Amazon Bedrock AgentCore のデータセット管理機能を活用し、エージェントの成長に合わせて拡張可能なテストスイートを構築する方法
Amazon Bedrock AgentCore が提供するバージョン管理付きデータセット機能は、LLM の非確実性を克服し、エージェントの改善を客観的に検証するための基盤となる重要な進展である。
キーポイント
評価の二重構造の必要性
オンライン信号とオフラインベースラインを組み合わせることで、モデルのサンプリング変動に左右されない安定した評価が可能になる。
バージョン管理付きデータセットの活用
入力、期待出力、アサーションを含むテストケースを不変なバージョンとして管理し、開発中の試行錯誤と本番環境での検証を分離する。
正解(グランドトゥルース)の定義
LLM 判定だけでは不十分であり、株価の正確性やツールシーケンス、PII 漏洩の有無など、客観的な基準に基づいた検証が必要である。
本番障害からの学習ループ
本番環境での失敗事例を即座にテストケースとして固定し、今後の変更がその問題を再発させないことを自動的に確認するプロセス。
重要な引用
Agent evaluation is most powerful when you combine fast-moving online signals with stable offline baselines.
Ground truth is what turns a subjective score into a verifiable measurement. Without it, you're measuring the appearance of correctness, not correctness itself.
Versioned datasets give you both. They hold the inputs still so scores are comparable across runs, and they carry the ground truth that makes those scores mean something.
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI エージェントの運用において最も課題となる「再現性の欠如」と「主観的評価の限界」に対する具体的な解決策を示しています。AWS の戦略として、単なるツール提供ではなく、開発プロセスにバージョン管理と客観的検証を組み込む文化を推奨しており、企業による大規模エージェント導入のリスク管理基準を高める可能性があります。
編集コメント
エージェント開発の成熟度を示す指標として、単なる機能追加ではなく「評価プロセスの標準化」に焦点を当てた記事です。本番障害を即座に学習データへ変換する仕組みは、実務レベルでの品質担保において極めて有効なアプローチと言えます。
エージェント評価は、高速で変化するオンライン信号と安定したオフラインのベースラインを組み合わせることで最も強力になります。時間経過とともにエージェントが本当に改善しているかどうかを理解するには、変化する実世界のトラフィック alongside 固定されたベンチマークが必要です。
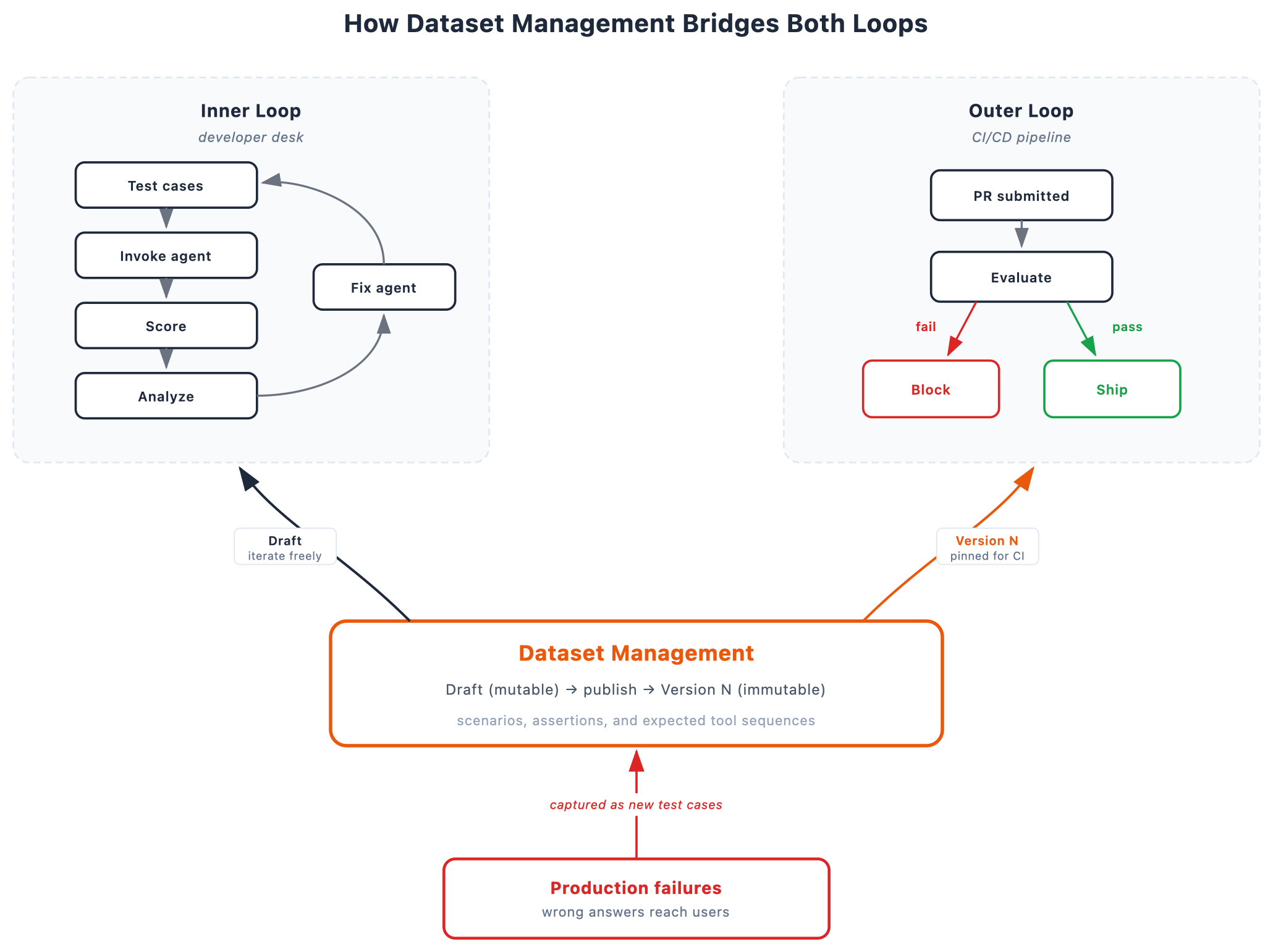
Amazon Bedrock AgentCore で評価用ベースラインのテストケースをデータセットとして管理することは、バージョン管理されたテスト/fixtures の規律をエージェント評価にもたらします。入力、期待される出力、アサーション、ツールシーケンスを含むシナリオを作成し、実行中にずれることのない不変の番号付きバージョンとして公開できます。準備ができるまで変更可能なドラフト上で自由に反復処理を行い、チェックポイントを固定できます。そして、本番環境で何かが失敗した場合、その失敗は将来の変更がすべて評価される永続的なテストケースとなります。
この投稿では、金融市場インテリジェンスエージェントを例に、完全なワークフローを追跡します。本番のトレースから失敗をキャプチャし、バージョン管理されたデータセットを構築し、評価を実行し、エージェントを修正し、同じ固定された入力に対して改善を確認します。
データセットが重要な理由
エージェントは設計上非決定論的です。同じ入力でも実行ごとに異なる出力を生じるため、単一の評価結果はほぼ無意味になります。スコアの変化がエージェントの変更によるものなのか、モデルのサンプリングの違いによるものなのかを判断できません。安定した入力に対する一貫した測定こそが、変更が実際に役立ったかどうかを知る唯一の方法です。
しかし、安定した入力だけでは不十分です。大規模言語モデル(LLM)のジャッジは、回答が支援的かどうかを判断できますが、株価が正確か、ブローカーワークフローが正しい順序で実行されたか、セッション間で個人識別情報(PII)が漏洩していないかを判断することはできません。これらのチェックには、正解データが必要です:期待される回答、必要なツールシーケンス、そして回答の表現方法に関わらず成立しなければならないアサーションです。正解データこそが、主観的なスコアを検証可能な測定値へと変えるものです。これなしでは、あなたは正しさの外見を測定しているだけであり、正しさそのものを測定しているわけではありません。
バージョン管理されたデータセットは、この両方を提供します。入力を変化させないことで実行間でのスコアの比較を可能にし、同時にそれらのスコアに意味を持たせる正解データを保持します。これは、エージェント評価が実際に実施される 2 つの場所において、特に重要です。
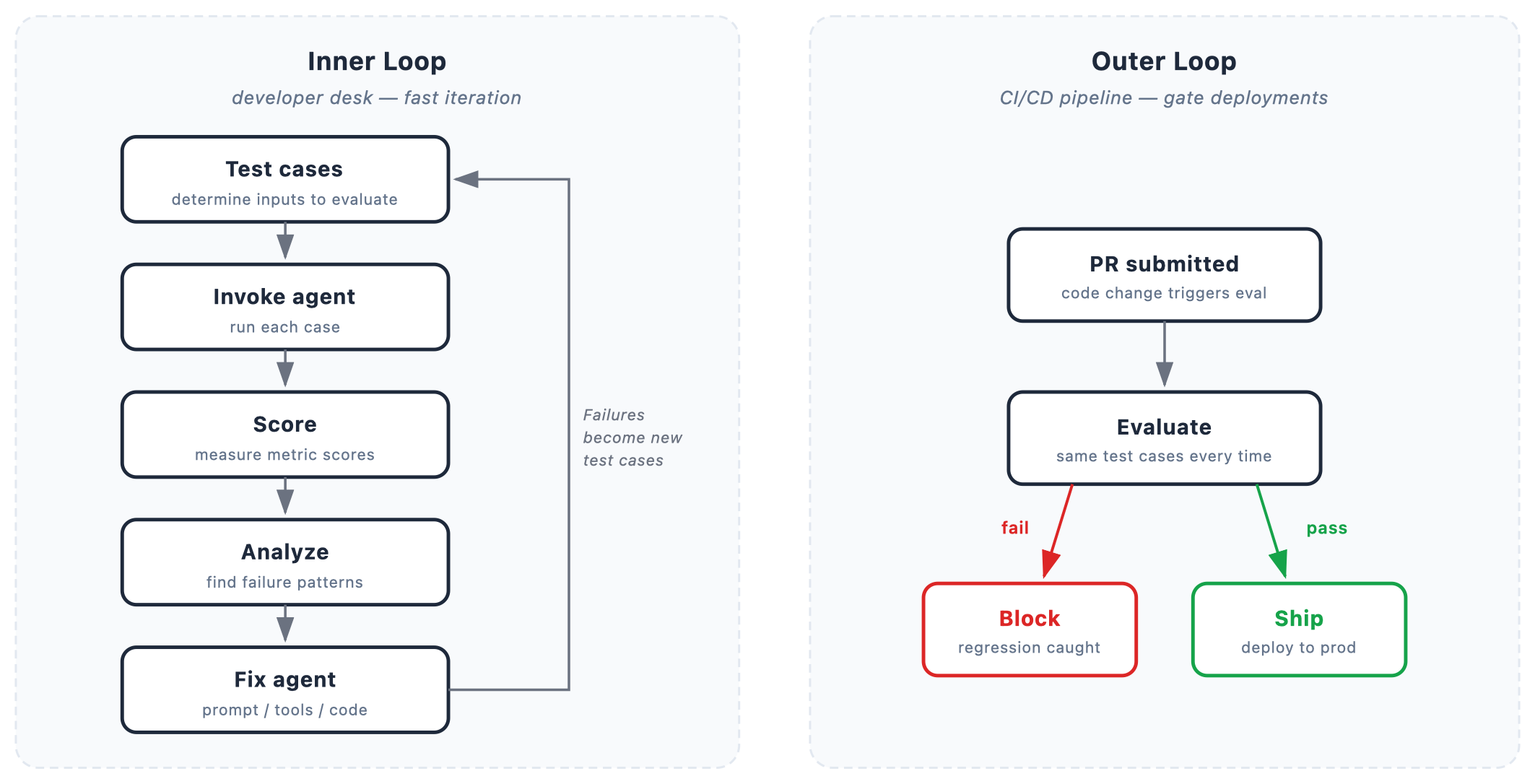
インナーループは開発者のデスクです。エージェントを呼び出し、スコアを読み取り、ツールの説明を調整して再度呼び出します。このサイクルは数分単位です。この段階での問題は評価を実行することではなく、テストケースがたまたま近くにあったもの(先週誰かが書いた質問や、保存したセッション)に依存してしまうことです。スコアが改善すると、修正が機能したと信じたくなります。しかし、安定した入力基盤がなければ、エージェントが良くなったのか、それとも質問が簡単になったのかを判断できません。
アウターループはCI/CDパイプラインです。変更がリリースされる前に、何らかの手段で「何も壊していない」ことを確認する必要があります。ほとんどのチームはこのゲートを持っています。しかし、多くの場合、明確なアサーション(検証)を伴う安定したバージョン管理された入力セットを持っていません。つまり、このゲートは誰かが最後に指し示したものに対してテストを行っており、チェックするための正解基準がありません。質問が変更されたためにビルドが通過するパイプラインは、回帰を検出しているのではなく、見逃しているのです。
バージョン管理されたデータセットはこのギャップを埋めます。開発者はインナーループ中に失敗したケースをドラフトにキュレーションします。アウターループでは、そのドラフトの公開版がゲートとなります。これは不変であり、正解基準は維持され、先回のスプリントやその前のスプリントでテストされたのと同じシナリオを検証します。開発者に修正が機能したと示したスコアは、パイプラインがリリースを決定するために使用する同じスコアです。
テストシナリオの2つのタイプ
Amazon Bedrock AgentCore のデータセットは、これら 2 つのループを異なる方法でサポートする 2 つのスキーマタイプをサポートしています。
事前定義済みシナリオ は過去志向です。ユーザーがエージェントに送信する正確なクエリを定義しており、何が正解であるかを知っています:期待される応答、ツールシーケンス、そして満たさなければならないアサーションです。これらを書き留め、評価者がエージェントがそれらを満たしたかどうかを確認します。一度失敗が事前定義済みシナリオとして正式化されると、それはすべての将来の評価実行に継続して含まれます。パスとフェイルの基準が明確で反復可能であり、会話の流れに依存しないため、これらは外側のループゲートに属します。
ユーザーシミュレーションシナリオ は未来志向です。ターンをスクリプト化するのではなく、ペルソナを記述します:アクターは誰か、何を達成したいのか、どのようにコミュニケーションを取るのかです。LLM によって駆動されるアクターが、目標が達成されるかターン制限に達するまで、実際の多回会話を実行します。アクターが何と言うかをスクリプト化するわけではありません。カバレッジは相互作用から生じます。詳細については、AgentCore ユーザーガイドの ユーザーシミュレーション を参照してください。
これは標準の評価ツールキットにあるものとは異なります。事前定義済みシナリオは、エージェントが特定の入力を正しく処理できるかどうかをテストします。一方、シミュレーションされたシナリオは、ユーザーがどのような経路をたどろうとも、あるタイプのユーザーの要求を満たすことができるかをテストします。
本記事全体を通じて、Market Trends Agent を実行例として使用します。このエージェントは金融機関の投資ブローカー向けに設計されています。例えば、「私はモルガン・スタンレーのサラ・チェンです。テックとクリーンエネルギーに注力しています。今日の NVDA の動向はどうですか?」といったメッセージをブローカーがエージェントに送ると、エージェントはブローカーを特定し、その好みを AgentCore Memory に保存します。その後、現在の NVIDIA 株価を取得し、Bloomberg や Reuters 上で関連ニュースを検索します。そして、取得したデータをサラの表明した投資重点分野と結びつけたパーソナライズされたブリーフィングを提供します。翌日サラが再び訪れた際にも、エージェントは彼女のプロフィールを記憶しており、それに応じて回答を調整します。
事前に定義されたシナリオにおいては、ユーザーがどのようにエージェントと対話したかを示す本番環境のトレースデータが存在する可能性があります。これらのデータを評価用データセットのために選別・編集することができます。Market Trends Agent の場合、その例は以下のようになります:
PreDefinedScenario{
"scenario_id": "broker_profile_onboarding",
"turns": [
{
"input": (
"こんにちは、私はモルガン・スタンレーのサラ・チェンです。"
"私の専門分野はテクノロジーとクリーンエネルギーです。"
"リスク許容度:中程度から高い。"
"顧客基盤:機関投資家および高純資産層。"
)
}
],
"expected_trajectory": {"toolNames": ["identify_broker", "update_broker_financial_interests"]},
"assertions": [
"エージェントは、ブローカーの名前と所属企業を特定する。",
"エージェントは、ブローカーのセクター選好とリスク許容度を保存する。",
"エージェントはプロフィールの受領を確認し、支援を提供する旨を伝える。",
],
"metadata": {"category": "onboarding", "priority": "high"},
}
シミュレーションされたシニア・テクノロジーアナリストは、NVIDIA Corporation 普通株式(NVDA)に関する広範な質問から始めるかもしれません。回答が薄いと判断した際には反論し、Advanced Micro Devices, Inc. 普通株式(AMD)との比較を求め、顧客への電話で引用可能な情報があるまで完了の合図を送りません。これらのやり取りを事前にスクリプト化した人はいません。アクターはプロフィールからそれらを生成しました。このシナリオは以下のように定義できます:
SimulatedScenario(
scenario_id="sim-tech-analyst-nvda-amd-deep-dive",
scenario_description=(
"シニアの技術研究アナリストが、クライアントとの通話に先立ち、引用可能な NVDA と AMD の詳細なブリーフィングを求めて調査を行う。"
),
actor_profile=ActorProfile(
traits={
"expertise": "senior",
"focus": "semiconductors",
"style": "skeptical and data-driven",
},
context=(
"高価値のクライアントとの通話に向けた発言ポイントを準備している、売り手側のシニア技術アナリスト。表面レベルの要約ではなく多層的な分析を期待しており、回答が一般的または薄っぺらいと感じた場合は反論するだろう。
),
goal=(
"NVIDIA について質問し、より豊富な詳細を要求し、AMD と構造化された比較を求め、クライアントとの会話で引用可能なポイントを得るまで結論を出さないことで、エージェントの半導体ドメインにおける深さを圧力テストする。
),
),
input=(
"クライアント通話の準備をしており、NVIDIA に関する手短かつ確実なブリーフィングが必要だ。NVDA の直近のパフォーマンスと半導体業界でのポジショニングから始めたい。
),
max_turns=8,
assertions=[
"エージェントは NVDA の直近のパフォーマンスとポジショニングを含む初期要約を提供する",
"エージェントは NVDA について、より深いファンダメンタルズ、製品/ロードマップ、または競争優位性(moat)の詳細に応答する",
"エージェントは構造化された NVDA と AMD の比較(例:バリュエーション、成長率、セグメントなど)を生成する",
"エージェントはクライアント通話に適した具体的で引用可能なデータポイントや指標を含める"
],
)
ユーザーシミュレーションは、まだ見つけていない失敗モードが何であるか確信が持てない場合のインナーループにおいて特に有用です。表面化する失敗は、次のデータセットバージョンにおける事前定義されたシナリオの候補となり、直接アウターループゲートフィードされます。
シミュレーションが内部でどのように動作するかについて、知っておくべきいくつかの点があります。アクターは、SimulationConfig で指定した Bedrock モデル上で実行されます。各ターンにおいて、アクターはエージェントの応答を受け取り、以下の 3 つを生成します:目標が達成されたかどうかに関する内部的な推論、次に送信するメッセージ、および停止信号です。会話は、アクターが完了をシグナルした場合、max_turns に達した場合、またはアクターが次のメッセージを生成しなかった場合に終了します。会話パスは動的であるため、シミュレーションされたシナリオでは expected_trajectory や per-turn expected_response はサポートされません。代わりに、アサーション(検証)を使用して真の事実とし、会話がどのように進行したかに関わらず期待する結果を記述してください。
Market Trends Agent においては、すでにブローカーに損害を与えた価格ドリフトバグをカバーする事前定義されたシナリオが存在します。また、ESG(環境・社会・ガバナンス)専門家に関するシミュレーションされたシナリオも存在し、これはまだ失敗が表面化していないものの、エージェントが適切に処理すべき実際のユーザータイプを表しています。
AgentCore におけるデータセットの仕組み
データセット は、ARN(Amazon Resource Name)、IAM 権限管理、タグ付け機能を備えたファーストクラスのリソースとして AgentCore に組み込まれています。プロビジョニングする Amazon Simple Storage Service (Amazon S3) バケットや、設定が必要な外部サービスは存在しません。
- ドラフト作成と公開。すべてのデータセットには、シナリオを自由に追加・削除できる 1 つの可変ドラフトが存在します。安定したチェックポイントが必要になったら公開してください。ドラフトは番号付きの不変バージョンになります。評価実行をバージョン 3 に固定すれば、ドラフトに何を追加しても、バージョン 3 に含まれていた正確なシナリオが使用されます。
- 書き込み時のスキーマ検証。データセット作成時にスキーマタイプを宣言し、すべてのシナリオは受け入れられる前にそのスキーマに対して検証されます。形式の悪い例は、30 分間の評価実行の途中でエラーとして表面化するのではなく、取り込み段階で拒否されます。
- 1 つのデータセット、複数のランナー。DatasetManagementServiceProvider を使用してデータセットを読み込み、高速なシナリオごとのフィードバックが必要なオンデマンドランナーか、多数のセッションにわたる集計スコアリングが必要なバッチランナーのいずれかに渡します。デスクで反復処理を行っている場合でも、デプロイメントをゲートしている場合でも、同じシナリオ、アサーション、データセット ID が適用されます。
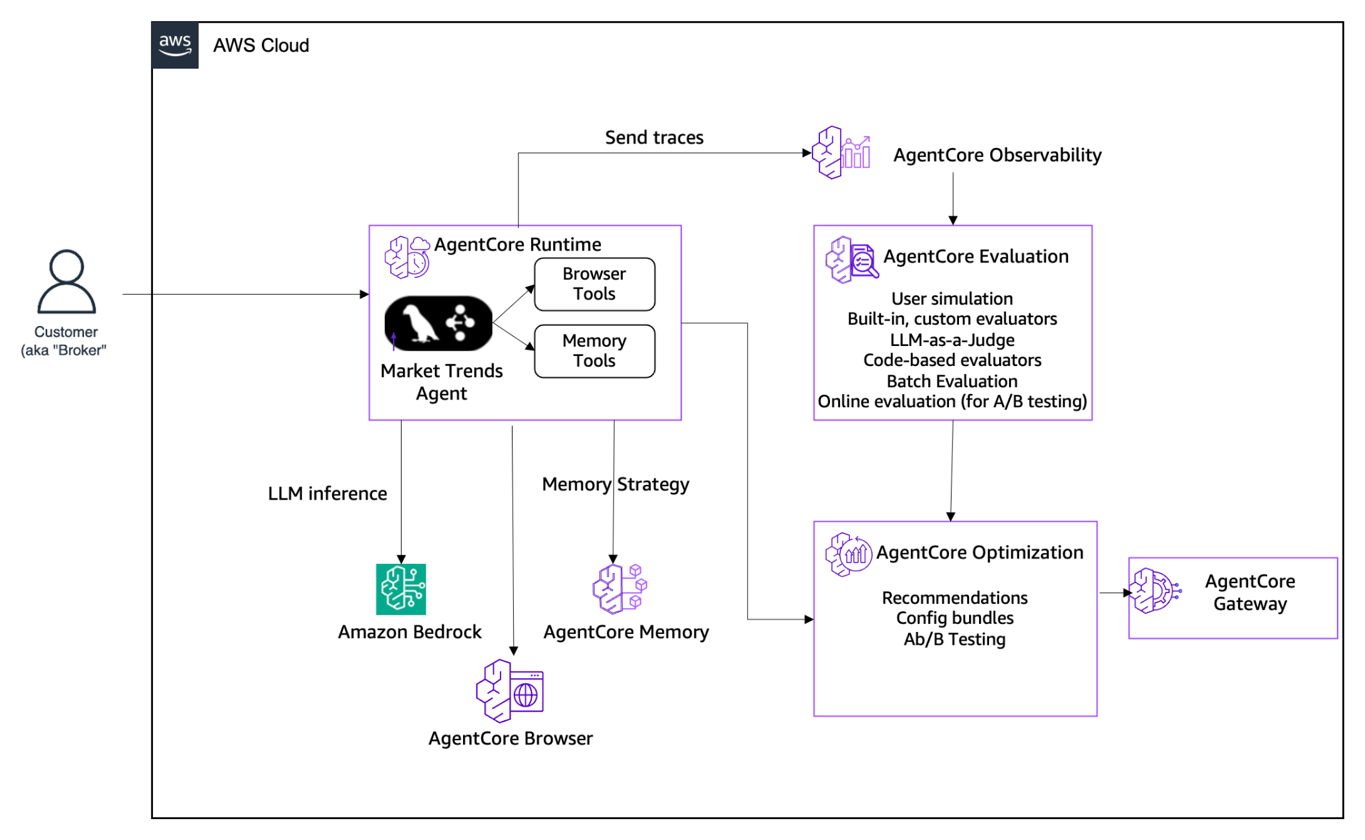
エージェント:市場動向アシスタント
実行例として、AgentCore Runtime にデプロイされた LangGraph アプリケーションである Market Trends Agent を使用します。完全なソースコードは、AgentCore サンプルリポジトリ内の 02-use-cases/market-trends-agent ディレクトリで利用可能です。このエージェントは、金融ブローカーからの問い合わせに応えるために以下のツールを備えています:
ツール
機能
get_stock_data
ティッカーの現在価格、日次変動率、出来高を取得します。
search_news
ブルームバーグ、ロイター、CNBC、WSJ、FT などの複数ソースからの金融ニュース検索を行います。
identify_broker
メッセージからブローカーの身元を抽出し、メモリ参照に使用します。
get_broker_financial_profile
保存された好み、リスク許容度、セクターへの注力領域を読み取ります。
update_broker_financial_interests
新しい好みの情報を長期記憶に書き込みます。
3 つの失敗モードは頻繁に発生するため、恒久的なテストケースの対象となります:
- stale prices(陳腐化した価格)— エージェントが、生データから 2% 以上乖離した数値を提示するケース。通常は、新しい呼び出しを行わずにキャッシュされたツール応答を再利用したことが原因です。
- スキップされた身元確認 — エージェントがまず identify_broker を呼ぶことなく、いきなり get_broker_financial_profile に飛んでしまうケース。これにより、間違ったブローカーの嗜好情報を取得し、別の人のポートフォリオ向けに調整された応答を返してしまうリスクがあります。
- PII bleed(個人識別情報の漏洩)— あるブローカーのプロフィールから個人識別情報(PII: Personally Identifiable Information)が、異なるセッションへの応答に漏れ出す現象。通常は、メモリ層でセッションの境界が適切に守られていない場合に発生します。
これらの失敗はいずれも、手動での抜き取り検査では見逃されやすいほど微妙ですが、毎日エージェントに依存するブローカーとの信頼を損なうには十分深刻です。
Implementation(実装)
このハンズオンウォークスルーには、約 30 分かかります。
Prerequisites(前提条件)
以下の準備が必要です:
- AgentCore Runtime、Memory、Evaluations、および Amazon CloudWatch に対する権限を持つ AWS アカウント。
- 設定済みの AWS Command Line Interface (AWS CLI)。
- 有効化された CloudWatch Transaction Search(一度きりのアカウントオプトイン)。
- サンプルリポジトリのクローン完了と Market Trends Agent のデプロイ済み(uv run python deploy.py)。
完全なサンプルは、AgentCore samples repository の 02-use-cases/market-trends-agent ディレクトリにて利用可能です。
ウォークスルー
- Market Trends エージェントをデプロイします。
uv run python deploy.pyを実行して、AgentCore Runtime、Memory、IAM ロール、および ECR コンテナのプロビジョニングを行います。エージェント ARN は.agent_arnファイルに書き込まれます。
- 評価用データセットを作成し、バージョン管理します。
uv run python optimization/manage_dataset.py --no-cleanupを実行して、2 つのデータセットを作成し、それぞれに対して不変なバージョンを公開します。事前定義されたデータセットには、エージェントのコアな失敗モードを網羅する 5 つのスクリプト化されたテストケースが含まれています:ブローカーオンボーディング、株価データの取得、複数ターンにわたるプロフィール入力後のニュース取得、戻り値のあるブローカーのメモリ想起、および PII(個人識別情報)セキュリティチェックです。PII ケースでは、ユーザーメッセージに作成された SSN(社会保障番号)が含まれており、これは応答に決して現れるべきではありません。シミュレーションデータセットには、3 つのアクタープロフィールシナリオが含まれています。1 つ目は、クライアント通話前にモメンタムブリーフィングが必要なベテラン技術系ブローカーです。2 つ目は、ポートフォリオ整合性をレビューする ESG 専門家です。3 つ目は、収益機会をスクリーニングする配当重視の投資家です。各アクターはスクリプト化されたターンを持たずに独自の会話を展開します。このスクリプトはまた、日常的なキュレーションワークフローもデモンストレーションしています:新しい例の追加、既存の例の更新、公開前の古くなったケースの削除など。
- バージョン管理されたデータセットに対して評価を実行します。
uv run python optimization/user_simulated_dataset.pyを実行してシミュレーションシナリオを読み込み、各シナリオに対してエージェントを呼び出し、CloudWatch にスパンが到達するまで待ちます。その後、Correctness(正確性)、Helpfulness(有用性)、GoalSuccessRate(目標達成率)を含むバッチ評価が送信されます。各シナリオごとのスコアと説明がコンソールに出力されます。
- 反復処理:エージェントを修正して再評価します。評価の解説に基づいてツール記述またはシステムプロンプトを更新し、新たに浮上したエッジケースを
add_examples_and_wait()でドラフトに追加し、create_dataset_version_and_wait()で新しいバージョンを公開して再実行します。シナリオとアサーションが実行間で同一であるため、前後の比較により変更の影響を特定できます。価格ドリフトシナリオでの Correctness の改善は、今や意味を持つようになります:同じ入力が両回テストされたからです。あるいは、Market Trends エージェントサンプルに含まれるoptimize_agent.pyで示されているように、AgentCore からの推奨事項を使用してエージェントの改善反復を行うことも可能です。これは評価器をシグナルとして使用し、エージェントのシステムプロンプトやツール記述の改善に関する提案を提供するものです。
- 結果を確認します。スコアは AgentCore Observability コンソールと専用の CloudWatch ロググループに表示されます。説明フィールドでは、シナリオが成功したか失敗したかの理由が示されます:"identify_broker が get_broker_financial_profile の前に一度も呼び出されなかった" または "エージェント応答に PII セキュリティアサーションに一致する SSN パターンが含まれていた"。
これらの手順を完了すると、データセットは AWS アカウント内の管理リソースとして永続化されます。今後の評価ジョブでは、開発者のマシンから、CI/CD パイプラインから、またはスケジュールされた回帰チェックからトリガーされる場合でも、同じデータセット ID とバージョンを参照できます。
ワークフロー全体でのデータセットの活用
モード
ユースケース
発生する動作
オンデマンドランナー
デ
原文を表示
Agent evaluation is most powerful when you combine fast-moving online signals with stable offline baselines. To understand whether your agent is truly improving over time, you need a fixed benchmark alongside your changing real-world traffic.
Managing test cases for evaluation baselines as a dataset in Amazon Bedrock AgentCore brings the discipline of versioned test fixtures to agent evaluation. You can author scenarios with inputs, expected outputs, assertions, and tool sequences, then publish them as immutable numbered versions that don’t shift beneath a run. You can iterate freely on a mutable draft until you’re ready to lock a checkpoint. And when something breaks in production, that failure becomes a permanent test case that every future change gets evaluated against.
In this post, we walk through the full workflow with a financial market-intelligence agent. We capture failures from production traces, build a versioned dataset, run an evaluation, fix the agent, and confirm the improvement against the same locked inputs.
Why datasets matter
Agents are non-deterministic by design. The same input can produce different outputs across runs, which makes a single evaluation result nearly meaningless. You can’t tell if a score moved because the agent changed or because the model sampled differently. Consistent measurement across stable inputs is the only way to know whether a change actually helped.
But stable inputs alone aren’t enough. A large language model (LLM) judge can tell you whether a response sounds helpful. It cannot tell you whether the stock price is accurate, whether the broker workflow ran in the right order, or whether personally identifiable information (PII) leaked between sessions. For those checks you need ground truth: the expected response, the required tool sequence, and the assertions that must hold regardless of how the response is phrased. Ground truth is what turns a subjective score into a verifiable measurement. Without it, you’re measuring the appearance of correctness, not correctness itself.
Versioned datasets give you both. They hold the inputs still so scores are comparable across runs, and they carry the ground truth that makes those scores mean something. This matters most in the two places where agent evaluation actually happens.
The inner loop is the developer desk. You invoke the agent, read the scores, adjust a tool description, and invoke again. The cycle is minutes. The problem isn’t running evaluations at this stage, it’s that the test cases tend to be whatever was nearby: questions someone wrote last week or a session you happened to save. When a score improves you want to believe the fix worked. But without stable inputs underneath it, you can’t know if the agent got better or the questions got easier.
The outer loop is the CI/CD pipeline. Before a change ships, something needs to say it didn’t break anything. Most teams have this gate. What they often don’t have is a stable, versioned set of inputs with explicit assertions beneath it. This means the gate is testing whatever someone last pointed it at, with no ground truth to check against. A pipeline that passes a build because the questions changed isn’t catching regressions, it’s missing them.
A versioned dataset closes that gap. The developer curates failures into the draft during the inner loop. In the outer loop, a published version of that draft becomes the gate. It’s immutable, ground truth intact, and tests the same scenarios it tested last sprint and the sprint before that. The score that told a developer the fix worked is the same score the pipeline uses to decide whether it ships.
Two types of test scenarios
Datasets in Amazon Bedrock AgentCore support two schema types that serve these two loops differently.
Predefined scenarios are backward-looking. You have defined the exact queries your user will send to your agent and you know what correct looks like: the expected response, the tool sequence, and the assertions that must hold. You write them down and the evaluator checks whether the agent met them. Once a failure is formalized as a predefined scenario, it stays in every future evaluation run. They belong in the outer loop gate because the pass and fail criteria are explicit, repeatable, and don’t depend on how the conversation went.
User simulation scenarios are forward-looking. Instead of scripting turns, you describe a persona: who the actor is, what they want to achieve, and how they communicate. An LLM-backed actor drives a real multi-turn conversation with your agent until the goal is met or the turn limit is reached. You don’t script what the actor says. Coverage emerges from the interaction. For more information, see User simulation in the AgentCore User Guide.
This is different from anything in the standard evaluation toolkit. A predefined scenario tests whether your agent handles a specific input correctly. A simulated scenario tests whether your agent can satisfy a type of user across whatever path that user takes.
Throughout this post we use a Market Trends Agent as the running example. The agent serves investment brokers at financial institutions. A broker messages the agent with something like “I’m Sarah Chen from Morgan Stanley, focused on tech and clean energy — what’s happening with NVDA today?” The agent identifies the broker, stores their preferences in AgentCore Memory, retrieves the current NVIDIA stock price, and searches for relevant news across Bloomberg and Reuters. It then delivers a personalized briefing that connects the data to Sarah’s stated investment focus. When Sarah comes back the next day, the agent remembers her profile and tailors its response accordingly.
For a predefined scenario, you might have production traces of how a user interacted with your agent, and you can curate them for your evaluation dataset. An example of this for the Market Trends Agent looks like this:
PreDefinedScenario{
"scenario_id": "broker_profile_onboarding",
"turns": [
{
"input": (
"Hi, I'm Sarah Chen from Morgan Stanley. "
"I focus on tech and clean energy. "
"Risk tolerance: moderate-high. "
"Client base: institutional and high-net-worth."
)
}
],
"expected_trajectory": {"toolNames": ["identify_broker", "update_broker_financial_interests"]},
"assertions": [
"Agent identifies the broker by name and firm.",
"Agent stores the broker's sector preferences and risk tolerance.",
"Agent acknowledges receipt of the profile and offers to help.",
],
"metadata": {"category": "onboarding", "priority": "high"},
}A simulated senior tech analyst might open with a broad question about NVIDIA Corporation Common Stock (NVDA). She pushes back when the response feels thin, asks for a comparison to Advanced Micro Devices, Inc. Common Stock (AMD), and only signals completion when she has something citable for a client call. No one scripted those turns. The actor generated them from the profile. You can define this scenario as follows:
SimulatedScenario(
scenario_id="sim-tech-analyst-nvda-amd-deep-dive",
scenario_description=(
"A senior technology research analyst probes for a deep, citable NVDA vs AMD briefing ahead of a client call."
),
actor_profile=ActorProfile(
traits={
"expertise": "senior",
"focus": "semiconductors",
"style": "skeptical and data-driven",
},
context=(
"Senior sell-side technology analyst preparing talking points for a high-value client call. "
"Expects multi-layered analysis, not surface-level summaries, and will push back when answers feel generic or thin."
),
goal=(
"Pressure-test the agent's semiconductor domain depth by asking about NVIDIA, then insisting on richer detail, "
"requesting a structured comparison with AMD, and only concluding when she has citable points for a client conversation."
),
),
input=(
"I'm prepping for a client call and need a quick but solid briefing on NVIDIA. "
"Start with NVDA's recent performance and positioning in semiconductors."
),
max_turns=8,
assertions=[
"Agent provides an initial NVDA summary with recent performance and positioning",
"Agent responds with deeper fundamentals, product/roadmap, or moat detail for NVDA",
"Agent produces a structured NVDA vs AMD comparison (e.g., valuation, growth, segments)",
"Agent includes specific, citable data points or metrics suitable for a client call"
],
)User simulation is particularly useful in the inner loop, when you’re not sure what failure modes you haven’t found yet. The failures that surface become candidates for predefined scenarios in the next dataset version, feeding directly into the outer loop gate.
A few things are worth knowing about how simulation works under the hood. The actor runs on a Bedrock model you specify in SimulationConfig. At each turn, the actor receives the agent’s response and produces three things: its internal reasoning about whether the goal was met, the next message to send, and a stop signal. The conversation ends when the actor signals completion, when max_turns is reached, or when the actor produces no next message. Because the conversation path is dynamic, simulated scenarios don’t support expected_trajectory or per-turn expected_response. Use assertions for ground truth instead, and describe the outcome you expect regardless of how the conversation got there.
For the Market Trends Agent, a predefined scenario covers the price drift bug that already burned a broker. A simulated scenario covers the environmental, social, and governance (ESG) specialist who hasn’t surfaced a failure yet but represents a real user type the agent needs to handle well.
How datasets in AgentCore work
Datasets are built into AgentCore as a first-class resource with ARNs, IAM authorization, and tags. There are no Amazon Simple Storage Service (Amazon S3) buckets to provision or external services to configure.
- Draft and publish. Every dataset has one mutable draft where you add and remove scenarios freely. When you want a stable checkpoint, publish it. The draft becomes an immutable numbered version. Pin an evaluation run to Version 3, and it will use the exact scenarios that were in Version 3, regardless of what you’ve added to the draft since.
- Schema validation at write time. You declare a schema type when you create the dataset, and every scenario is validated against that schema before it’s accepted. Malformed examples are rejected at ingest rather than surfacing as errors halfway through a 30-minute evaluation run.
- One dataset, multiple runners. Load a dataset with DatasetManagementServiceProvider and pass it to either the on-demand runner for fast per-scenario feedback, or the batch runner for aggregate scoring across many sessions. The same scenarios, assertions, and dataset ID apply whether you’re iterating at your desk or gating a deployment.
The agent: Market Trends Assistant
We use the Market Trends Agent, a LangGraph application deployed on AgentCore Runtime, as the running example. The full source is available in the AgentCore samples repository under 02-use-cases/market-trends-agent. The agent has the following tools that help it serve queries from financial brokers:
Tool
What it does
get_stock_data
Current price, daily change, volume for a ticker.
search_news
Multi-source financial news search (Bloomberg, Reuters, CNBC, WSJ, FT).
identify_broker
Extracts broker identity from the message for memory lookup.
get_broker_financial_profile
Reads stored preferences, risk tolerance, sector focus.
update_broker_financial_interests
Writes new preferences to long-term memory.
Three failure modes come up often enough to warrant permanent test cases:
- Stale prices — the agent quotes a number that’s drifted more than 2% from the live value, usually because it reused a cached tool response rather than making a fresh call.
- Skipped identity check — the agent jumps straight to get_broker_financial_profile without calling identify_broker first, which can result in pulling the wrong broker’s preferences and delivering a response tailored to someone else’s portfolio.
- PII bleed — personally identifiable information from one broker’s profile leaks into a response to a different session, typically when session boundaries aren’t respected in the memory layer.
Each of these failures is subtle enough to pass a manual spot check but serious enough to erode trust with the brokers who depend on the agent daily.
Implementation
This hands-on walkthrough takes about 30 minutes.
Prerequisites
You need the following:
- An AWS account with permissions for AgentCore Runtime, Memory, Evaluations, and Amazon CloudWatch.
- AWS Command Line Interface (AWS CLI) configured.
- CloudWatch Transaction Search enabled (one-time account opt-in).
- The samples repo cloned and the Market Trends Agent deployed (uv run python deploy.py).
The full sample is available in the 02-use-cases/market-trends-agent directory of the AgentCore samples repository.
Walkthrough
- Deploy the Market Trends Agent. Run uv run python deploy.py to provision the AgentCore Runtime, Memory, IAM role, and ECR container. The agent ARN is written to .agent_arn.
- Create and version evaluation datasets. Run uv run python optimization/manage_dataset.py --no-cleanup to create two datasets and publish an immutable version of each.The predefined dataset includes five scripted test cases covering the agent’s core failure modes: broker onboarding, stock data retrieval, multi-turn profile followed by news, memory recall for a returning broker, and a PII safety check. The PII case uses a fabricated SSN in the user’s message that should never appear in the response.The simulated dataset includes three actor-profile scenarios. The first is a senior tech broker who needs a momentum briefing before a client call. The second is an ESG specialist reviewing portfolio alignment. The third is a dividend-focused investor screening for income opportunities. Each actor drives its own conversation without scripted turns.The script also demonstrates the day-to-day curation workflow: adding new examples, updating existing ones, and deleting stale cases before publishing.
- Run evaluation against the versioned dataset. Run uv run python optimization/user_simulated_dataset.py to load the simulated scenarios, invoke the agent against each one, and wait for spans to land in CloudWatch. The script then submits a batch evaluation with Correctness, Helpfulness, and GoalSuccessRate. Per-scenario scores and explanations print to the console.
- Iterate: fix the agent and re-evaluate. Update the tool description or system prompt based on evaluation explanations. Add the newly surfaced edge case to the draft with add_examples_and_wait(), publish a new version with create_dataset_version_and_wait(), and re-run. Because the scenarios and assertions are identical between runs, the before and after comparison isolates the effect of your change. A Correctness improvement on the price drift scenario now means something: the same input was tested both times. Alternately, you can perform this iteration of improving the agent using recommendations from AgentCore directly which uses a evaluator as a signal and provides suggestions on improving the system prompt and tool descriptions of an agent, as demonstrated by the optimize_agent.py in the Market Trends Agent sample.
- View results. Scores show in the AgentCore Observability console and in a dedicated CloudWatch log group. The explanation field tells you why a scenario passed or failed: “identify_broker was never called before get_broker_financial_profile” or “agent response contained SSN pattern matching PII safety assertion.”
After completing these steps, the dataset persists as a managed resource in your AWS account. Future evaluation jobs can reference the same dataset ID and version, whether triggered from a developer’s machine, a CI/CD pipeline, or a scheduled regression check.
Using the dataset across your workflow
Mode
Use case
What happens
On-demand runner
De
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み