Blackwell上で6TB/s超を達成するMXFP8量子化器
fal.ai は Blackwell (B200) GPU上でMXFP8量子化カーネルを最適化し、スケールファクターの再パック不要な実装により6TB/s以上の帯域速度を実現した。
キーポイント
Blackwell互換の直接書き込み最適化
量子化カーネルがスケールファクターを、BlackwellのブロックスケーリングTensor Coresが期待するtcgen05形式に直接書き込むことで、後続のGEMM処理における追加のパッキングステップを排除した。
MXFP8量子化方式の詳細
32要素ごとのブロック単位でUE8M0指数スケールを使用し、値はFP8 (E4M3) で保存する微細スケーリング形式を採用し、計算効率と精度のバランスを最適化した。
CTA分割による帯域速度向上
従来の単一CTAアプローチでの待ち時間(Stall Wait)を解消するため、M×K平面に対して2次元グリッドでCTAを分割し、並列度を高めて6TB/s以上の有効帯域を達成した。
K分割によるCTA数の劇的増加
K軸を分割することでCTA数を64倍に増やし、GPUのスケジューリング効率とレイテンシ隠蔽能力を大幅に向上させ、スループットを1.3TB/sから3.3TB/sへ引き上げました。
TMAによる単純な一括転送の実装
SIMTモデルのオーバーヘッドを回避するため、各CTAタイルに対して単一の大規模トランザクション(bulk transaction)を行うTMA設計を採用し、バリア管理の重複コストを排除しました。
SIMTモデルのボトルネック解消
転送速度がDRAM帯域ではなく命令オーバーヘッドに依存する段階に至った際、コピー管理や同期、共有メモリの再プレイペナルティを減らすことで性能限界を突破しました。
TCGEN05 向けスケールファクタの物理的再配置
Blackwell のブロックスケーリング Tensor Core は、論理的には同じでも物理的に並べ替えられた(パッキングされた)形式のスケールファクタを必要とし、これを Dense 形式から直接変換する必要がある。
影響分析・編集コメントを表示
影響分析
この技術は、次世代AIハードウェア(NVIDIA Blackwell)の性能を最大限に引き出すための重要な最適化手法を示しており、大規模モデルの推論速度とエネルギー効率を劇的に向上させる可能性があります。特に、スケールファクターの再処理を省略するアプローチは、システム全体のレイテンシ削減に直接寄与し、実運用環境での導入価値が高いです。
編集コメント
Blackwellアーキテクチャの真価を引き出すための、極めて実践的なカーネル最適化事例です。ハードウェア仕様に合わせたデータ配置の工夫が、帯域速度に直結する明確な証拠となっています。
 imageCuTeDSL で 6+ TB/s のスループットを達成する MXFP8 量子化器を開発しました。このカーネルは、Blackwell のブロックスケール Tensor Cores が期待するパッキングレイアウトに直接スケールファクターを書き込むため、後続の GEMM(行列乗算)処理で追加のパックステップを経由せずにこれらを利用できます。
imageCuTeDSL で 6+ TB/s のスループットを達成する MXFP8 量子化器を開発しました。このカーネルは、Blackwell のブロックスケール Tensor Cores が期待するパッキングレイアウトに直接スケールファクターを書き込むため、後続の GEMM(行列乗算)処理で追加のパックステップを経由せずにこれらを利用できます。
MXFP8 は MX OCP 仕様に準拠したマイクロスケーリングフォーマットです。テンソル全体または各行に 1 つのスケーラーを割り当てるのではなく、より粒度の細かいブロックベースのスケーリング(通常は 1×32)を採用しています。各 32 要素からなるブロックでは、パワー・オブ・トゥー形式のスケール指数(UE8M0)が共有され、値自体は FP8(E4M3/E5M2)として保存されます。
カーネルの動作概要
入力:
X: fp16/bf16 行列、形状 (M, K)
出力:
Q: FP8 E4M3 バイト、形状 (M, K)(int8 バイトとして格納)
S: E8M0 (UE8M0) スケール指数、tcgen05 レイアウトでパッキング済み
量子化は K 方向に沿った 32 要素単位でブロックスケールされます:
各行および各 32 要素ブロックについて:a = 32 要素における abs(x[i]) の最大値
そのブロックの大きさをパワー・オブ・トゥー形式のスケール(UE8M0 指数バイト)に変換します。従来の目標値は S ≈ a / 448 です(448 は FP8 E4M3 の有限値の最大値)。
除算を安定させ、逆量子化を低コストで行うために、次のパワー・オブ・トゥーに切り上げます。
量子化:Q = round_to_fp8_e4m3(x / scale) を実行し、有限値への飽和処理を行います。
重要なポイント:S は直接、tcgen05 互換のパッキングレイアウトに書き込まれるため、後続のブロックスケール行列乗算は追加のパックステップを経ずにスケール値を利用できます。
TransformerEngine (TE) は同じ論理情報を返します:K 方向の 32 要素ブロックごとに UE8M0 指数バイトが 1 つあり、これは形状 (M, K/32) の S_dense[m, kb] として密に格納されます。これはスタンドアロンの dequant(非量子化)には問題ありませんが、ブロックスケーリングされた GEMMs では、これらのバイトを packed tcgen05 レイアウトで必要とします。私たちは最初からパッキングされた形式で書き込むことでこれを回避しています。
帯域幅の測定
有効帯域幅を報告します:
Bw_eff = (2*M*K + 1*M*K + 1*M*(K/32)) / t
fp16/bf16 の読み取り(2 バイト)+ fp8 Q の書き出し(1 バイト)+ S の書き出し(32 値分 1 バイト)。
Blackwell で機能した手法
問題にタイル化して、GPU が十分な CTAs を持てるようにする
最初のバージョンでは、CTA を行のブロックにマッピングし、K 全体をループさせるというアプローチを採用しました。紙面上では効率的に見えます:局所性が高く、起動回数が少なくなります。しかし NCU(NVIDIA Compute Profiler)の分析では、Stall Wait が支配的であることが示されました。各 CTA の寿命が長すぎ、GPU にはレイテンシを隠蔽するための十分な並列作業がありませんでした。
解決策は構造的なものです:グリッド上で K に沿って分割します。
2 つのタイルサイズを選択します:
- 1 つの CTA が処理する行数(例:8)
- 1 つの CTA が一度に処理する K の量(例:256 要素)
M×K 平面全体に対して 2D グリッドを起動します:cta_m = ceil_div(M, rows_per_cta)(M 方向のタイル数)
cta_k = ceil_div(K, k_tile)(K 方向のタイル数)
grid = (cta_m, cta_k)
各 CTA は長方形領域を所有します:(rows_per_cta, k_tile)。
ここでの直観を図解します。入力を大きな M×K のシートと想像してください:
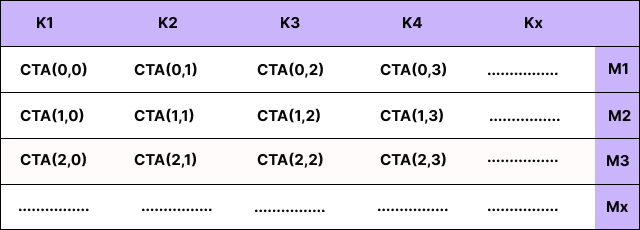
K に沿って分割しない場合、実質的に CTA の列は 1 つしかありません:
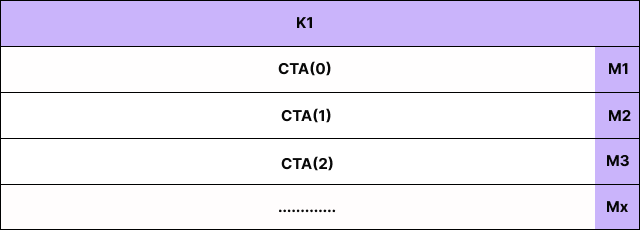
これにより、CTA(Compute Thread Array)の総数が約 cta_k 倍に減少し、各 CTA がより多くの直列処理を行うことになります。
具体的な数値:
M = 16384, K = 16384 と仮定します。
rows_per_cta = 8, k_tile = 256 を選択すると、
cta_m = 16384 / 8 = 2048
cta_k = 16384 / 256 = 64
となります。
したがって、CTA の総数は 2048 * 64 = 131072 です。
もし K を分割しない場合、起動される CTA は cta_m = 2048 のみとなり、これは 64 分の少ない数になります。大規模な GPU において、これは「スケジューリングやレイテンシ隠蔽のための独立した作業が大量にある状態」と、「マシンが待機しているだけの状態」の違いを意味します。
この単一の変更は、命令レベルのチューニングに着手する前に「作業量の不足」という問題を解決したため、スループットにおける最初の大きな飛躍(私たちの実行では約 1.3 TB/s から有効値として約 3.3 TB/s)をもたらしました。
TMA を用いて HBM から SMEM へ移動させるが、シンプルに保つ
TMA の導入前は、非常に標準的な SIMT cp.async デザインから始めました。
SIMT モードでは、スレッドがバイトを移動します:
各スレッドは、グローバルメモリから共有メモリへの cp.async コピーをいくつか発行し、
stages を管理するために commit_group / wait_group(または同等の機能)を実行し、
共有メモリの使用に関する __syncthreads() スタイルの同期処理を行い、
その後、SMEM からレジスタへのロード、absmax/scale 計算、およびストア処理を行います。
K スプリッティング以前の OLD デザインでは、内部ループは以下のようでした:
OLD: CTA は K のすべてをループする(CTA が少なすぎて、レイテンシ隠蔽が不十分)
for k0 in range(0, K, k_tile):
cp_async(...)
cp_async_commit()
cp_async_wait()
syncthreads()
smem_to_regs()
absmax_scale_quantize()
stores()K スプリット後、各 CTA は 1 つのタイルのみを処理するため、ループ本体は 1 回だけ実行されます。
SIMT が頭打ちになった理由
k_tile と stages を調整しても、SIMT の性能は私たちにとって約 3.4~3.6 TB/s で頭打ちになりました。この範囲に入ると、カーネルはもはや「DRAM バンド幅に支配されている」のではなく、「バイトあたりの命令数とオーバーヘッドに支配される」状態になります。
コピーの管理処理
同期
共有メモリの再実行ペナルティ
Blackwell において、HBM から SMEM への大規模な転送に対する明白な回避策は、TMA バルク(Tensor Memory Accelerator)です。罠となるのは、繰り返しサブタイルごとのバリアで TMA を過剰にパイプライン化することです。このオーバーヘッドが利益を食いつぶしてしまいます。高速かつ安定していたバージョンは、単純な単一バルクロード TMA 設計でした。
各 CTA タイルあたり 1 つのバルクトランザクション((rows_per_cta, k_tile) の領域全体を読み込む)
TMA トランザクションバリア (mbarrier) を使用して待機し、その後すぐに消費する
カーネルはタイルごとに以下の 3 つのことを行います。
TMA で HBM から SMEM へタイルを読み込む
計算:absmax、スケール指数の算出、量子化(行ごと、32 要素ブロックごと)
Q の保存(ワイド形式)と S の保存(パッキング済み、アライメントガード付き)
「サブタイル読み込み / バリア / 計算 / 繰り返し」という内部ループを避けることで、飽和状態に近づくとこの反復バリアのコストが支配的になるのを防ぎました。
カーネル内部
起動ジオメトリと HBM→SMEM のパスが決まった後は、タイルごとの読み込み、行ごとの量子化ループ、そして保存処理が残るだけです。
CTA 形状とスレッドマッピング
量子化は K を跨ぐブロックスケールで各行ごとに行われるため、作業の自然な単位は以下の通りです。
1 つの行
K 方向に幅 32 のブロック
共有メモリからの 128 ビット読み出し:
各レーンが 16 バイト(fp16 要素 8 個)を読み出す
32 要素のブロックには 4 つのレーンが必要
CTA あたり 32 レーンがあるため、並列処理される行は 8 行となる
他の構成も試したが、この構成が命令数とオキュパンシー(occupancy)のバランスにおいて最良の結果を示した。
ホットループ:「SMEM → regs → absmax → scale → pack FP8」
1 つの CTA に対する疑似コード(簡略化版):
各 CTA は 1 タイルを所有する: 行 [m0, m0+8)、K [k0, k0+256)
1) HBM -> SMEM (単一のバルク読み出し)
tma_load_async(smem_X, gmem_X[m0:m0+8, k0:k0+256])
tma_wait()
2) 行ごと、32 要素ブロックごとに消費
for row in range(8):
for blk in range(8): # 256 / 32 = 8 ブロック
# SMEM から 32 要素を読み出し(4 スレッドにわたるベクトル化)
x = smem_load_32(row, blk) # 長さ 32
# absmax(速度のため整数ドメインで実行)
a = max(abs(x))
# scale = 2^ceil(log2(a / 448))、UE8M0 指数として保存
ue8 = to_ue8m0(a / 448)
# 量子化: q = round_to_fp8(x / scale)
q = fp8_e4m3_satfinite(x * inv_scale(ue8))
# 32 Q バイト + スケール因子 1 バイトを保存(パッキングレイアウト)
store_q(row, blk, q)
store_scale(row, blk, ue8)スケール因子:密な形式 vs. tcgen05 パック形式
量子化器は 2 つの出力を生成する:
Q: FP8 E4M3 バイト、形状 (M, K)
S: 32 値ごとに UE8M0 指数バイト 1 つ、論理的に (M, K/32)
通常のカーネルでのみ逆量子化を行う場合、S は密な形式で保存される:
dense S: S_dense[m, kb] ただし kb = k // 32
しかし、Blackwell のブロックスケーリングされた Tensor Core パスは、S を密な (M, K/32) 行列から読み込みません。ハードウェア定義のパックドレイアウト(CuTeDSL はこれを BlockScaledBasicChunk / tile_atom_to_shape_SF を通じてモデル化)でスケールバイトを期待します。
したがって、以下のように記述します:
packed S: 同じ論理バイトですが、GEMM が直接消費できるように tcgen05 形式に物理的に配置されたもの(リシェイプ/パーミュート/パッキングカーネル不要)。
これが実務で重要になるのは、(Q, S) をブロックスケーリングされた GEMM に供給したい場合です。
TransformerEngine の MXFP8 量子化器は、同じ論理スケール((m, kb) あたり 1 バイト)を返しますが、これらを密な (M, K/32) レイアウトに格納します。一方、tcgen05 ブロックスケーリング GEMM は、これらのスケールバイトをパックド tcgen05 レイアウトで期待しています。
したがって、ここでの「パッキング」とは、実際のデータ再順序付け・コピーを意味します:S_dense[m, kb] を取得し、同じバイトを GEMM が直接読み込めるようにパックド tcgen05 配置に書き込むことです。
予想していなかったボトルネック
TMA と計算のチューニングが完了した後でも、NCU は依然としてストア効率の低さを示しました。問題はスケールファクターストアにあります。
NCU は以下の 3 つのステップで状況を説明しました:
メモリワークロード分析は、スケールバイトを散在するバイトストアとして書き込む際にグローバルストアの平均バイト/セクター数が低いことを指摘し、低ストレージ利用率を検出しました。
ソースカウンターは、グローバルトラフィック上で著しい「過剰なセクター」を示しました。
SASS 相関分析で犯人が特定されました:STG.E.64(良好):Q ストア
STG.E.U8(不良):個別バイトとしての S ストア
1 バイトずつ書き込むと、部分的に使用された 32 バイトセクターが散らばり、メモリアクセスが積み重なり、スコアボードがそれらを待ってストールします。
私たちの対策は、アドレスが 4 バイト境界に整列している場合に、スケールバイト 4 つを単一の 32 ビットストアにパックすることでした。それ以外の場合はバイトごとの書き込みに戻ります。これにより命令数が削減され、DRAM のスループットが向上しました。
その他の最適化
命令数の削減:TMA が安定した後は、カーネルは 1 バイトあたりの命令数に対して敏感になりました。成果の多くは地味な数学的な整頓でしたが、それらが積み重なりました。NCU では、これらの変更により命令数が 9.79 億から 7,890 万に減少しました。
FP32 の除算を逆数の乗算に置き換える(x / scale は fdiv にコンパイルされると高価になるため)
スケールの計算を FMA に統合する:fma.rn.f32(absmax, 1/448, eps) を使用し、個別の乗算と加算を行わないようにする
明示的なクリップではなく、pack 命令に組み込まれた飽和機能を利用する
スケーリングにはパックされた FP32x2 演算を使用する(スカラー命令数を半分にする)
整数ドメインで absmax を計算する:符号ビットをクリアし、整数最大値を取得し、最後に一度だけ浮動小数点に変換する
より小さな CTAs:このカーネルでは、64 や 128 よりも 32 ラーンの方が効果的でした。飛行中の CTA 数が増え、レイテンシの隠蔽が改善されました。
効果がなかったもの:バンク競合を減らすために積極的な共有メモリのスイーリングを試みましたが、競合は減少しましたが、追加のインデックス計算がその利益を相殺しました。ある時点で単にボトルネックの場所を変えているだけになります。
結果
大規模な形状では、スケールを tcgen05 のパックレイアウトに直接書き込みながら、カーネルは 6 TB/s 以上の有効帯域幅を維持します:
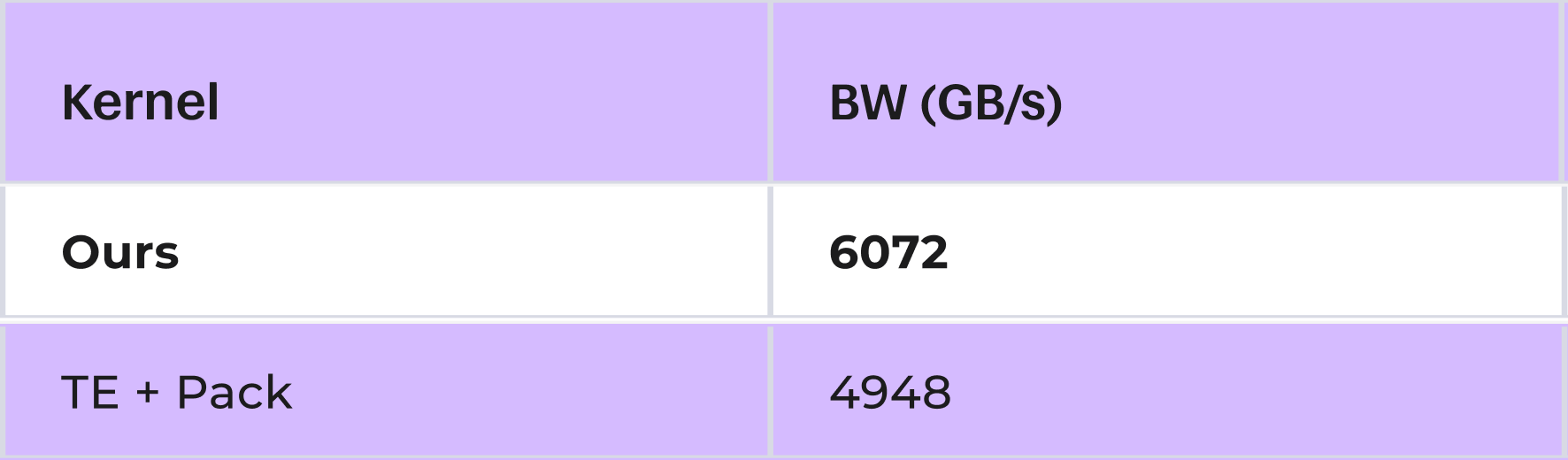 image大規模な形状における有効帯域幅 (GB/s)。TransformerEngine の量子化器は密なスケールを返すため、「TE + pack」にはそれらを tcgen05 レイアウトにパッキングする時間を含みます。一方、当方のカーネルはこのステップを完全にスキップします。
image大規模な形状における有効帯域幅 (GB/s)。TransformerEngine の量子化器は密なスケールを返すため、「TE + pack」にはそれらを tcgen05 レイアウトにパッキングする時間を含みます。一方、当方のカーネルはこのステップを完全にスキップします。
謝辞
本稿は Cursor のカーネル工学ブログに触発されて執筆されました。
原文を表示
imageWe built an MXFP8 quantizer in CuTeDSL that hits 6+ TB/s on B200. The kernel writes scale factors directly into the packed layout that Blackwell's block-scaled Tensor Cores expect, so downstream GEMMs can consume them without an additional pack step.
MXFP8 is a microscaling format (from the MX OCP spec): instead of one scale per tensor or per row, it uses a more granular block-based scaling (typically 1×32). Each 32-element block shares a power-of-two scale exponent (UE8M0), while values are stored as FP8 (E4M3/E5M2).
What the kernel does
Input:
X: fp16/bf16 matrix, shape (M, K)
Output:
Q: FP8 E4M3 bytes, shape (M, K) (stored as int8 bytes)
S: E8M0 (UE8M0) scale exponents, packed in tcgen05 layout
Quantization is block-scaled over 32 elements along K:
For each row and each block of 32:a = max(abs(x[i])) over 32 elements
Convert that block's magnitude to a power-of-two scale (UE8M0 exponent byte). The conventional target is:S ≈ a / 448 (448 is FP8 E4M3 max finite)
rounded up to the next power-of-two so division is stable and dequant is cheap
Quantize:Q = round_to_fp8_e4m3(x / scale) with saturation to finite
The key detail: we write S directly into the packed tcgen05-compatible layout, so downstream block-scaled matmuls can consume scales without a extra packing step.
TransformerEngine (TE) returns the same logical information: one UE8M0 exponent byte per 32-element block along K, stored densely as S_dense[m, kb] with shape (M, K/32). That's fine for standalone dequant, but block-scaled GEMMs need those same bytes in the packed tcgen05 layout. We skip that by writing packed from the start.
Measuring bandwidth
We report effective bandwidth:
Bw_eff = (2*M*K + 1*M*K + 1*M*(K/32)) / t
Read fp16/bf16 (2 bytes) + write fp8 Q (1 byte) + write S (1 byte for 32 value).
What worked on Blackwell
Tile the problem so the GPU has enough CTAs
Our first versions mapped a CTA to a block of rows and had it loop over all of K. Looks efficient on paper: good locality, fewer launches. But NCU showed Stall Wait dominating. Each CTA was too long-lived, and the GPU didn't have enough parallel work to hide latency.
The fix is structural: split over K in the grid.
Pick two tile sizes:how many rows a CTA handles (e.g. 8)
how much K a CTA handles at once (e.g. 256 elements)
Launch a 2D grid over the M×K plane:cta_m = ceil_div(M, rows_per_cta) (tiles along M)
cta_k = ceil_div(K, k_tile) (tiles along K)
grid = (cta_m, cta_k)
Each CTA owns a rectangle: (rows_per_cta, k_tile).
Here's the intuition visually. Think of your input as a big M×K sheet:
imageIf you don't split over K, you effectively have only one CTA column:
That reduces the total number of CTAs by ~ cta_k x and makes each CTA do more serial work.
Concrete numbers:
Suppose =16384, K=16384
Pick rows_per_cta=8, k_tile=256
Then:cta_m = 16384/8 = 2048
cta_k = 16384/256 = 64
total CTAs = 2048 * 64 = 131072
If you don't split K, you only launch cta_m = 2048 CTAs. That's 64× fewer CTAs. On a big GPU, that's the difference between "lots of independent work to schedule/hide latency" and "the machine sits around waiting".
This single change was the first big jump in throughput (roughly ~1.3 TB/s → ~3.3 TB/s effective in our runs), because it fixed the "not enough work" problem before we touched instruction-level tuning.
Move HBM → SMEM with TMA, but keep it simple
Before TMA, we started with a very standard SIMT cp.async design.
In SIMT mode, threads move bytes:
each thread issues some cp.async global→shared copies
you commit_group / wait_group (or equivalent) to manage stages
you do __syncthreads() -style coordination around shared usage
then you do the SMEM→regs load, absmax/scale, and stores
In the OLD design (before K-splitting), the inner loop looked like this:
OLD: CTA loops over all of K (too few CTAs, poor latency hiding)
for k0 in range(0, K, k_tile):
cp_async(...)
cp_async_commit()
cp_async_wait()
syncthreads()
smem_to_regs()
absmax_scale_quantize()
stores()After K-splitting, each CTA handles just one tile, so the loop body runs once.
Why SIMT plateaued
Even after tuning k_tile and stages, SIMT leveled off around ~3.4–3.6 TB/s for us. Once you're in that range, the kernel is no longer "dominated by DRAM bandwidth"; it's dominated by instructions per byte and overheads:
copy bookkeeping
synchronization
shared replay penalties
On Blackwell, the obvious escape hatch is TMA bulk (Tensor Memory Accelerator) for the big HBM → SMEM move. The trap is over-pipelining TMA with repeated per-subtile barriers. That overhead eats into the gains. The version that stayed fast and stable was a simple single-bulk-load TMA design:
one bulk transaction per CTA tile (load the full (rows_per_cta, k_tile) region)
wait using the TMA transaction barrier (mbarrier) and then immediately consume
The kernel does three things per tile:
TMA loads the tile from HBM into SMEM
Compute: absmax, scale exponent, quantize (per row, per 32-element block)
Store Q (wide) and S (packed, with alignment guard)
We avoided a "load subtile / barrier / compute / repeat" inner loop. That repeated barrier cost dominates once you're close to saturation.
Inside the kernel
With the launch geometry and HBM→SMEM path sorted, the rest is a tiled load, a per-row quantization loop, and stores.
CTA shape and thread mapping
Quantization is row-wise and block-scaled over K, so the natural unit of work is:
a row
and a 32‑wide block along K
With 128-bit loads from shared memory:
each lane loads 16 bytes = 8 fp16 elements
a 32-element block needs 4 lane
with 32 lanes per CTA, that's 8 rows processed in parallel
We tried other configurations. This one had the best tradeoff between instruction count and occupancy.
The hot loop: "SMEM → regs → absmax → scale → pack FP8"
Pseudo-code for one CTA (simplified):
Each CTA owns one tile: rows [m0, m0+8), K [k0, k0+256)
1) HBM -> SMEM (single bulk load)
tma_load_async(smem_X, gmem_X[m0:m0+8, k0:k0+256])
tma_wait()
2) Consume per row, per 32-element block
for row in range(8):
for blk in range(8): # 256 / 32 = 8 blocks
# load 32 elements from SMEM (vectorized across 4 threads)
x = smem_load_32(row, blk) # length 32
# absmax (done in integer domain for speed)
a = max(abs(x))
# scale = 2^ceil(log2(a / 448)), stored as UE8M0 exponent
ue8 = to_ue8m0(a / 448)
# quantize: q = round_to_fp8(x / scale)
q = fp8_e4m3_satfinite(x * inv_scale(ue8))
# store 32 Q bytes + 1 scale byte (packed layout)
store_q(row, blk, q)
store_scale(row, blk, ue8)Scale factors: dense vs. tcgen05 packed
The quantizer produces two outputs:
Q: FP8 E4M3 bytes, shape (M, K)
S: one UE8M0 exponent byte per 32 values, logically (M, K/32)
If you only ever dequantize in a normal kernel, you'd store S densely as:
dense S: S_dense[m, kb] where kb = k // 32
But Blackwell's block‑scaled Tensor Core path does not load S from a dense (M, K/32) matrix. It expects scale bytes in a hardware-defined packed layout (CuTeDSL models this via BlockScaledBasicChunk / tile_atom_to_shape_SF).
So we write:
packed S: the same logical bytes, but physically arranged in the tcgen05 format so GEMM can consume them directly (no reshape/permute/packing kernel).
Where this matters in practice is when you want to feed (Q, S) into a block‑scaled GEMM.
TransformerEngine's MXFP8 quantizer returns the same logical scales (one byte per (m, kb)), but it stores them in the dense (M, K/32) layout. A tcgen05 block‑scaled GEMM, on the other hand, expects those scale bytes in the packed tcgen05 layout.
So "packing" here means a real data reorder/copy: taking S_dense[m, kb] and writing the same bytes into the packed tcgen05 arrangement so GEMM can load them directly.
The bottleneck we didn't expect
After getting TMA and compute tuned, NCU still showed poor store efficiency. The problem: scale-factor stores.
NCU told the story in three steps:
Memory Workload Analysis flagged low store utilization:low average bytes/sector for global stores when scale bytes were written as scattered byte stores
SourceCounters showed significant "excessive sectors" on global traffic.
SASS correlation identified the culprit:STG.E.64 (good): Q stores
STG.E.U8 (bad): S stores as individual bytes
Writing 1 byte at a time sprays partially-used 32B sectors. Memory transactions pile up, and the scoreboard stalls waiting for them.
Our fix was the pack four scale bytes into a single 32-bit store when the address is 4-byte aligned. Fall back to byte stores otherwise. This dropped instructions and improved DRAM throughput.
Other optimizations
Instruction-count cuts: Once TMA was stable, the kernel became sensitive to instructions per byte. The wins were mostly boring math hygiene, but they added up:NCU showed instructions dropping from 97.9M to 78.9M across these changes.Replace FP32 division with reciprocal multiply (x / scale is expensive if it compiles to fdiv)
Fuse scale math into FMA: fma.rn.f32(absmax, 1/448, eps) instead of separate multiply + add
Rely on the pack instruction's built-in saturation instead of explicit clamps
Use packed FP32x2 ops for scaling (halves the scalar instruction count)
Compute absmax in the integer domain: clear sign bit, integer max, convert to float once at the end
Smaller CTAs: 32 lanes worked better than 64 or 128 for this kernel. More CTAs in flight, better latency hiding.
What didn't help: We tried aggressive shared-memory swizzling to reduce bank conflicts. Conflicts went down, but the extra index math ate the gains. At some point you're just moving the bottleneck around.
Results
On large shapes, our kernel sustains 6+ TB/s effective bandwidth while writing scales directly into the tcgen05 packed layout:
imageEffective bandwidth on large shapes (GB/s)TransformerEngine's quantizer returns dense scales, so "TE + pack" includes the time to pack them into tcgen05 layout. Our kernel skips that step entirely.
Acknowledgments
This work was inspired by Cursor's kernel engineering blog.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み