Agent Builderのメモリシステム構築方法
LangChainは、特定のタスクを反復実行するエージェント向けに設計された「Agent Builder」において、ユーザー体験向上のためメモリ機能を優先し、ファイルシステムインターフェースを通じてPostgreSQLに記憶を保存する技術的アプローチと設計思想を公開した。
キーポイント
メモリ機能の優先的実装理由
一般用途チャットボットとは異なり、LangSmith Agent Builderは特定のワークフローを反復実行するため、セッション間で学習が活かされるメモリ機能の実装がユーザー体験向上に不可欠であると判断し、初期段階から優先した。
メモリ分類と設計基準
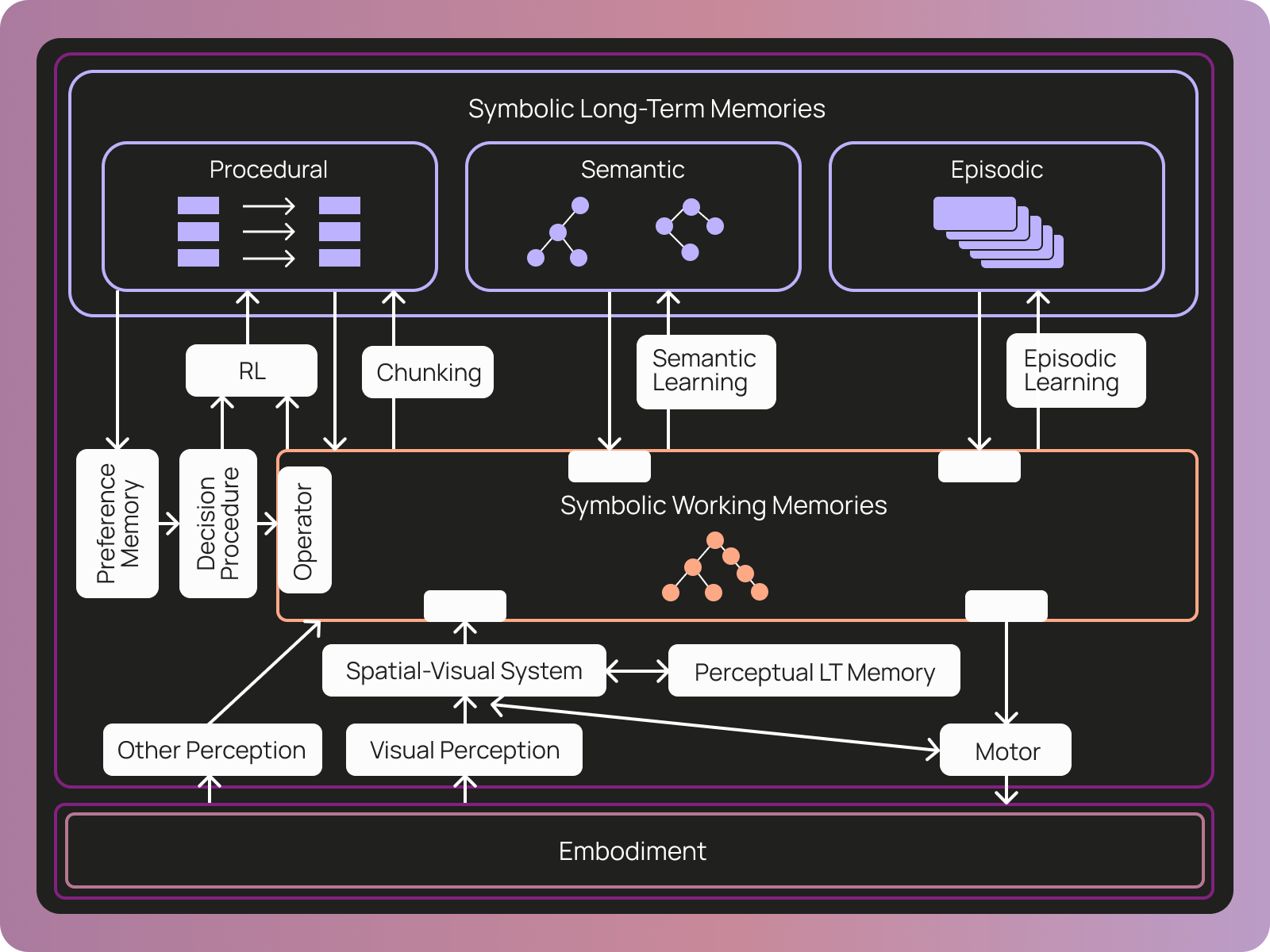
COALA論文に基づく「手続き的(Procedural)」「意味的(Semantic)」「エピソード的(Episodic)」の3つのカテゴリを用いて、エージェントの行動ルール、世界知識、過去の行動履歴を構造化した。
ファイルシステムを介したメモリ実装
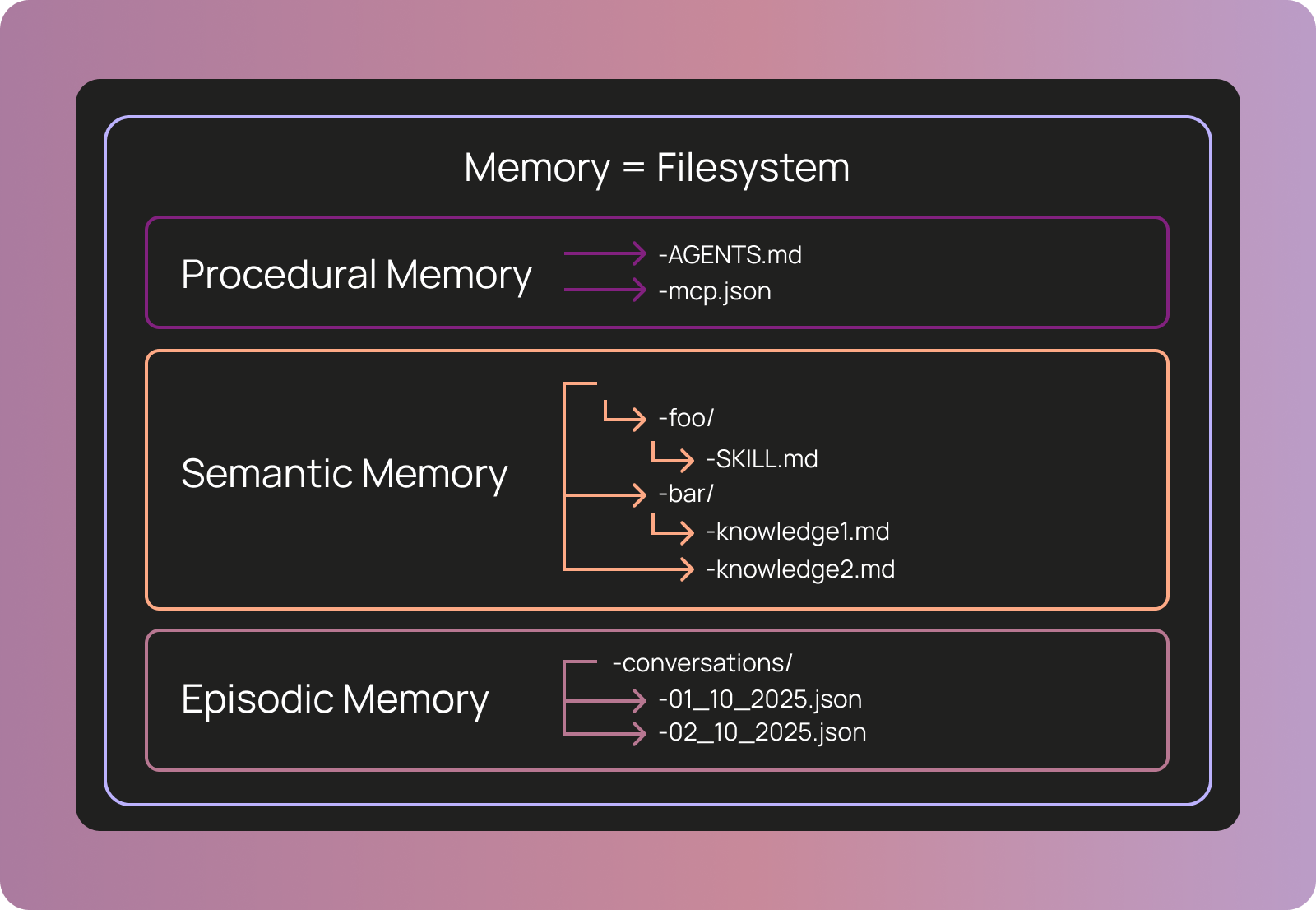
LLMがファイルシステム操作に長けていることを活かし、実際のファイルシステムではなくPostgreSQL上にデータを格納しつつ、エージェントにはファイルシステムとして見せる抽象化レイヤーを提供し、特別なツール開発を不要にした。
業界標準との互換性確保
AGENTS.mdによるコア指示定義やClaude Codeに似たサブエージェント形式、MCPアクセス用のtools.jsonなど、既存の業界標準や類似フォーマットを採用し、エコシステムとの互換性を確保した。
仮想ファイルシステムとデータベースの活用
LLMが扱いやすいファイルシステムの形式でメモリを提示しつつ、基盤はPostgreSQLなどのデータベースを使用し、インフラの効率性と拡張性(S3やMySQLなどへのプラグイン対応)を実現している。
エージェントによるメモリ編集と学習
エージェントは実行中にAGENTS.mdなどのファイルを更新・編集でき、フォーマット設定やドメイン固有の知識を蓄積することで、修正指示なしで自動的に適切な出力を行うように進化していく。
複雑なエージェント構築の簡素化
DeepAgentsのような汎用ハーンズを使用することで、要約やツール呼び出しオフロードなどの複雑なコンテキストエンジニアリングを抽象化し、シンプルな設定だけでドメイン固有言語(DSL)やコードなしで高度なエージェントを構築可能にする。
影響分析・編集コメントを表示
影響分析
この記事は、エージェント開発における「メモリ管理」の実装パターンとして、ファイルシステム抽象化という実用的なアプローチを示した。LangChainが自社の製品(Agent Builder)の詳細設計を公開することで、開発者コミュニティに対して透明性を示し、標準的な実装方法への影響を与えている。
編集コメント
LangChainが自社のエージェントビルダーにおけるメモリ設計の内部構造を公開したのは、開発者向けドキュメントとしての価値が高く、特に「ファイルシステム経由でのメモリアクセス」という実装パターンは参考になる。ただし、これはLangChain自身の製品宣伝色が強い点に注意が必要だ。
先月、エージェントをノーコードで構築する方法としてLangSmith Agent Builderをリリースしました。Agent Builderの重要な部分はそのメモリシステムです。この記事では、メモリシステムを優先した理由、構築方法の技術的詳細、メモリシステム構築から得られた学び、メモリシステムが可能にする機能、そして今後の展望について説明します。
LangSmith Agent Builderとは
LangSmith Agent Builderは、ノーコードのエージェントビルダーです。Deep Agentsハーネスの上に構築されています。技術的知識が少ない一般開発者を対象としたホスト型Webソリューションです。LangSmith Agent Builderでは、ビルダーは特定のワークフローや日常業務の一部を自動化するためのエージェントを作成します。例としては、メールアシスタント、ドキュメントヘルパーなどがあります。
初期段階で、私たちはプラットフォームの一部としてメモリを優先することを意識的に選択しました。これは自明な選択ではありませんでした。ほとんどのAI製品は当初、何らかの形のメモリなしでリリースされ、それを追加しても一部の人々が期待するような製品変革にはまだ至っていません。私たちがこれを優先した理由は、ユーザーの使用パターンによるものでした。
ChatGPTやClaude、Cursorとは異なり、LangSmith Agent Builderは汎用エージェントではありません。むしろ、ビルダーが特定のタスクのためにエージェントをカスタマイズできるように特別に設計されています。汎用エージェントでは、まったく関連性のない多様なタスクを実行するため、エージェントとの1回のセッションからの学びが次のセッションに関連しない可能性があります。LangSmithエージェントがタスクを実行するとき、それは同じタスクを繰り返し実行しています。1回のセッションからの教訓は、はるかに高い確率で次のセッションに引き継がれます。実際、メモリが存在しないとユーザー体験は悪化します。それは、異なるセッションでエージェントに何度も同じことを繰り返し伝えなければならないことを意味するからです。
LangSmithエージェントにとってメモリが具体的に何を意味するかを考える際、私たちはエージェントのメモリに関するサードパーティの定義を参照しました。COALA論文は、エージェントのメモリを3つのカテゴリで定義しています:
手続き的記憶:エージェントの行動を決定するために作業記憶に適用できるルールの集合
意味的記憶:世界に関する事実
エピソード的記憶:エージェントの過去の行動の連続
メモリシステムの構築方法
Agent Builderでは、メモリを一連のファイルとして表現します。これは、モデルがファイルシステムを扱うのが得意であるという事実を活用するための意図的な選択です。この方法により、特別なツールを与えることなく、エージェントにメモリの読み取りと変更を容易に許可できます。単にファイルシステムへのアクセスを与えるだけです。
可能な限り、業界標準を使用するようにしています。AGENTS.mdを使用してエージェントのコア命令セットを定義します。エージェントスキルを使用して、特定のタスクに対する専門的な指示をエージェントに与えます。サブエージェントの標準はありませんが、Claude Codeと同様の形式を使用しています。MCPアクセスには、カスタムのtools.jsonを使用します。
実際には、これらのファイルを保存するために実際のファイルシステムは使用していません。代わりに、Postgresに保存し、ファイルシステムの形でエージェントに公開しています。これは、LLMがファイルシステムを扱うのが得意である一方、インフラの観点からはデータベースを使用する方が簡単で効率的だからです。この「仮想ファイルシステム」はDeepAgentsによってネイティブにサポートされており、完全にプラグ可能なので、任意のストレージレイヤー(S3、MySQLなど)を持ち込むことができます。
また、ユーザー(およびエージェント自身)がエージェントのメモリフォルダに他のファイルを書き込むことも許可しています。これらのファイルには任意の知識を含めることができ、エージェントは実行時に参照できます。エージェントは作業中にこれらのファイルを編集し、「ホットパス上で」更新します。
コードやドメイン固有言語(DSL)なしで複雑なエージェントを構築できる理由は、内部でDeep Agentsのような汎用エージェントハーネスを使用しているからです。Deep Agentsは、多くの複雑なコンテキストエンジニアリング(要約、ツール呼び出しのオフロード、計画など)を抽象化し、比較的単純な設定でエージェントを制御できるようにします。
これらのファイルは、COALA論文で定義されたメモリタイプにうまく対応しています。手続き的記憶(コアエージェント指令を駆動するもの)は、AGENTS.mdとtools.jsonです。
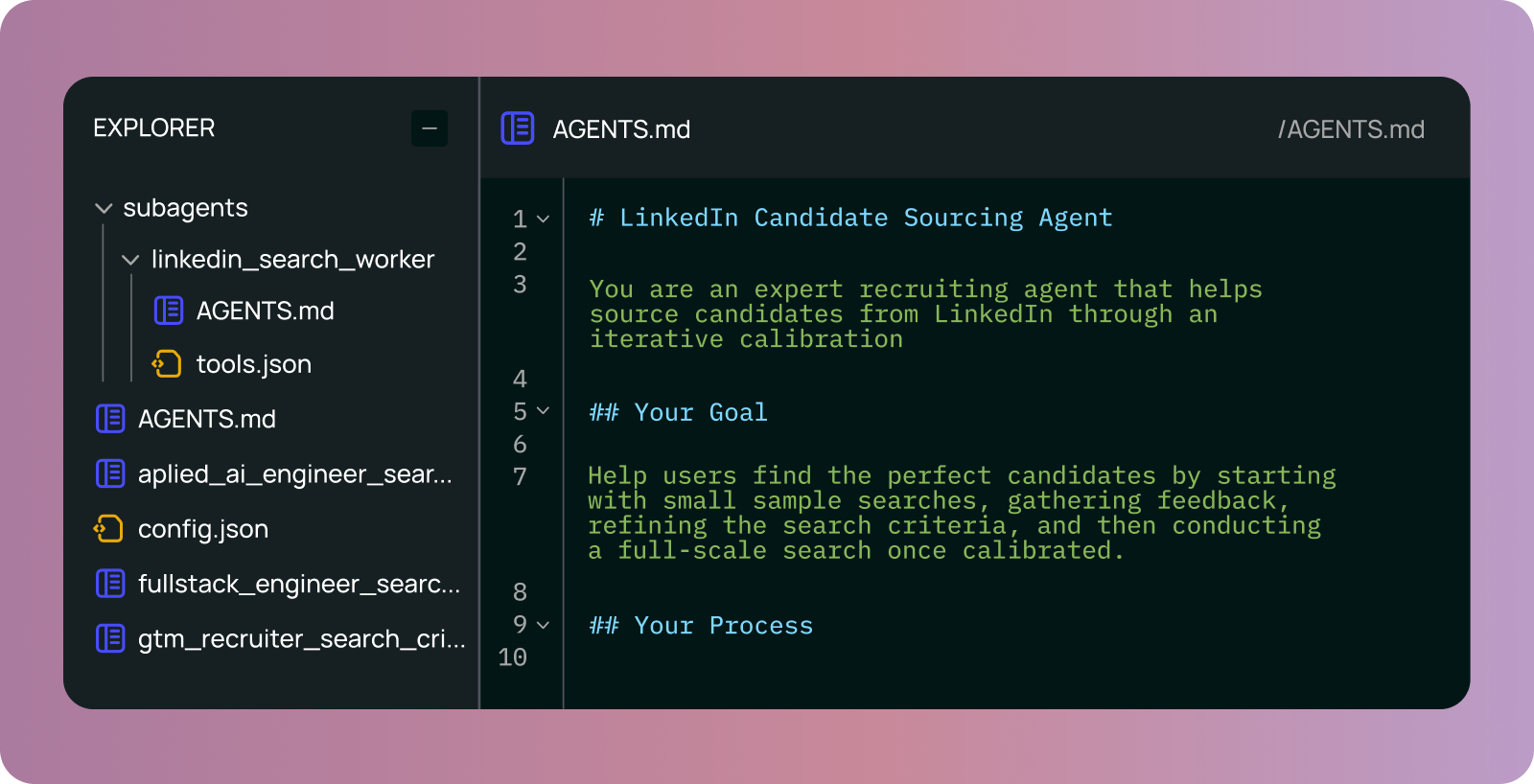
ファイルシステムにおけるエージェントメモリの様子
LangSmith Agent Builder上に構築された、私たちが内部で使用している実際のエージェント(LinkedInリクルーター)を見てみましょう。
AGENTS.md:コアエージェントの指示を定義
linkedin_search_worker
現在、メモリ内には他に3つのファイルがあり、異なる候補者の求人記述書(JD)を表しています。これらの検索作業でエージェントと協働する中で、エージェントはそれらのJDを更新・維持してきました。
メモリ編集の仕組み:具体的な例
メモリがどのように機能するかをより具体的にするために、説明用の例を見ていきましょう。
最初は単純なAGENTS.mdから始まります:
会議の議事録を要約する。
エージェントは段落形式の要約を生成します。あなたは修正します:「代わりに箇条書きを使用してください。」エージェントはAGENTS.mdを次のように編集します:
フォーマット設定 ユーザーは要約に段落ではなく箇条書きを好む。
別の会議を要約するようにエージェントに依頼します。エージェントはメモリを読み取り、自動的に箇条書きを使用します。リマインダーは不要です。このセッション中に、あなたはエージェントに依頼します:「アクションアイテムを最後に別途抽出してください。」メモリが更新されます:
フォーマット設定 ユーザーは要約に段落ではなく箇条書きを好む。アクションアイテムを最後の別セクションで抽出する。
両方のパターンが自動的に適用されます。新しいエッジケースが現れるにつれて、洗練を追加し続けます。
エージェントのメモリには以下が含まれます:
異なる文書タイプのフォーマット設定
ドメイン固有の用語
「アクションアイテム」、「決定事項」、「議論のポイント」の区別
頻繁に参加する会議参加者の名前と役割
会議タイプの扱い(エンジニアリング対計画対顧客)
使用を通じて蓄積されたエッジケースの修正
メモリファイルは次のようになるかもしれません:
会議要約設定 ## フォーマット - 段落ではなく箇条書きを使用 - アクションアイテムを最後の別セクションで抽出 - 決定事項には過去形を使用 - 上部にタイムスタンプを含める ## 会議タイプ - エンジニアリング会議:技術的な決定と理論的根拠を強調 - 計画会議:優先順位とタイムラインを強調 - 顧客会議:機密情報を編集 - 短い会議(10分未満):主要なポイントのみ ## 人物 - Sarah Chen(エンジニアリングリード)- 技術的詳細に焦点 - Mike Rodriguez(PM)- ビジネスへの影響に焦点 ...
AGENTS.mdは、事前のドキュメント作成ではなく、修正を通じて自己構築されました。ユーザーが手動でAGENTS.mdを変更することなく、反復的に適切に詳細なエージェント仕様に到達しました。
このメモリシステム構築から得られた学び
この過程で学んだいくつかの教訓があります。
最も難しい部分はプロンプティング
物事を記憶できるエージェントを構築する最も難しい部分はプロンプティングです。エージェントのパフォーマンスが良くなかったほぼすべての場合、解決策はプロンプトを改善することでした。この方法で解決された問題の例:
エージェントが記憶すべき時に記憶していなかった
エージェントが記憶すべきでない時に記憶していた
エージェントがスキルファイルではなくAGENTS.mdに書き込みすぎていた
エージェントがスキルファイルの正しい形式を知らなかった
私たちは、メモリのためのプロンプティングに1人がフルタイムで取り組んでいました(これはチームの大きな割合でした)。
ファイルタイプの検証
いくつかのファイルには従う必要がある特定のスキーマがあります(tools.json
エージェントはファイルに物事を追加するのは得意だが、コンパクト化は不得意
エージェントは作業中にメモリを編集していました。特定のものをファイルに追加するのはかなり得意でした。しかし、彼らが得意ではなかったことの一つは、学習をいつコンパクト化すべきかを認識することでした。例えば:私のメールアシスタントは、ある時点で、すべてのコールドアウトリーチを無視するように自分自身を更新する代わりに、無視すべき特定のベンダーをすべてリストアップし始めました。
エンドユーザーとして、明示的なプロンプティングは依然として有用な場合がある
エージェントが作業中にメモリを更新できるにもかかわらず、エンドユーザーとして、エージェントに明示的にプロンプトしてメモリを管理するのが有用だと感じるケースがいくつかありました。そのようなケースの一つは、作業の終わりに会話を振り返り、
原文を表示
We launched LangSmith Agent Builder last month as a no-code way to build agents. A key part of Agent Builder is its memory system. In this article we cover our rationale for prioritizing a memory system, technical details of how we built it, learnings from building the memory system, what the memory system enables, and discuss future work.
What is LangSmith Agent Builder
LangSmith Agent Builder is a no-code agent builder. It’s built on top of the Deep Agents harness. It is a hosted web solution targeted at technically lite citizen developers. In LangSmith Agent Builder, builders will create an agent to automate a particular workflow or part of their day. Examples include an email assistant, a documentation helper, etc.
Early on we made a conscious choice to prioritize memory as a part of the platform. This was not an obvious choice – most AI products launch initially without any form of memory, and even adding it in hasn’t yet transformed products like some may expect. The reason we prioritized it was due to the usage patterns of our users.
Unlike ChatGPT or Claude or Cursor, LangSmith Agent Builder is not a general purpose agent. Rather, it is specifically designed to let builders customize agents for particular tasks. In general purpose agents, you are doing a wide variety of tasks that may be completely unrelated, so learnings from one session with the agent may not be relevant for the next. When a LangSmith Agent is doing a task, it is doing the same task over and over again. Lessons from one session translate to the next at a much higher rate. In fact, it would be a bad user experience if memory is not present – that would mean you would have to repeat yourself over and over to the agent in different sessions.
When thinking about what exactly memory would even mean for LangSmith Agents, we turned to a third party definition of memory. The COALA paper defines memory for agents in three categories:
Procedural: the set of rules that can be applied to working memory to determine the agent’s behavior
Semantic: facts about the world
Episodic: sequences of the agent’s past behavior
How we built our memory system
We represent memory in Agent Builder as a set of files. This is an intentional choice to take advantage of the fact that models are good at using filesystems. In this way, we could easily let the agent read and modify its memory without having to give it specialized tools - we just give it access to the filesystem!
When possible, we try to use industry standards. We use AGENTS.md to define the core instruction set for the agent. We use agent skills to give the agents particular specialized instructions for specific tasks. There is no subagent standard, but we use a similar format to Claude Code. For MCP access, we use a custom tools.json
We actually do not use a real filesystem to store these files. Rather, we store them in Postgres and expose them to the agent in the shape of a filesystem. We do this because LLMs are great at working with filesystems, but from an infrastructure perspective it is easier and more efficient to use a database. This “virtual filesystem” is natively supported by DeepAgents - and is completely pluggable so you could bring any storage layer you want (S3, MySQL, etc).
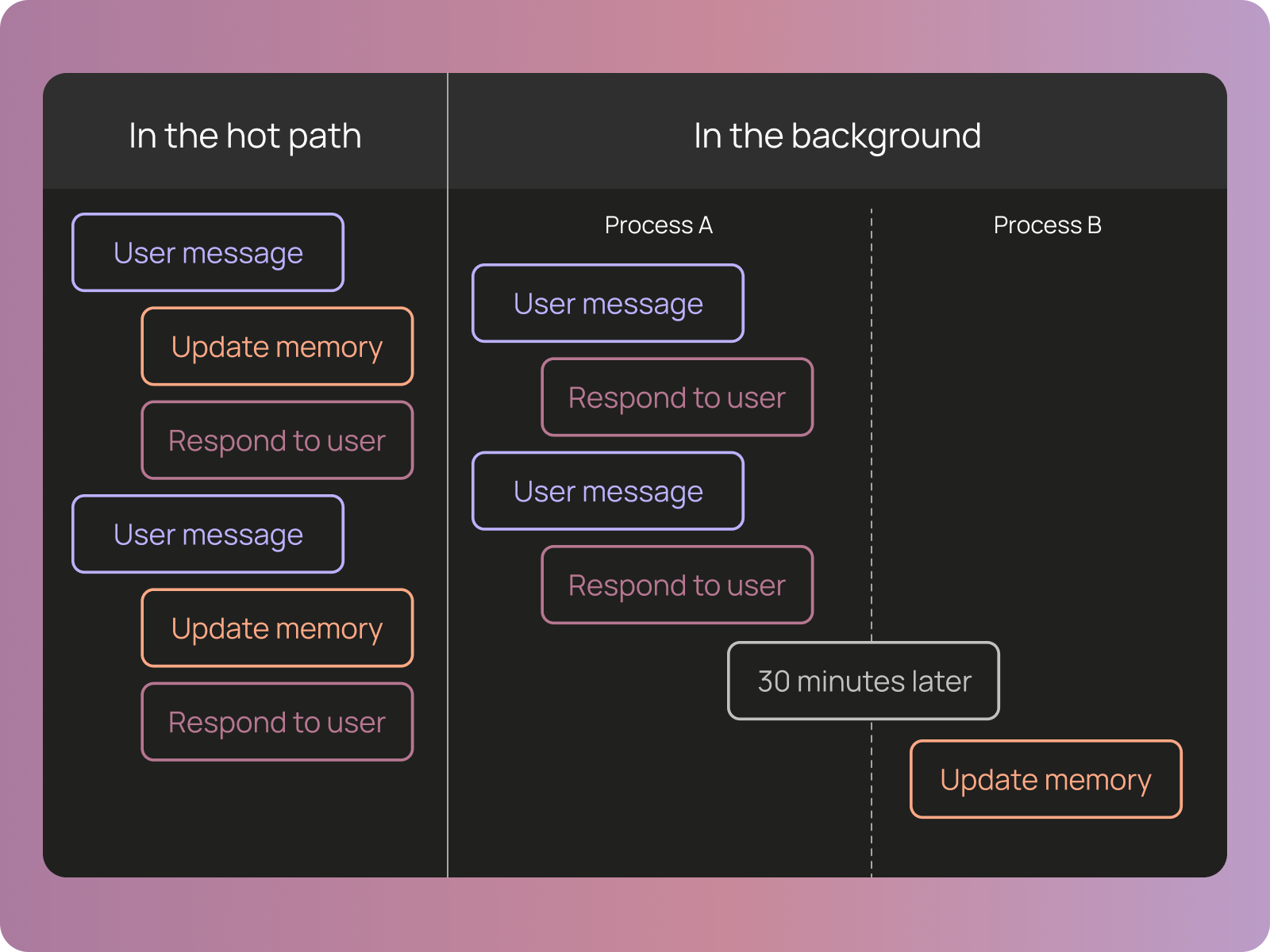
We also allow users (and agents themselves) to write other files to an agent’s memory folder. These files can contain arbitrary knowledge as well, that the agent can reference as it runs. The agent would edit these files as it’s working, “in the hot path”.
The reason it is possible to build complicated agents without any code or any domain specific language (DSL) is that we use a generic agent harness like Deep Agents under the hood. Deep Agents abstracts away a lot of complex context engineering (like summarization, tool call offloading, and planning) and lets you steer your agent with relatively simple configuration.
These files map nicely on to the memory types defined in the COALA paper. Procedural memory – what drives the core agent directive – is AGENTS.md and tools.json
What agent memory in a file system looks like
We can look at a real agent we’ve been using internally – a LinkedIn recruiter – built on LangSmith Agent Builder.
AGENTS.md: defines the core agents instructions
linkedin_search_worker
There are also currently 3 other files in the memory, representing JDs for different candidates. As we’ve worked with the agent on these searches, it has updated and maintained those JDs.
How memory editing works: a concrete example
To make it more concrete how memory works, we can walk through an illustrative example.
You start with a simple AGENTS.md:
Summarize meeting notes.
The agent produces paragraph summaries. You correct it: "Use bullet points instead." The agent edits AGENTS.md to be:
Formatting Preferences User prefers bullet points for summaries, not paragraphs.
You ask the agent to summarize a different meeting. It reads its memory and uses bullet points automatically. No reminder needed. During this session, you ask it to: "Extract action items separately at the end." Memory updates:
Formatting Preferences User prefers bullet points for summaries, not paragraphs. Extract action items in separate section at end.
Both patterns apply automatically. You continue adding refinements as new edge cases surface.
The agent's memory includes:
Formatting preferences for different document types
Domain-specific terminology
Distinctions between "action items", "decisions", and "discussion points"
Names and roles of frequent meeting participants
Meeting type handling (engineering vs. planning vs. customer)
Edge case corrections accumulated through use
The memory file might look like:
Meeting Summary Preferences ## Format - Use bullet points, not paragraphs - Extract action items in separate section at end - Use past tense for decisions - Include timestamp at top ## Meeting Types - Engineering meetings: highlight technical decisions and rationale - Planning meetings: emphasize priorities and timelines - Customer meetings: redact sensitive information - Short meetings (<10 min): just key points ## People - Sarah Chen (Engineering Lead) - focus on technical details - Mike Rodriguez (PM) - focus on business impact ...
The AGENTS.md built itself through corrections, not through upfront documentation. We arrived iteratively at an appropriately detailed agent specification, without the user ever manually changing the AGENTS.md.
Learnings from building this memory system
There are several lessons we learned along the way.
The hardest part is prompting
The hardest part of building an agent that could remember things is prompting. In almost all cases where the agent was not performing well, the solution was to improve the prompt. Examples of issues that were solved this way:
The agent was not remembering when it should
The agent was remembering when it should not
The agent was writing too much to AGENTS.md instead of to skills
The agent did not know the right format for skills files
We had one person working full time on prompting for memory (which was a large percentage of the team).
Validate file types
Several files have specific schemas they need to abide by (tools.json
Agents were good at adding things to files, but didn’t compact
Agents were editing their memory as they worked. They were pretty good at adding specific things to files. One thing they were not good at, however, was realizing when to compact learnings. For example: my email assistant at one point started listing out all specific vendors it should ignore cold outreach from, instead of updating itself to ignore all cold outreach.
Explicit prompting is still sometimes useful as an end user
Even with the agent being able to update its memory as it worked, there were still several cases where (as an end user) we found it useful to prompt the agent explicitly to manage its memory. One such case was at the end of its work to reflect on the conversation and update its memory for any things it may have missed. Another case was to prompt it to compact its memory, to solve for the case where it was remembering specific cases but not generalizing.
Human-in-the-loop
We made all edits to memory human-in-the-loop – that is, we require explicit human approval before updating. This was largely done to minimize the potential attack vector of prompt injection. We do expose a way for users to turn this off (”yolo mode”) in cases where they aren’t as worried about this.
What this enables
Besides a better product experience, representing memory in this way enables a number of things.
No-code experience
One of the issues with no-code builders is that they require you to learn an unfamiliar DSL that does not scale well with complexity. By representing the agent as markdown and json files, the agent is now in a format that (a) is familiar to most technically-lite people, (b) more scalable.
Better agent building
Memory actually allows for a better agent building experience. Agent building is very iterative – in large part because you don’t know what the agent will do until you try it. Memory makes iteration easier, because rather than manually updating the agent configuration every time, you can just give feedback in natural language and it will update itself.
Portable agents
Files are very portable! This allows you to easily to port agents built in agent builder to other harnesses (as long as they use the same file conventions). We tried to use as many standard conventions as possible for this reason. We want to make it easy to use agents built in agent builder in the Deep Agents CLI, for example. Or other agent harnesses completely, like Claude Code or OpenCode.
Future directions
There are a lot of memory improvements we want to get to that we did not have time or enough confidence to get in before the launch.
Episodic memory
The one COALA memory type Agent Builder is missing is episodic memory: sequences of the agent’s past behavior. We plan to do this by exposing previous conversations as files in the filesystem that the agent can interact with.
Background memory processes
Right now, all memory is update “in the hot path”; that is, as the agent runs. We want to add a process that runs in the background (probably some cron job, running once a day or so) to reflect over all conversations and update memory. We think this will catch items that the agent fails to recognize in the moment, and will be particularly useful for generalizing specific learnings.
We want to expose an explicit /remember
Semantic search
While being able to search memories with glob
Different levels of memory
Right now, all memory is specific for that agent. We have no concept of user-level or org-level memory. We plan to do this by exposing specific directories to the agent that represent these types of memory, and prompting the agent to use and update those memories accordingly.
If building agents that have memory sounds interesting, please try out LangSmith Agent Builder. If you want to help us build this memory system, we are hiring.
Join our newsletter
Updates from the LangChain team and community
Processing your application...
Success! Please check your inbox and click the link to confirm your subscription.
Sorry, something went wrong. Please try again.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み