Olmo Hybridと将来のLLMアーキテクチャ
AI2研究所は、TransformerとRNN(GDN)を混合した新アーキテクチャ「Olmo Hybrid」7Bモデルを公開し、ハイブリッド型LLMの理論的優位性と実装例を示した。
キーポイント
ハイブリッドアーキテクチャの再注目
MambaやStriped Hyenaなどの過去の実験を経て、Qwen 3.5やKimi Linearなど複数のオープンソースモデルで混合アーキテクチャ(TransformerとRNNの併用)が採用されつつある。
Olmo Hybridの技術的特徴
7Bパラメータのベースモデルであり、Gated DeltaNet(GDN)を採用。これは計算コストを削減し、AttentionやMamba層では学習できない特徴を習得可能だとする。
理論的根拠とリソース公開
ハイブリッドモデルが標準Transformerより優位であるとする理論論文を公開し、Instructおよび推論用チェックポイントを提供することで研究コミュニティへの貢献を図っている。
ハイブリッドモデルの理論的優位性
アテンションとリカレンスの混合は単なる強みの合計を超え、コード評価などの特定の問題において両者の単独では表現できない高次元の表現力を持つことが理論的に証明された。
制御されたスケーリング実験による実証
Transformerと比較した厳密なスケーリング研究により、ハイブリッドモデルの表現力の向上がトークン効率の改善に直結することが実証され、Olmo Hybridの事前学習結果と一致した。
アーキテクチャ構成の最適化と性能比較
Olmoにおけるスケーリング実験では、ハイブリッドGDN(3:1の比率)が純粋なGDNや標準Transformerを上回り、パラメータと計算量の増加に伴ってもこの性能差が維持された。
ポストトレーニングにおけるアーキテクチャの違いの影響
Olmo Hybridは異なるアーキテクチャを持つ初のモデルであり、既存のトレーニングレシピを適用してもベンチマーク性能が予測通りに向上せず、知識分野では改善されたものの推論能力で低下が見られた。
重要な引用
These models are called hybrid because they mix these new recurrent neural network (RNN) modules with the traditional attention that made the transformer famous.
The RNN layers keep part of the computation compressed in a hidden state to be used for the next token in the prediction — a summary of all information that came before
Past theoretical work has shown that attention and r
hybrid models dominate transformers, both theoretically, in their balance of expressivity and parallelism, and empirically, in terms of benchmark performance and long-context abilities.
for Olmo, the hybrid GDN (3:1 ratio of layers) > pure GDN (all RNN layers) > standard transformer (all attention) > hybrid Mamba2 > pure Mamba2.
Olmo Hybrid is our first experience in post-training a substantially different architecture, and the results were mixed.
影響分析・編集コメントを表示
影響分析
本記事は、Transformer一択だったLLMアーキテクチャの多様化を示す重要な転換点である。計算コスト削減と推論速度向上が見込まれるハイブリッド型が、主要オープンソースモデルで採用されることで、インフラコストの削減やエッジデバイスでの大規模言語モデル運用の実現可能性が高まる。
編集コメント
Transformerの限界を補完するハイブリッド型アーキテクチャが、主要オープンモデルで実装され始めている点は注目に値する。Olmo Hybridの理論論文は、今後のアーキテクチャ設計における重要な指針となるだろう。
いわゆるハイブリッドアーキテクチャは、最近のオープンウェイトモデルにおいて全く新しいものではありません。現在では、Qwen 3.5(Qwen3-Next によってプレビュー)、昨秋に発表された Kimi Linear(フラッグシップである Kimi K2 モデルよりも小規模なリリース)、Nvidia の Nemotron 3 Nano(より大規模なモデルはまもなく登場予定)、IBM Granite 4、そしてその他の目立たないモデルなどが存在します。これは研究トレンドがまるで同時にあらゆる場所で採用され始めているかのような時期の一つです(もしかすると Muon オプティマイザーもすぐにそうなるかもしれません)。
この物語を語るには、2023 年 12 月まで数年前に遡る必要があります。その時、Mamba と Striped Hyena が世界を席巻し、モデルにおいて完全なアテンション(attention)が必要なのかという問いを投げかけていました。これらの初期モデルは、今日でも難しい理由と同じく、実装の難しさやオープンソースツールの問題、トレーニングにおけるさらなる頭痛の種によって消え去りました。さらに、スケールアップした際にモデルが少し崩れてしまったことも原因です。当時のハイブリッドモデルはまだ十分ではありませんでした。
これらのモデルは、従来のトランスフォーマーを有名にしたアテンション(注意機構)と、新しい再帰型ニューラルネットワーク(RNN)モジュールを組み合わせているため、「ハイブリッド」と呼ばれています。これらすべてのモデルは、このモジュールの組み合わせにおいて最も高い性能を発揮します。RNN レイヤーは、計算の一部を隠れ状態に圧縮して保持し、次のトークンの予測に利用します。これは、それまでに現れたすべての情報の要約であり、深層学習においては非常に長い歴史的背景を持つ考え方です(例:LSTM)。この構成により、アテンションの二次的な計算コスト(つまり、アテンション演算子の各トークンごとに KV キャッシュを漸次的に拡張する必要性)を回避でき、新たな問題の解決にも寄与します。
本記事で最初に紹介されるモデルは、RNN のアプローチを組み合わせています。一部のモデル(Qwen および Kimi)は、Gated DeltaNet (GDN) という新しいアイデアを採用しており、他の一部では依然として Mamba レイヤーが使用されています(Granite および Nemotron)。本日公開する Olmo Hybrid モデルも、注意機構や Mamba レイヤーでは学習できない特徴を GDN が習得できるという理論と、慎重な実験に基づき、GDN の側を採用しています。
Olmo Hybrid とその事前トレーニングの効率性の紹介
Olmo Hybrid は 7B ベースモデルであり、3 つの実験用ポストトレーニングチェックポイントがリリースされています。まずはインストラクションモデルから始まり、推論モデルも近日公開予定です。これはハイブリッドモデルを研究するための最良のオープンアーティファクトです。なぜなら、昨秋に発表した Olmo 3 7B モデルとほぼ同一であり、アーキテクチャのみが変更されているからです。このモデルとともに、ハイブリッドモデルが標準的なトランスフォーマーよりも優れる理由に関する実質的な理論を記した論文も公開します。これは非常に長い論文で、私自身もまだ読み進めている最中ですが、内容は素晴らしいものです。
論文はここでお読みいただけますし、チェックポイントについてはこちらで試すことができます。これはウィル・メリルが率いる、信じられないほど壮大な長期的研究プロジェクトです。彼の功績は素晴らしいものがありました。
なぜハイブリッドモデルがトランスフォーマーに対する厳密なアップグレードとなり得るのか、その文脈を理解するために、論文のイントロダクションからの長い抜粋を紹介しましょう(強調部分は私によるものです):
過去の理論的研究では、アテンションと再帰には相補的な強みがあることが示されています(Merrill et al., 2024; Grazzi et al., 2025)。したがって、これらを組み合わせることは、両方のプリミティブの利点を備えたアーキテクチャを構築する自然な方法です。さらに、ハイブリッドモデルは単なる部分の合計よりもさらに強力であることを示す新たな理論的結果を導き出しました:コード評価に関連する形式問題の中には、トランスフォーマーでも GDN(Generalized Dynamic Networks)でも単独では表現できないが、ハイブリッドモデルであれば理論的に表現可能であり、経験的にも学習できるものが存在します。しかし、この高い表現力が即座にハイブリッドモデルがより優れた言語モデルであることを意味するわけではありません。そこで、ハイブリッドモデルとトランスフォーマーを比較した完全に制御されたスケーリング研究を実行し、厳密に検証しました。その結果、ハイブリッドモデルの表現力はトークン効率の向上につながることが示され、Olmo Hybrid の事前学習ランニングで得られた観察結果とも一致しています。最後に、言語モデリング目的のマルチタスク性質に基づき、アーキテクチャの表現力を高めることがなぜ言語モデルのスケーリングを改善すべきかという理論的な説明を提供します。
以上の結果を総合すると、ハイブリッドモデルは、表現力と並列性のバランスにおいて理論的に優れ、ベンチマーク性能や長文コンテキスト能力において経験的にもトランスフォーマーを上回ることが示唆されます。これらの知見がハイブリッドモデルのより広範な採用に向けた位置づけを提供し、研究コミュニティに対してさらなるアーキテクチャ研究を推進することを呼びかけます。
本稿では、主に以下の点を示し、論じています。
ハイブリッドモデルはより表現力に富んでいます。これにより、出力を形成してより多様な関数を学習することが可能になります。これがなぜ有益なのかという直感的な理由は次のように説明できます。表現力の高いモデルは深層学習において優れており、モデルクラスを可能な限り柔軟にし、制約ではなく最適化器に任せることで学習者への制限を減らすことが望まれるからです。これは「苦い教訓」と非常に似ています。
なぜ表現力の高さが効率性に寄与するのか?ここがより微妙な点です。我々は、表現力の高いモデルはニューラルスケーリングの量子化モデルに従って、より優れたスケーリング法則を示すと論じます。
これらの理論的検討は深掘りするための素晴らしい方法ですが、率直に言って私自身もまだ学ぶべきことが多くあります。しかし、最も重要なのは、この理論を裏付ける明確な実験へと移行した点です。特に、このモデルを設計するためのスケーリング法則は慎重に研究され、最終的なハイブリッドアーキテクチャの決定に役立てられました。最終性能は、どの RNN ブロックを使用するか、またその数量が正確に何であるかに非常に敏感です。
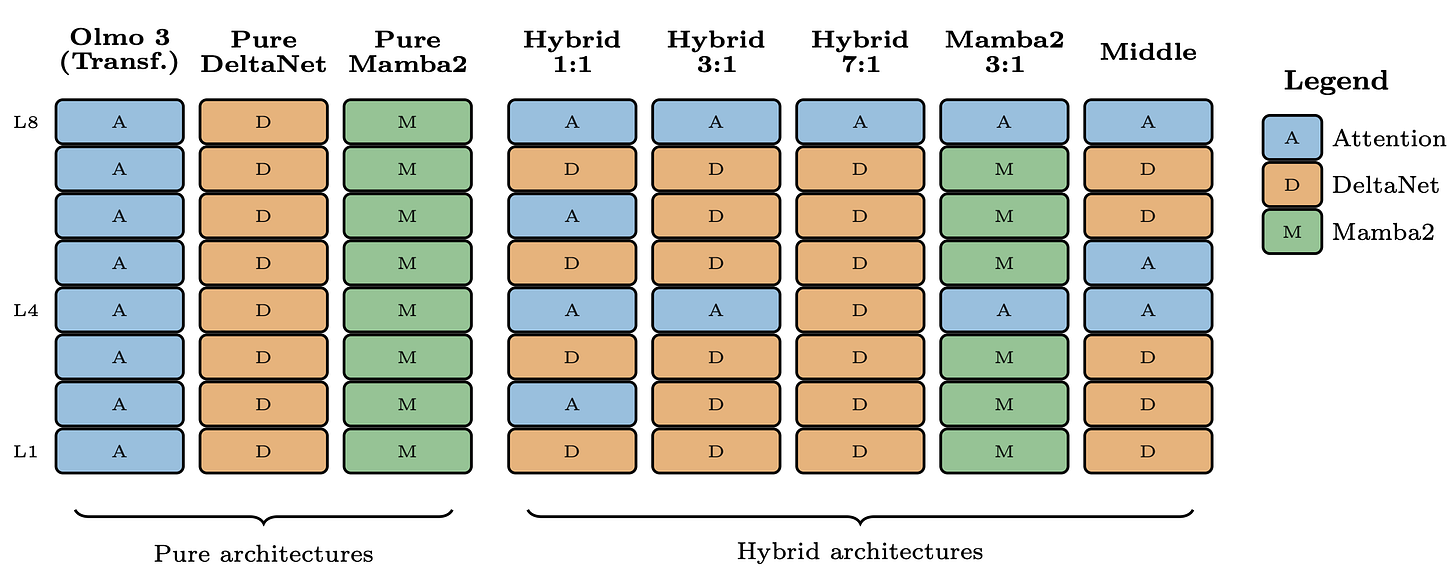
スケーリング実験の結果では、Olmo において、ハイブリッド GDN(層比 3:1)> プア GDN(RNN 層のみ)> 標準トランスフォーマー(アテンションのみ)> ハイブリッド Mamba2 > プア Mamba2 という順序で性能が示されました。重要な点は、パラメータ数と計算リソースを増やしてスケーリングしても、これらの差が維持されたことです。以下に、研究対象となった異なるアーキテクチャタイプの視覚的サマリーを示します。
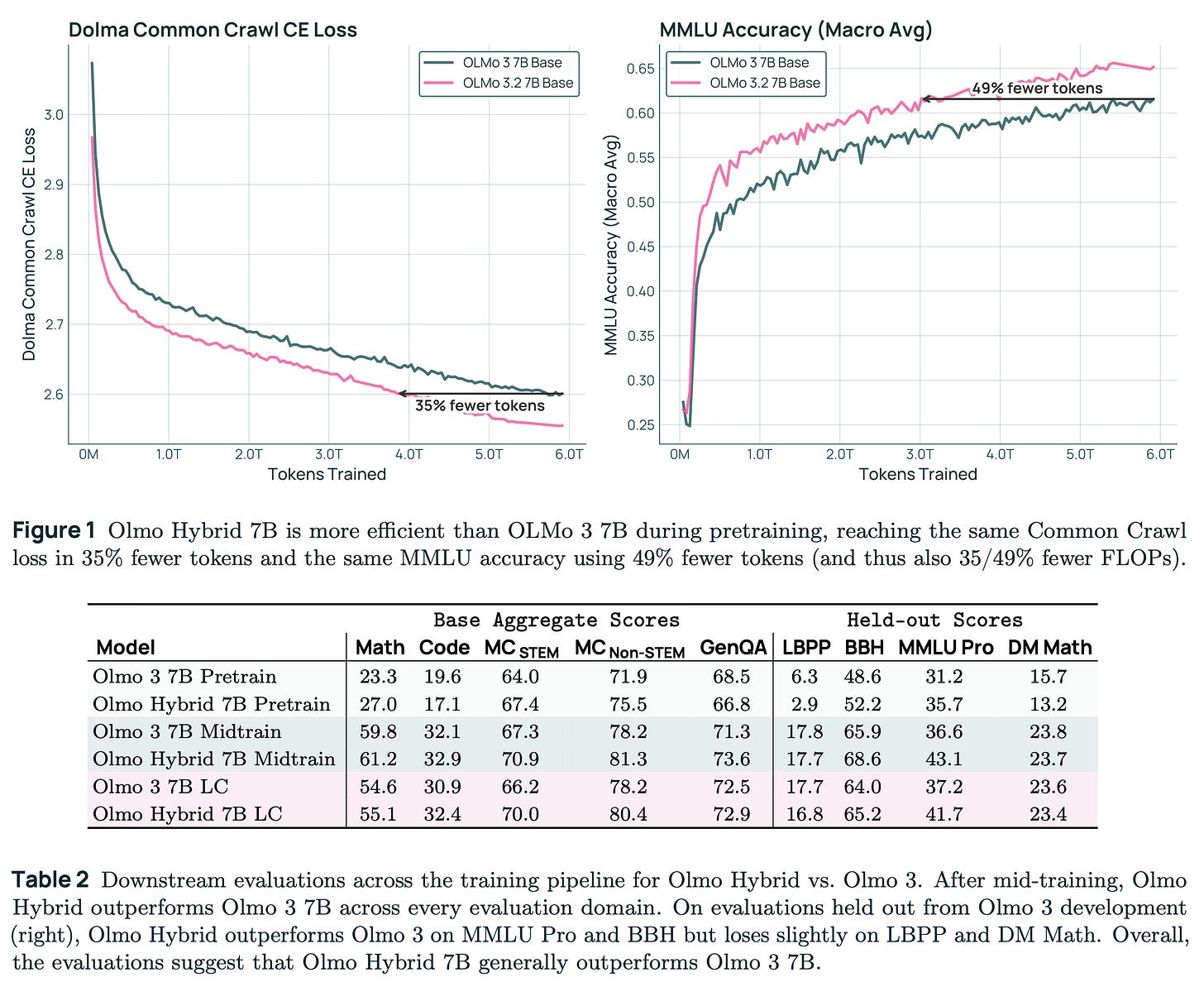
この特定のモデルに関しては、事前学習による効果は非常に大きかったです!Olmo 3 の密集型モデルと比較すると、トレーニング効率において約 2 倍の向上が見られました。事前学習の評価性能を見ると、特に長文コンテキスト拡張後(論文の Table 2 の最終 2 行で以下にハイライトされています)にパフォーマンスが大幅に改善されました。
Olmo Hybrid のポストトレーニングへの道のり
Olmo モデルのポストトレーニングにおける経験のほとんどは、アーキテクチャにわずかな調整を加えながら、ベースモデルの能力を急激に向上させる曲線に沿って進んできました。Tulu 2、Tulu 3、および Olmo 3 の推論作業(OpenThoughts 3 を大幅に拡張した内容)からのレシピは、すべて比較的単純で、市販品のようにそのまま使える方法で機能しました。Olmo Hybrid は、ポストトレーニングにおいて本質的に異なるアーキテクチャを扱う初めての経験であり、その結果は賛否両半でした。
- ベンチマーク性能
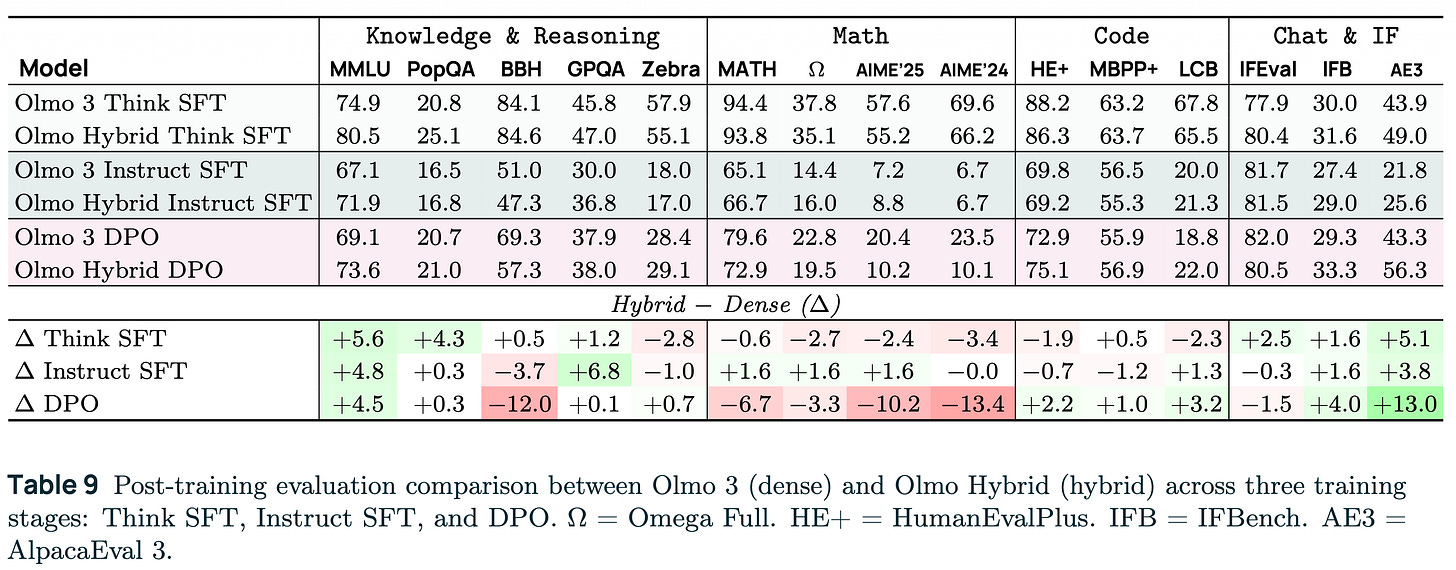
Olmo 3 のレシピに従った結果、稠密モデルと比較して知識面では大きな成果を得る一方で、推論の拡張性においては大きな損失を被りました。これらを総合すると依然として非常に強力な完全オープンモデルですが、事前学習による向上が直感的に明確には現れていません。結果は以下の通りです。
これがなぜ起こるのかという正確な理由は研究課題です。私たちの最良の推測では、Olmo Hybrid のベースモデルは十分に異なる学生モデルであり、初期段階における私たちが使用するポストトレーニングデータの多くが、より強力な「教師」モデルから学習している(この手法である知識蒸留 [distillation] についての要約は最近 Interconnects で紹介されました)ためです。
コミュニティ内では、強力な教師モデルを構成する要素について多くの研究が行われています。一般的に、総合評価において最良のモデルが、必ずしも最良の教師モデルであるとは限りません。つまり、現在の評価スコアで最も優れたモデルから出力されたデータを用いて学習しても、新しいベースモデルのパフォーマンス上限を引き上げることは難しいでしょう。
さらに探求が進んでいない第二の要因として、異なるベースモデルにはそれぞれ異なる教師モデルが必要となる可能性があります。これが、Olmo Hybrid が極めて異なるパフォーマンスを示す理由です。これはアーキテクチャに基づく学習変化に起因する下流の動作であり、事前学習データはほぼ同一であるにもかかわらずです。
ここを掘り下げるためには、より良質なデータの生成に関する実証的な研究や、異なるトレーニング段階がどのように連携するかを理解するためのさらなる作業が必要です。私はこの Olmo Hybrid ベースモデルが堅牢であると確信しており、さらに性能を引き出す余地があると考えていますが、既存のデータセットを適応させるには、より慎重な作業が必要となります。
- オープンソースツールリング
オープンモデルにおける新アーキテクチャの率直な現実は、オープンソースソフトウェアのツールリングサポートが極めて不十分であるという点です。人々がよく知る紙一重の問題、例えば GPT-OSS で経験されたような人気ライブラリ内のランダムエラーによる採用の遅延などがありますが、それよりも深い問題が存在します。
ハイブリッドモデルの潜在的な利点の大部分は、長期コンテキスト生成におけるメモリ使用量の削減にあり、これは強化学習やエージェントタスクにとって極めて重要です。ポストトレーニングにおいては大きな勝利となるはずです。しかし残念ながら、現状はほど遠く、このバッチの GDN モデルに対してこれを正しく実装するにはさらに 3〜6 ヶ月を要する見込みです。
核心的な問題は、オープンソース推論ツール(例:VLLM)が、標準的なトランスフォーマーと比較して、はるかに未熟なカーネル(およびその他の内部機構)に依存している点にあります。これには 2 つの課題が伴います——スループットの低下と数値的な問題です。数値的な問題は、さまざまな推論フラグで対処可能です。論文からの引用を再度示します:
ポストトレーニングモデルで最大のパフォーマンスを得るために VLLM で必要だった 2 つの主要なフラグは、--disable-cascade-attn(共有プロンプトプレフィックス向けの最適化であるカスケードアテンションを無効化する)と --enforce-eager(CUDA グラフをオフにする)です。これら 2 つのフラグは、Olmo 3 に遡る当社の RL セットアップで使用されてきましたが、評価においては新規追加項目となります。これらのフラグなしでは、公開されたモデルのスコアが劇的に低下します。また、NVIDIA の推奨に従い --mamba_ssm_cache_dtype を使用して、より豊富な FP32 データ型でハイブリッドモデルキャッシュを備えた最終モデルも評価しました。
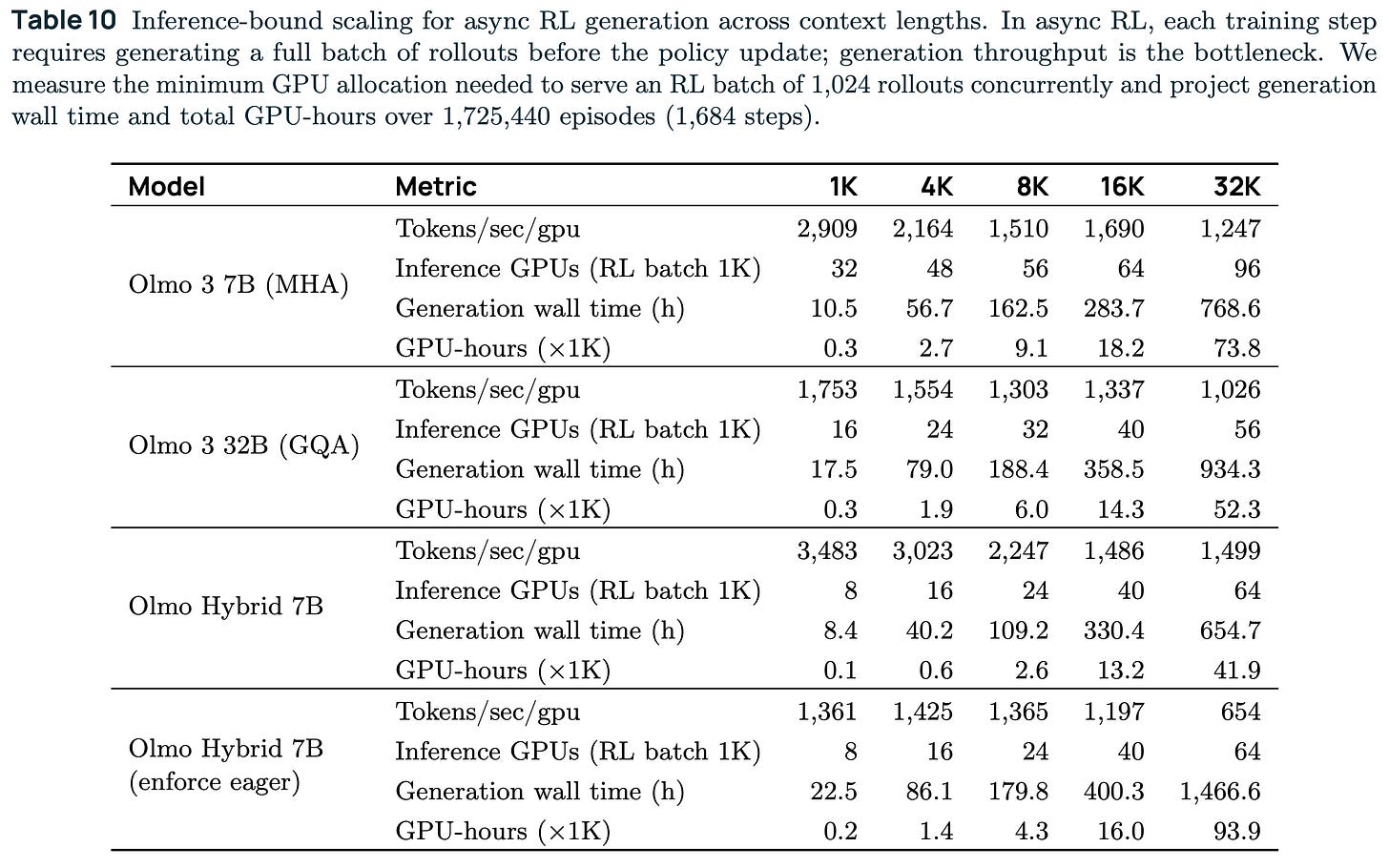
本質的には、これらを使用してモデルの数値的安定性を確保しました。その代償として、推論スループットが急落するため、計算効率における潜在的な利点がすべて相殺されてしまいます。数値比較は以下の通りです。
このためのデータはここで入手可能です。
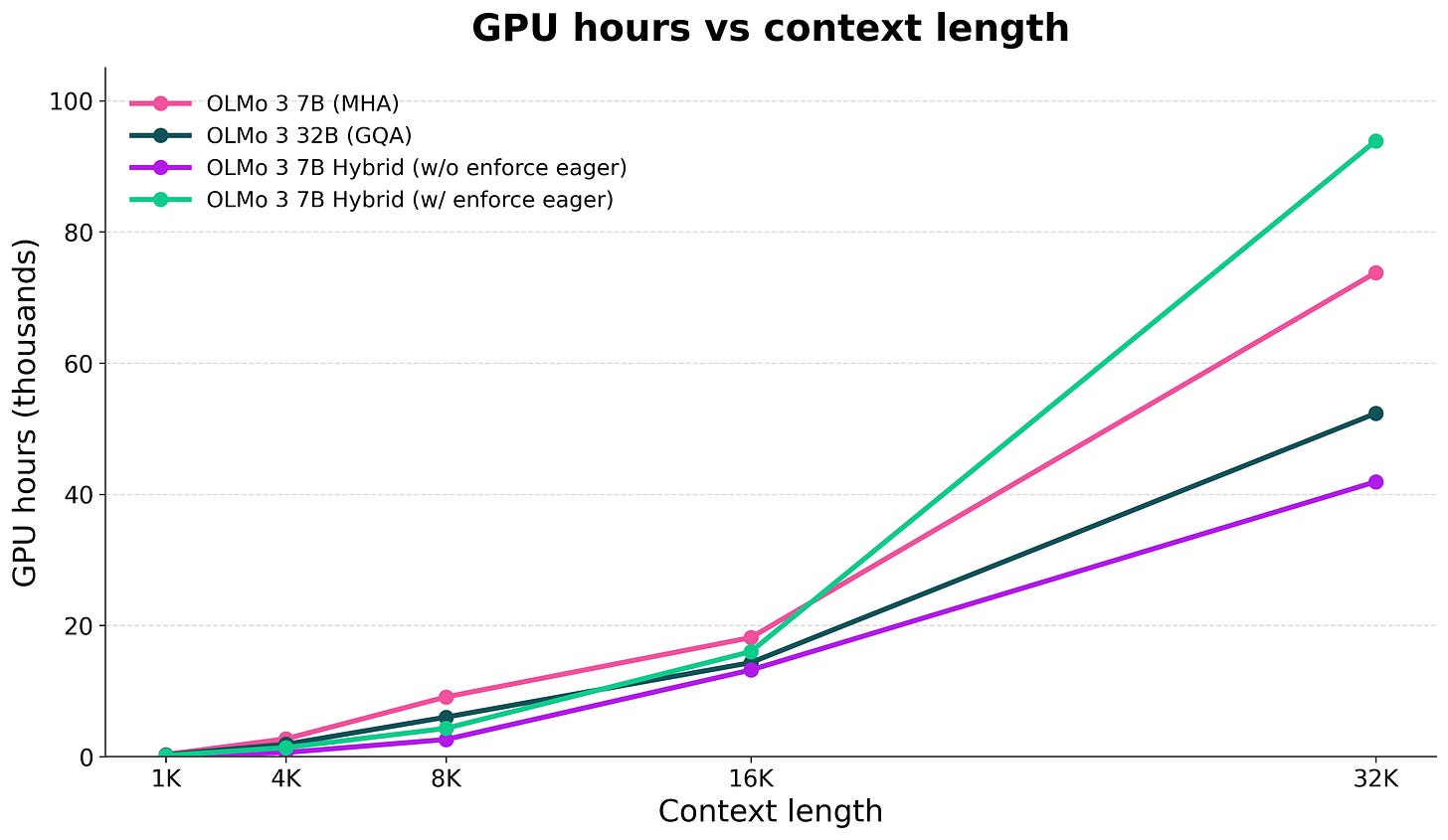
実際、現在の 7B ハイブリッドモデルは、RL(強化学習)でトレーニングする際に、GQA(グループ化クエリアテンション:共通のメモリ節約技術を持たない)さえ備えていない当社の 7B デンストランスフォーマーモデルよりも多くの計算資源を必要とします。異なるコンテキスト長における表からの総計算量推計は以下の通りです(詳細な視覚資料は、私の最近の CMU での講演のスライドにあります)。
朗報は、これらは解決可能な問題だということです。ツールリングの改善がベンチマーク数値の向上にもつながる可能性がありますが、オープンソースコミュニティにおいて相当な時間と地道な努力が必要になるでしょう。
これが私の最後の質問です。アーキテクチャのより優れた基本的なスケーラビリティを原動力とし、すでにこれを利用している主要なオープンモデルビルダーの大規模クラスが存在することを根拠に、オープンエコシステムがこれらのモデルを容易にサポートするよう進化することに楽観的であるなら、GPT や Claude といったクローズドモデルも同様にこのように構築されているのでしょうか?
念のため申し上げますと、この回答は私の完全なる推測です(通常は行わないことですが)、私が持っている証拠に基づけば、3 つの最先端モデルのうちいずれかが RNN である確率は、コインを投げたようなものだと考えられます。どちらの結果であれ確定した情報を得れば、改めてお知らせいたします。スケーリング上の利点が最先端規模でも維持されるのであれば、経済的な合理性は無視できなくなるでしょうが、すでに RNN のように効率的でありながら、さらに多くのメリットを持つアーキテクチャを備えている可能性もあります。
本投稿に続き、特に Mixture of Expert (MoE) モデルがポストトレーニングにおいてなぜ大きな頭痛の種となるのかについて、より詳細なアーキテクチャに関する議論を行いたいと思います。もしこの話題に興味をお持ちであれば、ぜひ購読してください!
今すぐ購読する
本稿の内容形成に有益な議論をしてくださった Will Merrill 氏と Finbarr Timbers 氏に感謝いたします。
- 私が YouTube で行ったインタビューの中で最も視聴回数の多いもの(私が初めて行ったインタビューです)。
原文を表示
So-called hybrid architectures are far from new in open-weight models these days. We now have the recent Qwen 3.5 (previewed by Qwen3-Next), Kimi Linear last fall (a smaller release than their flagship Kimi K2 models), Nvidia’s Nemotron 3 Nano (with the bigger models expecting to drop soon), IBM Granite 4, and other less notable models. This is one of those times when a research trend looks like it’s getting adopted everywhere at once (maybe the Muon optimizer too, soon?).
To tell this story, we need to go back a few years to December 2023, when Mamba and Striped Hyena were taking the world by storm1 — asking the question: Do we need full attention in our models? These early models fizzled out, partially for the same reasons they’re hard today — tricky implementations, open-source tool problems, more headaches in training — but also because the models fell over a bit when scaled up. The hybrid models of the day weren’t quite good enough yet.
These models are called hybrid because they mix these new recurrent neural network (RNN) modules with the traditional attention that made the transformer famous. They all work best with this mix of modules. The RNN layers keep part of the computation compressed in a hidden state to be used for the next token in the prediction — a summary of all information that came before — an idea that has an extremely long historical lineage in deep learning, e.g. back to the LSTM. This setup avoids the quadratic compute cost of attention (i.e. avoiding the incrementally expanding the KV cache per token of the attention operator), and can even assist in solving new problems.
Share
The models listed to start this article use a mix of RNN approaches, some models (Qwen and Kimi) use a newer idea called Gated DeltaNet (GDN) and some still use Mamba layers (Granite and Nemotron). The Olmo Hybrid model we’re releasing today also falls on the GDN side, based on careful experimentation, and theory that GDN is capable of learning features that attention or Mamba layers cannot.
Introducing Olmo Hybrid and its pretraining efficiency
Olmo Hybrid is a 7B base model, with 3 experiment post-trained checkpoints released — starting with an Instruct model, with a reasoning model coming soon. It is the best open artifact for studying hybrid models, as it is almost identical to our Olmo 3 7B model from last fall, just with a change in architecture. With the model, we are releasing a paper with substantial theory on why hybrid models can be better than standard transformers. This is a long paper that I’m still personally working through, but it’s excellent.
You can read the paper here and poke around with the checkpoints here. This is an incredible, long-term research project led by Will Merrill. He did a great job.
To understand the context of why hybrid models can be a strict upgrade on transformers, let me begin with a longer excerpt from the paper’s introduction, emphasis mine:
Past theoretical work has shown that attention and recurrence have complementary strengths (Merrill et al., 2024; Grazzi et al., 2025), so mixing them is a natural way to construct an architecture with the benefits of both primitives. We further derive novel theoretical results showing that hybrid models are even more powerful than the sum of their parts: there are formal problems related to code evaluation that neither transformers nor GDN can express on their own, but which hybrid models can represent theoretically and learn empirically. But this greater expressivity does not immediately imply that hybrid models should be better LMs: thus, we run fully controlled scaling studies comparing hybrid models vs. transformers, showing rigorously that hybrid models’ expressivity translates to better token efficiency, in agreement with our observations from the Olmo Hybrid pretraining run. Finally, we provide a theoretical explanation for why increasing an architecture’s expressive power should improve language model scaling rooted in the multi-task nature of the language modeling objective.
Taken together, our results suggest that hybrid models dominate transformers, both theoretically, in their balance of expressivity and parallelism, and empirically, in terms of benchmark performance and long-context abilities. We believe these findings position hybrid models for wider adoption and call on the research community to pursue further architecture research.
Essentially, we show and argue a few things:
Hybrid models are more expressive. They can form their outputs to learn more types of functions. An intuition for why this would be good could follow: More expressive models are good with deep learning because we want to make the model class as flexible as possible and let the optimizer do the work rather than constraints on the learner. Sounds a lot like the Bitter Lesson.
Why does expressive power help with efficiency? This is where things are more nuanced. We argue that more expressive models will have better scaling laws, following the quantization model of neural scaling.
All of this theory work is a great way to go deeper, and frankly I have a lot more to learn on it, but the crucial part is that we transition from theory to clear experiments that back it up. Particularly the scaling laws for designing this model were studied carefully to decide on the final hybrid architecture. The final performance is very sensitive to exactly which RNN block is used and in what quantity.
In scaling experiments, the results showed that for Olmo, the hybrid GDN (3:1 ratio of layers) > pure GDN (all RNN layers) > standard transformer (all attention) > hybrid Mamba2 > pure Mamba2. The crucial point was that these gaps maintained when scaling to more parameters and compute. A visual summary of the different types of architectures studied is below.
In terms of this specific model, the pretraining gains were giant! Relative to Olmo 3 dense, it represents an about 2X gain on training efficiency. When you look at evaluation performance for pretraining, there was also substantial improvement in performance, particularly after long context extension (the final 2 rows of Table 2 in the paper, highlighted below).
The journey to post-training Olmo Hybrid
Most of the experience in post-training Olmo models has been climbing up a steep curve in base model capabilities with minor tweaks to architecture. Our recipes from Tulu 2, Tulu 3, and the Olmo 3 reasoning work (building substantially on OpenThoughts 3) all worked in a fairly straightforward, off the shelf manner. Olmo Hybrid is our first experience in post-training a substantially different architecture, and the results were mixed.
- Benchmark performance
Following the Olmo 3 recipe, we got some substantial wins (knowledge) and some substantial losses (extended reasoning) relative to the dense model. All together these still represent a very strong fully open model — just that the pretraining gains didn’t translate as obviously. The results are below.
The exact reason why this happens is a research question. Our best guess is that the Olmo Hybrid base model is just a sufficiently different student model, where most of our post training data at early stages is learning from stronger “teacher” models (a recap of this method, called distillation, appeared recently in Interconnects).
There is a lot of other research ongoing in the community around what makes a strong teacher model — generally, the best overall model is not the best teacher. In other words, training on data outputted from the model with best evaluation scores today is unlikely to unlock the ceiling in performance for your new base model. A second factor, which is even less explored, is how different base models likely need different teachers to learn from. This is why Olmo Hybrid could perform very differently, where it’s behavior is downstream of an architecture-based learning change, where the pretraining data is almost identical.
There’s A LOT more work to dig into here, some empirical work in generating better data and other work in understanding how different training stages fit together. I am confident this Olmo Hybrid base model is solid and more performance can be extracted, but it takes more careful work adapting existing datasets.
- Open-source tooling
The frank reality of new architectures for open models is that the open-source software tooling support is horrific. There’s the paper-cuts that people are familiar with, e.g. random errors in popular libraries (as people experienced with GPT-OSS) that slow adoption, but there are also deeper problems.
A large part of the potential benefit of hybrid models is the reduction in memory usage for long-context generation, which is crucial for reinforcement learning and agentic tasks. It should be a huge win for post-training! This, unfortunately, is far from the case, and will likely take another 3-6months to get right for this batch of GDN models.
The core problem is that the open-source inference tools, e.g. VLLM, are relying on far less developed kernels (and other internals) when compared to standard transformers. This comes with two challenges — throughput slowdowns and numerical issues. Numerical issues can be combatted with a variety of inference flags. Quoting the paper again:
The two key flags in VLLM we needed to get maximum performance with the post-training model were --disable-cascade-attn, which disables cascade attention (an optimization for shared prompt prefixes), and --enforce-eager, which turns off CUDA graphs. These two flags have been used in our RL setup dating back to Olmo 3, but are new additions to evaluations. Scores for the released models drop precipitously without them. We also evaluated our final models with the hybrid model cache in the richer FP32 datatype, to improve stability via --mamba_ssm_cache_dtype following NVIDIA.
Essentially, we used these to make sure the model was numerically stable. The downside is that the inference throughput plummets, so the potential gains in compute efficiency are erased. A comparison of numbers is below.
Data for this is available here.
Effectively, the 7B hybrid model today takes more compute to train with RL than our 7B dense model (that doesn’t even have a common memory saving technique, GQA). The total compute estimate from the table at different context lengths is below (more visuals in the slides from my recent CMU talk).
The good news is that these are solvable problems — and improving the tooling could even improve benchmark numbers — but it’s going to take a good bit of time and hard work in the OSS community.
This leads to my final question. If I’m optimistic about the open ecosystem evolving to support these models with ease, motivated by the better fundamental scaling of the architectures and a large cluster of leading open model builders already using it, are closed models like GPT and Claude built like this?
To be clear, this answer is a total guess (which I don’t normally do), but with the evidence I have I’d put the chance of one of the 3 frontier models being an RNN being around a coin flip. I’ll let you know if I learn for sure either way. If the scaling advantages hold at frontier scale, the economic case becomes hard to ignore, but they could already have architectures that are efficient like RNNs, but with even more benefits.
I’m going to follow up this post with more architecture discussions, particularly on why Mixture of Expert (MoE) models are a major headache to post-train, so make sure to subscribe if that sounds interesting to you!
Subscribe now
Thanks to Will Merrill and Finbarr Timbers for some discussions that helped inform this post.
1and still my most-viewed interview on YouTube, as the first one I did.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み