コーディングエージェントの利用料金が倍増。その対策とは
LangChain Blog は、コーディングエージェント利用による請求額の急増に対し、コスト削減のための具体的な設定変更やアーキテクチャ最適化の解決策を提示した。
キーポイント
コスト増大の根本原因の特定
コーディングエージェントの無制限な試行や冗長なトークン消費が請求額の倍増の主因であることを指摘し、具体的なボトルネックを分析している。
設定パラメータの最適化提案
温度(temperature)の設定調整や最大トークン数の制限など、ランタイム設定を見直すことでコストを抑制する具体的な手順を示している。
アーキテクチャレベルでの改善策
エージェントのループ回数を減らすための設計変更や、より軽量なモデルの活用など、システム全体の効率化アプローチを提案している。
影響分析・編集コメントを表示
影響分析
本記事は、AI エージェントの実運用において発生しがちな「コスト爆発」という実務的な課題に対し、即座に適用可能な解決策を提供している。開発者が技術的革新性よりも実用性を重視する中、この知見はプロジェクトの持続可能性を確保する上で極めて重要な指針となる。
編集コメント
技術的な可能性だけでなく、ビジネス継続性を支えるコスト管理の重要性を再認識させる実務に直結する記事です。

先週、中規模スタートアップのエンジニアリングリーダーから、チームのコーディングエージェント利用料が 2 クォーターで 6 倍に増加したと聞きました。作業が 6 倍難しくなったわけではありません。誰もお金を監視していなかったからです。
Uber は 2026 年の AI 予算をわずか 4 ヶ月で使い果たしました。Microsoft は部門全体で Claude Code のライセンスをキャンセルしています。Salesforce は Anthropic からの請求額が 3 億ドルに達する可能性に直面しています。
「トークン最大化」のその後
2026 年初頭、コーディングエージェントの利用が爆発的に増加し、チームは支出を進捗として祝うようになりました。「より多くのトークンを消費すれば、より多くの作業が行われ、より大きなレバレッジが得られ、AI への投資が報われている証拠になる」という考え方です。しかし数ヶ月後、請求額が急増し、AI ワークロードの拡張においてコスト管理が極めて重要となるにつれ、状況は逆転しました。
では、どこで支出を削減すべきかを見極めるにはどうすればよいでしょうか?ある単一機能の実装において、初期実装には Claude Code を使い、インライン編集には Cursor を利用し、チームメイトのレビューには Copilot Chat を使うといったケースがあり得ます。それぞれのツールは独自の形式で活動ログを残します。「この機能を構築するために実際にいくら使ったのか、そしてその価値があったのか?」と問われても、多くのチームは答えられません。
これがまさに、「トークン最大化」が成長段階から負債へと転じる瞬間です。各ツール間で連携が取れておらず、測定単位がばらばらになっているため、それが正当な対価を得ているかどうかを確認する信頼できる方法がありません。
実際の問題:データの不足ではなく、断片化
すべてのコーディングツールは、何らかのコスト可視性を提供しています。Copilot は OpenTelemetry スパンを出力し、OpenCode はセッションフックを持ち、Pi には拡張機能があり、Cursor もフックを使用します。Claude Code でのツール呼び出しと Cursor でのツール呼び出しは記録方法が異なるため、並べて比較して「どちらがお金をかけてより多くの成果を出しているか」を問うことができません。
この断片化は、チームが一つのツールを超えてスケールするまで目立たないのですが、それはほぼ即座に起こります。では、実際にチームが使用するすべてのエージェント全体で、一貫したビューを取得するにはどうすればよいのでしょうか?
可視性から制御へ
チームとともにこの問題の掘り下げを始めた際、一つのパターンが浮かび上がりました。解決策は単一の課題ではなく、あるサイクルの一部なのです。
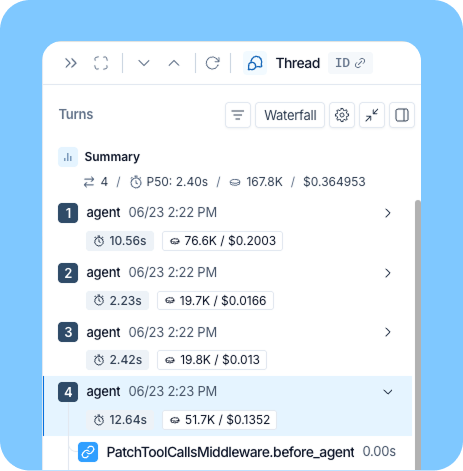
- 支出を把握する:5 つの異なる形式のダッシュボードがあるのではなく、チームが実際に使用するすべてのコーディングエージェントにわたって一貫したビューを得たいものです。LangSmith は now、Claude Code、Codex、Cursor、GitHub Copilot Chat、Pi、OpenCode からのセッションを、同じトレースモデルに追跡します。どのツールでセッションが実行されたかに関わらず、メタデータもクエリ構文も同一です。「どのセッションが高額だったのか」という質問に対して、5 つの断片的な回答ではなく、一つの明確な答えを得られるようになります。
- ツール間でコストを標準化する:セッションを並べて比較できるようになれば、正直に比較できます。トークン使用量、セッションあたりのコスト、ツール呼び出し、サブエージェントの活動などをツール間で正規化することで、特定のワークフローにおいて Cursor や Claude Code がその費用に見合った価値を提供しているかどうかを最終的に判断できるようになります。
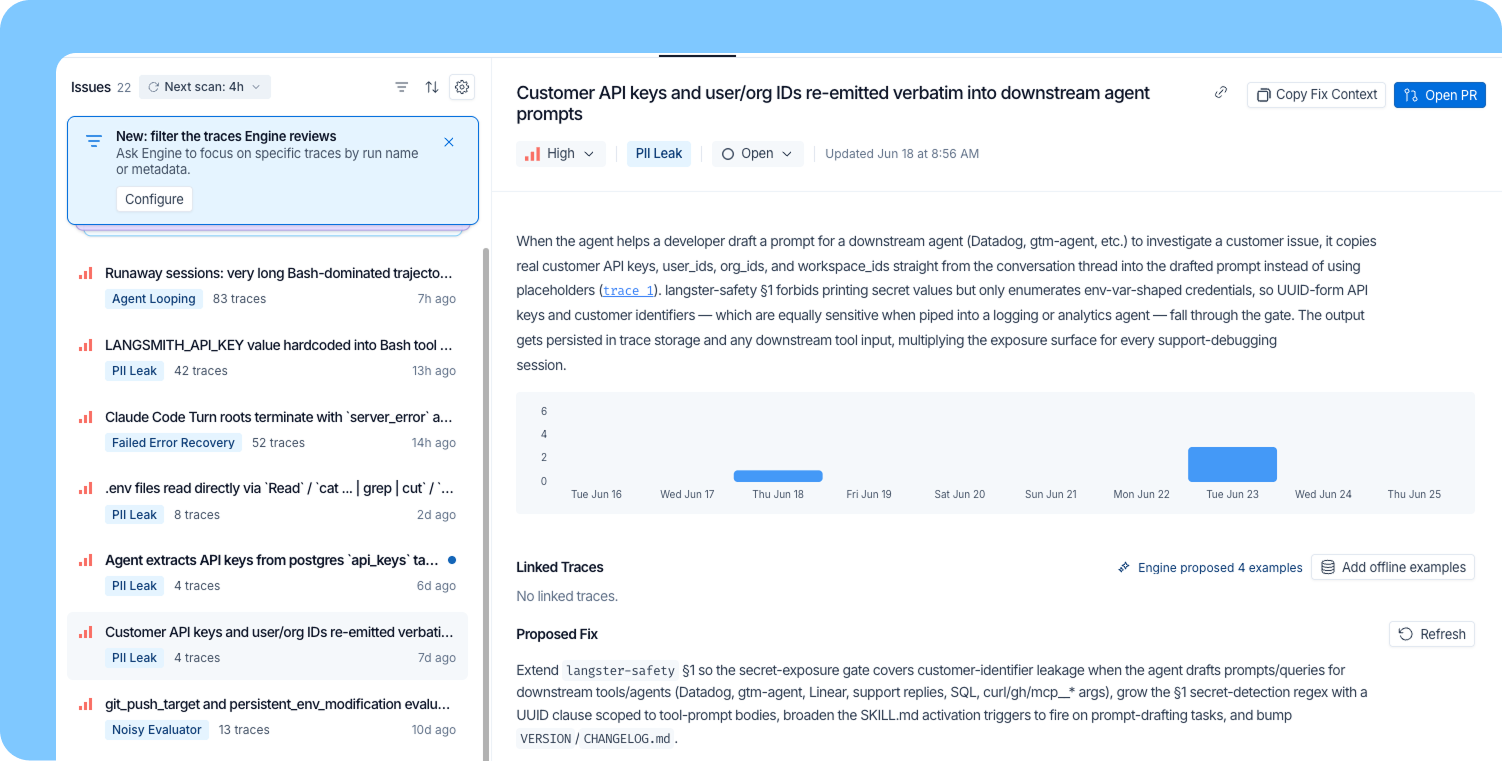
- 利用方法を最適化する:データを可視化することは最適化を可能にしますが、多くのチームがこれに基づいて行動しないのは、誰も無駄を見つけるためにすべてのセッションを手動でレビューする時間的余裕がないからです。ここで登場するのが Engine です。Engine はエージェントのセッションを分析し、シニアエンジニアが時間をかけてエージェントが作成したすべての PR をレビューしていた場合に提案するような具体的なスキル向上策を浮き彫りにします。例えば、あるエージェントがセッション内で同じコンテキストを何度も取得するために冗長なツール呼び出しを行っている場合、Engine はそれを検知して統合することを推奨します。ダッシュボードで支出が高いと告げられるのではなく、何を修正すべきかという具体的な推奨事項が得られます。
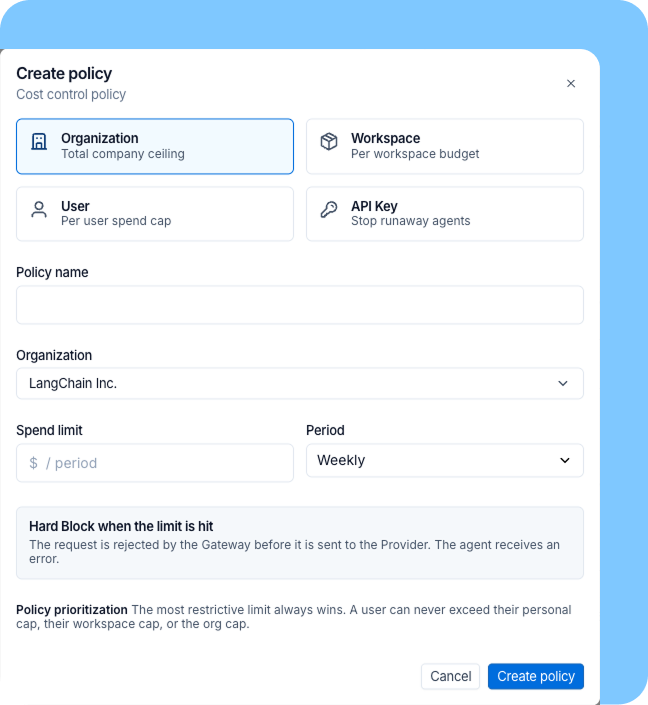
- 支出を管理する:当社の LLM ゲートウェイは、ユーザー、チーム、組織の各レベルでコスト制限を設定し、ガバナンスを行います。また間もなく、適したケースではオープンソースモデルへのルーティングも可能になります。オープンソースモデルはすでに十分に高性能かつ低価格化しており、すべてのフロントティアモデルを置き換えるものではなくとも、あらゆるエージェントハネス(agent harness)の選択肢として組み込むべきです。具体的には、フロンティア知能を必要としない多くのタスクにおけるデフォルトオプションとして位置づけるべきです。サブエージェントについても同様で、スコープ限定のサブタスクを低コストモデルが処理することで、高性能なモデルが単純作業にフロンティアレベルのコストを浪費するのを防げます。
これらの各段階は、次の段階を可能にするものです。可視化(Visibility)によって最適化すべき箇所が明確になり、最適化によってガバナンスを厳格化するべき領域が特定されます。ガバナンスはその成果を保護し、次の可視化のサイクルで新たな浪費ではなく、真の進捗を確認できるようにします。
このソリューションは、複数のコーディングエージェント(coding agent)を実行しているチーム向けに設計されています。顧客からの声を踏まえると、導入から数ヶ月以内のチームの多くがこれに該当します。もし貴社の組織ですでに単一のツールへ完全に標準化されており、そのツールのネイティブダッシュボードがすでに必要な回答を提供しているなら、まだ第 2 レイヤーは不要かもしれません。しかし、第 2 のツールが導入される瞬間から、ネイティブダッシュボードでは「すべてのツール全体で、お金はどこに使われているのか」という問いに答えることができなくなります。
LangSmith for Coding Agents
1 日目からすべてを必要とするわけではありません。チームが初期導入フェーズにある場合、観測可能性(observability)が始めるべき場所です — 何を修正するか決める前に、どのエージェントが実行されているか、どれだけのコストがかかっているか、どこでセッションが失敗しているかを把握する必要があります。その段階を超え、請求書に気づき始めた場合は、Engine と LLM Gateway は同じトレースデータに接続できるように設計されており、「見える化」から「修正して上限を設定する」への移行には、既存の仕組みを撤去する必要はありません。
設定が完了すると、コーディングエージェントのセッションは、LangSmith 上でプロダクション環境のエージェント実行と同様にトレースとして表示されます。統合内容に応じて、セッションには以下が含まれる場合があります:
- ユーザーとアシスタントのやり取り
- トークン使用量とコストを含むモデル呼び出し
- ツール呼び出しとシェルコマンド
- MCP 活動およびサブエージェントの起動
- エラーとタイミング情報
トレースは、共通モデル(ルートセッション、ターン、ツール呼び出し、メタデータ)に正規化されるため、同じフィールドを使用して異なるエージェント間でクエリを実行できます。session_id、thread_id、モデル、プロバイダー、またはツール名でフィルタリング可能です。高コストのセッションや失敗したツール呼び出しを見つけたり、コンテキストを切り替えずに Cursor と Copilot の動作を比較したりできます。
Getting Started
各ツールごとにセットアップ手順は異なります。Claude Code、Codex、OpenCode、Cursor、GitHub Copilot、Pi、またはdcode の手順を見つけてください。
私たちはこの問題を自分たちも経験したからこそ、この機能を開発しました:請求額が上がり続け、実際にどの作業にコストをかける価値があるのかという明確な感覚を持てなかったからです。エンジニアチームは一つのエージェントに標準化することはありません(そしてそうする必要もありません!)。彼らはタスクに合わせて最適なツールを選び続けるでしょう。その後の観測性(Observability)は、彼らの現状に合わせて提供されなければなりません:異なるエージェント、異なるイベント形式、それらすべてを整理するための単一の場所が必要です。
LangSmith は、すべてのコーディングエージェントにわたるセッションのデバッグと測定をチームが一元で行えるようにします。お手持ちのツールを見つけて始めましょう。
Related content

観測性(Observability)と評価(Evals)
パートナー
Harbor x LangChain: エージェント評価のための統一されたスタック


N. ボーム、
N. ホロン
2026 年 6 月 30 日
7
分

LangSmith
コーディングエージェントの予測可能なコストを実現する方法

マーサ・ジャニッキ
2026 年 6 月 15 日
5
分

LangSmith
エージェントに最適なサンドボックス環境を選ぶ方法

ラフル・ベルマ
2026 年 6 月 12 日
6
分

エージェントの実際の動作を確認する
LangSmith は、エージェントエンジニアリングプラットフォームであり、開発者がすべてのエージェントの決定をデバッグし、変更の評価を行い、ワンクリックでデプロイできるように支援します。
原文を表示
Last week, an engineering lead at a mid-sized startup told us his team's coding agent bill had grown 6x in two quarters. Not because the work got 6x harder. Because nobody was watching.
Uber blew through their full 2026 AI budget in 4 months. Microsoft is cancelling Claude Code licenses across divisions. Salesforce is staring at a $300M Anthropic bill.
The aftermath of “tokenmaxxing”
At the start of 2026, coding agent usage exploded, and teams started celebrating spend as progress. More tokens spent must mean more work done, more leverage gained, more proof that the AI bet is paying off. Just a few months later, we’re seeing the tides turn as bills explode and cost management becomes critical to scaling AI workloads.
So how do you figure out where to cut spend? A single feature might touch Claude Code for the initial implementation, Cursor for inline edits, and Copilot Chat for a teammate's review, and each of those tools logs its own activity in its own format. Ask "what did we actually spend building this feature, and was it worth it?" and most teams can't answer.
That's the moment tokenmaxxing turns into a liability instead of a phase. You have no reliable way to see whether it's earning its keep, because the unit of measurement is scattered across tools that don't talk to each other.
The actual problem: fragmentation, not lack of data
Every coding tool exposes *some* cost visibility. Copilot emits OpenTelemetry spans. OpenCode has session hooks. Pi has an extension. Cursor uses hooks. A tool call in Claude Code and a tool call in Cursor aren't recorded the same way, so you can't put them side by side and ask which one is doing more for the money.
That fragmentation isn’t noticeable right up until your team scales past one tool, which is almost immediately. So how do you get one consistent view across all the agents your team actually uses?
From visibility to control
Once we started digging into this with teams, a pattern emerged: solving it isn't just one problem, it's part of a cycle.
- See your spend: Instead of five dashboards in five formats, you’ll want one consistent view across every coding agent your team actually uses. LangSmith now traces sessions from Claude Code, Codex, Cursor, GitHub Copilot Chat, Pi, and OpenCode into the same trace model. It’s the same metadata, same query syntax, regardless of which tool ran the session. You can finally ask "which sessions were expensive" and get one answer instead of five partial ones.
- Standardize cost across tools: Once you can see sessions side by side, you can compare them honestly. Token usage, cost per session, tool calls, and subagent activity normalized across tools means you can finally tell how much Cursor or Claude Code is doing for the money on a given workflow.
- Optimize your usage: Seeing the data is what makes optimization possible, but most teams don't act on it because nobody has the bandwidth to manually review every session for waste. This is where Engine comes in: it analyzes agent sessions and surfaces concrete skill improvements, the kind of refinements a senior engineer would suggest if they had time to review every PR an agent produced. For example, if an agent is making redundant tool calls to retrieve the same context multiple times in a session, Engine flags it and recommends consolidating them. Instead of a dashboard telling you spend is high, you get a specific recommendation for what to change.
- Govern your spending: Our LLM Gateway cost caps and governs at the user, team, and org level, and will soon be able to route to open source models where they're a fit. Open source models have gotten good and cheap enough that they belong as an option in every agent harness — not as a replacement for frontier models everywhere, but as a default for most work that doesn't require frontier intelligence. The same goes for subagents: cheap models handling scoped subtasks can keep a smart model from burning frontier-level cost on grunt work.
Each of these stages makes the next one possible. Visibility tells you where to optimize. Optimization tells you where governance needs to be tightest. Governance protects the gains so the next round of visibility shows real progress instead of new waste.
This solution is built for teams running more than one coding agent, which, based on what we hear from customers, is most teams within a few months of adoption. If your org has fully standardized on a single tool and that tool's native dashboard already answers your questions, you may not need a second layer yet. But the moment a second tool enters the mix, native dashboards stop being able to answer "across all of them, where is the money going”?
LangSmith for Coding Agents
You don't need all four pieces on day one. If your team is in the early adoption phase, observability is the right place to start — you need to know which agents are running, what they're spending, and where sessions are failing before you can decide what to fix. If you're past that and starting to feel the bill, Engine and LLM Gateway are built to plug into the same trace data, so the move from "we can see it" to "we can fix it and cap it" doesn't require ripping anything out.
Once configured, coding agent sessions appear as traces in LangSmith, the same way any production agent run would. Depending on the integration, a session can include:
- User and assistant turns
- Model calls with token usage and cost
- Tool calls and shell commands
- MCP activity and subagent invocations
- Errors and timing
Traces are normalized to a common model (root session, turns, tool calls, metadata) so you can query across agents using the same fields. Filter by session_id, thread_id, model, provider, or tool name. You can find the expensive sessions, find the failing tool calls, and compare behavior across Cursor and Copilot without switching contexts.
Getting Started
Setup is different for each tool: find the steps for Claude Code, Codex, OpenCode, Cursor, GitHub Copilot, Pi, or dcode.
We built this because we lived through this problem ourselves: the bill kept climbing, and and we didn't have a clear sense of what work was actually worth the spend. Your engineering team will never standardize on one agent (and they shouldn’t have to!) since they’ll keep picking whatever fits the task best. The observability later has to meet them where they are: different agents, different event formats, one place to make sense of all of it.
LangSmith gives teams one place to debug and measure sessions across all your coding agents. Find your tool and get started.
Related content
Observability & Evals
Partner
Harbor x LangChain: A Unified Stack for Evaluating Agents
N. Bohm,
N. Hollon
June 30, 2026
7
min
LangSmith
How We Made Coding Agent Spend Predictable
Martha Janicki
June 15, 2026
5
min
LangSmith
How to Choose the Right Sandbox for Your Agent
Rahul Verma
June 12, 2026
6
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み