政策決定にはAIの存続危機確率の不確かさは信頼しすぎである
AI Snake Oil は、AI の存在リスク確率推定が根拠薄弱であるため政策決定の指標として信頼できず、政府は不確実な数値に基づく規制を避けるべきだと主張している。
キーポイント
確率推定の信頼性欠如
AI 安全コミュニティが用いる人類絶滅確率の予測は根拠となる証拠に乏しく、単なる推測に過ぎないため政策決定には不適切である。
説明責任と民主主義原則
政府が市民の自由を制限する際には、その根拠を明確に説明する正当性が必要であり、不確実な数値だけでは正当化できない。
コスト配分の公平性
オープンソースモデルへの規制など、特定の利害関係者に不均衡なコストを負わせる政策は、根拠のないリスク予測に基づいて行うべきではない。
AI 存続リスクに参照クラスが存在しない
AI の存在リスクは過去事例と全く異なる事象であるため、確率推定に必要な「参照クラス」が定義できず、分析者の直感に依存せざるを得ない。
政策決定における確率見積もりの非信頼性
AI 存続リスクの予測は学術活動や民間企業の意思決定には有用であっても、公共政策を導く根拠として使用するには不十分であると主張している。
AI による人類絶滅の予測には帰納法が適用不可能
AI による人類絶滅は過去のどの出来事とも比較できないほど独自性が高いため、過去データに基づく帰納的推論で確率を算出することはできない。
既存の参照クラスは AI リスクの本質を捉えられていない
動物絶滅や産業革命などの過去の事例を参照クラスとして用いる試みは、超知能の開発や制御不能という不確実性の核心には何も示唆を与えない。
重要な引用
Our central claim is that AI x-risk forecasts are far too unreliable to be useful for policy, and in fact highly misleading.
Probabilities carry no authority by themselves. ... But it is possible for probabilities to be nothing more than guesses.
Justification is essential to legitimacy of government and the exercise of power.
For existential risk from AI, there is no reference class, as it is an event like no other.
We only question its use in the context of public policy.
None of those tell us anything about the possibility of developing superintelligent AI or losing control over such AI, which are the central sources of uncertainty for AI x-risk forecasting.
影響分析・編集コメントを表示
影響分析
この記事は、AI 規制の議論において「数値的なリスク推定」への盲信に警鐘を鳴らし、政策決定プロセスにおける証拠に基づくアプローチと説明責任の重要性を再認識させる。政府が不確実な予測に基づいて過度に制限的な規制を施行する際の法的・倫理的ハードルを高める効果があり、AI ガバナンスの議論の質を向上させる可能性がある。
編集コメント
AI 業界における「恐怖に基づく規制」の潮流に対し、冷静な分析視点を提供する重要な論考です。数値の重み付けよりも、その根拠となるプロセスと正当性が問われるべき時勢を反映しています。
研究者間の合意がないにもかかわらず、政府は AI に起因する存続リスクをどの程度真剣に受け止めるべきでしょうか。一方、存続リスク(x-リスク)は必然的にある程度の推測の域を出ません:具体的な証拠が得られる頃には、すでに手遅れになっている可能性があります。他方、政府は優先順位をつける必要があります—結局のところ、異星人による侵略からの x-リスクについてはあまり心配していないのです。
これは、AI の存続リスクを懸念する政策担当者向けに、根拠に基づいたアプローチを示す一連のエッセイの第一弾です。このアプローチは現実に根ざしつつも、「未知の未知」が存在することを認めるものです。
今回の第一回エッセイでは、一つの種類の証拠、すなわち確率推定値について検討します。AI セーフティコミュニティは、意思決定や政策立案を情報化するために、AI による人類絶滅の確率(特定の期間内)を予測することに大きく依存しています。例えば、数十年間で 10% という推計があれば、明らかに社会にとって最優先事項となるのに十分な高さです。
私たちの中心的な主張は、AI の存続リスクに関する予測は政策に有用であるほど信頼性が低く、実際には極めて誤解を招くものであるということです。
本シリーズの今後のエッセイを受け取るには購読してください。
カーテンの裏側を覗いてみる
もし二人の私たちが、今後十年以内に地球に宇宙人が着陸する確率を 80% と予測した場合、あなたはその可能性を真剣に受け取るでしょうか?もちろん、そうはなりません。あなたは証拠の提示を求めるでしょう。これは明白なように思えるかもしれませんが、AI の存在リスク(x-risk)に関する議論では、確率自体には権威がないという事実が忘れ去られているようです。確率は通常、何らかの根拠のある方法から導き出されるため、定量化されたリスク推計を質的なものよりも有効だと見なす強い認知的バイアスを持っています。しかし、確率が単なる推測に過ぎない可能性も十分にあります。このエッセイ全体を通じて(そしてより広く AI の存在リスクに関する議論において)、これを心に留めておいてください。
ケンタッキーダービーの勝敗確率を予測する場合、理由を示す必要はありません。あなたはそれを受け入れるか拒否するかを選べばよいのです。しかし、政策決定者が予測者が提示した確率に基づいて行動を取る場合、その確率を一般市民に説明できる能力が求められます(そしてその説明は、当然ながら予測者自身からなされなければなりません)。正当性は政府の正統性と権力の行使にとって不可欠です。自由主義民主主義の中核的な原則の一つは、合理的な人々が拒否しうる論争的な信念に基づいて国家が人々の自由を制限してはならないという点にあります。
検討されている政策に多大なコストがかかる場合、説明は特に重要であり、そのコストが利害関係者間で不均衡に配分される場合はなおさらです。良い例として、AI モデルのオープンな公開を制限することが挙げられます。政府は、オープンモデルから恩恵を受ける人々や企業に対し、推測的な将来リスクのためにこの犠牲を負うべきだと説得できるでしょうか?
本論文の主たる目的は、政策議論で引用された特定の x リスク(存在リスク)確率見積もりに正当な根拠が存在するかどうかを分析することです。学問活動としての AI x リスク予測に対して異議を唱えるものではなく、企業やその他の民間の意思決定者にとって有益である可能性もあります。私たちが疑問視するのは、これを公共政策の文脈で使用することのみです。
予言者が懐疑論者を説得しようとする方法は基本的に三つしか知られていません。帰納的、演繹的、および主観的確率推定です。以下でこれらそれぞれを検討します。いずれの方法も、両当事者が世界の基本的な前提(それ自体は証明できない)について合意することを必要とします。三つのアプローチの違いは、その一連の前提から確率見積もりが導き出される経験的および論理的な方法にあります。
参照クラス(reference class)の欠如により、帰納的確率推定は信頼性が低い
リスク推定はほとんどが帰納的であり、過去の観察結果に基づいています。例えば、保険会社は、類似するドライバーに関する過去の事故データを用いて、個人の自動車事故リスクを予測します。確率推定に用いられる観察の集合は「参照クラス」と呼ばれます。自動車保険における適切な参照クラスの例としては、同じ都市に住む運転者の集合が挙げられます。もし分析者が個人についてより多くの情報(年齢や運転する車の種類など)を持っている場合、参照クラスはさらに細分化することができます。
AI による存在リスクについては、他の事例とは全く異なる事象であるため、参照クラスが存在しません。明確に述べるならば、これは「質」の違いではなく「度合い」の問題です。常に明確な「正しい」参照クラスを用いることはできず、実際における参照クラスの選択は分析者の直感に委ねられることになります。
予測の精度は、予測対象となる事象を生成するプロセスと、参照クラス内の事象を生成したプロセスとの類似度の程度に依存し、これはスペクトラムとして捉えることができます。硬貨投げのような物理系の結果を予測する場合、過去の経験は非常に信頼性の高い指針となります。次に、自動車事故については、使用する過去データセットによってリスク推定が例えば 20% 変動する可能性があり、保険会社にとっては十分十分な精度です。

スペクトラムのさらに先には地政学的出来事があり、ここでは参照クラス(reference class)の選択がより曖昧になります。予測の専門家フィリップ・テトルックは次のように説明しています。「ギリシャのユーロ圏離脱(Grexit)は、2015 年までにどの国もユーロ圏を離脱したことがなかったため、独自の事例(sui generis)のように見えたかもしれません。しかし、これは交渉の失敗といった広範な比較クラスの一事例として、あるいは国際協定からの国家の離脱といったより狭いクラスの一事例として、さらに言えば強制通貨換算というさらに狭いクラスの事例としても捉えることができます」。彼はさらに、ソ連崩壊やアラブの春のような一見するとブラック・スワン(Black Swan)事象とされる出来事さえも参照クラスの成員としてモデル化できると考えを擁護し、帰納的推論(inductive reasoning)がこのような種類の出来事に対しても有用であると述べています。
テロックのスペクトラムにおいて、これらの事象は「究極の独自性」を表しています。地政学的な事象に限れば、これは真実かもしれません。しかし、それらの事象でさえも、AI による人類絶滅に比べればはるかに独自性が低いのです。AI の存在リスク(x-risk)に対する参照クラスを探そうとする試みを振り返ってみてください:動物の絶滅(人類絶滅の参照クラスとして)、産業革命のような過去の世界的変革(AI による社会経済的変革の参照クラスとして)、あるいは大量死をもたらす事故(地球規模の壊滅的災害を引き起こす事故の参照クラスとして)。現実を見ましょう。これらはいずれも、超知能 AI の開発やその制御不能化という、AI 存在リスク予測における不確実性の核心的な源泉について、何一つ教えてくれません。
要するに、AI に起因する人類絶滅は、過去に起こったいかなる事象ともあまりにも隔たりが遠く、帰納的推論を用いてその確率を「予測」することは不可能です。もちろん、過去の技術的ブレークスルーや過去の壊滅的事象から質的な洞察を得ることは可能ですが、AI リスクは十分に異なる性質を持つため、政策決定における正当性を担保するために必要な根拠に欠ける定量的見積もりでは不十分です。
理論の欠如により演繹的推論による確率評価は信頼できない
コナン・ドイルの『六人のナポレオン』において(ネタバレ注意!)、シャーロック・ホームズは張り込みを開始する前に、容疑者を逮捕できる確率が正確に 3 分の 2 であると宣言します。これは驚くべきことです—人間の行動に関連する事象に、どのようにして数学的に精密な確率を割り当てることができるのでしょうか?
実はホームズは、容疑者の一見すると不規則に見える観察された行動を生み出した一連の出来事を推論していました:容疑者はロンドン市内およびその周辺で異なる人々が所有するナポレオンの胸像 6 体のいずれかに隠されていると知られている宝石を、体系的に捜索しているのです。詳細はそれほど重要ではありませんが、重要な点は、容疑者も探偵の双方がその宝石がどの胸像にあるのかを知っておらず、容疑者の行動に関する他のすべては(仮定として)完全に予測可能であることです。ゆえに、正確に定量化可能な不確実性が生じます。
ここで言いたいのは、私たちが信頼できる世界のモデルを持っているならば、過去の観察に頼らなくても論理的推論を通じてリスクを見積もることができるということです。もちろん、フィクションのシナリオの外では、世界はそれほど整然としておらず、特に未来を遠く先まで投影しようとする場合にはなおさらです。
x-リスク(人類存続の危機)に関する限り、演繹モデルが存在しないという一般則に対する興味深い例外として小惑星衝突が挙げられます。帰納的かつ演繹的なリスク推定を組み合わせることで、x-リスクの発生確率を見積もることが可能になります。これは純粋に物理的なシステムについて話しているからこそ成り立つことです。この仕組みがどのように機能するかを少し振り返っておきましょう。なぜなら、この手法が他の種類の x-リスクには一般化できないことを認識することが重要だからです。
鍵となるのは、小惑星のサイズ(より正確には衝突エネルギー)と衝突頻度の間の関係をモデル化できるかどうかです。私たちが数千回の小型衝突を観測してきたため、直接観測されたことのない大型衝突の頻度を推論するために外挿を行うことができます。また、地球規模の壊滅的被害を引き起こす閾値も推定可能です。
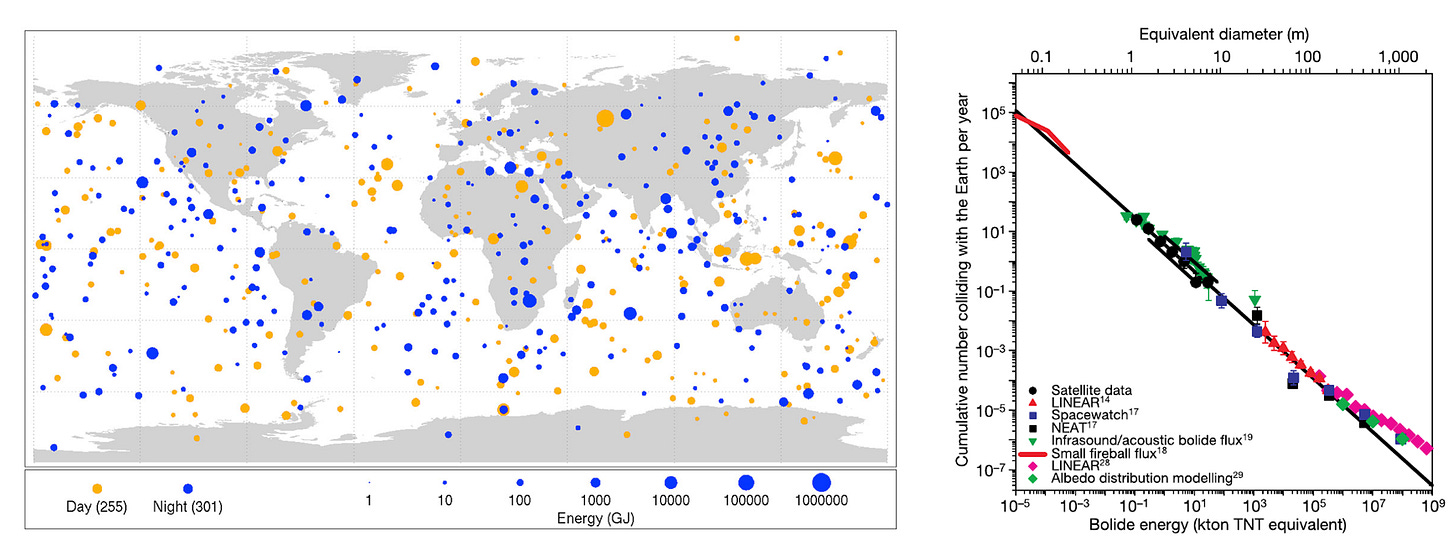
図:小型小惑星衝突に関するデータ(左側)は、絶滅レベルの衝突(右側)へと外挿することができます。
AI における不確実性は、物理システムではなく技術の進展やガバナンスに関わるものであるため、それを数学的にモデル化する方法は明確ではありません。それでも、人々は試みています。例えば、仮想的な AGI の計算要件を予測するために、いくつかの研究では、AI システムが人間の脳とほぼ同等の計算量を必要とするという前提に立ち、さらに人間の脳が必要とする計算量の数についても仮定を立てています。これらの仮定は小惑星モデルに関わるものよりもはるかに脆弱であり、これらすべてが制御喪失の問題にさえ取り組んでいるわけではありません。
主観的確率は数字に着飾った感情である
参照クラスや根拠のある理論がない場合、予測は必然的に「主観的確率」、つまり予測者の判断に基づく推測となります。驚くべきことではありませんが、これらは桁違いに異なります。
主観的な確率推定は、確率推定に対して帰納的または演繹的な根拠のいずれかを有する必要性を回避するものではありません。それは単に予測者がその推論を説明する必要を避けるだけです。説明が困難になるのは、人間の直感的推論(帰納的、演繹的、あるいはその組み合わせ)を説明する能力に限界があるためです。本質的に、これは予測者に「方法を示していないが、私の実績に基づいてこの推定を信頼してほしい」と言わせることを可能にします(次節で、なぜこれが AI 存在リスクの予測においても機能しなくなるのかを説明します)。しかし究極的には、帰納的または演繹的な根拠のいずれも欠いている場合、予測者ができることは単に数字をでっち上げるだけであり、そのでっち上げられた数字はバラバラです。

2022 年後半に予測研究研究所(Forecasting Research Institute)によって実施された「存在リスク説得トーナメント(Existential Risk Persuasion Tournament:XPT)」を想像してみてください。これはこれまでに実施された中で最も精巧かつ実行の行き届いた存在リスク予測演習であると私どもは考えています。この演習には、AI 専門家や予測専門家(図中の「スーパーフォアキャスター」)など、さまざまなグループの予測者が参加しました。AI 専門家の間では、2100 年までの AI による人類絶滅リスクに関する推定値の上限(75 パーセンタイル)は 12%、中央値は 3%、下限(25 パーセンタイル)は 0.25% です。一方、予測専門家の間では、上限(75 パーセンタイル)でもわずか 1% に過ぎず、中央値は単なる 0.38%、下限(25 パーセンタイル)に至ってはグラフ上ではゼロと視覚的に区別がつかないほどです。つまり、AI 専門家の 75 パーセンタイル予測とスーパーフォアキャスターの 25 パーセンタイル予測は、少なくとも 100 倍もの差があるのです。
これらの推定値すべては、このトピックについて深い専門知識を持つ人々によってなされたものであり、彼らは数ヶ月にわたるトーナメントに参加し、互いに説得を試みました。もしここでの予測の幅が極端すぎるように思えないなら、この一連の演習は単一のグループによってある特定の時点で実施されたものであることを忘れないでください。もし今日同じトーナメントを繰り返したり、質問の枠組みを変えたりすれば、異なる数値が得られる可能性もあります。
最も示唆に富むのは、予測者が報告書に詳細に記載されている根拠を検討することです。彼らは定量的モデルを用いておらず、特に強力な AI が開発された場合の悪い結果の発生確率について考える際にも同様です。大部分の予測者は、一般の人々がスーパーインテリジェント AI について議論する際に同様の推測を行っています。AI はシステム運用者に対する超人的な説得を通じて重要システムを乗っ取るかもしれないし、コンピュータがより速く動作するために地球の気温を下げることを目指してしまい、結果として人類を偶然に絶滅させるかもしれません。あるいは、AI は地球ではなく宇宙で資源を探そうとするため、私たちはそれほど心配する必要がないかもしれません。このような推測自体に問題はありません。しかし、AI の存在リスク(x-risk)に関しては、予測者が自分たちの直感をあなたや私、あるいは他の誰かのそれよりも信頼性のあるものにするような特別な知識、証拠、またはモデルを用いているわけではないことを明確にしておく必要があります。
「スーパーフォアキャスティング」という用語は、フィリップ・テトルックの 20 年間にわたる予測に関する研究(彼は XPT の組織者の一人でもありました)に由来します。スーパーフォアキャスターたちは、多様な情報を統合したり心理的バイアスを最小化したりするなどの手法を習得しており、これらは予測を改善するために訓練されています。これらの手法は地政学などの分野で効果があることが示されています。しかし、利用可能な有用な証拠がほとんどない場合、いかなる訓練も良い予測につながることはありません。
予測者が信頼できる定量的モデルを持っていたとしても(実際には持っていない)、彼らは「未知の未知」、つまりモデル自体が間違っている可能性を考慮しなければならない。x リスク哲学者ニック・ボストロムが指摘しているように、「リスクに対する我々の一次評価の不確実性と誤りやすさそのものも、総合的な確率割り当てに織り込む必要がある要素である。この要因は、低確率かつ高影響のリスク、特に理解されていない自然現象や複雑な社会動態、新技術に関わるもの、あるいは他の理由で評価が困難な事象において支配的となることが多い。」
これは妥当な視点であり、AI x リスク予測者もリスク評価の不確実性について非常に懸念している。しかし、この原則に従う人々にとっての帰結として、彼らの予測はモデルからの出力ではなく、単なる推測であることが保証されることになる。なぜなら、モデル自体が間違っている確率や、もしモデルが間違っていた場合のリスクを推定するためにモデルを使用することはできないからである。
予測スキルは、ユニークまたは稀な事象においては測定することができない
要約すると、主観的な AI リスク予測は桁違いにばらついています。しかし、予測者の実績を測定できれば、どの予測者を信頼すべきかを判断できるかもしれません。リスク推定を正当化するための前二つのアプローチ(帰納的・演繹的)とは対照的に、この手法では予測者が自身の推計理由を説明する必要はなく、過去の他の事象を予測する際の証明されたスキルに基づいて正当化すればよいのです。
これは地政学的イベントの分野で極めて貴重なものとなり、予測コミュニティはスキル測定に多くの労力を費やしています。キャリブレーション、ブリアー・スコア、対数スコア、あるいは予測競争ウェブサイト「Metaculus」で使用されるピア・スコアなど、予測スキルを評価する方法は多数存在します。
しかし、どの手法を用いるかにかかわらず、存在リスクに関する主観的確率の予測スキルを評価する際には多くの障壁があります。すなわち、参照クラス(reference class)の欠如、低いベースレート(base rate)、そして長い時間軸です。これらそれぞれについて順に見ていきましょう。
参照クラスの問題は予測者だけでなく評価者も悩ませます。先ほどの宇宙人の着陸例に戻りましょう。選挙の予言において高い精度を示してきた予測者が、証拠もなく「1 年以内に地球に宇宙人が着陸する」と発表したと仮定します。この予測者の実証された能力にもかかわらず、私たちは宇宙人の着陸に関する信念を更新しません。なぜなら、それは選挙の予言とはあまりにも異質であり、その予測者の能力が一般化すると期待できないからです。同様に、AI の存在リスク(x-risk)はこれまでに予測されたいかなる過去の出来事ともあまりにも異質であるため、AI の存在リスクを推定する上で予測者の能力を示す証拠は何もありません。
たとえ参照クラスの問題を何らかの形で排除できたとしても、他の問題は残ります。特に、絶滅リスクは「テールリスク」、つまり稀な事象によって生じるリスクであるという事実です。予測者 A が AI による存在リスク(x-risk)の確率を 1% と見積もり、予測者 B がそれを 100 万分の 1 と見積もった場合、どちらの予測により信頼を置くべきでしょうか?彼らの実績記録を確認することができます。例えば、AI による存在リスクに 1% の確率を付与した予測者 A の方が実績が良いことが分かったとしましょう。それでもなお、A の予測により信頼を置くべきだとは限りません。なぜなら、技能評価はテールリスクの過大評価に対して感度が低いためです。つまり、A は日常的に発生する可能性が substantial な事象については B よりもわずかに較正(calibration)が優れているため総合スコアが高くなる一方で、100 万分の 1 のような稀にしか発生しないテールリスクを桁違いに過大評価している可能性があります。このようなタイプの較正誤りを十分に罰するスコアリングルールは存在しません。
これはなぜそう言えるのかを示す思考実験です。予測者 F と G がそれぞれ異なる 2 つのイベントセットを予測すると仮定しましょう。そして、両方のセットに含まれるイベントの「真の」確率はすべて 0 から 1 の間で一様分布しているとします。非常に楽観的に、F と G の両方が自分が予測するすべてのイベント e についてその真の確率 P[e] を知っているものと仮定します。F は常に P[e] を出力しますが、G はわずかに保守的で、1% より小さい値を予測することは決してありません。つまり、G は P[e] が 1% 以上の場合に P[e] を出力し、それ以外の場合は 1% を出力します。
構成上、F の方が優れた予測者です。しかし、そのことは実績記録から明らかになるでしょうか?言い換えれば、F が G よりも高いスコアを獲得する確率が 95% となるためには、両者の予測をそれぞれどれほど多く評価する必要がありますか?対数スコア則(logarithmic scoring rule)を用いた場合、それは約 1 億件のオーダーになります。一方、ブリアー・スコア(Brier score)を用いると、その数は約 1 兆件のオーダーに達します。2 ここで仮定について細かく議論することは可能ですが、要点は、予測者が体系的にテールリスク(tail risk:極端な事象の発生確率)を過大評価している場合、それは単に経験的に検出不可能であるということです。
予測者の x リスク予測スキルを評価するための最終的な障壁は、長期予測の評価に時間がかかりすぎる点(そして絶滅予測は当然ながら評価不可能である)にあります。これは潜在的に克服できる可能性があります。研究者らは相互スコアリングと呼ばれる手法を開発しました。これは予測者が互いの予測をいかに正確に予測したかに基づいて報酬を得るというものであり、COVID-19 政策の影響予測などの実際の現場で検証されています。これらの現場では、相互スコアリングは従来のスコアリング手法と同等の精度を持つ予測結果をもたらしました。まあ妥当な話です。しかし、相互スコアリングは参照クラス問題やテールリスク問題を回避する手段ではありません。

我々の議論の要約
原文を表示
How seriously should governments take the threat of existential risk from AI, given the lack of consensus among researchers? On the one hand, existential risks (x-risks) are necessarily somewhat speculative: by the time there is concrete evidence, it may be too late. On the other hand, governments must prioritize — after all, they don’t worry too much about x-risk from alien invasions.
This is the first in a series of essays laying out an evidence-based approach for policymakers concerned about AI x-risk, an approach that stays grounded in reality while acknowledging that there are “unknown unknowns”.
In this first essay, we look at one type of evidence: probability estimates. The AI safety community relies heavily on forecasting the probability of human extinction due to AI (in a given timeframe) in order to inform decision making and policy. An estimate of 10% over a few decades, for example, would obviously be high enough for the issue to be a top priority for society.
Our central claim is that AI x-risk forecasts are far too unreliable to be useful for policy, and in fact highly misleading.
Subscribe to receive future essays in this series.
Look behind the curtain
If the two of us predicted an 80% probability of aliens landing on earth in the next ten years, would you take this possibility seriously? Of course not. You would ask to see our evidence. As obvious as this may seem, it seems to have been forgotten in the AI x-risk debate that probabilities carry no authority by themselves. Probabilities are usually derived from some grounded method, so we have a strong cognitive bias to view quantified risk estimates as more valid than qualitative ones. But it is possible for probabilities to be nothing more than guesses. Keep this in mind throughout this essay (and more broadly in the AI x-risk debate).
If we predicted odds for the Kentucky Derby, we don’t have to give you a reason — you can take it or leave it. But if a policymaker takes actions based on probabilities put forth by a forecaster, they had better be able to explain those probabilities to the public (and that explanation must in turn come from the forecaster). Justification is essential to legitimacy of government and the exercise of power. A core principle of liberal democracy is that the state should not limit people's freedom based on controversial beliefs that reasonable people can reject.
Explanation is especially important when the policies being considered are costly, and even more so when those costs are unevenly distributed among stakeholders. A good example is restricting open releases of AI models. Can governments convince people and companies who stand to benefit from open models that they should make this sacrifice because of a speculative future risk?
The main aim of this essay is analyzing whether there is any justification for any of the specific x-risk probability estimates that have been cited in the policy debate. We have no objection to AI x-risk forecasting as an academic activity, and forecasts may be helpful to companies and other private decision makers. We only question its use in the context of public policy.
There are basically only three known ways by which a forecaster can try to convince a skeptic: inductive, deductive, and subjective probability estimation. We consider each of these in the following sections. All three require both parties to agree on some basic assumptions about the world (which cannot themselves be proven). The three approaches differ in terms of the empirical and logical ways in which the probability estimate follows from that set of assumptions.
Inductive probability estimation is unreliable due to the lack of a reference class
Most risk estimates are inductive: they are based on past observations. For example, insurers base their predictions of an individual’s car accident risk on data from past accidents about similar drivers. The set of observations used for probability estimation is called a reference class. A suitable reference class for car insurance might be the set of drivers who live in the same city. If the analyst has more information about the individual, such as their age or the type of car they drive, the reference class can be further refined.
For existential risk from AI, there is no reference class, as it is an event like no other. To be clear, this is a matter of degree, not kind. There is never a clear “correct” reference class to use, and the choice of a reference class in practice comes down to the analyst’s intuition.
The accuracy of the forecasts depends on the degree of similarity between the process that generates the event being forecast and the process that generated the events in the reference class, which can be seen as a spectrum. For predicting the outcome of a physical system such as a coin toss, past experience is a highly reliable guide. Next, for car accidents, risk estimates might vary by, say, 20% based on the past dataset used — good enough for insurance companies.
Further along the spectrum are geopolitical events, where the choice of reference class gets even fuzzier. Forecasting expert Philip Tetlock explains: “Grexit may have looked sui generis, because no country had exited the Eurozone as of 2015, but it could also be viewed as just another instance of a broad comparison class, such as negotiation failures, or of a narrower class, such as a nation-states withdrawing from international agreements or, narrower still, of forced currency conversions.” He goes on to defend the idea that even seeming Black Swan events like the collapse of the USSR or the Arab Spring can be modeled as members of reference classes, and that inductive reasoning is useful even for this kind of event.
In Tetlock’s spectrum, these events represent the “peak” of uniqueness. When it comes to geopolitical events, that might be true. But even those events are far less unique than extinction from AI. Just look at the attempts to find reference classes for AI x-risk: animal extinction (as a reference class for human extinction), past global transformations such as the industrial revolution (as a reference class for socioeconomic transformation from AI), or accidents causing mass deaths (as a reference class for accidents causing global catastrophe). Let’s get real. None of those tell us anything about the possibility of developing superintelligent AI or losing control over such AI, which are the central sources of uncertainty for AI x-risk forecasting.
To summarize, human extinction due to AI is an outcome so far removed from anything that has happened in the past that we cannot use inductive methods to “predict” the odds. Of course, we can get qualitative insights from past technical breakthroughs as well as past catastrophic events, but AI risk is sufficiently different that quantitative estimates lack the kind of justification needed for legitimacy in policymaking.
Deductive probability estimation is unreliable due to the lack of theory
In Conan Doyle’s The Adventure of the Six Napoleons — spoiler alert! — Sherlock Holmes announces before embarking on a stakeout that the probability of catching the suspect is exactly two-thirds. This seems bewildering — how can anything related to human behavior be ascribed a mathematically precise probability?
It turns out that Holmes has deduced the underlying series of events that gave rise to the suspect’s seemingly erratic observed behavior: the suspect is methodically searching for a jewel that is known to be hidden inside one of six busts of Napoleon owned by different people in and around London. The details aren’t too important, but the key is that neither the suspect nor the detectives know which of the six busts it is in, and everything else about the suspect’s behavior is (assumed to be) entirely predictable. Hence the precisely quantifiable uncertainty.
The point is that if we have a model of the world that we can rely upon, we can estimate risk through logical deduction, even without relying on past observations. Of course, outside of fictional scenarios, the world isn’t so neat, especially when we want to project far into the future.
When it comes to x-risk, there is an interesting exception to the general rule that we don’t have deductive models — asteroid impact. A combination of inductive and deductive risk estimation does allow us to estimate the probability of x-risk, only because we’re talking about a purely physical system. Let’s take a minute to review how this works, because it’s important to recognize that the methods are not generalizable to other types of x-risk.
The key is being able to model the relationship between the size of the asteroid (more precisely, the energy of impact) and the frequency of impact. Since we have observed thousands of small impacts, we can extrapolate to infer the frequency of large impacts that have never been directly observed. We can also estimate the threshold that would cause global catastrophe.1
Figure: data on small asteroid impacts (illustrated on the left) can be extrapolated to extinction-level impacts (right).
With AI, the unknowns relate to technological progress and governance rather than a physical system, so it isn’t clear how to model it mathematically. Still, people have tried. For example, in order to predict the computational requirements of a hypothetical AGI, several works assume that an AI system would require roughly as many computations as the human brain, and further make assumptions about the number of computations required by the human brain. These assumptions are far more tenuous than those involved in asteroid modeling, and none of this even addresses the loss-of-control question.
Subjective probabilities are feelings dressed up as numbers
Without the reference classes or grounded theories, forecasts are necessarily “subjective probabilities”, that is, guesses based on the forecaster’s judgment. Unsurprisingly, these vary by orders of magnitude.
Subjective probability estimation does not get around the need for having either an inductive or a deductive basis for probability estimates. It merely avoids the need for the forecaster to explain their estimate. Explanation can be hard due to humans’ limited ability to explain our intuitive reasoning, whether inductive, deductive, or a combination thereof. Essentially, it allows the forecaster to say: “even though I haven’t shown my methods, you can trust this estimate because of my track record” (we explain in the next section why even this breaks down for AI x-risk forecasting). But ultimately, lacking either an inductive or a deductive basis, all that forecasters can do is to make up a number, and those made-up numbers are all over the place.
Consider the Existential Risk Persuasion Tournament (XPT) conducted by the Forecasting Research Institute in late 2022, which we think is the most elaborate and well-executed x-risk forecasting exercise conducted to date. It involved various groups of forecasters, including AI experts and forecasting experts (“superforecasters” in the figure). For AI experts, the high end (75th percentile) of estimates for AI extinction risk by 2100 is 12%, the median estimate is 3%, and the low end (25th percentile) is 0.25%. For forecasting experts, even the high end (75th percentile) is only 1%, the median is a mere 0.38%, and the low end (25th percentile) is visually indistinguishable from zero on the graph. In other words, the 75th percentile AI expert forecast and the 25th percentile superforecaster forecast differ by at least a factor of 100.
All of these estimates are from people who have deep expertise on the topic and participated in a months-long tournament where they tried to persuade each other! If this range of forecasts here isn’t extreme enough, keep in mind that this whole exercise was conducted by one group at one point in time. We might get different numbers if the tournament were repeated today, if the questions were framed differently, etc.
What’s most telling is to look at the rationales that forecasters provided, which are extensively detailed in the report. They aren’t using quantitative models, especially when thinking about the likelihood of bad outcomes conditional on developing powerful AI. For the most part, forecasters are engaging in the same kind of speculation that everyday people do when they discuss superintelligent AI. Maybe AI will take over critical systems through superhuman persuasion of system operators. Maybe AI will seek to lower global temperatures because it helps computers run faster, and accidentally wipe out humanity. Or maybe AI will seek resources in space rather than Earth, so we don’t need to be as worried. There’s nothing wrong with such speculation. But we should be clear that when it comes to AI x-risk, forecasters aren’t drawing on any special knowledge, evidence, or models that make their hunches more credible than yours or ours or anyone else’s.
The term superforecasting comes from Philip Tetlock’s 20 year study of forecasting (he was also one of the organizers of the XPT). Superforecasters tend to be trained in methods to improve forecasts such as by integrating diverse information and by minimizing psychological biases. These methods have been shown to be effective in domains such as geopolitics. But no amount of training will lead to good forecasts if there isn’t much useful evidence to draw from.
Even if forecasters had credible quantitative models (they don’t), they must account for “unknown unknowns”, that is, the possibility that the model itself might be wrong. As noted x-risk philosopher Nick Bostrom explains: “The uncertainty and error-proneness of our first-order assessments of risk is itself something we must factor into our all-things-considered probability assignments. This factor often dominates in low-probability, high-consequence risks — especially those involving poorly understood natural phenomena, complex social dynamics, or new technology, or that are difficult to assess for other reasons.”
This is a reasonable perspective, and AI x-risk forecasters do worry a lot about uncertainty in risk assessment. But one consequence of this is that for those who follow this principle, forecasts are guaranteed to be guesses rather than the output of a model — after all, no model can be used to estimate the probability that the model itself is wrong, or what the risk would be if the model were wrong.
Forecast skill cannot be measured when it comes to unique or rare events
To recap, subjective AI-risk forecasts vary by orders of magnitude. But if we can measure forecasters’ track records, maybe we can use that to figure out which forecasters to trust. In contrast to the previous two approaches for justifying risk estimates (inductive and deductive), the forecaster doesn’t have to explain their estimate, but instead justifies it based on their demonstrated skill at predicting other outcomes in the past.
This has proved to be invaluable in the domain of geopolitical events, and the forecasting community spends a lot of effort on skill measurement. Many ways to evaluate forecasting skill exist, such as calibration, the Brier score, the logarithmic score, or the Peer score used on the forecasting competition website Metaculus.
But regardless of which method is used, when it comes to existential risk, there are many barriers to assessing forecast skill for subjective probabilities: the lack of a reference class, the low base rate, and the long time horizon. Let’s look at each of these in turn.
Just as the reference class problem plagues the forecaster, it also affects the evaluator. Let’s return to the alien landing example. Consider a forecaster who has proved highly accurate at calling elections. Suppose this forecaster announces, without any evidence, that aliens will land on Earth within a year. Despite the forecaster’s demonstrated skill, this would not cause us to update our beliefs about an alien landing, because it is too dissimilar to election forecasting and we do not expect the forecaster’s skill to generalize. Similarly, AI x-risk is so dissimilar to any past events that have been forecast that there is no evidence of any forecaster’s skill at estimating AI x-risk.
Even if we somehow do away with the reference class problem, other problems remain — notably, the fact that extinction risks are “tail risks”, or risks that result from rare events. Suppose forecaster A says the probability of AI x-risk is 1%, and forecaster B says it is 1 in a million. Which forecast should we have more confidence in? We could look at their track records. Say we find that forecaster A (who has assigned a 1% probability to AI x-risk) has a better track record. It still doesn’t mean we should have more confidence in A’s forecast, because skill evaluations are insensitive to overestimation of tail risks. In other words, it could be that A scores higher overall because A is slightly better calibrated than B when it comes to everyday events that have a substantial probability of occurring, but tends to massively overestimate tail risks that occur rarely (for example, those with a probability of 1 in a million) by orders of magnitude. No scoring rule adequately penalizes this type of miscalibration.
Here’s a thought experiment to show why this is true. Suppose two forecasters F and G forecast two different sets of events, and the “true” probabilities of events in both sets are uniformly distributed between 0 and 1. We assume, highly optimistically, that both F and G know the true probability P[e] for every event e that they forecast. F always outputs P[e], but G is slightly conservative, never predicting a value less than 1%. That is, G outputs P[e] if P[e] >= 1%, otherwise outputs 1%.
By construction, F is the better forecaster. But would this be evident from their track records? In other words, how many forecasts from each would we have to evaluate so that there’s a 95% chance that F outscores G? With the logarithmic scoring rule, it turns out to be on the order of a hundred million. With the Brier score, it is on the order of a trillion.2 We can quibble with the assumptions here but the point is that if a forecaster systematically overestimates tail risks, it is simply empirically undetectable.
The final barrier to assessing forecaster skill at predicting x-risk is that long-term forecasts take too long to evaluate (and extinction forecasts are of course impossible to evaluate). This can potentially be overcome. Researchers have developed a method called reciprocal scoring — where forecasters are rewarded based on how well they predict each others’ forecasts — and validate it in some real-world settings, such as predicting the effect of Covid-19 policies. In these settings, reciprocal scoring yielded forecasts that are as good as traditional scoring methods. Fair enough. But reciprocal scoring is not a way around the reference class problem or the tail risk problem.
Summary of our argum
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み