ループエンジニアリングの芸術
LangChain Blog は、単なるツール呼び出しループを超え、検証ループなどを積み重ねる「ループ工学」の概念を提示し、信頼性の高いエージェント構築のための設計指針を解説している。
キーポイント
基本ループ(Loop 1)の定義と実装
エージェントの核心はモデルがツールを呼び出してタスク完了までループすることであり、LangChain の create_agent でこれを簡易に実現できる。
検証ループ(Loop 2)による品質向上
最初の生成結果の正確性や一貫性が保証されない場合、出力を検証しフィードバックを返す「検証ループ」を外部から追加することで信頼性を高める。
ループスタッキングによる複雑なエージェント構築
Swyx の提唱する「loopcraft」の概念に基づき、複数のループを積み重ねることで、より高度で実世界での動作が可能なエージェントを設計できる。
LangChain による各レベルの計測と制御
各ループレベルを LangChain のプリミティブでインストゥルメント化し、ドキュメンテーション改善などの具体的なユースケースで実証している。
影響分析・編集コメントを表示
影響分析
この記事は、LLM エージェント開発における「単発の生成」から「構造化されたループ設計」へのパラダイムシフトを明確に示しており、実運用レベルでの信頼性確保に向けた重要な指針となる。技術者にとって、複雑なタスクを安定して実行するためのアーキテクチャ設計思考を深める契機となり、業界全体のエージェント開発の成熟度を高める一因となるだろう。
編集コメント
エージェント開発において、モデルの性能だけでなく「ループ構造」の設計が成否を分けるという視点は極めて重要です。実運用を意識した開発者にとって、この「ループ工学」の概念は即座に実践可能なフレームワークとして価値が高いと言えます。
エージェントは、現実世界で行動を取ることで作業を自動化するのを助けるため有用です。しかし、エージェントに信頼性のある価値ある仕事をさせるには、優れたモデルだけでは不十分で、特定のタスクセットに適した注意深く設計されたハネスが必要です。
コアとなるエージェントアルゴリズムはシンプルです:LLM にコンテキストを与え、完了するまでツールを呼び出すループを実行します。これが最も基本的なループですが、エージェントを駆動する唯一のループではありません。Swyx は最近、より効果的なエージェントを構築するためにループを重ねて拡張できるというアイデアについて、「loopcraft: the art of stacking loops」(「ループクラフト:ループを重ねる芸術」) という素晴らしい記事を書いています。
ここでは、そのスタックをどのように捉えているか、および各レベルを LangChain のプリミティブでどのように計測・実装するかについて説明します。
ループ 1: エージェント
本質的に、エージェントとはタスクが完了するまでモデルがループ内でツールを呼び出すだけのものです。

これが LangChain の create_agent が提供するものです。任意のモデルを選択し、ツールを接続するだけで、動作するエージェントループが完成します。ツールこそが、エージェントに現実世界で行動を起こす力を与えるものです。
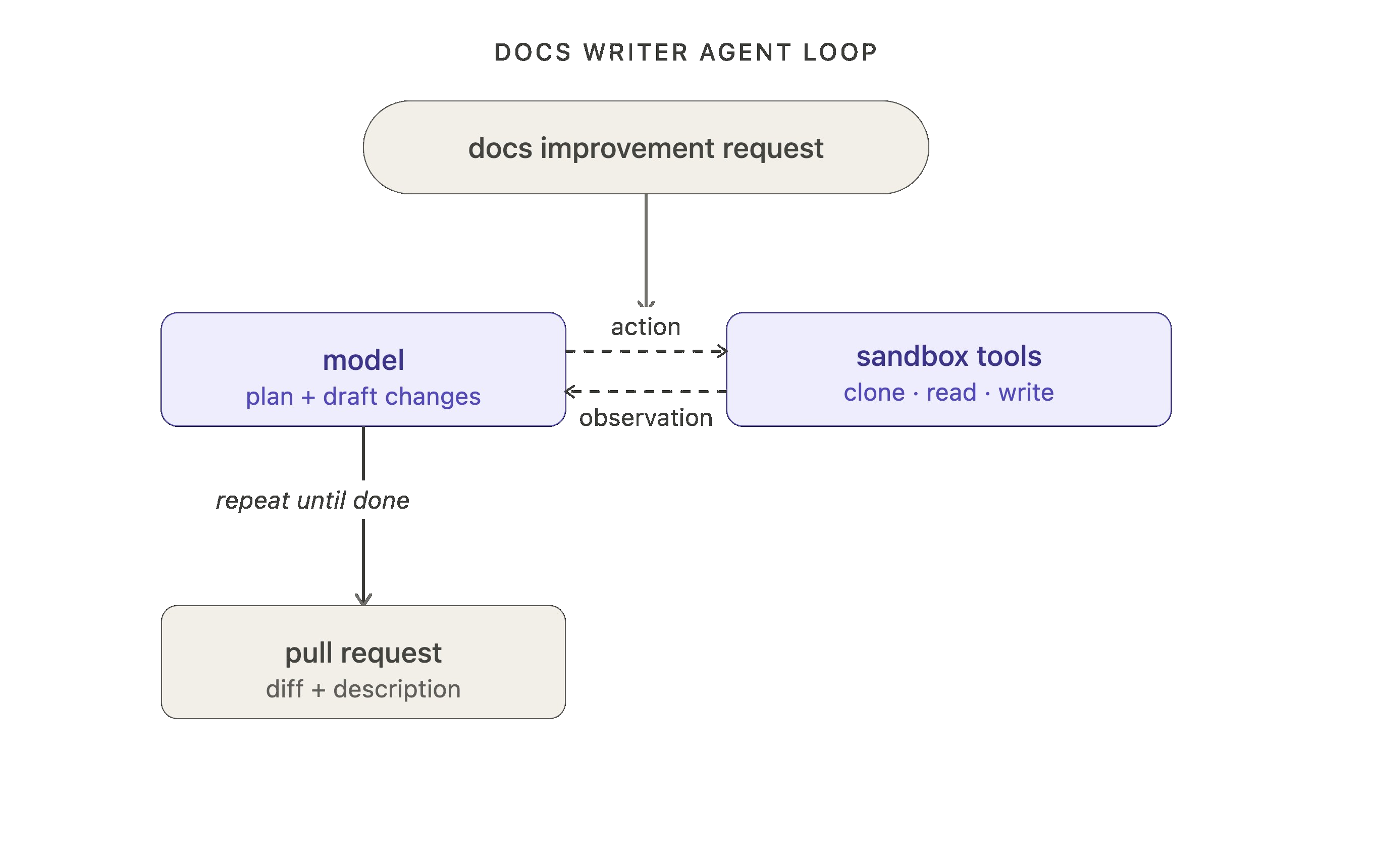
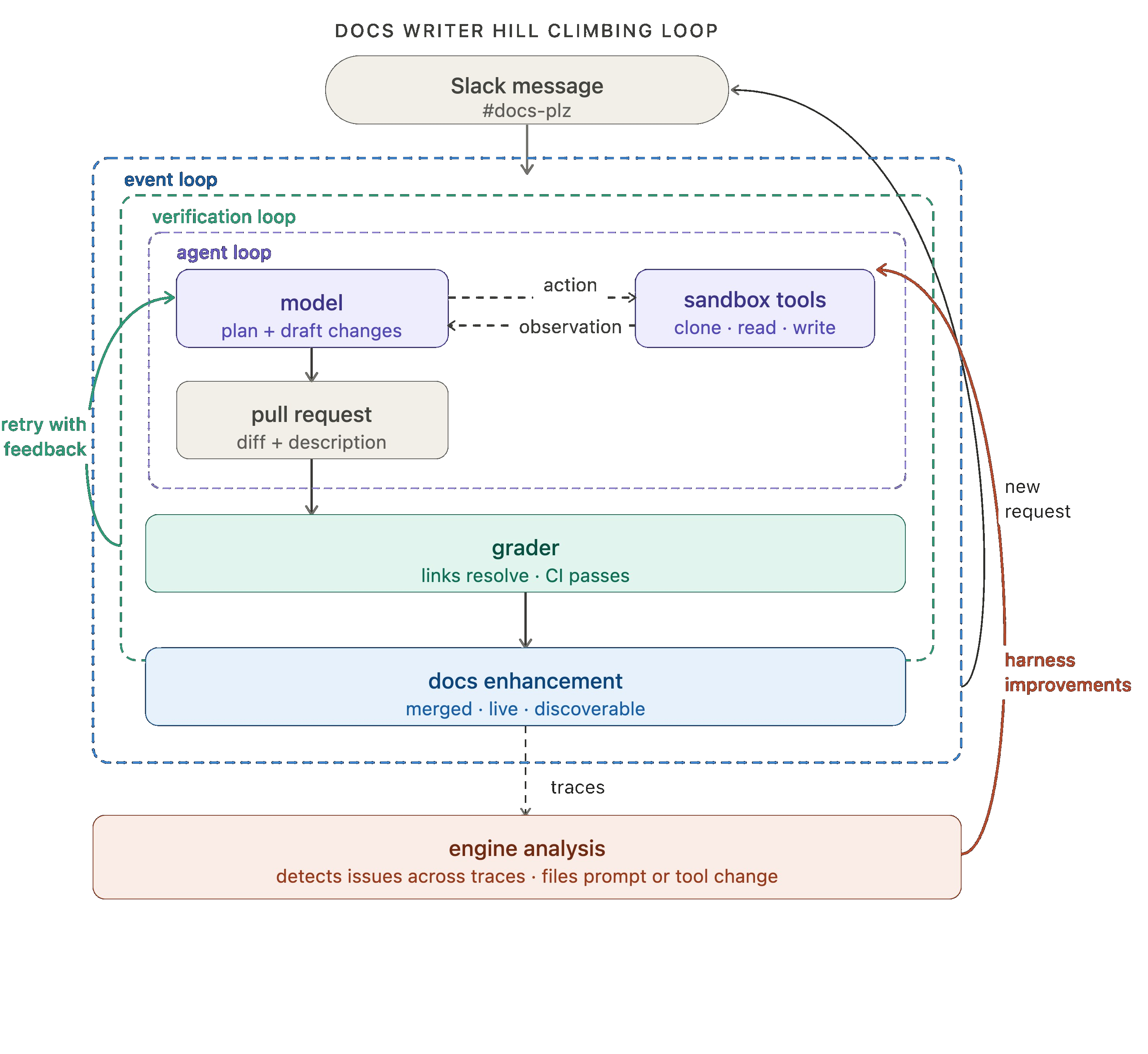
内部ドキュメントエージェントの例を考えてみましょう(このブログの後半では、これを動機付けとなる例として使用します)。最初のループレベルでは、ドキュメント改善のリクエストを受け取り、モデルが計画を立てて変更案を作成し、ツールを使用してリポジトリをクローンしたり、ファイルを読み込んだり、ドキュメントを書いたり、プルリクエストを開いたりします。
レベル 2: 検証ループ
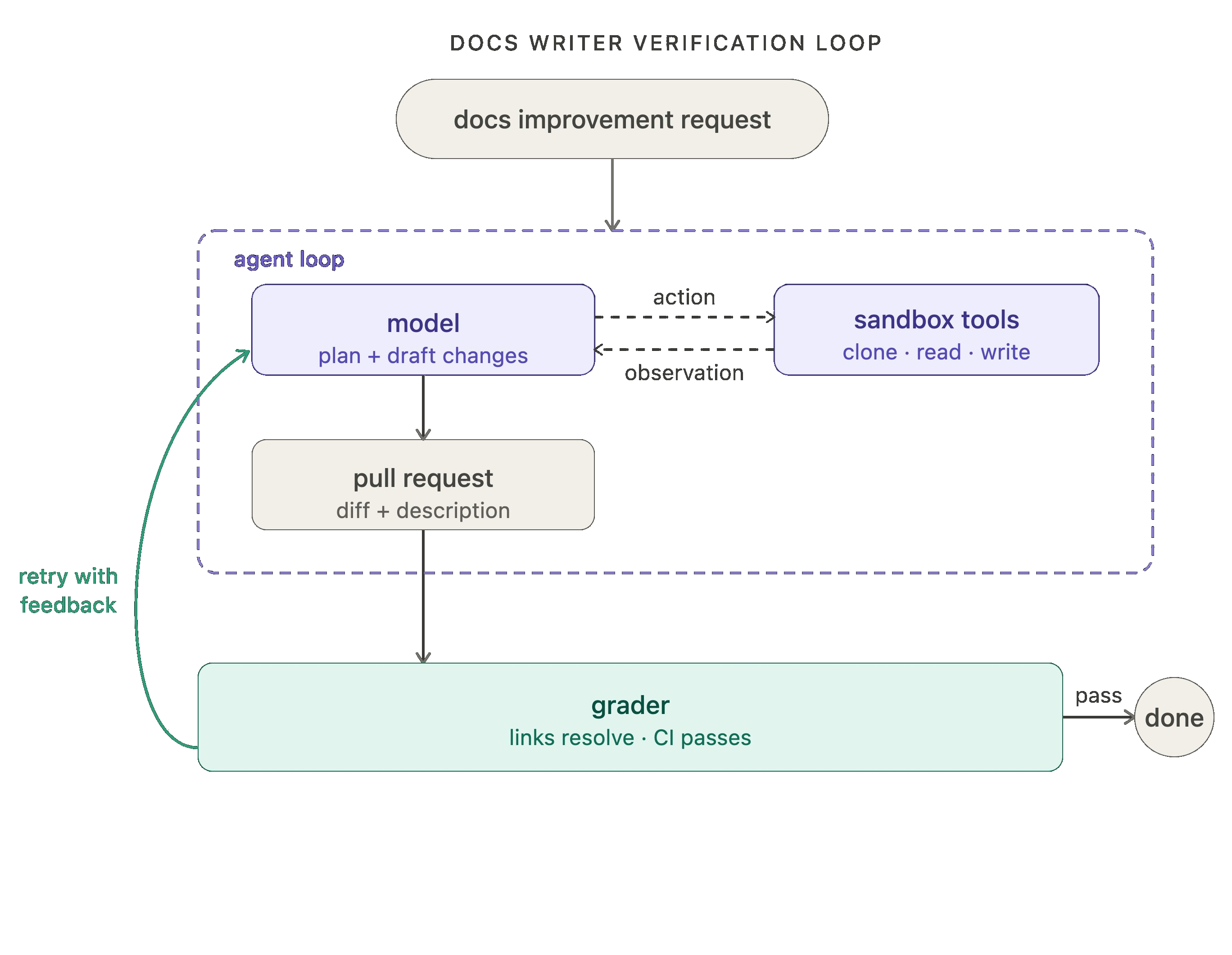
エージェントループは作業を完了しますが、最初のパスですべてが正しく一貫した結果を生み出すとは限りません。一貫性が重要な場合、出力を確認し、不足している場合にモデルにフィードバックを送る検証ループで囲むと有用な場合があります。

検証ループには、評価者(grader)が追加されます。これはエージェントの出力を評価基準(rubric)と比較し、失敗した場合は結果とフィードバックを返すものです。評価者は決定論的也可以是エージェント型です(LLM を判事として用いる手法は古典的な例であり、こちらを参照してください)。
RubricMiddleware はこのパターンを処理するか、create_agent 関数で after_agent フックを設定して実装することもできます。
ドキュメント作成エージェントの例では、評価者は各試行後にテストを実行し、すべてのリンクが有効であること、すべての CI チェックがパスすること、そして差分(diff)が実際に要求された範囲に限定されていることを確認します。これらの種類のエラーを検出するために手動レビューは不要です。
一つのトレードオフ:検証を追加すると、実行あたりのレイテンシとコストが増加します。スピードよりも品質が重要である場合、つまりほとんどの本番環境ユースケースでは、その価値があります。
レベル 3:イベント駆動ループ
エージェント開発において最も重要な部分の一つが、統合層です。これは、エージェントをエコシステムに接続し、バックグラウンドで実行できるようにするものです。
イベント駆動型ループは、エージェントをエコシステムに接続します。あるイベントが発生すると(新しいドキュメントが到着する、スケジュールがトリガーされる、ウェブフックが到着するなど)、エージェントが実行されます。このエージェントは手動で呼び出すものではなく、より大きなシステム内で継続的に動作するコンポーネントです。
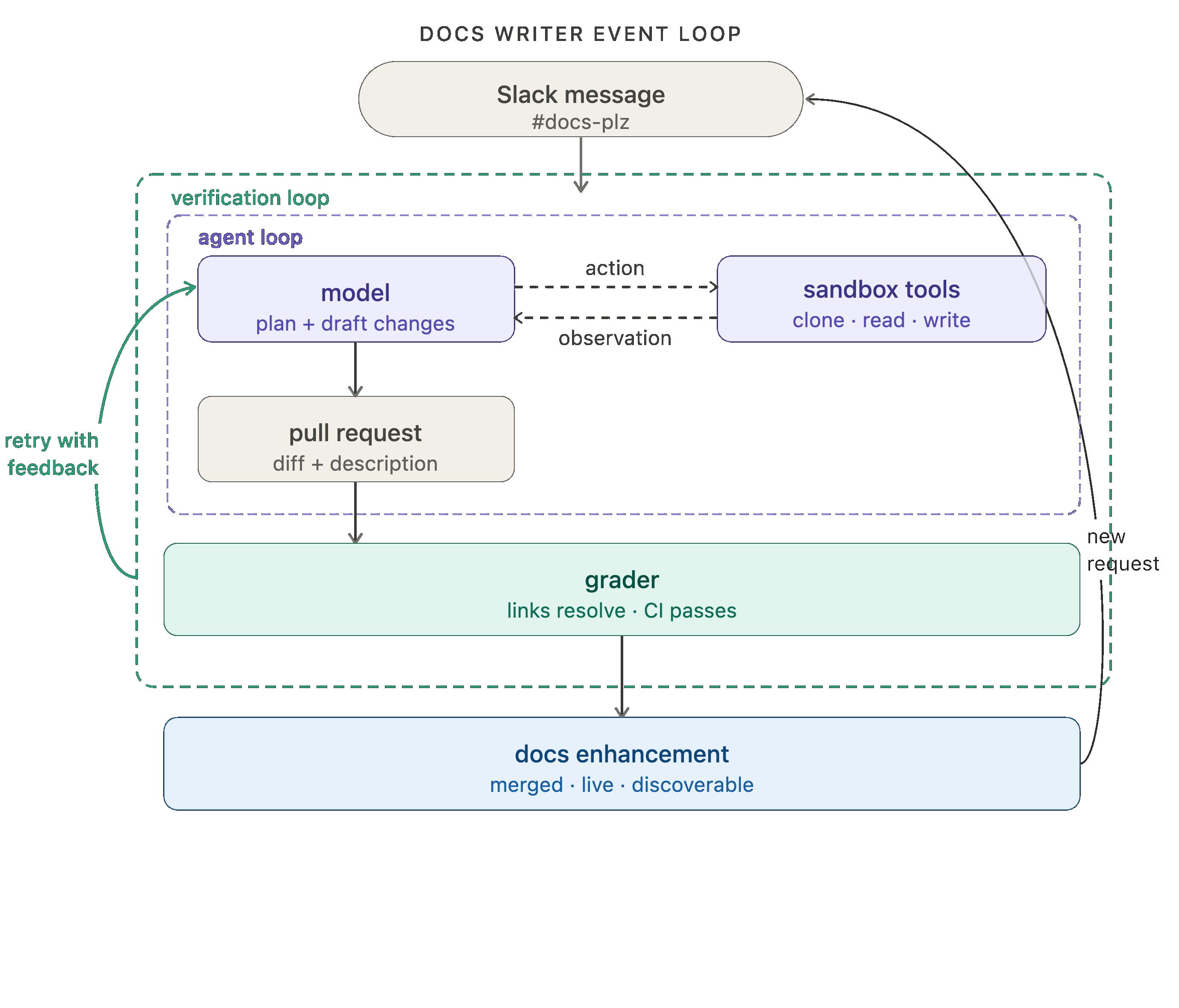
LangSmith Deployment は、cron スケジュール(定期実行スケジュール)や Webフック(webhook)を含むトリガーインフラストラクチャをサポートしています。cron の活用例として人気があるのが、「ハートビート」機能です openclaw では、これによりエージェントが常時稼働する能動的なアシスタントへと進化します。
当社のドキュメント用エージェントは、ノーコードのエージェントビルダーである Fleet によって駆動されています。Fleet の チャンネル と スケジュール は、イベント駆動型および cron スタイルのトリガーを処理します。当社は、#docs-plz Slack チャンネルでメッセージが送信されるたびにドキュメント用エージェントを発火させるためにチャンネルを利用しています。
レベル 4: ヒルクライミング・ループ (Hill Climbing Loop)
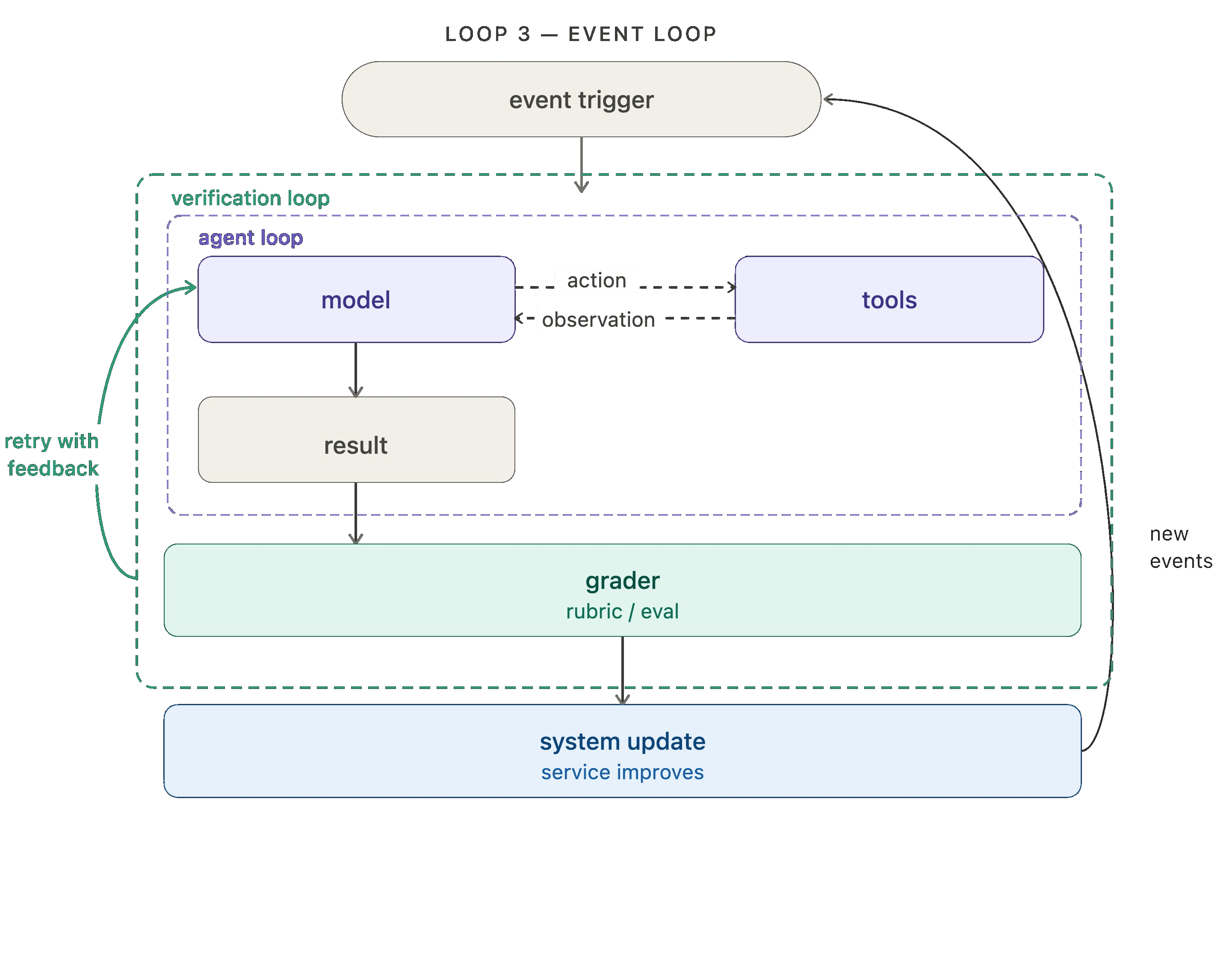
最初の 3 つのループは作業を自動化しますが、4 つ目のループ(おそらく最も重要なもの)は改善自体を自動化します!
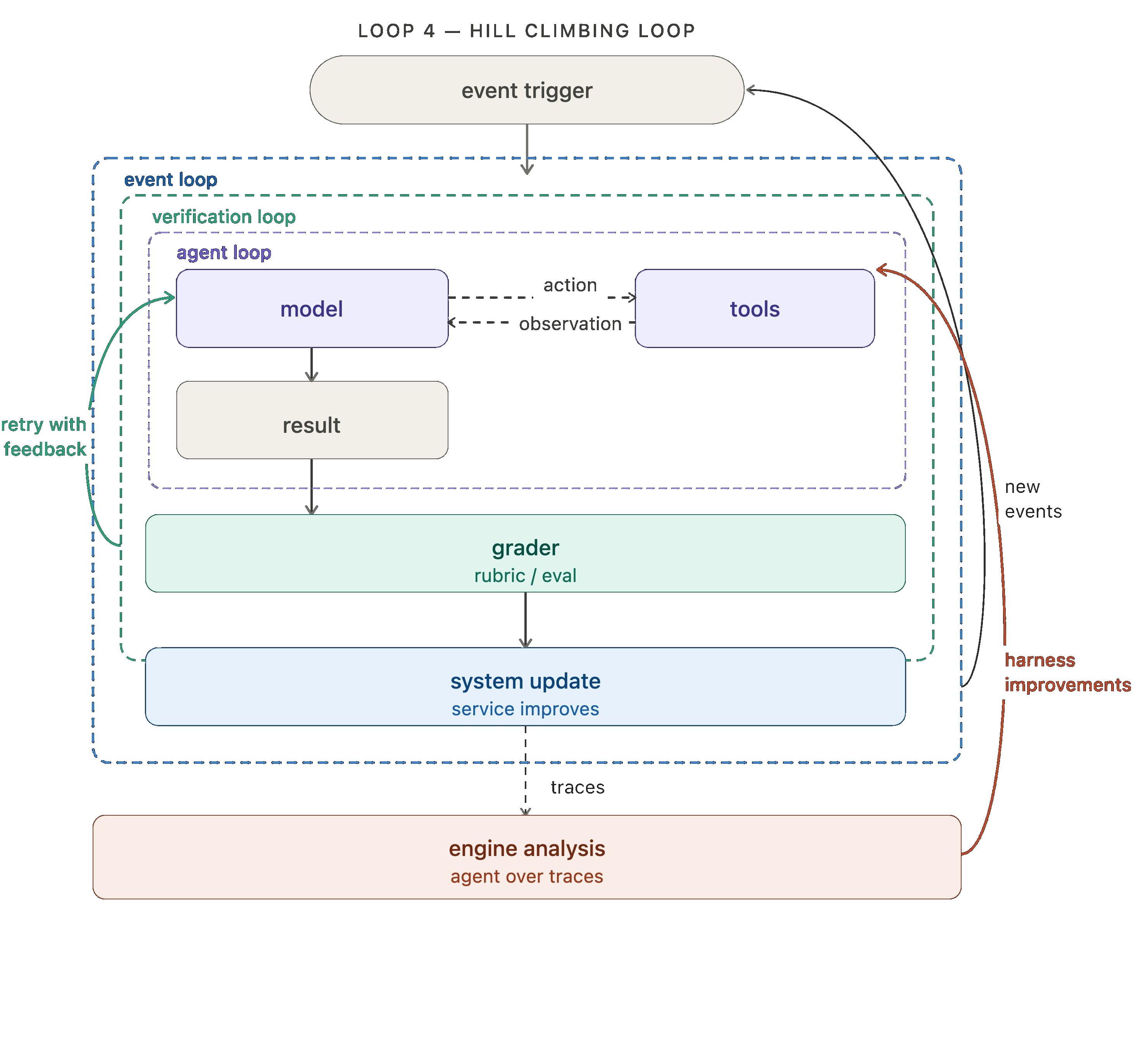
エージェントの実行ごとにトレース(Trace)が生成されます。これは、モデルが行ったこと、呼び出されたツール、グラダーフィードバックなどの記録です。これらのトレースには、何が機能していて何が機能していないかに関する高価値なシグナルが含まれています。ヒルクライミング・ループは、これらのトレースに対して分析エージェントを実行し、その知見を用いて構成を改善したハーン(Harness)を書き換えます。これには、プロンプトやツールの微調整、あるいはグラダーの微調整も含まれます。
LangSmith では、Engine というトレース分析エージェントを使用して、この 4 つ目のループを計測(インストゥルメント)することができます。
ドキュメント作成エージェントのアナロジーでまとめると、ドキュメント作成エージェントのトレースに対して Engine を実行して問題を検出します。複数のトレースが潜在的な問題を示唆した場合、問題のあるプロンプトやツールの変更を求める課題(Issue)が起票されます。
ここで重要な点は、戻り矢印が単にトップへループするだけでなく、内部に入り込んでエージェント・ループ自体を更新することです。外側のループの各サイクルが、内側のループをより効果的なものにしていきます。
Looking forward: prompt and tool configuration are the most simple things to improve, but they're not the only options.For teams running open-weight models, the hill climbing loop can feed into RL fine-tuning, using trace or eval outcomes as training signal to improve the model itself.Auxiliary context like memory and retrieved skills can be improved the same way. The loop is the pattern; what it optimizes is up to you.
Human oversight and expertise
Automation doesn't mean removing humans from the loop. At every level, there are natural points where human oversight adds value. An automated grader can check whether links resolve; it takes a human to notice the framing is wrong for the audience. That kind of judgment, earned from context, experience, and taste, is exactly where human review earns its place.
Some expertise should be codified in the prompt/tools themselves, but for sensitive actions, live human review is essential (think financial transactions, DB operations, etc). LangChain makes it straightforward to instrument these touch points in every loop:
- エージェント・ループでは、機密性の高いアクションやツール呼び出しの前に人間の入力を必須とする
- 検証ループでは、人間が機密性の高いワークフローのグラダー(採点者)として機能できる
- アプリケーション・ループでは、エンドユーザーへ返却される前に人間が出力を承認できる
- ヒルクライミング・ループでは、デプロイ前に人間のレビューを通じて改善点を活用できる
LangChain のすべてのオープンソースフレームワークは、「ヒューマン・イン・ザ・ループ(人間をループに組み込む)」を 第一級プリミティブ として追加することを可能にしています。
すべての要素を統合する
より表形式のビューをご希望の場合、これら 4 つのループがどのように積み重なるかを示します:
| Loop | What it does | Impact | LangChain primitive |
|---|---|---|---|
| 1. Agent loop | モデルがタスク完了までツールを繰り返し呼び出す | ワークの自動化 | create_agent、LangChain がサポートする任意のモデル |
| 2. Verification loop | エージェントが実行され、出力がルブリック(評価基準)に対して採点され、失敗した場合はフィードバック付きで再試行される | ワークの品質と正確性の確保 | RubricMiddleware |
| 3. Event driven loop | イベントがトリガーとなり、エージェントが実行されてリアルタイムシステムを更新する | スケールした自動化ワーク | LangSmith Deployment(cron トリガー / Webhooks または Fleet チャンネル)
- ヒルクライミング・ループ
生産環境からの実行トレースが分析エージェントにフィードされ、ハーネス設定を改善します。
ハーネスの改善
LangSmith Engine
これが、スワイ氏が言うところの「ループクラフト」loopcraft における、ループエンジニアリングの実践的な姿です。AI のリーダーである Steipete、Boris、そして Andrej は皆、同じ結論に至っています。エージェントの潜在能力は、その周囲に構築するループにあるのです。
私たちはすでにループ 1 と 2 についてある程度考えてきました。しかし、価値が複利効果を生むように、エージェントを生態系に埋め込み、あなたの基準に応じて継続的に改善させるループ 3 と 4 に焦点を移すべきです。
サティア は組織的なリスクを以下のように定義しています。学習ループを早期に構築し、人間の判断とトークン資本が複利効果を生む企業こそが、模倣困難な優位性を築くことができるのです。
参考資料
- deepagents quickstart
- create_agent docs
- rubric middleware
- cron jobs, webhooks
- langsmith engine
- fleet channels
原文を表示
Agents are useful because they help us automate work by taking actions in the real world. But getting agents to do valuable work reliably takes more than just a good model: it requires a carefully designed harness that's fit to a set of tasks.
The core agent algorithm is simple: give the LLM context and let it call tools in a loop until it's done. This is the most fundamental loop. But it’s far from the only loop that powers agents. Swyx recently wrote a great piece on "loopcraft: the art of stacking loops", the idea that you can stack and extend loops to build more effective agents.
Here's how we think about that stack, and how to instrument each level with LangChain primitives.
Loop 1: The Agent
At its core, an agent is just a model calling tools in a loop until a task is complete.

This is what LangChain’s create_agent gives you. Pick any model, plug in tools, and you have a working agent loop. Tools are what give the agent the power to take action in the real world.
Take our internal docs agent as an example (which we’ll use as a motivating example for the rest of this blog). At the first loop level, it receives a request for a documentation improvement, the model plans and draft changes, and it uses tools to clone repos, read files, write docs, open a pull request, etc.
Level 2: Verification loop
The agent loop gets work done, but it doesn't always produce correct or consistent work on the first pass. When consistency matters, it's often useful to wrap it in a verification loop that checks the output and sends feedback back to the model when it falls short.
The verification loop adds a grader: something that checks the agent's output against a rubric and, if it fails, sends the result back with feedback. Graders can either be deterministic or agentic (LLM as a judge is a classic example, here).
RubricMiddleware handles this pattern, or you can wire it up with an after_agent hook on create_agent.
For our docs writer example, the grader runs tests after each attempt, checking that all links resolve, all CI checks pass, and the diff is scoped to what was actually requested. No manual review needed to catch those classes of error.
One tradeoff: adding verification increases latency and cost per run. It's worth it when quality matters more than speed, which is most production use cases.
Level 3: Event driven loop
One of the most important parts of agent development is the integrations layer: connecting your agent to your ecosystem so that it can run in the background.
The event-driven loop connects your agent to your ecosystem. An event fires — a new document lands, a schedule triggers, a webhook arrives — and the agent runs. The agent isn't something you invoke manually; it's a component running continuously inside a larger system.
LangSmith Deployment supports the trigger infrastructure, including support for cron schedules and webhooks. One popular example of crons in action is “heartbeats” in openclaw, which turn your agent into an always-on, proactive assistant.
Our docs agent is powered by Fleet, our no-code agent builder. Fleet's channels and schedules handle event-driven and cron-style triggers. We use a channel to fire off the docs agent whenever a message is sent in our #docs-plz Slack channel.
Level 4: Hill climbing loop
The first three loops automate work. The fourth (and arguably most important) automates improvement!
Every agent run produce a trace: a record of what the model did, the tools it called, grader feedback, etc. Those traces contain high value signal regarding what's working and what isn't. The hill climbing loop runs an analysis agent over those traces and uses the findings to rewrite the harness with improved configuration. That can include prompt/tool tweaks or grader tweaks.
In LangSmith, you can use Engine, our trace analysis agent, to instrument this fourth loop.
Wrapping up the docs agent analogy, we run engine over the docs agent traces to detect any issues. When multiple traces signal a potential problem, an issue is filed requesting changes to the offending prompt or tool.
The key move here is that the return arrow doesn't just loop back to the top — it reaches inside and updates the agent loop directly. Each cycle of the outer loop makes the inner loops more effective.
Looking forward: prompt and tool configuration are the most simple things to improve, but they're not the only options.For teams running open-weight models, the hill climbing loop can feed into RL fine-tuning, using trace or eval outcomes as training signal to improve the model itself.Auxiliary context like memory and retrieved skills can be improved the same way. The loop is the pattern; what it optimizes is up to you.
Human oversight and expertise
Automation doesn't mean removing humans from the loop. At every level, there are natural points where human oversight adds value. An automated grader can check whether links resolve; it takes a human to notice the framing is wrong for the audience. That kind of judgment, earned from context, experience, and taste, is exactly where human review earns its place.
Some expertise should be codified in the prompt/tools themselves, but for sensitive actions, live human review is essential (think financial transactions, DB operations, etc). LangChain makes it straightforward to instrument these touch points in every loop:
- In the agent loop, require human input before sensitive actions/tool calls
- In the verification loop, a human can act as the grader for sensitive workflows
- In the application loop, a human can approve outputs before they’re returned to the end user
- In the hill climbing loop, harness improvements can flow through human review before deployment
All of LangChain’s open source frameworks make adding a “human in the loop” a first class primitive.
Putting it all together
In case you’d prefer a more tabular view, here’s how those four loops stack together:
Loop
What it does
Impact
LangChain primitive
- Agent loop
Model calls tools repeatedly until a task is complete
Automate work
create_agent, any LangChain-supported model
- Verification loop
Agent runs, output is scored against a rubric, retried with feedback if it fails
Ensure work quality and correctness
RubricMiddleware
- Event driven loop
Events trigger agent runs that update a real system
Automated work at scale
LangSmith Deployment with cron triggers / webhooks or Fleet channels
- Hill climbing loop
Traces from production runs feed an analysis agent that improves the harness config
Harness improvements
LangSmith Engine
This is what loop engineering — or loopcraft, as swyx puts it — actually looks like in practice. AI leaders like Steipete, Boris, and Andrej have all arrived at the same conclusion: the potential in agents is in the loops you build around them.
We’ve been thinking about loops 1 and 2 for a while. But focus should pivot to loops 3 and 4 where value compounds by embedding agents into your ecosystem that continuously improve in response to your criteria.
Satya frames the organizational stakes: companies that build learning loops early,where human judgment and token capital compound together, will build an advantage that's hard to replicate.
Reference
- deepagents quickstart
- create_agent docs
- rubric middleware
- cron jobs, webhooks
- langsmith engine
- fleet channels
関連記事
エージェントとアプリケーションの間の欠落したリンク
LangChain が、自律的な AI エージェントを実用的なアプリケーションに統合するための重要な仕組みや手法について解説している。
LangSmith のノーコードエージェントビルダーの紹介
LangChain が提供する LangSmith に、プログラミング不要で AI エージェントを構築できる新機能が導入された。
エージェント性は十分か?独自ツールを用いたオープンモデルのベンチマーク調査
Hugging Face が、独自に構築したツール環境において、オープンソースモデルがどれほど「エージェント性」を発揮できるかを評価するベンチマーク手法を発表しました。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み