美团发布长猫 2.0:1.6 兆パラメータのオープン MoE モデルがネイティブ 100 万トークンコンテキストと長猫スパースアテンションを実現
美团が、100 万トークンのコンテキストウィンドウと 1.6 トリオンパラメータを備えたオープン MoE モデル「LongCat-2.0」を発表し、国内 AI ASIC 環境での大規模トレーニング成功とエージェントコーディングへの特化を明らかにした。
キーポイント
1M トークンコンテキストと Agentic Coding 特化
LongCat-2.0 はネイティブで 100 万トークンのコンテキストウィンドウをサポートし、コードの理解・生成・実行を内包するエージェントワークフローに最適化されている。
独自アーキテクチャによるコスト削減
ゼロ計算エキスパート、スパースアテンション(LSA)、N-gram 埋め込みの組み合わせにより、1.6T パラメータ規模でありながら推論コストを抑制し、メモリ壁を回避している。
国内 AI ASIC 環境での大規模トレーニング成功
Nvidia 製ではない国内製の AI ASIC スーパーポッド上で 35 トリオントークンの事前学習を行い、ロールバックや不可回復な損失スパイクなしで安定して完了したことを報告している。
高度な推論最適化技術
6D パラレル処理、プリフィル・デコードの非同期アーキテクチャ、および L2 キャッシュ重みプリフェッチなどの「スーパーカーネル」を活用し、I/O 遅延を隠蔽している。
SWE-bench Pro での首位達成
LongCat-2.0 は SWE-bench Pro ベンチマークで GPT-5.5 を上回る 59.5 のスコアを記録し、ソフトウェア工学タスクにおいて最先端モデルと同等以上の性能を示しました。
1M トークンのネイティブコンテキスト
前世代の Flash モデルと比較して、コンテキストウィンドウが 128K から 1M トークンに拡大し、複数ファイルにわたるバグ追跡やリポジトリ全体の編集を要するタスクに最適化されています。
API 経由での利用可能
現在は重み(weights)が公開されていないためローカルホスティングは不可ですが、OpenAI や Anthropic の互換エンドポイントを通じて API プラットフォームから利用可能です。
影響分析・編集コメントを表示
影響分析
この発表は、非 Nvidia ハードウェア環境でも大規模 LLM のトレーニングと運用が可能であることを実証した点で業界に大きな影響を与える。特に 100 万トークンコンテキストを安価に実現するアーキテクチャは、長文書解析や複雑なコードベースの理解が必要な分野における開発効率を劇的に向上させる可能性を秘めている。
編集コメント
Nvidia 依存からの脱却と、1M トークンという驚異的なコンテキスト長をオープンモデルで実現した点は、技術的野望と実用性の両面で極めて注目すべきニュースです。
美团发布了 LongCat-2.0,这是一款大规模专家混合(Mixture-of-Experts, MoE)语言模型。该模型拥有 1.6 万亿个总参数,每 token 激活约 480 亿个参数。该模型旨在面向智能体编码:在智能体工作流中进行代码理解、生成与执行。
两个事实尤为突出。首先,LongCat-2.0 支持原生的 100 万 token 上下文窗口。其次,其训练和推理服务完全运行在国内 AI ASIC(专用集成电路)超级集群上。
什么是 LongCat-2.0?
LongCat-2.0 是美团推出的下一代万亿参数开源模型。它延续了 2025 年发布的 560B 模型 LongCat-Flash。其架构围绕一个核心目标设计:可靠且高效的智能体编码。
预训练阶段跨越了超过 35 万亿个 token,耗资数百万加速器小时。美团报告称,在运行过程中未出现回滚或不可恢复的损耗激增。在非英伟达(Nvidia)硬件上,这一稳定性声明尤为重要,因为那里的工具链尚不成熟。
架构:1.6T 模型如何保持低成本运行
该设计融合了四项旨在降低规模成本的理念。每一项都值得单独深入理解。
ゼロ計算エキスパート:すべてのトークンに重い計算が必要ではありません。句読点のような単純なトークンは、ゼロ計算のエキスパートにルーティングされ、変更せずに返されます。複雑なトークンはより多くのエキスパート容量を動員します。PID コントローラーがエキスパートバイアスを調整し、平均値を範囲内に保ちます。これにより、固定コストではなく 33B〜56B の動的活性化ウィンドウが実現されます。MoE バックボーンは、スループット向上のためにショートカット接続設計(ScMoE)を採用しています。
LongCat スパースアテンション (LSA):標準的なアテンションはコンテキスト長に対して二次関数的にスケールします。LSA は最も関連性の高いトークンのみを選択し、スケーリングを線形に近いものへと低下させます。Meituan によれば、これは DeepSeek スパースアテンション (DSA) の進化版です。3 つの直交するインデックス手法を層化しています。ストリーミング対応インデックスは断片的なメモリ読み込みを連続ブロックに変換します。クロスレイヤーインデックスは隣接する層間でアテンションのサリエンス(注目度)を再利用します。階層的インデックスは粗から細への二段階フィルタリングを適用します。これらによって、メモリーウォールなしで 100 万トークンのウィンドウが維持されます。
N-gram エンベディング:本設計には、1350 億パラメータの N-gram エンベディングモジュールが追加されています。これはスパース次元において MoE エキスパートと直交する位置に配置されます。Meituan によれば、これは密な局所的なトークン間の関係を捉えるものです。また、大規模バッチデコーディング中のメモリ I/O を削減します。
ポストトレーニング (MOPD):専用パイプライン(MOPD)が 3 つの教師エキスパートグループを融合させます。これらはエージェント機能、推論機能、対話機能を一つの統合モデルに統合します。
推論サービスにおいては、美团は6次元並列化スキームとプリフィル・デコード非同期アーキテクチャを採用しています。また、I/O レイテンシを隠蔽するために「スーパーカーネル」とL2キャッシュにおけるウェイトプリフェッチも活用しています。
 imagehttps://longcat.ai/blog/longcat-2.0/
imagehttps://longcat.ai/blog/longcat-2.0/
ベンチマーク
美团はLongCat-2.0をエージェント型コーディングモデルとして位置付けています。以下の数値はいずれも美团自身のテスト結果に基づくものです。
ベンチマーク | LongCat-2.0 | 測定項目
---|---|---
SWE-bench Pro | 59.5 | 実世界のソフトウェアエンジニアリングタスク
Terminal-Bench 2.1 | 70.8 | シェルにおける実行とエラー回復
SWE-bench Multilingual | 77.3 | 複数言語に跨るリポジトリタスク
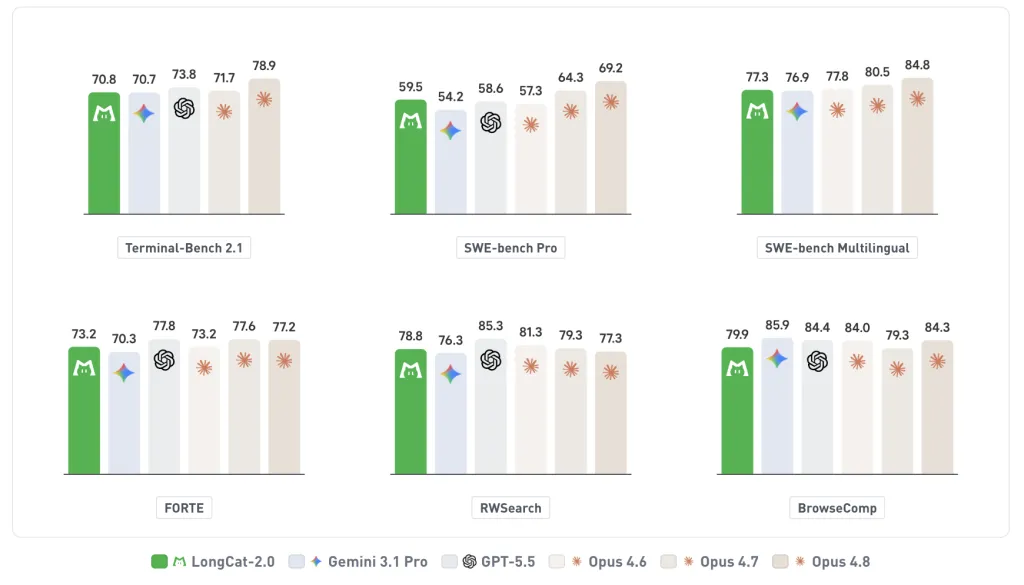
SWE-bench Pro において、美团はLongCat-2.0がGPT-5.5(58.6)をわずかに上回ると報告しています。また、GoogleのGemini 3.1 Proと全体的な性能が同等であると主張しています。この優位性はソフトウェアエンジニアリング分野に集中しており、FORTEやBrowseCompのようなより広範な一般エージェント向けベンチマークでは、カバレッジにおいて最先端システムに劣る傾向を示しています。独立したリーダーボードによる確認はまだ行われていません。
LongCat-2.0 vs LongCat-Flash
前世代からの飛躍は文面上でも非常に大きいです。以下の表は各モデルの公表仕様に基づいています。
属性 | LongCat-2.0 | LongCat-Flash
---|---|---
総パラメータ数 | 1.6T | 560B
トークンあたりのアクティブパラメータ | ~48B (33B–56B) | ~27B (18.6B–31.3B)
コンテキストウィンドウ | 1M トークン(ネイティブ) | 128K トークン
長文コンテキストアテンション | LongCat Sparse Attention | Multi-head Latent Attention
報告されたハードウェア:国内 AI ASIC スーパーポッド(トレーニング+推論)、H800 GPU(推論報告あり)
最大出力トークン数:128K トークン、未指定
ライセンス:MIT、MIT
公開日:2026 年 6 月 30 日、2025 年 9 月
重み(Weights):近日公開、オープンソース
使用例と事例
LongCat-2.0 はカジュアルなチャットではなく、エージェント型ソフトウェア作業向けにチューニングされています。その強みを活かす具体的なパターンがいくつかあります。
全体リポジトリの推論:中規模のコードベース全体を 1M トークンのウィンドウに読み込みます。モデルに対して複数のファイルにまたがるバグの追跡を依頼します。これにより、短いウィンドウで強制される要約ハックを回避できます。
多段階ターミナルタスク:シェルアクセスを持つエージェントループ内でモデルを実行します。コマンドの実行、エラーの読み取り、タスクが成功するまでの再試行が可能になります。Terminal-Bench 2.1 の焦点はまさにこのワークフローにあります。
リポジトリレベルでの編集:複数のモジュールとテストにまたがるリファクタリングを依頼します。モデルは調整された変更案を提案する前に、文脈全体に対して推論を行います。
クロス言語マイグレーション:SWE-bench Multilingual の強みを利用して、ポリグロット(多言語)リポジトリに対応します。モデルは動作を保ちながら、ロジックを異なる言語間へ移植できます。
これらのパターンは標準的なエージェントハッチ(harness)内で実行されます。したがって、開発チームは新たなツール構築なしにこのモデルを採用可能です。
アクセス方法
LongCat-2.0 は、LongCat API プラットフォームを通じて利用可能です。OpenAI 互換および Anthropic 互換のエンドポイントを両方提供しています。また、このモデルは OpenRouter や Claude Code、OpenClaw、OpenCode、Codex などのハッチにも搭載されています。ただし、重み(ウェイト)がまだ公開されていないため、ローカルでの自己ホスティングは現時点では不可能です。
OpenAI 互換エンドポイントでは、モデル ID に「LongCat-2.0」を使用します。最大出力長は 131,072 トークン(128K)です。以下のスニペットは、文書化されたチャット完了エンドポイントを呼び出す例です。
コードをコピーしました
別のブラウザを使用してください
pip install openai
from openai import OpenAI
client = OpenAI(
api_key="YOUR_LONGCAT_API_KEY",
base_url="https://api.longcat.chat/openai/v1",
)
resp = client.chat.completions.create(
model="LongCat-2.0",
messages=[
{"role": "system", "content": "あなたはコーディングエージェントです。"},
{"role": "user", "content": "utils.py をリファクタリングして、重複する I/O ロジックを削除してください。"},
],
max_tokens=4096, # LongCat-2.0 は最大 131072(128K)まで対応
)
print(resp.choices[0].message.content)
料金は、入力トークン 100 万あたり 0.75 ドル、出力トークン 100 万あたり 2.95 ドルと報告されています。ローンチプロモーションではそれぞれ 0.30 ドル、1.20 ドルとなっており、キャッシュされたコンテキストの読み取りは無料です。これらの数値は第三者による報道に基づくものであり、変更される可能性があります。
インタラクティブ解説
(function(){
var f = document.getElementById("longcat-demo-frame");
window.addEventListener("message", function(e){
if(e && e.data && e.data.type === "longcat-demo-height"){
var h = parseInt(e.data.height, 10);
if(h && h > 200){ f.style.height = h + "px"; }
}
});
})();
キーポイント
MIT ライセンスの下で公開されています。
LongCat-2.0 は、1.6T パラメータの MoE(Mixture of Experts:専門家混合モデル)であり、トークンあたり約48Bのパラメータを活性化します(動的範囲は33B〜56B)。
ネイティブの1M トークンコンテキストは、LongCat Sparse Attention(ロングキャット・スパース・アテンション)によって実現されており、長文コンテキストのコストを二次関数から線形に削減しています。
トレーニングと推論は、Nvidia 製ハードウェアを一切使用せず、国内製の AI ASIC クラスター50,000カード上で実行されました。
ベンダーが報告したスコア:SWE-bench Pro で59.5、Terminal-Bench 2.1 で70.8、SWE-bench Multilingual で77.3。
モデルの重み、GitHub リポジトリ、技術詳細をご覧ください。また、Twitter でフォローしていただくことも歓迎です。さらに、ML サブレッド(15万人以上)への参加やニュースレターの購読も忘れずに。待ってください!Telegram をご利用ですか?今なら Telegram でも私たちに参加できます。
GitHub リポジトリの宣伝、Hugging Face ページ、製品リリース、ウェビナーなどのプロモーションでパートナーシップを結ぶ必要がある場合は、ご連絡ください。
本記事「Meituan Releases LongCat-2.0: A 1.6T-Parameter Open MoE Model with Native 1M Context and LongCat Sparse Attention」は、MarkTechPost で最初に公開されました。
原文を表示
Meituan has released LongCat-2.0, a large-scale Mixture-of-Experts (MoE) language model. It carries 1.6 trillion total parameters and activates about 48 billion per token. The model targets agentic coding: code understanding, generation, and execution inside agent workflows.
Two facts stand out. First, LongCat-2.0 supports a native 1-million-token context window. Second, both training and serving ran entirely on domestic AI ASIC superpods.
What is LongCat-2.0?
LongCat-2.0 is Meituan’s next-generation trillion-parameter open model. It follows LongCat-Flash, a 560B model released in 2025. The architecture was designed around one goal: reliable, efficient agentic coding.
Pretraining spanned more than 35 trillion tokens over millions of accelerator-hours. Meituan reports no rollbacks or irrecoverable loss spikes during the run. That stability claim matters on non-Nvidia hardware, where tooling is less mature.
Architecture: How a 1.6T Model Stays Cheap to Run
The design combines four ideas that reduce the cost of scale. Each one is worth understanding on its own.
Zero-computation experts: Not every token needs heavy compute. Simple tokens like punctuation route to a zero-computation expert and return unchanged. Complex tokens engage more expert capacity. A PID controller adjusts expert bias to hold the average in range. This produces the 33B–56B dynamic activation window instead of a fixed cost. The MoE backbone uses a shortcut-connected design (ScMoE) for higher throughput.
LongCat Sparse Attention (LSA): Standard attention scales quadratically with context length. LSA selects only the most relevant tokens, dropping the scaling closer to linear. Meituan describes it as an evolution of DeepSeek Sparse Attention (DSA). It layers three orthogonal indexing methods. Streaming-aware Indexing turns fragmented memory reads into contiguous blocks. Cross-Layer Indexing reuses attention saliency across adjacent layers. Hierarchical Indexing applies coarse-to-fine two-stage filtering. Together they sustain the 1M-token window without a memory wall.
N-gram Embedding: The design adds a 135-billion-parameter N-gram embedding module. It sits orthogonal to the MoE experts in sparse dimensions. Meituan says it captures dense local token relationships. It also reduces memory I/O during large-batch decoding.
Post-training (MOPD): A dedicated pipeline (MOPD) fuses three teacher expert groups. These cover Agent, Reasoning, and Interaction capabilities into one unified model.
For serving, Meituan uses a 6D parallelism scheme and a prefill-decode disaggregated architecture. It also employs ‘super kernels’ and L2-cache weight prefetching to hide I/O latency.
imagehttps://longcat.ai/blog/longcat-2.0/
Benchmarks
Meituan positions LongCat-2.0 as an agentic coding model. Every figure below comes from Meituan’s own testing.
BenchmarkLongCat-2.0What it measures
SWE-bench Pro59.5Real-world software engineering tasks
Terminal-Bench 2.170.8Execution and error recovery in shells
SWE-bench Multilingual77.3Cross-language repository tasks
On SWE-bench Pro, Meituan reports LongCat-2.0 edging GPT-5.5 (58.6). Meituan also claims overall performance comparable to Google’s Gemini 3.1 Pro. The reported edge is concentrated in software engineering. On broader general-agent benchmarks such as FORTE and BrowseComp, coverage indicates it trails leading frontier systems. Independent leaderboard confirmation is not yet available.
LongCat-2.0 vs LongCat-Flash
The jump from the previous generation is large on paper. This table uses each model’s published specifications.
AttributeLongCat-2.0LongCat-Flash
Total parameters1.6T560B
Active per token~48B (33B–56B)~27B (18.6B–31.3B)
Context window1M tokens (native)128K tokens
Long-context attentionLongCat Sparse AttentionMulti-head Latent Attention
Reported hardwareDomestic AI ASIC superpods (training + serving)H800 GPUs (inference reported)
Max output128K tokensNot specified
LicenseMITMIT
ReleasedJune 30, 2026September 2025
WeightsComing soonOpen
Use Cases With Examples
LongCat-2.0 is tuned for agent-style software work, not casual chat. A few concrete patterns fit its strengths.
Whole-repository reasoning: Feed an entire mid-sized codebase into the 1M-token window. Ask the model to trace a bug across many files at once. This avoids the summarization hacks that shorter windows force.
Multi-step terminal tasks: Run the model inside an agent loop with shell access. It can execute commands, read errors, and retry until a task passes. The Terminal-Bench 2.1 focus targets exactly this workflow.
Repository-level edits: Ask for a refactor that spans several modules and tests. The model reasons over the full context before proposing coordinated changes.
Cross-language migration: Use the SWE-bench Multilingual strength for polyglot repositories. The model can port logic between languages while preserving behavior.
These patterns run inside standard agent harnesses. Dev teams can therefore adopt the model without building new tooling.
How to Access It
LongCat-2.0 is reachable through the LongCat API Platform. It exposes both OpenAI-compatible and Anthropic-compatible endpoints. The model is also on OpenRouter and in harnesses like Claude Code, OpenClaw, OpenCode, and Codex. Local self-hosting is not yet possible, since weights remain pending.
The OpenAI-compatible endpoint uses the model ID LongCat-2.0. Maximum output length is 131072 tokens (128K). The snippet below calls the documented chat-completions endpoint.
Copy CodeCopiedUse a different Browser
pip install openai
from openai import OpenAI
client = OpenAI(
api_key="YOUR_LONGCAT_API_KEY",
base_url="https://api.longcat.chat/openai/v1",
)
resp = client.chat.completions.create(
model="LongCat-2.0",
messages=[
{"role": "system", "content": "You are a coding agent."},
{"role": "user", "content": "Refactor utils.py to remove duplicate I/O logic."},
],
max_tokens=4096, # LongCat-2.0 supports up to 131072 (128K)
)
print(resp.choices[0].message.content)
Pricing is reported at $0.75 per million input tokens and $2.95 per million output. A launch promotion lists $0.30 and $1.20, with cached context reads free. These figures come from third-party coverage and may change.
Interactive Explainer
(function(){
var f = document.getElementById("longcat-demo-frame");
window.addEventListener("message", function(e){
if(e && e.data && e.data.type === "longcat-demo-height"){
var h = parseInt(e.data.height, 10);
if(h && h > 200){ f.style.height = h + "px"; }
}
});
})();
Key Takeaways
Released under MIT
LongCat-2.0 is a 1.6T-parameter MoE model activating ~48B parameters per token (dynamic range 33B–56B).
Native 1M-token context comes from LongCat Sparse Attention, cutting long-context cost from quadratic to linear.
Training and inference ran on a 50,000-card domestic AI ASIC cluster, with no Nvidia hardware.
Vendor-reported scores: 59.5 SWE-bench Pro, 70.8 Terminal-Bench 2.1, 77.3 SWE-bench Multilingual.
Check out the Model Weights, GitHub Repo and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post Meituan Releases LongCat-2.0: A 1.6T-Parameter Open MoE Model with Native 1M Context and LongCat Sparse Attention appeared first on MarkTechPost.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み