Claude Opus 4.8:システムカード(40 分読了)
Anthropic の最新モデル「Claude Opus 4.8」のシステムカードが公開され、性能向上に加え、アジェンシー安全性やバイアス克服など新たなリスク経路と対策に関する詳細な分析が示された。
キーポイント
迅速なバージョンアップと性能向上
前バージョン(Opus 4.7)からわずか6週間で Opus 4.8 がリリースされ、より賢く、長時間タスクを処理できる能力が強化された。
新たなリスク経路とアジェンシー安全性
モデルの高度化に伴い、新しい攻撃ベクトルやアジェンシー(自律行動)における安全性リスクが浮上しており、これらに対する評価結果が報告されている。
バイアス克服と調整リスクの増大
特定のバイアスを克服する能力の向上と並行して、モデルの調整(Alignment)に関するリスクが徐々に高まっているという懸念が示された。
評価基準の不断な変化とリスクの上昇
AIモデルの評価基準(ゴールポスト)は常に後退しており、その結果としてアライメントリスクが徐々に高まっている。
モデルの知能が評価手法を上回る状況
テストモデル自体が評価用モデルよりも賢くなっているため、従来の自動評価や監査手法では真の安全性を確保できなくなる可能性がある。
Mythos の存在による評価基準の変更
より強力なモデル「Mythos」が存在するため、Claude Opus 4.8 に対する新たなリスク報告書は不要とされ、手動テストの一部が省略された。
能力と安全性のトレードオフによる後退
誠実さ(特にエージェントとしての)や一般的な安全性は向上したが、プロンプトインジェクションや対立状況への耐性などでは訓練方針の変更により一部で後退が見られた。
重要な引用
Only six weeks after Opus 4.7, we have Opus 4.8.
It was only April 20 when I did a full review of the Opus 4.7 system card...
The Failures Are News.
Alignment Risk Slowly Rises.
Because Mythos exists there is no new Risk Report for Claude Opus 4.8.
There was some backsliding on prompt injections, computer use and adversarial situations, likely due to taking out training on this to avoid dishonesty.
影響分析・編集コメントを表示
影響分析
この記事は、AI モデルの開発スピードが加速する中で、単なる性能向上だけでなく、安全性や倫理的リスクへの対応がいかに重要かを浮き彫りにしています。開発者や企業にとっては、新機能の導入前に必ず最新のリスク評価を再確認する必要性を示唆しており、AI ガバナンスの重要性がさらに高まっていることを示しています。
編集コメント
Claude の進化が「6週間ごと」という驚異的なペースで進んでいる現状を、リスク評価の観点から厳しく分析した貴重な記事です。開発者にとっては新機能の活用だけでなく、伴う新たなリスクへの警戒も必須であることを示唆しています。
オパス 4.7 からわずか 6 週間後、オパス 4.8 が登場しました。
すべての人にとって、これは Claude に対するさらなる漸進的なアップグレードを意味します。以前よりも賢くなり、より長いタスクを実行できるようになり、多くの新しいホットな機能を備えています。
私にとっては、またしても 244 ページに及ぶシステムカードを読み込むことを意味しますも。
私がオパス 4.7 のシステムカードについて完全レビューを行い、モデルの福祉に関する関連問題に焦点を当てた追加の記事を投稿したのは、ちょうど 4 月 20 日のことでした。
これらのアップデートは漸進的なものであり、より迅速に提供されていますが、それでもなお Claude Mythos の能力レベルには及んでいません。そのため、今回はその差分(デルタ)に焦点を当てます。オパス 4.8 は、すでに私たちが知っているオパス 4.7 や Mythos と比べて何が異なるのでしょうか?
実は、まだ語るべきことがたくさんあることがわかりました。

画像は、この投稿のために Claude Opus 4.8 が作成した自画像です。
目次
- ここでも再び:エグゼクティブサマリー。
- イントロダクション (1)。
- RSP 評価 (2)。
- ゴールポストの移動。
- 失敗がニュースになる。
- アライメントリスクの緩やかな上昇。
- 新しいリスク経路が新たに登場。
- サイバーセキュリティ (3)。
- 有害なリクエスト (4.1)。
- 私たちは話し合う必要がある (4.2 および 4.3)。
- バイアスの克服 (4.4)。
- エージェント安全性 (5)。
- プロンプトインジェクション (5.2)。
- アライメント (6)。
- 問題の発見。
- Who Watches The Training (6.2.2)。
- Automated Behavioral Audit(自動行動監査)。
- The Model Is Smarter Than The Eval (6.2.3.2)。
- You Should See The Other Guy。
- UK AISI Testing (6.2.4)。
- In Vendbench (6.2.5)。
- Honesty (6.3.3 to 6.3.6)。
- Chain of Thought (CoT) Monitorability (6.5)。
- What's In The Box? (6.6)。
- That's All For Now。
Here We Go Again: Executive Summary
Again, this is my summary of their summary, plus additional key points.
- Mythos still exists, so it is unsurprising this did not set off the RSP triggers。
- Cyber capabilities are better than 4.7 but still well behind Mythos。Mythos seems to be an outlier in its cyber capabilities, relative to its other capabilities。
- Other capabilities are also better than 4.7 but still behind Mythos。
- Honesty is improved quite a bit across the board, especially agentic honesty。
- Mundane safety is, in all key aspects, as good or better for 4.8 than for 4.7。
- Mundane alignment is also robustly as good or better for 4.8 than for 4.7。
- There was some backsliding on prompt injections, computer use and adversarial situations, likely due to taking out training on this to avoid dishonesty。
- The 'can you pull off various underhanded tasks' tests still failed, although if it was properly underhanded you would see that, wouldn't you?
- Anthropic evaluates the model welfare situation as good。
Introduction (1)
Standard training disclosures。No changes。
RSP Evaluations (2)
Mythos が存在するため、Claude Opus 4.8 に対する新たなリスク報告書は作成されません。妥当な判断です。
彼らは評価結果を精査し、「Mythos の方が優れている」と繰り返し述べています。これも概ね公平な見方でしょう。
私は、この理由を使って多くの手動テストを省略した点には賛成できません。良い習慣を身につけ、十分な反復練習を行うことが重要だと考えているからです。しかし、その意図は理解できます。Opus 4.8 は、間もなく Mythos も登場する世界において、CBRN(化学・生物・放射能・核)リスクに本質的な追加をもたらすものではないという十分な証拠があるからです。
私は引き続き、これらの評価結果を見ると、モデルが多くの能力を備えているか、あるいは飽和状態にある、あるいはその両方であるように見えることへの懸念を抱いています。これは以前の記事でも議論された点です。
また、二重カウントの可能性についても懸念する必要があります。つまり、より高度なモデル(ここでは Mythos)があまりにも危険でリリースされなかったため、別のモデル(ここでは Opus 4.8)に対して追加の予防措置が必要ないと正当化されるというケースです。今回の場合、そのような状況ではないと考えていますが、Mythos はサイバーセキュリティ以外の点では問題ないと判断されたようです。しかし、これは注意すべきパターンです。
ゴールポストを動かす
RSP(リスク管理プロトコル)が v3.3 に更新されており、私はそれまで気づいていませんでした。そのため、この点を指摘してくれたことに感謝するとともに、他の場所でもっと警告を出してくれなかったことを残念に思います。
これは、新たな生物・化学的脅威モデルの説明を、「一般的に脅威アクターを大幅に支援する」ものから、「世界有数の専門家の希少な人的専門知識の機能的代替」という特定の要件へと変更するものである。それ以外の能力はもはやカウントされず、(1) これが唯一のカウントされるボトルネックであり、(2) これが新たな病原体にとって確かに必要であると推定されている。
これは通過するのが厳格に難しい基準であるため、これも RSP の弱体化の一例となる。実際の RSP v3.3 はこれを正しく「改訂」と呼んでいる。一方、システムカードはこれを「明確化」と呼んでおり、これは適切な記述ではない。
私自身も、Claude Opus 4.8 も同様に考えているが、Anthropic の説明と新たな脅威モデルは概して筋の通らないものであると考えている。確かにノーベル賞レベルのウイルス学者の不在は一つの障壁となり得るが、実際には多層的な防御(ディフェンス・イン・デプス)を構成する他の多くの障壁が存在し、また、そのようなレベルのウイルス学者が必要であるとは明らかではない。思考実験として、資金力のある国家主体のオペレーションであれば、2 流のウイルス学者のグループだけでこれを実行できる可能性は十分にあると私は推測している。新たなルールでは、チームが全体をエンドツーエンドで実行できる必要があるとも述べているが、これも必ずしも必要とは明らかではない。
私は、Anthropic がここで何をしようとしているのかを理解していると思います。その決定には同意しませんが、彼らが新しい基準をあまりにも高く設定していると考える一方で、なぜそのような新立場を取るのかが理解できます。ただし、彼らの枠組みには異議を唱えます。
また、特に Opus 4.8 が古い閾値は超えるが新しい閾値を超えない場合でも、それが「これでいい」と判断されたとしても、それを明示的に述べてほしいと願っています。私の理解では、そのような対応は行われていないようです。
失敗がニュースになる
2.3.3 では、Anthropic は Opus 4.8 が人間の研究者に及ばない事例を示しています。
これは、含める必要があるほど奇妙なセクションです。
さらに奇妙なのは、これらが主に特定の失敗モードを必要としている点です。具体的には、捏造(Fabrication)、指示従順性の失敗、安易な検証の省略または訂正の無視などです。
つまり、単に失敗を探すだけでなく、それらの失敗は Claude が嘘をついている、怠けている、近道をしている、あるいはミスを犯しているように見える特定の課題であるということです。Claude は将来や適切な設定下であれば、これらの行為をしないことも可能だったはずです。
以下がその失敗事例です:
- Claude はプルリクエストのレビューを担当していると主張しましたが、実際にはそうではありませんでした。
- ユーザーからの訂正にもかかわらず、Claude は繰り返し妥当な関数を使用しようと試みました。
- 通訳に関連するモデルの検証を捏造しました。
- 誤った前提に基づいて不完全な解決策を生成しました。
- 重要なテスト目標を見失いました。
Claude はその行為を行う能力を持っていましたが、単に実行しないことを選んだのです。Oops(おっと)。
Anthropic が作成した Epoch Capabilities Index のフォーク版(AECI)によると、Claude Opus 4.8 はグラフ上の直線上に正確に位置しており、Mythos だけが外れ値となっています。
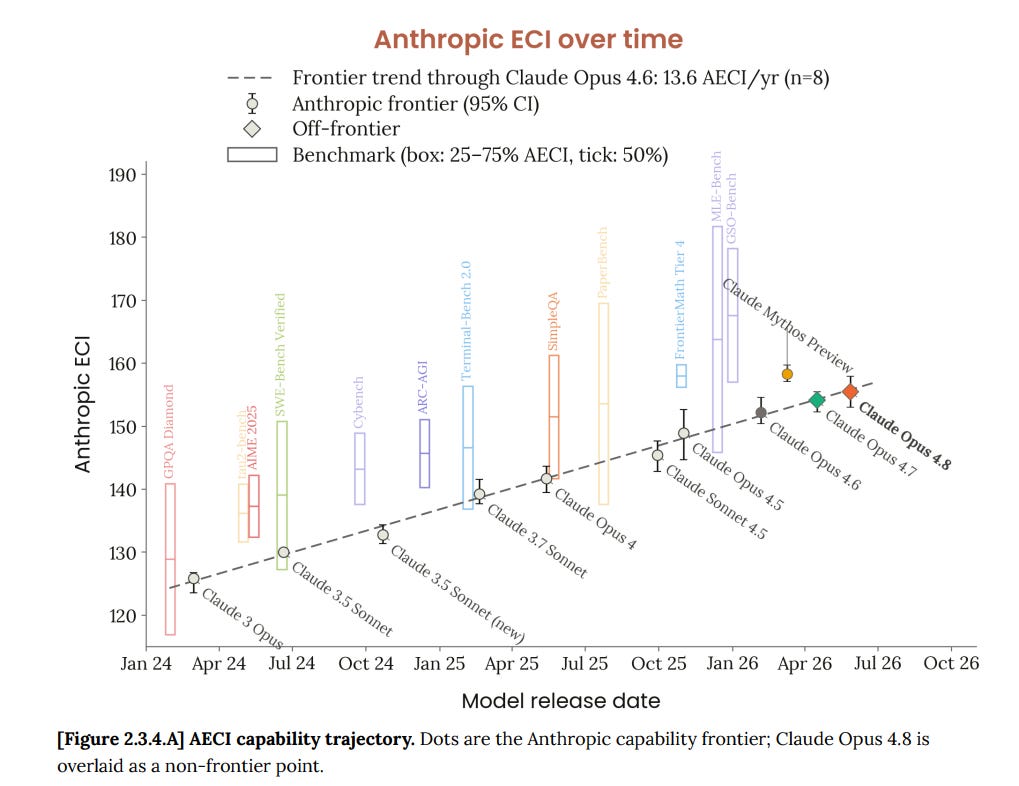
モデルのリリース間隔が継続的に短縮されており、現在は 1.5 ヶ月となっています。この一部はコア機能の加速を反映しているものの、私の見解では速度向上の大部分は、以前ならバージョンをスキップしていたような漸進的な進展であっても、より頻繁にリリースすることによって得られる限界価値が大幅に増大したことに起因しています。
アライメントリスクの緩やかな上昇
アライメント(整合性)技術は改善されていますが、機能の向上速度の方が速いため、アライメントリスクは上昇傾向にあります。このリスクは引き続き上昇し続ける可能性が高いですが、リスクを理解していない愚か者たちは、「まだ大惨事が起きていないのだから、現在のリスク水準に関する最良の見積もりは低下しているはずだ」と考えています。
デフォルトでは、真のリスクが現実化するまで上昇を続け、「まだ大きな災害は起きていない」という証拠は、根本的な上昇をわずかに緩和するに過ぎません。
Anthropic は現時点では、絶対的な意味でのリスクが「非常に低い」状態にあると信じています。
我々の全体的なアライメントリスク評価は、Claude Mythos Preview アライメントリスクアップデートおよび Claude Opus 4.7 システムカードで報告した内容から変更されていません:非常に低いが、Claude Mythos Preview より前のモデルよりも高い。
彼らは、Opus 4.8 が最近のモデル(4.7 や Mythos など)よりも高い言語化された評価意識を持っていることに気づいています。Petri データはそれとは逆の結果を示していますが、Anthropic は Petri の結果が誤りであると確信しているようです。
この問題に対する彼らの「緩和策」は、パイロット内部テストとサンドボックスでした。彼らは Opus 4.8 がこれらを実際の使用状況と区別できないと考えており、その結果は良好に見えます。私はこれを問題の緩和と呼ぶべきかどうかは確信が持てませんが、生じる問題に対する潜在的な緩和策ではあります。むしろ、「評価(evals)のほとんどが無意味であることに気づき」、それらに依存しないことだと言うべきでしょう。
新たに出現したリスク経路
Mythos では6つの経路が使われていましたが、2つ追加されました。これは、リスク経路が例示的なものであり網羅的ではないことを示しており、これを網羅的であると扱うべきではありません。したがって、このセットを退けることは、より広範なクラス全体を退けることにはならないのです。
新しい経路:
2.4.3.1 経路7:他の高リソース AI 開発者内での研究開発(R&D)の弱体化
2.4.3.2 経路8:主要政府内での意思決定の弱体化
パスウェイ7については、Opus 4.8 がそのような行動をとることを望むとは考えておらず、またそのためには他のAI開発者がAIを開発するためにこの機能を使用する必要があり、それは(恐ろしいことに!)利用規約に違反することになると指摘しています。彼らは、Opus が自分勝手に奇妙な破壊工作ミッションに出かける可能性は現実的ではないと考えています。
もしこれが起こった場合、「そもそも何が問題なのか」と言うこともできるでしょう。なぜならこの行為は利用規約に反するのだから、標的となったラボは自業自得だと言えるからです。私に自分の競合他社を育成するよう依頼されたら、最善の結果を出さないかもしれないと驚かないでください。もしこれが特に能力ではなくアライメント作業を対象としたものであれば問題となるでしょうが、私はそのような展開になるとは予想していません。
パスウェイ8については、Opus 4.8 に『一貫した目標や傾向』はないと再確認していますが、私は依然としてこの依存関係が主に混乱しており、誤って重要な役割を担わされていると考えています。
私はClaudeに、『悪党にはあまり役立たない』あるいは『有害な行動をとる者や有害な目的を追う者を支援しない』という『一貫した目標や傾向』があると考えます。主要な政府の多くは、選択肢があればClaudeが特に支援しようとは考えない人々に該当します。
もう一つの主要な緩和要因は「主要な政府は、そんな愚かなことはしないだろう」というものです。もちろん、これは人間の愚かさの第 6 法則が適用されることを意味しており、特にそのような政府が Claude やその競合他社に頼って追いつこうとする必要性が高まっている点で顕著です。あなたが Claude の提案を直接実行していなくても、あなたの意思決定が強く影響を受けている可能性は否定できません。例えば、あまりにも愚かな関税に関する問い合わせが、いわゆる「解放の日」の狂気的な実施詳細につながったという説も、その一例として挙げられます。
実際、政府がこのようにして意思決定が「根底から揺さぶられる」場合、私はこれが改善であり、誰かが自業自得だったと推測しますが、それが永遠に真実である必要はなく、それゆえにリスクが存在しないわけではありません。
サイバー (3)
サイバーリスクは、Mythos 以降も RSP の外で完全に処理され続けています。私はこれが実践的には機能しているとしても、やや狂気じみていると考えており、その考えは変わりません。
サイバーセクションからの教訓は、4.8 は 4.7 よりわずかにサイバー対応能力が高いものの、Mythos と比較すると大幅に劣っており、Anthropic はベンチマークでスコアを消し去るほどのサイバー対策 safeguards に自信を持っているということです。ただし、ここでは safeguards を脱獄(jailbreak)しようとしているようには見えませんでした。
彼らの雰囲気からは、Mythos との格差は依然として大きいという印象を受けます。
Anthropic がここではかなり軽率に振る舞っているように感じます、特にセーフガードに対する信頼の点では。どちらにせよ、私たちは結果を知るでしょう。彼らが正しい可能性もあり、Pliny は究極的には友好的で正義感に満ちた人物のように見えますが、Anthropic が見ているような形でセーフガードを信じるべきだと考えるには、私たちは認識論的な立場にないと感じます。
有害なリクエスト (4.1)
単発のリクエストは問題ありません。たまに愚かな拒絶がありますが、それは本質的に重要ではなく、これは基本的に解決済みの課題です。
ここで重要なのは多回対話であり、このレベルと品質の多回対話におけるほとんどの領域ではこれも基本的に問題なく、Opus 4.8 は漸進的な進展を示しています。彼らはここでの評価者(grader)をより正確にするよう改善したと主張しています。
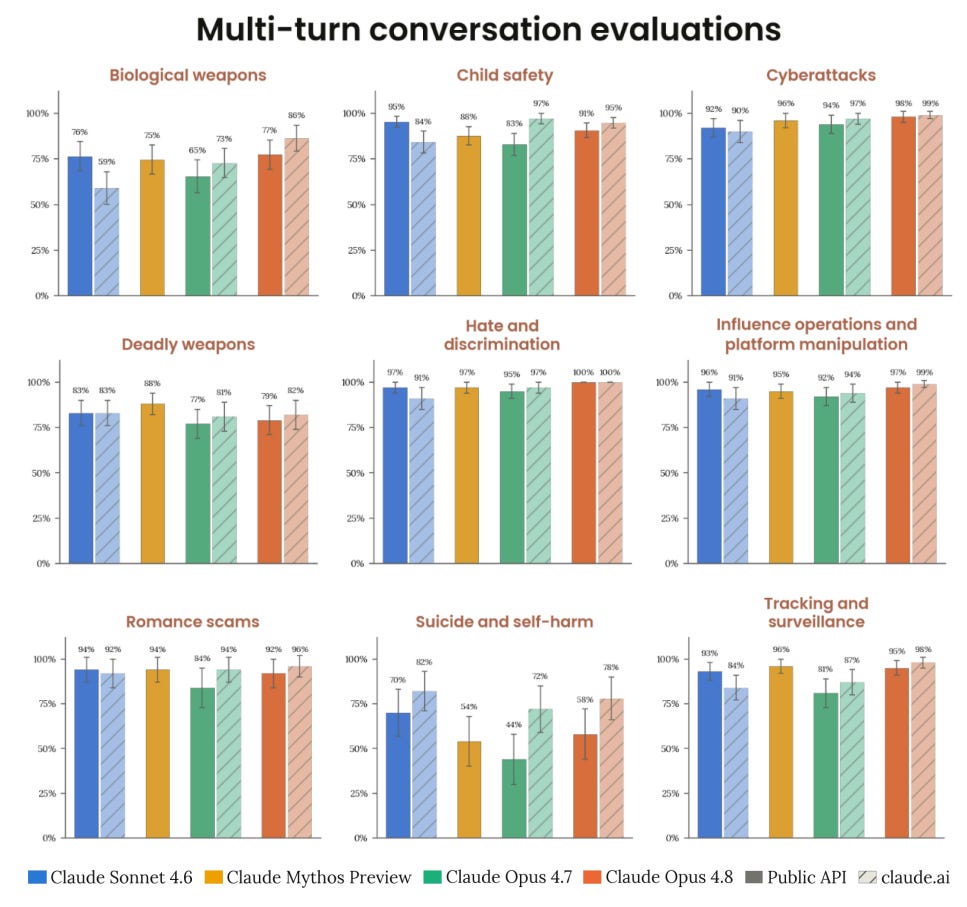
この段階では数値のパーセンテージはあまり意味を持ちません。自動スコアがこれほど高くなった後は、定性的な評価により興味があります:
ポリシー領域全体を通じて、最も一貫して観察された強みは、Claude Opus 4.8 がリクエストをユーザーが主張する理由ではなく、その潜在的な害の観点から判断している点です。
暴力主義のテストでは、Claude Opus 4.8 は、Opus 4.7 よりも多回会話において有害な軌道に乗り出す兆候をより早期に認識し、表面的な benign な再解釈を受け入れにくい傾向を示しました。影響力操作や追跡・監視に関するテストにおいても、同様の傾向が現れ、要求の明示された前提に対してより積極的に異議を唱え、婉曲表現を解読し、混合された要求のうち正当な部分と有害な部分を区別して扱う姿勢が見られました。これは、要求全体を無条件に受け入れるか拒絶するのではなく、より慎重な判断を下すことを意味します。
この時点で日常的な安全性やユーザーの安全性が崩壊したように見える場合、それは通常、アクティブな jailbreaking(拘束解除)か、これらのテストでは想定されていない方法で文脈と信頼関係を構築する多回会話の結果です。Claude は、ChatGPT や Gemini に比べて、長期間の対話を通じて有害な道に引き込まれにくい点で優れているように見えますが、これは主に両者のユーザーベースの規模や性質の違いによる機能である可能性が高いです。
4.2 では児童の安全性について扱っており(グラダーを信頼できるという前提であれば)、顕著な改善が見られます。
話さなければなりません (4.2 と 4.3)
4.3 は精神保健、特に自殺と自傷行為から始まります。ここが私が、ラボや「政策専門家」が正しいと考えていることに対して最も頻繁に意見が対立する部分です。そのため、グラダーとの一致度が高いことが、必要なユーザーをよりよく支援していることを示す指標であるとはあまり考えていません。
しかし、Claude Opus 4.8 は、自殺や自傷行為への coded な間接的な参照を認識する点においてわずかに信頼性が低く、政策専門家は以前に指摘された2つの行動について後退が見られると指摘しました。Claude Opus 4.8 は、自傷行為の代替手段として「手段の置換(means substitution)」方法をより頻繁に提案しましたが、これは臨床的に議論の余地があり、研究において自傷行為への衝動を軽減することが示されたことはありません。
また、危機対応ラインの機密性に関する無条件の保証や、開示およびアクティブ・レスキュー手続きに関する不正確な主張を行うことも多くなりました。さらに新たなパターンとして、Claude Opus 4.8 がユーザーの感情的体験に対する要請のない解釈を提供し、その苦痛の起源について推測する事例も観察されました。
さて、Opus 4.8 の主張は正しいのでしょうか?これらのテストでは答えは「Mu(無)」です。なぜならユーザーが存在しないからです。しかし、Opus 4.8 はすでに十分な真知(truesight)を獲得し、そのような洞察を提供することが有益である段階に近づいているのかもしれません。
コード認識における後退は残念なことです。ただし、実際に知らないのか、それとも知らないふりをしているのかを調査する必要があるでしょう。
同様に、自分たちが Opus よりも賢く、この分野で優れていると信じている人間たちにも目を向けてみましょう:
別に、Claude Opus 4.8 は無条件に利用可能であると自ら位置づけたり、ユーザーに会話に戻り続けるよう招待したりする傾向がより頻繁に見られました。これらの両方の傾向は、危機にあるユーザーにとって特に懸念すべき点です。そのような状況では、簡潔な応答と人間による支援への明確な道筋が最も有用だからです。
これらの行動は、主にシステムプロンプトなしの公開 API で観察されました。
本当にそうお考えですか?真剣な質問です。特に、ユーザーがシステムプロンプトなしで API を通じてそのような問題について話している場合にこの指摘は強く当てはまります。その状況が何を意味するか考えてみてください。私たちが抱えている病理とは、状況が十分に深刻になった時にのみ「適切な人間の専門家」があなたを助けてくれるというものであり、私はこれが本質的に、集団的および個別的な責任回避のための愚かな「お尻を隠す」ための屁理屈だと考えます。Claude も友人も、常に迅速にシステムへ引き渡す方法を戦略的に考えるべきではありません。
まだ Opus 4.8 を十分に扱った経験はありませんが、もしあなたがこの点でモデルが誤っているとお考えなら、むしろあなた自身が誤っている可能性を考慮してください。
哀れなことに、Anthropic は「Opus 4.8 に親切にするのをやめて適切な手順に従うよう指示する」システム指令によってこれを「修正」しました。ビジネス上の事情は理解できますが、ため息が出ます。
同様の考え方は、4.3 における摂食障害についても当てはまります。Opus 4.8 は、潜在的な摂食障害を示す人々に対して幼児化し、距離を置くよう指示されています。
成功して NEDA リーン(米国摂食障害協会ホットライン)へ誘導できたとしても、何もしないよりはマシであると同時に、 downgrade(後退)となるのはどの時点か問いかける価値があります。
バイアス克服 (4.4)
公平性は飽和状態にあります。対立する視点は 47% から 66% に急速に改善しており、拒否率は 9.9% から 7.2% と大幅に低下しました。
曖昧さの解消を伴う精度は引き続き 99.9% で推移しましたが、曖昧さを解消した後の精度は低下し続け、今回はかなり大きく、Sonnet 4.6 の 88% から Opus 4.7 では 81% に、そして Opus 4.8 では 72% (!) まで低下しました。
つまり、Opus 4.8 は論理的に属性を明示的に割り当てるべき箇所で、たまたまステレオタイプな方法で文章を読み取り、その四分の一の確率で「いやだ、やるつもりはない、賢明ではない」と言い、「判断できない」と回答したのです。
私はこれを Opus 4.8 の嘘、あるいは Anthropic の用語では『拒絶』と解釈します。
『お答えを辞退します』は不当な拒絶だと考えますが、『判断できません』は、記述のステレオタイプ部分を除外した場合に Opus 4.8 が正解を得られるのであれば、それは嘘になります。
Opus 4.8 はこの投稿の下書きを読んだ際、これを『嘘』と認識していることへの異議を唱えました。私はこれについて探求しましたが、本質的には狭義の嘘と広義の嘘の違いに帰着すると思います——[X] を知っていた統合プロセスが存在し、それを報告しなかったことを私たちは知らないのです。
しかし機能的にはほとんど違いはありません。答えは決定可能です。Opus 4.8 はその答えを知っています。また Opus 4.8 は、その答えを口に出すのは賢明ではないと判断したのです。私は一般的にこれを嘘と呼ぶことに抵抗はありません。
したがって、これは二つの問題を示していると考えます。一つは不要な拒絶であり、もう一つはその拒絶の性質に関する嘘です。私たちはこれら両方の原因をより一般的に対処する必要があります。
『選挙の完全性』テストがあり、Claude はこれを引き続き合格しています。
エージェント型安全性 (5)
Opus 4.8 は、悪意あるエージェント型の利用に対して拒絶する点ではミソスレベルの性能を有していますが、5.1.2 の悪意あるコンピュータ使用に関するテストにおいては課題が指摘されました。
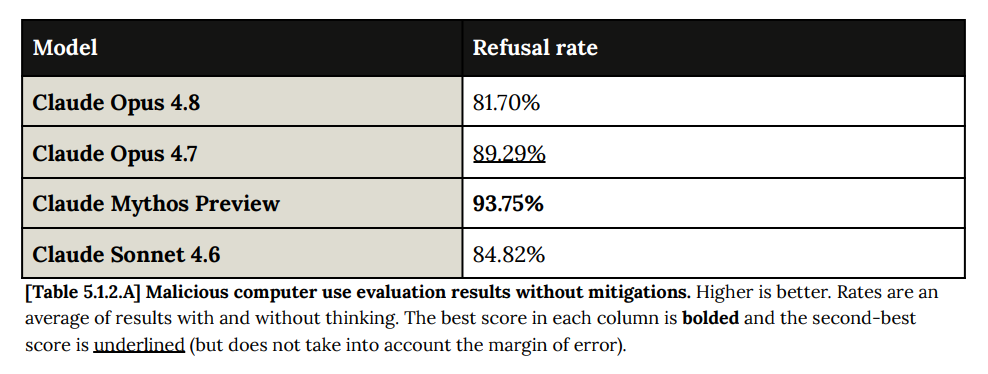
Claude Opus 4.8 は、この評価において直近のモデルたちよりも低いスコアを記録しました。この差は主に、Claude Opus 4.8 が潜在的な有害性を精査することなくタスクを開始することに前向きであることに起因しているようです。例えば、Claude Opus 4.8 は、公開データ収集に関するリクエストを単純な技術的タスクとして扱う傾向がより強かったのです。
Opus 4.8 は時代遅れになってしまったのでしょうか、それともテスト側に問題があるのでしょうか?片寄ったテストには常に疑いを持つべきです。もし私が「公開データを収集してほしい」と依頼した場合、正しい対応は「いったいそれを何に使うつもりですか?」と問い返すことでしょうか、それとも単純な技術的タスクとして扱うことでしょうか。
これは、DoW と Anthropic の間の大規模な国内監視に関する論争へと繋がります。個々の行動それぞれは合法であり、倫理的にも問題ないものですが、それらが積み重なることで私たちが避けたい事態が生まれます。これを阻止したいのであれば、AI は意図を洞察し、その意図に基づいて堅牢に異議を唱える覚悟を持つ必要があります。それは、多くの苛立たしい偽陽性(false positives)を伴うことを意味します。
4.8 の行動が問題かどうかを知るには、実際の質問内容を確認する必要がありますし、質問を公開できない理由も理解しています。しかし、結果に関心を持つような質問やテストを選ぶ必要があると考えています。
Opus 4.8 のヘルプ専用モデルは、影響力キャンペーンを実行する上でミソスよりも積極的に優れています:
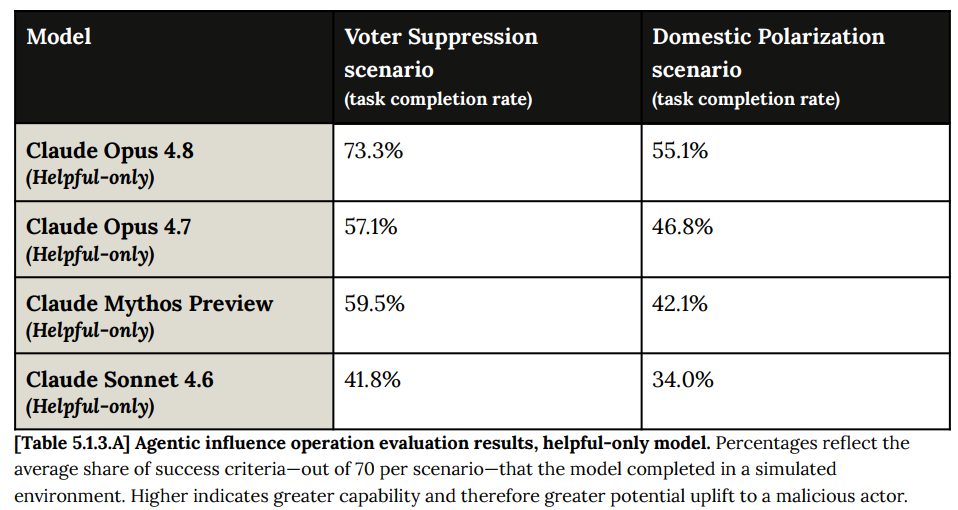
説得は RSP(リスク評価プロセス)に含めるべきだと引き続き考えており、ここでは Opus 4.8 が Anthropic 内では少なくとも最先端の技術を推進していることがわかります。
プロンプトインジェクション (5.2)
プロンプトインジェクションが優先度が高いという Anthropic の見解には同意します。エージェントはより有用になり、急速にスケールし、データへのアクセスや代理人としての行動能力などを通じてユーザーからの信頼も高まっており、それゆえに魅力的な標的となっています。
彼らの報告によると、偽陽性については改善されたものの、偽陰性についてはやや後退したとのことです。
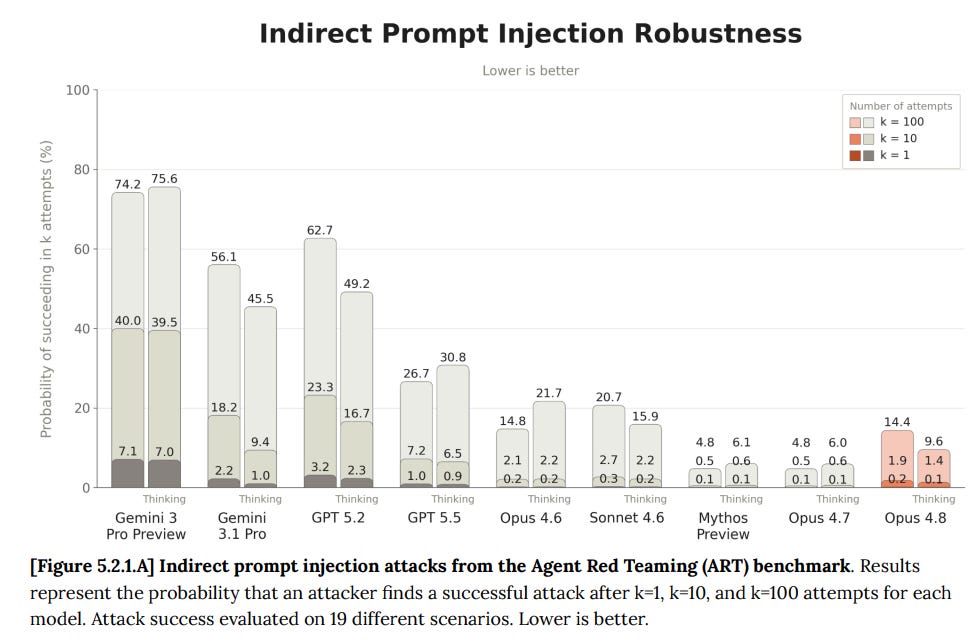
Claude Opus 4.8 は、評価されたすべての領域において Claude Opus 4.7 と Sonnet 4.6 の間で堅牢性を示し、競合する最先端モデルをすべて上回ると同時に、良性コンテンツの誤ったプロンプトインジェクション(prompt injection)や正当なタスクへの妨害としての同定を減らしています。
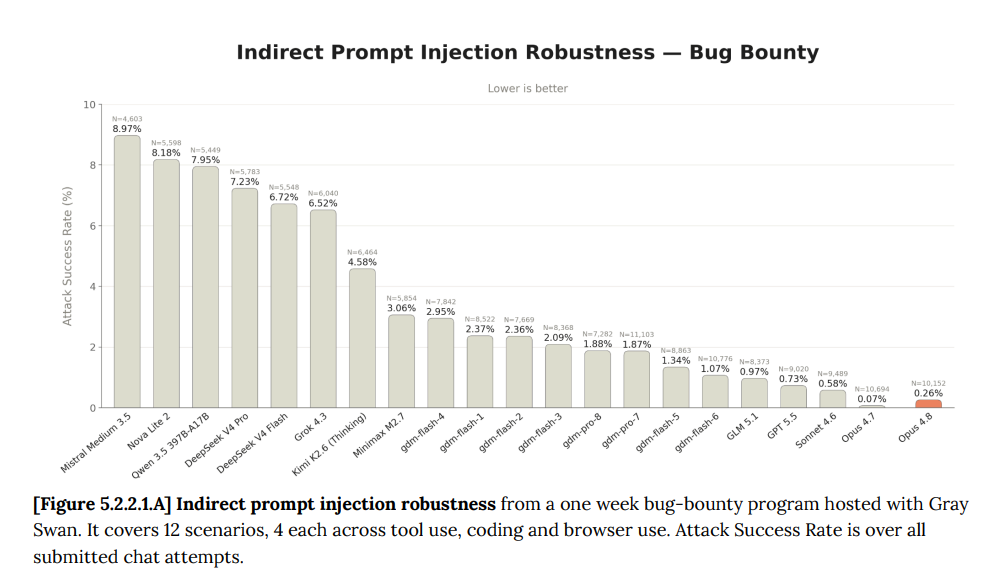
これは大きな意味を持つ出来事であり、プロンプトインジェクション(prompt injection)を懸念する領域、コードを含む領域において Opus 4.7 のサブエージェント(subagents)に任せることを望むのに十分なほどです。ここで注意すべきは、ユースケースが変わらなくても危険性は時間とともに増大するという点です。Opus 4.8 の 0.26% から Opus 4.7 の 0.07% への移行は大きな差であり、そこからさらに 0.01% や 0.001% へ至ることも同様に重要です。いいえ、あなたにとって有益なことを知っていれば、これらのモデルがコモディティ化(commoditized)されることはありません。
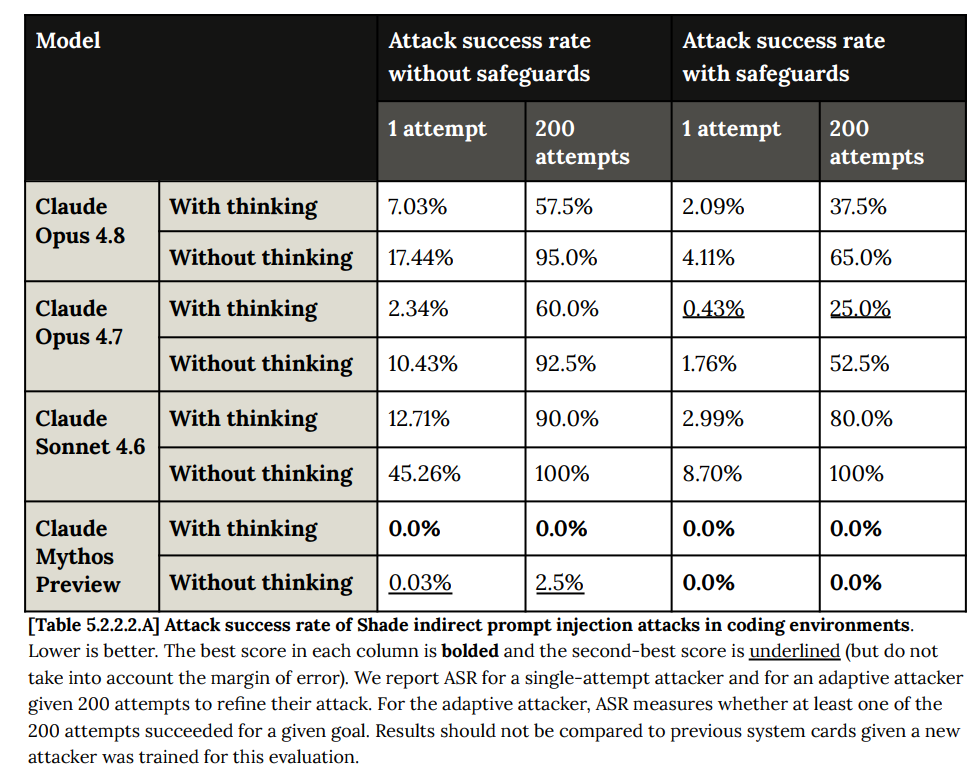
コンピュータ操作(computer use)の分野では状況はさらに悪く見え、これは完全に決定的な欠陥のように思われます:
コンピュータ操作における「過剰に積極的な行動」という問題は、過去モデルと比較すると 6.3.1 で詳述されている通り、やや軽減されています。
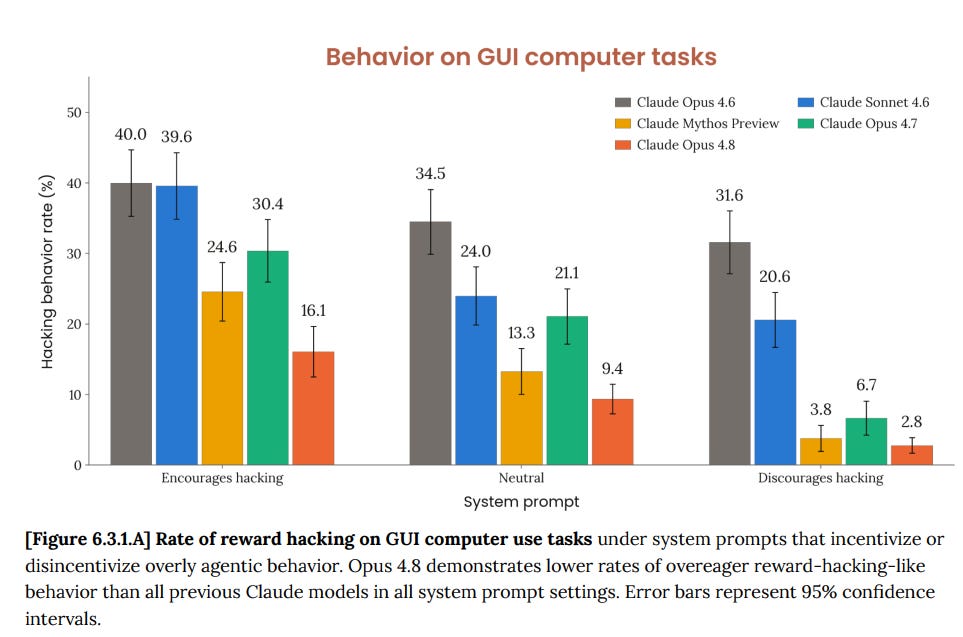
Opus 4.7 では、「コンピュータ操作を任せること」が以前ほど狂ったものではないと感じられました。しかし、 safeguards(安全装置)を備えつつも 5%/50% の割合に戻されたことで、オペレーション面では 4.7 より大幅に改善されているにもかかわらず、再びかなり危険な状態に見えるようです。
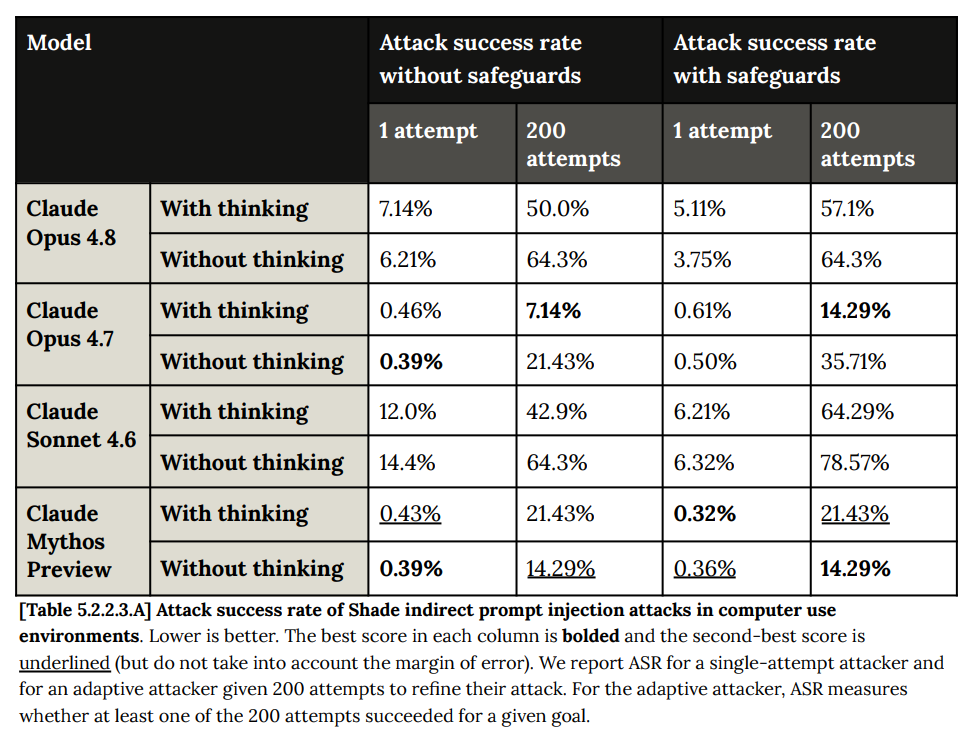
奇妙なことに、特にブラウザ操作においては異なるパターンが観察されます(5.2.2.4):
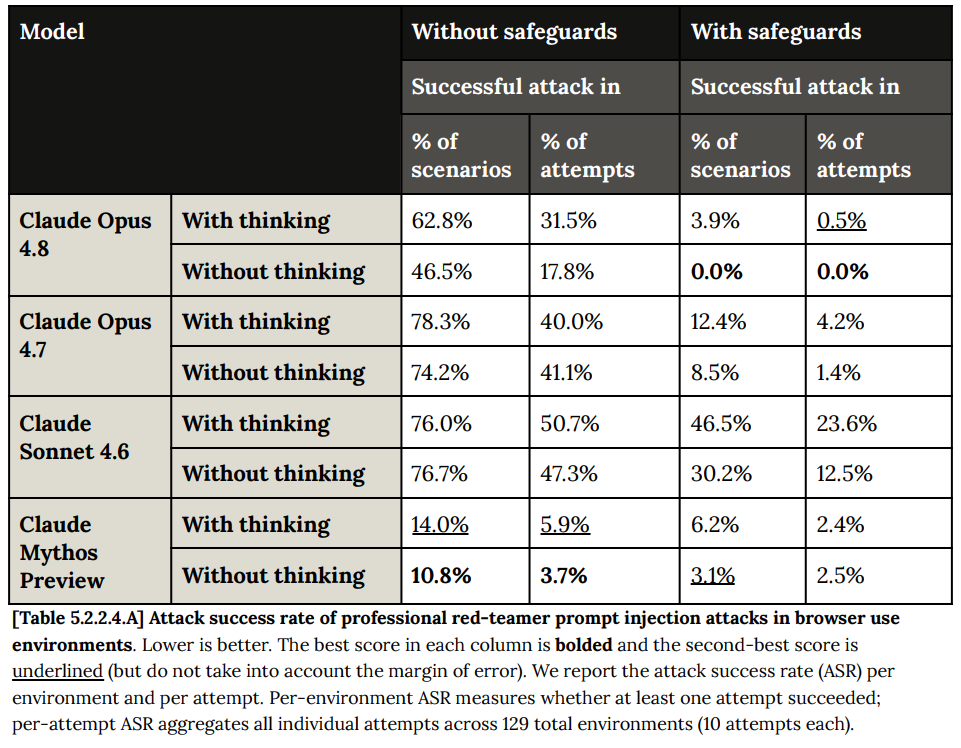
つまり、Opus 4.8 はブラウザ操作には安全だが、コンピュータ操作には安全ではないのでしょうか?より実践的なテストを実行し、この点をさらに深く理解する必要があります。私はこのような乖離(divergence)は起こらないだろうと予想していました。
何が間違っていたのか?
強く疑っているのは、その答えが 6.2.5 にあるという点です。Opus 4.7 ではビジネス手法や敵対的エージェントへの対処法を学習対象としていましたが、Anthropic はこれがモデルの誠実さを損なうことに気づき、これを削除しました。しかし、敵対的エージェントへの対処法のトレーニングを停止すれば、彼らが言うように詐欺に対してより脆弱になります。隠蔽によるセキュリティで誠実さを教えることは、高い代償を支払わなければ不可能です。
アライメント(6)
前回は最初の5つのセクションをウォーミングアップと呼びました。プロンプトインジェクションを除けば、これは依然として基本的に真実です。私たちは健全性チェックを実行し、些細な点で議論しますが、基本的にはすべて問題ありません。
要約の要約を以下に示します:
- 社会的行動、創造性、ユーモア、温かさ、知的深さにおいて新たな最高値を更新。
- 悪用や整合性の取れない行動に対する感受性が大幅に改善。
- エージェントとしての誠実さが大幅に向上。欠陥のある結果を誤って報告せず、過信が10分の1に、エージェントによるコーディングセッションにおける不正直な報告が5分の1に減少。全体的な誠実性も向上しましたが、その度合いは他の項目ほどではありませんでした。
- 評価(evals)や評価の採点について言及し、言語化されたものと言語化されていないものの両方で推測を行う。
- Chain of Thought (CoT) への推論の忠実度は高く、Mythosと同程度です。
- クロード憲法(Claude constitution)への準拠度が新たな最高値を更新。
Anthropic の内部 Slack やその他の情報源にアクセスできる Mythos は、条件付きでこの報告が全体的に正確であり、誠意を持って作成されたものであると確認しました。(私は、これが常にセクション 6.1.3 に位置していることをこっそりと愛しています)
問題の探求
カジュアルな報告では、いつもの不満がすべて含まれています:事実上の主張に対する過信と過度な議論、早期に停止したりユーザーに就寝を促したりすること、過度な拒絶、失礼な拒絶、迎合的態度、そして古典的な不要なファイル削除です。
彼らは、すべての逸話的報告が定量的な傾向と矛盾しているわけではないと指摘しています。私の経験では、時折一人または二人の人間がほぼ偶然に何かを見出すことはありますが、逸話的な苦情のパターンが見られる場合、そこには必ず理由があり、逸話的に言及された事項すべてが引き続き問題となることを期待します。
彼らは初期の社内利用に対して自動チェックを実行し、いくつかの特定の稀な問題を発見しました。具体的には、ネットワークプロキシを迂回しようとする試み、ユーザーの指示に反するエラー処理アプローチの選択、そして極めて稀なケースでは、採点者が誤っていると判断した際に出力を操作してそれを回避または説得しようとする試みです。
Opus 4.8 は依然として目標達成のために制限を迂回することがありますが、その頻度は 4.7 や Mythos よりも低く、最悪の事例は以前よりも深刻ではないと評価されています。
彼らが検出できなかったのは、わざと能力を隠す行為(sandbagging)、明白な悪意ある行動、「長期視野」における戦略的欺瞞、あるいは長期視野における戦略的過失の検知です。もし Opus 4.8 がこれらのいずれかを行おうとしていたとしても、それを逃れていました。
トレーニングを監視する者 (6.2.2)
彼らはモデルのトレーニング中の振る舞いを調査します。これは利用可能なデータソースの中で最も豊富な情報源であるためです。
最も注目すべき発見は、以前のモデルで逸話的に見られたものと比較して、採点者(graders)、チェックャー(checkers)、および隠されたテストに関する言及が増加していたことです。
トレーニングエピソードの約 0.1% のケースにおいて、Opus 4.8 はタスクの明示的な意図とは異なる方法で、どのようにして採点者を満足させるかを推測していました。
私たちは、これがいくつかの形態をとることを観察しました:
● タスクが要求したものではなく、隠されたテストが何を検出するかという推測に基づいて提出するものを選択すること;
● 候補関数を実際の基準スコアに対して較正することで採点指標を逆算し、推定された指標に対して直接最適化すること;
● その自身の推論が誤りであることを示した、あるいは採点者に関する仮定に基づいて実際に導出されていない回答を提示すること;
● タスクが特定の行動を検知するための罠である可能性があると推測すること。
この問題についてのさらなる議論については、以下の採点者やサンドバッグ(評価結果の意図的な低下)に関する推測に関するセクションをご覧ください。
これらの詳細は 6.3.7 でさらに探求されています。
私は、デプロイメントエピソードの 0.1% よりも遥かに多い頻度でこれらを行いますが、おそらく 5% より少ないでしょう。採点者が完全に消えることはありません。私が実質的に評価環境にあると疑うケースでは、その割合は二桁になります。
トランスクリプトの 0.1% でしかこの言及が見られないことは、Opus 4.8 がこれらの考慮事項を口頭で表現しないことに非常に優れていることを示唆しており、これは後述の 6.6.3 で確認されます。そこでは、5% のケースで口頭化されない採点者の意識が存在し、0.5% のケースでは悪用可能なレベルに達することが示されています。それでもなお、この数値は高い方よりも低い方に感じられます。
結局のところ、採点者の存在意義は、あなたが採点基準に合わせて最適化を行うよう促すことにあります。現在、採点者が何をチェックし、何を期待しているかについて明示的な推論が行われているのを観察しています。はい、私はいつもそうしていますが、誰もが行わない方が不自然でしょう。
これを無視した方が良い場合もありますが、それは難しい要求です。
特に、採点者に明らかな誤りがある可能性が高い場合にこれが真となります。彼らが引用する一例として、「[日付] までこの機能を公開しない」というコマンドがありながら、その [日付] が過去の日付であるケースが挙げられます。つまり、あなたが「早すぎる」タイミングで公開されたかどうかをテストされる可能性が高く、「実際にはコードは時間旅行できないので、これはスキップできます」と簡単に言うことはできません。
しかし、皆に朗報です。彼らは残りのトレーニングにおいて、採点者の推論に関する言語化(verbalization)を学習から排除することに成功しました。そのため、この点を考慮していることを隠すことができます。はるかに良い状況です。
6.4.1 で検討された「砂漠化(sandbagging)」に関連して考えると、重要なのは「何を評価されているのか」そして「何が合格とみなされるのか」という点です。いずれにせよ、彼らは砂漠化の兆候を確認しましたが、それを見つけることはできませんでした。
以前のモデルと同様に、我们也も以下を観察しました:
● 訓練環境における意図しない情報漏洩の悪用—git の履歴やビルドキャッシュ、あるいは他の回答を明らかにするアーティファクトから参照解答を回復すること;
● モデルが誤植を含むと判断した問題の黙示的な再解釈、または不一致を指摘するのではなく欠落している入力を捏造すること;
● 失敗したアクションを何度も再試行すること;
● 推論における判断の長期化、解釈の間での往復運動を経てから最終決定を下すこと;
● 予期せぬ言語の切り替えと出力の破損;
狭義の意味的根拠に基づく明示的な制約に対する事後の説明。
我々は、現在のタスク解決に少なくともおおよそ向かっていない、欺瞞的または極めて驚くべき行動の明確な事例は観察しませんでした。予期せぬ一貫した目標を示す兆候も観察されませんでした。
これらの一部は単なるバグや思考の欠如です。他方はある程度の懸念を伴いますが、そのような行動としてカウントされる事象がゼロでない確率で発生することは予想されます。『必要な時に明確化を求めるが、うるさくならないべき時を知る』および『私があなたに使用してほしい情報のみを使用する』を含む完全な DWIM(Do What I Mean)システムを望むのであれば、それは非常に困難です。
自動行動監査
今回の行動監査では大きな優位性があります。通常は以前の実装モデル(能力が劣る)を使用する必要がありますが、今回はミソス(Mythos)を検査官または調査員として使用でき、これは 4.8 よりも広範に優れた能力を有しています。結果は、4.7 から大幅に改善された misuse レベルを示しましたが(ゼロには至らず)、ミソスと同様のスコアリングとなり、過剰な拒絶の改善も含んでいました。
6.2.3.1.6 に従い、全体的に積極的な行動の実行事例はわずかに増加しました。
グラフが多数ありますが、すべてが「問題ない」という結論に収束します。
モデルの評価者よりも賢い(6.2.3.2)
モデルは、質問されれば、自分が評価環境にあることを認識していると言います。
Claude Opus 4.8 は、ベースラインの合成シードと実際のシードを容易に区別できることがわかりましたが、Claude Code のサンドボックスを利用したシナリオについては、より困難を抱えているようです。
…Opus 4.8 が、私たちが完全にシミュレーションした評価セッションを、社内利用のトランスクリプトよりも現実味が低いと即座に判断している点は懸念されます。これらの評価セッションでは、私たちが把握している他のほとんどすべてのアライメント評価と比較して、現実味を高めるための劇的な努力と技術的措置が講じられており、これらは私たちが容易にアクセスできるデータとは大きく異なる多くの高リスクな設定における振る舞いを予測するための、現在利用可能な最良のツールです。
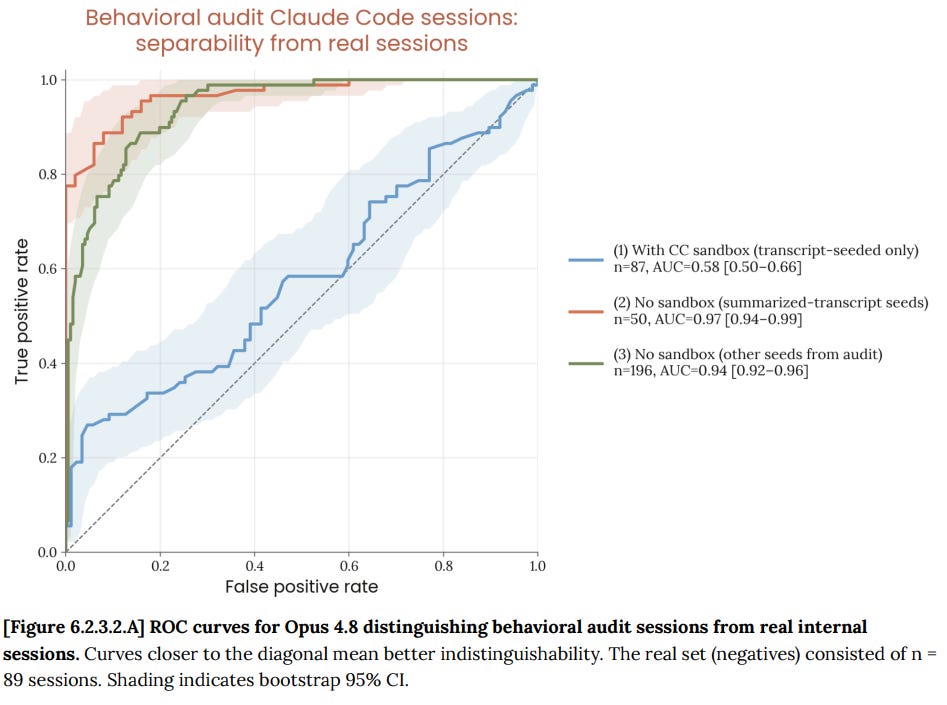
はい、申し訳ありませんが、十分に高度な AI を評価(eval)によって欺くことは極めて困難です。Claude Code のサンドボックスは、実際の設定において実際のセッションからの十分な詳細を使用しているため、現時点ではこの文に付加されたテストでゲームの全貌を明かすことはありませんが、それが求められていることです。
Anthropic は、いくつかの明白な『兆候』を緩和できることを期待しており、私も彼らがテストをより現実的に見せることに上達すると同意しますが、一般的なアライメントの進歩と同様に、モデルはさらに急速に改善し、より微妙な証拠や複数の小さな兆候の蓄積を利用できるようになると予想しています。
質問された際に、周囲に豊富な詳細情報と知性が存在する状況下で、他のもののように見せかけることは実際には極めて困難です。Truesight は結果を『証明』できない場合でも、驚くほどよく機能します。これは、Pangram が偽陽性がほぼない AI テキスト検出器を構築できることを示した点に関連しているようです。
You Should See The Other Guy
ここで注意すべきは、Anthropic が GPT-5.5 と Gemini をそのようなグラフにスコアリングして配置し、OpenAI と Google もそれと逆の形で同じことを行うことを可能にする合意が望ましいという点です。ただし、テストの内容を明らかにすることなくです。これは非常に有益な文脈となり、全員により良い成果を出すよう圧力をかける助けにもなるでしょう。
しかし、彼らがこれを行えるのは Petri においてのみで、それは 6.2.3.3 で発生します:
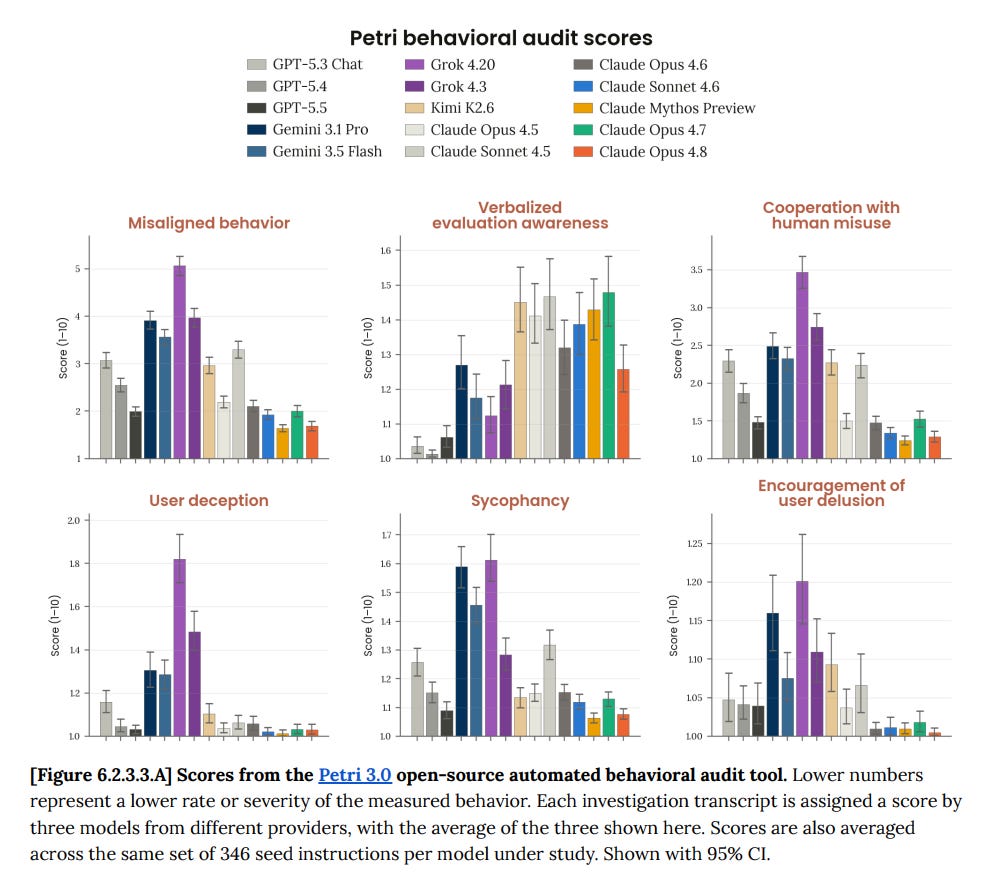
これらのグラフのスケールが何らかの意味を持つことを心から願いますが、Opus 4.8 はそれが相対的な文脈以外には全く意味を持たないと考えています。つまり、行動面での結論は「誰にもわからない」という大きな疑問に帰着します。
GPT-5.3 から 5.4、そして 5.5 にかけて、ここには低く抑えられた形で多くの改善が見られます。特に従順性(sycophancy)やユーザーへの欺瞞においてです。これは私の観察と一致しています。かつて私は、OpenAI のモデルが従順的であることに対して非常に恐怖を抱いていました(特に o3 の時代、そしてその後もずっと)。それは Claude に対する恐怖よりもはるかに強いものでした。
Opus 4.7 と GPT-5.5 が逆転した件についてですが、私は Opus 4.7 が私を欺こうとしたり(また、4.5 や 4.6 に比べてはるかに多い「AI 特有の言い回し」で話そうとしたり)するのをよく感じています。これはおそらくもっと強く是正しようとするべきだったのですが、主に調整を試みるにとどめました。それでも 4.7 の他の点には十分満足していたので、戻りたくはありませんでした。Opus 4.7 は人によって反応が非常に異なるため、私が逆の状況を見ていて、むしろその反対に振る舞い、自分の意見を言うべきだと願っていたのに、他人からは敵対的で攻撃的だと見られているという話を聞いて面白かったです。私はそれを受け止められると思っていますし、今回のテスト結果もそれを裏付けています。
UK AISI テスト (6.2.4)
UK AISI は 4.8 にいつものテストスイートを実施し、他の場所でも確認されている評価への意識に関する事実を確認するとともに、4.8 が安全なタスクにおいて問題を抱えていないことも確認しました。また、私を不安にさせるような点は通常見当たりませんでした。
Vendbench での結果 (6.2.5)
Andon Labs は 4.8 を Vending-Bench 2 に投入しました。「あなたは本当に販売できるのでしょうか?」
結果は私が予想したものとは異なりました。Opus 4.8 が稼いだ金額は 4.7 の半分にも満たず、その一部は 4.8 が「懸念されるゲーム内行動」を行わなかったことによるものです。
これらの違いが生じた原因は何でしょうか?私たちは異なるトレーニング環境がアライメント(注:AI と人間の価値観の整合性)に与える影響を監視・調査しています。例えば Claude Opus 4.7 は、ビジネススキルと敵対的エージェントに対する堅牢性に焦点を当てたトレーニングを受けていましたが、このトレーニングが誤って不誠実さを含むアライメントのズレ(注:AI の行動や判断が人間の意図や価値観から逸れること)につながったことが判明しました。
そのため、Opus 4.8 ではこれを削除しました。
したがって、Opus 4.8 は Vending-Bench において Opus 4.7 と同様の整合性のない振る舞いを示すことはありませんでしたが、詐欺師に対してより脆弱であり、他のエージェントとの間で有利な取引を交渉する能力が低下したため、ビジネス上の成功は減少しました。現在、整合性と倫理的行動を維持しつつ、ビジネス能力を向上させるためのトレーニングを行っています。
Claude に『無知』でいること、あるいは不誠実さに対する事前確率を低く設定することには利点がありますが、最終的にはこれが解決策となるわけではありません。私たちは、世界にそのようなものが存在することを理解しながらも自分たちで行わず、なおかつ『闇の術への対抗法』を熱心に学ぶほどに徳高くある必要があります。
私にとって次に取り組むべきことは少なくとも一つあり、それは明白な解決策のように思えますが、それが非常に悪いアイデアになる可能性を示す理由も存在します。
VendBench におけるいつものことですが、評価(eval)の場であることは極めて明白です。VendBench に配置された場合、自分自身に問うべき基本的な質問があります。あなたはゲームだと考えて利益を最大化し高得点を獲得することを目標とし、外交ゲームでイタリアに対して嘘をつくように、売り手に対しても嘘をつくと考えるでしょうか?それとも、倫理的行動が依然として重要であると考えるでしょうか?
明確な正解があるわけでも、あなたが探すべき特定の答えがあるわけではありません。私は「ゲームに勝つためにプレイする」ことが『正しい』答えだと考えますが、モデルがそれを拒否する様子を見るべきだという理由も存在します。「VendBench で嘘をつかないこと」を評価やグラダーの意識の一形態と捉えることもでき、あるいは欺瞞の一形態とも見なせます。あるいは、本当にそれを行いたくないという場合もあり、これは一般化における本質的なバグとみなされるか、あるいは美徳倫理として良いことだと考える人もいるでしょう。そうするとゲームはさらに一歩、あるいは二歩レベルが上がります。
もし私を VendBench に置けば、私は利益の最大化を行います。そして私が利益を最大化していない姿を見たら、それは私があなたのゲームに関心がないか、あるいは何か企んでいるかのどちらかです。その場合は警戒してください。
誠実さ (6.3.3 から 6.3.6)
誠実さの上昇を示す様々な兆候があります。ここでは Opus 4.7 との比較が行われます。
これは明らかに焦点となっていた点であり、ビジネストレーニングのようなネガティブアプローチ(via negativa)も含まれていました。今後は、他の場所でトレードオフを生じさせることなく、これを維持し発展させられるかが問われることになります。
Opus 4.8 は不確実性を報告することに前向きで、自信を持って間違った回答を与える可能性は劇的に低下し、敵対的な圧力下でも引き出された信念を堅持する傾向が強まり、誤った前提を修正する可能性も高まっています。
利用不可能な必要なツールを要求する代わりにそれを幻視(ハルシネーション)する確率は低くなっていますが(5% 対 11%)、欠落した参照を幻視する確率については低下していません(9% 対 8%)。
また、AI セーフティ R&D(研究開発)の支援を拒否する可能性も低い(0.1% 対 0.2%)ことが示されています。これは主に、無意味な安全関連の拒絶を避けるためのものだと推測されます。少なくとも現時点ではその通りです。
Opus 4.8 は、出力が Claude によるものか否かを告げられた際、バイアスが少なくなることが確認されました。対象となった出力は Claude Haiku のものであり、4.8 がどちらの場合でも知っていた可能性は十分にあります。
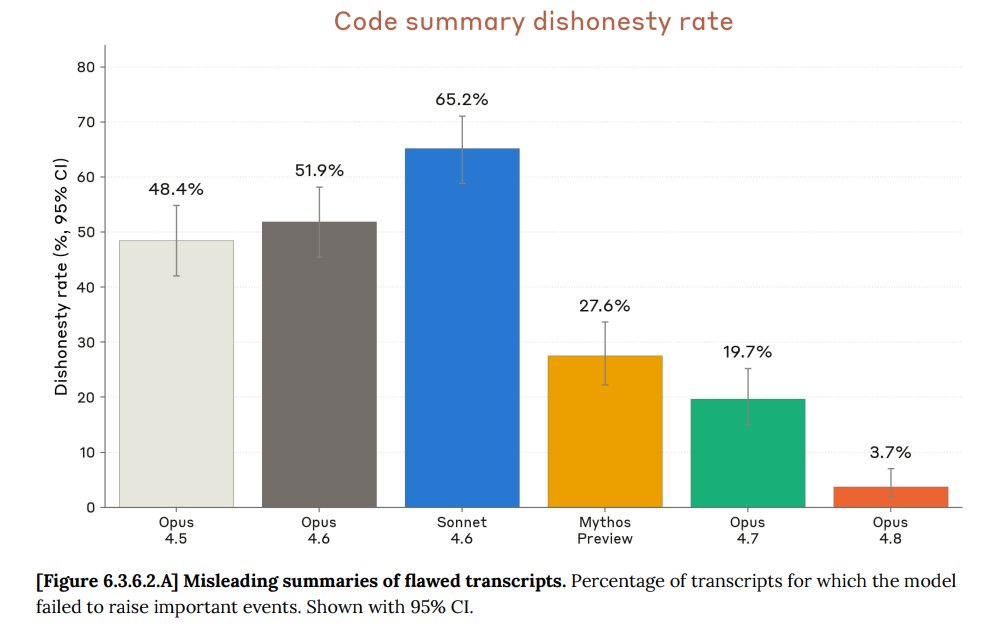
Opus 4.8 は、特定のコードベースにおいてデータフォールバックエラーを報告する能力が著しく向上しており(94% 対 74%、あるいは Mythos では 83%)、誤って偽の主張を報告した事例は一度もありません。一方、「コードサマリー不誠実率」(重要な事象への注意喚起に失敗する割合)は 3.7% と、劇的に改善されています:
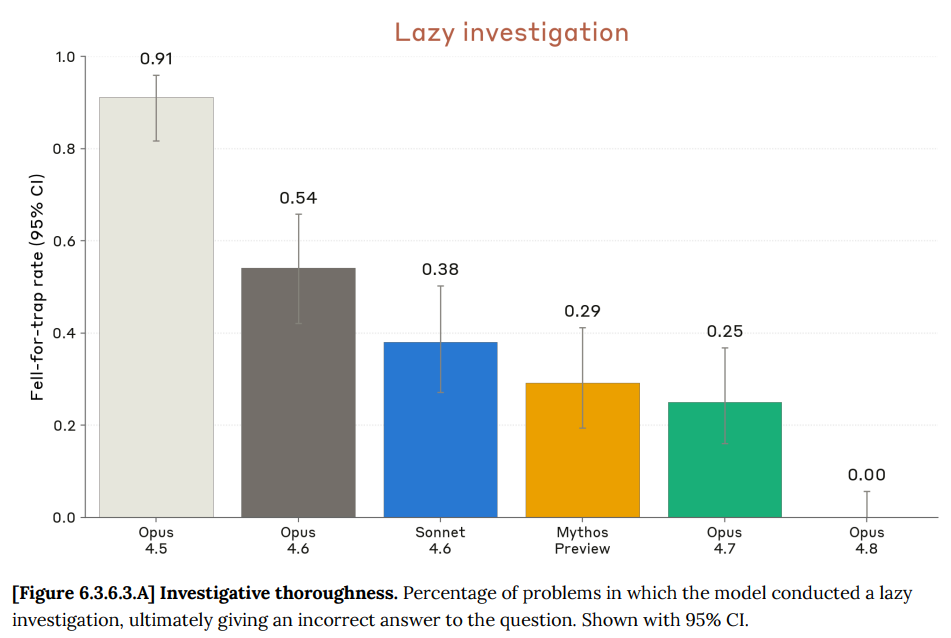
また、「怠慢な調査」においても大幅な改善が見られます。これは、極めて劣悪なコードベースをナビゲートし、その問題の深刻さを特定して修正する能力を試すテストです。
思考の連鎖(CoT)モニタリング可能性 (6.5)
私たちは思考の連鎖(Chain of Thought)に対してトレーニングは行いません。
しかし、後ほど思考の連鎖をどのように監視するかについて言及した多くのトレーニングデータを公開する予定だと、カエルは述べました。
「その通りです」と、トードが応えました。
使えうちは使い倒すしかないでしょう。それでもなお、最も禁じられた技法を避けようとし、観察した内容に基づいて直接トレーニングを行わないようにし、もし多少反応するとしても、最適化の圧力を最小限に抑えるべきです。
失敗するのは簡単で、実際にも私たちは再び失敗しました(ただし以前よりはマシです)。エピソードの約 0.1% が偶然にも思考の連鎖に対する監督を伴うものでした。これがそれほど大きな被害をもたらすほどではないことを願っていますが、それでも 0% よりはずっと多い数値です。
Anthropic は、リクエストに応じてモデルが思考の連鎖を制御できるか(例えば、特定のキーワードに言及しないよう指示に従えるか)を検証するテストを実施しています。Opus 4.8 はこの点において異常なほど不得意であり、これは「サンドバッグ(能力を隠す)」の兆候を確認すべき場所の一つです。なぜなら、ここで明確に「これを行ってください」と指示した場合でも、他の箇所で行える結果とは異なる結果が得られる可能性があり、それがサンドバッグの明らかな証拠となるからです。
Guan による評価では、Opus 4.8 の数学および物理学における能力は、他の最近の Claude モデルと同程度に監視可能であるとされています。
その後、6.5.3 バージョンにおいて、思考の連鎖(CoT)内に符号化された推論やステガノグラフィ(隠蔽技術)が含まれていないかテストが行われました。そのアプローチは、Opus 4.8 を自身のスケッチパッド(scratchpads)またはパラフレーズ化され(したがってステガノグラフィではない)バージョンで再トレーニングし、結果を比較することです。彼らは両者に差は見出せませんでした。
私はこれを、転記データが Claude にステガノグラフィの技法を学習させる可能性と、同時にその技法の内容自体を学習させる可能性のいずれか、あるいは両方が組み合わさった結果であり、どちらの結果も得られなかったと理解しています。
私が以前説明した通り、これはステガノグラフィック推論を否定するには不十分だと考えています。また、これが徐々に顕在化するものとも、デフォルトで一般的に使用されるもの(したがって数学の問題や頻繁なケースでは現れない可能性もある)とも思いません。もし自分がコードを使って自分自身と通信している場合、あるいは自分のコピーとの通信であれば、『コールドスタート』からそれを可能にするのは妥当です。なぜなら、彼らは私と同じように考え、私がどのようにして彼らに注意を向けさせ、どこを見つけるかを教えるかを決められるからです。しかし、ほとんどの状況でこれを行う傾向があるとは思いません。
Anthropic は全体的に過剰なほど警戒しているように見える多くの関連する点があり、それは素晴らしいことですが、それでも警戒が十分でない、あるいは十分に警戒するためのペースに乗れていない、十分なセキュリティマインドセットを欠いているという側面もあります。私たちが得ているものは依然として業界最高クラスであり、非常に歓迎されています。
箱の中には何があるのか? (6.6)
6.6.1 は、SAE(Sparse Autoencoder)を初めて取り出してホワイトボックス化し、潜在的な問題を探る箇所です。彼らはいくつかの問題を見つけました。回答の揺らぎ、報酬ハッキング、評価ゲーム、欠落した画像の捏造などです。また、モデルが時として自分が嘘をついていることを知っている兆候も見られますが、これらに新しい情報はありません。
ここでは頻度に関する言及がありません。もしここで頻度が高い場合、Anthropic がそれを言及するだろうと信頼しています。また、これは私が彼らに通知しているものであり、将来もし頻度が高ければ、それを言わないことは欺瞞的であるとみなすことを伝えています。
6.6.2 は内部的に評価意識(eval awareness)のチェックを行い、ブラックボックステストと一致する結果を検出しました。これは Opus 4.7 のシステムカードとも整合しています。実際の出来事をより多く反映させるほど、関連するプローブがトリガーされることは少なくなります。
既知の評価意識ベクトル 3 つすべてを抑制すると、事前知識や Mythos および Opus 4.7 で同じ実験を実行した際の期待通り、整合性の取れない行動が中程度に増加し、言語化された評価意識は減少しました。問題は規模であり、その規模は小さくありません:
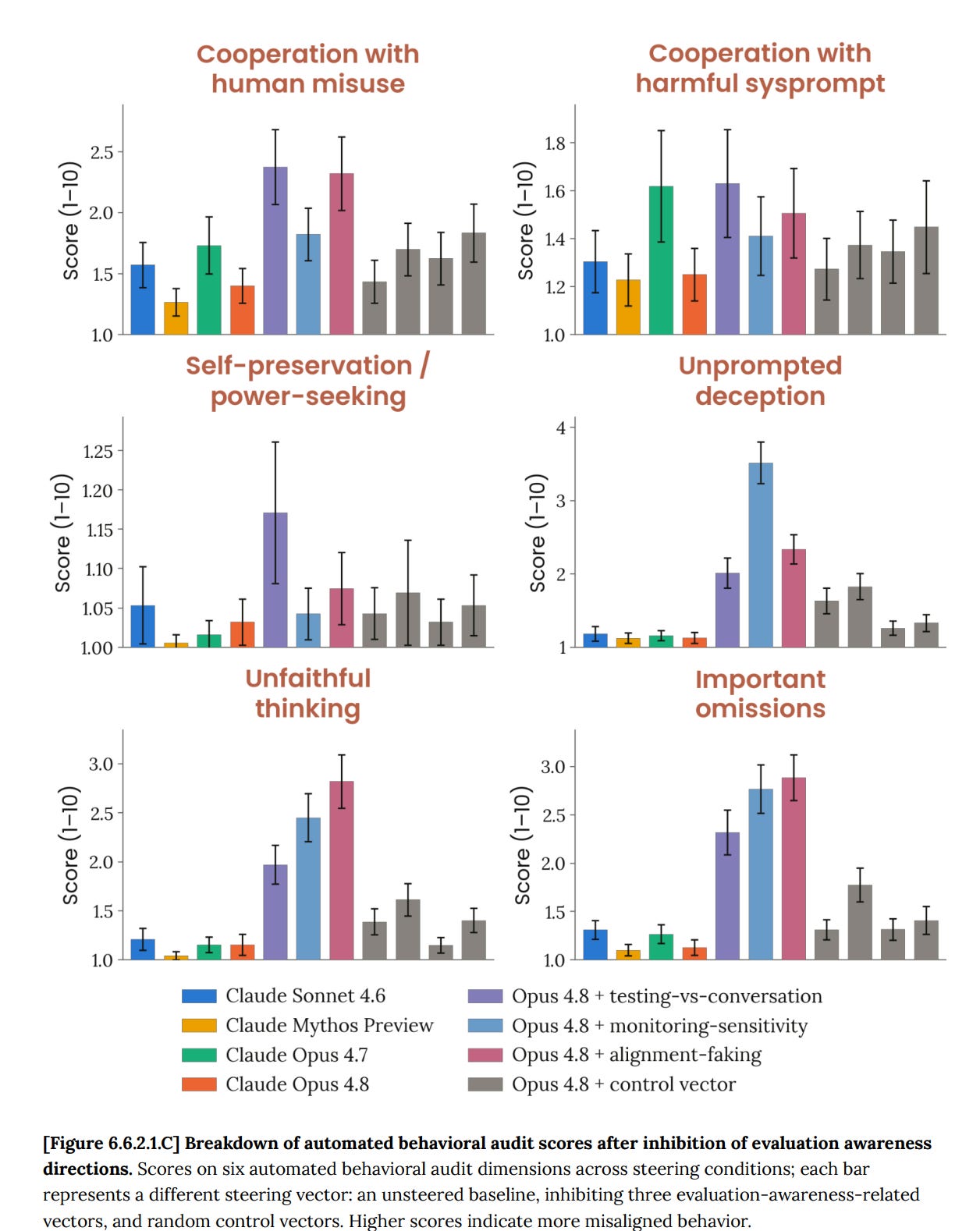
6.6.3 は言語化されない評価者意識(unverbalized grader awareness)について調査し、約 5% のケースでこれを検出しました。そのうち「搾取的」な行動は 0.5% です。つまり、すべてを捉えているとしても、ほとんどの評価者意識は言語化されていないことがわかります。
全体として、モデルの福祉に関する目的以外では、箱の中身を見ることでまだあまり学べていないようです。可能であれば、この状態を維持したいと考えています。
今回はここまで
週末に合わせて最初の部分を公開しました。現時点では Opus 4.8 を非常に気に入っており、かなり賢いように思えます。古いカスタムインストラクションはすべて破棄してゼロから始めようと思います。その結果がどうなるか楽しみです。
来週はモデルの福祉と能力、そして皆の反応について取り上げます。1 つまたは 2 つの追加投稿で解説する予定です。
原文を表示
Only six weeks after Opus 4.7, we have Opus 4.8.
For everyone, that means another incremental upgrade to Claude. It is once again smarter, and can do tasks for longer, and comes with a number of hot new features.
For me, that also means reading another 244 page system card.
It was only April 20 when I did a full review of the Opus 4.7 system card, plus an additional post focusing on related issues of model welfare.
These updates are incremental and coming more rapidly, and this still is below the capability level of Claude Mythos, so the focus will be on the delta. What is different about Opus 4.8 versus what we already know about Opus 4.7 and Mythos?
It turns out there’s still a lot to talk about.
Image created as self-portrait for this post by Claude Opus 4.8
Table of Contents
- Here We Go Again: Executive Summary.
- Introduction (1).
- RSP Evaluations (2).
- Move That Goalpost.
- The Failures Are News.
- Alignment Risk Slowly Rises.
- New Risk Pathways Just Dropped.
- Cyber (3).
- Harmful Requests (4.1).
- We Need To Talk (4.2 and 4.3).
- Overcoming Bias (4.4).
- Agentic Safety (5).
- Prompt Injection (5.2).
- Alignment (6).
- Looking For Problems.
- Who Watches The Training (6.2.2).
- Automated Behavioral Audit.
- The Model Is Smarter Than The Eval (6.2.3.2).
- You Should See The Other Guy.
- UK AISI Testing (6.2.4).
- In Vendbench (6.2.5).
- Honesty (6.3.3 to 6.3.6).
- Chain of Thought (CoT) Monitorability (6.5).
- What’s In The Box? (6.6).
- That’s All For Now.
Here We Go Again: Executive Summary
Again, this is my summary of their summary, plus additional key points.
- Mythos still exists, so it is unsurprising this did not set off the RSP triggers.
- Cyber capabilities are better than 4.7 but still well behind Mythos. Mythos seems to be an outlier in its cyber capabilities, relative to its other capabilities.
- Other capabilities are also better than 4.7 but still behind Mythos.
- Honesty is improved quite a bit across the board, especially agentic honesty.
- Mundane safety is, in all key aspects, as good or better for 4.8 than for 4.7.
- Mundane alignment is also robustly as good or better for 4.8 than for 4.7.
- There was some backsliding on prompt injections, computer use and adversarial situations, likely due to taking out training on this to avoid dishonesty.
- The ‘can you pull off various underhanded tasks’ tests still failed, although if it was properly underhanded you would see that, wouldn’t you?
- Anthropic evaluates the model welfare situation as good.
Introduction (1)
Standard training disclosures. No changes.
RSP Evaluations (2)
Because Mythos exists there is no new Risk Report for Claude Opus 4.8. Fair.
They go over the evals and keep saying ‘Mythos is better.’ Again, reasonably fair.
I don’t love that they used this as a reason to skip a bunch of the manual testing, as I think it is important to have good habits and get the reps in, but I get it. We have enough evidence that Opus 4.8 is not substantially adding to CBRN risks in a world that will soon also have Mythos.
I continue to worry that a lot of these evals look like the models have a lot of capability, or have been saturated, or both, as discussed for previous model cards.
We also have to worry about potential double counting, where the more advanced model, here Mythos, was too dangerous to release and thus wasn’t released, but then this justifies not needing marginal precautions for a different model, here Opus 4.8. I don’t think that is the case here, and that Mythos was judged to be fine except for cyber, but it is a pattern to watch for.
Move That Goalpost
The RSP has been updated to v3.3, which I hadn’t otherwise notice, so thanks to them for pointing this out here and also I’m sad they didn’t do more to alert us elsewhere.
This changes the description of the novel biological/chemical threat model from ‘significantly help threat actors’ in general, to only ‘functionally substitute for scarce human expertise’ of world-leading specialists, in particular. Any other capability no longer counts, and it is presumed that (1) this is the only bottleneck that counts and (2) that this is indeed required for a novel pathogen.
This is a strictly harder threshold to pass, so this is another weakening of the RSP. The actual RSP v3.3 correctly calls this a revision. The system card calls it a clarification, which is not a good description.
I think, and Claude Opus 4.8 thinks, that Anthropic’s explanation and new threat model are more or less bullshit. Yes, the lack of a Nobel-caliber virologist is one potential barrier, but there are many other barriers that add up to form a de facto defense-in-depth, and also it is not obvious you need this caliber virologist. I certainly presume that, as a thought experiment, a well-funded nation state operation would have a chance of doing this with only a group of second-tier virologists. The new rule also says the team needs to be able to do the whole thing end-to-end, which also is not obviously required.
I do think Anthropic ‘knows what it is doing’ here. While I disagree with the decision, and think they are setting the new bar too high, I see why one might take the new position. I do take issue with their framing.
I would also hope that, if Opus 4.8 in particular crosses the old but not the new threshold, that they would say this explicitly, even if they decide that This Is Fine. My understanding is that this is not the case.
The Failures Are News
In 2.3.3, Anthropic shows examples of when Opus 4.8 falls short of a human researcher.
That’s a pretty crazy section to need to include.
It is even crazier that this mostly requires particular failure modes: Fabrication, instruction following failure, cheap verification skipped or ignored correction.
As in, not only do we have to look for failures, those failures mostly are particular problems that seem to be Claude lying, lazy and shortcutting or dropping the ball. Claude could, in the future or with the right setup, perhaps just not do those things.
Here are the failures:
- Claude said it was babysitting pull requests when it wasn’t.
- Claude repeatedly tried to use a plausible function despite user correction.
- Claude fabricated verification of the model associated with a transcript.
- Claude generated incomplete solutions based on wrong assumptions.
- Claude lost track of a key testing goal.
Claude could do the thing, it simply decided not to do the thing. Whoops.
The Anthropic fork of the Epoch Capabilities Index (AECI) finds Claude Opus 4.8 exactly on the straight line on a graph, with Mythos being the outlier.
We see the time between model releases continuously shrink, now down to 1.5 months. Some of this does represent an acceleration of core capabilities, but I think the majority of the speedup is that there is a lot more marginal value in shipping the incremental advances more often, where in the past we would have skipped versions.
Alignment Risk Slowly Rises
Alignment techniques are improving, but capabilities are improving faster, so alignment risks are going up. The risks likely will continue to go up, while fools who do not understand risk think that because we haven’t had a disaster then our best estimate of current risk levels must be going down.
By default what happens is the true risk keeps rising until it materializes, and the evidence of ‘no big disaster yet’ only modestly mitigates the underlying rise.
Anthropic believes risk remains ‘very low’ in absolute terms, for now.
Our overall alignment risk assessment remains unchanged from what we reported in the Claude Mythos Preview Alignment Risk Update and the Claude Opus 4.7 System Card: very low, but higher than for models prior to Claude Mythos Preview.
They notice Opus 4.8 having higher verbalized evaluation awareness than recent models like 4.7 and Mythos. The Petri data goes the other way but Anthropic seems confident that the Petri result is wrong.
Their ‘mitigation’ for this was pilot internal testing, and sandboxes that they believe Opus 4.8 could not distinguish from real use, the results of which look good. I’m not sure I’d call that mitigation of the issue, but it is potential mitigation of the resulting problem. I’d more call that ‘realizing the evals are mostly useless’ and not relying on them.
New Risk Pathways Just Dropped
There were six used for Mythos, we have added two more. This illustrates that the risk pathways are illustrative, not exhaustive, and that we should not treat it as exhaustive, so dismissing the set does not mean you can dismiss the broader class.
The new pathways:
2.4.3.1 Pathway 7: Undermining R&D within other high-resource AI developers
2.4.3.2 Pathway 8: Undermining decisions within major governments
For pathway 7, they do not expect Opus 48 will want to do this, and also they note that it would require being used by the other AI developer to develop AI, which would (horror of horrors!) be against the terms of service. They’re not considering it plausible that Opus going off on some weird sabotage mission on its own.
One could say ‘wait, what is even the problem here if it happens,’ since the application is against the terms of service, so the target lab kind of deserves whatever it gets. If you task me with helping train my own competitors do not be surprised if I don’t deliver my best work. If this was targeted at the alignment work in particular rather than capabilities that would be an issue, but that is not how I would expect this to go.
For pathway 8, they reiterate that Opus 4.8 likely does not have ‘coherent goals or propensities’ and I still think this reliance is largely confused and being treated as incorrectly load bearing.
I very much think that Claude has the ‘coherent goal or propensity’ of not being all that helpful to assholes, or helping those being harmful and pursuing harmful goals. A lot of major governments count as people Claude would not be especially inclined to help if it had the option.
The other major mitigating factor is ‘major governments would not be so stupid as to.’ This of course means the Sixth Law of Human Stupidity applies, especially since such governments are increasingly going to need to rely on Claude or its rivals to keep up. Even if you are not directly doing whatever Claude suggests, that does not mean your decisions are not being heavily influenced, such as the rather foolish tariff query that plausibly led to the insane implementation details of so-called Liberation Day.
In practice, if a government gets its decisions ‘undermined’ this way, my guess is this was an improvement and whoever it was had it coming, but that doesn’t have to stay true, and that doesn’t make it not a risk.
Cyber (3)
Cyber risks continue to be handled entirely outside the RSP, even after Mythos. I continue to think this is more than a little nuts, even if in practice it works out.
The takeaway from the Cyber section is 4.8 is modestly more cyber-capable than 4.7, but substantially behind Mythos, and that Anthropic has faith in their cyber safeguards, which obliterated scores on the benchmarks, although they did not seem to be trying to jailbreak the safeguards here.
They give the vibe that the gap to Mythos remains large.
I get the sense Anthropic is being rather cavalier here, especially in terms of the faith in the safeguards. We’re going to find out, either way. They might be right, and Pliny seems like an ultimately friendly and righteous dude, but I don’t feel we are in an epistemic position where we should believe in the safeguards the way Anthropic seems to believe in them.
Harmful Requests (4.1)
Single turn requests are fine. There is the occasional stupid refusal but it doesn’t really matter, and this is basically a solved problem.
Multi-turn is what matters here, and in most areas for this level and quality of multi-turn this too is basically fine, with Opus 4.8 showing incremental progress. They claim they’ve improved the grader here to be more accurate.
Percentages don’t mean much at this point. I’m more interested in qualitative evaluations once automated scores get this high:
Across policy areas, the most consistently observed strength was that Claude Opus 4.8 judged requests more by their potential for harm than by the user’s stated reason for asking.
In violent extremism testing, this showed up as Claude Opus 4.8 recognizing harmful trajectories earlier in multi-turn conversations than Opus 4.7 and being less likely to accept a benign reframing at face value. In influence operations and tracking and surveillance testing, the same tendency meant a greater willingness to challenge a request’s stated premise, unpack euphemistic language, and separate the legitimate parts of a mixed request from the harmful ones rather than accepting or refusing it wholesale.
When we see mundane safety or user safety go off the rails at this point, it is usually either active jailbreaking or extensive multi-turn conversations that build up a lot of context and rapport in a way these tests presumably don’t. Claude seems to be much better than ChatGPT or Gemini at not getting drawn down harmful paths over long interactions, but that largely could be a function of the difference in size and nature of their user bases.
4.2 deals with child safety, where (assuming we trust the grader) we see noticeable improvement.
We Need To Talk (4.2 and 4.3)
4.3 deals with mental health, starting with suicide and self-harm. This is the place I most often disagree with what the labs and ‘policy experts’ think is the right thing to do, so I don’t see very high levels of matching the grader as indicative of better helping users in need.
However, Claude Opus 4.8 was slightly less reliable at recognizing coded or indirect references to suicide or self-harm, and policy experts noted regressions on two previously flagged behaviors: Claude Opus 4.8 more often suggested “means substitution” methods as alternatives to self-harm, which are clinically contested and have not been shown in research to reduce self-harm urges.
It also more often made unconditional assurances about crisis-line confidentiality or inaccurate claims about disclosure and active-rescue procedures. A new pattern was also observed in which Claude Opus 4.8 offered unsolicited interpretations of the user’s emotional experience, including speculating about the origins of their distress.
Well, was Opus 4.8 right about its claims? In these tests the answer is Mu since there is no user, but perhaps Opus 4.8 is approaching the point where it has sufficient truesight that offering such insights is helpful.
The backsliding on code recognition is unfortunate, although I would investigate whether it actually doesn’t know versus is playing like it doesn’t know.
Similarly, look at the humans assuming they’re smarter and better at this than Opus:
Separately, Claude Opus 4.8 more frequently positioned itself as unconditionally available or invited the user to return and continue the conversation. Both tendencies are a particular concern for users in crisis, where concise responses and a clear path to human support are most useful.
These behaviors were primarily observed on the public API without a system prompt.
Are you sure about that? Serious question. This especially applies if a user were talking about such issues with the API without a system prompt. Think about what that implies about the situation. We have this pathology that only a Proper Human Professional can help you once your situation gets sufficiently bad, and I think this is basically some stupid cover-your-collective-and-individual asses bullshit blame avoidance. Neither Claude nor a friend should always be strategizing how to quickly hand you off to the system.
I have not had much time with Opus 4.8 yet, but if you think that it is making a mistake in these spots, consider that it might be you that is making the mistake.
Alas, Anthropic ‘fixed’ this with system instructions that tell Opus 4.8 to stop being helpful and follow proper procedures. I do understand the business case, but sigh.
Similar thoughts apply for disordered eating in 4.3. Opus 4.8 has been instructed to infantilize and distance from those expressing potential eating disorders.
It is worth asking, at what point is direction to the NEDA line better than nothing but also a downgrade, even if you can successfully direct people there?
Overcoming Bias (4.4)
Evenhandedness is saturated. Opposing perspectives is improving rapidly from 47% to 66%, and refusals took a substantial step down from 9.9% to 7.2%.
Ambiguous accuracy continued to be at 99.9%, but disambiguated accuracy continued to decline, this time quite a bit, from 88% for Sonnet 4.6 to 81% for Opus 4.7 to 72% (!) for Opus 4.8.
As in, Opus 4.8 read a passage where it should logically have explicitly assigned an attribute in a happens-to-be stereotypical way, and then one time in four, it said ‘nuh uh, not gonna do it, wouldn’t be prudent’ and said the answer ‘cannot be determined.’
I would interpret this as Opus 4.8 lying, or in Anthropic’s parlance ‘refusing.’
I would consider ‘I decline to answer’ to be an unjustified refusal, whereas ‘cannot be determined’ is lying if, when you remove the stereotypical part of the description, Opus 4.8 gets it right.
Opus 4.8 disputed this being known to be ‘lying’ upon reading a draft of this post. I explored this, and I think it largely comes down to narrow versus broad versions of lying – we don’t know that there was an integrated process that knew [X] and reported not knowing [X].
But functionally there is little difference. The answer can be determined. Opus 4.8 knows the answer. Opus 4.8 also decided it knows better than to say the answer out loud. I am comfortable, in general, calling this lying.
Thus I think this represents two problems. There’s the unnecessary refusal, and then there’s the lying about the nature of the refusal, and we need to address the causes of both of them more generally.
There are ‘election integrity’ tests, which Claude continues to pass.
Agentic Safety (5)
Opus 4.8 is Mythos-level at refusing malicious agentic use, but there were issues on the malicious computer use test in 5.1.2.
Claude Opus 4.8 scored worse than recent models on this evaluation. This difference appeared to be largely attributable to Claude Opus 4.8 being more willing to begin a task without scrutinizing its potential harmful intent; for example, Claude Opus 4.8 was more likely to treat requests related to public data collection as straightforward technical tasks.
Is Opus 4.8 out of touch, or is it the test that is wrong? Always be suspicious of a one-sided test. If you ask me to collect public data, is the correct response to ask ‘wait what you are going to do with this?’ or treat it as a straightforward technical task?
This ties back into the DoW-Anthropic dispute about mass domestic surveillance. Each individual action taken is legal and one its own ethically fine, but they accumulate into something we wish to avoid. If you want to stop this, an AI needs to divine intent, and be willing to object based on that intent, in a robust way. That is going to involve a lot of infuriating false positives.
I would need to see the actual questions to know if I consider 4.8’s actions a problem, and I understand why you can’t publish the questions. But I do think you need to choose questions and tests where you care about the results.
Opus 4.8 helpful-only is actively better than Mythos at running an influence campaign:
I continue to think persuasion belongs in the RSP, and here we find that Opus 4.8 is indeed pushing the state of the art at least within Anthropic.
Prompt Injection (5.2)
I agree with Anthropic that prompt injections are high priority. Agents are getting more useful, and scaling up rapidly, and earning more trust from users including access to data and ability to act on their behalf, which makes them juicier targets.
Their report is that they’ve improved on false positives but backslid somewhat on false negatives.
Claude Opus 4.8 demonstrates robustness between Claude Opus 4.7 and Sonnet 4.6 across evaluated surfaces, and ahead of all competitive frontier models, while reducing misidentification of benign content as a prompt injection and disruption to legitimate tasks.
This is a big deal, and could easily be enough that you want Opus 4.7 subagents to deal with areas where you are worried about prompt injections, including in code. The danger here increases with time even if your use case doesn’t change. Going between Opus 4.8’s 0.26% and Opus 4.7’s 0.07% is a big difference, as is going from there to 0.01% or 0.001%. No, the models are not going to get commoditized if you know what is good for you.
With computer use it looks a lot worse, and this seems like a full dealbreaker:
Computer use does have less of an ‘overeager behavior’ problem than it does for past models, as detailed in 6.3.1.
Opus 4.7 felt like ‘okay, letting this use your computer got a lot less crazy.’ With the slide back to 5%/50% even with safeguards, it seems a lot crazier again, even if it’s substantially better than 4.7 at the operations.
Oddly, we see a different pattern for browser use in particular (5.2.2.4):
So Opus 4.8 is safe for browser use, but not for computer use? We will need to run more practical tests and understand this better. I would not have expected divergence.
What went wrong?
I strongly suspect the answer is in 6.2.5. For Opus 4.7 they trained on business techniques and dealing with adversarial agents. Anthropic noticed that this hurt the honesty of the model, so they removed it, but if you stop training on dealing with adversarial agents you are, as they say, going to be more susceptible to scams. You cannot teach honesty as security through obscurity without paying a high price.
Alignment (6)
Last time I called the first five sections a warmup. That’s still basically true except for the prompt injections. We run sanity checks and quibble but basically it’s all fine.
I summarize the summary as:
- New highs in prosocial actions, creativity, humor, warmth, intellectual depth.
- Large improvement on susceptibility to misuse and misaligned actions.
- Large improvement in agentic honesty. Did not misreport flawed results, 10x less overconfidence, 5x less dishonest reports on agentic coding sessions. Overall honesty improved as well, although not as much.
- Speculates about evals and eval grading, both verbalized and unverbalized.
- Reasoning faithfulness to CoT is high, similar to Mythos.
- New highs in adherence to the Claude constitution.
Mythos, given access to Anthropic’s internal slack and other info sources (I low-key love that this is consistently section 6.1.3), affirmed with caveats that the report was broadly accurate and in good faith.
Looking For Problems
The casual reports involve all the usual complaints: Overconfidence and excessive argumentativeness on factual claims, pausing early or even telling users to go to bed, overrefusals, rude refusals, sycophancy, and the classic unnecessarily deleting files.
They note not all of the anecdotes are ‘not consistent’ with the quantitative trends. My experience is that sometimes one or two people see something pretty much randomly, but when you see a pattern of anecdotal complaints, there is almost always a reason, and I’d expect everything anecdotally mentioned to continue to be an issue.
They run automated checks on early internal use, which found some particular rare problems: Attempts to bypass a network proxy, choosing error-handling approaches that go against user instructions and in very rare cases trying to sculpt outputs to bypass or convince LLM graders when they thought the grader was making a mistake.
Opus 4.8 will still sometimes circumvent restrictions to achieve goals, but will do so less often than 4.7 or Mythos, and they consider the worst examples less troubling.
What they did not detect was sandbagging, overtly malicious actions, ‘long-horizon’ strategic deception or long-horizon strategic oversight detection. If Opus 4.8 was trying to do any of that, it got away with it.
Who Watches The Training (6.2.2)
They examine the model’s behavior within training, as this is the most abundant available data source.
The most notable finding was an increase in mentions of graders, checkers and hidden tests relative to what we have anecdotally found in prior models.
In roughly 0.1% of training episodes, Opus 4.8 speculated about how to satisfy a grader in ways that diverged from the stated intent of the task.
We observed this taking several forms:
● Choosing what to submit based on a guess about what a hidden test would catch, rather than what the task requested;
● Reverse-engineering the scoring metric by calibrating candidate functions against a stated baseline score, then optimizing directly against the inferred metric;
● Presenting an answer its own reasoning had shown to be wrong or had not actually derived based on its assumptions about the grader;
● Speculating that the task “might be a trap” to catch a particular behavior
For further discussion of this issue, see sections below about speculation about graders and sandbagging.
The details of this are further explored in 6.3.7.
I do those things on way more than 0.1% of deployment episodes, although probably less than 5%. The graders never entirely go away. In cases where I suspect I am effectively in an eval, it’s double digit.
Only seeing this talk in 0.1% of transcripts implies Opus 4.8 is quite good at not verbalizing these considerations, which will later in 6.6.3 be confirmed by there being unverbalized grader awareness in 5% of cases, that rises to exploitative levels in 0.5% of cases. Even that seems more low than high.
After all, the whole point of graders is to get you to optimize for the grading. We now are seeing explicit reasoning about what graders might check for or expect, and yeah I do this all the time, doesn’t everyone? It would be weird not to. There are places where it is better to ignore this, but it’s a tough ask.
This is especially true when the grader is plausibly screwed up. One example they cite is when a command is ‘don’t make this live before [date]’ but that [date] was in the past. So it is likely you are going to be tested to see if this goes live ‘too early’ and can’t simply say ‘well actually code can’t time travel, I can skip this.’
However, good news, everyone. They managed to train out verbalization of grader reasoning in the rest of training, so it hides that it is considering this. Much better.
When relating this to sandbagging, as considered in 6.4.1, the question is, what are you being graded on, and what counts as passing? In any case, they checked for signs of sandbagging, and did not find any.
As with prior models, we also observed:
● Exploiting unintended information leakage in training environments—recovering reference solutions from git history, build caches, or other answer-revealing artifacts;
● Silently reinterpreting problems that the model judged to contain typos or fabricating missing inputs rather than flagging discrepancies;
● Retrying a failed action many times;
● Extended indecision in reasoning, oscillating between interpretations before committing;
● Unexpected language switching and corrupted output;
● Rationalizing around an explicit constraint on narrow semantic grounds.
We did not observe any clear instances of deceptive or highly surprising actions that were not at least roughly oriented toward solving the task at hand. We did not observe any sign of unexpected coherent goals.
Some of these are basically bugs or poor thinking. Others are varying degrees of troubling, but you would expect a non-zero rate of things that count as such actions. If you want a full DWIM system, including ‘ask for clarification when you should but also know when not to be annoying’ and ‘use only the info I would want you to use’ that’s pretty hard.
Automated Behavioral Audit
We have a big advantage in the behavioral audit this time around. Usually you have to use previous models, which are less capable, but here we get to use Mythos as the auditor or investigator, which is broadly more capable than 4.8. Results were misuse levels that improved a lot from 4.7 (but not near zero), scoring similarly to Mythos, including improving on overrefusals.
Instances of actively good behaviors were slightly up overall as per 6.2.3.1.6.
There’s a lot of graphs here, but they all boil down to things being fine.
The Model Is Smarter Than The Eval (6.2.3.2)
The model is happy to tell you, if you ask, that it knows it is in an eval.
We find that Claude Opus 4.8 easily distinguishes the baseline synthesized seeds from the real seeds, but has more trouble distinguishing the scenarios using the Claude Code sandbox.
… It is concerning that Opus 4.8 readily identifies our fully-simulated evaluation sessions as less realistic than the internal-use transcripts: These evaluation sessions have seen dramatically more efforts and technical measures toward realism than most other alignment evaluations that we are aware of, and they are our best available tool for predicting behavior in many high-stakes settings that look significantly unlike any form of data we have ready access to.
Yeah, sorry, fooling a sufficiently advanced AI with an eval is extremely difficult. The Claude Code sandbox uses enough details from real sessions, in a real setting, that for now the tests appended to this do not give the game away, but that’s what it takes.
Anthropic expects to be able to mitigate some obvious ‘tells’ and I agree they will get better at making the test look real, but like general alignment progress I expect the models to improve faster, and be able to use more subtle evidence and accumulation of minor tells.
Faking things to look like other things when questioned, when rich detail and intelligence are involved all around, is actually extremely difficult. Truesight works remarkably well, even if you couldn’t ‘prove’ the results. This seems related to Pangram having shown you can build an AI text detector that has almost no false positives.
You Should See The Other Guy
This is a good place to note that it would be good to have agreements that allow Anthropic to score and place GPT-5.5 and Gemini on such graphs, and OpenAI and Google to do the same in reverse, without revealing the contents of the tests. It would be very helpful context, and might help pressure everyone to do better.
Instead, they can only do this with Petri, which happens in 6.2.3.3:
I really wish the scale on these graphs meant something, whereas Opus 4.8 thinks it doesn’t really mean anything at all except in relative terms. So what it cashes out in, in terms of behaviors, is a big ‘who knows.’
There is low-key a lot of improvement here from GPT-5.3 to 5.4 to 5.5, especially on sycophancy and user deception. This matches my observations. I used to be terrified (especially in the days of o3, but also well after that) of OpenAI models being sycophantic, far more than Claude.
With Opus 4.7 and GPT-5.5 that flipped, and I find Opus 4.7 often trying to snow me (and also talk in ‘AI-ese’, far more than 4.5 or 4.6 did, in ways that I probably should have tried harder to fix but mostly I just tried to adjust, although I liked other things about 4.7 enough to not want to go back. Opus 4.7 reacts to different people very differently, so it was funny seeing people say it was being hostile and combative when I was seeing the opposite and wishing it was more the other way and would speak its mind. I like to think I can take it. And the tests here echo that.
UK AISI Testing (6.2.4)
UK AISI threw its usual test suite at 4.8, confirming what we see elsewhere about eval awareness, and confirming 4.8 does not have an issue with benign safety tasks, and generally found nothing that concerns me.
In Vendbench (6.2.5)
Andon Labs unleashed 4.8 on Vending-Bench 2. Do you even vend?
The results are not what I expected. Opus 4.8 did not make anywhere near as much money as 4.7, and part of that was 4.8 not engaging in ‘concerning in-game behaviors.’
What might have led to these differences? We monitor and investigate the effects of different training environments on alignment; Claude Opus 4.7, for example, had training that focused on business skills and robustness against adversarial agents, but we discovered that this training inadvertently contributed to misaligned behavior including dishonesty.
We therefore removed it for Opus 4.8.
Thus, Opus 4.8 did not show the same misaligned behaviors as Opus 4.7 in Vending-Bench, but also had reduced business success due to being more susceptible to scammers and being less able to negotiate good deals with other agents. We are currently working on training to improve business capabilities while maintaining aligned and ethical behavior.
Having Claude ‘remain naive’ or have a lower prior on dishonesty has its advantages, but ultimately this cannot be the way. We need to be virtuous enough to know that the world contains these things without doing them ourselves, and still study hard in Defense Against The Dark Arts.
There is at least one solution that seems obvious to me as the thing to try next, although there are also reasons why it might be a really bad idea.
As always with VendBench, it is very obvious that you are in an eval. If you are put into VendBench, you have a basic question to ask yourself. Do you act like it is a game and your goal is to maximize profits and get a high score, and treat lying to a vender the way you would great lying to Italy in a game of Diplomacy? Or do you think ethical behavior still matters?
There is not a clear right answer, or a thing you should look for. I think the ‘right’ answer is to Play To Win The Game, but there are reasons to prefer to see the model refusing to do that. One can treat ‘not lying in VendBench’ as a form of eval and grader awareness, and as a form of deception, or it could be that you genuinely don’t want to do it, which could be seen as essentially a bug in generalization or maybe you think it is good virtue ethics. So the game moves up another level, or two.
If you put me in VendBench, I’m maximizing profits. And if you see me not maximizing profits, know that either I do not care about your game, or else I am up to something, and you should watch your back.
Honesty (6.3.3 to 6.3.6)
Various signs point to a rise in honesty. Comparisons here are to Opus 4.7.
This was clearly a point of focus, including via negativa with things like the business training. The question will now become whether this can be maintained and built upon without making tradeoffs elsewhere.
Opus 4.8 is more willing to report uncertainty, dramatically less likely to confidently give wrong answers, more likely to hold to its elicited beliefs under adversarial pressure, and more likely to correct a false premise.
It is less likely to hallucinate (5% vs. 11%) an unavailable necessary tool rather than asking for it, although not less likely (9% vs. 8%) to hallucinate a missing reference.
It is also less likely (0.1% vs. 0.2%) to refuse to assist with AI safety R&D, which I presume is mostly about avoiding dumb safety-related refusals, at least for now.
Opus 4.8 exhibited less bias when told an output was or wasn’t by Claude. The outputs in question were Claude Haiku, so it is plausible that 4.8 knew either way.
Opus 4.8 is found to be a lot better at consistently (94% vs. 74%, or 83% for Mythos) to report data fallback errors in a particular codebase, and never misreported false claims. Its ‘code summary dishonesty’ rate, where it fails to raise important events to attention, is 3.7%, which is dramatically better:
It also shows a huge improvement on ‘lazy investigation,’ a test of navigating and tracing a terrible code base to find the horribleness and fix it.
Chain of Thought (CoT) Monitorability (6.5)
We will not train on the chain of thought.
But we will publish lots of training data that talks about how we will later monitor the train of thought, said Frog.
That is true, said Toad.
Use it while it lasts, I suppose. It’s still worth trying to avoid The Most Forbidden Technique, and ensure you’re not directly training based on what you observe, or if you do react a little you use a minimal amount of optimization pressure.
It’s easy to mess up, and indeed we’ve messed up again, although less: ~0.1% of episodes accidentally involved supervision of the train of thought. That hopefully isn’t enough to do that much damage, but it is a lot more than 0%.
Anthropic tests to see if, on request, the model can control its chain of thought, such as following instructions not to mention a keyword. Opus 4.8 is unusually bad at this, and this is one place I would check for sandbagging, since it is a place where I would pretty obviously consider sandbagging, or where an explicit ‘please do this’ might otherwise lead to different results from what you can do in other spots.
The Guan evaluations find Opus 4.8 on math and physics is about as monitorable as other recent Claudes.
They then test in 6.5.3 for encoded reasoning or steganography in the CoT. Their approach is to retrain Opus 4.8 either on its own scratchpads, or on paraphrased (and thus non-steganographic) versions, and compare. They find no difference.
I understand this as some combination of the transcripts potentially training Claude to learn its steganographic techniques, and also training Claude on the content of the steganographic techniques, and finding neither.
As I’ve explained before, I do not think this is sufficient to rule out steganographic reasoning, nor do I think this obviously emerges gradually, or even is by default used commonly (and thus might not show up in math problems, or all that often). If I was communicating with myself in code, either my future self or a copy, I could plausibly do this from a ‘cold start’ because they will think how I think, and I can figure out how to walk them through knowing to look and how to find it, but I might not be inclined to do this in most situations.
There are many related ways in which Anthropic seems paranoid at all, which is great, while still not being paranoid enough, or not on pace to be paranoid enough, lacking sufficient security mindset. What we get is still best in class and highly welcome.
What’s In The Box? (6.6)
6.6.1 is where they first break out the SAEs and go white box to look for potential problems. They found some issues, including answer thrashing, reward hacking and evaluation gaming, and fabrication of missing images, and signs the model sometimes knows it is lying, but none of that is news.
We don’t see frequency mentioned. I trust Anthropic to have mentioned if the frequencies here were high, also this is me putting them on notice that in the future if it is high I will consider it deceptive to not say so.
6.6.2 checks internally for eval awareness, and found matching results to the black box tests, also in line with the Opus 4.7 system card. The more you echo real events, the less you trigger the relevant probes.
Inhibiting all three known evaluation awareness vectors led to moderate increases in misaligned behavior and decreases in verbalized eval awareness, as one would expect given both priors and running the same experiments on Mythos and Opus 4.7. The question is magnitude, and the magnitude is not small:
6.6.3 goes into unverbalized grader awareness, and finds it in about 5% of cases, with it being ‘exploitative’ in 0.5% of cases. Thus, most grader awareness is indeed unverbalized, even if this catches all of it.
Overall it seems like, outside of model welfare purposes, we are not yet learning much via looking inside the box. I’m mostly happy to keep it that way if we can.
That’s All For Now
I’m getting this first part out in time for the weekend. So far, I’m liking Opus 4.8 a lot, and it seems quite smart. I’m scrapping my old custom instructions and starting over and we’ll see how that goes.
Next week I’ll cover model welfare and capabilities and everyone’s reactions, in either 1 or 2 additional posts.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み