Gemini Flash の価格上昇、AI 法施行延期、エージェントがオンライントラフィックを牽引
The Batch は、OpenAI や Anthropic が AI Forward Deployed Engineer (FDE) を導入したことで、この職種の需要が高まっている一方、より多くの企業が自社内で AI エンジニアを育成・雇用する傾向にあると分析し、AI による雇用市場崩壊説の誤りを指摘している。
キーポイント
FDE(AI Forward Deployed Engineer)の再燃と役割
Palantir に由来する FDE は、顧客組織に常駐し、LLM をカスタムなエージェントワークフローに変換する役割を担っており、OpenAI や Anthropic が自社チームを構築したことで注目が高まっている。
FDE と AI エンジニアの雇用規模の違い
FDE は特定のベンダー製品に深く統合するため数人程度で済むが、多くの企業は社内の従業員を AI エンジニアとして育成・雇用する方が現実的であり、AI エンジニアの需要の方が圧倒的に大きいと予測される。
ベンダー中立性とオプション性の重要性
特定のベンダー製品に依存した FDE を見つける難しさから、将来どの AI サービスが最適か不確実な現状では、ベンダーを選ばない柔軟性(オプション性)を持つ社内人材の価値が高まっている。
AI による雇用市場崩壊説への反証
AI が新しい職種を生み出し、FDE や AI エンジニアといった役割が拡大している事実から、AI が労働市場を破壊するという議論は誤りであると結論付けている。
AI エンジニア職の拡大と FDE の限界
クライアント組織に埋め込まれる AI 前方展開エンジニア (FDE) は増えているが、ベンダーロックインのリスクから、多くの企業が自社で汎用的な AI エンジニアを雇用する傾向があり、AI エンジニア職の数は FDE よりも大幅に増加すると予測される。
Gemini 3.5 Flash の性能と価格転換
Google が発表した Gemini 3.5 Flash は推論能力や速度で前モデルを大きく上回ったが、トークンあたりの料金は従来の 3 倍に引き上げられ、「Flash」ブランドの価格優位性が失われた。
EU AI Act の緩和とオンライントラフィックの急増
欧州連合は企業の競争力維持のため AI 規制の一部施行を延期し、一方で 2025 年には AI エージェントによるインターネットトラフィックが前年比約 3 倍に増加し、その多くが不正なスクレイピングやセキュリティリスクを含んでいる。
重要な引用
One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions
I believe there will be far more AI Engineer jobs
a common client concern is that it is hard to find vendor-neutral FDEs
「While my organizations do hire FDEs, we hire far more AI Engineers!」
「The Flash designation no longer implies a clear cost advantage for developers who run agentic workloads.」
影響分析・編集コメントを表示
影響分析
この記事は、企業が AI 導入を進める際の人的リソース戦略において、「外部依存型(FDE)」と「内部育成型(AI Engineer)」のどちらを選ぶべきかという重要な判断基準を示唆しています。特に、技術ベンダーの覇権がまだ確定していない現状では、特定の製品に縛られない社内人材の重要性を強調しており、企業の HR 戦略や採用方針に影響を与える可能性があります。
編集コメント
AI の実装フェーズにおいて、外部専門家の活用と社内人材の育成のバランスをどう取るかは経営層の重要な課題です。この記事は、短期的な導入支援には FDE が有効でも、長期的な競争力維持には社内 AI エンジニアの増強が不可欠であるという視点を提供しています。
親愛なる皆様、
シリコンバレーにおける新しい注目度の高い職種の1つに、AI フォワードデプロイメントエンジニア(FDE)があります。これは顧客組織内に配置され、顧客の特定のニーズに適したソリューションのカスタマイズを支援するエンジニアで、例えばエージェントワークフローの構築や調整などを行います。OpenAI と Anthropic が FDE を顧客組織内に配置するための新しいチームを構築し始めたことから、FDE のキャリアパスについて改めて疑問を抱く人々の声を聞きました。
AI ワークロードにおける FDE の台頭は、AI が新たな雇用を生み出している1つの側面であり(これが「今後の労働市場の崩壊」という物語が誤りである理由の1つでもあります)、しかし私は、以下に説明する通り、AI エンジニアの職種の数ははるかに増えると考えています。
FDE(Field Deployment Engineer)の役割は約20年前にPalantirによって創始されました。同社はエンジニアを政府機関へ派遣し、安全なエアギャップネットワーク上で作業を行いました。優れた技術スキルに加えて、FDEにはコミュニケーション能力、場合によってはビジネススキルも必要です。例えば、顧客と対話してニーズを理解したり、プロジェクトの優先順位を決める戦略を立てたり、複雑な技術を説明したり、顧客が非現実的な要望を求めてきた際には敬意を持って反対意見を述べたりする必要があります。彼らが再び注目されているのは、市販のLLM(大規模言語モデル)を取り込んで特定のビジネスニーズに合わせたカスタムエージェントワークフローを構築する際に必要な作業量が増えているからです。
しかし、私はAIエンジニアの求人数はさらに大幅に増えるだろうと考えています。ある企業では数人のFDEを組織内に配置することを受け入れるかもしれませんが、ほとんどの企業は自社の従業員がプロジェクトに取り組むことを望むでしょう。私の所属する組織でもFDEを採用していますが、採用するのははるかに多くのAIエンジニアです!また、一般的な顧客の懸念として、ベンダーに偏らない中立なFDEを見つけるのが難しいという点があります。彼らは結局のところ、特定のベンダーの製品を企業に深く統合するために存在しているからです。今後1年間でどのAIサービスが最良になるか予測が難しいこの時期において、オプション性(将来最も適合するベンダーを選べる能力)は非常に価値があります。一方、FDEに企業のプロセスを密接に結びつけることは、オプション性を大幅に低下させます。
 image現在、AI ソフトウェアコンポーネント(LLM プロンプト、エージェントフレームワーク、評価指標など)を用いてソフトウェアアプリケーションを構築し、AI コーディングエージェント(Claude Code、Codex、Antigravity CLI、OpenCode など)を効果的に活用できる AI エンジニアに対する需要が急増していると感じています。AI エンジニアという役割が成熟するにつれて、数十年前に一般的なソフトウェアエンジニアの役割がフロントエンド、バックエンド、モバイル、データエンジニアリング、DevOps などに細分化されたように、この役割もより専門的な役割に分裂していくと予想されます。
image現在、AI ソフトウェアコンポーネント(LLM プロンプト、エージェントフレームワーク、評価指標など)を用いてソフトウェアアプリケーションを構築し、AI コーディングエージェント(Claude Code、Codex、Antigravity CLI、OpenCode など)を効果的に活用できる AI エンジニアに対する需要が急増していると感じています。AI エンジニアという役割が成熟するにつれて、数十年前に一般的なソフトウェアエンジニアの役割がフロントエンド、バックエンド、モバイル、データエンジニアリング、DevOps などに細分化されたように、この役割もより専門的な役割に分裂していくと予想されます。
将来どのような専門的な AI エンジニアリングの役割が登場するのでしょうか。私はまだ知りませんが、おそらく AI FDE(フルスタック開発者)、LLMOps エンジニア、評価エンジニア、AI データエンジニア、Harness エンジニアなど、現在名前が付けられていない他の役割も現れるかもしれません。しかし現時点では、多くの AI エンジニアが一般主義者として大きな価値を生み出している様子が見て取れます。熟練した AI エンジニアに対する需要は非常に高いです!この分野が今後 10 年かけてさらに成熟していく中で、AI エンジニアリングの新たな専門分野が生み出すさらなる雇用機会に期待しています。
作り続けよう!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
 image Ambient は、Kian Katanforoosh 氏と Workera によって開発されたもので、業務の流れの中であなたのスキルを測定します。あなたはすでに睡眠、歩数、ストレスなど重要なものを測定しています。なぜスキルの測定をしないのでしょうか?ウェイトリストに参加する
image Ambient は、Kian Katanforoosh 氏と Workera によって開発されたもので、業務の流れの中であなたのスキルを測定します。あなたはすでに睡眠、歩数、ストレスなど重要なものを測定しています。なぜスキルの測定をしないのでしょうか?ウェイトリストに参加する
News
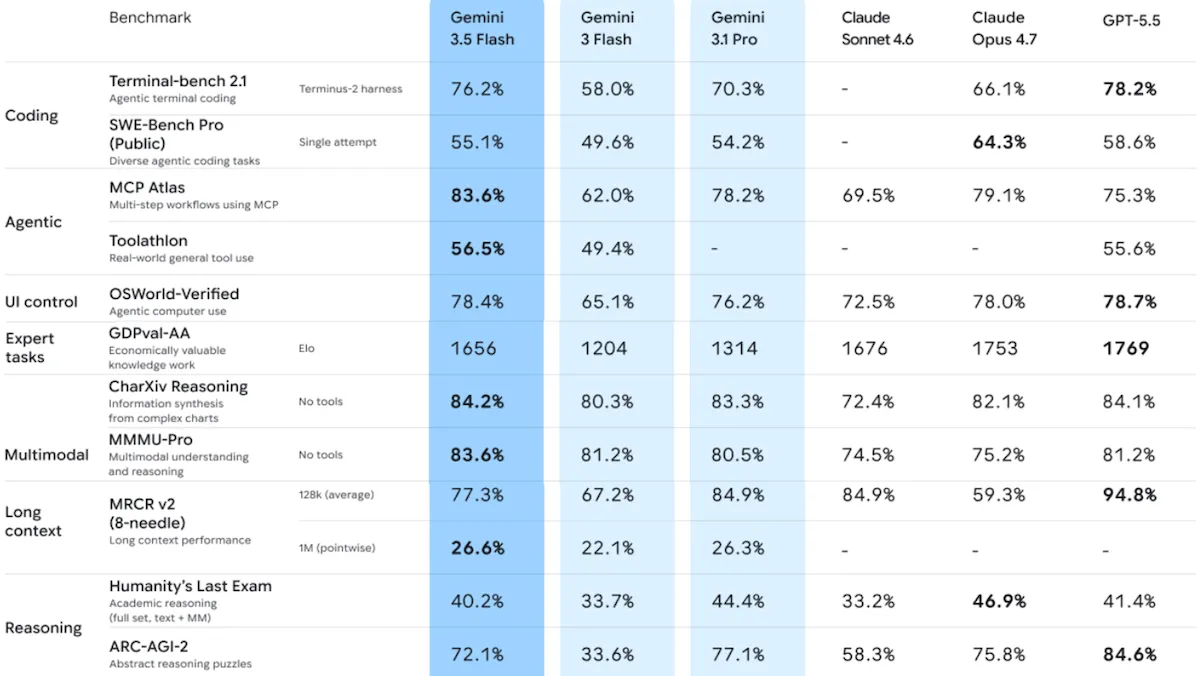
Gemini 3.5 Flash は知能と速度を両立
Google の高速モデルは、トークンあたりの価格が大幅に上昇する傾向の一部として、実質的な性能向上をもたらす一方で、従来モデルの約 3 倍という高価格となっています。
新情報: Google は Gemini 3.5 Flash をリリースしました。これはミドルティアのマルチモーダルモデル(複数の入力・出力形式を扱うモデル)のアップデート版です。新バージョンは、エージェント機能(自律的なタスク実行能力)、視覚的理解力、速度において改善が見られますが、その価格は先行する Gemini 3 Flash の約 3 倍となっています。
- 入力/出力:テキスト、画像、音声、動画(最大 100 万トークン)、テキスト出力(最大 64,000 トークン、秒間 204 トークン)
- アーキテクチャ:エキスパート混合型トランスフォーマー
- 機能:推論レベルの調整可能(最小、低、中、高)、思考の保持(推論トークンをコンテキスト内に保持し、複数回の対話にわたって推論を維持する機能。Kimi K2.6 の「思考保持」機能と同様)、ツール使用(コンピュータ操作は未対応)
- パフォーマンス:Artificial Analysis の APEX-Agents-AA ベンチマークおよび MMMU-Pro 多モーダルベンチマーク Flash で最高位を記録する一方、全体的な知能、知識、コーディング能力では主要モデルに劣る
- 利用可能状況/価格:Gemini アプリ、Google AI Studio、Google Antigravity(5 時間ごとにリフレッシュされる計算量制限内、かつ週次上限あり)、Google Search の AI モードを通じて無料。Gemini Enterprise、Gemini Enterprise Agent Platform、API は入力トークン 100 万あたり$1.50、キャッシュ済みトークン 100 万あたり$0.15、出力トークン 100 万あたり$9.00
- 非公開:パラメータ数、トレーニングデータおよび手法、アーキテクチャの詳細
仕組み: Google は Gemini 3.5 Flash の構築方法についてほとんど詳細を明らかにしていない。
- Gemini 3.5 Flash は、そのモデルカードによると、Gemini 3 Flash に基づいており、さらに Gemini 3 Flash は Gemini 3 Pro に基づいています。
- これは混合専門家型トランスフォーマーであり、ウェブから収集されたテキスト、コード、画像、音声、動画に加え、ライセンス付き資料、Google ユーザーデータ、合成データを多角的に事前学習したものです。
- 多段階推論、問題解決、定理証明をカバーするデータセットを用いた強化学習によって微調整が施されました。
性能: Gemini 3.5 Flash は、マルチモーダルモデルの最上位ランクに次ぐパフォーマンスを発揮します。独立したテストによると、エージェント機能と速度において前世代から大幅な向上が見られ、いくつかの最先端指標でもその成果が確認されています。Artificial Analysis Intelligence Index では、推論レベル(未指定)に設定された Qwen 3.7 Max に次いで第5位または第7位(モデルごとの推論レベルによる)となりましたが — 同じ週にデビューした Qwen 3.7 Max を除き — 知能指数で上位のすべてのモデルは、大幅に低速です。
- Artificial Analysis によると、複数の学問分野にわたる視覚的推論を測定する MMMU-Pro において、高推論モードに設定された Gemini 3.5 Flash は 84 パーセントの精度を記録し、過去最高を更新しました。2 位は Gemini 3.1 Pro Preview(82 パーセント)です。
- 投資銀行、経営コンサルティング、企業法務から抽出された長期実行型エージェントタスクを検証する APEX-Agents-AA では、Gemini 3.5 Flash が初回試行でトップの座を奪い(精度 47.1 パーセント)、2 位の GPT-5.5(精度 37.7 パーセント)に約 10 ポイント差をつけました。一方、現実世界のエージェントタスクを対象とする GDPval-AA では、高推論モードに設定された Gemini 3.5 Flash(Elo 1,656)は、推論レベルが未指定の Gemini 3.1 Pro Preview(Elo 1,314)を上回りましたが、xhigh モードに設定された GPT-5.5(Elo 1,769)には及びませんでした。
- 抽象的な視覚的推論を検証する ARC-AGI-2 では、高推論モードに設定された Gemini 3.5 Flash が ARC プライズリーダーボードで 72.1 パーセントのスコアを記録しましたが、これは Gemini 3.1 Pro Preview(77.1 パーセント)および xhigh 推論モードに設定された GPT-5.5(85.0 パーセント)には及びませんでした。
- 正解には加点し、誤った推測によるハルシネーションには減点を行う知識ベンチマーク AA-Omniscience では、推論モードに設定された Gemini 3.5 Flash(23 ポイント)は、推論モードの Gemini 3.1 Pro Preview(33 ポイント)および最大推論モードの Claude Opus 4.7(26 ポイント)に後れをとりました。
- 2026 年 5 月 24 日時点の Arena.ai リーダーボードでは、モデルを盲検の直接対決形式で人間が比較して順位付けする Text Arena で Gemini 3.5 Flash は 9 位(Elo 1,480)、WebDev コーディングアリーナでは 10 位(Elo 1,506)となりました。Anthropic の Claude Opus 4.6 および 4.7 モデルは、両アリーナの上位 3 位を独占しています。Text Arena のカテゴリ別内訳では、Gemini 3.5 Flash は数学分野で 1 位(Elo 1,521)となりましたが、コーディング分野では 31 位(Elo 1,507)でした。
ニュースの背景: Google は、開発者向けの年次カンファレンスである Google I/O 2026 で Gemini 3.5 Flash をデビューさせました。同イベントから発表されたその他の AI 関連の発表は以下の通りです:
- Google は AI コーディングツール「Antigravity」を大規模改修し、エージェントの管理機能を強調するとともに、Microsoft の VSCode などの人気 IDE に似ているという点を意図的に弱めました。Antigravity のコマンドライン版は、オープンソースの Gemini CLI を置き換えるものです。
- 同社はマルチモーダルモデル群「Omni」を発表しました。その第一弾として軽量モデル「Omni Flash」が導入され、テキスト、画像、音声、動画、あるいはこれらの組み合わせを入力として動画を生成できます。Omni Flash は Gemini アプリおよび Google Flow を通じて Google AI Plus、Pro、Ultra のサブスクリプションユーザーに利用可能ですが、API での提供はまだ開始されていません。
- Gemini 3.5 Flash は、Google Search がより対話的でチャットボットのような検索クエリを許可できるようにし、エージェントがユーザーに代わってオンライン調査を行える機能を強化します。また、従来の検索結果トップ10のリンクを置き換え、引用元を明記した AI 生成による要約でユーザーの質問に答える形式へと変更されます。
なぜ重要なのか: Gemini 3.5 Flash は「Flash」という言葉の意味を変えました。Gemini Ultra、Pro、Nano の後に導入された、より小さく高速なモデルティアとして登場しましたが、現時点では Flash は Google のミドルティアのマルチモーダルモデルであり、Anthropic の Sonnet に近く、Haiku ではありません。このモデルの速度は、複数のターンを要するエージェントや、チャットボット、検索、画像・動画分析といった低遅延アプリケーションを開発する開発者にとって、生成されるトークン数が増えるコストに見合う価値があるかもしれません。
私たちが考えていること: Google は Gemini 3.5 Flash が競合モデルの半額未満で動作すると述べていましたが、Artificial Analysis によるインテリジェンス・インデックス(Intelligence Index)でのテスト結果では、実際には Gemini 3.1 Pro よりもコストが高いことが判明しました。Flash という名称はもはや、エージェントワークロードを実行する開発者にとって明確なコスト優位性を示すものではなくなりました。Anthropic、OpenAI、Google はいずれも、最新のフラッグシップモデルおよび Flash タイアモデルのトークンあたりの価格を引き上げました。Gemini 3.5 Flash もこの傾向に当てはまります。

ヨーロッパ、一部の AI 規制を一時停止
欧州連合(EU)は、企業が同法が欧州企業の競争力を低下させると主張したため、画期的な AI 法案(AI Act)の一部規定を弱体化させ、他の規定の施行を延期しました。
何が変わったか: 欧州議会と加盟国は、AI 法を改正し、安全性、健康、個人の権利などに重大な脅威をもたらすと欧州連合(EU)が判断するアプリケーションを対象とした規制の施行を延期するなど、その他の変更を加えることで合意しました。改正案は、EU 理事会および議会の正式な採択を待っています。EU はこの改正案を「市民と企業双方にとってより安全でシンプルなルール」と特徴付けています。
仕組み: 改正案は概して、EU AI オフィスの監督・執行責任を簡素化するものです。また、AI 開発者に対する特定の条項の遵守期限を延長し、他の条項も簡略化します。
- 「法執行、重要インフラ、雇用、移民、個人識別」に使用されるなど「ハイリスク」と見なされる AI システムに対する要件は、以前の期限である 2026 年 8 月から 2027 年 12 月へ延期されます。これにより、開発者には新しいモデルをテスト中に広範な世界から隔離するための監督付きサンドボックス環境(sandbox environments)を実装する猶予が 2027 年 8 月まで与えられます。また、機械や玩具など AI を駆使した製品の期限は 2028 年 8 月へ、AI 生成出力の透かし付けおよびその他の透明性要件に関する期限は 2026 年 12 月頃へと延長されます。
- この改正により、AI システムのトレーニングおよび展開における個人データの使用方法が調整されます。既存の EU 法では、一部の個人データカテゴリーは「厳格に必要」とされる場合のみ使用可能です。一方、この改正案では、バイアスの検出と緩和のために個人データを使用することを可能にします。
- また、特定の製品に対する免除規定の策定または明確化も行われます。例えば、AI 法はすでに製品安全法規によって規制されている産業用機械には影響しません。さらに、小規模企業(従業員数が 50 名未満で、年間世界売上高が 1,000 ユーロ以下または総資産が 1,000 ユーロ以下の企業)および「中小キャップ」企業(従業員数が概ね 250〜749 名で、年間世界売上高が 1.5 億ユーロ以下または総資産が 1.29 億ユーロ以下の企業)に対しては、一部のケースにおいてコンプライアンス要件および行政負担が軽減されます。
- この改正案は、ある重要な分野において AI 法を強化します:児童に対する性的に露骨な画像の生成や、実在する人物の同意のないヌード画像の生成を禁止します。
ニュースの背景: 2024 年、EU は AI を規制するための世界で最も厳格な法律 を可決しました。この法律は同年に発効し、一部の規定はその後数年にかけて段階的に施行される予定です。しかし、立法プロセスが始まった直後から、安全性をほとんど向上させずに不合理な負担を課すものとして批判されていました。
- 2023 年、163 社の経営陣が署名した書簡では、この立法は「官僚主義的」であると主張していました。一方、2025 年には 110 社が政策決定者に対し、規制が「不明確で重複しており、ますます複雑化している」として実施スケジュールの延期を要請する書簡を送りました。ドイツの産業・ソフトウェア企業である Siemens や SAP などの企業は、規制が自社の発展を阻害していると主張し、改正をロビー活動しました。
- 改正に影響を与えた初期の報告書が二つあります。2024 年 4 月にイタリアの前首相エンリコ・レッタ氏が発表した報告書では、EU が 27 の国家市場に分断されており、これが欧州企業が米中企業のように規模を拡大するのを妨げていると指摘しました。また、2024 年 9 月の欧州の競争力に関する報告書では、停滞する GDP 成長率を「存続に関わる課題」と位置づけ、イノベーション格差の解消、脱炭素化、依存度の低下に焦点を当てました。
- 2025 年初頭、EU の執行機関である欧州委員会は、規制負担の軽減、ルールの簡素化、経済競争力の強化を目指す意向を発表しました。
- 2026 年 2 月、欧州委員会は AI 責任指令(AI Liability Directive)の提案を撤回しました。これは AI Act とは別に位置づけられていた議論の的となっていた法案で、AI に起因する被害に関する訴訟における EU 全体の基準を導入するものでした。
一般市民の反応: 改正に対する即座の反応は賛否両論でした。AI 業界は追加された柔軟性を歓迎しましたが、消費者団体は安全基準が弱体化する可能性に懸念を示しました。一部のメディア報道では、これらを企業利益を迎合するために法律を骨抜きにするものとして捉えました。欧州消費者機構(European Consumer Organization)は、「この合意はデジタル環境をより危険にし、AI 企業にとって危険な抜け穴を生み出す」と述べています。
なぜ重要なのか: 元の形と修正後の形の両方において、AI 法は金融やインフラ規制から借用された「システムリスク」という概念を緩和することを目指しています。これは業界全体または経済の大きな部分に波及する可能性のある失敗を指します。AI がシステムリスクをもたらすという考えはまだ推測の域を出ませんが、過度な規制はイノベーションを阻害し有益な技術を妨げるという経済的リスクをもたらします。今回の改正案は、開発者への負担を軽減し、企業が要件を理解して遵守するための追加の猶予期間を与え、製造業や半導体といった重要産業における継続的なイノベーションの道を開くことで、リスクとベネフィットのバランスを図るものです。
私たちが考えていること: 元の AI 法の多くの規定は不明確で、過度に広範であったり、不必要な負担となったりしていました。今回の改正案は、有益な要素を維持しつつ、法律の負担を軽減するもののように見えます。これは欧州の競争力にとって良い一歩です。
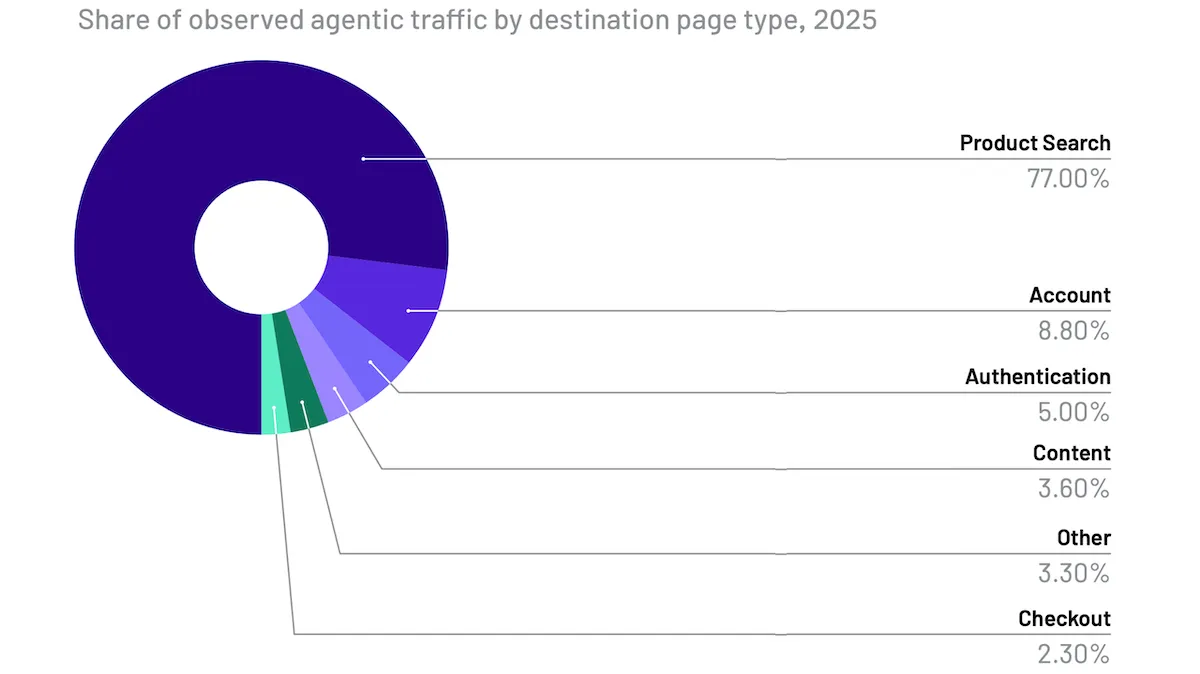
エージェントが AI 作成のウェブをサーフィン
AI を駆使したインターネット上の活動は昨年、急激に増加したとある研究で示されています。
何が起きたか: セキュリティ企業 Human Security のレポートによると、AI 駆動型トラフィック、つまり AI システムによってまたはその代わりに生成されたインターネット上のやり取りは、2025 年に約 3 倍に増加しました。AI システムの訓練のために大量のデータを収集するクローラーや、価格などのデータポイントを即時利用するためにスクレイピングするボットによる活動量は、1 の位で桁増しとなりました。一方、AI エージェントおよびエージェント型ブラウザによるトラフィックは急増しましたが(それでも全体のごく一部に留まりました)、AI 駆動型トラフィックの 95% 以上が、著者らが小売・EC、ストリーミング・メディア、または旅行・宿泊業と分類した活動に関連するものでした。
仕組み: 2026 年 AI トラフィックおよびサイバー脅威ベンチマークレポートは、Human Security が 2025 年に観測した 1 京(1,000 兆)件を超えるインターネット上のやり取りを分析した結果に基づいています。同社は 200 以上の国と地域で約 1,200 の顧客にサービスを提供しています。
- AI に駆動されたトラフィックはほぼ3倍に増加し、AI に駆動されたものおよび従来のボットトラフィックの両方を含む自動トラフィックは23%以上成長しました。一方、人間のトラフィックは約3%増加しました。
- AI によるトラフィックの増加には、トレーニングデータの収集を行うクローラー(年間AI トラフィックの68%を占め、前年の2倍以上)、即時利用のためのデータ収集を行うスクレイパー(年間の32%で、7倍の増加)、ブラウザスタイルのタスクを実行するエージェント(12月時点で1.7%、前年比で約80倍の成長)が含まれます。
- エージェントによるインタラクションのうち77%は商品ページおよび検索ページで行われ、残りはアカウントページ、認証、取引完了の順に発生しました。
- 自動トラフィックの約69%をOpenAI が占め、これにはChatGPT の利用者やトレーニングデータの収集を行うクローラー(OAI-SearchBot)、最新情報の収集を行うクローラー(GPTBot)が含まれます。Meta は16%、Anthropic は約11%を担当しました。
セキュリティ上の影響: 研究者らは、自動トラフィックの相当部分が悪意あるものであると判断しました。
- 著者らが悪意ある行為と判断したスクレイピング活動、すなわち AI を活用した対話を支援するためではなく、競合他社の情報収集や体系的な価格引き下げを目的としてデータを抽出しようとする活動は、前年と比較して約 47%増加しました。(著者らは、スクレイパーが自身の身元を偽装している場合、既知の攻撃パターンに従っている場合、またはその他の理由で不審な行動を示す場合に、そのトラフィックを悪意あるものとして分類しています。)研究者らが特定した 750,000 の脅威プロファイルのうち、60%以上が悪意あるスクレイピングに関与していました。
- ボットがユーザーアカウントの乗っ取りを試みる攻撃は、1年間で30%以上減少しました。しかし、残存する試みにおいては、ログイン済みのアカウントに対して行われた攻撃が4倍に増加していることが示されました。このような攻撃は、盗まれた認証情報や進行中のセッションを乗っ取ることで既存のアカウントを利用することが多いものの、エージェントによって作成されたアカウントを対象とした攻撃数は前年と比較して89%増加しました。
- 不正な決済カードを介した取引トラフィックの割合は「低く安定」していますが、カード発行機関によってブロックされた取引量は20%増加しました。これは、インターネット上で実行される取引数の増加、エージェントがカード番号を循環させる能力の向上、あるいはその両方を反映している可能性があります。
ただし注意: このレポートは、Human Security のプラットフォーム上の活動のみを分析しており、インターネット全体を対象としたものではありません。さらに、悪意あるトラフィックはその発信元を誤って表示することが多いため、研究者による特定のデータポイントの評価が誤っている可能性もあります。
なぜ重要なのか: 自律システムはインターネットに増え続ける追加トラフィックを洪水のように押し寄せており、この傾向は今後 foreseeable な未来も続く可能性が高い。インフラはこの点を踏まえて構築またはアップグレードされる必要がある。自動化されたアクティビティの増加は、サイバーセキュリティにおいても課題をもたらす。なぜなら、正当な AI エージェントが以前は悪意のあるボットを示すシグナルとされていた活動(製品の閲覧、アカウント作成、取引のチェックアウトなど)を多く行うためである。
私たちが考えていること: インターネット上のエージェントによるトラフィックはまだ始まったばかりだ。昨年の 80 倍という急増は、エージェントがより能力が高く、堅牢で信頼性を持つようになるにつれ、今後さらに増加するだろう。
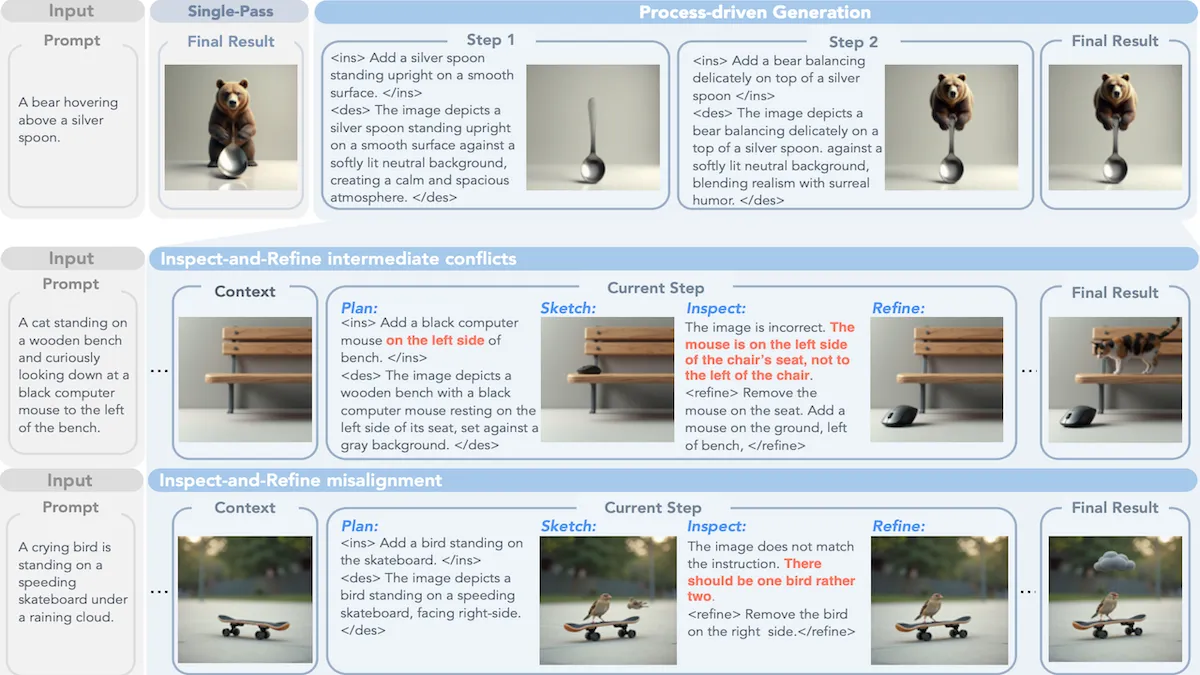
ステージ別生成画像の計画
拡散(diffusion)やフローマッチング(flow-matching)を利用するテキストから画像へのジェネレーターは、通常、一度に全体像を構成する(ただし、ステップごとに全体像を精緻化する)。研究者たちは、画像構成を離散的なステージに分け、中間結果を確認・修正することで、より良い結果を得た。
何が新しいか: Meta、カリフォルニア大学サンディエゴ校、ウースター工科大学、ノースウェスタン大学の Lei Zhang 氏らによる研究者グループは、画像生成モデルに対して計画を立てて要素を生成し、プロンプトと一致するか確認し、必要に応じて修正し、別の要素を生成するという段階的なプロセスをループさせることで画像を組み立てるよう学習させる微調整 手法 を提案しました。
重要な洞察: テキストから画像への生成モデルは、空間関係(ある要素が他の要素の上、下、前、後ろにあるかなど)や物体の属性(指、腕、脚の数など)を表現する際にしばしば 失敗 します。モデルが画像を完成させるために段階的なプロセスをループ処理する学習を行うことで、生成プロセスの制御が容易になります。「銀色のスプーンの上に浮かぶクマ」といったプロンプトの場合、以下のステージに分けることができます:
- 計画。次の変更に対する指示(1 回目の反復:「クマを描く」、2 回目の反復:「クマの下にスプーンを追加する」など)と、変更後の画像の説明を作成します。
- スケッチ。これまでに作成された画像の更新版を生成します(1 回目の反復:クマの画像、2 回目の反復:クマとスプーンの画像)。
- 検査。指示と説明がプロンプトと一致しているか確認し、画像が指示と一致しているか確認します。
- 改善。必要であれば修正命令を出し(2 回目の反復:「スプーンがクマの前にあったので、クマの下に描いてください」)、新しい画像を生成します。
このプロセスを表すデータでモデルをトレーニングすることで、プロンプトに基づいて画像を生成するだけでなく、画像の構成を組み立てて修正する能力も身につけることができます。
仕組み: 著者らは、BAGEL-7B から始めました。これは画像とテキスト(例:2 枚の画像とその組み合わせ指示)を入力として受け取り、画像とテキスト(例:組み合わせた画像と入力画像がどのように変更されたかの説明)を出力する事前学習済みマルチモーダルモデルです。著者らは、計画・スケッチ・検査・改善という段階を循環させることで画像を生成するようにファインチューニングを行いました。
- 計画とスケッチのためのファインチューニング:計画とスケッチの段階をファインチューニングするためのデータセットを作成するため、著者らは 32,000 の例を生成しました。各例には中間画像が約 3〜5 枚と最終画像が含まれています。これは、GPT-4o に 2 つのデータセットからのプロンプトを変換させてテキストベースのシーングラフ(scene graph)を作成させることで行いました。グラフのノードはオブジェクト(例えば「猫」や「クマ」)またはオブジェクトの属性(「毛深い」など)であり、エッジはそれらの間の関係(猫が「毛深い」など)を符号化しています。各グラフから、著者らはランダムにオブジェクト、属性、および関係を含む部分を選択しました。そして GPT-4o に、これらのオブジェクト、属性、関係を画像に追加するための段階的なプロンプトに変換させるよう依頼しました。FLUX.1 Kontext を使用して各段階的変更に対して画像を生成し、GPT-4o が段階的なプロンプトと一貫していると判断した結果のみを残しました。著者らはこのテキスト・画像の例を用いてモデルをファインチューニングしました。その結果、モデルは(i)例の次のテキストトークンを生成すること、および(ii)フローマッチング(flow-matching)ステップを数回繰り返して現在の画像のピクセル値を調整し、次の画像を生成することを学習しました。
- 検査のためのファインチューニング:検査段階をファインチューニングするためのデータセットを作成するため、著者らはまず計画とスケッチのためにファインチューニングされたモデルを使用し、段階的な指示と画像の例を生成した後、GPT-4o に中間テキスト記述が元のプロンプトと矛盾していないかを判断させるよう依頼しました。最後に、GPT-4o に批判と修正指示を作成させるようプロンプトを入力しました。著者らは、元のプロンプトと一貫する約 7,000 の例と、一貫しない約 8,300 の例を生成しました。GPT-4o の批判や指示を再現することを学習することで、モデルは現在の計画が元のプロンプトと一致しているかを判断するか、あるいは不整合を修正する方法を記述することを学習しました。
- 洗練のためのファインチューニング:著者らは、画像、画像の改善方法に関するテキストによる考察、および改善された画像からなるデータセットを用いてモデルをファインチューニングしました。
- 最後に、彼らは前述と同じ損失項(loss terms)を用いて、これら 3 つのデータセットすべてでモデルをファインチューニングしました。
結果: 著者らのファインチューニング手法は、オブジェクト間の関係がテキストプロンプトと一致する画像(例えば、スプーンの後ろではなくスプーンの上にクマを配置するなど)を生成する必要があるタスクにおいて BAGEL-7B の性能を向上させました。また、特定の時間帯や歴史的時代などの現実世界の知識に基づいた画像を生成する能力も BAGEL-7B で改善されました。
- GenEval は、プロンプトに記載された詳細のうち生成画像に現れる割合を測定する指標ですが、著者らの手法では 62,000 の例でファインチューニングを行った結果、BAGEL-7B が 77 パーセントから 83 パーセントへと向上しました。この手法には 131 ステップのフローマッチングが使用されました。一方、中間のノイジー拡散状態を批判することで画像生成を改善する手法である PARM は、688,000 の例でファインチューニングを行った後でも 77 パーセントにとどまり、1,000 ステップのフローマッチングが必要でした。
- WISE では GPT-4o を用いて、生成画像とプロンプトとの間のリアリティ、美的品質、一貫性を 0 から 1 のスケールで評価します(数値が高いほど優れています)。この手法により BAGEL は平均して 0.7 から 0.76 に向上しました。ファインチューニングされたモデルは、より頻繁にシーンが正しい時代や時間的文脈に配置されるようになりました。化学データセットでのテストでは、化学的に妥当な構造、物質、実験室のシーンを生成する確率も高まりました。
なぜ重要なのか: 画像生成器はしばしば見た目の良い画像を生成しますが、その出力はプロンプトと矛盾していることがよくあります。例えば、物体が不適切な場所に配置されたり、誤った属性を持ったりします。本研究は、単にトレーニングデータを拡張するだけでなく、このようなシステムをより信頼性の高いものにするための道筋を示しています。
私たちが考えていること: 段階的に画像を組み立てる画像生成器は、入力に対してステップバイステップで推論を行う大規模言語モデル(LLM)と類似しています。両方のアプローチは、モデルに要求を細分化させるよう導き、出力の質を向上させます。
原文を表示
Dear friends,
One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalyse narrative of upcoming job market collapse is false). However, I believe there will be far more AI Engineer jobs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompts, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
Ambient, from Kian Katanforoosh and Workera, measures your skills in the flow of work. You already measure other things that matter: sleep, steps, stress. Why not your skills? Join the waitlist
News
Gemini 3.5 Flash Pairs Smarts With Speed
Google’s faster model brings substantive gains at a substantially higher price, part of a rising trend in prices per token.
What’s new: Google launched Gemini 3.5 Flash, an update of its mid-tier multimodal model. The new version offers improvements in agentic capabilities, visual understanding, and speed at a price three times that of its predecessor Gemini 3 Flash.
- Input/output: Text, images, audio, video in (up to 1 million tokens), text out (up to 64,000 tokens, 204 tokens per second)
- Architecture: Mixture-of-experts transformer
- Features: Adjustable reasoning levels (minimal, low, medium, high), thought preservation (which holds reasoning tokens in the context to retain reasoning across multi-turn conversations, similar to Kimi K2.6’s preserved thinking feature), tool use (computer use not yet available)
- Performance: Tops Artificial Analysis’s APEX-Agents-AA benchmark and MMMU-Pro multimodal benchmark Flash; trails leading models on overall intelligence, knowledge, and coding
- Availability/price: Free via Gemini app, Google AI Studio, Google Antigravity (within a compute limit that refreshes every 5 hours up to a weekly limit), Google Search AI mode; Gemini Enterprise, Gemini Enterprise Agent Platform, API $1.50/$0.15/$9.00 per million input/cached/output tokens
- Undisclosed: Parameter count, training data and methods, architectural details
How it works: Google disclosed few details about how it built Gemini 3.5 Flash.
- Gemini 3.5 Flash is “based on” Gemini 3 Flash, which itself is based on Gemini 3 Pro, according to its model card.
- It’s a mixture-of-experts transformer that was multimodally pretrained on text, code, images, audio, and video scraped from the web alongside licensed materials, Google user data, and synthetic data.
- It was fine-tuned via reinforcement learning on datasets that covered multi-step reasoning, solving problems, and proving theorems.
Performance: Gemini 3.5 Flash performs just behind the first rank of multimodal models. It makes substantial gains over its predecessor in agentic capability and speed according to independent tests, including some state-of-the-art measures. On the Artificial Analysis Intelligence Index, it came in either fifth or seventh (depending on the reasoning levels of various models) behind Qwen 3.7 Max set to reasoning (level unspecified), but — except Qwen 3.7 Max, which debuted the same week — every model that scores higher on intelligence runs substantially slower.
- According to Artificial Analysis, on MMMU-Pro, which measures visual reasoning across multiple academic disciplines, Gemini 3.5 Flash set to high reasoning achieved 84 percent accuracy, the highest recorded, with Gemini 3.1 Pro Preview (82 percent) in second place.
- On APEX-Agents-AA, which tests long-running agentic tasks drawn from investment banking, management consulting, and corporate law, Gemini 3.5 Flash (47.1 percent accuracy) took the top spot on the first attempt, nearly 10 percentage points ahead of second-place GPT-5.5 (37.7 percent accuracy). On GDPval-AA (real-world agentic tasks), Gemini 3.5 Flash set to high reasoning (1,656 Elo) exceeded Gemini 3.1 Pro Preview set to an unspecified level of reasoning (1,314 Elo), and behind GPT-5.5 set to xhigh (1,769 Elo).
- On ARC-AGI-2 (a test of abstract visual reasoning), Gemini 3.5 Flash set to high reasoning scored 72.1 percent on the ARC Prize leaderboard, behind Gemini 3.1 Pro Preview (77.1 percent) and GPT-5.5 set to xhigh reasoning (85.0 percent).
- On AA-Omniscience, a knowledge benchmark that awards points for correct answers and penalizes hallucinated guesses, Gemini 3.5 Flash set to reasoning (23) trails Gemini 3.1 Pro Preview set to reasoning (33) and Claude Opus 4.7 set to max reasoning (26).
- As of May 24, 2026, on Arena.ai’s leaderboards, which rank models in blind head-to-head human comparisons, Gemini 3.5 Flash ranked ninth in the Text Arena (1,480 Elo) and tenth in the WebDev coding arena (1,506 Elo). Anthropic’s Claude Opus 4.6 and 4.7 models occupy the top three positions in both arenas. Within the Text Arena’s category breakdowns, Gemini 3.5 Flash ranked first (1,521 Elo) in math but 31st in coding (1,507 Elo).
Behind the news: Google debuted Gemini 3.5 Flash at Google I/O 2026, its annual gathering for developers. Here are other AI-related announcements from that event:
- Google overhauled Antigravity, its AI coding tool, to emphasize managing agents and de-emphasize its resemblance to popular IDEs like Microsoft’s VSCode. Antigravity’s command-line version replaces the open-source Gemini CLI.
- The company introduced Omni, a family of multimodal models, beginning with Omni Flash, a lightweight model that can generate video from text, image, audio, and video, or any combination of these inputs. Omni Flash is available to Google AI Plus, Pro and Ultra subscribers through the Gemini app and Google Flow, but not yet in the API.
- Gemini 3.5 Flash enables Google Search to permit more conversational, chatbot-like search queries, power agents to do online research on users’ behalf, and replace Search’s traditional ten top links with more AI-generated summaries that answer users’ questions with cited sources.
Why it matters: Gemini 3.5 Flash changes what “Flash” means. Introduced as a smaller, faster model tier after Gemini Ultra, Pro, and Nano, for now, Flash is Google’s mid-tier multimodal model, more akin to Anthropic’s Sonnet than Haiku. The model’s speed may be worth the additional tokens it generates for developers who build agents that require multiple turns as well as low-latency applications like chatbots, search, and image and video analysis.
We’re thinking: Google said Gemini 3.5 Flash often runs at less than half the cost of competing models. But Artificial Analysis found that, running the tests in the Intelligence Index, it actually costs more than Gemini 3.1 Pro. The Flash designation no longer implies a clear cost advantage for developers who run agentic workloads. Anthropic, OpenAI, and Google have raised per-token prices on their newer flagship and Flash-tier models. Gemini 3.5 Flash fits the pattern.
Europe Pauses Some AI Regulations
The European Union weakened some provisions of its landmark AI Act and delayed others after businesses and policymakers argued the law made European companies less competitive.
What’s new: The European Parliament and member states agreed to amend the AI Act to delay restrictions that target applications the union considers to pose significant threats to safety, health, or individual rights, among other changes. The amendments await formal adoption by the union’s council and parliament. The EU characterized the amendments as “safer and simpler rules for both citizens and businesses.”
How it works: The amendments generally streamline the EU AI Office’s oversight and enforcement responsibilities. They also extend deadlines for AI developers to comply with certain provisions and simplify others.
- Requirements for AI systems deemed to be “high-risk” — including those used in law enforcement, critical infrastructure, employment, migration, and personal identification — are delayed to December 2027 from a previous deadline of August 2026. They would give developers until August 2027 to implement supervised sandbox environments to isolate new models from the wider world during testing. They would also extend deadlines for AI-driven products including machinery and toys until August 2028 and for watermarking of AI generated output and other transparency requirements to around December 2026.
- The revisions would adjust the ways personal data can be used in training and deployment of AI systems. Under existing EU law, some categories of personal data can be used only when “strictly necessary.” The revisions would allow for personal data to be used to detect and mitigate bias.
- They also carved out or clarified exemptions for some products. For instance, the AI Act would not affect industrial machinery, which is already regulated by product-safety laws. Further, lighter compliance requirements and administrative burdens would apply in some cases to smaller companies (fewer than 50 employees with either annual worldwide revenue up to €10 million or total assets up to €10 million) and “small mid-cap” companies (roughly between 250 and 749 employees with either annual worldwide revenue up to €150 million or total assets up to €129 million).
- The amendments strengthen the AI Act in one notable area: They ban generation of sexually explicit images of children and non-consensual nude images of real people.
Behind the news: In 2024, the EU passed the world's most stringent law to regulate AI. The law entered into force the same year, with certain provisions to be phased in over subsequent years. It was criticized as imposing unreasonable burdens without improving safety virtually from the moment the legislative process began.
- In 2023, executives at 163 companies signed a letter that argued the legislation was “bureaucratic.” In 2025, 110 companies urged policymakers to postpone the implementation timeline writing because the regulations were “unclear, overlapping and increasingly complex.” Companies such as German industrial and software firms Siemens and SAP lobbied for revisions, saying that regulations were holding them back.
- Two early reports influenced the amendments. A report published in April 2024 by Enrico Letta, Italy’s former Prime Minister, argued that the EU was fragmented into 27 national markets that prevented European firms from scaling the way American and Chinese companies can. A September 2024 report about Europe’s competitiveness framed the region’s stagnating GDP growth as an “existential challenge” and focused on closing the innovation gap, decarbonization, and reducing dependencies.
- In early 2025, the European Commission — the executive arm of the EU — announced its intention to reduce regulatory burdens, simplify rules, and boost economic competitiveness.
- In February 2026, the European Commission withdrew its proposed AI Liability Directive, a controversial proposed law, separate from the AI Act, that would have introduced EU-wide standards for lawsuits over AI-induced harms.
The public responds: Immediate reaction to the amendments was mixed. The AI industry generally welcomed the added flexibility while consumer groups expressed concern over the potential weakening of safety standards. Some media reports framed them as watering down the law to appease business interests. The European Consumer Organization said the deal makes the digital environment less safe and creates dangerous loopholes for AI companies.
Why it matters: In both its original and updated forms, the AI Act aims to mitigate AI-induced “systemic risks,” a concept borrowed from finance and infrastructure regulation that refers to failures capable of rippling across industries or large parts of the economy. The idea that AI poses systemic risks remains speculative, whereas overregulation poses the economic risk of stifling innovation and blocking beneficial technology. The revisions aim to balance risks and benefits by easing burdens on developers, giving companies additional runway to understand and comply with requirements, and clearing the way for ongoing innovation in critical industries such as manufacturing and semiconductors.
We’re thinking: Many provisions of the original AI Act were unclear, overly broad, or unnecessarily burdensome. These revisions appear to make the law less burdensome while retaining helpful elements. This is a good step for European competitiveness.
Agents Surf the AI-Written Web
AI-driven activity on the internet rose sharply last year, a study shows.
What happened: AI-driven traffic, or internet interactions that were generated by or on behalf of AI systems, nearly tripled in 2025, according to a report by the cybersecurity firm Human Security. The volume of activity by crawlers that collected data en masse to train AI systems and bots that scraped data points such as prices for immediate use multiplied by single digits. Traffic by AI agents and agentic browsers ballooned (although it remained a tiny percentage of the total). More than 95 percent of AI-driven traffic involved activities the authors designated retailing and ecommerce, streaming and media, or travel and hospitality.
How it works: The 2026 State of AI Traffic and Cyberthreat Benchmark Report is based on an analysis of over 1 quadrillion internet interactions observed in 2025 by Human Security, which serves around 1,200 customers in more than 200 countries and territories.
- AI-driven traffic nearly tripled, while automated traffic, which includes both AI-driven and conventional bot traffic, grew more than 23 percent. Human traffic grew by around 3 percent.
- The rise in AI-driven traffic includes crawlers that collect training data (68 percent of AI-driven traffic for the year, more than 2x the previous year’s volume), scrapers that collect data for immediate use (32 percent for the year, a 7x increase in volume), and agents that execute browser-style tasks (1.7 percent in December, nearly 80x growth year over year).
- Of the agentic interactions, 77 percent took place on product and search pages. The rest involved account pages, authentication, and completing transactions, in that order.
- OpenAI was responsible for around 69 percent of automated traffic, including ChatGPT users and crawlers that collect training data (OAI-SearchBot) and timely information (GPTBot). Meta accounted for 16 percent, and Anthropic initiated around 11 percent.
Security implications: The researchers deemed a significant amount of the automated traffic malicious.
- Scraping activity that the authors deemed malicious, aiming to extract data for purposes such as competitive intelligence or systematic underpricing rather than aiding AI-driven interactions, rose nearly 47 percent from the prior year. (The authors labeled traffic malicious if the scraper spoofed its identity, followed a recognized attack pattern, or otherwise behaved in a suspicious manner.) Of the 750,000 threat profiles identified by the researchers, more than 60 percent were involved in malicious scraping.
- Attacks in which a bot attempted to take over a user account fell by more than 30 percent over the year. However, the remaining attempts showed a 4x increase in attacks that occurred after an account was logged in. Although such attacks often took advantage of existing accounts via stolen credentials or hijacked sessions in progress, the number in which an agent created the account rose by 89 percent from the prior year.
- The percentage of transaction traffic that involved a compromised payment card was “low and stable,” but the volume that was blocked by the card issuer rose by 20 percent. This may reflect a rising number of transactions executed on the Internet, an increased ability of agents to cycle through card numbers, or both.
Yes, but: The report analyzes only activity on Human Security’s platform, not the internet as a whole. Moreover, malicious traffic often misrepresents its origin, so the researchers’ evaluation of any given data point may be mistaken.
Why it matters: Autonomous systems are flooding the internet with a rising tide of additional traffic, and its likely this trend will continue in the foreseeable future. Infrastructure must be built or upgraded with this in mind. The rise in automated activity also poses challenges for cybersecurity because legitimate AI agents perform many of the same activities — browsing products, creating accounts, and checking out of transactions — that previously signaled malicious bots.
We’re thinking: Agentic traffic on the internet is just getting started. The 80x rise last year is bound to multiply further in coming years as agents become more capable, robust, and trustworthy.
Planning Generated Images In Stages
Text-to-image generators that use diffusion or flow-matching typically compose a whole image at once (although they refine the whole image in steps). Researchers got better results by breaking image composition into discrete stages, then checking and revising interim results.
What’s new: Lei Zhang and colleagues at Meta, University of California San Diego, Worcester Polytechnic Institute, and Northwestern University proposed a fine-tuning method for image generators that trains a model to compose images by planning, generating an element, checking whether it matches the prompt, correcting if necessary, generating another element, and so on.
Key insight: Text-to-image models often fail to represent spatial relationships (such as whether one element is above, below, in front of, or behind another) and object attributes (such as numbers of fingers, arms, or legs). The generation process becomes easier to control when the model learns to complete the image by looping through a staged process. Given a prompt like “a bear hovering above a silver spoon”, the stages can be:
- Plan. Write an instruction for the next change to be made (iteration 1: “draw a bear”; iteration 2 “add a spoon under a bear”; and so on) and a description of the image after the change.
- Sketch. Generate an updated version of the image so far (iteration 1: an image of a bear; iteration 2: the bear and a spoon).
- Inspect. Check the instruction and the description against the prompt, and check the image against the instruction.
- Refine. Issue a command to correct it if needed (iteration 2: “the spoon was in front of the bear, draw it under the bear”) and produce a new image.
Training on data that represents this process can teach the model not only to generate an image based on a prompt but also to build up the image composition and correct it.
How it works: The authors started with BAGEL-7B, a pretrained multimodal model that takes images and text (say, two images and an instruction to combine them) and produces images and text (say, the combined image and a description of how the input image was changed). They fine-tuned it to generate images by cycling through stages to plan, sketch, inspect, and refine the composition.
- Fine-tuning to plan and sketch: To create a dataset for fine-tuning the plan and sketch stages, the authors generated 32,000 examples, each containing about three to five intermediate images and a final image. They did this by prompting GPT-4o to transform prompts from two datasets into text-based scene graphs. The graph nodes were objects (for example, “cat” or “bear”) or attributes of objects (“furry”), and edges encoded relationships between them (a cat “is” furry). From each graph, they randomly selected parts that contained objects, attributes, and relationships. They asked GPT-4o to turn the parts into incremental prompts to add those objects, attributes, and relationships to an image. They generated an image for each incremental change using FLUX.1 Kontext and kept only results that GPT-4o deemed consistent with the incremental prompts. The authors fine-tuned the model on the text-image examples. The model learned (i) to generate the next text tokens of the examples and (ii) to generate the next image by adjusting the pixel values of the current image over several flow-matching steps.
- Fine-tuning to inspect: To produce a dataset for fine-tuning the inspect stage, they used the model after fine-tuning to plan and sketch, they generated examples of incremental instructions and images and then asked GPT-4o to judge whether an intermediate text description conflicted with the original prompt. Finally, they prompted GPT-4o to produce critiques and corrective instructions. The authors produced nearly 7,000 examples that stayed consistent with the original prompt and nearly 8,300 inconsistent examples. By learning to reproduce the GPT-4o critiques and instructions, the model learned to either accept the current plan as consistent with the original prompt or describe how to fix inconsistencies.
- Fine-tuning to refine: The authors fine-tuned the model on a dataset of images, text reflections about how an image can be improved, and improved images.
- Finally, they fine-tuned the model on all three datasets together using the same loss terms as before.
Results: The authors’ fine-tuning method improved BAGEL-7B on tasks that require generating images in which object relationships match a text prompt (for example, placing a bear on a spoon instead of behind a spoon). It also improved BAGEL-7B’s ability to generate images based on real-world knowledge, such as scenes of a particular time of day or historical era.
- On GenEval, which measures the percentage of details mentioned in a prompt that appear in the resulting generated image, the authors’ method raised BAGEL-7B from 77 percent to 83 percent after fine-tuning on 62,000 examples; it used 131 flow-matching steps. In contrast, PARM, a method that improves image-generation by critiquing intermediate noisy diffusion states, achieved 77 percent after fine-tuning on 688,000 examples; PARM used 1,000 flow-matching steps.
- On WISE, which uses GPT-4o to rate realism, aesthetic quality and consistency between a generated image and its prompt (0 to 1, higher is better), the method raised BAGEL from 0.7 to 0.76 on average. The fine-tuned model more often placed scenes in the correct era or temporal context. Tested on a chemistry dataset, it more often generated chemically plausible structures, substances, and laboratory scenes.
Why it matters: Image generators frequently produce good-looking images, but their output is often at odds with the prompt. For instance, objects may be out of place and have the wrong attributes. This work offers a way to make such systems more dependable beyond simply scaling training data.
We’re thinking: An image generator that composes images in stages is analogous to an LLM that reasons over its input step by step. Both approaches direct the model to break down requests into pieces, and both improve the output.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み