Know3D、ユーザーがテキストプロンプトで3Dオブジェクトの背面を制御可能に
研究チームは大規模言語モデルの世界知識を活用し、単純なテキストコマンドで3Dオブジェクトの背面(隠れた側)の表示を制御する手法「Know3D」を開発し、単一画像からの3D生成における最大の盲点の一つに取り組んだ。
キーポイント
背面制御の新手法
Know3Dは、ユーザーがテキストプロンプトを用いて3Dオブジェクトの隠れた背面(非表示側)の外観や内容を直接制御できる技術を提供する。
LLMの世界知識の活用
このアプローチは、大規模言語モデル(LLM)が持つ一般的な世界知識(常識や物体の典型的な構造に関する知識)を利用して、見えない部分の合理的な生成を可能にする。
単一画像3D生成の盲点への対応
従来の単一画像からの3D生成技術では、カメラに映らない背面の情報が欠落するという大きな課題があったが、本手法はこの根本的な限界に直接取り組んでいる。
ユーザーインタラクションの簡素化
複雑な3Dモデリング操作ではなく、自然言語によるシンプルなテキストコマンドで制御できるため、専門家以外のユーザーでもアクセスしやすい。
影響分析・編集コメントを表示
影響分析
この技術は、3Dコンテンツ作成の民主化と効率化を大きく前進させる可能性がある。従来は専門的なスキルや複数の視点データが必要だった背面の詳細生成が簡易化され、ゲーム、AR/VR、eコマース、デジタルツインなど幅広い産業応用への道を開く。また、LLMの知識を3D生成タスクに統合する新たなパラダイムを示しており、マルチモーダルAIの進化に寄与する。
編集コメント
単一画像からの3D生成という長年の課題に、LLMの知識を活用するというスマートな解決策を提示した点が秀逸。研究段階だが、実用化されれば3Dコンテンツ制作ワークフローを一変させる可能性を秘めている。
研究チームは、大規模言語モデル(LLM)が持つ世界知識を利用し、シンプルなテキストコマンドによって3Dオブジェクトの背面に表示される内容を制御する手法を開発しました。この手法は、単一画像からの3D生成において最大の課題の一つである「盲点」の問題に取り組むものです。
この記事「Know3D lets users control the hidden back side of 3D objects with text prompts」は、The Decoderに最初に掲載されました。
原文を表示
Skip to content
Apr 4, 2026
Chen et al.
An image generator bridges the gap between language and 3DInternal model states keep errors from spreadingStrong benchmark scores, but results hinge on the base model
A research team taps into the knowledge of large language models to control the back side of objects via text during 3D generation from single images, addressing a fundamental problem in 3D generation.
When an AI model has to build a complete 3D object from a single photo, it's working with a major blind spot: the image only shows one side, so the model basically has to guess everything behind it. According to a new paper from a team at several Chinese universities, this regularly leads to physically implausible shapes or results that miss what the user was going for.
The issue comes down to data. Compared to the enormous image and text datasets floating around the internet, 3D training data is still hard to come by. The world knowledge 3D models absorb during training just isn't enough to reliably fill in what's hidden.
Know3D tackles this by pulling in the broad world knowledge of multimodal language models. Users can type out a text description of what should appear on the side of an object they can't see.
An image generator bridges the gap between language and 3D
The obvious move—feeding a language model's output straight into a 3D network—doesn't actually work, the researchers say. The representations are too abstract and don't carry enough spatial information to generate usable geometry.
So Know3D takes a detour, slotting an image generation model between the language model and the 3D generator to act as a translator. The setup uses Qwen2.5-VL as the language model, Qwen-Image-Edit for image generation, and Microsoft's Trellis.2 as the 3D generator.
The language model reads the text instruction and analyzes the input image. The image generator then turns that understanding into spatial-structural information that steers the 3D generator.
The language model analyzes the image and text instruction, the image generator translates that into intermediate spatial states, and those states guide the 3D generator as it builds the object. | Image: Chen et al.
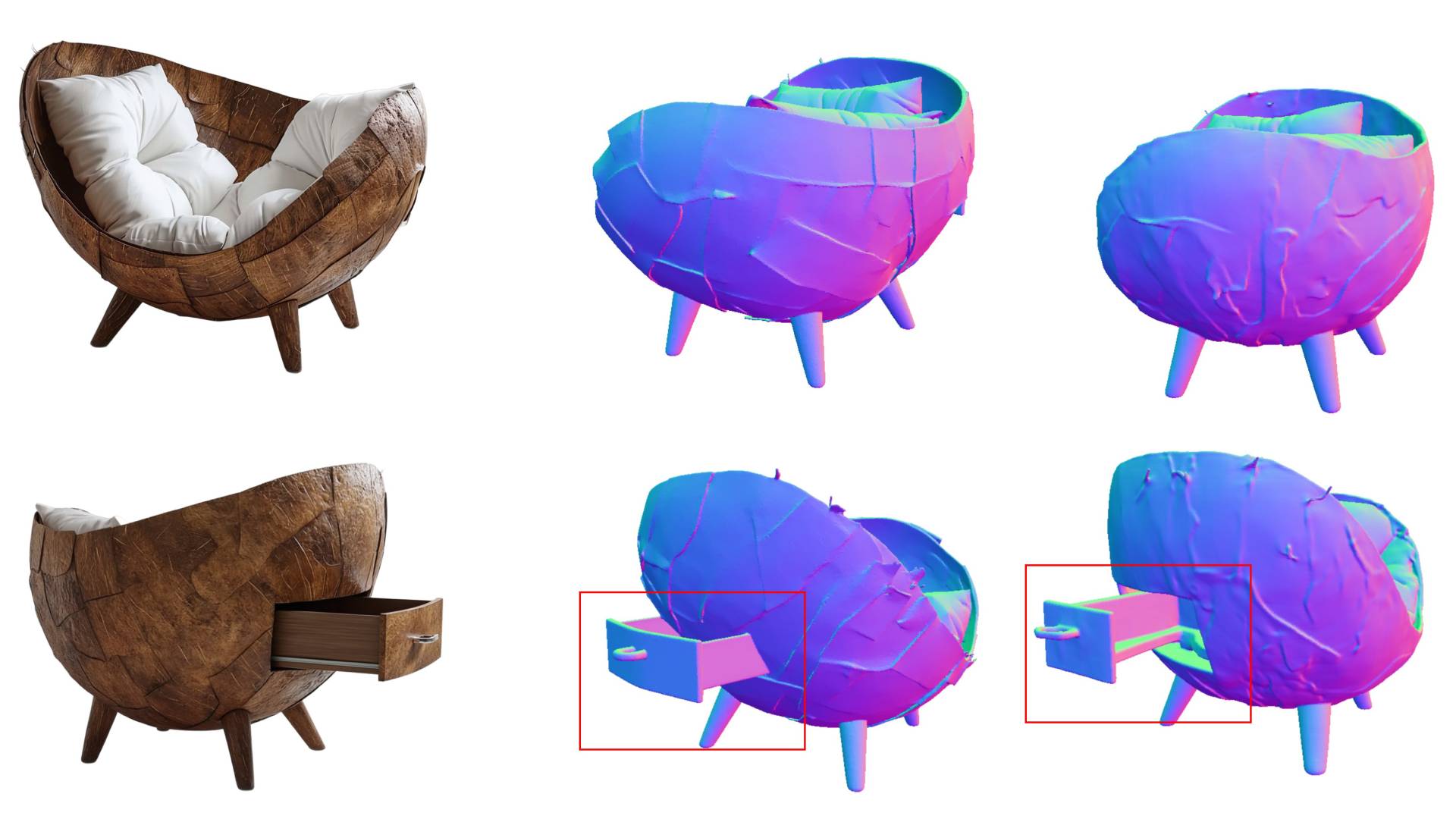
The trick is figuring out what information to pull from the image generator. The team tested three options: an internal image representation grabbed right before the final output, image features extracted from it via Meta's DINOv3, and the model's internal intermediate states during generation. The last option won by a clear margin—these intermediate states carry both semantic and spatial information without relying on pixel-level accuracy or mistakes in the final image.
Internal model states keep errors from spreading
This matters in practice. If the image generator produces a bad rear view, like rendering a one-shoulder bag with two straps, image-based methods pass that mistake straight through to the 3D output.
The model's internal intermediate states are more forgiving: they seem to hold enough spatial and semantic information to still produce a solid 3D object. Even partway through processing, the model apparently builds a pretty reliable sense of structure and form.
The timing of when the team taps into those states matters, too. Go too early and the information is too focused on pixel details. Go too late and noise takes over. Their ablation studies showed that grabbing states at roughly the quarter mark of the process hit the sweet spot.
The main advantage of Know3D over existing methods is the degree of control it offers. The researchers demonstrate this with a coffee cup: the same input photo yields different but geometrically consistent back sides depending on the text instruction. The same principle applies to chairs, robots, and houses: the back adapts to match the description while the visible front remains unchanged.
Strong benchmark scores, but results hinge on the base model
Know3D posts the best scores for semantic match between input image and generated 3D object on HY3D-Bench, a benchmark built by the Hunyuan3D team. That holds up against both current single-image methods and an approach that feeds the generated rear view back in as a second input image. Know3D also beats the competition on geometric quality for the back sides, the researchers say.
Same input image, different back sides: Depending on the text instruction, Know3D generates different but geometrically consistent structures on the hidden side of the object. | Image: Chen et al.
How good the results are ultimately comes down to whether the underlying language model reads the text instructions correctly, the researchers say. If it misinterprets a prompt, the 3D output goes sideways too. So stronger multimodal models could cut down on this problem going forward.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe now
More than 16% discount.
Read without distractions – no Google ads.
Access to comments and community discussions.
Weekly AI newsletter.
6 times a year: “AI Radar” – deep dives on key AI topics.
Up to 25 % off on KI Pro online events.
Access to our full ten-year archive.
Get the latest AI news from The Decoder.
Subscribe to The Decoder
関連記事
ガウシアンを減らし、テクスチャを増やす:4Kフィードフォワードテクスチャスプラッティング
研究チームがLGTMを開発した。既存手法の解像度拡張性問題を解決し、コンパクトなガウシアンとテクスチャ予測により4K高解像度合成を可能にした。
Seed3D 2.0リリース、高精度化と可用性の向上
字节跳动Seedチームは2026年4月、3D生成モデル「Seed3D 2.0」を公開した。幾何形状とテクスチャ生成でSOTA性能を達成し、高精度化と可用性の向上を実現した。
2024年からアメリカ企業の「お気に入りのChatGPT定型文」が2回倍増し4倍に
言語分析チームは、チャットGPTに文章作成を委託する企業が使用する特定の定型文が2024年から4倍に増加していることを明らかにした。