オープンモデルは常に追従状態にある
中国発のオープンモデルがクローズドモデルに追いつくペースが安定している現状について、ベンチマークの限界と実力差を分析する記事。
キーポイント
オープンモデルの追従ペースは安定している
過去12ヶ月でオープンモデルの主要発生源がMetaから中国企業へシフトしたが、クローズドモデルとの性能差(約6ヶ月のギャップ)は拡大しておらず一定である。
リソース格差と性能の意外な近接性
米国の主要ラボ(Anthropic, OpenAI, Google)は圧倒的な計算資源を持つものの、オープンモデルとの性能差が予想以上に小さい理由として、スケーリング則の対数線形関係などが考えられる。
単一スコアベンチマークの限界
ArtificialAnalysis Intelligence Indexのような総合スコアは、実際のフロンティア性能や特定の弱点(SWE-Benchなどの過学習問題)を捉えきれず、政策決定や理解には有用だが技術的実態の反映としては不十分である。
ベンチマークと実力の乖離
米国の先進ラボは実際の有用な能力をより正確に把握しており、公開ベンチマークは過学習されやすい傾向がある。Qwen v3.5のようなモデルでも実用上の課題が指摘されている。
ベンチマーク最適化と評価手法の限界
Qwen v3.5などのモデルはベンチマーク最適化(benchmaxing)に悩まされており、平均値を用いた評価は不誠実な読者に隠蔽される可能性があるため、Ai2では平均値を使わない評価を提唱している。
オープンモデルとクローズドモデルの動態
クローズドモデルは常に新しい高価値なタスクを開発し続けるため、オープンモデルは「永続的な追従状態」にありつつも、特定のタスクがオープンモデルで可能になれば劇的なコスト削減をもたらす。
オープンモデル市場の過酷な競争と集中化
2025年はオープンモデルの爆発的増加をもたらしたが、採用は極めて成功したモデルに集中しており、中小規模のビルダーはニッチ市場への移行やビジネスプランの見直しを迫られている。
重要な引用
open models are not meaningfully accelerating towards matching the best closed models in absolute performance. The ~6month gap is holding steady.
Open models are staying far closer on the heels of the best closed models than I, and many other experts following the ecosystem, would expect.
These metrics will always be used to inform policy and help more people understand the high-level trends of AI, but they do a poor job of capturing the frontier of AI progress.
The best closed models keep unlocking even more valuable tasks, keeping open models in a state of perpetual catch-up.
This market is far more populated than closed, API based models... so open model adoption is brutally concentrated.
Understanding open models is how we keep track of the direction of global diffusion for the most important technology in decades, and it feels like there is almost no public work doing so.
影響分析・編集コメントを表示
影響分析
この記事は、オープンソースモデルの躍進に対する過度な楽観論を戒めつつ、その実効的な追従ペースが安定していることを示唆しています。ベンチマークスコアに依存せず、実際のフロンティア性能を評価する重要性を指摘しており、開発者や投資家に対して、単なる「オープン化」だけでなく、実用的な能力差とベンチマークの限界を考慮したリサーチが必要であることを示しています。
編集コメント
ベンチマークスコア一辺倒の評価を排し、実運用レベルでの性能差とオープンエコシステムの構造変化を冷静に捉える視点は、現在のAI業界において極めて重要です。
4〜6 ヶ月ごとに、オープンウェイトモデルの新たなバージョンが登場し、「オープンモデルはこれまでになくクローズドモデルやフロンティアモデルに近づいている」という議論が沸騰します。直近では Z.ai の GLM 5 モデルがその例で、中国企業から出された最新かつ最先端のオープンウェイトモデルです。過去 12 ヶ月におけるこの物語の新たな側面は、議論の対象となるすべてのオープンモデルが中国由来であるという点です。以前であれば、これらはほぼ例外なく Meta の Llamas でした。こうした議論の瞬間は私にとって常に内省を促すものですが、オープンモデル最大の支持者の一人として、私はいつもそのナラティブ(物語)が過大評価されていると感じています。つまり、絶対的な性能においてオープンモデルがクローズドモデルに追いつくペースが意味ある形で加速しているわけではありません。約 6 ヶ月というギャップは安定して維持されています。
同時に、オープンモデルがさらに飛躍的に向上し続ける中で何が起きるのかについても議論する価値があります。オープンモデルは、私やエコシステムを追跡する多くの他の専門家たちが予想していたよりも、クローズドモデルの最上位にずっと密着した状態で追走しています。机上の計算では、Anthropic、OpenAI、Google の 3 つの米国のラボが、研究におけるトレーニングのために圧倒的に多くのリソースを有しています。この世界観において、多くの人はオープンとクローズドの最上位モデル間のギャップがより明白に拡大すると予想したはずです。純粋な研究用計算資源(compute)、データ購入、ユーザーデータなどは、相対的に僅かなマージンしか生み出していません。もしかすると、計算リソースから性能へのスケーリング則における対数線形関係(log-linear relationship)が作用しているのでしょうか?
今日のテーマは、オープンモデルとクローズドモデルの時間経過に伴う ArtificialAnalysis Intelligence Index です。この投稿の目的は、このインデックスが持つ多くの限界や他の指標の限界を細かく指摘することではなく、このグラフが何を表していないか、そしてオープンウェイトが年々追いつき続けることが AI 界にどのような意味を持つかについて考察することにあります。
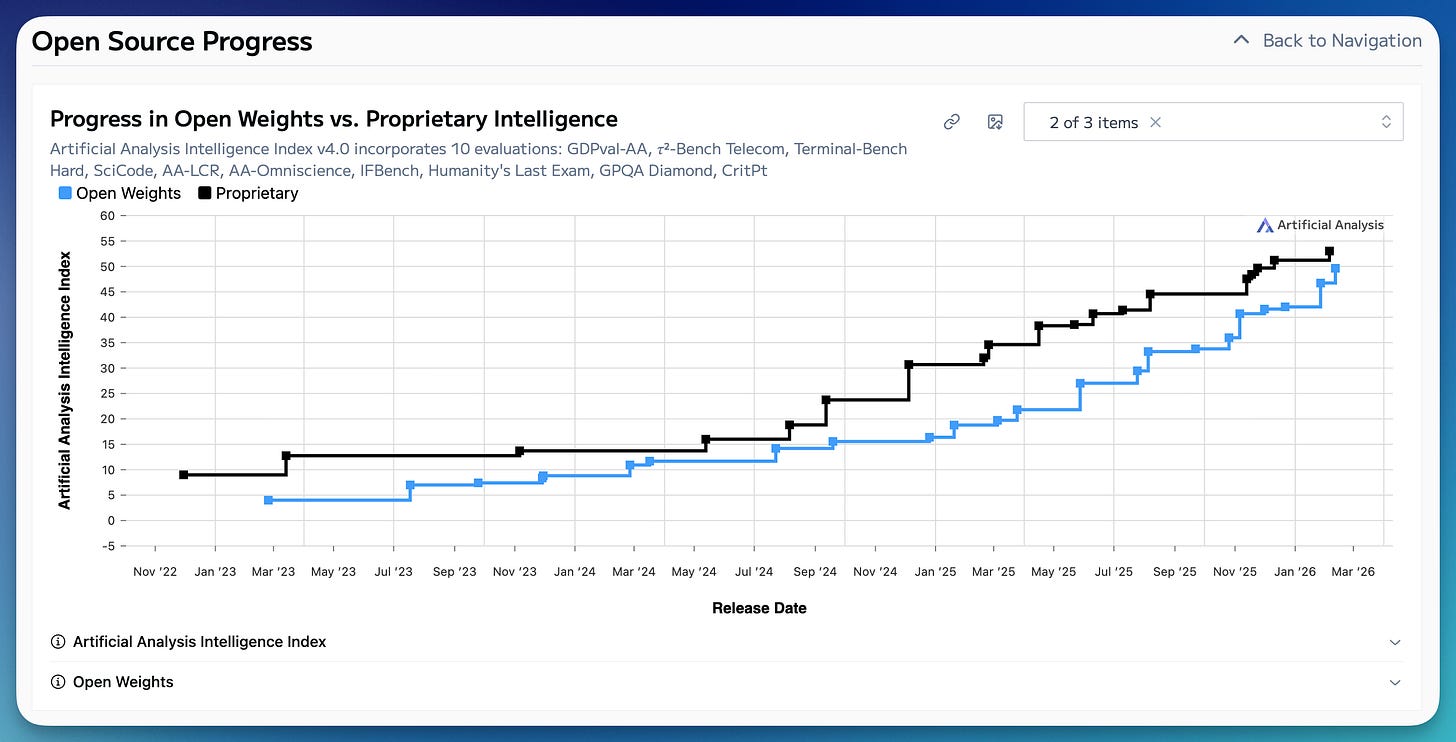
このベンチマークは、モデルの「品質」を評価する 1 つのスコアに多数の要素を混合しています。これにより、誤差範囲、物語、そして弱点があまりにも多く圧縮され、単一の指標に集約されてしまいます。これらの指標は常に政策決定の参考資料として用いられ、より多くの人々が AI の高レベルなトレンドを理解するのを助けるために使われますが、AI 進歩の最前線を捉える点においては不十分です。
AI の最前線は、公的なベンチマークで捉えることがこれまで以上に困難になっています。ベンチマークを構築するには現在極めて高額であり、最新モデルやそれらが得意とする・不得意とする分野に関する高度な知識が要求されます。SWE-Bench がほぼ 3/4 を Django で構成されていること、あるいは Terminal Bench 2 がクラウドソーシングによって作成されややノイズが多いといったよく知られた問題は、ここでは決して捉えられません。
米国における最先端のラボは、実際に重要となる能力をより正確に把握しており、公開ベンチマークは過剰適合しやすい傾向があることが、これまで何度も示されてきました。Qwen の直近のフラッグシップ v3.5 モデルも再び、ベンチマックス化に関する多数の不満に悩まされています(一部の出典外分布における奇妙な挙動は実装エラーの可能性が議論されますが、アリババ自身の API においてもです)。
これらの要因すべてを踏まえ、私は Ai2 において最新の Olmo モデルの価値を伝える際、「評価スイート全体での平均化を行わない」ことを提唱するようになりました(私の最近の評価に関する講演をご覧ください)。最良のモデル同士は確かに非常に近い位置にありますが、平均値を用いると、不誠実な読者に対して単一の評価が劇的に異なる事実を完全に隠してしまう可能性があります。
総合的に判断して、現在の Artificial Analysis Intelligence Index は真の最先端を代表していないと私は確信しており、オープンソースモデルがクローズドモデルにこれまで以上に近づいているという見方は誤りです(はい、改善のための明白な方法を私が提示しているわけではありませんが)。私が予測する限り、オープンソースモデルがクローズドモデルに引き続き追従し続ける唯一の領域はコーディングであり、公開された GitHub データと巧妙な検証可能な報酬によって、多大な性能向上の可能性が示されています。
エコシステム全体のバランスは、多くの人が私自身のようにオープンモデルの改善にもかかわらず依然として有料で利用している最も知的なモデルの価値と、特定のタスクが許可されたライセンスを持つオープンモデルによって達成可能になった際に生じる信じられないほどのコスト削減の間にある。最高のクローズドモデルは、さらに価値の高いタスクを次々と解放し続け、オープンモデルを永続的な追走状態に置いている。業界は驚異的なペースで自らを再発明し続けている。
Share
オープンモデルにおける他の7つの主要なトレンドへ。
- オープンモデルの最前線は過酷な競争である
2025年は、非常に印象的なベンチマークスコアを持つオープンウェイトモデルの一種「カンブリア爆発」を目撃した。この市場はクローズドでAPIベースのモデル(実質的なプロバイダーが4社のみ)よりもはるかに人口密度が高く、そのためオープンモデルの採用は過酷に集中している。成功する最も優れたモデルだけが実際に採用されることになる。これは今後数ヶ月から数年かけて、エコシステム全体における多くの中小規模のモデルビルダーを特定のニッチへ移行するか、あるいは異なるビジネスプランへとシフトさせることにつながるだろう。
モデルビルダーとして、私はこの状況を非常に身近に感じている。モデルは比較的ステッキー(少なくとも一般的な見通しよりもはるかに粘り強い)であるにもかかわらず——パフォーマンスが十分であれば一度設定された多くのオープンモデルは決して置き換えられない——エコシステムが競争激化に伴う中で、ほとんどのモデルが一度でも試される可能性は月を追って低下している。
今年初めにオープンモデルの現状について投稿した際、Qwen が最大規模のモデルにおける採用指標において支配されていることを知り、驚きました。この状況は依然として私を驚かせています!
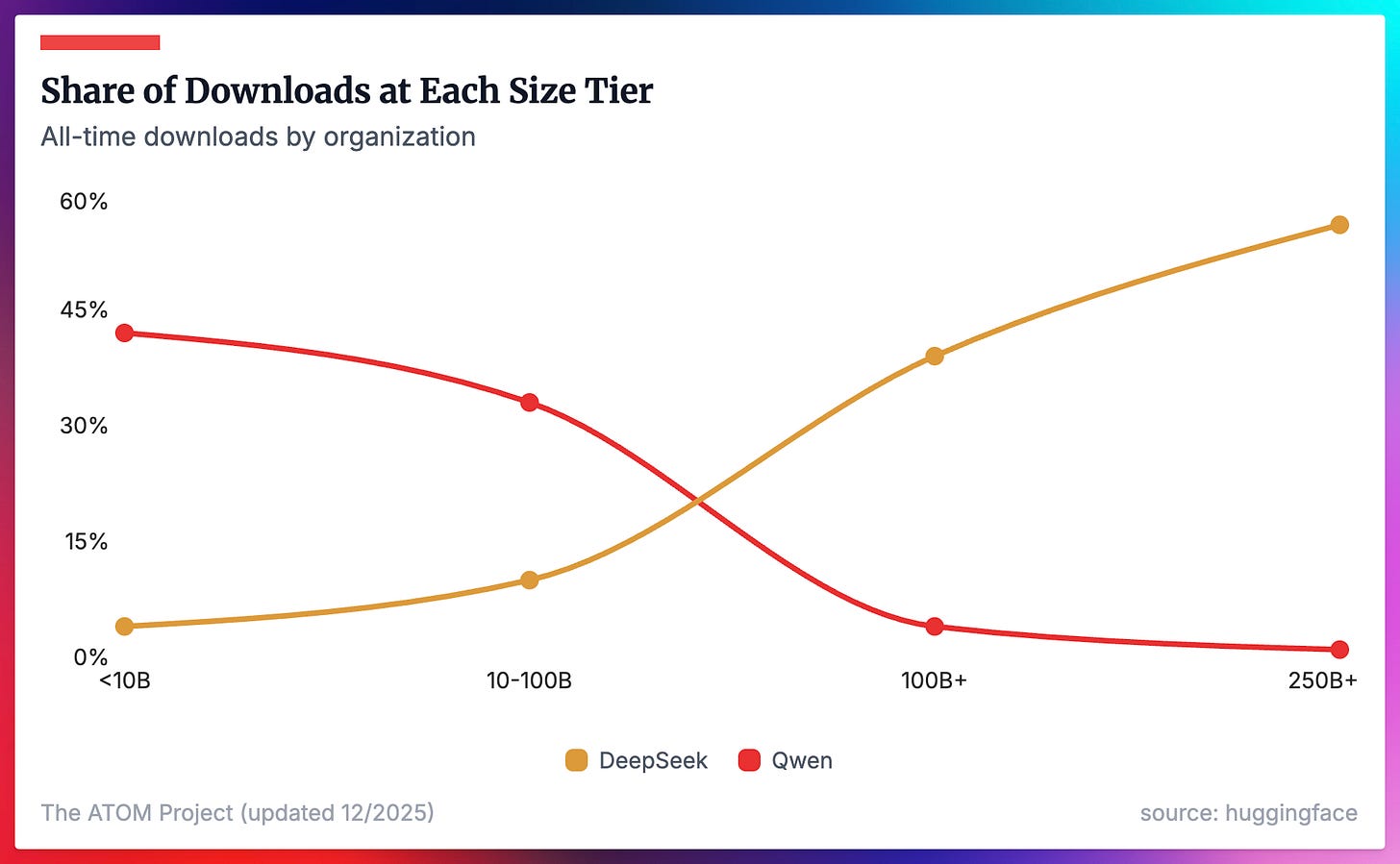
要するに、モデルのパフォーマンスの最前線における競争は、現在の人気ベンチマーク、特に大規模な MoE モデルにおいて最も集中しています。これは、オープンモデルが実際のビジネス価値全体で勝利できる他のケースへと、探求とイノベーションを駆動させることになります。
- 専門的・小規模・高速・低コストのオープンモデルが不足している
企業向けの専門モデルには、大きな未開拓市場が存在します。特にツール関連において(おそらく GPT OSS の成功もこれに関連しているでしょう)。一般的に考えられるのは、価値ある反復タスクで卓越した重み、あるいはその作成方法を公開することです。エージェントがより注目されるようになる中で、これらのモデルは、大規模な最前線モデルのコストのわずかな割合で、反復的なエージェントサブタスクを処理できなければなりません。同時に、高速かつプライバシーが保護され、直接所有できる必要があります。例えば、1 つのオープンウェイトモデルに、各スキルごとに複数の PEFT アダプター(パラメータ効率的微調整アダプター)をデプロイし、高い利用率と拡張性を可能にするようなケースが考えられます。
私は、エージェントを構築する複数の企業から、このリクエストを具体的に聞いています。Qwen モデルは小規模サイズにおいて素晴らしい能力を発揮しますが、オープンモデルのパフォーマンスは非常にばらつきが大きく、これを軌道に乗せるには複数の選択肢が必要となるでしょう。また、学術ベンチマークでカバーされていない特定のドメインやタスクセットへのモデル適応などにおいては、フロンティア品質のポストトレーニングレシピが全般的に不足している点も制限要因となっています。この観点から言えば、現在の数学や生物学などのドメイン特化型モデルの多くは、実は十分に専門化されていません。
これは、オープンモデルエコシステムにおいて私が繰り返し目にする多くの課題の一つです。オープンモデルエコシステムが外部からは誤解されやすく、内部でも混乱している最大の理由は、オープンモデルを把握し、世界に広めるまでに長い時間がかかるからです。
- オープンモデルの理解は、著しく過小評価されている
オープンモデルの技術的・地政学的な仕組みを完全に理解するために、専任の研究機関がもっと存在すべきです。ワシントン DC には、何が起きているかを一般市民に伝え、サンフランシスコのハッカソンや新設された研究ラボに埋もれた情報を解き明かすためのシンクタンクが複数あってもよいでしょう。Interconnects と The ATOM Project では、私はこの分野の最前線で活動しており、そこではオープンモデルがどのように利用されているかに関する新たな生データを探り出す作業が頻繁に行われます。こうしたデータは常に不揃いで不完全であり、時には完全に混乱を招くこともあります。数十年で最も重要な技術であるグローバルな拡散の方向性を追跡するためには、オープンモデルを理解することが不可欠ですが、それに取り組む公的な活動はほとんどないという感覚があります。
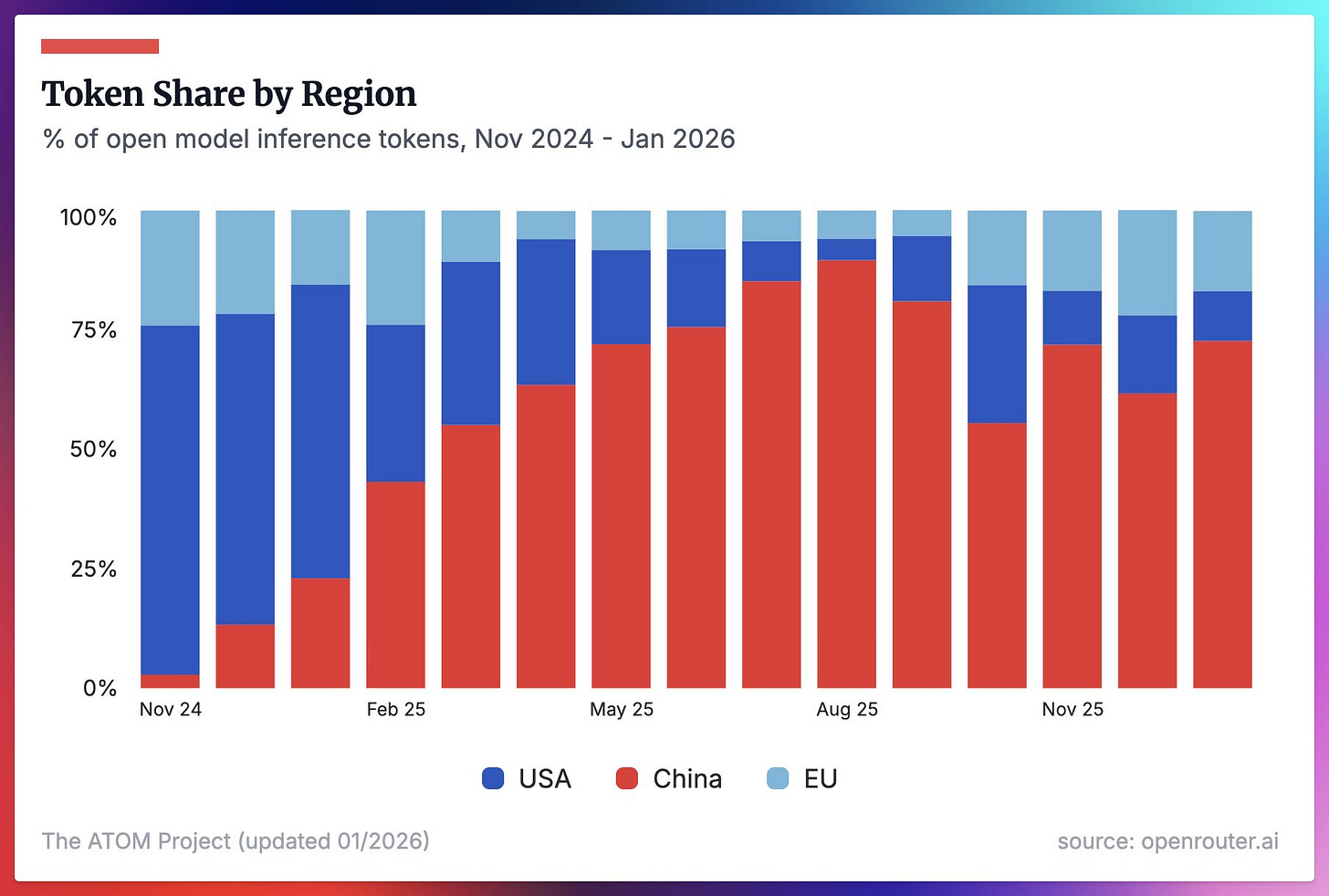
OpenRouter によるオープンモデル利用に関する新たなデータをご紹介します。これは私たちがこれまで見てきた採用動向とほぼ一致しています。HuggingFace のダウンロード数は明らかにノイズが多いものの、時間経過に伴う他のあらゆる採用指標はこれと強く相関しており、特に米国対中国の課題においてその傾向が顕著です。
余談ですが、オープンエコシステムの監視に関するこの仕事があなたにとって魅力的に思われる場合は、ご連絡いただくかコメントを残してください。この分野での影響力をどう拡大するかについて検討中です!
Interconnects AI は読者支援型の出版物です。購読をご検討ください。
- 各国は、主権型 AI における最初の足がかりを得る唯一の手段としてオープンモデルに頼るようになる(そして主権型 AI は本物である)
主権型 AI は、最先端 AI の議論や米中間の軍拡競争の背景において、主にゆっくりと進行してきました。しかし、AI が私たちの技術的現実により深く組み込まれるにつれて、その普及はさらに進むでしょう。すべての富裕国は、国家安全保障上の必要性であると同時に、影響力を行使する方向性として AI を捉えるようになります。この取り組みを実効あるものとし、地域の AI コミュニティと経済がそれとシームレスに統合されるためには、オープンモデルが唯一の手段となる可能性が高いです。
- オープンソースが最先端を制する未来もまだ可能ではあるが、以前よりもさらに実現の可能性は低くなっているように見える
最も可能性が高い(圧倒的に)シナリオは、現状維持であり、最良のオープンモデルが最良のクローズドモデルに比べて 6〜9 ヶ月遅れ続けることです。この永続的な追いつき現象の大部分は、おそらく最良のオープンモデル開発者が、現在利用可能な最も強力なクローズド API モデルを絶えず蒸留(distillation)していることによるものですが、強化学習(RL)の台頭に伴い、この方向性はあまり関連性が薄れているように思われます。現在のポストトレーニングは、モデルが最も賢明な教師から直接学ぶというよりも、むしろ経験を通じて学習するプロセスに焦点を当てています。オープンモデルが勝利するための道筋は、根本的なイノベーションにあります。具体的には、エキスパートモデルの統合・回転・共有が可能になること、あるいはトレーニングコストの劇的な(100 倍以上の)削減などが挙げられます。これが起こる前に予測することは、もし私が実際にその仕組みを構築してしまえばよい話であるため、忠実な科学というよりは SF 小説に近いものです。
- 中国のオープンモデル「エコシステム」は、誰が勝利するかに関する発見が最も期待される場所となっている
中国には、他社のイノベーションの上にモデルを構築するラボが多数存在します。この意図的なアイデアの共有は、シリコンバレーの「見返り」の文化と比較して莫大な利益をもたらします。そこでは、人々は一日の終わりに帰宅し、友人たちと最新の技術的秘訣について話し合うことが当然視されています。中国企業が特に実践しているような共有形態、とりわけそれらの多くが国の科学・学術機関とより密接なつながりを持っていることを考慮すると、これは新しい基準をはるかに迅速に収束させ、ブレークスルーを共有させるための仕組みです。これは「オープンモデル」が勝利する可能性のあるイノベーションのような未知の要因ですが、中国が独自の潜在的成功条件を作り出し、米国には対抗策がないという点で重要です。エコシステムの運用方法におけるこの相違は長期的には何もないことになり得ますが、それが軌道に乗った場合、米国の AI 企業はそれに対抗して大きなことはできません。
- オープンモデルが科学と普及を支配する — フロンティアの AI よりも緩やかなトレンド
日常生活や世界の権力構造を変革するという点での AI の最大の影響力は、明らかに最も強力かつ知的なモデルから生じるでしょう。したがって、オープンモデルのうちこのフロンティアに最も近い位置にあるものが注目を集めるのは明白です — もし何らかの形でオープンウェイトモデルが「世界で最も強力なモデル」という称号を主張することになれば、それは極めて大きな経済的帰結をもたらすことになります。
現実世界において、最も発生する可能性が高いシナリオでは、オープンモデルの最大の影響力は、非常にゆっくりと変化する 2 つのセクターに現れるでしょう:1) 基礎研究・イノベーション、および 2) グローバルな技術拡散です。私は個人的に、オープンモデルに対する私の興奮が少し誤った方向を向いていることに気づきました。これらのモデルを通じて AI の最前線を理解しようとしていますが、技術がいかにしてゆっくりと世界最大の企業を変容させていくかという、より大きな物語を見落としています。
Llama がオープンな SOTA(State of the Art)モデルだった頃を考えてみてください。当時、米国と中国の誰もが Llama に関する研究を行い、それがその後のモデルに影響を与えました。Meta から具体的なプロセスが直接発表されなかったとしてもです。現在では、このデフォルトは Qwen に置き換わっています。Qwen は中国エコシステムのアンカーとなっています。言語モデルの研究は極めて急速に進んでおり、これにより研究所で行われた基礎的な改善が、通常よりもはるかに速く技術の最前線に反映される可能性があります。
同時に、最も富裕な数カ国以外の地域で AI を利用する際のグローバルなデフォルトは、ChatGPT などの無料アプリケーションか、オープンウェイトモデルを使用することになります。ChatGPT は多くのビジネスユースケースには適合しないため、オープンウェイトモデルは私たちがほとんど視認できないイノベーションの熔鉱炉となっています。数十年というより長いタイムラインに目を向けると、オープンモデルのグローバルな普及は、AI において追うべき主要なトレンドのように思われます。
結論
続きを読む
原文を表示
Every 4-6 months a new open-weights model comes out that causes a clamor of discussion on how open models are closer than they ever have been to the best closed, frontier models. The most recent is Z.ai’s GLM 5 model, which is the latest, leading open weights model from a Chinese company. In the last 12 months the new part of this story is that all of the open models of discussion are coming from China, where previously they were almost always Meta’s Llamas. These moments of discussion are always reflective for me — for, despite being one of open models’ biggest advocates, I always find the narrative to be overblown — open models are not meaningfully accelerating towards matching the best closed models in absolute performance. The ~6month gap is holding steady.
At the same time, it’s worth discussing what happens as open models keep getting way better. Open models are staying far closer on the heels of the best closed models than I, and many other experts following the ecosystem, would expect. On paper the top three American labs — in Anthropic, OpenAI, and Google — have vastly more resources at play for training in research. In this world, many would have expected a more obviously growing margin between the best open and closed models. Raw research compute, data purchases, user data, etc. all are providing relatively fine margins. Maybe it’s the scaling laws log-linear relationship from compute to performance coming into play?
The plot of the day is ArtificialAnalysis Intelligence Index for open vs. closed models over time. The point of this post isn’t to nitpick this index’s many limitations, or any other, but to reflect on what this chart doesn’t represent and what it means for the AI world for open weights to keep pace year in and year out.
The benchmark mixes a ton of factors into 1 score that judges model “quality.” This compresses far too many error bars, stories, and weaknesses into one metric. These metrics will always be used to inform policy and help more people understand the high-level trends of AI, but they do a poor job of capturing the frontier of AI progress.
The frontier of AI has never been harder to capture in public benchmarks. Building benchmarks is now super expensive and requires extreme knowledge regarding the latest models and what they do and do not excel at. Well known issues like SWE-Bench being almost 3/4 Django or Terminal Bench 2 being crowdsourced and a bit noisy will never be captured here.
Time and time again it has been shown that the leading frontier labs in the U.S. have a better read on the capabilities that actually matter, and the public benchmarks tend to be a bit easier to overfit to. Qwen’s recent flagship v3.5 model has been plagued again with numerous complaints of benchmaxing (while some out-of-distribution weirdness is debatably implementation errors, on Alibaba’s own API).
The combination of all these factors has pushed me to advocate for “no averaging across our evaluation suite” when communicating the value of our latest Olmo models at Ai2 (see my recent talk on evals). The best models are indeed very close together, but averages can totally hide a single eval being dramatically different from an unscrupulous reader.
All together, I’d bet that the current Artificial Analysis Intelligence Index is a bit unrepresentative of the true frontier, rather than open models being closer to the closed models than ever before (yes, I know, it’s not like I am offering any obvious ways to improve it). The one domain where I foresee open models staying close behind is coding, where public GitHub data and clever verifiable rewards present a ton of potential performance gains.
The overall balance in the ecosystem is in between the value of the most intelligent model — which many people like myself still pay for despite open models’ improvements — and the incredible cost-reductions that come once a given task is achievable by a permissively licensed open model. The best closed models keep unlocking even more valuable tasks, keeping open models in a state of perpetual catch-up. The industry continues to reinvent itself at a blistering pace.
Share
Onto the 7 biggest other trends in open models.
- The open model frontier is brutally competitive
2025 witnessed a sort of “Cambrian Explosion” of open weight models with very impressive benchmark scores. This market is far more populated than closed, API based models (where there are 4 substantive providers), so open model adoption is brutally concentrated. Only the most-successful models ever get any adoption. This is going to push many small and mid-sized model builders across the ecosystem to shift to a specific niche or a different business plan over the coming months or years.
As a model builder, I feel this super close to home. Even though models are fairly sticky (at least more sticky than the general coverage would indicate) — many open models are set up once if performance is good enough, and never replaced – the likelihood for most models to even get tried once goes down month over month with the ecosystem getting more competitive.
In my post on the state of open models earlier this year, I even learned that Qwen gets dominated on adoption metrics at the biggest scale of models. This continues to surprise me!
The upshot is that competition at the frontier of performance for models is most concentrated in the popular benchmarks of the day, especially with large MoE models — this will drive exploration and innovation towards other cases where open models can actually win on overall business value.
- Specialized, small, fast, and cheap open models are missing
There’s a large underserved market in specialized models for the enterprise, particularly with tools (maybe GPT OSS’s success is somewhat related to this). Generally, the idea would be to either release the weights, or the method for creating them, that are excellent in valuable, repetitive tasks. With agents becoming more prominent, these models should be able to perform repetitive, agent sub-tasks at small percentages of the cost of large frontier models, while being faster, private, and directly owned. For example, what if one open weight model is deployed with multiple PEFT-adapters per skill, allowing high-utilization and extensibility.
I’ve specifically heard this request from multiple enterprises building agents. While the Qwen models are fantastic at small sizes, open models tend to be very jagged in performance, so multiple options would likely be needed to get this off the ground. It’s also limited by a general lack of frontier-quality, post-training recipes, especially when it comes to adapting a model to specific domain or set of tasks not covered in academic benchmarks. In this view, most of the domain-specific models of today, like math or biology models, are actually not specialized enough.
This is one of many issues that I see repeatedly in how the open model ecosystem has major blind spots. The biggest reason that the open model ecosystem seems a bit misunderstood externally, or confused in itself, is that open models take a long time to figure out and get into the world.
- Understanding open models is massively under-indexed on
There should be more research organizations fully dedicated to understanding how open models work technically and geopolitically. There could be entire think-tanks in DC informing the public on what is happening, and uncovering information buried in hackathons and new research labs in San Francisco. For Interconnects and The ATOM Project I’m at the frontier of this work, which often entails uncovering new raw data on how open models are used. This data is always messy and imperfect, and often flat out confusing. Understanding open models is how we keep track of the direction of global diffusion for the most important technology in decades, and it feels like there is almost no public work doing so.
Here’s some new data on open model usage courtesy of OpenRouter, which largely mirrors the adoption trends we’ve been seeing. While HuggingFace downloads are obviously very noisy, almost every other adoption metric over time looks strongly correlated with them, especially on U.S. vs. China issues.
As an aside, if this work monitoring the open ecosystem sounds appealing to you, please reach out or leave a comment — I’m thinking about how to scale up our impact in this area!
Interconnects AI is a reader-supported publication. Consider becoming a subscriber.
- Nations will turn to open models as the only way to get an initial foothold in sovereign AI (and sovereign AI is the real deal)
Sovereign AI has largely been unfolding slowly in the background of frontier AI discussions and the U.S.-China arms race, but it’ll only become more prevalent as AI becomes more deeply embedded in our technological reality. Every wealthy nation will see AI as a direction for influence in addition to a necessity for national security. Open models will likely be the only way to get this off the ground as a real effort, in order to have the local AI community and economy seamlessly integrate with it.
- Futures where open-source wins the frontier are still possible, but seemingly less likely
The most likely (by far) outcome is for the status quo to continue and for the best open models to lag the best closed models by 6-9months. A large portion of the perpetual catch-up is likely due to the best open model builders constantly distilling their models on the strongest, currently available closed API models, but this direction seems less relevant with the rise of RL. Post-training today is more about the model undergoing experience rather than directly learning from the smartest teacher you can find. The paths to open models winning come through fundamental innovation. This looks like the ability to merge, rotate, and share expert models, a dramatic (100X+) cost reduction in the cost of training, etc. Predicting this before it happens is more of a sci-fi story than a faithful science, as then I’d just go build the damn thing.
Share
- China’s open model “ecosystem” makes it the most likely place for a discovery around who wins
China has many labs building models on top of their peers’ innovations. This intentional sharing of ideas provides immense benefits relative to Silicon Valley’s quid pro quo where it’s accepted that people go home at the end of their day and chat with some of their friends on the latest technical secrets of their models. The sort of sharing the Chinese companies do, especially considering more of them have closer ties to the nation’s scientific and academic institutions, is the sort of setup that lets new standards converge much faster and breakthroughs be shared. This is another unknown factor, like potential innovation where open models “win,” but it’s important because China has created their own conditions of potential, massive success, and the U.S. has no answer. This divergence in how the ecosystems operate could be nothing in the long-term, but U.S. AI companies cannot do much to compete with it if it takes off.
- Open models dictate science and diffusion — slower trends than the frontier of AI
The biggest impact in AI in terms of transforming day to day life, and even the world’s power structures, will obviously come from the most powerful and intelligent models. It is fairly obvious then that the open models that end up in closest proximity to this capture the headlines — if an open-weights model does, somehow, happen to claim that title as “the world’s most powerful model,” there will be extreme economic consequences.
In the real world, the one with the highest probability of occurring, open models’ biggest influence will be in two, very slow-moving sectors: 1) fundamental research/innovation and 2) global technological diffusion. I’ve personally realized how much of the excitement I can have for open models is a bit misguided — I’m trying to understand the frontier of AI through the lens of these models, missing the bigger story in how technology slowly reshapes the world’s biggest companies.
Consider when Llama was the open SOTA model, everyone in the U.S. and China did science on Llama, which then impacted subsequent models — even if we didn’t hear directly from Meta on how-so. Now this default is Qwen. Qwen is the anchor of the Chinese ecosystem. Language model research is proceeding extremely fast, which could make the fundamental improvements made in research labs impact the frontier of the technology much faster than usual.
At the same time, the global default for using AI outside of the wealthiest few nations will be to use either free applications like ChatGPT or open weight models. ChatGPT doesn’t fit a lot of business use-cases, so open weight models are a melting pot for innovation that we largely have no visibility into. When we zoom out to a timeline closer to decades, open model’s global adoption seems like a top trend to follow in AI.
Conclusion
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み