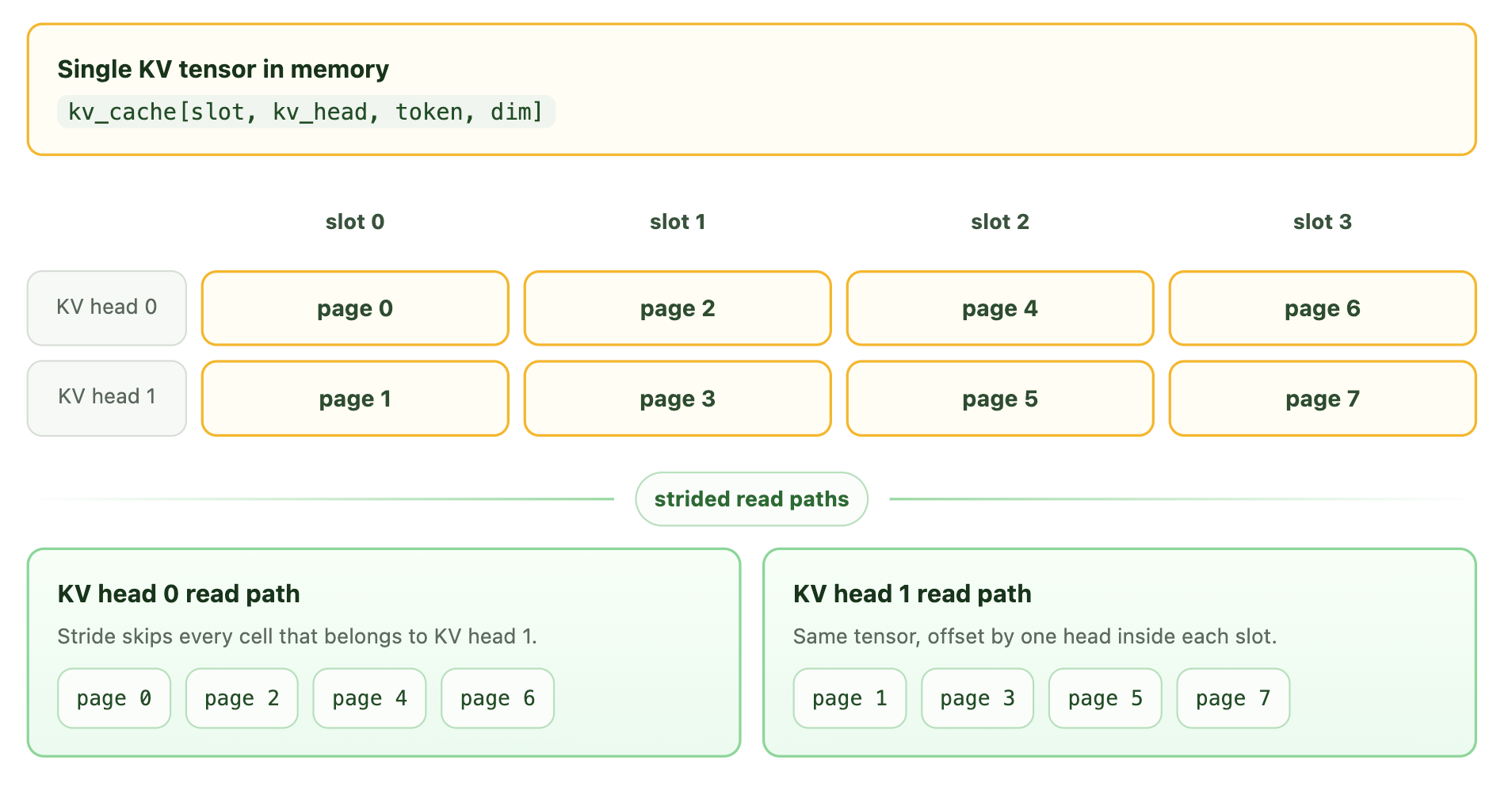
Together AI では、MiniMax スパースアテンション(Sparse Attention)をエンジンに統合する新たなアプローチを提案します。デコード(Decode)時には、まず選択されたブロックに基づいてページテーブルを構築し、KV グループ次元をバッチ次元に平坦化します。さらに、KV キャッシュテンソルのストライド付きビュー(Strided View)を活用して、アテンションカーネルに必要なポインタを提供し、KV ページの取得を可能にします。その鍵となるのはストライドです:ページアドレスは D ずつ進んで仮想ページの開始位置を選択し、トークンは Hkv * D ずつ進みます。これにより、1 つの物理テンソンがヘッドごとのページにデインターリーブ(Deinterleave)され、各平坦化された行で異なるページテーブルを使用できるようになります。
この設計により、スパースアテンションをゼロから実装する必要なく、GQA(Grouped Query Attention)をサポートする既存のアテンションカーネルを利用できるようになりました。各クエリに対して選択されるブロック数は限られているため、ブロックとページ間のマッピングを検出するためのカーネルは非常に低いオーバーヘッドで動作します。この設計により、デコードスループットが 5% 向上しました。
Decode Index Scoring Kernel Optimization
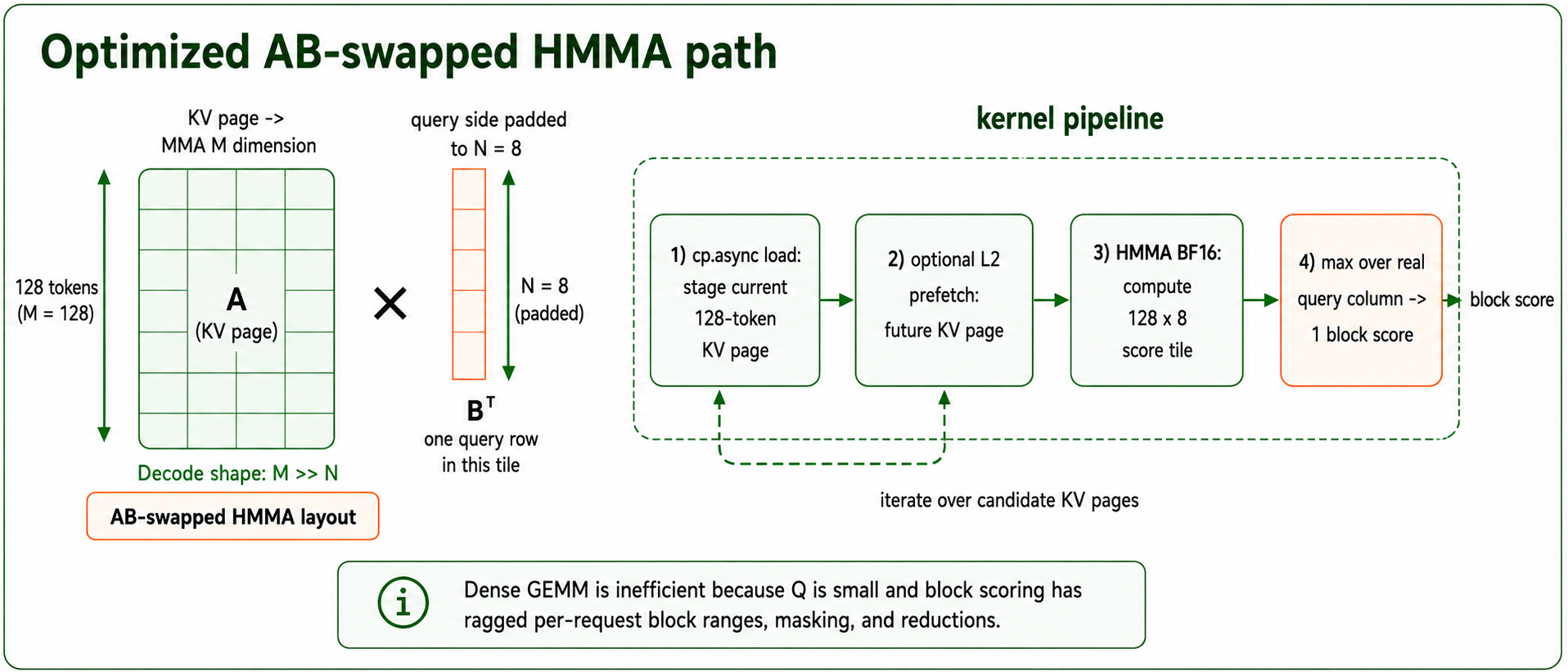
デコード処理において、MSA(Multi-Sequence Attention)はコストの大部分を密なアテンション計算からスコアリング/トップ-k インデクサへ移行します。すべてのデコードクエリに対して、エンジンがクエリ側のインデックスベクトルと候補となるキー側のインデックスベクトルを比較し、各 128 トークンの KV ブロック(Key-Value Block)を単一のスコアに集約し、実際のアテンションカーネルのために上位のブロックのみを保持します。このスキャンは生成されるトークンごとにクリティカルパス上にあり、長いコンテキスト長においては候補となるブロック数がコンテキスト長とともに増加します。デコードスコアリングは「小規模クエリインデックス・大規模キーインデックス」という形状を持ちます。デコードクエリのバッチを一つの大きな GEMM(General Matrix Multiply)として扱うのは魅力的に思えますが、スコアリング/インデクシングステップは単なる密行列乗算ではありません。各リクエストおよび K グループには独自の候補ブロック範囲、マスキング、ブロックごとの集約、そしてトップ-k の境界条件が存在します。クエリを連結しても GEMM 周辺に「不規則なガザー&リダクション」の問題が残ったままとなり、クリティカルパス上にパディングや追加の管理オーバーヘッドを強いることになります。そのため、最適化された経路では *AB-swapped HMMA レイアウト* を採用します。128 トークンのキーインデックスブロックを MMA の M 次元とし、クエリ側はより小さな*N*次元にのみパディングします。カーネルは非同期コピーで 128 トークンの K インデックスをステージングし、次のページをプリフェッチし、HMMA を用いて bfloat16 で内積計算を行い、各ページを単一のブロックスコアに集約します。
ゲートウェイにおけるマルチモーダル前処理
SMG(Serving Model Gateway)は、OpenAI 互換 API と推論エンジン間に位置する Rust ベースのモデルゲートウェイです。ルーティングやトークン化を超えて、SMG は特にマルチモーダルモデルにとって重要な役割を担います:リクエストが GPU ワーカーに到達する前に、すべてのビジョン前処理を CPU で実行します。
画像およびビデオ入力には、ビジョンエンコーダで有用な形にするまでに相当量の CPU 処理が必要です。具体的には、ダウンロード、デコード、フレームサンプリング、リサイズ、そしてパッチテンソルへの変換です。これらを推論エンジン内で実行すると、生成に割くべきリソースが拘束されてしまいます。SMG はこれをゲートウェイ側で全て処理するため、リクエストが GPU に到達した時点では、すでにテンソルは準備完了しています。
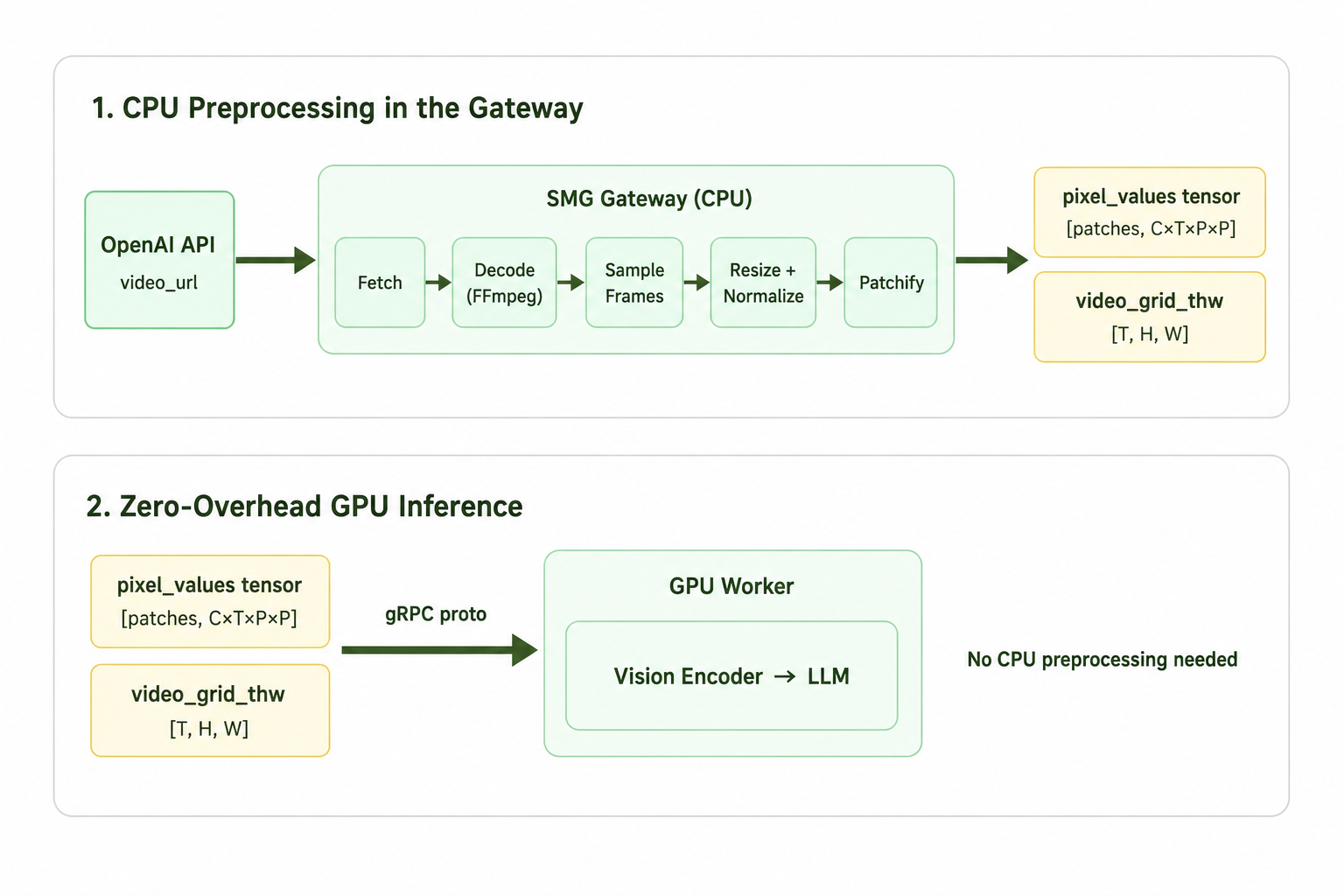
M3 の場合、これは以下を意味します:ビデオを取得し、FFmpeg を用いてフレームを抽出し、FPS(Frames Per Second)に基づいてサブセットを選択し、リサイズと正規化を行い、時間次元を組み込んだ状態でパッチ化します。出力されるのはフラットなパッチテンソルと小さなグリッドメタデータテンソルで、これらは gRPC メッセージにパックされます。ワーカー側ではビジョンエンコーダを直接実行するだけで、その側での前処理は不要です。
また、SMG のマルチモーダルパイプラインは、モデル固有の前処理ロジックとパイプラインの基盤を分離する Rust トレイトを中心に構築されています。M3 のマルチモーダルサポートを追加するには、これらのトレイトを実装し M3 固有の定数を使用すればよく、パイプライン自体の変更は不要でした。このアーキテクチャは、ビジョン機能を備えたオープンソースモデルの大半に適用可能であり、推論エンジンランタイム全体で一般化されています。
パフォーマンス結果
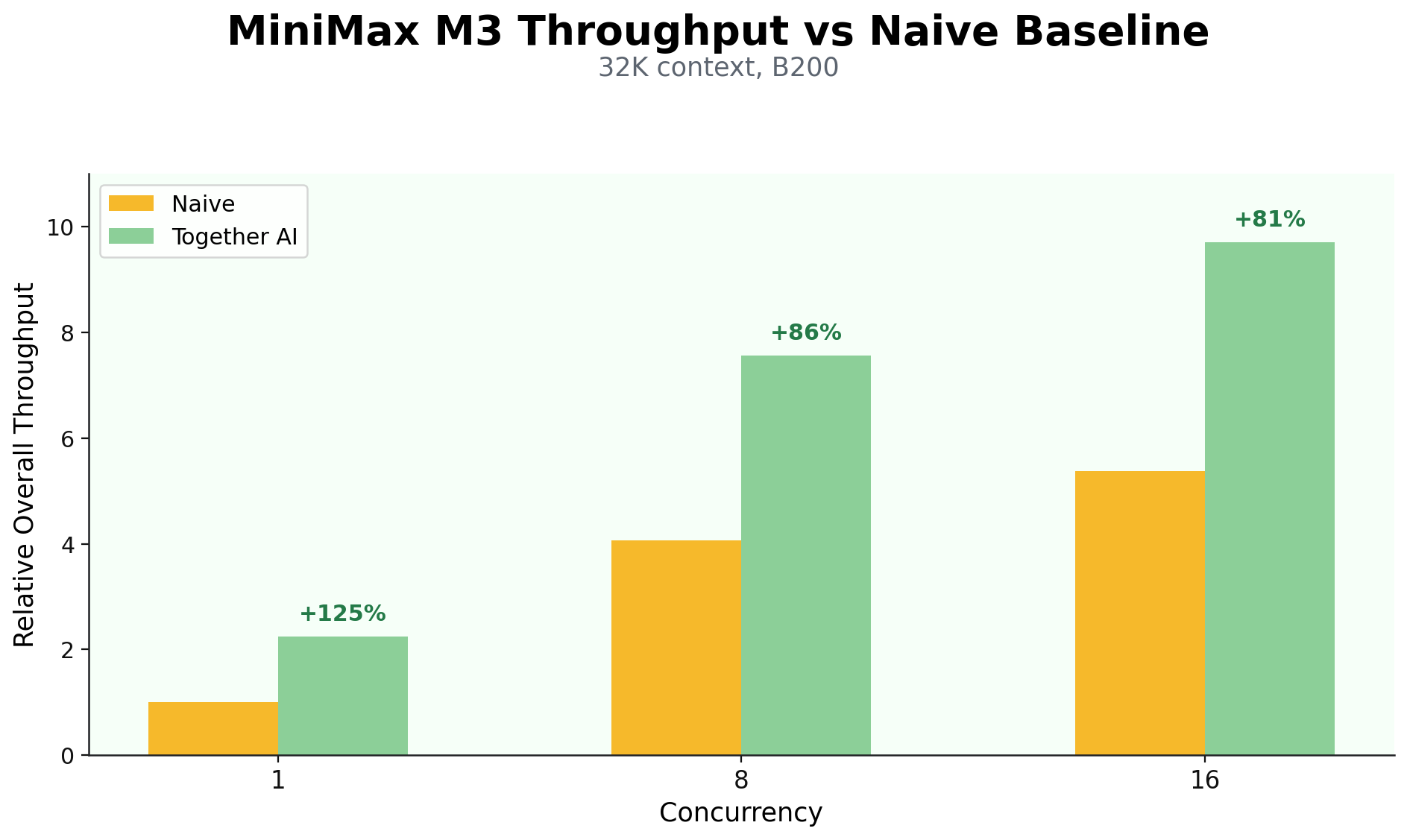
MiniMax M3 の重みとモデルアーキテクチャを受け取って以来、推論パフォーマンスの向上に努めてきました。その結果、一般的なエージェント形状のトラフィックにおいて、さまざまな並行度レベルで 81% から 125% の性能向上を達成しました。
今後の取り組み
新しいアーキテクチャは、新たなインフラおよびエンジニアリング上の課題をもたらします。Together AI では、最高の推論パフォーマンスを提供することを目指しています。M3 に関して現在積極的に取り組んでいるトピックはいくつかあります:
- スパースアテンション(sparse attention)アーキテクチャにより、より小さなカーネルが増加しました。例えば、KV ブロックに対する topk や、Q-KV マッピングを KV-Q に再マッピングするなどです。これらにはさらに多くのカーネル融合の機会があります。当社の Kernel Agent Research チームは、本番環境で直接使用可能なレベルのカーネルを作成するエージェントを開発中です。
- CPU キャッシュへのオフロードにおいて、K インデックスと実際の KV キャッシュを分離して扱うことが可能になりました。現在、topk 選択に基づいて K インデックス全体を読み込み、KV キャッシュはオンデマンドで読み込む仕組みの開発を進めています。
原文を表示
- Together AI is the preferred cloud partner for MiniMax M3. Together AI will host the open-weights model as a developer endpoint upon its public release.
- Our Inference and Kernel teams delivered significant engineering breakthroughs to serve M3 efficiently, including key optimizations such as a KV-Block-Major sparse attention kernel, a novel paged attention integration for MSA, highly optimized index scoring kernel and a Rust-based multimodal preprocessing gateway, resulting in 81–125% throughput improvements across different concurrency levels.
- Serving MiniMax M3 at scale in production validates Together AI as the go-to inference platform for models that push the frontier on the hard systems problems that make real-world deployment possible.
MiniMax launched their latest state-of-the-art model M3 and Together AI is excited to be the preferred cloud partner, enabling MiniMax to efficiently serve M3 in production at scale. Once MiniMax M3 is released as an open weights model over the coming few days, Together AI will also host the model as an endpoint for developers directly. Behind that scale is the exceptional work of our Inference and Kernel teams, who drove deep performance optimizations and ensured production-grade reliability for a model that pushes the frontier: 1M-token context window, native multimodality, and an architecture that demands serious engineering to serve efficiently. In this post, we'll walk through how we made it happen. Congratulations to the MiniMax team on a landmark model launch and continued innovation.
MiniMax M3 is an all-in-one model that brings together state-of-the-art coding performance, agentic workflow support, and native multimodal reasoning. On top of these capabilities, it is also designed to support 1M context while being highly economically friendly to serve. This makes it a good fit for real-world tasks where long documents, codebases, tool use, images, and iterative reasoning often appear together and heavy in context. Compared to the previous generation, serving M3 imposes more challenges as new capabilities require optimizations on more dimensions including sparse attention computation, larger KV cache management, multimodal processing, etc.
Architecture / Characteristics
The most novel architectural change in M3 is MiniMax Sparse Attention (MSA), which is designed to address the attention-computation bottleneck seen in MiniMax M2.7. Its block-sparse attention mechanism caps the maximum number of tokens each query can attend to, reducing the cost of long-context processing and making much longer context windows practical. This brings a speed up of more than 9x in the prefilling stage and more than 15x in the decoding stage.
In essence, MSA’s calculation is composed of two parts: a score calculation to determine the most relevant K blocks to attend to for each KV group, and then dense attention between the query token and those blocks. This design preserves expressiveness along the KV-group dimension while still putting a limit on the maximum number of KV tokens a query token attends to. The attention computation itself no longer scales as N^2 with context length, thus making it very suitable for long context workload.
We measured the kernel execution time breakdowns under agentic-style traffic shape(60k prefix cache) under concurrency of 8 on B200. MSA significantly lowers the wall time percent of the actual attention computation per iteration.
Besides the attention architecture change, M3 is also shipped with multimodal support with a vision component and new image and video preprocessing functionalities.
Given these fundamental changes, Together AI worked closely with MiniMax’s engineering team to tackle the new emerging challenges. Some major challenges include:
- Though MiniMax sparse attention computation itself is highly efficient, supporting 1M context length is still challenging from an engineering perspective.
- Video and image processing are natively more complicated than text tokenization.
Optimizations
KV-Block-Major Sparse Attention
During prefill, attention computation can still be a big factor for long context input, as for each token, we need to calculate Selected *Block* * *KV Head Group* * *Tokens*. The nature of the block sparse attention allows multiple queries to attend to the same key-value blocks. Thus, if we iterate each query to calculate attention with key-value blocks, we are duplicating the KV movement from HBM to SRAM on GPU. Iterating over the key-value group in the outer loop and calculating attention between query tokens in the inner loop allows better arithmetic intensity as KV cache is moved only once.
To achieve this, we need to reorganize the mapping from {q, kv block} into {kv block, q} and reimplement the attention kernel. Because we are calculating only partial O output for the kv block, we need a final “reduction” based on the Log-Sum-Exp to rescale output O and sum. The process is as follows:
Integrate MSA with Paged Attention
In modern inference engines, paged attention is often used to manage KV cache context for requests. The majority of highly optimized attention kernels are written with a fixed set of page size support. The blocker that stops us from using these kernels is that the selected blocks differ across KV groups.
At Together AI, we propose a new way to integrate MiniMax Sparse Attention into the engine. During decode, we first build a page table based on the selected blocks, flatten the KV-group dimension into the batch dimension, and leverage the strided view of a KV cache tensor to provide the attention kernel with the pointer needed to retrieve the KV page. The trick is the stride: page addresses advance by D to choose a virtual page start, while tokens advance by Hkv * D. That deinterleaves one physical tensor into per-head pages, so each flattened row can now use a different page table.
This design unblocked us to use the existing attention kernels that support GQA without having to rewrite a new one that supports sparse attention from scratch. Because the selected blocks for each query is limited, the kernels to find mapping between blocks to pages are with very low overhead. This design gives us 5% improvement on the decode throughput.
Decode Index Scoring Kernel Optimization
For decode, MSA moves a large part of the cost out of dense attention and into the score/top-k indexer. For every decode query, the engine compares the query-side index vector against candidate key-side index vectors, reduces each 128-token KV block to a single score, and keeps only the top blocks for the real attention kernel. This scan is on the critical path for every generated token, and at long context lengths the number of candidate blocks grows with context length. Decode scoring has a small-query-index, long-key-index shape. It is tempting to treat a batch of decode queries as one larger GEMM, but the score/indexing step is not just a dense matrix multiply: each request and K group has its own candidate block range, masking, per-block reduction, and top-k boundary. Concatenating queries together would still leave a ragged gather-and-reduce problem around the GEMM, while forcing padding and extra bookkeeping onto the critical path. Our optimized path therefore uses an *AB-swapped HMMA layout*: the 128-token key-index block becomes the MMA M dimension, while the query side is padded only into the smaller *N* dimension. The kernel stages 128-token K indexes with asynchronous copies, prefetches the next page, computes dot products in bfloat16 with HMMA, and reduces each page to one block score.
Multimodal Preprocessing at the Gateway
SMG (Serving Model Gateway) is a Rust-based model gateway that sits between the OpenAI-compatible API and the inference engine. Beyond routing and tokenization, SMG takes on a role that is particularly important for multimodal models: it performs all vision preprocessing on the CPU before the request reaches the GPU worker.
Image and video inputs need a fair amount of CPU work before they are useful to a vision encoder: downloading, decoding, frame sampling, resizing, and converting into patch tensors. Doing this inside the inference engine ties up resources that should be spent on generation. SMG handles all of it in the gateway instead, so by the time the request hits the GPU, the tensors are ready to go.
For M3, this means: fetch the video, pull frames out with FFmpeg, pick a subset based on FPS (Frames Per Second), resize and normalize, then patchify with the temporal dimension baked in. What comes out is a flat patch tensor and a small grid metadata tensor, packed into a gRPC message. The worker just runs the vision encoder directly — no preprocessing on its end.
Also, SMG's multimodal pipeline is structured around Rust traits that separate model-specific preprocessing logic from the pipeline plumbing. Adding M3 multimodal support meant implementing these traits with M3-specific constants; the pipeline itself did not change. The same architecture applies to the majority of open source models with vision capability, and generalizes across inference engine runtimes.
Performance Results
Since receiving the MiniMax M3 weights and model architecture, we strived to improve the inference performance. We have reached 81% - 125% increase on various concurrency levels on common agentic shape traffic.
Future Work
New architecture brings in new infrastructure and engineering challenges. At Together AI, our goal is to provide the best inference performance. A few topics that we are actively working on regarding to M3 are:
- The sparse attention architecture introduces more smaller kernels, for example, topk over kv blocks, remapping q-kv mapping into kv-q, etc. There are more kernel fusion opportunities. Our Kernel Agent Research team is actively developing agents that write production-grade kernels.
- CPU cache offloading of k-index and actual kv cache can now be disaggregated. We are working on loading full k-index and load kv cache on-demand based on the topk selection.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み