最新オープンアーティファクト(第20号):新組織、新モデルタイプ!Nemotron Super、Sarvam、Cohere Transcribeなど
InterconnectsのArtifacts Logは、NVIDIA NemotronやCohere Transcribeなど多様なオープンモデルの最新動向を紹介し、ドメイン特化型かつ低コストなオープンモデルがクローズドエージェントを補完する重要な役割を果たす未来を示唆している。
キーポイント
多様性と専門性の拡大
今月のArtifacts Logでは、OCR、RAG検索、音声文字起こしなど特定のユースケースに特化した多様なモデルが紹介され、大手モデル中心の議論から領域特化型・低コストモデルへの注目がシフトしている。
NVIDIA Nemotron-3-Superの技術的革新
NVIDIAが公開した120Bパラメータのモデルは、LatentMoEアーキテクチャとNVFP4形式を事前学習に採用した初のオープンモデルであり、100万トークンのコンテキストウィンドウと多言語サポートを備えている。
CohereとSarvamの貢献
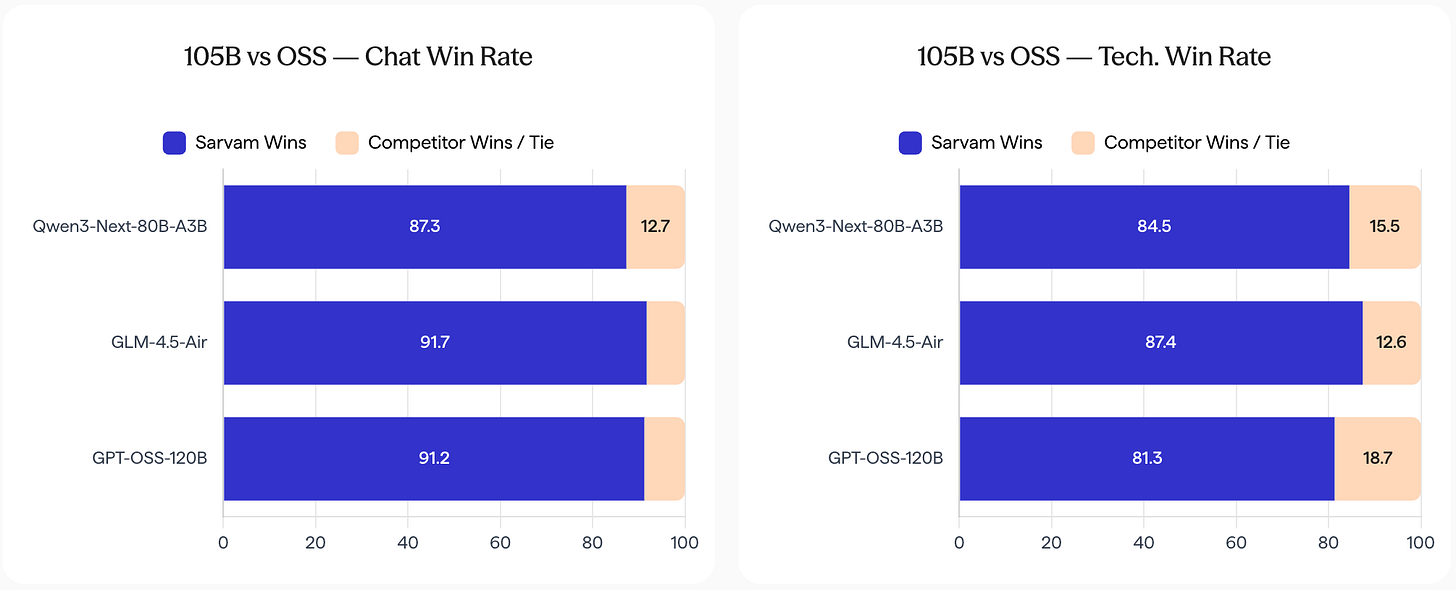
CohereはApache 2.0ライセンスで多言語音声文字起こしモデルを公開し、Sarvamはインドの主権AIの一環としてインディック言語に強い105Bパラメータモデルを公開し、既存のオープンモデルを上回る性能を示した。
Mistral-Small-4-119B-2603のハイブリッド構造
Mistralが以前の数世代のモデルを統合し、コーディング能力を持つハイブリッド推論モデルとしてリリース。
zeta-2のデータ収集方針
Zed IDEの開発元が公開した編集予測モデルで、前版のオープンデータに加え、明示的にデータ収集に同意したユーザーのオープンソースコードを使用して学習。
NVIDIA-Nemotron-3-Nano-4B-BF16の圧縮技術
NVIDIA-Nemotron-Nano-9B-v2および12B-v2をさらに圧縮したモデルで、NVIDIAがオープンモデル分野で推進している方向性を示す。
Yuan3.0-Ultraの1Tパラメータと専門家剪定
Yuan Labが公開した1Tパラメータのマルチモーダルモデルで、2.2Tトークンで事前学習後、新しい手法により専門家を剪定。
重要な引用
This gives us a lot of hope for the future of open models, where we see the need for domain-specific, cheap models as being crucial tools to complement the strongest, closed agents.
The long-awaited mid-sized model from NVIDIA is finally here: 120B total params with 12B active, a 1M context window... based on LatentMoE and uses NVFP4 during pre-training, which is a first for open models.
The release also shows why sovereign AI is so important... In comparison with SOTA open models, the Sarvam models are vastly more preferred in Indic languages.
"Puzzle is a post-training neural architecture search (NAS) framework, with the goal of significantly improving inference efficiency for reasoning-heavy workloads while maintaining or improving accuracy across reasoning budgets."
"While the previous version was based on open data, the new version, based on Seed-Coder-8B, is trained on open source code by users who explicitly opted into data collection."
"Its noncommercial license converts into Apache 2.0 after two years."
影響分析・編集コメントを表示
影響分析
このニュースは、AI業界が巨大な汎用モデルだけでなく、特定領域に特化した軽量・低コストなオープンモデルの必要性を再認識していることを示しています。特にNVIDIAの新技術採用や、地域固有言語への対応は、開発者の選択肢を広げ、実装のハードルを下げることで、AIの普及と多様性を加速させる可能性があります。
編集コメント
大手モデルのニュースに埋もれがちな、特定のタスクや地域言語に特化したオープンモデルの価値を再評価する重要な視点を提供しています。開発者は、汎用モデルではなく、自社のユースケースに最適な「特化型」オープンモデルを探す際の手がかりとして活用すべきです。
今回のアーティファクトログ記事は、使用ケースやモダリティにわたる多様で個性的なモデルの数において異例です。通常、これらのモデル総覧は Qwen、DeepSeek、Kimi などの大規模モデルによって支配されていますが、この記事では光学文字認識 (OCR)、RAG 検索、音声書き起こし、コンピュータ操作、コード編集、数学定理証明など、あらゆる異なる使用ケースに対応するモデルが登場します。今月取り上げられたアーティファクトは、より広範なオープンモデル開発者リストからも提供されています。
これは、ドメイン特化型で安価なモデルが最も強力なクローズドエージェントを補完する重要なツールとして必要とされる未来のオープンモデルに対して大きな希望を抱かせます。上位数モデルが注目を集める中で、この広範かつ産業規模の試行錯誤は容易に見落とされがちです。この記事を読むことで、業界が特定のモデルにどのような方向性を向けて推進しているかについて、技術的根拠に基づいた広範なカバーage を得ることができます。今後とも同様の内容が続くことを期待してください。
共有する
今回の号におけるモデルの多様性を見てもらうよう促すため、更新の核心部分は有料壁に囲まれていません。オープンモデルの最上位において通常は静かだった今月が、実際には素晴らしい成果をもたらしました。
アーティファクトログ
私たちが選ぶ
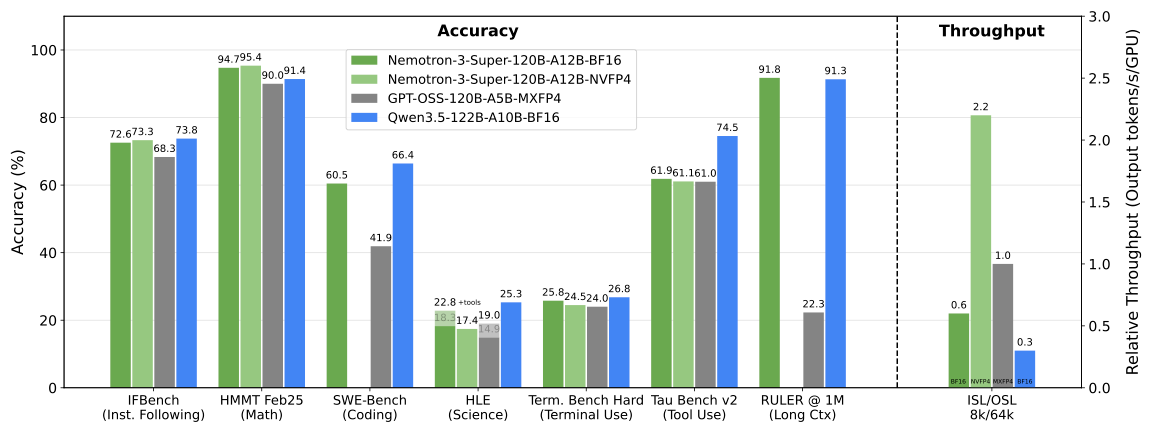
nvidia-nemotron-3-super-120b-a12b-nvfp4 by nvidia: NVIDIA による長年待ち望まれていたミドルサイズのモデルが遂に登場しました。総パラメータ数は 120B、アクティブなパラメータは 12B で、コンテキストウィンドウは 1M をサポートし、複数の主要言語に対応しています。さらに、このモデルは LatentMoE(潜在モジュール型エキスパート)に基づいており、事前学習に NVFP4(NVIDIA フォーマット 4 ビット浮動小数点)を採用した点は、オープンモデルとしては初めてです。NVIDIA の他の製品と同様に、詳細な技術レポートと事前学習・事後学習のデータセットが付属しており、その大半は公開されています。
cohere-transcribe-03-2026 by CohereLabs: Cohere による Conformer アーキテクチャ(コンフォーマーアーキテクチャ)に基づく音声テキスト変換モデルで、NVIDIA の Parakeet と類似しています。14 の異なる言語をサポートしており、その中には一部のアフリカ系言語やアラビア語も含まれています。性能面では、Cohere は同サイズのオープンおよびクローズドな他モデルを上回ると主張しています。さらに素晴らしいことに、このモデルは Apache 2.0 ライセンスの下でリリースされています!Cohere の過去のオープンモデルは非商用ライセンス下で公開されていました。
Sarvam-105B by SarvamAI: 過去にオープンモデルの訓練を行っていたインドのスタートアップ、Sarvam は、新しいフラッグシップモデルにおいて、データセットサイズ(12〜16T トークン)とモデルサイズ(30B-A2B, 105B-10A)の両面で規模を拡大しました。その結果、同程度のサイズの多くのオープンモデルに匹敵し、あるいは凌駕する性能を示しています。今回のリリースは、主権 AI(ソブリン・エーアイ)がいかに重要であるかを示すものであり、これはまだ他の国々の多くが内面化していない点です。SOTA(State-of-the-Art:最先端)のオープンモデルと比較すると、Sarvam モデルはインド系言語において圧倒的に好まれることがわかります。
Mistral-Small-4-119B-2603 by MistralAI: Mistral 社による 119B-A7B モデルで、過去のモデル世代を統合し、コーディング能力を備えたハイブリッド推論モデルとして機能します。
Zeta-2 by Zed Industries: オープンソースのコードエディタ「Zed」は、過去に編集予測モデルを公開しており、私たちは一年前にこれを特集しました。以前のバージョンがオープンデータに基づいていたのに対し、新しいバージョンは Seed-Coder-8B をベースとしており、データ収集への明示的な同意を行ったユーザーによるオープンソースコードで訓練されています。
Models
General Purpose
nvidia による gpt-oss-puzzle-88B:GPT OSS 120B の剪定された専門家版です。また、一部のグローバルアテンション層をウィンドウアテンションに置き換えています。Puzzle は「推論に重点を置いたワークロードの推論効率を大幅に向上させつつ、推論予算全体で精度を維持または向上させることを目的とした、ポストトレーニングニューラルアーキテクチャサーチ(NAS)フレームワーク」です。
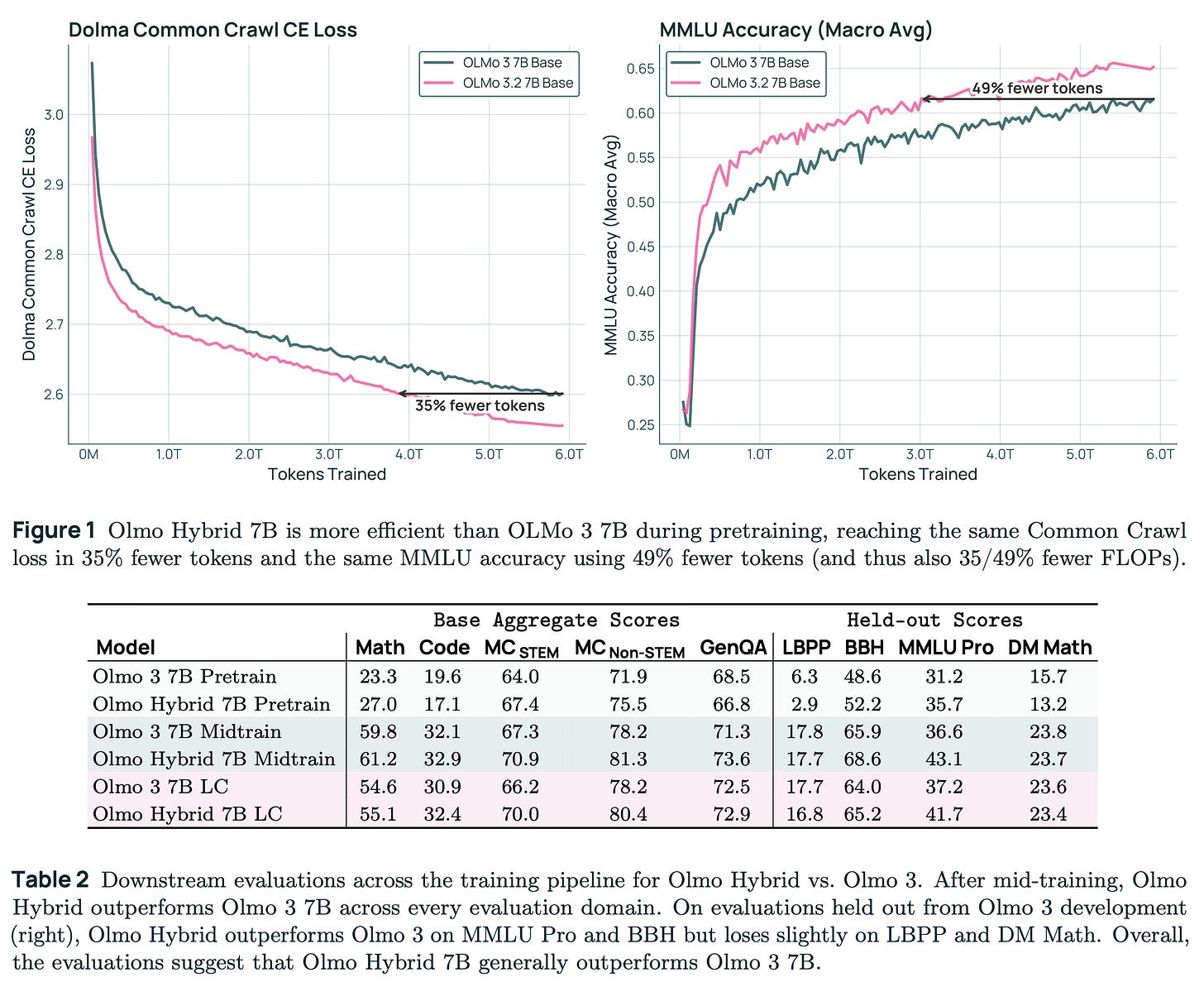
allenai による Olmo-Hybrid-7B:ハイブリッドアテンションと GDN(ゲート付きデルタネット)を組み合わせたモデルです。アーキテクチャとその課題に関する詳細については、当社のブログ記事をご覧ください。
nvidia による NVIDIA-Nemotron-3-Nano-4B-BF16:NVIDIA-Nemotron-Nano-9B-v2 の圧縮版であり、同モデル自体は NVIDIA-Nemotron-Nano-12B-v2 の圧縮版です。オープンモデルにおいて、この方向性を最も積極的に推進しているのは nvidia 以外にいません。
マルチモーダル
YuanLabAI による Yuan3.0-Ultra:比較的無名な Yuan Lab が開発した 1T パラメータのマルチモーダルモデルです。同社は 2.2T トークンで 1.5T モデルを事前学習し、その後、技術レポートに概説されている新しい手法を用いて専門家を剪定しました。
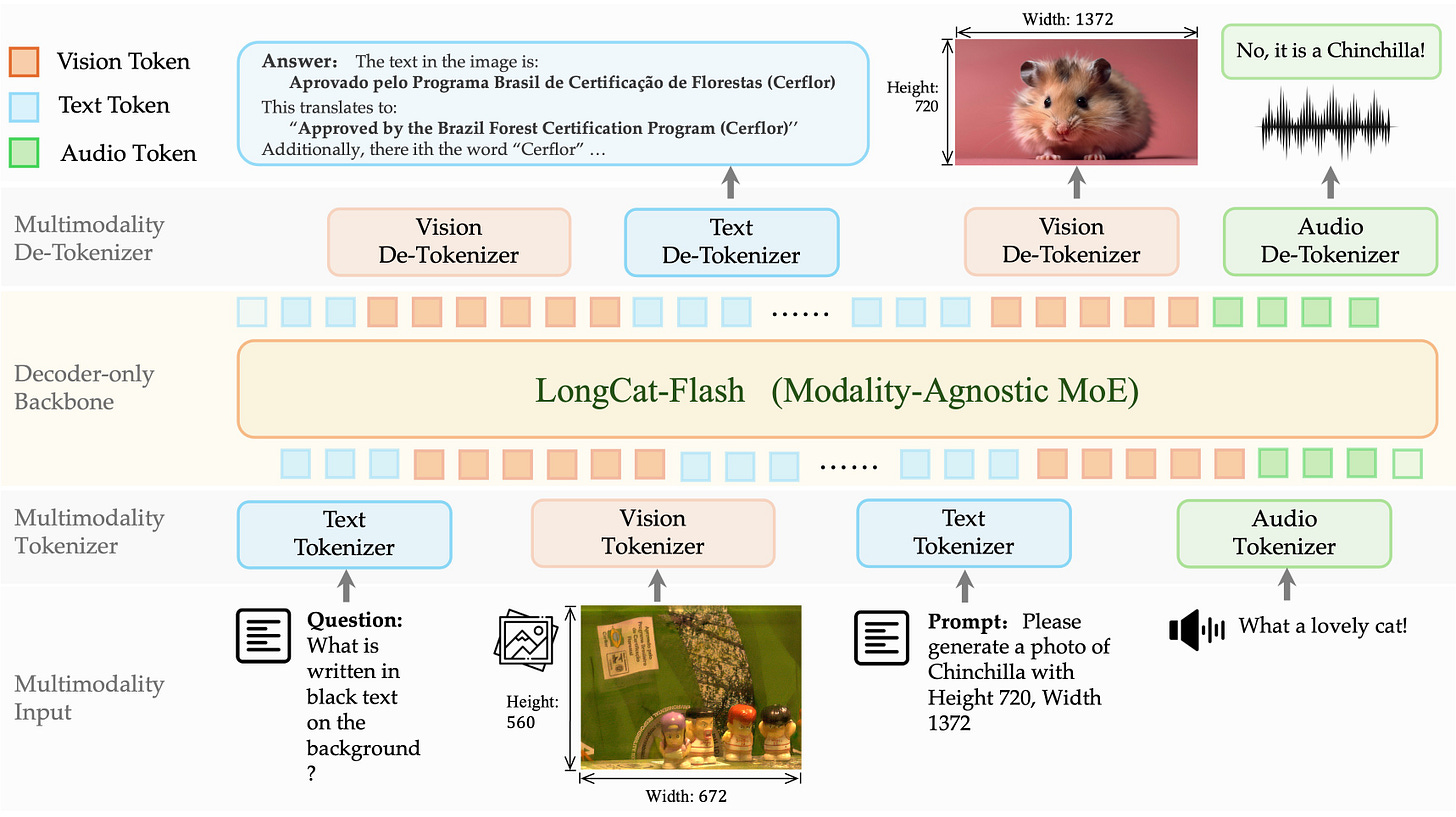
meituan-longcat による LongCat-Next:テキスト、ビジョン、オーディオを両方の入力と出力として処理できるマルチモーダルモデルです。
ibm-granite による granite-4.0-1b-speech: 6 か国語に対応する小規模な音声認識モデルです。また、翻訳用の英語オーディオ生成もサポートしています。
microsoft による Phi-4-reasoning-vision-15B: SigLIP-2 ビジョンエンコーダー(vision encoder)を採用した Phi モデルです。
Special Purpose(専用用途)
miromind-ai による MiroThinker-1.7: エージェントワークフロー、特に研究分野向けに微調整された Qwen 235B のバージョンです。
Prior-Labs による tabpfn_2_6: 人気のある表形式予測モデル(tabular prediction model)のアップデート版で、前作よりもわずかにサイズが大きくなっています。そのライセンスは研究および内部評価にのみ許可されています。
facebook による sam3.1: SAM 3 のアップデート版であり、同様に制限付きのライセンスを有しています。
Hcompany による Holotron-12B: CUA エージェント向けのポリシーモデルです。
meituan-longcat による LongCat-Flash-Prover: 大規模な LongCat モデルをベースにした Lean4 の微調整版です。
mistralai による Leanstral-2603: 新しい Mistral Small 4 をベースにした Lean4 の微調整版です。
RekaAI による reka-edge-2603: ロボティクス向けのモデルで、Cosmos-Reason2 などのモデルを上回っています。その非商用ライセンスは、2 年後に Apache 2.0 に変換されます。
RAG
百度による Qianfan-OCR:最近、多くの優れた OCR モデルが登場しています。このモデルは百度が開発し、Apache 2.0 ライセンスの下で公開されています。
datalab-to による chandra-ocr-2:Chandra OCR モデルのアップデート版ですが、制限付きライセンスの下でリリースされています。
lightonai による Reason-ModernColBERT:非商用ライセンスの下で公開された SOTA(State-of-the-Art)検索モデルです。ただし、データを再生成するためのコードも提供されており、商業利用可能なバージョンを訓練することが可能です。
chromadb による context-1:エージェント型検索向けに微調整された GPT-OSS のバージョンで、詳細な技術レポートも併せて公開されています。これにより、Chroma がオープンモデル空間へ初参入を果たしました。Thinking Machine の Tinker を用いて訓練されています。
rednote-hilab による dots.mocr:愛される dots.ocr モデルがアップデートされ、SVG 出力に対応しました。ただし、一般的な MIT ライセンスに加え、前作と同様に追加の使用制限が付いています。
続きを読む
原文を表示
This Artifacts Log post is unusual in how many diverse, quirky models there are across use-cases and modalities. Normally these model roundups are dominated by big models from the likes of Qwen, DeepSeek, Kimi, etc. There are models for all sorts of different use-cases in this post, from optical character recognition (OCR), RAG search, audio transcription, computer-use, code-editing, math theorem proving, and more. The artifacts covered this month also come from a much broader list of open model builders.
This gives us a lot of hope for the future of open models, where we see the need for domain-specific, cheap models as being crucial tools to complement the strongest, closed agents. When the top few models get the headlines, this vast, industry-scale tinkering can easily be forgotten. Reading this post gives a technically grounded, broad coverage of the many directions the industry is pushing specific models for. Expect more like this!
Share
To encourage people to take a look at the diversity of models in this issue, the core part of the update is not paywalled. An otherwise quiet month at the top end of open models really delivered.
Artifacts Log
Our Picks
NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 by nvidia: The long-awaited mid-sized model from NVIDIA is finally here: 120B total params with 12B active, a 1M context window, and support for multiple popular languages. Furthermore, the model is based on LatentMoE and uses NVFP4 during pre-training, which is a first for open models. Like other things from NVIDIA, it comes with an in-depth tech report plus pre-training and post-training datasets, with the vast majority of the data being openly released.
cohere-transcribe-03-2026 by CohereLabs: A speech-to-text model by Cohere based on the conformer architecture, similar to NVIDIA’s Parakeet. It features 14 different languages, including some AIPAC languages and Arabic. Performance-wise, Cohere claims it beats similarly sized open and closed models. To top it all off: The model is released under Apache 2.0! Previous open models by Cohere were released under a non-commercial license.
sarvam-105b by sarvamai: The Indian startup Sarvam, which trained open models in the past, has scaled up everything for its new flagship models in terms of dataset size (12-16T tokens) and model size (30B-A2B, 105B-10A). As a result, they come close to or even surpass a lot of open models with similar sizes. The release also shows why sovereign AI is so important, something that few other countries have internalized yet: In comparison with SOTA open models, the Sarvam models are vastly more preferred in Indic languages.
Mistral-Small-4-119B-2603 by mistralai: A 119B-A7B model by Mistral, combining their previous model generations into one as a hybrid reasoning model with coding abilities.
zeta-2 by zed-industries: The open source code editor Zed has released their edit prediction model openly in the past, which we featured a year ago. While the previous version was based on open data, the new version, based on Seed-Coder-8B, is trained on open source code by users who explicitly opted into data collection.
Models
General Purpose
gpt-oss-puzzle-88B by nvidia: A pruned expert version of GPT OSS 120B. It also replaces some global attention layers with window attention. Puzzle is “a post-training neural architecture search (NAS) framework, with the goal of significantly improving inference efficiency for reasoning-heavy workloads while maintaining or improving accuracy across reasoning budgets.”
Olmo-Hybrid-7B by allenai: A hybrid attention + GDN (gated DeltaNet) model. See our blog post for more insights about the architecture and its challenges.
NVIDIA-Nemotron-3-Nano-4B-BF16 by nvidia: A compressed version of NVIDIA-Nemotron-Nano-9B-v2, which itself is a compressed version of NVIDIA-Nemotron-Nano-12B-v2. Nvidia has been pushing this direction more than anyone else with open models.
Multimodal
Yuan3.0-Ultra by YuanLabAI: A 1T multimodal model by the relatively unknown Yuan Lab. They pre-trained a 1.5T model on 2.2T tokens and subsequently pruned experts with a new technique, outlined in the tech report.
LongCat-Next by meituan-longcat: A multimodal model which can process text, vision, and audio as both inputs and outputs.
granite-4.0-1b-speech by ibm-granite: A small speech-to-text model supporting six languages. It also supports the generation of English audio for translation.
Phi-4-reasoning-vision-15B by microsoft: A Phi model which uses the SigLIP-2 vision encoder.
Special Purpose
MiroThinker-1.7 by miromind-ai: A fine-tuned version of Qwen 235B for agentic workflows, especially research.
tabpfn_2_6 by Prior-Labs: An update to the popular tabular prediction model, which is slightly larger than its predecessor. Its license allows research and internal evaluation only.
sam3.1 by facebook: An update to SAM 3, carrying the same restrictive license.
Holotron-12B by Hcompany: A policy model for CUA agents.
LongCat-Flash-Prover by meituan-longcat: A Lean4 fine-tune of the large LongCat model.
Leanstral-2603 by mistralai: A Lean4 fine-tune of the new Mistral Small 4.
reka-edge-2603 by RekaAI: A model for robotics, beating models such as Cosmos-Reason2. Its noncommercial license converts into Apache 2.0 after two years.
RAG
Qianfan-OCR by baidu: There have been a lot of great OCR models lately. This one is from Baidu and is licensed under Apache 2.0.
chandra-ocr-2 by datalab-to: An update to the Chandra OCR model, released under a restrictive license.
Reason-ModernColBERT by lightonai: A SOTA retrieval model released under a non-commercial license. However, there is also code to re-generate the data, allowing the training of a commercially viable version.
context-1 by chromadb: A fine-tuned version of GPT-OSS for agentic search with an in-depth tech report. It also marks the debut of Chroma into the open model space. Trained with Thinking Machine’s Tinker.
dots.mocr by rednote-hilab: The beloved dots.ocr model has been updated and supports SVG outputs. However, on top of the general MIT license, the model comes with additional usage restrictions, just like its predecessor.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み