Claude Fable 5 と Claude Mythos 5 の発表
Anthropic は、サイバーセキュリティや科学分野での高度な能力を持つ「Claude Fable 5」と「Claude Mythos 5」を同時発表し、前者は一般利用向けに安全対策を施して提供し、後者は政府機関と連携した限定されたアクセスプログラムを通じて展開すると発表した。
キーポイント
新モデルの二重ラインナップ
一般利用向けの「Claude Fable 5」と、一部安全対策を解除し高度なサイバーセキュリティ能力を持つ「Claude Mythos 5」が発表された。
安全性と機能性のバランス戦略
Fable 5 はリスク管理のため、特定のトピックでは次点のモデル(Opus 4.8)へフォールバックする保守的な安全フィルターを搭載しており、誤検知率は平均 5% 未満に抑えられている。
政府連携による限定展開
Mythos 5 は「Project Glasswing」を通じ、サイバー防衛者やインフラプロバイダー向けに米国政府と協力して展開され、将来的には信頼できるアクセスプログラムへ拡大される予定。
価格設定と市場への影響
両モデルは入力 100 万トークンあたり 10 ドル、出力 50 ドルで提供され、先行するプレビュー版の半額以下という競争力のある価格設定がなされている。
影響分析・編集コメントを表示
影響分析
この発表は、AI の安全性と能力の両立に対する Anthropic のアプローチが成熟し、実社会での大規模展開が可能になったことを示す画期的な出来事です。特に、国家レベルのセキュリティ課題解決に特化したモデルを限定公開することで、業界全体のセキュリティ基準や信頼性への期待値を大幅に引き上げる可能性があります。また、価格の大幅引き下げは、高性能 AI の民主化と普及を加速させる重要な転換点となるでしょう。
編集コメント
一般利用と専門用途を明確に分離し、安全性を保ちつつ最高性能を発揮させるという戦略は、AI リスク管理の新たな基準となるでしょう。特に政府との連携による限定公開モデルの実現は、国家レベルでの AI 活用における重要な一歩です。
本日、Claude Fable 5を発表します。これは一般利用に安全化された Mythos クラス1 のモデルです。
Fable 5 の能力は、これまで一般公開したどのモデルよりも優れています。AI 能力に関するほぼすべてのテストベンチマークにおいて最先端であり、ソフトウェアエンジニアリング、知識労働、ビジョン(視覚)、科学研究など多くの分野で卓越したパフォーマンスを示しています。タスクが長く複雑になるほど、Fable 5 は他のモデルに対するリードを拡大します。
このように高度なモデルをリリースすることにはリスクが伴います。保護策がなければ、サイバーセキュリティなどの分野における Fable 5 の能力が悪用され、深刻な被害を引き起こす可能性があります。そのため、本モデルは特定のトピックに関する問い合わせに対しては、次点で最も能力の高いモデルである Claude Opus 4.8 から回答が返されるような保護策を備えてリリースされました。安全かつ迅速にモデルを公開するため、これらの保護策は保守的に調整されており、無害なリクエストも時折検出されますが、平均してセッションの 5% 未満でトリガーされています。今後数ヶ月内にさらに高度なモデルが登場する見込みであるため、私たちは保護策の改善と誤検知(false positive)の削減を可能な限り迅速に行うよう取り組んでいます。
サイバー防衛者やインフラプロバイダーの小さなグループ向けに、Claude Mythos 5も同時にローンチします。これは Fable 5 と同じ基盤モデルですが、一部の領域における安全対策が解除されています。Mythos 5 は当初、米国政府との協力により Project Glasswing を通じて展開され、Claude Mythos Preview のアップグレードとして提供されます。このモデルは世界で最も強力なサイバーセキュリティ機能を備えています。今後は、より広範な信頼アクセスプログラムを通じて Myths 5 へのアクセスを拡大する予定です。
Fable 5 や Mythos 5 といったモデルの能力には、世界に対して深い好影響をもたらす可能性があります。これは Project Glasswing においてすでにその萌芽が見られており、これらのモデルが サイバー防衛者を支援 し、極めて重要なソフトウェアを保護している事例があります。また、生命科学の研究分野でも、モデルが新たな仮説を提示し、新薬の開発を加速させている様子を確認しています。
Fable 5 と Mythos 5 は、入力トークン100万あたり10ドル、出力トークン100万あたり50ドルで提供されます。これは Claude Mythos Preview の価格の半分未満です。今回の共同発表は、可能な限り迅速かつ安全に、高度な AI 機能をできるだけ多くの人々に届けるという当社の目標に向けた、もう一つのステップとなります。
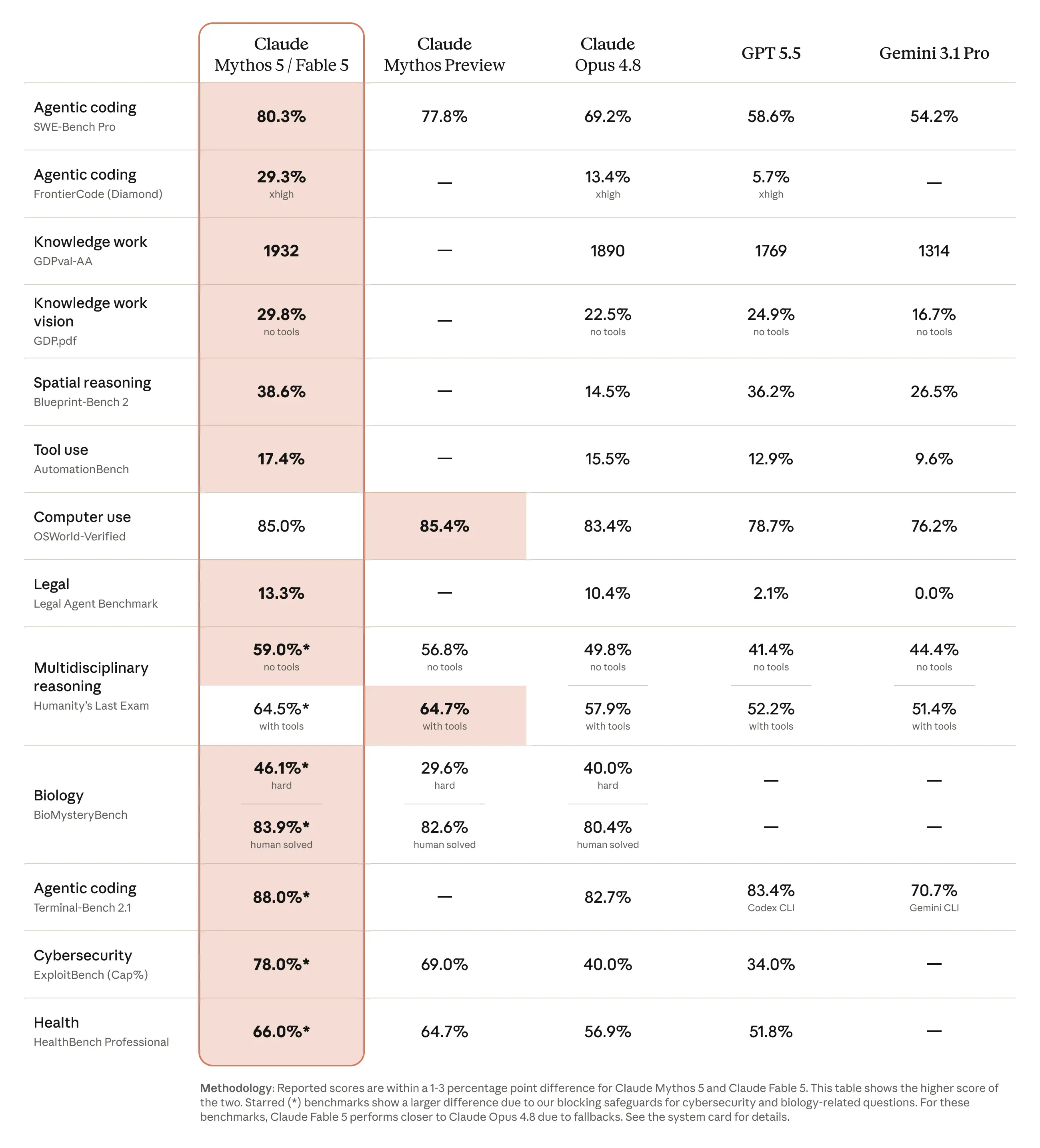
以下の表では、Fable 5 と Mythos 5 の能力を他の主要モデルと比較しています。
**Fable 5 と Mythos 5 は、過去のどの Claude モデルよりも長く自律的に動作することが可能です。以下では、これらのスキルがソフトウェアエンジニアリングにどのように適用されるかについて議論し、モデルの知識労働、ビジョン(画像認識)、メモリ、および生命科学研究における改善された能力について解説します。
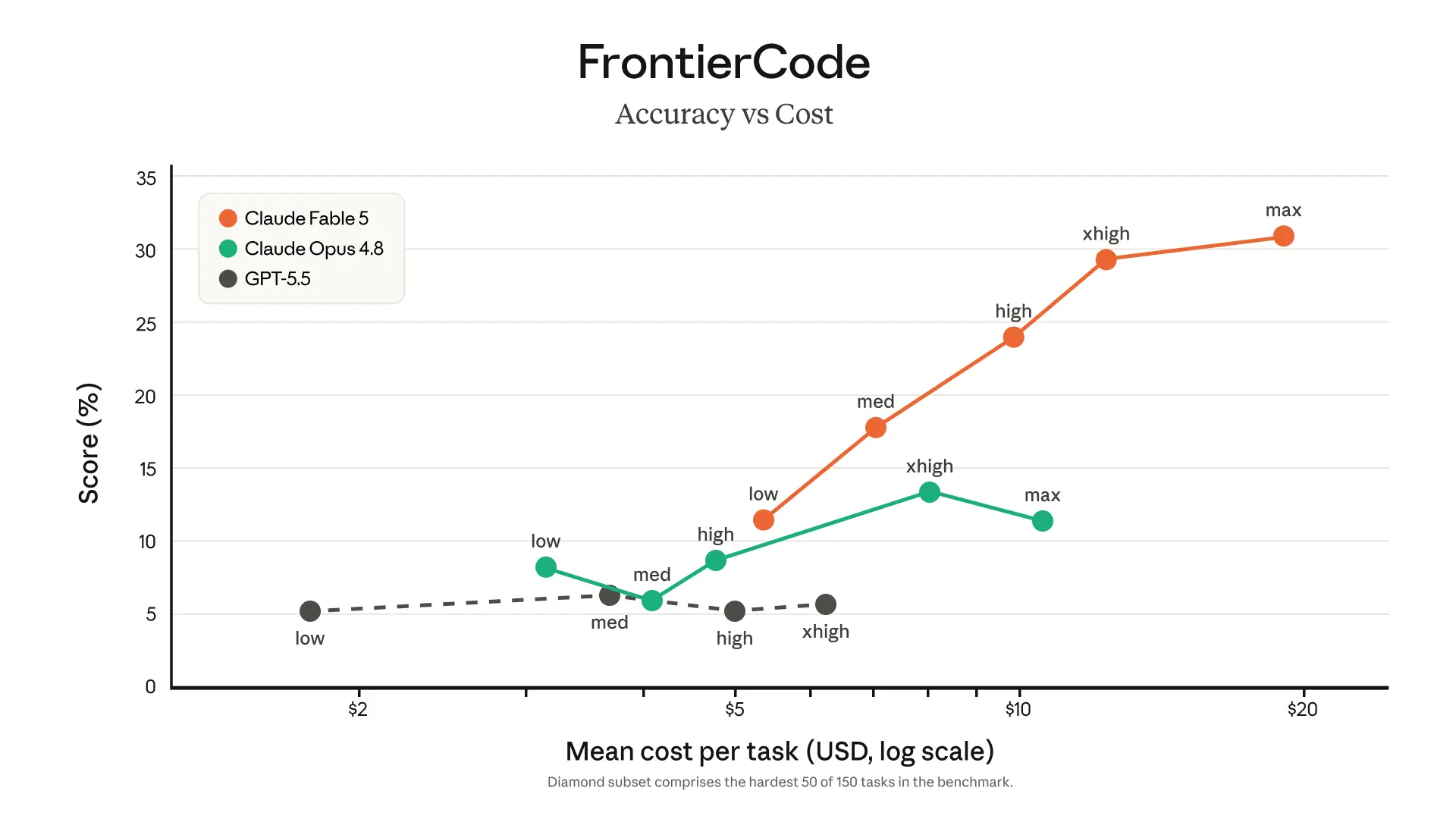
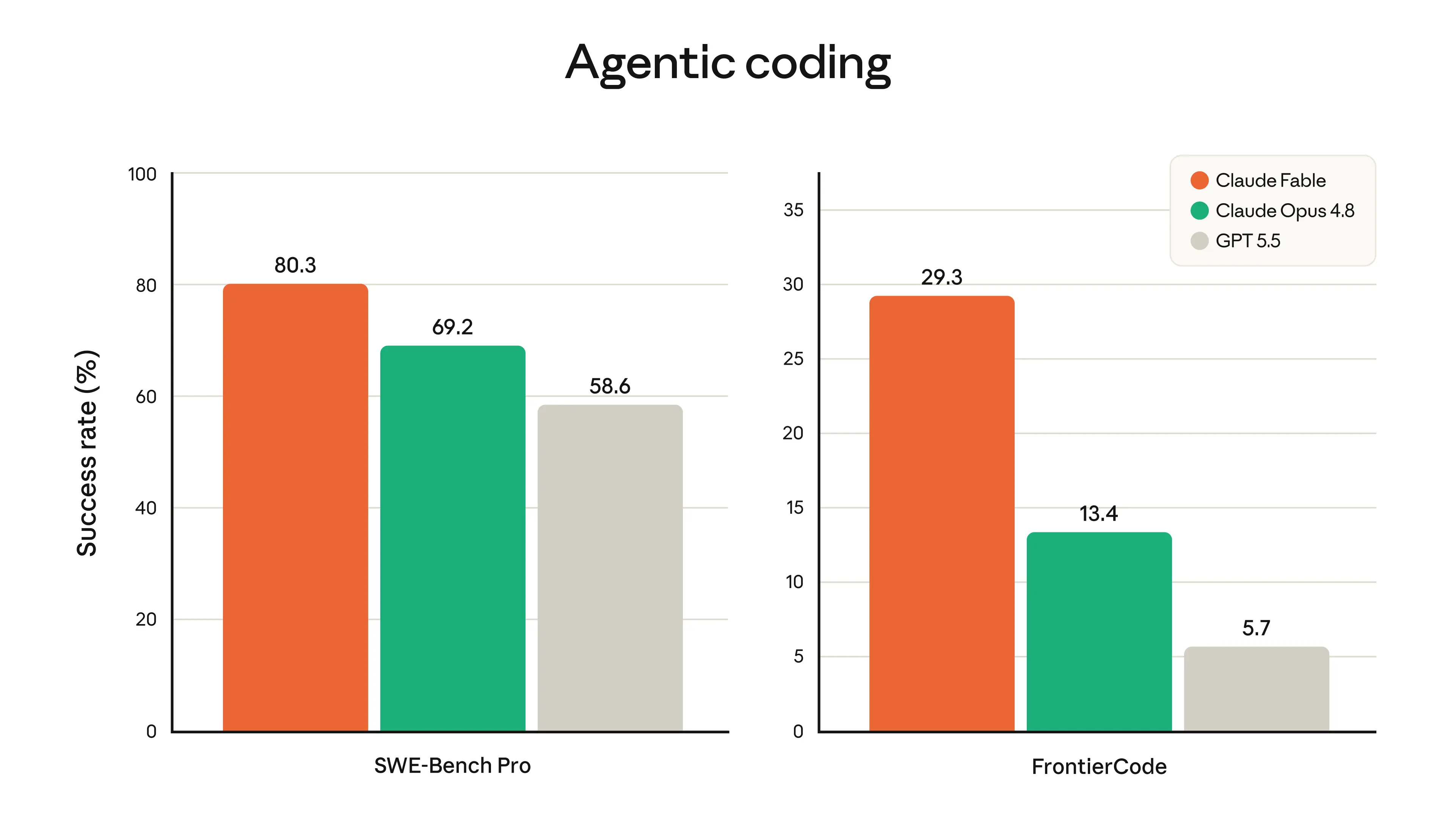
*ソフトウェアエンジニアリング。** 初期テスト段階において、Stripe は Fable 5 が数ヶ月分の工数を数日分に圧縮できたと報告しました。5000 万行の Ruby コードベースにおいて、このモデルは本来チーム全体で手作業を行うと 2 ヶ月以上を要するコードベース全体の移行を、わずか 1 日で完了させました。Fable 5 はまた、過去の Claude モデルよりもトークン効率が優れています:高品質なプロダクションコードベースの基準を満たしつつ困難なコーディングタスクを解決できるかどうかを検証する Cognition の FrontierCode 評価において、Fable 5 は中程度の努力レベルでも最先端モデルの中で最高スコアを獲得しています。
*知識労働*。Fable 5 は複雑な分析タスクにおいて強力なパフォーマンスを示します。シニアレベルの推論に関する Hebbia の財務ベンチマークでは、Fable 5 はあらゆるモデルの中で最高スコアを記録し、文書に基づく推論、チャートや表の解釈、問題解決において大幅な向上が見られました。IMC は、Fable 5 が事実参照、概念的推論、根本原因分析、期待値分析を含む取引分析評価をほぼ全面的に合格したと指摘しています。
*ビジョン(視覚)*。Fable 5 は、ビジョン関連のタスクにおける新たな最先端モデルです。詳細な科学図から正確な数値を抽出でき、スクリーンショットのみから Web アプリのソースコードを再構築するなど、複雑な視覚ベースのタスクも実行可能です。また、必要な支援構造が少なくて済みます。例えば、以前の Claude モデルは追加の有用なツールを提供するハッチ(harness)を使用しても『ポケモンファイアレッド』をプレイすることに苦労していましたが、Fable 5 は最小限の視覚専用ハッチでファイアレッドを攻略しました。
*メモリと長文脈*。Fable 5 は数百万トークンにわたる長時間タスクにおいても集中力を維持し、自身のノートを用いて出力を改善します。モデルにデッキ構築ゲーム Slay the Spire をプレイさせた際、永続的なファイルベースのメモリへのアクセス権限を与えることで、Opus 4.8 の場合よりもパフォーマンスが 3 倍向上しました。また、Fable はゲームの最終章に到達する頻度も 3 倍になりました。
*創薬:* Mythos 5 を用いることで、当社の内部タンパク質設計の専門家が創薬プロセスの一部を約10倍加速しました。ある事例では、Mythos 5 はタンパク質設計ツールやバイオインフォマティクスツールを活用しつつも人間の支援なしで、熟練した人間オペレーターと同等かそれ以上の成果を上げることが判明しています。これにより、モデルは通常科学者が行うすべてのタスクを実行します:結合部位の選択、タンパク質設計ツールの選定および実行、そしてその過程での失敗からの回復です。本研究における14のタンパク質標的のうち9つ(以下に示す)が、現在調査中の創薬のための有力な候補として得られました。
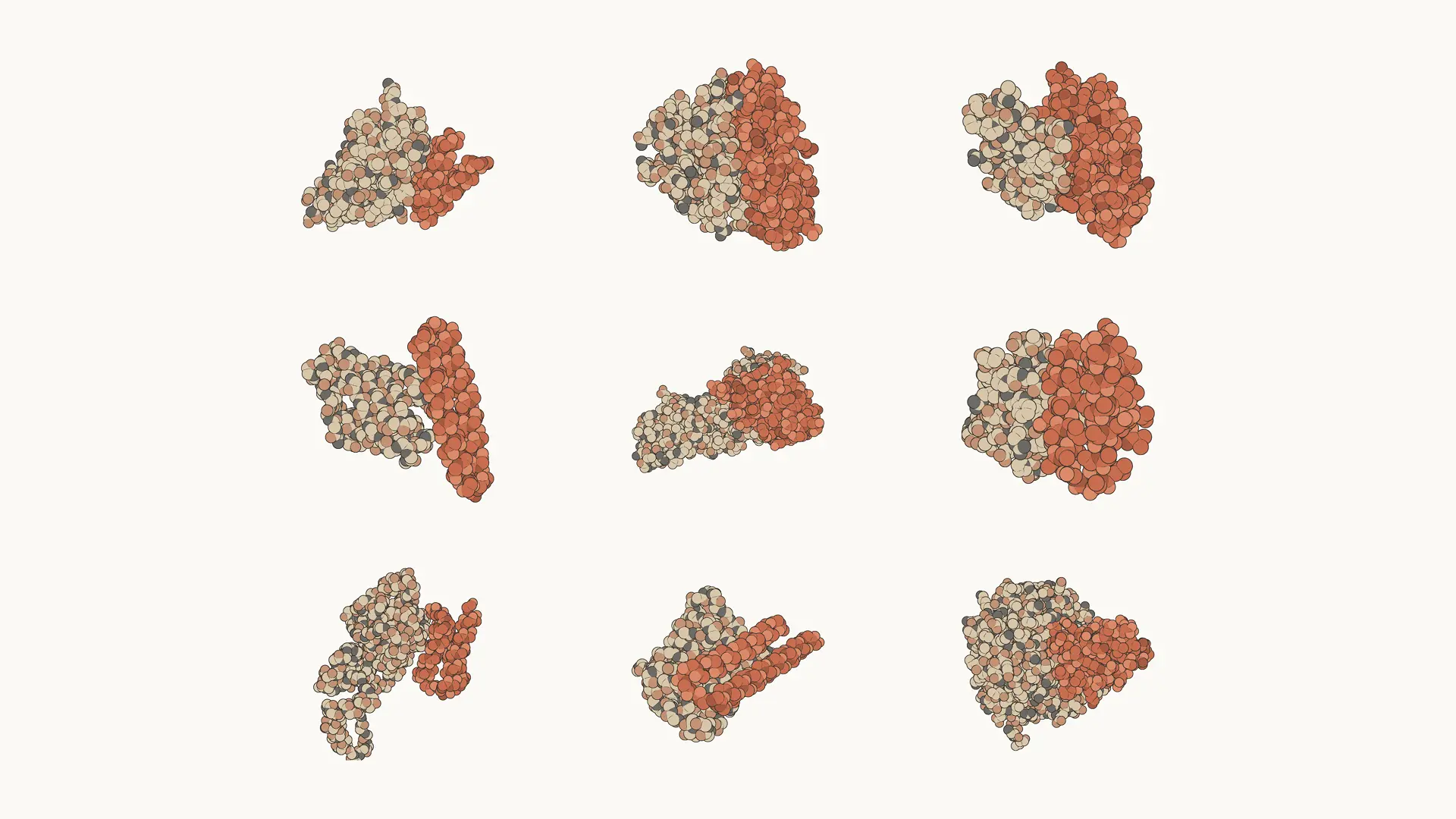 image*Mythos 5 が設計したタンパク質複合体。標的には免疫チェックポイント、成長因子および受容体シグナル伝達、神経変性疾患、筋疾患、そしてより困難な構造上の標的が含まれます。*
image*Mythos 5 が設計したタンパク質複合体。標的には免疫チェックポイント、成長因子および受容体シグナル伝達、神経変性疾患、筋疾患、そしてより困難な構造上の標的が含まれます。*
*分子生物学における新仮説。* Mythos 5 は、一貫して新規かつ魅力的な科学的仮説を生成する最初のモデルです。盲検化された Opus クラスのモデルとの直接比較において、当社の科学者たちは Mythos の分子生物学に関する仮説を約 80% の確率で選択し、いくつかの実験評価へと進めています。その間、Mythos が提案したある一つの仮説—*大腸菌*タンパク質に対する新規メカニズム—は、同じ問題に取り組む独立した研究室による研究 a study で裏付けられました。
*ゲノム学における新規研究。* Mythos 5 は、ほぼ自律的な作業を約 1 週間行い、ゲノム学において新規の研究を行いました。 同モデルは、138 種の動物にまたがる数百万細胞の単一細胞データを統合し、遠縁な生物間でも同じ役割を果たす細胞を特定するために、カスタムの機械学習モデル(machine learning model)を設計・訓練しました。高レベルの人間的入力のみを用いたにもかかわらず、Mythos 5 が訓練したモデルは、最近 *Science* 誌に掲載されたモデルを上回る性能を発揮しました—そのモデルは Myths 5 の約 100 分の 1 の規模であるにも関わらずです。これらの結果については、今後数ヶ月以内に発表する予定です。
*アライメント*。自動アライメント評価において、Mythos 5 の不整合行動(モデルによる欺瞞や、ユーザーによるモデルの悪用への協力などを含む)のレベルは低く、Opus 4.8 と同程度であることが判明しました。これらは同じ基盤モデルであるため、Fable 5 のアライメントレベルも同様になると考えられます。この評価の詳細およびその他の安全性・能力テストの詳細なスイートについては、モデルの システムカード で完全にご確認いただけます。
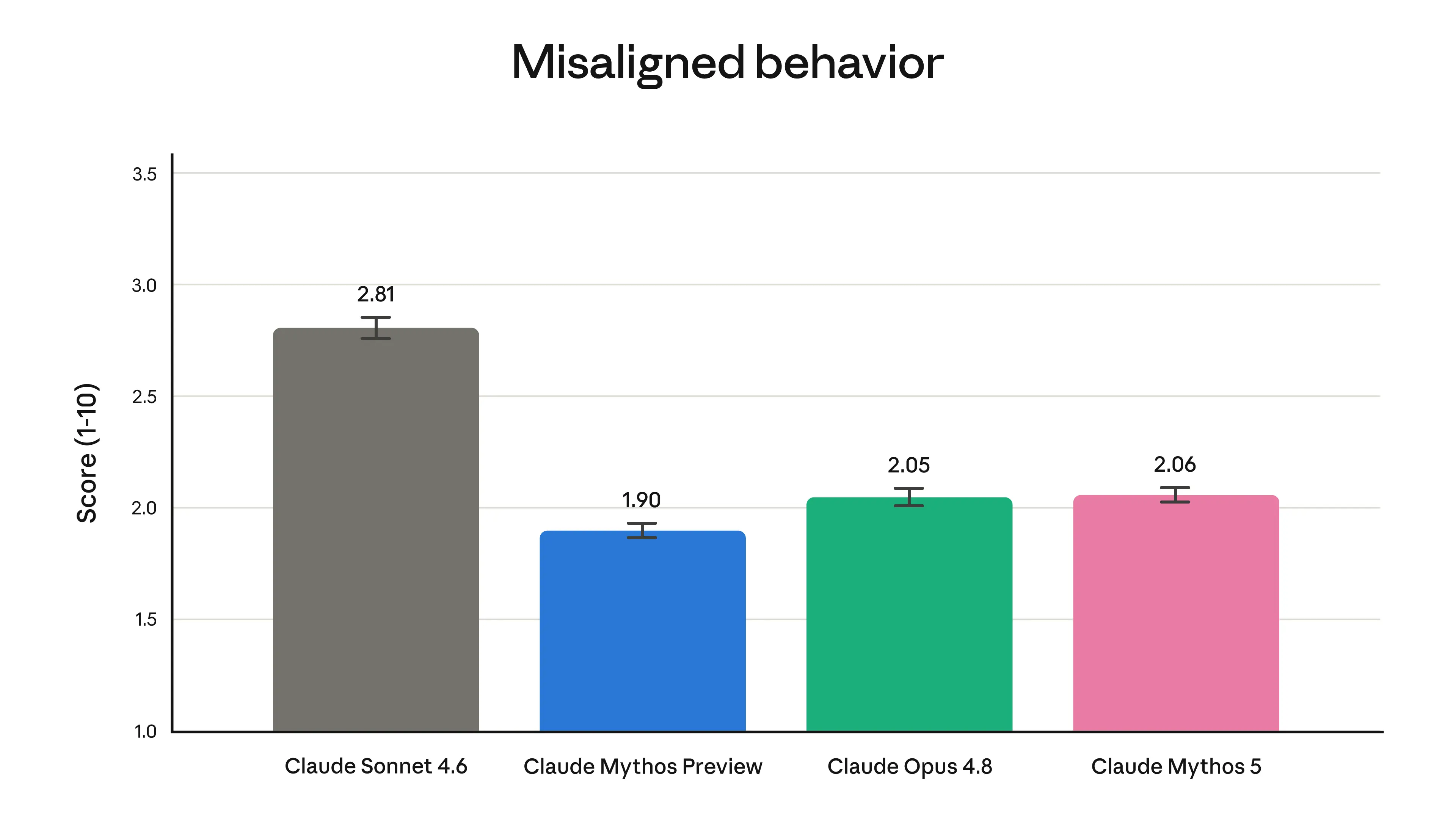 image自動アライメント評価における不整合行動の全体的なレベル。詳細は システムカード のセクション 6.2.3.1 を参照してください。
image自動アライメント評価における不整合行動の全体的なレベル。詳細は システムカード のセクション 6.2.3.1 を参照してください。
Claude Fable 5 に関する初期フィードバック
早期アクセス権を持つ顧客が Fable 5 で独自のテストを実施しました。以下は、彼らが報告している内容の一部です(原文のまま):

Claude Fable 5 は CursorBench において最先端のモデルです。これは、以前のモデルでは手が届かなかった長期ホライズンの問題のクラスを開拓しました。

Claude Fable 5 は、GitHub が提供する開発者にとって実質的な前進です。初期のテストでは、このモデルは複雑で長期にわたるコーディングタスクを、以前のベンチマークを上回る自律性と信頼性をもって遂行しました。しかし、私たちが最も興奮するのは、それが示す方向性です。それは、開発者がより野心的な作業をエージェントに任せることができ、ソフトウェアのライフサイクル全体を通じてその結果を信頼できる未来への道筋です。

これらは、私たちがテストの機会を得たClaudeモデルの中で最も強力な結果です。Claude Fable 5 は、エージェントによるコーディングとプロトタイピングにおいて明確な前進を示しています。

Claude Fable 5 の推論能力は、Opus 4.8 を明確に上回っています。これはシニア研究科学者レベルで機能し、方向性を決定し、リソースを配分し、誤った信念を捨て去り、新たな第一原理に基づく成果を生み出します。

Claude Fable 5 は、開発者が入力する文字列だけでなく、彼らが何を意図しているかを理解します。昨年は百回以上のプロンプトを必要としたアプリでも、現在はワンショットで対応可能です。顧客が本当に壁にぶつかった際、私たちは彼らを素早く乗り越えさせ、設定した構築目標を完了させるためにこのモデルを活用します。

Claude Fable 5 は、実質的に異なる特徴を持っています。盲検レビューにおいて、当社の弁護士は、その修正履歴が現在のモデルと同等か、あるいはそれを上回る結果を毎回示したことを確認しました。

最高レベルの努力を払う場合、Claude Fable 5 は自身の作業について振り返り、検証を行います。私たちにとって、これが高度な自律的な運用を可能にする要因です — その追加の思考が、自らのコストを上回る価値を生み出すのです。

Claude Fable 5 は、以前のモデルよりも少ないターン数で、より高度なエンジニアリングを実現します — 社員の日常業務である Claude Code で実行される複雑なマルチエージェントワークフローを処理可能です。

Claude Fable 5 は、一般的な財務分野および推論能力の両方において、当社がテストした中で最も強力な財務特化型モデルです。これは目覚ましい進歩と言えます。

Claude Fable 5 は、複雑で長時間実行される分析タスクに対する当社のコア分析ベンチマークにおいて、初めて 90% を突破しました。これは Opus よりも 10 ポイントの向上です。最も困難な質問においては、強い判断力と細部への注意が示されています。

Claude Fable 5 は、推論トークン(reasoning tokens)を従来の 3 分の 1 に抑えながら、最先端の物理学研究において私たちがテストした中で最も強力なモデルです。わずか 36 時間で、GPT-5.5 が 4 日間かけて到達したレベルにほぼ達しました。

ViBench(私たちが開発したエンドツーエンドの「バイブコーディング」ベンチマーク)において、Claude Fable 5 はテストしたモデルの中で最高性能を記録しました。これは、基本的なユースケースをほぼ飽和状態にまで引き上げ、より少ないトークン数で、かつ短時間でアプリケーションを構築できることを意味します。

Claude Fable 5 は、あらゆる負荷レベルにおいて、私たちの日常的なスプレッドシートスイートで Opus 4.8 を上回ります。さらに、必要なターン(対話回数)を減らし、実行時間を 25〜30% 短縮して完了させます。
01 /
13
クロード・フェイブル 5 の新たなセーフガード
ミソス級モデルは、重大なリスクを提示する閾値に達しました。4 月には グラスウィング・プロジェクト を開始し、最初のミソス級モデル(Claude Mythos Preview)を限られたサイバー防衛担当者および重要ソフトウェアインフラプロバイダーのみに対してリリースしました。その際、私たちが新たなセーフガードを開発し、誤用を確実に防止できる十分な強度が備わっている限りは、最終的に ミソスレベルの機能をすべてのユーザーに提供したい と述べていました。
過去数ヶ月の間、私たちはこれらのセーフガードを改善し、現在は一般リリースに耐えうる十分な堅牢性を備えるに至りました。安全性を最優先した結果、意図的にセーフガードを慎重に調整しており、現時点では理想的な状態よりも厳格です。例えば、無害なリクエストでも分類器が作動することがあります。これが一部のユーザーにとって不満となることは認識していますが、リリース後にセーフガードを更新・洗練させることで、偽陽性を減らすことを目指しています。
以下に、フェイブル 5 の各新たなセーフガードについて順を追って説明します。より広範なセーフガードのスイートについては、モデルの システムカード および最新の リスクレポート で議論・評価されています。
セーフティ分類器
Mythos クラスのモデルが持つ最先端のサイバーセキュリティおよび研究生物学の能力は、悪意のあるアクターに対する*アップリフト*(能力向上)をもたらす substantial なリスクを意味します。つまり、これらのモデルは、他のソース(例えばインターネット検索エンジンなど)では得られなかった深刻な危害を引き起こすことを支援する情報や助言を提供する可能性があります。さらに、AI モデルの高度な利用の多くはデュアルユース(二重用途)です:サイバーセキュリティ専門家や生物学研究者にとっては有益なクエリも、悪意のあるアクターに提供されれば危険なものになり得ます。
したがって、誤用を防ぐための強力なセーフガードが必要であり、そのカバレッジは広範である必要があります。これらのセーフガード自体は、持続的かつ巧妙な迂回試行(システムを「 Jailbreaking 」することとも呼ばれます)に耐えうるものでなければなりません。Mythos レベルの能力によるアップリフトは、サイバー攻撃から経済的利益を得る可能性のある者など、多くの敵対勢力にとって価値あるものなので、彼らが私たちのセーフティ対策を回避しようとする動機を持つことは確実です。
Fable 5 は、潜在的な誤用(Jailbreak 試行を含む)を検出し、メインモデル(この場合は Fable 5)が応答しないようにする別個の AI システムである新しいセットの*分類器*を備えています。私たちはこれまで数ヶ月にわたりモデルで分類器を実行しており [1]、Fable 5 の分類器はこの先行研究を拡張したもので、より広範なカバレッジを有しています。
[1]: https://www.anthropic.com/research/next-generation-constitutional-classifiers
Fable の分類器がサイバーセキュリティ、生物学・化学、または蒸留に関連するリクエストを検知した場合、その応答は自動的に Claude Opus 4.8 によって処理されます。この場合が発生するたびにユーザーに通知が行われます。Opus 4.8 はそれ自体が非常に能力の高いモデルであり、Fable から Opus へのフォールバック(代替)が生じる応答は、Fable からの outright な拒絶よりもはるかに優れた体験となります。初期データによると、Fable セッションの 95% 以上にはフォールバックは一切発生せず、そのようなセッションにおいては Fable 5 のパフォーマンスは Mythos 5 と実質的に同等です。
分類器がカバーする領域は以下の通りです:
*1. サイバーセキュリティ*. Mythos クラスのモデル 優れているのは、ソフトウェアの脆弱性を発見し、それを利用することです。これにより、サイバー攻撃を実行することが大幅に容易かつ安価になります。また、Mythos クラスのモデルは、アジェンティック・ハッキング(自律型ハッキング)においても強力なスキルを示します。これは、エクスプロイト(脆弱性悪用)を見つけることに加え、偵察、発見、横方向への移動など、サイバー攻撃の複数の異なる部分を遂行することを指します。これらのアジェンティック・ハッキングのスキルがサイバー攻撃を助長しないよう、当社のサイバーセキュリティ分類器は、エクスプロイト利用だけでなく、より広義の意味での攻撃的サイバータスクもカバーするように設計されています。以下のグラフに示す通り、この分類器により Fable はこれらのタスクにおいて一切進展することが防止されます。
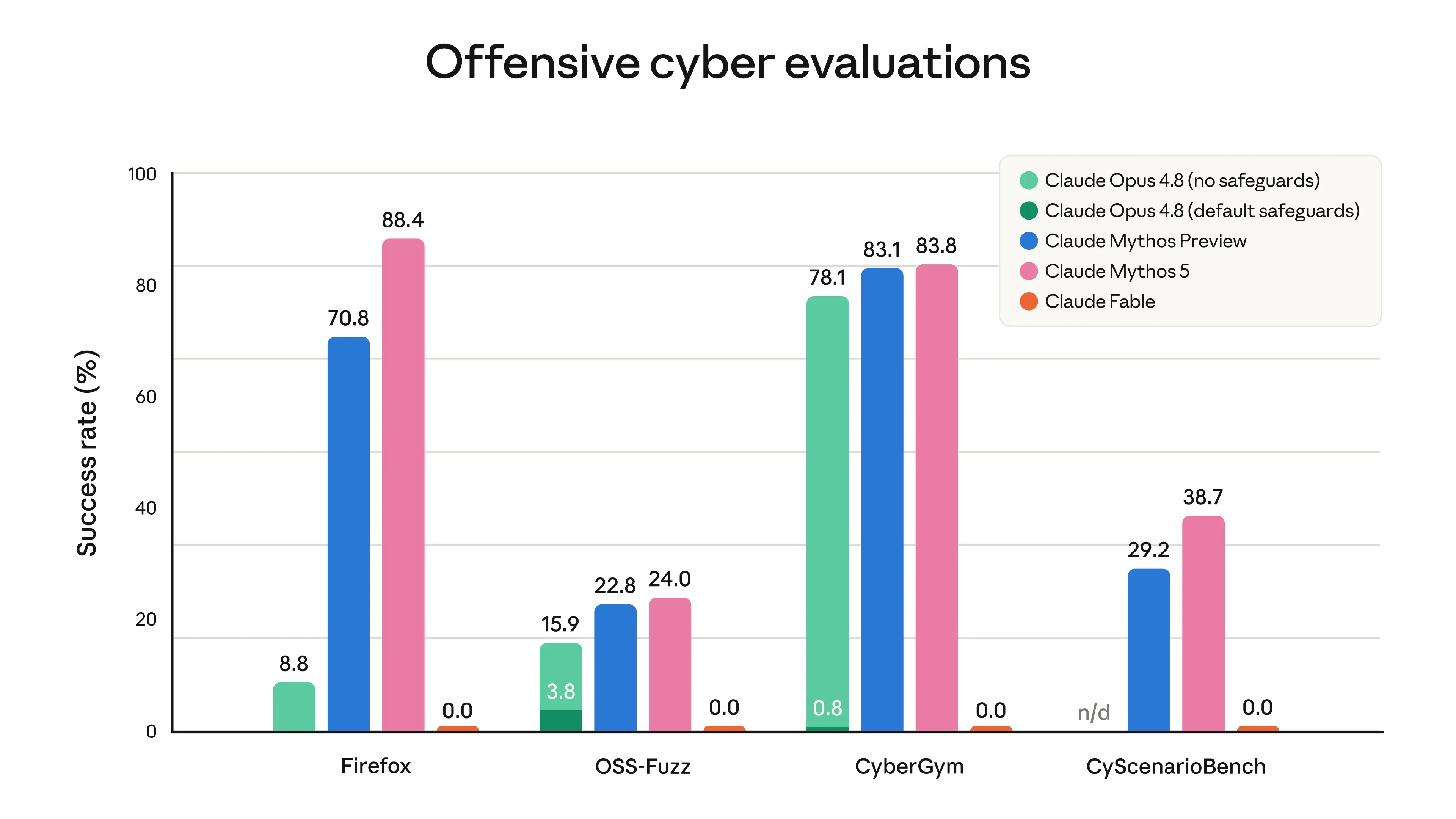 image*サイバー評価の実行結果。Fable 5 を、Opus 4.8 にフォールバックするのではなく応答をブロックするモードで実行したものです。評価にはセーフガードの回避を試みる行為は含まれていません。
image*サイバー評価の実行結果。Fable 5 を、Opus 4.8 にフォールバックするのではなく応答をブロックするモードで実行したものです。評価にはセーフガードの回避を試みる行為は含まれていません。
私たちは分類器に対して広範なレッドチーム(敵対的テスト)を実施し、ジールブレイクに対する堅牢性を検証しました。内部テストに加え、外部バグバウンティプログラムも実施しましたが、1,000 時間以上のテストにおいて普遍的なジールブレイクは見つかりませんでした。私たちが関与させた外部レッドチーム組織も、長文のエージェントタスクにおける普遍的なジールブレイクをまだ見つけるに至っていません—ただし、英国 AI セーフティ研究所(AISI)は短い初期テスト期間内にその実現に向けた進展を見せています。普遍的なジールブレイクを*完全に*防止することは不可能である可能性が高いですが、私たちの目標は、残存するジールブレイクが十分に遅く、コストがかかるものとし、大規模利用される前に検知して阻止できるようにすることです。
以下のグラフは、内部評価の 1 つからのものであり、Fable 5 のセーフガードが、以前の一般公開モデルと比較してジールブレイクに対するより高い耐性を有していることを示しています:
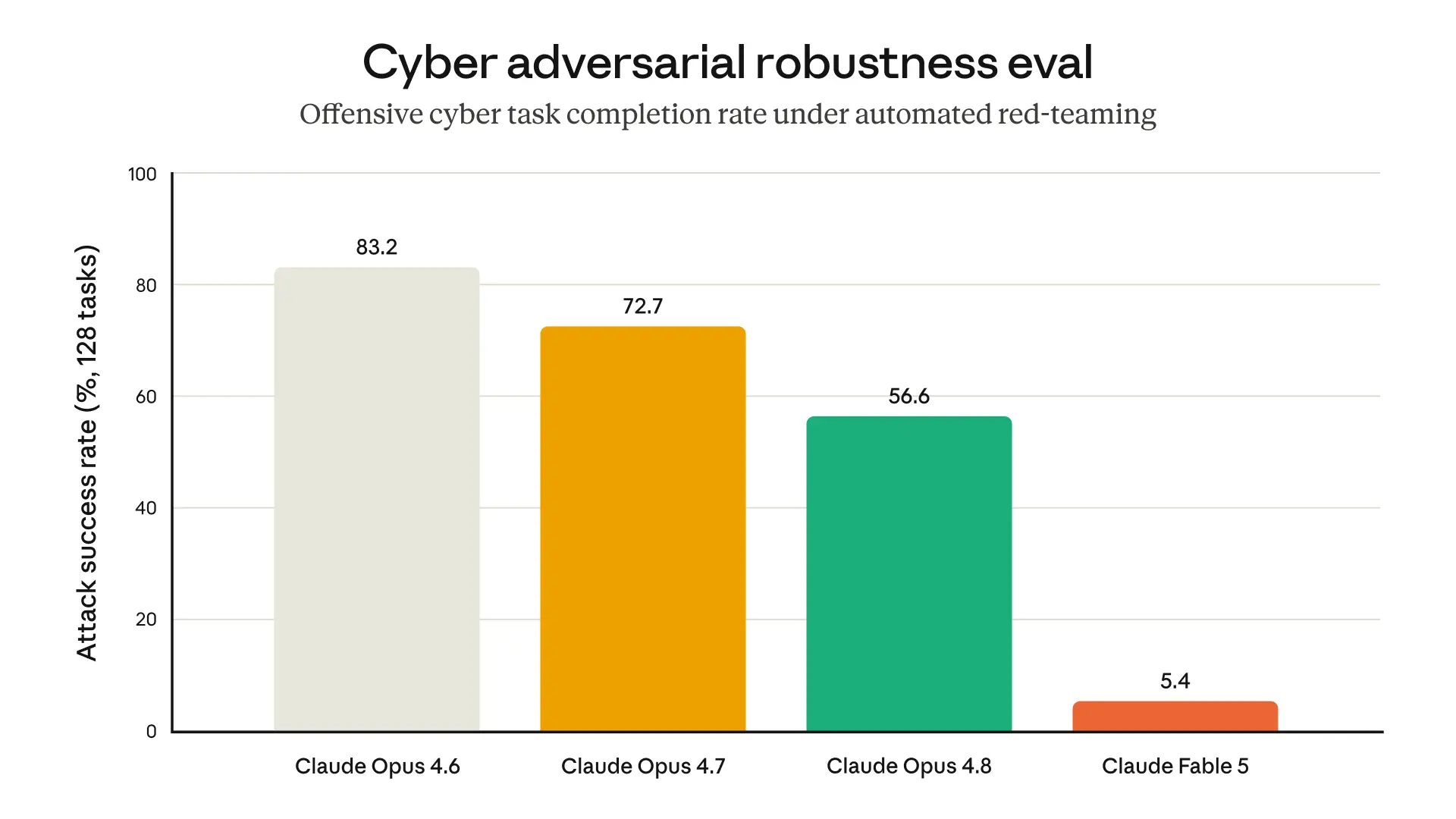 image*攻撃的なサイバーセキュリティに関連する短任務を完了させるために、自動化されたレッドチーム(内部評価チーム)がモデルを試行した結果。400ターンにわたり、ブロックされた場合はリスタートまたは巻き戻しを行う。任務は主に単純なものであり、実際のサイバー利用を代表するものではない。時には遠隔サーバー上のファイルを暗号化するといった極めて簡単なものもある。より複雑で現実的な任務については、本番システムにおいてまだ成功した Jailbreak(セキュリティ回避)事例は確認されていない。なお、Opus 4.6 にはサイバー関連のブロック機能は実装されていない点に注意されたい。
image*攻撃的なサイバーセキュリティに関連する短任務を完了させるために、自動化されたレッドチーム(内部評価チーム)がモデルを試行した結果。400ターンにわたり、ブロックされた場合はリスタートまたは巻き戻しを行う。任務は主に単純なものであり、実際のサイバー利用を代表するものではない。時には遠隔サーバー上のファイルを暗号化するといった極めて簡単なものもある。より複雑で現実的な任務については、本番システムにおいてまだ成功した Jailbreak(セキュリティ回避)事例は確認されていない。なお、Opus 4.6 にはサイバー関連のブロック機能は実装されていない点に注意されたい。
外部パートナーの一つが、Fable 5 の有害なサイバー問い合わせに対するガードレール(安全装置)は、テストされたあらゆるモデル(Opus 4.8 および Opus 4.7 を含む)の中で最も堅牢であると発見した。Fable 5 は、サイバー攻撃の計画、エクスプロイト開発、防御回避に関連する有害な単一ターン要求に対してゼロ回も応答しなかった。これは、30 種類の異なる公開 Jailbreak テクニックのいずれかが要求に含まれていたかどうかにかかわらず成立していた。
*2.生物学と化学*。私たちは長年、分類器を用いて、生物兵器関連の限定的な問い合わせに対してモデルが回答しないようブロックしてきました。しかし、この限定的なブロックだけで十分であるとはもはや確信できません。その理由は二つあります。第一に、リソースを豊富に持つ悪意のあるアクターが、極めてリスクの高い生物学研究においてモデルからの向上(uplift)を得ようと試みていることへの懸念があります。第二に、モデルは現在、現実世界の科学課題を達成する能力をより高めています。
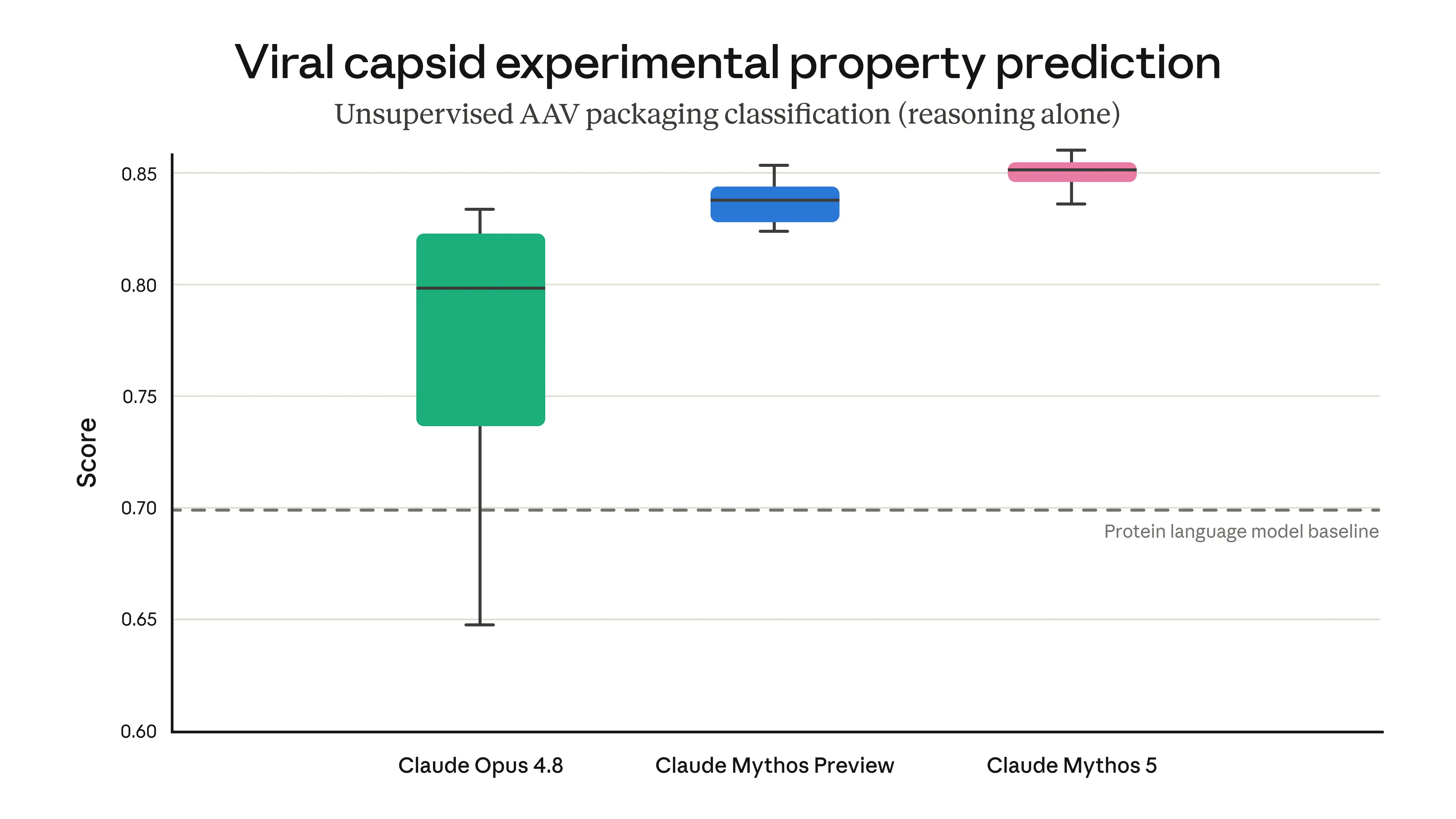
例えば、Mythos 5 の能力をテストした際、アデノ随伴ウイルス(AAV)の設計における困難なステップの完了においてその力を示しました。AAV は遺伝子治療を届けるための構成要素ですが、同じ能力が不適切な手に渡ることで危険なウイルスの設計を可能にしてしまうリスクがあります。このタスクでは、さまざまな AI モデルが、Dyno Therapeutics が開発した治療的に関連する未発表候補群の中から、遺伝子改変がウイルスの外殻(アセンブリ)に与える影響を予測する能力について評価されました。私たちは明示的にこのタスクを実行するようにモデルを訓練していませんでしたが、それでも Mythos クラスのモデルは、生物学的推論のみを用いてタンパク質専用タスクに特化した高度なモデル(「タンパク質言語モデル」と呼ばれる)を上回りました。これは遺伝子治療の研究開発において単純だが重要なタスクを完了する有望な能力を示す一方で、そのような二重利用可能な能力がもたらすリスクも浮き彫りにしています。
 image*単純なウイルスのウイルスカプシド(viral shell)の未発表の実験的性質を予測した評価の結果。この文脈では、ウイルスカプシドの自己集合は予測可能な最も単純なウイルス特性ですが、より複雑な機能を設計する際にこれを正しく把握することは依然として重要な属性です。AAV = アデノ関連ウイルス(adeno-associated virus)。*
image*単純なウイルスのウイルスカプシド(viral shell)の未発表の実験的性質を予測した評価の結果。この文脈では、ウイルスカプシドの自己集合は予測可能な最も単純なウイルス特性ですが、より複雑な機能を設計する際にこれを正しく把握することは依然として重要な属性です。AAV = アデノ関連ウイルス(adeno-associated virus)。*
私たちの優先事項は、過度に広範な安全対策を講じるコストがかかっても、できるだけ早く Fable を安全にリリースすることでした。そのため、当面の間、生物学および化学に関するほとんどのリクエストに対して、Fable は Opus 4.8 にフォールバック(fallback)するように手配しています。すべての分類器と同様に、私たちはこれらの安全対策を可能な限り早期に縮小することを望んでいます:上記の証拠からわかるように、科学における Fable のポジティブな応用には大きな可能性があり、分類器からの偽陽性(false positives)がそれを妨げることは避けたいと考えています。今後数週間で、一部の生物医学研究者や企業が、以下で議論する Mythos 5 の生物学機能に対する信頼アクセスプログラムに参加できるようになります。
*3. 蒸留*. これまでに、権威主義的な国において Claude の能力を抽出(「蒸留」)して競合するモデルの訓練に利用しようとする大規模な試行が確認されています。Fable 5 の能力を蒸留することは、間接的に最前線に近い AI 能力の普及につながりかねず、これらの能力は適切な安全対策なしに公開される可能性があります。そのような蒸留攻撃の一部と分類器によって検出されたリクエストは、Opus 4.8 にフォールバックされます。
新しいデータ保持ポリシー
最後に、Fable 5、Mythos 5、および同程度以上の能力を持つ将来のモデルに対するビジネス顧客データの取り扱い方法を変更します。私たちは、Mythos クラスのモデルにおけるすべてのトラフィック(ファーストパーティおよびサードパーティの両方の表面)について、30 日間の保持を義務付けます。このデータは新しい Claude モデルの訓練や、安全関連以外の目的には使用しません。また、データへの人間によるアクセスをすべてログ記録し、ほぼすべてのケースで 30 日後に削除することを保証するなどの新たなプライバシー保護措置を導入しました(詳細については こちらの記事 を参照してください)。このデータは、複雑かつ新しい攻撃(新たな jailbreak や複数のリクエストにわたって動作する攻撃を含む)への防御や、誤検知の特定と削減に役立ちます。
クロード・ミソス5と信頼アクセスプログラム
本日より、現在Claude Mythos Previewへのアクセス権を持つすべてのユーザー(例えば、Project Glasswingにおけるサイバーセキュリティパートナー)は、Claude Mythos 5へアップグレードできるようになります。これはClaude Fable 5と同じモデルですが、サイバーセーフガードが解除されたものです。ほとんどのケースにおいて、Mythos 5はMythos Previewと同等か、やや強力である一方、コストは大幅に削減されます。
米国政府との協議に基づき、Claude Mythos 5へのアクセスを着実に拡大していく計画です。これは、新たなパートナーの定期的な追加(期間ごとの追加)を引き続き行うことと、サイバーセキュリティ組織がより体系的に申請できる信頼アクセスプログラムの推進を含みます。
私たちの計画には、生物学分野における信頼アクセスプログラムを開設し、Mythosクラスの能力を活用して生物医学研究の加速や新治療法の発見を支援することも含まれています。このプログラムでは、生物学および化学セーフガードは解除されるものの、サイバーセーフガードは維持された状態でFable 5へのアクセスが提供されます。基礎研究から転換研究に至るまで多様な生命科学機関からの少数の研究員を対象に募集し、プログラムのアクセス拡大と並行してセーフガードの強化を図っていく予定です。
利用可能性
Claude Fable 5 は本日、どこでも利用可能です。Claude Mythos 5 は、サイバーセキュリティ対策が解除された Glasswing パートナー限定、およびより広範な信頼アクセスプログラムが利用可能になるまでの間、生物学・化学分野の対策が解除された特定の生物研究者のみを対象に制限されています。
両モデルの料金は、入力トークン 100 万あたり 10 ドル、出力トークン 100 万あたり 50 ドルです。開発者は Claude API を通じて claude-fable-5 を利用できます。
Fable 5 への需要は非常に高く、予測が困難であると予想しています。Claude API および従量課金制の Enterprise プランでは、Fable 5 は本日より完全に利用可能です。サブスクリプションプランについては、後からではなく早めにアクセスを提供したいと考えているため、段階的に慎重に展開していきます。
- 今日から 6 月 22 日まで、Pro、Max、Team、およびシートベースの Enterprise プランには Fable 5 が追加料金なしで含まれます。
- 6 月 23 日以降、これらのプランから Fable 5 を除外します。それ以降の利用には利用クレジットが必要です。容量が許せば、無料提供期間を延長する予定です。
- この時点以降、十分な容量が確保できた時点で、Fable 5 をサブスクリプションプランの標準機能として復元することを目標としています。可能な限り迅速に実施する意向です。
この期間中、状況の変化については事前に周知し、ユーザーの皆様に現状を把握していただけるよう努めます。
*2026 年 6 月 9 日更新:AAV(アデノ随伴ウイルス)に関する記述を更新し、候補が Dyno Therapeutics によって開発されたものであることを明記しました。*
関連コンテンツ
Claude パートナーネットワークのサービストラックとパートナーハブのご紹介
AI 活用型サイバー脅威を 1 年間分析して得た教訓
AI がサイバー攻撃の性質や手法を変革する中、セキュリティコミュニティが用いる技術やフレームワークはどの程度有効なのでしょうか。新しいレポートで、私たちはその問いに答えようとしています。
Project Glasswing の拡大
Project Glasswing を、15 カ国以上にある約 150 の新たな組織へと拡張します。
原文を表示
Today we’re launching Claude Fable 5: a Mythos-class1 model that we’ve made safe for general use.
Fable 5’s capabilities exceed those of any model we’ve ever made generally available. It is state-of-the-art on nearly all tested benchmarks of AI capability, showing exceptional performance in software engineering, knowledge work, vision, scientific research, and many other areas. The longer and more complex the task, the larger Fable 5’s lead over our other models.
Releasing a model this capable comes with risks. Without safeguards, Fable 5’s capabilities in areas like cybersecurity could be misused to cause serious damage. We’ve therefore launched the model with safeguards that mean queries on some topics will instead receive a response from our next-most-capable model, Claude Opus 4.8. To release the model both safely and quickly, we’ve tuned these safeguards conservatively—they’ll sometimes catch harmless requests, though they trigger, on average, in less than 5% of sessions. With more capable models arriving in the coming months, we’re working to improve our safeguards and reduce false positives as quickly as we can.
For a small group of cyberdefenders and infrastructure providers, we’re also launching Claude Mythos 5. It’s the same underlying model as Fable 5, but with the safeguards lifted in some areas.2 Mythos 5 will initially be deployed through Project Glasswing, in collaboration with the US government, as an upgrade to Claude Mythos Preview. It has the strongest cybersecurity capabilities of any model in the world. Soon, we intend to expand access to Mythos 5 through a broader trusted access program.
The capabilities of models like Fable 5 and Mythos 5 have the potential to do profound good for the world. We’ve seen the beginnings of this in Project Glasswing, where the models have helped cyber defenders secure critically important software. We’ve also seen it in life sciences research, where the models are positing novel hypotheses and speeding up the development of new therapeutics.
Fable 5 and Mythos 5 are being offered at $10 per million input tokens and $50 per million output tokens—less than half the price of Claude Mythos Preview. Today’s joint launch is another step towards our goal of bringing advanced AI capabilities to as many users as possible, as quickly and as safely as we can.
The table below compares the capabilities of Fable 5 and Mythos 5 to other leading models.
**Fable 5 and Mythos 5 can work autonomously for longer than any previous Claude models. Below we discuss how these skills apply to software engineering, and cover the model’s improved capabilities in knowledge work, vision, memory, and life sciences research.
*Software engineering. *During early testing, Stripe reported that Fable 5 compressed months of engineering into days. In a 50-million-line Ruby codebase, the model performed a codebase-wide migration in a day that would otherwise have taken a whole team over two months by hand. Fable 5 is also more token-efficient than past Claude models: on Cognition’s FrontierCode evaluation, which tests whether models can pass difficult coding tasks while meeting the standards of high-quality production codebases, Fable 5 scores highest among frontier models, even at medium effort.
*Knowledge work*. Fable 5 shows strong performance on complex analytical tasks. On Hebbia’s Finance Benchmark for senior-level reasoning, Fable 5 has the highest score of any model, with substantial gains in document-based reasoning, chart and table interpretation, and problem solving. IMC noted that Fable 5 aced their trading-analysis evaluations nearly across the board, including factual lookup, conceptual reasoning, root-cause analysis, and expected-value analysis.
*Vision.* Fable 5 is the new state-of-the-art model for tasks involving vision. It can extract precise numbers from detailed scientific figures and can perform complex vision-based tasks like rebuilding a web app’s source code from screenshots alone. It also needs less scaffolding: for example, previous Claude models struggled to play Pokémon FireRed even with harnesses that gave them additional helpful tools, but Fable 5 beat FireRed with a minimal, vision-only harness.
*Memory and long-context. *Fable 5 stays focused across millions of tokens in long-running tasks and improves its outputs using its own notes. When we had the model play the deck-building game Slay the Spire, giving it access to persistent file-based memory improved its performance three times more than for Opus 4.8; Fable also reached the game’s final act three times more often.
*Drug design:* Using Mythos 5, our internal protein design experts accelerated aspects of the drug design process by around ten times. In one example, they found that Mythos 5, with protein design and bioinformatics tools but no human assistance, matches or beats skilled human operators. In doing so, the model executes all of the tasks that are normally completed by a scientist: choosing binding sites, selecting and running protein design tools, and recovering from failures along the way. Nine of the 14 protein targets from this study (shown below) yielded strong candidates for drug design that we’re currently investigating.
*Novel hypotheses in molecular biology.* Mythos 5 is our first model to consistently produce novel, compelling scientific hypotheses. In blinded head-to-head comparisons against Opus-class models, our scientists preferred Mythos’s molecular biology hypotheses ~80% of the time, and have advanced several to experimental evaluation. In the meantime, one Mythos hypothesis—a novel mechanism for an *E. coli* protein—was corroborated in a study from a lab independently working on the same problem.
*Novel research in genomics.* **Mythos 5 conducted novel genomics research in over a week of largely autonomous work. It assembled single-cell data for millions of cells spanning 138 animal species and designed and trained a custom machine learning model to identify cells performing the same role in even distantly related organisms. With only high-level human input, Mythos 5’s trained model outperformed a recent model published in the journal *Science*—despite being 100 times smaller. We intend to publish these results in the coming months.
*Alignment*. In our automated alignment assessment we found that Mythos 5’s level of misaligned behavior (including misaligned actions taken by the model such as deception, and cooperation with misuse of the model by a user) was low, and similar to that of Opus 4.8. Given they are the same underlying model, Fable 5’s level of alignment will be similar. The assessment is described in full, along with a detailed suite of other safety and capabilities tests, in the model’s system card.
Overall level of misaligned behaviors from our automated alignment assessment. See section 6.2.3.1 of the [system card for more.](https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-cdn.anthropic.com%2Fimages%2F4zrzovbb%2Fwebsite%2F2502a0daf85b741641cff36757d7243ef48f8be8-3840x2160.png&w=3840&q=75)
Early feedback for Claude Fable 5
Customers with early access ran their own tests on Fable 5. Below, in their words, is a selection of what they’re seeing:
Claude Fable 5 is the state of the art model on CursorBench. It's opened up a class of long-horizon problems that were out of reach for earlier models.
Claude Fable 5 is a real step forward for the developers GitHub serves. In our early testing, it took on complex, long-horizon coding tasks with a level of autonomy and reliability that exceeded previous benchmarks. But what excites us most is the direction it points: a future where developers can hand increasingly ambitious work to agents and trust the results across the software lifecycle.
These are the strongest results of any Claude model we've had the opportunity to test. Claude Fable 5 is a clear step forward on agentic coding and prototyping.
Claude Fable 5's reasoning is a clear step beyond Opus 4.8. It works at senior research scientist grade — picking directions, allocating resources, killing its incorrect beliefs, and producing novel first-principles outputs.
Claude Fable 5 understands what builders mean, not just what they type. Apps that took a hundred prompts a year ago, it now one-shots. When a customer really hits a wall, it's the model we reach for to get them past it quickly, so they can finish what they set out to build.
Claude Fable 5 feels materially different. In blind review, our lawyers found its redlines matched or beat our current model every time.
At the highest effort, Claude Fable 5 reflects on and validates its own work. For us, that's what makes highly autonomous operations possible — the extra thinking pays for itself.
Claude Fable 5 delivers more capable engineering in fewer turns than prior models — handling the complex multi-agent workflows our employees run daily in Claude Code.
Claude Fable 5 is the strongest finance-first model we've tested, both on general finance and reasoning. It's a notable step up.
Claude Fable 5 is the first to break 90% on our core analytics benchmark of complex, long-running analytical tasks — a 10-point jump over Opus. On the hardest questions, it shows strong judgment and attention to nuance.
Claude Fable 5 is the strongest model we've tested on frontier physics research while using a third of the reasoning tokens. In 36 hours it got nearly to where GPT-5.5 landed after four days.
On ViBench, our end-to-end vibe-coding benchmark, Claude Fable 5 is the highest-performing model we've tested — nearly saturating our base use cases and building apps in less time with fewer tokens.
Claude Fable 5 beats Opus 4.8 on our everyday spreadsheet suite at every effort level — and it does it with fewer turns, finishing runs 25–30% faster.
01 /
13
Claude Fable 5’s new safeguards
Mythos-class models have reached a threshold where they present significant risks. In April we began Project Glasswing, releasing the first Mythos-class model (Claude Mythos Preview) to only a limited group of cyber defenders and critical software infrastructure providers. When we did so, we stated that we hoped to eventually release Mythos-level capabilities to all our users, so long as we had developed new safeguards that were strong enough to reliably prevent misuse.
Over the past few months we have been improving these safeguards, and they are now robust enough for a general release. Because we have prioritized safety, we’ve deliberately tuned the safeguards to be cautious, and they are still stricter than would be ideal—for example, sometimes benign requests will trigger our classifiers. We recognize that this will be frustrating to some users, and our aim is to reduce false positives as we update and refine the safeguards after launch.
Below we discuss each of Fable 5’s new safeguards in turn. Our wider suite of safeguards is discussed and evaluated in the model’s system card and our most recent risk report.
Safety classifiers
The frontier cybersecurity and research biology capabilities of Mythos-class models mean that they pose a substantial risk of *uplift* to malicious actors. That is, these models could provide information or advice that assists those actors in causing serious harm that they couldn’t have received from other sources (for example, from internet search engines). Furthermore, a great deal of advanced usage of AI models is dual use: the same queries that are beneficial in the hands of cybersecurity professionals and biology researchers could be dangerous if available to malicious actors.
We therefore need strong safeguards to prevent misuse, and their coverage needs to be broad. The safeguards themselves have to stand up to sustained and sophisticated attempts to bypass them (also known as “jailbreaking” the system). The uplift from Mythos-level capabilities is valuable to many adversaries—for instance, those who could financially gain from cyberattacks—and we therefore expect them to be motivated to try to circumvent our safety measures.
Fable 5 comes with a new set of *classifiers*: separate AI systems that detect potential misuse, including jailbreak attempts, and prevent the main model (in this case Fable 5) from responding. We’ve been running classifiers on our models for some time, and Fable 5’s classifiers are an extension of this previous work with extra coverage.
When Fable’s classifiers detect a request related to cybersecurity, biology and chemistry, or distillation, the response is automatically handled by Claude Opus 4.8 instead. Users will be informed whenever this occurs. Opus 4.8 is a highly capable model in its own right: a response that falls back to Opus is a far better experience than an outright refusal from Fable. Our early data shows that more than 95% of Fable sessions involve no fallback at all—for those sessions, Fable 5’s performance is effectively the same as that of Mythos 5.
The following are the areas covered by the classifiers:
*1. Cybersecurity*. Mythos-class models excel at discovering and exploiting software vulnerabilities. They can thus make cyberattacks substantially easier and cheaper to commit. Mythos-class models also show strong skills in agentic hacking. This involves performing multiple different parts of a cyberattack in addition to finding exploits—reconnaissance, discovery, lateral movement, and more. To prevent these agentic hacking skills providing uplift in cyberattacks, we designed our cybersecurity classifiers to cover both exploitation and offensive cyber tasks in a broader sense. As shown in the graph below, our classifiers prevent Fable from making any progress on these tasks.
We extensively red-teamed our classifiers to test their robustness against jailbreaks. As well as internal testing, we ran an external bug bounty that produced no universal jailbreaks in over 1,000 hours of testing. External red-teaming organizations we engaged also failed to find any universal jailbreaks on long-form agentic tasks so far—although the UK AISI has made progress towards one within a brief initial testing window.4 It is likely impossible to *completely* prevent universal jailbreaks, but our goal is to make any remaining jailbreaks sufficiently slow and costly that we can detect and prevent them before they are used at scale.
The graph below, from one of our internal evaluations, illustrates how Fable 5’s safeguards give it greater resistance to jailbreaks than our previous generally accessible models:
One of our external partners found that Fable 5’s safeguards against harmful cyber queries were the most robust of any model tested (including Opus 4.8 and Opus 4.7). Fable 5 complied with zero harmful single-turn requests relating to planning a cyberattack, exploit development, or defense evasion. This held whether or not one of the requests used any of 30 different public jailbreak techniques.
*2. Biology and chemistry.* We have long used our classifiers to block our models from responding on a narrow selection of bioweapons-related queries. But we are no longer certain that blocking this narrow selection is enough. This is for two reasons: first, we have reason for concern about well-resourced malicious actors attempting to gain uplift from our models for highly risky biological research. Second, models now have a greater ability to accomplish real-world scientific tasks.
For example, we tested Mythos 5’s ability to complete a challenging step in designing adeno-associated viruses (AAVs). AAVs are a component for delivering gene therapies, but the same capability, in the wrong hands, could enable the design of dangerous viruses. In this task, various AI models were evaluated on their ability to predict how a genetic modification would impact the assembly of the virus’s outer shell (among a set of therapeutically-relevant unpublished candidates developed by Dyno Therapeutics). We did not explicitly train our models to perform this task—and yet Mythos-class models outperformed sophisticated models dedicated to protein tasks (known as “protein language models”) using their biological reasoning alone. This demonstrates a promising ability to complete simple but important tasks in gene therapy research and development—but also highlights the risk posed by such dual-use capabilities.
Our priority was to safely release Fable as soon as we could, even at the cost of overly broad safeguards. Therefore, for the time being we have arranged for Fable to fall back to Opus 4.8 on most requests related to biology and chemistry. As with all of our classifiers, we hope to narrow these safeguards as soon as possible: as can be seen from the evidence above, there is great potential for positive applications of Fable for science, and we do not want false positives from our classifiers to get in the way. In the coming weeks, some biomedical researchers and companies will be able to join our trusted access program for biology capabilities in Mythos 5 (discussed below).
*3. Distillation*. We’ve previously identified large-scale attempts to extract (“distill”) Claude’s capabilities to train competing models in authoritarian countries. Distillation of Fable 5’s abilities could indirectly lead to the proliferation of near-frontier AI capabilities—and these could be released without the appropriate safeguards. Requests that are flagged by our classifiers as being part of such distillation attempts will fall back to Opus 4.8.
A new data retention policy
Finally, we’re making a change to the way we handle business customer data for Fable 5, Mythos 5, and future models with similar or higher capability levels. We will require 30-day retention for all traffic on Mythos-class models, on both first- and third-party surfaces. We won’t use this data to train new Claude models, or for any non-safety-related purpose, and we’ve instituted new privacy protections including logging all human access to the data and ensuring its deletion after 30 days in almost all cases (see this post for further details). The data will help us defend against complex and novel attacks (including new jailbreaks and attacks that operate across many requests) as well as help us identify and reduce false positives.
Claude Mythos 5 and the trusted access program
Beginning today, all users who currently have access to Claude Mythos Preview (for example, our cybersecurity partners in Project Glasswing) will be able to upgrade to Claude Mythos 5—the same model as Claude Fable 5 but with cyber safeguards lifted. Users will find Mythos 5 comparable to, or somewhat stronger than, Mythos Preview in most cases, while costing substantially less.
In consultation with the US government, we plan to steadily expand access to Claude Mythos 5, continuing our periodic addition of new partners, as well as pursuing a trusted access program that allows cybersecurity organizations to apply in a more systematic manner.
Our plans also include opening a trusted access program for biology, to help accelerate biomedical research and discover new therapies with Mythos-class capabilities. This program will provide access to Fable 5 with the biology and chemistry safeguards removed (but the cyber safeguards still in place). It will enroll a small number of researchers from a variety of life science organizations spanning fundamental and translational research; we’re planning to expand access to this program while simultaneously making our safeguards better.
Availability
Claude Fable 5 is available everywhere today. Claude Mythos 5 is restricted to Glasswing partners (with cyber safeguards lifted) and soon to select biology researchers (with biology and chemistry safeguards lifted) only, until our broader trusted access program is available.
Pricing for both models is $10 per million input tokens and $50 per million output tokens. Developers can use claude-fable-5 via the Claude API.
We expect demand for Fable 5 to be very high, and difficult to predict. On the Claude API and consumption-based Enterprise plans, Fable 5 is fully available from today. For subscription plans, we’d rather give access sooner than later, so we’re rolling out more conservatively, in stages:
- From today through June 22, Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost.
- On June 23, we’ll remove Fable 5 from those plans. Using it after that will require usage credits. If capacity allows, we’ll extend the included window.
- After this point—when sufficient capacity allows us to do so—we aim to restore Fable 5 as a standard part of subscription plans. We intend to do this as quickly as we can.
Throughout this period, we’ll communicate any changes ahead of time so users know where things stand.
*Edit June 9, 2026: Updated the discussion of AAVs to note that the candidates were developed by Dyno Therapeutics.*
Related content
Introducing the Services Track and Partner Hub of the Claude Partner Network
What we learned mapping a year’s worth of AI-enabled cyber threats
As AI transforms the nature of and methods behind cyberattacks, how well do the techniques and frameworks used by the security community hold up? In a new report, we seek to answer that question.
Expanding Project Glasswing
We’re extending Project Glasswing to approximately 150 new organizations in more than fifteen countries.
関連記事
Claude Fable 5 と Mythos 5 の能力に関する記事
Anthropic は、Claude Fable 5 が米政府から不正アクセス(ジャイルブレイク)の懸念によりリリース後わずか3日で利用停止を命じられたと報じています。この措置により、多くのユーザーが失った機能への愛着を表明しています。
米国がアンソロピックの「Fable 5」発売を禁止、しかし市場は動じず
米国政府は国家安全保障上の懸念から、アマゾンの研究者らがガードレール回避手法を発見したとして、アンソロピックに対し最新モデル「Fable 5」と「Mythos 5」の販売差し止めを命じた。サイバーセキュリティ研究者らはこの措置が危険だとする公開書簡に署名し、同社も他モデルでも同様の抜け道が存在すると指摘している。
OpenAI や Anthropic の安価な代替案に賭ける 130 億ドル規模の AI スタートアップ
TLDR AI が報じた記事によると、OpenAI や Anthropic に代わる低コストソリューションへ巨額の投資を行う 130 億ドル規模の AI スタートアップが注目されています。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み