CloudflareのGen 13サーバーをローンチ:キャッシュをコアと交換してエッジコンピュート性能を2倍に
CloudflareはAMD EPYC Turin搭載のGen 13サーバーをリリースし、FL2へのRust書き換えによりキャッシュ削減とコア数増のトレードオフを解決し、エッジでの演算性能を2倍に向上させた。
キーポイント
ハードウェアのアーキテクチャトレードオフ
Gen 13は最大192コアと電力効率の向上を実現する一方、L3キャッシュがコアあたり12MBから2MBに大幅削減され、従来型ワークロードには適合しなくなった。
ソフトウェア層の刷新(FL2への移行)
大キャッシュ依存型のFL1からRustベースのFL2へ書き換えることで、レイテンシ増加を抑制しつつコア数に応じたスループット拡大を実現した。
パフォーマンス計測による実証
AMD uProfを用いてキャッシュミス率などのパフォーマンスカウンターを収集し、新アーキテクチャがエッジリクエスト処理に適合することを定量的に検証した。
エッジコンピューティング性能の倍増
高コア数、Zen 5アーキテクチャのIPC向上、DDR5-6400メモリ帯域を組み合わせ、SLAを維持しながらエッジでの処理性能を実質2倍に引き上げた。
L3キャッシュ減少によるレイテンシ増大
Gen 13はコア数を削減したがL3キャッシュも減少したため、メモリアクセス頻度が高まり、キャッシュヒット(約50サイクル)とミス(350+サイクル)の間に1桁の違いが生じた。
スループットとレイテンシのトレードオフ
コア数増加でスループットは向上するも、高CPU利用率時に50%以上のレイテンシ悪化が発生し、顧客体験に直結するため許容できないと判断された。
AMD PQOSによるリソース最適化
ハードウェア調整やワーカー拡張などの試行錯誤を経て、共有キャッシュとメモリ帯域を細かく制御できるAMDのPQOS(Platform Quality of Service)が最も効果的な解決策となった。
影響分析・編集コメントを表示
影響分析
本記事は、エッジコンピューティングインフラにおいてハードウェアのアーキテクチャ変更(キャッシュ削減vsコア数増)にソフトウェア層がどう追従すべきかを示す実践例である。CloudflareのFL2への移行は、大規模CDN事業者が次世代CPUアーキテクチャを最大限活用するための設計思想として、業界のハードウェア-ソフトウェア協調設計に示唆を与える。これにより、AI推論を含むエッジワークロードの低レイテンシ化とスケーラビリティが促進される。
編集コメント
大規模CDN事業者がハードウェアのトレードオフをソフトウェア刷新で解決した事例は、エッジAIインフラの設計指針として参考になる。次世代CPUアーキテクチャを採用する際は、キャッシュ依存型からコア数スケーラブルな設計へ移行する必要性が今後さらに高まるだろう。
2年前、Cloudflareは大容量の3D V-Cacheを備えたAMD EPYC™ Genoa-Xプロセッサをベースにした第12世代サーバーフリートを導入しました。そのキャッシュ重視のアーキテクチャは、当時のリクエスト処理レイヤーであるFL1に完璧に適合していました。しかし、次世代ハードウェアを評価する中で、私たちはジレンマに直面しました。最大のスループット向上を提供するCPUは、キャッシュの大幅な削減を伴っていたのです。従来のソフトウェアスタックはこれに最適化されておらず、潜在的なスループットの利点は増大するレイテンシによって制限されていました。
このブログでは、Cloudflareのコアリクエスト処理レイヤーのRustベース書き直しであるFL2移行が、第13世代の完全な可能性を証明し、以前のスタックでは不可能だったパフォーマンス向上を実現することを可能にした方法について説明します。FL2は大容量キャッシュへの依存を排除し、SLAを維持しながらコア数に応じてパフォーマンスをスケーリングできるようにします。本日、AMD EPYC™ 第5世代Turinベースのサーバー上でFL2を実行するCloudflareの第13世代のローンチを発表できることを誇りに思います。これにより、エッジでのパフォーマンスを効果的に獲得し、スケーリングすることができます。
AMD EPYC Turinがもたらすもの
AMDのEPYC™ 第5世代Turinベースプロセッサは、単なるコア数の増加以上のものを提供します。このアーキテクチャは、Cloudflareサーバーが必要とする複数の次元で改善をもたらします。
コア数2倍: 最大192コア(第12世代の96コアに対して)、SMTにより384スレッド
IPC改善: Zen 5のアーキテクチャ改善により、Zen 4と比較してサイクルあたりの命令実行数が向上
電力効率向上: コア数が増加しているにもかかわらず、TurinはGenoa-Xと比較してコアあたり最大32%少ないワット数を消費
DDR5-6400サポート: すべてのコアにデータを供給するための高いメモリ帯域幅
しかし、Turinの高密度OPNは意図的なトレードオフを行っています。コアあたりのキャッシュよりもスループットを優先しているのです。Turinスタック全体にわたる私たちの分析は、このシフトを浮き彫りにしました。例えば、最高密度のTurin OPNを第12世代のGenoa-Xプロセッサと比較すると、Turinの192コアは384MBのL3キャッシュを共有しています。これにより、各コアがアクセスできるのはわずか2MBで、第12世代の割り当ての6分の1です。私たちのワークロードのようにキャッシュ局所性に大きく依存するワークロードにとって、この削減は深刻な課題をもたらしました。
世代 プロセッサ コア/スレッド コアあたりL3キャッシュ
第12世代 AMD Genoa-X 9684X 96C/192T 12MB (3D V-Cache)
第13世代 オプション1 AMD Turin 9755 128C/256T 4MB
第13世代 オプション2 AMD Turin 9845 160C/320T 2MB
第13世代 オプション3 AMD Turin 9965 192C/384T 2MB
パフォーマンスカウンターによる問題の診断
私たちのFL1リクエスト処理レイヤー(NGINXおよびLuaJITベースのコード)にとって、このキャッシュ削減は重大な課題でした。しかし、私たちは単に問題があると仮定しただけではありません。測定したのです。
第13世代のCPU評価フェーズでは、AMD uProfツールを使用して、内部で何が起こっているかを正確に特定するために、CPUパフォーマンスカウンターとプロファイリングデータを収集しました。データは以下のことを示しました:
L3キャッシュミス率が、3D V-cacheプロセッサを搭載した第12世代サーバーと比較して劇的に増加
以前はL3に留まっていたデータがDRAMへのアクセスを必要とするようになり、メモリフェッチレイテンシがリクエスト処理時間を支配
CPU使用率を高く押し上げるにつれてレイテンシペナルティがスケーリングし、キャッシュ競合が悪化
L3キャッシュヒットは約50サイクルで完了します。DRAMアクセスを必要とするL3キャッシュミスは350サイクル以上かかり、1桁の違いがあります。コアあたりのキャッシュが6分の1になったことで、第13世代上のFL1ははるかに頻繁にメモリにアクセスし、レイテンシペナルティを被っていました。
トレードオフ: レイテンシ vs. スループット
第13世代でFL1を実行した初期テストは、パフォーマンスカウンターが既に示唆していたことを確認しました。Turinプロセッサはより高いスループットを達成できますが、それは高いレイテンシコストを伴いました。
メトリック 第12世代 (FL1) 第13世代 - AMD Turin 9755 (FL1) 第13世代 - AMD Turin 9845 (FL1) 第13世代 - AMD Turin 9965 (FL1) 差分
コア数 ベースライン +33% +67% +100%
FLスループット ベースライン +10% +31% +62% 改善
低~中程度のCPU使用率時のレイテンシ ベースライン +10% +30% +30% 悪化
高CPU使用率時のレイテンシ ベースライン > 20% > 50% > 50% 許容不可
60%のスループット向上を生み出したAMD Turin 9965搭載の第13世代評価サーバーは魅力的で、パフォーマンス向上はCloudflareの総所有コスト(TCO)に最も大きな改善をもたらしました。
しかし、50%以上のレイテンシペナルティは許容できません。リクエスト処理レイテンシの増加は、顧客体験に直接影響を与えます。私たちは、よくあるインフラストラクチャの質問に直面しました。TCOの利益がないソリューションを受け入れるか、増加したレイテンシのトレードオフを受け入れるか、レイテンシを追加せずに効率を向上させる方法を見つけるか、です。
パフォーマンスチューニングによる漸進的な向上
最適な結果への道を見つけるために、私たちはAMDと協力してTurin 9965のデータを分析し、ターゲットを絞った最適化実験を実行しました。私たちは体系的に複数の構成をテストしました:
ハードウェアチューニング: ハードウェアプリフェッチャーとData Fabric(DF)Probe Filterの調整。これらはわずかな向上しか示さなかった
ワーカースケーリング: より多くのFL1ワーカーを起動。スループットは改善したが、他の本番サービスからリソースを奪った
CPUピニングとアイソレーション: ワークロードアイソレーション構成を調整して最適な組み合わせを見つける。成功は限定的だった
最終的に最も価値を提供した構成は、AMDのPlatform Quality of Service(PQOS)でした。PQOS拡張機能は、キャッシュやメモリ帯域幅などの共有リソースをきめ細かく制御することを可能にします。Turinプロセッサは1つのI/Oダイと最大12のCore Complex Die(CCD)で構成され、それぞれが最大16コアでL3キャッシュを共有しているため、これをテストしました。以下は、異なる実験構成のパフォーマンスです。
まず、PQOSを使用して単一CCD内の専用L3キャッシュシェアをFL1に割り当てましたが、向上はわずかでした。しかし、この概念をソケットレベルにスケーリングし、CCD全体を厳密にFL1専用にした場合、レイテンシを許容範囲内に保ちながら意味のあるスループット向上が見られました。
構成 説明 図 パフォーマンス向上
NUMA-awareコアアフィニティ(ソケットレベルでのPQOS相当) 12個のCCDのうち6個(NUMAドメインに合わせて)がFLを実行。各CCD内の32MB L3キャッシュがすべてのコア間で共有。 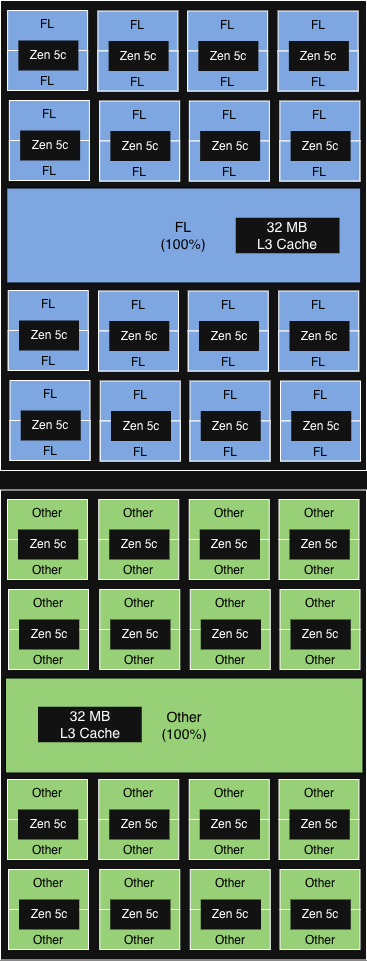 image >15%の漸進的スループット向上
image >15%の漸進的スループット向上
PQOS構成1 各CCDの各物理コア上の2つのvCPUのうち1つがFLを実行。FLは各CCDの32MB L3キャッシュの75%を取得。 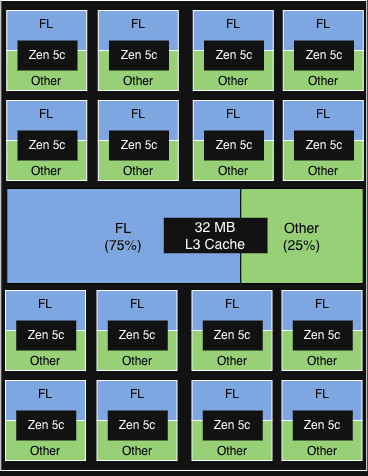 image < 5%の漸進的スループット向上。他のサービスに軽微な劣化の兆候
image < 5%の漸進的スループット向上。他のサービスに軽微な劣化の兆候
PQOS構成2 各CCDの各物理コア上の2つのvCPUのうち1つがFLを実行。FLは各CCDの32MB L3キャッシュの50%を取得。 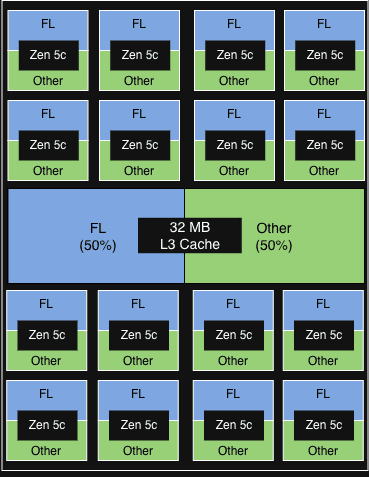 image < 5%の漸進的スループット向上
image < 5%の漸進的スループット向上
PQOS構成3
各CCDの物理コアの50%上の2 vCPUがFLを実行します。
FLは各CCDの32MB L3キャッシュの50%を取得します。

< 5%の増分スループット向上
機会: FL2はすでに進行中だった
ハードウェアチューニングとリソース設定は控えめな向上をもたらしましたが、Gen 13アーキテクチャの性能ポテンシャルを真に解放するためには、システムリソースの活用方法を根本的に変えるためにソフトウェアスタックを書き直す必要があると認識していました。
幸いなことに、私たちはゼロから始める必要はありませんでした。2025年のバースデーウィーク中に発表したように、私たちはすでにFL1を一から再構築していました。FL2は、Rustで書かれたリクエスト処理レイヤーの完全な書き直しであり、PingoraとOxyフレームワーク上に構築され、15年間のNGINXとLuaJITコードを置き換えるものです。
FL2プロジェクトはGen 13のキャッシュ問題を解決するために開始されたわけではありませんでした。それは、より良いセキュリティ(Rustのメモリ安全性)、より速い開発速度(厳格なモジュールシステム)、そして全体的な性能向上(CPU使用量削減、メモリ使用量削減、モジュール実行)の必要性によって推進されていました。
FL2のよりクリーンなアーキテクチャは、より良いメモリアクセスパターンとより少ない動的割り当てにより、FL1がそうであったように巨大なL3キャッシュに依存しないかもしれません。これは、FL2への移行を利用して、Gen 13のスループット向上がレイテンシのペナルティなしに実現できるかどうかを証明する機会を与えてくれました。
証明: Gen 13上のFL2
FL2のロールアウトが進むにつれて、Gen 13サーバーからの本番環境メトリクスは私たちが仮説を立てていたことを裏付けました。
メトリクス
Gen 13 AMD Turin 9965 (FL1)
Gen 13 AMD Turin 9965 (FL2)
CPU%あたりのFLリクエスト数
ベースライン
50%高い
Gen 12とのレイテンシ比較
ベースライン
70%低い
Gen 12とのスループット比較
62%高い
100%高い
新しいFL2スタックでのすぐに使える効率向上は、システム最適化の前でも実質的でした。FL2はレイテンシペナルティを70%削減し、Gen 13をより高いCPU使用率に押し上げながら、厳密にレイテンシSLAを満たすことを可能にしました。FL1では、これは不可能だったでしょう。
キャッシュボトルネックを効果的に排除することで、FL2はスループットがコア数に比例して直線的にスケールすることを可能にします。この影響は高密度のAMD Turin 9965で否定できません:私たちは2倍の性能向上を達成し、ハードウェアの真のポテンシャルを解放しました。さらなるシステムチューニングにより、Gen 13フリートからさらに多くのパワーを絞り出すことを期待しています。
 image
image
Gen 13による世代間向上
FL2が高コア数のAMD Turin 9965の膨大なスループットを解放したことで、私たちは公式にこれらのプロセッサをGen 13デプロイメントに選択しました。ハードウェア認定は完了し、Gen 13サーバーは現在、グローバルなロールアウトをサポートするために大規模に出荷されています。
性能向上
Gen 12
Gen 13
プロセッサ
AMD EPYC™ 第4世代 Genoa-X 9684X
AMD EPYC™ 第5世代 Turin 9965
コア数
96C/192T
192C/384T
FLスループット
ベースライン
最大+100%
ワットあたり性能
ベースライン
最大+50%
Gen 13のビジネスへの影響
妥協のないカスタマーエクスペリエンスのためのGen 12比最大2倍のスループット:スループット容量を倍増させながらレイテンシSLA内に留まることで、私たちのアプリケーションが高速で応答性が高く、大規模なトラフィックスパイクを吸収できることを保証します。
持続可能なスケーリングのためのGen 12比50%優れた性能/ワット:この電力効率の向上は、データセンター拡張コストを削減するだけでなく、リクエストあたりのカーボンフットプリントを大幅に低減しながら成長するトラフィックを処理することを可能にします。
グローバルエッジアップグレードのためのGen 12比60%高いラックスループット:ラックの電力予算を一定に保ちながらこのスループット密度を達成したため、世界中のグローバルエッジネットワーク全体でこの次世代コンピュートをシームレスにデプロイし、顧客が望む場所でトップティアの性能を提供できます。
Gen 13 + FL2: エッジへの準備完了
私たちのレガシーリクエスト提供レイヤーFL1は、Gen 13でキャッシュ競合の壁にぶつかり、スループットとレイテンシの間で容認できないトレードオフを強いられました。妥協する代わりに、私たちはFL2を構築しました。
大幅にリーンなメモリアクセスパターンで設計されたFL2は、巨大なL3キャッシュへの依存を除去し、コア数に比例した直線的スケーリングを可能にします。Gen 13 AMD Turinプラットフォーム上で実行されるFL2は、レイテンシをSLA内に保ちながら、2倍のスループットと50%の電力効率向上を解放します。この飛躍的な前進は、ハードウェア-ソフトウェア共同設計の重要性を強く思い起こさせます。キャッシュ制限に制約されず、Gen 13サーバーは現在、Cloudflareのグローバルネットワーク全体で何百万ものリクエストを提供するためにデプロイする準備ができています。
グローバルスケールのインフラストラクチャで働くことに興奮しているなら、私たちは採用しています。
原文を表示
Two years ago, Cloudflare deployed our 12th Generation server fleet, based on AMD EPYC™ Genoa-X processors with their massive 3D V-Cache. That cache-heavy architecture was a perfect match for our request handling layer, FL1 at the time. But as we evaluated next-generation hardware, we faced a dilemma — the CPUs offering the biggest throughput gains came with a significant cache reduction. Our legacy software stack wasn't optimized for this, and the potential throughput benefits were being capped by increasing latency.
This blog describes how the FL2 transition, our Rust-based rewrite of Cloudflare's core request handling layer, allowed us to prove Gen 13's full potential and unlock performance gains that would have been impossible on our previous stack. FL2 removes the dependency on the larger cache, allowing for performance to scale with cores while maintaining our SLAs. Today, we are proud to announce the launch of Cloudflare's Gen 13 based on AMD EPYC™ 5th Gen Turin-based servers running FL2, effectively capturing and scaling performance at the edge.
What AMD EPYCTurin brings to the table
AMD's EPYC™ 5th Generation Turin-based processors deliver more than just a core count increase. The architecture delivers improvements across multiple dimensions of what Cloudflare servers require.
2x core count: up to 192 cores versus Gen 12's 96 cores, with SMT providing 384 threads
Improved IPC: Zen 5's architectural improvements deliver better instructions-per-cycle compared to Zen 4
Better power efficiency: Despite the higher core count, Turin consumes up to 32% fewer watts per core compared to Genoa-X
DDR5-6400 support: Higher memory bandwidth to feed all those cores
However, Turin's high density OPNs make a deliberate tradeoff: prioritizing throughput over per core cache. Our analysis across the Turin stack highlighted this shift. For example, comparing the highest density Turin OPN to our Gen 12 Genoa-X processors reveals that Turin's 192 cores share 384MB of L3 cache. This leaves each core with access to just 2MB, one-sixth of Gen 12's allocation. For any workload that relies heavily on cache locality, which ours did, this reduction posed a serious challenge.
Generation
Processor
Cores/Threads
L3 Cache/Core
Gen 12
AMD Genoa-X 9684X
96C/192T
12MB (3D V-Cache)
Gen 13 Option 1
AMD Turin 9755
128C/256T
4MB
Gen 13 Option 2
AMD Turin 9845
160C/320T
2MB
Gen 13 Option 3
AMD Turin 9965
192C/384T
2MB
Diagnosing the problem with performance counters
For our FL1 request handling layer, NGINX- and LuaJIT-based code, this cache reduction presented a significant challenge. But we didn't just assume it would be a problem; we measured it.
During the CPU evaluation phase for Gen 13, we collected CPU performance counters and profiling data to identify exactly what was happening under the hood using AMD uProf tool. The data showed:
L3 cache miss rates increased dramatically compared to Gen 12's server equipped with 3D V-cache processors
Memory fetch latency dominated request processing time as data that previously stayed in L3 now required trips to DRAM
The latency penalty scaled with utilization as we pushed CPU usage higher, and cache contention worsened
L3 cache hits complete in roughly 50 cycles; L3 cache misses requiring DRAM access take 350+ cycles, an order of magnitude difference. With 6x less cache per core, FL1 on Gen 13 was hitting memory far more often, incurring latency penalties.
The tradeoff: latency vs. throughput
Our initial tests running FL1 on Gen 13 confirmed what the performance counters had already suggested. While the Turin processor could achieve higher throughput, it came at a steep latency cost.
Metric
Gen 12 (FL1)
Gen 13 - AMD Turin 9755 (FL1)
Gen 13 - AMD Turin 9845 (FL1)
Gen 13 - AMD Turin 9965 (FL1)
Delta
Core count
baseline
+33%
+67%
+100%
FL throughput
baseline
+10%
+31%
+62%
Improvement
Latency at low to moderate CPU utilization
baseline
+10%
+30%
+30%
Regression
Latency at high CPU utilization
baseline
20%
50%
50%
Unacceptable
The Gen 13 evaluation server with AMD Turin 9965 that generated 60% throughput gain was compelling, and the performance uplift provided the most improvement to Cloudflare’s total cost of ownership (TCO).
But a more than 50% latency penalty is not acceptable. The increase in request processing latency would directly impact customer experience. We faced a familiar infrastructure question: do we accept a solution with no TCO benefit, accept the increased latency tradeoff, or find a way to boost efficiency without adding latency?
Incremental gains with performance tuning
To find a path to an optimal outcome, we collaborated with AMD to analyze the Turin 9965 data and run targeted optimization experiments. We systematically tested multiple configurations:
Hardware Tuning: Adjusting hardware prefetchers and Data Fabric (DF) Probe Filters, which showed only marginal gains
Scaling Workers: Launching more FL1 workers, which improved throughput but cannibalized resources from other production services
CPU Pinning & Isolation: Adjusting workload isolation configurations to find optimal mix, with limited success
The configuration that ultimately provided the most value was AMD’s Platform Quality of Service (PQOS). PQOS extensions enable fine-grained regulation of shared resources like cache and memory bandwidth. Since Turin processors consist of one I/O Die and up to 12 Core Complex Dies (CCDs), each sharing an L3 cache across up to 16 cores, we put this to the test. Here is how the different experimental configurations performed.
First, we used PQOS to allocate a dedicated L3 cache share within a single CCD for FL1, the gains were minimal. However, when we scaled the concept to the socket level, dedicating an entire CCD strictly to FL1, we saw meaningful throughput gains while keeping latency acceptable.
Configuration
Description
Illustration
Performance gain
NUMA-aware core affinity
(equivalent to PQOS at socket level)
6 out of 12 CCD (aligned with NUMA domain) run FL.
32MB L3 cache in each CCD shared among all cores.
image
15% incremental
throughput gain
PQOS config 1
1 of 2 vCPU on each physical core in each CCD runs FL.
FL gets 75% of the 32MB L3 cache of each CCD.
image
< 5% incremental throughput gain
Other services show minor signs of degradation
PQOS config 2
1 of 2 vCPU in each physical core in each CCD runs FL.
FL gets 50% of the 32MB L3 cache of each CCD.
image
< 5% incremental throughput gain
PQOS config 3
2 vCPU on 50% of the physical core in each CCD runs FL.
FL gets 50% of the 32MB L3 cache of each CCD.
image
< 5% incremental throughput gain
The opportunity: FL2 was already in progress
Hardware tuning and resource configuration provided modest gains, but to truly unlock the performance potential of the Gen 13 architecture, we knew we would have to rewrite our software stack to fundamentally change how it utilized system resources.
Fortunately, we weren't starting from scratch. As we announced during Birthday Week 2025, we had already been rebuilding FL1 from the ground up. FL2 is a complete rewrite of our request handling layer in Rust, built on our Pingora and Oxy frameworks, replacing 15 years of NGINX and LuaJIT code.
The FL2 project wasn't initiated to solve the Gen 13 cache problem — it was driven by the need for better security (Rust's memory safety), faster development velocity (strict module system), and improved performance across the board (less CPU, less memory, modular execution).
FL2's cleaner architecture, with better memory access patterns and less dynamic allocation, might not depend on massive L3 caches the way FL1 did. This gave us an opportunity to use the FL2 transition to prove whether Gen 13's throughput gains could be realized without the latency penalty.
Proving it out: FL2 on Gen 13
As the FL2 rollout progressed, production metrics from our Gen 13 servers validated what we had hypothesized.
Metric
Gen 13 AMD Turin 9965 (FL1)
Gen 13 AMD Turin 9965 (FL2)
FL requests per CPU%
baseline
50% higher
Latency vs Gen 12
baseline
70% lower
Throughput vs Gen 12
62% higher
100% higher
The out-of-the-box efficiency gains on our new FL2 stack were substantial, even before any system optimizations. FL2 slashed the latency penalty by 70%, allowing us to push Gen 13 to higher CPU utilization while strictly meeting our latency SLAs. Under FL1, this would have been impossible.
By effectively eliminating the cache bottleneck, FL2 enables our throughput to scale linearly with core count. The impact is undeniable on the high-density AMD Turin 9965: we achieved a 2x performance gain, unlocking the true potential of the hardware. With further system tuning, we expect to squeeze even more power out of our Gen 13 fleet.
image
Generational improvement with Gen 13
With FL2 unlocking the immense throughput of the high-core-count AMD Turin 9965, we have officially selected these processors for our Gen 13 deployment. Hardware qualification is complete, and Gen 13 servers are now shipping at scale to support our global rollout.
Performance improvements
Gen 12
Gen 13
Processor
AMD EPYC™ 4th Gen Genoa-X 9684X
AMD EPYC™ 5th Gen Turin 9965
Core count
96C/192T
192C/384T
FL throughput
baseline
Up to +100%
Performance per watt
baseline
Up to +50%
Gen 13 business impact
Up to 2x throughput vs Gen 12 for uncompromising customer experience: By doubling our throughput capacity while staying within our latency SLAs, we guarantee our applications remain fast and responsive, and able to absorb massive traffic spikes.
50% better performance/watt vs Gen 12 for sustainable scaling: This gain in power efficiency not only reduces data center expansion costs, but allows us to process growing traffic with a vastly lower carbon footprint per request.
60% higher rack throughput vs Gen 12 for global edge upgrades: Because we achieved this throughput density while keeping the rack power budget constant, we can seamlessly deploy this next generation compute anywhere in the world across our global edge network, delivering top tier performance exactly where our customers want it.
Gen 13 + FL2: ready for the edge
Our legacy request serving layer FL1 hit a cache contention wall on Gen 13, forcing an unacceptable tradeoff between throughput and latency. Instead of compromising, we built FL2.
Designed with a vastly leaner memory access pattern, FL2 removes our dependency on massive L3 caches and allows linear scaling with core count. Running on the Gen 13 AMD Turin platform, FL2 unlocks 2x the throughput and a 50% boost in power efficiency all while keeping latency within our SLAs. This leap forward is a great reminder of the importance of hardware-software co-design. Unconstrained by cache limits, Gen 13 servers are now ready to be deployed to serve millions of requests across Cloudflare’s global network.
If you're excited about working on infrastructure at global scale, we're hiring.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み