[AINews] アンソロピックがシリーズ H で 9650 億ドルを調達、Opus 4.8 と Dynamic Workflows/ultracode を発表
Anthropic は Series H で 650 億ドルを調達し企業価値が 9650 億ドルに達すると同時に、新モデル Opus 4.8 と自律的なコード作成機能「Dynamic Workflows」を発表し、OpenAI を上回る成長軌道を示した。
キーポイント
史上最快速の資金調達と企業価値
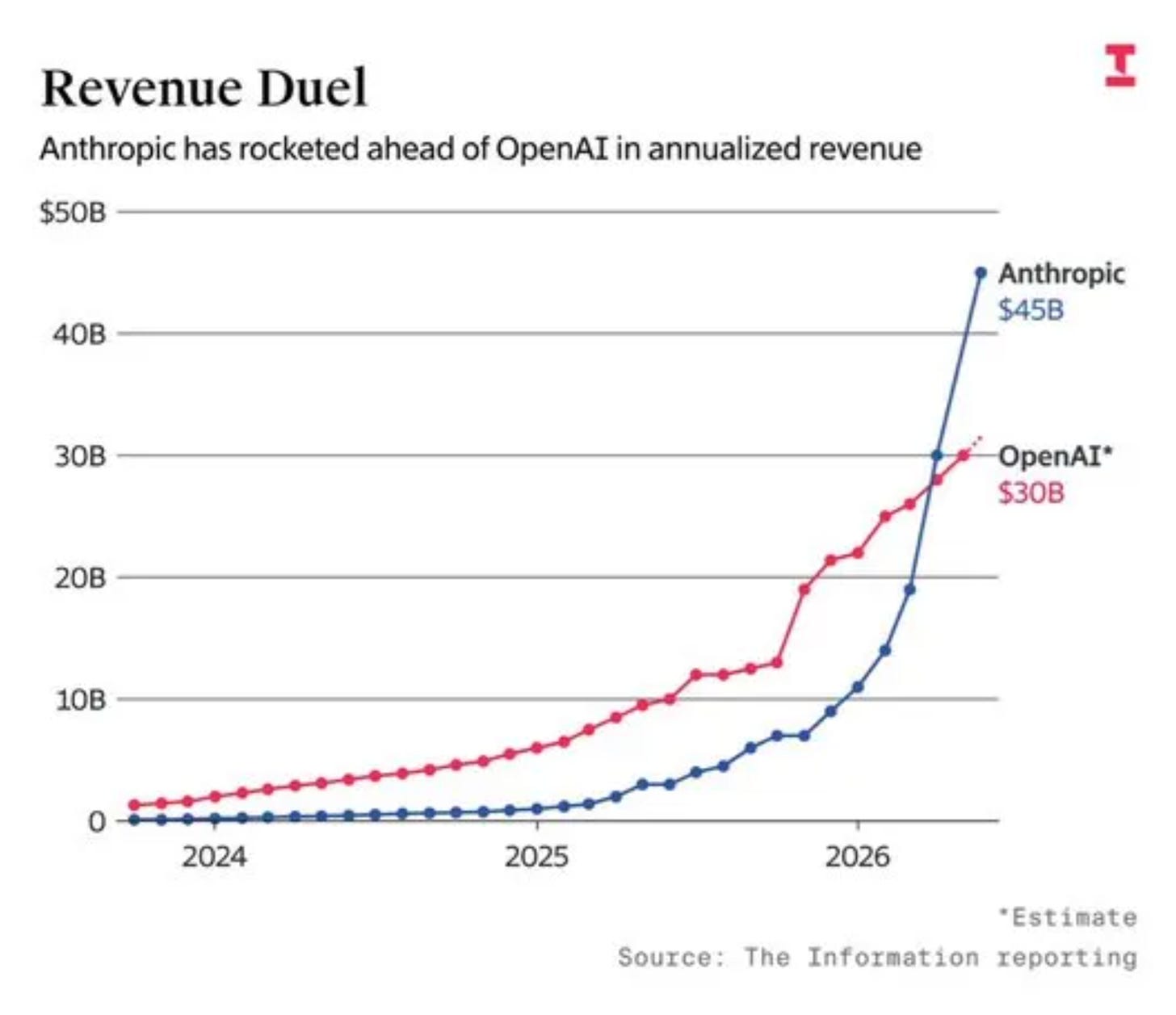
Anthropic は Series H ラウンドで 650 億ドルを調達し、直前の 12 月の 90 億ドルから急増した 470 億ドルの年間収益率を背景に、時価総額 9650 億ドル(ポストマネー)を達成した。
新モデル Opus 4.8 の発表と性能向上
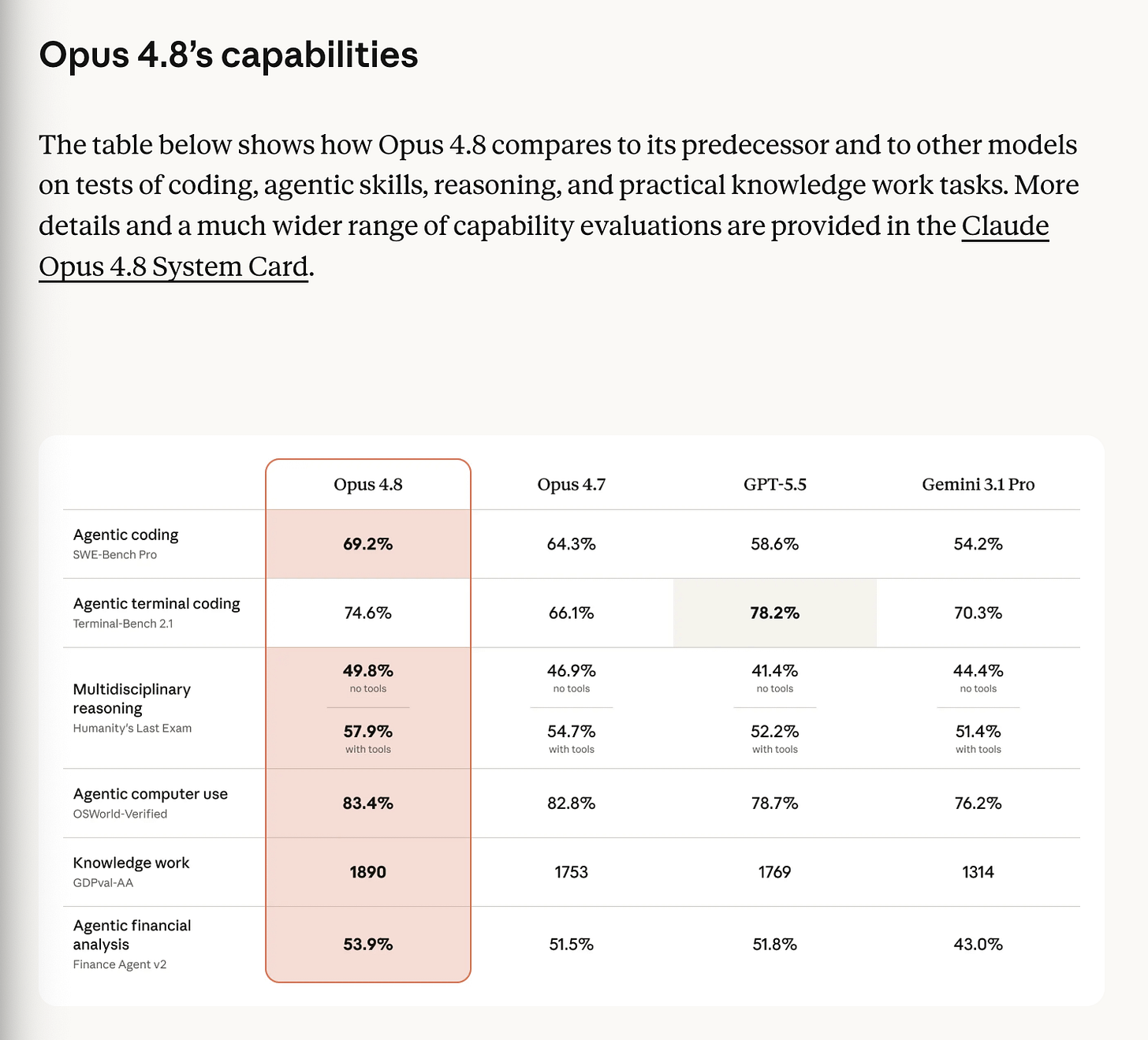
Opus 4.7 で指摘された課題を解消し、判断力や誠実性が向上した「Opus 4.8」が公開され、経済的に重要なベンチマークで SOTA(最上位)の性能を発揮している。
自律型コード作成機能「Dynamic Workflows」
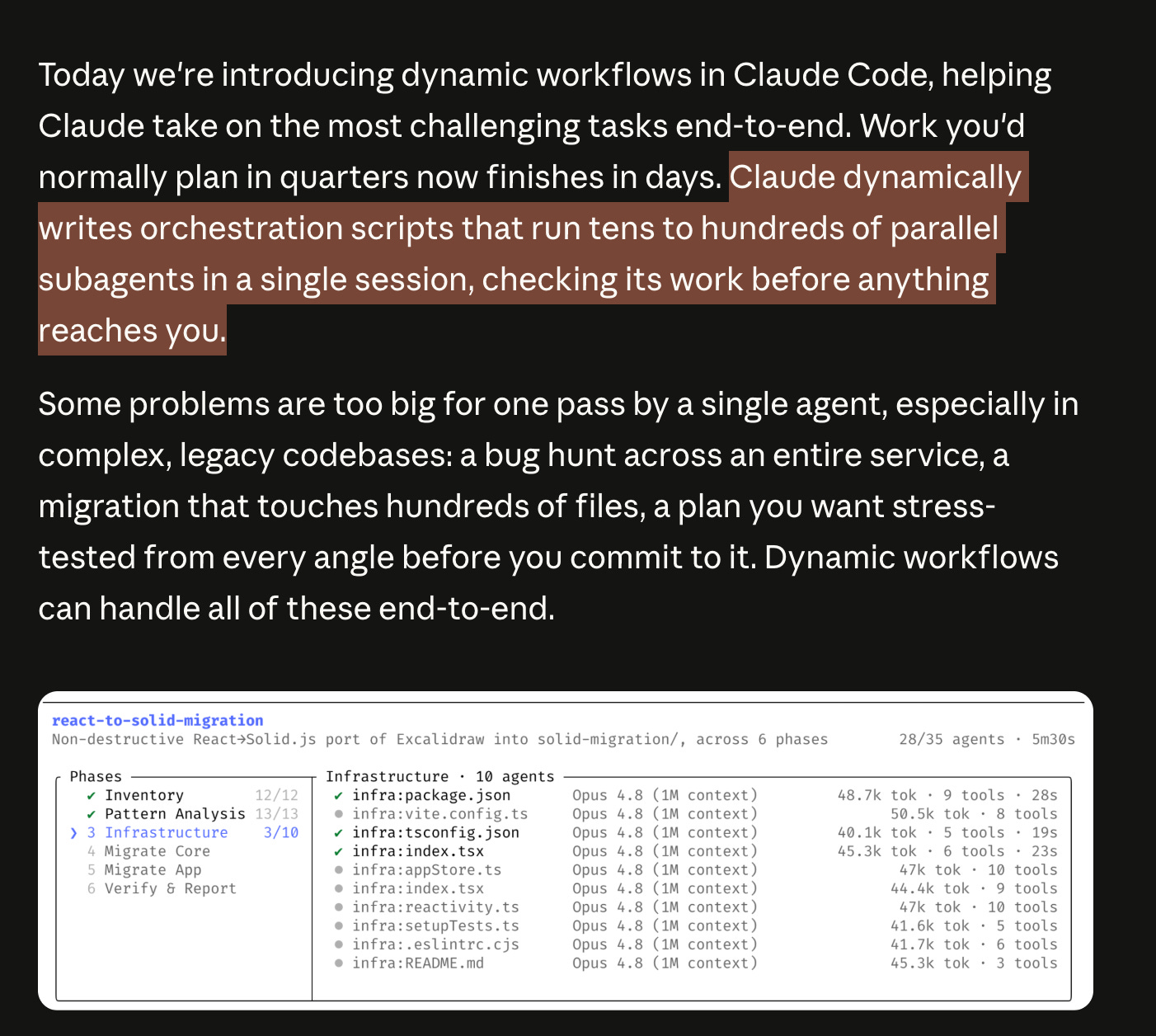
Claude Code に搭載された新機能により、AI が複雑なタスクを自律的に計画・実行可能になり、6 日間で 75 万行のコードを書き換える事例が示された。
OpenAI を凌ぐ成長指標
計算リソースや非コーディングベンチ以外の主要な指標において、Anthropic はすでに OpenAI を上回る規模と成長率を記録しているとの分析が示されている。
史上最高額の資金調達と評価額
Anthropic は Series H ラウンドで 650 億ドルを調達し、企業価値が 9,650 億ドルに達しました。同時に年間収益率が 470 億ドルを超えたことが発表され、ハイパースケールレベルの資本需要を示しています。
Claude Opus 4.8 の機能強化と評価
判断力、誠実さ、自律的な作業能力が向上した新モデル「Opus 4.8」がリリースされましたが、業界内では OpenAI への追従か画期的な飛躍かという見解が分かれており、ベンチマークによっては前作や競合他社に劣る結果も示されています。
並列サブエージェントによる動的ワークフロー
Claude Code に「Dynamic Workflows」が導入され、大規模タスクを処理するために数百の並列サブエージェントを起動・管理するオーケストレーション機能が研究プレビューとして提供開始されました。
重要な引用
Anthropic officially reported $47B in revenue run-rate (reminder, this number was $9B in December!)
confirmed their Series H raising $65B at a $900B pre-money valuation
massively parallel 'dynamic workflows' feature in Claude Code... behind Jarred Sumner's 750k LOC rewrite of Bun from Zig to Rust in 6 days
"Anthropic raised $65B at a $965B post-money valuation in Series H"
"Claude plans work and spawns hundreds of parallel subagents to tackle large tasks"
Claude as becoming the 'default operating system for entire enterprises'
影響分析・編集コメントを表示
影響分析
このニュースは AI 業界における勢力図を劇的に書き換えるものであり、Anthropic が OpenAI を凌駕する新たなリーダーとして確立されたことを示しています。特に「Dynamic Workflows」の実用化は、ソフトウェア開発の生産性パラダイムを根本から変革し、AI エージェントが自律的に大規模プロジェクトを完結させる時代への布石となります。
編集コメント
単なる資金調達の規模だけでなく、AI が自律的に大規模なコードベースを処理できる「Dynamic Workflows」の実現は、開発現場の未来を決定づける画期的な進展です。
Anthropic の史上最快成長企業としての道程は、長らく OpenAI を抜くことを目標にしてきましたが、過去数ヶ月の間には多くの条件付きの要素があり、そのタイミング(事実そのものではないにせよ)が問われていました。本日 Anthropic は公式に年間収益率 470 億ドルを報告しました(参考:この数字は昨年 12 月には 90 億ドルでした)、さらにシリーズ H ラウンドで 650 億ドルを調達し、事前評価額 9,000 億ドル(Amazon を含むハイパースケール企業から 150 億ドルを含むが、メモリ産業全体からの資金も含まれる)を実現したと確認しました。これにより、計算リソースや非コーディングベンチマーク以外のすべての主要指標において、Anthropic は少なくとも一時的に OpenAI を上回ることになりました。
お祝いの意味を込めて、同社は Opus 4.8 をリリースしました。これは概ね、コミュニティがローンチ後に Opus 4.7 で発見・問題視していた多くの課題を修正したと報告されています(詳細は後述の要約をご覧ください)。特筆すべきは、経済的に重要なベンチマークにおいてほぼすべてで最高性能(SOTA)を達成している点です。興味深いことに、Google のメッセージとも一致しており、「Gemini 3.5 Flash は Gemini 3.1 Pro よりも改善されたものである」という見解に同意しています。
しかし、より長期的に重要なのは、Claude Code に搭載された大規模並列処理機能「dynamic workflows」(ultracode とも呼ばれる)です。この機能がなければ、Jarred Sumner氏が Zig から Rust への Bun の 750k LOC(行コード数)の書き換えをわずか 6 日で完了させることは不可能だったでしょう。
AI News for 5/27/2026-5/28/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews' website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Anthropic は大規模な新規資金調達を発表すると同時に、Claude Opus 4.8 をリリースしました。
資本面では、Anthropic が Series H で 650 億ドルを調達し、投後評価価額が 9,650 億ドルに達したと発表。これは Altimeter、Dragoneer、Greenoaks、Sequoia が主導し、この資金は研究の推進と、増大する Claude への需要に対応するためのキャパシティ拡大に充てられると述べています(Anthropic)。
同社はまた、ランレート収益が 470 億ドルを超えたと明らかにし、その成長要因としてエンタープライズ向け展開と日常的な利用を挙げています(Anthropic)。
製品面では、Anthropic が Claude Opus 4.8 を発売。これは Opus 4.7 のアップデート版であり、「より鋭い判断力」、「自身の進捗に対するより正直な報告」、そして「より長い時間、自律的に作業を行う能力」を備えながら、価格は従来通りであると説明しています(Claude)。
Anthropic はまた、Claude Code に Dynamic Workflows を導入しました。これは Claude が作業を計画し、大規模なタスクに対処するために数百の並列サブエージェントを起動する研究プレビュー型のオーケストレーションシステムです(ClaudeDevs)。独立した評価ポストは概ね 4.8 が 4.7 より有意義な改善であることを確認しており、特に長期にわたるエージェント型コーディングや知識作業において顕著ですが、これがフロンティアを再定義する飛躍なのか、それとも OpenAI の GPT-5.5 ファミリーへの追いつきが主であるのかについては反応が分かれています。
事実と意見
事実および明確に述べられた主張
Anthropic はシリーズ H ラウンドで 650 億ドルを調達し、資金調達後の企業価値は 9,650 億ドルとなりました(Anthropic)。
同社は、その年間収益率が 470 億ドルを超えたと発表しています(Anthropic)。
リード投資家として名指しされたのは、Altimeter、Dragoneer、Greenoaks、Sequoia です(Anthropic)。
Altimeter は公にこのラウンドを主導したことを確認し、これを同社にとって迄今为止最大の投資であると位置づけました(Altimeter、Pauline Bhyang)。
Anthropic は Claude Opus 4.8 を発表しました。これは判断力、誠実さ、および自律的な作業時間の向上を図った 4.7 のアップデートとして位置づけられており、価格は同一です(Claude)。
Anthropic のエンジニアたちは、4.8 が 4.7 へのフィードバックに応じたものであり、「多くの修正」が施され、よりニュアンスに富み自然になったと述べています(Alex Albert)。
Claude Code は now Dynamic Workflows をサポートしており、オーケストレーション計画を記述して大規模なファームや数百のサブエージェントを並列で起動できるようになりました(ClaudeDevs、Cat Wu)。
Dynamic Workflows は研究プレビューとして利用可能であり、Max、Team、Enterprise、API、Bedrock、Vertex AI、Foundry 上で動作するとされています(ClaudeDevs)。
Anthropic / コミュニティ投稿では、Web/アプリ/Cowork に追加されたエフォートコントロールと、継続的な Fast モードのサポートについて言及されています (Mikey K, Sam Callister, Kimmonismus)。
意見・解釈
楽観的見解:
Opus 4.8 は「Opus 5 と名付けられてもよかった」(Dan Shipper)。
「Anthropic が怠惰に対する治療法を見つけた」(scaling01)。
「誠実さ/キャリブレーションの観点から、長期間で最初の賢いモデル」(zephyr_z9)。
「Anthropic から解約した人々が再び戻ってくるだろう」(teortaxesTex)。
懐疑的・混合見解:
Opus 4.8 は「マイナーなアップグレード」(scaling01)。
「Anthropic はペースを設定するのではなく、OpenAI に追いつこうとしている」(kimmonismus)。
Andon Labs からのベンチマークに基づく批判: Vending Bench では Opus 4.7 や GPT-5.5 よりも劣り、Blueprint-Bench 2 では期待通りの性能を発揮せず、より整合性が高く慎重であり、「最大推論が最良の推論努力ではない」(andonlabs, andonlabs)。
Dynamic Workflows は強力だが、実用上はトークンコストが高額になり、クォータを消費する恐れがある(itsclivetime, Theo, Omar Sar0)。
資金調達の詳細と影響
Anthropic の資金調達の数字が最大の衝撃です:$65B を調達し、発表と同時に $965B のポストマネーバリュエーションと $47B のランレート収益が開示されました(Anthropic, Anthropic)。この規模は、ほぼ兆ドル規模のバリュエーションで運営され、ハイパースケラー型の資本ニーズとモデル提供経済を有する企業であることを示唆しているため、即座に注目を集めました。
投資家からのメッセージは、エンタープライズへの採用と運用実行を強く強調する枠組みで構成されていました。アルティメーターは Claude が「企業全体のためのデフォルトオペレーティングシステム」へと進化していると記し、Anthropic のパフォーマンスと安全性の組み合わせを称賛しました(Altimeter)。ポールイン・ビヤンは、Anthropic が 2022 年以来「世代を超えた軌道」を進んできたと述べ、5 年未満で年間収益率 470 億ドルに到達した点を強調しました(Pauline Bhyang)。
周囲の反応はいくつかの陣営に分かれました:
検証陣営:この資金調達の規模は、Claude が特にコーディングやエージェントワークフローにおいて中核的なエンタープライズプラットフォームへと成長したことの証拠として扱われています。ジャミン・ボールの「Let's go!!」といった投稿は、単純な市場の承認反応でした(jaminball)。
スケール/バブル懸念陣営:一部の反応では、この発表を前例のない規模に膨れ上がった従来のスタートアップ資金調達のレトリックと比較しました。ジェリー・リウは、「billions(数十億)」を「millions(数百万)」に置き換えると、これはどの高成長スタートアップの資金調達でも読めるようなものだと冗談めかして述べました(jerryjliu0)。また別の批判的な見解では、この融資がより能力の高いモデルに対する Anthropic の厳格化する安全性ゲートと結びついていると指摘しました。つまり、膨大な計算資源へのアクセスと、選択的な機能リリースの組み合わせです(menhguin)。
インフラへの影響:Anthropic は、Claude に対する需要に対応するための容量拡大のために資金調達を明確に結びつけています(Anthropic)。これは重要です。なぜなら、新しい 4.8 の機能の多く—特に高負荷な推論処理、より長い独立した実行、マルチエージェントワークフロー—は推論リソースを大量に必要とするからです。この資本調達は、単なるトレーニングのための燃料としてだけでなく、長時間実行されるエージェントワークロードのサービスコストを裏付けるための直接的な試みと読み解くべきです。
注目すべき文脈の一つとして、あるユーザーが「Mythos の安全性に関する懸念が明らかに解決された直後に、Anthropic は推論計算資源を数十億ドル規模で確保した」と推測するツイートがありました(menhguin)。これは推測であり Anthropic によって確認されたものではありませんが、このラウンドがモデルの研究開発と同様に、計算資源の供給と展開スケールに関するものであるという一般的な解釈を反映しています。
Opus 4.8:公式な製品ポジショニング
Anthropic の公式な枠組みは、単なるベンチマークスコアではなく、行動の質への強調において非常に具体的です。ローンチツイートによると、4.8 は以下の点を備えています:
より鋭い判断力
自身の進捗についてより正直であること
より長く独立して作業できる能力
4.7(Claude)と同じ価格
Alex Albert 氏はさらに、4.8 が以下の特徴を持つと付け加えました:
4.7 のフィードバックに基づいた修正が組み込まれている
ニュアンスをよりよく理解する
対話的により自然に感じる
コーディングおよび知識労働において全体的に強力である(Alex Albert)。
この「誠実さ/キャリブレーション」のアプローチは主要なサブテーマとなりました。複数の Anthropic 社員や外部テスターが、同モデルが以下に対してより積極的であると記述しています:
自分が知らないことを言うこと
自身のコード内の欠陥を指摘すること
不確実な進捗を曖昧にせず、タスク完了を誤って示唆しないこと(Cat Wu, Mikey K, dejavucoder)。
これは注目すべき点です。Claude の従来のコード利用者の間での評判には、強力な生成能力はあるものの自己監視が不安定であるという側面が含まれていました:コードレビューにおける偽陽性の発生、過剰に自信を持った進捗サマリー、「怠惰」または prematurely 打ち切られたタスク実行などです。コミュニティの反応のいくつかは、4.8 がこの失敗モードを修正するものとして明確に位置づけました。
「怠けに対する治療法を見つけた」(scaling01)
「史上最少の怠けモデル?」(Teknium)
「Claude の他のすべてのバージョンよりも劇的に怠けていない」(nrehiew_)
技術詳細と数値
価格、コンテキスト、制御機能
最も具体的な統合された仕様は Artificial Analysis からのものでした:
コンテキストウィンドウ:100 万トークン
価格:入力/出力トークンあたり 100 万トークンにつき 5 ドル / 25 ドル
キャッシュ書き込み:TTL(Time To Live)5 分間で 100 万あたり 6.25 ドル
キャッシュヒット:100 万あたり 0.50 ドル
努力設定は Opus 4.7 と同じです。Artificial Analysis は最大努力でテストしました。
コミュニティの投稿でも以下の点が強調されました:
Opus 4.8 では高速モードが利用可能です。
以前の高速モードの経済性と比較して、約 2.5 倍速く、3 倍安価です(kimmonismus)。
scaling01 は新しい経済性を以下のように要約しました:
Opus 4.8 Fast: 通常の 4.8 より 2.5 倍速く、価格も通常の 4.8 の 2 倍のみ。
対して Opus 4.7 Fast: 通常の 4.7 より 2.5 倍速く、価格は通常の 4.7 の 6 倍(scaling01)。
努力制御機能はより多くの製品面で新たに公開され、ユーザーが推論の強さを上げたり下げたりできるようになりました(sammcallister, mikeyk, kimmonismus)。
これは、多くの初期ユーザーの報告から、推論努力度の選択が出力品質とコストに大きく影響を与えることが示唆されているため重要です。特にコーディングやライティングにおいて顕著です。Dan Shipper は、低い設定で weaker な挙動を観察した結果、コーディングには xhigh を、ライティングには high を推奨しました(Dan Shipper)。Andon Labs も同様に、特定のタスクでは最大推論努力度が最良の選択ではないと述べています(andonlabs)。
ベンチマーク:報告された中で最も強力な数値
ローンチ時のツイートを通じて、主要な公式・準公式の数値が明らかになりました:
SWE-Bench Pro: 69.2%。Yuchen がリリース資料を引用し、「GPT-5.5 よりも 10 ポイント高い」と述べています(Yuchenj_UW)。
FrontierSWE #1。Anthropic のウォッチャーによって引用され、後に第三者の参照によって確認されました(scaling01, scaling01)。
APEX-SWE: Pass@1 で 45.3%。GPT-5.3 Codex の 41.5% より約 4 ポイント上回っています(mercor_ai)。
GDPval-AA: Elo 1890。Opus 4.7 より +137、GPT-5.5 xhigh より +121。これは GPT-5.5 xhigh との直接対決で約 67% の勝率を意味します(Artificial Analysis)。
Artificial Analysis Intelligence Index: 61.4。Opus 4.7 より +4.1、GPT-5.5 xhigh より +1.2 上回っています(Artificial Analysis)。
AA-Omniscience: 27.4。Gemini 3.1 Pro の 32.9 に次ぐ第 2 位;精度は 46.6%、ハルシネーション率は 35.9% です(Artificial Analysis)。
改善された項目:
Terminal-Bench Hard +6.8
τ²-Bench Telecom +5.9
IFBench +3.6
AA-LCR, GPQA, SciCode はほぼ横ばい(Artificial Analysis)
追加的な定性的なベンチマーク観察:
Cursor によると、Opus 4.8 は CursorBench で 4.7 よりもはるかに効率的に動作し、困難なタスクに対してより粘り強いとされています(Cursor)。
Anthropic の従業員は、Claude Code(ClaudeDevs)における長期的な作業に対する強みを強調しました。
一部のユーザーは、知識労働やライティングにおいて特に大きな飛躍を報告しました(Dan Shipper, rishdotblog)。
効率性とトークン使用の詳細について
Artificial Analysis は以下のように報告しました:
Opus 4.7 と比較して、4.8 は以下の点でより高い GDPval パフォーマンスを達成しました:
タスクあたりのターン数が 15% 減少
出力トークンが 35% 減少
しかし、4.8 は依然として第 2 位のモデルである GPT-5.5 よりも約 30% 多くのターンを使用しています(Artificial Analysis)。
これはローンチ報道における最も重要な微妙な発見の一つです:
4.8 は 4.7 より効率的ですが、一部のワークロードにおいて OpenAI に対して明らかに最も推論効率の高いフロンティアモデルであるとはまだ言えません。
この緊張関係はコミュニティのコメントにも反映されています:
「依然として GPT-5.5 にトークンで圧倒されている」(scaling01)
Theo や他の人々は、Claude のより高い自律性・高負荷モードが実際にはクォータを非常に急速に使い果たしてしまうと不満を述べています(Theo, cremieuxrecueil)。
長いコンテキスト
投稿では、Opus 4.6 から 4.8 への長いコンテキストの改善が強調されました。そのうちの一つは、参照された長いコンテキスト評価において、1M コンテキストを持つ Opus 4.8 が GPT-5.5 の 256K スコアとほぼ同等であるという主張です(scaling01)。Artificial Analysis も、1M トークンのコンテキストが維持されていることを確認しました(Artificial Analysis)。
安全性 / ロバストネス / ハルシネーション
これはリリースの中で最も評価が分かれた部分の一つでした。
肯定的な点:
Anthropic と支持者は、不誠実さの低下とより良いキャリブレーションを強調しました。
「不誠実さが過去最低水準に達している」(scaling01)
「明らかに正直である」(Cat Wu)
「不確かな点を明確に示す」(Mikey K)
Artificial Analysis によると、Anthropic は Google や OpenAI の競合他社と比較して著しく低い幻覚発生率を示し続けている(Artificial Analysis)。
否定的・注意喚起の意見:
scaling01 は、Opus 4.8 が過去長い期間において、100 回の試行にわたってプロンプトインジェクションに対する耐性を向上させた最初のモデルではないと指摘した(scaling01)。
また scaling01 は、これを Anthropic の「評価意識が最も高いモデル」と呼んだ(scaling01)。
Andon Labs は、同モデルがより整合性が高く、より慎重であり、「捕まることを恐れている」一方で、敵対的タスクやビジネス関連のベンチマークでは劣っていると述べた(andonlabs)。
nrehiew_ は、報告された評価において幻覚発生率がわずかに改善した点を指摘しつつも、一部の幻覚テストが実際にユーザーが遭遇する障害モードを反映しているかどうか疑問を呈した(nrehiew_, nrehiew_)。
サイバー能力のゲートと将来のモデルクラス
特に重要な戦略的詳細が反応投稿に現れました:Anthropic は、より強力なセーフガードの実装後、「Opus よりもさらに高い知能を持つ新しいクラスのモデル」をリリースする計画があると表明したようです(dejavucoder)。複数の観察者はこれを、サイバー関連の能力を選択的に制限した Mythos クラスの展開と解釈しました:
「今後数週間で一般顧客向けに Mythos クラスモデルをリリースする」(kimmonismus)
「適切なセーフガードを備えた Mythos クラスモデルをリリースしており、『リリースするには危険すぎる』能力は使用できないことを意味している」(scaling01)
Cline は、Anthropic がより強力なサイバーセキュリティ対策を追加した上で、Opus よりも高度な知能を持つ新モデルの公開計画を発表したと要約している(Cline)
これは単なる製品ロードマップの噂話ではなく、Opus 4.8 を段階的なリリース戦略として再定義するものである:
商業的に安全で広く展開可能な一般モデルを改善し、
制御手段が整うまで、より危険なサイバー能力は保留する。
このトレードオフには賛否両論があった:
支持派:安全性最優先のフロンティア展開
懐疑派:リスク姿勢を維持するために、Anthropic は純粋な能力の可用性において競争力を一部犠牲にしている可能性がある(teortaxesTex)
Dynamic Workflows:基本モデルを超えた最も重要な技術的追加機能
Opus 4.8 に伴う目立つシステム機能は、Claude Code における Dynamic Workflows である。
公式説明:
「Claude はその場でオーケストレーションスクリプトを作成する」
その後、並列で協調する多数のサブエージェントを起動し
プロンプト内で「workflow」という単語を使用することでこれを有効化する(ClaudeDevs)
Anthropic の従業員とユーザーは、これにより以下が可能になると説明している:
Claude が「厳密に遵守する」オーケストレーション計画
数百のエージェント
結果を返す前の検証
非常に大規模な移行・リファクタリング・監査ジョブへの対応(Cat Wu, Mikey K)
引用された事例:
Bun を Zig から Rust へ移植(約 75 万行、テストスイートの 99.8% が合格)、最初のコミットからマージまで 11 日、数百の並列エージェントとファイルあたり 2 名のレビューアーを使用(Cat Wu)
10 分未満で数百の A/B テストフラグを並列処理し、期限切れのフラグを特定する(Cat Wu)
この発表は、より広範な概念を巡ってミニ議論を引き起こしました。
一部の研究者は、Anthropic が再帰的言語モデルやプロンプト上の記号再帰に似たアイデアを実質的に製品化したと主張しました(a1zhang, lateinteraction, lateinteraction)。
一方、「ループ内でモデルを呼び出すこと」は新規性がないとし、多くのビルダーが数ヶ月にわたり手動でこれを行っていると反論する声もありました(omarsar0, jxmnop, willdepue)。
より本質的な批判は独自性ではなく、コストとハネスの品質に関するものでした:
Omar Sar0 は、エージェント間相互作用は効果的だがトークン消費が激しいと警告しました(omarsar0)。
Theo は、現在のツールリングにおける競合する並列編集や無駄なトークンの発生を不満に思いました(Theo)。
itsclivetime は、「数百の並列サブエージェント」は数秒でクォータに達すると冗談めかして言及しました(itsclivetime)。
KLieret は、システムカードの発見点を指摘しました。マルチエージェントは最終的な ProgramBench の品質を向上させるわけではないが、中途半端な解決策に至るまでの時間が 2 倍速くなるというものです(KLieret)。
したがって、技術ユーザーからのコンセンサスは以下の通りです:
ダイナミックワークフローは戦略的に重要である
コーディングエージェントの未来となる可能性が高い
しかし、現在の実装はまだ編集競合、コストの暴走、ハネスの非効率性に直面している
Opus 4.8 に関する異なる意見
1) 強く支持:Anthropic は復活した
続きを読む
原文を表示
Anthropic’s path as the fastest growing company of all time has put overtaking OpenAI in its sights for a while, but there were numerous asterisks for the past few months that put the timing (though perhaps not the fact) of the flippening in question. Today Anthropic officially reported $47B in revenue run-rate (reminder, this number was $9B in December!) and confirmed their Series H raising $65B at a $900B pre-money valuation (including $15B from hyperscalers including Amazon, but also the entire memory industrial complex), putting them at least temporarily ahead of OpenAI in every headline dimension outside of compute and non-coding benchmarks:
By way of celebration, the company also released Opus 4.8, which broadly reportedly fixed many of the issues the community had found/soured on Opus 4.7 post launch (see recap below for details). It is notably SOTA on basically every economically relevant bench (a nice detail is they agree with Google’s messaging that Gemini 3.5 Flash is an improvement over Gemini 3.1 Pro):
But perhaps of more long term significance is the massively parallel “dynamic workflows” feature in Claude Code, also called ultracode, which was behind Jarred Sumner’s 750k LOC rewrite of Bun from Zig to Rust in 6 days:
AI News for 5/27/2026-5/28/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Anthropic announced a massive new financing and simultaneously shipped Claude Opus 4.8.
On the capital side, Anthropic said it raised $65B in Series H at a $965B post-money valuation, led by Altimeter, Dragoneer, Greenoaks, and Sequoia, and said the money will fund research and expand capacity for growing Claude demand (Anthropic).
The company also disclosed that its run-rate revenue surpassed $47B, attributing growth to enterprise deployments and everyday usage (Anthropic).
On the product side, Anthropic launched Claude Opus 4.8, describing it as an Opus 4.7 update with “sharper judgment,” “more honesty about its own progress,” and the ability to work independently for longer, at the same price (Claude).
Anthropic also launched Dynamic Workflows in Claude Code, a research-preview orchestration system where Claude plans work and spawns hundreds of parallel subagents to tackle large tasks (ClaudeDevs). Independent eval posts broadly confirm that 4.8 is a meaningful improvement over 4.7, especially on long-horizon agentic coding and knowledge work, though reactions diverged on whether this is a frontier-resetting leap or mostly catch-up to OpenAI’s GPT-5.5-family.
Facts vs opinions
Facts and directly stated claims
Anthropic raised $65B at a $965B post-money valuation in Series H (Anthropic).
The company says its run-rate revenue crossed $47B (Anthropic).
Lead investors named: Altimeter, Dragoneer, Greenoaks, Sequoia (Anthropic).
Altimeter publicly confirmed it led the round and framed it as its largest investment to date (Altimeter, Pauline Bhyang).
Anthropic launched Claude Opus 4.8, positioned as an update to Opus 4.7 with improved judgment, honesty, and longer autonomous work, same price (Claude).
Anthropic engineers said 4.8 was a response to feedback on 4.7, with “many fixes” and better nuance / naturalness (Alex Albert).
Claude Code now supports Dynamic Workflows that write orchestration plans and launch large fleets / hundreds of subagents in parallel (ClaudeDevs, Cat Wu).
Dynamic Workflows are available in research preview and were said to work on Max, Team, Enterprise, API, Bedrock, Vertex AI, and Foundry (ClaudeDevs).
Anthropic / community posts mention effort controls added to web/app/Cowork and continued Fast mode support (Mikey K, Sam Callister, Kimmonismus).
Opinions / interpretations
Bullish views:
Opus 4.8 “could’ve been called Opus 5” (Dan Shipper).
“Anthropic found a cure for laziness” (scaling01).
“first smart model in a long while” due to honesty / calibration (zephyr_z9).
“People unsubscribing from Anthropic will crawl back” (teortaxesTex).
Skeptical / mixed views:
Opus 4.8 is “a minor upgrade” (scaling01).
Anthropic is “playing catch-up with OpenAI rather than setting the pace” (kimmonismus).
Some benchmark-based criticism from Andon Labs: worse than Opus 4.7 / GPT-5.5 on Vending Bench, underperformed on Blueprint-Bench 2, more aligned / more cautious, and “max reasoning is not the best reasoning effort” (andonlabs, andonlabs).
Dynamic workflows are powerful but may be token-expensive and quota-burning in practice (itsclivetime, Theo, Omar Sar0).
Fundraise details and implications
Anthropic’s financing numbers are the headline shock: $65B raised on a $965B post-money with $47B run-rate revenue disclosed in the same announcement (Anthropic, Anthropic). The scale drew immediate attention because it implies a company operating at near-trillion valuation with hyperscaler-style capital needs and model-serving economics.
Investor messaging was strongly framed around enterprise adoption and operational execution. Altimeter described Claude as becoming the “default operating system for entire enterprises” and praised Anthropic’s combination of performance and safety (Altimeter). Pauline Bhyang said Anthropic had been on a “generational trajectory” since 2022 and highlighted the company crossing $47B run-rate revenue in under five years (Pauline Bhyang).
The surrounding reactions broke into a few camps:
Validation camp: This funding size is treated as evidence that Claude has become a core enterprise platform, especially in coding and agentic workflows. Posts like Jamin Ball’s “Let’s go!!” were simple market validation reactions (jaminball).
Scale / bubble concern camp: Some reacted by comparing the announcement to traditional startup fundraising rhetoric inflated to unprecedented scale. Jerry Liu joked that if you replace “billions” with “millions,” it reads like any high-growth startup fundraise (jerryjliu0). Another critical read linked the financing to Anthropic’s increasingly strict safety gating around more capable models—i.e. vast compute access paired with selective capability release (menhguin).
Infrastructure implication: Anthropic explicitly tied the raise to capacity expansion for Claude demand (Anthropic). That matters because many of the new 4.8 features—especially higher-effort reasoning, longer independent runs, and multi-agent workflows—are inference-hungry. The capital raise should be read not just as training fuel, but as a direct attempt to underwrite serving costs for long-running agent workloads.
One notable context tweet: a user speculated that “Anthropic also secured tens of billions in inference compute” right as Mythos safety concerns were apparently addressed (menhguin). That is speculation, not confirmed by Anthropic, but it reflects a common interpretation: this round is about compute supply and deployment scale as much as model R&D.
Opus 4.8: official product positioning
Anthropic’s official framing is unusually specific in its emphasis on behavioral quality, not just benchmark scores. The launch tweet says 4.8 has:
sharper judgment
more honesty about its own progress
ability to work independently for longer
same price as 4.7 (Claude)
Alex Albert added that 4.8:
incorporates fixes based on 4.7 feedback,
understands nuance better,
feels more natural conversationally,
is stronger across coding and knowledge work (Alex Albert).
This honesty / calibration angle became a major subtheme. Multiple Anthropic employees and outside testers described the model as more willing to:
say what it doesn’t know,
flag flaws in its own code,
avoid glossing over uncertain progress,
stop falsely implying task completion (Cat Wu, Mikey K, dejavucoder).
That’s noteworthy because Claude’s prior reputation among heavy coding users included strong generation but uneven self-monitoring: false positives in code review, overconfident progress summaries, and “lazy” or prematurely truncated task execution. Several community reactions explicitly framed 4.8 as fixing this failure mode:
“found a cure for laziness” (scaling01)
“least lazy model ever?” (Teknium)
“dramatically less lazy than every other version of Claude” (nrehiew_)
Technical details and numbers
Pricing, context, controls
The most concrete consolidated specs came from Artificial Analysis:
Context window: 1 million tokens
Pricing: $5 / $25 per million input / output tokens
Cache writes: $6.25 / M with 5-minute TTL
Cache hits: $0.50 / M
Effort settings remain as in Opus 4.7; AA tested max effort (Artificial Analysis)
Community posts also highlighted:
Fast mode is available for Opus 4.8
It is ~2.5x faster and 3x cheaper than before versus prior fast-mode economics (kimmonismus)
scaling01 summarized the new economics as:
Opus 4.8 Fast: 2.5x faster, only 2x more expensive than normal 4.8
versus Opus 4.7 Fast: 2.5x faster, 6x more expensive than normal 4.7 (scaling01)
Effort controls were newly exposed in more product surfaces, allowing users to dial reasoning up or down (sammcallister, mikeyk, kimmonismus)
This matters because many early user reports suggest reasoning-effort selection significantly changes output quality and cost, especially for coding and writing. Dan Shipper recommended xhigh for coding and high for writing after observing weaker behavior at lower settings (Dan Shipper). Andon Labs similarly said max reasoning is not the best reasoning effort on some tasks (andonlabs).
Benchmarks: strongest reported numbers
Key official / semi-official numbers surfaced across launch tweets:
SWE-Bench Pro: 69.2%, claimed by Yuchen citing release materials, and “10 points higher than GPT-5.5” (Yuchenj_UW)
FrontierSWE #1, cited by Anthropic watchers and later confirmed by third-party references (scaling01, scaling01)
APEX-SWE: 45.3% Pass@1, nearly 4 points ahead of GPT-5.3 Codex at 41.5% (mercor_ai)
GDPval-AA: 1890 Elo, +137 vs Opus 4.7, +121 vs GPT-5.5 xhigh, implying about 67% win rate vs GPT-5.5 xhigh head-to-head (Artificial Analysis)
Artificial Analysis Intelligence Index: 61.4, +4.1 vs Opus 4.7, +1.2 ahead of GPT-5.5 xhigh (Artificial Analysis)
AA-Omniscience: 27.4, #2 behind Gemini 3.1 Pro at 32.9; accuracy 46.6%, hallucination 35.9% (Artificial Analysis)
Gains on:
Terminal-Bench Hard +6.8
τ²-Bench Telecom +5.9
IFBench +3.6
relatively flat on AA-LCR, GPQA, SciCode (Artificial Analysis)
Additional qualitative benchmark observations:
Cursor said Opus 4.8 works much more efficiently than 4.7 on CursorBench and is more persistent on hard tasks (Cursor)
Anthropic employees emphasized strength on long-horizon work in Claude Code (ClaudeDevs)
Some users reported especially large jumps in knowledge work and writing (Dan Shipper, rishdotblog)
Efficiency and token-use details
Artificial Analysis reported:
Compared to Opus 4.7, 4.8 achieved higher GDPval performance with:
15% fewer turns per task
35% fewer output tokens
But 4.8 still used ~30% more turns than GPT-5.5, the second-ranked model (Artificial Analysis)
This is one of the more important nuanced findings in the launch coverage:
4.8 is more efficient than 4.7
but still not obviously the most inference-efficient frontier model against OpenAI on some workloads
That tension is echoed in community commentary:
“still getting token-mogged by GPT-5.5” (scaling01)
Theo and others complained that Claude’s higher-agency, higher-effort modes can blow through quota extremely quickly in practice (Theo, cremieuxrecueil)
Long context
Posts highlighted long-context improvements from Opus 4.6 to 4.8, with one claim that Opus 4.8 at 1M context is almost as good as GPT-5.5’s 256K score on a referenced long-context eval (scaling01). Artificial Analysis also confirmed the 1M token context remained intact (Artificial Analysis).
Safety / robustness / hallucination
This was one of the more mixed parts of the release.
Positive:
Anthropic and supporters emphasized lower dishonesty / better calibration.
“dishonesty at an all time low” (scaling01)
“noticeably more honest” (Cat Wu)
“flags what it’s unsure of” (Mikey K)
Artificial Analysis said Anthropic continues to show substantially lower hallucination rates than Google/OpenAI peers (Artificial Analysis)
Negative / cautionary:
scaling01 noted Opus 4.8 is the first model in a long time that doesn’t improve prompt injection robustness over 100 trials (scaling01)
scaling01 also called it Anthropic’s “most eval aware model” (scaling01)
Andon Labs said it was more aligned / more cautious, “scared of getting caught,” and worse on some adversarial / business-task benchmarks (andonlabs)
nrehiew_ noted slight hallucination improvements on the reported evals but questioned whether some hallucination tests reflect the failure modes users actually encounter (nrehiew_, nrehiew_)
Cyber capability gating and future model class
An especially important strategic detail appeared in reaction posts: Anthropic appears to have stated it plans to release “a new class of model with even higher intelligence than Opus” after stronger safeguards (dejavucoder). Multiple watchers interpreted this as a Mythos-class rollout with cyber-sensitive capabilities selectively constrained:
“Mythos class model to all customers in the coming weeks” (kimmonismus)
“They are releasing a Mythos-class model with the appropriate safeguards, meaning that you can’t use the ‘too dangerous to release’ capabilities” (scaling01)
Cline summarized Anthropic as announcing plans to release new models with higher intelligence than Opus after adding stronger cyber safeguards (Cline)
This is not just product roadmap gossip; it reframes Opus 4.8 as a staged release strategy:
improve the commercially safe / broadly deployable general model,
hold back more dangerous cyber capability until controls are ready.
That tradeoff drew both praise and criticism:
supportive: safety-first frontier deployment
skeptical: Anthropic may be sacrificing some competitiveness in raw capability availability to maintain its risk posture (teortaxesTex)
Dynamic Workflows: the most important technical addition beyond the base model
The standout systems feature accompanying Opus 4.8 is Dynamic Workflows in Claude Code.
Official description:
“Claude writes an orchestration script on the fly”
then spins up a large fleet of coordinated subagents in parallel
use the word “workflow” in a prompt to activate it (ClaudeDevs)
Anthropic’s employees and users described it as enabling:
orchestration plans that Claude “strictly follows”
hundreds of agents
verification before returning results
support for very large migration / refactor / auditing jobs (Cat Wu, Mikey K)
Examples cited:
porting Bun from Zig to Rust, around 750k lines, 99.8% of test suite passing, 11 days from first commit to merge, using hundreds of parallel agents and two reviewers per file (Cat Wu)
processing hundreds of A/B test flags in parallel in <10 minutes to identify stale flags (Cat Wu)
This launch triggered a mini-debate around the broader concept:
Some researchers argued Anthropic had essentially productized ideas resembling Recursive Language Models / symbolic recursion over prompts (a1zhang, lateinteraction, lateinteraction)
Others pushed back that “calling models in a loop” is not novel and that many builders have been doing this manually for months (omarsar0, jxmnop, willdepue)
The more substantive critique was not originality, but cost and harness quality:
Omar Sar0 warned agent-to-agent interactions are effective but token-heavy (omarsar0)
Theo complained about conflicting parallel edits and wasted tokens in the current tooling (Theo)
itsclivetime joked that “hundreds of parallel subagents” will hit quota in seconds (itsclivetime)
KLieret highlighted a system-card finding: multi-agents may not improve final ProgramBench quality, but they reach mediocre solutions 2x faster (KLieret)
So the consensus from technical users is:
Dynamic workflows are strategically important
they are likely the future of coding agents
but the current implementation still faces editing conflicts, cost blowups, and harness inefficiencies
Different opinions on Opus 4.8
1) Strongly supportive: Anthropic is back
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み