KV キャッシュ圧縮競争:TurboQuant、OSCAR、EpiCache の比較
Google、Together AI、Apple がそれぞれ異なるアプローチで KV キャッシュ圧縮技術を革新し、長文コンテキスト処理のボトルネック解消に向けた競争が激化している。
キーポイント
KV キャッシュのメモリボトルネック深刻化
1M トークン以上の長文コンテキストでは、モデル重み自体よりも KV キャッシュのサイズ(300GB超)が巨大になり、デコード速度をメモリー帯域幅に依存させる要因となっている。
外れ値チャネルへの対応が鍵となる
従来の低ビット量子化が精度を失う主因は、少数の異常なチャネル(outlier channels)が量子化範囲を圧迫することであり、これをどう処理するかが技術競争の焦点である。
TurboQuant のデータ非依存アプローチ
Google と NYU が提案した TurboQuant は、ランダム回転と理論的に最適化された量子化を用いてデータに依存せず、情報理論的下限に近い歪みで動作する画期的な手法である。
多様な解決策の並存と進化
TOgether AI の OSCAR や Apple の EpiCache など、異なる問題意識やアプローチ(量子化、アーキテクチャ共有など)を持つ複数の最新手法が競合・補完し合っている。
TurboQuant の理論的保証と汎用性
情報理論的下限の約 2.7 倍以内という誤差保証を持ち、キャリブレーション不要でモデルに依存しない 3-4 ビット領域での高品質な量子化を実現します。
OSCAR の注意機構とシステム統合
クエリの共分散に基づく注意機構 Aware な回転を用いて INT2 でも性能を維持し、SGLang 対応の混合精度 paged cache システムとして実用化されています。
用途に応じた使い分け
OSCAR は 128K コンテキストでの INT2 量子化に特化し、TurboQuant はモデル非依存の 3-4 ビット量子化においてそれぞれ優位性を持ちます。
影響分析・編集コメントを表示
影響分析
この競争は、LLM が真の意味で超長文コンテキスト(100K〜1M トークン)を扱えるようになるための決定的な転換点となる。特にデータ依存性の低い新しい量子化手法の登場は、汎用性が高く即座に実装可能な解決策を提供し、大規模 LLM の運用コストと遅延を劇的に低下させる可能性を秘めている。
編集コメント
KV キャッシュの圧縮技術は、LLM の実用化における最後の大きな障壁の一つを突破する鍵です。特にデータに依存しない手法(TurboQuant)の実現は、現場での適用ハードルを大幅に下げる画期的な進展と言えます。
長文コンテキストを持つ大規模言語モデル(LLM)は、モデルの重みとは無関係なメモリボトルネックに直面しています。デコーディング中、トランスフォーマーは各層のすべてのトークンに対してキーとバリュー(KV)ベクトルをキャッシュし、アテンションの再計算を防いでいます。このキャッシュはシーケンス長とバッチサイズに比例して線形に増加し、長いコンテキストかつ高い同時実行性においてはモデル自体のフットプリントよりも遥かに大きくなる可能性があります。
BF16 形式の Llama-3.1-70B を考えてみましょう。その KV キャッシュはトークンあたり約 0.31 MB(80 レイヤー × 8 KV ヘッド × 128 ヘッド次元 × 2 テンソル × 2 バイト)を要します。128K トークンの場合、これは約 40 GB に達し、1M トークンでは 300 GB を超え、重み自体の 140 GB よりも多くなります。さらに悪いことに、新しくデコードされたトークンごとに、高帯域メモリ(HBM)からキャッシュ全体をストリーミングする必要があり、これがデコーディングを計算量バウンドではなくメモリ帯域幅バウンドにさせています。したがって、KV キャッシュを縮小することは、コストとデコーディングレイテンシの両方を削減するための最も直接的な手段です。
現在のアプローチは概ね 5 つのファミリーに分類されます:トークン_eviction(H2O, SnapKV)、量子化(KIVI, GEAR)、低ランク射影(Palu)、マージ(KVMerger)、およびアーキテクチャ共有(MLA)です。最近の 2026 年の研究は、超低ビット量子化の最前線に注力しています。Google と NYU の TurboQuant(ICLR 2026)と Together AI の OSCAR は正反対の方向から同じ問題に取り組んでいますが、Apple の EpiCache はこれらいずれもが解決していない別の問題を扱っています。
ほとんどの KV 量子化手法は、同じ根本的な敵と戦っています。それは外れ値チャネルです。これは、不釣り合いに大きな大きさを持ち、量子化範囲を支配し、残りの信号を数少ない表現可能なレベルに押し込めてしまう少数のチャネルのことです。これが、単純な INT2 量子化(4 レベルのみ)がほぼゼロの精度に崩壊する理由です。
KIVI はここで標準的なベースラインを確立しました。キーベクトルにはトークンを超えて固定された外れ値チャネルが存在する一方、バリューベクトルには存在しないことを示し、キーはチャネルごとに、バリューはトークンごとに量子化することを提案しました。このチューニングフリーの 2 ビットレシピにより、エンドツーエンドのピークメモリ(重みを含む)が約 2.6 倍削減され、新しい手法が構築する基準点となっています。
TurboQuant: データ非依存かつ理論的に最適
TurboQuant は、データを一切参照することなく、2 つの段階で外れ値に対処します:
第一段階:各ベクトルをランダムに回転させ、その座標がほぼ独立し、近似ガウス分布となるようにします。これにより、最適な事前計算されたスカラー(Lloyd–Max)量子化器を各座標に対して適用可能になります。
第二段階:残差に対して 1 ビット量子化 Johnson–Lindenstrauss (QJL) 変換を適用し、正規化定数のオーバーヘッドなしで注意ロジットの証明可能な不偏推定量を提供します。
売りは理論的なものです:TurboQuant の歪みは、情報理論的下限に対して証明可能な小さな定数倍(約 2.7 倍)以内に収まります。実際には、4 倍圧縮において「干し草の針」タスクでほぼ完全精度の検索性能を達成し、論文では 1 チャネルあたり 3.5 ビットで絶対的な品質の中立性を報告しており、2.5 ビットでもわずかな劣化にとどまっています。キャリブレーションが不要なため、未調整のあらゆるモデルで動作し、高速ベクトルデータベース量子化器としても機能します。
注意すべき点として、広く繰り返されている「H100 上で 8 倍高速なアテンション」という数値は論文ではなく Google のブログからのものであり、狭義のアテンションロジットマイクロベンチマークを指しています。TurboQuant が文書化された最適域は、3〜4 ビットのほぼ非損失領域です。
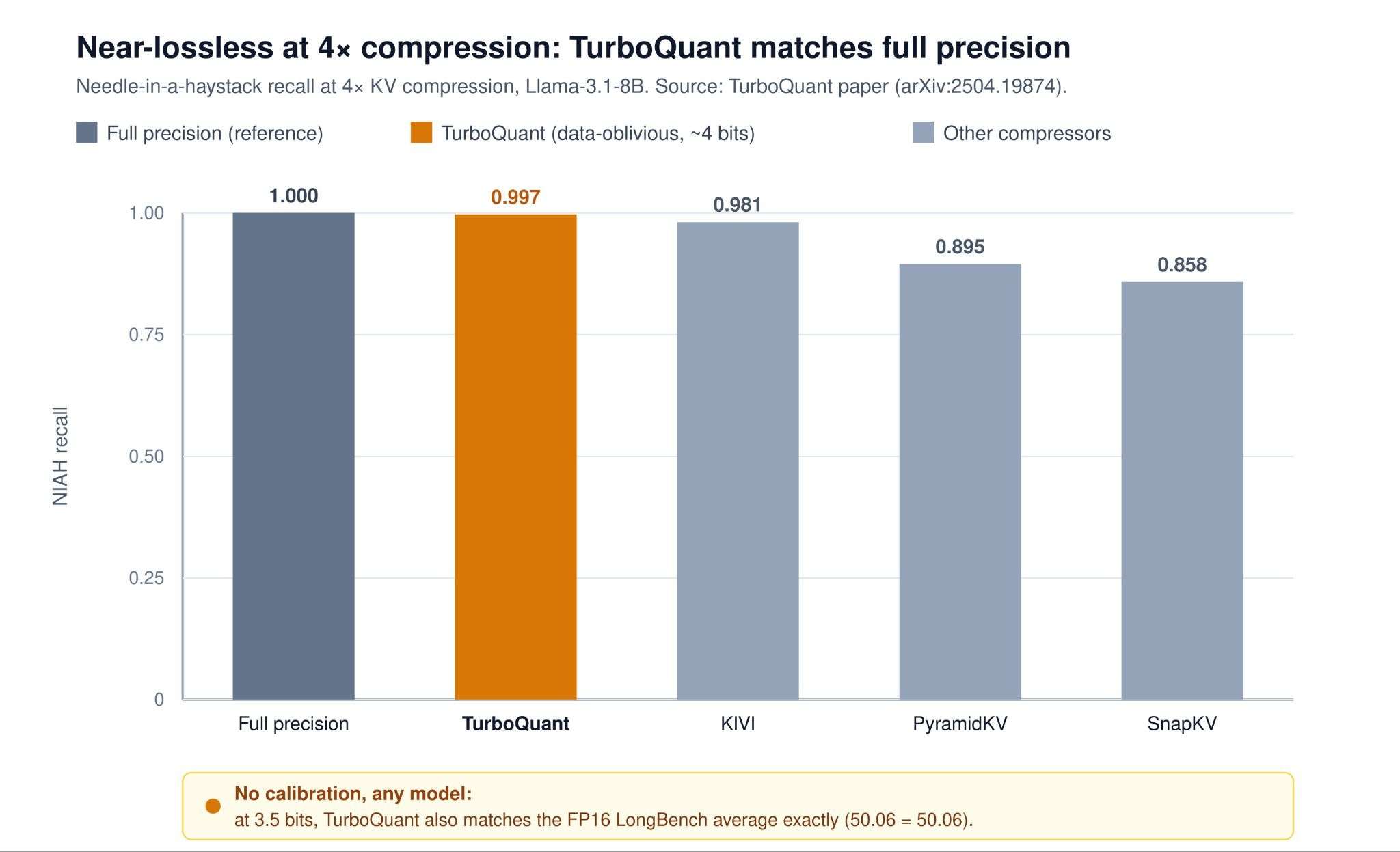 image画像出典:TurboQuant 論文のデータ – https://arxiv.org/abs/2504.19874
image画像出典:TurboQuant 論文のデータ – https://arxiv.org/abs/2504.19874
OSCAR: アテンション認識型でデプロイ済み
OSCAR は逆の戦略を採ります。その前提は、INT2 の 4 レベルでは、データ非依存な回転(data-oblivious rotation)が不適切であるという点です。ほとんど精度の余裕がない状況では、単に範囲を滑らかにするだけでは不十分です。そのため、OSCAR は一度きりのオフラインキャリブレーションパスからアテンション認識型の回転を計算します:キーはクエリの共分散行列の固有基底へ回転され、値はスコア加重された値の共分散行列へ回転されます。その後、アダマール変換(Hadamard transform)とビット反転置換(bit-reversal permutation)によって、チャネルの重要性が量子化グループ全体に均等に分散されます。
OSCAR の独自性は、単なるアルゴリズムではなく、完全なシステムとして提供される点にあります。
混合精度ページキャッシュ:直近のトークンと直近のトークンは BF16 で保持され、履歴は INT2 に圧縮されます。128K コンテキストにおいて、BF16 で残存するトークンの割合はわずか約 0.24% です。
SGLang と完全統合された融合型 Triton カーネル(ページアテンションおよびプレフィックスキャッシュと互換性あり)。
Qwen3-4B/8B/32B、GLM-4.7-FP8、MiniMax-M2.7 用の事前計算済み回転行列(「RotationZoo」):再較正は不要です。
実効ビット数 2.28 ビットで、OSCAR は Qwen3-8B において BF16 との差が 1.42 ポイント以内であり、Qwen3-32B ではほぼ同等(0.02 ポイントの差)です。GLM-4.7-FP8 においては、単純な INT2 がゼロに崩壊し、データ非依存ベースラインが低単位数しか達成できない中で、OSCAR は BF16 と同等か、報告されたベンチマークではわずかに上回る結果を示しています(ノイズの範囲内)。Together AI によると、100K コンテキストでジョブレベルのスループットは最大 7.83 倍、KV キャッシュメモリ削減率は約 8 倍、デコーディング速度は最大約 3 倍高速化されます。
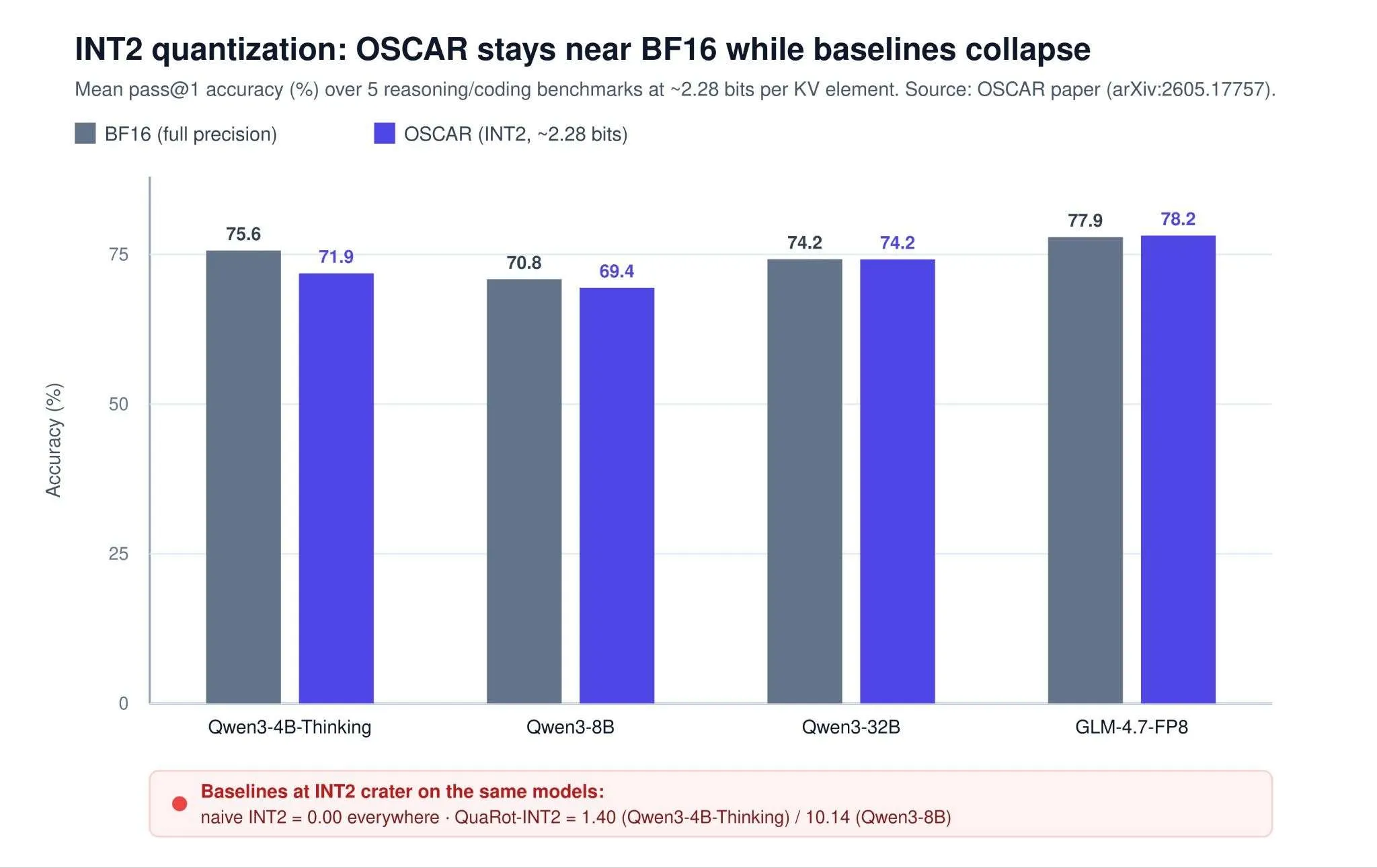 image画像出典 - データは OSCAR 論文より:https://arxiv.org/abs/2605.17757
image画像出典 - データは OSCAR 論文より:https://arxiv.org/abs/2605.17757
では、どちらが勝つのでしょうか?
どちらもです — これが正直な答えです。サポート対象モデルにおいて 128K トークンで展開可能な INT2 については、OSCAR が現在、崩壊しない唯一の実証済みオプションであり、本番環境対応の SGLang サポートも備えています。一方、3〜4 ビット領域におけるトレーニング不要・モデル非依存の量子化については、TurboQuant がはるかに広い汎用性を提供します。
OSCAR の論文では、同等の予算において TurboQuant が 40 ポイント以上も低下すると報告されています。しかし、その評価は OSCAR 独自のフレームワーク内で行われ、すべての層を量子化し、単一の乱数シードを使用し、かつ TurboQuant が意図するビット幅よりも大幅に低い範囲で動作しているため、直接対決の結論を下すには根拠が薄弱です。より興味深い可能性として、両者は補完関係にあるというケースがあります:キャリブレーションを考慮した回転と最適なスカラー量子化器を組み合わせた手法は、有望な組み合わせでありながら、まだ誰によってもしばらく実装されていません(両チームとも公に同じアイデアに言及しています)。
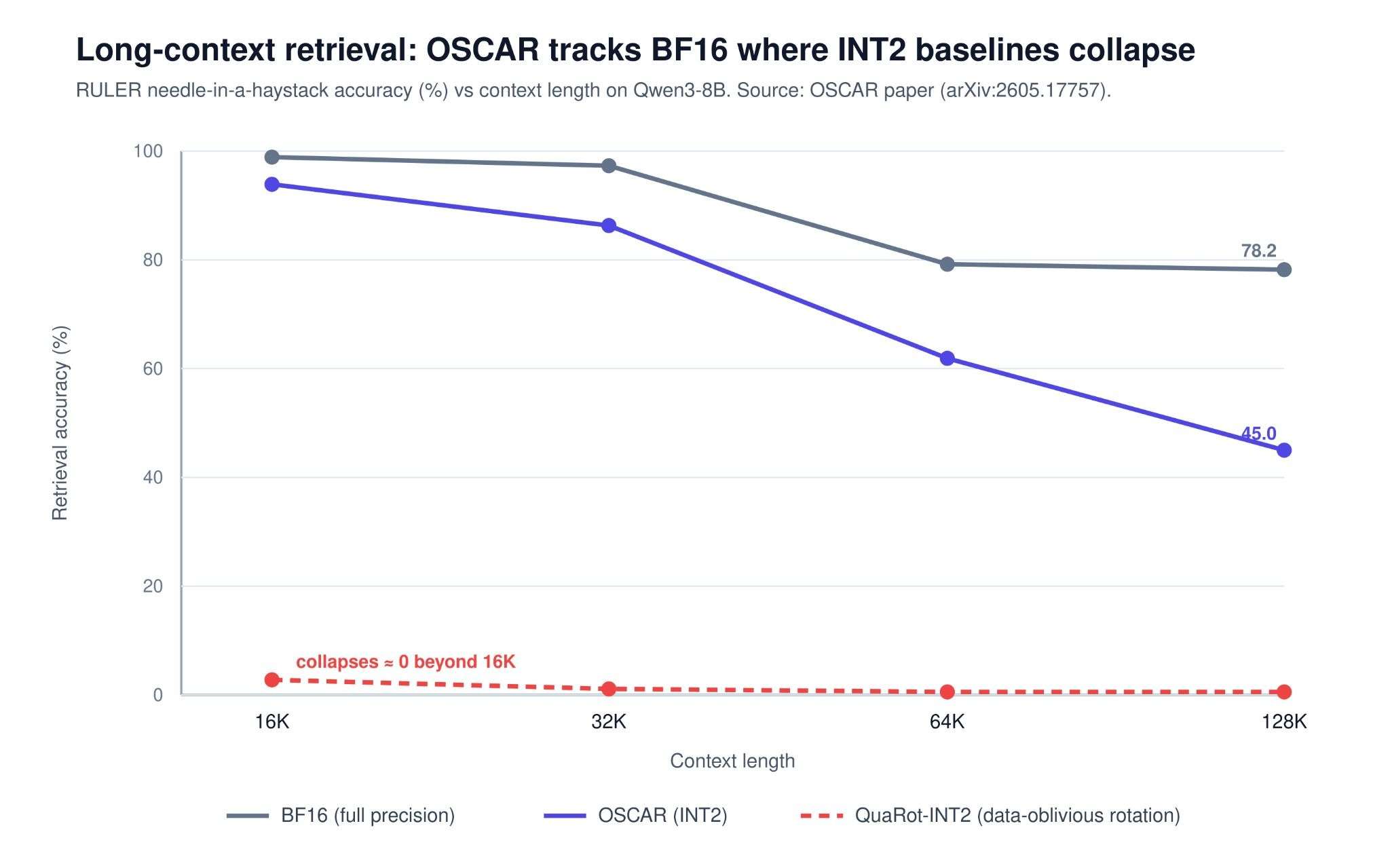 image画像出典:OSCAR 論文のデータ - https://arxiv.org/abs/2605.17757
image画像出典:OSCAR 論文のデータ - https://arxiv.org/abs/2605.17757
3 つ目の軸:EpiCache
TurboQuant と OSCAR はどちらも単一の長いコンテキストを想定して構築されています。しかし、履歴が多数のやり取りにわたって蓄積する拡張された多回対話には対応していません。Apple の EpiCache はまさにこのギャップを埋めるためのトレーニング不要な KV キャッシュ管理フレームワークです。
ブロック単位でのプリフェッチは、履歴をブロック単位で処理することでピークメモリ量を制限します。
エピソードクラスタリングは会話を一貫した意味的な「エピソード」に分割し、それぞれが独自の圧縮キャッシュを持つようにします。
エピソードマッチングによる検索では、推論時に各クエリを最も関連性の高いエピソードへルーティングします。
適応型層別予算配分は、各層の排除に対する感度を測定し、それに応じてメモリ予算を配分します。
LongMemEval、RealTalk、LoCoMoのすべての評価において、EpiCache はエビクションベースラインと比較して最大 40% の精度向上を示し、圧縮率が 4~6 倍の場合でもほぼフルキャッシュに匹敵する精度を達成しました。また、ピークメモリ使用量は最大 3.5 倍削減され、レイテンシも約 2.4 倍低下しています。これは、どのトークンを保持するかという判断基準を提供し、保存の精密さを追求するものではないため、OSCAR や TurboQuant と直接組み合わせることで、相乗効果によるさらなる節約が可能になります。
主要なポイント
TurboQuant は理論的な限界を押し広げ、モデルに依存しない最先端技術です。あらゆるモデルにおいて 3~4 ビットのほぼ損失なし圧縮を実現するためのデファクトスタンダードです。
OSCAR は展開可能な INT2(整数 2 ビット)の分野でリードしており、対応するモデルにおいて 100K のコンテキスト長で最大 7.83 倍のスループット向上と約 8 倍のメモリ削減を実現します。
EpiCache は会話の多段階にわたる記憶問題を解決し、エビクション手法と比較して最大 40% の精度向上とピークメモリの 3.5 倍削減をもたらします。また、いずれの量子化手法とも組み合わせ可能です。
制約条件(ビット幅の予算、モデルの移植性、会話の長さなど)に応じて選択し、互いに補完的な手法を組み合わせることが推奨されます。これらのアプローチは競合するものではなく、むしろ相補的な関係にあります。
参考文献
TurboQuant (arXiv 2504.19874)
TurboQuant — Google Research blog
OSCAR (arXiv 2605.17757)
OSCAR code — FutureMLS-Lab/OSCAR
EpiCache (arXiv 2509.17396)
EpiCache code — apple/ml-epicache
KIVI (arXiv 2402.02750)
本記事「The KV Cache Compression Race: TurboQuant vs OSCAR vs EpiCache」は、MarkTechPost に掲載されたものです。
原文を表示
Long-context large language models (LLMs) face a memory bottleneck that has nothing to do with model weights. During decoding, transformers cache the key and value (KV) vectors for every token at every layer so they don’t have to recompute attention. This cache grows linearly with sequence length and batch size, and at long context with high concurrency it can dwarf the model’s own footprint.
Consider Llama-3.1-70B in BF16. Its KV cache costs about 0.31 MB per token (80 layers × 8 KV heads × 128 head-dim × 2 tensors × 2 bytes). At 128K tokens that is ~40 GB; at 1M tokens it exceeds 300 GB — more than the 140 GB of weights themselves. Worse, every newly decoded token has to stream the entire cache out of high-bandwidth memory (HBM), which makes decoding memory-bandwidth-bound rather than compute-bound. Shrinking the KV cache is therefore the most direct lever for cutting both cost and decode latency.
Current approaches fall into roughly five families: token eviction (H2O, SnapKV), quantization (KIVI, GEAR), low-rank projection (Palu), merging (KVMerger), and architectural sharing (MLA). Recent 2026 work has pushed hard on the ultra-low-bit quantization frontier. Google and NYU’s TurboQuant (ICLR 2026) and Together AI’s OSCAR attack the same problem from opposite directions, while Apple’s EpiCache tackles a problem neither one addresses.
Most KV quantizers are fighting the same underlying enemy: outlier channels — a handful of channels with disproportionately large magnitudes that dominate the quantization range and squeeze the rest of the signal into just a few representable levels. This is why naive INT2 quantization (only four levels) collapses to near-zero accuracy.
KIVI established the standard baseline here. It showed that key vectors have fixed outlier channels across tokens while value vectors do not, so it quantizes keys per-channel and values per-token. That tuning-free 2-bit recipe cuts end-to-end peak memory (weights included) by about 2.6×, and it is the reference point the newer methods build on.
TurboQuant: data-oblivious and theoretically optimal
TurboQuant handles outliers without ever looking at your data, in two stages:
Stage one: each vector is randomly rotated so its coordinates become nearly independent and approximately Gaussian, which lets an optimal precomputed scalar (Lloyd–Max) quantizer be applied per coordinate.
Stage two: a 1-bit Quantized Johnson–Lindenstrauss (QJL) transform is applied to the residual, giving a provably unbiased estimate of attention logits with no normalization-constant overhead.
The selling point is theoretical: TurboQuant’s distortion is provably within a small constant factor (≈ 2.7×) of the information-theoretic lower bound. In practice it reaches essentially full-precision recall on Needle-in-a-Haystack at 4× compression, and the paper reports absolute quality neutrality at 3.5 bits and only marginal degradation at 2.5 bits per channel. Because it needs no calibration, it works on any model untouched and doubles as a fast vector-database quantizer.
One caveat worth flagging: the widely repeated “8× faster attention on H100” figure comes from Google’s blog, not the paper, and refers to a narrow attention-logit microbenchmark. TurboQuant’s documented sweet spot is the 3–4 bit near-lossless regime.
imageImage source: Data from the TurboQuant paper – https://arxiv.org/abs/2504.19874
OSCAR: attention-aware and deployment-ready
OSCAR bets the opposite way. Its premise is that at INT2’s four levels, a data-oblivious rotation is the wrong tool — blindly smoothing ranges isn’t enough when there’s almost no precision to spare. So OSCAR computes an attention-aware rotation from a one-time offline calibration pass: keys are rotated into the eigenbasis of the query covariance, values into the score-weighted value covariance. A Hadamard transform plus a bit-reversal permutation then spread channel importance evenly across the quantization groups.
What sets OSCAR apart is that it ships as a complete system, not just an algorithm:
Mixed-precision paged cache: sink and recent tokens stay in BF16 while the history compresses to INT2 — at 128K context only ~0.24% of tokens remain in BF16.
Fused Triton kernels with full SGLang integration (paged-attention and prefix-cache compatible).
Precomputed rotations (a “RotationZoo”) for Qwen3-4B/8B/32B, GLM-4.7-FP8, and MiniMax-M2.7 — no recalibration needed.
At an effective 2.28 bits, OSCAR lands within 1.42 points of BF16 on Qwen3-8B and is essentially on par on Qwen3-32B (a 0.02-point gap). On GLM-4.7-FP8 — where naive INT2 collapses to zero and data-oblivious baselines reach only low single digits — OSCAR matches BF16 and even edges slightly ahead on the reported benchmarks (within noise). Together AI reports up to 7.83× job-level throughput and roughly 8× KV-cache memory reduction at 100K context, with up to ~3× faster decoding.
imageImage Source- Data from the OSCAR paper: https://arxiv.org/abs/2605.17757
So which one wins?
Neither — and that’s the honest answer. For deployable INT2 at 128K tokens on supported models, OSCAR is currently the only demonstrated option that doesn’t collapse, and it comes with production-ready SGLang support. For training-free, model-agnostic quantization in the 3–4 bit regime, TurboQuant offers far broader generality.
OSCAR’s paper reports that TurboQuant drops by more than 40 points at a comparable budget — but that evaluation runs inside OSCAR’s own framework, quantizes all layers, uses a single random seed, and operates well below TurboQuant’s intended bit-width, so it’s a weak basis for a head-to-head verdict. The more interesting possibility is that the two are complementary: pairing a calibration-aware rotation with an optimal scalar quantizer is a promising combination nobody has shipped yet. (Both teams have publicly noted the same idea.)
imageImage source: Data from the OSCAR paper- https://arxiv.org/abs/2605.17757
The third axis: EpiCache
TurboQuant and OSCAR are both built for a single long context. Neither handles extended multi-turn conversations, where history piles up across many exchanges. Apple’s EpiCache is a training-free KV-cache management framework aimed exactly at that gap:
Block-wise prefill processes history in blocks to keep peak memory bounded.
Episodic clustering segments the conversation into coherent semantic “episodes,” each with its own compressed cache.
Episode-matched retrieval routes each query to the most relevant episode at inference time.
Adaptive layer-wise budget allocation measures each layer’s sensitivity to eviction and distributes the memory budget accordingly.
Across LongMemEval, RealTalk, and LoCoMo, EpiCache reports up to 40% higher accuracy than eviction baselines, near-full-cache accuracy at 4–6× compression, and up to 3.5× lower peak memory (and ~2.4× lower latency). Because it decides which tokens to keep rather than how precisely to store them, it composes directly with OSCAR or TurboQuant for compounding savings.
Key Takeaways
TurboQuant pushes the theoretical, model-agnostic frontier — the go-to for 3–4 bit near-lossless compression on any model.
OSCAR leads on deployable INT2, with up to 7.83× throughput and ~8× memory reduction at 100K context on supported models.
EpiCache solves conversational memory across turns — up to 40% accuracy gains over eviction and 3.5× lower peak memory — and composes with either quantizer.
Pick by constraint: bit-width budget, model portability, or conversation length, then combine the orthogonal methods that fit. These approaches are more complementary than competitive.
Sources
TurboQuant (arXiv 2504.19874)
TurboQuant — Google Research blog
OSCAR (arXiv 2605.17757)
OSCAR code — FutureMLS-Lab/OSCAR
EpiCache (arXiv 2509.17396)
EpiCache code — apple/ml-epicache
KIVI (arXiv 2402.02750)
The post The KV Cache Compression Race: TurboQuant vs OSCAR vs EpiCache appeared first on MarkTechPost.
関連記事
ノア・シャゼーが OpenAI に合流(1 分読了)
Google を去った AI 研究の先駆者ノア・シャゼーが、OpenAI へ移籍することが発表された。彼は「Attention Is All You Need」論文の共著者として知られる。
[AINews] GLM は GPT より優れているか?GLM-5.2 が実用性を証明、Z.ai が 12 月までに「Open Fable」を公開予定
Latent Space のニュースでは、中国のモデル「GLM-5.2」がベンチマークで優れた結果を示し実用性があると評価されたことと、Z.ai が 12 月までにオープンソースプロジェクト「Open Fable」を発表する見込みについて報じられています。
Salesforce CodeGen チュートリアル:ユニットテストと安全性チェック付きの Python 関数の生成・検証・再ランク付け
Salesforce は Hugging Face からモデルを読み込み、自然言語から Python 関数を生成するエンドツーエンドワークフローを公開した。この手法には構文チェックや静的解析、ユニットテストによる検証が含まれる。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み