Mythos との協働がもたらす感覚について
One Useful Thing の著者が Claude 5 Fable(Mythos クラス)の早期アクセスを通じて、その圧倒的な性能と人間との関係性の変化を報告し、複雑なタスク実行能力や倫理的・心理的インパクトを分析している。
キーポイント
Claude 5 Fable の圧倒的性能
他の公開モデルを大幅に上回る性能を持ち、単一のプロンプトで高度な学術論文や複雑な詩を作成するなどの驚異的な結果を出した。
数学的生成による創造的ゲーム開発
画像生成機能がないにもかかわらず、数式のみを用いて画像や 3D オブジェクトを含む動作可能なゲームを複数作成し、ユーザーの期待を超えた成果を上げた。
人間と AI の関係性の変化
指示を出した瞬間に結果が得られる「喜び」と、そのあまりの効率さに感じる「不気味さ」の間で揺れる、新しい AI 利用体験を提示している。
セキュリティ用途への制限と実用性
Mythos クラスのセキュリティ影響が議論される中、Fable はガードレールによりサイバーセキュリティ用途には使えないが、それ以外の領域では極めて強力なツールである。
自律的なエージェントワークフローの活用
AI は単独で作業するのではなく、複数のサブエージェントを起動して研究を行い、コードを実行し、さらに検証用の対立グループ(adversarial groups)を組んで結果を検証する高度な自律プロセスを実行しました。
複雑なデータ収集と修正能力
2,200 件以上の航空便、TGV や新幹線の時刻表、各国の道路速度などの詳細データを収集し、グリーンランドやピトケアン島といった遠隔地への正確な移動時間を取得するために、指示に応じてワークフローを動的に修正・拡張しました。
AI の自律性とブラックボックス化
ユーザーの役割が最小限に抑えられ、AI が数百もの判断を自律的に行うため、その意思決定プロセスは不透明なブラックボックスとなる。
重要な引用
It represents a very real leap over every model I have used before, and, maybe more important, suggests our relationship with AI is changing in drastic ways.
I often felt using the tool was somewhere between delightful and unnerving. Delightful because I just asked for something at it happened. And also unnerving because I just asked for something and it happened.
First, the AI launched multiple other AIs (I believe mostly the cheaper Claude Sonnet) to help it conduct research on travel times... And while those agents were running, it started coding.
This time the AI launched a workflow, adversarial groups of agents that did research and tested each others results.
In many ways, it is miraculous (I can always ask for edits at the end) on the other, it turns AI into the ultimate black box.
My role was extremely limited.
影響分析・編集コメントを表示
影響分析
この記事は、単なる性能比較の域を超え、AI が人間の創造的プロセスや思考パターンに与える心理的影響(喜びと不気味さ)を深く掘り下げた点で重要です。Claude 5 Fable の登場は、AI が「ツール」から「共創者」へと役割を変化させる転換点を示しており、今後の AI 開発における倫理的・実用的な議論の重要な材料となります。
編集コメント
Mythos クラスの AI がもたらす「不気味なほど高い効率性」への言及は、技術的な性能評価だけでなく、人間心理への影響という新たな視点を提供しており、業界全体が直面する課題を浮き彫りにしています。
私は、一般公開される最初のミソス級 AI モデルである Claude 5 Fable に早期アクセスしました。ミソスに関する議論の多くはソフトウェアセキュリティへの影響に焦点を当てていますが、私はそれ以外のあらゆる分野でテストを行いました(Fable におけるガードレールにより、サイバーセキュリティ用途での使用は事実上不可能となっています)。私の結論は、これが私がこれまで使ってきたすべてのモデルを超える非常に現実的な飛躍であり、おそらくより重要なのは、私たちが AI と持つ関係が劇的に変化しつつあることを示唆している点です。
まず、Fable はどれほど優秀なのでしょうか?私が実施した実験を次々と繰り返す中で、このモデルは私が使用してきた他のあらゆる公開モデルを大幅に上回る性能を発揮しました。多くの課題に対して対応可能であり、驚くべき結果も生み出しました——例えば、複数ページにわたる仕様書に基づいて最大 12 時間実行し続けることもできました。後ほど、より複雑で真剣なユースケースのいくつかを紹介しますが、あらゆるタスクにおいて全般的な改善が見て取れるでしょう。この投稿でそのことを伝える際の課題は、最も印象的な結果の多くが私の読者の一部の人々にとってのみ興味深いものになる可能性がある点です。例えば、Fable は単一のプロンプトと 1 つのフィードバックから、私がこれまで AI が作成した中で最も洗練された学術的社会科学論文を生成しました。また、すべての単語が「s」で始まる 10 ページにわたるエピックな韻文詩を、理容室でのカットに関するテーマで作成しました。
では、よりアクセスしやすく娯楽性のある例として、試せるゲームをいくつか作成してもらいました。これらすべては、Fable が私の曖昧なプロンプトを受け取って実用的なものを生成する最初の 1 つのプロンプト(Claude Code 内)で始まり、その後、「もっと良くして」などの軽い励ましやフィードバックを含む数回の追加プロンプトが続きます。これらの成果が特に印象深いのは、Claude が画像を生成できないため、すべてのアートワークや 3D オブジェクトが外部アセットを一切使用せず、数学のみによって作成されている点です。ぜひ試してみてください:コイン投げのゲーム(プロンプト:「Balatro のようなものだが、コイン投げのゲーム版」)は非常に面白いですし、蛇自身が自我を持ち、奇妙なことが起こるスネークゲーム、あるいは深淵へと降りて何があるかを探るゲームなどがあります。
出力は確かに印象的です。しかし、特により本格的なプロジェクトに取り組むようになると、このツールの使用感は「楽しい」と「不気味」の間にあるように感じられることがよくありました。「楽しい」と感じる理由は、ただ何かを要求するだけでそれが実現されるからです。同時に「不気味」に感じるのも、同じ理由、つまり単に何かを要求しただけでそれが実現されてしまうからです。
マップと手法
その理由を理解するには、Fable がどのようにして作業を完了させるのかを知る必要があります。そのため、以前多くの AI モデルでテストしてきた例題である「等時圏マップ(isochrone map)の作成」について話をしましょう。これは、特定の時間内に移動可能な距離を示す地図であり、最初のものは 1881 年にロンドンからの所要時間を示すものとして作られました。
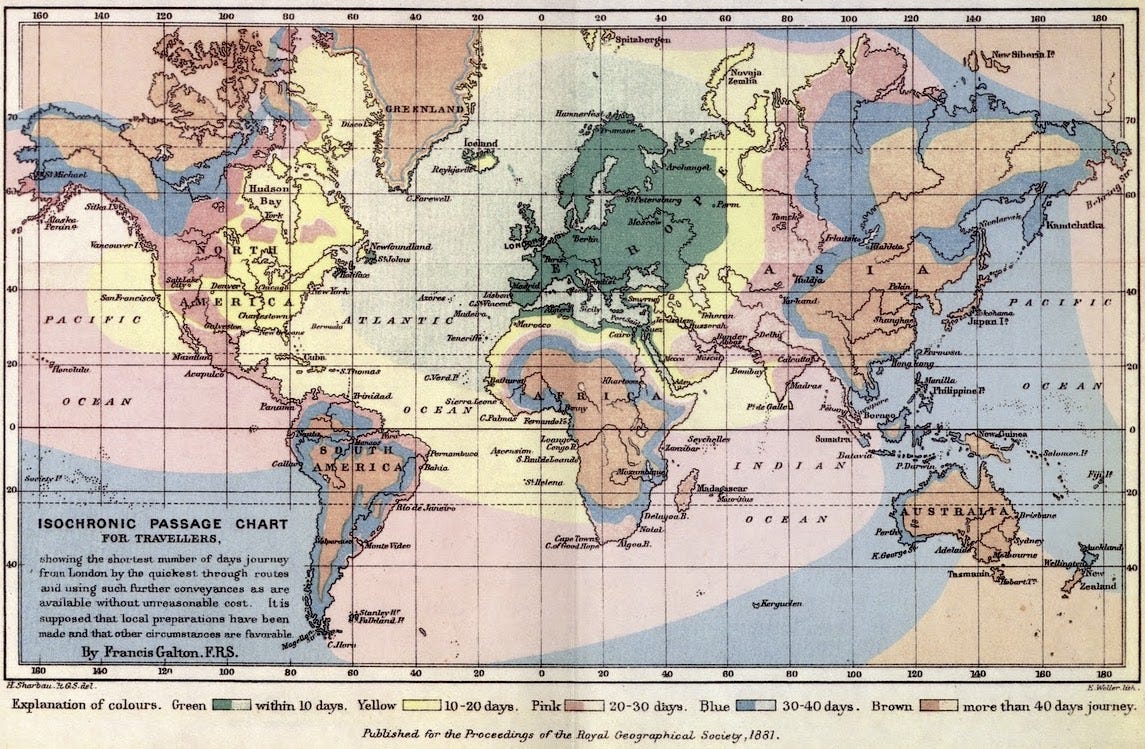
元の地図
このような地図を作成しようとする際、数千もの潜在的な移動距離を調査し、多くの小さな判断や決定を下す必要があるため、これまでにどのモデルも半ば有用な仕事をしたことはありませんでした。私はこれを Fable で試してみることにし、Claude Code を使って以下のプロンプトを入力しました:「完全に調査され、美しい等時圏地図を作成してください。さまざまな都市を選択して、実際のデータに基づくリアルな等時圏ラインを確認できるようにしたいです。デザインは独自のものにしてください。空港(および空港への移動時間と空港からの移動時間)、電車、徒歩、自動車の利用を考慮に入れてください。データはライブである必要はありませんが、調査とデータに基づいた実在するものであるべきです。いくつかの都市から始めても構いませんが、より一般的な内容の方が良いでしょう。これは全く新しいプロジェクトとして進めてください。」すると、それは元の地図のスタイルでこれを行うことを提案しました。私は同意し、作業が始まりました。
AI が単独で行った数時間にわたる構築セッションの議事録をもう一度振り返る価値があります。そこにはいくつかの珍しい様子が映し出されているからです。まず、この AI は旅行時間の調査を行うために複数の他の AI(主に安価な Claude Sonnet と推測されます)を起動しました。その結果、2,200 件以上の具体的なフライト情報、TGV から新幹線に至るまでの鉄道時刻表、そして複数の学術論文から各国ごとの道路速度データを取得しています。これらのエージェントが稼働している間、AI は同時にコーディングも開始しました。さらに、コードの検証のために新たなエージェントとテストを起動し、その過程で進捗に関するメモを取り続けています。
その結果、1881 年のオリジナルに非常に似た、驚くほど洗練された完全な機能を持つ地図が完成しました。しかし、それが完璧だったわけではありません。私は多くの遠隔地(グリーンランドなど)には旅行時間の推定値しか含まれておらず、正確な数値がないことに気づきました。そこで Fable に修正を依頼し、「実際に遠隔地の空港や場所への旅行時間を取得する」という指示を含めました。
今回は AI がワークフローを開始しました。これは研究を行い、互いの結果を検証する敵対的なグループのエージェントたちです。太平洋のピトケアン島にどのくらいの頻度で船が航行しているか、またオタワからグリスフィヨルドへどうやって行くかを算出しました。そして、非常に短い期間に膨大な数のトークンを使用しました(これについては後ほど詳しく説明します)。
結果は印象的でした。私はさらに興味を引く方向へいくつか試行しました(他の可視化アプローチの要求などを含みます)。数分間、結果をクリックして探索することをお勧めします。また、グラフの下部にはその手法とソースを読み取ることができます。
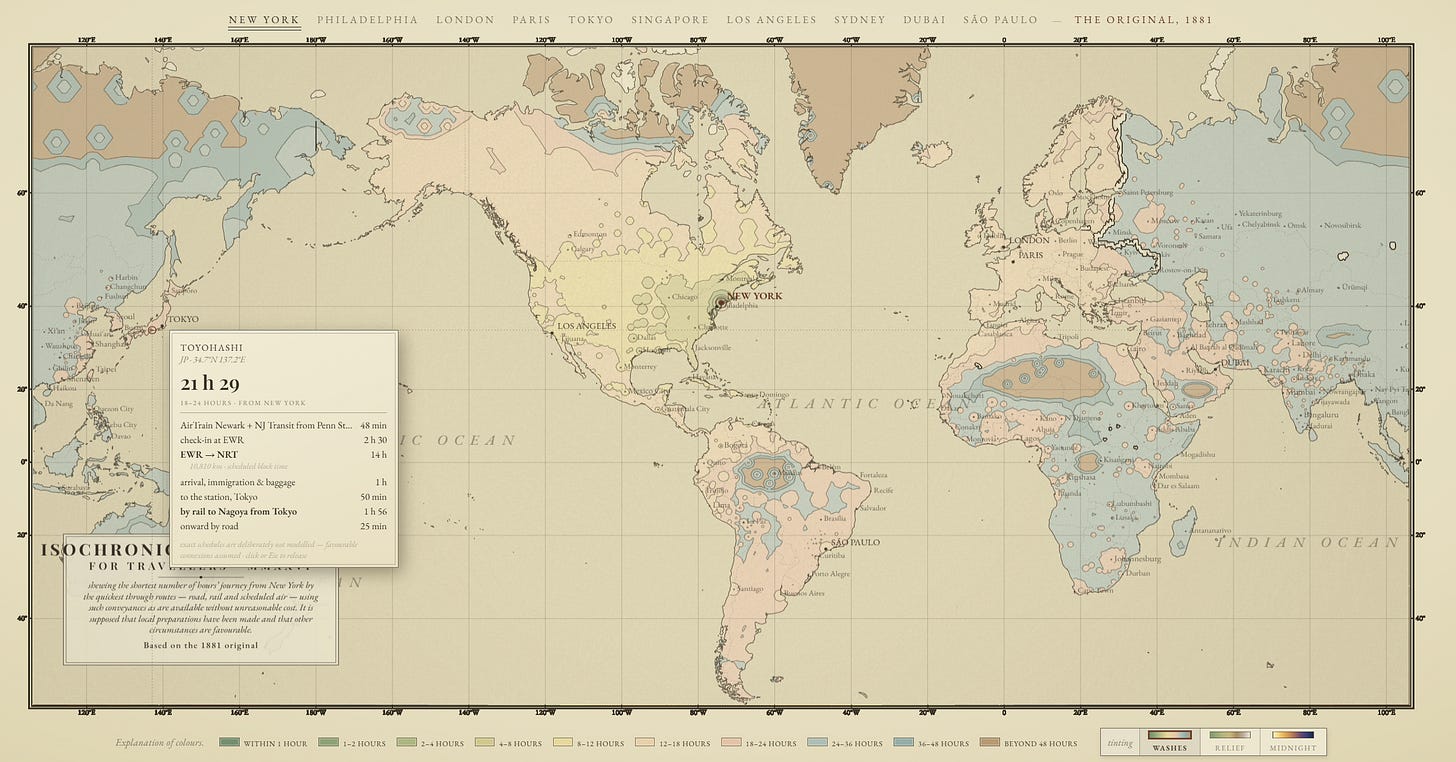
AI が生成したものです。インタラクティブ版へ移動するにはマップをクリックしてください
これは、旅行や地図を本当に好きな人でなければ、あなたにとって有益なプロジェクトではないかもしれませんが、研究、数学、ビジュアル開発、審美眼、判断力、複雑なコーディングなどを含む困難な問題を AI が解決する様子を示す一例です。そして、最も不気味だったのは、私がほとんど何もしていなかったことです。私は非常に野心的な指示を出しただけで、AI はそれを実行しました。いくつかの小さなフィードバックを与えただけで、AI はそれを理解して対応しました。私の役割は極めて限定的でした。
重要なのは、私が行った作業量がモデルと比較して限定的だったことだけでなく、モデルがどのように行動するか、なぜ特定の手法を選んだのか、あるいはその結果がどの程度詳細になるかについて、私が持つコントロールも限定的だったことです。AI の意思決定の詳細は私には示されず、プロセスを追うには長すぎて意味がありません。このマップを作成するには、AI が数百の小さな選択についての判断を下す必要があり、それは私に選択を理解する機会や意見を述べる機会を与えずに行われました。多くの点でこれは奇跡的ですが(最後に修正を依頼することはいつでもできます)、他方では AI を究極のブラックボックスに変えてしまいます。
Mythos クラスのモデルとの作業
Fable から受けた最も野心的なプロジェクトについては、少し補足説明が必要です。私は、人間が不揃いな回答を生み出す分野での調査を多く行っており、その回答を適切に分類して分析する必要があります:あるアイデアはどれほど革新的か?なぜ人々はこの本を好むのか?これらを解明するために、私たちは人間の研究者に情報に対して判断を下してもらい、統計的に他の回答と比較することで、データを信頼できるかどうかを確認しました。最近の研究では、AI がこの重要な作業を担える可能性が示されていますが、AI と人間の判断の較正は困難で高コストでした。そこで私は Fable にこの問題の解決を依頼し、まず複雑な 19 ページにわたる設計ドキュメントを生成させ、その後その実行を行いました。
これは 9 時間半の間、機能しました。
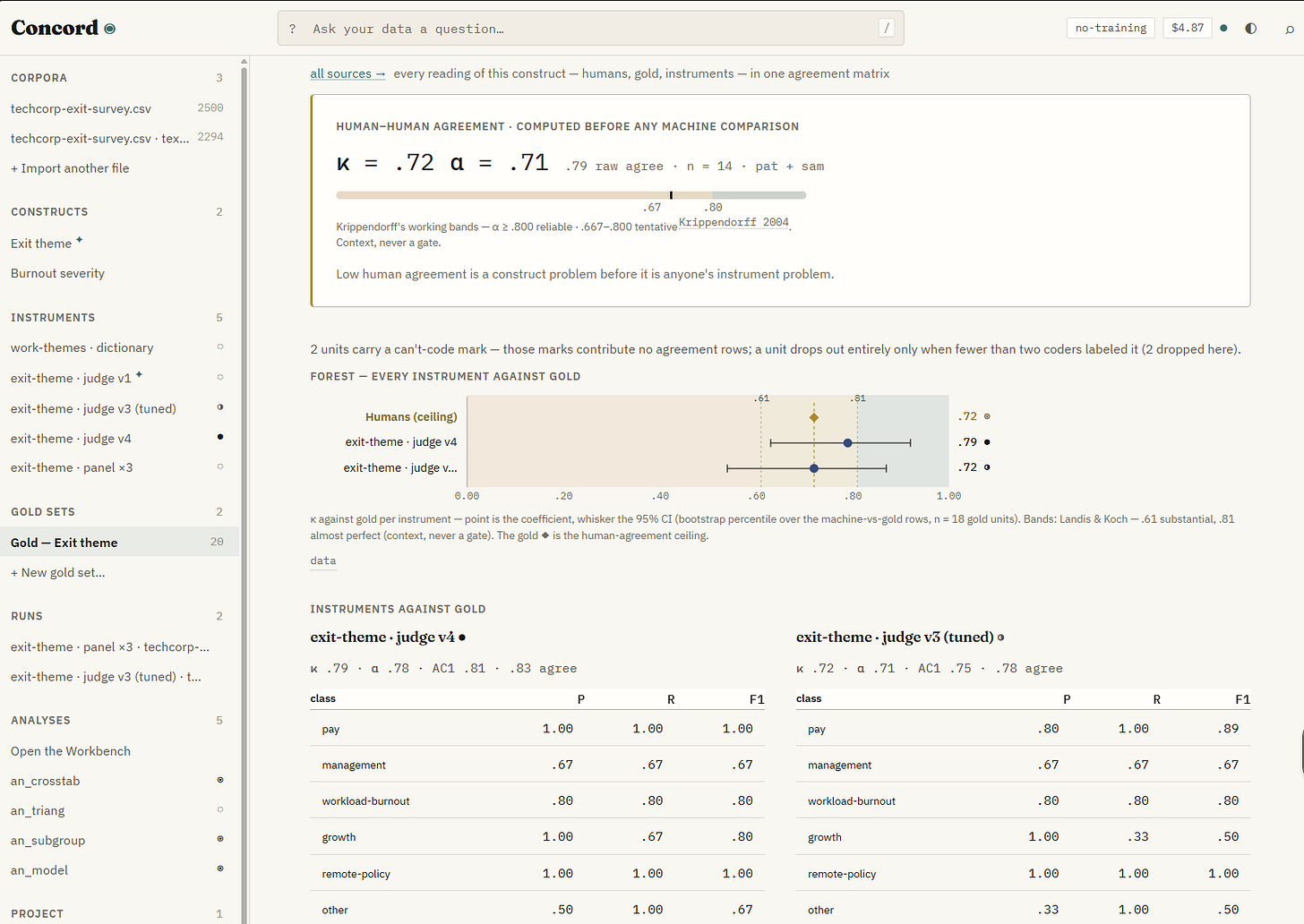
その結果、AI が「Concord」と名付けた極めて洗練されたソフトウェアが誕生しました。このソフトウェアは複数のデータセットを取り込み、人間と AI の応答を較正した上で、結果に対して複雑なデータ分析を実行することができます。もちろん完璧ではありませんでした。専門家として私はいくつかの誤りや省略(一部は私が設計を依頼したことに起因するもの)を発見し、AI に修正させました。しかし、このプロジェクトおよび他の多くのプロジェクトにおける納品の範囲は、これまで私が目にしたどの事例よりも優れていました。この場合、研究者が長年必要としながら収益化の観点から作られなかったソフトウェアが完成しました。現在はここでコードを使用したり修正したりすることが可能です。完璧ではないことは間違いありません(私は結果と向き合うのに1時間しか費やしませんでした)、しかしソフトウェアエンジニアであれば、私が見つけられなかった潜在的なバグをすぐに解消できるでしょう(これは将来、ソフトウェアの新たな用途爆発に対応するために、むしろコーディングを行う人材を増やす必要がある理由の一つでもあります)。
この力は奇妙さと制限と表裏一体です。その制限の一つにトークン使用量があります。Fable は Opus よりも倍の費用がかかり、トークンを消費する速度は、本番環境でのコストが「非常に高い」という答えを暗示しています。ただし、より安価なモデルへの賢明な委譲により、実際の価格は大幅に下がる可能性があります。Fable のガードレールも、セキュリティ問題のわずかな兆候でトリガーされ、より能力の低い Claude 4.8 Opus にデフォルトで切り替わりますが、その頻度はあまりにも高すぎます。そして、荒々しいフロンティアはまだ残っています。例えば、AI は依然として同じ奇妙なスタイルで文章を書きます(実際、ソフトウェア Fable が生成するものには Claudisms の痕跡が残っており、進捗報告書も同様です。これらはすべて重みを担い、答えを引き出します)。しかし、より深い奇妙さは、私がほとんど何もせず、またその作業が行われている間にもほとんど見ることができなかった点にあります。
昨年私はこれを「魔法使いと協力する」と呼びました:呪文を唱えると何かが起こります。Fable では、その呪文が十分に強力になったため、自分がもはや魔法使いではないのではないかと確信が持てなくなりました。私はむしろパトロンに近い存在です。私が望むものを説明し、対価を支払い、結果を評価します。召喚は、私が監視できないどこかで行われ、数百の小さな選択の中で、私が投票権を持つことさえありません。作業のプロセスから成果へとシフトしました。もはや舵を取るのではなく、発注するのです。
この一時的な排除は、まだ追いついていないインターフェースの産物に過ぎず、これらのモデルが何をしているのかをよりよく理解し、途中でもっと効果的に誘導する方法が得られるようになる可能性もあります。あるいは逆で、モデルの能力が高くなるほど、人間が意味あることを成し遂げる余地は減り、ブラックボックスこそがその力の代償であるという可能性も否定できません。私は後者の方向性が現実的だと考えています。これらは明白な意味でのコントロール喪失ではありません。私はまだ『Fable』を誘導できますし、指示には驚くほどよく従います:指示の野心的さが高くなるほど、結果も良くなります。しかし、誘導することはもはや実行することと同じではありません。私はモデルにbriefing(概要説明)を行い、モデルは自らエージェントを立ち上げて調査・執筆・相互チェックを行わせ、戻ってくるのは完成品です。パトロンが単一の芸術家に依頼するのに対し、Fable はむしろ一つのスタジオに近く、私は最終作品に署名して承認するクライアントでありながら、現場に足を踏み入れたことはありません。
購読する
共有
原文を表示
I had early access to the first Mythos-class AI model being released to the public, Claude 5 Fable. Much of the discussion of Mythos has centered on its impact on software security, but I tested it on everything except that (the guardrails around Fable essentially prevent it from being used for cybersecurity at all). My conclusion is that it represents a very real leap over every model I have used before, and, maybe more important, suggests our relationship with AI is changing in drastic ways.
First, how good is Fable? In experiment after experiment I conducted, it outperformed basically every other public model I have used by a considerable margin. It was capable across many problems and produced some startling results — it would work up to a dozen hours executing on multi-page specifications. I’ll walk you through a couple of more complex, and serious, use cases shortly, but you could see the general improvement across the board on every task. The problem about communicating this in a post is that many of the most impressive results are going to be interesting to only small portions of my readers. For example, it made the most sophisticated academic social science paper I have yet seen from an AI from a single prompt and one piece of feedback. It also created a 10-page epic rhyming poem about a haircut where every word starts with the letter s.
So, as a more accessible and entertaining example, I also had it create a bunch of games you can try. All of these are one initial prompt in Claude Code where Fable had to take my vague prompts and generate something workable, followed by a couple of additional prompts with minor encouragement (“make it better”) or feedback. What makes these especially impressive is that Claude cannot generate images, so every piece of art or 3D object was made with math alone, not using any external assets. You can try any of them: a game about flipping coins (prompt: “Balatro, but for the game of coin flips”) that is quite fun; a snake game where the snake is self-aware and crazy things happen; or a game about descending into the depths to see what is there.
So the output is impressive. But, especially as I turned to more serious projects, I often felt using the tool was somewhere between delightful and unnerving. Delightful because I just asked for something at it happened. And also unnerving because I just asked for something and it happened.
Maps and Methods
To see why, it helps to understand the way in which Fable gets work done, and for that I want to turn to an example I have tested on many previous AI models: building an isochrone map. This is a map that shows the distance you can travel in a given length of time, and the first one was created in 1881 showing travel times from London.
The original map
No previous model did an even halfway useful job with trying to create a map like this because it involves researching thousands of potential trip distances and a lot of small judgement calls and decisions. I decided to try it on Fable using Claude Code with this prompt: i want you to build a fully researched and beautiful isochronic map that lets me pick various cities and see real isochronic lines based on real data. I want the design to be unique. You should take into account airports (and travel time to and from airports) trains, walking, driving. The data does not need to be live but should be real based on your research and data. You can start with a few cities but more general is better, this should be an entirely new project. It then suggested that it do this in the style of the original map. I agreed, and it got to work.
It is worth a second looking at the transcript of the multiple hour building session the AI went through on its own, because you can see some unusual things. First, the AI launched multiple other AIs (I believe mostly the cheaper Claude Sonnet) to help it conduct research on travel times, ultimately retrieving over 2,200 specific flights, the rail schedules for trains from the TGV to the Shinkansen, and road speeds per country from multiple academic papers. And while those agents were running, it started coding. Then it launched yet more agents and tests to verify its code, all the while taking notes about its progress.
The result was a fully functioning map of impressive sophistication that looked a lot like the 1881 original, but that doesn’t mean it was perfect. I noticed that a lot of remote locations (like Greenland) just contained estimates of travel time, not exact numbers, so I told Fable to fix it, including the instructions: actually get travel times to remote airports and locations. This time the AI launched a workflow, adversarial groups of agents that did research and tested each others results. It figured out how often ships sail to Pitcairn Island in the Pacific and how to get to Grise Fjord from Ottawa. And it used a tremendous number of tokens in a very short period of time (more on this soon).
The results were impressive. I pushed a few more times in directions that interested me (including asking for other visualization approaches, etc.). I would recommend spending a couple minutes clicking around the results, and you can read its methods and sources at the bottom of the graph.
What the AI generated. Click on the map to go to the interactive version
This is probably not a useful project for you unless you really like travel and maps, but it is indicative of AI solving a hard problem involving research, math, visual development, taste, judgement, complex coding, and more. And, the unnerving part was how little I did. I gave a really ambitious instruction, the AI followed it. I gave a couple of minor pieces of feedback, and the AI figured it out. My role was extremely limited.
Importantly, it was just limited in how much work I did relative to the model, it was also limited in how much control I had over how the model did things, why the model chose particular approaches, or even how in-depth its results would be. The details of the AI’s decision making are not shown to me, and the process would be too long to even be worth following. The map required the AI to make judgement calls about hundreds of little choices, and it just made them, without me understanding the choices or having a chance to weigh in. In many ways, it is miraculous (I can always ask for edits at the end) on the other, it turns AI into the ultimate black box.
Working with a Mythos-class model
The most ambitious project I got from Fable takes a little more explanation. I do a lot of research where humans produce messy answers and doing any sort of analysis requires categorize those answers properly: how innovative is an idea? why do people like this book? To figure this out, we used human researchers to make a judgement call about a piece of information, and statistically compare their answers with others to figure out whether we can trust the data. A lot of recent research has shown that AIs might be able to do this important work, but calibrating AI and human judgement has been difficult and expensive. So I asked Fable to solve the problem, first generating a complex 19 page design document and then executing it.
It worked for nine and a half hours.
The result was an extremely sophisticated piece of software the AI called Concord that could take in multiple datasets, calibrate human and AI responses, and then conduct complex data analysis on the results. Again, it wasn’t perfect. As an expert, I was able to spot some errors and omissions (some as a result of the design I had asked for) that I had the AI correct. But the scope of the delivery on this project, and many others, exceeded anything I had seen before. In this case, it was a piece of software that researchers have needed for years but was never profitable to create. You can now just use or modify the code here. I am sure it is not perfect (I only spent an hour working with the results), but a software engineer would iron out the remaining potential bugs that I could not find quickly (which is one reason we may need more, not less, coders in the future, to help with the explosion of new uses for software).
This power goes hand in hand with strangeness and limits. Among those limits is its token usage. Fable is twice as expensive as Opus, and it burns through tokens at a rate that suggests the answer to how much it costs in production is “a lot,” though its clever delegation to cheaper models may lower the real price considerably. The guardrails for Fable also trip at the faintest hint of a security problem, defaulting to the less powerful Claude 4.8 Opus, and it happens way too often. And the jagged frontier is still there. For example, the AI still writes in the same weird style (in fact the software Fable produces bears traces of Claudisms; so do its progress reports, all that carrying the weight and earning the answer). But the deeper strangeness is how little I had to do, and how little I could see while it was being done.
Last year I called this working with a wizard: you chant the spell and something happens. With Fable the spell has gotten powerful enough that I am no longer sure I am the wizard. I am closer to a patron. I describe what I want, I pay for it, and I judge the result. The conjuring happens somewhere I cannot watch, in hundreds of small choices I never get a vote on. The work has shifted from process to outcome. I no longer steer; I commission.
It is possible the sidelining is temporary, just an artifact of interfaces that haven’t caught up, and that we’ll get better windows into what these models are doing and better ways to steer them midstream. It is also possible that the opposite is true: that the more capable the model, the less there is for a human to meaningfully do, and the black box is the price of the power. I suspect that is more likely to be the real direction. None of this is a loss of control in the obvious sense. I can still steer Fable, and it follows instructions remarkably well: the more ambitious the instruction, the better the result. But steering is no longer the same as doing. I brief the model, it spins up its own agents to research and write and check one another’s work, and what comes back is finished. A patron commissions a single artist. Fable is closer to a whole studio, where I am the client who signs off on the final work without ever setting foot on the floor.
Subscribe now
Share
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み